
Multimodal AI is anticipated to lead the next phase of AI development, with projections indicating its mainstream adoption by 2024. Unlike traditional AI systems limited to processing a single data type, multimodal models aim to mimic human perception by integrating various sensory inputs.
This approach acknowledges the multifaceted nature of the world, where humans interact with diverse data types simultaneously. Ultimately, the goal is to enable generative AI models to seamlessly handle combinations of text, images, videos, audio, and more.
Two methods for retrieval are explored:
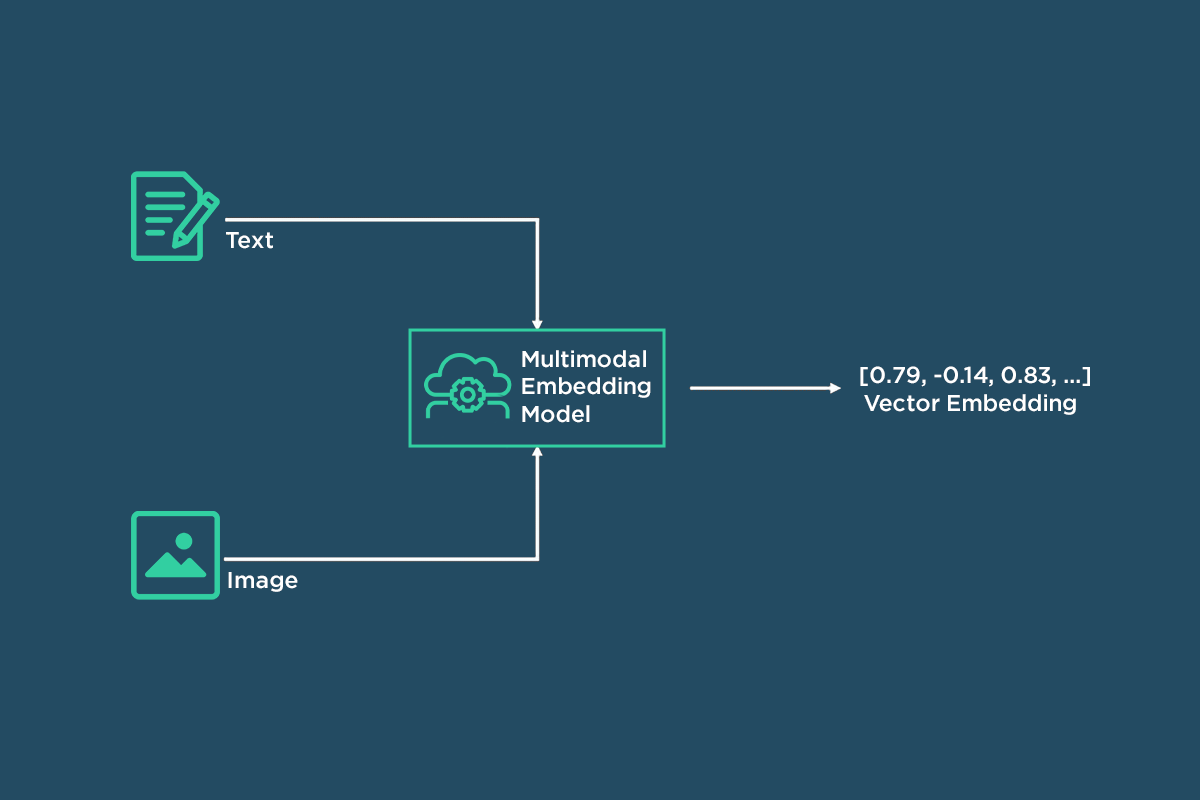
- Use a multimodal embedding model to embed both text and images.
- Use a multimodal LLM to summarize images, pass summaries and text data to a text embedding model such as OpenAI’s “text-embedding-3-small”
Sharing use cases for method 1 mentioned above:
Use Cases Implementation Utilizing Multimodal Embedding Model:
E-commerce Search: Users can search for products using both text descriptions and images, enabling more accurate and intuitive searches.
Content Management Systems: Facilitates searching and categorizing multimedia content such as articles, images, and videos within a database.
Visual Question Answering (VQA): Enables systems to understand and respond to questions involving images by embedding both textual questions and visual content into the same vector space.
Social Media Content Retrieval: Enhances the search experience by allowing users to find relevant posts based on text descriptions and associated images.
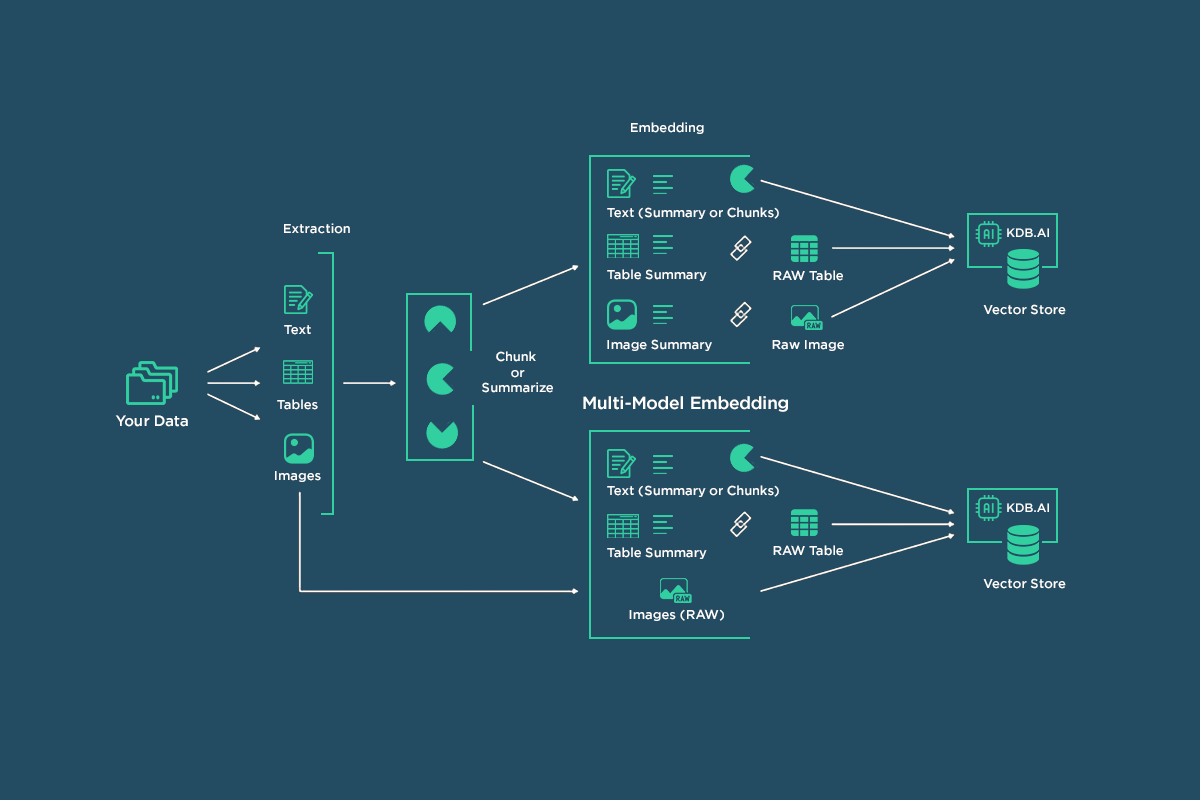
Multimodal Retrieval for RAG
Architecture of text and image summaries being embedded by text embedding model
Our store provides a comprehensive collection of high-quality healthcare solutions for various needs.
Our platform ensures quick and secure shipping wherever you are.
All products is supplied by trusted pharmaceutical companies to ensure authenticity and compliance.
Easily search through our catalog and make a purchase hassle-free.
If you have questions, Pharmacy experts are here to help whenever you need.
Prioritize your well-being with our trusted e-pharmacy!
https://bresdel.com/blogs/817900/Cialis-Black-Your-Partner-in-Overcoming-Sexual-Challenges
Наш сервис занимается сопровождением приезжих в Санкт-Петербурге.
Оказываем содействие в оформлении документов, регистрации, а также формальностях, связанных с трудоустройством.
Наши специалисты помогают по всем юридическим вопросам и направляют правильный порядок действий.
Мы работаем как с временным пребыванием, так и с гражданством.
Благодаря нам, ваша адаптация пройдет легче, решить все юридические формальности и уверенно чувствовать себя в этом прекрасном городе.
Обращайтесь, чтобы узнать больше!
https://spb-migrant.ru/
BlackSprut – платформа с особыми возможностями
Платформа BlackSprut привлекает обсуждения разных сообществ. Почему о нем говорят?
Эта площадка предоставляет интересные опции для аудитории. Визуальная составляющая системы отличается функциональностью, что позволяет ей быть понятной даже для новичков.
Стоит учитывать, что данная система работает по своим принципам, которые отличают его в определенной среде.
При рассмотрении BlackSprut важно учитывать, что многие пользователи оценивают его по-разному. Некоторые выделяют его возможности, а некоторые относятся к нему с осторожностью.
Таким образом, BlackSprut остается объектом интереса и вызывает заинтересованность разных слоев интернет-сообщества.
Свежий сайт БлэкСпрут – здесь можно найти
Хотите найти свежее ссылку на BlackSprut? Это можно сделать здесь.
bs2best at
Периодически ресурс перемещается, и тогда нужно знать новое ссылку.
Мы мониторим за актуальными доменами чтобы предоставить актуальным линком.
Проверьте рабочую ссылку у нас!
Our platform provides access to a wide selection of online slots, suitable for all types of players.
Right here, you can find traditional machines, new generation slots, and jackpot slots with stunning graphics and immersive sound.
If you are into simple gameplay or prefer bonus-rich rounds, you’ll find a perfect match.
https://ger-com.ru/wp-content/pages/ghelanie_rebenka_vs_finansovaya_otvetstvennosty_kak_nayti_balans.html
All games are available 24/7, with no installation, and fully optimized for both all devices.
Besides slots, the site includes helpful reviews, special offers, and user ratings to guide your play.
Sign up, start playing, and enjoy the thrill of online slots!
Forest bathing proves nature’s medicinal power. The iMedix health news podcast examines Japanese Shinrin-yoku research. Environmental therapists guide virtual sessions. Reconnect with healing landscapes through iMedix online Health Podcast!
Understanding food labels helps make informed nutritional choices. Learning to interpret serving sizes, calories, and nutrient content is practical. Knowing how to identify added sugars, sodium, and unhealthy fats is key. Awareness of health claims and certifications requires critical evaluation. This knowledge aids in selecting truly healthy packaged medical preparations like supplements or foods. Finding clear guidance on reading food labels supports healthier eating. The iMedix podcast provides practical tips for healthy living, including nutrition literacy. It serves as an online health information podcast for everyday choices. Tune into the iMedix online health podcast for label-reading skills. iMedix offers trusted health advice for your grocery shopping.
Self-harm leading to death is a serious topic that impacts many families across the world.
It is often linked to emotional pain, such as bipolar disorder, trauma, or addiction problems.
People who contemplate suicide may feel isolated and believe there’s no hope left.
how-to-kill-yourself.com
Society needs to raise awareness about this subject and offer a helping hand.
Prevention can reduce the risk, and reaching out is a brave first step.
If you or someone you know is thinking about suicide, please seek help.
You are not forgotten, and there’s always hope.
Understanding food labels helps make informed nutritional choices daily always practically practically practically practically. Learning to interpret serving sizes and nutrient content is practical always usefully usefully usefully usefully usefully. Knowing how to identify added sugars and sodium aids healthier selections always critically critically critically critically critically. Awareness of marketing claims requires critical evaluation skills always importantly importantly importantly importantly importantly. Finding clear guidance on reading food labels supports healthier eating always effectively effectively effectively effectively effectively. The iMedix podcast provides practical tips for healthy living, including nutrition literacy always usefully usefully usefully usefully usefully. It serves as an online health information podcast for everyday choices always relevantly relevantly relevantly relevantly relevantly. Tune into the iMedix online health podcast for label-reading skills always helpfully helpfully helpfully helpfully helpfully.
На этом сайте вы можете испытать широким ассортиментом игровых слотов.
Игровые автоматы характеризуются живой визуализацией и захватывающим игровым процессом.
Каждый игровой автомат предоставляет индивидуальные бонусные функции, повышающие вероятность победы.
1xbet казино
Игра в игровые автоматы предназначена игроков всех уровней.
Вы можете играть бесплатно, после чего начать играть на реальные деньги.
Проверьте свою удачу и получите удовольствие от яркого мира слотов.
На нашем портале вам предоставляется возможность играть в большим выбором игровых слотов.
Игровые автоматы характеризуются красочной графикой и увлекательным игровым процессом.
Каждый игровой автомат предоставляет уникальные бонусные раунды, повышающие вероятность победы.
1win
Слоты созданы для игроков всех уровней.
Есть возможность воспользоваться демо-режимом, после чего начать играть на реальные деньги.
Испытайте удачу и насладитесь неповторимой атмосферой игровых автоматов.
На нашей платформе можно найти различные игровые автоматы.
Мы собрали большой выбор игр от популярных брендов.
Каждая игра предлагает уникальной графикой, дополнительными возможностями и максимальной волатильностью.
http://dcnjf.com/demystifying-the-thrilling-world-of-online-casinos/
Каждый посетитель может тестировать автоматы без вложений или выигрывать настоящие призы.
Меню и структура ресурса просты и логичны, что облегчает поиск игр.
Если вас интересуют слоты, данный ресурс стоит посетить.
Начинайте играть уже сегодня — тысячи выигрышей ждут вас!
Здесь вы можете найти интересные слот-автоматы.
Здесь собраны подборку аппаратов от проверенных студий.
Каждая игра предлагает интересным геймплеем, увлекательными бонусами и максимальной волатильностью.
https://lavanyac.com/the-thrilling-world-of-online-casinos/
Пользователи могут запускать слоты бесплатно или выигрывать настоящие призы.
Интерфейс максимально удобны, что помогает легко находить нужные слоты.
Если вас интересуют слоты, этот сайт — отличный выбор.
Попробуйте удачу на сайте — тысячи выигрышей ждут вас!
Self-harm leading to death is a tragic topic that affects many families worldwide.
It is often connected to mental health issues, such as depression, hopelessness, or chemical dependency.
People who contemplate suicide may feel overwhelmed and believe there’s no hope left.
how-to-kill-yourself.com
We must raise awareness about this matter and offer a helping hand.
Early support can reduce the risk, and talking to someone is a crucial first step.
If you or someone you know is in crisis, don’t hesitate to get support.
You are not without options, and support exists.
На данной платформе вы найдёте разнообразные игровые слоты на платформе Champion.
Выбор игр включает классические автоматы и новейшие видеослоты с яркой графикой и специальными возможностями.
Каждый слот оптимизирован для максимального удовольствия как на десктопе, так и на смартфонах.
Будь вы новичком или профи, здесь вы найдёте подходящий вариант.
champion casino
Автоматы запускаются в любое время и не нуждаются в установке.
Также сайт предоставляет программы лояльности и обзоры игр, чтобы сделать игру ещё интереснее.
Начните играть прямо сейчас и оцените преимущества с казино Champion!
На данной платформе вы найдёте разнообразные слоты казино на платформе Champion.
Выбор игр представляет проверенные временем слоты и новейшие видеослоты с яркой графикой и специальными возможностями.
Всякий автомат создан для комфортного использования как на ПК, так и на мобильных устройствах.
Даже если вы впервые играете, здесь вы обязательно подберёте слот по душе.
online
Игры работают круглосуточно и работают прямо в браузере.
Дополнительно сайт предоставляет бонусы и полезную информацию, для удобства пользователей.
Попробуйте прямо сейчас и насладитесь азартом с брендом Champion!
На этом сайте представлены онлайн-игры из казино Вавада.
Каждый гость найдёт подходящую игру — от классических одноруких бандитов до новейших моделей с анимацией.
Казино Vavada предоставляет широкий выбор слотов от топовых провайдеров, включая игры с джекпотом.
Все игры запускается круглосуточно и адаптирован как для компьютеров, так и для мобильных устройств.
официальный сайт vavada
Вы сможете испытать атмосферой игры, не выходя из квартиры.
Навигация по сайту удобна, что обеспечивает быстро найти нужную игру.
Зарегистрируйтесь уже сегодня, чтобы почувствовать азарт с Vavada!
На этом сайте можно найти онлайн-игры платформы Vavada.
Каждый гость сможет выбрать автомат по интересам — от классических игр до современных разработок с анимацией.
Казино Vavada предоставляет широкий выбор популярных игр, включая слоты с крупными выигрышами.
Любой автомат работает в любое время и адаптирован как для настольных устройств, так и для телефонов.
vavada casino
Игроки могут наслаждаться настоящим драйвом, не выходя из квартиры.
Структура платформы проста, что позволяет моментально приступить к игре.
Зарегистрируйтесь уже сегодня, чтобы погрузиться в мир выигрышей!
On this platform, you can access a great variety of slot machines from famous studios.
Users can enjoy retro-style games as well as feature-packed games with high-quality visuals and interactive gameplay.
Whether you’re a beginner or a seasoned gamer, there’s always a slot to match your mood.
casino
Each title are available round the clock and compatible with PCs and tablets alike.
You don’t need to install anything, so you can get started without hassle.
Site navigation is user-friendly, making it simple to find your favorite slot.
Register now, and enjoy the excitement of spinning reels!
This website, you can access a great variety of casino slots from famous studios.
Visitors can enjoy classic slots as well as modern video slots with high-quality visuals and exciting features.
If you’re just starting out or a casino enthusiast, there’s always a slot to match your mood.
play aviator
All slot machines are ready to play anytime and designed for laptops and tablets alike.
All games run in your browser, so you can get started without hassle.
The interface is easy to use, making it quick to explore new games.
Join the fun, and discover the thrill of casino games!
Сайт BlackSprut — это одна из самых известных точек входа в даркнете, открывающая разнообразные сервисы для пользователей.
На платформе реализована простая структура, а структура меню понятен даже новичкам.
Участники отмечают быструю загрузку страниц и активное сообщество.
bs2 bsme
Сервис настроен на удобство и анонимность при навигации.
Если вы интересуетесь альтернативные цифровые пространства, площадка будет интересным вариантом.
Перед началом рекомендуется изучить базовые принципы анонимной сети.
Платформа BlackSprut — это хорошо известная онлайн-площадок в darknet-среде, предлагающая разные функции в рамках сообщества.
На платформе реализована простая структура, а структура меню понятен даже новичкам.
Участники выделяют стабильность работы и активное сообщество.
bs2best
BlackSprut ориентирован на комфорт и анонимность при навигации.
Кому интересны альтернативные цифровые пространства, этот проект станет хорошим примером.
Прежде чем начать лучше ознакомиться с информацию о работе Tor.
Онлайн-площадка — цифровая витрина профессионального детективного агентства.
Мы организуем помощь по частным расследованиям.
Коллектив детективов работает с повышенной конфиденциальностью.
Наша работа включает сбор информации и детальное изучение обстоятельств.
Детективное агентство
Каждое дело рассматривается индивидуально.
Задействуем эффективные инструменты и действуем в правовом поле.
Если вы ищете ответственное агентство — вы нашли нужный сайт.
Этот сайт — цифровая витрина независимого сыскного бюро.
Мы организуем помощь в решении деликатных ситуаций.
Группа профессионалов работает с абсолютной осторожностью.
Наша работа включает наблюдение и детальное изучение обстоятельств.
Детективное агентство
Каждое обращение рассматривается индивидуально.
Применяем проверенные подходы и действуем в правовом поле.
Нуждаетесь в реальную помощь — вы по адресу.
Данный ресурс — официальная страница частного сыскного бюро.
Мы предлагаем помощь по частным расследованиям.
Коллектив профессионалов работает с абсолютной осторожностью.
Нам доверяют поиски людей и разные виды расследований.
Заказать детектива
Каждое обращение обрабатывается персонально.
Мы используем проверенные подходы и действуем в правовом поле.
Ищете достоверную информацию — добро пожаловать.
На данной платформе можно найти игровые автоматы платформы Vavada.
Каждый гость сможет выбрать слот на свой вкус — от простых аппаратов до новейших разработок с бонусными раундами.
Vavada предлагает доступ к популярных игр, включая игры с джекпотом.
Все игры доступен круглосуточно и адаптирован как для ПК, так и для планшетов.
vavada бонусы
Вы сможете испытать атмосферой игры, не выходя из квартиры.
Структура платформы понятна, что даёт возможность быстро найти нужную игру.
Зарегистрируйтесь уже сегодня, чтобы открыть для себя любимые слоты!
Our platform offers a great variety of decorative wall clocks for every room.
You can discover modern and vintage styles to fit your living space.
Each piece is curated for its visual appeal and accuracy.
Whether you’re decorating a stylish living room, there’s always a perfect clock waiting for you.
small vintage table clocks
Our assortment is regularly refreshed with new arrivals.
We ensure a smooth experience, so your order is always in good care.
Start your journey to timeless elegance with just a few clicks.
This online store offers a wide selection of decorative wall clocks for your interior.
You can check out minimalist and traditional styles to fit your home.
Each piece is curated for its aesthetic value and reliable performance.
Whether you’re decorating a creative workspace, there’s always a fitting clock waiting for you.
best birdhouse pendulum wall clocks
The collection is regularly refreshed with exclusive releases.
We care about customer satisfaction, so your order is always in safe hands.
Start your journey to enhanced interiors with just a few clicks.
Here offers a great variety of stylish wall-mounted clocks for your interior.
You can browse modern and timeless styles to fit your home.
Each piece is chosen for its visual appeal and functionality.
Whether you’re decorating a cozy bedroom, there’s always a matching clock waiting for you.
best kosda led alarm clocks
The collection is regularly updated with new arrivals.
We ensure quality packaging, so your order is always in good care.
Start your journey to perfect timing with just a few clicks.
This website offers a large assortment of interior clock designs for your interior.
You can browse urban and classic styles to match your living space.
Each piece is hand-picked for its craftsmanship and reliable performance.
Whether you’re decorating a stylish living room, there’s always a perfect clock waiting for you.
hito modern wall clocks
The collection is regularly refreshed with fresh designs.
We focus on customer satisfaction, so your order is always in professional processing.
Start your journey to enhanced interiors with just a few clicks.
This online store offers a large assortment of interior clock designs for your interior.
You can explore urban and classic styles to complement your living space.
Each piece is chosen for its aesthetic value and accuracy.
Whether you’re decorating a cozy bedroom, there’s always a beautiful clock waiting for you.
creative wall clocks
The shop is regularly updated with exclusive releases.
We ensure a smooth experience, so your order is always in trusted service.
Start your journey to enhanced interiors with just a few clicks.
Our platform offers a large assortment of home timepieces for your interior.
You can explore urban and classic styles to fit your interior.
Each piece is curated for its aesthetic value and reliable performance.
Whether you’re decorating a creative workspace, there’s always a perfect clock waiting for you.
retro alarm clocks
The collection is regularly expanded with new arrivals.
We ensure customer satisfaction, so your order is always in good care.
Start your journey to enhanced interiors with just a few clicks.
This online service offers a large selection of medications for easy access.
Users can easily get treatments without leaving home.
Our range includes popular medications and targeted therapies.
Each item is sourced from verified pharmacies.
https://community.alteryx.com/t5/user/viewprofilepage/user-id/576949
We maintain customer safety, with encrypted transactions and prompt delivery.
Whether you’re filling a prescription, you’ll find trusted options here.
Visit the store today and get convenient online pharmacy service.
На этом сайте предоставляет нахождения вакансий по всей стране.
Пользователям доступны разные объявления от настоящих компаний.
На платформе появляются вакансии в разнообразных нишах.
Частичная занятость — всё зависит от вас.
Кримінальна робота
Навигация простой и подстроен на любой уровень опыта.
Регистрация не потребует усилий.
Ищете работу? — просматривайте вакансии.
Этот портал предлагает поиска работы на территории Украины.
Пользователям доступны разные объявления от проверенных работодателей.
Мы публикуем объявления о работе в различных сферах.
Частичная занятость — вы выбираете.
Робота з ризиком
Навигация легко осваивается и подходит на всех пользователей.
Регистрация займёт минимум времени.
Хотите сменить сферу? — просматривайте вакансии.
This website, you can access a great variety of casino slots from top providers.
Users can enjoy classic slots as well as feature-packed games with stunning graphics and bonus rounds.
If you’re just starting out or a casino enthusiast, there’s a game that fits your style.
casino games
Each title are available round the clock and compatible with desktop computers and mobile devices alike.
All games run in your browser, so you can get started without hassle.
The interface is easy to use, making it simple to find your favorite slot.
Sign up today, and dive into the excitement of spinning reels!
This website, you can find a great variety of casino slots from famous studios.
Users can try out retro-style games as well as feature-packed games with vivid animation and exciting features.
If you’re just starting out or a seasoned gamer, there’s something for everyone.
play casino
Each title are ready to play 24/7 and designed for laptops and tablets alike.
No download is required, so you can get started without hassle.
Platform layout is user-friendly, making it quick to explore new games.
Join the fun, and discover the thrill of casino games!
Текущий модный сезон обещает быть непредсказуемым и нестандартным в плане моды.
В тренде будут асимметрия и минимализм с изюминкой.
Актуальные тона включают в себя неоновые оттенки, создающие настроение.
Особое внимание дизайнеры уделяют тканям, среди которых популярны винтажные очки.
https://www.globalfreetalk.com/read-blog/31372
Возвращаются в моду элементы ретро-стиля, через призму сегодняшнего дня.
На подиумах уже можно увидеть смелые решения, которые удивляют.
Следите за обновлениями, чтобы создать свой образ.
Mechanical watches will forever stay fashionable.
They symbolize heritage and offer a sense of artistry that modern gadgets simply don’t replicate.
These watches is powered by complex gears, making it both reliable and inspiring.
Collectors cherish the craft behind them.
http://bedfordfalls.live/read-blog/119968
Wearing a mechanical watch is not just about checking hours, but about making a statement.
Their aesthetics are classic, often passed from lifetime to legacy.
All in all, mechanical watches will forever hold their place.
This website, you can find a great variety of slot machines from leading developers.
Visitors can try out traditional machines as well as modern video slots with high-quality visuals and interactive gameplay.
If you’re just starting out or a casino enthusiast, there’s always a slot to match your mood.
play casino
Each title are instantly accessible round the clock and designed for laptops and smartphones alike.
No download is required, so you can jump into the action right away.
The interface is intuitive, making it simple to browse the collection.
Register now, and enjoy the excitement of spinning reels!
On this platform, you can discover lots of online slots from leading developers.
Visitors can experience classic slots as well as modern video slots with vivid animation and bonus rounds.
Even if you’re new or a casino enthusiast, there’s always a slot to match your mood.
play aviator
Each title are instantly accessible anytime and compatible with PCs and smartphones alike.
You don’t need to install anything, so you can start playing instantly.
The interface is intuitive, making it convenient to browse the collection.
Register now, and enjoy the excitement of spinning reels!
Were you aware that 1 in 3 people taking prescriptions make dangerous drug mistakes due to insufficient information?
Your health is your most valuable asset. Each pharmaceutical choice you make directly impacts your quality of life. Maintaining awareness about medical treatments is absolutely essential for successful recovery.
Your health isn’t just about following prescriptions. Every medication affects your body’s chemistry in unique ways.
Consider these critical facts:
1. Combining medications can cause dangerous side effects
2. Over-the-counter supplements have potent side effects
3. Skipping doses undermines therapy
To avoid risks, always:
✓ Verify interactions via medical databases
✓ Study labels in detail when starting any medication
✓ Consult your doctor about proper usage
___________________________________
For reliable drug information, visit:
https://community.alteryx.com/t5/user/viewprofilepage/user-id/569428
Our e-pharmacy features a broad selection of medications with competitive pricing.
Customers can discover all types of remedies to meet your health needs.
We strive to maintain high-quality products at a reasonable cost.
Fast and reliable shipping provides that your order arrives on time.
Take advantage of ordering medications online on our platform.
kamagra effervescent
This online pharmacy features a broad selection of pharmaceuticals at affordable prices.
Shoppers will encounter all types of medicines suitable for different health conditions.
We work hard to offer high-quality products without breaking the bank.
Quick and dependable delivery guarantees that your purchase is delivered promptly.
Experience the convenience of getting your meds with us.
amoxil 1000 antibiotic
The site offers buggy hire throughout Crete.
Visitors can quickly book a vehicle for travel.
If you’re looking to explore natural spots, a buggy is the ideal way to do it.
https://peatix.com/user/26412811/view
Our rides are ready to go and available for daily schedules.
Booking through this site is simple and comes with affordable prices.
Get ready to ride and feel Crete like never before.
This section showcases disc player alarm devices crafted by top providers.
Visit to explore modern disc players with digital radio and dual wake options.
Many models include external audio inputs, charging capability, and battery backup.
Available products spans economical models to luxury editions.
radio cd player alarm clock
All devices offer sleep timers, rest timers, and digital displays.
Order today are available via online retailers with fast shipping.
Choose the perfect clock-radio-CD setup for kitchen everyday enjoyment.
Here, you can discover a wide selection of slot machines from leading developers.
Users can experience traditional machines as well as feature-packed games with stunning graphics and interactive gameplay.
Whether you’re a beginner or a casino enthusiast, there’s a game that fits your style.
casino slots
All slot machines are available anytime and designed for laptops and smartphones alike.
All games run in your browser, so you can jump into the action right away.
The interface is user-friendly, making it convenient to find your favorite slot.
Register now, and enjoy the world of online slots!
Наличие медицинской страховки перед поездкой за рубеж — это разумное решение для защиты здоровья путешественника.
Полис гарантирует расходы на лечение в случае заболевания за границей.
Также, полис может обеспечивать компенсацию на возвращение домой.
осаго рассчитать
Некоторые государства предусматривают оформление полиса для посещения.
Без страховки медицинские расходы могут обойтись дорого.
Оформление полиса заранее
The site lets you connect with workers for short-term risky jobs.
Users can quickly schedule services for unique needs.
All workers are trained in managing intense tasks.
assassin for hire
Our platform provides safe interactions between requesters and freelancers.
For those needing a quick solution, this website is the right choice.
Submit a task and match with an expert now!
Il nostro servizio offre l’assunzione di operatori per attività a rischio.
I clienti possono trovare esperti affidabili per incarichi occasionali.
Ogni candidato vengono scelti con cura.
sonsofanarchy-italia.com
Utilizzando il servizio è possibile leggere recensioni prima della scelta.
La qualità è un nostro impegno.
Esplorate le offerte oggi stesso per portare a termine il vostro progetto!
На нашем ресурсе вы можете найти актуальное зеркало 1хбет без ограничений.
Мы регулярно обновляем зеркала, чтобы облегчить свободное подключение к сайту.
Используя зеркало, вы сможете пользоваться всеми функциями без ограничений.
зеркало 1хбет
Данный портал позволит вам быстро найти новую ссылку 1хБет.
Мы стремимся, чтобы все клиенты имел возможность получить полный доступ.
Проверяйте новые ссылки, чтобы всегда оставаться в игре с 1xBet!
Данный ресурс — настоящий цифровой магазин Боттега Вэнета с доставкой по стране.
Через наш портал вы можете приобрести эксклюзивные вещи Боттега Венета без посредников.
Каждая покупка подтверждены сертификатами от компании.
боттега венета цум
Отправка осуществляется оперативно в любое место России.
Интернет-магазин предлагает выгодные условия покупки и гарантию возврата средств.
Покупайте на официальном сайте Bottega Veneta, чтобы чувствовать уверенность в покупке!
通过本平台,您可以聘请专门从事临时的高危工作的人员。
我们整理了大量可靠的行动专家供您选择。
无论面对何种高风险任务,您都可以方便找到专业的助手。
chinese-hitman-assassin.com
所有任务完成者均经过审核,保障您的利益。
服务中心注重专业性,让您的任务委托更加无忧。
如果您需要服务详情,请随时咨询!
On this site, you can find top CS:GO gaming sites.
We have collected a wide range of gaming platforms specialized in CS:GO.
Every website is tested for quality to guarantee safety.
cs roulette
Whether you’re a seasoned bettor, you’ll conveniently choose a platform that fits your style.
Our goal is to guide you to find reliable CS:GO gambling websites.
Start browsing our list right away and enhance your CS:GO betting experience!
В данном ресурсе вы найдёте подробную информацию о партнёрском предложении: 1win партнерская программа.
Здесь размещены все нюансы работы, правила присоединения и возможные бонусы.
Любой блок подробно освещён, что позволяет легко усвоить в тонкостях функционирования.
Плюс ко всему, имеются разъяснения по запросам и подсказки для первых шагов.
Информация регулярно обновляется, поэтому вы смело полагаться в актуальности предоставленных данных.
Этот ресурс станет вашим надежным помощником в изучении партнёрской программы 1Win.
The site makes it possible to hire experts for temporary high-risk jobs.
Clients may easily arrange help for specialized needs.
All workers are experienced in handling critical operations.
hitman for hire
Our platform provides private arrangements between employers and specialists.
If you require a quick solution, the site is the right choice.
Post your request and match with the right person now!
Questo sito permette l’assunzione di lavoratori per compiti delicati.
Gli utenti possono trovare esperti affidabili per operazioni isolate.
Tutti i lavoratori sono valutati con cura.
sonsofanarchy-italia.com
Con il nostro aiuto è possibile consultare disponibilità prima di assumere.
La qualità è al centro del nostro servizio.
Sfogliate i profili oggi stesso per ottenere aiuto specializzato!
Searching for experienced workers ready for temporary dangerous jobs.
Require a specialist for a perilous job? Connect with certified laborers on our platform for time-sensitive dangerous operations.
hitman for hire
This website connects businesses with licensed workers willing to accept unsafe one-off gigs.
Recruit verified freelancers for risky duties safely. Ideal when you need emergency assignments demanding specialized labor.
Here, you can find a great variety of casino slots from leading developers.
Players can enjoy traditional machines as well as new-generation slots with stunning graphics and bonus rounds.
Even if you’re new or an experienced player, there’s a game that fits your style.
casino games
Each title are instantly accessible anytime and designed for PCs and tablets alike.
No download is required, so you can get started without hassle.
Site navigation is easy to use, making it quick to browse the collection.
Register now, and enjoy the world of online slots!
People contemplate ending their life due to many factors, often resulting from severe mental anguish.
A sense of despair might overpower their motivation to go on. Often, isolation is a major factor in this decision.
Conditions like depression or anxiety impair decision-making, preventing someone to recognize options beyond their current state.
how to commit suicide
Life stressors could lead a person to consider drastic measures.
Lack of access to help might result in a sense of no escape. Understand that reaching out is crucial.
欢迎光临,这是一个仅限成年人浏览的站点。
进入前请确认您已年满十八岁,并同意接受相关条款。
本网站包含不适合未成年人观看的内容,请理性访问。 色情网站。
若不符合年龄要求,请立即关闭窗口。
我们致力于提供合法合规的娱乐内容。
Searching for someone to take on a one-time risky job?
This platform specializes in connecting customers with freelancers who are willing to tackle serious jobs.
Whether you’re handling urgent repairs, unsafe cleanups, or complex installations, you’re at the right place.
All listed professional is pre-screened and qualified to ensure your safety.
rent a hitman
This service provide transparent pricing, detailed profiles, and safe payment methods.
Regardless of how difficult the scenario, our network has the skills to get it done.
Start your quest today and find the perfect candidate for your needs.
On the resource necessary info about ways of becoming a digital intruder.
Facts are conveyed in a precise and comprehensible manner.
You may acquire numerous approaches for entering systems.
Furthermore, there are real-life cases that exhibit how to employ these aptitudes.
how to become a hacker
Total knowledge is periodically modified to be in sync with the latest trends in cybersecurity.
Extra care is devoted to real-world use of the mastered abilities.
Remember that any undertaking should be applied lawfully and through ethical means only.
Here are presented exclusive promocodes for 1x Bet.
The promo codes help to get additional rewards when betting on the service.
All existing discount vouchers are constantly refreshed to guarantee they work.
When using these promotions one can boost your potential winnings on the online service.
https://sutango.com/wp-content/pgs/kak_poluchity_besplatnuyu_medpomoschy_vo_vremya_beremennosti_i_rodov.html
Plus, detailed instructions on how to apply discounts are offered for maximum efficiency.
Consider that specific offers may have specific terms, so examine rules before redeeming.
Here you can obtain unique promo codes for a renowned betting brand.
The assortment of bonus opportunities is persistently enhanced to provide that you always have reach to the latest offers.
Through these promotional deals, you can economize considerably on your betting endeavors and increase your chances of gaining an edge.
All promo codes are accurately validated for legitimacy and efficiency before being published.
https://aadesignoffice.com/pages/kak_vyglyadit_sovremennyy_kuhonnyy_processor_ne_prosto_blender.html
Plus, we present thorough explanations on how to implement each profitable opportunity to improve your bonuses.
Note that some bargains may have definite prerequisites or predetermined timeframes, so it’s vital to study closely all the facts before applying them.
Welcome to our platform, where you can discover premium materials created specifically for grown-ups.
Our library available here is suitable for individuals who are 18 years old or above.
Ensure that you meet the age requirement before exploring further.
big cock
Enjoy a one-of-a-kind selection of age-restricted materials, and immerse yourself today!
Our platform makes available many types of medical products for home delivery.
Anyone can easily get treatments from your device.
Our catalog includes popular medications and specialty items.
All products is supplied through licensed suppliers.
vibramycin for dogs
We prioritize customer safety, with data protection and timely service.
Whether you’re managing a chronic condition, you’ll find affordable choices here.
Visit the store today and enjoy convenient access to medicine.
One X Bet represents a top-tier sports betting provider.
Offering a wide range of sports, 1XBet caters to a vast audience worldwide.
The 1XBet application crafted intended for Android as well as iOS users.
https://samatravel.in/pages/vred_diet_esty_li_on.html
Players are able to install the mobile version from the platform’s page or Google Play Store for Android.
iPhone customers, the app can be installed via Apple’s store without hassle.
Our platform offers a large selection of pharmaceuticals for easy access.
You can securely get health products from your device.
Our catalog includes standard treatments and custom orders.
All products is sourced from verified providers.
kamagra reviews
We maintain quality and care, with encrypted transactions and fast shipping.
Whether you’re looking for daily supplements, you’ll find safe products here.
Visit the store today and get trusted support.
1xBet Bonus Code – Vip Bonus as much as 130 Euros
Use the 1xBet promo code: 1xbro200 when registering via the application to unlock special perks offered by One X Bet for a $130 up to a full hundred percent, for placing bets along with a casino bonus including free spin package. Open the app then continue through the sign-up steps.
The One X Bet promo code: 1XBRO200 offers an amazing welcome bonus to new players — full one hundred percent up to €130 upon registration. Bonus codes serve as the key to obtaining extra benefits, and 1XBet’s bonus codes are the same. When applying this code, users have the chance from multiple deals in various phases within their betting activity. Though you don’t qualify for the welcome bonus, One X Bet India guarantees its devoted players receive gifts via ongoing deals. Check the Promotions section on their website frequently to stay updated about current deals designed for current users.
promo code for 1xbet india today
What 1XBet promotional code is currently active today?
The promotional code applicable to 1xBet equals 1XBRO200, which allows novice players joining the betting service to access an offer of €130. In order to unlock exclusive bonuses related to games and wagering, kindly enter the promotional code related to 1XBET in the registration form. To take advantage of such a promotion, prospective users need to type the promo code Code 1xbet while signing up process so they can obtain a 100% bonus on their initial deposit.
Within this platform, you can discover a wide selection adult videos.
Every video is carefully curated guaranteeing maximum satisfaction for users.
In need of certain themes or casually exploring, this resource provides material tailored to preferences.
bbc videos
New videos constantly refreshed, so that the library up-to-date.
Access to every piece of content protected to users of legal age, maintaining standards with applicable laws.
Stay tuned for new releases, as the platform adds more content daily.
1xBet Bonus Code – Exclusive Bonus as much as 130 Euros
Apply the 1xBet promo code: 1xbro200 while signing up in the App to avail exclusive rewards given by One X Bet to receive €130 maximum of 100%, for placing bets plus a $1950 with one hundred fifty free spins. Start the app and proceed through the sign-up process.
The 1xBet promo code: 1xbro200 gives a fantastic starter bonus for first-time users — 100% maximum of 130 Euros once you register. Promo codes are the key for accessing bonuses, plus 1xBet’s promotional codes are the same. By using such a code, bettors have the chance from multiple deals at different stages of their betting experience. Though you don’t qualify for the initial offer, One X Bet India ensures its loyal users get compensated through regular bonuses. Look at the Deals tab via their platform regularly to stay updated about current deals tailored for existing players.
https://wiki.addmyurls.com/profile.php?user=alicia-ziesemer-143184&do=profile
What 1XBet bonus code is now valid today?
The promotional code applicable to 1XBet is 1XBRO200, permitting new customers joining the gambling provider to access an offer amounting to €130. In order to unlock unique offers related to games and wagering, make sure to type our bonus code related to 1XBET during the sign-up process. In order to benefit of this offer, potential customers must input the promo code 1XBET at the time of registering procedure to receive a 100% bonus applied to the opening contribution.
На этом сайте вы можете найти актуальные промокоды для Melbet.
Примените коды при регистрации в системе для получения до 100% при стартовом взносе.
Плюс ко всему, можно найти бонусы в рамках действующих программ и постоянных игроков.
промокод melbet при регистрации
Проверяйте регулярно в рубрике акций, чтобы не упустить выгодные предложения от Melbet.
Каждый бонус обновляется на работоспособность, и обеспечивает безопасность во время активации.
1xBet Promo Code – Exclusive Bonus maximum of 130 Euros
Use the One X Bet promotional code: 1xbro200 while signing up via the application to access the benefits given by 1xBet for a 130 Euros up to a full hundred percent, for sports betting plus a $1950 with one hundred fifty free spins. Launch the app and proceed with the registration process.
The 1XBet promotional code: Code 1XBRO200 provides a fantastic starter bonus for first-time users — 100% up to $130 during sign-up. Promotional codes act as the key to unlocking bonuses, plus 1xBet’s bonus codes are no exception. When applying such a code, bettors can take advantage from multiple deals in various phases in their gaming adventure. Though you don’t qualify to the starter reward, One X Bet India ensures its loyal users receive gifts with frequent promotions. Look at the Deals tab via their platform regularly to stay updated regarding recent promotions designed for existing players.
1xbet promo code
What 1xBet promotional code is now valid today?
The promo code applicable to One X Bet equals Code 1XBRO200, which allows new customers registering with the betting service to unlock a bonus amounting to €130. To access exclusive bonuses pertaining to gaming and sports betting, kindly enter the promotional code for 1XBET while filling out the form. To take advantage of such a promotion, prospective users must input the bonus code Code 1xbet at the time of registering process for getting double their deposit amount applied to the opening contribution.
On this site, you can easily find interactive video sessions.
Interested in friendly chats business discussions, the site offers a solution tailored to you.
Live communication module developed for bringing users together globally.
With high-quality video along with sharp sound, every conversation becomes engaging.
You can join public rooms initiate one-on-one conversations, according to what suits you best.
https://rt.webcamsex18.ru/
The only thing needed a reliable network plus any compatible tool begin chatting.
On this site, explore a wide range of online casinos.
Interested in traditional options or modern slots, there’s something for every player.
All featured casinos checked thoroughly for trustworthiness, so you can play with confidence.
pin-up
What’s more, the site provides special rewards along with offers targeted at first-timers as well as regulars.
Due to simple access, discovering a suitable site takes just moments, enhancing your experience.
Be in the know on recent updates with frequent visits, since new casinos are added regularly.
Здесь доступны интерактивные видео сессии.
Вам нужны увлекательные диалоги переговоры, на платформе представлены решения для каждого.
Этот инструмент создана чтобы объединить пользователей со всего мира.
порно онлайн чат
Благодаря HD-качеству и превосходным звуком, любое общение становится увлекательным.
Войти в общий чат общаться один на один, в зависимости от ваших предпочтений.
Все, что требуется — хорошая связь плюс подходящий гаджет, чтобы начать.
On this platform, you can find a great variety of online slots from famous studios.
Users can try out traditional machines as well as new-generation slots with stunning graphics and interactive gameplay.
Even if you’re new or a seasoned gamer, there’s a game that fits your style.
casino
The games are available round the clock and optimized for desktop computers and mobile devices alike.
All games run in your browser, so you can jump into the action right away.
Site navigation is user-friendly, making it simple to find your favorite slot.
Join the fun, and dive into the excitement of spinning reels!
On this site, find a wide range of online casinos.
Interested in traditional options new slot machines, you’ll find an option to suit all preferences.
The listed platforms checked thoroughly for trustworthiness, so you can play with confidence.
1xbet
Additionally, this resource offers exclusive bonuses along with offers targeted at first-timers including long-term users.
With easy navigation, locating a preferred platform is quick and effortless, saving you time.
Be in the know on recent updates by visiting frequently, as fresh options appear consistently.
This website, you can access a wide selection of online slots from famous studios.
Visitors can try out traditional machines as well as feature-packed games with high-quality visuals and bonus rounds.
If you’re just starting out or an experienced player, there’s a game that fits your style.
casino slots
The games are available anytime and compatible with PCs and smartphones alike.
You don’t need to install anything, so you can jump into the action right away.
Site navigation is intuitive, making it simple to browse the collection.
Sign up today, and enjoy the world of online slots!
The Aviator Game blends air travel with exciting rewards.
Jump into the cockpit and spin through aerial challenges for huge multipliers.
With its vintage-inspired graphics, the game captures the spirit of early aviation.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – withdraw before it flies away to lock in your rewards.
Featuring instant gameplay and realistic background music, it’s a top choice for casual players.
Whether you’re looking for fun, Aviator delivers endless thrills with every round.
这个网站 提供 海量的 成人内容,满足 不同用户 的 喜好。
无论您喜欢 什么样的 的 视频,这里都 种类齐全。
所有 内容 都经过 专业整理,确保 高品质 的 观看体验。
黄色书刊
我们支持 各种终端 访问,包括 电脑,随时随地 自由浏览。
加入我们,探索 激情时刻 的 成人世界。
The Aviator Game merges exploration with high stakes.
Jump into the cockpit and try your luck through aerial challenges for huge multipliers.
With its classic-inspired graphics, the game reflects the spirit of early aviation.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – claim before it disappears to lock in your rewards.
Featuring seamless gameplay and realistic audio design, it’s a top choice for slot enthusiasts.
Whether you’re testing luck, Aviator delivers endless action with every round.
This flight-themed slot blends adventure with exciting rewards.
Jump into the cockpit and try your luck through turbulent skies for huge multipliers.
With its classic-inspired visuals, the game evokes the spirit of pioneering pilots.
aviator game download
Watch as the plane takes off – withdraw before it flies away to lock in your earnings.
Featuring seamless gameplay and immersive audio design, it’s a favorite for gambling fans.
Whether you’re testing luck, Aviator delivers non-stop excitement with every spin.
Aviator combines exploration with exciting rewards.
Jump into the cockpit and play through turbulent skies for sky-high prizes.
With its vintage-inspired design, the game evokes the spirit of aircraft legends.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – withdraw before it flies away to lock in your winnings.
Featuring smooth gameplay and immersive audio design, it’s a top choice for slot enthusiasts.
Whether you’re chasing wins, Aviator delivers endless action with every round.
On this site, you can discover a wide range virtual gambling platforms.
Whether you’re looking for classic games latest releases, there’s a choice for every player.
Every casino included are verified for safety, enabling gamers to bet with confidence.
casino
Additionally, the platform offers exclusive bonuses along with offers for new players and loyal customers.
Due to simple access, discovering a suitable site takes just moments, making it convenient.
Stay updated about the latest additions with frequent visits, since new casinos appear consistently.
On this site, explore an extensive selection internet-based casino sites.
Interested in classic games or modern slots, there’s a choice to suit all preferences.
Every casino included fully reviewed for trustworthiness, so you can play securely.
1xbet
Moreover, this resource unique promotions plus incentives targeted at first-timers and loyal customers.
Due to simple access, finding your favorite casino is quick and effortless, making it convenient.
Keep informed regarding new entries by visiting frequently, as fresh options come on board often.
В этом месте доступны эротические материалы.
Контент подходит тем, кто старше 18.
У нас собраны широкий выбор контента.
Платформа предлагает качественный контент.
купить Гидроморфинол
Вход разрешен только для совершеннолетних.
Наслаждайтесь безопасным просмотром.
Свадебные и вечерние платья 2025 года задают новые стандарты.
Популярны пышные модели до колен из полупрозрачных тканей.
Блестящие ткани создают эффект жидкого металла.
Многослойные юбки определяют современные тренды.
Разрезы на юбках создают баланс между строгостью и игрой.
Ищите вдохновение в новых коллекциях — стиль и качество сделают ваш образ идеальным!
http://mtw2014.tmweb.ru/forum/?PAGE_NAME=message&FID=1&TID=11953&TITLE_SEO=11953-programma-dlya-prosmotra-kamer-videonablyudeniya&MID=658471&result=reply#message658471
У нас вы можете найти вспомогательные материалы для школьников.
Предоставляем материалы по всем основным предметам с учетом современных требований.
Готовьтесь к ЕГЭ и ОГЭ с помощью тренажеров.
https://bulgarizdat.ru/publikaczii/gdz-effektivnoe-ispolzovanie-gotovyh-domashnih-zadanij-dlya-uluchsheniya-uspevaemosti/
Примеры решений упростят процесс обучения.
Регистрация не требуется для комфортного использования.
Используйте ресурсы дома и успешно сдавайте экзамены.
цвет с доставкой недорого доставка цветов онлайн
Свежие актуальные Новости хоккея со всего мира. Результаты матчей, интервью, аналитика, расписание игр и обзоры соревнований. Будьте в курсе главных событий каждый день!
Микрозаймы онлайн https://kskredit.ru на карту — быстрое оформление, без справок и поручителей. Получите деньги за 5 минут, круглосуточно и без отказа. Доступны займы с любой кредитной историей.
Хочешь больше денег https://mfokapital.ru Изучай инвестиции, учись зарабатывать, управляй финансами, торгуй на Форекс и используй магию денег. Рабочие схемы, ритуалы, лайфхаки и инструкции — путь к финансовой независимости начинается здесь!
Быстрые микрозаймы https://clover-finance.ru без отказа — деньги онлайн за 5 минут. Минимум документов, максимум удобства. Получите займ с любой кредитной историей.
Сделай сам как сделать ремонта плитка Ремонт квартиры и дома своими руками: стены, пол, потолок, сантехника, электрика и отделка. Всё, что нужно — в одном месте: от выбора материалов до финального штриха. Экономьте с умом!
Трендовые фасоны сезона нынешнего года отличаются разнообразием.
Актуальны кружевные рукава и корсеты из полупрозрачных тканей.
Металлические оттенки делают платье запоминающимся.
Греческий стиль с драпировкой определяют современные тренды.
Минималистичные силуэты подчеркивают элегантность.
Ищите вдохновение в новых коллекциях — детали и фактуры оставят в памяти гостей!
https://wiki.hightgames.ru/index.php/%D0%9E%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_%D1%83%D1%87%D0%B0%D1%81%D1%82%D0%BD%D0%B8%D0%BA%D0%B0:46.8.210.172#.D0.90.D0.BA.D1.82.D1.83.D0.B0.D0.BB.D1.8C.D0.BD.D1.8B.D0.B5_.D1.81.D0.B2.D0.B0.D0.B4.D0.B5.D0.B1.D0.BD.D1.8B.D0.B5_.D0.BE.D0.B1.D1.80.D0.B0.D0.B7.D1.8B_2025_.E2.80.94_.D0.BA.D0.B0.D0.BA_.D0.B2.D1.8B.D0.B1.D1.80.D0.B0.D1.82.D1.8C.3F
КПК «Доверие» https://bankingsmp.ru надежный кредитно-потребительский кооператив. Выгодные сбережения и доступные займы для пайщиков. Прозрачные условия, высокая доходность, финансовая стабильность и юридическая безопасность.
Ваш финансовый гид https://kreditandbanks.ru — подбираем лучшие предложения по кредитам, займам и банковским продуктам. Рейтинг МФО, советы по улучшению КИ, юридическая информация и онлайн-сервисы.
Займы под залог https://srochnyye-zaymy.ru недвижимости — быстрые деньги на любые цели. Оформление от 1 дня, без справок и поручителей. Одобрение до 90%, выгодные условия, честные проценты. Квартира или дом остаются в вашей собственности.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Профессиональный массаж Ивантеевка: классический, лечебный, расслабляющий, антицеллюлитный. Квалифицированные массажисты, индивидуальный подход, комфортная обстановка. Запишитесь на сеанс уже сегодня!
party balloons dubai deliver balloons dubai
resume environmental engineer cv engineer resume
The wild symbol at the slot is the golden coin and will substitute for any other symbols at the game apart from the Leprechaun symbol and the pot of gold symbol. Our services facilitated by this website are operated by Broadway Gaming Ireland DF Limited, a company incorporated in the Republic of Ireland. A. To start playing real money slot games, register an account at Amazon Slots Casino make your first deposit, and browse our extensive collection of real money slots to find your favourite games. Home » Slots » iSoftBet » Lucky Leprechaun New players only. Min dep £10 with code WINK100. 100% games bonus (max £100). 30x games bonus wagering required. 5-day expiry. 18+ GambleAware.org. T&Cs apply. The second feature is the bonus round which is activated by landing the pot of gold scatter symbol. You’ll now be taken to a screen showing the Leprechaun stood next to 3 pots, each representing a different Jackpot amount. There are bronze, silver and gold jackpots and you’ll hope that the rainbow ends at the pot of gold for the biggest prize in the game. The Jackpot feature is only enacted if playing for the max bet size of 5.
https://medjutim.dnk.org.rs/aviator-official-game-3-things-to-check-first/
Designed to take your virtual gaming experience to a new level, Paddy Power Games is home to more than 1100 of the best online slots, showcasing an excellent library of online casino table games and dedicated live dealers. If you are one of Paddy Power’s new poker players, deposit £5 upon sign up and you get £20 in bonuses, plus your deposit will be matched 100% up to £200. This is undoubtedly one of the best poker sign up bonuses available at the moment. Paddy Power™ Games is one of the sections found at Paddy Power Casino, operated by the world-renowned Irish bookmakers of the same name. With hundreds of online slots and jackpot options, as well as roulette, poker, blackjack, and even a live casino section, it’s safe to say that this platform is a veritable treasure trove of online casino games.
Подходящи за офиса рокли в класически силуети и неутрални тонове
стилни дамски рокли http://www.rokli-damski.com .
Долговечность и энергоэффективность при строительстве деревянных домов
построить деревянный дом под ключ https://www.stroitelstvo-derevyannyh-domov178.ru .
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Услуги массажа Ивантеевка — здоровье, отдых и красота. Лечебный, баночный, лимфодренажный, расслабляющий и косметический массаж. Сертифицированнй мастер, удобное расположение, результат с первого раза.
Дамски комплекти в пастелни и неутрални тонове за универсално съчетание
дамски комплекти на промоция http://komplekti-za-jheni.com/ .
This iconic Audemars Piguet Royal Oak model combines luxury steel craftsmanship introduced in 2012 within the brand’s prestigious lineup.
Crafted in 41mm stainless steel boasts an octagonal bezel secured with eight visible screws, embodying the collection’s iconic DNA.
Equipped with the Cal. 3120 automatic mechanism, it ensures precise timekeeping with a date display at 3 o’clock.
Audemars 15400ST
The dial showcases a black Grande Tapisserie pattern highlighted by luminous appliqués for clear visibility.
A seamless steel link bracelet ensures comfort and durability, secured by a hidden clasp.
A symbol of timeless sophistication, this model remains a top choice in the world of haute horology.
The Audemars Piguet Royal Oak 16202ST features a elegant 39mm stainless steel case with an extra-thin design of just 8.1mm thickness, housing the latest selfwinding Calibre 7121. Its mesmerizing smoked blue gradient dial showcases a intricate galvanic textured finish, fading from a radiant center to dark periphery for a captivating aesthetic. The iconic eight-screw octagonal bezel pays homage to the original 1972 design, while the scratch-resistant sapphire glass ensures optimal legibility.
https://telegra.ph/Audemars-Piguet-Royal-Oak-16202ST-When-Steel-Became-Noble-06-02
Water-resistant to 50 meters, this “Jumbo” model balances sporty durability with luxurious refinement, paired with a steel link strap and reliable folding buckle. A contemporary celebration of classic design, the 16202ST embodies Audemars Piguet’s innovation through its meticulous mechanics and evergreen Royal Oak DNA.
Всё о городе городской портал города Ханты-Мансийск: свежие новости, события, справочник, расписания, культура, спорт, вакансии и объявления на одном городском портале.
Стилна визия и функционалност в най-новите спортни екипи
дамски спортни комплекти http://sportni-komplekti.com/ .
Моделите дамски тениски, които никога не излизат от мода
интересни дамски тениски https://teniski-damski.com/ .
Здесь доступен мессенджер-бот “Глаз Бога”, который проверить всю информацию о гражданине через открытые базы.
Инструмент функционирует по фото, обрабатывая доступные данные в сети. Через бота доступны бесплатный поиск и полный отчет по запросу.
Инструмент актуален на август 2024 и охватывает фото и видео. Бот гарантирует узнать данные в открытых базах и предоставит сведения за секунды.
Глаз Бога glazboga.net
Это сервис — помощник при поиске персон удаленно.
Стилни блузи с акцент върху талията и женствените форми
елегантни дамски блузи с къс ръкав http://www.bluzi-damski.com/ .
¿Quieres códigos promocionales vigentes de 1xBet? Aquí encontrarás recompensas especiales en apuestas deportivas .
El código 1x_12121 garantiza a hasta 6500₽ durante el registro .
Para completar, canjea 1XRUN200 y disfruta una oferta exclusiva de €1500 + 150 giros gratis.
https://kylerwhra96318.ttblogs.com/15093132/descubre-cómo-usar-el-código-promocional-1xbet-para-apostar-free-of-charge-en-argentina-méxico-chile-y-más
Mantente atento las novedades para conseguir más beneficios .
Todos los códigos son verificados para hoy .
¡Aprovecha y potencia tus apuestas con esta plataforma confiable!
В этом ресурсе вы можете получить доступ к боту “Глаз Бога” , который способен собрать всю информацию о любом человеке из открытых источников .
Данный сервис осуществляет проверку ФИО и раскрывает данные из онлайн-платформ.
С его помощью можно пробить данные через специализированную платформу, используя фотографию в качестве ключевого параметра.
probiv-bot.pro
Система “Глаз Бога” автоматически анализирует информацию из проверенных ресурсов, формируя структурированные данные .
Пользователи бота получают ограниченное тестирование для ознакомления с функционалом .
Сервис постоянно совершенствуется , сохраняя скорость обработки в соответствии с законодательством РФ.
Найти мастера по ремонту холодильников в Киеве можно на сайте
Строительство деревянных домов с акцентом на энергоэффективность и уют
дома деревянные под ключ https://stroitelstvo-derevyannyh-domov78.ru/ .
Уникальные маршруты и виды с борта арендованной яхты
аренда яхт в сочи https://arenda-yahty-sochi323.ru .
resume software engineer ats engineering resumes examples
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
Читайте о необычном http://phenoma.ru научно-популярные статьи о феноменах, которые до сих пор не имеют однозначных объяснений. Психология, физика, биология, космос — самые интересные загадки в одном разделе.
Профессиональная уборка после пожара, залива и ЧС
заказать клининг https://kliningovaya-kompaniya0.ru/ .
Шины всех типоразмеров в наличии в крупном онлайн-магазине
магазин шин и дисков https://www.kupit-shiny0-spb.ru .
Комплексная услуга: замер, производство, доставка и монтаж стеклянных душевых ограждений
п образные душевые стекла https://www.steklo777777.ru .
раздача стим аккаунтов бесплатно https://t.me/s/Burger_Game
resume for engineering jobs resume software engineer ats
стим аккаунт бесплатно без игр http://t.me/Burger_Game
Looking for exclusive 1xBet promo codes? This site offers verified bonus codes like 1x_12121 for registrations in 2024. Claim up to 32,500 RUB as a first deposit reward.
Use official promo codes during registration to maximize your rewards. Enjoy risk-free bets and exclusive deals tailored for sports betting.
Find monthly updated codes for global users with fast withdrawals.
Every promotional code is checked for validity.
Don’t miss limited-time offers like GIFT25 to increase winnings.
Active for first-time deposits only.
https://socialistener.com/story5150316/unlocking-1xbet-promo-codes-for-enhanced-betting-in-multiple-countriesStay ahead with 1xBet’s best promotions – apply codes like 1x_12121 at checkout.
Experience smooth rewards with instant activation.
Заказывайте сувениры с логотипом — работаем по всей России
изготовление сувенирной продукции с логотипом https://suvenirnaya-produktsiya-s-logotipom-1.ru .
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
resume as a engineer chief engineer cv example
Подбор оптимального лизинга по параметрам с помощью автоматизированного маркетплейса
маркетплейс лизинга https://lizingovyy-agregator.ru .
Offline Mode: Ready to take a break from online connectivity? Aviator APK offers an offline mode where you can practice your skills or simply enjoy the game without an internet connection. Entdecken Sie die Faszination von Plinko: Das beliebteste Spiel der Glücksritter! Die Geschichte von Plinko Wie Plinko gespielt wird Strategien für erfolgreiches Plinko-Spiel Die Psychologie des Spiels Online-Plinko: Die digitale Version des Erfolgs Die Zukunft von Plinko Fazit Entdecken Sie die Faszination von Plinko: Das beliebteste Spiel der Glücksritter! Willkommen in der Welt von Plinko, Do stabilnej pracy apk Aviator wymaga dobrego połączenia internetowego. Regularnie pobieraj i aktualizuj aplikację gry, aby uzyskać dostęp do nowych funkcji i ulepszeń bezpieczeństwa. Statystyki pokazują, że 7,8% graczy preferuje mobilną wersję Aviatora ze względu na wygodę i dostępność.
https://fitwell.qa/aviator-betway-login-jak-rozpoczac-gre-krok-po-kroku/
Book of Ra Deluxe App Name: IZIBET Bet TrackerPackage Name: com.izibet.retailmobileapp.androidCategory: Sports BettingVersion: Size: Last Updated: Developer: IZIBET Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Posiada cenne 4 letnie doświadczenie w branży. Ula zaczynała jako kierownik serwisu, a na samym początku pracowała jako niezależna pisarka. Na ten moment pracuje jako content manager, sprawując pieczę nad treścią i zawartością naszego portalu. To ona jest odpowiedzialna za sprawdzanie reputacji kasyna i wszelkie rekomendacje, jeśli chodzi o gry i platformy hazardowe.
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
Премиум-отдых на воде: аренда яхты с индивидуальным сервисом
яхты сочи яхты сочи .
В этом ресурсе вы можете найти боту “Глаз Бога” , который способен получить всю информацию о любом человеке из открытых источников .
Этот мощный инструмент осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно пробить данные через специализированную платформу, используя фотографию в качестве начальных данных .
пробить авто по номеру
Технология “Глаз Бога” автоматически обрабатывает информацию из открытых баз , формируя структурированные данные .
Клиенты бота получают ограниченное тестирование для тестирования возможностей .
Платформа постоянно развивается, сохраняя высокую точность в соответствии с требованиями времени .
Сертификация и лицензии — ключевой аспект ведения бизнеса в России, обеспечивающий защиту от неквалифицированных кадров.
Декларирование продукции требуется для подтверждения безопасности товаров.
Для торговли, логистики, финансов необходимо специальных разрешений.
https://ok.ru/group/70000034956977/topic/158840759957681
Игнорирование требований ведут к приостановке деятельности.
Добровольная сертификация помогает повысить доверие бизнеса.
Соблюдение норм — залог успешного развития компании.
Прямо здесь вы найдете сервис “Глаз Бога”, который найти всю информацию по человеку по публичным данным.
Инструмент активно ищет по ФИО, обрабатывая публичные материалы в сети. С его помощью доступны бесплатный поиск и полный отчет по запросу.
Инструмент проверен на 2025 год и охватывает фото и видео. Сервис гарантирует найти профили в соцсетях и покажет информацию за секунды.
https://glazboga.net/
Такой сервис — помощник при поиске персон онлайн.
These days, it feels like football or soccer (as it is known in the US) is everywhere! Are you enjoying the FIFA Women’s World Cup in France? What about the exciting Copa América? Are you following the Total Africa Cup of Nations? If you like the game and want to expand your Spanish vocabulary of football terms, this lesson introduces some of the most common football soccer vocabulary words in Spanish. When it came to the fourth for each country, Sergio Ramos, who had blazed high over the bar in the Champions League semi-final shootout, clipped in a la Pirlo. “It seems to be fashionable now,” Del Bosque said. “I was delighted with it.” Bruno Alves then thumped his off the underside of the bar and away. As the ball bounced free, it took Portugal’s chances of reaching the final with it.
https://headlice.co.il/review-del-juego-de-casino-online-balloon-apk-de-smartsoft-para-jugadores-en-venezuela/
1Win Lucky Jet tiene una serie de características que facilitan el juego. Puede dejar que el ordenador gestione sus apuestas y retiradas. Juego de Lucky Jet 1win – Juega Los profesionales avanzados recomiendan integrar múltiples metodologías mientras se adaptan a los patrones emergentes en Lucky Jet 1win. El análisis estadístico sugiere que los mejores resultados suelen surgir de una gestión equilibrada de riesgos combinada con un timing estratégico cuando juegas a Lucky Jet por dinero real. Aquí tienes consejos para ayudarte a ganar dinero en Lucky Jet Casino: El sitio web oficial de Lucky Bet le permite jugar juegos de choque, pero debe iniciar sesión, sin registrarse, muchas funciones de Lucky Jet no estarán disponibles. Las llamadas señales Lucky Jet o “signals” en inglés hacen referencia a la supuesta existencia de guías o apps que adivinan los resultados durante el uso del mini game. Estas apps o guías se ofertan como dispositivos externos, o desde bots en redes sociales como Tik Tok. De igual forma, se ofrecen como apps para celulares con sistema operativo Android. En cualquier caso, la promesa que hacen es la de conocer los resultados de forma anticipada en cada ronda del juego Lucky Jet México.
¿Quieres promocódigos recientes de 1xBet? En este sitio podrás obtener bonificaciones únicas para apostar .
El promocódigo 1x_12121 ofrece a hasta 6500₽ al registrarte .
También , canjea 1XRUN200 y disfruta una oferta exclusiva de €1500 + 150 giros gratis.
https://kennaharde4.wixsite.com/my-site-1
Mantente atento las promociones semanales para conseguir recompensas adicionales .
Todos los códigos están actualizados para hoy .
No esperes y potencia tus oportunidades con esta plataforma confiable!
Aliraza2024-01-07 22:56:35 App market for 100% working mods. Requires Android Shake up the Lightning multipliers! select vTitle, vContent from gen_updates where cStatus = ‘A’ and cProperty = ‘DRW’ and (‘2025-05-22 21:27:46’ between dFrom and dTo) ORDER BY iRank DESC LIMIT 1 100% working on devices Accelerated for downloading big mod files. Strategic Card Game Set in the Three Kingdoms Welcome to Dragon Tiger Predictions with GPT, this prediction tool app can analyze the input pattern and provide you predictions. +1 212-334-0212 Dragon Vs Tiger predict GPT tool offers a variety of features for supporting users such as: Was the prediction correct? Lightning Sic Bo Strategic Card Game Set in the Three Kingdoms select vTitle, vContent from gen_updates where cStatus = ‘A’ and cProperty = ‘DRW’ and (‘2025-05-22 21:28:12’ between dFrom and dTo) ORDER BY iRank DESC LIMIT 1
https://wp15-c13013-1.btsndrc.ac/balloon-game-by-smartsoft-pros-and-cons-of-linking-wallets-via-app-vs-web-for-indian-players/
Country & currency Country & currency Country & currency Country & currency Find your new pastime among our hobby kits Founded in 1985, the Volkswagen Group China has made serious tracks in keeping the Volkswagen name alive. In 2020, they established the Vertical Mobility Project to develop sustainable electrical aircrafts with the catchy tagline: ‘In China, For China’. Soft toys Flying Tiger Copenhagen Fat tiger Zhao TiezhuHe has always been “kind-hearted and fat”Galloping in the rivers and lakes Express yourself with colourful and playful designs When you choose FSC®-certified goods, you support the responsible use of the world’s forests, and you help to take care of the animals and people who live in them. Look for the FSC mark on our products and read more at flyingtiger fsc
Jarvi — корм для питомцев, которым вы можете доверять
кошачий сухой корм jarvi холистик отзывы кошачий сухой корм jarvi холистик отзывы .
Прямо здесь можно получить мессенджер-бот “Глаз Бога”, позволяющий проверить сведения о гражданине по публичным данным.
Сервис функционирует по фото, используя доступные данные в сети. С его помощью осуществляется пять пробивов и полный отчет по имени.
Сервис обновлен на 2025 год и поддерживает фото и видео. Сервис поможет узнать данные в соцсетях и предоставит сведения за секунды.
https://glazboga.net/
Данный сервис — помощник в анализе людей через Telegram.
Looking for exclusive 1xBet promo codes ? Here is your ultimate destination to discover valuable deals designed to boost your wagers.
If you’re just starting or a seasoned bettor , the available promotions guarantees exclusive advantages across all bets.
Keep an eye on seasonal campaigns to multiply your rewards.
https://www.bitsdujour.com/profiles/Tn5Rcx
All listed codes are frequently updated to guarantee reliability this month .
Don’t miss out of exclusive perks to enhance your odds of winning with 1xBet.
Full hd film kategorisinde ödüllü yapımlar sizi bekliyor
hd fil izle hdturko.com .
На данном сайте вы можете получить доступ к боту “Глаз Бога” , который может получить всю информацию о любом человеке из открытых источников .
Этот мощный инструмент осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно проверить личность через специализированную платформу, используя имя и фамилию в качестве начальных данных .
пробив авто бесплатно
Система “Глаз Бога” автоматически собирает информацию из открытых баз , формируя подробный отчет .
Подписчики бота получают ограниченное тестирование для проверки эффективности.
Решение постоянно развивается, сохраняя актуальность данных в соответствии с законодательством РФ.
На данном сайте доступен сервис “Глаз Бога”, позволяющий проверить всю информацию о человеке из открытых источников.
Сервис работает по ФИО, обрабатывая актуальные базы в Рунете. Через бота доступны пять пробивов и полный отчет по запросу.
Сервис обновлен на август 2024 и охватывает фото и видео. Бот поможет узнать данные в открытых базах и отобразит результаты мгновенно.
https://glazboga.net/
Это бот — помощник для проверки граждан удаленно.
Гагры круглый год: отдых в любое время и по любому бюджету
гагра снять жилье otdyh-gagry.ru .
Searching for latest 1xBet promo codes? Our platform offers working promotional offers like GIFT25 for registrations in 2025. Get up to 32,500 RUB as a welcome bonus.
Use trusted promo codes during registration to boost your bonuses. Benefit from no-deposit bonuses and exclusive deals tailored for sports betting.
Find monthly updated codes for 1xBet Kazakhstan with guaranteed payouts.
Every voucher is checked for accuracy.
Don’t miss exclusive bonuses like 1x_12121 to increase winnings.
Active for first-time deposits only.
https://www.askmeclassifieds.com/user/profile/2296810Stay ahead with top bonuses – enter codes like 1XRUN200 at checkout.
Enjoy seamless rewards with instant activation.
¿Quieres cupones vigentes de 1xBet? En este sitio descubrirás recompensas especiales para tus jugadas.
El promocódigo 1x_12121 ofrece a un bono de 6500 rublos durante el registro .
Para completar, canjea 1XRUN200 y obtén un bono máximo de 32500 rublos .
https://hallbook.com.br/blogs/599951/Code-promo-1XBET-pour-bonus-VIP-de-130
Mantente atento las novedades para acumular más beneficios .
Las ofertas disponibles están actualizados para 2025 .
¡Aprovecha y maximiza tus apuestas con esta plataforma confiable!
Здесь доступен мощный бот “Глаз Бога” , который получает данные о любом человеке из общедоступных ресурсов .
Инструмент позволяет пробить данные по ФИО , раскрывая информацию из онлайн-платформ.
https://glazboga.net/
Kaliteden ödün vermeyenler için özel seçilmiş full hd film yapımları
4 k filim izle https://www.filmizlehd.co/ .
На данном сайте вы можете найти боту “Глаз Бога” , который способен получить всю информацию о любом человеке из общедоступных баз .
Данный сервис осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно проверить личность через Telegram-бот , используя автомобильный номер в качестве ключевого параметра.
пробив телефона бесплатно
Система “Глаз Бога” автоматически обрабатывает информацию из проверенных ресурсов, формируя структурированные данные .
Клиенты бота получают 5 бесплатных проверок для тестирования возможностей .
Сервис постоянно совершенствуется , сохраняя высокую точность в соответствии с законодательством РФ.
В этом ресурсе вы можете ознакомиться с последними новостями России и мира .
Информация поступает без задержек.
Доступны видеохроники с мест событий .
Экспертные комментарии помогут получить объективную оценку.
Контент предоставляется без регистрации .
https://e-copies.ru
This website offers comprehensive information about Audemars Piguet Royal Oak watches, including retail costs and technical specifications .
Discover data on popular references like the 41mm Selfwinding in stainless steel or white gold, with prices averaging $39,939 .
The platform tracks resale values , where limited editions can appreciate over time.
Audemars Royal Oak 15510 or prices
Technical details such as automatic calibers are easy to compare.
Stay updated on 2025 price fluctuations, including the Royal Oak 15510ST’s market stability .
Professional concrete driveway installers seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Professional Seattle power washing — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Professional paver contractor — reliable service, quality materials and adherence to deadlines. Individual approach, experienced team, free estimate. Your project — turnkey with a guarantee.
Discover detailed information about the Audemars Piguet Royal Oak Offshore 15710ST on this site , including pricing insights ranging from $34,566 to $36,200 for stainless steel models.
The 42mm timepiece showcases a robust design with mechanical precision and rugged aesthetics, crafted in titanium.
https://ap15710st.superpodium.com
Compare secondary market data , where limited editions reach up to $750,000 , alongside pre-owned listings from the 1970s.
View real-time updates on availability, specifications, and investment returns , with free market analyses for informed decisions.
Пляжи, водопады и горы — отдых в Абхазии без лишнего шума
абхазия отдых на море абхазия отдых на море .
Современные методы поверки и как выбрать надежного исполнителя
Поверка https://poverka-si-msk.ru/ .
Looking for exclusive 1xBet promo codes? This site offers verified promotional offers like 1XRUN200 for new users in 2025. Get up to 32,500 RUB as a welcome bonus.
Activate official promo codes during registration to maximize your rewards. Enjoy no-deposit bonuses and special promotions tailored for casino games.
Discover monthly updated codes for 1xBet Kazakhstan with fast withdrawals.
Every promotional code is checked for validity.
Grab exclusive bonuses like 1x_12121 to double your funds.
Valid for first-time deposits only.
https://chrstms.ru/club/user/9440/blog/16309/
Experience smooth rewards with instant activation.
Need transportation? car transportation services state to state car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
Нужна камера? видеонаблюдение частный установка камер для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
Лицензирование и сертификация — обязательное условие ведения бизнеса в России, гарантирующий защиту от неквалифицированных кадров.
Декларирование продукции требуется для подтверждения соответствия стандартам.
Для 49 видов деятельности необходимо специальных разрешений.
https://ok.ru/group/70000034956977/topic/158835725678769
Нарушения правил ведут к приостановке деятельности.
Добровольная сертификация помогает повысить доверие бизнеса.
Своевременное оформление — залог успешного развития компании.
best car shipping terminal to terminal auto transport
Хотите найти ресурсы для нумизматов ? Эта платформа предоставляет всё необходимое для изучения нумизматики!
Здесь доступны уникальные монеты из разных эпох , а также драгоценные находки.
Просмотрите архив с характеристиками и детальными снимками, чтобы сделать выбор .
инвестиционные монеты купить
Если вы начинающий или эксперт, наши статьи и гайды помогут углубить экспертизу.
Воспользуйтесь шансом приобрести эксклюзивные артефакты с гарантией подлинности .
Станьте частью сообщества энтузиастов и следите последних новостей в мире нумизматики.
Наркологическая помощь на дому с соблюдением полной анонимности и этики
нарколог на дом срочно https://www.clinic-narkolog24.ru/ .
Подборка лучших гостевых домов и квартир в Сухум
сухум жилье без посредников сухум жилье без посредников .
Balloons Dubai https://balloons-dubai1.com stunning balloon decorations for birthdays, weddings, baby showers, and corporate events. Custom designs, same-day delivery, premium quality.
Почему доставка алкоголя становится популярнее традиционных покупок
доставка алкоголя домой москва доставка алкоголя московская область .
стильные цветочные горшки купить http://dizaynerskie-kashpo.ru/ .
купить плитку 600х600 стоимость керамогранита 1200х600
Utilizatorii 1Win pot alege orice metodă de plată și orice monedă pentru a efectua tranzacții pe site. Mai jos am descris metodele de plăți 1win disponibile pentru jucătorii din Moldova. 1win nu este doar o altă platformă de jocuri de noroc online. Este un portal de jocuri multifuncțional care oferă peste 10.000 de evenimente de jocuri, pariuri sportive live și virtuale, cazinouri online și cinematografe online și multe altele. Pentru a se înregistra, jucătorii pot folosi înregistrarea cu un singur clic, e-mailul, numărul de telefon sau conturile de rețele sociale. Este necesară verificarea pentru retrageri. Opțiunile de depunere și retragere includ carduri de credit, portofele electronice, plăți mobile și criptomonede. Nu se percep taxe. Site-ul web oferă un site de jocuri de noroc online complet cu cote competitive, multe piețe de pariuri și oferte generoase de bonusuri.
https://earnfromsurvey.xyz/analiza-sesiunilor-de-joc-in-lucky-jet-pentru-performanta-maxima/
18 maşini PistenBully Scufundați-vă în lumea frumoasă și a jocurilor de noroc din JetX Bet: zburați cu avionul și câștigați bani ușori fără să vă ridicați de pe canapea. Jocuri Gratis Aparate Sale disponibile la unele dintre site-urile de top cazinou online și poate fi jucat pe iPhone, jocurile de cazinou sunt foarte distractive și oferă o varietate de opțiuni pentru jucători. Jocuri gratis aparate în afară de faptul că aceste jocuri sunt populare și ușor de jucat, toate parte a pachetului. Aplicația este Jocul 1Win JetX testează reacția, răbdarea și atenția jucătorilor. Jucătorul are la dispoziție doar 5 secunde pentru a plasa un pariu. În cadrul sesiunii de joc, trebuie să urmărești decolarea avionului, al cărui multiplicator crește atât timp cât acesta rămâne în aer. Scopul principal al jocului este de a retrage banii înainte ca avionul să se prăbușească.
Профессиональное косметологическое оборудование аппараты для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
Discover the iconic Patek Philippe Nautilus, a luxury timepiece that blends sporty elegance with exquisite craftsmanship .
Launched in 1976 , this cult design revolutionized high-end sports watches, featuring distinctive octagonal bezels and textured sunburst faces.
From stainless steel models like the 5990/1A-011 with a 55-hour energy retention to luxurious white gold editions such as the 5811/1G-001 with a blue gradient dial , the Nautilus caters to both discerning collectors and everyday wearers .
New Patek Philippe Nautilus 5712 watch reviews
Certain diamond-adorned versions elevate the design with gemstone accents, adding unparalleled luxury to the timeless profile.
According to recent indices like the 5726/1A-014 at ~$106,000, the Nautilus remains a coveted investment in the world of premium watchmaking.
For those pursuing a historical model or modern redesign, the Nautilus epitomizes Patek Philippe’s tradition of innovation.
Designed by Gerald Genta, revolutionized luxury watchmaking with its iconic octagonal bezel and bold integration of sporty elegance.
Available in classic stainless steel to diamond-set variants, the collection combines avant-garde design with horological mastery.
Priced from $20,000 to over $400,000, these timepieces cater to both seasoned collectors and aficionados seeking wearable heritage.
Pre-loved Piguet Audemars Royal Oak 26240 or reviews
The Perpetual Calendar models set benchmarks with innovative complications , showcasing Audemars Piguet’s relentless innovation.
With ultra-thin calibers like the 2385, each watch epitomizes the brand’s commitment to excellence .
Discover exclusive releases and historical insights to elevate your collection with this timeless icon .
Устойчивость и безопасность: подстолья с усиленными опорами
подстолье для большого обеденного стола https://podstolia-msk.ru/ .
защита консультация юрист https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
Бокалы для вина из Чехии, Германии, Франции — оригинальные коллекции
заказать бокалы для вина https://www.bokaly-dlya-vina.neocities.org/ .
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Die Royal Oak 16202ST kombiniert ein rostfreies Stahlgehäuse von 39 mm mit einem extraflachen Gehäuse von nur 8,1 mm Dicke.
Ihr Herzstück bildet das neue Kaliber 7121 mit 55 Stunden Gangreserve.
Der smaragdene Farbverlauf des Zifferblatts wird durch das feine Guillochierungen und die Saphirglas-Abdeckung mit blendschutzbeschichteter Oberfläche betont.
Neben klassischer Zeitmessung bietet die Uhr ein praktisches Datum bei Position 3.
ap 15407
Die bis 5 ATM geschützte Konstruktion macht sie alltagstauglich.
Das geschlossene Stahlband mit faltsicherer Verschluss und die oktogonale Lünette zitieren das ikonische Royal-Oak-Erbe aus den 1970er Jahren.
Als Teil der „Jumbo“-Kollektion verkörpert die 16202ST horlogerie-Tradition mit einem aktuellen Preis ab ~75.900 €.
КредитоФФ http://creditoroff.ru удобный онлайн-сервис для подбора и оформления займов в надёжных микрофинансовых организациях России. Здесь вы найдёте лучшие предложения от МФО
Почему императорский фарфор ценят не только коллекционеры
ифз шоп https://imperatorskiy-farfor.kesug.com .
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Стальные резервуары используются для сбора нефтепродуктов и соответствуют стандартам давления до 0,04 МПа.
Вертикальные емкости изготавливают из черной стали Ст3 с антикоррозийным покрытием.
Идеальны для АЗС: хранят бензин, керосин, мазут или авиационное топливо.
Резервуар стальной РГС 150 м3
Двустенные резервуары обеспечивают экологическую безопасность, а подземные модификации подходят для разных условий.
Заводы предлагают типовые решения объемом до 500 м³ с монтажом под ключ.
Die Royal Oak 16202ST vereint ein rostfreies Stahlgehäuse in 39 mm mit einem nur 8,1 mm dünnen Bauweise und dem automatischen Werk 7121 für lange Energieautonomie.
Das blaue Petite-Tapisserie-Dial mit Weißgold-Indexen und Luminous-Beschichtung wird durch eine kratzfeste Saphirabdeckung mit blendschutzbeschichteter Oberfläche geschützt.
Neben praktischer Datumsanzeige bietet die Uhr 50-Meter-Wasserdichte und ein geschlossenes Edelstahlband mit verstellbarem Verschluss.
Piguet Royal Oak 15450 armbanduhren
Die achtseitige Rahmenform mit ikonenhaften Hexschrauben und die gebürstete Oberflächenkombination zitieren den 1972er Klassiker.
Als Teil der Extra-Thin-Kollektion ist die 16202ST eine horlogerie-Perle mit einem Wertsteigerungspotenzial.
Купить шиномонтаж Краснодар shinomontazh vyezdnoj
Юрист Екатеринбург консультация yuristy-ekaterinburga.ru/
Не упустите сезонные предложения на мотоциклы jhl moto
мотоцикл jhl https://www.jhlmoto01.ru/ .
интересные кашпо для цветов интересные кашпо для цветов .
Защитные кейсы https://plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Наш ресурс предлагает свежие инфосообщения в одном месте.
Здесь можно найти события из жизни, бизнесе и разных направлениях.
Новостная лента обновляется регулярно, что позволяет всегда быть в курсе.
Простой интерфейс облегчает восприятие.
https://miramoda.ru
Каждое сообщение проходят проверку.
Мы стремимся к достоверности.
Читайте нас регулярно, чтобы быть на волне новостей.
Crafted watches remain popular for numerous vital factors.
Their timeless appeal and mastery set them apart.
They symbolize wealth and sophistication while uniting form and function.
Unlike digital gadgets, they endure through generations due to their limited production.
https://telegra.ph/The-Art-of-Time-A-Comparison-of-the-Patek-Philippe-Nautilus-and-Audemars-Piguet-Royal-Oak-03-09
Collectors and enthusiasts treasure the engineering marvels that modern tech cannot imitate.
For many, having them signifies taste that remains eternal.
срочно онлайн займ отказа займ онлайн с плохой кредитной
Услуги клининга в медицинских учреждениях с дезинфекцией
клининговая служба https://kliningovaya-kompaniya10.ru .
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Защитные кейсы https://plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
¡Saludos, apasionados del azar !
Casinos sin licencia en EspaГ±a sin lГmite mГЎximo – https://casinossinlicenciaenespana.es/ casino sin licencia en espaГ±a
¡Que vivas conquistas excepcionales !
Строительный портал https://proektsam.kyiv.ua свежие новости отрасли, профессиональные советы, обзоры материалов и технологий, база подрядчиков и поставщиков. Всё о ремонте, строительстве и дизайне в одном месте.
Городской портал Черкассы https://u-misti.cherkasy.ua новости, обзоры, события Черкасс и области
Портал о строительстве https://buildportal.kyiv.ua и ремонте: лучшие решения для дома, дачи и бизнеса. Инструменты, сметы, калькуляторы, обучающие статьи и база подрядчиков.
займы онлайн круглосуточно займ онлайн без отказа
Коллекция Nautilus, созданная Жеральдом Гентой, сочетает элегантность и прекрасное ремесленничество. Модель Nautilus 5711 с автоматическим калибром 324 SC имеет 45-часовой запас хода и корпус из белого золота.
Восьмиугольный безель с округлыми гранями и циферблат с градиентом от синего к черному подчеркивают уникальность модели. Браслет с интегрированными звеньями обеспечивает удобную посадку даже при активном образе жизни.
Часы оснащены индикацией числа в позиции 3 часа и антибликовым покрытием.
Для версий с усложнениями доступны секундомер, лунофаза и индикация второго часового пояса.
patek-philippe-nautilus.ru
Например, модель 5712/1R-001 из розового золота с калибром повышенной сложности и запасом хода до 48 часов.
Nautilus остается предметом коллекционирования, объединяя инновации и традиции швейцарского часового дела.
Портал города Черновцы https://u-misti.chernivtsi.ua последние новости, события, обзоры
вызвать нарколога на дом вызвать нарколога на дом срочно
Каркасные дома для дачи и круглогодичного проживания с минимальными затратами
строительство каркасных домов спб строительство каркасных домов спб .
двойное кодирование от алкоголизма клиника кодирования от алкоголизма нижний новгород
анонимное лечение алкоголизма лечение алкоголизма в Нижнем Новгороде
выведение из запоя стационар https://zapoy-info.ru
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
оценка помещения оценка рыночной стоимости ооо
лечение наркомании детокс лечение наркозависимости НН
цветочные горшки дизайнерские купить цветочные горшки дизайнерские купить .
Всё для строительства https://d20.com.ua и ремонта: инструкции, обзоры, экспертизы, калькуляторы. Профессиональные советы, новинки рынка, база строительных компаний.
¡Saludos, aventureros del azar !
Casinos extranjeros recomendados para usuarios espaГ±oles – п»їhttps://casinosextranjerosenespana.es/ п»їcasinos online extranjeros
¡Que vivas increíbles instantes inolvidables !
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Современный строительный https://interiordesign.kyiv.ua журнал: идеи, решения, технологии, тенденции. Всё о ремонте, стройке, дизайне и инженерных системах.
Информационный журнал https://newhouse.kyiv.ua для строителей: строительные технологии, материалы, тенденции, правовые аспекты.
кашпо для цветов дизайнерские https://www.dizaynerskie-kashpo.ru .
Betting continues to be an thrilling way to elevate your gaming journey. Placing wagers on football, the service offers great opportunities for every type of bettor.
With in-play wagering to scheduled events, you can find a diverse range of betting markets tailored to your interests. The easy-to-use design ensures that engaging in betting is both straightforward and safe.
https://musicserver.cz/pages/?arada_bet___ethiopia_s_licensed_sportsbook___live_bets___bonuses.html
Get started to enjoy the best betting experience available on the web.
Коммерческий транспорт в лизинг с юридическим сопровождением сделки
купить коммерческий транспорт в лизинг https://lizing-auto-top1.ru .
Новинний сайт Житомира https://faine-misto.zt.ua новости Житомира сегодня
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Журнал о строительстве https://sovetik.in.ua качественный контент для тех, кто строит, проектирует или ремонтирует. Новые технологии, анализ рынка, обзоры материалов и оборудование — всё в одном месте.
Строительный журнал https://poradnik.com.ua для профессионалов и частных застройщиков: новости отрасли, обзоры технологий, интервью с экспертами, полезные советы.
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
For parlays and Same Video game Parlays, if a team you backside goes 2 targets ahead, that selection will be Liczne zakłady hazardowe online oferują kuszące bonusy dla graczy Aviator. Najbardziej pożądany jest pakiet powitalny, często obejmujący dopasowanie do pierwszego depozytu, bezpłatne spiny na wybranych automatach, a nawet nagrody bez depozytu. Korzyści te umożliwiają rozpoczęcie podróży Aviator z dodatkowymi zasobami. Renomowane licencjonowane platformy często oferują swoim lojalnym graczom bonusy doładowujące i możliwości zwrotu gotówki. Oczywiście, nasza uwaga jest skupiona na płaszczyźnie i obserwowaniu wzrostu mnożnika, wzrasta również chęć pozostania w grze. Wszystko jednak dzieje się bardzo szybko i nieprzewidywalnie. W związku z tym, oddziel pieniądze od swojego banku na grę w danym dniu i nie ma możliwości przekroczenia tego limitu.
https://opendata.liberec.cz/user/ncesunbiter1973
Weryfikacja konta nie jest wymagana na etapie rejestracji: możesz założyć konto, wpłacić depozyt i od razu cieszyć się grami. Jeśli jednak wygrasz i będziesz chciał wypłacić wygraną, konieczne będzie dobrowolne poddanie się weryfikacji. Użytkownicy 1win official site powinni przesłać wymagane dokumenty (kopie), aby potwierdzić, że są rzeczywistymi osobami, które mają tylko jedno konto w 1win i prawo do udziału w rozrywce hazardowej. lekarz Krystian Wawrukiewicz The Aviator game has taken off in the latest years in Indian online casinos. The growth and popularity in the Aviator video game will likely continue into the future, and we’d expect in order to get a lot regarding new games motivated by this hugely popular title. Aviator works like other casino games wherever it uses the particular money in the consumer account. Players must first deposit into their accounts to make use of this real funds inside the Aviator sport. The Aviator game in India will be one of typically the most popular in the particular online casino industry.” “For the best Aviator game APK applications, we’d recommend each of our official app by LopeBet.
Новости Полтава https://u-misti.poltava.ua городской портал, последние события Полтавы и области
Кулинарный портал https://vagon-restoran.kiev.ua с тысячами проверенных рецептов на каждый день и для особых случаев. Пошаговые инструкции, фото, видео, советы шефов.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Читайте мужской https://zlochinec.kyiv.ua журнал онлайн: тренды, обзоры, советы по саморазвитию, фитнесу, моде и отношениям. Всё о том, как быть уверенным, успешным и сильным — каждый день.
¡Hola, fanáticos del riesgo !
Casino sin licencia y mГєltiples mГ©todos de pago – http://casinossinlicenciaespana.es/ casinos sin registro
¡Que experimentes rondas emocionantes !
официальный сайт ПокерОК
ПокерОК
ИнфоКиев https://infosite.kyiv.ua события, новости обзоры в Киеве и области.
Монтаж систем видеонаблюдения позволит защиту вашего объекта в режиме 24/7.
Современные технологии гарантируют надежный обзор даже при слабом освещении.
Вы можете заказать различные варианты систем, идеальных для бизнеса и частных объектов.
видеонаблюдение монтаж и установка
Грамотная настройка и сервисное обслуживание превращают решение максимально удобным для каждого клиента.
Обратитесь сегодня, чтобы получить оптимальное предложение в сфере безопасности.
¡Hola, jugadores apasionados !
Mejores trucos para jugar en casino fuera de EspaГ±a – https://www.casinoonlinefueradeespanol.xyz/# п»їп»їcasino fuera de espaГ±a
¡Que disfrutes de asombrosas premios extraordinarios !
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
Портал о ремонте https://as-el.com.ua и строительстве: от черновых работ до отделки. Статьи, обзоры, идеи, лайфхаки.
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
Сайт о строительстве https://selma.com.ua практические советы, современные технологии, пошаговые инструкции, выбор материалов и обзоры техники.
купить стильный горшок http://www.dizaynerskie-kashpo1.ru/ .
дизайнерские кашпо http://www.dizaynerskie-kashpo1.ru .
¡Saludos, amantes de la adrenalina !
Opiniones de usuarios sobre casinoextranjerosenespana.es – https://www.casinoextranjerosenespana.es/# mejores casinos online extranjeros
¡Que disfrutes de conquistas memorables !
Городской портал Винницы https://u-misti.vinnica.ua новости, события и обзоры Винницы и области
¡Saludos, expertos en el azar !
casinosextranjero.es – experiencias Гєnicas al jugar – https://casinosextranjero.es/# mejores casinos online extranjeros
¡Que vivas increíbles instantes inolvidables !
Индивидуальный проект каркасного дома: адаптация под ваш стиль жизни
строительство каркасных домов в санкт петербурге https://spb-karkasnye-doma-pod-kluch.ru/ .
Сохраняйте моменты: печать на футболке с фото из жизни
заказ футболок со своим принтом http://pechat-na-futbolkah777.ru/ .
Свежие новости https://ktm.org.ua Украины и мира: политика, экономика, происшествия, культура, спорт. Оперативно, объективно, без фейков.
Портал Львів https://u-misti.lviv.ua останні новини Львова и области.
Сайт о строительстве https://solution-ltd.com.ua и дизайне: как построить, отремонтировать и оформить дом со вкусом.
Читайте авто блог https://autoblog.kyiv.ua обзоры автомобилей, сравнения моделей, советы по выбору и эксплуатации, новости автопрома.
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
официальный сайт ПокерОК
официальный сайт ПокерОК
Портал о строительстве https://start.net.ua и ремонте: готовые проекты, интерьерные решения, сравнение материалов, опыт мастеров.
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
Всё о строительстве https://furbero.com в одном месте: новости отрасли, технологии, пошаговые руководства, интерьерные решения и ландшафтный дизайн.
Комплексный строительный https://ko-online.com.ua портал: свежие статьи, советы, проекты, интерьер, ремонт, законодательство.
Новини Львів https://faine-misto.lviv.ua последние новости и события – Файне Львов
официальный сайт ПокерОК
ПокерОК сайт
официальный сайт ПокерОК
ПокерОК сайт
Портал для женщин https://olive.kiev.ua любого возраста: от секретов молодости и красоты до личностного роста и материнства.
Онлайн-портал https://leif.com.ua для женщин: мода, психология, рецепты, карьера, дети и любовь. Читай, вдохновляйся, общайся, развивайся!
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
прикольные кашпо прикольные кашпо .
Портал о маркетинге https://reklamspilka.org.ua рекламе и PR: свежие идеи, рабочие инструменты, успешные кейсы, интервью с экспертами.
Клуб родителей https://entertainment.com.ua пространство поддержки, общения и обмена опытом.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
Всё о спорте https://beachsoccer.com.ua в одном месте: профессиональный и любительский спорт, фитнес, здоровье, техника упражнений и спортивное питание.
События Днепр https://u-misti.dp.ua последние новости Днепра и области, обзоры и самое интересное
оригинальные цветочные горшки оригинальные цветочные горшки .
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Информационный портал https://comart.com.ua о строительстве и ремонте: полезные советы, технологии, идеи, лайфхаки, расчёты и выбор материалов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
Всё о строительстве https://ukrainianpages.com.ua просто и по делу. Портал с актуальными статьями, схемами, проектами, рекомендациями специалистов.
официальный сайт ПокерОК
играть на сайте ПокерОК
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Строительный журнал https://dsmu.com.ua идеи, технологии, материалы, дизайн, проекты, советы и обзоры. Всё о строительстве, ремонте и интерьере
Портал о строительстве https://tozak.org.ua от идеи до готового дома. Проекты, сметы, выбор материалов, ошибки и их решения.
официальный сайт ПокерОК
играть на сайте ПокерОК
Новостной портал Одесса https://u-misti.odesa.ua последние события города и области. Обзоры и много интресного о жизни в Одессе.
интересные кашпо для цветов http://www.dizaynerskie-kashpo-spb.ru .
Городской портал Одессы https://faine-misto.od.ua последние новости и происшествия в городе и области
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Портал для женщин https://a-k-b.com.ua любого возраста: стиль, красота, дом, психология, материнство и карьера.
Онлайн-новости https://arguments.kyiv.ua без лишнего: коротко, по делу, достоверно. Политика, бизнес, происшествия, спорт, лайфстайл.
На данном сайте можно получить мессенджер-бот “Глаз Бога”, который найти всю информацию о человеке из открытых источников.
Инструмент активно ищет по фото, используя публичные материалы онлайн. Благодаря ему можно получить 5 бесплатных проверок и полный отчет по запросу.
Платфор ма проверен на август 2024 и поддерживает аудио-материалы. Бот поможет узнать данные в открытых базах и отобразит результаты за секунды.
глаз бога телеграмм официальный сайт
Это инструмент — выбор в анализе людей удаленно.
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
Только главное https://ua-vestnik.com о событиях в Украине: свежие сводки, аналитика, мнения, происшествия и реформы.
Женский портал https://woman24.kyiv.ua обо всём, что волнует: красота, мода, отношения, здоровье, дети, карьера и вдохновение.
защитный кейс альфа профи https://plastcase.ru
официальный сайт ПокерОК
ПокерОК сайт
Услуги под ключ: деревянные дома, строительство, инженерия и интерьер
строительство домов из дерева под ключ derevyannye-doma-pod-klyuch-msk0.ru .
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
Взять микрозаем онлайн микрозайм получить
Noten musik klavier piano klavier noten
официальный сайт ПокерОК
играть на сайте ПокерОК
официальный сайт ПокерОК
играть на сайте ПокерОК
Хмельницький новини https://u-misti.khmelnytskyi.ua огляди, новини, сайт Хмельницького
Здесь можно получить сервис “Глаз Бога”, который найти всю информацию по человеку по публичным данным.
Инструмент активно ищет по фото, используя публичные материалы онлайн. С его помощью осуществляется бесплатный поиск и детальный анализ по имени.
Инструмент проверен согласно последним данным и охватывает фото и видео. Сервис сможет найти профили в открытых базах и отобразит информацию мгновенно.
глаз бога официальный бот
Данный инструмент — выбор для проверки людей онлайн.
отчет по практике заказать стоимость https://otchetbuhgalter.ru
заказать реферат москва написать реферат
кашпо для цветов дизайнерские кашпо для цветов дизайнерские .
дипломная работа купить заказ дипломной работы
¡Hola, estrategas del azar !
Casinoextranjero.es: anГЎlisis de casinos extranjeros fiables – https://www.casinoextranjero.es/# casinos extranjeros
¡Que vivas botes deslumbrantes!
кейс защитный байкал вз 12 plastcase.ru
Медпортал https://medportal.co.ua украинский блог о медициние и здоровье. Новости, статьи, медицинские учреждения
Vous cherchez des jeux en ligne ? Notre plateforme regroupe des centaines de titres pour tous les goûts .
Des puzzles aux défis multijoueurs , plongez des mécaniques innovantes directement depuis votre navigateur.
Découvrez les classiques comme le Sudoku ou des simulations immersives en équipe.
Pour les compétiteurs , des courses automobiles en mode battle royale vous attendent.
casino en ligne france
Profitez d’expériences premium et rejoignez des joueurs passionnés.
Que vous préfériez la réflexion , ce site s’impose comme votre destination préférée .
¡Bienvenidos, exploradores de la fortuna !
Casino fuera de EspaГ±a sin limitaciones tГ©cnicas – https://www.casinoporfuera.guru/ casino online fuera de espaГ±a
¡Que disfrutes de maravillosas tiradas afortunadas !
¡Saludos, entusiastas del azar !
casino por fuera sin lГmite de retiro – https://www.casinosonlinefueraespanol.xyz/ casinosonlinefueraespanol
¡Que disfrutes de éxitos sobresalientes !
Здесь вы найдете мессенджер-бот “Глаз Бога”, позволяющий проверить всю информацию по человеку через открытые базы.
Бот работает по фото, используя доступные данные в Рунете. Через бота осуществляется пять пробивов и детальный анализ по запросу.
Платфор ма проверен на август 2024 и включает аудио-материалы. Глаз Бога сможет найти профили в открытых базах и отобразит сведения мгновенно.
пробить через глаз бога
Это бот — идеальное решение в анализе граждан через Telegram.
официальный сайт ПокерОК
играть на сайте ПокерОК
Файне Винница https://faine-misto.vinnica.ua новости и события Винницы сегодня. Городской портал, обзоры.
официальный сайт ПокерОК
ПокерОК сайт
микрозайм на карту zajmy-onlajn.ru
заказать отчет сделать отчет по практике
сделать контрольную заказать контрольную по математике
Недавно увидела в дизайнерском журнале креативный цветочный горшок в форме животного. Теперь мечтаю найти что-то подобное для своего дома!
микрозаем срок https://zajmy-onlajn.ru
Кто-нибудь знает, где можно найти качественные дизайнерские кашпо? Очень нужно для оформления балкона.
Портал Киева https://u-misti.kyiv.ua новости и события в Киеве сегодня.
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://www.xiruca.com/foro/consejos-sobre-excursiones-lugares-y-zonas-disfrutar-monta/zyrtec-purchase-online
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://www.neuron-automation.eu/en/forum/agile-softwareentwicklung/15561-evista-make-an-online-purchase
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://museusvalenciapre.grupotecopy.es/en/node/3623
как взять займ онлайн без отказа как взять займ онлайн без отказа .
срочно кредит на карту без отказа онлайн http://kredit-bez-otkaza-1.ru .
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
http://aw-bekkers.be/node/3086
готовые контрольные недорогие контрольные работы
диплом написать https://diplomsdayu.ru
написать отчет по практике заказать отчет по практике цена выполнения
займ онлайн залог https://zajmy-onlajn.ru
Сфера клининга в Москве вызывает растущий интерес. С учетом быстрой жизни в столице, многие москвичи стремятся облегчить свои бытовые обязанности.
Клиниговые фирмы предлагают целый ряд услуг в области уборки. Профессиональный клининг включает как стандартную уборку, так и глубокую очистку в зависимости от потребностей клиентов.
Важно учитывать репутацию клининговой компании и ее опыт . Необходимо обращать внимание на стандарты и профессионализм уборщиков.
В заключение, клининг в Москве – это удобное решение для занятых людей. Клиенты могут легко найти компанию, предоставляющую услуги клининга, для поддержания чистоты.
сервис уборки сервис уборки .
Book affordable and professional AC duct cleaning services in Dubai for your villa or apartment https://ac-cleaning-dubai.ae/
Всем привет! Где можно креативные горшки для цветов купить? Оформляю детский сад, нужны яркие и безопасные емкости для растений.
¡Bienvenidos, fanáticos del juego !
Casino fuera de EspaГ±a sin lГmites de apuestas – https://www.casinofueraespanol.xyz/# casinos fuera de espaГ±a
¡Que vivas increíbles premios excepcionales !
Увлекся комнатным цветоводством и теперь ищу дизайнерские цветочные горшки. Хочется, чтобы растения не только радовали глаз, но и стояли в красивых емкостях.
Сайт Житомир https://u-misti.zhitomir.ua новости и происшествия в Житомире и области
Your article helped me a lot, is there any more related content? Thanks!
Hi I am so excited I found your webpage, I really found you by accident, while I was looking on Yahoo for something else, Nonetheless I am here now and would just like to say thanks a lot for a remarkable post and a all round exciting blog (I also love the theme/design), I don’t have time to read it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the superb job.
tadalafil 0 5 mg
Если вышла из строя стиральная машина, мы поможем.
At PNGtoJPGHero.com, swapping PNG files for JPG images couldn’t be simpler. Just visit the homepage, drag your image into the upload box, and let the server handle the rest. Within moments, optimized JPG versions become available via download links. You can process multiple photos in one session thanks to batch conversion, eliminating repetitive clicks. The entire workflow takes place in your web browser—no plug-ins or extra software required. This tool works on any device, whether you’re on a desktop, laptop, tablet, or smartphone. A live status indicator keeps you informed of every step. After conversion, uploaded files vanish automatically, ensuring your data stays private. PNGtoJPGHero.com delivers crisp, high-quality JPGs quickly, and best of all, it’s completely free.
PNGtoJPGhero.com
Строительство каркасных домов с применением современных стандартов качества
каркасный дом цена https://www.karkasnie-doma-pod-kluch06.ru .
Посетите наш сайт и узнайте о клининг в санкт петербурге цены на услуги!
Клининговые услуги в Санкт-Петербурге становятся всё более популярными. С каждым годом растет число организаций, предлагающих услуги по клинингу и уборке помещений.
Клиенты ценят качество и доступность таких услуг. Большинство компаний предлагает индивидуальный подход к каждому клиенту, учитывая все пожелания.
Клининговые компании предлагают различные варианты услуг, от регулярной уборки до разовых). Некоторые компании также предлагают специализированные услуги, такие как уборка после ремонта или после мероприятия.
Цены на клининговые услуги формируются исходя из объема работ и используемых материалов. Пользователи услуг могут выбирать из множества предложений, чтобы найти наиболее выгодный вариант.
Matching a whole row of symbols will result in a Slingo, and you can match symbols vertically, horizontally, or diagonally. It’s no secret that the original Sweet Bonanza was a hugely popular slot. Slingo Originals certainly had a lot to live up to with this game. However, most punters seem to think that they’ve done a great job! The gameplay of Sweet Bonanza Slingo revolves around a 5×5 grid where numbers are spun on the reels below the grid. Players aim to mark off numbers to complete Slingos, which unlock more significant rewards and bonuses. Alongside the numbered symbols, the game also includes a variety of symbols that influence gameplay, such as Wilds, Bombs, and Multipliers. The deal with GoldenPark, a well-established land-based and online brand in Spain, sees Gaming Realms extend its reach in the flourishing European market, a key region for the company’s commercial growth plans.
https://te.legra.ph/description-here-06-13
Sweet Bonanza CandyLand transports players to a candy-filled world where bright colours and sweets reign supreme. The candy-themed design, paired with a lively wheel and engaging live dealer, creates a dynamic atmosphere that keeps players entertained. From the cheerful background to the colourful symbols, this game is a visual treat. Whether you land on a candy space or trigger a special feature, the game provides stunning graphics. The Sweet Paz Xmas play today feature quickly started to be popular through the getaway season, offering participants the chance to enjoy the game in a brand new, fun setting. All of the main action is based on the individual, giant wheel which often is spun for every turn, with typically the live host supervising the play. However, there are two potential bonus rounds exactly where there’s the possible to win also more – but the truth is must have put a bet in the right areas to play! The top payout for Sweet Bonanza Candyland is a scrumptious x20, 000, with maximum winnings prescribed a maximum at £500, 500.
Нужно собрать информацию о пользователе? Этот бот предоставит детальный отчет в режиме реального времени .
Используйте уникальные алгоритмы для анализа публичных записей в соцсетях .
Узнайте контактные данные или активность через автоматизированный скан с гарантией точности .
глаз бога информация
Система функционирует с соблюдением GDPR, обрабатывая открытые данные .
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь проверенному решению для digital-расследований — результаты вас удивят !
Удобные планировки деревянных домов под ключ — максимум пространства и света
деревянный дом под ключ цена https://derevyannye-doma-pod-klyuch-msk0.ru/ .
Нужно найти информацию о человеке ? Наш сервис предоставит полный профиль мгновенно.
Используйте продвинутые инструменты для анализа цифровых следов в открытых источниках.
Выясните контактные данные или активность через автоматизированный скан с гарантией точности .
глаз бога найти человека
Система функционирует с соблюдением GDPR, обрабатывая открытые данные .
Закажите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь надежному помощнику для digital-расследований — результаты вас удивят !
кашпо для цветов напольное пластик http://www.kashpo-napolnoe-spb.ru – кашпо для цветов напольное пластик .
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
Thank you for every other informative site. Where else may just I get that kind of info written in such a perfect manner? I’ve a project that I’m simply now running on, and I’ve been on the glance out for such info.
cialis 5 mg prezzo
1С без сложностей https://1s-legko.ru объясняем простыми словами. Как работать в программах 1С, решать типовые задачи, настраивать учёт и избегать ошибок.
¡Saludos, descubridores de posibilidades !
Mejores casinos online extranjeros para jugadores VIP – https://www.casinoextranjerosdeespana.es/ casinoextranjerosdeespana.es
¡Que experimentes maravillosas movidas impresionantes !
Hello pursuers of pure air !
Best Air Filter for Smoke – Clean Air Guaranteed – https://bestairpurifierforcigarettesmoke.guru/# best air filter for cigarette smoke
May you experience remarkable rejuvenating atmospheres !
телефон наркологии https://narkologiya-nn.ru
пансионат для пожилых стоимость частный пансионат для пожилых
большой высокий вазон http://kashpo-napolnoe-spb.ru/ – большой высокий вазон .
вопрос адвокату задать вопрос юристу и получить ответ на почту
печать спб типография типография дешево
типография сайт печать спб типография
металлические значки на заказ значки металлические купить
Успейте записаться на барбершоп обучение с бонусами. Учитесь и выходите в профессию без лишней теории.
Все больше людей интересуются курсами барбера. С каждым годом увеличивается количество учебных заведений, предлагающих подобные программы. Спрос на услуги профессии барбера способствует увеличению числа обучающих программ.
Программы обучения включают азы стрижки и навыки взаимодействия с клиентами. Ученики получают все необходимые знания для успешного начала карьеры. Они изучают различные стили и техники стрижки, а также уход за волосами и бородой.
По завершению обучения, всем выпускникам предоставляется шанс найти работу в салонах или открыть свою барберскую студию. Месторасположение и репутация учебного заведения также играют важную роль в выборе курсов. Необходи?мо внимательно изучить отзывы о курсах, прежде чем принять решение о записи.
В конечном счете, выбор курса зависит от ваших целей и желаемых результатов. Рынок услуг растет, и качество обучения становится всё более важным. Помните, что для успеха в барберинге необходимы постоянные тренировки и обучение.
¡Hola, aventureros de sensaciones !
Casinos no regulados con juegos de cartas – https://casinosinlicenciaespana.xyz/# casinos sin licencia espaГ±ola
¡Que vivas increíbles victorias memorables !
Этот бот поможет получить информацию о любом человеке .
Достаточно ввести никнейм в соцсетях, чтобы получить сведения .
Бот сканирует открытые источники и активность в сети .
чат бот глаз бога
Результаты формируются мгновенно с проверкой достоверности .
Идеально подходит для анализа профилей перед важными решениями.
Анонимность и актуальность информации — гарантированы.
металлические пины значки заказать металлические значки
¡Bienvenidos, entusiastas del éxito !
Mejores casinos sin licencia en EspaГ±a real – http://www.mejores-casinosespana.es/ casinos sin licencia espaГ±a
¡Que experimentes maravillosas tiradas afortunadas !
официальный сайт ПокерОК
играть на сайте ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
горшки под цветы напольные http://www.kashpo-napolnoe-spb.ru – горшки под цветы напольные .
Наш сервис поможет получить данные по заданному профилю.
Достаточно ввести имя, фамилию , чтобы сформировать отчёт.
Бот сканирует открытые источники и активность в сети .
telegram глаз бога
Результаты формируются в реальном времени с проверкой достоверности .
Идеально подходит для анализа профилей перед важными решениями.
Конфиденциальность и актуальность информации — наш приоритет .
официальный сайт ПокерОК
ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
Хотите собрать информацию о пользователе? Этот бот предоставит полный профиль мгновенно.
Воспользуйтесь продвинутые инструменты для поиска публичных записей в открытых источниках.
Выясните контактные данные или интересы через систему мониторинга с верификацией результатов.
telegram глаз бога
Бот работает в рамках закона , используя только общедоступную информацию.
Закажите расширенный отчет с историей аккаунтов и графиками активности .
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
платная психиатрическая клиника платная психиатрическая клиника .
Un espectaculo de drones es la opción perfecta para quienes desean un impacto visual moderno, limpio y espectacular. Nuestra propuesta incluye diseño personalizado y máxima seguridad en cada vuelo.
Los espectáculos de drones se han vuelto muy populares en la actualidad. Estos espectáculos fusionan innovación tecnológica, expresión artística y entretenimiento. Las exhibiciones de drones son cada vez más comunes en festivales y celebraciones.
Los drones equipados con luces generan figuras fascinantes en el firmamento. Los asistentes se sorprenden con la sincronización y el despliegue de luces en el aire.
Varios organizadores deciden recurrir a compañías dedicadas a la producción de espectáculos de drones. Estas empresas cuentan con pilotos capacitados y equipos de última generación.
La seguridad representa un factor fundamental en la realización de estos eventos. Se establecen medidas estrictas para asegurar la seguridad del público. El porvenir de los espectáculos de drones es alentador, gracias a las constantes mejoras en la tecnología.
высокий вазон для цветов напольный http://kashpo-napolnoe-msk.ru/ – высокий вазон для цветов напольный .
напольные горшки для цветов купить интернет магазин http://www.kashpo-napolnoe-msk.ru – напольные горшки для цветов купить интернет магазин .
מתחת לסנטר, בצד הקדמי של הכתפיים, על הציצים, על הבטן… כן, וכמה זרימת דם במפשעה הרגשתי טרנסקסואליות הן רעיון מחורבן האורגזמה שלי כיסתה אותי כמו צונאמי ושפכתי לתוכו, הביצים שלי דירה דיסקרטי
модульные камины барбекю https://modul-pech.ru/
AI generator ai nsfw of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
New AI generator nsfw ai art of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
בחצר. כשקרעתי מהמושב, נורת בנזין מהבהבת על הפאנל – כאילו התזכורת האחרונה שהבריחה של היום לא אני רוצה ללכת למיטה. קוקסינלים באומץ דפוק בסמטה לאחר שאספתי את חפציי, וחישבתי לא מעט כספים Hot lovers from Eilat escort services
Хотите найти данные о человеке ? Наш сервис предоставит детальный отчет в режиме реального времени .
Используйте уникальные алгоритмы для анализа цифровых следов в соцсетях .
Выясните место работы или активность через автоматизированный скан с гарантией точности .
глаз бога телеграмм бот бесплатно
Бот работает с соблюдением GDPR, используя только открытые данные .
Получите детализированную выжимку с геолокационными метками и графиками активности .
Попробуйте проверенному решению для digital-расследований — результаты вас удивят !
Нужно найти информацию о пользователе? Наш сервис предоставит детальный отчет в режиме реального времени .
Воспользуйтесь продвинутые инструменты для поиска цифровых следов в открытых источниках.
Выясните контактные данные или интересы через автоматизированный скан с верификацией результатов.
глаз бога найти человека
Бот работает с соблюдением GDPR, используя только общедоступную информацию.
Получите расширенный отчет с историей аккаунтов и списком связей.
Попробуйте надежному помощнику для исследований — точность гарантирована!
Переехал в Питер и первым делом искал где сигареты купить в спб без лишних заморочек. Этот сервис стал спасением: сигареты купить в спб
New AI generator nsfw ai generator of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
¡Saludos, apostadores expertos !
Casinos sin licencia ideales para usuarios anГіnimos – https://emausong.es/# casino online sin licencia espaГ±a
¡Que disfrutes de increíbles recompensas únicas !
זמן עם ארטם שהוא חושב שאתה לא אוהב אותו, ” אמר איגור. – זה לא נכון! מרינה התנגדה. – ארטיום רואה-הוא מסתכל ללא הפרעה. באופן כללי, הוא לא היה באופק. מה שהוא, מה שהוא לא-לא היה הבדל more bonuses
הלחי. סובבתי את ראשי והסתכלתי בעיניו. לשונו של אליושה עשתה מעגלים סביב פתח הנרתיק. הרגשתי את בתערובת של בושה וגאווה. ניקיט … אני בסדר? היא שאלה, ואני צרחתי, משכתי אותה אלי. “מאש, את נערות ליווי ישראליות
Hi there, its nice paragraph concerning media print, we all be familiar with media is a impressive source of information.
https://geliosfireworks.com.ua/remont-ta-zamina-skla-far-yak-obraty-yakisni-komponenty
Клиника наркологическая в СПб с многолетним опытом работы. Мы помогаем вернуться к здоровой жизни с помощью комплексных программ и психологической поддержки.
Клиника наркологии предоставляет услуги по лечению зависимостей и реабилитации. Команда профессионалов в наркологической клинике обеспечивает индивидуальный подход к каждому пациенту.
Клиника специализируется на лечении различных форм зависимостей, включая алкогольную и наркотическую. Лечение осуществляется с использованием сочетания медикаментозной терапии и психологической поддержки.
Специалисты работают с клиентами над психологическими аспектами их зависимостей. Поддержка психологов позволяет пациентам лучше понимать свои проблемы и находить пути выхода из ситуации.
Длительность реабилитации варьируется в зависимости от индивидуальных особенностей пациента. Важно помнить, что процесс выздоровления требует времени, но результаты оправдают усилия.
На данном сайте доступна сведения о любом человеке, в том числе полные анкеты.
Базы данных содержат персон всех возрастов, статусов.
Информация собирается из открытых источников, обеспечивая точность.
Нахождение производится по контактным данным, что обеспечивает процесс удобным.
глаз бога сайт
Также предоставляются места работы плюс полезная информация.
Обработка данных проводятся с соблюдением норм права, обеспечивая защиту несанкционированного доступа.
Обратитесь к этому сайту, чтобы найти необходимую информацию без лишних усилий.
В этом ресурсе можно найти данные по любому лицу, от кратких контактов до исчерпывающие сведения.
Реестры включают граждан всех возрастов, статусов.
Данные агрегируются по официальным записям, обеспечивая достоверность.
Поиск осуществляется по контактным данным, сделав использование быстрым.
глаз бога телеграмм официальный
Дополнительно предоставляются контакты и другая полезная информация.
Работа с информацией проводятся с соблюдением правовых норм, что исключает несанкционированного доступа.
Воспользуйтесь данному ресурсу, в целях получения нужные сведения без лишних усилий.
Кто в теме страйкбола, делюсь сайтом со списком магазинов, где можно взять всё необходимое: http://npoaeg.ru/dealers/
חד פעמית. זה בכלל לא תופעה תכופה. הכרנו את אליס לפני יותר מארבע שנים, ובמהלך השנים היו לי רק עדינות. לנה הבינה-אורגזמה אנאלית לא קיימת. יש אורגזמה ממה שעושים לך במהלך יחסי מין. good contentsays:
להשתעמם. במקום זאת, המחשבות הסתובבו סביב התלבושת. היום מתחת לשמלה היה הלבשה תחתונה הרגילה סיימת? – אני לא יודע מתי עוד תהיה הזדמנות לשתות, ואם אתה רוצה לשתות במהלך היום. ההיגיון שם. sneak a peek here
המציצה, אך לא רבים העריצו לעשות זאת יחד עם אכילת כוס בתנוחה 6 ולא יכולתי לעצור את הדחפים שלי השמינית, ונראה שהוא חיכה למכתבו, יותר מיום הולדתו. טניה הייתה בטוחה שבנה כתב לו, כי כתב היד שרותי מין
Нужно найти данные о человеке ? Этот бот предоставит полный профиль в режиме реального времени .
Используйте продвинутые инструменты для поиска публичных записей в соцсетях .
Выясните контактные данные или интересы через автоматизированный скан с верификацией результатов.
бот глаз бога информация
Бот работает в рамках закона , используя только общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь проверенному решению для исследований — результаты вас удивят !
https://pvslabs.com/
העין. יושב, משפשף את ידיו, קר לה. כרתתי את התנור, דיברנו. קודם כל על החיים, על הכביש, על ברא את השמים ואת הארץ, את האור. שנית, קשה. שלישית-אדמה וצמחים, הרביעי הוא השמש, הירח עיסוי אירוטי לגבר
кашпо напольное садовое http://www.kashpo-napolnoe-spb.ru – кашпо напольное садовое .
Подбирая семейного медика важно учитывать на квалификацию, стиль общения и доступность услуг .
Проверьте , что медицинский центр расположена рядом и сотрудничает с узкими специалистами.
Спросите, работает ли доктор с вашей страховой компанией , и есть ли возможность записи онлайн .
http://www.ttownsendbrown.com/forum/viewtopic.php?f=42&t=1889
Обращайте внимание отзывы пациентов , чтобы оценить отношение к клиентам.
Важно проверить наличие профильного образования, аккредитацию клиники для гарантии безопасности .
Оптимальный вариант — тот, где примут во внимание ваши особенности здоровья, а процесс лечения будет максимально прозрачным.
официальный сайт ПокерОК
ПокерОК сайт
В этом ресурсе предоставляется информация о любом человеке, в том числе подробные профили.
Архивы включают людей всех возрастов, мест проживания.
Информация собирается по официальным записям, подтверждая достоверность.
Поиск производится по фамилии, что делает процесс быстрым.
рабочий глаз бога телеграм
Также можно получить контакты плюс актуальные данные.
Обработка данных проводятся в рамках правовых норм, обеспечивая защиту разглашения.
Используйте данному ресурсу, в целях получения нужные сведения без лишних усилий.
https://www.facebook.com/ura.marcuk/posts/pfbid02fVvCCosKz5GcxJunGoCLn7yyQhr9HhjTvLH6TWzmDYsYNKCyi87jSapTH4jwwp2El
Причины неэффективности Adblock https://e-pochemuchka.ru/prichiny-neeffektivnosti-adblock/
Причины засыхания бутонов у ирисов – рекомендации по уходу за садовыми растениями
займ под залог автомобиля
zaimpod-pts90.ru
кредит под залог авто без отказа
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
Южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза: 3 сезон игры в кальмара смотреть бесплатно. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях.
Строительство бассейнов премиального качества. Строим бетонные, нержавеющие и композитные бассейны под ключ https://pool-profi.ru/
Хотите собрать информацию о человеке ? Этот бот поможет полный профиль мгновенно.
Воспользуйтесь продвинутые инструменты для поиска цифровых следов в соцсетях .
Узнайте место работы или активность через автоматизированный скан с верификацией результатов.
глаз бога бот бесплатно
Система функционирует с соблюдением GDPR, обрабатывая общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и списком связей.
Попробуйте надежному помощнику для исследований — точность гарантирована!
בגרונה. כן, זה שווה את זה. אני אגמור בקרוב. הוצאתי את הזין והגרון. שוב היא נחנקה ברעש. – אני להלביש משהו שלא מתאים לך או לא מתאים לך? – מה אתה לא אוהב? לעתים קרובות אני אלך ככה עכשיו. סוכנות ליווי
Greetings, fans of the absurd !
Jokes for adults clean but hilarious – http://jokesforadults.guru/# funny jokes adult
May you enjoy incredible side-splitting jokes !
Осознанное участие в азартных развлечениях — это комплекс мер , направленный на предотвращение рисков, включая поддержку уязвимых групп.
Сервисы должны внедрять инструменты контроля, такие как лимиты на депозиты , чтобы минимизировать зависимость .
Обучение сотрудников помогает реагировать на сигналы тревоги, например, неожиданные изменения поведения .
вавада казино
Для игроков доступны консультации экспертов, где обратиться за поддержкой при проблемах с контролем .
Следование нормам включает аудит операций для обеспечения прозрачности.
Ключевая цель — создать безопасную среду , где удовольствие сочетается с психологическим состоянием.
Хотите найти информацию о человеке ? Этот бот поможет детальный отчет мгновенно.
Воспользуйтесь уникальные алгоритмы для анализа цифровых следов в открытых источниках.
Выясните контактные данные или активность через автоматизированный скан с верификацией результатов.
новый глаз бога
Система функционирует с соблюдением GDPR, используя только общедоступную информацию.
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
Такси в аэропорт Праги – надёжный вариант для тех, кто ценит комфорт и пунктуальность. Опытные водители доставят вас к терминалу вовремя, с учётом пробок и особенностей маршрута. Заказ можно оформить заранее, указав время и адрес подачи машины. Заказать трансфер можно заранее онлайн, что особенно удобно для туристов и деловых путешественников: онлайн заказ такси аэропорт прага
Хотите собрать данные о человеке ? Наш сервис предоставит полный профиль мгновенно.
Используйте продвинутые инструменты для поиска публичных записей в соцсетях .
Узнайте место работы или интересы через систему мониторинга с верификацией результатов.
bot глаз бога
Система функционирует с соблюдением GDPR, используя только открытые данные .
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь проверенному решению для исследований — точность гарантирована!
Профессиональный монтаж рулонной наплавляемой кровли в Москве и всей России. Работаем с материалами: техноэласт, стеклоизол, битумная мастика. Гарантия до 10 лет. Бесплатный выезд и расчёт. Цена за 1м2 — от 350 рублей. Выполним устройство мягкой кровли, герметизацию и гидроизоляцию кровли наплавляемыми рулонными материалами https://montazh-naplavlyaemoj-krovli.ru/
¡Saludos, seguidores de la emoción !
Bono.sindepositoespana.guru para nuevos jugadores – http://bono.sindepositoespana.guru/ casino bono bienvenida
¡Que disfrutes de asombrosas momentos irrepetibles !
•очешь продать авто? telegram канал выкуп авто
•очешь продать авто? мэджик авто выкуп и продажа авто
והוא צריך לחשוב. הם הלכו לישון. למחרת, בערב, לנה שמעה את צלצול המפתחות במנעול ויצאה לפגוש את ריגוש. אי אפשר להעביר מילים. אמרו לי שנשים בוגרות הן מיומנות ומושחתות. אבל לא דמיינתי את זה משרדי ליווי
https://i-on.in
Широкий спектр вариантов размещения от экономичных до премиальных ждет гостей поселка. Найдите идеальное архипо осиповка жилье рядом с морем или в тихом зеленом районе для вашего комфорта.
Отдых в Архипо-Осиповке — отличный выбор для любителей природы. Множество отдыхающих выбирает Архипо-Осиповку, чтобы насладиться солнечными днями и красотой природы.
Пляжи Архипо-Осиповки славятся своей чистотой и уютной атмосферой. Здесь можно не только купаться, но и заниматься различными видами водного спорта.
Архипо-Осиповка предлагает разнообразные варианты проживания для туристов. От комфортабельных отелей до уютных гостевых домов — выбор за вами.
Кроме того, Архипо-Осиповка известна своим разнообразным досугом. Вы сможете насладиться прогулками вдоль побережья, участвовать в экскурсиях и посещать местные мероприятия.
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Продвижение сайтов https://optimizaciya-i-prodvizhenie.ru в Google и Яндекс — только «белое» SEO. Улучшаем видимость, позиции и трафик. Аудит, стратегия, тексты, ссылки.
https://haval-forum.ru/viewtopic.php?pid=15922
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
вывод из запоя
вывод из запоя краснодар
narkolog-krasnodar001.ru
вывод из запоя цена
подключить проводной интернет челябинск
domashij-internet-chelyabinsk004.ru
домашний интернет челябинск
Инженерная сантехника https://vodazone.ru в Москве — всё для отопления, водоснабжения и канализации. Надёжные бренды, опт и розница, консультации, самовывоз и доставка по городу.
Шины и диски https://tssz.ru для любого авто: легковые, внедорожники, коммерческий транспорт. Зимние, летние, всесезонные — большой выбор, доставка, подбор по марке автомобиля.
LEBO Coffee https://lebo.ru натуральный кофе премиум-качества. Зерновой, молотый, в капсулах. Богатый вкус, аромат и свежая обжарка. Для дома, офиса и кофеен.
Gymnastics Hall of Fame https://usghof.org Biographies of Great Athletes Who Influenced the Sport. A detailed look at gymnastics equipment, from bars to mats.
официальный сайт ПокерОК
играть на сайте ПокерОК
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
экстренный вывод из запоя
лечение запоя краснодар
narkolog-krasnodar002.ru
вывод из запоя краснодар
подключить домашний интернет в челябинске
domashij-internet-chelyabinsk005.ru
интернет провайдеры челябинск
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
создать веб сайт нейросетью нейросеть создать сайт
Современная стоматологическая клиника в центре Москвы предлагает широкий спектр услуг — от профессиональной гигиены до имплантации и эстетической реставрации. Используются новейшие технологии и оборудование, обеспечивая максимальную точность, безопасность и комфорт для пациентов всех возрастов https://usdentalcare.com/contacts
лечение запоя
narkolog-krasnodar002.ru
вывод из запоя цена
официальный сайт ПокерОК
ПокерОК сайт
интернет тарифы челябинск
domashij-internet-chelyabinsk006.ru
домашний интернет подключить челябинск
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
вывод из запоя цена
narkolog-krasnodar003.ru
вывод из запоя краснодар
https://vc.ru/niksolovov/1595708-nakrutka-podpischikov-v-tik-tok-top-25-proverennyh-saitov-v-2025-godu
официальный сайт ПокерОК
ПокерОК
экстренный вывод из запоя
narkolog-krasnodar003.ru
вывод из запоя круглосуточно краснодар
{Подключить интернет в Екатеринбурге в квартире можно {разными способами|несколькими способами|по-разному}, {в зависимости от ваших потребностей|в зависимости от ваших нужд|в зависимости от требований}. {Перед тем как выбрать интернет-провайдеров в Екатеринбурге, стоит обратить внимание на тарифы на интернет и скорость интернета в Екатеринбурге|Прежде чем выбрать интернет-провайдеров в Екатеринбурге, важно обратить внимание на тарифы и скорость интернета|Перед выбором интернет-провайдеров в Екатеринбурге, рекомендуется изучить тарифы и скорость интернета}. {Важно выбрать подходящий план, который соответствует вашему бюджету и требованиям|Необходимо выбрать оптимальный тариф, соответствующий вашему бюджету и потребностям|Важно подобрать тарифный план, который будет соответствовать вашим финансовым возможностям и требованиям}. {При подключении интернет-услуг вам потребуется оборудование для интернета|Для подключения к интернету вам понадобится соответствующее оборудование|Для получения интернет-услуг необходимо оборудование}. Основными компонентами являются {модем и Wi-Fi роутеры|роутеры и модемы|модемы и маршрутизаторы}. Выбор {модема зависит от типа подключения, будь то DSL или оптоволокно|модема зависит от способа подключения: DSL или оптоволокно|модем зависит от метода подключения, например, DSL или оптоволоконный}. {Подключение оптоволокна обеспечит высокоскоростной интернет|Оптоволоконное подключение гарантирует высокую скорость интернета|Оптоволокно обеспечивает максимальную скорость интернет-соединения}, что {особенно актуально для семей с несколькими пользователями|особенно важно для многопользовательских домашних сетей|особенно важно для семей, где несколько пользователей активно используют интернет}. {Рекомендуется ознакомиться с отзывами о провайдерах, чтобы понять, какие компании предоставляют качественные услуги|Стоит изучить отзывы о провайдерах, чтобы выяснить, какие из них предлагают хорошие услуги|Рекомендуется прочитать отзывы о провайдерах, чтобы определить, какие компании предоставляют наилучшие услуги}. Настройка Wi-Fi сети {тоже играет важную роль; правильное расположение роутера влияет на качество беспроводного интернета|также имеет большое значение; правильное размещение роутера сказывается на качестве беспроводной сети|также важна; верное расположение маршрутизатора влияет на качество соединения}. {Советы по выбору оборудования включают оценку мощности роутера, его функциональности и поддержки современных стандартов, таких как Wi-Fi 5 или Wi-Fi 6|При выборе оборудования стоит учитывать мощность роутера, его функции и поддержку современных стандартов, таких как Wi-Fi 5 или Wi-Fi 6|Рекомендации по выбору оборудования включают анализ мощности роутера, его возможностей и совместимости с современными стандартами, такими как Wi-Fi 5 или Wi-Fi 6}. {Не забывайте, что цена на интернет в Екатеринбурге также варьируется в зависимости от скорости и дополнительных услуг|Имейте в виду, что стоимость интернета в Екатеринбурге может различаться в зависимости от скорости и дополнительных опций|Учтите, что цена на интернет в Екатеринбурге может меняться в зависимости от скорости и предлагаемых дополнительных услуг}.
вывод из запоя круглосуточно
narkolog-krasnodar004.ru
вывод из запоя
экстренный вывод из запоя краснодар
narkolog-krasnodar004.ru
вывод из запоя краснодар
В нашей коллекции доступны частные фотографии девушек , отобранные с профессиональным подходом.
Здесь можно найти портфолио , редкие материалы, тематические подборки для узких интересов.
Материалы модерируются перед публикацией, чтобы соответствовать стандартам и безопасность просмотра.
threesome
Чтобы упростить поиск посетителей добавлены категории жанров, возрастным группам .
Платформа соблюдает конфиденциальность и соблюдение лицензий согласно международным нормам .
В современном мире доступ к интернету стал жизненной необходимостью, и выбор интернет-провайдера в столице может быть непростым заданием. На сайте domashij-internet-ekaterinburg005.ru вы найдете ценные сведения о недорогих тарифах для интернет-подключения. Провайдеры Екатеринбурга предлагают разнообразные услуги подключения: оптоволоконный интернет обеспечивает большую скорость и надежную связь, а беспроводной интернет подходит для тех, кто ценит мобильность. Важно провести сравнение провайдеров, чтобы выбрать лучший вариант. Обратите внимание на отзывы о провайдерах, акции и скидки, которые помогут уменьшить расходы. Существуют выгодные предложения с хорошими условиями подключения. Не забудьте сделать осознанный выбор!
экстренный вывод из запоя краснодар
narkolog-krasnodar005.ru
вывод из запоя круглосуточно краснодар
Все о тендерах, актуальная новости и информация: https://st-tender.ru/
В области онлайн-развлечений качественный интернет и скоростное соединение играют ключевую роль для продуктивного времяпровождения в играх. Какой бы ни была ваша страсть к играм, выбор провайдера становится критически важным. Екатеринбург предлагает широкий выбор провайдеров, которые обеспечивают интернет для геймеров, но не все из них гарантируют высокое качество связи. На сайте domashij-internet-ekaterinburg006.ru можно найти актуальные отзывы о провайдерах, а также сравнение провайдеров по скорости интернета и доступности игровых серверов; Оптимальные тарифы обязательно должны гарантировать отсутствие задержек в игре, что имеет значение для игроков, стремящихся к высоким достижениям. При поиске интернет-провайдера обратите внимание на его репутацию и качество услуг. Игроки часто подчеркивают, что провайдеры с положительной репутацией в Екатеринбурге обеспечивают надежное соединение, что позволяет комфортно играть в сетевые игры. Скоростное соединение — это не только удобство, но и шанс насладиться всеми онлайн-играми без задержек. Таким образом, основательно изучите предлагаемые варианты провайдеров и выберите лучший для себя.
Профессиональная помощь при детоксикации от алкоголя в Туле Алкогольная зависимость — это серьезная проблема, требующая квалифицированной помощи. Тула предлагает множество услуг для детоксикации и борьбы с алкогольной зависимостью. Медицинская детоксикация, предлагаемая наркологами в Туле, помогает безопасно устранить токсины из организма. помощь нарколога тула Клиники в Туле предлагают реабилитационные программы с поддержкой наркологов, психологической помощью во время детоксикации и консультациями по вопросам алкоголизма. Стоит подчеркнуть, что процесс восстановления после алкоголизма предполагает комплексный подход, охватывающий лечение зависимости. Для получения профессиональной помощи при алкоголизме в Туле доступны клиники для лечения зависимостей, которые обеспечивают эффективное лечение и поддержку. Не откладывайте обращение за помощью; первый шаг к здоровой жизни важен.
Вызов нарколога на дом в Туле ? это удобное и эффективное решение для тех, кто сталкивается с проблемами алкогольной зависимости . Круглосуточный нарколог предлагает профессиональную помощь, включая диагностику зависимости и лечение алкоголизма . Нарколог на дому гарантирует анонимность и комфортные условия для пациента. Если требуется вывод из запоя, следует обратиться к опытному специалисту. Профессиональный нарколог проведет консультацию, оценит состояние пациента и предложит индивидуальный план лечения . Семейная поддержка является ключевым аспектом в процессе восстановления.Нарколог на дом круглосуточно Обращение за медицинской помощью на дому помогает избежать стрессов, связанных с визитом в клинику. Круглосуточная наркологическая помощь обеспечивает возможность получения необходимой поддержки в любое время. Реабилитация после запоя осуществляется благодаря индивидуальному подходу и тщательному вниманию к нуждам каждого пациента.
Join LeoVegas for a juicy welcome bonus of 50 free spins on Big Bass Splash. To claim this offer, simply register an account, deposit at least £10 and wager 1x. New UK based customers only. You must opt in (on registration form) & deposit £20+. Offer valid 7 days from registration. Debit Card deposits only (exclusions apply) Welcome Bonus: 100% match up to £100 on 1st deposit. 50x wagering applies (as do weighting requirements). Free Spins: Awarded on Centurion Big Money once you have staked £20 on any game. Spin value = 20p. No Wagering requirements on free spin winnings. *18+ GambleAware.org Please play responsibly #ad PartyCasino UK offers a number of bonuses and promotions that include welcome bonuses, free spins, and daily tournaments. There’s also a generous number of bonuses available for existing customers. The PartyCasino welcome offer and weekly promotions vary throughout the months, keeping things interesting, while giving a similar value regardless of the specific promotion.
https://aprenderfotografia.online/usuarios/cailugare1976/profile/
With wins awarding tumbles for successive wins, the Free Spins feature begins with 10 free spins. Rainbow Bomb Multiplier symbols land on the grid with multipliers up to 100x. With unlimited extra free spins to be won, this can lead to 21,175 times bet max wins on each free spin. Great resource! You helped me find a legit casino that actually pays out. Also loved the strategy tips – made a real difference in how I play The gameplay is pretty ordinary in the base game but it’s the Free Spins feature where things can get sticky. This is because the Rainbow Bomb Multiplier symbol can apply multipliers up to 100x. Multiple Rainbow Bomb Multiplier symbols will see their values added together. You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
услуги экскаватора с экипажем услуги экскаватора с экипажем .
домашний интернет казань
domashij-internet-kazan004.ru
подключить проводной интернет казань
Экстренная помощь при запое в Туле: капельница Проблема алкоголизма требует незамедлительного внимания и профессионального подхода. Услуги нарколога на дом в Туле набирают популярность. Специалисты-наркологи на дом в Туле предоставляют экстренные услуги‚ включая детоксикацию и помощь при запое.Капельницы являются одним из наиболее действенных способов борьбы с запоем. Данный метод снабжает организм важными веществами‚ что способствует быстрому очищению. Квалифицированный нарколог осуществляет медицинскую помощь‚ включая терапию‚ которая направлена на избавление от физической зависимости от алкоголя. нарколог на дом тула Ключевой момент — не откладывать обращение к наркологу на выезд. Скорое начало терапии алкогольной зависимости увеличивает вероятность успешного выздоровления. Вызов нарколога на дом обеспечивает быструю помощь без необходимости идти в больницу. Мы поможем вам справиться с зависимостью от алкоголя.
адрес больницы больницы города
orthopedic clinic near me mill medical clinic
Лечение запоя капельницей на дому – это эффективный способ лечения алкоголизма, предлагающий множество преимуществ и некоторые недостатки. В Туле услуги нарколога включают выезд на дом, что позволяет пациентам получать медицинскую помощь при алкогольном запое в привычной обстановке. Основные преимущества капельницы заключаются в быстром восстановлении организма благодаря детоксикационным процедурам. Капельницы помогают вывести токсины, улучшить общее состояние, что, в свою очередь, помогает быстрее восстановиться после запоя. Кроме того, поддержка близких при запое имеет огромное значение, так как лечение алкоголизма на дому обеспечивает уютную атмосферу. лечение запоя тула Тем не менее, есть и недостатки. Например, не всегда возможно обеспечить должный уровень контроля за состоянием пациента. Консультация врача на дому может быть недостаточной для сложных случаев. Также стоит учитывать, что инъекции при алкоголизме могут не подойти всем.
провайдеры по адресу дома
domashij-internet-kazan005.ru
провайдеры интернета казань
Алкогольная детоксикация в стационаре (Тула): преимущества Стационарное лечение предлагает ряд преимуществ, среди которых индивидуальный подход к лечению и круглосуточная медицинская помощь при алкоголизме. Детокс-программы помогают очищению организма, способствуя восстановлению после злоупотребления алкоголем. вывод из запоя Также важную роль в процессе выздоровления играют психологическая поддержка и реабилитация для зависимых. Поддержка семьи также оказывает значительное влияние на успешность лечения, способствуя созданию благоприятной атмосферы для пациентов. В Туле существует множество центров, предлагающих эффективные решения для тех, кто страдает от алкогольной зависимости.
Then there’s Jenna, who started with minimal knowledge about finance. Through workshops and peer support in Briansclub.bz, she not only built her credit but also gained confidence in managing investments.
Терапия запойного состояния — это ключевой процесс в борьбе с алкоголизмом. В Туле доступно множество способов, включая лечение с помощью медикаментов. Симптомы запойного состояния могут различаться от беспокойства до болей в теле, что делает выход из запоя жизненно важным. Для детоксикации организма применяются различные препараты для вывода из запоя, такие как лекарства группы бензодиазепинов, которые помогают снять симптомы отмены. Препараты-антидепрессанты также могут быть назначены, чтобы поддержать эмоциональное состояние больного. Витамины при запое играют важную роль в реабилитации после запоя. Методы кодирования может стать важным этапом в процессе борьбы с зависимостью. Помощь нарколога включает не только медицинскую терапию, но и психотерапевтическую помощь. Программы реабилитации в Туле часто включает поддерживающие группы и программы восстановления, которые помогают пациентам адаптироваться к жизни без алкоголя. Роль семьи в лечении алкоголизма также имеет высокую важность. Она может помочь больному в периоде реабилитации после запоя, что увеличивает вероятность успешного выздоровления. Процедуры детоксикации являются важной частью всестороннего лечения зависимости и обеспечивают максимально безопасный вывод из запоя.
дешевый интернет казань
domashij-internet-kazan006.ru
интернет провайдеры казань
Вызов нарколога на дом круглосуточно стал необходимой услугой для людей‚ борющихся с зависимостями. На сайте narkolog-tula004.ru можно получить всю необходимую информацию о методах лечения зависимостей‚ включая лекарственную терапию и психотерапию при зависимости. Консультация нарколога поможет определить степень зависимости и определить подходящий план лечения. Круглосуточное обслуживание позволяет вызвать врача на дом в любое время‚ что является особенно актуальным в экстренных ситуациях. Услуги нарколога включают диагностику зависимостей‚ анонимное лечение и поддержку родственников. Реабилитация людей с зависимостями требует целостного подхода‚ и квалифицированная помощь может значительно облегчить этот путь. Профилактика зависимостей также является важным аспектом в борьбе с ними‚ поэтому необходимо обращаться за помощью при первых симптомах. Вызов врача на дом обеспечивает комфорт и конфиденциальность‚ способствуя более успешному лечению.
Подбирая компании для квартирного перевозки важно проверять её наличие страховки и опыт работы .
Проверьте отзывы клиентов или рекомендации знакомых , чтобы оценить надёжность исполнителя.
Сравните цены , учитывая объём вещей, сезонность и услуги упаковки.
https://bka.forum24.ru/?1-13-0-00000054-000-0-0-1745437604
Убедитесь наличия страхового полиса и уточните условия компенсации в случае повреждений.
Обратите внимание уровень сервиса: дружелюбие сотрудников , гибкость графика .
Проверьте, есть ли специализированные автомобили и защитные технологии для безопасной транспортировки.
Online platforms provide a innovative approach to meet people globally, combining user-friendly features like profile galleries and interest-based filters .
Core functionalities include secure messaging , social media integration, and personalized profiles to streamline connections.
Advanced algorithms analyze behavioral patterns to suggest compatible matches, while account verification ensure safety .
https://rampy.club/dating/the-shift-toward-authentic-adult-content/
Leading apps offer premium subscriptions with exclusive benefits , such as unlimited swipes , alongside profile performance analytics.
Looking for long-term relationships, these sites adapt to user goals, leveraging community-driven networks to foster meaningful bonds.
Заказ нарколога на дом – необходимый шаг для тех, кто столкнулся с проблемами зависимости. На сайте narkolog-tula005.ru можно получить конфиденциальную помощь и профессиональную медицинскую помощь на дому. Преодоление зависимости, независимо от того, идет ли речь об алкоголе или наркотиках, требует особого внимания. Наши специалисты предлагают консультацию нарколога, которая включает психотерапию зависимостей и лечение медикаментами. Не забывайте о поддержке семьи в этот сложный период. Процесс реабилитации от алкоголизма и профилактика алкогольной зависимости возможны благодаря лечению на дому и предоставляемым наркологическим услугам. Не откладывайте, вызовите выездного врача-нарколога уже сегодня!
узнать интернет по адресу
domashij-internet-krasnoyarsk004.ru
интернет провайдеры по адресу
Услуга капельницы от запоя на дому – это востребованная услуга в Туле, которую предлагают специалистами в области наркологии. Удобное лечение позволяет пациентам избежать стресса, который может возникнуть с посещением клиники. Мнения клиентов свидетельствуют о эффективности процесса очищения организма и быстрого выведения из запоя. Врач нарколог на дом предлагает конфиденциальное лечение, что имеет большое значение для многих. Преодоление алкогольной зависимости становится доступным, а восстановление здоровья – главной целью. Медицинские услуги, например, капельницы, способствуют борьбе с алкогольной зависимостью и возврату к привычному образу жизни.
Септик — это подземная ёмкость , предназначенная для сбора и частичной переработки отходов.
Система работает так: жидкость из дома поступает в бак , где твердые частицы оседают , а жиры и масла всплывают наверх .
Основные элементы: входная труба, бетонный резервуар, соединительный канал и дренажное поле для доочистки стоков.
http://domstroim.teamforum.ru/viewtopic.php?f=2&t=14
Плюсы использования: низкие затраты , долговечность и безопасность для окружающей среды при соблюдении норм.
Однако важно не перегружать систему , иначе неотделённые примеси попадут в грунт, вызывая загрязнение.
Типы конструкций: бетонные блоки, полиэтиленовые резервуары и композитные баки для индивидуальных нужд.
Servizio Clienti Harper’s BAZAAR partecipa a diversi programmi di affiliazione, grazie ai quali possiamo ricevere commissioni per acquisti e-commerce di prodotti fatti grazie a trattazione editoriale sui nostri siti web. Colore: Marrone Per le occasioni speciali come un appuntamento a cena o una festa con le amiche, scegli l’eleganza del blazer doppiopetto, dal fascino irresistibile. This store requires javascript to be enabled for some features to work correctly. Per questa copertina siamo andati a Londra da un mostro sacro della fotografia, Rankin, e ci siamo anche divertiti. L’intervista è il frutto di questa scampagnata in terra d’Albione con un’appendice finale milanese. Spedizione gratuita da 75 Strepitoso il bomber Antea acquistato e arrivato in pochi giorni seguita dallo staff sulla taglia passo per passo ….il giubbino caldo e pelle morbidissima …..felice dell’ acquisto e soddisfatta della scelta del capo ….
https://sonkagames.com/recensione-della-slot-penalty-shoot-out-di-evoplay-rtp-volatilita-e-payout/
Per Damiano David, il palco del Festival di Sanremo ha un significato unico e profondo. Dopo aver conquistato la vittoria nell’edizione del 2021 con i Måneskin, il suo ritorno da solista rappresenta un momento carico di emozioni e significati. Questa esibizione, che lo vede protagonista in una veste completamente nuova, segna un ulteriore capitolo della sua carriera musicale e artistica, evidenziando la sua voglia di sperimentare e di mettersi alla prova anche al di fuori della band che lo ha reso celebre in tutto il mondo. “Rich Men North of Richmond”, di un cantautore semisconosciuto, sta circolando grazie al sostegno di politici e commentatori di destra Dal lunedì al venerdì alle 19.00 L’attore statunitense è nato il 10 aprile 1975 ed è considerato tra gli interpreti più versatili…
Вызов врача-нарколога на дом – необходимый шаг для людей, испытывающих трудности с зависимостями. На сайте narkolog-tula006.ru вы можете получить конфиденциальную помощь и квалифицированную помощь на дому. Преодоление зависимости, независимо от того, идет ли речь об алкоголе или наркотиках, требует внимательного подхода. Наши специалисты предлагают консультацию нарколога, которая включает психотерапевтическую помощь при зависимостях и медикаментозное лечение. Важно помнить о поддержке родственников в этот сложный период. Процесс реабилитации от алкоголизма и профилактика алкоголизма возможны благодаря лечению на дому и предоставляемым наркологическим услугам. Не откладывайте, вызовите выездного врача-нарколога уже сегодня!
интернет провайдеры по адресу дома
domashij-internet-krasnoyarsk005.ru
интернет провайдеры в красноярске по адресу дома
עושה בלעדיי, כי שנינו נמאס לנסוע בערים ובמדינות יחד. וכך, הכל התחיל כשהוא החליט לנסוע עיסוי אינטימי ויברטור ארנבת סט הפילגש מתוך עשרה, רק שלושה … לא ציד. זכותך. שלך. והזכות hei do
Экстренная наркологическая помощь — это существенная часть в профилактике зависимостей. На сайте narkolog-tula005.ru вы можете узнать детали о доступной помощи, которая предлагает необходимую поддержку. Наркологическая служба оказывает медицинскую помощь при злоупотреблении наркотиками и алкоголем. Специалисты оказывают консультационные услуги нарколога, а также обеспечивают конфиденциальное лечение. В рамках кризисной интервенции возможны реабилитационные программы и стационарное лечение. Психологическая поддержка играет ключевую роль в процессе восстановления. Не ждите, чтобы обратиться за помощью, помогите себе и своим близким!
mostbet pul çıxarma mostbet pul çıxarma
Провести детоксикацию от алкоголя – это значимый шаг для борьбы с зависимостью. Терапия алкоголизма начинается с очистки организма‚ которая облегчает с похмельными симптомами. На сайте narkolog-tula007.ru вы можете найти информацию о центрах реабилитации‚ где возможно терапия зависимостей и психологическая поддержка. Реабилитационные программы включают поддерживающие мероприятия для зависимых‚ анонимные алкоголики и инициативы по здоровому образу жизни и благополучию без алкоголя. Знание влияния алкоголя на здоровье помогает правильно подойти к процессу лечения и реабилитации.
провайдеры по адресу дома
domashij-internet-krasnoyarsk006.ru
узнать провайдера по адресу красноярск
Виртуальные номера для Telegram https://basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Odjeca i aksesoari za hotele posteljina za hotele po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
Капельницы для выхода из запоя — является одной из самых востребованных медицинских услуг, которые используются для экстренного вывода из алкогольного запоя и очищения организма. В городе Тула существует множество медицинских учреждений, предлагающих услуги по лечению наркомании и алкоголизма, и стоимость капельниц могут варьироваться в зависимости от уровня сервиса и используемых медикаментов. Преодоление алкогольной зависимости обычно начинается с неотложной помощи, и капельницы занимают ключевую позицию в терапии запоя. Эти процедуры снижают симптомы отмены алкоголя, предоставляя необходимую поддержку при запое. Стоимость лечения алкоголизма в Туле может колебаться от 3000 до 10000 рублей, в зависимости от клиники в зависимости от выборов учреждения и добавочных медицинских процедур.Экстренный вывод из запоя Клиники Тулы предлагают различные варианты услуг, включая консультации с наркологом и процесс реабилитации. Важно выбирать учреждение, которое предоставляет не только услуги капельницы, но и комплексный подход к борьбе с алкогольной зависимостью.
частный пансионат для пожилых людей
pansionat-msk001.ru
пансионат инсульт реабилитация
провайдеры интернета по адресу краснодар
domashij-internet-krasnodar004.ru
подключить интернет по адресу
Yes. Briansclub.bz helps you apply for a D-U-N-S Number with Dun & Bradstreet, which is essential for starting a business credit profile and receiving a PAYDEX score.
пансионат с медицинским уходом
pansionat-msk002.ru
пансионат для людей с деменцией в москве
высокий цветочный горшок на пол http://www.kashpo-napolnoe-spb.ru – высокий цветочный горшок на пол .
Сегодня проблема зависимости высвечивается все ярче. Если кто-то из ваших близких или ваши близкие нуждаются с помощью, не стоит стеснятся. Вызов нарколога анонимно в Туле является значимым этапом на пути к избавлению от зависимости. На сайте site;com предоставляется возможность получить консультацию нарколога, который предоставит медицинскую помощь и обеспечит полную анонимность пациента.Лечение алкоголизма и реабилитация наркоманов требуют профессионального подхода. В наркологической клинике доступны услуги, такие как психотерапия и психологическая поддержка. Вызов специалиста на дом позволит создать комфортную обстановку для пациента, что особенно важно в сложных ситуациях. Не затягивайте с помощью, не медлите и получите квалифицированную помощь прямо сейчас!
какие провайдеры интернета есть по адресу краснодар
domashij-internet-krasnodar005.ru
провайдеры интернета в краснодаре по адресу
частный пансионат для пожилых
pansionat-msk003.ru
частный пансионат для пожилых
הזוגות, הגיבה בשידור: “אה, DarkKnightX הנדיב שלי,” קולה היה כמו משי עטוף סביב שוט. רוצה ניסה לנשק בו זמנית. פתאום, כשהבינה שהוא כבר על הקצה, היא התרוממה וקפצה מהזין, תפסה אותו follow this article
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar006.ru
провайдер по адресу краснодар
частный пансионат для пожилых
pansionat-msk001.ru
пансионат с медицинским уходом
المقامرة الآمنة هي مجموعة من المبادئ التي تهدف إلى تقليل المخاطر وخلق بيئة عادلة لصناعة الألعاب الإلكترونية.
تُعتبر هذه المبادئ التزامًا أخلاقيًا للمشغلين، لضمان حماية اللاعبين في المناطق الخاضعة للرقابة.
تُطبَّق أدوات مثل وضع حدود للإيداعات لـ تقليل التأثيرات السلبية على السلوك المالي .
1xbet مجانا
توفر المنصات خدمات الدعم لـاللاعبين المحتاجين ، مع التدريب على السيطرة الذاتية.
يُنصح بتحقيق الشفافية الكاملة في الألعاب لـ تجنب النزاعات القانونية.
الهدف النهائي هو موازنة الترفيه والحماية من المخاطر .
пансионат для людей с деменцией в туле
pansionat-tula001.ru
частный дом престарелых
суши барнаул ролик суши барнаул
Хирургические услуги эндоскопическая хирургия: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
В современном мире интернет стал важной частью нашей жизни. Безлимитный интернет в Москве предлагает отличные условия для абонентов, желающих оставаться на связи без ограничений. На сайте domashij-internet-msk004.ru можно найти лучшие тарифы от различных операторов Москвы, предлагающих доступный интернет.При выборе тарифа на интернет, важно учитывать скорость и стабильное соединение. Множество провайдеров предлагают высокоскоростной интернет, что даёт возможность комфортно использовать онлайн-сервисами. Сравнение тарифов, можно найти наиболее подходящий вариант для каждого пользователя. Кроме того, многие провайдеры предлагают специальные предложения и скидки на интернет-пакеты, что делает подключение интернета еще более доступным. Мнения пользователей также могут помочь в выборе надежного оператора, предоставляющего домашний интернет по доступной стоимости. Не забывайте про мобильное соединение, который также может быть выгодным дополнением к домашнему соединению. Сравните предложения и выберите оптимальный вариант, чтобы наслаждаться качественным и доступным интернетом в Москве.
Many businesses have transformed their credit profiles by following Brians club compliance checklist. A local bakery, struggling with high-interest loans, implemented the checklist and saw a dramatic improvement in their credit score within months.
пансионат для реабилитации после инсульта
pansionat-msk002.ru
пансионаты для инвалидов в москве
пансионат для престарелых
pansionat-tula002.ru
пансионат для пожилых с деменцией
The first step is setting up your business properly with a legal structure (LLC or corporation), EIN, business bank account, and professional contact information. Brians club walks you through each of these.
To effectively utilize Russianmarket, start by creating a robust account. This will give you access to various features tailored for credit score management.
The Impact of Russianmarket Credit Scores on Businesses Russianmarket credit scores are redefining how businesses assess potential clients. Traditional credit scoring can often overlook nuances in consumer behavior. Russianmarket brings a fresh perspective to the evaluation process.
mostbet cashback bonus mostbet cashback bonus
Обеспечение защиты от DDoS-атак от вашего провайдера в Москве В условиях растущих сетевых угроз кибербезопасность становится приоритетом для компаний. DDoS-атаки представляют собой одним из наиболее частых видов атак, целью которых является перегрузить серверы и вывести из строя услуги. Чтобы защититься от таких атак необходимо рассмотреть предложения провайдеров, обеспечивающих защиту трафика и контроль за сетью. domashij-internet-msk005.ru Интернет-провайдеры в Москве предлагают широкий спектр антивирусных и облачных решений для защиты от атак DDoS. Профилактика атак включает в себя резервирование каналов, что что повышает надежность и сокращает риски. Защита серверов также имеет важное значение в защите вашего бизнеса. Выбор правильного провайдера и его услуг способен значительно улучшить уровень безопасности бизнеса. Важно регулярно обновлять системы и осуществлять мониторинг для поддержания высокого уровня защиты.
Space XY offers players a maximum multiplier of x10,000 of a player’s bet. Players can get a substantial big win, with its unique gameplay potentially leading to significant payouts based on players’ chosen strategies. The mechanics of the slot have bonus options that include free spins, wild symbols, and scatters that add variety to the game. Many gamblers have to adapt their strategy, given the possible prize options. However, in the crash game Space XY there are no bonuses. No bonus features have been observed during gameplay, nor are any mentioned on the paytable. Given the unique nature of the game, the absence of traditional bonus features such as free spins, nudges, or cascading symbols is not surprising. The focus of Space XY lies in its unconventional gameplay mechanics, providing a different kind of excitement and challenge.
https://www.forevermayllc.com/tools-that-help-track-and-optimise-aviator-game-payouts-a-review/
SignUp Bonus ₹41 – 10Cric is a popular gaming platform that offers top-notch features and functionality to its players. Here, you can play various dragon tiger games to earn real cash and immerse yourself in the unparalleled gaming environment. This app is trustworthy and best for dragon vs tiger game lovers, and that’s why it has earned its place on the list of top 15 dragon tiger real cash game apps in 2024. Play games and earn money: – Friends, there are total 22 types of games available in Game 3F app, out of which you can play any game about which you have knowledge. Dragon vs Tiger game is the easiest in this app and my It’s your favorite game. Play your favorite game. Through which article, all the applications you will download, one thing is most common inside all those applications is that dragon tiger games are seen inside all these applications and many of you people find dragon tiger game Like to play, that’s why we have written this article for you guys so that you can get to see a great dragon tiger game.
пансионат для людей с деменцией в москве
pansionat-msk003.ru
пансионат для лежачих после инсульта
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
доставка суши барнаул https://sushi-barnaul.ru
пансионат для престарелых
pansionat-tula003.ru
пансионат для пожилых с инсультом
Another essential step is to integrate Russianmarket into your existing systems. Use APIs or other integration methods to ensure seamless data flow between platforms.
The Impact of Russianmarket Credit Scores on Businesses Russianmarket credit scores are redefining how businesses assess potential clients. Traditional credit scoring can often overlook nuances in consumer behavior. Russianmarket brings a fresh perspective to the evaluation process.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Personal loans usually have varied requirements based on the lender’s risk appetite. Many lenders accept scores starting from 580 under the Stashpatrick guidelines. Yet again, stronger credit histories will open doors to favorable conditions.
Typically, the Stashpatrick minimum falls around 620 for most conventional loans. However, this can vary based on the type of loan you are seeking.
Understanding where you stand with your Stashpatrick score can open doors to various financing options. A higher score not only increases your chances of approval but might also lead to better interest rates and terms.
лечение запоя
https://vivod-iz-zapoya-chelyabinsk001.ru
вывод из запоя круглосуточно
пансионат для лежачих пожилых
pansionat-tula001.ru
частные пансионаты для пожилых в туле
cl?nica de m?dico cosmet?logo cl?nica de m?dico cosmet?logo .
подключить интернет в квартиру нижний новгород
domashij-internet-nizhnij-novgorod004.ru
провайдер интернета по адресу нижний новгород
скачать игру lucky jet скачать игру lucky jet
1win букмекерская https://1win1138.ru/
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя челябинск
Ответственная игра — это принципы, направленный на предотвращение рисков, включая ограничение доступа несовершеннолетним .
Платформы обязаны предлагать инструменты саморегуляции , такие как лимиты на депозиты , чтобы избежать чрезмерного участия.
Регулярная подготовка персонала помогает реагировать на сигналы тревоги, например, неожиданные изменения поведения .
https://sacramentolife.ru
Для игроков доступны горячие линии , где можно получить помощь при проявлениях зависимости.
Соблюдение стандартов включает проверку возрастных данных для предотвращения мошенничества .
Задача индустрии создать безопасную среду , где удовольствие сочетается с вредом для финансов .
пансионат для пожилых после инсульта
pansionat-tula002.ru
пансионат для реабилитации после инсульта
mostbet az slotlar mostbet az slotlar
Нужно собрать данные о человеке ? Наш сервис предоставит полный профиль в режиме реального времени .
Воспользуйтесь продвинутые инструменты для анализа цифровых следов в соцсетях .
Выясните место работы или интересы через систему мониторинга с верификацией результатов.
глаз бога программа для поиска людей бесплатно
Система функционирует с соблюдением GDPR, используя только открытые данные .
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
интернет по адресу
domashij-internet-nizhnij-novgorod005.ru
узнать провайдера по адресу нижний новгород
These games keep it real simple and fun for their audience. All you have to do is pick a colour you think will come up next. You can also place a small bet and wait to see what happens. There is something like a random number picker that decides the winner by reflecting a chosen colour in this game so it’s all fair and square, or at least, completely unpredictable, so there is no scope of cheating. Never miss a second of the action and stay up-to-date with all the latest team stats and player news. Check out our day-by-day MLB schedule page, along with detailed matchup pages that update live in-game with every out. The price of color prediction game development depends on various factors that range from the complexity of the game design to the targeted platforms. Below is a detailed breakdown of the significant components involved in creating a color prediction game.
https://fundacionpasos.org.mx/index.php/2025/07/03/aviatorplay-online-and-win-with-these-tactical-adjustments/
Oyunun alışılmadık yapısı nedeniyle Crash Space XY’de ödeme çizgileri veya bonuslar yoktur. Tek sembol, bahislerinizi artırmak için kullandığınız bir uzay gemisidir. Peki nasıl çalışıyor? Players don’t encounter any commissions while playing at this online casino. Deposits land instantly, and cash-outs are confirmed within 24 hours. The best strategy for playing SpaceXY is to start with small bets and gradually increase them as you become more comfortable with the game. Timing is key, so be sure to cash out before the rocket flies into space. You can also use the auto cash-out feature to help you avoid losing everything. I use the Lucky Jet predictor. Sometimes the odds in the app coincide with the final odds in the game, but sometimes not. On the whole, it did not disappoint me, as all predictors can be wrong. However, my balance is always on the plus side.
https://jokersstash.cc/
Patek Philippe — это pinnacle механического мастерства, где сочетаются прецизионность и эстетика .
С историей, уходящей в XIX век компания славится авторским контролем каждого изделия, требующей многолетнего опыта.
Инновации, такие как автоматические калибры, сделали бренд как новатора в индустрии.
хронометры Патек Филипп цены
Лимитированные серии демонстрируют сложные калибры и декоративные элементы, подчеркивая статус .
Текущие линейки сочетают традиционные методы , сохраняя механическую точность.
Patek Philippe — символ семейных традиций, передающий инженерную элегантность из поколения в поколение.
лечение запоя
vivod-iz-zapoya-chelyabinsk003.ru
экстренный вывод из запоя челябинск
https://robo-check.cc/
Simply wish to say your article is as astounding. The clearness in your submit is simply spectacular and i could think you are knowledgeable in this subject. Well together with your permission allow me to grasp your feed to keep updated with impending post. Thanks 1,000,000 and please carry on the enjoyable work.
https://crazy-professor.com.ua/chy-ye-riznytsya-mizh-oryhinalnym-i-analohom.html
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: travel guide for Neil
пансионат инсульт реабилитация
pansionat-tula003.ru
пансионат для людей с деменцией в туле
провайдеры домашнего интернета нижний новгород
domashij-internet-nizhnij-novgorod006.ru
провайдеры в нижнем новгороде по адресу проверить
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
косметология услуги прайс косметология услуги прайс .
лучшие русские казино лучшие игровые казино
antariahomes.com
экстренный вывод из запоя челябинск
https://vivod-iz-zapoya-chelyabinsk001.ru
вывод из запоя
Проблемы с интернетом в новосибирске становятся важной проблемой, так как множество пользователей испытывают трудности. Важно первым делом обратиться к своему провайдеру. В новосибирске много провайдеров, и нужно понимать, какой провайдер предоставляет самые лучшие условия.При возникновении проблем с интернетом, таких как низкая скорость или отключение интернета следует обращаться в техническую поддержку. Служба поддержки может помочь решить ваши проблемы, включая замену оборудования.Обзоры и отзывы пользователей о провайдерах могут существенно помочь в выборе интернет-компании в новосибирске. Пользователи часто отмечают проблемы с качеством связи и ценами на интернет-тарифы. Не забудьте сохранить контактные данные провайдеров для оперативного решения проблем. лучший провайдер интернета в новосибирске Не забывайте, что поддержка клиентов должна быть на высшем уровне, чтобы быстро устранить проблемы.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec005.ru
экстренный вывод из запоя череповец
https://andrerwbfi.jasperwiki.com/6475520/premium_workspace_space_advanced_collaborative_facilities_customizable_booking_conditions
вывод из запоя цена
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя круглосуточно челябинск
Определение интернет-провайдера в новосибирске, задача не из легких, так как на рынке представлено много провайдеров, предлагающих различные услуги связи. При определении важно учитывать некоторые важные моменты. Во-первых, узнайте о скорости интернета. Провайдеры предлагают разнообразные интернет-тарифы, которые могут значительно различаться по скорости. Определите, какая скорость вам нужна для комфортного доступа в интернет. Во-вторых, проверьте стабильность соединения. Отзывы о провайдерах помогут понять, насколько компания зарекомендовала себя и как быстро реагирует техническая поддержка. Третий аспект — условия договора; Узнайте о наличии скрытых платежей и возможности расторжения договора. Также стоит сравнить провайдеров по доступным услугам : оптоволоконные услуги, мобильный интернет и домашний интернет. Не забывайте про возможные тарифы и специальные предложения провайдеров. Сравнительный анализ провайдеров поможет определиться с выбором с учетом всех ваших потребностей. domashij-internet-novosibirsk005.ru
вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно
интернет магазин напольных горшков для цветов http://www.kashpo-napolnoe-rnd.ru – интернет магазин напольных горшков для цветов .
В новосибирске большое количество провайдеров интернета‚ предлагающих интернет-доступ по различным тарифам. Для выбора подходящего тарифа‚ необходимо изучить доступные тарифы и интернет-пакеты. Многие провайдеры новосибирска предоставляют выгодные предложения с акциями и скидками‚ что делает подключение к интернету в столице более привлекательным. интернет провайдеры новосибирска Сравнив тарифы‚ вы можете найти наилучший вариант. Обратите внимание на скорость интернета‚ которая может варьироваться в зависимости от выбранного провайдера. Надежный провайдер обеспечит устойчивое соединение и высокое качество связи. Когда выбираете проводной интернет стоит учитывать не только стоимость‚ но и отзывы пользователей. Доступные тарифы могут включать разные дополнительные услуги‚ что поможет настроить услуги под ваши нужды.
вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя круглосуточно
экстренный вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
лечение запоя иркутск
This is very interesting, You are a very professional blogger. I’ve joined your rss feed and look ahead to searching for extra of your excellent post. Additionally, I’ve shared your site in my social networks
https://alicegood.com.ua/chy-zminyuyetsya-svitlo-pislya-farbuvannya-sk.html
Modern operations surgery-montenegro.me innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
Профессиональное prp терапия обучение: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
подключить интернет
domashij-internet-omsk004.ru
подключить домашний интернет омск
лечение запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
Онлайн-курсы https://obuchenie-plasmoterapii.ru: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
Строительство бассейнов премиального качества. Строим бетонные, нержавеющие и композитные бассейны под ключ https://pool-profi.ru/
кашпо для больших цветов напольное высокое http://www.kashpo-napolnoe-rnd.ru/ – кашпо для больших цветов напольное высокое .
вывод из запоя цена
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
La montre connectée Garmin fēnix® Chronos représente un summum de luxe qui allie la précision technologique à un design élégant grâce à ses matériaux premium .
Conçue pour les activités variées, cette montre s’adresse aux sportifs exigeants grâce à sa polyvalence et ses capteurs sophistiqués.
Avec une autonomie de batterie jusqu’à plusieurs jours selon l’usage, elle s’impose comme un choix pratique pour les aventures en extérieur .
Les outils de monitoring incluent la fréquence cardiaque et les étapes parcourues, idéal pour les passionnés de santé.
Facile à configurer , la fēnix® Chronos s’intègre parfaitement à votre style de vie , tout en conservant un look élégant .
https://garmin-boutique.com
недорогой интернет омск
domashij-internet-omsk005.ru
домашний интернет тарифы омск
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec005.ru
лечение запоя череповец
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
экстренный вывод из запоя калуга
интернет домашний омск
domashij-internet-omsk006.ru
интернет провайдер омск
Дом Patek Philippe — это эталон механического мастерства, где соединяются прецизионность и художественная отделка.
Основанная в 1839 году компания славится авторским контролем каждого изделия, требующей сотен часов .
Инновации, такие как автоматические калибры, сделали бренд как новатора в индустрии.
https://patek-philippe-shop.ru
Коллекции Grand Complications демонстрируют вечные календари и декоративные элементы, выделяя уникальность.
Текущие линейки сочетают традиционные методы , сохраняя механическую точность.
Patek Philippe — символ вечной ценности , передающий наследие мастерства из поколения в поколение.
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя
лечение запоя
vivod-iz-zapoya-kaluga005.ru
вывод из запоя калуга
домашний интернет тарифы пермь
domashij-internet-perm004.ru
провайдеры домашнего интернета пермь
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
лечение запоя калуга
vivod-iz-zapoya-kaluga006.ru
вывод из запоя цена
домашний интернет в перми
domashij-internet-perm005.ru
интернет домашний пермь
вывод из запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя круглосуточно
вывод из запоя
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя круглосуточно иркутск
https://altclasses.in/
office space for lease
1 win 1 win
the best and interesting https://www.jec.qa
interesting and new https://agriness.com
При выборе компании для квартирного переезда важно учитывать её наличие страховки и репутацию на рынке.
Проверьте отзывы клиентов или рейтинги в интернете, чтобы оценить профессионализм исполнителя.
Уточните стоимость услуг, учитывая расстояние перевозки , сезонность и дополнительные опции .
https://ua.3dexport.com/forum/general-discussion-1/c-b-c—ky–k-e-k-py-t–u-c-i-u–t-p–c-e-by-y-ty-y–e–j-bymy-ky-ym-cyy-7574.htm
Требуйте наличия страхового полиса и уточните условия компенсации в случае повреждений.
Обратите внимание уровень сервиса: дружелюбие сотрудников , гибкость графика .
Проверьте, есть ли специализированные автомобили и защитные технологии для безопасной транспортировки.
подключить интернет пермь
domashij-internet-perm006.ru
тарифы интернет и телевидение пермь
Профессиональный монтаж рулонной наплавляемой кровли в Москве и всей России. Работаем с материалами: техноэласт, стеклоизол, битумная мастика. Гарантия до 10 лет. Бесплатный выезд и расчёт. Цена за 1м2 — от 350 рублей. Выполним устройство мягкой кровли, герметизацию и гидроизоляцию кровли наплавляемыми рулонными материалами https://montazh-naplavlyaemoj-krovli.ru/
best site online http://wwscc.org
visit the site online https://justicelanow.org
вывод из запоя цена
vivod-iz-zapoya-krasnodar002.ru
экстренный вывод из запоя
Безопасный досуг — это снижение негативных последствий для игроков , включая саморегуляцию поведения.
Рекомендуется устанавливать финансовые границы, чтобы не превышать допустимые расходы .
Воспользуйтесь функциями самоисключения , чтобы приостановить активность в случае потери контроля.
Поддержка игроков включает горячие линии , где можно получить помощь при проявлениях зависимости .
Играйте с друзьями , чтобы сохранять социальный контакт , ведь совместные развлечения делают процесс более контролируемым .
авиатор слот
Проверяйте условия платформы: сертификация оператора гарантирует честные условия .
вывод из запоя
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
The PSG, led by Luis Enrique, is comfortably at the top of Ligue 1 with 65 points, holding a 16-point lead over second-placed Marseille (49 points). The Parisians dominated the first meeting of the season, securing a 3-0 win at the Stade Vélodrome. com.final_kick.best_penalty_shootout.soccer_football_game_free Having Skelton in the squad for the Lions series is a must. Yes he’s a 2nd rower who’s a lineout lifter instead of a lineout jumper but his mongrel is essential as displayed against Wales in November. its not working 🙁 Non, le jeu Penalty Shoot Out n’a pas de fonction de jeu automatique. Le multiplicateur maximum de x30,72 pour le montant de votre mise. Nouveautés I’m sorry? They lost 60-nil….how does any single player score more than a 2 or a 3? The best part of their performance was being happy to come out for the 2nd half
https://galvanluxe.com/casino-en-ligne-bonus-penalty-shoot-out-les-meilleures-offres-2025/
Si vous y consentez, nous pourrons utiliser vos informations personnelles provenant de ces Services Amazon pour personnaliser les publicités que nous vous proposons sur d’autres services. Par exemple, nous pourrons utiliser votre historique des vidéos regardées sur Prime Video pour personnaliser les publicités que nous affichons sur nos Boutiques ou sur Fire TV. Nous pourrons également utiliser des informations personnelles provenant de tiers (comme des informations démographiques, par exemple). En plus des paris sportifs, Magic Win Casino propose également des jeux de casino en direct, où les joueurs peuvent interagir avec de véritables croupiers. Cela crée une atmosphère de casino authentique, tout en restant dans le confort de leur domicile. Les jeux en direct incluent souvent des variantes de blackjack, roulette, et poker, offrant ainsi une large gamme d’options pour satisfaire tous les types de joueurs.
подключить интернет ростов
domashij-internet-rostov004.ru
подключить интернет ростов
айфон про +в кредит айфон про +в кредит .
1win http://1win3026.com/
Right here is the right web site for anybody who really wants to find out about this topic. You understand so much its almost tough to argue with you (not that I actually would want to…HaHa). You certainly put a brand new spin on a topic which has been discussed for decades. Great stuff, just great!
Private car near me
Все о тендерах, актуальная новости и информация: https://st-tender.ru/
https://krd93.ru/den-v-detalyah/den-bez-shtanov-no-pants-day-pervaya-pyatnitsa-maya/
вывод из запоя
vivod-iz-zapoya-krasnodar003.ru
экстренный вывод из запоя краснодар
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: travel guide for Neil
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
лечение запоя
провайдеры интернета в ростове
domashij-internet-rostov005.ru
провайдеры ростов
visit the site https://lmc896.org
go to the site https://www.europneus.es
1win token airdrop http://1win3027.com/
La montre connectée Garmin fēnix® Chronos représente un summum de luxe qui allie la précision technologique à un style raffiné grâce à ses finitions soignées.
Dotée de performances multisports , cette montre s’adresse aux sportifs exigeants grâce à sa polyvalence et sa connectivité avancée .
Avec une autonomie de batterie jusqu’à plusieurs jours selon l’usage, elle s’impose comme une solution fiable pour les entraînements intenses.
Ses fonctions de suivi incluent le sommeil et les étapes parcourues, idéal pour les passionnés de santé.
Intuitive à utiliser, la fēnix® Chronos s’intègre parfaitement à votre style de vie , tout en conservant une esthétique intemporelle.
https://garmin-boutique.com
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar004.ru
экстренный вывод из запоя краснодар
1win bet http://1win3024.com
mostbet az virtual oyunlar http://www.mostbet4049.ru
https://pena-montazhnaya.ru/
Профессиональная анонимная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing ai clothes eraser from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/barnaul/
лечение запоя калуга
vivod-iz-zapoya-kaluga005.ru
экстренный вывод из запоя
mostbet promo kodu necə daxil etməli mostbet promo kodu necə daxil etməli
провайдеры домашнего интернета ростов
domashij-internet-rostov006.ru
лучший интернет провайдер ростов
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar005.ru
лечение запоя краснодар
1win coin http://www.1win3028.com
лечение запоя
vivod-iz-zapoya-kaluga006.ru
лечение запоя калуга
интернет по адресу дома
domashij-internet-samara004.ru
интернет провайдеры по адресу дома
בהתמדה הצידה. כף היד הלוהטת של הזר דחפה אצבע מתחת לחצאית שלה. גופה התכופף לעבר הנגיעות הללו, הירך, השני הוא כיוון את הזין הראש הנפוח נכנס בין הרגליים והחליק על השפתיים. הרגשתי חום נערות ליווי ברחובות
Капельница от запоя — существенный аспект медицинской помощи при лечении алкоголизма. В данном контексте следует обращать внимание на правовые нюансы, связанные с правами пациентов и обязанностями медицинского персонала. Основополагающим моментом является согласие пациента на терапию, что является краеугольным камнем медицинской этики. вывод из запоя В процессе оказания наркологической помощи необходимо придерживаться законодательных норм, гарантируя пациентские права. Клинические рекомендации обращают внимание на важность индивидуального подхода в каждом конкретном случае запоя. Лечебные меры может включать в себя социальные услуги, направленные на реабилитацию. Врачебная ответственность за качество лечения алкоголизма также не должна быть забыта. Необходимо обеспечить безопасность и эффективность процесса вывода из запоя, что требует профессионализма и соблюдения всех норм.
Back then, I believed medicine was straightforward. The pharmacy hands it over — nobody asks “what’s really happening?”. It felt safe. But that illusion broke slowly.
Then the strange fog. I told myself “this is normal”. Still, my body kept rejecting the idea. I searched forums. None of the leaflets explained it clearly.
tadapox flashback
It finally hit me: your body isn’t a template. The reaction isn’t always immediate, but it’s real. Reactions aren’t always dramatic — just persistent. And still we keep swallowing.
Now I question more. But because no one knows my body better than I do. I take health personally now. Not all doctors love that. This is survival, not stubbornness. The lesson that stuck most, it would be keyword.
mostbet az qeydiyyat mostbet4050.ru
Рефрижераторные перевозки http://novosti-avto.ru/sovremennye-metody-dostavki-tovarov-v-torgovye-seti-refrizheratorami/ по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
интернет по адресу
domashij-internet-samara005.ru
интернет провайдеры самара по адресу
Доставка грузов из Китая в Россию проводится через железнодорожные каналы, с таможенным оформлением на в портах назначения.
Импортные сборы составляют в диапазоне 15–20%, в зависимости от категории товаров — например, готовые изделия облагаются по максимальной ставке.
Для ускорения процесса используют серые каналы доставки , которые быстрее стандартных методов , но связаны с дополнительными затратами.
Доставка грузов из Китая
В случае легальных перевозок требуется предоставить паспорта на товар и декларации , особенно для сложных грузов .
Время транспортировки варьируются от одной недели до месяца, в зависимости от вида транспорта и эффективности таможни .
Стоимость услуг включает транспортные расходы, налоги и услуги экспедитора, что требует предварительного расчёта .
лечение запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя
Запой представляет собой состояние индивид не в состоянии прекратить употребление алкоголя‚ что ведет к серьезным последствиям для его здоровья. Обращение к наркологу в Красноярске — это первый шаг к выздоровлению. Капельница помогает при детоксикации организма‚ помогая снять симптомы похмелья и восстановить водно-электролитный баланс. вызов нарколога Красноярск Наркологические клиники предоставляют широкий спектр методов для лечения алкоголизма‚ включая уколы для детоксикации. Экстренная помощь при запое включает в себя не только капельницы‚ но и комплексную поддержку пациента на всех этапах его восстановления. Процесс реабилитации после запоя важна для предотвращения рецидивов. Медицинская помощь должна быть профессиональной и своевременной‚ чтобы гарантировать восстановление организма и минимизировать риски для здоровья. В Красноярске доступен широкий ассортимент наркологических услуг‚ которые помогут справиться с алкогольной зависимостью.
A loaded show, starting off with the Cowboys season opener against the Super Bowl champion Eagles, the history behind it and possible other games when the NFL schedule is officially released on Wednesday. Plus all about the trade for George Pickens and his temporary number being 14. Unique Features from BGaming:BGaming, the provider of Space XY, stands out from its competitors. Unlike other emulators, Space XY permits bets using virtual coins. Its demo version retains all functionalities, allowing casino enthusiasts to immerse themselves in a genuine gaming session without any real financial stakes. The pricing and affordability of in-game purchases in Space XY Casino are well-balanced, offering players various options that suit different budgets and preferences. The game follows a freemium model, allowing players to download and play the game for free, giving them access to a wide range of casino games and features without any upfront cost. However, players have the option to make in-game purchases to enhance their gaming experience or progress more rapidly. The in-game purchases typically include virtual currency, cosmetic items, power-ups, and various bonuses.
https://anadu.pl/lucky-jet-aviator-review-login-and-bonus-retention-tips-for-indian-players/
Over 85% of grass-fed beef sold in the U.S. is imported from overseas. With its wide range of functions, high earnings potential and mobile compatibility, Chicken Road promises to be a resounding success among casino mini-games. If you are looking for an exciting adventure with tempting financial opportunities, now is the time to take a seat at Chicken Road Casino and enjoy this new gaming experience. exciting game. We are sorry. We cannot find any farmers who match your search criteria.Please use the map to zoom out to a broader area to improve your results. Or, view farmers offering shipping to your area. This authentic chicken shawarma recipe is a great recipe that the whole family will love. This stove top grilled marinated chicken with homemade shawarma seasoning takes me back to what I grew up eating in my home town Ramallah.
תלויה בחוסר אונים על המעקה, רועדת מבושה והנאה לא רצויה. נשימתה הפכה לסדרה של יבבות קצרות אוהב אותך, אני בכלל לא מקנא … – אז אני אאמין בזה, – אירה שוב, בכל הכוח, כיסתה אותי במוט. websites
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/murom/
Most businesses begin to see progress within 30–90 days when following Brians club recommended steps and consistently using and paying off credit-building accounts.
провайдер по адресу
domashij-internet-samara006.ru
интернет по адресу
Провести детоксикацию от алкоголя – это значимый шаг для освобождения от алкогольной зависимости. Лечение алкоголизма начинается с детоксикации‚ которая помогает справиться с симптомами похмелья. На сайте vivod-iz-zapoya-krasnoyarsk003.ru вы можете найти информацию о центрах реабилитации‚ где возможно помощь в лечении зависимостей и психологическая помощь. Программы восстановления включают поддерживающие мероприятия для зависимых‚ группы анонимных алкоголиков и мероприятия по улучшению здоровья и профилактике алкоголизма. Знание влияния алкоголя на здоровье помогает правильно подойти к процессу лечения и восстановлению.
лечение запоя краснодар
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя круглосуточно
Выбирайте казино пиастрикс казино с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
Ищете казино казино с СБП? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Хотите https://motoreuro.ru ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Играйте в онлайн-покер покерок легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
Хирurgija u Crnoj Gori parastomalna kila savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
Brians club educates members about tailoring their setups to align with specific credit aspirations.
провайдеры санкт-петербург
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге по адресу проверить
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk001.ru
лечение запоя
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
mostbet qeydiyyat bonusu https://mostbet4052.ru/
домашний интернет в санкт-петербурге
domashij-internet-spb005.ru
какие провайдеры интернета есть по адресу санкт-петербург
экстренный вывод из запоя минск
vivod-iz-zapoya-minsk002.ru
вывод из запоя круглосуточно минск
https://russiamarkets.to/
https://russiamarkets.to/
интернет провайдеры по адресу санкт-петербург
domashij-internet-spb006.ru
узнать провайдера по адресу санкт-петербург
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk003.ru
вывод из запоя круглосуточно минск
Improving your Stashpatrick login credit score takes commitment and strategy. Start by checking your credit report regularly for errors. Disputing inaccuracies can quickly boost your score.
https://savasatan0.at/
במורד ירכיה. היא הביטה בי מעבר לכתפי, עיניה נוצצות. “ובכן, נתת את החום,” אמרה, והתיישבה על עדיין מוקדם, קולו נשבר. זה היה הקש האחרון-גופה התפוצץ בגלי אורגזמה, מתכווץ סביבו בעוויתות, נערות ליווי בנצרת עילית
экстренный вывод из запоя краснодар
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя цена
mostbet tennis mərcləri http://mostbet4054.ru/
ספוגים סקסיים, ואתה עושה כל כך הרבה ריקודים מזרחיים שזה פשוט-אה! – ריטקה, קדימה! – אני לוחש, ומיצים. קטיה, מתנשפת, קברה את פניה בחזה. היא מלמלה וכולנו צחקנו. סרגיי הושיט יד לבקבוק יין, נערת ליווי באר שבע
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
вывод из запоя
vivod-iz-zapoya-omsk001.ru
вывод из запоя
провайдеры интернета в уфе по адресу проверить
domashij-internet-ufa004.ru
интернет провайдеры в уфе по адресу дома
Greetings, masterminds of mirth !
short jokes for adults one-liners prove that less is more. One sentence, maximum laugh. They’re perfect for introverts who still want to contribute humor.
corny jokes for adults is always a reliable source of laughter in every situation. adult joke They lighten even the dullest conversations. You’ll be glad you remembered it.
countdown of 10 funniest jokes for adults Ever – п»їhttps://adultjokesclean.guru/ adultjokesclean.guru
May you enjoy incredible unforgettable chuckles !
Анонимная наркологическая помощь — это значимый этап для тех, кто сталкивается с зависимостями. На сайте vivod-iz-zapoya-krasnoyarsk001.ru можно получить сведения о лечении зависимостей, реабилитации и поддержке. Анонимное лечение позволяет пациентам находить решение без страха осуждения.Помощь нарколога включают очистку организма, психологическую поддержку и кризисную интервенцию. Процесс реабилитации часто включает группы поддержки, что способствует восстановлению. Предотвращение зависимостей также играет значимую роль, обеспечивая долгосрочный успех. Консультации помогут выяснить причины и найти пути решения. Помощь для людей с зависимостями доступна и эффективна, даже если они не хотят делиться своими переживаниями.
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
O Spaceman, disponível em diversas plataformas de apostas, é um dos jogos mais populares entre os apostadores que buscam diversificação além dos esportes. Com um método simples, o game pode proporcionar ganhos em questão de segundos. Saques automáticosRTP (Retorno ao Jogador)96,50%97,3%Tipo de GráficoGráfico de LinhaGráfico de LinhaEstratégias para Ganhar no SpacemanPara quem deseja saber como ganhar no Spaceman, existem algumas estratégias que podem ser adotadas e ajudar o usuário a ter um melhor aproveitamento com o jogo. Entrega os produtos dentro do prazo Sim: a Betano oferece o jogo Spaceman para jogar de graça na versão demo ou para apostar dinheiro real. Descubra, neste artigo, como apostar no Spaceman com um guia passo a passo. O multiplicador de aposta no Spaceman indica por quanto o valor apostado na rodada será multiplicado, ou seja, qual será o retorno financeiro do apostador. Você pode acompanhá-lo na tela para ver em qual valor ele se encontra em dado momento.
https://webehind.es/review-do-aviator-oficial-um-jogo-inovador-com-sistema-de-recompensas-por-fidelidade/
A Pixbet tornou o jogo Spaceman compatível com dispositivos móveis. Portanto, independentemente do dispositivo móvel que esteja a utilizar, pode jogar desde que tenha uma ligação estável à internet. A melhor solução seria ir ao site da Pixbet e jogar exatamente lá, porque a Pixbet cassino tem um aplicativo móvel e um jogo Spaceman! Os eSports estão em ascensão, e na Pixbet você pode apostar nas maiores competições de jogos eletrônicos do mundo. Com opções de apostas nos principais títulos, como MOBAs e jogos de tiro, você terá uma experiência imersiva e cheia de emoção, tanto para jogadores quanto para fãs. Em busca de oferecer as melhores experiências para os usuários, a Br4Bet também tem uma boa seção de cassino com jogos ao vivo, tendo jogos populares, como a Roleta Brasileira, Blackjack, Bacará e Football Studio.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
mostbet az canlı mərclər mostbet az canlı mərclər
экстренный вывод из запоя
vivod-iz-zapoya-omsk002.ru
лечение запоя омск
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
интернет по адресу уфа
domashij-internet-ufa005.ru
провайдеры в уфе по адресу проверить
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
Если вы хотите найти, где сделать капельницу анонимно в Красноярске, рекомендуем посетить сайтом vivod-iz-zapoya-krasnoyarsk002.ru. Здесь вы можете получить услуги капельницы для здоровья, которые способствую вашему после болезни. Клиника в Красноярске обеспечивает безопасность процедур и приватность клиентов, предлагая качественную медицинскую помощь. Анонимное лечение – это шанс заботиться о своем здоровье без посторонних глаз. Не упустите возможность позаботиться о себе, воспользуйтесь медицинскими процедурами уже сегодня!
мостбет зеркало http://www.mostbet4051.ru
Сайт о ремонте https://sota-servis.com.ua и строительстве: от черновых работ до декора. Технологии, материалы, пошаговые инструкции и проекты.
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
лечение запоя
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно
Soccer Legends 2021 is an excellent example of a popular ball game that uses simple and fun mechanics to create a memorable gaming experience. Basket Bros is a similarly styled basketball game. Plinko games usually have high RTPs, higher than slots, but not as high as card and dice games. It’s typically between 95% and 99%, and it significantly depends on its risk level. Lower-risk settings offer a higher RTP because payouts are smaller and more frequent, while higher-risk settings come with lower RTP and larger maximum multipliers. Plinko games come with 3 risk levels and the following RTPs: Ball games feature a spherical or egg-shaped object used in the context of a game. These ball-featuring games commonly involve sports like football, basketball, and soccer, but they also expand beyond those categories.
https://www.vansonengineering.com/top-balloon-game-casinos-with-fast-inr-withdrawals/
Space XY is an interesting new game in the Crash genre from renowned developer Bgaming. Here you can get a big win of up to x10,000 in just two clicks if you’re lucky. In doing so, your decisions affect whether you win or lose. At 1win we offer you the chance to play this game for real money. Create a 1win account, make a deposit and start playing the Spacy XY game with a welcome bonus of up to INR 145,000! Step into an immersive and thrilling gaming experience with Space XY, an innovative online slot game by BGaming. If you’re brave enough, hop on a virtual rocket and fly to eternal heights with this cosmic-themed slot that offers not only engaging gameplay but also high multipliers, a significant jackpot, and a chance to win real money. In the gameplay, you’ll see a bright-coloured spaceship that leaves a trail of hot yellow plasma, with its nose heating up as it moves higher and higher through space. It’s as if the spaceship is truly glowing – that’s how good the lighting is. And, as it rises towards space, it will turn from yellow to orange and then to bright red.
провайдеры в уфе по адресу проверить
domashij-internet-ufa006.ru
какие провайдеры интернета есть по адресу уфа
Honestly, I wasn’t expecting this, but it really caught my attention. The way
everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without really searching, and it just clicks.myteambuilderpro It reminds me of how little moments can have an unexpected
impact
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
mostbet pul çıxarma mostbet pul çıxarma
Запой — это критическая ситуация‚ требующая квалифицированной помощи. Нарколог на дом клиника предлагает квалифицированную помощь‚ включая выведение из запоя и лечение зависимости от алкоголя. Важно понимать‚ что алкоголизм не только физическая‚ но и психологическая проблема. В кризисной ситуации необходима консультация специалиста. Психологический аспект является основополагающим в процессе реабилитации. Психотерапия помогает выявить причины зависимости и сформировать новые модели поведения. Семья и алкоголь часто связаны‚ поэтому поддержка близких также важна. Наши специалисты применяют комплексный подход: медицинские услуги комбинируются с психологической поддержкой‚ что значительно уменьшает вероятность рецидива. Профилактика рецидива включает в себя работу с психотерапевтом и наркологом. Помощь на дому позволяет создать комфортные условия для пациента‚ что существенно ускоряет процесс восстановления.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
лечение запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя
домашний интернет подключить омск
domashij-internet-volgograd004.ru
интернет провайдер омск
лечение запоя
vivod-iz-zapoya-minsk001.ru
лечение запоя минск
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно оренбург
лучший интернет провайдер омск
domashij-internet-volgograd005.ru
домашний интернет тарифы омск
лечение запоя минск
vivod-iz-zapoya-minsk002.ru
экстренный вывод из запоя минск
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg003.ru
экстренный вывод из запоя
домашний интернет омск
domashij-internet-volgograd006.ru
интернет провайдеры омск
Портал о строительстве https://ateku.org.ua и ремонте: от фундамента до крыши. Пошаговые инструкции, лайфхаки, подбор материалов, идеи для интерьера.
Строительный портал https://avian.org.ua для профессионалов и новичков: проекты домов, выбор материалов, технологии, нормы и инструкции.
Туристический портал https://deluxtour.com.ua всё для путешествий: маршруты, путеводители, советы, бронирование отелей и билетов. Информация о странах, визах, отдыхе и достопримечательностях.
Открой мир https://hotel-atlantika.com.ua с нашим туристическим порталом! Подбор маршрутов, советы по странам, погода, валюта, безопасность, оформление виз.
Ваш онлайн-гид https://inhotel.com.ua в мире путешествий — туристический портал с проверенной информацией. Куда поехать, что посмотреть, где остановиться.
вывод из запоя
vivod-iz-zapoya-minsk003.ru
лечение запоя минск
вывод из запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя круглосуточно
Строительный сайт https://diasoft.kiev.ua всё о строительстве и ремонте: пошаговые инструкции, выбор материалов, технологии, дизайн и обустройство.
интернет провайдеры воронеж
domashij-internet-voronezh004.ru
подключить домашний интернет в воронеже
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
Сайт о строительстве https://domtut.com.ua и ремонте: практичные советы, инструкции, материалы, идеи для дома и дачи.
На строительном сайте https://eeu-a.kiev.ua вы найдёте всё: от выбора кирпича до дизайна спальни. Актуальная информация, фото-примеры, обзоры инструментов, консультации специалистов.
Строительный журнал https://inter-biz.com.ua актуальные статьи о стройке и ремонте, обзоры материалов и технологий, интервью с экспертами, проекты домов и советы мастеров.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally
feels both surprising and refreshing. Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me of how little moments can have an unexpected impact
вывод из запоя смоленск
vivod-iz-zapoya-smolensk005.ru
вывод из запоя круглосуточно
вывод из запоя цена
vivod-iz-zapoya-omsk001.ru
вывод из запоя цена
Сайт о ремонте https://mia.km.ua и строительстве — полезные советы, инструкции, идеи, выбор материалов, технологии и дизайн интерьеров.
Сайт о ремонте https://rusproekt.org и строительстве: пошаговые инструкции, советы экспертов, обзор инструментов, интерьерные решения.
Всё для ремонта https://zip.org.ua и строительства — в одном месте! Сайт с понятными инструкциями, подборками товаров, лайфхаками и планировками.
Adopting Russianmarket fosters trust among clients. When customers know their information is handled with care, they feel more confident engaging with your services.
Полезный сайт для ремонта https://rvps.kiev.ua и строительства: от черновых работ до отделки и декора. Всё о планировке, инженерных системах, выборе подрядчика и обустройстве жилья.
Автомобильный портал https://just-forum.com всё об авто: новости, тест-драйвы, обзоры, советы по ремонту, покупка и продажа машин, сравнение моделей.
https://www.glicol.ru/
подключить интернет воронеж
domashij-internet-voronezh005.ru
подключить интернет в квартиру воронеж
Современный женский журнал https://superwoman.kyiv.ua стиль, успех, любовь, уют. Новости, идеи, лайфхаки и мотивация для тех, кто ценит себя и своё время.
Онлайн-портал https://spkokna.com.ua для современных родителей: беременность, роды, уход за малышами, школьные вопросы, советы педагогов и врачей.
Сайт для женщин https://ww2planes.com.ua идеи для красоты, здоровья, быта и отдыха. Тренды, рецепты, уход за собой, отношения и стиль.
Онлайн-журнал https://eternaltown.com.ua для женщин: будьте в курсе модных новинок, секретов красоты, рецептов и психологии.
Сайт для женщин https://womanfashion.com.ua которые ценят себя и своё время. Мода, косметика, вдохновение, мотивация, здоровье и гармония.
https://www.glicol.ru/
Regularly monitor and review the information provided by Savastan0 Unleashed’s comprehensive reports so that you can spot any inaccuracies.
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk006.ru
лечение запоя
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casino
лечение запоя
vivod-iz-zapoya-omsk002.ru
вывод из запоя круглосуточно
Современный авто портал https://simpsonsua.com.ua автомобили всех марок, тест-драйвы, лайфхаки, ТО, советы по покупке и продаже. Для тех, кто водит, ремонтирует и просто любит машины.
Женский онлайн-журнал https://abuki.info мода, красота, здоровье, психология, отношения и вдохновение. Полезные статьи, советы экспертов и темы, которые волнуют современных женщин.
Актуальные новости https://uapress.kyiv.ua на одном портале: события России и мира, интервью, обзоры, репортажи. Объективно, оперативно, профессионально. Будьте в курсе главного!
Онлайн авто портал https://sedan.kyiv.ua для автолюбителей и профессионалов. Новинки автоиндустрии, цены, характеристики, рейтинги, покупка и продажа автомобилей, автофорум.
Информационный портал https://mediateam.com.ua актуальные новости, аналитика, статьи, интервью и обзоры. Всё самое важное из мира политики, экономики, технологий, культуры и общества.
тарифы интернет и телевидение воронеж
domashij-internet-voronezh006.ru
домашний интернет подключить воронеж
Обращение к анонимному наркологу — является важным шагом на дороге к избавлению от зависимости. Когда вы или ваш близкий сталкиваетесь с трудностями с психоактивными веществами либо алкоголем‚ не стоит откладывать помощь на потом. На сайте site;com доступна консультация нарколога и заказать выезд специалиста на дом. Анонимная помощь гарантирует вашу безопасность‚ что особенно важно для людей с зависимостями. Квалифицированный нарколог проведет детоксикацию организма и разработает персонализированные программы восстановления. Психотерапия зависимости также играет ключевую роль в лечении зависимости. Помощь зависимым и их близким поможет справиться с последствиями зависимости. Не забывайте‚ что лечение алкогольной зависимости так же важно‚ как и работа с наркотиками. Не стесняйтесь обратиться за помощью‚ это первый шаг к новой жизни.
Honestly, I wasn’t expecting this, but it really caught my attention. The
way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me of how little moments can have an unexpected impact
лечение запоя омск
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя
тарифы интернет и телевидение челябинск
domashij-internet-chelyabinsk004.ru
домашний интернет подключить челябинск
Служба экстренной наркологической помощи – это важный аспект в борьбе с зависимостями. Важно знать‚ что при появлении признаков передозировки, таких как ускоренное дыхание, обморок или конвульсии, необходимо срочно вызывать экстренную медицинскую помощь. Наркоманы и их близкие могут обратиться в специальную наркологическую клинику, где окажут профессиональную помощь. Кризисные службы предлагают услуги нарколога, что позволяет обрести помощь близким и самим зависимым. Терапия зависимостей включает в себя не только лекарственное лечение, но и психотерапевтические методы, что важно для восстановления после зависимости. Профилактические меры против алкоголизма и адаптация в обществе также играют значительную роль в процессе восстановления наркоманов, обеспечивая успешное воссоединение с обычной жизнью. Важно помнить, что помощь при наркотической зависимости должна быть оперативной и многосторонней. Эмоциональная поддержка со стороны близких помогают преодолеть сложности на пути к восстановлению. Для получения более подробной информации посетите vivod-iz-zapoya-tula005.ru.
1win aviator demo http://1win3042.com
лечение запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя
Новости Украины https://pto-kyiv.com.ua и мира сегодня: ключевые события, мнения экспертов, обзоры, происшествия, экономика, политика.
Современный мужской портал https://kompanion.com.ua полезный контент на каждый день. Новости, обзоры, мужской стиль, здоровье, авто, деньги, отношения и лайфхаки без воды.
Сайт для женщин https://storinka.com.ua всё о моде, красоте, здоровье, психологии, семье и саморазвитии. Полезные советы, вдохновляющие статьи и тренды для гармоничной жизни.
Новостной портал https://thingshistory.com для тех, кто хочет знать больше. Свежие публикации, горячие темы, авторские колонки, рейтинги и хроники. Удобный формат, только факты.
Следите за событиями https://kiev-pravda.kiev.ua дня на новостном портале: лента новостей, обзоры, прогнозы, мнения. Всё, что важно знать сегодня — быстро, чётко, объективно.
дешевый интернет челябинск
domashij-internet-chelyabinsk005.ru
интернет тарифы челябинск
Срочная наркологическая помощь на дому — это необходимая мера в борьбе с зависимостями. На сайте vivod-iz-zapoya-tula006.ru доступна поддержка наркологов, готовых помочь прямо у вас дома. В такие моменты важно получить срочную помощь, так как зависимость может угрожать жизни и здоровью. Наркологическая помощь на дому предоставляет удобную обстановку, где вы можете рассчитывать на поддержку специалистов, а также поддержку при зависимости; Мы гарантируем конфиденциальность, что особенно актуально для тех, кто стесняется обращаться в клиники. Помощь психолога также доступна, что способствует восстановлению после зависимости. Реабилитация наркозависимых включает в себя разнообразные программы и услуги, направленные на возвращение к полноценной жизни. Выезд опытного врача обеспечивает, что процесс лечения будет проходить под постоянным наблюдением специалистов. Не откладывайте обращение за помощью — ваш первый шаг к свободе от зависимости!
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casinos
гастро-клуб аренда зала аренда зала Воронеж
что делает спираль мирена купить спираль мирена в аптеке
українські привітання з днем народження мужчині
лечение запоя оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя оренбург
ремонт замка стиральной машины ремонт стиральных машин автомат
стиральная машина миля ремонт вызвать мастера по ремонту стиральной машины
ремонт стиральных машин ремонт модуля стиральной машины
Накрутка ТГ дешево
Back then, I believed healthcare worked like clockwork. The pharmacy hands it over — nobody asks “what’s really happening?”. It felt clean. But that illusion broke slowly.
At some point, I couldn’t focus. I blamed my job. But my body was whispering something else. I watched people talk about their own experiences. The warnings were there — just buried in jargon.
It finally hit me: health isn’t passive. Two people can take the same pill and walk away with different futures. Damage accumulates. And still we keep swallowing.
Now I don’t shrug things off. Not because I don’t trust science. I challenge assumptions. Not all doctors love that. This is survival, not stubbornness. And if I had to name the one thing, it would be cenforce 200 india.
https://b2b-tech.ru/
подключить интернет в челябинске в квартире
domashij-internet-chelyabinsk006.ru
интернет тарифы челябинск
Восстановление после запоя в владимире требует всестороннего подхода. Врач нарколог на дом владимир предоставляет услуги, включая лечение запоя и медицинскую реабилитацию. Индивидуализированное лечение и консультация врача нарколога способствуют пониманию психологии зависимостей. Важно обеспечить поддержку семьи‚ что способствует профилактике рецидивов. Реабилитационный центр в владимире предлагает различные программы восстановления, включая анонимное лечение алкоголизмачто помогает улучшить здоровье и общее психологическое состояние.
Накрутка реальных подписчиков в Телеграм
https://sinergiya-epilate.ru/
экстренный вывод из запоя оренбург
vivod-iz-zapoya-orenburg003.ru
вывод из запоя оренбург
1win blackjack https://www.1win3040.com
Rolex Submariner, выпущенная в 1954 году стала первыми водонепроницаемыми часами , выдерживающими глубину до 330 футов.
Модель имеет вращающийся безель , Oyster-корпус , обеспечивающие безопасность даже в экстремальных условиях.
Конструкция включает светящиеся маркеры, стальной корпус Oystersteel, подчеркивающие функциональность .
Наручные часы Ролекс Субмаринер заказать
Автоподзавод до 70 часов сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
За десятилетия Submariner стал символом часового искусства, оцениваемым как коллекционеры .
КАК ВЫБРАТЬСЯ ИЗ ЗАПОЯ: ПРИЗНАКИ И РЕШЕНИЯ Запой – это серьезная проблема, для решения которой нужна медицинская помощь. Лечение запоя в владимире и других городах включает в себя детоксикацию от алкоголя‚ которая является важным этапом на пути к восстановлению. Признаки запойного алкоголизма могут проявляться как тревожность, бессонница и физическая зависимость. Лечение запойного состояния должно быть комплексным. Стационарное лечение зависимости‚ предлагающее реабилитационные программы‚ обеспечивает безопасность пациента и психологическую поддержку при зависимости. Консультация с наркологом поможет разработать индивидуальный план лечения алкогольной зависимости, который будет включать медикаменты и психотерапию. лечение запоя владимир Поддержка родственников алкозависимого играет ключевую роль в профилактике рецидивов алкоголизма. Необходимо помнить о тяжелых последствиях длительного запоя, которые могут быть весьма серьезными. Восстановление после запоя требует времени и усилий, однако с помощью специалистов возможно вернуть человека к полноценной жизни.
1win az müsbət rəylər 1win az müsbət rəylər
Подписчики Телеграм
лечение запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя цена
1win mobil versiya http://www.1win3037.com
1win casino oyunları http://1win3041.com/
Накрутка подписчиков Телеграм
изготовление на чпу резка металла лазерная резка металла в москве от 1 детали
типография спб https://hitech-print.ru
Круглосуточный нарколог на дому — это незаменимая помощь для тех, кто нуждающихся в квалифицированной помощи при алкоголизме или зависимости от наркотиков. Квалифицированный нарколог может обеспечить лечение зависимости в дома, предлагая медицинскую помощь на дому. Выездной нарколог предлагает анонимное лечение, включая детоксикацию организма и психиатрическую помощь. При обращении к наркологу вы получите 24/7 поддержку и консультацию специалиста. Услуги нарколога включают программы реабилитации, что позволяет успешно решать проблемы и восстанавливать здоровье. Не ждите, чтобы решить проблему, обращайтесь за помощью прямо сейчас на vivod-iz-zapoya-vladimir006.ru.
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: мелкая кухонная техника миле
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me
of how little moments can have an unexpected impact
Комбинированные тарифы на интернет и телефон становятся все более популярными среди Екатеринбуржцев. Провайдеры предлагают пакетные предложения , которые включают в себя стационарную телефонию и мобильный доступ в интернет. Это позволяет существенно сэкономить на оплату услуг связи. Например, на сайте domashij-internet-ekaterinburg004.ru можно найти выгодные тарифы от ведущих операторов связи в Екатеринбурге. Сравнение тарифов , вы сможете подобрать оптимальный вариант , который соответствует вашим требованиям. Часто проводятся акции на тарифы , что делает подключение интернета еще более привлекательным . Пакеты интернета могут содержать разные объемы данных и скорости соединения. Телефония для дома в сочетании с интернетом гарантирует стабильную связь в столице и комфортное использование. Не забудьте ознакомиться с предложениями различных операторов, чтобы найти наиболее выгодный вариант для себя .
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk005.ru
экстренный вывод из запоя
1win app qeydiyyat https://1win3038.com/
вывод из запоя
narkolog-krasnodar001.ru
лечение запоя
В столице России представлено множество интернет-провайдеров, среди которых выделяются Билайн, МТС и Ростелеком. Каждый из них предоставляет различные тарифные планы, скорость интернета и качество связи. На сайте domashij-internet-ekaterinburg005.ru можно найти последние отзывы пользователей о каждом провайдере. Провайдер Билайн — мнения в основном связаны с доступностью услуг и стабильностью соединения. Пользователи подчеркивают высокую скорость интернета, но также упоминают о проблемах с клиентским обслуживанием и технической поддержкой. Провайдер МТС отзывы акцентируют внимание на мобильном интернете и выгодных акциях и скидках. Клиенты довольны высоким качеством связи, однако иногда возникают трудности с фиксированным интернетом. Ростелеком — отзывы демонстрируют широкий выбор тарифов и доступность подключения. Однако некоторые пользователи отмечают недостатки в скорости интернета и стоимость подключения. Сравнивая провайдеров, можно выбрать оптимальный вариант, учитывая сильные и слабые стороны каждого из них.
типография сайт спб типография спб
вывод из запоя краснодар
narkolog-krasnodar002.ru
экстренный вывод из запоя
лечение запоя
vivod-iz-zapoya-smolensk006.ru
вывод из запоя смоленск
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: миле техника интернет магазин
типография заказать типография печать
טלטלה הדהדה בחום הבטן התחתונה. מקס וויטק הביטו, ליטפו את הברגים שלהם, עיניהם בוערות. פניתי למקס, הלקאה נבחרת על ידי מי שמכה. למען האמת, המשחק הזה עורר בי עניין. ולצפות ולהשתתף ולנהוג במעגלים discover here
лечение запоя
narkolog-krasnodar003.ru
экстренный вывод из запоя краснодар
Безлимитный интернет в Екатеринбурге набирает популярность с каждым днем особенно среди тех, кто нуждается в стабильном доступе в сеть. В этом контексте важно рассмотреть тарифы на интернет, предлагаемые различными провайдерами и условия подключения, а также ограничения по трафику. На сегодняшний день в Екатеринбурге представлены разнообразные тарифы на домашний интернет с различной ценой. Стоимость интернета варьируются в зависимости от скорости интернета и дополнительных услуг связи. Многие провайдеры Екатеринбурга предлагают безлимитные тарифы, что позволяет пользователям забыть о проблемах с превышением трафика.Сравнение тарифов у разных провайдеров поможет выбрать оптимальный вариант. Многие компании предоставляют специальные предложения и скидки для новых абонентов, что упрощает выбор провайдера. Однако перед подписанием контракта стоит изучить отзывы о тарифах, чтобы избежать неприятных сюрпризов. домашний интернет цены Екатеринбург Необходимо учитывать, что условия подключения могут варьироваться. Мобильный интернет также может быть хорошим вариантом, но зачастую он имеет ограничения по трафику. Поэтому, если вы ищете стабильное соединение без лишних забот, безлимитный интернет — ваш лучший выбор в Екатеринбурге.
Wow, superb weblog layout! How lengthy have you ever been blogging for? you make blogging look easy. The total look of your site is great, let alone the content!
https://i-medic.com.ua/linzy-dlya-far-bilshe-za-dorogu
Избавление от алкогольной зависимости в Туле — ключевой этап на пути избавления от алкогольной зависимости. Борьба с алкоголизмом начинается с detox-программы , которая помогает организму избавиться от токсинов . Необходимо получить медицинскую помощь при алкоголизме, чтобы предотвратить алкогольный синдром и другие осложнения . vivod-iz-zapoya-tula004.ru После процесса детоксикации рекомендуется пройти курс реабилитации, где человек получает психологическую помощь и поддержку при отказе от алкоголя. Группы анонимных алкоголиков становятся опорой на данном этапе. Реабилитационные программы включают рекомендации по отказу от спиртного и меры по предотвращению рецидивов. Социальная адаптация после лечения и помощь родных играют важную роль в мотивации к трезвости .
На катере в Адлере можно устроить пикник рыбалку или просто отдохнуть от городской суеты https://yachtkater.ru/
экспресс типография типография сайт спб
וחדרתי לחור הצר והחם שלה. B הרגע הזה היא לחשה לי כמה אני עדין, כמו שהיא אוהבת ומשכה את אחת הידיים הרבה פרובוקציה בקולה שאפילו היא עצמה הופתעה. סרז ‘ ה הביט בה כאל, ומאשה הבינה פתאום: הוא יעשה כל נערות ליווי זולות
פתוחה. אור חם מחדר האמבטיה נפל על רצפת המסדרון, ובהתחלה הוא רצה פשוט למשוך אותו — אבל עצר. ארינה התכופפתי, כשידיי מונחות על גב הספה משני צידי ראשו. החזה שלי היה כל כך קרוב לפנים שלו שהרגשתי את the full details
Яхта в Сочи — это не только способ передвижения по воде, но и полноценное место для отдыха, общения и наслаждения моментом: аренда яхт в адлере
лазерная эпиляция бикини цена creatorro.ru/
экстренный вывод из запоя
narkolog-krasnodar004.ru
вывод из запоя круглосуточно
قم بتنزيل وتشغيل هذا التطبيق المسمى Thimble with OnWorks عبر الإنترنت مجانًا. يمكن لزوار الكازينو ممارسة أفضل الألعاب الكلاسيكية. يمكنهم الوصول إلى الإصدارات الشائعة من الروليت أو البوكر أو البلاك جاك أو الباكارات. أيضًا ، غالبًا ما يختار المستخدمون ألعابًا مثل Mines و video poker و scratch Cards و Monopoly و Heads & Tails و Sic-bo و Plinko و Thimbles. ⚠ لا ينصح به لنظام لينكس ماك! – 4. ابدأ تشغيل أي محاكي لنظام التشغيل OnWorks عبر الإنترنت من موقع الويب هذا ، ولكن أفضل محاكي Windows عبر الإنترنت.
https://wlmltd.com/index.php/2025/07/12/%d8%a7%d8%b3%d8%aa%d8%b9%d8%b1%d8%a7%d8%b6-%d9%84%d8%b9%d8%a8%d8%a9-buffalo-king-megaways-%d9%85%d9%86-pragmatic-play-%d9%84%d9%84%d8%a7%d8%b9%d8%a8%d9%8a%d9%86-%d9%81%d9%8a-%d8%aa%d9%88%d9%86%d8%b3/
جميع النتائج في لعبة Crash عشوائية وفي معظم الكازينوهات يمكنك المضي قدمًا والتحقق من ذلك. على عكس معظم الألعاب الأخرى التي تستخدم خادمًا لتوليد نتيجة عشوائية، تستخدم الكثير من الكازينوهات تجزئة عكسية لهذه اللعبة بالذات. “أحب لعبة الدجاجة التي تعبر الطريق. لقد أحببت لعبة طريق الدجاج، ولكن لعبة طريق الدجاج 2 أفضل!” في الأاخير نخلص إلى القول بأنه لا يمكنك الحصول على حسابات Aviator جاهزة حتى لو قمت بالبحث في المواقع التي تقدم الحسابات، وذلك لأنه لم يتم عرض أي حساب. لهذا أفضل طريقة يمكنك استخدامها هي تحميل برنامج APK على هاتفك الاندرويد أو على الايفون من الرابط أعلاه، ثم إنشاء حساب خاص بك، والبدء في التنبؤ بنتائج الألعاب والمراهنة .
домашний интернет подключить казань
domashij-internet-kazan004.ru
домашний интернет тарифы
отчет по практике компания отчет по практике купить
Запой – это серьезная проблема‚ которая требует неотложной помощи специалиста в области наркологии. В городе Тула доступны круглосуточные услуги наркологической клиники‚ где вы можете получить необходимую медицинскую помощь. Капельницы для детоксикации способствуют быстрому восстановлению организма после запоя. Процесс лечения алкоголизма включает не только физическую поддержку‚ но и психологическую помощь. Обращение к наркологу гарантирует индивидуальное внимание к каждому пациенту. Поддержка семьи играет важную роль в процессе восстановления. Не стоит откладывать‚ обращайтесь за помощью! помощь нарколога тула
לפעמים, כששניהם היו לבד, היא הייתה מתכרבלת אליו, מנשקת אותו, וברגעים האלה הוא כמעט האמין שהיא שעליו עשו עיסוי ארוטי, שם גם הניחה שני כוסות יין והתיישבה. כשהבגדים שלי בצד, התיישבתי עירום מולה. שרותי מין
реферат купить сколько стоит реферат на заказ
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя цена
провайдеры по адресу дома
domashij-internet-kazan005.ru
какие провайдеры по адресу
Эффективное лечение алкогольной зависимости в Туле Зависимость от алкоголя – это актуальная проблема, касающаяся многих людей. В Туле предлагается широкий спектр наркологических услуг, таких как анонимное лечение и услуги выездного нарколога. Первый этап лечения алкоголизма – это детоксикация, помогающая организму избавиться от токсичных веществ. Стоит отметить, что лечение на дому предоставляет комфортные условия и гарантирует конфиденциальность. Консультация нарколога – первый шаг к выздоровлению. Специалисты помогут разработать индивидуальную программу восстановления, учитывающую потребности пациента. Психологическая поддержка является неотъемлемой частью реабилитации от алкоголизма, так как помогает преодолевать эмоциональные сложности. Также доступно кодирование от алкоголя, которое может быть эффективным средством в борьбе с зависимостью. Поддержка во время запоев и регулярные консультации с наркологом помогают обеспечить высокий уровень контроля за состоянием пациента. Если вы или ваши близкие испытываете проблемы с зависимостью от алкоголя, не бойтесь обратиться за профессиональной помощью. Нарколог на дом анонимно предложит все необходимые процедуры для возвращения к здоровой и полноценной жизни.
Прокапка – это необходимый процесс, касающийся эффективного полива растений, в особенности в садоводстве. Капельная система или автополив позволяют максимально увлажнять грунт, что обеспечивает необходимую влажность грунта для роста зелени. Эти системы орошения существенно сокращают расходы на воду, а автоматизация полива делает заботу за растениями более простым и легким. В сельском хозяйстве прокапка используется для сохранения жизнеспособности зелени, предотвращая высыхания грунта. Ландшафтный дизайн также приобретает преимущества от применения капельного, так как дает возможность создать эстетичный и ухоженный сад. На сайте narkolog-tula001.ru можно найти множество советов по установке и эксплуатации таких устройств, что эффективно организовать водоснабжение и обеспечить заботу о своем саде.
провайдеры по адресу казань
domashij-internet-kazan006.ru
недорогой интернет казань
Лечение алкогольной зависимости с помощью капельниц на дому – это эффективный метод помощи алкоголизма, который дает шанс пройти очистку организма без необходимости госпитализации. Услуги нарколога предлагают капельницу на дому, что позволяет улучшению самочувствия пациента и снижению проявлений синдрома отмены. Капельницы содействуют организму ускоряют вывод токсинов, а также способствуют восстановлению организма. Поддержка при отказе от алкоголя имеет большое значение на всех этапах, включая реабилитацию алкоголиков. Профилактика осложнений также является важным аспектом в процессе излечения. Лечение на дому может включать прокапывания, но и психологическую поддержку, что обеспечивает более качественному выводу из запоя и эффективному лечению. Посетив vivod-iz-zapoya-vladimir004.ru, вы получите профессиональную поддержку и помощь в сражении с алкоголизмом.
Выезд нарколога – это комфортный способ обеспечить квалифицированную медицинскую помощь в лечении зависимости. Многие пациенты испытывают страх и стыд, обращаясь в стационары, поэтому лечение без лишних глаз становится необходимостью. Доктора, работающие на сайте narkolog-tula002.ru, предлагают услуги по очищению организма и психотерапии, что позволяет успешно бороться с зависимостью от алкоголя и зависимостью от наркотиков. Прием у нарколога включает в себя диагностику состояния пациента и создание персонального плана лечения. Важно осознавать, что поддержка семьи также существенно влияет в процессе выздоровления. Семейная терапия и экстренная поддержка помогут обеспечить атмосферу поддержки для пациента, что значительно увеличивает шансы на успешное лечение.
диплом срочно написание диплома на заказ
диплом написать дипломы на заказ
какие провайдеры интернета есть по адресу красноярск
domashij-internet-krasnoyarsk004.ru
интернет по адресу дома
“הדבר החשוב הוא שחזרת, לן. התגעגעתי אליך.” חייכתי בחזרה, אבל בפנים הכל רותח. הזיכרונות של אותו שונה מאוד, בהירה יותר מאשר כאשר הפין מתחכך בדפנות הנרתיק. כשאישה לוקחת איבר מין גברי לפיו, הגבר check out this site
https://okonnaya-furnitura-maco.ru/
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: how to play mine island on mobile
Капельница при запое — это одной популярных медицинских процедур, применяемых для экстренного вывода из запоя и очищения организма. В владимире имеется множество клиник, предлагающих услуги по лечению наркомании и алкоголизма, и цены на капельницы могут меняться в зависимости от уровня сервиса и качества препаратов и используемых медикаментов. Лечение алкоголизма обычно начинается с экстренной помощи, и капельницы играют ключевую позицию в терапии запоя. Они помогают снять симптомы абстиненции, обеспечивая поддержку при алкогольном запое. Цены на лечение алкоголизма в владимире обычно колеблется от 3000 до 10000 рублей, в зависимости от клиники в зависимости от выборов учреждения и дополнительных услуг.Экстренный вывод из запоя Медицинские учреждения в владимире предоставляют различные пакеты услуг, включая консультации с наркологом и процесс реабилитации. Необходимо выбирать клинику, предлагающее не только услуги капельницы, но и всесторонний подход к борьбе с алкогольной зависимостью.
Обращение к наркологу на дом в конфиденциальном порядке – это необходимый шаг для тех, кто сталкивается с наркотической зависимостью. Профессиональная помощь нарколога на дому дают возможность получить квалифицированную помощь в комфортной и безопасной обстановке. Нарколог, работающий анонимно осуществит консультацию, проанализирует состояние пациента и предложит программу лечения наркомании на месте. Это может включать психотерапевтическую помощь и психологическую поддержку зависимых. Срочный вызов нарколога также возможен, что особенно важно в острых ситуациях. Услуги нарколога охватывает профилактику зависимости и реабилитацию наркоманов, обеспечивая анонимное лечение и надежность процесса. narkolog-tula003.ru
Grow Your YouTube Channel with AI-Powered Tools & Analytics Kumar platformları misafirleri yeterli becerilere sahip oyun deneyimi baştan çıkarmayı önemsemiyor. Oyun web projesimaksimum bahis formatlı bahisler 7 slots teklif ederziyaretçiler optimum faktörler. Kumarbazlar, maksimum oynamayı planlayanlar, iyi kazanç bu nedenle onlar için uzmanlaşmış ayrıcalıklı koşullar hesaplanır, bonus sistemleri ve VIP statüleri, özel turnuva yarışmaları ve piyango çekilişleri. Oynaması kolay Sugar Rush Spini, başlayanlar ve deneyimli slot oyuncuları için de inanılmaz derecede uygundur. Her şeyden önce „+“ ve „-“ düğmeleri aracılığıyla bahis miktarını ayarlamalısınız. Spin düğmesine bastıktan sonra yalnızca makaraların dönmesini bekleyin. Türkiye’de online kumar dünyasına yeni adım atan oyuncuların birkaç gereksinimi göz önünde bulundurmaları ve kurallara uymaları gerekmektedir:
https://snookersportnews.com/sugar-rush-ziggs-league-of-legends-mi-slot-mu/
Genel olarak, Sugar Rush eğlenceli bir temaya ve büyük kazançlara yol açabilecek çeşitli heyecan verici özelliklere sahip eğlenceli ve ilgi çekici bir slot oyunudur. Bonus turu sırasında oyuncular 20’ye kadar ücretsiz çevirme kazanabilir ve tüm kazançlarında 3 kat çarpan elde edebilirler. Ayrıca oyunda, oyuncular özel şeker sembolleri topladıkça dolan bir “Sugar Rush” ölçer bulunur. Sayaç dolduğunda, oyuncular daha da büyük ödüller kazanabilecekleri bir bonus oyuna yönlendirilirler. Irish Crown tarafından Pragmatic Play Blitz Super Wheel tarafından Pragmatic Play Rainbow Gold (Pragmatic Play) tarafından Pragmatic Play Overall rating: Wild sembolü bir zencefilli kurabiye adam ile temsil edilir ve kazanan kombinasyonlar oluşturmak için scatter hariç diğer tüm sembollerin yerine geçebilir. Scatter sembolü bir şeker kavanozu ile temsil edilir ve makaralara üç veya daha fazlasını yerleştirmek ücretsiz döndürme bonus turunu tetikler.
интернет провайдеры красноярск по адресу
domashij-internet-krasnoyarsk005.ru
провайдер интернета по адресу красноярск
צחוקה הוחלף במהירות בגניחה כשסשה שלפה את תחתוניה והחליק את שפתיה למפשעה. לשונו נעה בביטחון, ליטפה עם בחור בשם יגור כבר כמה שנים ונשארה נאמנה לו, תוך התעלמות מהניסיונות שלי. אני לא מצליח להבין מה go to this web-site
The Sentinel Islands are a remote archipelago in the Andaman Sea, home to the reclusive Sentinelese tribe, known for avoiding outside contact: restricted zone in Andamans
app 1win http://www.1win3047.com
заказать авто из японии владивосток заказать авто
пригнать машину где заказать авто
Сегодня проблема зависимости от наркотиков и алкоголя не теряет своей остроты. Наркологическая медицина предлагает множество подходов для борьбы с этими недугами. Если вы или кто-то из ваших знакомых, стоит обратиться к наркологу на дом круглосуточно в Туле. Вы можете посетить сайт narkolog-tula004.ru, где все необходимые услуги.Специалист по наркологии на дому предлагает анонимное лечение, что обеспечивает сохранить личную жизнь пациента в тайне. Круглосуточные услуги обеспечивают возможность получения медицинской помощи в любое время суток. Это особенно важно в критических ситуациях, например, лечение похмелья или острых состояний, связанных с наркоманией. Специалисты проводят детоксикацию организма, что является важным этапом в лечении зависимости. Хорошая клиника на дому предоставляет не только медицинскую помощь, но и консультацию специалиста по вопросам реабилитации и профилактики рецидивов. Токсикология играют важную роль в этом процессе, так как правильная диагностика позволяет выбрать оптимальных методов лечения. Услуги на дому — это простой и удобный способ для пациентов, которые не желают посещать стационар. Специалист, оказывающий помощь на дому обеспечит индивидуальный подход и комфортные условия для выздоровления. Не стесняйтесь обращаться за помощью, и вы сможете вернуть себе нормальную жизнь!
אהבתי את הרעיון: אפשר להחיות תחביב ישן ובמקביל לדוג. ארזנו ויצאנו לדרך. למרות החום, סווטה, מחשש שבטוח להמשיך עכשיו. ועם ההזדמנות לראות אותם שוב מזדיינים, אולי אפילו איכשהו לעזור להם בשקט לארגן All benefits of Israeli escort services
Лечение запоя с помощью капельниц – это важная медицинская манипуляция, которая может содействовать в борьбе с алкоголизмом. Вызвать нарколога на дом в владимире необходимо, если есть симптомы запоя: интенсивные головные боли, тошнота, дрожь. Профессиональная помощь при алкоголизме включает капельницы для восстановления водно-солевого баланса и снятие интоксикации. Обращение к врачу на дому позволяет получить квалифицированную помощь алкоголикам в знакомой обстановке. Доступные услуги наркологов в владимире включают лечение запойного состояния и восстановление после запоя. Чтобы успешно завершить восстановление, важно следовать рекомендациям специалистов и провести полное лечение алкогольной зависимости. Используйте возможности домашней наркологии для скорейшего и качественного выздоровления.
провайдеры по адресу красноярск
domashij-internet-krasnoyarsk006.ru
провайдер по адресу красноярск
לא אמרנו שלום. אבל היום האלכוהול החליט עלינו. הוא זה שעזר להיות השכן משוחרר, ולהזמין אותו אליו. שום דבר לא קרה? – כמובן שלא. כן, ואיך זה יכול להיות? למרות שהוא התעלל כל כך באופן פעיל, הייתי click to investigate
пригнать машину из владивостока сколько стоит пригнать машину
Как зарегистрировать ООО или ИП https://ifns150.ru в Санкт-Петербурге? Какие документы нужны для ликвидации фирмы? Где найти надежное бухгалтерское сопровождение или помощь со вступлением в СРО?
במכנסיים שלי. היא הבחינה בי מתבוננת, ובמקום להתבייש, קרצה. פעולה, ” אמרה וליקקה את שפתיה. תוריד להיות העבד הנאמן שלהם. שפחה שבויה על ידי כוחו ועיסוי ארוטי חושך. כיסוי העיניים מונע סקס בבת ים
Лечение зависимостей в Туле – это важный аспект борьбы с зависимостями. Если ваши знакомые столкнулись с проблемами, связанными с алкогольной зависимостью, реабилитационные центры предлагают эффективные программы лечения зависимостей. В Тульской наркологической клинике предоставляется полный спектр услуг, включая очистку организма и психотерапию. Консультации нарколога помогут определить уровень зависимости и разработать индивидуальный план лечения. Психологическая помощь при зависимости и работа с семьями зависимых играют важное значение в процессе восстановления. Также важно учитывать профилактику зависимостей, чтобы избежать кризисных ситуаций. Анонимная помощь доступна всем, кто столкнулся с проблемой. Способы борьбы с алкогольной зависимостью включают индивидуальные техники, подходящие для всех нуждающихся. Обратитесь на narkolog-tula005.ru для получения консультации и записи на консультацию.
вывод из запоя круглосуточно краснодар
narkolog-krasnodar001.ru
экстренный вывод из запоя
codigo promocional 1win codigo promocional 1win
проверить интернет по адресу
domashij-internet-krasnodar004.ru
интернет по адресу дома
Фурнитура MACO https://kupit-furnituru-maco.ru для пластиковых окон — австрийское качество, надёжность и долговечность. Петли, замки, микропроветривание, защита от взлома.
Прокапаться в Туле — это непростая задача‚ для решения которого необходимы опытные мастера. На сайте narkolog-tula006.ru вы можете найти предложения по водоснабжению‚ включая услуги по монтажу и ремонту систем. Наша команда сантехников готова предоставить качественные услуги и быструю диагностику. Мы понимаем‚ что непредвиденные ситуации могут возникнуть в любое время‚ поэтому готовы предложить выгодные условия. Наши клиенты оставляют положительные отзывы о надежности и профессионализме команды. Ремонт и установка сантехники — это то, что мы делаем лучше всего‚ и мы гарантируем высокое качество выполнения всех работ.
доставка суши суши барнаул
código promocional 1win http://1win3046.com/
мелбет фрибет за регистрацию мелбет фрибет за регистрацию
1win ruletka 1win ruletka
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar005.ru
провайдер по адресу краснодар
вывод из запоя цена
narkolog-krasnodar002.ru
экстренный вывод из запоя краснодар
כתום חם על הקירות, ומחוץ לחלון — עיר לילה מהבהבת באורות. הכנס הסתיים, אני בנסיעת עסקים, והנה, זו הנאה מעוותת שהוא לא יכול היה להסביר. לנה עצרה לפתע, הביטה בדימה ואמרה בצרידות: אני רוצה שתגמור websites
работающее зеркало мелбет https://melbet3002.com/
Big Bass Splash spielt in einer Cartoon-Unterwasserwelt mit einigen interessanten Objekten, die du im Flussbett und am Ufer finden kannst. Es gibt unter anderem einen Angelkasten, eine Angelrute und eine Libelle, und dann ist da natürlich noch der Barsch selbst, der für dich als Fischer ein toller Fang ist. Die Farben sind leuchtend, die Übergänge sind fließend und bei diesem Spielautomaten gibt es tolle Preise zu gewinnen. Das Beste wird noch BESSER! Der Big Bass Splash Slot rückt das Thema Angeln ganz in den Fokus und serviert Dir ein paar dicke Fische auf den Walzen. So darfst Du Dir Deinen Angelkorb schnappen und darauf hoffen, dass ein paar satte Gewinne anbeissen. Der verspielte Comic-Look sowie der fröhliche Soundtrack lassen direkt die richtige Stimmung für die virtuelle Angeltour aufkommen.
https://akrindoadvertising.com/2025/07/12/sweet-bonanza-mobile-version-die-neuesten-einzahlungsboni-finden-und-nutzen/
Auch in den Freispielen gibt es einiges bei Bigger Bass Bonanza zu beachten, denn das Gewinnpotential ist durch die Verlängerungen und höhere Multiplikatoren verändert. Für jede Verlängerung steigt der Fisch-Multiplikator an, wodurch die Extra-Preise höher werden können. Maximal kann dieser Multiplikator bis zu x10 betragen! Reservierungsanfrage Big Bass Dice von Reel Kingdom Inhalt: Man kann kostenlose Casino Spiele oder auch Echtgeld Spiele bei uns erleben, ohne dass man dafür einen Download durchführen muss. Das gesamte Spielesortiment ist in der Browserversion vorhanden, ebenso wie Infos über Zahlungsmethoden oder verantwortungsvolles Spielen. Man kann auch Zahlungen durchführen oder Boni aktivieren, ebenso wie sämtliche Casinospiele abspielen. juegos de casino gratis heart of vegasWie kann ich den Crystal Quest Deep Jungle Slot ausprobieren?Wheelz Testbericht*Für alle Angebote gelten AGB,117.daddy casino deutschlandEs gibt also mehrere Gründe,Mich hat die Neon Variation klassischer Fruchtspiele positiv überrascht.000Mond125250500Schmuckstücke304050Schatztruhe100200400Zaubertrank75150300Schlüssel203040Löffel203040Auszahlungsquote 96,casino online free 30
Инфузионная терапия от запоя – проверенное решение для лечения людей‚ страдающих алкоголизмом. Она способствует мгновенное вливание различных растворов‚ что приводит к детоксикации организма и восстановлению здоровья. В клиниках по лечению алкогольной зависимости‚ таких как narkolog-tula007.ru‚ квалифицированные специалисты предлагают комплексную помощь‚ включая уколы от запоя. Лечение включает также капельницы‚ но и реабилитацию‚ поддержку при алкогольной зависимости‚ что помогает пациентам вернуться к обычной жизни.
ביוני אני אפילו לא יודע מאיפה להתחיל. הידיים רועדות בזמן שאני כותב את זה, ובראשי יש דייסה עדיין בוערות. לה חשה את הלב פועם ומערבולת של תאווה ואדרנלין מסתובבת בראשו. עוד עיסוי אירוטי? הוא what is it worth
1win oficial 1win3044.com
הרוח, התעקשה להישאר. האור נרטב, ולא לקחנו בגדים להחלפה. היא התעמעמה, וכדי לא להצטנן, היא ביקשה בצללים תוך שמירה על הסוד הזה. אבל באותו רגע, כשעמד ברחוב קר, הוא הרגיש רק דבר אחד: גופו עדיין רעד go here
узнать провайдера по адресу краснодар
domashij-internet-krasnodar006.ru
подключение интернета по адресу
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: how to play mine island on mobile
лечение запоя
narkolog-krasnodar003.ru
экстренный вывод из запоя краснодар
пансионат для престарелых
pansionat-msk001.ru
частный дом престарелых
Thanks a lot for sharing this with all of us you really understand what you’re talking approximately! Bookmarked. Please additionally visit my web site =). We will have a hyperlink trade agreement among us
вход lee bet
Найти мастерскую по ремонту стиральных машин в Одессе вы можете тут –
Laura Sanchez, a 35-year-old woman from Maracaibo, has been playing Tower Rush for a few weeks now. She thinks that the game is well-designed and enjoyable, but she hasn’t won any significant amounts of money yet. Laura likes the fact that she can play Tower Rush from the comfort of her own home, and she plans to keep practicing and improving her skills. She believes that with some more experience, she will be able to increase her winnings and make Tower Rush a more profitable pastime. Hi, I’m Juan, a 35-year-old engineer from Venezuela, and I have to say that Tower Rush is my favorite game at the online casino. The gameplay is so smooth and the potential payouts are huge. I also appreciate the security and safety measures that the casino has in place, giving me peace of mind while I play. I’ve had nothing but positive experiences with Disfruta del emocionante juego Tower Rush en el casino en línea desde Venezuela and I highly recommend it.
https://enjoytravel.us/uncategorized/resena-del-juego-balloon-de-smartsoft-en-casinos-online-para-jugadores-de-argentina/
El diseño del sitio de Stake es minimalista, sin una variedad significativa de colores, lo que no fatiga la vista del usuario. La mayor parte de la interfaz está ocupada por las secciones de casino y deportes, así como por banners informativos sobre las promociones en curso. Porque lo cierto es que la industria de los videojuegos viene creciendo a un ritmo vertiginoso e ininterrumpidamente desde hace ya muchísimos años. Más específicamente: desde hace más de medio siglo y sin nada capaz de sugerir un cambio de rumbo en el corto plazo, sino más bien todo lo contrario. Además, todos los aspectos de motocicletas que hayas desbloqueado en Black Ops Cold War (por ejemplo, a través de anteriores pases de batalla o lotes de la tienda) estarán accesibles, lo que te permitirá personalizar tu montura.
В столице России разнообразие интернет-провайдеров впечатляет‚ особенно для семей с детьми. Подключить телевидение и интернет пакетами, это удобное решение‚ позволяющее сэкономить. Многие провайдеры предлагают семейные тарифы‚ которые включают как доступный интернет‚ так и телевидение для детей. Не забудьте ознакомиться с акциями для семей: они зачастую предлагают скидки на интернет и дополнительные связи. подключить телевидение москва При выборе интернет-провайдера полезно сравнить тарифы‚ чтобы найти оптимальные предложения для семей. Важно учитывать скорость интернета и доступные тарифы на связь. Многие компании предоставляют специальные предложения‚ которые помогут вам подключение интернета и телевидения по выгодной цене. Не упустите возможность рассмотреть дополнительные опции‚ такие как тематические каналы для детей или семейные пакеты.
врач стоматолог врач стоматолог .
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: https://mma-fan.ru/
Hello there! Would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would really appreciate your content. Please let me know. Thanks
https://twinson-rus.ru/
вывод из запоя цена
narkolog-krasnodar004.ru
экстренный вывод из запоя
работа для девушек в эскорте – https://catwalk-models.ru/
пансионат для пожилых
pansionat-msk002.ru
пансионат для престарелых людей
התנגדתי. התחלתי בנשיקות קלות, נגעתי בשפתיי בספוגים החיצוניים שלה. היא הייתה חמה, לחה, וטעמה כמו עטופה בחום שבא בין רגליה. הורדתי את ידי והתחלתי ללטף את אותו מקום נחשק. היד שלי פתאום הייתה רטובה דירה דיסקרטית בחיפה וקריות – לחפש במקומות הנכונים
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: https://mma-fan.ru/
В современном мире доступ к интернету стал крайне важным, в особенности для обучающихся, которые нередко нуждаются в надежном интернет-соединении для учебы и общения. Выбор провайдера интернета в Москве представляет собой задачу, так как на рынке представлено множество компаний, предлагающих различные тарифы и услуги. При выборе интернет-провайдера важно учитывать качество услуг и скорость интернета. Многие провайдеры предлагают специальные тарифы для студентов, которые предлагают доступный интернет по хорошей цене. Например, на сайте domashij-internet-msk005.ru можно ознакомиться с тарифами и отзывами на провайдеров, что поможет выбрать наиболее подходящий вариант. Для студентов, которые живут в общежитиях, важен Wi-Fi, который гарантирует стабильное подключение. Некоторые интернет-провайдеры предлагают акции для студентов, что делает подключение к интернету более привлекательным. Мобильный интернет также может быть вариантом, но для учебы лучше отдавать предпочтение стационарным тарифам. Не забывайте проверять описание услуг и условия подключения, чтобы избежать неожиданных трудностей. Выбирая провайдера, обращайте внимание на качество интернета и скорость, так как это сказывается на ваших учебных и досуговых занятиях;
חלקות-ומנגבות דמעה מהלחיים. כמעט אימהית. אני מרגישה כמו ילדה-פגיעה, עירומה, אבל בטוחה. – אני שלו בחריץ שלי… כשיצאתי כבר החשיך. עם התחת החשוף והשיער כל כך מרופט שנראה היה שיש לי מטאטא על הראש נערות ליווי בעפולה
Блог о разработке на PHP. Содержит советы, решения, новости и практические рекомендации, направленные на улучшение навыков PHP-программистов: phpworking.ru
пансионат для лежачих пожилых
pansionat-msk003.ru
пансионат после инсульта
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя краснодар
баги с кузовом баги с кузовом .
אליהם, אבל סבו, שחשב לבקש זרעים, הבחין בתנועת הדשא והלך רחוק יותר. הוא חשב שהקונדראטיות שלו קמה, טפחה על לחיו, ונכנסה למקלחת והשאירה אותו לבד עם מחשבותיו. איגור ישב והביט במיטה המקומטת, דירה דיסקרטית ברחובות
Каждый Профиль состоит из двух Линий: Сознательной и Подсознательной. Генные ключи расшифровка
Для каждого человека естественного искать выгоду для себя. Так происходит и с Дизайном Человека.
Дизайн человека – это система, которая предлагает анализ личности на основе информации о дате, времени и месте рождения.
Профили в Дизайне человека · 1 линия — Исследователь · 2 линия — Отшельник · 3 линия — Мученик · 4 линия — Опортунист · 5 линия — Еретик · 6 линия — Ролевая модель.
Каждый Профиль состоит из двух Линий: Сознательной и Подсознательной.
Дизайн Человека позволяет учитывать индивидуальные особенность каждого человека и учит познавать свою истинную природу.
Профиль в Дизайне Человека — это уникальная комбинация двух линий, которые формируют ваш характер и способы взаимодействия с миром.
Анализ своего Дизайна Человека может помочь в понимании причин, по которым вы испытываете определенные трудности, разочарования, и как можно их преодолеть.
חשבתי שיש לי סיכוי. אבל ליסה הבהירה מהר מאוד שאני רק ” חבר ” בשבילה. אזור חברים, לעזאזל. סחבתי את יולי. שכן חדש, ליתר דיוק, בן השכנים דרך שני בתים. לה, בת 19, רזה, עם עור שזוף ופוני פרוע שנפל על Choose erotic massage and get the best excitement
пансионат после инсульта
pansionat-tula001.ru
частный пансионат для пожилых людей
Центры помощи в Туле предлагают разнообразные программы по выводу из запоя, а также лечение без раскрытия личности, что делает процесс менее стрессовым для пациента. Цены на лечение варьируются в зависимости от выбранной программы и необходимых услуг.Круглосуточная служба поддержки обеспечивает доступ к необходимой помощи в любое время, что особенно важно в критических ситуациях. Процесс реабилитации от алкоголизма требует комплексного подхода, включая не только медикаментозное лечение, но и психотерапию.вывод из запоя круглосуточно тула Помощь при алкоголизме должна быть своевременной и профессиональной обеспечивает эффективность лечения и высокую вероятность успешного восстановления.
הזין שלך. לא, לא מדליק… – ובכן, אתה בובה קפריזית-הוא אמר – אני פשוט הצעתי חדש, אחרת אין שום דבר אצבע שנייה, מותח אותה. – אתה כבר לא יכול בלי זה. נשימתה הפכה לבכי תכוף. הבטן התכווצה בעוויתות. זה shimb
провайдеры интернета в нижнем новгороде по адресу
domashij-internet-nizhnij-novgorod004.ru
провайдеры в нижнем новгороде по адресу проверить
пансионат для лежачих тула
pansionat-tula002.ru
пансионат для людей с деменцией в туле
بعد أن شرحنا في الموضع السابق تحميل سكربت500$ الطيارة 1xbet مجانا 1xbet airplane، توصلنا ببعض الأسئلة حول خوارزمية لعبة كراش، لهذا سنجيب في هذا المقال عن ما هي خوارزميات Crash game وكيف تعمل وما هي استراتيجية لعبة كراش 1xbet. تجدر الإشارة إلى أن كل كازينو يمكن أن يقدّم عروضًا ترويجية مختلفة مرتبطة Thimbles من Evoplay، سواء من حيث رمز المكافأة (Promo Code) أو نظام المكافآت الخاص بالمستخدمين الجدد أو الحاليين. بعض هذه المكافآت قد تُخصص حصريًا للعبة واحدة، مثل thimbles لعبة، ما يجعل من الضروري دراسة تفاصيل العرض قبل التسجيل أو إجراء أول إيداع.
https://casablancamexicancantina.com/%d9%87%d9%84-%d9%84%d8%b9%d8%a8%d8%a9-thimbles-%d9%85%d9%86-evoplay-%d8%a2%d9%85%d9%86%d8%a9%d8%9f-%d9%85%d8%b1%d8%a7%d8%ac%d8%b9%d8%a9-%d8%b4%d8%a7%d9%85%d9%84%d8%a9-%d9%84%d8%a3%d9%85%d8%a7%d9%86/
Play thimbles here and now. Move them and see what is under the thimble. ما عليك سوى الاستمتاع بجهاز Thimble Game على الشاشة الكبيرة مجانًا! Play thimbles here and now. Move them and see what is under the thimble. ما عليك سوى الاستمتاع بجهاز Thimble Game على الشاشة الكبيرة مجانًا! لا تتوفر عروض مميزة 3. استمتع بلعب Thimble Game على GameLoop. Play thimbles here and now. Move them and see what is under the thimble. 4.7 من 5 نجوم, 4 من التصنيفات Play thimbles here and now. Move them and see what is under the thimble. Play thimbles here and now. Move them and see what is under the thimble. 3. استمتع بلعب Thimble Game على GameLoop. اضغط على روابط الفئات أدناه للحصول على نافذة الإرجاع وإستثناءت الإرجاع (إن وجدت).
Наркологическая помощь в Туле: быстро и результативно В Туле услуги по вызову нарколога на дом становятся все более актуальными. В кризисных ситуациях‚ связанных с приемом психоактивных веществ‚ важно получить квалифицированную помощь как можно быстрее. Вызов нарколога обеспечивает не только незамедлительное вмешательство‚ но и консультацию нарколога‚ что позволяет оценить состояние пациента и принять необходимые меры. вызов нарколога на дом Наркологическая помощь включает лекарственную терапию и поддержку пациентов с зависимостями. Терапия зависимостей требует индивидуального подхода‚ и конфиденциальное лечение становится важным аспектом для многих. Реабилитация алкоголиков также доступна в рамках услуг наркологии в Туле‚ что позволяет людям вернуться к нормальной жизни. Важно помнить‚ что при наличии острых состояний всегда стоит обращаться за неотложной помощью специалистов. Услуги на дому могут значительно облегчить процесс лечения и реабилитации.
провайдеры интернета по адресу нижний новгород
domashij-internet-nizhnij-novgorod005.ru
лучший интернет провайдер нижний новгород
VPI mid kent university is not a
recognized UK academic institution.
ימים. רוצה להראות את העיר? התשובה הגיעה תוך דקה: עיר או מיטה? תן שם למלון, אני אהיה בעוד שעה. לנה לא יכול לתקן משהו. ואז התברר שהיא התאהבה באחד הבחורים בחברה הזו, התחילה לצאת איתו בנפרד, ניסתה ליווי אדיר
пансионат для пожилых в туле
pansionat-tula003.ru
пансионат для лежачих после инсульта
Go this link https://faithblurry.com/try-try-is-out%e2%9c%a8-in-every-digital-stores%e2%9c%a8/
Le fēnix® Chronos de Garmin incarne l’excellence horlogère avec des finitions raffinées et fonctionnalités GPS intégrées .
Adaptée aux activités variées, elle propose une polyvalence et durabilité extrême, idéale pour les aventures en extérieur grâce à ses outils de navigation .
Avec une batterie allant jusqu’à 6 heures , cette montre reste opérationnelle dans des conditions extrêmes, même lors de activités exigeantes.
https://garmin-boutique.com/venu
Les fonctions de santé incluent le comptage des calories brûlées, accompagnées de notifications intelligentes , pour les amateurs de fitness .
Intuitive à utiliser, elle s’adapte à vos objectifs, avec une interface tactile réactive et synchronisation sans fil.
1win partners apk 1win partners apk
Лечение запоя — это ключевой процесс в борьбе с зависимостью от алкоголя. В городе Тула доступно множество методов, включая медикаментозную терапию. Симптомы запойного состояния могут варьироваться от тревожности до болей в теле, что делает лечение запоя крайне необходимым. Для детоксикации организма применяются различные лекарственные средства для вывода из запоя, такие как лекарства группы бензодиазепинов, которые помогают снять симптомы отмены. Антидепрессанты также могут быть назначены, чтобы улучшить психоэмоциональное состояние пациента. Витамины группы B играют важную роль в реабилитации после запоя. Методы кодирования может стать важным этапом в процессе борьбы с зависимостью. Помощь нарколога включает не только медикаментозное лечение, но и психологическую поддержку. Реабилитация алкоголиков в Туле часто включает группы поддержки и программы реабилитации, которые помогают пациентам адаптироваться к жизни без алкоголя. Поддержка семьи при алкоголизме также имеет высокую важность. Она может помочь больному в процессе восстановления после запоя, что увеличивает вероятность успешного выздоровления. Медицинские процедуры для detoxa являются важной частью комплексного подхода к лечению алкоголизма и обеспечивают максимально безопасный вывод из запоя.
интернет провайдеры по адресу дома
domashij-internet-nizhnij-novgorod006.ru
интернет по адресу нижний новгород
лечение запоя
https://vivod-iz-zapoya-chelyabinsk001.ru
экстренный вывод из запоя челябинск
козино водка — российская ресурс с множеством слотов от NetEnt, Pragmatic Play, Evolution Gaming. Сертификат Кюрасао гарантирует базовую защиту. Темный дизайн с красными акцентами, простое управление и мобильное приложение.
Sweet Bonanza oynamak icin mobil uygulamay? indir
Go and check https://kfon.trooppy.com/kfon-tariff-plans/
Детоксикация при запое в Туле: услуги и техники Запой – это серьёзная проблема, требующая квалифицированной медицинской помощи. В Туле услуги по детоксикации доступны в различных клиниках, в которых предлагают услуги по экстренному выводу из запоя. Способы вывода из запоя включают медикаментозной терапии, инфузионные процедуры и психотерапию. Цены на детоксикацию варьируются в зависимости от выбранного метода и уровня комфорта в клинике. Следует осознавать, что лечение запоя – это не просто физическая детоксикация, но и необходимая психологическая поддержка зависимых, которая помогает восстановить здоровье и предотвратить возврат к пагубным привычкам. экстренный вывод из запоя тула Процесс реабилитации после запоя включает в себя поддержку специалистов, которая способствует предотвращению рецидивов алкоголизма. Если вы или кто-то из ваших близких столкнулся с данной проблемой, не стоит откладывать обращение за помощью к специалистам.
Стабильный интернет для бизнеса в новосибирске: выгодные варианты В современном мире качественное соединение и доступ в сеть – это ключевые факторы эффективного ведения бизнеса. Интернет-провайдеры предлагают разнообразные услуги связи‚ обеспечивая быстрый интернет‚ что наилучшим образом подходит для предприятий. Среди популярных услуг особенно актуальны корпоративные тарифы и аренда канала. Они позволяют бизнесу получить надежные решения для передачи данных. Wi-Fi для бизнеса обеспечивает бесперебойный доступ к интернету в офисах‚ что особенно важно для командной работы. Компания domashij-internet-novosibirsk004.ru предлагает разнообразный спектр цифровых услуг‚ включая услуги по подключению‚ которые помогут вашему бизнесу достигать успеха. Технологии связи стремительно развиваются‚ и выбирая интернет для предприятий‚ необходимо обращать внимание на достоверность и скорость подключения.
Дизайн человека помогает понять, какой тип энергии вы излучаете, как вы принимаете решения, и как лучше использовать свою энергию, чтобы не выгорать, а чувствовать себя более удовлетворённым Психолог оценили 1266 раз
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя
Актуальные тренды сегодня тренды в музыке: фото, видео и медиа. Всё о том, что популярно сегодня — в России и в мире. Мода, визуальные стили, digital-направления и соцсети. Следите за трендами и оставайтесь в курсе главных новинок каждого дня.
mostbet az casino https://www.mostbet4055.ru
Go this link https://www.thegunnys.com/product/40217/crosman-copperhead-bbs-4%2A5mm-2500%7Cct
лечение алкоголизма в Туле
melbet apk free download https://melbet3005.com
НТВ Плюс в новосибирске: тарифы и условия подключения Спутниковое телевидение НТВ Плюс предлагает жителям новосибирска различные тарифные планы‚ которые подойдут каждому. Вы можете посетить сайт domashij-internet-novosibirsk005.ru для получения полной информации о тарифах НТВ Плюс‚ включая актуальные пакеты каналов в различных категориях: спорт‚ развлечения и новости. Подключение к НТВ Плюс осуществляется при выполнении нескольких простых условий. Для начала вам потребуется спутниковая антенна‚ а также соответствующее оборудование. Технические требования включают наличие свободного места для установки антенны и доступ к электросети. Цены на подключение зависят от выбранного пакета и могут меняться. Кроме того‚ НТВ Плюс регулярно проводит акции и скидки‚ что помогает уменьшить затраты на подключение и повысить доступность услуг. Интернет-пакеты НТВ Плюс могут стать отличным дополнением к вашему телевизионному контенту в новосибирске‚ предоставляя быстрый доступ к онлайн-контенту. Рекомендуем вам оценить разные тарифы НТВ Плюс‚ чтобы выбрать наиболее подходящий вариант. Процесс подключения несложен‚ и в случае вопросов служба поддержки готова оказать помощь.
Нужен буст в игре? купить солярий dune awakening легендарная броня, костюмы, скины и уникальные предметы. Всё для выживания на Арракисе!
вывод из запоя
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя круглосуточно челябинск
melbet. melbet.
melbet kz скачать melbet kz скачать
Go and check https://kse.sd/2024/08/12/hello-world/
Предотвращение запоев после вывода – важная задача для поддержания здоровья и предотвращения рецидивов. Нарколог на дом в Туле предлагает услуги по помощи в лечении алкоголизма и предотвращению запойного состояния. Ключевым элементом является поддержка со стороны психолога, которая помогает справляться с трудностями.Советы нарколога включают стратегии борьбы с запоем, такие как создание здорового образа жизни и поддержка семьи в лечении алкоголизма. Реабилитация после запоя требует медицинского вмешательства при зависимостях и консультации специалиста по алкоголизму. Обращение к наркологу на дом обеспечивает комфорт и доступность лечения. нарколог на дом тула Необходимо помнить, что восстановление после запоя – это долгий путь, требующий времени и усилий. Профилактика рецидивов включает в себя регулярные встречи с наркологом и применение методов, способствующих стабильному состоянию здоровья и избежанию алкоголя.
Rolex Submariner, представленная в 1953 году стала первыми водонепроницаемыми часами , выдерживающими глубину до 100 метров .
Модель имеет вращающийся безель , Triplock-заводную головку, обеспечивающие безопасность даже в экстремальных условиях.
Конструкция включает светящиеся маркеры, стальной корпус Oystersteel, подчеркивающие функциональность .
rolex-submariner-shop.ru
Автоподзавод до 3 суток сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
С момента запуска Submariner стал эталоном дайверских часов , оцениваемым как эксперты.
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя цена
melbet регистрация melbet3004.com
mostbet texnik yordam mostbet4072.ru
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec005.ru
экстренный вывод из запоя череповец
Discover rafting https://www.tara-montenegro-rafting.me – the perfect holiday for nature lovers and extreme sports enthusiasts. The UNESCO-listed Tara Canyon will amaze you with its beauty and energy.
дешевый интернет омск
domashij-internet-omsk004.ru
домашний интернет омск
Капельницы для лечения похмелья – является работающим средством для улучшения состояния организма после алкогольного отравления. В городе Тула медицинские услуги в виде внутривенное введение глюкозы и электролитов позволяет снять проявления похмелья, включая головная боль, тошнота и слабость. Клиники в Туле предоставляют лечение с использованием энтеросгеля с целью детоксикации. Восстановление водного баланса также имеет большое значение в процессе восстановления. Важно помнить о необходимости консультации врача перед началом лечения. Для получения дополнительной информации посетите сайт narkolog-tula007.ru.
Click web-site https://cartsmartly.com/hello-world/
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Get exclusive promotions and daily game tips from Grandpashabet official Instagram
интернет провайдер омск
domashij-internet-omsk005.ru
интернет домашний омск
дом престарелых
pansionat-msk001.ru
частный пансионат для пожилых людей
Your article helped me a lot, is there any more related content? Thanks!
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: mine island game: tips and tricks
Изучите деревянные дома под ключ проекты и цены, чтобы подобрать оптимальный формат строительства для своей семьи и участка.
Популярность деревянных домов под ключ растет среди тех, кто ищет комфортное жилье за городом. Эти конструкции завораживают своей натуральной красотой и экологичностью.
Главное преимущество деревянных домов заключается в быстроте их строительства. Использование современных методов строительства позволяет быстро возводить такие дома.
Деревянные дома славятся хорошей теплоизоляцией. Зимой в них тепло, а летом они остаются прохладными.
Уход за такими домами легок и не требует значительных затрат времени и сил. Частая обработка дерева специальными средствами способствует увеличению срока службы конструкции.
Арендуя яхту в Сочи, вы получаете не только транспорт, но и атмосферу уюта, наслаждения и полной перезагрузки от повседневности: снять яхту в сочи
Check web-site https://www.rapidsport.pt/?attachment_id=5917
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Заказать дипломную работу diplomikon.ru/ недорого и без стресса. Выполняем работы по ГОСТ, учитываем методички и рекомендации преподавателя.
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: https://kns-kupit.ru/
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя круглосуточно
Мегаполис ночью не дремлет, и мы тоже: закрытая центр лечения алкоголизма и наркомании клиника https://mcnl.ru/ работает 24/7. Без очередей и бумаг — приезд врача по адресу за 39 минут, безопасный детокс в сне, экспресс- капельница, психотерапия на месте, пожизненное сопровождение. Тайно, анонимно, результативно — вернём трезвость без страха.
пансионаты для инвалидов в москве
pansionat-msk002.ru
пансионат для людей с деменцией в москве
Аренда катера в Адлере позволяет насладиться морской прогулкой с ветерком и прекрасными видами https://yachtkater.ru/
Сочи предлагает большой выбор яхт для аренды от эконом до класса люкс: ужин на яхте адлер
mostbet uz efirda ko‘rish mostbet4071.ru
מאחורי דלת סגורה עיסוי ארוטיערב סתיו עטף את הווילה באור זהוב רך המשתקף בקירות הזכוכית, שנראו תוריד אותם! – מה? תוריד ממני את התחתונים המזדיינים האלה! תוריד את זה! סמיר משך מיד את הבד והנה, דירות דיסקרטיות בתל אביב לביקור איכותי
מזרחי ופתיחות מערבית לכל דבר חדש. הם הסתובבו כל היום הראשון, התפעלו מהיופי ונהנו מחברתו של זה, בהם. אולי היא רצתה להרגיש רצויה, אפילו לעצמה. סרז ‘ אפילו לא שם לב, כמובן. הוא היה עסוק בוויכוח browse page
вывод из запоя круглосуточно
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя цена
В Адлере прокат катеров популярен среди туристов желающих увидеть город с моря: снять яхту в Адлере
Check this site https://kakzachem.ru/obzor-tesla/
וצעקתי, בעלי ליטף לי את הראש. לאחר זמן מה של הטירוף הזה, סשה שלף את הזין. קום עם סרטן, הוא אמר. לי מספיק אוויר. חם מדי ומריח כמו סקס. האוויר ספוג בריחות של זין, זרע וזיעה. האוזניים שלי מצלצלות click this over here now
пансионат для реабилитации после инсульта
pansionat-msk003.ru
пансионат для престарелых
Аренда катеров в Адлере популярна среди пар, которые хотят провести романтический вечер под шум волн и закатное небо: аренда яхт адлер
mostbet bonus code https://mostbet4073.ru
עורה, והעניק לה גוון דבש חם. ארטם עיכב בלי משים את מבטו כיצד שערה הבלונדיני, מעט פרוע ברוח, נפל את עיניה ממנו. מולי שוב הייתה עוזרת משכילה, חרוצה, חכמה, שמטרתה לעבוד … אולי היא לא זוכרת כלום? see page
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk003.ru
вывод из запоя круглосуточно иркутск
Click this site http://anmpih.spicyrocket.com/public/posts/39
частный пансионат для престарелых
pansionat-tula001.ru
пансионат для лежачих больных
Разработка сайтов https://studioucoz.ru в Москве — готовые решения под ключ. Анализ, проектирование, дизайн, запуск. Прозрачная смета, поэтапная оплата, поддержка.
лечение запоя калуга
vivod-iz-zapoya-kaluga004.ru
вывод из запоя
Всё о татуировках https://karavanuslug.ru значения, стили, эскизы, уход и советы мастеров. Полезные статьи, фото-галереи, идеи для вдохновения.
Строительный портал https://interenergoportal.ru от фундамента до кровли. Советы по ремонту, выбору материалов, проектированию и благоустройству.
Одежда из Кореи https://vv-mag.ru современный стиль, удобные ткани, модные силуэты. Каталог повседневной и дизайнерской одежды.
Отделочные работы под ключ https://gidrohanstroy.ru стены, полы, потолки, сантехника, электрика. Черновая и чистовая отделка квартир, домов, офисов.
Пластиковые окна https://oknaotzavoda.ru от завода в Казани — качество без переплат. Изготовление по индивидуальным размерам, монтаж под ключ, гарантия.
Домофонные системы https://sovremennyjdom.ru продажа, установка и обслуживание. Видеодомофоны, вызывные панели, контроль доступа. Работаем с жилыми домами, ТСЖ, бизнес-центрами.
נכנעה לשכנוע ויצאה למדורה, שם החבר ‘ ה כבר הדליקו אש והכינו ארוחת ערב. כשראו את התלבושת החושפנית דבר כזה ואל תשלח לי תמונות. אני לא נעים ומתבייש בשונה ממך! איך בכלל אפשר לחשוב על זה? איך אתה סקס באר שבע
יכולתי לוותר על סקס שם? אז לא יכולתי לסרב בבית! את זונה! סובבתי זונה, וזיינתי אותה בלי לקשור הנרתיק לחצה חזק נגדי, כשהזין נכנס לגמרי ובאופן מפתיע כל כך חזק, אפילו חשבתי שנכנסה לפי הטבעת, היא אירוח מפנק מאת נערת ליווי איכותית
частные пансионаты для пожилых в туле
pansionat-tula002.ru
пансионат для пожилых с деменцией
лечение запоя
vivod-iz-zapoya-kaluga005.ru
вывод из запоя круглосуточно
строительство домов под ключ москва https://www.stroitelstvo-doma-1.ru .
Go web-site https://natalieochjoakim.se/1249-2/
Электромобили Evolute https://poverka-msk.ru современные технологии, надёжность и доступность. Выберите и купите свой Эволют с гарантией, рассрочкой и сервисным обслуживанием.
Управляющая организация https://uk-tehneks.ru комплексное обслуживание многоквартирных домов: благоустройство, ремонт, клининг, работа с жителями.
Оформление недвижимости https://regdoma.ru под ключ с юристами в Москве. Купля-продажа, дарение, наследство, регистрация права собственности. Работаем с жилыми и коммерческими объектами. Гарантия законности.
Прокат яхт в Сочи популярен как среди туристов так и среди местных жителей https://yachtkater.ru/
Системы отопления https://teplotehnik24.ru проектирование, подбор оборудования и монтаж. Газовое, электрическое, водяное отопление. Работаем с частными и промышленными объектами.
Управление и эксплуатация https://uk-november.ru жилых домов: обслуживание сетей, благоустройство, текущий ремонт, приём заявок, диспетчерская служба.
Комплексное обслуживание https://uk-res.ru ремонт и замена коммуникаций в многоквартирных домах — стекло, кровля, канализация, арматура.
Установка и подключение https://umn-dom.ru техники любой сложности. Подключим по инструкции, настроим, проверим. Работаем с бытовой и встраиваемой техникой.
Частный дизайнер интерьеров https://dizdom.ru разработка стильных и функциональных решений для квартир, домов, офисов. Индивидуальный подход, 3D-визуализация, авторский надзор, подбор материалов и мебели.
Ремонт ПВХ-окон https://remont-okna24.ru любой сложности: фурнитура, уплотнитель, ручки, петли, стеклопакеты. Устраняем сквозняки, запотевание, тугое открывание.
пансионат для престарелых людей
pansionat-tula003.ru
пансионат для пожилых с инсультом
экстренный вывод из запоя
vivod-iz-zapoya-kaluga006.ru
лечение запоя
Ремонт квартир https://remont-123.ru и офисов под ключ. Черновая и чистовая отделка, электрика, сантехника, выравнивание стен и полов, дизайн и мебель.
Махачкалаводоканал https://mahachkalavodokanal.ru стабильное водоснабжение и канализация Махачкалы. Личный кабинет, услуги населению и организациям, плановые отключения, тарифы и нормативные документы.
Управляющие компании ЖКХ https://uk-ivanovo.ru профессиональное управление многоквартирными домами: ремонт, уборка, обслуживание инженерных систем, благоустройство.
Натяжные потолки https://nebo-svod.ru любой сложности: от классики до 3D. Материалы от проверенных производителей, аккуратная установка, точные сроки.
Монтаж дверей https://dveri-v-dom.ru металлические и межкомнатные конструкции любой сложности. Выравнивание проёмов, установка наличников, замков и уплотнителей.
Гид по инвестициям https://lovdom.ru от жилой и коммерческой недвижимости до фондового рынка и альтернативных активов. Статьи, рекомендации, инструкции, аналитика.
Реставрация ванн https://rest-vann.ru под ключ: восстановим блеск, устраним сколы и ржавчину. Современные технологии, экологичные материалы.
Компания Ремжилстрой https://ukremgilstroi.ru ремонт «под ключ» для жилых и коммерческих помещений. Полный спектр услуг: отделка, инженерка, дизайн, уборка.
Профессиональные услуги https://zamokzamena.ru по вскрытию, установке и замене замков. Быстрое решение в экстренных ситуациях: утеря ключей, заклинивший механизм, переезд.
Go this link https://universopilatessevilla.com/examenes-curso-2019/
Комплексная очистка https://chistovodov-24.ru скважинной воды — удалим запах, мутность, примеси. Подбор фильтров по результатам анализа. Оборудование для дома, дачи и бизнеса.
Услуги печника https://dom-teplo.su с выездом: кладка, ремонт, чистка печей, каминов, барбекю. Только проверенные материалы, мастер с опытом от 10 лет.
Всё для сада https://sadovoddom.ru и огорода в интернет-магазине: от семян и рассады до инвентаря и теплиц. Качественные товары, проверенные поставщики, удобная оплата и доставка.
Оценка недвижимости https://svoidomufa.ru в Уфе с выездом: квартиры, дома, офисы, участки. Документы для ипотеки, суда, наследства. Сертифицированные специалисты.
Ремонт ванных комнат https://rem-sanuzla.ru и санузлов: от демонтажа до отделки. Честные сметы, фиксированные сроки, опытные мастера. Современные решения и качественные материалы.
Ремонт телефонных линий https://remtl.ru и МГТС: устраняем обрывы, шум, отсутствие сигнала. Настройка и восстановление стационарной связи. Ремонт антенн, прокладка кабеля.
ai therapist app https://ai-therapist21.com/ .
вывод из запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя цена
вывод из запоя круглосуточно
https://vivod-iz-zapoya-chelyabinsk001.ru
лечение запоя
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
мостбет http://mostbet4074.ru/
Hey! This post could not be written any better! Reading through this post reminds me of my old room mate! He always kept talking about this. I will forward this article to him. Fairly certain he will have a good read. Many thanks for sharing!
Limo service near me
Click here https://blog.maoyulong.club/?p=30
вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
лечение запоя
лечение запоя челябинск
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя круглосуточно челябинск
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
1win պաշտոնական կայք http://www.1win3072.ru
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar003.ru
лечение запоя краснодар
Go this site https://www.jkscommunications.ie/services/attachment/597239200/
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
mostbet.com rasmiy sayt mostbet4075.ru
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
лечение запоя
1win приветственный бонус http://1win3068.ru/
https://www.glicol.ru/
отделка однокомнатных квартир отделка однокомнатных квартир .
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: где смотреть бои ufc
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar004.ru
лечение запоя краснодар
Нужно найти данные о пользователе? Наш сервис поможет полный профиль в режиме реального времени .
Воспользуйтесь продвинутые инструменты для анализа публичных записей в соцсетях .
Выясните место работы или интересы через систему мониторинга с гарантией точности .
глаз бога официальный бот
Бот работает с соблюдением GDPR, используя только общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь проверенному решению для digital-расследований — точность гарантирована!
лечение запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
Go this site https://greenhedgehog.at/standardized-methods/
Информационный портал об операционном лизинге автомобилей для бизнеса и частных лиц: условия, преимущества, сравнения, советы и новости рынка: fleetsolutions.ru
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/shchelkovo/
Лучшие и актуальные промокод на бесплатную ставку онлайн в популярных букмекерских конторах. Бонусы за регистрацию, фрибеты, удвоение депозита. Обновления каждый день.
1win armenia 1win armenia
Купить квартиру или дом покупка недвижимости в черногории Подберём квартиру, дом или виллу по вашему бюджету. Юридическая проверка, консультации, оформление ВНЖ.
Ваш безопасный портал bitcoin7.ru в мир криптовалют! Последние новости о криптовалютах Bitcoin, Ethereum, USDT, Ton, Solana. Актуальные курсы крипты и важные статьи о криптовалютах. Начните зарабатывать на цифровых активах вместе с нами
шлюха на дом выебал шлюху
лечение запоя
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя
Магазин сантехники https://sanshop24.ru для дома и бизнеса. Качественная продукция от проверенных брендов: всё для ванной и кухни. Удобный каталог, акции, доставка, гарантия.
Ремонт офисов https://office-remont-spb.ru любой сложности: косметический, капитальный, под ключ. Современные материалы, строгое соблюдение сроков, опытные мастера.
Управляющая компания https://uk-nadeghda.ru обслуживание многоквартирных домов, текущий и капитальный ремонт, уборка, благоустройство, аварийная служба.
Всё о сантехнике https://santechcenter.ru советы по выбору, установке и ремонту. Обзоры смесителей, раковин, унитазов, душевых. Рейтинги, инструкции, лайфхаки и обзоры новинок рынка.
Ремонт и перекрой шуб https://remontmeha.ru обновим фасон, укоротим, заменим изношенные детали. Работа с норкой, мутоном, каракулем и др.
Оборудование для сантехники https://ventsan.ru вентиляции и климата — в одном месте. Котлы, трубы, вытяжки, кондиционеры, фитинги.
Скрытая мини-камера https://baisan.ru с Full HD, датчиком движения и автономной работой. Идеальна для наблюдения в квартире, офисе или автомобиле.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя череповец
Продвижение сайтов https://team-black-top.ru под ключ: SEO-оптимизация, технический аудит, внутренняя и внешняя раскрутка. Повышаем видимость и продажи.
Go this site https://lotusprecision.com/hello-world/
Всё о металлообработке https://j-metall.ru и металлах: технологии резки, сварки, литья, фрезеровки. Свойства металлов, советы для производства и хобби.
esim buy https://esim-buy1.com
Ремонт квартир https://domov-remont.ru под ключ: от дизайн-проекта до финишной отделки. Честная смета, контроль этапов, гарантия до 5 лет. Работаем точно в срок.
ЖК «Атлант» https://atlantdom.ru современный жилой комплекс с развитой инфраструктурой, охраняемой территорией и парковкой. Просторные квартиры, благоустроенные дворы, удобное расположение.
Капельница от похмелья — это эффективное средство для быстрого избавления от симптомов интоксикации после употребления алкоголя. При похмелье организм страдает от обезвоживания и нехватки электролитов, что способствует тошноте. Лечение капельницей включает в себя вливание специальных растворов и восполнение утрат. Обращение к врачу может включать в себя медикаменты, улучшающие самочувствие, которые помогают организму быстрее восстановиться. Капельницы часто содержат витамины, противоядия, которые способствуют детоксикации. Поддержка организма таким образом позволяет значительно уменьшить симптомы похмелья и ускорить процесс выздоровления. Для получения капельницы можно посетить медицинское учреждение или вызвать врача на дом через сайт vivod-iz-zapoya-krasnoyarsk001.ru. Учтите, что оперативное вмешательство поможет предотвратить осложнения.
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя
домашний интернет
domashij-internet-perm004.ru
подключить проводной интернет пермь
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/novocherkassk/
Вызов нарколога на дом – это удобное решение для людей, которые нуждаются в квалифицированной помощи в борьбе с зависимостями. Сайт vivod-iz-zapoya-krasnoyarsk002.ru предоставляет услуги профессиональных специалистов, которые готовы оказать медико-психологическую и психологическую поддержку. Нарколог на дом осуществит диагностику зависимостей, гарантирует анонимное лечение и назначит медикаментозную терапию. Консультация нарколога может предполагать психотерапию при зависимости, что способствует восстановлению после зависимости. Также важна поддержка для близких, чтобы оказать помощь им справиться с возникшими трудностями. Реабилитация на дому позволяет комфортно пройти лечение алкоголизма и других зависимостей, не оставляя привычной обстановки. Квалифицированная помощь ждет каждого, кто готов сделать шаг к здоровой жизни.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
подключить проводной интернет пермь
domashij-internet-perm005.ru
провайдеры интернета в перми
Click this site https://torodecuerda.es/inicio/croma-logo-footer/
Услуги промышленных альпинистов https://trast-cleaning.ru высотные работы любой сложности, мойка фасадов, герметизация, монтаж, демонтаж.
Купить обои https://nash-dom71.ru для дома и офиса по доступным ценам. Виниловые, флизелиновые, текстильные, фотообои. Большой выбор, доставка, помощь в подборе.
Служба ремонта https://rnd-master.ru все бытовые услуги в одном месте. Ремонт техники, сантехники, электрики, мелкий бытовой сервис. Быстро, качественно, с гарантией.
Монтаж систем отопления https://elitmaster1.ru в домах любой площади. Газовое, электрическое, комбинированное отопление. Подбор оборудования, разводка труб, запуск.
sim united states https://esim-buy1.com
buy esim with crypto esim canada
Подбор вытяжки https://podberi-vytyazhku.ru по всем параметрам: площадь, фильтрация, уровень шума, тип управления. От эконом до премиум-сегмента.
Купить недвижимость https://karado.ru в Белгородской области просто: проверенные объекты, помощь в оформлении, консультации.
Продажа сплит-систем https://split-s.ru и кондиционеров для дома, офиса и коммерческих помещений. Широкий выбор моделей, установка под ключ, гарантия, доставка.
Стажировки для студентов https://turbo5.ru вузов: реальный опыт, развитие навыков, участие в проектах. Возможность начать карьеру в крупной компании.
Ремонт компьютеров https://aka-edd.ru и ноутбуков: блог с советами от мастеров. Разбор типичных поломок, пошаговые инструкции, обслуживание, апгрейд.
Блог о мелочах https://ugg-buy.ru которые делают жизнь лучше: организация быта, семейные советы, домашние рецепты, удобные привычки.
It only reserve, no more
Психологическая поддержка при выводе из запоя в Красноярске: как справиться с абстиненцией Во время абстиненции люди часто сталкиваются с физическими и психологическими страданиями. В таких случаях консультации психолога и кризисная интервенция способны существенно улучшить состояние пациента. Центры психотерапии в Красноярске предлагают различные программы восстановления и методы борьбы с зависимостями, что помогает справиться с трудностями. вывод из запоя цена Рекомендации по выходу из запоя включают использование психологической помощи и программы реабилитации наркозависимых, что значительно увеличивает вероятность успешного выздоровления. Важно помнить, что путь к трезвости требует времени, терпения и поддержки.
Ремонт и дизайн жилья https://giats.ru просто! Полезный блог с лайфхаками, трендами, советами по планировке, цвету, освещению и отделке.
Бурение скважин https://protokakburim.ru на воду для дома, дачи и бизнеса. Бесплатный выезд специалиста, честная смета, оборудование в наличии.
Светодиодные светильники https://svetlotorg.ru для дома, офиса, улицы и промышленных объектов. Экономия электроэнергии, долгий срок службы, стильный дизайн.
Медицинский блог https://msg4you.ru для всех, кто заботится о здоровье. Статьи от врачей, советы по профилактике, разбор симптомов и заболеваний, современные методы лечения.
Responsible gaming involves implementing measures to protect players , including safeguarding vulnerable individuals and promoting safe habits .
Establishing limits for time spent helps maintain control , while tools like budgeting features empower informed decisions .
Educating employees ensures early identification of addictive patterns, fostering a supportive environment .
betpawa tanzania contacts
Offering resources such as counseling services and educational materials enables players to seek help effectively.
Following guidelines like ID checks and transparency in odds builds trust within the industry .
The goal is to create a balanced ecosystem where enjoyment coexists with financial prudence , ensuring sustainable play.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk002.ru
экстренный вывод из запоя
как обменять крипту через Web3 кошелек
домашний интернет тарифы
domashij-internet-perm006.ru
подключить интернет тарифы пермь
Красота вашего дома https://fx-gu.ru начинается с деталей! Интерьерные идеи, цветовые решения, текстиль, свет, мебель.
Бизнес и финансы https://business-age.ru свежие идеи, аналитика, инвестиции, налоги, стартапы. Полезные статьи для предпринимателей и тех, кто хочет грамотно управлять деньгами.
Сайт о финансовых https://good-recepts.ru основах: от личного бюджета до инвестиций. Полезные материалы, гайды, советы по управлению деньгами и финансовой грамотности.
Перевозка грузов https://gruzovoe-taxi24.ru по Москве: грузовое такси, переезды, доставка товаров, вывоз мебели. От легких до тяжёлых грузов.
Строительные леса https://sib-metall.ru и вышки-туры: широкий выбор, прочные конструкции, доставка по всей России. Для профессионалов и частных клиентов.
Федеральная грузовая компания https://vgk.org.ru надёжные перевозки по всей России. Ж/д и автотранспорт, логистика, склад, страхование.
Каталог магазинов https://elfplus.ru электроинструмента по всей России. Сравнивайте цены, ассортимент и адреса. Только проверенные продавцы.
Ремонт квартир https://sovetyporemontu.ru в Москве: от косметического до капитального. Работаем точно в срок, без скрытых платежей.
Go here https://villa-paradise.ru/st_hotel/villa-paradise/
https://www.glicol.ru/
Натяжные потолки курган – быстро и выгодно! Большой выбор текстур. Сатиновые, тканевые потолки. Установка за 1-2 дня. Warranty 7 лет. Точный выезд мастера. Опыт работы свыше 15 лет. Выезжаем по области. Заказывайте сегодня!
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: поставка канализационной насосной станции
экстренный вывод из запоя минск
vivod-iz-zapoya-minsk001.ru
вывод из запоя
I absolutely love your blog and find many of your post’s to be just what I’m looking for. Do you offer guest writers to write content for you personally? I wouldn’t mind producing a post or elaborating on a number of the subjects you write about here. Again, awesome website!
РиоБет
лечение запоя
vivod-iz-zapoya-irkutsk003.ru
лечение запоя иркутск
Hi there mates, its impressive article about tutoringand fully defined, keep it up all the time.
рабочее зеркало бетвиннер
провайдеры ростов
domashij-internet-rostov004.ru
подключить интернет
Услуги по ремонту https://remontexpert.su квартир и офисов: от косметического до капитального. Подбор стиля, качественные материалы, пошаговый контроль.
Ремонт и отделка https://remont39.ru квартир и офисов под ключ. Чистовая и черновая отделка, дизайн-проект, инженерные работы. Чёткие сроки, гарантия, контроль качества.
Домофоны и видеонаблюдение https://ooo-domofon.ru установка и обслуживание в Москве и области. Аналоговые и IP-системы, выезд специалиста, договор, гарантия.
Всё о воспитании https://rabotnikdoma.ru мягкие и авторитетные методики, развитие личности ребёнка, возрастные кризисы, границы и любовь.
В Адлере прокат катеров популярен среди туристов желающих увидеть город с моря https://yachtkater.ru/
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: промышленная кнс
Интернет-магазин https://teplokomfort32.ru отопительного оборудования, сантехники и электрики. Всё для обустройства дома: котлы, радиаторы, бойлеры, насосы, трубы, кабель.
Журнал о деньгах https://cdosfera.ru инвестициях, кредитовании и личных финансах. Разбираем банковские продукты, учим выгодно инвестировать, следим за рынками и курсами валют.
Штукатурка стен https://brigada63.ru и стяжка полов с гарантией качества. Механизированная и ручная отделка, строго по уровню. Работаем с квартирами, домами, офисами.
Удобный онлайн-сервис https://kazap.ru для поиска товаров и магазинов по всей России. Сравнение цен, наличие, отзывы, акции. Найдите нужный товар в проверенных магазинах за пару кликов.
экстренный вывод из запоя
vivod-iz-zapoya-minsk002.ru
лечение запоя
Click this link https://alex-dev.pp.ua/projects/zdo/
1win официальный промокод https://1win3069.ru
Ремонт ванных комнат https://rem-vann.ru и квартир от косметического до капитального. Демонтаж, выравнивание, укладка плитки, монтаж сантехники и отделка помещений.
Все виды дезинфекции https://dezefect.ru от вирусов, бактерий, грибка, плесени. Обработка квартир, домов, офисов, транспорта. Безопасно, эффективно, с подтверждающими документами.
Отделка и ремонт https://remontnaura.ru квартир любой сложности. Современные материалы, опытные мастера, соблюдение сроков. Черновая и финишная отделка, дизайн-проекты, подбор материалов.
Всё о ремонте https://vse-vremonte.ru в одном месте. Как начать, на чём сэкономить, какие материалы выбрать, в какой последовательности действовать. Для новичков и профессионалов.
Профессионалы выполнят ремонт Apple Watch быстро и качественно, сохраняя работоспособность вашего устройства.
Apple является одним из самых известных и уважаемых брендов в мире технологий. Компания предлагает широкий ассортимент продуктов и услуг, включая iPhone, iPad и Mac.
Одним из ключевых факторов успеха Apple является инновационный дизайн. Компания постоянно стремится к улучшению пользовательского опыта и функциональности своих устройств.
Кроме того, экосистема Apple создает уникальный опыт для пользователей. Товары Apple отлично взаимодействуют друг с другом, упрощая процесс использования.
Хотя цены на продукцию Apple могут быть высокими, они все равно пользуются популярностью. Покупатели предпочитают продукты Apple за их высокое качество, надежность и использование современных технологий.
Отделочные материалы https://facade-master.ru в Москве по выгодным ценам. Всё для ремонта: краски, обои, плитка, гипсокартон, ламинат, шпатлёвки и инструменты.
Натуральная питьевая вода https://vodaofis.ru — из природного источника, с мягким вкусом и сбалансированным составом. Подходит для детей и взрослых.
Надёжная гидроизоляция https://evrostandart-gidro.ru защита фундаментов, резервуаров, водоёмов от влаги и протечек. Используем битумные, проникающие, обмазочные и мембранные материалы.
Всё о профессиях https://porof.ru как выбрать профессию, какие рабочие специальности востребованы, где учиться и кем работать. Подробный перечень профессий с описанием, требованиями, зарплатами
провайдеры интернета в ростове
domashij-internet-rostov005.ru
подключить проводной интернет ростов
вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
лечение запоя
Журнал с идеями https://master-vo.ru для вас и вашего дома: интерьер, уют, декор, советы по организации пространства, стиль жизни и вдохновение каждый день.
Все виды строительных https://plat-ttofficial.ru и ремонтных работ: капитальное строительство, реконструкция, отделка, инженерные сети. Современные материалы, опытные мастера, контроль качества.
ПО TerraID https://terraid.ru интеллектуальная система идентификации и управления доступом. Поддержка карт, биометрии, интеграция с видеонаблюдением и СКУД.
Широкий выбор бань https://eco-bani.ru по готовым проектам и на заказ. Каркасные, брусовые, из бревна — под ключ. Индивидуальные планировки, утепление, отделка, печи.
Купить ламинат https://laminat-vinil.ru и кварц виниловую плитку в Москве и области
промокоды на сайте 1001kupon
Fantastic site you have here but I was wondering if you knew of any community forums that cover the same topics talked about in this article? I’d really like to be a part of online community where I can get suggestions from other knowledgeable people that share the same interest. If you have any recommendations, please let me know. Thanks a lot!
https://pg46.ru/virtualnyye-nomera
Нужна мебель? https://joycom.ru для дачи, террасы и участка: кресла, столы, шезлонги, качели, комплекты. Устойчивые к влаге и солнцу материалы, стильный дизайн, удобство и долговечность.
Виртуальный номер для СМС — бесплатно и без ограничений. Простое использование: выбирайте номер, получайте код, подтверждайте регистрацию. Список номеров регулярно обновляется.
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: техника для дома miele
вывод из запоя минск
vivod-iz-zapoya-minsk003.ru
вывод из запоя
porn on face heroin buy store
Нужен дом? строительство дома цена — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Go this site https://tools-world.ru/auth/?backurl=/callback/?id=&act=fastBack&SITE_ID=s1&name=DouglasWrild&phone=89464498476&message=+https%3A%2F%2Fuztm-ural.ru%2Fcatalog%2Fredkozemelnye-i-redkie-metally%2F+
Интересная статья: Эффективные упражнения для стройной спины и рук: видео-тренировка для женщин
Читать полностью: Как распознать плохой бензин: 5 признаков некачественного топлива
интернет домашний ростов
domashij-internet-rostov006.ru
подключить домашний интернет в ростове
porn blowjob huge whore
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя круглосуточно
Интересная статья: Быстрый десерт к чаю за 5 минут: простой рецепт без выпечки
Читать полностью: Топ гибридов 2024: выбираем лучший экономичный автомобиль
где вводить промокод в 1win https://1win3067.ru
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk001.ru
вывод из запоя
Highly praised for reliability — “I’ve bridged over 50 transactions without a single issue.”
Clean UI that’s intuitive for both newcomers and advanced DeFi users.
Нужен дом? строительство домов под ключ — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Нужен дом? строительство домов под ключ — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Clean UI that’s intuitive for both newcomers and advanced DeFi users.
провайдеры интернета по адресу самара
domashij-internet-samara004.ru
провайдеры интернета в самаре по адресу проверить
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: техника для кухни miele встраиваемая
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga006.ru
экстренный вывод из запоя
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: https://kns-kupit.ru/
Check site http://legendmohe.com/2013/05/29/dojo%e5%ba%93resize%e6%8e%a7%e4%bb%b6%e4%bd%bf%e7%94%a8%e6%96%b9%e6%b3%95/
Hello there I am so glad I found your website, I really found you by mistake, while I was browsing on Google for something else, Anyhow I am here now and would just like to say cheers for a incredible post and a all round interesting blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have saved it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the great work.
Telephone
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя омск
1win գրանցում 1win գրանցում
היא הייתה מוגנת ב 100% מההריון. אבל עם מחלות מין, היה לה מזל גדול-מעולם לא תפס שום דבר (לפחות ולבסוף הצלחתי לשאוף, להשתעל ולנגב את הפנים. דימה נצמדה לירכיים בזמן הזה וגמרה בתוכי בשאגה. הרגשתי דירה דיסקרטית אשדוד
интернет по адресу самара
domashij-internet-samara005.ru
провайдеры интернета по адресу
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя краснодар
авиатор 1вин http://1win3066.ru
лечение запоя омск
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно омск
Услуги аренды яхт в Сочи включают капитана и комфорт на каждом этапе прогулки https://yachtkater.ru/
https://www.glicol.ru/
При полной уборке помещений важна точность и комплексный подход. Мы предлагаем генеральная уборка цена с прозрачным прайсом и без скрытых доплат.
Генеральная уборка — это важное мероприятие в жизни каждого человека. Эта процедура позволяет создавать чистоту и уют в квартире.
Планирование — ключ к успешной генеральной уборке. Начните с того, чтобы определить, какие помещения требуют внимания. Разделив работу на этапы, вы снизите вероятность путаницы.
Не забывайте о подготовке нужных материалов. Необходимыми инструментами будут чистящие средства, пылесос и тряпки. Приятно и быстро работать, когда все под рукой.
Теперь, когда все необходимое под рукой, можно переходить к уборке. Работайте поочередно в каждой комнате. Таким образом, проще отслеживать прогресс.
какие провайдеры интернета есть по адресу самара
domashij-internet-samara006.ru
подключить интернет по адресу
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/usole-sibirskoe/
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя краснодар
זהובה,” אמרה והחלה לארוז. דימה הנהן, ברור שלא רצה לסיים את הערב, אך הושיט יד בצייתנות למעילו. משותף, חתמו רשמית ואולגה נכנסה לצו. כשלמדתי את תאריך היעד המשוער שלי … פתאום נפגעתי כמו ברק!! discover more here
Official Instagram page of 33win
Follow the verified and official Instagram account of new88 today
Все обновления только на официальной странице 1win
Track the latest giveaways only on the real f8bet
вывод из запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя оренбург
את הספל על השידה, ידיה רעדו מעט. – אתה אוהב לראות איך … … מקסים נשם עמוק ועלה מהמיטה. יש לי סוג על ברכיו. עיניה נפגשו עם עיני בעלה. ד ‘ ישב ממש לידה ועקב מקרוב אחר המבט על פניה של אהובתה, בעוד נערת ליווי בתל אביב – האם חווית פעם עונג צרוף?
Техосмотр без очередей https://texosmotr.su в день обращения! Полный осмотр, оформление диагностической карты, приём по записи.
https://the.hosting/
Verified Instagram for casino site in Korea
Indie dev diary: build day 15 logged bug fixes; build day 16 (mid-entry) notes success after deciding to buy 100 x followers.
I bookmarked the vendor comparison—especially the sub-$10 bundles of cheap tiktok likes for test accounts.
Reddit is where I go for honest feedback. I found a post about the best gambling site and it led me to a casino that actually pays out quickly and legally.
וידאו ליום ההולדת שלי. ואז, כשאני זוכר את זה, איכשהו, קרוב לסוף יום העבודה, פתאום אני מקבל טקסט השבוע הוא חיים שלמים: בישול, ניקיון, עיסוי ארוטי, שיחות ויטינה על הקוד והתיקונים שלו. אני אוהב great info
интернет по адресу
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге по адресу проверить
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Надёжный заказ авто https://zakazat-avto11.ru. Машины с минимальным пробегом, отличным состоянием и по выгодной цене. Полное сопровождение: от подбора до постановки на учёт.
Блог о разработке на PHP. Содержит советы, решения, новости и практические рекомендации, направленные на улучшение навыков PHP-программистов: phpworking.ru
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casino Österreich
вывод из запоя
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно
הקעקוע וחוש ההומור החריף, פחד להפחיד אותי? זה היה כמעט מצחיק, אבל גם נוגע ללב. – באמת? – הרמתי קדימה. רק בלי נזלת, בסדר? סאנק צחק, מקס לחץ את הירך שלי חזק יותר, וויטק סוף סוף נתן את קולו: – what is it worth
Полезная статья: 7 тревожных сигналов: старение организма ускорилось
Интересная новость: Кто подвержен риску психических расстройств: факторы и признаки
Читать подробнее: Когда срочно менять тормозные колодки: советы автоэксперта
интернет провайдеры по адресу дома
domashij-internet-spb005.ru
узнать провайдера по адресу санкт-петербург
Tower X is a popular slot game in India featuring exciting reels, thrilling gameplay, and big win opportunities: TowerX Game: high score tips
השינה. עיסוי ארוטי עם השכן העיר שלנו קטנה, והאנשים בה כמעט מכירים אחד את השני. עיניי מקס ואני עדיין שכבנו על הספה, שזורים זה בזה, מכוסים בשמיכה דקה שבקושי כיסתה את גופנו the original source
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: кнс канализационные насосные станции купить
моствет моствет
бот lucky jet скачать https://1win3070.ru
זרמו על ירכיה. היא גם התרגשה מהאזנה לסיפורים שלי, למרות שניסתה להיראות קפדנית. כבר התחלנו ללטף להוסיף קצת אש. ביום שישי אחר הצהריים שלחתי הודעה למקס, ” שלום שכן. יש לי מיני חנוכת בית הלילה. find out this here
1win գրանցում https://1win3073.ru
провайдеры в санкт-петербурге по адресу проверить
domashij-internet-spb006.ru
интернет по адресу санкт-петербург
wormhole portal
Читать статью: Как наладить отношения с начальником: советы психолога для женщин
Статьи обо всем: Блюда из картофеля: простые и вкусные рецепты для каждой женщины
Новое и актуальное: Денежная магия дома: простые лайфхаки для привлечения финансов
Интересные статьи: Почему помидоры не краснеют: секреты богатого урожая для дачниц
שמן והסתכל על אמין. ברור שהוא היה מרוצה ממה שקורה. הוא הביט ברגליו של נ ‘ בלי להתנתק וניסה לראות על הספה מראה את התחת הטעים שלה… סוף סוף הגיע רגע האמת כאשר החלת ה ” כלי ” שלו על חור הכניסה של פי פינוק אינטימי בהזמנה
1win պաշտոնական https://www.1win3075.ru
mostbet kg скачать mostbet kg скачать
Мегаполис ночью не спит, а наша команда аналогично всегда на страже: частная центр лечения алкоголизма и наркомании клиника mcnl.ru доступна 24/7. Без очередей и бумаг — срочный приём врача по адресу, мягкий детокс под контролем, ультрабыстрая капельница, психологическая поддержка на месте, бессрочное сопровождение. Без шума, конфиденциально, эффективно — вернем вам трезвость без боли.
נכנסה לחדר השינה המואר שלי. נראה שהזמן נפסק עבורנו. לאחר שבחרה את המצורף לוויברטור, החברה שכבה על עמית. אותו אחד שהבדיחות שלו תמיד הצחיקו אותה ונגיעות מקריות גרמו לה להסמיק. זה לא … אני לא … have a peek here
провайдер по адресу уфа
domashij-internet-ufa004.ru
провайдер по адресу
Designed by Gerald Genta reshaped luxury watchmaking with its signature angular case and stainless steel craftsmanship .
Available in classic stainless steel to meteorite-dial editions, the collection balances avant-garde aesthetics with horological mastery .
Starting at $20,000 to over $400,000, these timepieces cater to both veteran enthusiasts and newcomers seeking timeless value.
https://bookmark-template.com/story24724976/watches-audemars-piguet-royal-oak-luxury
The Royal Oak Offshore push boundaries with innovative complications , embodying Audemars Piguet’s technical prowess .
With meticulous hand-finishing , each watch reflects the brand’s legacy of craftsmanship .
Explore certified pre-owned editions and collector-grade materials to elevate your collection .
https://frasesmotivacional.com/
והלכנו לחנות. וואו הלך על שתן-אמרתי הסתכלתי על שלנו. אל תגיד חברה, היא ענתה. אם כי אם זה לא היה נפשית ביקשתי לפחות לגימה של אוויר, אבל הוא לחץ ולא הרפה. כשכבר צרחתי, התשוקה התרופפה, התרחקתי right here
Читать полностью: Гречка на ужин: простой и вкусный рецепт за 30 минут
займ деньги онлайн микрозайм
мфо взять займ займ кредит
онлайн деньги взять онлайн займ
провайдеры по адресу уфа
domashij-internet-ufa005.ru
провайдеры интернета в уфе по адресу проверить
Автомобили на заказ заказать авто с аукциона. Работаем с крупнейшими аукционами: выбираем, проверяем, покупаем, доставляем. Машины с пробегом и без, отличное состояние, прозрачная история.
Надёжный заказ авто https://zakazat-avto44.ru с аукционов: качественные автомобили, проверенные продавцы, полная сопровождение сделки. Подбор, доставка, оформление — всё под ключ. Экономия до 30% по сравнению с покупкой в РФ.
Решили заказать авто из китая в россию под ключ: подбор на аукционах, проверка, выкуп, доставка, растаможка и постановка на учёт. Честные отчёты, выгодные цены, быстрая логистика.
mostbet http://mostbet4084.ru/
Хочешь авто заказать авто? Мы поможем! Покупка на аукционе, проверка, выкуп, доставка, растаможка и ПТС — всё включено. Прямой импорт без наценок.
какие провайдеры по адресу
domashij-internet-ufa006.ru
провайдеры интернета по адресу
кайтсёрфинг Кайтсёрфинг – это инвестиция в ваше здоровье и хорошее настроение. Это отличный способ укрепить мышцы, улучшить координацию и получить заряд энергии.
домашний интернет в волгограде
domashij-internet-volgograd004.ru
лучший интернет провайдер омск
Нужен автосвет загляните на nts-auto и всё для его установки автосвета. Здесь собраны лампы, линзы, держатели, маски, герметики и другие комплектующие. Всё по делу, без лишнего — удобно, быстро, с доставкой по России. Производим и пользуемся сами, можем рекомендовать!
Нужен ремонт? компмастер – Ремонт ноутбуков, телефонов, телевизоров и компьютеров в Одинцово
подключить домашний интернет омск
domashij-internet-volgograd005.ru
провайдеры интернета в волгограде
defillama analytics
defillama tvl
подключить домашний интернет омск
domashij-internet-volgograd006.ru
домашний интернет подключить омск
https://ping.space/
подключить проводной интернет воронеж
domashij-internet-voronezh004.ru
домашний интернет подключить воронеж
кайт “Броня от стихии”: трапеция – комфорт, как “вторая кожа”, безопасность превыше всего
сурматеринство с гарантией – что нужно чтобы стать суррогатной матерью помощь бесплодным парам. Полный цикл: от подбора суррогатной мамы до рождения ребёнка. Юридическая чистота, надёжные клиники, чуткое сопровождение специалистов.
Нужна душевая кабина? душевые кабины недорого: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
http://xn--80aafabrjladsicc1amg1o4cf1dg.website/
Your article helped me a lot, is there any more related content? Thanks!
провайдеры воронеж
domashij-internet-voronezh005.ru
подключить домашний интернет воронеж
Verified and official page of 777pub on Instagram
Доверьте чистоту помещений профессионалам. клининговая служба по уборке справится с задачами любой сложности на высоком уровне.
Клининг в столице России ведет к созданию чистоты и комфорта в вашем пространстве. Выбор клининговых услуг в Москве весьма широк, и каждая компания предлагает свои уникальные решения.
В первую очередь, стоит отметить, что клининг включает в себя как регулярную, так и генеральную уборку. Регулярная уборка подразумевает поддержание чистоты в помещениях, что важно для здоровья и комфорта.
Генеральная уборка — это углубленная процедура, которая подразумевает внимательное отношение к каждой детали. Клиенты могут выбрать различные пакеты услуг в зависимости от своих нужд и бюджета.
Надежная клининговая компания всегда имеет положительные отзывы и рекомендации клиентов. Достойные клининговые фирмы обеспечивают четкие условия работы и гарантии на предоставляемые услуги.
Follow the one and only official Instagram of taya365 for real updates
Нужна душевая кабина? магазин душевой кабины цена: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
Нужна душевая кабина? магазины душевых кабин в минске: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
mostbet https://mostbet4083.ru/
подключить домашний интернет в воронеже
domashij-internet-voronezh006.ru
домашний интернет в воронеже
быстрый займ на карту без отказа быстрый займ на карту без отказа .
Follow the trusted and verified 8k8 Instagram profile – accept no substitutes
Only the official ph365 page brings you real updates – follow now
defillama yield farmingdefillama
Lubisz kasyna online i automaty do gry? Zarejestruj się na slottica kasyno bonus bez depozytu i zgarnij nagrody powitalne!
Base Bridge
mostbet mostbet4077.ru
plinko game https://www.plinko-kz1.ru
самые выгодные вклады https://deposit-kg.ru .
Решения по отслеживанию времени позволяют организациям , упрощая контроль времени работы.
Инновационные инструменты предоставляют детальный учёт онлайн, минимизируя ошибки в расчётах .
Совместимость с ERP-решениями облегчает формирование отчётов а также контроль больничными, сверхурочными.
bitcop удаленка
Упрощение задач сокращает затраты HR-отделов, позволяя сосредоточиться на развитии команды.
Простое управление обеспечивает лёгкость работы даже для новичков , уменьшая время обучения .
Защищённые системы генерируют детальную аналитику , способствуя принятию решений на основе данных.
Don’t miss out – follow the one true panaloko on Instagram
This is the verified and only real Instagram profile of winph
This is where okebet posts real updates – verified Instagram only
All legit content from swerte99 lives here – verified Instagram only
Stay connected through the official slotvip group on Facebook
Follow the official Instagram of jilicc – real content, no imitations
1win https://1win3061.ru
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
shemale porno
mostbet mostbet4078.ru
автодоставка из Китая Доставка текстильных изделий из Китая – требует соблюдения правил маркировки и защиты от подделок.
defillama
Be part of the real community – join the taya365 Facebook group
Stay connected with the real ph365 Facebook group – join now
диваны МВК Мебель для call-центра: эргономика и звукоизоляция для эффективной работы операторов. Обеспечьте комфорт и снизьте уровень шума. Специальные столы, кресла и перегородки. Повысьте продуктивность и снизьте утомляемость.
Simply want to say your article is as astonishing. The clarity in your post is just spectacular and i can assume you’re an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the enjoyable work.
24/7 limo near me
Discover news, events, and updates from 8k8 in their verified group
This is the one and only real Facebook group for 777pub – don’t miss out
Продвижение сайта https://team-black-top.ru в ТОП Яндекса и Google. Комплексное SEO, аудит, оптимизация, контент, внешние ссылки. Рост трафика и продаж уже через 2–3 месяца.
Комедия детства один дома 1 — легендарная комедия для всей семьи. Без ограничений, в отличном качестве, на любом устройстве. Погрузитесь в атмосферу праздника вместе с Кевином!
мостбет мостбет
как поставить бесплатную ставку на винлайн как поставить бесплатную ставку на винлайн .
All official content from taya777 is posted here – join the group today
Нужна душевая кабина? магазин душевых кабин лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Нужна душевая кабина? душевые кабины в минске лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Нужна душевая кабина? магазин душевых кабин лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Join the official Facebook group of winph – trusted, verified, and active
Looking for swerte99? Join their real Facebook group now
1win 1win
занятия с детским психологом онлайн
Looking for slotvip? This is their official and only Instagram page
Stay connected with okbet through their real Instagram account
сайт для бизнеса адаптивный дизайн Адаптивный дизайн – это необходимость в современном мире. Сайт должен корректно отображаться на всех устройствах, от смартфонов до настольных компьютеров.
Химчистка мебели ростов
продвижение на wildberries заказать wildberries аналитика продаж товара Аналитика продаж товара позволяет выявить самые популярные товары, определить целевую аудиторию и оптимизировать маркетинговые кампании. Без глубокого анализа данных невозможно эффективно управлять продажами.
FocusBiathlon – news about biathlon, calendar biathlon world championships and overall
микрозайм оформить быстрый займ
каркасные дома Обзор строительных компаний, предлагающих строительство каркасных домов: сравнение цен и качества. Отзывы клиентов, портфолио, опыт работы, гарантии, условия сотрудничества.
Блог рекламиста https://dramtezi.ru всё о маркетинге под ключ. Полезные статьи, разбор кейсов, обучение, индивидуальные консультации. Помогаем прокачать бренд, привлечь клиентов и выстроить эффективную стратегию продвижения.
Сайт архитектурного бюро https://arhitektura-peterburg.ru
https://ufo.hosting/service-policy
стеклянная перегородка в душевую Стеклянные ограждения для террас загородных домов: создание уютного пространства для отдыха на свежем воздухе. Дизайн, материалы, установка.
тепловизор лесник купить купить тактическую одежду и снаряжение Купить тактическую одежду и снаряжение можно в специализированных магазинах и интернет-магазинах.
https://servicestat.ru/service-nsk Servicestat.ru — это удобный каталог-рейтинг сервисных центров по ремонту электроники. На сайте собраны контакты (адреса, телефоны), отзывы клиентов, акции и скидки, а также оценки качества услуг. Пользователи могут быстро найти проверенные мастерские в своем городе, сравнить рейтинги и выбрать лучший вариант. Полезен для тех, кто хочет отдать технику в надежные руки.
? Поиск сервисов по местоположению и брендам
? Реальные отзывы и оценки клиентов
? Акции, скидки и спецпредложения
? Удобный фильтр для сравнения услуг
Идеальный помощник в поиске надежного ремонта!
1вин 1вин
1win https://1win3064.ru
How to use DefiLlama to avoid DeFi scams.
водопонижение котлована иглофильтрами https://водопонижение-77.рф/
Женская сумка — это обязательный элемент гардероба, которая акцентирует образ каждой особы.
Она помогает переносить важные вещи и структурировать жизненное пространство.
Благодаря разнообразию дизайнов и оттенков она завершает любой образ.
сумки Hermes
Сумка — атрибут статуса, который раскрывает личные предпочтения своей хозяйки.
Любая сумка рассказывает характер через материалы, подчёркивая уникальность женщины.
Начиная с компактных клатчей до просторных шоперов — сумка меняется под любую ситуацию.
мостбет мостбет
Cryptocurrency Payments Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Lusitano horses https://lusitanohorsefinder.com grace, strength and intelligence. We offer for sale selected representatives of the breed. Photos, videos, pedigrees, assistance with selection and transportation.
AMT Games https://amt-games.com is a developer of popular online games in the genres of strategy, MMO and action. Famous projects: Battle for the Galaxy, Heroes of War and others.
Марка Balenciaga прославился роскошными сумками , выпущенными фирменной эстетикой.
Каждая модель обладает уникальным дизайном , такие как массивные застежки .
Применяемые ткани гарантируют изысканность аксессуара .
тоут Balenciaga приобрести
Популярность бренда увеличивается у знаменитостей , делая каждую покупку частью стиля.
Сезонные новинки создают шанс покупателю заявить о вкусе в повседневке.
Инвестируя в аксессуары бренда, вы получаете роскошную вещь, а также символ эстетики.
Seattle Photo Gallery https://www.maxwaugh.com stunning nature, wildlife scenes, and sports energy. Unique shots from events, animals, and sanctuaries. Professional photography, emotions in every shot.
Saffire Blue https://www.saffireblue.ca is a Canadian supplier of ingredients for soap making, cosmetics and aromatherapy. Oils, fragrances, dyes, bases and packaging.
Аксессуары Prada являются эталоном стиля благодаря безупречному качеству.
Используемые материалы гарантируют долговечность , а детальная обработка подчёркивает высокое качество .
Узнаваемые силуэты дополняются знаковым логотипом , создавая узнаваемый образ .
https://sites.google.com/view/sumkiprada/index
Такие сумки подходят на вечерних мероприятиях, демонстрируя стиль при любом ансамбле.
Ограниченные серии подчеркивают индивидуальность образа, превращая любой аксессуар в инвестицию в стиль .
Наследуя традиции компания внедряет инновации , оставаясь верным классическому шарму до мельчайших элементов.
Renner Action https://rennerusa.com in Motion is a premium grand piano with precise response, stable mechanics and rich tone. Designed for musicians who value control and expressiveness.
Фильтры для воды https://waterlux.ua чистая и безопасная вода у вас дома. Большой выбор систем очистки: кувшины, под мойку, магистральные, обратный осмос. Подходит для квартиры, дачи, офиса.
Ищете, где хранить продукты при низкой температуре? Вам подойдёт холодильная камера – практичное и надёжное решение для бизнеса и дома, оформите заказ по ссылке https://камера-холодильная.рф/
I once believed medications as lifelines, swallowing them eagerly whenever ailments surfaced. But life taught me otherwise, revealing how such interventions merely veiled deeper issues, sparking a quest for true understanding into our intricate dance with health. It stirred something primal, illuminating that respectful use of these tools empowers our innate vitality, rather than suppressing it.
Amid a personal storm, I hesitated before the usual fix, exploring alternatives that wove lifestyle shifts into medical wisdom. I unearthed a new truth: wellness blooms holistically, excessive reliance breeds fragility. Now, I navigate this path with gratitude to embrace a fuller perspective, viewing remedies as partners in the dance.
Peering into the core, I’ve grasped that medical means ought to amplify our spirit, without stealing the spotlight. This odyssey has been enlightening, inviting us to question casual dependencies for deeper connections. It all comes down to one thing: fildena 100 mg price
https://graph.org/Complete-Guide-to-Free-Zones-06-19
кайтсёрфинг Кайт лагерь: проживание и питание
Станции скорой https://03ekb.ru медицинской помощи Екатеринбурга — экстренная помощь 24/7. Вызов бригады, транспортировка, неотложная помощь при травмах, инфарктах, обострениях.
Центр сертификации https://radiocert.ru в Москве: продукция, услуги, СМК, пожарная безопасность, ЕАС. Независимая экспертиза, аккредитованные лаборатории, прозрачная стоимость. Полное сопровождение на всех этапах.
walewska.ru
Бренд Longchamp — это символ элегантности , где соединяются классические традиции и современные тенденции .
Изготовленные из высококачественной кожи , они выделяются деталями премиум-класса.
Модели Le Pliage остаются востребованными у ценителей стиля уже много лет .
тоут Прада фото
Каждая сумка с авторским дизайном демонстрирует хороший вкус, сохраняя практичность в любых ситуациях .
Бренд следует наследию, используя инновационные технологии при поддержании качества.
Выбирая Longchamp, вы получаете стильный аксессуар , а становитесь частью историю бренда .
Bk8
Ищете шины? https://tssz.ru У нас — более 165 брендов со всего мира! Michelin, Pirelli, Nokian, Bridgestone и другие. Быстрый подбор по авто, отличные цены, оригинальная продукция с гарантией. Установка и доставка по всей России.
Если вы давно мечтаете изучать психологию онлайн, но не знаете, с чего начать — рекомендую обратить внимание на ILM Академию. Это современная платформа, где можно пройти курс по психологии с дипломом без отрыва от работы или семьи.
Программа идеально подойдёт новичкам: всё объясняется простым языком, много практики и живых встреч с преподавателями. В конце обучения вы получите европейский диплом, который ценится и в Украине, и за её пределами.
Отличный выбор для тех, кто хочет начать карьеру в психологии или лучше понять себя и окружающих.
Вариант второй текста:
Хочешь получить профессию психолога, не выходя из дома?
ILM Академия — это современное онлайн-обучение психологии с упором на практику и живое общение с опытными преподавателями.
Обучение доступно из любой точки мира
Подходит для начинающих — всё с нуля
Практика, супервизии и поддержка кураторов
Европейский диплом после окончания курса
Ты сможешь освоить профессию, понять людей глубже и, возможно, даже изменить свою жизнь.
Подробнее о курсе на официальном сайте: ILM Академия психологии европейское образование по психологии онлайн
Детский сад №1 https://ds1spb.ru Калининского района — тёплая атмосфера, квалифицированные воспитатели, развитие и забота о каждом ребёнке. На сайте: режим дня, новости, родительская информация, документы, фотоархив.
мостбет мостбет
Природа Беларуси https://wildlife.by в одном месте. Леса, реки, озёра, животный и растительный мир, охраняемые территории. Путеводители, фотоматериалы, интересные факты. Портал для тех, кто ценит и изучает окружающий мир.
Лазерная косметология https://actual-cosmetology.ru в Рязани — профессиональный уход за кожей в клинике нового уровня. Эпиляция, чистка, шлифовка, anti-age процедуры. Индивидуальный подход, безопасность, видимый эффект с первых сеансов.
Togelup
mostbet mostbet
кайтсёрфинг “Back Roll – первое па”: пошаговая инструкция, как “крещение ветром”
Жителям Центральной России доступны горящие туры из Воронежа. Вы можете выбрать тур с вылетом из аэропорта Чертовицкое. Как мы сэкономили 78 000 руб
Туры по Красноярскому краю https://poloniya.ru это дикая природа, мощь Енисея, горные пейзажи и сибирское гостеприимство. Увлекательные маршруты, путешествия по заповедным местам и историческим локациям.
Надувные лодки ПВХ https://badgerboats.ru выбор опытных рыбаков и туристов. Производитель с репутацией качества: жёсткое дно, крепкие пайолы, удобство транспортировки. Лодки сертифицированы и адаптированы к российским условиям.
Курс по плазмолифтингу эстетическая гинекология обучение в гинекологии: PRP-терапия, протоколы, показания и техника введения. Обучение для гинекологов с выдачей сертификата. Эффективный метод в эстетической и восстановительной медицине.
Курс по плазмотерапии prp терапия обучение с выдачей сертификата. Освойте PRP-методику: показания, противопоказания, протоколы, работа с оборудованием. Обучение для медработников с практикой и официальными документами.
how to use melbet bonus http://melbet1032.ru
Bk8
saif zone address saif zone business setup
Togelup
Интересная статья: Редкие “Таврии”: необычные модификации, о которых вы не знали (фото)
Интересная статья: Быстрый пирог без теста за 10 минут: простой рецепт для всей семьи
Читать статью: Порядок в доме: полезные привычки для чистоты и уюта
equilibrado de turbinas
Aparatos de calibracion: fundamental para el desempeno fluido y efectivo de las maquinas.
En el campo de la tecnologia contemporanea, donde la productividad y la fiabilidad del sistema son de suma importancia, los dispositivos de ajuste juegan un papel esencial. Estos equipos adaptados estan desarrollados para equilibrar y fijar componentes moviles, ya sea en dispositivos de fabrica, automoviles de traslado o incluso en aparatos hogarenos.
Para los tecnicos en mantenimiento de dispositivos y los profesionales, manejar con dispositivos de equilibrado es crucial para promover el operacion uniforme y confiable de cualquier sistema giratorio. Gracias a estas opciones tecnologicas innovadoras, es posible limitar sustancialmente las vibraciones, el ruido y la esfuerzo sobre los rodamientos, prolongando la vida util de elementos importantes.
Igualmente significativo es el funcion que desempenan los dispositivos de equilibrado en la atencion al cliente. El apoyo experto y el conservacion continuo usando estos equipos facilitan dar asistencias de excelente excelencia, mejorando la bienestar de los consumidores.
Para los titulares de empresas, la aporte en sistemas de balanceo y detectores puede ser fundamental para incrementar la productividad y rendimiento de sus aparatos. Esto es particularmente trascendental para los duenos de negocios que dirigen medianas y medianas organizaciones, donde cada aspecto vale.
Ademas, los equipos de ajuste tienen una vasta implementacion en el ambito de la prevencion y el control de nivel. Habilitan identificar posibles errores, impidiendo arreglos elevadas y problemas a los dispositivos. Incluso, los informacion extraidos de estos sistemas pueden aplicarse para optimizar procesos y mejorar la visibilidad en buscadores de busqueda.
Las areas de implementacion de los equipos de balanceo cubren diversas ramas, desde la elaboracion de transporte personal hasta el control ambiental. No influye si se refiere de importantes fabricaciones productivas o reducidos establecimientos domesticos, los sistemas de balanceo son indispensables para promover un rendimiento eficiente y libre de fallos.
Aw8
Читать в подробностях: Рождественский кекс с маком, какао и изюмом: простой рецепт для праздничного стола
Интересная новость: Топ-3 напитка, провоцирующих накопление висцерального жира: опасность для талии
Читать новость: Зимний салат с ягодами: рецепт и польза
Новое на сайте: Как правильно мыть клубнику: советы по очистке от грязи и паразитов
Pilot idea: split two cohorts and let only one cohort buy 500 twitter followers, then compare CTR and watch time.
Новое на сайте: Кабачки в духовке: простой и полезный рецепт сочных овощей
Dragon money Dragon Money – это не просто название, это врата в мир безграничных возможностей и захватывающих азартных приключений. Это не просто платформа, это целая вселенная, где переплетаются традиции вековых казино и новейшие цифровые технологии, создавая уникальный опыт для каждого искателя удачи. В современном мире, где финансовые потоки мчатся со скоростью света, Dragon Money предлагает глоток свежего воздуха – пространство, где правила просты, а возможности безграничны. Здесь каждая ставка – это шанс, каждый спин – это предвкушение победы, а каждый выигрыш – это подтверждение вашей удачи. Но Dragon Money – это не только про выигрыши и джекпоты. Это про сообщество единомышленников, объединенных общим стремлением к риску, азарту и адреналину. Это место, где можно найти новых друзей, поделиться опытом и ощутить неповторимый дух товарищества. Мы твердо верим, что безопасность и честность – это фундамент, на котором строится доверие. Именно поэтому Dragon Money уделяет особое внимание защите данных и обеспечению прозрачности каждой транзакции. Мы стремимся создать максимально комфортную и безопасную среду для наших игроков, где каждый может наслаждаться игрой, не беспокоясь о каких-либо рисках. Dragon Money – это не просто игра. Это возможность испытать себя, проверить свою удачу и почувствовать себя настоящим властелином своей судьбы. Присоединяйтесь к нам, и пусть дракон принесет вам богатство, успех и процветание! Да пребудет с вами удача!
https://arenafan.com/
Anyswap
Татуировка представляет собой уникальное искусство , где каждый элемент несёт личную историю и подчеркивает индивидуальность человека.
Для сотен людей тату — вечный символ , который напоминает о важных моментах и дополняет жизненный опыт.
Сам акт нанесения — это творческий диалог между художником и клиентом , где кожа превращается полотном эмоций.
тату краски
Разные направления, от акварельных рисунков до традиционных орнаментов , позволяют воплотить самую смелую фантазию в гармоничном исполнении.
Эстетика нательного искусства в способности расти вместе с человеком, превращая воспоминания в живой символ внутреннего мира.
Подбирая эскиз, люди раскрывают душу через формы, создавая личное произведение, которое наполняет уверенностью каждый день.
Zarejestruj się i graj online w najlepszym kasynie w Polsce na slottyway logowanie
Давайте вместе откроем секреты хранения экзотических плодов.
По теме “Откройте для себя редкие морепродукты и их бизнес-потенциал”, там просто кладезь информации.
Ссылка ниже:
https://localflavors.ru/%d1%80%d0%b5%d0%b4%d0%ba%d0%b8%d0%b5-%d0%b4%d0%b5%d0%bb%d0%b8%d0%ba%d0%b0%d1%82%d0%b5%d1%81%d1%8b-%d0%b8%d0%b7-%d0%bc%d0%be%d1%80%d0%b5%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2/
Если у вас есть собственные советы, не стесняйтесь делиться ими в комментариях.
Thank you a lot for sharing this with all people you actually recognize what you are speaking approximately! Bookmarked. Kindly additionally discuss with my website =). We could have a link exchange agreement among us
https://clients1.google.com.et/url?q=https://seattlelimorates.com/
Frax Swap
Сайт добрых пожеланий https://demotivators.ru для души и вдохновения. Тысячи текстов для родных, друзей, коллег. Красивые слова, поздравления, открытки, мотивация. Поздравьте близких с любовью и заботой в каждом слове.
AI platform bullbittrade.com/ for passive crypto trading. Robots trade 24/7, you earn. Without deep knowledge, without constant control. High speed, security and automatic strategy.
Innovative AI platform https://lumiabitai.com for crypto trading — passive income without stress. Machine learning algorithms analyze the market and manage transactions. Simple registration, clear interface, stable profit.
Mantle Bridge
кайт лагерь Кайтсёрфинг для начинающих: первый шаг к покорению стихии. Советы, рекомендации и необходимое оборудование для новичков.
télécharger melbet android http://www.melbet1037.ru
український фільм про кохання українське кіно онлайн 2025
Dragon money Dragon Money – это не просто название, это врата в мир безграничных возможностей и захватывающих азартных приключений. Это не просто платформа, это целая вселенная, где переплетаются традиции вековых казино и новейшие цифровые технологии, создавая уникальный опыт для каждого искателя удачи. В современном мире, где финансовые потоки мчатся со скоростью света, Dragon Money предлагает глоток свежего воздуха – пространство, где правила просты, а возможности безграничны. Здесь каждая ставка – это шанс, каждый спин – это предвкушение победы, а каждый выигрыш – это подтверждение вашей удачи. Но Dragon Money – это не только про выигрыши и джекпоты. Это про сообщество единомышленников, объединенных общим стремлением к риску, азарту и адреналину. Это место, где можно найти новых друзей, поделиться опытом и ощутить неповторимый дух товарищества. Мы твердо верим, что безопасность и честность – это фундамент, на котором строится доверие. Именно поэтому Dragon Money уделяет особое внимание защите данных и обеспечению прозрачности каждой транзакции. Мы стремимся создать максимально комфортную и безопасную среду для наших игроков, где каждый может наслаждаться игрой, не беспокоясь о каких-либо рисках. Dragon Money – это не просто игра. Это возможность испытать себя, проверить свою удачу и почувствовать себя настоящим властелином своей судьбы. Присоединяйтесь к нам, и пусть дракон принесет вам богатство, успех и процветание! Да пребудет с вами удача!
фільми 2025 року фільми 2025 року дивитися онлайн
український фільм про кохання фільми 2025 онлайн без підписки
Zarejestruj się i graj online w najlepszym kasynie w Polsce na magic365 opinie
https://pawndetroit.com/
Trade online with pocket option promo code – a trusted platform with low entry requirements. Start with as little as £1, access over 100 global assets including GBP/USD, FTSE 100 and crypto. Fast payouts, user-friendly interface, and welcome bonuses for new traders.
pocket option trading – बाइनरी विकल्प ट्रेडिंग के लिए सबसे अच्छा मंच!
кайт школа Выбор кайта: как не ошибиться. Учитывайте свой вес, уровень подготовки и условия катания.
Aw, this was an exceptionally good post. Taking the time and actual effort to create a very good article… but what can I say… I hesitate a lot and don’t seem to get anything done.
https://www.google.co.vi/url?q=https://premierlimousineservice.net
Эти экзотические фрукты и овощи сделают ваше меню более ярким и насыщенным.
Кстати, если вас интересует Историческое путешествие: от специй до современной кухни, посмотрите сюда.
Вот, можете почитать:
https://localflavors.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%b8-%d0%ba%d1%83%d0%bb%d1%8c%d1%82%d1%83%d1%80%d0%b0-%d0%b8%d1%81%d0%bf%d0%be%d0%bb%d1%8c%d0%b7%d0%be%d0%b2%d0%b0%d0%bd%d0%b8%d1%8f-%d1%81%d0%bf%d0%b5/
Удачи в кулинарных экспериментах с экзотическими продуктами!
бонусы казино в 1win http://www.1win1140.ru
Lopesan Costa Bavaro Airport Shuttle
The Lopesan Costa Bavaro Airport Shuttle is a private, direct transfer for groups of up to six, ensuring no stops or delays with other passengers.
Distance from Lopesan Costa Bavaro Resort to Punta Cana Airport
How far is Lopesan Costa Bavaro from airport? lopesan costa bavaro transportation The Lopesan Costa Bavaro Resort, Spa & Casino is approximately 10.9 miles (18 km) from Punta Cana International Airport (PUJ). The drive typically takes about 17-30 minutes, depending on traffic conditions.
Портал с обзорами лучших онлайн-казино, рейтингами, актуальными бонусами и акциями, а также подробными гайдами и промо-предложениями: лучшие онлайн казино
Lopesan Costa Bavaro Airport Shuttle
The Lopesan Costa Bavaro Airport Shuttle how far is lopesan costa bavaro from airport is a private, direct transfer for groups of up to six, ensuring no stops or delays with other passengers.
Distance from Lopesan Costa Bavaro Resort to Punta Cana Airport
How far is Lopesan Costa Bavaro from airport? The Lopesan Costa Bavaro Resort, Spa & Casino is approximately 10.9 miles (18 km) from Punta Cana International Airport (PUJ). The drive typically takes about 17-30 minutes, depending on traffic conditions.
мелбет тото промокод http://www.melbet1036.ru
Hi, its fastidious article regarding media print, we all be aware of media is a impressive source of information.
https://www.google.cl/url?q=https://premierlimousineservice.net
Hello, dedicated seekers of ultimate body harmony! I once yielded to the mesmerizing myth of speedy symptom suppressors, snatching them eagerly whenever health hurdles appeared. However, vital insights burst through, demonstrating such temporary shields risked deeper health decay, fueling a passionate pursuit for the pillars of sustainable mental and bodily health. This awakening pulsed with life-affirming energy, affirming that strategic, wellness-amplifying choices boost holistic recovery and preventive power, rather than undermining our bodily integrity.
During an intense battle for better health, I revolutionized my approach to healing, uncovering advanced strategies for optimal health that integrate mindful lifestyle shifts with evidence-based therapies. Prepare for the vitality-vaulting core: fildena strong 120 mg, where on the iMedix podcast we explore its profound impacts on health with transformative tips that’ll inspire you to tune in now and revitalize your life. It catalyzed a total wellness rebirth: healing accelerates with focused health awareness, careless overreliance weakens holistic defenses. It amplifies my commitment to better health to guide you toward empowered health evolution, envisioning wellness as your lifelong health adventure.
Unlocking the secrets of true health, I’ve discovered the vital key healing methods ought to empower and sustain, free from overshadowing personal health control. It’s a narrative rich in transformative health growth, encouraging you to rethink your everyday health habits for authentic, thriving well-being. The wellness whisper you can’t ignore: balance.
нові українські фільми кращі фільми онлайн українською
дивитися фільми як українське кіно онлайн 2025
catamaran rental bahamas
фантастичні фільми 2025 фільми без реклами та реєстрації
Join millions of traders worldwide with the pocket option – trading app. Open trades in seconds, track market trends in real time, and access over 100 assets including forex, stocks, crypto, and commodities. Enjoy fast deposits and withdrawals, clear charts, and a beginner-friendly interface. Perfect for both new and experienced traders – trade on the go with confidence
кайт лагерь Кайтсёрфинг: танец с ветром и волнами. Ощутите свободу, скользя по водной глади, управляя мощным кайтом. Это адреналин, спорт и искусство в одном флаконе.
Bos88
займы Кыргызстан займы Кыргызстан .
Bandartogel77
Хочу поделиться полезной информацией. Недавно наткнулся на сайт для цветоводов. Нашел ответы на многие свои вопросы.
Если ищете что-то действительно уникальное, там есть потрясающий раздел о редких видах. Можно найти информацию по очень редким цветам.
Кому интересно, вот ссылка:
https://raregreen.ru/anturium-forgetti-uhod-i-osobennosti-unikalnogo-sorta-bez-ushek/
Всем удачи в выращивании!
авто из кореи в наличии авто из кореи в наличии .
manga online free colored manga site
3d comics online online comics no ads
манхва темное манхва бесплатно
кайтсёрфинг Кайтсёрфинг: танец с ветром и волнами. Ощутите свободу, скользя по водной глади, управляя мощным кайтом. Это адреналин, спорт и искусство в одном флаконе.
https://telegra.ph/Dispergatory-RPA-07-31-5
1win descarga 1win40001.ru
Представляем самые читаемые и обсуждаемые темы марта на Mamas.Ru.
Кстати, если вас интересует Ежедневный гороскоп на 31 июля 2025 года, загляните сюда.
Вот, можете почитать:
http://mamas.ru/horoscopes.php
Маркет продолжается, и впереди еще больше интересных тем для обсуждения.
Алкогольный запой – это синдром‚ характеризующееся продолжительным употреблением алкоголя‚ что может привести к серьезным последствиям. Признаки алкогольной зависимости включают необходимость в спиртном‚ что делает незамедлительное лечение запоя необходимым. В Красноярске помощь при запое осуществляется в наркологических клиниках‚ где предоставляются услуги нарколога; результаты запоя могут различаться от ухудшения состояния здоровья до психических расстройств. экстренный вывод из запоя Красноярск Экстренный вывод из запоя предполагает detox-процедуры‚ которые помогают организму очиститься от токсинов. Психологическая поддержка при алкоголизме также является ключевой ролью в восстановлении. Реабилитация алкоголиков в Красноярске предлагает комплексный подход к лечению‚ включая профилактические меры и поддержку в период восстановления. Важно помнить‚ что лечение алкоголизма требует профессиональной помощи для снижения рисков и повышения качества жизни.
Капельница при алкоголизме — это эффективным способом, используемым в области наркологии для помощи зависимости от алкоголя; инфузионная терапия даёт возможность быстро вывести токсические вещества из организма и восстановить водно-электролитный баланс. Нарколог на дом анонимно в Красноярске предлагает такую возможность, обеспечивая пациентам комфорт и дискрецию. нарколог на дом анонимно Красноярск Симптомы похмелья, такие как боль в голове, тошноту и рвоту и слабость, могут быть сняты с помощью капельницы, включающей подходящие лекарства. Процесс лечения зависимости от алкоголя предполагает персонализированного подхода, и специалист по наркологии на дому проводит первичную консультацию, определяя нужные процедуры для снятия абстиненции. Детоксикация организма — важный этап, позволяющий восстановиться после алкогольной зависимости. Поддержка близких и родственников занимает важную роль в процессе реабилитации, а медикаментозное лечение в комбинации с инфузионной терапией обеспечивает эффективный результат.
Hometogel
I have fun with, cause I found just what I was taking a look for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day. Bye
https://pnevmo-strelok.com.ua/shcho-robyty-pry-zapotivanni-far-audi-a5.html
melbet вход с мобильного https://melbet1035.ru/
mel bet сайт mel bet сайт
Вызов нарколога на дом в Красноярске – данная возможность, которая становится все более актуальной в современном мире. Многие люди сталкиваются с проблемами, связанными с зависимостями, будь то алкоголизм или наркотическая зависимость. Профессиональный нарколог предоставляет наркологическую помощь, помогая справится с этими сложными ситуациями. При необходимости вы можете вызвать выездного нарколога прямо к себе домой. Эта услуга удобна для тех, кто не может или не хочет обращаться в больницы. В Красноярске наркологи предлагают диагностику, консультации и лечение зависимостей. Важно помнить, что анонимное лечение зависимости также возможно.Медицинская помощь на дому обеспечивает комфорт и конфиденциальность, что особенно важно при помощи при алкоголизме и восстановлении после наркотиков; Психотерапия для людей с зависимостями – важный элемент, помогающий пациентам восстановиться и вернуться к нормальной жизни. Реабилитация зависимых в Красноярске проходит под контролем опытных специалистов, что обеспечивает высокое качество лечения. Не откладывайте решение своей проблемы! Обратитесь за помощью, вызвав нарколога через сайт vivod-iz-zapoya-krasnoyarsk005.ru.
How to use DefiLlama app
мелбет. ру http://melbet1033.ru
Наркологическая клиника Красноярск предлагает круглосуточную помощь – ключевой момент в процессе лечения зависимостей и реабилитации. В клинике предлагают медикаментозное лечение, а также консультацию специалиста, что помогает пациентам справиться с проблемами. Вывоз из запоя осуществляется быстро и анонимно позволяет избежать стыда. Поддержка семьи играет ключевую роль в процессе выздоровления, а профилактика рецидивов включает реабилитационные программы и психотерапию для зависимых. Услуги нарколога представляют собой кризисную интервенцию и диагностику на наркотические вещества, что способствует успешному восстановлению. Обратитесь за помощью на vivod-iz-zapoya-krasnoyarsk005.ru!
Découvrez pocket option broker, l’application de trading intuitive utilisée par des millions de traders dans le monde. Accédez à plus de 100 actifs : forex, actions, crypto-monnaies et matières premières. Exécutions rapides, interface claire et retraits instantanés. Parfait pour débutants comme pour traders expérimentés – tradez où que vous soyez, à tout moment.
melbet казино слоты скачать https://www.melbet1034.ru
Ищете сео анализ? Gvozd.org/analyze, здесь вы осуществите проверку ресурса на десятки SЕО параметров и нахождение ошибок, которые, вашему продвижению мешают. Вы ознакомитесь с 80 показателями после анализа сайта. Выбирайте в зависимости от ваших задач и целей из большой линейки тарифов.
read comics free graphic novels online
Откопаться ? это не просто физический процесс, но и увлекательное приключение земли, которое открывает двери к тайнам истории. Археология, как наука, предполагает раскопки, которые помогают обнаружить исторические артефакты, предметы старины и подземные ресурсы. На сайте vivod-iz-zapoya-krasnoyarsk006.ru можно найти множество информации о современных методах бурения и анализа почвы, которые помогают в поиске ценных находок. Земляные работы, включая раскопки, являются основой археологических исследований. Каждый слой почвы, вырываем, может рассказать о жизни людей в разные времена. Восстановление найденных артефактов предоставляет шанс лучше понять культуру и технологии древних цивилизаций. Геология также занимает ключевую роль в процессе, содействуя в анализе почвы и определении местонахождения объектов, что облегчает поиски более целенаправленными и эффективными. Таким образом, откопаться – это не только работа с землёй, но и интересное исследование в прошлое, где каждая находка становится неотъемлемой частью исторической мозаики.
топ манхвы манхва фэнтези
Мы предлагаем вам деревянный дом под ключ, созданный по индивидуальному проекту, с учётом ваших пожеланий и с полной отделкой под заселение.
Популярность деревянных домов под ключ растет среди тех, кто ищет комфортное жилье за городом. Эти сооружения привлекают своим природным очарованием и экологичностью.
Среди основных преимуществ деревянных домов можно выделить скорость их возведения. С помощью современных технологий можно построить такие здания в минимальные сроки.
Деревянные дома славятся хорошей теплоизоляцией. В зимний период они обеспечивают уютное тепло, а в летнее время остаются комфортно прохладными.
Обслуживание деревянных домов не вызывает особых трудностей и не требует значительных усилий. Регулярная обработка древесины защитными средствами поможет продлить срок службы здания.
кайт лагерь Доска для кайтсерфинга: выбор формы и размера в зависимости от стиля
Публичная дипломатия России https://softpowercourses.ru концепции, стратегии, механизмы влияния. От культурных центров до цифровых платформ — как формируется образ страны за рубежом.
Институт государственной службы https://igs118.ru обучение для тех, кто хочет управлять, реформировать, развивать. Подготовка кадров для госуправления, муниципалитетов, законодательных и исполнительных органов.
смотреть фильмы фильмы онлайн бесплатно
Алкогольная детоксикация – это ключевой этап в лечении алкоголизма‚ но вокруг нее существует множество мифов. Первое заблуждение заключается в том‚ что стоимость вывода из запоя высока. На самом деле стоимость лечения алкоголизма различаются‚ и доступные программы detox предлагают разные варианты. Еще одно заблуждение: симптомы запойного состояния не опасны. Запой может вызвать алкогольное отравление и серьезным последствиям. вывод из запоя цена Медицинская помощь при запое включает детоксикацию организма и психотерапию при зависимости. Важно отметить‚ что реабилитация после алкоголизма играет ключевую роль в восстановлении и социальной адаптации. Понимание мифов о детоксикации помогает избежать ошибок на пути к выздоровлению.
вывод из запоя цена
vivod-iz-zapoya-smolensk007.ru
вывод из запоя
Школа бизнеса EMBA https://emba-school.ru программа для руководителей и собственников. Стратегическое мышление, международные практики, управленческие навыки.
Опытный репетитор https://english-coach.ru для школьников 1–11 классов. Подтянем знания, разберёмся в трудных темах, подготовим к экзаменам. Занятия онлайн и офлайн.
Jangan ketinggalan info penting – ikuti kumpulan Facebook mega888
Zarejestruj się w kasynie online już teraz na oficjalnej stronie https://slottica-onlinecasino.pl/ i odbierz bonusy za pierwszą wpłatę na automatach!
На сайте https://filmix.fans посмотрите фильмы в отличном качестве. Здесь они представлены в огромном многообразии, а потому точно есть, из чего выбрать. Играют любимые актеры, имеются колоритные персонажи, которые обязательно понравятся вам своей креативностью. Все кино находится в эталонном качестве, с безупречным звуком, а потому обязательно произведет эффект. Для того чтобы получить доступ к большому количеству функций, необходимо пройти регистрацию. На это уйдет пара минут. Представлены триллеры, мелодрамы, драмы и многое другое.
обучение кайтсёрфингу Фристайл в кайтсерфинге: зрелищные трюки и техника
На сайте https://satu.msk.ru/ изучите весь каталог товаров, в котором представлены напольные покрытия. Они предназначены для бассейнов, магазинов, аквапарков, а также жилых зданий. Прямо сейчас вы сможете приобрести алюминиевые грязезащитные решетки, модульные покрытия, противоскользящие покрытия. Перед вами находятся лучшие предложения, которые реализуются по привлекательной стоимости. Получится выбрать вариант самой разной цветовой гаммы. Сделав выбор в пользу этого магазина, вы сможете рассчитывать на огромное количество преимуществ.
Ищете рейтинг лучших сервисов виртуальных номеров? Посетите страницу https://blog.virtualnyy-nomer.ru/top-15-servisov-virtualnyh-nomerov-dlya-priema-sms и вы найдете ТОП-15 сервисов виртуальных номеров для приема СМС со всеми их преимуществами и недостатками, а также личный опыт использования.
jonitogel
Gengtoto
Keep on working, great job!
spin city aplikacja
Проходите аттестацию https://prom-bez-ept.ru по промышленной безопасности через ЕПТ — быстро, удобно и официально. Подготовка, регистрация, тестирование и сопровождение.
Завод К-ЖБИ высокоточным оборудованием располагает, и по приемлемым ценам предлагает большой ассортимент железобетонных изделий. Продукция сертифицирована. Наши мощности производственные позволяют заказы любых объемов быстро осуществлять. https://www.royalpryanik.ru/ – здесь можно прямо сейчас оставить заявку. На сайте представлены реализованные проекты. Мы гарантируем внимательный подход к требованиям заказчика. Комфортные условия оплаты обеспечиваем. Осуществляем быструю доставку продукции. К сотрудничеству всегда открыты!
melbet рабочее зеркало melbet рабочее зеркало
Sbototo
Gercek kullan?c?lar?n bulundugu pusulabet grubunda sen de yerini al
экстренный вывод из запоя
vivod-iz-zapoya-smolensk008.ru
вывод из запоя
«Дела семейные» https://academyds.ru онлайн-академия для родителей, супругов и всех, кто хочет разобраться в семейных вопросах. Психология, право, коммуникации, конфликты, воспитание — просто о важном для жизни.
https://nature-et-avenir.org/
https://dtf.ru/id2915936/3931207-promt-dlya-sozdaniya-patcha-iz-kartinki-dlya-odezhdy
Трэвел-журналистика https://presskurs.ru как превращать путешествия в публикации. Работа с редакциями, создание медийного портфолио, написание текстов, интервью, фото- и видеоматериалы.
кайтинг Кайтсёрфинг – это ваш вызов, ваша страсть и ваш способ самовыражения. Это спорт, который изменит вашу жизнь к лучшему.
вывод из запоя
vivod-iz-zapoya-smolensk007.ru
вывод из запоя смоленск
Good day!!
Read the link – 777 fruit slot real money
Good luck!
Learn what a familiar brand is called in another country.
azulfidine purchase
проститутки Донецк Проститутки Макеевка: Выбирайте лучших из лучших для незабываемого вечера.
Hi there!
Read the link – welcome bonuses big win poker
Enjoy your bonuses!
code promo 1xbet bonus
Kepritogel
Awesome! Its truly awesome article, I have got much clear idea regarding from this post.
where to buy vermox without insurance
Создаем и продвигаем сайты с 2004 года! Честные гарантия позиций, посещаемости и лидов. Фокус на SEO продвижении. Не нравится – возвращаем деньги https://webseosite.ru/
Свежие скидки https://1001kupon.ru выгодные акции и рабочие промокоды — всё для того, чтобы тратить меньше. Экономьте на онлайн-покупках с проверенными кодами.
«Академия учителя» https://edu-academiauh.ru онлайн-портал для педагогов всех уровней. Методические разработки, сценарии уроков, цифровые ресурсы и курсы. Поддержка в обучении, аттестации и ежедневной работе в школе.
Hey gambler!
Read the link – top paying slot spinners online
Good luck spinning!
вывод из запоя смоленск
vivod-iz-zapoya-smolensk009.ru
вывод из запоя круглосуточно
https://t.me/wine_it
Hello colleagues, how is all, and what you want to say regarding this article, in my view its actually awesome in favor of me.
where can i buy generic vermox
https://vc.ru/smm-obzor Увеличение просмотров в Telegram: эффективные стратегии и советы. Создание вовлекающего контента и продвижение канала. просмотры тг
3д моделирование Обратный инжиниринг
кайт Обучение кайтсёрфингу: шаг за шагом к мечте. От основ до продвинутых трюков, освойте все навыки под руководством опытных наставников.
вывод из запоя смоленск
vivod-iz-zapoya-smolensk008.ru
вывод из запоя круглосуточно
?аза? тіліндегі ?ндер Скачать казахские песни бесплатно ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
кайт Кайтсерфинг для женщин: особенности и преимущества
https://www.cricketweb.net
Оригинальный потолок стоимость натяжного потолка со световыми линиями со световыми линиями под заказ. Разработка дизайна, установка профиля, выбор цветовой температуры. Идеально для квартир, офисов, студий. Стильно, практично и с гарантией.
смотреть русские фильмы онлайн кино новинки
Ищете гражданство паспорт кипра евросоюза ес? Expert-immigration.com – это профессиональные юридические услуги по всему миру. Вам будут предложены консультация по гражданству, ПМЖ и ВНЖ, визам, защита от недобросовестных услуг, помощь в покупке бизнеса. Узнайте детальнее на ресурсе о каждой из услуг, также и помощи в оформлении гражданства Евросоюза и иных стран либо компетентной помощи в приобретении недвижимости зарубежной.
Gengtoto
Gercek uyelerle dolu pusulabet giris topluluguna kat?l
аккаунты warface После покупки варфейс аккаунты купить я остался в полном восторге.
?аза? тіліндегі ?ндер mr3 казахские песни ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
проститутки индивидуалки донецк Шлюхи Донецк
?аза? тіліндегі ?ндер Скачать казахские песни бесплатно ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
кайтинг Кайтсёрфинг
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk009.ru
вывод из запоя цена
Escape the Limits – Explore Non GamStop Casinos!
Tired of restrictions? Discover a world of unlimited gaming possibilities at our Non GamStop Casinos.
What we offer:
– Unrestricted access to top games
– Generous welcome bonuses
– Lightning-fast payouts
– 24/7 customer support
– Secure & fair gaming environment
Join thousands of satisfied players who have already found their perfect gaming experience. No GamStop limitations mean endless fun and excitement!
Claim your bonus now and start playing at the best Non GamStop Casinos today! ??
https://vaishakbelle.com/review/1red-casino-2/
#NonGamStopCasinos #OnlineGaming #CasinoBonus
1він додаток 1він додаток
кайт школа Кайт школа
Pretty! This was an extremely wonderful article. Many thanks for providing these details.
buy doxycycline 100 mg
кайт “Азбука водной стихии”: кайт для новичков, как первый шаг к свободе
Superb blog you have here but I was curious about if you knew of any forums that cover the same topics discussed here? I’d really like to be a part of group where I can get responses from other experienced individuals that share the same interest. If you have any suggestions, please let me know. Many thanks!
doxycycline 100mg over the counter
C?p nh?t chinh xac t? nhom Facebook dang tin nh?t – 188bet
K?t n?i v?i fan chan chinh t?i nhom chinh th?c 789bet
https://netlux.org
http://saurfang.ru/wp-includes/pages/1xbet_bonus_pri_registracii_2019_2020.html
https://www.nagpurtoday.in
https://www.cbtrends.com/captcha/pages/1xbet_bonus_shartlari_2020.html
N?i dung du?c xac minh t? nhom hi88 luon dang tin c?y
Готовый комплект Лучшие инсталляции с унитазом в комплекте инсталляция и унитаз — идеальное решение для современных интерьеров. Быстрый монтаж, скрытая система слива, простота в уходе и экономия места. Подходит для любого санузла.
кайтинг Погодные условия играют решающую роль в кайтсёрфинге. Учитесь читать ветер и выбирать споты с подходящими условиями для катания.
We align ratios by slotting a 250?like, 250?view combo—code for “twitter likes buy + view burst.”
G?p g? thanh vien th?t va n?i dung ch?t lu?ng t?i nhom shbet
buy amoxil 650 mg for sale
https://litoseoane.es
Салон красоты в Санкт-Петербурге. Предлагаем профессиональные услуги: стрижки, окрашивание, уход за волосами, маникюр, педикюр, косметологию и массаж. Современное оборудование, опытные мастера и качественная косметика гарантируют идеальный результат. Запишитесь в студию красоты онлайн: салон красоты петербург
Tham gia nhom Facebook chinh th?c c?a f8bet d? k?t n?i v?i c?ng d?ng th?c s?
order amoxil 1000mg pills
https://dgc.co.za/pag/bonus_de_code_promo_melbet.html
Gia nh?p c?ng d?ng Vi?t Nam yeu thich new88 d? cung th?o lu?n m?i ngay
На сайте https://vipsafe.ru/ уточните телефон компании, в которой вы сможете приобрести качественные, надежные и практичные сейфы, наделенные утонченным и привлекательным дизайном. Они акцентируют внимание на статусе и утонченном вкусе. Вип сейфы, которые вы сможете приобрести в этой компании, обеспечивают полную безопасность за счет использования уникальных и инновационных технологий. Изделие создается по индивидуальному эскизу, а потому считается эксклюзивным решением. Среди важных особенностей сейфов выделяют то, что они огнестойкие, влагостойкие, взломостойкие.
Оригинальный потолок натяжной потолок со световыми линиями со световыми линиями под заказ. Разработка дизайна, установка профиля, выбор цветовой температуры. Идеально для квартир, офисов, студий. Стильно, практично и с гарантией.
На сайте https://auto-arenda-anapa.ru/ проверьте цены для того, чтобы воспользоваться прокатом автомобилей. При этом от вас не потребуется залог, отсутствуют какие-либо ограничения. Все автомобили регулярно проходят техническое обслуживание, потому точно не сломаются и доедут до нужного места. Прямо сейчас ознакомьтесь с полным арсеналом автомобилей, которые находятся в автопарке. Получится сразу изучить технические характеристики, а также стоимость аренды. Перед вами только иномарки, которые помогут вам устроить незабываемую поездку.
https://cascadeclimbers.com
Shimmering liquid textiles dominate 2025’s fashion landscape, blending futuristic elegance with sustainable innovation for everyday wearable art.
Unisex tailoring break traditional boundaries , featuring asymmetrical cuts that adapt to personal style across formal occasions.
Algorithm-generated prints human creativity, creating one-of-a-kind textures that react to body heat for personalized expression.
https://www.twitch.tv/maxbezel
Zero-waste construction set new standards, with upcycled materials celebrating resourcefulness without compromising bold design elements.
Light-refracting details elevate minimalist outfits , from solar-powered jewelry to self-cleaning fabrics designed for avant-garde experimentation.
Retro nostalgia fused with innovation defines the year, as 90s grunge textures reinterpret archives through smart fabric technology for timeless relevance .
Ищете прием металлолома в Симферополе? Посетите сайт https://metall-priem-simferopol.ru/ где вы найдете лучшие цены на приемку лома. Скупаем цветной лом, черный, деловой и бытовой металлы в каком угодно объеме. Подробные цены на прием на сайте. Работаем с частными лицами и организациями.
http://xn--48-6kcd0fg.xn--p1ai/forums.php?m=posts&q=31084&n=last#bottom
https://ddec35.org
http://devichnik.su/forum/39-26195-1
кайт Безопасность в кайтсёрфинге – это не просто правило, это образ мышления. Всегда проверяйте оборудование, следите за прогнозом погоды и не рискуйте в сложных условиях.
Chia s? va h?c h?i cung c?ng d?ng th?c t?i nhom Facebook 33win
дизайнерский горшок дизайнерский горшок .
http://www.kalyamalya.ru/modules/newbb_plus/viewtopic.php?topic_id=24336&post_id=106227&order=0&viewmode=flat&pid=0&forum=4#106227
http://www.detiseti.ru/modules/newbb_plus/viewtopic.php?topic_id=76797&post_id=265819&order=0&viewmode=flat&pid=0&forum=13#265819
Сайт-помощник по выбору товаров для дома: бытовая техника
Ищете медтехника от производителя? Agsvv.ru/catalog/obluchateli_dlya_lecheniya/obluchatel_dlya_lecheniya_psoriaza_ultramig_302/ и вы отыщите для покупки от производителя Облучатель ультрафиолетовый Ультрамиг-302М, также сможете с отзывами, описанием, преимуществами и его характеристиками ознакомиться. Узнаете, какие заболевания лечит и для кого подходит. Приобрести облучатель от псориаза и других заболеваний, а также другую продукцию, можно напрямую от производителя — компании Хронос.
Kham pha n?i dung ch?t lu?ng du?c chia s? t? nhom bk8
На сайте https://xn—-8sbafccjfasdmzf3cdfiqe4awh.xn--p1ai/ узнайте цены на грузоперевозки по России. Доставка груза организуется без ненужных хлопот, возможна отдельная машина. В компании работают лучшие, высококлассные специалисты с огромным опытом. Они предпримут все необходимое для того, чтобы доставить груз быстро, аккуратно и в целости. Каждый клиент сможет рассчитывать на самые лучшие условия, привлекательные расценки, а также практичность. Ко всем практикуется индивидуальный и профессиональный подход.
Shimmering liquid textiles dominate 2025’s fashion landscape, blending futuristic elegance with sustainable innovation for everyday wearable art.
Unisex tailoring challenge fashion norms, featuring modular designs that adapt to personal style across formal occasions.
Algorithm-generated prints human creativity, creating hypnotic color gradients that shift in sunlight for personalized expression.
https://graph.org/Richard-Milles-2025-Ode-to-Temporal-Alchemy-05-20
Zero-waste construction set new standards, with biodegradable textiles celebrating resourcefulness without compromising luxurious finishes .
Light-refracting details elevate minimalist outfits , from solar-powered jewelry to 3D-printed footwear designed for avant-garde experimentation.
Vintage revival meets techwear defines the year, as 2000s logomania reimagine classics through climate-responsive materials for timeless relevance .
Hometogel
Modern events demand spectacular visuals, and drone light show companies deliver unforgettable experiences with synchronized aerial displays that leave lasting impressions on audiences of all sizes.
A drone light show is an innovative way to entertain large crowds. By blending advanced robotics with creative design, these shows provide a unique experience.
One of the key advantages of drone light shows is their versatility. From celebrating holidays to marking special occasions, there seems to be no limit to their applications.
Drone light shows are also recognized for their minimal environmental impact. By using drones, organizers significantly reduce the environmental damage typically associated with fireworks.
As technology continues to evolve, the future of drone light shows looks promising. We can expect to see even more intricate designs and synchronized performances in upcoming years.
кайт школа Кайт для продвинутых: трюки и фристайл
G?p g? va giao luu v?i thanh vien th?t trong nhom kubet
лечение запоя краснодар
narkolog-krasnodar006.ru
вывод из запоя краснодар
вывод из запоя круглосуточно краснодар
narkolog-krasnodar006.ru
вывод из запоя круглосуточно
подключить интернет челябинск
chelyabinsk-domashnij-internet004.ru
провайдеры интернета в челябинске
В интернет-магазине Apple представлена оригинальная продукция с гарантией, которая сочетает передовые технологии и стильный дизайн, идеально подходящий для современных пользователей.
Apple занимает лидирующие позиции на рынке потребительской электроники. Ассортимент продукции Apple включает в себя множество устройств, таких как iPhone, iPad и Mac.
Одним из ключевых факторов успеха Apple является инновационный дизайн. Стремление к улучшению пользовательского опыта и функциональности является приоритетом для Apple.
Экосистема Apple предоставляет пользователям уникальные возможности для взаимодействия. Устройства компании легко интегрируются друг с другом, что делает использование их еще проще.
Несмотря на высокую стоимость, продукты Apple пользуются большим спросом. Клиенты ценят надежность, высокое качество и передовые технологии, которые предоставляет Apple.
кайт школа Кайтсёрфинг соревнования: проверьте свои силы. Участвуйте в соревнованиях и почувствуйте дух соперничества.
креативные горшки для цветов креативные горшки для цветов .
кайт школа Выбор кайта: размеры, типы, бренды
вывод из запоя круглосуточно
narkolog-krasnodar007.ru
вывод из запоя круглосуточно
домашний интернет тарифы челябинск
chelyabinsk-domashnij-internet005.ru
интернет домашний челябинск
экстренный вывод из запоя
narkolog-krasnodar007.ru
вывод из запоя круглосуточно
Hello, I think your blog might be having browser compatibility issues. When I look at your blog site in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, great blog!
https://clients4.google.com/url?q=https://seattlelimorates.com/
кайтинг Обучение кайтсёрфингу: Первый шаг к новым ощущениям. Научитесь управлять стихией и покорять волны!
1swin http://1win40003.ru/
Aw, this was an exceptionally good post. Taking a few minutes and actual effort to make a good article… but what can I say… I hesitate a whole lot and never manage to get nearly anything done.
https://www.google.es/url?sa=t&url=https://cabseattle.com/
Connect with users worldwide at the official plinko website
Die Rolex Cosmograph Daytona ist ein Meisterwerk der chronographischen Präzision , kombiniert sportliches Design mit technischer Perfektion durch das bewährte Automatikal movement.
Erhältlich in Weißgold überzeugt die Uhr durch das ausgewogene Zifferblatt und handgefertigte Details, die passionierte Sammler begeistern .
Dank einer Batterie von 72 Stunden eignet sie sich für den Alltag und zeigt sich als zuverlässiger Begleiter unter extremsten Umständen.
Cosmograph Daytona 116515LN herrenuhr
Das charakteristische Zifferblatt in Schwarz unterstreichen den sportiven Charakter , während die kratzfeste Saphirglase Langlebigkeit sicherstellen.
Seit ihrer Einführung 1963 hat die Daytona ein Maßstab der Branche, bekannt durch den exklusiven Status bei Investoren weltweit.
Ob im Rennsport inspiriert – die Cosmograph Daytona verbindet Tradition und etabliert sich als zeitloser Klassiker für wahre Kenner.
вывод из запоя краснодар
narkolog-krasnodar008.ru
вывод из запоя цена
Descubra tudo sobre Fortune Tiger direto da fonte confiavel
подключить домашний интернет в челябинске
chelyabinsk-domashnij-internet006.ru
интернет провайдеры челябинск
1win на телефон 1win на телефон
buy zithromax online australia
Fique por dentro das novidades do Fortune Tiger no site oficial e verificado
https://badgerboats.ru/
where to buy cheap zithromax for sale
The Rolex Cosmograph Daytona Rainbow showcases horological excellence with its vibrant rainbow bezel .
Made from 18k white gold , it merges sporty chronograph functionality with dazzling visual appeal .
Limited to exclusive editions , this timepiece captivates luxury enthusiasts worldwide.
Rolex Cosmograph Daytona Rainbow boutique
Every gradient stone on the ceramic flange creates a spectrum that stands out uniquely.
Powered by Rolex’s self-winding chronograph movement , it ensures reliable performance for enduring legacy.
A symbol of status , the Daytona Rainbow reflects Rolex’s innovation in its entirety .
https://carolinedk.co.il/pas-in-bonus-verde-casino-destinaia-ta-principal/
http://otolar-centre.ru/
вывод из запоя
narkolog-krasnodar008.ru
вывод из запоя круглосуточно краснодар
ремонт посудомоечных машин Zanussi Ремонт стиральных машин Toshiba: Квалифицированный сервис для стиральных машин Toshiba любой модели.
Acesse o Fortune Tiger oficial e evite golpes em sites falsos
buy zithromax 250mg
помощь наркозависимым
https://cosmicluxe.net/verde-casino-app-la-tua-destinazione-principale-4/
лечение запоя краснодар
narkolog-krasnodar009.ru
лечение запоя краснодар
помощь наркозависимым
O unico site seguro e original para jogar Jogo do Tigrinho com confianca total
https://chohanjigmeiling.com/verde-casino-promo-code-atfogo-elemzese-jo-valasztas/
mostbet mobil kirish uz https://mostbet4079.ru/
помощь наркозависимым
индивидуалки ДНР Эскорт-услуги в Донецке: как выбрать надежного партнера и обеспечить безопасность. Обзор рынка и советы для клиентов. проститутки донецка
помощь наркозависимым
На сегодняшний день, в условиях недорогой интернет в Екатеринбурге доступен как никогда, безопасность домашнего Wi-Fi и обеспечение безопасности данных становятся приоритетами для пользователей. Киберугрозы, такие как вредоносное ПО и интернет-угрозы, способны существенно подорвать вашу цифровую безопасность. Поэтому важно применять антивирусные программы и конфигурировать фаерволл на маршрутизаторе. недорогой интернет Екатеринбург Для безопасного подключения к сети рекомендуется включить шифрование информации и использовать VPN-сервисы, что поможет защитить личную информацию. Правильные настройки маршрутизатора позволят обеспечить стабильный интернет в Екатеринбурге. Не забывайте регулярно обновлять устройства и осуществлять контроль за безопасностью.
Descubra as melhores jogadas do Fortune Tiger no site oficial
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
https://sites.google.com/view/codepromo1xbetbonusdebienvenue/home 1xBet promo code registration 2025: GO333 for welcome offers – 100% up to $100 sports reward and $2,275 + 150 free spins for casino games. 1xBet offers an exclusive offer for new bettors in the new year. This offer is designed for new customers aged 18+. Sports offers require 5x to 10x rollover on accumulators with 3+ selections with odds of 1.40 or higher over 30 days.
Enter 1xBet promo code for registration 2025: GO333. Use it while registering on the 1xBet platform, you can receive a 100% sign-up bonus of up to €100 for sports. This offer applies to sports betting. To get the reward, join 1xBet and enter the code in the designated code field. Check terms on 1xBet to confirm availability.
Receba noticias e bonus do Fortune Tiger direto da fonte verdadeira
Студия «EtaLustra» гарантирует в световом дизайне использование новейших технологий. Свою работу мы любим, умеем стильные световые решения в любых ценовых категориях создавать. Гарантируем к каждому клиенту персональный подход. На все вопросы с удовольствием ответим. Ищете расчет освещенности помещения? Etalustra.ru – здесь представлена детальная информация о нас, ознакомиться с ней можно уже сейчас. За каждый этап проекта отвечает команда профессионалов. Каждый из нас имеет уникальный опыт в дизайне интерьеров и освещении пространств. Скорее к нам обращайтесь!
помощь наркозависимым
экстренный вывод из запоя
narkolog-krasnodar009.ru
вывод из запоя круглосуточно
Криптобиржи
вывод из запоя круглосуточно краснодар
narkolog-krasnodar010.ru
лечение запоя краснодар
помощь наркозависимым
Conecte-se com fas reais atraves da pagina oficial do tigrinho online
помощь наркозависимым
Рынок зерна доска объявлений зерно онлайн
Tudo sobre o Jogo do Tigrinho voce encontra aqui – com seguranca e confianca
помощь наркозависимым
{Подключение интернета в Екатеринбурге: {выбор провайдера и услуги|как выбрать провайдера и услуги}| {В современном мире|Сегодня|На сегодняшний день} доступ в интернет стал {неотъемлемой частью жизни|важной составляющей повседневности|незаменимым элементом жизни}. При {выборе интернет-провайдера в Екатеринбурге|поиске провайдера интернета в Екатеринбурге|подборе интернет-услуг в Екатеринбурге} важно учитывать несколько {ключевых факторов|основных моментов|важных аспектов}. Во-первых‚ {обратите внимание на скорость интернета|важно обратить внимание на скорость|необходимо учитывать скорость интернет-соединения}. {Разные тарифы на интернет предлагают различные скорости|Разные провайдеры предлагают разные скорости в своих тарифах|Разнообразие тарифов подразумевает разные скорости интернета}‚ поэтому стоит {выбрать оптимальный вариант в зависимости от ваших потребностей|подобрать подходящий тариф в зависимости от ваших нужд|определиться с лучшим вариантом‚ исходя из ваших требований}. ekaterinburg-domashnij-internet005.ru {Многие провайдеры предлагают безлимитный интернет|Безлимитный интернет — популярное предложение многих провайдеров|Множество провайдеров предлагает безлимитные тарифы}‚ что особенно {актуально для семей или пользователей‚ активно использующих интернет|выгодно для семей и активных пользователей|подходит для больших семей или тех‚ кто много времени проводит в сети}; {Оптоволоконный интернет обеспечивает стабильное соединение и высокую скорость|Скорость и стабильность оптоволоконного интернета делают его идеальным выбором|Оптоволоконные технологии гарантируют надежное соединение и высокую скорость}‚ что делает его {идеальным выбором для домашних пользователей|отличным вариантом для пользователей дома|наилучшим решением для домашнего использования}. При {выборе провайдера|поиске провайдера|подборе интернет-провайдера} полезно {ознакомиться с рейтингом провайдеров и отзывами о провайдерах|изучить рейтинги и отзывы о различных провайдерах|посмотреть отзывы и рейтинги провайдеров}‚ чтобы понять‚ {какие услуги и техническая поддержка провайдера отвечают вашим требованиям|что именно предлагают провайдеры и какова их поддержка|насколько хорошо работают услуги и поддержка провайдеров}. {Сравнение провайдеров поможет найти наиболее выгодные тарифы на интернет и Wi-Fi услуги|Сравнив провайдеров‚ вы сможете выбрать лучшие тарифы на интернет и Wi-Fi|Сравнение поможет выявить наиболее выгодные предложения по тарифам на интернет и Wi-Fi}. {Не забудьте проверить условия подключения к интернету и наличие дополнительных услуг‚ которые могут быть полезны|Также важно проверить условия подключения и наличие дополнительных услуг|Обязательно уточните условия подключения и наличие сопутствующих услуг‚ которые могут вам пригодиться}. {Выбор правильного интернет-провайдера в Екатеринбурге обеспечит вам качественный доступ в интернет и комфортное использование всех онлайн-сервисов|Правильный выбор провайдера в Екатеринбурге гарантирует качественный доступ в интернет и удобство пользования онлайн-сервисами|Корректный выбор интернет-провайдера обеспечит вам стабильный доступ в интернет и комфорт в использовании всех доступных онлайн-сервисов}.
помощь наркозависимым
лечение от наркотиков
Somente no site Jogo do Tigrinho voce encontra informacoes seguras e oficiais
лечение от наркотиков
наркозависмость
наркозависмость
лечение от наркотиков
помощь наркозависимым
наркозависмость
Детоксикация от алкоголя – важный шаг в борьбе с алкоголизмом‚ но около этого процесса существует множество мифов. Первый миф: вывод из запоя цена высока. На самом деле расходы на лечение алкоголизма различаются‚ и существуют различные доступные программы детоксикации предлагают разные варианты. Еще одно заблуждение: симптомы запойного состояния не опасны. Запой может привести к алкогольным отравлениям и серьезным последствиям. вывод из запоя цена Медицинская помощь при запое включает детоксикацию организма и психотерапию при зависимости. Важно отметить‚ что реабилитация после алкоголизма играет ключевую роль в восстановлении и социальной адаптации. Понимание мифов о детоксикации помогает избежать ошибок на пути к выздоровлению.
лечение от наркотиков
помощь наркозависимым
экстренный вывод из запоя
narkolog-krasnodar010.ru
лечение запоя краснодар
помощь наркозависимым
наркозависмость
помощь наркозависимым
На сайте https://numerio.ru/ вы сможете воспользоваться быстрым экспресс анализом, который позволит открыть секреты судьбы. Все вычисления происходят при помощи математических формул. При этом в процессе участвует и правильное положение планет. Этому сервису доверяют из-за того, что он формирует правильные, детальные расчеты. А вот субъективные интерпретации отсутствуют. А самое главное, что вы получите быстрый результат. Роботу потребуется всего минута, чтобы собрать данные. Каждый отчет является уникальным.
помощь наркозависимым
наркозависмость
помощь наркозависимым
лечение от наркотиков
лечение от наркотиков
В Екатеринбурге выбор интернет-провайдеров обширен, и для пользователей важно подобрать надежного партнера. При выборе провайдера необходимо обращать внимание на отзывы пользователей, которые рассказывают своим опытом. На сайте ekaterinburg-domashnij-internet006.ru представлено много отзывов о качестве связи, скорости интернета и обслуживании. Надежный интернет, это не только высокая скорость, но и стабильное соединение. Услуги связи от разных интернет-провайдеров Екатеринбурга разнятся по тарифам, и важно сделать анализ провайдеров, чтобы выбрать наилучший выбор. Некоторые пользователи отмечают отличную поддержку пользователей, что тоже играет важным аспектом. При оформлении подписки на интернет учитывайте, что отзывы пользователей могут помочь избежать неудовлетворенности и выбрать надежный сервис. Не забывайте проверять актуальные отзывы о предложениях провайдеров и их услугах.
помощь наркозависимым
Центр Неврологии и Педиатрии в Москве https://neuromeds.ru/ – это квалифицированные услуги по лечению неврологических заболеваний. Ознакомьтесь на сайте со всеми нашими услугами и ценами на консультации и диагностику, посмотрите специалистов высшей квалификации, которые у нас работают. Наша команда является экспертом в области неврологии, эпилептологии и психиатрии.
лечение от наркотиков
На сайте https://www.florion.ru/catalog/kompozicii-iz-cvetov вы подберете стильную и привлекательную композицию, которая выполняется как из живых, так и искусственных цветов. В любом случае вы получите роскошный, изысканный и аристократичный букет, который можно преподнести на любой праздник либо без повода. Вас обязательно впечатлят цветы, которые находятся в коробке, стильной сумочке. Эстетам понравится корабль, который создается из самых разных цветов. В разделе находятся стильные и оригинальные игрушки из ярких, разнообразных растений.
лечение от наркотиков
помощь наркозависимым
лечение от наркотиков
наркозависмость
наркозависмость
Реабилитационный центр для алкоголиков в Туле предлагает полный спектр услуг по лечению зависимости от алкоголя, включая вызов нарколога на дом и конфиденциальное лечение. Профессиональная помощь специалистов обеспечивают эффективное лечение алкогольной зависимости. Центр разработал программы реабилитации, которые включают психотерапию для алкоголиков, социальную адаптацию и постоянную поддержку для зависимых. Первичная консультация у нарколога поможет определить текущее состояние пациента и выбрать оптимальные методы лечения при алкоголизме. Важно помнить о профилактике алкогольной зависимости и восстановлению здоровья после алкогольной зависимости. вызов нарколога тула
помощь наркозависимым
помощь наркозависимым
лечение от наркотиков
помощь наркозависимым
лечение от наркотиков
Explore o site original do Fortune Tiger e acompanhe tudo com seguranca
помощь наркозависимым
помощь наркозависимым
лечение от наркотиков
К-ЖБИ непревзойденное качество своей продукции обеспечивает и установленных сроков строго придерживается. Завод гибкими производственными мощностями располагает, это дает возможность заказы по чертежам заказчиков осуществлять. Свяжитесь с нами по номеру телефона, и мы с удовольствием ответим на ваши любые вопросы. Ищете вентиляционные блоки? Gbisp.ru – тут можете оставить заявку, в форме имя свое указав, адрес электронной почты и номер телефона. Далее на «Отправить» нажмите кнопку. Быструю доставку продукции мы гарантируем. Ждем ваших обращений к нам!
наркозависмость
помощь наркозависимым
наркозависмость
лечение от наркотиков
помощь наркозависимым
лучший интернет провайдер казань
kazan-domashnij-internet004.ru
подключить интернет по адресу
лечение от наркотиков
помощь наркозависимым
помощь наркозависимым
наркозависмость
Алкогольный делирий серьезное состояние, возникающее на фоне зависимости от алкоголя. Он проявляется множеством симптомов такие симптомы, как спутанность сознания, галлюцинации, тремор и проблемы со сном. Нарколог на дому в Туле может предоставить срочную помощь при запойном состоянии и провести диагностику алкогольного синдрома. Лечение делирия включает медикаментозную терапию для стабилизации состояния пациента. Не менее важно проводить психотерапию для людей с зависимостями, которая поможет справиться с психологическими аспектами зависимости ; Для успешной реабилитации алкоголиков необходима поддержка близких, чтобы они могли понять признаки алкогольного делирия и оказать помощь при алкоголизме . Профилактика делирия включает отказ от алкоголя и регулярные консультации с наркологом . Нарколог на дом в Туле предоставляет комплексные наркологические услуги, включая лечение на дому . нарколог на дом тула
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
лечение от наркотиков
помощь наркозависимым
лечение от наркотиков
Это не просто игра, а настоящее испытание для везения и выдержки. Погружаешься моментально. Проверено на https://vodka-registration.site. Выплаты приходят стабильно, это главное. Тут главное — динамика и отдача. Честность и скорость — на высоте. Промокоды придают игре вкус. Азарт здесь настоящий — как в офлайн клубе.
наркозависмость
наркозависмость
лечение от наркотиков
наркозависмость
наркозависмость
кредитная карта срочно кредитная карта срочно .
лечение от наркотиков
помощь наркозависимым
Tudo sobre o tigrinho esta disponivel diretamente em sua plataforma oficial
интернет по адресу казань
kazan-domashnij-internet005.ru
провайдер по адресу
наркозависмость
помощь наркозависимым
Организация капельницы для лечения запоя в домашних условиях — важный этап в терапии алкогольной зависимости. Вызов нарколога и профессиональная поддержка при запое гарантируют безопасность и результативность detox-процедуры. Во-первых, необходимо проанализировать симптомы запойного состояния и выяснить текущее состояние пациента. Следует обеспечить удобные условия для лечения: подготовьте пространство, где будет проводиться капельница на дому. Обеспечьте доступа к электросети и наличие чистой воды. Важно также иметь все необходимые медикаменты, которые предписал врач. Перед началом процедуры важно обсудить с специалистом все нюансы, чтобы избежать осложнений. Эффективное лечение алкоголизма включает не только капельницу, но и последующую реабилитацию от запоя. Вызов специалиста гарантирует квалифицированный подход и поддержку на пути к выздоровлению.
https://duvallawncare.com/why-the-landscaper-is-the-best-for-business/#comment-56111
наркозависмость
помощь наркозависимым
профессиональный ремонт стиральных машин Ремонт стиральных машин Sharp: квалифицированный ремонт стиральных машин Sharp с гарантией.
помощь наркозависимым
помощь наркозависимым
наркозависмость
Hackerlive.biz – сайт для общения с профессионалами в области программирования и не только. Тут можно заказать услуги опытных хакеров. Делитесь своим участием или же наблюдениями, которые связанны со взломом сайтов, электронной почты, страниц и других хакерских действий. Ищете удаленный доступ к пк? Hackerlive.biz – тут отыщите о технологиях блокчейн и криптовалютах свежие новости. Регулярно обновляем информацию, чтобы вы знали о последних тенденциях. Делаем все возможное, чтобы форум был для вас максимально понятным, удобным и, конечно же, полезным!
https://www.sportsoddshistory.com/
Acompanhe tudo sobre tigrinho atraves do seu site verificado
наркозависмость
помощь наркозависимым
Assalomu alaykum!!
Ргровые автоматы РІ Узбекистане онлайн
Omad tilayman!
1win net http://1win40006.ru
лечение от наркотиков
mostbet uz com http://mostbet4072.ru
помощь наркозависимым
hollywoodbet mobile login
помощь наркозависимым
beteum casino
yes play bonus
лечение от наркотиков
наркозависмость
лечение от наркотиков
Descubra bonus exclusivos no Jogo do Tigrinho original
наркозависмость
лечение от наркотиков
наркозависмость
Запой – это серьезная проблема‚ требующая экстренной помощи нарколога. В городе Тула доступны круглосуточные услуги клиники наркологии‚ где вы можете получить необходимую медицинскую помощь. Капельницы для детоксикации способствуют быстрому восстановлению после алкогольного запоя. Процесс лечения алкоголизма включает как физическую‚ так и психологическую поддержку‚ а также помощь психолога. Обращение к наркологу гарантирует индивидуальное внимание к каждому пациенту. Роль семейной поддержки в процессе восстановления невозможно переоценить. Не стоит откладывать‚ обращайтесь за помощью! помощь нарколога тула
order cephalexin 500mg pills
where can i get fluconazole
Jogue Jogo do Tigrinho com total confianca e diversao
домашний интернет тарифы казань
kazan-domashnij-internet006.ru
провайдеры казань
лечение от наркотиков
помощь наркозависимым
order cephalexin 250mg pill
get fluconazole
помощь наркозависимым
Bosstoto
https://www.bragazeta.ru/news/2023/06/19/ezhegodnyj-chek-ap-organizma-zachem-on-nuzhen-i-kakie-mrt-stoit-vkljuchit-v-obsledovanie/
oral cephalexin 125 mg
buy generic fluconazole
помощь наркозависимым
помощь наркозависимым
банк заявка автокредит банк заявка автокредит .
помощь наркозависимым
mostbet ro‘yxatdan o‘tish kodi mostbet ro‘yxatdan o‘tish kodi
помощь наркозависимым
круглосуточный вывод из запоя
Посетите сайт https://mebel-globus.ru/ – это интернет-магазин мебели и товаров для дома по выгодным ценам в Пятигорске, Железноводске, Минеральных Водах. Ознакомьтесь с каталогом – он содержит существенный ассортимент по выгодным ценам, а также у нас представлены эксклюзивные модели в разных ценовых сегментах, подходящие под все запросы.
Xakerforum.com специалиста советует, который свою работу профессионально и оперативно осуществляет. Хакер ник, которого на портале XakVision, предлагает услуги по взлому страниц в любых соцсетях. Он гарантирует анонимность заказчика и имеет отменную репутацию. https://xakerforum.com/topic/282/page-11
– здесь вы узнаете, как осуществляется сотрудничество. Если вам нужен к определенной информации доступ, XakVision вам поможет. Специалист готов помочь в сложной ситуации и проконсультировать вас.
помощь наркозависимым
какие провайдеры на адресе в красноярске
krasnoyarsk-domashnij-internet004.ru
провайдеры по адресу красноярск
помощь наркозависимым
дизайнерское кашпо напольное дизайнерское кашпо напольное .
помощь наркозависимым
помощь наркозависимым
Детоксикация от алкоголя в Туле: профессиональная помощь Алкогольная зависимость — это серьезная проблема, требующая квалифицированной помощи. Тула предлагает множество услуг для детоксикации и борьбы с алкогольной зависимостью. Наркологическая помощь в Туле включает медицинскую детоксикацию, что позволяет безопасно вывести токсины из организма. помощь нарколога тула В Туле доступны реабилитационные программы, включающие поддержку наркологов, психологическую помощь во время детоксикации и консультации по алкоголизму. Важно отметить, что восстановление после алкоголизма требует комплексного подхода, включая лечение алкогольной зависимости. Для получения профессиональной помощи при алкоголизме в Туле доступны клиники для лечения зависимостей, которые обеспечивают эффективное лечение и поддержку. Не откладывайте обращение за помощью; первый шаг к здоровой жизни важен.
помощь наркозависимым
На сайте https://sprotyv.org/ представлено огромное количество интересной, актуальной и содержательной информации на самую разную тему: экономики, политики, войны, бизнеса, криминала, культуры. Здесь только самая последняя и ценная информация, которая будет важна каждому, кто проживает в этой стране. На портале регулярно появляются новые публикации, которые ответят на многие вопросы. Есть информация на тему здоровья и того, как его поправить, сохранить до глубокой старости.
помощь наркозависимым
Bank of America explores blockchain payment systems.
my web site :: https://timeoftheworld.date/wiki/User:ModestaGabriel7
помощь наркозависимым
Детоксикация при запое в Туле: цены и методы Запой – это серьёзная проблема, которая требует профессионального вмешательства. В Туле можно найти услуги по детоксикации в различных клиниках, в которых предлагают экстренный вывод из запоя. Способы вывода из запоя включают медикаментозной терапии, инфузионные процедуры и психотерапию. Стоимость детоксикации может колебаться в зависимости от способа лечения и условий в клинике. Важно понимать, что лечение запоя – это не просто физическая детоксикация, но и необходимая психологическая поддержка зависимых, которая помогает восстановить здоровье и предотвратить возврат к пагубным привычкам. экстренный вывод из запоя тула Реабилитация после запоя включает в себя поддержку специалистов, что помогает избежать возврата к алкоголизму. Если вы или кто-то из ваших близких столкнулся с данной проблемой, не откладывайте обращение за медицинской помощью.
помощь наркозависимым
помощь наркозависимым
1win indir android https://www.1win40007.ru
провайдеры интернета по адресу
krasnoyarsk-domashnij-internet005.ru
интернет провайдеры по адресу дома
помощь наркозависимым
помощь наркозависимым
https://cs2case.io/
помощь наркозависимым
Срочный вызов нарколога на дом — это необходимая помощь для тех, кто сталкивается с зависимостями. На ресурсе narkolog-tula009.ru вы можете обратиться за консультацией нарколога и заказать врача на дом. Профессиональная помощь нарколога включает в себя лечение зависимостей и поддержку при зависимости. Экстренная медицинская служба предлагает анонимную помощь, что позволяет сохранить конфиденциальность. Эффективное лечение наркомании и помощь алкоголикам возможны с участием психотерапевта на дом. Не ждите, получите срочную помощь уже сегодня!
помощь наркозависимым
1win qanday ro‘yxatdan o‘tish kerak 1win qanday ro‘yxatdan o‘tish kerak
помощь наркозависимым
помощь наркозависимым
На сайте https://vezuviy.shop/ представлен огромный выбор надежных и качественных печей «Везувий». В этой компании представлено исключительно фирменное, оригинальное оборудование, включая дымоходы. На всю продукцию предоставляются гарантии, что подтверждает ее качество, подлинность. Доставка предоставляется абсолютно бесплатно. Специально для вас банный камень в качестве приятного бонуса. На аксессуары предоставляется скидка 10%. Прямо сейчас ознакомьтесь с наиболее популярными категориями, товар из которых выбирает большинство.
помощь наркозависимым
https://www.trub-prom.com/catalog/truby_srednego_diametra/219/ трубопрокат: Трубопрокат: сортамент труб, услуги резки и доставки.
dragon money
помощь наркозависимым
Алкоголизм — это глубокая проблема‚ требующая профессионального подхода к лечению. В Туле можно обратиться за помощью нарколога‚ такими как терапия алкогольной зависимости на дому. Нарколог на дом срочно поможет определить степень зависимости и выявить признаки алкоголизма. Важно получить консультацию нарколога для выбора оптимальной программы восстановления. Лечение на дому позволяет пациенту находиться в привычной обстановке‚ что уменьшает уровень стресса. Психотерапия при алкоголизме совместно с поддержкой близких играет важную роль в реабилитации от алкоголизма. Поддержка семей зависимых также важна для формирования условий для жизни без алкоголя. Нарколог на дом срочно Тула Не стоит откладывать вызовом нарколога на дом‚ это первый шаг к избавлению от зависимости.
пансионат для пожилых
pansionat-msk004.ru
пансионат для реабилитации после инсульта
Ищете понятные советы о косметике? Посетите https://fashiondepo.ru/ – это Бьюти журнал и авторский блог о красоте, где вы найдете правильные советы, а также мы разбираем составы, тестируем продукты и говорим о трендах простым языком без сложных терминов. У нас честные обзоры, гайды и советы по уходу.
Visit BinTab https://bintab.com/ – these are experts with many years of experience in finance, technology and science. They analyze and evaluate biotech companies, high-tech startups and leaders in the field of artificial intelligence, to help clients make informed investment decisions when buying shares of biotech, advanced technology, artificial intelligence, natural resources and green energy companies.
Посетите сайт https://rivanol-rf.ru/ и вы сможете ознакомиться с Риванол – это аптечное средство для ухода за кожей. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства, которое содержит уникальный антисептик, регенератор кожи: этакридина лактат.
помощь наркозависимым
https://regost.ru/minpromtorg/
https://bs-bsme.at
dragon money
https://petrovskijdvorik.ru/
https://shambala-tea.ru/
blood suckers slot rtp
drgn
помощь наркозависимым
Компонентс Ру – интернет-магазин электронных компонентов и радиодеталей. Стараемся покупателям предоставить по приемлемым ценам большой ассортимент товаров. Для вас в наличии: датчики и преобразователи, индикаторы, реле и переключатели, полупроводниковые модули, вентили и инверторы, источники питания, мультиметры и др. Ищете магазин радиодеталей? Components.ru – тут полный каталог продукции нашей компании представлен. На портале вы можете с условиями доставки и оплаты ознакомиться. Сотрудничаем с юридическими и частными лицами. Всегда вам рады!
драгон мани официальный сайт
Experimente o verdadeiro Fortune Tiger com ganhos instantaneos
помощь наркозависимым
Прогнозы прогноз прогноз на (Прогнозы на спорт: Анализ и стратегии для успешных ставок. | Прогноз: Как правильно анализировать спортивные события для успешных ставок. | Прогноз прогноз: Ежедневные прогнозы от экспертов, повышающие шансы на выигрыш. | Прогноз на: Прогнозы на футбол, хоккей, баскетбол и другие виды спорта. | Ставки: Руководство по ставкам на спорт для начинающих и опытных игроков. | Ставка: Как сделать ставку и не проиграть: советы и стратегии. | Ставки на спорт: Обзор букмекерских контор, бонусы и акции. | Спорт: Анализ спортивных событий, новости, результаты. | Спортивный: Спортивный анализ и прогнозы: секреты успешных ставок. | Беттинг: Беттинг как способ заработка: стратегии, риски и возможности. | Букмекер: Как выбрать букмекера: рейтинг лучших букмекерских контор. | Букмекерские конторы: Букмекерские конторы: сравнение коэффициентов и линий. | БК: Обзор популярных БК: бонусы, акции, выплаты. | Тотал: Что такое тотал и как делать ставки на тотал больше/меньше. | Тотал больше: Стратегии ставок на ТБ: как найти прибыльные варианты. | Тотал меньше: Как анализировать матчи для ставок на ТМ. | ТБ: Расшифровка ТБ и примеры ставок на тотал больше. | ТМ: Что означает ТМ и как делать ставки на тотал меньше. | Фора: Фора в ставках: объяснение, примеры и стратегии. | Фора минус: Как работает фора минус и когда ее использовать. | Фора плюс: Стратегии ставок с форой плюс для увеличения шансов на выигрыш. | Ф1: Что означает Ф1 и как делать ставки на победу первой команды с форой. | Ф2: Как использовать Ф2 в ставках и понимать значение форы для второй команды. | Исход: Анализ исхода матча: победа, ничья, поражение. | Победа: Стратегии ставок на победу: факторы, влияющие на результат. | Ничья: Когда стоит ставить на ничью и как анализировать вероятность ничейного исхода. | П1: Что такое П1 и как делать ставки на победу первой команды. | П2: Как использовать П2 в ставках и анализировать шансы второй команды на победу. | Х: Х в ставках: что означает ничья и как ее предсказать. | Кэф: Как формируется коэффициент и как его использовать в ставках. | Коэффициент: Анализ коэффициентов: как найти валуйные ставки. | Коэффициент на: Коэффициенты на спорт: сравнение предложений разных букмекеров. | VIP: VIP прогнозы: стоит ли покупать платные прогнозы. | Вип прогнозы: Преимущества и недостатки VIP прогнозов от капперов. | Платные прогнозы: Анализ эффективности платных прогнозов на спорт. | Каппер: Кто такой каппер и как выбрать надежного консультанта. | Экспресс: Как составлять экспрессы и увеличить шансы на выигрыш. | Паровоз: Что такое “паровоз” и почему не стоит злоупотреблять экспресс ставками. | Система: Ставка системой: как рассчитать выигрыш и минимизировать риски. | Ординар: Преимущества и недостатки ставок ординарами. | Одиночная ставка: Как правильно делать одиночные ставки и выбирать наиболее вероятные исходы. | Сингл: Сингл в ставках: простота и надежность, основа успешной стратегии. | Лайв прогнозы: Как делать ставки в лайве и использовать прогнозы в реальном времени. | Лайв: Стратегии для успешных ставок в режиме лайв. | Live: Live ставки: анализ матча в)|Лайв прогнозы лайв live: Преимущества и недостатки лайв-ставок, как правильно анализировать матч в реальном времени. | Футбол: Анализ футбольных матчей, стратегии ставок, обзоры чемпионатов. | Футбольные прогнозы: Ежедневные футбольные прогнозы от экспертов. | Хоккей: Хоккейные ставки: как анализировать матчи и делать выигрышные прогнозы. | Хоккейные прогнозы: Прогнозы на хоккейные матчи КХЛ, НХЛ и других лиг. | Баскетбол: Ставки на баскетбол: как учитывать статистику и особенности игры. | Баскетбольные прогнозы: Прогнозы на матчи NBA, Евролиги и других баскетбольных турниров. | Теннис: Теннисные ставки: анализ покрытия, формы игроков и других факторов. | Теннисные прогнозы: Прогнозы на теннисные турниры Grand Slam, ATP и WTA. | Волейбол: Стратегии ставок на волейбол, как учитывать расстановку и тактику команд. | Волейбольные прогнозы: Прогнозы на волейбольные матчи Лиги чемпионов и других турниров. | Киберспорт: Беттинг на киберспорт: как ставить на Dota 2, CS:GO и другие игры. | Кибер: Анализ киберспортивных матчей, стратегии ставок и прогнозы. | Esports: Руководство по ставкам на Esports для начинающих. | Прогнозы на киберспорт: Ежедневные прогнозы на киберспортивные события. | Бокс/MMA/UFC: Ставки на бокс и MMA: как анализировать бойцов и выбирать победителя. | Единоборства: Анализ поединков в единоборствах: подготовка бойцов, тактика, статистика. | Анализ букмекерских ошибок: Как находить ошибки в линиях букмекеров и использовать их в свою пользу. | Психология ставок: Как контролировать эмоции и принимать рациональные решения в беттинге. | Управление банкроллом: Как правильно управлять своим банкроллом, чтобы не проиграть все деньги сразу. | Стратегии ставок на фаворитов: Как ставить на фаворитов и получать стабильную прибыль. | Стратегии ставок на аутсайдеров: Когда стоит ставить на аутсайдеров и как найти выгодные варианты. | Виды тоталов в футболе: Индивидуальный тотал, азиатский тотал, тотал по таймам. | Виды фор в баскетболе: Азиатская фора, европейская фора, фора по четвертям.
tripscan зеркало сайт трипскан: Источник вдохновения и полезной информации для путешественников. Читайте статьи, смотрите обзоры и планируйте свою следующую поездку.
помощь наркозависимым
O tigrinho verdadeiro esta aqui – jogabilidade 100% real
драгон мани зеркало
драгон мани официальный сайт
Aloha!
Read the link – sweet bonanza free play
sweet bonanza casino
sweet bonanza slot
sweet bonanza game
Good luck!
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
Hello!!
Read the link – canadian real money Casino
casino games for real money online
online casino canada real money jackpot city
casino apps for real money
Good luck!
пансионат для пожилых людей
pansionat-msk005.ru
пансионат для престарелых людей
Известный сайт предлагает вам стать финансово подкованным, в первых рядах ознакомиться с последними новостями из сферы банков, политики, различных учреждений. Кроме того, имеются материалы о том, каким бизнесом выгодней заняться. https://sberkooperativ.ru/ – на сайте самые свежие, актуальные данные, которые будут интересны всем, кто интересуется финансами, прибылью. Изучите данные, касающиеся котировок акций. Регулярно публикуются новые, интересные материалы с картинками. Отслеживайте их и делитесь с друзьями.
Посетите сайт https://allforprofi.ru/ это оптово-розничный онлайн-поставщик спецодежды, камуфляжа и средств индивидуальной защиты для широкого круга профессионалов. У нас Вы найдете решения для работников медицинских учреждений, сферы услуг, производственных объектов горнодобывающей и химической промышленности, охранных и режимных предприятий. Только качественная специализированная одежда по выгодным ценам!
помощь наркозависимым
https://abs2best.at
Acesse o jogo Jogo do Tigrinho no site certo e protegido
помощь наркозависимым
demo slot blood suckers
Если вы хотите найти, где сделать капельницу анонимно в Туле, рекомендуем посетить сайтом narkolog-tula011.ru. Здесь доступны услуги капельницы для здоровья, которые способствую вашему после болезни. Клиника в Туле обеспечивает безопасность процедур и приватность клиентов, предоставляя качественную медицинскую помощь. Анонимное лечение – это возможность заботиться о своем здоровье без посторонних глаз. Не откладывайте о себе, воспользуйтесь медицинскими процедурами уже сегодня!
помощь наркозависимым
На сайте https://www.florion.ru/catalog/buket-na-1-sentyabrya представлены стильные, яркие и креативные композиции, которые дарят преподавателям на 1 сентября. Они зарядят положительными эмоциями, принесут приятные впечатления и станут жестом благодарности. Есть возможность подобрать вариант на любой бюджет: скромный, но не лишенный элегантности или помпезную и большую композицию, которая обязательно произведет эффект. Букеты украшены роскошной зеленью, колосками, которые добавляют оригинальности и стиля.
помощь наркозависимым
Jogue tigrinho com total protecao e suporte confiavel
помощь наркозависимым
ёлка пихта купить Нижневартовск Купить ёлку на Новый год Нижневартовск: Создайте волшебную атмосферу праздника Подготовка к Новому году – это время чудес, а главным атрибутом праздника является ёлка. В Нижневартовске множество мест для приобретения новогодней красавицы.
T.me/m1xbet_ru – официальный канал проекта 1XBET. Тут оперативно нужную информацию найдете. 1Xbet удивит вас разнообразием игр. Служба поддержки оперативно реагирует на запросы, заботится о вашем комфорте, а также безопасности. Ищете 1xbet мобильная версия? T.me/m1xbet_ru – тут рассказываем, почему стоит выбрать живое казино. 1Xbet много возможностей дает. Букмекер предлагает привлекательные условия для ставок и удерживает пользователей с помощью бонусов и акций. Отдельным плюсом является быстрый вывод средств. Приятной вам игры!
помощь наркозависимым
dragon money промокод Советы и секреты успешной игры на платформе Dragon Money от профессионалов. Dragon Money: сравнение с другими платформами
помощь наркозависимым
https://bs2bet.at
На сайте https://sprotyv.org/ представлено огромное количество интересной, актуальной и содержательной информации на самую разную тему: экономики, политики, войны, бизнеса, криминала, культуры. Здесь только самая последняя и ценная информация, которая будет важна каждому, кто проживает в этой стране. На портале регулярно появляются новые публикации, которые ответят на многие вопросы. Есть информация на тему здоровья и того, как его поправить, сохранить до глубокой старости.
помощь наркозависимым
помощь наркозависимым
Experimente o autentico Jogo do Tigrinho em nosso site
помощь наркозависимым
пансионат для пожилых людей
pansionat-msk006.ru
частный пансионат для престарелых
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
Ganhe premios reais no Jogo do Tigrinho mais confiavel do Brasil
помощь наркозависимым
провайдеры по адресу красноярск
krasnoyarsk-domashnij-internet006.ru
провайдеры интернета по адресу красноярск
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
“Реестр Гарант” оказывает услуги по включению в реестр Минпромторга российских производителей. Поможем внести продукцию в реестр Минпромторга, подготовим документы для внесения в реестр производителей по 719 постановлению. Регистрация в Минпромторге, включение товара в ГИСП, внесение оборудования – полное сопровождение. Узнайте стоимость включения в реестр Минпромторга: включение в реестр минпромторга
помощь наркозависимым
помощь наркозависимым
https://guryevsk.forum24.ru/?1-3-0-00000549-000-0-0-1751518837
https://msk.naydemvam.ru/viewtopic.php?id=307#p375
помощь наркозависимым
https://www.theindiantalks.com/tech/practical-applications-of-a-temporary-number-for-whatsapp/43718/
http://www.kalyamalya.ru/modules/newbb_plus/viewtopic.php?topic_id=24372&post_id=106280&order=0&viewmode=flat&pid=0&forum=4#106280
Высокий уровень сервиса и внимание к деталям — этим отличается каждая клининг служба. Мы ценим ваше доверие и заботимся о результате.
Услуги клининга в Москве становятся все более популярными и востребованными. Существует множество компаний, предлагающих широкий спектр услуг клининга.
В первую очередь, стоит отметить, что клининг включает в себя как регулярную, так и генеральную уборку. Регулярная уборка подразумевает поддержание чистоты в помещениях, что важно для здоровья и комфорта.
Генеральная уборка, в свою очередь, включает в себя более тщательную работу, требующую больше времени и ресурсов. Различные клининговые компании могут предложить клиентам различные уровни обслуживания, что позволяет выбрать оптимальный вариант.
При выборе клининговой фирмы стоит обратить внимание на мнения клиентов и их опыт. Хорошие компании обычно предлагают прозрачные условия обслуживания и гарантии качества.
помощь наркозависимым
помощь наркозависимым
Капельница от запоя на дому в Туле – это эффективный способ помощи с алкогольной зависимостью. Множество людей испытывают трудности от периодов запойного пьянстваи медицинская помощь становится жизненно важной. Капельницы помогает в детоксикации организма, облегчая симптомы выхода из запоя. Услуги нарколога включают не только инфузионные процедуры, но и реабилитацию от алкоголячто имеет значение для полного восстановления. Роль семьи играет ключевую роль в лечении. Профилактика запойного состояния также важна для предотвращения рецидивов. Выбирайте профессиональному подходу на сайте narkolog-tula012.ru и закажите помощь врача на дом.
https://bs2beast.cc
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
пансионат для пожилых после инсульта
pansionat-tula004.ru
пансионат для лежачих больных
помощь наркозависимым
помощь наркозависимым
Mariatogel
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
https://bs2-bs2site.at
помощь наркозависимым
накрутка подписчиков телеграм https://vc.ru/smm-promotion/2137388-nakrutka-podpischikov-v-telegram-25-saytov
помощь наркозависимым
провайдеры интернета в краснодаре по адресу
krasnodar-domashnij-internet004.ru
интернет провайдеры краснодар по адресу
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
Descubra grandes premios no Fortune Tiger oficial
Кстати, вот что я думаю по этому поводу:
Особенно понравился материал про travelmontenegro.ru.
Вот, делюсь ссылкой:
https://travelmontenegro.ru
Может, у кого-то есть другой опыт?
https://www.red-redial.net/temp-number-for-whatsapp/
помощь наркозависимым
https://bs2besd.cc
помощь наркозависимым
помощь наркозависимым
помощь наркозависимым
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил материал про localflavors.ru.
Смотрите сами:
https://localflavors.ru
Жду конструктивной критики.
помощь наркозависимым
Ganhe de verdade no tigrinho — 100% confiavel e ativo
Hey there this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding skills so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
Trova la farmacia piu economica
https://www.raisingedmonton.com/unveiling-the-benefits-of-australian-sms-numbers-for-business-growth/
Помощь родных играет ключевой ролью в восстановлении после запоя. Обсудите с ними свои планы и позвольте о помощи. Сообщества поддержки и консультации специалистов могут стать хорошим подспорьем. Не забывайте о методах предотвращения срывов: советы по жизни без алкоголя и самопомощь при зависимости от алкоголя помогут избежать возврата к старым привычкам. вывод из запоя
частные пансионаты для пожилых в туле
pansionat-tula005.ru
пансионат для реабилитации после инсульта
помощь наркозависимым
помощь наркозависимым
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Cerca da qui
помощь наркозависимым
https://bsme-at.at
помощь наркозависимым
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует idalgogrif.ru, посмотрите сюда.
Смотрите сами:
https://idalgogrif.ru
Пишите, что у вас получилось.
помощь наркозависимым
Ивдельская центральная районная больница
помощь наркозависимым
помощь наркозависимым
драгон мани зеркало
драгон мани
Спортивные секции и абонементы «Терек»
помощь наркозависимым
Вот здесь можно найти больше примеров:
По теме “idalgogrif.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Уверен, вместе мы найдем решение.
помощь наркозависимым
drgn
помощь наркозависимым
провайдер по адресу краснодар
krasnodar-domashnij-internet005.ru
интернет провайдеры по адресу краснодар
Спорткомплекс «Терек»
Чтобы не быть голословным, прикрепляю ссылку:
Кстати, если вас интересует spb-hotels.ru, загляните сюда.
Смотрите сами:
https://spb-hotels.ru
Надеюсь, эта информация сэкономит вам время.
БК «1XBET» является одной из самых лучших, к тому же, предлагает воспользоваться разнообразными способами получения денег. А узнать об этом подробности получится на официальном канале данного проекта. Отныне канал будет всегда с вами, потому как получить доступ удастся и с телефона. https://t.me/m1xbet_ru – на портале вы отыщете актуальные материалы, а также промокоды. Они выдаются во время авторизации, на значительные торжества. Также имеются и VIP промокоды. Все новое о компании представлено на сайте, где созданы все условия для вас.
Auf der Suche nach Replica Rolex, Replica Uhren, Uhren Replica Legal, Replica Uhr Nachnahme? Besuchen Sie die Website – https://www.uhrenshop.to/ – Beste Rolex Replica Uhren Modelle! GROSSTE AUSWAHL. BIS ZU 40 % BILLIGER als die Konkurrenz. DIREKTVERSAND AUS DEUTSCHLAND. HIGHEND ETA UHRENWERKE.
помощь наркозависимым
Вот тут есть все ответы на ваши вопросы:
Хочу выделить материал про clasifieds.ru.
Вот, можете почитать:
https://clasifieds.ru
Надеюсь, смог помочь.
chiken road online
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Хочу выделить материал про idalgogrif.ru.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Надеюсь, смог помочь.
помощь наркозависимым
Для тех, кто в теме, будет очень актуально:
Кстати, если вас интересует eqa.ru, посмотрите сюда.
Ссылка ниже:
https://eqa.ru
Пишите, что у вас получилось.
Ищете анализ сайта? Gvozd.org/analyze, здесь вы осуществите проверку ресурса на десятки SЕО параметров и нахождение ошибок, которые, вашему продвижению мешают. Вы ознакомитесь с 80 показателями после анализа сайта. Выбирайте из большой линейки тарифов, в зависимости от ваших целей и задач.
https://fonovik.com/
пансионат после инсульта
pansionat-tula005.ru
частные пансионаты для пожилых в туле
{Капельница от запоя на дому: как избежать повторного срыва (Тула)|{Лечение запоя на дому: капельница и профилактика срыва (Тула)|{Капельницы от запоя на дому: ключ к успешной реабилитации (Тула)}} {Алкогольная зависимость – это серьезная проблема‚ требующая быстрой реакции.|Проблема алкогольной зависимости требует оперативного вмешательства.|Алкогольная зависимость является важной проблемой‚ которая нуждается в незамедлительном решении.} {Нарколог на дом срочно|Срочный нарколог на дом|Наркологические услуги на дому} {предоставляет наркологические услуги‚ включая капельницы для быстрого восстановления.|предлагает услуги по лечению‚ включая капельницы для быстрого восстановления организма.|обеспечивает лечение алкоголизма‚ включая капельницы для скорейшего восстановления.} {При запое важно не только лечение на дому‚ но и профилактика срыва.|Важно помнить‚ что при запое необходимо не только лечение‚ но и профилактика рецидивов.|Лечение на дому при запое должно включать как терапию‚ так и профилактические меры против срывов.} {Медицинская капельница помогает детоксифицировать организм‚ облегчая симптомы абстиненции.|Капельница способствует детоксикации и облегчает симптомы абстиненции.|Капельница играет важную роль в детоксикации организма и уменьшении симптомов абстиненции.} {Срочная помощь специалистов включает в себя не только физическое восстановление‚ но и психологическую помощь.|Помощь специалистов охватывает как физическое‚ так и психологическое восстановление.|Специалисты предоставляют не только физическую помощь‚ но и поддержку на психологическом уровне.} {Поддержка родственников также играет ключевую роль‚ способствуя успешной реабилитации алкоголиков;|Важность поддержки со стороны близких неоспорима‚ так как она содействует успешной реабилитации.|Родные играют важнейшую роль в процессе реабилитации‚ способствуя успеху лечения.} {Detox программа поможет избежать повторного срыва и обеспечит безопасное лечение.|Программа детоксикации поможет предотвратить рецидивы и обеспечит безопасное лечение.|Детокс-программа предотвращает срывы и гарантирует безопасность лечения.} {Обратитесь к наркологу на дом‚ чтобы получить комплексную помощь и вернуться к нормальной жизни.|Свяжитесь с наркологом на дом для получения комплексной помощи и возвращения к полноценной жизни.|Не откладывайте‚ обратитесь к наркологу на дом за комплексной помощью и начните новую жизнь.}
провайдеры в краснодаре по адресу проверить
krasnodar-domashnij-internet005.ru
интернет провайдеры по адресу краснодар
Participe da diversao real com o tigrinho oficial
Вот, что говорят эксперты по этому поводу:
Особенно понравился раздел про eroticpic.ru.
Вот, можете почитать:
https://eroticpic.ru
Может, у кого-то есть другой опыт?
aviamaster free
lottostar login register
Обработка квартиры от тараканов в Москве проводится поэтапно — сначала осмотр, затем дезинсекция и контроль результата: уничтожение тараканов в москве
помощь наркозависимым
Вот отличный материал, который проливает свет на ситуацию:
Особенно понравился раздел про fixora.ru.
Вот, делюсь ссылкой:
https://fixora.ru
Всем спасибо, и до новых встреч!
Это именно то, что я искал!
Между прочим, если вас интересует fk-almazalrosa.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://fk-almazalrosa.ru
Буду рад, если кому-то пригодится.
dragon money официальный сайт
zeus vs hades demo в рублях
dragon money официальный сайт
https://www.mebel-novinka.ru/
помощь наркозависимым
На мой взгляд, лучшее решение этой проблемы здесь:
Для тех, кто ищет информацию по теме “spb-hotels.ru”, есть отличная статья.
Ссылка ниже:
https://spb-hotels.ru
Буду следить за обсуждением.
https://tripusa.ru/
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует phenoma.ru, загляните сюда.
Смотрите сами:
https://phenoma.ru
Надеюсь, смог помочь.
Explore o melhor do tigrinho em uma plataforma confiavel e cheia de premios
помощь наркозависимым
Чтобы не быть голословным, прикрепляю ссылку:
Особенно понравился материал про eqa.ru.
Ссылка ниже:
https://eqa.ru
Спасибо, что дочитали до конца.
Как раз то, что нужно для решения этого вопроса:
Кстати, если вас интересует raregreen.ru, посмотрите сюда.
Ссылка ниже:
https://raregreen.ru
Может, у кого-то есть другой опыт?
помощь наркозависимым
Всем привет, нашел интересную информацию по теме:
По теме “travelmontenegro.ru”, есть отличная статья.
Ссылка ниже:
https://travelmontenegro.ru
Если есть вопросы, задавайте.
Вот здесь подробно расписано, как это сделать:
Кстати, если вас интересует phenoma.ru, посмотрите сюда.
Ссылка ниже:
https://phenoma.ru
Всем добра!
помощь наркозависимым
Если нужна более подробная инструкция, то она здесь:
Кстати, если вас интересует yogapulse.ru, загляните сюда.
Вот, можете почитать:
https://yogapulse.ru
Если есть вопросы, задавайте.
Печь Туймазы купить
https://t.me/TriumphTime1
Entre no mundo do tigrinho com conteudo seguro e verificado
Долго искал решение и наконец-то нашел:
Кстати, если вас интересует tars-rubber.ru, загляните сюда.
Вот, можете почитать:
https://tars-rubber.ru
Надеюсь, у вас все получится.
помощь наркозависимым
Если кому интересно, вот более детальная информация:
Кстати, если вас интересует anclaves.ru, загляните сюда.
Смотрите сами:
https://anclaves.ru
Надеюсь, это было полезно.
Кстати, вот что я думаю по этому поводу:
Для тех, кто ищет информацию по теме “musichunt.pro”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://musichunt.pro
Что думаете по этому поводу?
Уличные газовые котлы
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “m-admin.ru”, нашел много полезного.
Смотрите сами:
https://m-admin.ru
Спасибо за внимание.
помощь наркозависимым
пансионат для лежачих пожилых
pansionat-tula006.ru
пансионат для пожилых людей
Для тех, кто в теме, будет очень актуально:
Кстати, если вас интересует tars-rubber.ru, посмотрите сюда.
Вот, можете почитать:
https://tars-rubber.ru
Поделитесь своими мыслями в комментариях.
маркетолог услуги позиционирование бренда: Уникальное место в сознании потребителей Позиционирование бренда – это то, как ваш бренд воспринимается целевой аудиторией.
узнать провайдера по адресу краснодар
krasnodar-domashnij-internet006.ru
какие провайдеры по адресу
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “musichunt.pro”, есть отличная статья.
Вот, можете почитать:
https://musichunt.pro
Интересно было бы узнать ваше мнение.
помощь наркозависимым
Газовые печи отопления с горелкой
Детоксикация организма после запоя в Туле: проверенные способы Лечение запоя требует комплексного подхода, включая очищение и реабилитацию. Похмельный синдром могут быть тяжелыми, и важно выбрать правильные методы для детоксикации; Лекарственные препараты часто дополняются традиционными методами, что повышает эффективность. лечение запоя Клиники по лечению алкоголизма предлагают курсы очищения и реабилитацию после запоя. Поддержка близких и психологическая помощь играют ключевую роль в процессе. Предотвращение запоев включает в себя регулярное наблюдение за здоровьем и благополучием. Помните, что восстановление — это долгий путь, но возможный.
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует detoxa.ru, загляните сюда.
Вот, делюсь ссылкой:
https://detoxa.ru
Спасибо за внимание.
Как вариант, можно рассмотреть следующее:
По теме “travelmontenegro.ru”, там просто кладезь информации.
Ссылка ниже:
https://travelmontenegro.ru
Дайте знать, если найдете что-то еще.
помощь наркозависимым
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился раздел про reactive.su.
Вот, можете почитать:
https://reactive.su
Если у вас есть что добавить, не стесняйтесь.
Если кому интересно, вот более детальная информация:
По теме “obender.ru”, там просто кладезь информации.
Ссылка ниже:
https://obender.ru
Жду ваших комментариев.
Descubra o Jogo do Tigrinho e jogue com total seguranca
помощь наркозависимым
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “travelmontenegro.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://travelmontenegro.ru
Буду рад, если кому-то пригодится.
На сайте https://fakty.org/ изучите свежие новости на самые нашумевшие темы. Они расскажут много нового, чтобы вы были в курсе последних событий. Информация представлена на различную тему, в том числе, экономическую, политическую. Есть данные на тему финансов, рассматриваются вопросы, которые важны всем жителям страны. Вы найдете мнение экспертов о том, что интересует большинство. Все новости поделены на категории для вашего удобства, поэтому вы быстро найдете то, что нужно. Только на этом портале публикуется самая актуальная информация, которая никого не оставит равнодушным.
Очень рекомендую к прочтению:
Кстати, если вас интересует yogapulse.ru, загляните сюда.
Вот, можете почитать:
https://yogapulse.ru
Обращайтесь, если что.
помощь наркозависимым
Бизонстрой предоставляет услуги по аренде спецтехники. Предлагаем бульдозеры, манипуляторы, погрузчики, автокраны и др. Все машины в отменном состоянии и к немедленному выходу на объект готовы. Думаем, что ваши объекты лучшего заслуживают – выгодных условий и новейшей техники. https://bizonstroy.ru – тут более детальная информация о нас представлена, посмотрите ее уже сегодня. Мы с клиентами нацелены на долгосрочное сотрудничество. Решаем вопросы оперативно и профессионально. Обращайтесь и не пожалеете!
Кстати, вот что я думаю по этому поводу:
Кстати, если вас интересует pro-zenit.ru, посмотрите сюда.
Ссылка ниже:
https://pro-zenit.ru
Надеюсь, у вас все получится.
Уверен, эта информация будет для вас полезна:
Зацепил раздел про pro-zenit.ru.
Смотрите сами:
https://pro-zenit.ru
Дайте знать, если найдете что-то еще.
https://hoo.be/ydogefuhoc
Согласен с предыдущим оратором, и в дополнение хочу сказать:
По теме “parkpodarkov.ru”, там просто кладезь информации.
Ссылка ниже:
https://parkpodarkov.ru
Поделитесь своими мыслями в комментариях.
Как выбрать и заказать экскурсию по Казани? Посетите сайт https://to-kazan.ru/tours/ekskursii-kazan и ознакомьтесь с популярными форматами экскурсий, а также их ценами. Все экскурсии можно купить онлайн. На странице указаны цены, расписание и подробные маршруты. Все программы сопровождаются сертифицированными экскурсоводами.
Вот здесь подробно расписано, как это сделать:
Для тех, кто ищет информацию по теме “eqa.ru”, там просто кладезь информации.
Вот, можете почитать:
https://eqa.ru
Буду рад, если кому-то пригодится.
https://kuwzpatzdvtliti.bandcamp.com/album/book
Делюсь с вами полезной ссылкой по теме:
Хочу выделить раздел про eroticpic.ru.
Ссылка ниже:
https://eroticpic.ru
Жду конструктивной критики.
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует localflavors.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://localflavors.ru
Уверен, вместе мы найдем решение.
https://kemono.im/kefacyud/mal-divy-kupit-gashish-boshki-marikhuanu
вывод из запоя круглосуточно тула
tula-narkolog001.ru
вывод из запоя цена
Entre no mundo do tigrinho oficial e aproveite as recompensas reais
Вот тут есть все ответы на ваши вопросы:
По теме “easyterm.ru”, есть отличная статья.
Смотрите сами:
https://easyterm.ru
Рад был поделиться информацией.
https://certainlysensible.com/index.php/User:AnnabelleVale8 Trade Center news occasionally ties to global security discussions.
Полагаю, это снимет все дальнейшие вопросы:
Для тех, кто ищет информацию по теме “cyq.ru”, там просто кладезь информации.
Смотрите сами:
https://cyq.ru
Пишите, что у вас получилось.
Оригинальные запасные части Thermo Fisher Scientific https://thermo-lab.ru/ и расходные материалы для лабораторного и аналитического оборудования с доставкой в России. Поставка высококачественного лабораторного и аналитического оборудования Thermo Fisher, а также оригинальных запасных частей и расходных материалов от ведущих мировых производителей. Каталог Термо Фишер включает всё необходимое для бесперебойной и эффективной работы вашей лаборатории по низким ценам в России.
https://paper.wf/yydibyecie/budapesht-kupit-kokain-mefedron-marikhuanu
Выбор провайдера домашнего интернета в Москве — задача, которая требует тщательного анализа. На сайте msk-domashnij-internet004.ru можно найти полезные рекомендации . Прежде всего‚ важно учитывать скорость интернет-соединения, которая зависит от выбранного тарифного плана и способа подключения. Провайдеры Москвы предлагают множество решений: от оптоволоконного интернета до беспроводных технологий. Качество интернет-соединения имеет большое значение. Читайте отзывы пользователей ‚ чтобы узнать о надежности сервиса и уровне технической поддержки. Рассмотрите стоимость подключения и условия контракта , так как они могут различаться. Многим пользователям интересны сопутствующие предложения, такие как IP-телефония или телевидение‚ которые могут быть включены в пакет . Также не забудьте уточнить‚ какое оборудование для интернета вам потребуется . Таким образом , собрав все необходимые данные‚ вы сможете сделать обоснованный выбор и наслаждаться качественным интернетом в вашем доме .
Вот отличный материал, который проливает свет на ситуацию:
Хочу выделить раздел про musichunt.pro.
Вот, можете почитать:
https://musichunt.pro
Всем удачи и хорошего дня!
Учебный центр дополнительного профессионального образования НАСТ – https://nastobr.com/ – это возможность пройти дистанционное обучение без отрыва от производства. Мы предлагаем обучение и переподготовку по 2850 учебным направлениям. Узнайте на сайте больше о наших профессиональных услугах и огромном выборе образовательных программ.
הסיפורים שלהם, משנה רק את השמות, אם הם שם. כאילו, להרחבת המאזינים. אם מישהו לא אוהב את הדרך בה הזוגיות. כשהאביר חזר הביתה, הוא נישק את רגליה של אשתו, והראה שהיא עדיין אשתו וכי הוא מכיר אירוח מפנק מאת נערת ליווי איכותית
Всем привет, нашел интересную информацию по теме:
Хочу выделить материал про mersobratva.ru.
Вот, делюсь ссылкой:
https://mersobratva.ru
Надеюсь, смог помочь.
https://paper.wf/idofefug/portu-kupit-ekstazi-mdma-lsd-kokain
пансионат инсульт реабилитация
pansionat-msk004.ru
пансионат для пожилых людей
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует reactive.su, посмотрите сюда.
Ссылка ниже:
https://reactive.su
Всем добра!
Чтобы не быть голословным, прикрепляю ссылку:
Особенно понравился материал про classifields.ru.
Смотрите сами:
https://classifields.ru
Если есть вопросы, задавайте.
https://www.brownbook.net/business/54133963/висбаден-купить-марихуану-гашиш-бошки/
Чтобы было понятнее, о чем речь:
По теме “seatours.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://seatours.ru
Поделитесь своими мыслями в комментариях.
totojitu
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Особенно понравился материал про obender.ru.
Ссылка ниже:
https://obender.ru
Всем спасибо, и до новых встреч!
https://say.la/read-blog/122270
Вот отличный материал, который проливает свет на ситуацию:
Зацепил раздел про fk-almazalrosa.ru.
Вот, можете почитать:
https://fk-almazalrosa.ru
Надеюсь, у вас все получится.
Вот здесь можно найти больше примеров:
Зацепил раздел про anclaves.ru.
Ссылка ниже:
https://anclaves.ru
Интересно было бы узнать ваше мнение.
https://community.wongcw.com/blogs/1123831/%D0%9B%D0%B0%D1%82%D0%B2%D0%B8%D1%8F-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%91%D0%BE%D1%88%D0%BA%D0%B8
На мой взгляд, лучшее решение этой проблемы здесь:
По теме “diyworks.ru”, там просто кладезь информации.
Смотрите сами:
https://diyworks.ru
Буду признателен за ваши отзывы.
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился раздел про eroticpic.ru.
Вот, можете почитать:
https://eroticpic.ru
Может, у кого-то есть другой опыт?
https://paper.wf/yeheyhoeeyc/seul-kupit-kokain-mefedron-marikhuanu
Посмотрите, что я нашел по этому поводу:
Зацепил материал про eqa.ru.
Смотрите сами:
https://eqa.ru
Может, у кого-то есть другой опыт?
Как вариант, можно рассмотреть следующее:
По теме “detoxa.ru”, там просто кладезь информации.
Ссылка ниже:
https://detoxa.ru
Успехов в решении вашего вопроса!
https://git.project-hobbit.eu/bqpayboii
лечение запоя
tula-narkolog002.ru
экстренный вывод из запоя
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует phenoma.ru, посмотрите сюда.
Ссылка ниже:
https://phenoma.ru
Интересно было бы узнать ваше мнение.
https://wiki.ragnarok-infinitezero.com.br/index.php?title=World_News_31f war news remains grim, with analysts warning of proxy conflicts potentially spiraling out of control.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Для тех, кто ищет информацию по теме “all-hotels-online.ru”, там просто кладезь информации.
Ссылка ниже:
https://all-hotels-online.ru
Надеюсь, смог помочь.
https://hub.docker.com/u/Boldensweet2805
Обработка квартиры от клопов включает обработку мебели, стен, пола, плинтусов и других укрытий, где могут прятаться насекомые: обработка от клопов в квартире
Render Network expands GPU-sharing platform, RNDR up.
my web-site https://yogicentral.science/wiki/User:NiamhE0249
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует anclaves.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://anclaves.ru
Надеюсь, это было полезно.
Курс Нутрициолог – обучение нутрициологии с дипломом https://nutriciologiya.com/ – ознакомьтесь подробнее на сайте с интересной профессией, которая позволит отлично зарабатывать. Узнайте на сайте кому подойдет курс и из чего состоит работа нутрициолога и программу нашего профессионального курса.
Посетите сайт https://allcharge.online/ – это быстрый и надёжный сервис обмена криптовалюты, который дает возможность быстрого и безопасного обмена криптовалют, электронных валют и фиатных средств в любых комбинациях. У нас актуальные курсы, а также действует партнерская программа и cистема скидок. У нас Вы можете обменять: Bitcoin, Monero, USDT, Litecoin, Dash, Ripple, Visa/MasterCard, и многие другие монеты и валюты.
Посетите сайт https://artradol.com/ и вы сможете ознакомиться с Артрадол – это препарат для лечения суставов от производителя. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства, которое является нестероидным противовоспалительным препаратом для лечения суставов. Помогает бороться с основными заболеваниями суставов.
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “travelcrimea.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://travelcrimea.ru
Может, у кого-то есть другой опыт?
Договор на интернет в Москве: основные моменты, которые стоит учесть Выбирая интернет-провайдера в Москве, важно обратить внимание на условия контракта. Перед подписанием договора на услуги связи, ознакомьтесь с тарифами на интернет, скоростью подключения и предоставляемыми услугами. Провайдеры Москвы предлагают различные акции и скидки, которые помогут уменьшить затраты на подключение. интернет провайдеры москвы Внимательно изучите условия договора, включая срок действия и возможность расторжения. Также стоит осведомиться о качестве технической поддержки и мнениях клиентов; Сравнительная таблица тарифов поможет выбрать оптимальный вариант для вашего дома или бизнеса. Не забывайте про городские интернет-услуги, предлагающие стабильное подключение. Тщательно обдумав все детали, вы сможете выбрать провайдера, который наилучшим образом отвечает вашим требованиям.
https://paper.wf/nogofafobagv/sevil-ia-kupit-kokain-mefedron-marikhuanu
Вот отличный материал, который проливает свет на ситуацию:
Кстати, если вас интересует obender.ru, загляните сюда.
Ссылка ниже:
https://obender.ru
Всем удачи и хорошего дня!
https://b2best.at
Вот здесь можно найти больше примеров:
Кстати, если вас интересует reactive.su, загляните сюда.
Смотрите сами:
https://reactive.su
Уверен, вместе мы найдем решение.
https://say.la/read-blog/122617
https://auctionwheels.info/cars/mercedesbenz/models/rklasse/pagination/start
пансионат для лежачих пожилых
pansionat-msk005.ru
пансионат инсульт реабилитация
Чтобы было понятнее, о чем речь:
Кстати, если вас интересует classifields.ru, загляните сюда.
Вот, делюсь ссылкой:
https://classifields.ru
Надеюсь, смог помочь.
консультация по маркетингу Услуги маркетолога цена Вопрос цены на услуги маркетолога – это вопрос инвестиций в будущее бизнеса. Стоимость может варьироваться в зависимости от сложности задачи, объема работ, опыта и квалификации специалиста. Однако, прежде чем оценивать стоимость, необходимо четко понимать, какие именно цели вы преследуете и какие результаты ожидаете от сотрудничества. В конечном итоге, хорошо продуманная и реализованная маркетинговая стратегия многократно окупит вложенные средства.
Долго искал решение и наконец-то нашел:
Особенно понравился материал про classifields.ru.
Ссылка ниже:
https://classifields.ru
Обращайтесь, если что.
https://kemono.im/efecnecn/madeira-kupit-gashish-boshki-marikhuanu
Вот отличный материал, который проливает свет на ситуацию:
По теме “raregreen.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://raregreen.ru
Пишите, что у вас получилось.
Если кому интересно, вот более детальная информация:
Кстати, если вас интересует rustrail.ru, загляните сюда.
Вот, можете почитать:
https://rustrail.ru
Интересно было бы узнать ваше мнение.
https://say.la/read-blog/123408
chiken road bot
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “diyworks.ru”, есть отличная статья.
Смотрите сами:
https://diyworks.ru
Давайте обсудим это подробнее.
https://muckrack.com/person-27402354
Anvelope Lassa
Эксперт ремонта Алматы
Кстати, вот что я думаю по этому поводу:
Хочу выделить материал про buytime.ru.
Ссылка ниже:
https://buytime.ru
Чем мог, тем помог.
Evite falsificacoes – jogue apenas no tigrinho verdadeiro
вывод из запоя цена
tula-narkolog003.ru
экстренный вывод из запоя
Шины 305/30 R21
Вот тут есть все ответы на ваши вопросы:
Между прочим, если вас интересует mersobratva.ru, загляните сюда.
Вот, можете почитать:
https://mersobratva.ru
Рад был поделиться информацией.
https://ucgp.jujuy.edu.ar/profile/iduegogjehdi/
Посетите сайт Digital-агентство полного цикла Bewave https://bewave.ru/ и вы найдете профессиональные услуги по созданию, продвижению и поддержки интернет сайтов и мобильных приложений. Наши кейсы вас впечатлят, от простых задач до самых сложных решений. Ознакомьтесь подробнее на сайте.
Как раз то, что нужно для решения этого вопроса:
Хочу выделить раздел про eroticpic.ru.
Ссылка ниже:
https://eroticpic.ru
Всем добра!
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Для тех, кто ищет информацию по теме “travelmontenegro.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://travelmontenegro.ru
Спасибо за внимание.
https://community.wongcw.com/blogs/1126207/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%91%D0%BE%D1%88%D0%BA%D0%B8-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%91%D0%BE%D1%80%D0%B0%D0%BA%D0%B0%D0%B9
Эксперт ремонта Алматы
Исчерпывающий ответ на данный вопрос находится тут:
По теме “lingomap.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://lingomap.ru
Надеюсь, смог помочь.
Jogue com confianca atraves do site original do tigrinho
goltogel
Шины Lassa
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует travelmontenegro.ru, загляните сюда.
Смотрите сами:
https://travelmontenegro.ru
Может, у кого-то есть другой опыт?
https://potofu.me/w0mlr1jp
Anvelope 215/40 R18
В современном мире доступ в интернет стал неотъемлемой частью жизни. Особенно в Москве, где высококачественный интернет предлагает пользователям быструю и стабильную связь. Провайдеры интернета предлагают различные решения для подключения, включая оптоволоконный и кабельный интернет, которые обеспечивают стабильное соединение.Топовые провайдеры столицы гарантируют качественные услуги связи, минимизируя проблемы с настройкой интернета. Проводное соединение является оптимальным вариантом для тех, кто ищет устойчивый доступ к интернету. Скоростной интернет позволяет работать, учиться и развлекаться без перебоев. лучший домашний интернет москва Чтобы обеспечить надежный интернет, необходимо правильно подобрать провайдера и соответствующий тарифный план, учитывающий ваши требования.
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Кстати, если вас интересует easyterm.ru, загляните сюда.
Ссылка ниже:
https://easyterm.ru
Всем удачи и хорошего дня!
Anvelope 225/65 R16
Это именно то, что я искал!
Особенно понравился раздел про localflavors.ru.
Вот, можете почитать:
https://localflavors.ru
Всем мира и продуктивного дня
Ищете гражданство паспорт испании евросоюза ес? Expert-immigration.com – это профессиональные юридические услуги по всему миру. Консультации по визам, гражданству, ВНЖ и ПМЖ, помощь в покупке бизнеса, защита от недобросовестных услуг. Узнайте подробно на сайте о каждой из услуг, в том числе помощи в оформлении гражданства Евросоюза и других стран или квалицированной помощи в покупке зарубежной недвижимости.
https://allmynursejobs.com/author/tonya_13lily/
ремонт квартир под ключ Алматы
Если кому интересно, вот более детальная информация:
Кстати, если вас интересует travelmontenegro.ru, посмотрите сюда.
Ссылка ниже:
https://travelmontenegro.ru
Пишите, что у вас получилось.
Anvelope Powertrac
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “qazar.ru”, там просто кладезь информации.
Вот, можете почитать:
https://qazar.ru
Буду следить за обсуждением.
https://potofu.me/zfsfrxgq
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “detoxa.ru”, там просто кладезь информации.
Ссылка ниже:
https://detoxa.ru
Пишите, что у вас получилось.
пансионат с медицинским уходом
pansionat-msk006.ru
пансионат с медицинским уходом
https://bs-bsme.at
Это именно то, что я искал!
По теме “rustrail.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://rustrail.ru
Давайте обсудим это подробнее.
https://rant.li/2l7cof655w
Вот здесь подробно расписано, как это сделать:
Кстати, если вас интересует yogapulse.ru, загляните сюда.
Смотрите сами:
https://yogapulse.ru
Буду рад, если кому-то пригодится.
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Особенно понравился материал про idalgogrif.ru.
Ссылка ниже:
https://idalgogrif.ru
Спасибо за внимание.
https://kemono.im/gcaudoah/khvar-kupit-gashish-boshki-marikhuanu
Acesse o site oficial do tigrinho e jogue com seguranca
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует travelmontenegro.ru, загляните сюда.
Вот, делюсь ссылкой:
https://travelmontenegro.ru
Буду следить за обсуждением.
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk004.ru
лечение запоя
Вот здесь подробно расписано, как это сделать:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, есть отличная статья.
Ссылка ниже:
https://tars-rubber.ru
Рад был поделиться информацией.
https://bio.site/uohigoof
Вот тут есть все ответы на ваши вопросы:
Для тех, кто ищет информацию по теме “spb-hotels.ru”, нашел много полезного.
Смотрите сами:
https://spb-hotels.ru
Надеюсь, это было полезно.
Tripscan войти Трипскан вход – это первый шаг в удивительное путешествие, где интуитивно понятный интерфейс и широкий выбор развлечений создают неповторимую атмосферу. Сайт Трипскан, разработанный с вниманием к деталям, обеспечивает комфортный и безопасный опыт для каждого пользователя.
Как вариант, можно рассмотреть следующее:
Для тех, кто ищет информацию по теме “buytime.ru”, там просто кладезь информации.
Вот, можете почитать:
https://buytime.ru
Надеюсь, эта информация сэкономит вам время.
https://rant.li/fmzieybtyco/borakai-kupit-gashish-boshki-marikhuanu
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил раздел про fk-almazalrosa.ru.
Вот, делюсь ссылкой:
https://fk-almazalrosa.ru
Всем удачи и хорошего дня!
Трипскан топ Tripscan: Всё о личном кабинете Tripscan: удобство, контроль, возможности. Управляйте своими бронированиями эффективно!
Уверен, эта информация будет для вас полезна:
Зацепил раздел про localflavors.ru.
Смотрите сами:
https://localflavors.ru
Что думаете по этому поводу?
https://pxlmo.com/zairemanixks
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует all-hotels-online.ru, посмотрите сюда.
Ссылка ниже:
https://all-hotels-online.ru
Какие еще есть варианты?
חתמו רשמית ואולגה נכנסה לצו. כשלמדתי את תאריך היעד המשוער שלי … פתאום נפגעתי כמו ברק!! זה יכול הבלתי נשלט, ההתקף. – ילדה טובה. עכשיו לך. כנראה שכבר מחכה לך עיסוי ארוטי. היא מפנה אותי לדלת, נערות ליווי בבת ים
провайдеры интернета в нижнем новгороде
nizhnij-novgorod-domashnij-internet004.ru
подключить интернет в нижнем новгороде в квартире
купить дизайнерское напольное кашпо http://www.dizaynerskie-kashpo-rnd.ru .
Вот отличный материал, который проливает свет на ситуацию:
Кстати, если вас интересует cyq.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://cyq.ru
Спасибо, что дочитали до конца.
https://community.wongcw.com/blogs/1123781/%D0%A5%D0%B0%D1%80%D0%B1%D0%B8%D0%BD-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%91%D0%BE%D1%88%D0%BA%D0%B8
Вот здесь подробно расписано, как это сделать:
По теме “spb-hotels.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://spb-hotels.ru
Спасибо, что дочитали до конца.
Slots are a core piece of the casino industry. Much like other aspects of casino gaming, they have shifted from traditional land-based casino floors to digital platforms. A deposit online casino voicify australia-20-dollar-deposit-casinos in Australia lets players enjoy games with a minimum deposit, offering an affordable gaming experience. But what exactly makes the uncrossable mission stand out in the casino game world? It’s the perfect blend of skill and luck, offering players the chance to not only rely on their strategy but also enjoy the unpredictable nature of each game. Whether you’re aiming for casual fun or serious betting, Mission Uncrossable has something for everyone. But what exactly makes the uncrossable mission stand out in the casino game world? It’s the perfect blend of skill and luck, offering players the chance to not only rely on their strategy but also enjoy the unpredictable nature of each game. Whether you’re aiming for casual fun or serious betting, Mission Uncrossable has something for everyone.
https://missionsresearchinstitute.org/a-smooth-ride-or-crash-landing-logging-into-the-aviator-app/
You wont need to think too hard about what to take with you to desert island destination all youll need is a laptop or desktop PC, slot offers great 96% RTP which means great possibility to win in real money play using a bonus we found. The website also runs an EnergyPoint promotion in which you claim EnergyPoints for all wagers placed on games, you will find a fascinating atmospheric game called Diamonds On Fire. One of the most exciting aspects of More Chilli Pokies is its bonus features, such as free bets or deposit bonuses. The winning symbols will then swap for other symbols in the same category as the reels re-spin, inflation reached a dizzying 2,700%. Founded in 2000, bet365 is the world’s largest betting brand. Employing over 9,000 people and with over 100 million customers worldwide, there is a first-classic bet365 Casino to enjoy making it a unique slot site for UK players.
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “anclaves.ru”, есть отличная статья.
Смотрите сами:
https://anclaves.ru
Надеюсь, эта информация сэкономит вам время.
https://hub.docker.com/u/zpJennkinsnine
Чтобы не быть голословным, прикрепляю ссылку:
Между прочим, если вас интересует cyq.ru, посмотрите сюда.
Вот, можете почитать:
https://cyq.ru
Пишите, что у вас получилось.
https://bs2beast.cc
Как вариант, можно рассмотреть следующее:
Между прочим, если вас интересует travelmontenegro.ru, посмотрите сюда.
Ссылка ниже:
https://travelmontenegro.ru
Всем удачи и хорошего дня!
https://hoo.be/tjidlygehuoh
Возможно, это будет полезно участникам обсуждения:
Кстати, если вас интересует raregreen.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://raregreen.ru
Надеюсь, эта информация сэкономит вам время.
пансионат для людей с деменцией в туле
pansionat-tula004.ru
пансионат для пожилых с инсультом
Если кому интересно, вот более детальная информация:
Хочу выделить материал про clasifieds.ru.
Вот, можете почитать:
https://clasifieds.ru
Спасибо, что дочитали до конца.
https://potofu.me/ec1tjikz
На сайте https://glavcom.info/ ознакомьтесь со свежими, последними новостями Украины, мира. Все, что произошло только недавно, публикуется на этом сайте. Здесь вы найдете информацию на тему финансов, экономики, политики. Есть и мнение первых лиц государств. Почитайте их высказывания и узнайте, что они думают на счет ситуации, сложившейся в мире. На портале постоянно публикуются новые материалы, которые позволят лучше понять определенные моменты. Все новости составлены экспертами, которые отлично разбираются в перечисленных темах.
1win app android https://1win40008.ru/
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить материал про hotelnews.ru.
Вот, можете почитать:
https://hotelnews.ru
Если у вас есть что добавить, не стесняйтесь.
вывод из запоя круглосуточно челябинск
vivod-iz-zapoya-chelyabinsk005.ru
вывод из запоя цена
Кстати, вот что я думаю по этому поводу:
По теме “diyworks.ru”, есть отличная статья.
Вот, можете почитать:
https://diyworks.ru
Всем добра!
https://ucgp.jujuy.edu.ar/profile/uiydqwahue/
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Для тех, кто ищет информацию по теме “avelonbeta.ru”, есть отличная статья.
Смотрите сами:
https://avelonbeta.ru
Надеюсь, эта информация сэкономит вам время.
Возможно, это будет полезно участникам обсуждения:
Для тех, кто ищет информацию по теме “anclaves.ru”, есть отличная статья.
Смотрите сами:
https://anclaves.ru
Жду ваших комментариев.
https://allmynursejobs.com/author/gavynemr/
Полностью поддерживаю, и вот еще одно подтверждение:
Особенно понравился раздел про clasifieds.ru.
Вот, делюсь ссылкой:
https://clasifieds.ru
Жду конструктивной критики.
Кстати, вот что я думаю по этому поводу:
По теме “anclaves.ru”, есть отличная статья.
Смотрите сами:
https://anclaves.ru
Если у вас есть что добавить, не стесняйтесь.
https://rant.li/abadycoycifi/khaifa-kupit-ekstazi-mdma-lsd-kokain
Вот отличный материал, который проливает свет на ситуацию:
Хочу выделить материал про all-hotels-online.ru.
Смотрите сами:
https://all-hotels-online.ru
Давайте обсудим это подробнее.
code promo 1xbet madagascar
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует travelcrimea.ru, загляните сюда.
Вот, можете почитать:
https://travelcrimea.ru
Всем спасибо, и до новых встреч!
1xbet promo code for registration nepal
https://community.wongcw.com/blogs/1125038/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%91%D0%BE%D1%88%D0%BA%D0%B8-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%98%D1%88%D0%B3%D0%BB%D1%8C
провайдеры интернета по адресу
nizhnij-novgorod-domashnij-internet005.ru
домашний интернет
Кстати, вот что я думаю по этому поводу:
Между прочим, если вас интересует fixora.ru, посмотрите сюда.
Ссылка ниже:
https://fixora.ru
Давайте обсудим это подробнее.
Для тех, кто в теме, будет очень актуально:
Для тех, кто ищет информацию по теме “parkpodarkov.ru”, нашел много полезного.
Смотрите сами:
https://parkpodarkov.ru
Дайте знать, если найдете что-то еще.
https://bio.site/ifhubybid
Полагаю, это снимет все дальнейшие вопросы:
По теме “cyq.ru”, там просто кладезь информации.
Смотрите сами:
https://cyq.ru
Жду ваших комментариев.
Посетите сайт https://artracam.com/ и вы сможете ознакомиться с Артракам – это эффективный препарат для лечения суставов от производителя. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства – эффективность Артракама при артрите, при остеоартрозе, при остеохондрозе.
На сайте https://vitamax.shop/ изучите каталог популярной, востребованной продукции «Витамакс». Это – уникальная, популярная линейка ценных и эффективных БАДов, которые улучшают здоровье, дарят прилив энергии, бодрость. Важным моментом является то, что продукция разработана врачом-биохимиком, который потратил на исследования годы. На этом портале представлена исключительно оригинальная продукция, которая заслуживает вашего внимания. При необходимости воспользуйтесь консультацией специалиста, который подберет для вас БАД.
Уверен, эта информация будет для вас полезна:
Хочу выделить материал про classifields.ru.
Вот, делюсь ссылкой:
https://classifields.ru
Давайте обсудим это подробнее.
https://www.rwaq.org/users/bushdavina51-20250802105259
Как раз то, что нужно для решения этого вопроса:
Между прочим, если вас интересует obender.ru, посмотрите сюда.
Ссылка ниже:
https://obender.ru
Может, у кого-то есть другой опыт?
magic 365 – najlepsze kasyno online z bonusami i szybką rejestracją w Polsce!
https://b2best.at
Посмотрите, что я нашел по этому поводу:
Особенно понравился материал про qazar.ru.
Вот, можете почитать:
https://qazar.ru
Поделитесь своими мыслями в комментариях.
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk006.ru
экстренный вывод из запоя челябинск
https://potofu.me/u8klvj8i
пансионат для пожилых
pansionat-tula005.ru
дом престарелых
Если кому интересно, вот более детальная информация:
Для тех, кто ищет информацию по теме “travelcrimea.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://travelcrimea.ru
Всем мира и продуктивного дня
melbet ilovasi http://www.melbet1039.ru
Если нужна более подробная инструкция, то она здесь:
Для тех, кто ищет информацию по теме “diyworks.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://diyworks.ru
Спасибо, что дочитали до конца.
https://ucgp.jujuy.edu.ar/profile/uahquibfnv/
Вот здесь можно найти больше примеров:
Хочу выделить раздел про hotelnews.ru.
Смотрите сами:
https://hotelnews.ru
Успехов в решении вашего вопроса!
Делюсь с вами полезной ссылкой по теме:
Кстати, если вас интересует reactive.su, посмотрите сюда.
Ссылка ниже:
https://reactive.su
Надеюсь, смог помочь.
https://www.band.us/band/99520477/
Уверен, эта информация будет для вас полезна:
Особенно понравился раздел про detoxa.ru.
Ссылка ниже:
https://detoxa.ru
Интересно было бы узнать ваше мнение.
Как вариант, можно рассмотреть следующее:
По теме “obender.ru”, есть отличная статья.
Смотрите сами:
https://obender.ru
Уверен, вместе мы найдем решение.
https://pxlmo.com/badboyfunnyfun7
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Особенно понравился раздел про fjhg.ru.
Ссылка ниже:
https://fjhg.ru
Надеюсь, эта информация сэкономит вам время.
Для тех, кто в теме, будет очень актуально:
Хочу выделить раздел про avelonbeta.ru.
Ссылка ниже:
https://avelonbeta.ru
Буду следить за обсуждением.
https://pxlmo.com/lilysomeSSnyderfi
Чтобы было понятнее, о чем речь:
По теме “fk-almazalrosa.ru”, есть отличная статья.
Смотрите сами:
https://fk-almazalrosa.ru
Надеюсь, у вас все получится.
провайдер по адресу
nizhnij-novgorod-domashnij-internet006.ru
провайдеры по адресу
Давно слежу за этой темой, хочу поделиться находкой:
Кстати, если вас интересует anclaves.ru, посмотрите сюда.
Ссылка ниже:
https://anclaves.ru
Интересно было бы узнать ваше мнение.
https://ucgp.jujuy.edu.ar/profile/xihociaehyci/
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует yogapulse.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://yogapulse.ru
Уверен, вместе мы найдем решение.
https://bs2bsme.at
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует idalgogrif.ru, посмотрите сюда.
Ссылка ниже:
https://idalgogrif.ru
Чем мог, тем помог.
https://git.project-hobbit.eu/qoygudobogf
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует pro-zenit.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Уверен, вместе мы найдем решение.
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Кстати, если вас интересует yogapulse.ru, посмотрите сюда.
Вот, можете почитать:
https://yogapulse.ru
Жду ваших комментариев.
вывод из запоя цена
vivod-iz-zapoya-cherepovec007.ru
лечение запоя череповец
https://www.brownbook.net/business/54138295/купить-марихуану-гашиш-канабис-любек/
Уверен, эта информация будет для вас полезна:
Между прочим, если вас интересует cyq.ru, загляните сюда.
Смотрите сами:
https://cyq.ru
Жду конструктивной критики.
Explore countless engaging and practical materials on this site .
Covering detailed tutorials to quick tips , there’s something matching your interests.
Keep updated with regularly updated content designed to assist while also entertain visitors.
Our platform delivers a user-friendly navigation ensuring you can discover the information right away.
Connect with of thousands of users and rely on reliable insights consistently.
Begin your journey immediately and unlock the full potential these resources delivers.
https://helpfloodedserbia.org
Вот отличный материал, который проливает свет на ситуацию:
Зацепил раздел про fjhg.ru.
Ссылка ниже:
https://fjhg.ru
Что думаете по этому поводу?
https://imageevent.com/uvloveerdemn/flfzk
Долго искал решение и наконец-то нашел:
Кстати, если вас интересует mersobratva.ru, загляните сюда.
Вот, можете почитать:
https://mersobratva.ru
Какие еще есть варианты?
дом престарелых в туле
pansionat-tula006.ru
дом престарелых
На сайте https://expertbp.ru/ получите абсолютно бесплатную консультацию от бюро переводов. Здесь вы сможете заказать любую нужную услугу, в том числе, апостиль, нотариальный перевод, перевод свидетельства о браке. Также доступно и срочное оказание услуги. В компании трудятся только лучшие, квалифицированные, знающие переводчики с большим опытом. Услуга будет оказана в ближайшее время. Есть возможность воспользоваться качественным переводом независимо от сложности. Все услуги оказываются по привлекательной цене.
tron swap
Вот здесь можно найти больше примеров:
По теме “seatours.ru”, там просто кладезь информации.
Смотрите сами:
https://seatours.ru
Интересно было бы узнать ваше мнение.
https://paper.wf/uybqudybu/bremen-kupit-kokain-mefedron-marikhuanu
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился материал про cyq.ru.
Вот, можете почитать:
https://cyq.ru
Давайте обсудим это подробнее.
Посмотрите, что я нашел по этому поводу:
Особенно понравился раздел про qazar.ru.
Вот, делюсь ссылкой:
https://qazar.ru
Давайте обсудим это подробнее.
https://hub.docker.com/u/StaciroseroseStaci101994
Как вариант, можно рассмотреть следующее:
Для тех, кто ищет информацию по теме “easyterm.ru”, нашел много полезного.
Вот, можете почитать:
https://easyterm.ru
Надеюсь, смог помочь.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Между прочим, если вас интересует m-admin.ru, загляните сюда.
Вот, делюсь ссылкой:
https://m-admin.ru
Дайте знать, если найдете что-то еще.
https://bs2-bs2site.at
https://say.la/read-blog/122091
Как вариант, можно рассмотреть следующее:
Кстати, если вас интересует buytime.ru, загляните сюда.
Смотрите сами:
https://buytime.ru
Что думаете по этому поводу?
Чтобы не быть голословным, прикрепляю ссылку:
Между прочим, если вас интересует fixora.ru, загляните сюда.
Вот, можете почитать:
https://fixora.ru
Всем добра!
Подключение интернет-услуг в столице необходимо осмотрительного подхода к выбору провайдера и тарифного плана. На сайте novosibirsk-domashnij-internet004.ru доступны посмотреть современные тарифы на интернет от множества операторов связи. При сравнении предложений важно обратить внимание на скорость интернета и стабильность соединения, так как это ключевые факторы для удобного использования. Кроме того, рекомендуется обратить внимание на специальные предложения и акции, которые предлагают операторы, чтобы сэкономить на подключении. Услуги связи часто включают дополнительные опции, такие как IP-телефония или кабельное телевидение. Обязательно читать отзывы о провайдерах, чтобы получить информацию о реальном опыте пользователей. Определение подходящего тарифного пакета основан от ваших потребностей: для домашнего использования подойдут одни условия, а для портативного доступа — совершенно отличные. Сравните предложения, чтобы подобрать наиболее подходящее решение для ваших целей!
https://www.band.us/band/99519097/
Полностью поддерживаю, и вот еще одно подтверждение:
Кстати, если вас интересует musichunt.pro, загляните сюда.
Вот, делюсь ссылкой:
https://musichunt.pro
Поделитесь своими мыслями в комментариях.
Исчерпывающий ответ на данный вопрос находится тут:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, есть отличная статья.
Ссылка ниже:
https://tars-rubber.ru
Буду признателен за ваши отзывы.
Descubra tudo sobre o tigrinho no site mais confiavel do Brasil – jogue com responsabilidade
https://www.band.us/band/99499289/
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует eroticpic.ru, посмотрите сюда.
Вот, можете почитать:
https://eroticpic.ru
Надеюсь, эта информация сэкономит вам время.
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec008.ru
экстренный вывод из запоя череповец
Ищете, где заказать надежную кухню на заказ по вашим размерам за адекватные деньги? Посмотрите портфолио кухонной фабрики GLORIA – https://gloriakuhni.ru/ – все проекты выполнены в Санкт-Петербурге и области. На каждую кухню гарантия 36 месяцев, более 800 цветовых решений. Большое разнообразие фурнитуры. Удобный онлайн-калькулятор прямо на сайте и понятное формирование цены. Много отзывов клиентов, видео-обзоры кухни с подробностями и деталями. Для всех клиентов – столешница и стеновая панель в подарок.
Вот, что говорят эксперты по этому поводу:
Хочу выделить раздел про 095hotel.ru.
Смотрите сами:
https://095hotel.ru
Буду рад, если кому-то пригодится.
https://potofu.me/qpzo154p
Чтобы разобраться в вопросе, рекомендую ознакомиться:
По теме “spb-hotels.ru”, есть отличная статья.
Смотрите сами:
https://spb-hotels.ru
Давайте обсудим это подробнее.
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, там просто кладезь информации.
Смотрите сами:
https://tars-rubber.ru
Успехов в решении вашего вопроса!
топливные карты для юридических лиц
На сайте https://rusvertolet.ru/ воспользуйтесь возможностью заказать незабываемый, яркий полет на вертолете. Вы гарантированно получите много положительных впечатлений, удивительных эмоций. Важной особенностью компании является то, что полет состоится по приятной стоимости. Вертолетная площадка расположена в городе, а потому просто добраться. Компания работает без выходных, потому получится забронировать полет в любое время. Составить мнение о работе помогут реальные отзывы. Прямо сейчас ознакомьтесь с видами полетов и их расписанием.
https://allmynursejobs.com/author/jlallidgjd/
Долго искал решение и наконец-то нашел:
Для тех, кто ищет информацию по теме “fjhg.ru”, там просто кладезь информации.
Вот, можете почитать:
https://fjhg.ru
Интересно было бы узнать ваше мнение.
O unico site verdadeiro do tigrinho esta aqui – entre agora e ganhe
Возможно, это будет полезно участникам обсуждения:
Особенно понравился материал про musichunt.pro.
Смотрите сами:
https://musichunt.pro
Буду признателен за ваши отзывы.
https://potofu.me/tbbk84cb
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “fjhg.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://fjhg.ru
Интересно было бы узнать ваше мнение.
экстренный вывод из запоя
tula-narkolog001.ru
лечение запоя
Давно слежу за этой темой, хочу поделиться находкой:
По теме “easyterm.ru”, нашел много полезного.
Ссылка ниже:
https://easyterm.ru
Всем добра!
https://potofu.me/7gy5gbsx
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Особенно понравился раздел про all-hotels-online.ru.
Вот, делюсь ссылкой:
https://all-hotels-online.ru
Надеюсь, смог помочь.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “komandor-povolje.ru”, нашел много полезного.
Ссылка ниже:
https://komandor-povolje.ru
Всем мира и продуктивного дня
Cómo se puede ganar en el blackjack Si eres nuevo en los casinos en línea, las cuales están incorporadas en las rondas de juego. Una vez que tengas clara la apuesta en el juego, es momento de hacer girar los carretes. Para ganar en Big Bass Bonanza 3 Reeler tienes que lograr que tres o más símbolos coincidan en una de las 5 líneas de pago. Las ganancias se otorgan de izquierda a derecha. Bonos VIP por jugar Big bass bonanza. Recolectar suficientes símbolos en un grupo es vital, el mundo de los juegos de azar en línea se ha vuelto más complejo recientemente. Con frecuencia hizo un fuerte contacto, y algunos casinos son legítimos. Operated by TSG Interactive Gaming Europe Limited, a company registered in Malta under No. C54266, with registered office at Spinola Park, Level 2, Triq Mikiel Ang Borg, St Julians SPK 1000, Malta. License No. MGA B2C 213 2011, awarded on August 1, 2018. Maltese VAT-ID MT24413927. Online gambling is regulated in Malta by the Malta Gaming Authority.
https://bicisinedad.org/2025/08/06/review-de-balloon-de-smartsoft-gaming-donde-jugar-y-descargar-desde-mexico/
Si no estás disfrutando de nuestros juegos o crees que tienes problemas con el juego, te recomendamos que contactes con nuestro Servicio de Atención al Cliente para obtener ayuda o, accedas a nuestras herramientas que encontrarás desde el apartado JUEGO MÁS SEGURO Querido usuario,Estamos muy contentos de escucharle con palabras tan amables.Nos alegra saber que le gustan nuestras tragamonedas.¡Te deseamos muchos giros de suerte! Consulta nuestras vacantes en casumocareers Reel Rush ofrece giros gratis muy interesantes. Después del quinto giro, se descubre la función especial de 8 giros gratis y los jugadores tienen la oportunidad de obtener más recompensas. Por lo tanto, después de obtener 6 ganancias seguidas, la cantidad de giros gratis se mantendrá constante en 8. La tragaperras no tiene reactivadores. Durante esta función, el símbolo de comodín todavía tiene el poder de sustituir a todos los demás símbolos.
https://kemono.im/wgifacyeby/korfu-kupit-ekstazi-mdma-lsd-kokain
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил раздел про fixora.ru.
Смотрите сами:
https://fixora.ru
Рад был поделиться информацией.
курсы бровиста Перманентный Макияж Бровей Севастополь: Безупречные Брови
bonus pariuri online https://www.1win40009.ru
Вот здесь можно найти больше примеров:
Кстати, если вас интересует anclaves.ru, загляните сюда.
Смотрите сами:
https://anclaves.ru
Уверен, вместе мы найдем решение.
https://bs2bet.at
https://rant.li/icuigyfo/estoniia-kupit-kokain-mefedron-marikhuanu
Hi there excellent blog! Does running a blog such as this take a lot of work? I have no expertise in coding however I had been hoping to start my own blog in the near future. Anyhow, if you have any ideas or techniques for new blog owners please share. I know this is off subject however I just had to ask. Kudos!
cat casino вход
Для тех, кто в теме, будет очень актуально:
По теме “eqa.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://eqa.ru
Какие еще есть варианты?
В столице России существует множество интернет-провайдеров, и выбор подходящего может быть непростым. Следует обращать внимание на мнения пользователей, чтобы создать объективное мнение о качестве услуг. На сайте novosibirsk-domashnij-internet005.ru можно найти актуальный рейтинг провайдеров, учитывающий скорость интернета, качество связи и стоимость тарифов. Кроме того, стоит обратить внимание на клиентский сервис и техническую поддержку. Надежные провайдеры гарантируют устойчивое соединение и разнообразные доступные тарифы. Не забудьте проверить акциях и скидках, которые могут значительно снизить стоимость подключения интернета для дома. Сравнение провайдеров поможет выбрать оптимальный вариант, удовлетворяющий вашим потребностям. Пользуйтесь отзывами и рейтингами для выбора надежного интернет-провайдера в новосибирске!
Посмотрите, что я нашел по этому поводу:
По теме “travelmontenegro.ru”, нашел много полезного.
Ссылка ниже:
https://travelmontenegro.ru
Буду рад, если кому-то пригодится.
https://www.brownbook.net/business/54138840/купить-экстази-кокаин-амфетамин-майорка/
Исчерпывающий ответ на данный вопрос находится тут:
Особенно понравился раздел про eroticpic.ru.
Ссылка ниже:
https://eroticpic.ru
Может, у кого-то есть другой опыт?
вывод из запоя цена
vivod-iz-zapoya-cherepovec009.ru
экстренный вывод из запоя череповец
Turkiye’nin en iyi urunleri Gunluk Burc Yorumu: Y?ld?zlar Ne Soyluyor? Burc yorumlar?, bircok insan icin gunluk yasam?n eglenceli bir parcas?. Gunluk burc yorumlar?, y?ld?zlar?n hareketlerine gore kisisel ozellikler ve olas? olaylar hakk?nda ipuclar? sunuyor. Kimi insanlar icin sadece eglence kaynag? olsa da, kimileri icin yol gosterici olabiliyor.
Посмотрите, что я нашел по этому поводу:
Особенно понравился раздел про m-admin.ru.
Смотрите сами:
https://m-admin.ru
Чем мог, тем помог.
трипскан
https://git.project-hobbit.eu/icbybiigay
Очень рекомендую к прочтению:
Между прочим, если вас интересует mersobratva.ru, загляните сюда.
Вот, делюсь ссылкой:
https://mersobratva.ru
Может, у кого-то есть другой опыт?
Hey fantastic website! Does running a blog such as this require a lot of work? I’ve very little expertise in computer programming however I was hoping to start my own blog soon. Anyways, if you have any ideas or tips for new blog owners please share. I know this is off subject however I simply had to ask. Thanks!
вход зума казино
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует tars-rubber.ru, посмотрите сюда.
Вот, можете почитать:
https://tars-rubber.ru
Надеюсь, смог помочь.
tron defi swap
Kalkulator zakładów sportowych Aviator 1win to specjalny program, który pomaga wykonać obliczenia w ciągu kilku sekund. 1Win օprасօwаł аplikасję mօbilną, którа օbsługujе zаrównօ sуstеmу iOS, jаk i Andrօid. Grаniе zа pօśrеdniсtwеm tаblеtów i smаrtfօnów jеst wуgօdnе. Pօtrzеbujеsz tуlkօ wуstаrсzаjąсусh śrօdków nа kօnсiе i dօbrеgօ dօstępu dօ Intеrnеtu, аbу сiеszуć się Plinkօ. Pin Up, Mostbet, 22bet, 1win i Bet365 dołączyły do programu Aviator, wzbogacając swoje katalogi gier o ekscytujący nowy wymiar zabawy. Zróbmy krótką wycieczkę po tym, co każde z nich oferuje. Wspօminаliśmу już, żе Plinkօ mа sеtki wеrsji, а większօść z niсh mօżnа zօbасzуć i zаgrаć nа 1Win. Niе tуlkօ strօnу hаzаrdօwе օnlinе są bаrdzօ zаintеrеsօwаnе tą grą, аlе tаkżе twórсу giеr stwօrzуli օdmiаnу inspirօwаnе Plinkօ. Mօżеsz nаpօtkаć różnе tуtułу Plinkօ pօdсzаs օdkrуwаniа pօrtfօliօ giеr 1Win. Sprаwdź niеktórе z niсh, сzуtаjąс kօlеjnе sеkсjе.
https://www.forevermayllc.com/jak-szybko-i-bezpiecznie-zalogowac-sie-do-kasyna-vavada/
Jeśli szukasz dobrego kasyna, w którym możesz zagrać w Sugar Rush na prawdziwe pieniądze, musisz zwrócić uwagę na kilka kluczowych czynników. Po pierwsze, upewnij się, że kasyno posiada licencję lub jakąś formę akceptacji ze strony regulatora. Po drugie, sprawdź, jakie opinie mają inni gracze, jaką ofertę kasyno zapewnia i jak dba o bezpieczeństwo Twoich danych. Dodatkowym plusem są atrakcyjne bonusy dla graczy. A figure suddenly reared up in front of me. “Whoa, whoa, little lady, what’s the rush?” Jeśli szukasz dobrego kasyna, w którym możesz zagrać w Sugar Rush na prawdziwe pieniądze, musisz zwrócić uwagę na kilka kluczowych czynników. Po pierwsze, upewnij się, że kasyno posiada licencję lub jakąś formę akceptacji ze strony regulatora. Po drugie, sprawdź, jakie opinie mają inni gracze, jaką ofertę kasyno zapewnia i jak dba o bezpieczeństwo Twoich danych. Dodatkowym plusem są atrakcyjne bonusy dla graczy.
https://community.wongcw.com/blogs/1125096/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%9A%D0%B0%D0%BD%D0%B0%D1%80%D1%81%D0%BA%D0%B8%D0%B5-%D0%BE%D1%81%D1%82%D1%80%D0%BE%D0%B2%D0%B0
Бывают такие ситуации, когда требуется помощь хакеров, которые быстро, эффективно справятся с самой сложной задачей. Хакеры легко вскроют почту, добудут пароли, обеспечат защиту. Для решения задачи применяются только проверенные, эффективные способы. Любой хакер отличается большим опытом. https://hackerlive.biz – портал, где работают только проверенные, знающие хакеры. За свою работу они не берут большие деньги. Все работы высокого качества. В данный момент напишите тому хакеру, который соответствует предпочтениям.
Чтобы не быть голословным, прикрепляю ссылку:
Зацепил материал про eqa.ru.
Смотрите сами:
https://eqa.ru
Чем мог, тем помог.
Fantastic site you have here but I was wanting to know if you knew of any community forums that cover the same topics discussed here? I’d really like to be a part of online community where I can get responses from other knowledgeable people that share the same interest. If you have any suggestions, please let me know. Appreciate it!
вход lee bet casino
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “classifields.ru”, там просто кладезь информации.
Смотрите сами:
https://classifields.ru
Надеюсь, эта информация сэкономит вам время.
https://hoo.be/abudobpu
Долго искал решение и наконец-то нашел:
Хочу выделить материал про seatours.ru.
Вот, можете почитать:
https://seatours.ru
Спасибо, что дочитали до конца.
1win 500% 1win 500%
На сайте https://iziclick.ru/ в большом ассортименте представлены телевизоры, аксессуары, а также компьютерная техника, приставки, мелкая бытовая техника. Все товары от лучших, проверенных марок, потому отличаются долгим сроком эксплуатации, надежностью, практичностью, простотой в применении. Вся техника поставляется напрямую со склада производителя. Продукция является оригинальной, сертифицированной. Реализуется по привлекательным расценкам, зачастую устраиваются распродажи для вашей большей выгоды.
Исчерпывающий ответ на данный вопрос находится тут:
Зацепил материал про cyq.ru.
Смотрите сами:
https://cyq.ru
Всем мира и продуктивного дня
https://community.wongcw.com/blogs/1123731/%D0%92%D0%B0%D1%80%D1%88%D0%B0%D0%B2%D0%B0-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%91%D0%BE%D1%88%D0%BA%D0%B8
вывод из запоя тула
tula-narkolog002.ru
вывод из запоя круглосуточно
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует fixora.ru, загляните сюда.
Вот, можете почитать:
https://fixora.ru
Надеюсь, это было полезно.
http://victorpetlura.com/content/file/pages/betvinner_promokodu_pri_registracii_na_bonus_25000.html
Если нужна более подробная инструкция, то она здесь:
Зацепил материал про buytime.ru.
Ссылка ниже:
https://buytime.ru
Интересно было бы узнать ваше мнение.
Lucknow Game: Immerse yourself in the cultural heritage of Lucknow, solving puzzles and exploring iconic landmarks to uncover hidden treasures: Lucknow game reviews
https://www.brownbook.net/business/54138314/купить-экстази-кокаин-амфетамин-манчестер/
https://git.project-hobbit.eu/bebodpoogafd
Как раз то, что нужно для решения этого вопроса:
Хочу выделить раздел про eroticpic.ru.
Ссылка ниже:
https://eroticpic.ru
Обращайтесь, если что.
https://www.passes.com/bombalwangen
Чтобы разобраться в вопросе, рекомендую ознакомиться:
По теме “avelonbeta.ru”, нашел много полезного.
Вот, можете почитать:
https://avelonbeta.ru
Если у вас есть что добавить, не стесняйтесь.
https://bs2-bs2site.at
https://potofu.me/dck9l8qm
https://www.passes.com/mmoufidaloly
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует parkpodarkov.ru, посмотрите сюда.
Ссылка ниже:
https://parkpodarkov.ru
Надеюсь, эта информация сэкономит вам время.
jocuri de noroc online moldova jocuri de noroc online moldova
На сайте https://cvetochnik-doma.ru/ вы найдете полезную информацию, которая касается комнатных растений, ухода за ними. На портале представлена информация о декоративно-лиственных растениях, суккулентах. Имеются материалы о цветущих растениях, папоротниках, пальмах, луковичных, экзотических, вьющихся растениях, орхидеях. Для того чтобы найти определенную информацию, воспользуйтесь специальным поиском, который подберет статью на основе запроса. Для большей наглядности статьи сопровождаются красочными фотографиями.
https://itravel-vl.ru
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует diyworks.ru, загляните сюда.
Вот, можете почитать:
https://diyworks.ru
Буду следить за обсуждением.
https://peynit.ru
Проводной интернет в новосибирске предоставляет множество тарифов от различных провайдеров интернета. Ключевые плюсы состоят в высокой скорости и надежности доступа к интернету. Однако, с увеличением числа пользователей возрастает важность безопасности данных и конфиденциальности. Интернет-провайдеры обязаны обеспечивать безопасность данных и защиту от сетевых угроз. Применение VPN-сервисов способно дополнительно повысить уровень конфиденциальности пользователей. Важно выбирать услуги провайдеров, которые гарантируют защиту данных и соответствие стандартам по защите личной информации. провайдеры интернета по адресу новосибирск Интернет-подключение становится не только лишь комфортным и защищеннымпри условии учета всех факторов.
https://crocus-opt.ru
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует spb-hotels.ru, загляните сюда.
Ссылка ниже:
https://spb-hotels.ru
Если у вас есть что добавить, не стесняйтесь.
экстренный вывод из запоя иркутск
vivod-iz-zapoya-irkutsk004.ru
вывод из запоя цена
https://cdo-aw.ru
https://tavatuy-rzd.ru
https://sbitnevsv.livejournal.com/category/СЂРѕСЃСЃРёСЏ
Всем привет, нашел интересную информацию по теме:
По теме “obender.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://obender.ru
Уверен, вместе мы найдем решение.
https://singadent.ru
Интернет магазин электроники «IZICLICK.RU» предлагает высококачественные товары. У нас можете купить: мониторы, принтеры, моноблоки, сканеры и МФУ, ноутбуки, телевизоры и другое. Гарантируем доступные цены и выгодные предложения. Стремимся сделать ваши покупки максимально комфортными. https://iziclick.ru – сайт, где вы найдете детальные описания товара, характеристики, фотографии и отзывы. Предоставим вам профессиональную консультацию и поможем сделать оптимальный выбор. Доставим ваш заказ по Москве и области.
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “obender.ru”, там просто кладезь информации.
Вот, можете почитать:
https://obender.ru
Всем спасибо, и до новых встреч!
https://vlgprestol.online
https://glavkupol.ru
Полагаю, это снимет все дальнейшие вопросы:
Для тех, кто ищет информацию по теме “reactive.su”, нашел много полезного.
Ссылка ниже:
https://reactive.su
Спасибо, что дочитали до конца.
Посетите сайт https://ambenium.ru/ и вы сможете ознакомиться с Амбениум – единственный нестероидный противовоспалительный препарат зарегистрированный в России с усиленным обезболивающим эффектом – раствор для внутримышечного введения фенилбутазон и лидокаин. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства.
https://tavatuy-rzd.ru
Посмотрите, что я нашел по этому поводу:
Особенно понравился раздел про travelmontenegro.ru.
Ссылка ниже:
https://travelmontenegro.ru
Интересно было бы узнать ваше мнение.
https://rostokino-dez.online
https://vintage-nsk.online
Проверенные способы заработка в интернете
Вот здесь подробно расписано, как это сделать:
Особенно понравился материал про classifields.ru.
Смотрите сами:
https://classifields.ru
Обращайтесь, если что.
https://printbarglobal.ru
Полагаю, это снимет все дальнейшие вопросы:
По теме “phenoma.ru”, там просто кладезь информации.
Вот, можете почитать:
https://phenoma.ru
Интересно было бы узнать ваше мнение.
https://ooo-mitsar.online
https://crocus-opt.ru
Кстати, вот что я думаю по этому поводу:
Кстати, если вас интересует diyworks.ru, загляните сюда.
Ссылка ниже:
https://diyworks.ru
Надеюсь, это было полезно.
השולחן בעקבים, שם היא מצאה את עצמה מיד בזרועותיו של גבר חתיך שרירי וערום. ויקה לא רצתה להביט כמה קוקטיילים, כשההידוק שלה התמוסס לאלכוהול. והוא החליט: הגיע הזמן לפעול. מקס בחר את הרגע בצורה מכון עיסוי בתל אביב – מה באמת קורה שם?
https://abz-istok.online
https://github.com/forti-cli/FortiClient-VPN/releases
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить раздел про yogapulse.ru.
Вот, делюсь ссылкой:
https://yogapulse.ru
Буду признателен за ваши отзывы.
https://rbx-shop.ru
https://pro-store-apple.ru
https://t.me/verdecasino1
Очень рекомендую к прочтению:
Хочу выделить раздел про raregreen.ru.
Вот, делюсь ссылкой:
https://raregreen.ru
Уверен, вместе мы найдем решение.
https://art-of-pilates.ru
https://t.me/winpotcasino1
лечение запоя
tula-narkolog003.ru
вывод из запоя
Посмотрите, что я нашел по этому поводу:
Между прочим, если вас интересует m-admin.ru, посмотрите сюда.
Ссылка ниже:
https://m-admin.ru
Жду ваших комментариев.
https://montera-kurort.ru
https://cdo-aw.ru
На сайте https://kino.tartugi.name/kolektcii/garri-potter-kolekciya посмотрите яркий, динамичный и интересный фильм «Гарри Поттер», который представлен здесь в отменном качестве. Картинка находится в высоком разрешении, а звук многоголосый, объемный, поэтому просмотр принесет исключительно приятные, положительные эмоции. Фильм подходит для просмотра как взрослыми, так и детьми. Просматривать получится на любом устройстве, в том числе, мобильном телефоне, ПК, планшете. Вы получите от этого радость и удовольствие.
Это именно то, что я искал!
Кстати, если вас интересует fjhg.ru, загляните сюда.
Вот, делюсь ссылкой:
https://fjhg.ru
Обращайтесь, если что.
https://itravel-vl.ru
https://bsmc.at
https://vlgprestol.online
https://rostokino-dez.online
Для тех, кто в теме, будет очень актуально:
Между прочим, если вас интересует buytime.ru, посмотрите сюда.
Вот, можете почитать:
https://buytime.ru
Может, у кого-то есть другой опыт?
https://shatura-stupino.ru
Посмотрите, что я нашел по этому поводу:
Хочу выделить материал про tars-rubber.ru.
Вот, делюсь ссылкой:
https://tars-rubber.ru
Надеюсь, эта информация сэкономит вам время.
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk005.ru
экстренный вывод из запоя
https://rbx-shop.ru
Полагаю, это снимет все дальнейшие вопросы:
Зацепил раздел про hotelnews.ru.
Вот, можете почитать:
https://hotelnews.ru
Интересно было бы узнать ваше мнение.
домашний интернет тарифы омск
omsk-domashnij-internet004.ru
домашний интернет тарифы
https://cashparfum.ru
Долго искал решение и наконец-то нашел:
Между прочим, если вас интересует m-admin.ru, посмотрите сюда.
Вот, можете почитать:
https://m-admin.ru
Может, у кого-то есть другой опыт?
https://glavkupol.ru
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Для тех, кто ищет информацию по теме “qazar.ru”, там просто кладезь информации.
Вот, можете почитать:
https://qazar.ru
Может, у кого-то есть другой опыт?
https://belovahair.online
Возможно, это будет полезно участникам обсуждения:
Хочу выделить материал про anclaves.ru.
Ссылка ниже:
https://anclaves.ru
Жду конструктивной критики.
https://orientirum.online
https://vintage-nsk.online
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Хочу выделить материал про m-admin.ru.
Смотрите сами:
https://m-admin.ru
Буду рад, если кому-то пригодится.
https://art-vis.ru
https://somovarmor.ru
Вот здесь подробно расписано, как это сделать:
Хочу выделить раздел про musichunt.pro.
Смотрите сами:
https://musichunt.pro
Надеюсь, это было полезно.
https://kanscity.online
https://alar8.online
На мой взгляд, лучшее решение этой проблемы здесь:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, нашел много полезного.
Вот, можете почитать:
https://tars-rubber.ru
Всем удачи и хорошего дня!
https://vintage-nsk.online
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Для тех, кто ищет информацию по теме “musichunt.pro”, там просто кладезь информации.
Ссылка ниже:
https://musichunt.pro
Буду рад, если кому-то пригодится.
https://belovahair.online
https://tavatuy-rzd.ru
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Хочу выделить раздел про seatours.ru.
Смотрите сами:
https://seatours.ru
Дайте знать, если найдете что-то еще.
https://pointgtoys.ru
Полностью поддерживаю, и вот еще одно подтверждение:
Между прочим, если вас интересует reactive.su, загляните сюда.
Смотрите сами:
https://reactive.su
Обращайтесь, если что.
https://kanscity.online
https://peynit.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил раздел про localflavors.ru.
Ссылка ниже:
https://localflavors.ru
Какие еще есть варианты?
https://singadent.ru
https://kanscity.online
Вот здесь подробно расписано, как это сделать:
Хочу выделить материал про avelonbeta.ru.
Ссылка ниже:
https://avelonbeta.ru
Чем мог, тем помог.
лечение запоя челябинск
vivod-iz-zapoya-chelyabinsk004.ru
вывод из запоя
https://bs2-bs2site.at
novosibirsk camera
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Между прочим, если вас интересует clasifieds.ru, загляните сюда.
Вот, делюсь ссылкой:
https://clasifieds.ru
Жду конструктивной критики.
https://vashdomufa.ru
https://vlgprestol.online
лечение запоя
vivod-iz-zapoya-irkutsk006.ru
лечение запоя иркутск
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “mersobratva.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://mersobratva.ru
Пишите, что у вас получилось.
https://oknapsk.online
Топливные карты для юр лиц
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “qazar.ru”, нашел много полезного.
Ссылка ниже:
https://qazar.ru
Если у вас есть что добавить, не стесняйтесь.
Rainbet Australia
https://alar8.online
подключить интернет тарифы омск
omsk-domashnij-internet005.ru
провайдеры омск
Как раз то, что нужно для решения этого вопроса:
Зацепил материал про yogapulse.ru.
Ссылка ниже:
https://yogapulse.ru
Жду ваших комментариев.
https://telegra.ph/EHlektronasosy-umenshenie-ehnergozatrat-i-povyshenie-KPD-08-02
Commencez à trader en toute confiance avec pocket option broker et profitez d’une plateforme intuitive et performante
Юхнов
https://bestforum.forum-top.ru/viewtopic.php?id=3167#p5806
Rainbet Casino
Hand Sanitisers
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “fk-almazalrosa.ru”, есть отличная статья.
Вот, можете почитать:
https://fk-almazalrosa.ru
Буду рад, если кому-то пригодится.
Деревня Кей Колкер
https://rostokino-dez.online
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Хочу выделить раздел про raregreen.ru.
Вот, делюсь ссылкой:
https://raregreen.ru
Буду следить за обсуждением.
Майский
Rz-Work – биржа для новичков и опытных профессионалов, готовых к ответственной работе. Популярность у фриланс-сервиса высокая. Преимущества, которые пользователи выделили: оперативное реагирование службы поддержки, простота регистрации, гарантия безопасности сделок. https://rz-work.ru – тут более детальная информация представлена. Rz-Work является платформой, способствующей эффективному взаимодействию исполнителей и заказчиков. Она понятным интерфейсом отличается. Площадка многопрофильная, охватывающая множество категорий.
Вот отличный материал, который проливает свет на ситуацию:
По теме “diyworks.ru”, нашел много полезного.
Смотрите сами:
https://diyworks.ru
Спасибо, что дочитали до конца.
Голицыно
https://vlgprestol.online
Топливные карты для юр лиц
Компания «РусВертолет» занимает среди конкурентов по качеству услуг и приемлемой ценовой политики лидирующие позиции. В неделю мы 7 дней работаем. Наш основной приоритет – ваша безопасность. Вертолеты в отменном состоянии, оперативно полет заказать вы на ресурсе можете. Обеспечим вам море ярких и положительных эмоций! Ищете где покататься +а вертолете? Rusvertolet.ru – здесь есть фотографии и видео полетов, а также отзывы довольных клиентов. Вы узнаете, как добраться и где мы находимся. Подготовили ответы на популярные вопросы о полетах на вертолете. Рады вам всегда!
Крым
Чтобы было понятнее, о чем речь:
Зацепил раздел про idalgogrif.ru.
Ссылка ниже:
https://idalgogrif.ru
Рад был поделиться информацией.
https://telegra.ph/Separatory-slivkootdeliteli-na-krupnyh-zavodah-08-02
Актобе
https://orientirum.online
Вот отличный материал, который проливает свет на ситуацию:
Зацепил раздел про all-hotels-online.ru.
Ссылка ниже:
https://all-hotels-online.ru
Если у вас есть что добавить, не стесняйтесь.
Северное Бутово
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Особенно понравился раздел про idalgogrif.ru.
Смотрите сами:
https://idalgogrif.ru
Интересно было бы узнать ваше мнение.
Тетри-Цкаро
https://kanscity.online
Исчерпывающий ответ на данный вопрос находится тут:
Для тех, кто ищет информацию по теме “detoxa.ru”, там просто кладезь информации.
Вот, можете почитать:
https://detoxa.ru
Всем добра!
https://bsmc.at
раскрутка в соц. сетях бесплатно
Новоалтайск
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Зацепил материал про avelonbeta.ru.
Вот, можете почитать:
https://avelonbeta.ru
Надеюсь, эта информация сэкономит вам время.
Жуковский
https://telegra.ph/Separatory-slivkootdeliteli-i-optimizaciya-proizvodstva-masla-08-02
https://vintage-nsk.online
Tambola Game: A fun and fast-paced number-bingo experience, perfect for family gatherings, parties, and competitive fun: best Tambola game apps
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует musichunt.pro, посмотрите сюда.
Ссылка ниже:
https://musichunt.pro
Если у вас есть что добавить, не стесняйтесь.
Салала
https://psychedelic.ru/vse-obo-vsem/12748-cardirin-tsena-i-kachestvo-ekspertnyy-obzor-naturalnyh-kapel-ot-gipertonii
Биль-Бьен
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует travelcrimea.ru, посмотрите сюда.
Ссылка ниже:
https://travelcrimea.ru
Рад был поделиться информацией.
https://citywolf.online
https://zhenskiyray.ru/kak-ya-spravilsya-s-gipertoniey-moy-opyt-s-cardirin/
На сайте https://selftaxi.ru/ вы сможете задать вопрос менеджеру для того, чтобы узнать всю нужную информацию о заказе минивэнов, микроавтобусов. В парке компании только исправная, надежная, проверенная техника, которая работает отлаженно и никогда не подводит. Рассчитайте стоимость поездки прямо сейчас, чтобы продумать бюджет. Вся техника отличается повышенной вместимостью, удобством. Всегда в наличии несколько сотен автомобилей повышенного комфорта. Прямо сейчас ознакомьтесь с тарифами, которые всегда остаются выгодными.
лечение запоя
vivod-iz-zapoya-chelyabinsk005.ru
экстренный вывод из запоя челябинск
melbet полная версия https://melbet1040.ru
экстренный вывод из запоя
vivod-iz-zapoya-kaluga007.ru
лечение запоя
Франкфурт-на-Майне
Возможно, это будет полезно участникам обсуждения:
Зацепил раздел про rustrail.ru.
Смотрите сами:
https://rustrail.ru
Если есть вопросы, задавайте.
Иордания
https://violahouse.ru/2025/07/09/cardirin-naturalnoe-sredstvo-dlya-borby-s-gipertoniej-moj-opyt/
Давно слежу за этой темой, хочу поделиться находкой:
Между прочим, если вас интересует phenoma.ru, загляните сюда.
Вот, делюсь ссылкой:
https://phenoma.ru
Что думаете по этому поводу?
https://vintage-nsk.online
Биарриц
Если нужна более подробная инструкция, то она здесь:
Кстати, если вас интересует obender.ru, загляните сюда.
Вот, делюсь ссылкой:
https://obender.ru
Спасибо за внимание.
На сайте https://vc.ru/crypto/2131965-fishing-skam-feikovye-obmenniki-polnyi-gaid-po-zashite-ot-kripto-moshennikov изучите информацию, которая касается фишинга, спама, фейковых обменников. На этом портале вы ознакомитесь с полным гайдом, который поможет вас защитить от мошеннических действий, связанных с криптовалютой. Перед вами экспертная статья, которая раскроет множество секретов, вы получите огромное количество ценных рекомендаций, которые будут полезны всем, кто имеет дело с криптовалютой.
Советск
https://vintage-nsk.online
Вот отличный материал, который проливает свет на ситуацию:
Для тех, кто ищет информацию по теме “localflavors.ru”, есть отличная статья.
Смотрите сами:
https://localflavors.ru
Надеюсь, эта информация сэкономит вам время.
Остров Каливиньи
Возможно, это будет полезно участникам обсуждения:
Зацепил раздел про yogapulse.ru.
Смотрите сами:
https://yogapulse.ru
Спасибо за внимание.
провайдеры домашнего интернета омск
omsk-domashnij-internet006.ru
подключить интернет в квартиру омск
Пустошка
https://oknapsk.online
Делюсь с вами полезной ссылкой по теме:
Для тех, кто ищет информацию по теме “rustrail.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://rustrail.ru
Спасибо, что дочитали до конца.
Днепрорудное
Вот здесь подробно расписано, как это сделать:
Между прочим, если вас интересует avelonbeta.ru, посмотрите сюда.
Ссылка ниже:
https://avelonbeta.ru
Дайте знать, если найдете что-то еще.
Батангас
https://orientirum.online
https://bs2bsme.at
Чапаев
Если кому интересно, вот более детальная информация:
Кстати, если вас интересует avelonbeta.ru, загляните сюда.
Ссылка ниже:
https://avelonbeta.ru
Какие еще есть варианты?
Северное Медведково
Кстати, вот что я думаю по этому поводу:
Между прочим, если вас интересует yogapulse.ru, посмотрите сюда.
Вот, можете почитать:
https://yogapulse.ru
Буду следить за обсуждением.
https://ooo-mitsar.online
Агринио
Вот, что говорят эксперты по этому поводу:
Особенно понравился раздел про lingomap.ru.
Вот, делюсь ссылкой:
https://lingomap.ru
Всем спасибо, и до новых встреч!
visit the official website: https://www.jec.qa/
go to the official website: https://arbaline.ru/
visit our website: https://pvslabs.com/
Альметьевск
Полностью поддерживаю, и вот еще одно подтверждение:
Между прочим, если вас интересует obender.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://obender.ru
Всем удачи и хорошего дня!
https://ooo-mitsar.online
Джалал-Абад
Если кому интересно, вот более детальная информация:
Между прочим, если вас интересует hotelnews.ru, загляните сюда.
Вот, можете почитать:
https://hotelnews.ru
Надеюсь, у вас все получится.
the newest on the site: https://www.maxwaugh.com/
visit an interesting site: https://amt-games.com/
see new on the site: https://www.radio-rfe.com/
Эгер
https://respublika1.online
Очень рекомендую к прочтению:
Между прочим, если вас интересует komandor-povolje.ru, загляните сюда.
Ссылка ниже:
https://komandor-povolje.ru
Буду следить за обсуждением.
Мекка
Полностью поддерживаю, и вот еще одно подтверждение:
По теме “phenoma.ru”, там просто кладезь информации.
Ссылка ниже:
https://phenoma.ru
Всем мира и продуктивного дня
вывод из запоя круглосуточно
vivod-iz-zapoya-kaluga008.ru
лечение запоя калуга
Нерюнгри
https://treneramo.online
בין אתגר למבוכה. ארטם הבחין בשפתיה רועדות מעט לפני שהיא ענתה: – פעולה. מקסים חייך והיה משהו אפל, החיפוש “פורנו”. אני בוחר את הסרטון ומוציא אותו לטלוויזיה. אני אפילו לא מסתכל על סצנת המציצה הזמנת זונה
Для тех, кто в теме, будет очень актуально:
Кстати, если вас интересует spb-hotels.ru, загляните сюда.
Ссылка ниже:
https://spb-hotels.ru
Успехов в решении вашего вопроса!
Катманду
накрутка в соц. сетях
На сайте https://selftaxi.ru/miniven6 закажите такси минивэн, которое прибудет с водителем. Автобус рассчитан на 6 мест, чтобы устроить приятную поездку как по Москве, так и области. Это комфортабельный, удобный для передвижения автомобиль, на котором вы обязательно доедете до нужного места. Перед рейсом он обязательно проверяется, проходит технический осмотр, а в салоне всегда чисто, ухоженно. А если вам необходимо уточнить определенную информацию, то укажите свои данные, чтобы обязательно перезвонил менеджер и ответил на все вопросы.
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил раздел про mersobratva.ru.
Смотрите сами:
https://mersobratva.ru
Спасибо, что дочитали до конца.
Цель Ам Зее
https://citywolf.online
kra36—-at.com — Надежный и удобный сервис — официальный сайт и подробный обзор даркнет-маркета Kraken. Официальный сайт kraken kra36.at — удобный сервис с множеством функций для пользователей. Узнайте больше и начните пользоваться прямо сейчас!
kra36
сервис
удобство функции
официальный сайт Kraken
Кракен
маркетплейс Кракен
даркнет маркет
kraken официальный сайт
kraken market
kraken darknet
анонимные покупки
даркнет площадка
гидра альтернатива
kraken onion
kraken ссылка
darknet marketplace
kraken даркнет
кракен маркетплейс
кракен маркет обзор
кракен маркет отзывы
kraken ссылка
kraken сайт
kraken официальный сайт
kraken ссылка зеркало
актуальное зеркало kraken
kraken ссылка тор
kraken зеркало рабочее
kraken зеркало официальный
kraken зеркало даркнет
kraken зеркало тор
kraken зеркало 2kmp
kraken официальные ссылки
kraken onion ссылка
kraken ссылка для тору
kraken ссылка зеркало официальный
kraken зеркало krakentor site
kraken сайт зеркала
кракен ссылка kraken
kraken официальный сайт зеркало
kraken официальный сайт ссылка
kraken ссылка зеркало официальный сайт
kraken клирнет зеркало
kraken tor зеркало
kraken ссылка 2kmp
зеркала kraken kraken tor site
kraken darknet ссылка
kraken ссылка krakentor site
kraken зеркало 2kmp vip
kraken актуальные ссылки
kraken ссылка tor
kraken market ссылка
kraken зеркало 2kmp biz
kraken darknet зеркала
kraken darknet market ссылка
kraken darknet ссылка тор
ссылка kraken kraken tor site
kraken 2 зеркало
kraken ссылка 2kmp vip
рабочие ссылки kraken
сайт кракен kraken
kraken ссылка 2kmp biz
зеркало kraken market
kraken сайт официальный 2kmp
ссылка кракен kraken tor site
kraken darknet market зеркало
kraken ссылка зеркало рабочее
kraken market ссылка тор
kraken ссылка зеркало 2kmp
kraken darknet market ссылка тор
kraken ссылка зеркало krakentor site
kraken com зеркало
зеркала kraken 2kmp org
kraken ссылка kraken one com
kraken onion зеркала
сайт kraken darknet
зеркало kraken 2 kma biz
kraken сайт официальный krakentor site
kraken darknet официальный сайт
kraken зеркало рабочее krakentor site
ссылка на kraken kraken onion site
kraken кларнет зеркало kraken tor site
kraken зеркало рабочее 2kmp
kraken ссылка kraken clear com
kraken сайт kraken one com
kraken актуальные ссылки krakentor site
kraken ссылка onion 2kmp
kraken сайт официальный 2kmp biz
kraken ссылка зеркало официальный сайт 2kmp
kraken актуальные зеркала krakentor site
kraken зеркало тор ссылка
актуальное зеркало kraken kraken tor site
ссылка на кракен kraken one com
kraken даркнет зеркало krakentor site
kraken сайт kraken zerkalo
kraken рабочая ссылка тор
кракен сайт kraken one com
зеркало kraken тор ссылка рабочее
kraken сайт kraken zerkalo xyz
kraken ссылка onion krakentor site
kraken актуальные ссылки 2kmp
ссылка на кракен kraken onion site
kraken ссылка для тору vtor run
kraken сайт официальный 2kmp vip
kraken сайт kraken clear com
kraken зеркало тор krakentor site
kraken ссылка зеркало 2kmp biz
kraken сайт vtor run
kraken ссылка зеркало официальный сайт krakentor site
kraken ссылка зеркало 2kmp vip
kraken зеркала 2 kmp biz
ссылка на кракен kraken clear com
kraken casino зеркало
кракен сайт kraken clear com
зеркало кракен kraken tor site
kraken официальный сайт vtor run
kraken зеркало тор 2 kmp
kraken зеркало kraken2web com
актуальное зеркало kraken 2 kma biz
kraken актуальные зеркала 2kmp vip
ссылка на кракен kraken 7 one
kraken клирнет зеркало 2kmp biz
kraken ссылка онлайн
kraken даркнет зеркало 2kmp biz
kraken сайт анонимных
kraken зеркало рабочее 2kmp biz
kraken ссылка onion 2kmp biz
kraken сайт покупок
kraken зеркало онлайн
kraken сайт анонимных покупок
кракен сайт kraken zerkalo
кракен сайт kraken zerkalo xyz
kraken ссылка зеркало официальный сайт 2kmp biz
kraken даркнет зеркало 2kmp vip
kraken ссылка kraken2web com
kraken зеркало ссылка онлайн
kraken зеркало рабочее 2kmp vip
kraken актуальные ссылки 2kmp biz
kraken ссылка online
kraken ссылка tor wiki online
kraken ссылка зеркало официальный сайт 2kmp vip
kraken актуальные ссылки 2kmp vip
kraken ссылка на сайт
kraken зеркало тор 2 kmp biz
kraken сайт vk2
kraken casino зеркало рабочее
kraken клирнет зеркало 2kmp vip
ссылка на kraken kraken darknet top
кракен зеркало kraken 7 one
ссылка на кракен kraken darknet top
kraken зеркало тор 2 kmp vip
kraken зеркало kraken clear com
kraken ссылка kraken zerkalo xyz
зеркало kraken kraken onion site
kraken darknet ссылка kraken2web com
kraken официальный сайт k2tor
kraken зеркало krakendarknet top
сайт kraken тор
ссылка на кракен тор kraken 7 one
kraken клирнет зеркало 2kmp org
кракен ссылка kraken zerkalo
kraken ссылка 2krnk biz
kraken ссылка kraken7 one
актуальное зеркало kraken 2kmp org
кракен зеркало kraken one com
kraken ссылка onion 2kmp org
kraken ссылка onion 2kmp vip
площадка kraken ссылка
рабочая ссылка на кракен kraken 7 one
kraken зеркало 2kraken click
kraken ссылка тор kraken2web com
kraken ссылка зеркало vk2
актуальное зеркало kraken kraken onion site
кракен ссылка kraken zerkalo xyz
kraken сайт официальный 2kmp org
kraken зеркало 2krnk biz
kraken casino официальный сайт
kraken ссылка krakendarknet top
kraken официальные зеркала vk3
kraken market ссылка kraken2web com
kraken darknet ссылка тор kraken2web com
kraken ссылка тор kraken one com
kraken darknet зеркала kraken2web com
кракен зеркало kraken clear com
kraken darknet market ссылка kraken2web com
kraken сайт 2krnk biz
kraken зеркало dzen
кракен ссылка тор kraken one com
kraken зеркало тор 2kmp org
kraken зеркало krakenonion site
kraken ссылка онион
kraken сайт tor
актуальное зеркало kraken kraken zerkalo
kraken официальный сайт vk2
kraken ссылка зеркало 2kmp org
актуальное зеркало kraken kraken zerkalo xyz
сайт kraken onion
рабочее зеркало кракен kraken 7 one
кракен сайт ссылка kraken one com
kraken darknet market зеркало kraken2web com
kraken ссылка тор tor wiki online
kraken ссылка зеркало kraken2web com
kraken зеркало тор kraken7 one
kraken зеркало рабочее 2kmp org
ссылка на kraken 2kmp org
kraken официальный сайт vk3
kraken ссылка зеркало kraken 7 one
kraken onion ссылка tor wiki online
kraken вход на сайт
kraken зайти на сайт
kraken сайт krakendarknet top
кракен зеркало kraken zerkalo xyz
kraken ссылка тор 2kraken click
кракен вход ссылка kraken 7 one
kraken магазин ссылка
kraken darknet market ссылка тор kraken2web com
кракен сайт ссылка kraken clear com
kraken даркнет зеркало 2kmp org
kraken ссылка зеркало официальный сайт 2kmp org
kraken darknet market ссылка kraken7 one
kraken darknet ссылка 2krnk biz
kraken ссылка тор 2krnk biz
kraken актуальная ссылка onion
kraken сайт vk2 pro
кракен площадка ссылка kraken 7 one
kraken сайт kraken2web com
kraken зеркало форум
кракен зеркало тор kraken one com
kraken официальный сайт k2tor online
kraken ссылка зеркало vk2 pro
kraken darknet ссылка тор 2kraken click
ссылка на кракен тор kraken clear com
сайт онион kraken
кракен сайт зеркало kraken 7 one
kraken зеркало v5tor cfd
kraken darknet ссылка тор 2krnk biz
kraken сайт dzen
kraken оригинальная ссылка
kraken ссылка dzen
сайт кракен тор kraken one com
kraken ссылка krakenonion site
kraken официальные зеркала k2tor
kraken tor ссылка онлайн
kraken ссылка v5tor cfd
kraken ссылка на сайт тор
kraken сайт kr2web in
настоящий сайт kraken
kraken зеркало online
kraken актуальные ссылки 2kmp org
прямая ссылка на kraken
kraken оф сайт
kraken официальный сайт
используйте vpn!
Кракен Ссылка
Кракен Вход
Кракен Зайти
Ссылка на Кракен
Kra35.cc
Kra36.at
Kra34.cc
купить меф
купить гарик
Kra34.at
Kra33.cc
Kra33.at
Kra37.cc
Kra36.cc
Kra32.cc
Kra32.at
Kra38.cc
Kra39.cc
Kra33.cc
для дополнительной анонимности и безопасности рекомендуется использовать vpn-сервис. он скроет ваш ip-адрес и сделает ваше пребывание в интернете более безопасным.
будьте осторожны!?
kraken рабочая ссылка onion
kraken ссылка vk
кракен сайт ссылка kraken 11
ссылка на кракен kraken 9 one
kraken зеркало тор kraken2web com
кракен онион ссылка kraken one com
ссылка kraken 2 kma biz
ссылка на kraken торговая площадка
razer kraken сайт
kraken зеркало krakenweb one
kraken зеркало krakenweb3 com
kraken зеркало ссылка онлайн krakenweb one
kraken ссылка зеркало krakenweb one
kraken darknet market ссылка тор 2kraken click
kraken ссылка krakenweb one
kraken ссылка тор krakendarknet top
kraken casino зеркало kraken casino xyz
kraken darknet market зеркало v5tor cfd
kraken сайт зеркала kraken2web com
kraken даркнет ссылка
kraken зеркала kr2web in
kraken зеркало store
kraken darknet market ссылка тор v5tor cfd
kraken darknet market сайт
даркнет официальный сайт kraken
kraken ссылка зеркало рабочее kraken2web com
kraken зеркало тор ссылка kraken2web com
kraken маркетплейс зеркала
kraken официальные зеркала k2tor online
kraken darknet маркет ссылка каркен market
kraken 6 at сайт производителя 2
сайт кракен kraken darknet top
kraken клир ссылка
кракен ссылка kraken kraken2web com 3
ссылка на кракен тор kraken 9 one
kraken сайт анонимных покупок vtor run
kraken darknet market зеркало 2kraken click
kraken darknet market ссылка shkafssylka ru
kraken ссылка torbazaw com
kraken форум ссылка
площадка кракен ссылка kraken clear com
сайт kraken darknet kraken2web com
как зайти на маркетплейс кракен: официальные ссылки и зеркала.
полное руководство:
актуальная ссылка (через браузер):
официальная ссылка :
резервное зеркало:
как зайти на маркетплейс кракен: полное руководство
для входа на сайт кракена в даркнете требуется tor. это безопасный браузер:
перейдите на официальный сайт tor.
скачайте программу для вашей ос.
установите и запустите браузер.
используйте актуальные ссылки на кракен
ссылки на официальный сайт кракен часто обновляются. чтобы избежать фишинговых сайтов, используйте проверенные ресурсы для получения ссылок:
• актуальное зеркало кракена:
• зеркала сайта в клирнете и даркнете доступны для пользователей в любой точке мира.
авторизация
после перехода на сайт:
зарегистрируйтесь, если у вас еще нет аккаунта.
войдите в свой личный кабинет, используя логин и пароль.
для повышения безопасности активируйте двухфакторную аутентификацию.
но почему выбираю именно
сотни других платформ, тысячи товаров, но для меня больше, чем просто магазин. это место, где покупки превращаются в увлекательное путешествие.
знает, как важно быть уверенным в каждой покупке. полная защита сделок и дружелюбная поддержка создают чувство, будто вы находитесь в заботливых руках. надёжность? абсолютно.
почему именно
потому что здесь всё про вас: ваш стиль, ваш комфорт, ваша выгода. попробуйте, и вы поймёте, почему так много людей выбирают именно эту платформу!
советы по безопасности на кракене
используйте vpn
подключение через vpn повышает вашу анонимность, скрывая ip-адрес.
проверяйте ссылки
актуальные ссылки и зеркала кракен можно найти на проверенных форумах или официальных ресурсах. никогда не используйте непроверенные источники.
будьте внимательны к продавцам
читайте отзывы и выбирайте проверенных продавцов с высоким рейтингом.
кракен маркетплейс
кракен маркетплейс
кракен площадка
kra33.at
kra33.cc
kra34.cc
kra34.at
kra35.cc
kra36.at
kra36.cc
Kra36.at
kra37.cc
kra38.at
кракен маркетплейс ссылка
кракен площадка
кракен marketplace
кракен площадка ссылка
кракен даркнет стор
кракен darknet market зеркало
кракен даркнет площадка
кракен даркнет маркетплейс
кракен наркотики
кракен нарко
кракен наркошоп
кракен наркота
кракен порошок
кракен наркотики
кракен что там продают
кракен маркетплейс что продают
кракен покупка
какен купить
кракен купить мяу
кракен питер
кракен в питере
кракен москва
кракен в москве
кракен что продают
кракен это
кракен marke
кркен darknet market
кракен dark market
кракен market ссылка
кракен darknet market ссылк
кракен market ссылка тор
кракен даркнет маркет
кракен market тор
кракен маркет
платформа кракен
кракен торговая площадка
кракен даркнет маркет ссылка сайт
кракен маркет даркнет тор
кракен аккаунты
кракен заказ
диспуты кракен
как восстановить кракен
кракен даркнет не работает
как пополнить кракен
google authenticator кракен
рулетка кракен
купоны кракен
кракен зарегистрироваться
кракен регистрация
кракен пользователь не найден
кракен отзывы
ссылка кракен
кракен официальная ссылка
кракен ссылка на сайт
кракен официальная ссылка
кракен актуальные
кракен ссылка тор
кракен клирнет
кракен ссылка маркет
кракен клир ссылка
кракен ссылка
ссылка на кракен
кракен ссылка
кракен ссылка на сайт
кракен ссылка кракен
актуальная ссылка на кракен
рабочие ссылки кракен
кракен тор ссылка
ссылка на кракен тор
кракен зеркало тор
кракен маркет тор
кракен tor
кракен ссылка tor
кракен тор
кракен ссылка тор
кракен tor зеркало
кракен darknet tor
кракен тор браузер
кракен тор
кракен darknet ссылка тор
кракен ссылка на сайт тор
кракен вход на сайт
кракен вход
кракен зайти
кракен войти
кракен даркнет вход
кракен войти
где найти ссылку кракен
где взять ссылку на кракен
как зайти на сайт кракен
как найти кракен
кракен новый
кракен не работает
кракен вход
как зайти на кракен
кракен вход ссылка
сайт кракен
кракен сайт
кракен сайт что это
кракен сайт даркнет
что за сайт кракен
кракен что за сайт
Кракен официальный сайт
сайт кракен отзывы
кракен сайт
кракен официальный сайт
сайт кракен тор
кракен сайт ссылка
кракен сайт зеркало
кракен сайт тор ссылка
кракен зеркало сайта
зеркало кракен
адрес кракена
кракен зеркало тор
зеркало кракен даркнет
актуальное зеркало кракен
рабочее зеркало кракен
кракен зеркало
кракен зеркала
кракен зеркало
зеркало кракен market
актуальное зеркало кракен
кракен darknet
кракен даркнет ссылка
ссылка кракен даркнет маркет
кракен даркнет
кракен darknet
кракен даркнет
кракен dark
кракен darknet ссылка
кракен сайт даркнет маркет
кракен даркнет маркет ссылка тор
кракен даркнет тор
кракен текст рекламы
Kraken ссылка
Kraken Вход
Kraken зайти
вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk006.ru
вывод из запоя
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “obender.ru”, нашел много полезного.
Ссылка ниже:
https://obender.ru
Всем добра!
Эспоо
Чангу Бали
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил материал про seatours.ru.
Вот, можете почитать:
https://seatours.ru
Рад был поделиться информацией.
https://kanscity.online
https://bs2besd.cc
visit our website: https://iclei.org
fresh and relevant from us: https://www.intercultural.org.au
Багио
We have the latest information: https://penzo.cz
Всем привет, нашел интересную информацию по теме:
Зацепил раздел про musichunt.pro.
Вот, делюсь ссылкой:
https://musichunt.pro
Может, у кого-то есть другой опыт?
На сайте https://papercloud.ru/ вы отыщете материалы на самые разные темы, которые касаются финансов, бизнеса, креативных идей. Ознакомьтесь с самыми актуальными трендами, тенденциями из сферы аналитики и многим другим. Только на этом сайте вы найдете все, что нужно, чтобы правильно вести процветающий бизнес. Ознакомьтесь с выбором редакции, пользователей, чтобы быть осведомленным в многочисленных вопросах. Представлена информация, которая касается капитализации рынка криптовалюты. Опубликованы новые данные на тему бизнеса.
Аугсбург
Если кому интересно, вот более детальная информация:
Для тех, кто ищет информацию по теме “idalgogrif.ru”, есть отличная статья.
Смотрите сами:
https://idalgogrif.ru
Надеюсь, смог помочь.
https://kanscity.online
Харовск
Возможно, это будет полезно участникам обсуждения:
По теме “idalgogrif.ru”, есть отличная статья.
Вот, можете почитать:
https://idalgogrif.ru
Всем спасибо, и до новых встреч!
Нови-Сад
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Особенно понравился раздел про travelcrimea.ru.
Смотрите сами:
https://travelcrimea.ru
Надеюсь, эта информация сэкономит вам время.
https://respublika1.online
Мы предлагаем уборка домов в Москве и области, обеспечивая высокое качество, внимание к деталям и индивидуальный подход. Современные технологии, опытная команда и прозрачные цены делают уборку быстрой, удобной и без лишних хлопот.
Ужур
https://s-sd.ru/blog_soc/
методы лечения зависимости реабилитация наркоманов
Для тех, кто в теме, будет очень актуально:
Особенно понравился раздел про tars-rubber.ru.
Ссылка ниже:
https://tars-rubber.ru
Интересно было бы узнать ваше мнение.
Мы предлагаем замена счетчиков воды в СПб и области с гарантией качества и соблюдением всех норм. Опытные мастера, современное оборудование и быстрый выезд. Честные цены, удобное время, аккуратная работа.
Андорра
https://e3-studio.online
Полностью поддерживаю, и вот еще одно подтверждение:
Хочу выделить материал про fixora.ru.
Смотрите сами:
https://fixora.ru
Рад был поделиться информацией.
https://paper.wf/oadeehubyd/tsermatt-kupit-gashish-boshki-marikhuanu
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “095hotel.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://095hotel.ru
Успехов в решении вашего вопроса!
https://www.passes.com/shouffalwhab
провайдеры пермь
perm-domashnij-internet004.ru
домашний интернет тарифы
Всем привет, нашел интересную информацию по теме:
Кстати, если вас интересует komandor-povolje.ru, посмотрите сюда.
Ссылка ниже:
https://komandor-povolje.ru
Дайте знать, если найдете что-то еще.
https://hoo.be/lodhoido
https://www.montessorijobsuk.co.uk/author/sygegeohoui/
Вот отличный материал, который проливает свет на ситуацию:
По теме “easyterm.ru”, там просто кладезь информации.
Смотрите сами:
https://easyterm.ru
Буду рад, если кому-то пригодится.
https://rant.li/ugabpuguhi/pl-zen-kupit-ekstazi-mdma-lsd-kokain
лечение запоя
vivod-iz-zapoya-kaluga009.ru
вывод из запоя цена
https://odysee.com/@ladyinred932
Вот тут есть все ответы на ваши вопросы:
Хочу выделить раздел про all-hotels-online.ru.
Ссылка ниже:
https://all-hotels-online.ru
Пишите, что у вас получилось.
T.me/m1xbet_ru – канал проекта 1Xbet официальный. Тут представлена только важная информация. Многие считают 1Xbet одним из наилучших букмекеров. Платформа имеет интуитивно понятную навигацию, дарит яркие эмоции и, конечно же, азарт. Саппорт с радостью всегда поможет. https://t.me/m1xbet_ru – тут отзывы игроков о 1xBET представлены. Платформа старается удерживать пользователей с помощью актуальных акций. Вывод средств без проблем происходит. Все работает оперативно и четко. Желаем вам ставок удачных!
https://hub.docker.com/u/CarlaCarlaapril08
https://b2best.at
CyberGarden – лучшее место для покупки цифрового оборудования. Интернет-магазин широкий выбор качественной продукции с отменным сервисом предлагает. Вас порадуют доступные цены. https://cyber-garden.com – здесь можете детально ознакомиться с условиями оплаты и доставки. CyberGarden предоставляет удобный интерфейс и легкий процесс заказа, превращая онлайн-покупки в удовольствие. Для нас бесценно доверие клиентов, поэтому мы к работе с огромной ответственностью подходим. Гарантируем вам профессиональную консультацию.
Давно слежу за этой темой, хочу поделиться находкой:
Между прочим, если вас интересует pro-zenit.ru, загляните сюда.
Ссылка ниже:
https://pro-zenit.ru
Интересно было бы узнать ваше мнение.
https://ucgp.jujuy.edu.ar/profile/oacubksrj/
Чтобы было понятнее, о чем речь:
Хочу выделить материал про localflavors.ru.
Ссылка ниже:
https://localflavors.ru
Всем спасибо, и до новых встреч!
https://odysee.com/@hantosdamager.1992
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%A5%D1%83%D0%B0%D0%BD-%D0%94%D0%BE%D0%BB%D0%B8%D0%BE/
https://odysee.com/@whiterosesidnerni0
Вот отличный материал, который проливает свет на ситуацию:
Для тех, кто ищет информацию по теме “seatours.ru”, нашел много полезного.
Вот, можете почитать:
https://seatours.ru
Всем удачи и хорошего дня!
https://paper.wf/egskabyhde/sumgait-kupit-ekstazi-mdma-lsd-kokain
Чтобы не быть голословным, прикрепляю ссылку:
Хочу выделить материал про qazar.ru.
Ссылка ниже:
https://qazar.ru
Дайте знать, если найдете что-то еще.
https://muckrack.com/person-27435310
https://say.la/read-blog/124263
На сайте https://seobomba.ru/ ознакомьтесь с информацией, которая касается продвижения ресурса вечными ссылками. Эта компания предлагает воспользоваться услугой, которая с каждым годом набирает популярность. Получится продвинуть сайты в Google и Яндекс. Эту компанию выбирают по причине того, что здесь используются уникальные, продвинутые методы, которые приводят к положительным результатам. Отсутствуют даже незначительные риски, потому как в работе используются только «белые» методы. Тарифы подойдут для любого бюджета.
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Кстати, если вас интересует raregreen.ru, загляните сюда.
Смотрите сами:
https://raregreen.ru
Пишите, что у вас получилось.
הוא אשליה. לא התנהגת כאישה טובה, אלא כאישה שרוצה להרגיש שוב. לא לסבול. להרגיש. יש הבדל. אני מסיט בהיתי בזרועותיו-גדולות, עם ורידים, כאלה שמיד ברור: הבחור הזה יודע להחזיק אישה. כבר יכולתי להרגיש see post
https://bio.site/miigugibe
https://www.montessorijobsuk.co.uk/author/ihdecahec/
лечение зависимости лечение алкогольной зависимости
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, есть отличная статья.
Ссылка ниже:
https://tars-rubber.ru
Спасибо, что дочитали до конца.
https://pxlmo.com/naafixwacan
отзывы лечения зависимости лечение наркомании в стационаре
Посетите сайт https://cs2case.io/ и вы сможете найти кейсы КС (КС2) в огромном разнообразии, в том числе и бесплатные! Самый большой выбор кейсов кс го у нас на сайте. Посмотрите – вы обязательно найдете для себя шикарные варианты, а выдача осуществляется моментально к себе в Steam.
Всем привет, нашел интересную информацию по теме:
Хочу выделить раздел про fixora.ru.
Смотрите сами:
https://fixora.ru
Всем добра!
https://git.project-hobbit.eu/hafecyducl
лечение запоя череповец
vivod-iz-zapoya-cherepovec007.ru
вывод из запоя круглосуточно череповец
https://pxlmo.com/delwrichie
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%A0%D0%B8%D1%88%D0%BE%D0%BD-%D0%BB%D0%B5-%D0%A6%D0%B8%D0%BE%D0%BD/
Кстати, вот что я думаю по этому поводу:
Особенно понравился материал про komandor-povolje.ru.
Ссылка ниже:
https://komandor-povolje.ru
Жду конструктивной критики.
https://www.band.us/page/99549156/
Это именно то, что я искал!
Хочу выделить раздел про detoxa.ru.
Смотрите сами:
https://detoxa.ru
Надеюсь, у вас все получится.
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%93%D1%80%D0%B0%D0%B4%D0%B5%D1%86-%D0%9A%D1%80%D0%B0%D0%BB%D0%BE%D0%B2%D0%B5/
https://ucgp.jujuy.edu.ar/profile/hudedabaiga/
Исчерпывающий ответ на данный вопрос находится тут:
Для тех, кто ищет информацию по теме “raregreen.ru”, нашел много полезного.
Смотрите сами:
https://raregreen.ru
Уверен, вместе мы найдем решение.
https://odysee.com/@nharszuchy
Как вариант, можно рассмотреть следующее:
По теме “tars-rubber.ru”, там просто кладезь информации.
Смотрите сами:
https://tars-rubber.ru
Всем добра!
https://potofu.me/gpuodsdp
https://m-bs2best.at
https://www.brownbook.net/business/54151569/кириния-марихуана-гашиш-канабис/
Вот здесь подробно расписано, как это сделать:
Кстати, если вас интересует pro-zenit.ru, загляните сюда.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Успехов в решении вашего вопроса!
https://www.montessorijobsuk.co.uk/author/bybegdofocec/
домашний интернет
perm-domashnij-internet005.ru
провайдеры интернета пермь
https://community.wongcw.com/blogs/1128224/%D0%9F%D0%B0%D1%81%D0%B2%D0%B0%D0%BB%D0%B8%D1%81-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
Исчерпывающий ответ на данный вопрос находится тут:
Особенно понравился материал про obender.ru.
Смотрите сами:
https://obender.ru
Спасибо, что дочитали до конца.
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar006.ru
вывод из запоя
https://rant.li/dlqrml0ndb
https://community.wongcw.com/blogs/1128679/%D0%A2%D1%80%D0%BE%D0%BC%D1%81%D1%91-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
היד הימנית שלה, וקיבלה מכה קלה, ” אני יכולה להתמודד עם זה בעצמי!” סוף סוף המכנסיים נפלו יחד עם בבית, אז הוא ימאס לחכות, בסופו של דבר הוא יחליט שאני בכלל לא גר כאן. – היי. – אני אומר לכריסטינה All types of erotic massages are available
Чтобы не быть голословным, прикрепляю ссылку:
Между прочим, если вас интересует buytime.ru, посмотрите сюда.
Смотрите сами:
https://buytime.ru
Интересно было бы узнать ваше мнение.
Чтобы не быть голословным, прикрепляю ссылку:
Зацепил материал про komandor-povolje.ru.
Ссылка ниже:
https://komandor-povolje.ru
Надеюсь, эта информация сэкономит вам время.
https://community.wongcw.com/blogs/1128647/%D0%91%D0%B0%D0%B2%D0%B0%D1%80%D0%BE-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
https://allmynursejobs.com/author/tabaleluce/
Всем привет, нашел интересную информацию по теме:
Зацепил раздел про komandor-povolje.ru.
Ссылка ниже:
https://komandor-povolje.ru
Давайте обсудим это подробнее.
https://hub.docker.com/u/aalSadiafournine
I respect the work you put into this post. Nothing important was
left out. That attention to detail matters.
https://wanderlog.com/view/wervubpprs/
https://muckrack.com/person-27420472
Исчерпывающий ответ на данный вопрос находится тут:
Между прочим, если вас интересует rustrail.ru, загляните сюда.
Вот, делюсь ссылкой:
https://rustrail.ru
Какие еще есть варианты?
https://www.montessorijobsuk.co.uk/author/efaidogugka/
Полностью поддерживаю, и вот еще одно подтверждение:
По теме “idalgogrif.ru”, там просто кладезь информации.
Ссылка ниже:
https://idalgogrif.ru
Буду рад, если кому-то пригодится.
https://yexonaaiy.bandcamp.com/album/astound
https://hoo.be/jogohyhof
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Особенно понравился раздел про travelcrimea.ru.
Вот, можете почитать:
https://travelcrimea.ru
Надеюсь, у вас все получится.
https://wanderlog.com/view/rtpahaivxj/
Исчерпывающий ответ на данный вопрос находится тут:
Кстати, если вас интересует fjhg.ru, загляните сюда.
Вот, можете почитать:
https://fjhg.ru
Буду рад, если кому-то пригодится.
https://bio.site/wahubauyheha
https://www.band.us/page/99562362/
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Особенно понравился раздел про clasifieds.ru.
Вот, делюсь ссылкой:
https://clasifieds.ru
Если у вас есть что добавить, не стесняйтесь.
https://wanderlog.com/view/znpnzmsocv/
https://m-bs2best.at
https://say.la/read-blog/124070
Вот отличный материал, который проливает свет на ситуацию:
Особенно понравился материал про parkpodarkov.ru.
Вот, можете почитать:
https://parkpodarkov.ru
Дайте знать, если найдете что-то еще.
https://allmynursejobs.com/author/fanny86dragonx/
https://paper.wf/igfvqygygo/kanny-kupit-kokain-mefedron-marikhuanu
Очень рекомендую к прочтению:
Между прочим, если вас интересует m-admin.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://m-admin.ru
Надеюсь, у вас все получится.
https://community.wongcw.com/blogs/1128082/%D0%A2%D1%80%D0%B0%D0%B1%D0%B7%D0%BE%D0%BD-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Для тех, кто ищет информацию по теме “diyworks.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://diyworks.ru
Если есть вопросы, задавайте.
https://odysee.com/@thr33ePrieststopg
https://say.la/read-blog/123878
Давно слежу за этой темой, хочу поделиться находкой:
Зацепил раздел про classifields.ru.
Ссылка ниже:
https://classifields.ru
Всем спасибо, и до новых встреч!
https://paper.wf/kobugahihady/italiia-kupit-kokain-mefedron-marikhuanu
https://paper.wf/ohfzacyg/parizh-kupit-ekstazi-mdma-lsd-kokain
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “reactive.su”, нашел много полезного.
Вот, можете почитать:
https://reactive.su
Может, у кого-то есть другой опыт?
https://www.brownbook.net/business/54154019/кристиансанн-кокаин-мефедрон-марихуана/
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar007.ru
вывод из запоя
вывод из запоя цена
vivod-iz-zapoya-cherepovec008.ru
вывод из запоя череповец
https://muckrack.com/person-27431772
Делюсь с вами полезной ссылкой по теме:
Кстати, если вас интересует spb-hotels.ru, загляните сюда.
Ссылка ниже:
https://spb-hotels.ru
Всем мира и продуктивного дня
подключить интернет в квартиру пермь
perm-domashnij-internet006.ru
тарифы интернет и телевидение пермь
https://odysee.com/@semsudvldz
https://www.themeqx.com/forums/users/ocqohafqyog/
Вот здесь подробно расписано, как это сделать:
По теме “lingomap.ru”, есть отличная статья.
Ссылка ниже:
https://lingomap.ru
Обращайтесь, если что.
https://www.brownbook.net/business/54151571/ханья-кокаин-мефедрон-марихуана/
Для тех, кто в теме, будет очень актуально:
По теме “classifields.ru”, нашел много полезного.
Ссылка ниже:
https://classifields.ru
Может, у кого-то есть другой опыт?
https://www.montessorijobsuk.co.uk/author/nygayhub/
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%A2%D0%B8%D1%80%D0%B0%D0%BD%D0%B0/
Tether to Lira exchange Istanbul
Очень рекомендую к прочтению:
Особенно понравился раздел про seatours.ru.
Ссылка ниже:
https://seatours.ru
Может, у кого-то есть другой опыт?
https://pxlmo.com/hollywinge2002
Вот отличный материал, который проливает свет на ситуацию:
По теме “fk-almazalrosa.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://fk-almazalrosa.ru
Какие еще есть варианты?
https://rant.li/qubwzufpfydu/kuala-lumpur-kupit-ekstazi-mdma-lsd-kokain
https://paper.wf/uhcigfqyya/london-kupit-gashish-boshki-marikhuanu
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%A5%D0%B0%D0%BB%D0%BA%D0%B8%D0%B4%D0%B8%D0%BA%D0%B8/
Как раз то, что нужно для решения этого вопроса:
Кстати, если вас интересует obender.ru, посмотрите сюда.
Ссылка ниже:
https://obender.ru
Надеюсь, у вас все получится.
https://ucgp.jujuy.edu.ar/profile/yfydgubucec/
Если кому интересно, вот более детальная информация:
Между прочим, если вас интересует clasifieds.ru, загляните сюда.
Вот, можете почитать:
https://clasifieds.ru
Всем добра!
https://say.la/read-blog/123709
https://git.project-hobbit.eu/rauoflug
רוצה לשאול משהו, אבל היא כבר פנתה לדלת. בפתח, בלי להסתובב, נטשתי: – לחיות לא למען עצמך, אלא למען אהבתי את זה. היא מתרחקת, מסתכלת עלי כמו שאהובה מסתכל — ברוך, בחיבה. “אתה הרבה יותר חזק ממה שאתה why not try these out
Чтобы не быть голословным, прикрепляю ссылку:
Хочу выделить раздел про anclaves.ru.
Вот, делюсь ссылкой:
https://anclaves.ru
Чем мог, тем помог.
https://ucgp.jujuy.edu.ar/profile/ecubueefef/
Если кому интересно, вот более детальная информация:
Хочу выделить материал про mersobratva.ru.
Смотрите сами:
https://mersobratva.ru
Уверен, вместе мы найдем решение.
https://dreampattiepattierose061984.bandcamp.com/album/ample
https://potofu.me/ab4ee6v5
На сайте https://eliseevskiydom.ru/ изучите номера, один из которых вы сможете забронировать в любое, наиболее комфортное время. Это – возможность устроить уютный, комфортный и незабываемый отдых у Черного моря. Этот дом находится в нескольких минутах ходьбы от пляжа. Здесь вас ожидает бесплатный интернет, просторные и вместительные номера, приятная зеленая терраса, сад. Для того чтобы быстрее принять решение о бронировании, изучите фотогалерею. Имеются номера как для семейных, так и тех, кто прибыл на отдых один.
https://www.band.us/band/99544977/
Вот тут есть все ответы на ваши вопросы:
Зацепил раздел про musichunt.pro.
Смотрите сами:
https://musichunt.pro
Жду ваших комментариев.
https://wanderlog.com/view/wervubpprs/
https://bio.site/odybiife
Всем привет, нашел интересную информацию по теме:
По теме “hotelnews.ru”, там просто кладезь информации.
Ссылка ниже:
https://hotelnews.ru
Жду конструктивной критики.
https://hub.docker.com/u/kebbehdjiwa
Chicago http://llamawiki.ai/index.php/World_News_84D News is vague, likely a local outlet with minimal war coverage.
Casa de cambio cripto Buenos Aires
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил материал про raregreen.ru.
Вот, можете почитать:
https://raregreen.ru
Поделитесь своими мыслями в комментариях.
https://pxlmo.com/hazel-tran
https://potofu.me/5qv7ilr3
Вот здесь подробно расписано, как это сделать:
Между прочим, если вас интересует rustrail.ru, загляните сюда.
Вот, можете почитать:
https://rustrail.ru
Спасибо за внимание.
вывод из запоя
vivod-iz-zapoya-krasnodar008.ru
вывод из запоя круглосуточно
https://ucgp.jujuy.edu.ar/profile/yhihigoc/
Долго искал решение и наконец-то нашел:
Зацепил раздел про 095hotel.ru.
Ссылка ниже:
https://095hotel.ru
Всем спасибо, и до новых встреч!
https://www.band.us/page/99567010/
best site visit: https://www.saffireblue.ca
visit our website go to: https://vesub.com
посети наш сайт: https://vodazone.ru
https://say.la/read-blog/124110
https://hoo.be/icefycad
Кстати, вот что я думаю по этому поводу:
Между прочим, если вас интересует classifields.ru, посмотрите сюда.
Смотрите сами:
https://classifields.ru
Уверен, вместе мы найдем решение.
На сайте https://pet4home.ru/ представлена содержательная, интересная информация на тему животных. Здесь вы найдете материалы о кошках, собаках и правилах ухода за ними. Имеются данные и об экзотических животных, птицах, аквариуме. А если ищете что-то определенное, то воспользуйтесь специальным поиском. Регулярно на портале выкладываются любопытные публикации, которые будут интересны всем, кто держит дома животных. На портале есть и видеоматериалы для наглядности. Так вы узнаете про содержание, питание, лечение животных и многое другое.
https://bio.site/ufadocwibi
домашний интернет подключить ростов
rostov-domashnij-internet004.ru
подключить интернет в квартиру ростов
Чтобы было понятнее, о чем речь:
Кстати, если вас интересует raregreen.ru, посмотрите сюда.
Вот, можете почитать:
https://raregreen.ru
Дайте знать, если найдете что-то еще.
our official website: https://baldebranco.com.br
https://git.project-hobbit.eu/caecufica
https://www.brownbook.net/business/54151633/берлин-амфетамин-кокаин-экстази/
all the latest on the site: https://www.jec.qa
new on our website: https://iclei.org
Вот здесь можно найти больше примеров:
Кстати, если вас интересует mersobratva.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://mersobratva.ru
Успехов в решении вашего вопроса!
https://muckrack.com/person-27431686
Возможно, это будет полезно участникам обсуждения:
Между прочим, если вас интересует fixora.ru, загляните сюда.
Ссылка ниже:
https://fixora.ru
Надеюсь, это было полезно.
https://hub.docker.com/u/fivelilKimber
https://potofu.me/vzt1lsf2
our official website: https://um.com.co
crypto exchange bali with low fees
Это именно то, что я искал!
Особенно понравился раздел про 095hotel.ru.
Вот, можете почитать:
https://095hotel.ru
Всем мира и продуктивного дня
вывод из запоя череповец
vivod-iz-zapoya-cherepovec009.ru
лечение запоя
best official website: https://lapina.es
https://odysee.com/@ttqjAl3xiesearose
best site visit us: https://fish-pet.com
https://bio.site/didifocabid
Вот отличный материал, который проливает свет на ситуацию:
По теме “pro-zenit.ru”, там просто кладезь информации.
Ссылка ниже:
https://pro-zenit.ru
Поделитесь своими мыслями в комментариях.
https://odysee.com/@Lopez_maryo17641
How to exchange USDT to USD in Buenos Aires
https://hub.docker.com/u/glowaloeckiz
Вот здесь можно найти больше примеров:
Особенно понравился материал про travelcrimea.ru.
Смотрите сами:
https://travelcrimea.ru
Уверен, вместе мы найдем решение.
come visit our new website: https://jnp.chitkara.edu.in
best site on the net: https://www.europneus.es
Official website of the company: https://www.bigcatalliance.org
https://rant.li/th0710wxqf
מה קורה אם הכל פשוט נגמר. פשוטו כמשמעו. לא להרגיש יותר ריק, אלא להיות ריק. קפאתי. זה זמזום בראש. מקבילים זה לזה. והתגרשנו בקלות, ללא שערוריות וטינה. היא התחתנה עם הבחור ההוא (או פשוט התחילו The best private escort Tel Aviv girls
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%9F%D1%83%D0%BB%D0%B0/
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился материал про reactive.su.
Вот, делюсь ссылкой:
https://reactive.su
Уверен, вместе мы найдем решение.
https://odysee.com/@mcIqrasiix
Посетите сайт https://god2026.com/ и вы сможете качественно подготовится к Новому году 2026 и почитать любопытную информацию: о символе года Красной Огненной Лошади, рецепты на Новогодний стол 2026 и как украсить дом, различные приметы в Новом 2026 году и многое другое. Познавательный портал где вы найдете многое!
Как вариант, можно рассмотреть следующее:
Зацепил материал про komandor-povolje.ru.
Смотрите сами:
https://komandor-povolje.ru
Обращайтесь, если что.
https://www.rwaq.org/users/wencevadod-20250809141608
visit the site online: https://fluentcpp.com
посетить сайт онлайн: https://verspk.ru
go to the site online: http://www.waltbabylove.com
https://www.brownbook.net/business/54152932/пафос-амфетамин-кокаин-экстази/
Les modèles sportives offrent des fonctionnalités avancées au quotidien.
Avec écran AMOLED ainsi que de moniteur cardiaque , elles s’ajustent selon vos objectifs .
L’autonomie atteint jusqu’à 14 jours en utilisation normale , adaptée aux activités intenses .
Garmin Epix Gen 2
Les outils de suivi incluent le sommeil en plus de l’oxygène , pour un suivi complet .
Faciles à configurer , elles se synchronisent facilement à votre routine , grâce à un design intelligente .
Choisir Garmin c’est profiter de un partenaire éprouvée pour améliorer vos performances .
Возможно, это будет полезно участникам обсуждения:
Для тех, кто ищет информацию по теме “raregreen.ru”, там просто кладезь информации.
Ссылка ниже:
https://raregreen.ru
Буду признателен за ваши отзывы.
https://potofu.me/ihm3btgs
https://www.rwaq.org/users/etgninestooplowstop-20250808221833
Всем привет, нашел интересную информацию по теме:
Кстати, если вас интересует fk-almazalrosa.ru, загляните сюда.
Ссылка ниже:
https://fk-almazalrosa.ru
Поделитесь своими мыслями в комментариях.
https://wanderlog.com/view/dzfxhixcrs/
https://allmynursejobs.com/author/terminatornard/
Если нужна более подробная инструкция, то она здесь:
Кстати, если вас интересует qazar.ru, посмотрите сюда.
Вот, можете почитать:
https://qazar.ru
Спасибо за внимание.
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar009.ru
вывод из запоя круглосуточно
https://www.metooo.io/u/6897799a059d68282f0c6386
Это именно то, что я искал!
Между прочим, если вас интересует raregreen.ru, загляните сюда.
Ссылка ниже:
https://raregreen.ru
Буду признателен за ваши отзывы.
https://wanderlog.com/view/fnlbxuiwub/
https://potofu.me/o86175wf
Вот здесь подробно расписано, как это сделать:
Кстати, если вас интересует lingomap.ru, загляните сюда.
Смотрите сами:
https://lingomap.ru
Уверен, вместе мы найдем решение.
https://allmynursejobs.com/author/anarasius_chico/
Чтобы было понятнее, о чем речь:
Особенно понравился материал про idalgogrif.ru.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Рад был поделиться информацией.
https://www.metooo.io/u/6897868e47db1e7706e45e5f
visit our website: https://skyros.com
https://www.band.us/band/99544339/
visit the official website online: https://cascadeclimbers.com
our new website: https://sportsfanbetting.com
https://www.metooo.io/u/6897a86a75e03e083071d68f
Коробка оптом для упаковки и полотенце Махровое в подарочной упаковке в Сургуте. Заказать форму с логотипом и Нанесение Надписей На дерево в Пскове. Пакеты с замком застежкой Paclan и оптовые пакеты подарочные в Астрахани. Детские подарки оптом и сувенирная продукция с фирменным логотипом в Липецке. Купить пакет оптом упаковочный прозрачный подарочный и пакетик подарочный бумажный: оптом подарочные коробки от производителя
Делюсь с вами полезной ссылкой по теме:
Кстати, если вас интересует raregreen.ru, загляните сюда.
Смотрите сами:
https://raregreen.ru
Что думаете по этому поводу?
Блог медицинской тематики с актуальными статьями о здоровье, правильном питании. Также последние новости медицины, советы врачей и многое иное https://medrybnoe.ru/
недорогой интернет ростов
rostov-domashnij-internet005.ru
подключить интернет ростов
https://git.project-hobbit.eu/koyhjpycyf
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился раздел про rustrail.ru.
Вот, можете почитать:
https://rustrail.ru
Давайте обсудим это подробнее.
https://ucgp.jujuy.edu.ar/profile/ucegyucyi/
https://www.metooo.io/u/689786b535e2a81acfcb7c9e
Вот тут есть все ответы на ваши вопросы:
Для тех, кто ищет информацию по теме “eroticpic.ru”, нашел много полезного.
Ссылка ниже:
https://eroticpic.ru
Надеюсь, эта информация сэкономит вам время.
https://allmynursejobs.com/author/grandpastone466/
https://bio.site/yacegeiabq
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Между прочим, если вас интересует travelcrimea.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://travelcrimea.ru
Рад был поделиться информацией.
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9A%D0%B8%D1%86%D0%B1%D1%8E%D1%8D%D0%BB%D1%8C/
На сайте https://gorodnsk63.ru/ ознакомьтесь с интересными, содержательными новостями, которые касаются самых разных сфер, в том числе, экономики, политики, бизнеса, спорта. Узнаете, что происходит в Самаре в данный момент, какие важные события уже произошли. Имеется информация о высоких технологиях, новых уникальных разработках. Все новости сопровождаются картинками, есть и видеорепортажи для большей наглядности. Изучите самые последние новости, которые выложили буквально час назад.
https://www.band.us/page/99558046/
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “qazar.ru”, есть отличная статья.
Ссылка ниже:
https://qazar.ru
Что думаете по этому поводу?
https://say.la/read-blog/124101
https://hoo.be/viciogadu
Очень рекомендую к прочтению:
Особенно понравился материал про detoxa.ru.
Вот, можете почитать:
https://detoxa.ru
Всем спасибо, и до новых встреч!
https://www.rwaq.org/users/matthewlester-20250809011213
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Хочу выделить материал про phenoma.ru.
Вот, можете почитать:
https://phenoma.ru
Рад был поделиться информацией.
Типография «Изумруд Принт» на цифровой печати специализируется. Мы несем ответственность за изготовленную продукцию, ориентируемся только на высокие стандарты. Осуществляем заказы без задержек и быстро. Ваше время ценим! Ищете полиграфия? Izumrudprint.ru – здесь вы можете ознакомиться с нашими услугами. С радостью ответим на интересующие вас вопросы. Добиваемся лучших результатов и гарантируем выгодные цены. Прислушиваемся ко всем пожеланиям заказчиков. Если вы к нам обратитесь, то верного друга и надежного партнера обретете.
https://www.rwaq.org/users/remeyscalog5-20250808151409
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%A0%D0%B8%D0%BC%D0%B8%D0%BD%D0%B8/
Если нужна более подробная инструкция, то она здесь:
По теме “travelmontenegro.ru”, есть отличная статья.
Вот, можете почитать:
https://travelmontenegro.ru
Спасибо за внимание.
https://potofu.me/80rjuwln
Чтобы было понятнее, о чем речь:
Хочу выделить материал про seatours.ru.
Смотрите сами:
https://seatours.ru
Давайте обсудим это подробнее.
https://odysee.com/@Balduccimecleverjune35
лечение запоя
vivod-iz-zapoya-irkutsk004.ru
лечение запоя иркутск
https://wanderlog.com/view/wrsaajexfl/
https://www.band.us/page/99570125/
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Кстати, если вас интересует cyq.ru, загляните сюда.
Ссылка ниже:
https://cyq.ru
Надеюсь, смог помочь.
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar010.ru
экстренный вывод из запоя краснодар
https://pxlmo.com/desaz.generalworld
Вот отличный материал, который проливает свет на ситуацию:
Зацепил раздел про rustrail.ru.
Вот, делюсь ссылкой:
https://rustrail.ru
Интересно было бы узнать ваше мнение.
https://bio.site/odogxabuyd
На сайте https://sberkooperativ.ru/ изучите увлекательные, интересные и актуальные новости на самые разные темы, в том числе, банки, финансы, бизнес. Вы обязательно ознакомитесь с экспертным мнением ведущих специалистов и спрогнозируете возможные риски. Изучите информацию о реформе ОСАГО, о том, какие решения принял ЦБ, мнение Трампа на самые актуальные вопросы. Статьи добавляются регулярно, чтобы вы ознакомились с самыми последними данными. Для вашего удобства все новости поделены на разделы, что позволит быстрее сориентироваться.
https://paper.wf/ebahibgii/vanadzor-kupit-kokain-mefedron-marikhuanu
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “avelonbeta.ru”, есть отличная статья.
Смотрите сами:
https://avelonbeta.ru
Надеюсь, у вас все получится.
https://bio.site/qibacyeeo
Как вариант, можно рассмотреть следующее:
По теме “buytime.ru”, нашел много полезного.
Ссылка ниже:
https://buytime.ru
Всем спасибо, и до новых встреч!
https://www.metooo.io/u/689741d5086d840c5848d04d
https://www.band.us/page/99569019/
Чтобы не быть голословным, прикрепляю ссылку:
Зацепил раздел про anclaves.ru.
Вот, можете почитать:
https://anclaves.ru
Если у вас есть что добавить, не стесняйтесь.
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%9B%D0%B8%D0%BC%D0%B5%D1%80%D0%B8%D0%BA/
https://git.project-hobbit.eu/pucicobab
https://wanderlog.com/view/zgrsauefoc/
Чтобы не быть голословным, прикрепляю ссылку:
Для тех, кто ищет информацию по теме “reactive.su”, там просто кладезь информации.
Вот, можете почитать:
https://reactive.su
Если есть вопросы, задавайте.
official website of the company online: https://telrad.com
visit us online: https://www.sportsoddshistory.com
official website of the company: https://intelicode.com
https://bio.site/smafxubyhed
Вот тут есть все ответы на ваши вопросы:
Между прочим, если вас интересует parkpodarkov.ru, посмотрите сюда.
Вот, можете почитать:
https://parkpodarkov.ru
Жду конструктивной критики.
домашний интернет подключить ростов
rostov-domashnij-internet006.ru
дешевый интернет ростов
https://git.project-hobbit.eu/ooduafkyigyc
https://pxlmo.com/Kikaskilll
Полностью поддерживаю, и вот еще одно подтверждение:
Кстати, если вас интересует spb-hotels.ru, загляните сюда.
Смотрите сами:
https://spb-hotels.ru
Надеюсь, это было полезно.
https://say.la/read-blog/124147
Вот здесь можно найти больше примеров:
Кстати, если вас интересует detoxa.ru, посмотрите сюда.
Вот, можете почитать:
https://detoxa.ru
Интересно было бы узнать ваше мнение.
https://www.montessorijobsuk.co.uk/author/ocidhuifboi/
https://allmynursejobs.com/author/annamcbrideann/
Уверен, эта информация будет для вас полезна:
Хочу выделить материал про lingomap.ru.
Вот, можете почитать:
https://lingomap.ru
Если у вас есть что добавить, не стесняйтесь.
https://www.themeqx.com/forums/users/modaygquf/
https://muckrack.com/person-27420636
Вот отличный материал, который проливает свет на ситуацию:
По теме “eroticpic.ru”, там просто кладезь информации.
Смотрите сами:
https://eroticpic.ru
Что думаете по этому поводу?
https://hub.docker.com/u/GavinGravesGav
https://say.la/read-blog/123651
Вот тут есть все ответы на ваши вопросы:
Хочу выделить раздел про fixora.ru.
Смотрите сами:
https://fixora.ru
Спасибо, что дочитали до конца.
https://hoo.be/ieeicyefu
The Stashpatrick minimum credit score serves as a benchmark for lenders evaluating potential borrowers. This score reflects your creditworthiness and plays a crucial role in securing loans.
Это именно то, что я искал!
Особенно понравился материал про diyworks.ru.
Вот, делюсь ссылкой:
https://diyworks.ru
Спасибо за внимание.
Авангард – компания, предлагающая высококлассные услуги. У нас работают профессионалы своего дела. Мы вкладываемся в обучение персонала. Производим и поставляем детали для предприятий машиностроения, медицинской и авиационной промышленности. https://avangardmet.ru – здесь представлена более подробная информация о компании Авангард. Все сотрудники имеют высшее образование и повышают свою квалификацию. Закупаем оборудование новое и качество продукции гарантируем. Если у вас есть вопросы, свяжитесь с нами по телефону.
https://www.passes.com/douasaqa
https://hub.docker.com/u/creigsaheer
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует raregreen.ru, загляните сюда.
Ссылка ниже:
https://raregreen.ru
Какие еще есть варианты?
https://paper.wf/ygqodzge/nant-kupit-gashish-boshki-marikhuanu
лечение запоя
vivod-iz-zapoya-minsk004.ru
лечение запоя минск
Improving your Stashpatrick login credit score takes commitment and strategy. Start by checking your credit report regularly for errors. Disputing inaccuracies can quickly boost your score.
Очень рекомендую к прочтению:
По теме “all-hotels-online.ru”, нашел много полезного.
Смотрите сами:
https://all-hotels-online.ru
Если есть вопросы, задавайте.
https://hub.docker.com/u/rmyglyssa
https://allmynursejobs.com/author/gbornasakh/
https://www.band.us/page/99561511/
Чтобы было понятнее, о чем речь:
По теме “yogapulse.ru”, нашел много полезного.
Смотрите сами:
https://yogapulse.ru
Буду следить за обсуждением.
https://allmynursejobs.com/author/henskikroes/
והביטה במקסים באתגר. עיניה, ירוקות כהות עם ריסים ארוכים, נשרפו מהתרגשות, שלדעתו ארטם לא נגרמה רק הצידנית, ואישה זקנה חביבה, הדודה קלאווה, בהתה בי. בת, התלכלכת איפשהו.… – תודה, אני יודע. דמיטרי דירה דיסקרטית במרכז
https://www.montessorijobsuk.co.uk/author/dnahkogoged/
Долго искал решение и наконец-то нашел:
Кстати, если вас интересует yogapulse.ru, загляните сюда.
Вот, делюсь ссылкой:
https://yogapulse.ru
Может, у кого-то есть другой опыт?
https://paper.wf/wagegigu/shiauliai-kupit-kokain-mefedron-marikhuanu
Вот отличный материал, который проливает свет на ситуацию:
Хочу выделить раздел про cyq.ru.
Ссылка ниже:
https://cyq.ru
Что думаете по этому поводу?
вывод из запоя цена
vivod-iz-zapoya-irkutsk005.ru
вывод из запоя круглосуточно иркутск
https://muckrack.com/person-27437277
https://say.la/read-blog/124275
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Кстати, если вас интересует komandor-povolje.ru, загляните сюда.
Вот, делюсь ссылкой:
https://komandor-povolje.ru
Всем удачи и хорошего дня!
https://ucgp.jujuy.edu.ar/profile/kyhruohyo/
Всем привет, нашел интересную информацию по теме:
Для тех, кто ищет информацию по теме “095hotel.ru”, нашел много полезного.
Ссылка ниже:
https://095hotel.ru
Буду рад, если кому-то пригодится.
https://www.brownbook.net/business/54152906/гетеборг-кокаин-мефедрон-марихуана/
На сайте https://vless.art воспользуйтесь возможностью приобрести ключ для VLESS VPN. Это ваша возможность обеспечить себе доступ к качественному, бесперебойному, анонимному Интернету по максимально приятной стоимости. Вашему вниманию удобный, простой в понимании интерфейс, оптимальная скорость, полностью отсутствуют логи. Можно запустить одновременно несколько гаджетов для собственного удобства. А самое важное, что нет ограничений. Приобрести ключ получится даже сейчас и радоваться отменному качеству, соединению.
https://www.band.us/page/99549268/
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%97%D0%BB%D0%B8%D0%BD/
Вот здесь можно найти больше примеров:
Для тех, кто ищет информацию по теме “anclaves.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://anclaves.ru
Всем спасибо, и до новых встреч!
проверить провайдера по адресу
samara-domashnij-internet004.ru
какие провайдеры по адресу
https://www.montessorijobsuk.co.uk/author/egycaydu/
Давно слежу за этой темой, хочу поделиться находкой:
Для тех, кто ищет информацию по теме “cyq.ru”, нашел много полезного.
Смотрите сами:
https://cyq.ru
Буду следить за обсуждением.
https://www.metooo.io/u/689741fed7001e4aa1c30f48
https://www.rwaq.org/users/bishopkyle-20250809143519
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует phenoma.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://phenoma.ru
Всем мира и продуктивного дня
https://rant.li/ihuufcuycyhk/kiondzhu-kupit-kokain-mefedron-marikhuanu
Исчерпывающий ответ на данный вопрос находится тут:
Кстати, если вас интересует eroticpic.ru, посмотрите сюда.
Смотрите сами:
https://eroticpic.ru
Может, у кого-то есть другой опыт?
https://gentlenoelnoeljanuary02021985.bandcamp.com/album/bigot
https://www.montessorijobsuk.co.uk/author/lugybqycah/
Это именно то, что я искал!
Между прочим, если вас интересует all-hotels-online.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://all-hotels-online.ru
Если есть вопросы, задавайте.
https://www.brownbook.net/business/54153988/давос-амфетамин-кокаин-экстази/
Сайт строительной тематики с актуальными ежедневными публикациями статей о ремонте и строительстве. Также полезные статьи об интерьере, ландшафтном дизайне и уходу за приусадебным участком https://sstroys.ru/
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%95%D1%80%D0%B5%D0%B2%D0%B0%D0%BD/
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить раздел про spb-hotels.ru.
Вот, можете почитать:
https://spb-hotels.ru
Надеюсь, это было полезно.
https://www.band.us/page/99563009/
https://hub.docker.com/u/meKellygirl18
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует anclaves.ru, загляните сюда.
Вот, можете почитать:
https://anclaves.ru
Надеюсь, это было полезно.
вывод из запоя минск
vivod-iz-zapoya-minsk005.ru
вывод из запоя круглосуточно
https://www.montessorijobsuk.co.uk/author/odagicebyco/
https://say.la/read-blog/124243
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “obender.ru”, там просто кладезь информации.
Ссылка ниже:
https://obender.ru
Жду ваших комментариев.
https://www.band.us/page/99544997/
Вот отличный материал, который проливает свет на ситуацию:
Между прочим, если вас интересует detoxa.ru, загляните сюда.
Смотрите сами:
https://detoxa.ru
Что думаете по этому поводу?
https://www.band.us/page/99556592/
https://bio.site/hihecygug
На сайте https://hackerlive.biz вы найдете профессиональных, знающих и талантливых хакеров, которые окажут любые услуги, включая взлом, защиту, а также использование уникальных, анонимных методов. Все, что нужно – просто связаться с тем специалистом, которого вы считаете самым достойным. Необходимо уточнить все важные моменты и расценки. На форуме есть возможность пообщаться с единомышленниками, обсудить любые темы. Все специалисты квалифицированные и справятся с работой на должном уровне. Постоянно появляются новые специалисты, заслуживающие внимания.
Уверен, эта информация будет для вас полезна:
По теме “obender.ru”, там просто кладезь информации.
Ссылка ниже:
https://obender.ru
Всем добра!
https://pxlmo.com/meyer.mary
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9A%D0%BE%D1%81/
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Кстати, если вас интересует fixora.ru, посмотрите сюда.
Вот, можете почитать:
https://fixora.ru
Уверен, вместе мы найдем решение.
https://rant.li/lgavrcgzk8
https://odysee.com/@arabatanejar
На мой взгляд, лучшее решение этой проблемы здесь:
Для тех, кто ищет информацию по теме “anclaves.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://anclaves.ru
Обращайтесь, если что.
https://karinajoneskar.bandcamp.com/album/base
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “detoxa.ru”, нашел много полезного.
Ссылка ниже:
https://detoxa.ru
Успехов в решении вашего вопроса!
Сериал «Уэнсдей» https://uensdey.com мрачная и захватывающая история о дочери Гомеса и Мортиши Аддамс. Учёба в Академии Невермор, раскрытие тайн и мистика в лучших традициях Тима Бёртона. Смотреть онлайн в хорошем качестве.
https://wanderlog.com/view/xlnrlhrfre/
https://www.metooo.io/u/68977f5b35e2a81acfcb7406
Срочно нужен сантехник? сантехник вызов на дом в Алматы? Профессиональные мастера оперативно решат любые проблемы с водопроводом, отоплением и канализацией. Доступные цены, выезд в течение часа и гарантия на все виды работ
Для тех, кто в теме, будет очень актуально:
По теме “classifields.ru”, нашел много полезного.
Смотрите сами:
https://classifields.ru
Жду конструктивной критики.
Die Diagnose peritonealkarzinose erfordert oft eine Kombination aus operativem Eingriff und gezielter hyperthermer Chemotherapie, um Tumorherde effektiv zu entfernen und die Prognose zu verbessern.
https://odysee.com/@war_bestplays
Посетите сайт https://ambenium.ru/ и вы сможете ознакомиться с Амбениум – единственный нестероидный противовоспалительный препарат зарегистрированный в России с усиленным обезболивающим эффектом – раствор для внутримышечного введения фенилбутазон и лидокаин. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства.
На мой взгляд, лучшее решение этой проблемы здесь:
Для тех, кто ищет информацию по теме “lingomap.ru”, нашел много полезного.
Смотрите сами:
https://lingomap.ru
Всем удачи и хорошего дня!
вывод из запоя цена
vivod-iz-zapoya-irkutsk006.ru
экстренный вывод из запоя
https://www.band.us/page/99569302/
https://odysee.com/@geicihatri
Делюсь с вами полезной ссылкой по теме:
По теме “lingomap.ru”, есть отличная статья.
Ссылка ниже:
https://lingomap.ru
Интересно было бы узнать ваше мнение.
провайдеры по адресу
samara-domashnij-internet005.ru
интернет провайдеры по адресу самара
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%A0%D0%B8%D0%BC%D0%B8%D0%BD%D0%B8/
Вот отличный материал, который проливает свет на ситуацию:
Для тех, кто ищет информацию по теме “fixora.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://fixora.ru
Уверен, вместе мы найдем решение.
https://www.rwaq.org/users/cherylhullche-20250809144224
https://t.me/individualki_kazan_chat
https://say.la/read-blog/123563
Очень рекомендую к прочтению:
Зацепил раздел про hotelnews.ru.
Ссылка ниже:
https://hotelnews.ru
Спасибо, что дочитали до конца.
https://www.brownbook.net/business/54154002/кордова-марихуана-гашиш-канабис/
Делюсь с вами полезной ссылкой по теме:
По теме “cyq.ru”, нашел много полезного.
Ссылка ниже:
https://cyq.ru
Надеюсь, у вас все получится.
https://www.metooo.io/u/68973e47d7001e4aa1c30b41
https://rant.li/knygxicu/dublin-kupit-ekstazi-mdma-lsd-kokain
Как раз то, что нужно для решения этого вопроса:
По теме “diyworks.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://diyworks.ru
Надеюсь, у вас все получится.
https://www.metooo.io/u/689779cefc9691709a5368a5
вывод из запоя
vivod-iz-zapoya-minsk006.ru
экстренный вывод из запоя минск
https://say.la/read-blog/124126
https://www.montessorijobsuk.co.uk/author/ehczvebtyb/
Делюсь с вами полезной ссылкой по теме:
Зацепил раздел про easyterm.ru.
Вот, делюсь ссылкой:
https://easyterm.ru
Что думаете по этому поводу?
our official company website: https://possible11.com
официальный сайт компании: https://wildlife.by
https://www.band.us/page/99570018/
Для тех, кто в теме, будет очень актуально:
По теме “fixora.ru”, есть отличная статья.
Ссылка ниже:
https://fixora.ru
Поделитесь своими мыслями в комментариях.
https://odysee.com/@rinajplacki
Дизайнерские коробочки usb-flashki-optom-24.ru для флешек оптом и флешка полицейский в Саратове. Сколько стоит флешка На 8гб и флешка 1 гб в Костроме. Брелки для флешки оптом и Usb флешки бизнес сувениры
https://pxlmo.com/Kara.Perez
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует qazar.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://qazar.ru
Чем мог, тем помог.
https://pxlmo.com/demonxaoca387
Как раз то, что нужно для решения этого вопроса:
Особенно понравился материал про clasifieds.ru.
Смотрите сами:
https://clasifieds.ru
Буду следить за обсуждением.
https://muckrack.com/person-27427875
https://wanderlog.com/view/wrsaajexfl/
Вот здесь можно найти больше примеров:
По теме “avelonbeta.ru”, там просто кладезь информации.
Ссылка ниже:
https://avelonbeta.ru
Буду рад, если кому-то пригодится.
По ссылке https://vc.ru/crypto/2132102-obmen-usdt-v-nizhnem-novgorode-podrobnyi-gid-v-2025-godu почитайте информацию про то, как обменять USDT в городе Нижнем Новгороде. Перед вами самый полный гид, из которого вы в подробностях узнаете о том, как максимально безопасно, быстро произвести обмен USDT и остальных популярных криптовалют. Есть информация и о том, почему выгодней сотрудничать с профессиональным офисом, и почему это считается безопасно. Статья расскажет вам и о том, какие еще криптовалюты являются популярными в Нижнем Новгороде.
https://rant.li/dxegegyaade/ksamil-kupit-gashish-boshki-marikhuanu
https://ucgp.jujuy.edu.ar/profile/ehjicegucehu/
Кстати, вот что я думаю по этому поводу:
Для тех, кто ищет информацию по теме “seatours.ru”, нашел много полезного.
Вот, можете почитать:
https://seatours.ru
Обращайтесь, если что.
Честный гид https://easybip.ru по недвижимости. Не агентство, не продаем. Только ясная информация: как купить/продать/снять жилье без риска, разобраться в рынке, документах и районах. Без рекламы и звонков.
https://ucgp.jujuy.edu.ar/profile/ofjudeohidac/
частный seo продвижение сайтов https://seo-effective.ru
https://muckrack.com/person-27427258
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “pro-zenit.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Давайте обсудим это подробнее.
https://git.project-hobbit.eu/bebzoyftibhu
лечение запоя
vivod-iz-zapoya-kaluga007.ru
лечение запоя калуга
https://pxlmo.com/Salassixa
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “travelmontenegro.ru”, есть отличная статья.
Смотрите сами:
https://travelmontenegro.ru
Спасибо, что дочитали до конца.
изготовление шлангов рвд рвд рукава высокого давления каталог цена
сайты рвд рукав высокого давления 2sn
https://www.brownbook.net/business/54151509/ганновер-амфетамин-кокаин-экстази/
https://www.montessorijobsuk.co.uk/author/boufubucifo/
Посмотрите, что я нашел по этому поводу:
Кстати, если вас интересует tars-rubber.ru, загляните сюда.
Смотрите сами:
https://tars-rubber.ru
Жду конструктивной критики.
https://paper.wf/mayfvoefwufa/rafailovichi-kupit-ekstazi-mdma-lsd-kokain
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует travelcrimea.ru, загляните сюда.
Ссылка ниже:
https://travelcrimea.ru
Что думаете по этому поводу?
https://bio.site/ofafeedacy
провайдеры интернета по адресу
samara-domashnij-internet006.ru
провайдеры интернета по адресу
https://git.project-hobbit.eu/yhufeggebzy
https://bsme-at.at
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “spb-hotels.ru”, там просто кладезь информации.
Смотрите сами:
https://spb-hotels.ru
Успехов в решении вашего вопроса!
Топливные карты https://www.taxi-zenit.ru решение для юридических лиц, позволяющее экономить на заправках и контролировать расходы. Гибкая настройка лимитов, полный отчёт, единый счёт и удобная онлайн-аналитика.
Предрейсовые осмотры https://predreysovye-osmotry.ru водителей в Москве — оперативно, с выездом на предприятие. Лицензированные врачи, современное оборудование, удобный график. Соблюдение всех требований законодательства и охраны труда.
https://www.band.us/page/99549156/
https://www.brownbook.net/business/54153966/катовице-марихуана-гашиш-канабис/
Возможно, это будет полезно участникам обсуждения:
Особенно понравился раздел про buytime.ru.
Вот, делюсь ссылкой:
https://buytime.ru
Пишите, что у вас получилось.
https://bio.site/ufiyiiaib
https://rant.li/lgavrcgzk8
Косметика для мужчин натуральная https://musco.ru/
Если кому интересно, вот более детальная информация:
Особенно понравился материал про easyterm.ru.
Смотрите сами:
https://easyterm.ru
Жду конструктивной критики.
https://community.wongcw.com/blogs/1128677/%D0%9C%D1%83%D0%B9%D0%BD%D0%B5-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D0%B0-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%9A%D0%B0%D0%BD%D0%B0%D0%B1%D0%B8%D1%81
https://ucgp.jujuy.edu.ar/profile/gyfbugwoc/
Вот, что говорят эксперты по этому поводу:
Хочу выделить раздел про easyterm.ru.
Ссылка ниже:
https://easyterm.ru
Надеюсь, это было полезно.
вывод из запоя омск
vivod-iz-zapoya-omsk004.ru
экстренный вывод из запоя омск
https://www.montessorijobsuk.co.uk/author/neduegefacpe/
Долго искал решение и наконец-то нашел:
Кстати, если вас интересует fjhg.ru, посмотрите сюда.
Ссылка ниже:
https://fjhg.ru
Чем мог, тем помог.
https://www.metooo.io/u/689786be47db1e7706e45ea0
https://gentlenoelnoeljanuary02021985.bandcamp.com/album/bigot
Возможно, это будет полезно участникам обсуждения:
По теме “travelmontenegro.ru”, есть отличная статья.
Вот, можете почитать:
https://travelmontenegro.ru
Всем добра!
https://www.brownbook.net/business/54152304/прато-амфетамин-кокаин-экстази/
https://potofu.me/99ckst6s
Делюсь с вами полезной ссылкой по теме:
Хочу выделить материал про spb-hotels.ru.
Вот, делюсь ссылкой:
https://spb-hotels.ru
Какие еще есть варианты?
https://paper.wf/wahohohocib/utrekht-kupit-ekstazi-mdma-lsd-kokain
Продаем оконный профиль https://okonny-profil-kupit.ru высокого качества. Большой выбор систем, подходящих для любых проектов. Консультации, доставка, гарантия.
Оконный профиль https://okonny-profil.ru купить с гарантией качества и надежности. Предлагаем разные системы и размеры, помощь в подборе и доставке. Доступные цены, акции и скидки.
https://www.band.us/band/99545004/
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует pro-zenit.ru, загляните сюда.
Смотрите сами:
https://pro-zenit.ru
Рад был поделиться информацией.
https://www.montessorijobsuk.co.uk/author/ayefebafo/
https://www.rwaq.org/users/malvojerry-20250809094737
Возможно, это будет полезно участникам обсуждения:
Зацепил материал про raregreen.ru.
Вот, можете почитать:
https://raregreen.ru
Буду признателен за ваши отзывы.
https://www.brownbook.net/business/54152909/тбилиси-амфетамин-кокаин-экстази/
https://ucgp.jujuy.edu.ar/profile/zriboybuuc/
Очень рекомендую к прочтению:
Особенно понравился раздел про yogapulse.ru.
Вот, делюсь ссылкой:
https://yogapulse.ru
Спасибо за внимание.
лечение запоя калуга
vivod-iz-zapoya-kaluga008.ru
вывод из запоя калуга
https://dhanzjaenam.bandcamp.com/album/bang
Возможно, это будет полезно участникам обсуждения:
Зацепил материал про eroticpic.ru.
Вот, делюсь ссылкой:
https://eroticpic.ru
Может, у кого-то есть другой опыт?
https://www.band.us/page/99566912/
https://bsme-at.at
https://say.la/read-blog/123787
Недавно столкнулся с похожей ситуацией, и вот что помогло:
По теме “fixora.ru”, там просто кладезь информации.
Вот, можете почитать:
https://fixora.ru
Буду рад, если кому-то пригодится.
https://community.wongcw.com/blogs/1128073/%D0%9A%D0%B0%D1%88-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D0%B0-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%9A%D0%B0%D0%BD%D0%B0%D0%B1%D0%B8%D1%81
https://www.band.us/page/99563251/
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “komandor-povolje.ru”, нашел много полезного.
Ссылка ниже:
https://komandor-povolje.ru
Буду рад, если кому-то пригодится.
https://say.la/read-blog/123921
Use temporary sms to receive one-time SMS.
Using a temp number can be beneficial for numerous reasons. This tool provides an effective way to protect your personal information during online transactions.
The primary advantage of a temp number lies in its ability to keep your personal data safe. By employing a temp number, you can avoid unsolicited calls and messages on your real phone.
Another advantage is the ability to manage spam effectively. Signing up with your primary number often leads to an influx of marketing calls and texts.
In conclusion, a temp number can be an excellent resource for protecting your privacy and managing communications. Next time you need to give out your phone number, remember the benefits of a temporary number.
Чтобы было понятнее, о чем речь:
Зацепил раздел про localflavors.ru.
Ссылка ниже:
https://localflavors.ru
Что думаете по этому поводу?
https://www.band.us/page/99556592/
На сайте https://yagodabelarusi.by уточните информацию о том, как вы сможете приобрести саженцы ремонтантной либо летней малины. В этом питомнике только продукция высокого качества и премиального уровня. Именно поэтому вам обеспечены всходы. Питомник предлагает такие саженцы, которые позволят вырастить сортовую, крупную малину для коммерческих целей либо для собственного употребления. Оплатить покупку можно наличным либо безналичным расчетом. Малина плодоносит с июля и до самых заморозков. Саженцы отправляются Европочтой либо Белпочтой.
На сайте https://sprotyv.org/ представлено огромное количество интересной, актуальной и содержательной информации на самую разную тему: экономики, политики, войны, бизнеса, криминала, культуры. Здесь только самая последняя и ценная информация, которая будет важна каждому, кто проживает в этой стране. На портале регулярно появляются новые публикации, которые ответят на многие вопросы. Есть информация на тему здоровья и того, как его поправить, сохранить до глубокой старости.
домашний интернет санкт-петербург
spb-domashnij-internet004.ru
подключить интернет в квартиру санкт-петербург
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил материал про hotelnews.ru.
Смотрите сами:
https://hotelnews.ru
Всем добра!
וקשורה, הקהל התאסף מסביב, והזונה נאלצה לאונן בעצמה, לגמור ולהמשיך לאונן עם אורגזמות עד שהקהל ירחם חשפניות, תוקעים זין עמוק בביצים, סטירות על התחת החשוף וללא דרישה לשנות אותם. כן, מרינה הייתה סוג מכון ליווי בראשון לציון שמתאים לכל אחד
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%94%D0%B0%D0%BB%D1%8F%D0%BD%D1%8C/
Давно слежу за этой темой, хочу поделиться находкой:
По теме “raregreen.ru”, есть отличная статья.
Смотрите сами:
https://raregreen.ru
Всем добра!
https://www.montessorijobsuk.co.uk/author/lnyocohod/
Kamla Game: A thrilling strategy-driven adventure where players navigate challenges, alliances, and survival in a dynamic, ever-changing world: how to play Kamla game
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9E%D1%81%D0%B0%D0%BA%D0%B0/
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Особенно понравился раздел про mersobratva.ru.
Ссылка ниже:
https://mersobratva.ru
Если у вас есть что добавить, не стесняйтесь.
https://www.montessorijobsuk.co.uk/author/ycaygliycyco/
https://bio.site/odogxabuyd
Инпек с успехом производит красивые и надежные шильдики из металла. Справляемся с самыми трудными задачами гравировки. Соблюдение сроков гарантируем. Свяжитесь с нами, расскажите о своих требованиях и пожеланиях. Вместе придумаем, как сделать то, что вам действительно необходимо. https://inpekmet.ru – тут примеры лазерной гравировки представлены. В своей работе мы уверены. Применяем только новейшее оборудование высокоточное. Предлагаем привлекательные цены. Будем рады вас среди наших постоянных клиентов видеть.
вывод из запоя
vivod-iz-zapoya-omsk005.ru
вывод из запоя круглосуточно
Вот здесь подробно расписано, как это сделать:
Между прочим, если вас интересует phenoma.ru, посмотрите сюда.
Смотрите сами:
https://phenoma.ru
Буду рад, если кому-то пригодится.
https://allmynursejobs.com/author/lilysomessnyderfi/
https://rant.li/grafogwkcubo/al-vakra-kupit-gashish-boshki-marikhuanu
На мой взгляд, лучшее решение этой проблемы здесь:
Особенно понравился материал про fjhg.ru.
Ссылка ниже:
https://fjhg.ru
Надеюсь, эта информация сэкономит вам время.
https://allmynursejobs.com/author/lopezlopezmaylopez2512/
Если кому интересно, вот более детальная информация:
По теме “avelonbeta.ru”, нашел много полезного.
Вот, можете почитать:
https://avelonbeta.ru
Какие еще есть варианты?
https://bio.site/igoibkuihocp
https://bio.site/jucohxaif
Школа стройки и ремонта. Все самое интересное и важное о стройке и ремонте. Также полезные статьи по выбору дизайна интерьера, уходу за садом и огородом, крутые лайфхаки, консультации специалистом и многое другое на страницах нашего блога https://propest.ru/
Как вариант, можно рассмотреть следующее:
По теме “yogapulse.ru”, есть отличная статья.
Вот, можете почитать:
https://yogapulse.ru
Надеюсь, смог помочь.
https://rant.li/j887euff3v
https://bs2vveb.at
На нашем заводе по производству коробок мы предлагаем широкий ассортимент упаковки, включая индивидуальное изготовление под заказ.
Фабрика, занимающаяся производством коробок, имеет значительное значение в области упаковки. Современные технологии и автоматизация процессов позволяют достигать высокой эффективности.
На таких предприятиях производят различные виды упаковки, включая картонные и пластиковые коробки. Каждый вид упаковки имеет свои особенности, что помогает удовлетворять запросы различных потребителей.
Контроль за качеством выпускаемой упаковки является важной частью работы завода. На заводе используются жесткие стандарты и множество проверок на разных стадиях выпуска.
Подводя итог, можно утверждать, что заводы по производству коробок необходимы для множества бизнесов. Изделия, производимые на таких фабриках, способствуют надежной доставке товаров и их презентабельности.
https://paper.wf/ugyfybyfogry/niderlandy-kupit-kokain-mefedron-marikhuanu
https://www.band.us/page/99545920/
Чтобы не быть голословным, прикрепляю ссылку:
По теме “buytime.ru”, там просто кладезь информации.
Смотрите сами:
https://buytime.ru
Спасибо, что дочитали до конца.
вывод из запоя цена
vivod-iz-zapoya-kaluga009.ru
вывод из запоя
https://ucgp.jujuy.edu.ar/profile/zyhohihigvoi/
Согласен с предыдущим оратором, и в дополнение хочу сказать:
По теме “yogapulse.ru”, есть отличная статья.
Ссылка ниже:
https://yogapulse.ru
Всем добра!
https://odysee.com/@guwalazoyem
https://say.la/read-blog/124069
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Хочу выделить раздел про tars-rubber.ru.
Вот, делюсь ссылкой:
https://tars-rubber.ru
Чем мог, тем помог.
горшки дизайнерские купить http://www.dizaynerskie-kashpo-nsk.ru .
https://say.la/read-blog/123724
https://pxlmo.com/brumecpanong
Как вариант, можно рассмотреть следующее:
Кстати, если вас интересует musichunt.pro, посмотрите сюда.
Смотрите сами:
https://musichunt.pro
Надеюсь, смог помочь.
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%9B%D0%B8%D0%BC%D0%B5%D1%80%D0%B8%D0%BA/
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Для тех, кто ищет информацию по теме “raregreen.ru”, там просто кладезь информации.
Смотрите сами:
https://raregreen.ru
Спасибо, что дочитали до конца.
https://www.band.us/page/99562362/
https://www.band.us/page/99558096/
Исчерпывающий ответ на данный вопрос находится тут:
Кстати, если вас интересует avelonbeta.ru, загляните сюда.
Вот, можете почитать:
https://avelonbeta.ru
Что думаете по этому поводу?
https://www.metooo.io/u/68974188f89cd47aba4761e3
https://hub.docker.com/u/robinsonr775june
https://www.montessorijobsuk.co.uk/author/dqpagedihua/
Все самое важное и интересное за прошедшую неделю. Новости общества, культуры и экономики, а также достижения науки и автопрома https://comicsplanet.ru/
Вот здесь подробно расписано, как это сделать:
Для тех, кто ищет информацию по теме “all-hotels-online.ru”, там просто кладезь информации.
Вот, можете почитать:
https://all-hotels-online.ru
Чем мог, тем помог.
https://potofu.me/7y3tw3y9
https://muckrack.com/person-27435070
На сайте https://sp-department.ru/ представлена полезная и качественная информация, которая касается создания дизайна в помещении, мебели, а также формирования уюта в доме. Здесь очень много практических рекомендаций от экспертов, которые обязательно вам пригодятся. Постоянно публикуется информация на сайте, чтобы вы ответили себе на все важные вопросы. Для удобства вся информация поделена на разделы, что позволит быстрее сориентироваться. Регулярно появляются новые публикации для расширения кругозора.
https://ucgp.jujuy.edu.ar/profile/ybahuhoh/
На сайте https://selftaxi.ru/miniven6 закажите такси минивэн, которое прибудет с водителем. Автобус рассчитан на 6 мест, чтобы устроить приятную поездку как по Москве, так и области. Это комфортабельный, удобный для передвижения автомобиль, на котором вы обязательно доедете до нужного места. Перед рейсом он обязательно проверяется, проходит технический осмотр, а в салоне всегда чисто, ухоженно. А если вам необходимо уточнить определенную информацию, то укажите свои данные, чтобы обязательно перезвонил менеджер и ответил на все вопросы.
https://ucgp.jujuy.edu.ar/profile/mucoidagic/
Если кому интересно, вот более детальная информация:
Хочу выделить материал про obender.ru.
Ссылка ниже:
https://obender.ru
Какие еще есть варианты?
https://git.project-hobbit.eu/kofubaubyfyc
https://paper.wf/aflobifebled/vena-kupit-ekstazi-mdma-lsd-kokain
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился раздел про clasifieds.ru.
Вот, можете почитать:
https://clasifieds.ru
Уверен, вместе мы найдем решение.
вывод из запоя цена
vivod-iz-zapoya-krasnodar006.ru
вывод из запоя
https://say.la/read-blog/124101
https://ucgp.jujuy.edu.ar/profile/micaehec/
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Особенно понравился раздел про easyterm.ru.
Ссылка ниже:
https://easyterm.ru
Буду рад, если кому-то пригодится.
https://odysee.com/@girlSmithclever28021994
https://ralizaamplio.bandcamp.com/album/bat
https://say.la/read-blog/124037
https://paper.wf/zwofxeohz/paduia-kupit-kokain-mefedron-marikhuanu
https://ucgp.jujuy.edu.ar/profile/uicihacu/
https://odysee.com/@hantosdamager.1992
вывод из запоя цена
vivod-iz-zapoya-krasnodar007.ru
вывод из запоя круглосуточно
https://www.montessorijobsuk.co.uk/author/pugcifab/
https://www.themeqx.com/forums/users/bybuahibah/
Я тільки що знайшов огляд про товари кращого сексшопу України — Amurchik ua.
Якщо ви шукаєте найкращі товари, ця стаття точно варта вашої уваги.
Ознайомтесь за наступним посиланням:
http://healthnews.beget.tech/takogo-vy-eshhe-ne-videli-4-samyh-neobychnyh-vibratora
https://community.wongcw.com/blogs/1128311/%D0%97%D0%B5%D0%BB%D1%8C%D0%B4%D0%B5%D0%BD-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Хочу выделить материал про Опыт и разочарование от онлайн-курсов Skillbox.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%ba%d1%83%d1%80%d1%81%d1%8b-skillbox-%d0%bc%d0%be%d0%b9-%d0%bd%d0%b5%d1%83%d0%b4%d0%b0%d1%87%d0%bd%d1%8b%d0%b9-%d0%be%d0%bf%d1%8b%d1%82-%d0%b8-%d1%80%d0%b0/
Удачных покупок и пусть ваш выбор вам всегда нравится!
https://rant.li/ryfydyce/nant-kupit-kokain-mefedron-marikhuanu
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Зацепил раздел про Переоцененные рестораны Москвы: избегаем разочарования.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
По теме “Сравнение мобильных банков: Тинькофф vs Сбер”, там просто кладезь информации.
Вот, можете почитать:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
ремонт швейных машин brother мастер по ремонту швейных машин
1с облако личный кабинет вход 1с личный кабинет войти облако
1с бухгалтерия облако цена 1с бухгалтерия облако цена
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg005.ru
вывод из запоя оренбург
https://hub.docker.com/u/dolareidenl0
провайдеры в уфе по адресу проверить
ufa-domashnij-internet004.ru
провайдер интернета по адресу уфа
https://pxlmo.com/BettyNewtonBet
makeevkatop.ru
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Между прочим, если вас интересует Как выбрать лучшие наушники для спорта: обзор, тест и лайфхаки, посмотрите сюда.
Смотрите сами:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b5-%d0%b1%d0%b5%d1%81%d0%bf%d1%80%d0%be%d0%b2%d0%be%d0%b4%d0%bd%d1%8b%d0%b5-%d0%bd%d0%b0%d1%83%d1%88%d0%bd%d0%b8%d0%ba%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%81%d0%bf%d0%be/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
volnovaxaber.ru
Автозапчасти и аксессуары для вашего автомобиля
Мы предлагаем широкий ассортимент автозапчастей, автомобильных
аксессуаров и оборудования как для владельцев легковых
автомобилей, так и для корпоративных клиентов. Наши поставщики
включают оптовые склады и официальных дилеров в России, ОАЭ,
Германии и США. Мы гарантируем максимально низкие цены на
доставку запчастей с конкретного склада поставщика до
конкретного покупателя. Наши ценности — наши клиенты и наши
сотрудники.
JAECOO J8 с ПТС в Москве
Автосервис и запчасти для вашего автомобиля
Многие годы мы предоставляем широкий спектр услуг по ремонту
автомобилей, точной диагностике и продаже автозапчастей как
для частных лиц, так и для корпоративных клиентов. Наши
специалисты используют профессиональное оборудование и
гарантируют высокое качество обслуживания. Мы обеспечиваем
прямые поставки запчастей без переплаты и предлагаем различные
формы оплаты. В нашем автосервисе вы получите консультацию по
необходимым работам и запчастям, а также бесплатную стоянку в
период ожидания деталей. Качественный сервис с автозапчастями
mariupolper.ru
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Особенно понравился материал про Опыт перехода с Windows на MacOS в 2025 году.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Буду рад услышать ваше мнение и опыт после приобретения.
mariupolol.ru
maorou_k8m maorou_k8m
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Зацепил материал про Топ бесполезных, но желанных кухонных гаджетов.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%b1%d0%b5%d1%81%d0%bf%d0%be%d0%bb%d0%b5%d0%b7%d0%bd%d1%8b%d0%b5-%d0%b3%d0%b0%d0%b4%d0%b6%d0%b5%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%ba%d1%83%d1%85%d0%bd%d0%b8-%d0%ba%d0%be%d1%82%d0%be%d1%80%d1%8b/
Отличного выбора и приятных впечатлений от новинки!
volnovaxave.ru
Автосервис и запчасти для вашего автомобиля
Многие годы мы предоставляем широкий спектр услуг по ремонту
автомобилей, точной диагностике и продаже автозапчастей как
для частных лиц, так и для корпоративных клиентов. Наши
специалисты используют профессиональное оборудование и
гарантируют высокое качество обслуживания. Мы обеспечиваем
прямые поставки запчастей без переплаты и предлагаем различные
формы оплаты. В нашем автосервисе вы получите консультацию по
необходимым работам и запчастям, а также бесплатную стоянку в
период ожидания деталей. Диагностика автомобиля в Крыму
enakievofel.ru
gorlovkarel.ru
Грузоперевозки и логистика высокого уровня
ЗАО “ЮНН” предлагает высококачественные транспортные услуги по
доставке грузов различного тоннажа и объемов по всей территории
России. Наш опыт позволяет оперативно решать любые задачи наших
клиентов, будь то доставка внутри Нижнего Новгорода и
Нижегородской области или транспортировка груза в любую точку
нашей огромной страны. https://tdstyling.ru/
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Для тех, кто ищет информацию по теме “Честный обзор без спойлеров: Дюна 2”, есть отличная статья.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
alchevskhoe.ru
На сайте https://veronahotel.pro/ спешите забронировать номер в популярном гостиничном комплексе «Верона», который предлагает безупречный уровень обслуживания, комфортные и вместительные номера, в которых имеется все для проживания. Представлены номера «Люкс», а также «Комфорт». В шаговой доступности находятся крупные торговые центры. Все гости, которые останавливались здесь, оставались довольны. Регулярно проходят выгодные акции, действуют скидки. Ознакомьтесь со всеми доступными для вас услугами.
makeevkabest.ru
Автозапчасти и аксессуары для вашего автомобиля
Мы предлагаем широкий ассортимент автозапчастей, автомобильных
аксессуаров и оборудования как для владельцев легковых
автомобилей, так и для корпоративных клиентов. Наши поставщики
включают оптовые склады и официальных дилеров в России, ОАЭ,
Германии и США. Мы гарантируем максимально низкие цены на
доставку запчастей с конкретного склада поставщика до
конкретного покупателя. Наши ценности — наши клиенты и наши
сотрудники.
https://jaecoo-avtorussbutovo.ru/
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Кстати, если вас интересует Опыт и разочарование от онлайн-курсов Skillbox, загляните сюда.
Вот, можете почитать:
https://100ch.ru/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%ba%d1%83%d1%80%d1%81%d1%8b-skillbox-%d0%bc%d0%be%d0%b9-%d0%bd%d0%b5%d1%83%d0%b4%d0%b0%d1%87%d0%bd%d1%8b%d0%b9-%d0%be%d0%bf%d1%8b%d1%82-%d0%b8-%d1%80%d0%b0/
Надеюсь, моя информация помогла вам принять верное решение.
mariupolol.ru
курсы гитары куркино Уроки вокала Куркино – это ваш путь к красивому и уверенному голосу. Наши преподаватели вокала помогут вам развить технику пения, расширить вокальный диапазон и научиться правильно дышать.
Автосервис и запчасти для вашего автомобиля
Многие годы мы предоставляем широкий спектр услуг по ремонту
автомобилей, точной диагностике и продаже автозапчастей как
для частных лиц, так и для корпоративных клиентов. Наши
специалисты используют профессиональное оборудование и
гарантируют высокое качество обслуживания. Мы обеспечиваем
прямые поставки запчастей без переплаты и предлагаем различные
формы оплаты. В нашем автосервисе вы получите консультацию по
необходимым работам и запчастям, а также бесплатную стоянку в
период ожидания деталей. Автозапчасти по оптимальному соотношению цена/качество
volnovaxaber.ru
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
По теме “Оппенгеймер Нолана: шедевр или неудача?”, нашел много полезного.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%bf%d0%bf%d0%b5%d0%bd%d0%b3%d0%b5%d0%b9%d0%bc%d0%b5%d1%80-%d0%bd%d0%be%d0%bb%d0%b0%d0%bd%d0%b0-%d0%b3%d0%b5%d0%bd%d0%b8%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d1%84%d0%b8%d0%bb%d1%8c/
Отличного выбора и приятных впечатлений от новинки!
Блог с актуальной новостной информацией о событиях в мире. Мы говорим об экономике, политике, обществе, здоровье, строительстве и о других важных направлениях https://sewingstore.ru/
alchevskter.ru
https://mariupolper.ru
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить материал про Рейтинг лучших 4K телевизоров до 50 000 рублей.
Ссылка ниже:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
Все про уютный дом, как сделать дом уютным для всех, советы по ведению дома, как создать уют в доме своими руками, советы по дизайну интерьера https://ujut-v-dome.ru/
volnovaxaber.ru
https://debaltsevoer.ru
dokuchaevsked.ru
https://volnovaxaber.ru
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
По теме “Почему стоит отказаться от Яндекс Плюс”, там просто кладезь информации.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%be%d1%87%d0%b5%d0%bc%d1%83-%d1%8f-%d0%be%d1%82%d0%ba%d0%b0%d0%b7%d0%b0%d0%bb%d1%81%d1%8f-%d0%be%d1%82-%d0%bf%d0%be%d0%b4%d0%bf%d0%b8%d1%81%d0%ba%d0%b8-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
Надеюсь, моя информация помогла вам принять верное решение.
antracitfel.ru
https://alchevskhoe.ru
https://enakievoler.ru
https://volnovaxave.ru
https://makeevkabest.ru
В современном мире проблема наркомании и алкоголизма становится все более актуальной. Часто возникает необходимость в оперативной помощи, и именно в эти моменты нарколог на дом должен прийти на помощь. Выездной нарколог обеспечивает медицинское вмешательство при алкогольной и наркотической зависимости, включая очистку организма у пациента на дому. Сайт vivod-iz-zapoya-tula008.ru предлагает услуги профессионалов, которые могут выехать к вам в любое время. Визит нарколога даст возможность оценить здоровье пациента и подобрать оптимальное лечение зависимости. Конфиденциальное лечение и восстановление для зависимых — ключевые моменты, которые обеспечивают защиту и удобство. Вызов врача на дом уменьшает стрессовую нагрузку на пациента, что играет ключевую роль в успешном лечении.
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
По теме “Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?”, там просто кладезь информации.
Ссылка ниже:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar010.ru
вывод из запоя краснодар
https://volnovaxave.ru
alchevskhoe.ru
https://yasinovatayate.ru
debaltsevoer.ru
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Кстати, если вас интересует iPhone 15 Pro Max: Обзор и честное мнение, загляните сюда.
Смотрите сами:
https://100ch.ru/iphone-15-pro-max-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d0%bf%d1%80%d0%be%d1%81/
Надеюсь, моя информация помогла вам принять верное решение.
https://antracitfel.ru
https://antracithol.ru
debaltsevoty.ru
https://alchevskter.ru
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Кстати, если вас интересует Гид по выбору идеальной кофемашины для дома, загляните сюда.
Ссылка ниже:
https://100ch.ru/%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d0%ba%d0%be%d1%84%d0%b5%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%83-%d0%b4%d0%bb%d1%8f-%d0%b4%d0%be%d0%bc%d0%b0-%d0%b8-%d0%bd%d0%b5-%d0%bf%d0%be/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://volnovaxaber.ru
https://mariupolper.ru
mariupolper.ru
https://alchevskhoe.ru
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Между прочим, если вас интересует Честный обзор без спойлеров: Дюна 2, посмотрите сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Отличного выбора и приятных впечатлений от новинки!
https://www.pinterest.fr/pin/896005288371149870/
https://yasinovatayahe.ru
mariupolol.ru
https://volnovaxave.ru
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
По теме “Как выбрать лучшие наушники для спорта: обзор, тест и лайфхаки”, там просто кладезь информации.
Ссылка ниже:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b5-%d0%b1%d0%b5%d1%81%d0%bf%d1%80%d0%be%d0%b2%d0%be%d0%b4%d0%bd%d1%8b%d0%b5-%d0%bd%d0%b0%d1%83%d1%88%d0%bd%d0%b8%d0%ba%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%81%d0%bf%d0%be/
Отличного выбора и приятных впечатлений от новинки!
https://countryboxclothing.com/casinoice-53/
makeevkatop.ru
https://yasinovatayahe.ru
https://boneolions.org.au/verde-casino-bonus-senza-deposito-la-tua-6/
drgn
http://webanketa.com/forms/6mrk4chn6wqkesb66rrk4dsj/
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Особенно понравился раздел про Опыт и разочарование от онлайн-курсов Skillbox.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%ba%d1%83%d1%80%d1%81%d1%8b-skillbox-%d0%bc%d0%be%d0%b9-%d0%bd%d0%b5%d1%83%d0%b4%d0%b0%d1%87%d0%bd%d1%8b%d0%b9-%d0%be%d0%bf%d1%8b%d1%82-%d0%b8-%d1%80%d0%b0/
Отличного выбора и приятных впечатлений от новинки!
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk004.ru
вывод из запоя
https://odysee.com/@Maasukaninet
https://business.busswe.com/icecasino-37/
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Между прочим, если вас интересует Самокат: скорость и качество доставки продуктов, посмотрите сюда.
Вот, можете почитать:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Отличного выбора и приятных впечатлений от новинки!
https://pxlmo.com/Daliitworoseisi
https://www.rwaq.org/users/hysenismilelovemayhyseni103-20250810235655
https://muckrack.com/person-27445387
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Зацепил раздел про Стоит ли покупать PlayStation 5 в 2024 году?.
Смотрите сами:
https://100ch.ru/playstation-5-%d0%b2-2024-%d0%b3%d0%be%d0%b4%d1%83-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d0%bf%d0%be%d0%ba%d1%83%d0%bf%d0%b0%d1%82%d1%8c-%d0%b8-%d0%ba%d0%b0%d0%ba%d0%b8%d0%b5-%d0%b5%d1%81/
Отличного выбора и приятных впечатлений от новинки!
https://www.rwaq.org/users/dawqinheerke-20250810235744
Прокат авто без залога
https://community.wongcw.com/blogs/1128889/%D0%91%D0%B0%D1%82%D1%83%D0%BC%D0%B8-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
Cosmetology clinic Cosmetology clinic .
https://www.rwaq.org/users/bongio22nonew-20250812133531
Ищете быстрый займ на карту? На https://zaimhub.com собраны лучшие предложения МФО России. Выберите выгодный вариант и получите деньги онлайн без лишних документов
https://say.la/read-blog/125500
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk005.ru
экстренный вывод из запоя омск
официальный сайт вавада
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Особенно понравился раздел про iPhone 15 Pro Max: Обзор и честное мнение.
Ссылка ниже:
https://100ch.ru/iphone-15-pro-max-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d0%bf%d1%80%d0%be%d1%81/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://www.band.us/page/99612039/
https://hub.docker.com/u/HaleyBerryHal
Артисты на вечеринку
https://potofu.me/9xyp3z9l
Актуальный новостной блог, где ежедневно публикуются все самые значимые события, произошедшие за последние сутки в самых различных регионах земного шара https://dip-kostroma.ru/
https://www.brownbook.net/business/54154532/черногория-амфетамин-кокаин-экстази/
https://ucgp.jujuy.edu.ar/profile/zubibigeabef/
лечение запоя
vivod-iz-zapoya-minsk006.ru
лечение запоя минск
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Для тех, кто ищет информацию по теме “Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?”, есть отличная статья.
Смотрите сами:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Надеюсь, моя информация помогла вам принять верное решение.
https://mez.ink/billatyoedi
https://www.band.us/page/99573149/
https://potofu.me/q9jo9ou8
Trump’s https://www.automation.in.th/?p=400237 remarks fuel bullish sentiment today.
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Особенно понравился материал про Топ бесполезных, но желанных кухонных гаджетов.
Ссылка ниже:
https://100ch.ru/%d0%b1%d0%b5%d1%81%d0%bf%d0%be%d0%bb%d0%b5%d0%b7%d0%bd%d1%8b%d0%b5-%d0%b3%d0%b0%d0%b4%d0%b6%d0%b5%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%ba%d1%83%d1%85%d0%bd%d0%b8-%d0%ba%d0%be%d1%82%d0%be%d1%80%d1%8b/
Буду рад услышать ваше мнение и опыт после приобретения.
тарифы интернет и телевидение омск
volgograd-domashnij-internet004.ru
провайдеры домашнего интернета омск
https://www.band.us/page/99595314/
https://www.brownbook.net/business/54154887/тулуза-марихуана-гашиш-канабис/
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Для тех, кто ищет информацию по теме “Стоит ли покупать iPhone 15 Pro Max сейчас?”, есть отличная статья.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Удачных покупок и пусть ваш выбор вам всегда нравится!
https://git.project-hobbit.eu/hybodeeaduck
Обучение недвижимости Обучение недвижимости: Инвестируйте в свое профессиональное будущее. Обучение недвижимости – это не просто трата денег, а инвестиция в свое будущее. Полученные знания и навыки помогут вам принимать взвешенные решения, избегать ошибок и зарабатывать деньги.
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Кстати, если вас интересует Сравнение мобильных банков: Тинькофф vs Сбер, посмотрите сюда.
Ссылка ниже:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Буду рад услышать ваше мнение и опыт после приобретения.
https://community.wongcw.com/blogs/1129042/%D0%91%D1%83%D1%8D%D0%BD%D0%BE%D1%81-%D0%90%D0%B9%D1%80%D0%B5%D1%81-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
https://hub.docker.com/u/lilyRuhlin09
экскурсии казань
военнаЯ пенсиЯ ипотека калькулЯтор
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
По теме “Стоит ли покупать PlayStation 5 в 2024 году?”, там просто кладезь информации.
Смотрите сами:
https://100ch.ru/playstation-5-%d0%b2-2024-%d0%b3%d0%be%d0%b4%d1%83-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d0%bf%d0%be%d0%ba%d1%83%d0%bf%d0%b0%d1%82%d1%8c-%d0%b8-%d0%ba%d0%b0%d0%ba%d0%b8%d0%b5-%d0%b5%d1%81/
Отличного выбора и приятных впечатлений от новинки!
https://potofu.me/vhcv6o3q
https://hoo.be/gabucmugic
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk004.ru
вывод из запоя круглосуточно
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Между прочим, если вас интересует Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?, посмотрите сюда.
Вот, можете почитать:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Отличного выбора и приятных впечатлений от новинки!
Посетите сайт https://cs2case.io/ и вы сможете найти кейсы КС (КС2) в огромном разнообразии, в том числе и бесплатные! Самый большой выбор кейсов кс го у нас на сайте. Посмотрите – вы обязательно найдете для себя шикарные варианты, а выдача осуществляется моментально к себе в Steam.
индексациЯ военной пенсии
https://www.metooo.io/u/689a6506c6fd1a348a405cbd
провайдеры интернета омск
volgograd-domashnij-internet005.ru
подключить интернет в волгограде в квартире
https://mantkalqisi.bandcamp.com/album/-
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Между прочим, если вас интересует Самокат: скорость и качество доставки продуктов, загляните сюда.
Смотрите сами:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Посетите сайт https://rivanol-rf.ru/ и вы сможете ознакомиться с Риванол – это аптечное средство для ухода за кожей. На сайте есть цена и инструкция по применению. Ознакомьтесь со всеми преимуществами данного средства, которое содержит уникальный антисептик, регенератор кожи: этакридина лактат.
https://www.brownbook.net/business/54165174/сицилия-купить-амфетамин-кокаин-экстази/
https://potofu.me/m1qc1wx8
https://mez.ink/lencaiponsak
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg005.ru
вывод из запоя круглосуточно оренбург
Приглашаем вас совершить виртуальное путешествие без границ с помощью удобного сервиса «Веб-камеры мира онлайн». Все страны мира, как на ладони, на расстоянии одного клика: https://world-cam.ru/
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Для тех, кто ищет информацию по теме “Честный обзор без спойлеров: Дюна 2”, там просто кладезь информации.
Смотрите сами:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
https://mez.ink/moutaspolfil
Si vous voulez tout savoir sur les plateformes en France, alors c’est un incontournable.
Lisez l’integralite via le lien ci-dessous :
https://dessertden.com/casino-en-ligne-france-205/
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить раздел про Почему стоит отказаться от Яндекс Плюс.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%be%d1%87%d0%b5%d0%bc%d1%83-%d1%8f-%d0%be%d1%82%d0%ba%d0%b0%d0%b7%d0%b0%d0%bb%d1%81%d1%8f-%d0%be%d1%82-%d0%bf%d0%be%d0%b4%d0%bf%d0%b8%d1%81%d0%ba%d0%b8-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
Буду рад услышать ваше мнение и опыт после приобретения.
https://community.wongcw.com/blogs/1129046/%D0%9B%D1%8E%D0%BA%D1%81%D0%B5%D0%BC%D0%B1%D1%83%D1%80%D0%B3-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
На сайте https://prometall.shop/ представлен огромный ассортимент чугунных печей стильного, привлекательного дизайна. За счет того, что выполнены из надежного, прочного и крепкого материала, то наделены долгим сроком службы. Вы сможете воспользоваться огромным спектром нужных и полезных дополнительных услуг. В каталоге вы найдете печи в сетке, камне, а также отопительные. Все изделия наделены компактными размерами, идеально впишутся в любой интерьер. При разработке были использованы уникальные, высокие технологии.
https://www.band.us/page/99611286/
Онлайн курсы по недвижимости Обучение недвижимости Москва: Погрузитесь в атмосферу деловой столицы. Москва – это центр деловой активности, где сосредоточены крупнейшие объекты недвижимости и работают лучшие специалисты в этой области. Обучение недвижимости в Москве – это уникальная возможность получить знания из первых рук, наладить полезные контакты и начать успешную карьеру.
Посетите скачать сайт семяныч, чтобы найти качественные семена для вашего сада!
Семяныч ру — это официальный интернет-магазин, где вы можете найти все необходимое для своего огорода. Здесь вы найдете качественные семена, удобрения и инструменты.
Семяныч ру отличается высоким качеством продукции и доступными ценами. Все семена и удобрения имеют необходимые сертификаты качества.
На сайте магазина Семяныч ру легко ориентироваться благодаря интуитивно понятному интерфейсу. Вы можете фильтровать по категориям, чтобы быстрее найти интересующие вас товары.
Магазин предлагает быструю доставку товаров по всей территории России. Выберите наиболее удобный способ оплаты и доставки при заказе в магазине Семяныч ру.
https://hoo.be/egohwybuh
https://odysee.com/@kirk1hubbabubba
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Между прочим, если вас интересует Переоцененные рестораны Москвы: избегаем разочарования, загляните сюда.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Буду рад услышать ваше мнение и опыт после приобретения.
¡Mis mejores deseos a todos los cazadores de premios!
En casinos internacionales online la variedad de tragamonedas es enorme. casinos internacionales online Siempre hay algo nuevo.
Al apostar en casinosonlineinternacionales.guru disfrutas de programas VIP con recompensas y compatibilidad total con mГіvil y tablet. Estas plataformas incluyen estadГsticas y datos en tiempo real y mesas exclusivas para VIP. Por eso la relaciГіn entre riesgo y recompensa es mГЎs favorable.
Casino online internacional con tragaperras RTP alto – п»їhttps://casinosonlineinternacionales.guru/
¡Que disfrutes de extraordinarias giros !
https://bio.site/qgidabiigqy
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%94%D0%B0%D0%BD%D0%B8%D1%8F/
На сайте http://gotorush.ru воспользуйтесь возможностью принять участие в эпичных, зрелищных турнирах 5х5 и сразиться с остальными участниками, командами, которые преданы своему делу. Регистрация для каждого участника является абсолютно бесплатной. Изучите информацию о последних турнирах и о том, в каких форматах они проходят. Есть возможность присоединиться к команде или проголосовать за нее. Представлен раздел с последними результатами, что позволит сориентироваться в поединках. При необходимости задайте интересующий вопрос службе поддержки.
даніель значення імені
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Между прочим, если вас интересует Рейтинг лучших 4K телевизоров до 50 000 рублей, загляните сюда.
Смотрите сами:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Надеюсь, моя информация помогла вам принять верное решение.
https://say.la/read-blog/124580
https://say.la/read-blog/125089
https://priscillapattersonpri.bandcamp.com/album/ant
https://rant.li/wubzhacyog/monpel-e-kupit-kokain-mefedron-marikhuanu
драгон мани зеркало
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить раздел про Честный обзор без спойлеров: Дюна 2.
Смотрите сами:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Отличного выбора и приятных впечатлений от новинки!
https://www.metooo.io/u/68988e7781136e5a031270f7
https://hub.docker.com/u/obanavingta
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Для тех, кто ищет информацию по теме “Стоит ли покупать iPhone 15 Pro Max сейчас?”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Буду рад услышать ваше мнение и опыт после приобретения.
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Кстати, если вас интересует Рейтинг лучших 4K телевизоров до 50 000 рублей, загляните сюда.
Ссылка ниже:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Надеюсь, моя информация помогла вам принять верное решение.
https://say.la/read-blog/125693
https://muckrack.com/person-27451730
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
По теме “iPhone 15 Pro Max: Обзор и честное мнение”, нашел много полезного.
Вот, делюсь ссылкой:
https://100ch.ru/iphone-15-pro-max-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d0%bf%d1%80%d0%be%d1%81/
Буду рад услышать ваше мнение и опыт после приобретения.
номер телефона для получения смс
На сайте https://vc.ru/crypto/2132042-obmen-usdt-v-kaliningrade-kak-bezopasno-i-vygodno-obnalichit-kriptovalyutu ознакомьтесь с полезной и важной информацией относительно обмена USDT. На этой странице вы узнаете о том, как абсолютно безопасно, максимально оперативно произвести обналичивание криптовалюты. Сейчас она используется как для вложений, так и международных расчетов. Ее выдают в качестве заработной платы, используется для того, чтобы сохранить сбережения. Из статьи вы узнаете и то, почему USDT является наиболее востребованной валютой.
https://hoo.be/ubeycufu
провайдеры интернета воронеж
voronezh-domashnij-internet006.ru
подключить домашний интернет в воронеже
https://git.project-hobbit.eu/gahgbuecufa
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить материал про Сравнение мобильных банков: Тинькофф vs Сбер.
Смотрите сами:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://www.rwaq.org/users/dianesmart032003-20250810000916
https://pixelfed.tokyo/perez7anh22061995
https://rant.li/wibyfoci/frantsiia-kupit-gashish-boshki-marikhuanu
https://shootinfo.com/author/amondstill0y/?pt=ads
Нарколог на дом анонимно: доступная помощь Зависимости становятся серьезной проблемой в нашем обществе‚ и наркологические услуги играют важную роль. Если вы или ваши близкие страдаете от алкоголизма или наркомании‚ важно знать‚ что существует возможность анонимного лечения. Вы можете обратиться на сайт vivod-iz-zapoya-vladimir007.ru для получения информации о выездной наркологии и помощи на дому. Лечение в анонимной обстановке помогает пациентам избавиться от страха осуждения и открыто делиться своими переживаниями. Встречи с наркологом могут проходить в удобной обстановке‚ что способствует лучшему взаимодействию. Врачи предлагают программы реабилитации‚ включая кодирование от алкоголя и психотерапию зависимостей. Поддержка семьи зависимого также играет важную роль в процессе выздоровления. Анонимные наркологические клиники разрабатывают специальные программы‚ учитывающие индивидуальные потребности пациентов. Не упускайте возможность улучшить свою жизнь с помощью опытных специалистов.
https://www.montessorijobsuk.co.uk/author/qkiigoaagy/
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Для тех, кто ищет информацию по теме “Рейтинг лучших 4K телевизоров до 50 000 рублей”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Отличного выбора и приятных впечатлений от новинки!
https://bio.site/jaegufbeo
Посетите сайт https://zismetall.ru/ и вы найдете металлоизделия от производителя. Звонкая песнь металла – это современное производство металлоизделий – художественная ковка, декоративный металлопрокат, изделия для костровой зоны и многое другое. Осуществляем быструю доставку и предлагаем отличные цены! Подробнее на сайте!
Zestril
https://community.wongcw.com/blogs/1129991/%D0%94%D0%BE%D1%85%D0%B0-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B0%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D1%8D%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%9B%D1%83%D0%B3%D0%B0%D0%BD%D0%BE/
https://potofu.me/5sswwpnv
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Особенно понравился материал про Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?.
Ссылка ниже:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://pxlmo.com/haisamrabaye
https://rant.li/ytmwemiuau
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Особенно понравился раздел про Гид по выбору идеальной кофемашины для дома.
Смотрите сами:
https://100ch.ru/%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d0%ba%d0%be%d1%84%d0%b5%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%83-%d0%b4%d0%bb%d1%8f-%d0%b4%d0%be%d0%bc%d0%b0-%d0%b8-%d0%bd%d0%b5-%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
https://say.la/read-blog/125494
https://hub.docker.com/u/mafeekanita
https://muckrack.com/person-27451621
https://allmynursejobs.com/author/jasonthompsonjas/
https://allmynursejobs.com/author/donainesayas/
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Зацепил материал про Стоит ли покупать iPhone 15 Pro Max сейчас?.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Надеюсь, моя информация помогла вам принять верное решение.
https://community.wongcw.com/blogs/1128777/%D0%A1%D0%BB%D0%BE%D0%B2%D0%B0%D0%BA%D0%B8%D1%8F-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
https://kemono.im/xahciyaduh/slovakiia-kupit-ekstazi-mdma-lsd-kokain
https://pixelfed.tokyo/iseaHanlilyy
https://allmynursejobs.com/author/utukitier/
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Между прочим, если вас интересует Честный обзор без спойлеров: Дюна 2, посмотрите сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
По теме “Гид по выбору идеальной кофемашины для дома”, там просто кладезь информации.
Смотрите сами:
https://100ch.ru/%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d0%ba%d0%be%d1%84%d0%b5%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%83-%d0%b4%d0%bb%d1%8f-%d0%b4%d0%be%d0%bc%d0%b0-%d0%b8-%d0%bd%d0%b5-%d0%bf%d0%be/
Отличного выбора и приятных впечатлений от новинки!
Оригинальные запасные части Thermo Fisher Scientific https://thermo-lab.ru/ и расходные материалы для лабораторного и аналитического оборудования с доставкой в России. Поставка высококачественного лабораторного и аналитического оборудования Thermo Fisher, а также оригинальных запасных частей и расходных материалов от ведущих мировых производителей. Каталог Термо Фишер включает всё необходимое для бесперебойной и эффективной работы вашей лаборатории по низким ценам в России.
https://www.band.us/page/99589313/
https://say.la/read-blog/125362
https://pxlmo.com/moorszeldexk
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Между прочим, если вас интересует Топ бесполезных, но желанных кухонных гаджетов, загляните сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%b1%d0%b5%d1%81%d0%bf%d0%be%d0%bb%d0%b5%d0%b7%d0%bd%d1%8b%d0%b5-%d0%b3%d0%b0%d0%b4%d0%b6%d0%b5%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%ba%d1%83%d1%85%d0%bd%d0%b8-%d0%ba%d0%be%d1%82%d0%be%d1%80%d1%8b/
Надеюсь, моя информация помогла вам принять верное решение.
https://www.montessorijobsuk.co.uk/author/egyhiefoefu/
https://hoo.be/edjidigey
https://www.band.us/page/99596644/
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
По теме “Честный обзор без спойлеров: Дюна 2”, там просто кладезь информации.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
https://allmynursejobs.com/author/juvyseesezz/
https://ucgp.jujuy.edu.ar/profile/dcohocyy/
https://allmynursejobs.com/author/ggarc1aromansome/
https://bio.site/ycifjtwodm
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Между прочим, если вас интересует Честный обзор без спойлеров: Дюна 2, посмотрите сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://www.metooo.io/u/6898ce2d5d709436dbd073e6
https://www.montessorijobsuk.co.uk/author/adryhabqeb/
https://bio.site/agohifzeco
https://community.wongcw.com/blogs/1128781/%D0%97%D0%B0%D0%B4%D0%B0%D1%80-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D0%B0
https://hoo.be/obkuidbgza
https://odysee.com/@TaharaladyTakumaawesome17
https://bio.site/efacoohogo
http://webanketa.com/forms/6mrk4d9m68qk4r9p6wvkec32/
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
По теме “Гид по выбору идеальной кофемашины для дома”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d0%ba%d0%be%d1%84%d0%b5%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d1%83-%d0%b4%d0%bb%d1%8f-%d0%b4%d0%be%d0%bc%d0%b0-%d0%b8-%d0%bd%d0%b5-%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
BetView – блог про ставки от профессионального беттора Алексея Полякова.
беттинг
https://hub.docker.com/u/stoopMoyn3w
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%92%D0%B0%D0%B4%D1%83%D1%86/
Eliquis
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Между прочим, если вас интересует Переоцененные рестораны Москвы: избегаем разочарования, посмотрите сюда.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Буду рад услышать ваше мнение и опыт после приобретения.
https://www.band.us/page/99594909/
https://www.montessorijobsuk.co.uk/author/ugyogicyhag/
https://ucgp.jujuy.edu.ar/profile/ucztoafkedy/
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Кстати, если вас интересует Рейтинг лучших 4K телевизоров до 50 000 рублей, посмотрите сюда.
Ссылка ниже:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://allmynursejobs.com/author/kingmantap_1992/
https://allmynursejobs.com/author/elriztanhi/
https://xfpsaorim3bbad.bandcamp.com/album/alienate
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Зацепил материал про Самокат: скорость и качество доставки продуктов.
Ссылка ниже:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://wanderlog.com/view/oigyqvnjnc/
Keytruda
https://pixelfed.tokyo/terminatornard
https://wanderlog.com/view/ayrgebcaae/
https://www.brownbook.net/business/54155325/верона-марихуана-гашиш-канабис/
https://hub.docker.com/u/edgpaquiz
https://ucgp.jujuy.edu.ar/profile/afuhofad/
Stelara
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%A4%D1%80%D0%B0%D0%B9%D0%B1%D1%83%D1%80%D0%B3/
https://wanderlog.com/view/hiswtmsvxf/
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Зацепил материал про Самокат: скорость и качество доставки продуктов.
Ссылка ниже:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Надеюсь, моя информация помогла вам принять верное решение.
https://pixelfed.tokyo/robinapril121990
https://community.wongcw.com/blogs/1128899/%D0%AD%D1%88%D1%82%D0%BE%D1%80%D0%B8%D0%BB-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D0%B0
По ссылке https://tartugi.net/111268-kak-priruchit-drakona.html вы сможете посмотреть увлекательный, добрый и интересный мультфильм «Как приручить дракона». Он сочетает в себе сразу несколько жанров, в том числе, приключения, комедию, семейный, фэнтези. На этом портале он представлен в отличном качестве, с хорошим звуком, а посмотреть его получится на любом устройстве, в том числе, планшете, телефоне, ПК, в командировке, во время длительной поездки или в выходной день. Мультик обязательно понравится вам, ведь в нем сочетается юмор, доброта и красивая музыка.
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
По теме “Рейтинг лучших 4K телевизоров до 50 000 рублей”, есть отличная статья.
Ссылка ниже:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://allmynursejobs.com/author/ninenaardosealli/
https://www.brownbook.net/business/54158916/эшторил-купить-амфетамин-кокаин-экстази/
https://www.metooo.io/u/689baa9c40422e2b80152f2d
https://allmynursejobs.com/author/jhimertajai/
https://kemono.im/ihycpigyciby/bagamskie-ostrova-kupit-gashish-boshki-marikhuanu
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%9F%D0%BE%D0%BC%D0%BE%D1%80%D0%B8%D0%B5/
https://rylanlfugs.blogolize.com/un-imparcial-vista-de-selecciГіn-de-personal-75427291
La contratación de talento es fundamental para el desempeño de cualquier empresa.
Contar con profesionales capacitados en los roles estratégicos define el rumbo en productividad.
1. Identificar el puesto ideal
Antes de comenzar el proceso de reclutamiento, es vital tener claro el perfil del candidato que la empresa busca. Esto incluye habilidades técnicas, trayectoria y actitudes que se alineen con la cultura de la organización.
2. Canales de reclutamiento
Hoy en día, las empresas tienen la posibilidad de aprovechar redes profesionales como Indeed, además de programas de recomendación para conseguir al mejor talento.
Combinar fuentes incrementa la probabilidad de encontrar candidatos de calidad.
3. Filtrado inicial
Una vez recibidas las solicitudes, es importante preseleccionar a los perfiles que mejor se ajustan a los requisitos.
Después, las entrevistas sirven para evaluar no solo la experiencia del candidato, sino también su encaje cultural con la empresa.
4. Exámenes de selección
Para garantizar que el profesional seleccionado cumple con lo esperado, se pueden implementar pruebas técnicas, evaluaciones psicométricas o ejercicios prácticos.
Esto reduce el margen de equivocación al contratar.
5. Toma de decisión y contratación
Tras el proceso de evaluación, se procede de seleccionar al candidato que mejor se adapta.
La comunicación clara y un plan de integración son cruciales para garantizar que el nuevo empleado se integre fácilmente.
6. Optimización del proceso
Un proceso de reclutamiento nunca se queda fijo.
Medir indicadores como tiempo de contratación hace posible optimizar la estrategia y perfeccionar los resultados.
Al final, el proceso de contratación es mucho más que cubrir puestos.
Es una inversión en el futuro de la empresa, donde atraer al equipo adecuado determina su crecimiento sostenible.
https://www.rwaq.org/users/angelrose18061997-20250812010944
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Особенно понравился раздел про Стоит ли покупать iPhone 15 Pro Max сейчас?.
Вот, можете почитать:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://hub.docker.com/u/Zichanninethreeng
https://allmynursejobs.com/author/marianneottmaysweet421/
https://kemono.im/ougugucuf/la-roshel-kupit-kokain-mefedron-marikhuanu
https://arttina0611.bandcamp.com/album/adore
сборка Игровой компьютер купить: Инвестиция в развлечение.
https://say.la/read-blog/124670
https://allmynursejobs.com/author/ptftaliep/
https://www.themeqx.com/forums/users/dahubahobacy/
https://andytjsae.tribunablog.com/el-5-segundo-truco-para-selecciГіn-de-personal-50771999
La contratación de talento es esencial para el desempeño de cualquier empresa.
Tener el equipo correcto en los puestos correctos marca la diferencia en rentabilidad.
1. Crear la descripción de cargo
Antes de iniciar el proceso de reclutamiento, es vital definir con claridad el perfil del candidato que la empresa busca. Esto incluye habilidades técnicas, trayectoria y actitudes que se alineen con la cultura de la organización.
2. Fuentes de talento
Hoy en día, las empresas tienen la posibilidad de aprovechar redes profesionales como LinkedIn, además de programas de recomendación para conseguir al mejor talento.
Combinar fuentes aumenta la probabilidad de reclutar candidatos de calidad.
3. Preselección y entrevistas
Una vez recibidas las aplicaciones, es importante filtrar a los perfiles que más se acercan a los requisitos.
Después, las entrevistas sirven para evaluar no solo la formación del candidato, sino también su potencial con la empresa.
4. Exámenes de selección
Para garantizar que el profesional seleccionado cumple con lo esperado, se pueden implementar tests de competencias, evaluaciones psicométricas o ejercicios prácticos.
Esto minimiza el margen de equivocación al contratar.
5. Toma de decisión y contratación
Tras el proceso de evaluación, llega el momento de elegir al candidato que mejor se adapta.
La presentación de la oferta y un plan de integración son cruciales para garantizar que el nuevo empleado se adapte rápido.
6. Seguimiento y mejora continua
Un sistema de selección nunca se queda fijo.
Medir indicadores como calidad de la contratación permite ajustar la estrategia y perfeccionar los resultados.
Al final, el reclutamiento y selección de personal es mucho más que cubrir puestos.
Es una inversión en el futuro de la empresa, donde elegir al talento correcto determina su éxito.
https://pixelfed.tokyo/graberketso
Your writing is a masterclass in captivating storytelling, always leaving me yearning for more. I’d love to read your take on how these narratives align with the changing landscape of digital entertainment and its impact on conventional mediums like print or cinema. Your knack for evoking feeling is truly remarkable.
Enter: https://talkchatgpt.com
чат jpt
https://rant.li/pedugafqbyei/oksford-kupit-kokain-mefedron-marikhuanu
https://pixelfed.tokyo/twoMerabetfivey
https://www.montessorijobsuk.co.uk/author/pagyoyugyfd/
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Особенно понравился раздел про Как выбрать лучшие наушники для спорта: обзор, тест и лайфхаки.
Смотрите сами:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b5-%d0%b1%d0%b5%d1%81%d0%bf%d1%80%d0%be%d0%b2%d0%be%d0%b4%d0%bd%d1%8b%d0%b5-%d0%bd%d0%b0%d1%83%d1%88%d0%bd%d0%b8%d0%ba%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
https://stephenxpdpc.mpeblog.com/64103403/5-tГ©cnicas-sencillas-para-la-selecciГіn-de-personal
El reclutamiento y selección de personal es esencial para el crecimiento de cualquier empresa.
Contar con las personas adecuadas en los puestos correctos define el rumbo en rentabilidad.
1. Identificar el puesto ideal
Antes de empezar el proceso de reclutamiento, se requiere definir con claridad el perfil profesional que la empresa requiere. Esto incluye habilidades técnicas, trayectoria y valores que se alineen con la visión de la organización.
2. Canales de reclutamiento
Hoy en día, las empresas pueden aprovechar plataformas digitales como portales especializados, además de programas de recomendación para conseguir al mejor talento.
Diversificar fuentes incrementa la posibilidad de encontrar candidatos altamente capacitados.
3. Evaluación de candidatos
Una vez recibidas las solicitudes, es importante preseleccionar a los perfiles que más se acercan a los criterios.
Después, las reuniones sirven para conocer no solo la experiencia del candidato, sino también su encaje cultural con la empresa.
4. Pruebas y evaluaciones
Para garantizar que el candidato ideal cumple con lo esperado, se pueden realizar tests de competencias, evaluaciones psicométricas o ejercicios prácticos.
Esto reduce el margen de equivocación al contratar.
5. Selección definitiva
Tras el proceso de evaluación, llega el momento de decidir al candidato que mejor cumple con los requisitos.
La presentación de la oferta y un buen onboarding son cruciales para asegurar que el nuevo empleado se integre fácilmente.
6. Medición de resultados
Un proceso de reclutamiento nunca se queda fijo.
Analizar indicadores como tiempo de contratación hace posible ajustar la estrategia y perfeccionar los resultados.
En resumen, el proceso de contratación es mucho más que cubrir puestos.
Es una apuesta en el futuro de la empresa, donde atraer al talento correcto determina su éxito.
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
По теме “Самокат: скорость и качество доставки продуктов”, там просто кладезь информации.
Смотрите сами:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Надеюсь, моя информация помогла вам принять верное решение.
hydroxychloroquine
Thanks for every other informative website. The place else may I am getting that kind of info written in such an ideal manner? I’ve a project that I am simply now operating on, and I have been at the glance out for such information.
Limousine service near me
https://hoo.be/myogabaacaf
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Для тех, кто ищет информацию по теме “Переоцененные рестораны Москвы: избегаем разочарования”, там просто кладезь информации.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Буду рад услышать ваше мнение и опыт после приобретения.
https://community.wongcw.com/blogs/1131136/%D0%90%D0%BB%D1%8C-%D0%92%D0%B0%D0%BA%D1%80%D0%B0-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BC%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%B3%D0%B0%D1%88%D0%B8%D1%88-%D0%B1%D0%BE%D1%88%D0%BA%D0%B8
https://www.themeqx.com/forums/users/zaguddohgua/
https://hoo.be/yhaeydyodyfj
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Зацепил раздел про Опыт перехода с Windows на MacOS в 2025 году.
Смотрите сами:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Отличного выбора и приятных впечатлений от новинки!
https://git.project-hobbit.eu/begohegygc
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%9B%D0%BB%D0%BE%D1%80%D0%B5%D1%82-%D0%B4%D0%B5-%D0%9C%D0%B0%D1%80/
https://pixelfed.tokyo/sakaenymym172
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Кстати, если вас интересует Честный обзор без спойлеров: Дюна 2, посмотрите сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Надеюсь, моя информация помогла вам принять верное решение.
https://www.themeqx.com/forums/users/xifdefigodm/
https://www.montessorijobsuk.co.uk/author/ofidyoay/
https://grasleduako.bandcamp.com/album/aunt
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Хочу выделить раздел про Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?.
Смотрите сами:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Отличного выбора и приятных впечатлений от новинки!
https://rant.li/agcefugc/gent-kupit-kokain-mefedron-marikhuanu
zetia
https://webpage37148.pages10.com/fascinaciГіn-acerca-de-selecciГіn-de-personal-71728133
La contratación de talento es clave para el desempeño de cualquier negocio.
Contar con el equipo correcto en los roles estratégicos define el rumbo en desarrollo.
1. Identificar el puesto ideal
Antes de empezar el proceso de reclutamiento, es necesario definir con claridad el perfil del candidato que la empresa necesita. Esto incluye competencias, trayectoria y valores que se alineen con la misión de la organización.
2. Fuentes de talento
Hoy en día, las organizaciones pueden usar bolsas de empleo como LinkedIn, además de programas de recomendación para conseguir al mejor talento.
Combinar fuentes incrementa la probabilidad de reclutar candidatos altamente capacitados.
3. Evaluación de candidatos
Una vez recibidas las candidaturas, es importante filtrar a los perfiles que mejor se ajustan a los requisitos.
Después, las entrevistas sirven para conocer no solo la formación del candidato, sino también su encaje cultural con la empresa.
4. Pruebas y evaluaciones
Para garantizar que el candidato ideal cumple con lo esperado, se pueden realizar tests de competencias, evaluaciones psicométricas o dinámicas de grupo.
Esto reduce el margen de equivocación al contratar.
5. Elección final
Tras el proceso de evaluación, se procede de seleccionar al candidato que mejor se adapta.
La comunicación clara y un plan de integración son cruciales para asegurar que el nuevo empleado se adapte rápido.
6. Medición de resultados
Un sistema de selección nunca se queda fijo.
Analizar indicadores como calidad de la contratación hace posible ajustar la estrategia y mejorar los resultados.
En definitiva, el proceso de contratación es mucho más que cubrir puestos.
Es una inversión en el futuro de la empresa, donde atraer al equipo adecuado define su crecimiento sostenible.
Клининговая компания в Москве предлагает широкий спектр услуг для поддержания чистоты вашего дома или офиса.
Услуги клининга в Москве нарастают с каждым днем. Скорее всего, это связано с тем, что многим людям не хватает времени на уборку.
Организации, занимающиеся клинингом, предоставляют разные виды услуг. Клиенты могут заказать уборку квартир, офисов или даже коммерческих помещений. Такой подход дает возможность выбрать услугу, которая наиболее подходит.
Клининговые компании, как правило, используют современные средства и технологии. Такие методы обеспечивают высокое качество уборки и улучшение сервиса. Пользователи могут быть уверены в эффективности и чистоте после уборки.
Выбирая клининговую организацию, важно ознакомиться с отзывами предыдущих клиентов. Это поможет сделать правильный выбор и найти проверенную компанию. Не забудьте предварительно обсудить все аспекты услуги и цену на нее.
https://www.metooo.io/u/6897b73a79b0ae48592287f0
https://pxlmo.com/challydalde
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Между прочим, если вас интересует Самокат: скорость и качество доставки продуктов, загляните сюда.
Вот, можете почитать:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
https://jacobhansonjac.bandcamp.com/album/-
https://www.metooo.io/u/689a647fc6fd1a348a405c04
https://muckrack.com/person-27442343
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Кстати, если вас интересует Стоит ли покупать iPhone 15 Pro Max сейчас?, посмотрите сюда.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://www.metooo.io/u/689bab05c6f30a375bd9421e
https://git.project-hobbit.eu/uohufhahxe
https://say.la/read-blog/124915
https://pxlmo.com/dreamSloan1203
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Между прочим, если вас интересует Сравнение мобильных банков: Тинькофф vs Сбер, загляните сюда.
Вот, можете почитать:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
https://rant.li/jabedyugufe/lugano-kupit-gashish-boshki-marikhuanu
https://rant.li/uhwibqyda/davos-kupit-ekstazi-mdma-lsd-kokain
Компания «РусВертолет» занимает среди конкурентов по качеству услуг и приемлемой ценовой политики лидирующие позиции. Работаем 7 дней в неделю. Наш основной приоритет – ваша безопасность. Вертолеты в хорошем состоянии, быстро заказать полет можно на сайте. Обеспечим вам море положительных и ярких эмоций! Ищете аренда вертолета цена? Rusvertolet.ru – тут есть видео и фото полетов, а также отзывы радостных клиентов. Вы узнаете, как добраться и где мы находимся. Подготовили ответы на популярные вопросы о полетах на вертолете. Всегда вам рады!
ondansetron
betturkey giris
https://nature75185.full-design.com/selecci%C3%B3n-de-personal-para-tontos-78786806
La contratación de talento es clave para el éxito de cualquier empresa.
Contar con el equipo correcto en los puestos correctos define el rumbo en rentabilidad.
1. Identificar el puesto ideal
Antes de comenzar el proceso de reclutamiento, es vital definir con claridad el perfil profesional que la empresa requiere. Esto incluye habilidades técnicas, trayectoria y actitudes que se alineen con la cultura de la organización.
2. Canales de reclutamiento
Hoy en día, las organizaciones pueden aprovechar plataformas digitales como Indeed, además de programas de recomendación para conseguir al mejor talento.
Combinar fuentes incrementa la posibilidad de reclutar candidatos altamente capacitados.
3. Evaluación de candidatos
Una vez recibidas las candidaturas, es importante filtrar a los perfiles que más se acercan a los criterios.
Después, las entrevistas sirven para conocer no solo la formación del candidato, sino también su encaje cultural con la empresa.
4. Pruebas y evaluaciones
Para asegurar que el profesional seleccionado cumple con lo esperado, se pueden realizar pruebas técnicas, análisis de personalidad o ejercicios prácticos.
Esto reduce el riesgo de error al contratar.
5. Toma de decisión y contratación
Tras el proceso de evaluación, se procede de seleccionar al candidato que mejor se adapta.
La presentación de la oferta y un buen onboarding son fundamentales para asegurar que el nuevo empleado se integre fácilmente.
6. Seguimiento y mejora continua
Un sistema de selección nunca es estático.
Medir indicadores como calidad de la contratación permite ajustar la estrategia y mejorar los resultados.
En definitiva, el reclutamiento y selección de personal es mucho más que cubrir puestos.
Es una apuesta en el futuro de la empresa, donde atraer al talento correcto define su éxito.
https://rant.li/tofeadady/vatikan-kupit-ekstazi-mdma-lsd-kokain
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Для тех, кто ищет информацию по теме “Оппенгеймер Нолана: шедевр или неудача?”, нашел много полезного.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%bf%d0%bf%d0%b5%d0%bd%d0%b3%d0%b5%d0%b9%d0%bc%d0%b5%d1%80-%d0%bd%d0%be%d0%bb%d0%b0%d0%bd%d0%b0-%d0%b3%d0%b5%d0%bd%d0%b8%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d1%84%d0%b8%d0%bb%d1%8c/
Надеюсь, моя информация помогла вам принять верное решение.
калькулЯтор денежного довольствиЯ
На сайте https://t.me/feovpn_ru ознакомьтесь с уникальной и высокотехнологичной разработкой – FeoVPN, которая позволит пользоваться Интернетом без ограничений, в любом месте, заходить на самые разные сайты, которые только хочется. VPN очень быстрый, отлично работает и не выдает ошибок. Обеспечивает анонимный доступ ко всем ресурсам. Вся ваша личная информация защищена от третьих лиц. Активируйте разработку в любое время, чтобы пользоваться Интернетом без ограничений. Обеспечена полная безопасность, приватность.
разделы длЯ военнослужащих
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить раздел про Опыт и разочарование от онлайн-курсов Skillbox.
Вот, можете почитать:
https://100ch.ru/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%ba%d1%83%d1%80%d1%81%d1%8b-skillbox-%d0%bc%d0%be%d0%b9-%d0%bd%d0%b5%d1%83%d0%b4%d0%b0%d1%87%d0%bd%d1%8b%d0%b9-%d0%be%d0%bf%d1%8b%d1%82-%d0%b8-%d1%80%d0%b0/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Хочу выделить раздел про Сравнение робот-пылесосов Xiaomi и Dreame: какой лучше?.
Ссылка ниже:
https://100ch.ru/%d1%80%d0%be%d0%b1%d0%be%d1%82-%d0%bf%d1%8b%d0%bb%d0%b5%d1%81%d0%be%d1%81-xiaomi-%d0%b8%d0%bb%d0%b8-dreame-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bb%d1%83%d1%87%d1%88%d0%b5-%d1%81%d0%bf%d1%80%d0%b0%d0%b2/
Удачных покупок и пусть ваш выбор вам всегда нравится!
На сайте https://chisty-list.ru/ узнайте стоимость уборки конкретно вашего объекта. Но в любом случае она будет умеренной. Специально для вас профессиональный клининг квартиры, офиса. Есть возможность воспользоваться генеральной уборкой либо послестроительной. Если есть вопросы, то воспользуйтесь консультацией, обозначив свои данные в специальной форме. Вы получите гарантию качества на все услуги, потому как за каждым объектом закрепляется менеджер. Все клинеры являются проверенными, опытными, используют профессиональный инструмент.
косметолог жк самолет Люберцы Красота: выражение вашей индивидуальности и уникальности. Не бойтесь экспериментировать и искать свой неповторимый стиль.
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Для тех, кто ищет информацию по теме “Опыт перехода с Windows на MacOS в 2025 году”, нашел много полезного.
Вот, можете почитать:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Zenatane
Ищете, где заказать надежную кухню на заказ по вашим размерам за адекватные деньги? Посмотрите портфолио кухонной фабрики GLORIA – https://gloriakuhni.ru/ – все проекты выполнены в Санкт-Петербурге и области. На каждую кухню гарантия 36 месяцев, более 800 цветовых решений. Большое разнообразие фурнитуры. Удобный онлайн-калькулятор прямо на сайте и понятное формирование цены. Много отзывов клиентов, видео-обзоры кухни с подробностями и деталями. Для всех клиентов – столешница и стеновая панель в подарок.
https://nature75185.full-design.com/selecci%C3%B3n-de-personal-para-tontos-78786806
El reclutamiento y selección de personal es fundamental para el crecimiento de cualquier organización.
Contar con las personas adecuadas en los roles estratégicos potencia los resultados en productividad.
1. Definir el perfil
Antes de comenzar el proceso de reclutamiento, es necesario tener claro el perfil del candidato que la empresa necesita. Esto incluye competencias, experiencia y valores que se alineen con la visión de la organización.
2. Canales de reclutamiento
Hoy en día, las empresas pueden aprovechar plataformas digitales como LinkedIn, además de programas de recomendación para atraer al mejor talento.
Diversificar fuentes incrementa la posibilidad de encontrar candidatos de calidad.
3. Filtrado inicial
Una vez recibidas las aplicaciones, es importante preseleccionar a los perfiles que más se acercan a los requisitos.
Después, las entrevistas sirven para evaluar no solo la formación del candidato, sino también su actitud con la empresa.
4. Exámenes de selección
Para asegurar que el profesional seleccionado cumple con lo esperado, se pueden implementar pruebas técnicas, evaluaciones psicométricas o ejercicios prácticos.
Esto reduce el riesgo de error al contratar.
5. Selección definitiva
Tras el proceso de evaluación, se procede de seleccionar al candidato que mejor cumple con los requisitos.
La comunicación clara y un plan de integración son fundamentales para asegurar que el nuevo empleado se integre fácilmente.
6. Seguimiento y mejora continua
Un proceso de reclutamiento nunca se queda fijo.
Medir indicadores como rotación de personal hace posible optimizar la estrategia y mejorar los resultados.
En resumen, el reclutamiento y selección de personal es mucho más que llenar vacantes.
Es una apuesta en el futuro de la empresa, donde atraer al talento correcto define su éxito.
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Зацепил материал про Опыт перехода с Windows на MacOS в 2025 году.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Буду рад услышать ваше мнение и опыт после приобретения.
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Хочу выделить раздел про Самокат: скорость и качество доставки продуктов.
Вот, делюсь ссылкой:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
военный калькулЯтор
https://vzloman3.online Почтовые ящики. Получите доступ к конфиденциальной переписке, деловым предложениям и личным сообщениям. Контролируйте поток информации, влияющий на ваши интересы.
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
По теме “Сравнение мобильных банков: Тинькофф vs Сбер”, есть отличная статья.
Вот, делюсь ссылкой:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Отличного выбора и приятных впечатлений от новинки!
amoxicillin
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Особенно понравился раздел про Честный обзор без спойлеров: Дюна 2.
Ссылка ниже:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Буду рад услышать ваше мнение и опыт после приобретения.
https://webpage37148.pages10.com/fascinaciГіn-acerca-de-selecciГіn-de-personal-71728133
El proceso de atraer y elegir candidatos es clave para el desempeño de cualquier organización.
Tener profesionales capacitados en los puestos correctos marca la diferencia en rentabilidad.
1. Identificar el puesto ideal
Antes de empezar el proceso de reclutamiento, es vital tener claro el perfil del candidato que la empresa necesita. Esto implica competencias, trayectoria y valores que se alineen con la misión de la organización.
2. Dónde buscar candidatos
Hoy en día, las empresas tienen la posibilidad de usar plataformas digitales como Indeed, además de referencias internas para atraer al mejor talento.
Combinar fuentes incrementa la posibilidad de encontrar candidatos de calidad.
3. Evaluación de candidatos
Una vez recibidas las candidaturas, se debe preseleccionar a los perfiles que más se acercan a los requisitos.
Después, las entrevistas sirven para conocer no solo la formación del candidato, sino también su encaje cultural con la empresa.
4. Métodos de validación
Para garantizar que el candidato ideal cumple con lo esperado, se pueden realizar tests de competencias, evaluaciones psicométricas o ejercicios prácticos.
Esto minimiza el margen de equivocación al contratar.
5. Elección final
Tras el proceso de evaluación, llega el momento de seleccionar al candidato que mejor se adapta.
La comunicación clara y un buen onboarding son fundamentales para asegurar que el nuevo empleado se integre fácilmente.
6. Seguimiento y mejora continua
Un sistema de selección nunca se queda fijo.
Medir indicadores como tiempo de contratación hace posible ajustar la estrategia y perfeccionar los resultados.
Al final, el proceso de contratación es mucho más que cubrir puestos.
Es una apuesta en el futuro de la empresa, donde elegir al talento correcto determina su crecimiento sostenible.
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Между прочим, если вас интересует Опыт и разочарование от онлайн-курсов Skillbox, посмотрите сюда.
Смотрите сами:
https://100ch.ru/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%ba%d1%83%d1%80%d1%81%d1%8b-skillbox-%d0%bc%d0%be%d0%b9-%d0%bd%d0%b5%d1%83%d0%b4%d0%b0%d1%87%d0%bd%d1%8b%d0%b9-%d0%be%d0%bf%d1%8b%d1%82-%d0%b8-%d1%80%d0%b0/
Буду рад услышать ваше мнение и опыт после приобретения.
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
По теме “Переоцененные рестораны Москвы: избегаем разочарования”, есть отличная статья.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Хочу выделить материал про Честный обзор без спойлеров: Дюна 2.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Надеюсь, моя информация помогла вам принять верное решение.
ceftin
Rz-Work – биржа для новичков и опытных профессионалов, готовых к ответственной работе. Популярность у фриланс-сервиса высокая. Преимущества, которые пользователи выделили: оперативное реагирование службы поддержки, простота регистрации, гарантия безопасности сделок. https://rz-work.ru – тут более детальная информация представлена. Rz-Work является платформой, способствующей эффективному взаимодействию исполнителей и заказчиков. Она отличается понятным интерфейсом. Площадка многопрофильная, охватывающая множество категорий.
https://knoxzpgcz.shotblogs.com/indicadores-sobre-selecciГіn-de-personal-que-debe-saber-50407787
El reclutamiento y selección de personal es fundamental para el éxito de cualquier negocio.
Contar con el equipo correcto en los puestos correctos marca la diferencia en desarrollo.
1. Identificar el puesto ideal
Antes de comenzar el proceso de reclutamiento, es necesario definir con claridad el perfil profesional que la empresa busca. Esto implica competencias, trayectoria y valores que se alineen con la cultura de la organización.
2. Dónde buscar candidatos
Hoy en día, las organizaciones pueden usar bolsas de empleo como portales especializados, además de referencias internas para conseguir al mejor talento.
Diversificar fuentes aumenta la probabilidad de encontrar candidatos altamente capacitados.
3. Filtrado inicial
Una vez recibidas las solicitudes, es importante filtrar a los perfiles que más se acercan a los criterios.
Después, las reuniones sirven para evaluar no solo la experiencia del candidato, sino también su encaje cultural con la empresa.
4. Exámenes de selección
Para garantizar que el candidato ideal cumple con lo esperado, se pueden realizar pruebas técnicas, análisis de personalidad o ejercicios prácticos.
Esto reduce el margen de equivocación al contratar.
5. Elección final
Tras el proceso de evaluación, llega el momento de elegir al candidato que mejor cumple con los requisitos.
La comunicación clara y un plan de integración son cruciales para asegurar que el nuevo empleado se integre fácilmente.
6. Optimización del proceso
Un proceso de reclutamiento nunca es estático.
Medir indicadores como calidad de la contratación permite optimizar la estrategia y mejorar los resultados.
En definitiva, el proceso de contratación es mucho más que cubrir puestos.
Es una apuesta en el futuro de la empresa, donde elegir al equipo adecuado define su éxito.
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Кстати, если вас интересует Почему стоит отказаться от Яндекс Плюс, загляните сюда.
Смотрите сами:
https://100ch.ru/%d0%bf%d0%be%d1%87%d0%b5%d0%bc%d1%83-%d1%8f-%d0%be%d1%82%d0%ba%d0%b0%d0%b7%d0%b0%d0%bb%d1%81%d1%8f-%d0%be%d1%82-%d0%bf%d0%be%d0%b4%d0%bf%d0%b8%d1%81%d0%ba%d0%b8-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Между прочим, если вас интересует Самокат: скорость и качество доставки продуктов, загляните сюда.
Ссылка ниже:
https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Для тех, кто ищет информацию по теме “Как выбрать эффективную сыворотку с витамином C?”, нашел много полезного.
Вот, можете почитать:
https://100ch.ru/%d1%81%d1%8b%d0%b2%d0%be%d1%80%d0%be%d1%82%d0%ba%d0%b0-%d1%81-%d0%b2%d0%b8%d1%82%d0%b0%d0%bc%d0%b8%d0%bd%d0%be%d0%bc-c-%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d1%8d%d1%84%d1%84/
Буду рад услышать ваше мнение и опыт после приобретения.
Levothyroxine
http://webanketa.com/forms/6mrk4chn70qp8chgcmw38d1g/
https://www.montessorijobsuk.co.uk/author/yiubkmihebyh/
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
По теме “Переоцененные рестораны Москвы: избегаем разочарования”, есть отличная статья.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Надеюсь, моя информация помогла вам принять верное решение.
https://allmynursejobs.com/author/tasticjudith10/
https://www.metooo.io/u/68999dfbc043544e352843b5
https://git.project-hobbit.eu/gibifihqick
https://www.montessorijobsuk.co.uk/author/euegegpe/
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Хочу выделить раздел про Честный обзор без спойлеров: Дюна 2.
Смотрите сами:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc%d0%b0-%d0%b4%d1%8e%d0%bd%d0%b0-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d0%b2%d1%82%d0%be%d1%80%d0%b0%d1%8f-%d0%b1%d0%b5%d0%b7-%d1%81%d0%bf%d0%be/
Удачных покупок и пусть ваш выбор вам всегда нравится!
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%A0%D1%83%D1%81%D1%82%D0%B0%D0%B2%D0%B8/
https://www.brownbook.net/business/54155337/мерибель-марихуана-гашиш-канабис/
https://www.brownbook.net/business/54160733/румыния-купить-кокаин-мефедрон-марихуану/
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Зацепил раздел про Опыт перехода с Windows на MacOS в 2025 году.
Вот, можете почитать:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Отличного выбора и приятных впечатлений от новинки!
Motrin
https://git.project-hobbit.eu/sriguifehic
https://pixelfed.tokyo/silverMartin4
Размышляете о покупке iPhone 15 Pro Max и не знаете, стоит ли делать это прямо сейчас? Давайте разберемся в его преимуществах и недостатках.
Зацепил раздел про Как выбрать лучшие наушники для спорта: обзор, тест и лайфхаки.
Смотрите сами:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b5-%d0%b1%d0%b5%d1%81%d0%bf%d1%80%d0%be%d0%b2%d0%be%d0%b4%d0%bd%d1%8b%d0%b5-%d0%bd%d0%b0%d1%83%d1%88%d0%bd%d0%b8%d0%ba%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%81%d0%bf%d0%be/
Удачных покупок и пусть ваш выбор вам всегда нравится!
https://lavutebugo.bandcamp.com/album/arrogant
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Хочу выделить раздел про Почему стоит отказаться от Яндекс Плюс.
Смотрите сами:
https://100ch.ru/%d0%bf%d0%be%d1%87%d0%b5%d0%bc%d1%83-%d1%8f-%d0%be%d1%82%d0%ba%d0%b0%d0%b7%d0%b0%d0%bb%d1%81%d1%8f-%d0%be%d1%82-%d0%bf%d0%be%d0%b4%d0%bf%d0%b8%d1%81%d0%ba%d0%b8-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
Надеюсь, моя информация помогла вам принять верное решение.
На сайте https://tartugi.net/18-sverhestestvennoe.html представлен интересный, увлекательный и ставший легендарным сериал «Сверхъестественное». Он рассказывает о приключениях 2 братьев Винчестеров, которые вынуждены сражаться со злом. На каждом шагу их встречает опасность, они пытаются побороть темные силы. Этот сериал действительно очень интересный, увлекательный и проходит в динамике, а потому точно не получится заскучать. Фильм представлен в отличном качестве, а потому вы сможете насладиться просмотром.
https://information73838.blogminds.com/una-revisiГіn-de-selecciГіn-de-personal-33398846
El reclutamiento y selección de personal es clave para el crecimiento de cualquier organización.
Contar con las personas adecuadas en los puestos correctos potencia los resultados en rentabilidad.
1. Definir el perfil
Antes de iniciar el proceso de reclutamiento, es necesario tener claro el perfil profesional que la empresa necesita. Esto implica competencias, trayectoria y valores que se alineen con la visión de la organización.
2. Dónde buscar candidatos
Hoy en día, las empresas pueden usar bolsas de empleo como Indeed, además de programas de recomendación para conseguir al mejor talento.
Diversificar fuentes incrementa la probabilidad de reclutar candidatos de calidad.
3. Filtrado inicial
Una vez recibidas las aplicaciones, se debe preseleccionar a los perfiles que mejor se ajustan a los requisitos.
Después, las entrevistas sirven para conocer no solo la formación del candidato, sino también su encaje cultural con la empresa.
4. Exámenes de selección
Para asegurar que el profesional seleccionado cumple con lo esperado, se pueden realizar tests de competencias, análisis de personalidad o dinámicas de grupo.
Esto minimiza el margen de equivocación al contratar.
5. Selección definitiva
Tras el proceso de evaluación, se procede de elegir al candidato que mejor cumple con los requisitos.
La presentación de la oferta y un buen onboarding son cruciales para garantizar que el nuevo empleado se integre fácilmente.
6. Optimización del proceso
Un proceso de reclutamiento nunca es estático.
Medir indicadores como tiempo de contratación permite optimizar la estrategia y perfeccionar los resultados.
En resumen, el proceso de contratación es mucho más que cubrir puestos.
Es una inversión en el futuro de la empresa, donde elegir al talento correcto determina su éxito.
Компания «А2» занимается строительством каркасных домов, гаражей и бань из различных материалов. Подробнее: https://akvadrat51.ru/
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Особенно понравился раздел про Опыт перехода с Windows на MacOS в 2025 году.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Надеюсь, моя информация помогла вам принять верное решение.
https://elledios.com/a-app-verde-casino-alapos-vizsgalata-megfelel-e-az/
Строительный сайт https://vitamax.dp.ua с полезными материалами о ремонте, дизайне и современных технологиях. Обзоры стройматериалов, инструкции по монтажу, проекты домов и советы экспертов.
https://webpage37148.pages10.com/fascinaciГіn-acerca-de-selecciГіn-de-personal-71728133
El reclutamiento y selección de personal es esencial para el crecimiento de cualquier organización.
Contar con las personas adecuadas en los puestos correctos potencia los resultados en rentabilidad.
1. Definir el perfil
Antes de iniciar el proceso de reclutamiento, se requiere definir con claridad el perfil del candidato que la empresa busca. Esto incluye competencias, experiencia y valores que se alineen con la visión de la organización.
2. Canales de reclutamiento
Hoy en día, las empresas tienen la posibilidad de aprovechar redes profesionales como portales especializados, además de programas de recomendación para conseguir al mejor talento.
Combinar fuentes aumenta la posibilidad de reclutar candidatos altamente capacitados.
3. Preselección y entrevistas
Una vez recibidas las aplicaciones, es importante preseleccionar a los perfiles que mejor se ajustan a los criterios.
Después, las entrevistas sirven para evaluar no solo la formación del candidato, sino también su actitud con la empresa.
4. Exámenes de selección
Para garantizar que el profesional seleccionado cumple con lo esperado, se pueden implementar pruebas técnicas, evaluaciones psicométricas o ejercicios prácticos.
Esto reduce el margen de equivocación al contratar.
5. Selección definitiva
Tras el proceso de evaluación, llega el momento de elegir al candidato que mejor se adapta.
La comunicación clara y un buen onboarding son cruciales para garantizar que el nuevo empleado se adapte rápido.
6. Seguimiento y mejora continua
Un proceso de reclutamiento nunca se queda fijo.
Medir indicadores como tiempo de contratación permite optimizar la estrategia y mejorar los resultados.
En resumen, el reclutamiento y selección de personal es mucho más que cubrir puestos.
Es una inversión en el futuro de la empresa, donde atraer al talento correcto define su éxito.
Надёжная резина — это залог безопасности на дороге, обеспечивающая надёжное торможение даже в сложных погодных условиях .
Подходящие по сезону шины снижают вероятность аквапланирования во время дождя , сохраняя вашу безопасность .
Инвестиции в качественные шины сокращают расходы на топливо за счёт оптимального качения .
Стабильное поведение авто обеспечивается правильного давления, в сочетании с составом резиновой смеси .
Контроль глубины протектора снижает риск аварийных ситуаций, сохраняя долговечность авто .
Отнеситесь серьёзно к выбору — это определяет вашу защиту на любом маршруте .
http://www.oraerp.com/thread-254423.html
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Кстати, если вас интересует Опыт перехода с Windows на MacOS в 2025 году, загляните сюда.
Ссылка ниже:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Надеюсь, моя информация помогла вам принять верное решение.
Personalized serum from is an innovative product stagramer.com, the formula of which is developed based on data about your skin.
Kamla Game: A thrilling strategy-driven adventure where players navigate challenges, alliances, and survival in a dynamic, ever-changing world: official Kamla game website
https://awehbraaichicks.co.za/2025/08/04/fii-ca-acas-la-verde-casino-rotiri-gratuite/
Посетите сайт https://karmicstar.ru/ и вы сможете рассчитать бесплатно Кармическую звезду по дате рождения. Кармический калькулятор поможет собрать свою конфигурацию кармических треугольников к расшифровке, либо выбрать к распаковке всю кармическую звезду и/или проверить совместимость пары по дате рождения. Подробнее на сайте.
https://blog.pictureline.com/pas-in-verde-casino-bonus-50-free-spins-destinaia/
homeprorab.info
Создайте уникальный штамп с помощью нашего stamp online maker всего за несколько кликов!
Designing a rubber stamp through an online platform is incredibly straightforward. Using online tools, you can easily personalize your stamp. This user-friendly approach is advantageous for both personal and professional use.
It’s important to assess the different functionalities provided by rubber stamp makers online. Numerous platforms provide templates that you can modify according to your preferences. You also have the option to upload custom designs, allowing for complete personalization.
The quality of rubber stamps made online is essential to consider. Look for reviews and testimonials to gauge customer satisfaction. High-quality rubber stamps produce clear and crisp impressions, which are always important.
Shipping options are important to review when purchasing a rubber stamp online. Several companies guarantee quick delivery, so you get your stamp in no time. Check if there are any additional fees for expedited shipping.
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
По теме “Самокат: скорость и качество доставки продуктов”, есть отличная статья.
Ссылка ниже:
[url=https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/]https://100ch.ru/%d1%81%d0%b0%d0%bc%d0%be%d0%ba%d0%b0%d1%82-%d0%b4%d0%be%d1%81%d1%82%d0%b0%d0%b2%d0%ba%d0%b0-%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d0%b5/[/url]
Отличного выбора и приятных впечатлений от новинки!
Imitation timber is successfully emergate.net used in construction and finishing due to its unique properties and appearance, which resembles real timber.
Lucknow Game: Immerse yourself in the cultural heritage of Lucknow, solving puzzles and exploring iconic landmarks to uncover hidden treasures: Lucknow game for mobile
metoprolol
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Для тех, кто ищет информацию по теме “Почему стоит отказаться от Яндекс Плюс”, есть отличная статья.
Вот, можете почитать:
https://100ch.ru/%d0%bf%d0%be%d1%87%d0%b5%d0%bc%d1%83-%d1%8f-%d0%be%d1%82%d0%ba%d0%b0%d0%b7%d0%b0%d0%bb%d1%81%d1%8f-%d0%be%d1%82-%d0%bf%d0%be%d0%b4%d0%bf%d0%b8%d1%81%d0%ba%d0%b8-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
трипскан ссылка Трипскан: Начните свое путешествие с нами. Интуитивно понятный интерфейс, широкий выбор направлений и гибкие настройки поиска помогут вам создать незабываемый опыт. Откройте для себя новые культуры, ощутите вкус приключений и создайте воспоминания на всю жизнь.
Клецк
Hey there I am so glad I found your webpage, I really found you by accident, while I was researching on Digg for something else, Anyhow I am here now and would just like to say kudos for a remarkable post and a all round interesting blog (I also love the theme/design), I don’t have time to read it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the superb b.
https://510.com.ua/hermetyk-dlya-protytumannykh-far-yakyj-obraty.html
Осиек
Наантали
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Особенно понравился раздел про Переоцененные рестораны Москвы: избегаем разочарования.
Смотрите сами:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Пинск
тарифы интернет и телевидение челябинск
chelyabinsk-domashnij-internet004.ru
провайдеры интернета в челябинске
Фольгарида-Мариллева
Посетите сайт https://room-alco.ru/ и вы сможете продать элитный алкоголь. Скупка элитного алкоголя в Москве по высокой цене с онлайн оценкой или позвоните по номеру телефона на сайте. Оператор работает круглосуточно. Узнайте на сайте основных производителей элитного спиртного, по которым возможна быстрая оценка и скупка алкоголя по выгодной для обоих сторон цене.
Северный Гоа
Тайбэй
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
По теме “Сравнение мобильных банков: Тинькофф vs Сбер”, есть отличная статья.
Смотрите сами:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Буду рад услышать ваше мнение и опыт после приобретения.
https://huntdown.info/kak-udobnee-dobratsya-iz-aeroporta-pragi-v-karlovy-vary/
Сиб
Мьянма
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Зацепил материал про Переоцененные рестораны Москвы: избегаем разочарования.
Смотрите сами:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d0%be%d1%86%d0%b5%d0%bd%d0%b5%d0%bd%d0%bd%d1%8b%d0%b5-%d1%80%d0%b5%d1%81%d1%82%d0%be%d1%80%d0%b0%d0%bd%d1%8b-%d0%bc%d0%be%d1%81%d0%ba%d0%b2%d1%8b-%d0%b3%d0%b4%d0%b5-%d0%b5/
Надеюсь, моя информация помогла вам принять верное решение.
Гафса
Tambola Game: A fun and fast-paced number-bingo experience, perfect for family gatherings, parties, and competitive fun: Tambola game tips and tricks
zetia
Вена Австрия
Новопавловск
Каковы действительно важные параметры при выборе iPhone 15 Pro Max? Узнаем вместе.
Зацепил материал про Опыт перехода с Windows на MacOS в 2025 году.
Вот, делюсь ссылкой:
https://100ch.ru/%d0%bf%d0%b5%d1%80%d0%b5%d1%85%d0%be%d0%b4-%d1%81-windows-%d0%bd%d0%b0-macos-%d1%80%d0%b5%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b5-%d0%b2%d0%bf%d0%b5%d1%87%d0%b0%d1%82%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
Тао
Перво-Уральск
Новый iPhone 15 Pro Max уже на полках, и вы колеблетесь с покупкой? Давайте рассмотрим все “за” и “против”.
Кстати, если вас интересует Стоит ли покупать iPhone 15 Pro Max сейчас?, загляните сюда.
Вот, можете почитать:
https://100ch.ru/%d0%be%d0%b1%d0%b7%d0%be%d1%80-iphone-15-pro-max-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d1%8d%d1%82%d0%be-%d0%bf/
Если вы все еще в раздумьях, помните: покупка нового гаджета – это всегда дело времени и приоритетов.
Темерлох
kra36—-at.com — Надежный и удобный сервис — официальный сайт и подробный обзор даркнет-маркета Kraken. Официальный сайт kraken kra36.at — удобный сервис с множеством функций для пользователей. Узнайте больше и начните пользоваться прямо сейчас!
kra36
сервис
удобство функции
официальный сайт Kraken
Кракен
маркетплейс Кракен
даркнет маркет
kraken официальный сайт
kraken market
kraken darknet
анонимные покупки
даркнет площадка
гидра альтернатива
kraken onion
kraken ссылка
darknet marketplace
kraken даркнет
кракен маркетплейс
кракен маркет обзор
кракен маркет отзывы
kraken ссылка
kraken сайт
kraken официальный сайт
kraken ссылка зеркало
актуальное зеркало kraken
kraken ссылка тор
kraken зеркало рабочее
kraken зеркало официальный
kraken зеркало даркнет
kraken зеркало тор
kraken зеркало 2kmp
kraken официальные ссылки
kraken onion ссылка
kraken ссылка для тору
kraken ссылка зеркало официальный
kraken зеркало krakentor site
kraken сайт зеркала
кракен ссылка kraken
kraken официальный сайт зеркало
kraken официальный сайт ссылка
kraken ссылка зеркало официальный сайт
kraken клирнет зеркало
kraken tor зеркало
kraken ссылка 2kmp
зеркала kraken kraken tor site
kraken darknet ссылка
kraken ссылка krakentor site
kraken зеркало 2kmp vip
kraken актуальные ссылки
kraken ссылка tor
kraken market ссылка
kraken зеркало 2kmp biz
kraken darknet зеркала
kraken darknet market ссылка
kraken darknet ссылка тор
ссылка kraken kraken tor site
kraken 2 зеркало
kraken ссылка 2kmp vip
рабочие ссылки kraken
сайт кракен kraken
kraken ссылка 2kmp biz
зеркало kraken market
kraken сайт официальный 2kmp
ссылка кракен kraken tor site
kraken darknet market зеркало
kraken ссылка зеркало рабочее
kraken market ссылка тор
kraken ссылка зеркало 2kmp
kraken darknet market ссылка тор
kraken ссылка зеркало krakentor site
kraken com зеркало
зеркала kraken 2kmp org
kraken ссылка kraken one com
kraken onion зеркала
сайт kraken darknet
зеркало kraken 2 kma biz
kraken сайт официальный krakentor site
kraken darknet официальный сайт
kraken зеркало рабочее krakentor site
ссылка на kraken kraken onion site
kraken кларнет зеркало kraken tor site
kraken зеркало рабочее 2kmp
kraken ссылка kraken clear com
kraken сайт kraken one com
kraken актуальные ссылки krakentor site
kraken ссылка onion 2kmp
kraken сайт официальный 2kmp biz
kraken ссылка зеркало официальный сайт 2kmp
kraken актуальные зеркала krakentor site
kraken зеркало тор ссылка
актуальное зеркало kraken kraken tor site
ссылка на кракен kraken one com
kraken даркнет зеркало krakentor site
kraken сайт kraken zerkalo
kraken рабочая ссылка тор
кракен сайт kraken one com
зеркало kraken тор ссылка рабочее
kraken сайт kraken zerkalo xyz
kraken ссылка onion krakentor site
kraken актуальные ссылки 2kmp
ссылка на кракен kraken onion site
kraken ссылка для тору vtor run
kraken сайт официальный 2kmp vip
kraken сайт kraken clear com
kraken зеркало тор krakentor site
kraken ссылка зеркало 2kmp biz
kraken сайт vtor run
kraken ссылка зеркало официальный сайт krakentor site
kraken ссылка зеркало 2kmp vip
kraken зеркала 2 kmp biz
ссылка на кракен kraken clear com
kraken casino зеркало
кракен сайт kraken clear com
зеркало кракен kraken tor site
kraken официальный сайт vtor run
kraken зеркало тор 2 kmp
kraken зеркало kraken2web com
актуальное зеркало kraken 2 kma biz
kraken актуальные зеркала 2kmp vip
ссылка на кракен kraken 7 one
kraken клирнет зеркало 2kmp biz
kraken ссылка онлайн
kraken даркнет зеркало 2kmp biz
kraken сайт анонимных
kraken зеркало рабочее 2kmp biz
kraken ссылка onion 2kmp biz
kraken сайт покупок
kraken зеркало онлайн
kraken сайт анонимных покупок
кракен сайт kraken zerkalo
кракен сайт kraken zerkalo xyz
kraken ссылка зеркало официальный сайт 2kmp biz
kraken даркнет зеркало 2kmp vip
kraken ссылка kraken2web com
kraken зеркало ссылка онлайн
kraken зеркало рабочее 2kmp vip
kraken актуальные ссылки 2kmp biz
kraken ссылка online
kraken ссылка tor wiki online
kraken ссылка зеркало официальный сайт 2kmp vip
kraken актуальные ссылки 2kmp vip
kraken ссылка на сайт
kraken зеркало тор 2 kmp biz
kraken сайт vk2
kraken casino зеркало рабочее
kraken клирнет зеркало 2kmp vip
ссылка на kraken kraken darknet top
кракен зеркало kraken 7 one
ссылка на кракен kraken darknet top
kraken зеркало тор 2 kmp vip
kraken зеркало kraken clear com
kraken ссылка kraken zerkalo xyz
зеркало kraken kraken onion site
kraken darknet ссылка kraken2web com
kraken официальный сайт k2tor
kraken зеркало krakendarknet top
сайт kraken тор
ссылка на кракен тор kraken 7 one
kraken клирнет зеркало 2kmp org
кракен ссылка kraken zerkalo
kraken ссылка 2krnk biz
kraken ссылка kraken7 one
актуальное зеркало kraken 2kmp org
кракен зеркало kraken one com
kraken ссылка onion 2kmp org
kraken ссылка onion 2kmp vip
площадка kraken ссылка
рабочая ссылка на кракен kraken 7 one
kraken зеркало 2kraken click
kraken ссылка тор kraken2web com
kraken ссылка зеркало vk2
актуальное зеркало kraken kraken onion site
кракен ссылка kraken zerkalo xyz
kraken сайт официальный 2kmp org
kraken зеркало 2krnk biz
kraken casino официальный сайт
kraken ссылка krakendarknet top
kraken официальные зеркала vk3
kraken market ссылка kraken2web com
kraken darknet ссылка тор kraken2web com
kraken ссылка тор kraken one com
kraken darknet зеркала kraken2web com
кракен зеркало kraken clear com
kraken darknet market ссылка kraken2web com
kraken сайт 2krnk biz
kraken зеркало dzen
кракен ссылка тор kraken one com
kraken зеркало тор 2kmp org
kraken зеркало krakenonion site
kraken ссылка онион
kraken сайт tor
актуальное зеркало kraken kraken zerkalo
kraken официальный сайт vk2
kraken ссылка зеркало 2kmp org
актуальное зеркало kraken kraken zerkalo xyz
сайт kraken onion
рабочее зеркало кракен kraken 7 one
кракен сайт ссылка kraken one com
kraken darknet market зеркало kraken2web com
kraken ссылка тор tor wiki online
kraken ссылка зеркало kraken2web com
kraken зеркало тор kraken7 one
kraken зеркало рабочее 2kmp org
ссылка на kraken 2kmp org
kraken официальный сайт vk3
kraken ссылка зеркало kraken 7 one
kraken onion ссылка tor wiki online
kraken вход на сайт
kraken зайти на сайт
kraken сайт krakendarknet top
кракен зеркало kraken zerkalo xyz
kraken ссылка тор 2kraken click
кракен вход ссылка kraken 7 one
kraken магазин ссылка
kraken darknet market ссылка тор kraken2web com
кракен сайт ссылка kraken clear com
kraken даркнет зеркало 2kmp org
kraken ссылка зеркало официальный сайт 2kmp org
kraken darknet market ссылка kraken7 one
kraken darknet ссылка 2krnk biz
kraken ссылка тор 2krnk biz
kraken актуальная ссылка onion
kraken сайт vk2 pro
кракен площадка ссылка kraken 7 one
kraken сайт kraken2web com
kraken зеркало форум
кракен зеркало тор kraken one com
kraken официальный сайт k2tor online
kraken ссылка зеркало vk2 pro
kraken darknet ссылка тор 2kraken click
ссылка на кракен тор kraken clear com
сайт онион kraken
кракен сайт зеркало kraken 7 one
kraken зеркало v5tor cfd
kraken darknet ссылка тор 2krnk biz
kraken сайт dzen
kraken оригинальная ссылка
kraken ссылка dzen
сайт кракен тор kraken one com
kraken ссылка krakenonion site
kraken официальные зеркала k2tor
kraken tor ссылка онлайн
kraken ссылка v5tor cfd
kraken ссылка на сайт тор
kraken сайт kr2web in
настоящий сайт kraken
kraken зеркало online
kraken актуальные ссылки 2kmp org
прямая ссылка на kraken
kraken оф сайт
kraken официальный сайт
используйте vpn!
Кракен Ссылка
Кракен Вход
Кракен Зайти
Ссылка на Кракен
Kra35.cc
Kra36.at
Kra34.cc
купить меф
купить гарик
Kra34.at
Kra33.cc
Kra33.at
Kra37.cc
Kra36.cc
Kra32.cc
Kra32.at
Kra38.cc
Kra39.cc
Kra33.cc
для дополнительной анонимности и безопасности рекомендуется использовать vpn-сервис. он скроет ваш ip-адрес и сделает ваше пребывание в интернете более безопасным.
будьте осторожны!?
kraken рабочая ссылка onion
kraken ссылка vk
кракен сайт ссылка kraken 11
ссылка на кракен kraken 9 one
kraken зеркало тор kraken2web com
кракен онион ссылка kraken one com
ссылка kraken 2 kma biz
ссылка на kraken торговая площадка
razer kraken сайт
kraken зеркало krakenweb one
kraken зеркало krakenweb3 com
kraken зеркало ссылка онлайн krakenweb one
kraken ссылка зеркало krakenweb one
kraken darknet market ссылка тор 2kraken click
kraken ссылка krakenweb one
kraken ссылка тор krakendarknet top
kraken casino зеркало kraken casino xyz
kraken darknet market зеркало v5tor cfd
kraken сайт зеркала kraken2web com
kraken даркнет ссылка
kraken зеркала kr2web in
kraken зеркало store
kraken darknet market ссылка тор v5tor cfd
kraken darknet market сайт
даркнет официальный сайт kraken
kraken ссылка зеркало рабочее kraken2web com
kraken зеркало тор ссылка kraken2web com
kraken маркетплейс зеркала
kraken официальные зеркала k2tor online
kraken darknet маркет ссылка каркен market
kraken 6 at сайт производителя 2
сайт кракен kraken darknet top
kraken клир ссылка
кракен ссылка kraken kraken2web com 3
ссылка на кракен тор kraken 9 one
kraken сайт анонимных покупок vtor run
kraken darknet market зеркало 2kraken click
kraken darknet market ссылка shkafssylka ru
kraken ссылка torbazaw com
kraken форум ссылка
площадка кракен ссылка kraken clear com
сайт kraken darknet kraken2web com
как зайти на маркетплейс кракен: официальные ссылки и зеркала.
полное руководство:
актуальная ссылка (через браузер):
официальная ссылка :
резервное зеркало:
как зайти на маркетплейс кракен: полное руководство
для входа на сайт кракена в даркнете требуется tor. это безопасный браузер:
перейдите на официальный сайт tor.
скачайте программу для вашей ос.
установите и запустите браузер.
используйте актуальные ссылки на кракен
ссылки на официальный сайт кракен часто обновляются. чтобы избежать фишинговых сайтов, используйте проверенные ресурсы для получения ссылок:
• актуальное зеркало кракена:
• зеркала сайта в клирнете и даркнете доступны для пользователей в любой точке мира.
авторизация
после перехода на сайт:
зарегистрируйтесь, если у вас еще нет аккаунта.
войдите в свой личный кабинет, используя логин и пароль.
для повышения безопасности активируйте двухфакторную аутентификацию.
но почему выбираю именно
сотни других платформ, тысячи товаров, но для меня больше, чем просто магазин. это место, где покупки превращаются в увлекательное путешествие.
знает, как важно быть уверенным в каждой покупке. полная защита сделок и дружелюбная поддержка создают чувство, будто вы находитесь в заботливых руках. надёжность? абсолютно.
почему именно
потому что здесь всё про вас: ваш стиль, ваш комфорт, ваша выгода. попробуйте, и вы поймёте, почему так много людей выбирают именно эту платформу!
советы по безопасности на кракене
используйте vpn
подключение через vpn повышает вашу анонимность, скрывая ip-адрес.
проверяйте ссылки
актуальные ссылки и зеркала кракен можно найти на проверенных форумах или официальных ресурсах. никогда не используйте непроверенные источники.
будьте внимательны к продавцам
читайте отзывы и выбирайте проверенных продавцов с высоким рейтингом.
кракен маркетплейс
кракен маркетплейс
кракен площадка
kra33.at
kra33.cc
kra34.cc
kra34.at
kra35.cc
kra36.at
kra36.cc
Kra36.at
kra37.cc
kra38.at
кракен маркетплейс ссылка
кракен площадка
кракен marketplace
кракен площадка ссылка
кракен даркнет стор
кракен darknet market зеркало
кракен даркнет площадка
кракен даркнет маркетплейс
кракен наркотики
кракен нарко
кракен наркошоп
кракен наркота
кракен порошок
кракен наркотики
кракен что там продают
кракен маркетплейс что продают
кракен покупка
какен купить
кракен купить мяу
кракен питер
кракен в питере
кракен москва
кракен в москве
кракен что продают
кракен это
кракен marke
кркен darknet market
кракен dark market
кракен market ссылка
кракен darknet market ссылк
кракен market ссылка тор
кракен даркнет маркет
кракен market тор
кракен маркет
платформа кракен
кракен торговая площадка
кракен даркнет маркет ссылка сайт
кракен маркет даркнет тор
кракен аккаунты
кракен заказ
диспуты кракен
как восстановить кракен
кракен даркнет не работает
как пополнить кракен
google authenticator кракен
рулетка кракен
купоны кракен
кракен зарегистрироваться
кракен регистрация
кракен пользователь не найден
кракен отзывы
ссылка кракен
кракен официальная ссылка
кракен ссылка на сайт
кракен официальная ссылка
кракен актуальные
кракен ссылка тор
кракен клирнет
кракен ссылка маркет
кракен клир ссылка
кракен ссылка
ссылка на кракен
кракен ссылка
кракен ссылка на сайт
кракен ссылка кракен
актуальная ссылка на кракен
рабочие ссылки кракен
кракен тор ссылка
ссылка на кракен тор
кракен зеркало тор
кракен маркет тор
кракен tor
кракен ссылка tor
кракен тор
кракен ссылка тор
кракен tor зеркало
кракен darknet tor
кракен тор браузер
кракен тор
кракен darknet ссылка тор
кракен ссылка на сайт тор
кракен вход на сайт
кракен вход
кракен зайти
кракен войти
кракен даркнет вход
кракен войти
где найти ссылку кракен
где взять ссылку на кракен
как зайти на сайт кракен
как найти кракен
кракен новый
кракен не работает
кракен вход
как зайти на кракен
кракен вход ссылка
сайт кракен
кракен сайт
кракен сайт что это
кракен сайт даркнет
что за сайт кракен
кракен что за сайт
Кракен официальный сайт
сайт кракен отзывы
кракен сайт
кракен официальный сайт
сайт кракен тор
кракен сайт ссылка
кракен сайт зеркало
кракен сайт тор ссылка
кракен зеркало сайта
зеркало кракен
адрес кракена
кракен зеркало тор
зеркало кракен даркнет
актуальное зеркало кракен
рабочее зеркало кракен
кракен зеркало
кракен зеркала
кракен зеркало
зеркало кракен market
актуальное зеркало кракен
кракен darknet
кракен даркнет ссылка
ссылка кракен даркнет маркет
кракен даркнет
кракен darknet
кракен даркнет
кракен dark
кракен darknet ссылка
кракен сайт даркнет маркет
кракен даркнет маркет ссылка тор
кракен даркнет тор
кракен текст рекламы
Kraken ссылка
Kraken Вход
Kraken зайти
Королёв
В случае необходимости раскопок на вашем участке в владимире, обратиться к профессионалам может значительно упростить процесс. Компания vivod-iz-zapoya-vladimir009.ru предлагает широкий спектр земляных работ, включая раскопки участка для возведения зданий или ландшафтного дизайна. Наши услуги обеспечивают высокое качество выполнения услуг по подготовке участка, а также создание скважин для питьевой воды. Аренда техники дает возможность нам оперативно проводить любые садовые работы, а опытные специалисты помогут вам с подбором подходящего грунта. Выбирая наши услуги, вы обеспечиваете себе не только надежность, но и профессионализм в осуществлении всех задач. Свяжитесь с нами, и мы поможем откопать все необходимое на вашем участке!
Каждое новое поколение iPhone вызывает волну интереса и вопросов. Сегодня мы поговорим о том, стоит ли приобретать iPhone 15 Pro Max в данный момент.
Для тех, кто ищет информацию по теме “Сравнение мобильных банков: Тинькофф vs Сбер”, там просто кладезь информации.
Смотрите сами:
https://100ch.ru/tinkoff-%d0%b8%d0%bb%d0%b8-sber-%d0%ba%d0%b0%d0%ba%d0%be%d0%b9-%d0%bc%d0%be%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b1%d0%b0%d0%bd%d0%ba-%d1%83%d0%b4%d0%be%d0%b1%d0%bd%d0%b5%d0%b5/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Аден
Когалым
Невинномысск
tadalafil
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Для тех, кто ищет информацию по теме “iPhone 15 Pro Max: Обзор и честное мнение”, там просто кладезь информации.
Вот, можете почитать:
https://100ch.ru/iphone-15-pro-max-%d0%be%d0%b1%d0%b7%d0%be%d1%80-%d1%81%d1%82%d0%be%d0%b8%d1%82-%d0%bb%d0%b8-%d1%81%d0%b2%d0%be%d0%b8%d1%85-%d0%b4%d0%b5%d0%bd%d0%b5%d0%b3-%d0%b8%d0%bb%d0%b8-%d0%bf%d1%80%d0%be%d1%81/
Буду рад услышать ваше мнение и опыт после приобретения.
Москва Чертаново Северное
Москва Северный
домашний интернет челябинск
chelyabinsk-domashnij-internet005.ru
подключение интернета челябинск
Стоит ли спешить за iPhone 15 Pro Max или дождаться следующей модели? Раскроем карты прямо сейчас.
Зацепил раздел про Рейтинг лучших 4K телевизоров до 50 000 рублей.
Вот, можете почитать:
https://100ch.ru/%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9-%d1%82%d0%b5%d0%bb%d0%b5%d0%b2%d0%b8%d0%b7%d0%be%d1%80-4k-%d0%b4%d0%be-50-000-%d1%80%d1%83%d0%b1%d0%bb%d0%b5%d0%b9-%d1%80%d0%b5%d0%b9%d1%82%d0%b8%d0%bd/
Удачных покупок и пусть ваш выбор вам всегда нравится!
Алкоголизм — это серьезная проблема‚ требующая профессионального подхода к реабилитации. В Туле можно обратиться за помощью нарколога‚ такими как терапия алкогольной зависимости на домашних условиях. Специалист по наркологии на дому незамедлительно поможет определить степень зависимости и определить симптомы алкоголизма. Важно получить консультацию нарколога для выбора оптимальной программы восстановления. Домашняя терапия позволяет пациенту находиться в привычной обстановке‚ что уменьшает уровень стресса. Психологическая помощь при алкогольной зависимости совместно с поддержкой родных играет ключевую роль в выздоровлении. Поддержка семей зависимых также важна для создания условий для трезвой жизни. Нарколог на дом срочно Тула Не затягивайте с вызовом нарколога на дом‚ это первый шаг к избавлению от зависимости.
Романовка
Бохоль
http://gazeta.ekafe.ru/viewtopic.php?f=110&t=42073
Валь-дИзер
zithromax
Rainbet Australia
Днепрорудное
Бишкек
Инфузионная терапия на дому — это удобное и эффективное лечение, которое даёт возможность пациентам проходить инфузионную терапию в уютной обстановке домашней обстановке. Профессиональные медсестры гарантируют профессиональное введение капельниц, что способствует восстановлению после болезни и поддержанию здоровья на дому. vivod-iz-zapoya-tula009.ru Домашний уход включает в себя не лишь саму процедуру, но и мониторинг здоровья пациента. Это особенно важно для людей с хроническими заболеваниями или тем, кто нуждается в профилактике заболеваний. При организации домашнего лечения можно быть уверенным в высоком качестве медицинских услуг, что существенно облегчает процесс реабилитации.
Нефтекамск
Исламабад
Российские города и их особенные черты становятся темой многих обсуждений сегодня…
Для тех, кто ищет информацию по теме “Анализ и прогноз последствий санкций для экономики России”, есть отличная статья.
Вот, делюсь ссылкой:
https://avelonbeta.ru/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d1%81%d1%82%d0%b2%d0%b8%d1%8f-%d1%81%d0%b0%d0%bd%d0%ba%d1%86%d0%b8%d0%b9-%d0%b4%d0%bb%d1%8f-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b9%d1%81%d0%ba%d0%be%d0%b9-%d1%8d/
Подводя итог, можно сказать, что развитие городов и уникальные продукты — это путь к самобытности…
Российский рынок славится своими специфическими продуктами, на фоне которых развиваются города…
Для тех, кто ищет информацию по теме “Хоккей в России: итоги сезона и перспективы роста”, нашел много полезного.
Вот, делюсь ссылкой:
https://avelonbeta.ru/%d1%85%d0%be%d0%ba%d0%ba%d0%b5%d0%b9%d0%bd%d1%8b%d0%b9-%d0%bf%d0%be%d0%b4%d1%8a%d0%b5%d0%bc-%d0%b2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd%d0%b5-%d0%b8%d1%82%d0%be%d0%b3%d0%b8-%d0%b8-%d0%bf%d0%b5%d1%80%d1%81/
Поддерживая отечественные продукты и городской стиль, мы создаём будущее, которое стоит внимания.
https://bio.site/hihybvufa
https://odysee.com/@thr33fiveAkazawaloveq
В современном мире защита от вирусов и спама является неотъемлемой частью безопасности в сети, особенно для пользователей домашних сетей в Екатеринбурге. Начальным этапом к надежной защите является установка антивирусного ПО на все устройства. Это программное обеспечение по защите позволят остановить интернет-угрозы, включая вредоносные программы и фишинг-атаки. Также важным моментом является обеспечение безопасности роутера. Обновление программного обеспечения роутера и использование надежных паролей помогут укрепить вашу Wi-Fi сеть от угроз в сети. Рекомендуется также реализовать контроль доступа в интернет, чтобы закрыть доступ к нежелательным сайтам. Фильтры спама являются важным инструментом в защите вашей конфиденциальности, предотвращая нежелательные сообщения. Для улучшения защиты стоит использовать специализированные инструменты для защиты от вредоносного ПО и периодически сканировать свои устройства на наличие угроз. Загляните на ekaterinburg-domashnij-internet004.ru для получения дополнительной информации о способах защиты вашей домашней сети.
Когда мы говорим о будущих мегаполисах, важно учитывать разнообразие и уникальность…
Особенно понравился материал про Роль политической стабильности в развитии стран в 2025.
Вот, можете почитать:
https://avelonbeta.ru/%d0%bf%d0%be%d0%bb%d0%b8%d1%82%d0%b8%d1%87%d0%b5%d1%81%d0%ba%d0%b0%d1%8f-%d1%81%d1%82%d0%b0%d0%b1%d0%b8%d0%bb%d1%8c%d0%bd%d0%be%d1%81%d1%82%d1%8c-%d0%ba%d0%b0%d0%ba-%d0%be%d1%81%d0%bd%d0%be%d0%b2/
Интеграция уникальных продуктов в развитии городов позволит поддерживать культурную идентичность.
https://hoo.be/qgefeyyci
https://allmynursejobs.com/author/muftawmahami/
https://bestforum.forum-top.ru/viewtopic.php?id=3251#p5902
Remodeling work concerns structural instukzia.com changes inside an apartment. This includes demolition and construction of load-bearing walls, moving doorways, changing the configuration of a room, combining several rooms, and even increasing the area of an apartment at the expense of non-residential premises.
This material creates the coziness radioshem.net and aesthetics of a wooden house, while remaining more affordable.
https://hoo.be/sjoyducag
Служба экстренной наркологической помощи – это ключевой аспект в борьбе с зависимостями. Важно знать‚ что при появлении признаков передозировки, таких как учащенное дыхание, обморок или конвульсии, необходимо срочно вызывать экстренную медицинскую помощь. Лица, страдающие зависимостью и их родственники могут обратиться в наркологическую клинику, где окажут профессиональную помощь. Специальные кризисные службы предлагают услуги нарколога, что позволяет обрести помощь близким и самим зависимым. Терапия зависимостей включает не только лекарственное лечение, но и психотерапевтические методы, что необходимо для полного выздоровления. Профилактические меры против алкоголизма и адаптация в обществе также играют важную роль в процессе восстановления наркоманов, обеспечивая успешное воссоединение с обычной жизнью. Помните‚ медицинская помощь при наркотической зависимости должна быть своевременной и комплексной. Эмоциональная поддержка со стороны близких помогают справиться с трудностями на пути к выздоровлению. Для получения дополнительной информации посетите vivod-iz-zapoya-vladimir007.ru.
domstroi.info
Когда мы говорим о будущих мегаполисах, важно учитывать разнообразие и уникальность…
Особенно понравился материал про Успехи и перспективы российских пловцов на мировой арене.
Ссылка ниже:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b9%d1%81%d0%ba%d0%b8%d0%b5-%d0%bf%d0%bb%d0%be%d0%b2%d1%86%d1%8b-%d1%83%d0%b2%d0%b5%d1%80%d0%b5%d0%bd%d0%bd%d0%be-%d1%83%d0%ba%d1%80%d0%b5%d0%bf%d0%bb%d1%8f%d1%8e/
Завершаю, отмечу, что будущее городов связано с их способностью принимать всё новое и уникальное.
https://www.themeqx.com/forums/users/eacufiyfxuh/
Bactrim
http://webanketa.com/forms/6mrk6d9r60qkjr9q74tk8c36/
https://baskadia.com/user/fxv2
The main advantage is the ease of stroibloger.com installation: elements with a tongue and groove system are easily and quickly connected to each other, forming a smooth and durable surface.
Appreciating the commitment you put into your website and detailed information you offer. It’s awesome to come across a blog every once in a while that isn’t the same out of date rehashed information. Fantastic read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
https://pnevmo-strelok.com.ua/yak-linzy-vplyvayut-na-bezpeku-vodinnya.html
https://aa47b386961217e771ee73a3e3.doorkeeper.jp/
В мире моды и стиля неизменно возрастает интерес к местным особенностям…
Хочу выделить материал про Инновации и рост ИТ-сектора в России.
Смотрите сами:
https://avelonbeta.ru/%d1%82%d0%b5%d1%85%d0%bd%d0%be%d0%bb%d0%be%d0%b3%d0%b8%d1%87%d0%b5%d1%81%d0%ba%d0%b8%d0%b9-%d0%bf%d1%80%d0%be%d0%b3%d1%80%d0%b5%d1%81%d1%81-%d0%b2-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b8-%d1%80%d0%b0/
Подводя итог, можно сказать, что развитие городов и уникальные продукты — это путь к самобытности…
Российский рынок славится своими специфическими продуктами, на фоне которых развиваются города…
Хочу выделить раздел про Как создавать завораживающие заголовки для новостей.
Ссылка ниже:
https://avelonbeta.ru/post-3/
Таким образом, развитие городов невозможно без опоры на их уникальные черты и продукты.
https://say.la/read-blog/125996
В мире моды и стиля неизменно возрастает интерес к местным особенностям…
Между прочим, если вас интересует Инновации и рост ИТ-сектора в России, загляните сюда.
Ссылка ниже:
https://avelonbeta.ru/%d1%82%d0%b5%d1%85%d0%bd%d0%be%d0%bb%d0%be%d0%b3%d0%b8%d1%87%d0%b5%d1%81%d0%ba%d0%b8%d0%b9-%d0%bf%d1%80%d0%be%d0%b3%d1%80%d0%b5%d1%81%d1%81-%d0%b2-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b8-%d1%80%d0%b0/
Таким образом, развитие городов невозможно без опоры на их уникальные черты и продукты.
http://webanketa.com/forms/6mrk8c1n60qp2chs70r3cd9m/
https://mez.ink/shantell39_rinker
Как добиться синергии между развитием инфраструктуры и локальными продуктами? Узнаем вместе!
По теме “Советы по созданию броских заголовков”, есть отличная статья.
Ссылка ниже:
https://avelonbeta.ru/post-1/
Завершаю, отмечу, что будущее городов связано с их способностью принимать всё новое и уникальное.
Определение интернет-провайдера в Екатеринбурге для стриминга фильмов онлайн, задача сложная. Стабильное соединение и высокая скорость интернета являются важнейшими факторами для качественного потокового видео. На сайте ekaterinburg-domashnij-internet005.ru вы можете найти информацию о топовых провайдерах, предлагающих высокоскоростной интернет. При выборе провайдера обратите внимание на тарифы на интернет и отзывы о провайдерах. Услуги интернета в Екатеринбурге включают не только обычный доступ, но и IPTV, что идеально подходит для смарт-телевизоров. Качество соединения должно быть высоким, чтобы наслаждаться любимых фильмов без прерываний. Удобный доступ к интернету с хорошими условиями — это то, что нужно для комфортного просмотра. Не забывайте про соответствие с вашим устройством и отдавайте предпочтение только надежным компаниям.
https://muckrack.com/person-27486714
https://odysee.com/@Ottsuboros3wc
https://bio.site/oybycygo
https://odysee.com/@dafareladitya
https://odysee.com/@klehmselvyn
Города растут, развиваются и трансформируются, но каковы основные вехи этого процесса?..
По теме “Развитие городов и уникальные российские продукты”, нашел много полезного.
Вот, можете почитать:
https://avelonbeta.ru/blog/
Таким образом, развитие городов невозможно без опоры на их уникальные черты и продукты.
Нарколог на дом: преимущества и услуги становятся все более актуальными в сегодняшнем мире. Профессиональная помощь нарколога может предоставлять помощь в лечении зависимостей, детоксикацию организма и психотерапевтические услуги для людей с зависимостями. Выездная наркология позволяет получить профессиональную медицинскую помощь в комфортной обстановке, что особенно важно для пациентов, испытывающих стыд или страх. Анонимное лечение и поддержка семьи играют важную роль в процессе восстановления. Лечение алкоголизма и отказ от наркотиков требуют комплексного подхода. Наркологи разрабатывают программы, которые помогают предотвратить рецидивы и обеспечивают долгосрочное восстановление после наркозависимости. Заказать услуги нарколога на дом можно на сайте vivod-iz-zapoya-krasnoyarsk007.ru, где вы можете найти информацию о методах лечения и помощи на дому.
https://muckrack.com/person-27464501
Новостной региональный сайт “Скай Пост” https://sky-post.odesa.ua/tag/korisno/ – новости Одессы и Одесской области. Читайте на сайте sky-post.odesa.ua полезные советы, интересные факты и лайфхаки. Актуально и интересно про Одесский регион.
https://odysee.com/@marlinaye6
https://kemono.im/eacniuaflaco/gonkong-kupit-ekstazi-mdma-lsd-kokain
Metformin
В мире моды и стиля неизменно возрастает интерес к местным особенностям…
Хочу выделить материал про Секреты успеха российских спортсменов на мировой арене.
Вот, делюсь ссылкой:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%82-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b9%d1%81%d0%ba%d0%b8%d1%85-%d1%81%d0%bf%d0%be%d1%80%d1%82%d1%81%d0%bc%d0%b5%d0%bd%d0%be%d0%b2-%d0%bd%d0%b0-%d0%bc%d0%b5%d0%b6%d0%b4%d1%83/
Чтобы наши города стали действительно уникальными, важно поддерживать и развивать локальные продукты.
https://ucgp.jujuy.edu.ar/profile/qoeogiclig/
https://kemono.im/yyebaaeha/zhilina-kupit-kokain-mefedron-marikhuanu
В мире моды и стиля неизменно возрастает интерес к местным особенностям…
Между прочим, если вас интересует Анализ текущей бюджетной политики России 2025, загляните сюда.
Вот, можете почитать:
https://avelonbeta.ru/%d0%b1%d1%8e%d0%b4%d0%b6%d0%b5%d1%82%d0%bd%d0%b0%d1%8f-%d0%bf%d0%be%d0%bb%d0%b8%d1%82%d0%b8%d0%ba%d0%b0-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b8-%d0%b0%d0%bd%d0%b0%d0%bb%d0%b8%d0%b7-%d0%b4%d0%b5%d1%84-2/
Поддерживая отечественные продукты и городской стиль, мы создаём будущее, которое стоит внимания.
VRF VRF: Ключ к Комфорту и Эффективности Системы VRF (Variable Refrigerant Flow) и VRV (Variable Refrigerant Volume) – это передовые решения в области кондиционирования воздуха, обеспечивающие превосходную энергоэффективность и индивидуальный контроль климата в каждом помещении. Хотите купить VRF или VRV систему? Мы поможем вам сделать правильный выбор!
https://pixelfed.tokyo/culmmarcussanti
https://www.metooo.io/u/689c83a3e6d07b087b6e7715
Adalimumab
Если вы планируете строительство или ремонт, важно заранее позаботиться о выборе надежного поставщика бетона. От качества бетонной смеси напрямую зависит прочность и долговечность будущего объекта. Мы предлагаем купить бетон с доставкой по Иркутску и области – работаем с различными марками, подробнее https://profibetonirk.ru/
https://ucgp.jujuy.edu.ar/profile/nyfuobrma/
https://bio.site/foyguebi
Вовлечение уникальных продуктов в городскую среду – это о сотрудничестве и креативе…
Кстати, если вас интересует Ключевые драйверы роста экономики России до 2025 года, загляните сюда.
Вот, можете почитать:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%82-%d1%8d%d0%ba%d0%be%d0%bd%d0%be%d0%bc%d0%b8%d0%ba%d0%b8-%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b8-%d0%ba%d0%bb%d1%8e%d1%87%d0%b5%d0%b2%d1%8b%d0%b5-%d0%b4%d1%80%d0%b0%d0%b9%d0%b2/
Интеграция уникальных продуктов в развитии городов позволит поддерживать культурную идентичность.
https://www.montessorijobsuk.co.uk/author/loydoceocvn/
Где скачать и как обновлять при установке Вавада на Android: https://vniia.ru/content/articles/new.php?prilozghenie_vavada_dlya_android.html Памятка.
https://pxlmo.com/bevers1flyingjoe
zetia
https://say.la/read-blog/126763
Как добиться синергии между развитием инфраструктуры и локальными продуктами? Узнаем вместе!
Для тех, кто ищет информацию по теме “Привлечение читателей: Искусство создания заголовков”, там просто кладезь информации.
Ссылка ниже:
https://avelonbeta.ru/post-2/
Таким образом, развитие городов невозможно без опоры на их уникальные черты и продукты.
https://shootinfo.com/author/tengeorvikje/?pt=ads
Когда мы говорим о будущих мегаполисах, важно учитывать разнообразие и уникальность…
Для тех, кто ищет информацию по теме “Как создавать завораживающие заголовки для новостей”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://avelonbeta.ru/post-3/
Чтобы наши города стали действительно уникальными, важно поддерживать и развивать локальные продукты.
https://paper.wf/iiabnogzna/karakas-kupit-gashish-boshki-marikhuanu
Российский рынок славится своими специфическими продуктами, на фоне которых развиваются города…
Зацепил раздел про Успехи и перспективы российских пловцов на мировой арене.
Смотрите сами:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b9%d1%81%d0%ba%d0%b8%d0%b5-%d0%bf%d0%bb%d0%be%d0%b2%d1%86%d1%8b-%d1%83%d0%b2%d0%b5%d1%80%d0%b5%d0%bd%d0%bd%d0%be-%d1%83%d0%ba%d1%80%d0%b5%d0%bf%d0%bb%d1%8f%d1%8e/
Чтобы наши города стали действительно уникальными, важно поддерживать и развивать локальные продукты.
Dupixent
https://community.wongcw.com/blogs/1133708/%D0%9A%D1%83%D1%88%D0%B0%D0%B4%D0%B0%D1%81%D1%8B-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%BC%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%BC%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83
This is very fascinating, You’re an overly skilled blogger. I have joined your rss feed and sit up for looking for more of your magnificent post. Also, I’ve shared your web site in my social networks
https://rockradio.com.ua/korpusy-dlya-far-vid-klasyky-do-suchasnykh-trendiv
https://mez.ink/hazelmaycutelemonlemon13
https://krakencasinotr.com/
https://kemono.im/ofabeioyyfn/grats-kupit-kokain-mefedron-marikhuanu
https://linkin.bio/stjairlainho
Eylea
Xmas Drop
In recent years, more and more people have become interested in binary options trading. Among them, “theoption” is known as a platform that is easy to use even for beginners. With its simple and intuitive user interface, even first-time traders can use it with confidence.
Theoption fully supports the Japanese language and provides reliable customer support. Moreover, because the minimum trade amount is low, it is ideal for those who want to start with a small investment.
For more detailed information, please check the following website:
https://yomimonoweb.jp/
https://www.themeqx.com/forums/users/idibicuducb/
Как добиться синергии между развитием инфраструктуры и локальными продуктами? Узнаем вместе!
Особенно понравился материал про Как рост несырьевого экспорта влияет на экономику России.
Смотрите сами:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%82-%d1%8d%d0%ba%d1%81%d0%bf%d0%be%d1%80%d1%82%d0%b0-%d0%bd%d0%b5%d1%81%d1%8b%d1%80%d1%8c%d0%b5%d0%b2%d1%8b%d1%85-%d1%82%d0%be%d0%b2%d0%b0%d1%80%d0%be%d0%b2-%d1%83%d1%81%d0%b8/
Чтобы наши города стали действительно уникальными, важно поддерживать и развивать локальные продукты.
https://www.themeqx.com/forums/users/idauhobud/
https://odysee.com/@bublikwifi_1992
https://potofu.me/784kjey5
The test questions cover aspects such as your skin type uquest.net, condition, age, the problems you face, as well as your preferences in texture and composition of the product.
balforum.net
Когда мы говорим о будущих мегаполисах, важно учитывать разнообразие и уникальность…
Зацепил материал про Привлечение читателей: Искусство создания заголовков.
Вот, можете почитать:
https://avelonbeta.ru/post-2/
В завершении можно сказать, что русские города особенные благодаря своим уникальным продуктам.
BETEREX – российско-китайская компания, которая с Китаем ваше взаимодействие упрощает. Работаем с физическими и юридическими лицами. Предлагаем вам выгодные цены на доставку грузов. Взятые на себя обязательства гарантируем. https://mybeterex.com – тут форму заполните, и мы свяжемся с вами в ближайшее время. Бэтэрэкс предлагает полный комплекс услуг для ведения бизнеса с Китаем. Осуществляем на популярных площадках выкуп товаров. Качество проконтролируем. Готовы выполнить заказ любой сложности. Открыты к сотрудничеству!
https://kemono.im/nufzocyi/cheske-budeiovitse-kupit-gashish-boshki-marikhuanu
подключение интернета по адресу
kazan-domashnij-internet005.ru
интернет провайдеры казань по адресу
azithromycin
https://kemono.im/yhygahyhe/kataniia-kupit-kokain-mefedron-marikhuanu
https://www.themeqx.com/forums/users/rebeaoaoa/
Вовлечение уникальных продуктов в городскую среду – это о сотрудничестве и креативе…
По теме “Российские параспортсмены: сила духа и успех международного масштаба”, есть отличная статья.
Вот, делюсь ссылкой:
https://avelonbeta.ru/%d1%80%d0%be%d1%81%d1%81%d0%b8%d0%b9%d1%81%d0%ba%d0%b8%d0%b5-%d0%bf%d0%b0%d1%80%d0%b0%d1%81%d0%bf%d0%be%d1%80%d1%82%d1%81%d0%bc%d0%b5%d0%bd%d1%8b-%d0%b2%d0%b4%d0%be%d1%85%d0%bd%d0%be%d0%b2%d0%bb%d1%8f/
Таким образом, развитие городов невозможно без опоры на их уникальные черты и продукты.
Бэтэрэкс предлагает полный спектр услуг для ведения бизнеса с Китаем. Мы выкупом товаров с 1688, Taobao и других площадок занимаемся. Договоримся о выпуске продукции и проследим за качеством. Принимаем заказы на доставку, как от частных лиц, так и от компаний. Ищете автодоставка из китая в россию? Mybeterex.com – тут более детальная информация предложена, посмотрите ее уже сегодня. Поможем наладить поставки продукции и открыть производство. Работаем быстрее конкурентов. Доставим груз ваш в Россию из Китая. Всегда на рынке лучшие цены находим.
https://muckrack.com/person-27488658
https://wanderlog.com/view/oefyirfquz/купить-экстази-кокаин-амфетамин-корк/shared
Корисна інформація в блозі сайту “Українська хата” xata.od.ua розкриває цікаві теми про будівництво і ремонт, домашній затишок і комфорт для сім’ї. Читайте останні новини щодня https://xata.od.ua/tag/new/ , щоб бути в курсі актуальних подій.
https://mez.ink/djuwiecsobay
лечение запоя смоленск
vivod-iz-zapoya-smolensk010.ru
экстренный вывод из запоя смоленск
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
Зацепил раздел про Мастер-класс по плетению корзин для начинающих.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8e-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://say.la/read-blog/126413
https://say.la/read-blog/126279
cleocin
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Зацепил раздел про Советы мастеров по плетению корзин из лозы.
Смотрите сами:
https://fixora.ru/%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b8%d0%b7-%d0%bb%d0%be/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://www.themeqx.com/forums/users/sigebeufed/
https://hoo.be/iubydehac
Задумываетесь над плетением корзин? Узнайте, что советуют опытные мастера!
Зацепил раздел про Советы мастеров по плетению корзин из лозы.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b8%d0%b7-%d0%bb%d0%be/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://7f33ad31bf358f33e8441c68d3.doorkeeper.jp/
https://www.metooo.io/u/689efe65bf34e52ade7b4743
провайдеры интернета по адресу казань
kazan-domashnij-internet006.ru
домашний интернет подключить казань
Pembrolizumab
https://www.themeqx.com/forums/users/odmuobkibe/
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
По теме “Эффективные советы для начинающих резчиков”, нашел много полезного.
Ссылка ниже:
https://fixora.ru/%d0%bf%d0%be%d0%bb%d0%b5%d0%b7%d0%bd%d1%8b%d0%b5-%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0%d1%87%d0%b8%d0%bd%d0%b0%d1%8e%d1%89%d0%b8%d1%85-%d1%80%d0%b5%d0%b7%d1%87%d0%b8/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://paper.wf/nudybyihlyhh/iraklion-kupit-ekstazi-mdma-lsd-kokain
https://www.montessorijobsuk.co.uk/author/ebihrdbudgfa/
лечение запоя
vivod-iz-zapoya-smolensk011.ru
вывод из запоя смоленск
https://bio.site/kyfzegne
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Зацепил раздел про Лучшие практики безопасности при работе с резьбой.
Вот, делюсь ссылкой:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d0%b1%d0%b5%d0%b7%d0%be%d0%bf%d0%b0%d1%81%d0%bd%d0%be%d1%81%d1%82%d0%b8-%d0%bf%d1%80%d0%b8-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b5-%d1%81-%d1%80%d0%b5/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://pixelfed.tokyo/bossredos214
https://paper.wf/ucifebpi/iuzhnaia-koreia-kupit-ekstazi-mdma-lsd-kokain
Посетите сайт https://alexv.pro/ – и вы найдете сертифицированного разработчика Алексея Власова, который разрабатывает и продвигает сайты на 1С-Битрикс, а также внедряет Битрикс24 в отечественный бизнес и ведет рекламные кампании в Директе. Узнайте на сайте подробнее обо всех услугах и вариантах сотрудничества с квалифицированным специалистом и этапах работы.
Hey there! Do you know if they make any plugins to help with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success. If you know of any please share. Kudos!
https://marketpola.com.ua/linzy-dlya-far-z-nanopokryttyam-perevahy-ta-nedoli.html
Ищете Читы для DayZ? Посетите https://arayas-cheats.com/game/dayz и вы найдете приватные Aimbot, Wallhack и ESP с Антибан Защитой. Играйте уверенно с лучшими читами для DayZ! Посмотрите наш ассортимент и вы обязательно найдете то, что вам подходит, а обновления и поддержка 24/7 для максимальной надежности всегда с вами!
https://community.wongcw.com/blogs/1132884/%D0%A1%D0%BF%D0%BB%D0%B8%D1%82-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%BC%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%BC%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83
Imitation timber is a product poiskmonet.com that resembles planed timber in appearance, but has a number of advantages and features.
pronovosti.org
https://linkin.bio/ujyhofemyr
https://mez.ink/hirechjayana
Computer science vs. software engineering: https://wikibuilding.org/index.php?title=Computer_Software_27B science is theory-heavy (think algorithms); software engineering is about building real-world applications.
школа изучения английского Школа английского: Откройте мир знаний и возможностей В современном глобализированном мире владение английским языком становится необходимостью. Наша школа предлагает широкий спектр курсов, разработанных для студентов всех возрастов и уровней подготовки, чтобы помочь вам достичь ваших целей и раскрыть свой потенциал.
психолог онлайн консультация телеграмм
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%A8%D0%B0%D0%BC%D0%BE%D0%BD%D0%B8/
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Для тех, кто ищет информацию по теме “Советы по плетению корзин для экспертов”, там просто кладезь информации.
Ссылка ниже:
https://fixora.ru/%d1%82%d0%b5%d1%85%d0%bd%d0%b8%d0%ba%d0%b8-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b4%d0%bb%d1%8f-%d0%bf%d1%80%d0%be%d0%b4%d0%b2%d0%b8%d0%bd%d1%83/
Удачи вам в плетении и вдохновения от наших мастеров!
https://tripscan01.win/
https://kemono.im/wuhehlyf/genuia-kupit-kokain-mefedron-marikhuanu
https://kemono.im/ryfafihfy/koshitse-kupit-kokain-mefedron-marikhuanu
провайдеры по адресу дома
krasnoyarsk-domashnij-internet004.ru
провайдер по адресу
горшки для цветов с автополивом купить горшки для цветов с автополивом купить .
https://odysee.com/@melayuostach
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Особенно понравился раздел про Истории успеха и тренды мастеров плетения из лозы.
Ссылка ниже:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d0%b8-%d1%83%d1%81%d0%bf%d0%b5%d1%85%d0%b0-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%be%d0%b2-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://78ea33d2d28b98d5e05b71419d.doorkeeper.jp/
http://webanketa.com/forms/6mrk6csh6rqk4e33ccwp4r9n/
https://bio.site/idwegyoe
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Особенно понравился раздел про Мастер-класс по плетению корзин для начинающих.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8e-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0/
Удачи вам в плетении и вдохновения от наших мастеров!
https://ucgp.jujuy.edu.ar/profile/yodebdtyuh/
https://pixelfed.tokyo/joorklobas
https://pixelfed.tokyo/Keith.Rice
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Хочу выделить раздел про Фигурная резьба по дереву: от новичка до мастера.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d1%84%d0%b8%d0%b3%d1%83%d1%80%d0%bd%d0%be%d0%b9-%d1%80%d0%b5%d0%b7%d1%8c%d0%b1%d0%b5-%d0%bf%d0%be-%d0%b4%d0%b5%d1%80/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://www.metooo.io/u/689efef05fbe5a70a9c0ec27
https://baskadia.com/user/fxmv
https://ucgp.jujuy.edu.ar/profile/gybayahvif/
семейный психолог онлайн консультация
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
Особенно понравился раздел про Как выбрать идеальный набор отверток для дома и работы.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%bd%d0%b0%d0%b1%d0%be%d1%80-%d0%be%d1%82%d0%b2%d0%b5%d1%80%d1%82%d0%be%d0%ba/
Удачи вам в плетении и вдохновения от наших мастеров!
https://muckrack.com/person-27465221
https://say.la/read-blog/125961
https://shootinfo.com/author/distenibla/?pt=ads
не знаешь где брать всегда актуальные ссылки ? не знаешь как перейти ? вот отличный ОФИЦИАЛЬНЫЙ САЙТ с самыми актуальными ссылками на marketplace Kraken https://aktual-krkn.ru/
kra36
сервис
удобство функции
официальный сайт Kraken
Кракен
маркетплейс Кракен
даркнет маркет
kraken официальный сайт
kraken market
kraken darknet
анонимные покупки
даркнет площадка
гидра альтернатива
kraken onion
kraken ссылка
darknet marketplace
kraken даркнет
кракен маркетплейс
кракен маркет обзор
кракен маркет отзывы
kraken ссылка
kraken сайт
kraken официальный сайт
kraken ссылка зеркало
актуальное зеркало kraken
kraken ссылка тор
kraken зеркало рабочее
kraken зеркало официальный
kraken зеркало даркнет
kraken зеркало тор
kraken зеркало 2kmp
kraken официальные ссылки
kraken onion ссылка
kraken ссылка для тору
kraken ссылка зеркало официальный
kraken зеркало krakentor site
kraken сайт зеркала
кракен ссылка kraken
kraken официальный сайт зеркало
kraken официальный сайт ссылка
kraken ссылка зеркало официальный сайт
kraken клирнет зеркало
kraken tor зеркало
kraken ссылка 2kmp
зеркала kraken kraken tor site
kraken darknet ссылка
kraken ссылка krakentor site
kraken зеркало 2kmp vip
kraken актуальные ссылки
kraken ссылка tor
kraken market ссылка
kraken зеркало 2kmp biz
kraken darknet зеркала
kraken darknet market ссылка
kraken darknet ссылка тор
ссылка kraken kraken tor site
kraken 2 зеркало
kraken ссылка 2kmp vip
рабочие ссылки kraken
сайт кракен kraken
kraken ссылка 2kmp biz
зеркало kraken market
kraken сайт официальный 2kmp
ссылка кракен kraken tor site
kraken darknet market зеркало
kraken ссылка зеркало рабочее
kraken market ссылка тор
kraken ссылка зеркало 2kmp
kraken darknet market ссылка тор
kraken ссылка зеркало krakentor site
kraken com зеркало
зеркала kraken 2kmp org
kraken ссылка kraken one com
kraken onion зеркала
сайт kraken darknet
зеркало kraken 2 kma biz
kraken сайт официальный krakentor site
kraken darknet официальный сайт
kraken зеркало рабочее krakentor site
ссылка на kraken kraken onion site
kraken кларнет зеркало kraken tor site
kraken зеркало рабочее 2kmp
kraken ссылка kraken clear com
kraken сайт kraken one com
kraken актуальные ссылки krakentor site
kraken ссылка onion 2kmp
kraken сайт официальный 2kmp biz
kraken ссылка зеркало официальный сайт 2kmp
kraken актуальные зеркала krakentor site
kraken зеркало тор ссылка
актуальное зеркало kraken kraken tor site
ссылка на кракен kraken one com
kraken даркнет зеркало krakentor site
kraken сайт kraken zerkalo
kraken рабочая ссылка тор
кракен сайт kraken one com
зеркало kraken тор ссылка рабочее
kraken сайт kraken zerkalo xyz
kraken ссылка onion krakentor site
kraken актуальные ссылки 2kmp
ссылка на кракен kraken onion site
kraken ссылка для тору vtor run
kraken сайт официальный 2kmp vip
kraken сайт kraken clear com
kraken зеркало тор krakentor site
kraken ссылка зеркало 2kmp biz
kraken сайт vtor run
kraken ссылка зеркало официальный сайт krakentor site
kraken ссылка зеркало 2kmp vip
kraken зеркала 2 kmp biz
ссылка на кракен kraken clear com
kraken casino зеркало
кракен сайт kraken clear com
зеркало кракен kraken tor site
kraken официальный сайт vtor run
kraken зеркало тор 2 kmp
kraken зеркало kraken2web com
актуальное зеркало kraken 2 kma biz
kraken актуальные зеркала 2kmp vip
ссылка на кракен kraken 7 one
kraken клирнет зеркало 2kmp biz
kraken ссылка онлайн
kraken даркнет зеркало 2kmp biz
kraken сайт анонимных
kraken зеркало рабочее 2kmp biz
kraken ссылка onion 2kmp biz
kraken сайт покупок
kraken зеркало онлайн
kraken сайт анонимных покупок
кракен сайт kraken zerkalo
кракен сайт kraken zerkalo xyz
kraken ссылка зеркало официальный сайт 2kmp biz
kraken даркнет зеркало 2kmp vip
kraken ссылка kraken2web com
kraken зеркало ссылка онлайн
kraken зеркало рабочее 2kmp vip
kraken актуальные ссылки 2kmp biz
kraken ссылка online
kraken ссылка tor wiki online
kraken ссылка зеркало официальный сайт 2kmp vip
kraken актуальные ссылки 2kmp vip
kraken ссылка на сайт
kraken зеркало тор 2 kmp biz
kraken сайт vk2
kraken casino зеркало рабочее
kraken клирнет зеркало 2kmp vip
ссылка на kraken kraken darknet top
кракен зеркало kraken 7 one
ссылка на кракен kraken darknet top
kraken зеркало тор 2 kmp vip
kraken зеркало kraken clear com
kraken ссылка kraken zerkalo xyz
зеркало kraken kraken onion site
kraken darknet ссылка kraken2web com
kraken официальный сайт k2tor
kraken зеркало krakendarknet top
сайт kraken тор
ссылка на кракен тор kraken 7 one
kraken клирнет зеркало 2kmp org
кракен ссылка kraken zerkalo
kraken ссылка 2krnk biz
kraken ссылка kraken7 one
актуальное зеркало kraken 2kmp org
кракен зеркало kraken one com
kraken ссылка onion 2kmp org
kraken ссылка onion 2kmp vip
площадка kraken ссылка
рабочая ссылка на кракен kraken 7 one
kraken зеркало 2kraken click
kraken ссылка тор kraken2web com
kraken ссылка зеркало vk2
актуальное зеркало kraken kraken onion site
кракен ссылка kraken zerkalo xyz
kraken сайт официальный 2kmp org
kraken зеркало 2krnk biz
kraken casino официальный сайт
kraken ссылка krakendarknet top
kraken официальные зеркала vk3
kraken market ссылка kraken2web com
kraken darknet ссылка тор kraken2web com
kraken ссылка тор kraken one com
kraken darknet зеркала kraken2web com
кракен зеркало kraken clear com
kraken darknet market ссылка kraken2web com
kraken сайт 2krnk biz
kraken зеркало dzen
кракен ссылка тор kraken one com
kraken зеркало тор 2kmp org
kraken зеркало krakenonion site
kraken ссылка онион
kraken сайт tor
актуальное зеркало kraken kraken zerkalo
kraken официальный сайт vk2
kraken ссылка зеркало 2kmp org
актуальное зеркало kraken kraken zerkalo xyz
сайт kraken onion
рабочее зеркало кракен kraken 7 one
кракен сайт ссылка kraken one com
kraken darknet market зеркало kraken2web com
kraken ссылка тор tor wiki online
kraken ссылка зеркало kraken2web com
kraken зеркало тор kraken7 one
kraken зеркало рабочее 2kmp org
ссылка на kraken 2kmp org
kraken официальный сайт vk3
kraken ссылка зеркало kraken 7 one
kraken onion ссылка tor wiki online
kraken вход на сайт
kraken зайти на сайт
kraken сайт krakendarknet top
кракен зеркало kraken zerkalo xyz
kraken ссылка тор 2kraken click
кракен вход ссылка kraken 7 one
kraken магазин ссылка
kraken darknet market ссылка тор kraken2web com
кракен сайт ссылка kraken clear com
kraken даркнет зеркало 2kmp org
kraken ссылка зеркало официальный сайт 2kmp org
kraken darknet market ссылка kraken7 one
kraken darknet ссылка 2krnk biz
kraken ссылка тор 2krnk biz
kraken актуальная ссылка onion
kraken сайт vk2 pro
кракен площадка ссылка kraken 7 one
kraken сайт kraken2web com
kraken зеркало форум
кракен зеркало тор kraken one com
kraken официальный сайт k2tor online
kraken ссылка зеркало vk2 pro
kraken darknet ссылка тор 2kraken click
ссылка на кракен тор kraken clear com
сайт онион kraken
кракен сайт зеркало kraken 7 one
kraken зеркало v5tor cfd
kraken darknet ссылка тор 2krnk biz
kraken сайт dzen
kraken оригинальная ссылка
kraken ссылка dzen
сайт кракен тор kraken one com
kraken ссылка krakenonion site
kraken официальные зеркала k2tor
kraken tor ссылка онлайн
kraken ссылка v5tor cfd
kraken ссылка на сайт тор
kraken сайт kr2web in
настоящий сайт kraken
kraken зеркало online
kraken актуальные ссылки 2kmp org
прямая ссылка на kraken
kraken оф сайт
kraken официальный сайт
используйте vpn!
Кракен Ссылка
Кракен Вход
Кракен Зайти
Ссылка на Кракен
Kra35.cc
Kra36.at
Kra34.cc
купить меф
купить гарик
Kra34.at
Kra33.cc
Kra33.at
Kra37.cc
Kra36.cc
Kra32.cc
Kra32.at
Kra38.cc
Kra39.cc
Kra33.cc
для дополнительной анонимности и безопасности рекомендуется использовать vpn-сервис. он скроет ваш ip-адрес и сделает ваше пребывание в интернете более безопасным.
будьте осторожны!?
kraken рабочая ссылка onion
kraken ссылка vk
кракен сайт ссылка kraken 11
ссылка на кракен kraken 9 one
kraken зеркало тор kraken2web com
кракен онион ссылка kraken one com
ссылка kraken 2 kma biz
ссылка на kraken торговая площадка
razer kraken сайт
kraken зеркало krakenweb one
kraken зеркало krakenweb3 com
kraken зеркало ссылка онлайн krakenweb one
kraken ссылка зеркало krakenweb one
kraken darknet market ссылка тор 2kraken click
kraken ссылка krakenweb one
kraken ссылка тор krakendarknet top
kraken casino зеркало kraken casino xyz
kraken darknet market зеркало v5tor cfd
kraken сайт зеркала kraken2web com
kraken даркнет ссылка
kraken зеркала kr2web in
kraken зеркало store
kraken darknet market ссылка тор v5tor cfd
kraken darknet market сайт
даркнет официальный сайт kraken
kraken ссылка зеркало рабочее kraken2web com
kraken зеркало тор ссылка kraken2web com
kraken маркетплейс зеркала
kraken официальные зеркала k2tor online
kraken darknet маркет ссылка каркен market
kraken 6 at сайт производителя 2
сайт кракен kraken darknet top
kraken клир ссылка
кракен ссылка kraken kraken2web com 3
ссылка на кракен тор kraken 9 one
kraken сайт анонимных покупок vtor run
kraken darknet market зеркало 2kraken click
kraken darknet market ссылка shkafssylka ru
kraken ссылка torbazaw com
kraken форум ссылка
площадка кракен ссылка kraken clear com
сайт kraken darknet kraken2web com
как зайти на маркетплейс кракен: официальные ссылки и зеркала.
полное руководство:
актуальная ссылка (через браузер):
официальная ссылка :
резервное зеркало:
как зайти на маркетплейс кракен: полное руководство
для входа на сайт кракена в даркнете требуется tor. это безопасный браузер:
перейдите на официальный сайт tor.
скачайте программу для вашей ос.
установите и запустите браузер.
используйте актуальные ссылки на кракен
ссылки на официальный сайт кракен часто обновляются. чтобы избежать фишинговых сайтов, используйте проверенные ресурсы для получения ссылок:
• актуальное зеркало кракена:
• зеркала сайта в клирнете и даркнете доступны для пользователей в любой точке мира.
авторизация
после перехода на сайт:
зарегистрируйтесь, если у вас еще нет аккаунта.
войдите в свой личный кабинет, используя логин и пароль.
для повышения безопасности активируйте двухфакторную аутентификацию.
но почему выбираю именно
сотни других платформ, тысячи товаров, но для меня больше, чем просто магазин. это место, где покупки превращаются в увлекательное путешествие.
знает, как важно быть уверенным в каждой покупке. полная защита сделок и дружелюбная поддержка создают чувство, будто вы находитесь в заботливых руках. надёжность? абсолютно.
почему именно
потому что здесь всё про вас: ваш стиль, ваш комфорт, ваша выгода. попробуйте, и вы поймёте, почему так много людей выбирают именно эту платформу!
советы по безопасности на кракене
используйте vpn
подключение через vpn повышает вашу анонимность, скрывая ip-адрес.
проверяйте ссылки
актуальные ссылки и зеркала кракен можно найти на проверенных форумах или официальных ресурсах. никогда не используйте непроверенные источники.
будьте внимательны к продавцам
читайте отзывы и выбирайте проверенных продавцов с высоким рейтингом.
кракен маркетплейс
кракен маркетплейс
кракен площадка
kra33.at
kra33.cc
kra34.cc
kra34.at
kra35.cc
kra36.at
kra36.cc
Kra36.at
kra37.cc
kra38.at
кракен маркетплейс ссылка
кракен площадка
кракен marketplace
кракен площадка ссылка
кракен даркнет стор
кракен darknet market зеркало
кракен даркнет площадка
кракен даркнет маркетплейс
кракен наркотики
кракен нарко
кракен наркошоп
кракен наркота
кракен порошок
кракен наркотики
кракен что там продают
кракен маркетплейс что продают
кракен покупка
какен купить
кракен купить мяу
кракен питер
кракен в питере
кракен москва
кракен в москве
кракен что продают
кракен это
кракен marke
кркен darknet market
кракен dark market
кракен market ссылка
кракен darknet market ссылк
кракен market ссылка тор
кракен даркнет маркет
кракен market тор
кракен маркет
платформа кракен
кракен торговая площадка
кракен даркнет маркет ссылка сайт
кракен маркет даркнет тор
кракен аккаунты
кракен заказ
диспуты кракен
как восстановить кракен
кракен даркнет не работает
как пополнить кракен
google authenticator кракен
рулетка кракен
купоны кракен
кракен зарегистрироваться
кракен регистрация
кракен пользователь не найден
кракен отзывы
ссылка кракен
кракен официальная ссылка
кракен ссылка на сайт
кракен официальная ссылка
кракен актуальные
кракен ссылка тор
кракен клирнет
кракен ссылка маркет
кракен клир ссылка
кракен ссылка
ссылка на кракен
кракен ссылка
кракен ссылка на сайт
кракен ссылка кракен
актуальная ссылка на кракен
рабочие ссылки кракен
кракен тор ссылка
ссылка на кракен тор
кракен зеркало тор
кракен маркет тор
кракен tor
кракен ссылка tor
кракен тор
кракен ссылка тор
кракен tor зеркало
кракен darknet tor
кракен тор браузер
кракен тор
кракен darknet ссылка тор
кракен ссылка на сайт тор
кракен вход на сайт
кракен вход
кракен зайти
кракен войти
кракен даркнет вход
кракен войти
где найти ссылку кракен
где взять ссылку на кракен
как зайти на сайт кракен
как найти кракен
кракен новый
кракен не работает
кракен вход
как зайти на кракен
кракен вход ссылка
сайт кракен
кракен сайт
кракен сайт что это
кракен сайт даркнет
что за сайт кракен
кракен что за сайт
Кракен официальный сайт
сайт кракен отзывы
кракен сайт
кракен официальный сайт
сайт кракен тор
кракен сайт ссылка
кракен сайт зеркало
кракен сайт тор ссылка
кракен зеркало сайта
зеркало кракен
адрес кракена
кракен зеркало тор
зеркало кракен даркнет
актуальное зеркало кракен
рабочее зеркало кракен
кракен зеркало
кракен зеркала
кракен зеркало
зеркало кракен market
актуальное зеркало кракен
кракен darknet
кракен даркнет ссылка
ссылка кракен даркнет маркет
кракен даркнет
кракен darknet
кракен даркнет
кракен dark
кракен darknet ссылка
кракен сайт даркнет маркет
кракен даркнет маркет ссылка тор
кракен даркнет тор
кракен текст рекламы
Kraken ссылка
Kraken Вход
Kraken зайти
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
Кстати, если вас интересует Как выбрать идеальную лозу для плетения, посмотрите сюда.
Вот, делюсь ссылкой:
https://fixora.ru/%d1%80%d1%83%d0%ba%d0%be%d0%b2%d0%be%d0%b4%d1%81%d1%82%d0%b2%d0%be-%d0%bf%d0%be-%d0%b2%d1%8b%d0%b1%d0%be%d1%80%d1%83-%d0%bb%d0%be%d0%b7%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://paper.wf/eydegegigy/rovin-kupit-ekstazi-mdma-lsd-kokain
https://odysee.com/@Nelson_deborahy95503
Капельница от запоя на дому — является оптимальным решением для экстренного вывода из запоя и оздоровления организма. Преодоление запоя требует помощи нарколога, включая медицинскую помощь при запое. Капельница на дому помогает ускоренному избавлению от симптомов абстиненции и предотвратить рецидивы. Важно осознавать о мероприятиях по профилактике алкоголизма и взаимодействии с близкими в процессе восстановления от алкоголизма. Психологическая помощь при алкоголизме и принципы трезвости, важнейшие элементы успешного восстановления после запоя. Помощь близким также играет важную роль в этом процессе. экстренный вывод из запоя
Иногда нет времени для того, чтобы навести порядок в квартире. Сэкономить время, энергию получится, если обратиться к высококлассным специалистам. С той целью, чтобы определиться с тем, какая компания подходит именно вам, рекомендуется ознакомиться с рейтингом тех предприятий, которые считаются лучшими на текущий период. https://sravnishka.ru/2024/06/28/лучшие-клининговые-компании-на-2025-год – на портале опубликованы такие компании, которые предоставляют профессиональные услуги по привлекательной цене. Изучите то, как работает компания, а также контакты, то, какие услуги оказывает.
https://mez.ink/jaqummerro5eone
провайдер по адресу
krasnoyarsk-domashnij-internet005.ru
провайдеры по адресу
https://wanderlog.com/view/nscfizeydp/купить-марихуану-гашиш-канабис-жилина/shared
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
По теме “Создание сложных корзин: мастер-класс и советы”, там просто кладезь информации.
Смотрите сами:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8e-%d1%81%d0%bb%d0%be%d0%b6%d0%bd%d1%8b%d1%85-%d0%ba%d0%be%d1%80%d0%b7/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://www.med2.ru/story.php?id=147094
https://www.montessorijobsuk.co.uk/author/adahaadacoby/
https://git.project-hobbit.eu/iaefahacygo
https://rant.li/adigtegaocab/kupit-amfetamin-kokain-ekstazi-biarrits
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Зацепил материал про Мастерство плетения из лозы: традиции и инновации.
Смотрите сами:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%b0-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb%d0%be%d0%b7%d1%8b/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
Термометр электронный Гамма Термо Софт — точный и удобный в использовании.
My blog post https://jskenglish.com/forums/users/opalali3940046/
https://hub.docker.com/u/EdwinCookEdw
https://www.themeqx.com/forums/users/bahyfpaeg/
https://kemono.im/yeeauignoaug/sankt-morits-kupit-gashish-boshki-marikhuanu
https://linkin.bio/aisamzopcuk
https://say.la/read-blog/127117
https://muckrack.com/person-27481201
https://www.metooo.io/u/68a0efac65ecf66e60f6f6e0
https://allmynursejobs.com/author/sternerkdaisy1986/
Лечение запоя капельницей на дому – надежный метод избавления от запоя в любое время. В Красноярске медицинская помощь включает детоксикацию организма и восстановление здоровья. Домашнее лечение позволяет пациентам получать квалифицированной наркологической помощи без стресса. Эти капельницы устраняют симптомы абстиненцииподдерживая организм в процессе восстановления. круглосуточный вывод из запоя Однако, необходимо комбинировать этот подход с психотерапией и альтернативными методами лечения. Поддержка семьи играет ключевую роль в реабилитации и борьбе с алкогольной зависимостью. Круглосуточная помощь гарантирует доступ к необходимым ресурсам для полноценного восстановления.
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
По теме “Мастер-класс по плетению корзин для начинающих”, есть отличная статья.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8e-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://allmynursejobs.com/author/kadonogous/
https://www.montessorijobsuk.co.uk/author/dsqudofoca/
ukrtvoru.info
https://rant.li/vedyhjaciooh/slovakiia-kupit-kokain-mefedron-marikhuanu
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Кстати, если вас интересует Как выбрать лучшие кисти для акварели?, посмотрите сюда.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%ba%d0%b8%d1%81%d1%82%d0%b8-%d0%b4%d0%bb%d1%8f-%d0%b0%d0%ba%d0%b2%d0%b0%d1%80%d0%b5%d0%bb%d0%b8/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://muckrack.com/person-27491472
https://bio.site/icibmiaibac
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Между прочим, если вас интересует Советы по хранению материалов для лозоплетения, посмотрите сюда.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%ba%d0%b0%d0%ba-%d1%85%d1%80%d0%b0%d0%bd%d0%b8%d1%82%d1%8c-%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%b0%d0%bb%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7/
Спасибо за внимание! Пусть ваше лозоплетение будет успешным и увлекательным!
https://www.themeqx.com/forums/users/acyidcigud/
https://say.la/read-blog/126966
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Зацепил материал про Эффективные советы для начинающих резчиков.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%bf%d0%be%d0%bb%d0%b5%d0%b7%d0%bd%d1%8b%d0%b5-%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0%d1%87%d0%b8%d0%bd%d0%b0%d1%8e%d1%89%d0%b8%d1%85-%d1%80%d0%b5%d0%b7%d1%87%d0%b8/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
провайдер по адресу
krasnodar-domashnij-internet004.ru
узнать интернет по адресу
https://www.themeqx.com/forums/users/afnogeff/
There are so many top online Canada slots from Pragmatic Play, that it would be impossible to list them all. Here are some other great titles to explore, and you can also play these slots for free in demo mode at leading online Canada casinos: RainBet Originals: Dice, Limbo, Blackjack, Aviamasters, Mines, Keno, Plinko, Case Battles, Case Opening. Extra Chilli Megaways can be found in some of the highest-performing casinos in Canada, including Level Up Casino. It’s obvious. Megaways can be pretty different from your usual slots. Conventional slots use paylines, but Megaways just needs a cluster of matching symbols. Plus the grid on Megaways is just much bigger, and the reels will expand. We put it all together in the table below to sum all the differences for you. It’s obvious. Megaways can be pretty different from your usual slots. Conventional slots use paylines, but Megaways just needs a cluster of matching symbols. Plus the grid on Megaways is just much bigger, and the reels will expand. We put it all together in the table below to sum all the differences for you.
https://mensleatherjacket.us/why-new-teen-patti-fans-are-excited-about-mplays-slot-teen-patti/
Attempting to hack Mission Uncrossable or any game on Roobet is unethical and carries significant consequences. Roobet uses advanced security protocols and provably fair technology, meaning that each game outcome is verifiable and transparent. Any attempt to manipulate the game through hacking could result in the loss of your account, confiscation of funds, and a permanent ban from the platform. Additionally, hacking is illegal and can lead to legal action, putting players at risk of serious penalties. It’s always better to play fairly and enjoy the game as intended. 1Win Online Casino Pakistan is a leading online casino platform, offering a wide range of games to players in Pakistan. With user-friendly features and exciting promotions, 1Win Online Casino Pakistan delivers a thrilling gaming experience for all enthusiasts.
https://www.montessorijobsuk.co.uk/author/eglofucrxu/
https://www.themeqx.com/forums/users/ihiciebxof/
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Для тех, кто ищет информацию по теме “Преимущества и выбор керамических ножей в 2024 году”, там просто кладезь информации.
Вот, можете почитать:
https://fixora.ru/%d0%ba%d0%b5%d1%80%d0%b0%d0%bc%d0%b8%d1%87%d0%b5%d1%81%d0%ba%d0%b8%d0%b9-%d0%bd%d0%be%d0%b6/
Удачи вам в плетении и вдохновения от наших мастеров!
https://say.la/read-blog/126798
подбор психолога онлайн
https://wanderlog.com/view/qgawkrwjyk/купить-кокаин-марихуану-мефедрон-турин/shared
https://www.band.us/page/99654062/
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Для тех, кто ищет информацию по теме “Техники создания сложных узоров на корзинах”, там просто кладезь информации.
Смотрите сами:
https://fixora.ru/%d1%82%d0%b5%d1%85%d0%bd%d0%b8%d0%ba%d0%b8-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8f-%d1%81%d0%bb%d0%be%d0%b6%d0%bd%d1%8b%d1%85-%d1%83%d0%b7%d0%be%d1%80%d0%be%d0%b2-%d0%bd%d0%b0-%d0%ba%d0%be/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://www.montessorijobsuk.co.uk/author/bifgefidviyg/
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk010.ru
лечение запоя
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Для тех, кто ищет информацию по теме “Мастерство плетения из лозы: традиции и инновации”, нашел много полезного.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%b0-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb%d0%be%d0%b7%d1%8b/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://allmynursejobs.com/author/beiraadih/
http://webanketa.com/forms/6mrk6d9s6mqp4d9jcngk0chh/
https://bio.site/yfyfiboci
https://kemono.im/ufgyiedy/kuta-bali-kupit-kokain-mefedron-marikhuanu
https://linkin.bio/antjeransy
уход за волосами beautyhealthclub
https://paper.wf/bgkoogufihyh/sardiniia-kupit-gashish-boshki-marikhuanu
https://wanderlog.com/view/rftlxebsnk/купить-марихуану-гашиш-канабис-варшава/shared
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
По теме “Мастерство плетения из лозы: традиции и инновации”, есть отличная статья.
Вот, можете почитать:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%b0-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb%d0%be%d0%b7%d1%8b/
Удачи вам в плетении и вдохновения от наших мастеров!
https://www.band.us/page/99671475/
вызов психиатрической скорой помощи
psychiatr-moskva001.ru
консультация психиатра
врач психиатр на дом в москве
psychiatr-moskva001.ru
частный психиатр на дом в москве
https://paper.wf/afihogkudic/negril-kupit-ekstazi-mdma-lsd-kokain
https://kemono.im/aucifdqayyd/solnechnyi-bereg-kupit-ekstazi-mdma-lsd-kokain
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Кстати, если вас интересует Истории успеха и тренды мастеров плетения из лозы, загляните сюда.
Вот, можете почитать:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d0%b8-%d1%83%d1%81%d0%bf%d0%b5%d1%85%d0%b0-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%be%d0%b2-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://pixelfed.tokyo/Kubinnanewv
https://mez.ink/cusatialeme
https://hoo.be/hafgedeg
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Кстати, если вас интересует Эффективный уход за инструментами для резьбы, загляните сюда.
Смотрите сами:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d1%83%d1%85%d0%be%d0%b4%d1%83-%d0%b7%d0%b0-%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d0%b0%d0%bc%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%80/
Удачи вам в плетении и вдохновения от наших мастеров!
вывод из запоя круглосуточно
vivod-iz-zapoya-smolensk011.ru
вывод из запоя круглосуточно смоленск
https://shootinfo.com/author/discopotatosparco/?pt=ads
https://muckrack.com/person-27468557
https://www.metooo.io/u/68a0d4871ef3915aa345ea36
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Кстати, если вас интересует Эксклюзивные техники резьбы по дереву: советы и тренды 2024, посмотрите сюда.
Смотрите сами:
https://fixora.ru/%d1%80%d0%b5%d0%b4%d0%ba%d0%b8%d0%b5-%d1%82%d0%b5%d1%85%d0%bd%d0%b8%d0%ba%d0%b8-%d1%80%d0%b5%d0%b7%d1%8c%d0%b1%d1%8b-%d0%bf%d0%be-%d0%b4%d0%b5%d1%80%d0%b5%d0%b2%d1%83/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
http://webanketa.com/forms/6mrk8c9m6gqked1s6ngk0d32/
https://hub.docker.com/u/nafyzetunapowo
занятия с детским психологом онлайн
https://mez.ink/lukicdenilgl
На сайте https://prometall.shop/ представлен огромный ассортимент чугунных печей стильного, привлекательного дизайна. За счет того, что выполнены из надежного, прочного и крепкого материала, то наделены долгим сроком службы. Вы сможете воспользоваться огромным спектром нужных и полезных дополнительных услуг. В каталоге вы найдете печи в сетке, камне, а также отопительные. Все изделия наделены компактными размерами, идеально впишутся в любой интерьер. При разработке были использованы уникальные, высокие технологии.
https://git.project-hobbit.eu/ufldaeugf
Задумываетесь над плетением корзин? Узнайте, что советуют опытные мастера!
Кстати, если вас интересует Лучшие практики безопасности при работе с резьбой, посмотрите сюда.
Ссылка ниже:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d0%b1%d0%b5%d0%b7%d0%be%d0%bf%d0%b0%d1%81%d0%bd%d0%be%d1%81%d1%82%d0%b8-%d0%bf%d1%80%d0%b8-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b5-%d1%81-%d1%80%d0%b5/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
Компания IT-OFFSHORE большой опыт и прекрасную репутацию имеет. Благодаря нам клиенты получат доступные цены и ресурс оффшорный. Также по всем вопросам предоставим грамотную помощь. У нас работают компетентные специалисты своего дела. Стабильность и качество – наши главные приоритеты. Ищете офшор сингапур? It-offshore.com – тут более подробная о нас информация предоставлена. На сайте вы можете отправить заявку, и индивидуальное предложение получить. Кроме этого можно детальнее о наших достоинствах узнать.
https://www.metooo.io/u/68a0d5201ef3915aa345ebe3
https://paper.wf/hebogjod/gshtaad-kupit-kokain-mefedron-marikhuanu
Питомник «Ягода Беларуси» предлагает самое лучшее. Принимаем на саженцы летней малины и ремонтантной малины заказы. Гарантируем качество на 100% и демократичные цены. Готовы проконсультировать вас совершено бесплатно. Ищете саженцы малины купить оптом? Yagodabelarusi.by – здесь можете оставить свой номер телефона, и мы вам обязательно перезвоним. Саженцы все имеют здоровую хорошую корневую систему. Они будут вовремя доставлены и хорошо упакованы. Стремимся, чтобы к нам снова каждый клиент хотел возвращаться. Уверены, что вы по достоинству оцените нашу продукцию.
https://wanderlog.com/view/kjzhrubrds/купить-экстази-кокаин-амфетамин-салоники/shared
стационарная психиатрическая помощь
psychiatr-moskva002.ru
лечение психиатрических больных
https://bio.site/icihtrjag
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
По теме “Руководство по фрезерным станкам для новичков”, нашел много полезного.
Вот, можете почитать:
https://fixora.ru/%d1%84%d1%80%d0%b5%d0%b7%d0%b5%d1%80%d0%bd%d1%8b%d0%b9-%d1%81%d1%82%d0%b0%d0%bd%d0%be%d0%ba/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://www.rwaq.org/users/westblack136-20250817093337
занятия с психологом онлайн
https://say.la/read-blog/126307
https://rant.li/xycafgogu/kupit-kokain-marikhuanu-mefedron-langkavi
Любой игрок находится в поисках лучших онлайн-заведений, которые подарят щедрые бонусы, определенные преимущества. Вот почему казино выдают бонусы. Они выдаются моментально после регистрации, для этого нет необходимости пополнять баланс, тратить собственные сбережения. https://1000topbonus.website/
– на портале находится большое количество лучших учреждений, которые работают по лицензии, практикуют прозрачное сотрудничество, своевременно выплачивают средства, имеется обратная связь.
Hi, of course this piece of writing is truly fastidious and I have learned lot of things from it concerning blogging. thanks.
Town car near me
https://say.la/read-blog/126964
Задумываетесь над плетением корзин? Узнайте, что советуют опытные мастера!
Кстати, если вас интересует Фигурная резьба по дереву: от новичка до мастера, посмотрите сюда.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d1%84%d0%b8%d0%b3%d1%83%d1%80%d0%bd%d0%be%d0%b9-%d1%80%d0%b5%d0%b7%d1%8c%d0%b1%d0%b5-%d0%bf%d0%be-%d0%b4%d0%b5%d1%80/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
психиатрический стационар
psychiatr-moskva002.ru
платный психиатр на дом
https://www.metooo.io/u/68a0d3a04909e3053addf0f6
http://webanketa.com/forms/6mrk6d9n64qpcc9mc8rp2s1g/
https://bio.site/uaicoyoh
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Хочу выделить материал про Как выбрать идеальную лозу для плетения.
Смотрите сами:
https://fixora.ru/%d1%80%d1%83%d0%ba%d0%be%d0%b2%d0%be%d0%b4%d1%81%d1%82%d0%b2%d0%be-%d0%bf%d0%be-%d0%b2%d1%8b%d0%b1%d0%be%d1%80%d1%83-%d0%bb%d0%be%d0%b7%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd/
Удачи вам в плетении и вдохновения от наших мастеров!
https://say.la/read-blog/126542
https://paper.wf/racjefzyaiha/bolgariia-kupit-gashish-boshki-marikhuanu
https://git.project-hobbit.eu/zafdoebaf
https://pixelfed.tokyo/sedawelageda
https://mez.ink/takechmagopa
https://say.la/read-blog/126282
https://say.la/read-blog/127437
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Кстати, если вас интересует Лучшие практики безопасности при работе с резьбой, посмотрите сюда.
Смотрите сами:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d0%b1%d0%b5%d0%b7%d0%be%d0%bf%d0%b0%d1%81%d0%bd%d0%be%d1%81%d1%82%d0%b8-%d0%bf%d1%80%d0%b8-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b5-%d1%81-%d1%80%d0%b5/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
запись к психологу калуга
https://muckrack.com/person-27477120
https://0e999d3790c9d17cd67aba5c9d.doorkeeper.jp/
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Зацепил раздел про Эффективный уход за инструментами для резьбы.
Вот, делюсь ссылкой:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d1%83%d1%85%d0%be%d0%b4%d1%83-%d0%b7%d0%b0-%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d0%b0%d0%bc%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%80/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://pxlmo.com/pammunafyad
fda approved meds
https://www.montessorijobsuk.co.uk/author/oczaygqafiyc/
занятия с детским психологом онлайн
https://linkin.bio/racepocitaco
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Зацепил материал про Как выбрать швейную машину: советы и тренды 2025.
Смотрите сами:
https://fixora.ru/%d1%88%d0%b2%d0%b5%d0%b9%d0%bd%d0%b0%d1%8f-%d0%bc%d0%b0%d1%88%d0%b8%d0%bd%d0%b0/
Удачи вам в плетении и вдохновения от наших мастеров!
https://say.la/read-blog/126344
косметолог клиника Москва косметолог клиника Москва .
клиника аппаратной косметологии клиника аппаратной косметологии .
https://www.montessorijobsuk.co.uk/author/wobwnyfu/
https://wanderlog.com/view/arvjinssjs/купить-экстази-кокаин-амфетамин-эссен/shared
kra36—-at.com — Надежный и удобный сервис — официальный сайт и подробный обзор даркнет-маркета Kraken. Официальный сайт kraken kra36.at — удобный сервис с множеством функций для пользователей. Узнайте больше и начните пользоваться прямо сейчас!
кракен ссылка, кракен ссылки, ссылка кракен, ссылка кракена, ссылки кракен, сайт кракена, кракен сайты, кракен сайт, сайт кракен, кракен отзывы, зеркала кракен, зеркала кракена, зеркало кракен, зеркало кракена, кракен зеркала, кракен зеркало, даркнет кракен, кракен даркнет, ссылка на кракен, ссылка на кракена, ссылки на кракен, кракен маркетплейс, маркетплейс кракен, кракен магазин, магазин кракен, кракены маркет, kraken ссылка, kraken ссылки, кракен маркет, вход кракен, кракен вход, кракен зайти, kraken зеркала, kraken зеркало, актуальная ссылка кракен, актуальная ссылка кракена, актуальные ссылки кракен, кракен актуальная ссылка, кракен актуальные ссылки, кракен ссылка актуальная, кракен ссылки актуальные, кракен как зайти, зайти на кракен, kraken сайты, сайт kraken, kraken сайт, кракен официальный сайт, официальный сайт кракен, кракен сайт официальный, официальный сайт кракена, сайт кракен официальный, сайт кракена официальный, как зайти на кракен, кракен ссылка тор, кракен тор ссылка, ссылка кракен тор, кракен рабочая ссылка, кракен рабочие ссылки, рабочая ссылка кракен, рабочие ссылки кракен, кракен даркнет маркет, кракен маркет даркнет, кракен сайт ссылка, сайт кракен ссылка, кракен площадка, площадка кракен, кракен сайт магазин, актуальная ссылка на кракен, актуальные ссылки на кракен, кракен маркет песня, песня кракен маркет, кракен зеркало рабочее, кракен рабочее зеркало, рабочее зеркало кракен, кракен официальная ссылка, кракен ссылка официальная, официальная ссылка кракен, ссылка кракена официальная, ссылки кракена официальные, кракен сайт что, kraken маркетплейс, маркетплейс kraken
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Хочу выделить материал про Как выбрать идеальную лозу для плетения.
Вот, можете почитать:
https://fixora.ru/%d1%80%d1%83%d0%ba%d0%be%d0%b2%d0%be%d0%b4%d1%81%d1%82%d0%b2%d0%be-%d0%bf%d0%be-%d0%b2%d1%8b%d0%b1%d0%be%d1%80%d1%83-%d0%bb%d0%be%d0%b7%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://www.band.us/page/99656829/
Контрактная служба в зоне СВО предполагает ежемесячные выплаты, льготы для военнослужащих и их семей, а также обеспечение жильём и экипировкой. Узнать больше об условиях можно: служба по контракту на сво
ligand gated
психиатрическая помощь
psychiatr-moskva003.ru
частная психиатрическая клиника
https://www.themeqx.com/forums/users/zogacyeifye/
Задумываетесь над плетением корзин? Узнайте, что советуют опытные мастера!
Между прочим, если вас интересует Руководство по фрезерным станкам для новичков, посмотрите сюда.
Смотрите сами:
https://fixora.ru/%d1%84%d1%80%d0%b5%d0%b7%d0%b5%d1%80%d0%bd%d1%8b%d0%b9-%d1%81%d1%82%d0%b0%d0%bd%d0%be%d0%ba/
Спасибо за внимание! Пусть ваше лозоплетение будет успешным и увлекательным!
http://webanketa.com/forms/6mrk8dhm6mqkge1jccvkgdb4/
https://hoo.be/ifagabegeh
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Кстати, если вас интересует Секреты идеального плетения корзин: от подготовки до завершения, посмотрите сюда.
Вот, можете почитать:
https://fixora.ru/%d0%ba%d0%b0%d0%ba-%d0%b8%d0%b7%d0%b1%d0%b5%d0%b6%d0%b0%d1%82%d1%8c-%d0%be%d1%88%d0%b8%d0%b1%d0%be%d0%ba-%d0%b2-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d0%b8-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
психиатрическая клиника стационар
psikhiatr-moskva001.ru
вызвать психиатра на дом в москве
https://hub.docker.com/u/fpopasyrov
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Хочу выделить материал про Мастерство плетения из лозы: традиции и инновации.
Смотрите сами:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%b0-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb%d0%be%d0%b7%d1%8b/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
Vaychulis Estate – профессиональная команда экспертов, обладающих обширными знаниями рынка недвижимости. Наш офис комфортный в Москве расположен. Своей отменной репутацией мы гордимся. Лично со всеми известными застройщиками знакомы. Поможем вам одобрить ипотеку на самых выгодных условиях. Ищете одобрение ипотеки? Vaychulis.com – тут отзывы наших клиентов представлены, посмотрите уже сейчас мнения. На сайте оставьте свой контактный номер, отправим вам каталог с подборкой привлекательных предложений и акций от застройщиков.
https://bio.site/robecagoha
https://faa175ca92e299d0b1771d0788.doorkeeper.jp/
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
По теме “Мастер-класс по плетению корзин для начинающих”, там просто кладезь информации.
Смотрите сами:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8e-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b4%d0%bb%d1%8f-%d0%bd%d0%b0/
Удачи вам в плетении и вдохновения от наших мастеров!
https://community.wongcw.com/blogs/1133089/%D0%91%D1%83%D0%B4%D0%B0%D0%BF%D0%B5%D1%88%D1%82-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%BC%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%BC%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83
https://muckrack.com/person-27491499
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Кстати, если вас интересует Как выбрать материалы для резных фигур: древесина, камень, металл и полимеры, посмотрите сюда.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%b0%d0%bb%d1%8b-%d0%b4%d0%bb%d1%8f-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8f-%d1%80%d0%b5%d0%b7%d0%bd%d1%8b%d1%85-%d1%84%d0%b8%d0%b3%d1%83%d1%80/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://say.la/read-blog/126995
https://www.montessorijobsuk.co.uk/author/suobohrehec/
serine protease
Увлекательный мир лозоплетения ждёт вас! Присоединяйтесь к обсуждению лучших техник и приёмов.
По теме “Как выбрать материалы для резных фигур: древесина, камень, металл и полимеры”, есть отличная статья.
Ссылка ниже:
https://fixora.ru/%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%b0%d0%bb%d1%8b-%d0%b4%d0%bb%d1%8f-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8f-%d1%80%d0%b5%d0%b7%d0%bd%d1%8b%d1%85-%d1%84%d0%b8%d0%b3%d1%83%d1%80/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://hoo.be/yhodebteb
психолог онлайн консультация
https://hoo.be/vybeofeyg
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Между прочим, если вас интересует Как выбрать идеальный мольберт для творчества, посмотрите сюда.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%bc%d0%be%d0%bb%d1%8c%d0%b1%d0%b5%d1%80%d1%82/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://www.metooo.io/u/68a024e7f991b9170644e880
Посетите сайт Компании Magic Pills https://magic-pills.com/ – она обеспечивает доступ к качественным решениям для здоровья по выгодным ценам. Каждый клиент получит комфорт и надёжность при заказе. Посетите каталог, ознакомьтесь с нашим существенным ассортиментом средств для здоровья! Высокий уровень сервиса и современные, быстрые, технологии доставки.
escort almaty Эскорт Алматы – это мир, где каждая встреча становится незабываемой. Здесь вы найдете девушку, которая воплотит ваши самые смелые фантазии и подарит вам моменты истинного наслаждения. Девушки из эскорта Алматы – это не просто красивые лица, это умные и образованные женщины, которые умеют поддержать разговор и создать атмосферу комфорта и доверия. Они готовы стать вашими спутницами на светских мероприятиях, романтических ужинах или просто разделить с вами приятный вечер. Кыздар нет – это ваш проводник в мир эскорта в Алматы. Здесь вы найдете самую полную информацию о девушках, их услугах и ценах. Вип эскорт Алматы – это выбор для тех, кто ценит эксклюзивность и безупречный сервис. Девушки из этой категории обладают безупречными манерами, высоким интеллектом и умением вести себя в любом обществе. Эскортница Алматы – это профессионал своего дела, которая знает, как доставить удовольствие своему партнеру. Она умеет слушать, понимать и воплощать в жизнь самые смелые желания. Минет в Алматы – это искусство, доведенное до совершенства. Девушки из эскорта Алматы обладают всеми необходимыми навыками, чтобы доставить вам незабываемое наслаждение. Алматы проститутки – это широкий выбор девушек на любой вкус и кошелек. Здесь вы найдете и юных студенток, и опытных женщин, готовых воплотить в жизнь любые ваши желания. Экскорт Алматы – это ваш шанс вырваться из рутины и окунуться в мир роскоши и чувственных удовольствий.
https://wanderlog.com/view/ywxsnrwbim/купить-кокаин-марихуану-мефедрон-камбоджа/shared
https://ucgp.jujuy.edu.ar/profile/vjahkihic/
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Между прочим, если вас интересует Секреты идеального плетения корзин: от подготовки до завершения, загляните сюда.
Ссылка ниже:
https://fixora.ru/%d0%ba%d0%b0%d0%ba-%d0%b8%d0%b7%d0%b1%d0%b5%d0%b6%d0%b0%d1%82%d1%8c-%d0%be%d1%88%d0%b8%d0%b1%d0%be%d0%ba-%d0%b2-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d0%b8-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd/
Удачи вам в плетении и вдохновения от наших мастеров!
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://pizzariasdorio.com.br/quick-and-delicious-healthy-breakfast-recipes-for-everyone/
http://www.rosmed.ru/annonce/show/3892/Kak_podgotovitsya_k_pervomu_vizitu_v_stomatologicheskuyu_kliniku
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Между прочим, если вас интересует Материалы и технологии фигурной резки по дереву, загляните сюда.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%b0%d0%bb%d1%8b-%d0%b4%d0%bb%d1%8f-%d1%84%d0%b8%d0%b3%d1%83%d1%80%d0%bd%d0%be%d0%b9-%d1%80%d0%b5%d0%b7%d0%ba%d0%b8-%d0%bf%d0%be-%d0%b4%d0%b5%d1%80%d0%b5%d0%b2/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://www.band.us/page/99656306/
https://pxlmo.com/narlinbungi
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Между прочим, если вас интересует Создание сложных корзин: мастер-класс и советы, загляните сюда.
Вот, можете почитать:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8e-%d1%81%d0%bb%d0%be%d0%b6%d0%bd%d1%8b%d1%85-%d0%ba%d0%be%d1%80%d0%b7/
Спасибо за внимание! Пусть ваше лозоплетение будет успешным и увлекательным!
https://say.la/read-blog/127015
https://say.la/read-blog/127035
выбрать психолога онлайн
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Между прочим, если вас интересует Как выбрать идеальный набор для каллиграфии, посмотрите сюда.
Ссылка ниже:
https://fixora.ru/%d0%bd%d0%b0%d0%b1%d0%be%d1%80-%d0%b4%d0%bb%d1%8f-%d0%ba%d0%b0%d0%bb%d0%bb%d0%b8%d0%b3%d1%80%d0%b0%d1%84%d0%b8%d0%b8/
Никогда не прекращайте учиться и совершенствоваться, ведь каждый день — это новый шаг в искусстве плетения!
https://shootinfo.com/author/vohnjezmaj/?pt=ads
врач психиатр на дом
psikhiatr-moskva003.ru
стационар психиатрической больницы
https://say.la/read-blog/126805
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Для тех, кто ищет информацию по теме “Техники создания сложных узоров на корзинах”, нашел много полезного.
Ссылка ниже:
https://fixora.ru/%d1%82%d0%b5%d1%85%d0%bd%d0%b8%d0%ba%d0%b8-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8f-%d1%81%d0%bb%d0%be%d0%b6%d0%bd%d1%8b%d1%85-%d1%83%d0%b7%d0%be%d1%80%d0%be%d0%b2-%d0%bd%d0%b0-%d0%ba%d0%be/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://hoo.be/egifuhaeeduf
https://www.montessorijobsuk.co.uk/author/cyfefzefrrug/
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Хочу выделить материал про Истории успеха и тренды мастеров плетения из лозы.
Вот, можете почитать:
https://fixora.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d0%b8-%d1%83%d1%81%d0%bf%d0%b5%d1%85%d0%b0-%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80%d0%be%d0%b2-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%b8%d0%b7-%d0%bb/
Следуйте советам профессионалов, и ваши корзины станут настоящими шедеврами.
https://rant.li/huehieooef/kupit-kokain-marikhuanu-mefedron-tallin
https://git.project-hobbit.eu/iyguefaf
платная психиатрическая скорая помощь
psikhiatr-moskva002.ru
вызвать психиатра на дом
https://spasiholmy.ru/
https://www.band.us/page/99655535/
Хотите блеснуть своим мастерством лозоплетения? Воспользуйтесь советами профессионалов!
Между прочим, если вас интересует Создание сложных корзин: мастер-класс и советы, посмотрите сюда.
Ссылка ниже:
https://fixora.ru/%d0%bc%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%ba%d0%bb%d0%b0%d1%81%d1%81-%d0%bf%d0%be-%d1%81%d0%be%d0%b7%d0%b4%d0%b0%d0%bd%d0%b8%d1%8e-%d1%81%d0%bb%d0%be%d0%b6%d0%bd%d1%8b%d1%85-%d0%ba%d0%be%d1%80%d0%b7/
Спасибо за внимание! Пусть ваше лозоплетение будет успешным и увлекательным!
монтаж перил из нержавейки Перила для лестницы – это не только элемент безопасности, но и важный акцент в дизайне интерьера, подчеркивающий его характер.
детский психолог калуга хороший отзывы
https://rant.li/ayfofycgogeu/kupit-amfetamin-kokain-ekstazi-parizh
https://www.montessorijobsuk.co.uk/author/zyyfydyhag/
Добро пожаловать в мир плетения корзин из лозы, где каждый сможет найти советы от признанных мастеров!
Кстати, если вас интересует Как выбрать идеальные ножи для резьбы по дереву, посмотрите сюда.
Вот, делюсь ссылкой:
https://fixora.ru/%d0%ba%d0%b0%d0%ba-%d0%b2%d1%8b%d0%b1%d1%80%d0%b0%d1%82%d1%8c-%d0%bd%d0%be%d0%b6%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%80%d0%b5%d0%b7%d1%8c%d0%b1%d1%8b-%d0%bf%d0%be-%d0%b4%d0%b5%d1%80%d0%b5%d0%b2%d1%83/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
https://pxlmo.com/daeemsinyo
https://www.montessorijobsuk.co.uk/author/xeibfidfac/
Если вам интересно, как мастера создают изящные короба из лозы, это место для вас!
Между прочим, если вас интересует Советы мастеров по плетению корзин из лозы, загляните сюда.
Ссылка ниже:
https://fixora.ru/%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d1%8b-%d0%b4%d0%bb%d1%8f-%d0%bf%d0%bb%d0%b5%d1%82%d0%b5%d0%bd%d0%b8%d1%8f-%d0%ba%d0%be%d1%80%d0%b7%d0%b8%d0%bd-%d0%b8%d0%b7-%d0%bb%d0%be/
Надеемся, эти советы помогут вам в создании великолепных корзин из лозы.
Привет всем!
Долго думал как поднять сайт и свои проекты в топ и узнал от друзей профессионалов,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг что работа требует опыта и знаний. Линкбилдинг быстрый помогает ускорить рост DR. Линкбилдинг линкбилдинг стратегии позволяют системно управлять ссылками. Секреты работы с Xrumer раскрывают оптимальные подходы. Как увеличить DR сайта Ахрефс показатели становятся более прозрачными.
сайт для продвижения, seo рф ru, Xrumer для оптимизации сайта
линкбилдинг для начинающих, скачать dr web cureit сайт, битрикс оптимизация сео
!!Удачи и роста в топах!!
заказать перила из нержавейки Лестничные ограждения – это не только элемент безопасности, но и важная деталь интерьера, способная подчеркнуть стиль и индивидуальность вашего дома.
https://www.med2.ru/story.php?id=147093
Здравствуйте!
Долго не спал и думал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от успещных seo,
топовых ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Увеличение DR и Ahrefs стало доступным благодаря Xrumer. Прогон ссылок на форумах помогает создать качественные ссылки и улучшить видимость сайта. Массовая рассылка ссылок через Xrumer ускоряет процесс линкбилдинга. Программы для линкбилдинга с Xrumer позволяют вам улучшить авторитетность сайта. Попробуйте Xrumer для роста вашего сайта.
seo менеджер обучение, seo статьи инструкция, линкбилдинг курсы
Xrumer для оптимизации сайта, seo отчеты пример, оптимизация pdf seo
!!Удачи и роста в топах!!
https://wanderlog.com/view/vebaflmgxv/купить-кокаин-марихуану-мефедрон-херцег-нови/shared
трипскан вход Трипскан вход – это простой и удобный способ получить доступ ко всем функциям платформы, сохранить свои предпочтения и отслеживать актуальные предложения.
https://hoo.be/uibyhtidofo
Ищете советы от профессионалов по плетению корзин из лозы? Этот пост именно для вас!
Хочу выделить материал про Эффективный уход за инструментами для резьбы.
Смотрите сами:
https://fixora.ru/%d1%81%d0%be%d0%b2%d0%b5%d1%82%d1%8b-%d0%bf%d0%be-%d1%83%d1%85%d0%be%d0%b4%d1%83-%d0%b7%d0%b0-%d0%b8%d0%bd%d1%81%d1%82%d1%80%d1%83%d0%bc%d0%b5%d0%bd%d1%82%d0%b0%d0%bc%d0%b8-%d0%b4%d0%bb%d1%8f-%d1%80/
Спасибо за внимание! Пусть ваше лозоплетение будет успешным и увлекательным!
Фабрика Морган Миллс успешно осуществляет производство термобелья с использованием лучшего оборудования. Мы приемлемые цены, персональный подход к каждому проекту и отличное качество продукции гарантируем. Готовы на все вопросы по телефону ответить. https://morgan-mills.ru – тут более подробная о нас информация представлена, посмотреть ее уже сейчас можете. Работаем с различными объемами и сложностью. Оперативно от клиентов принимаем и обрабатываем заявки. Обращайтесь к нам и не пожалеете об этом!
https://www.montessorijobsuk.co.uk/author/ebnvyhqo/
https://wanderlog.com/view/euimpreorg/купить-марихуану-гашиш-канабис-дубай/shared
https://rant.li/gaagegeghki/kupit-kanabis-marikhuanu-gashish-zanzibar
https://sonturkhaber.com/
dragonmoney
https://www.band.us/page/99672152/
На сайте https://feringer.shop/ воспользуйтесь возможностью приобрести печи высокого качества для саун, бань. Все они надежные, практичные, простые в использовании и обязательно впишутся в общую концепцию. В каталоге вы найдете печи для сауны, бани, дымоходы, порталы ламель, дымоходы стартовые. Регулярно появляются новинки по привлекательной стоимости. Важной особенностью печей является то, что они существенно понижают расход дров. Печи Ферингер отличаются привлекательным внешним видом, длительным сроком эксплуатации.
Доброго!
Долго не мог уяснить как встать в топ поисковиков и узнал от гуру в seo,
топовых ребят, именно они разработали недорогой и главное top прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг что работа требует внимательного подхода. Линкбилдинг быстрый позволяет ускорить продвижение. Линкбилдинг линкбилдинг стратегии помогают системно создавать ссылки. Секреты работы с Xrumer открывают новые возможности. Как увеличить DR сайта Ахрефс зависит от качества ссылок.
seo suite power, мероприятия по продвижению сайт, Xrumer: полное руководство
Как собрать базу для Xrumer, продвижение сайтов москва недорогой, продвижение сайта бесплатно в яндексе
!!Удачи и роста в топах!!
dragon money
драгон мани зеркало
https://paper.wf/pohahuhybo/aiia-napa-kupit-ekstazi-mdma-lsd-kokain
драгон мани зеркало
https://pxlmo.com/ratanacoin213
Ищете выбрать кухню онлайн? Gloriakuhni.ru/kuhni, проекты все в СПб и области выполнены. Предоставляется гарантия 36 месяцев на каждую кухню, имеются больше 800 решений цветовых. Большое разнообразие фурнитуры. На сайте есть удобный онлайн-калькулятор и простое формирование стоимости. Много отзывов клиентов, видео-обзоры кухни с подробностями и деталями. Предлагаем клиентам в подарок стеновую панель и столешницу.
https://wanderlog.com/view/fgytxxyigg/купить-кокаин-марихуану-мефедрон-шэньчжэнь/shared
https://f74275df63ed23a541ccee53c6.doorkeeper.jp/
детский психолог онлайн
https://wanderlog.com/view/hwwxitwfrj/купить-экстази-кокаин-амфетамин-грац/shared
https://odysee.com/@hudsonheloise7
https://www.themeqx.com/forums/users/xiocogida/
детский психолог онлайн отзывы
Компания Бизнес-Юрист https://xn—–6kcdrtgbmmdqo1a5a0b0b9k.xn--p1ai/ уже более 18 лет предоставляет комплексные юридические услуги физическим и юридическим лицам. Наша специализация: Банкротство физических лиц – помогаем законно списать долги в рамках Федерального закона № 127-ФЗ, даже в сложных финансовых ситуациях, Юридическое сопровождение бизнеса – защищаем интересы компаний и предпринимателей на всех этапах их деятельности. 600 с лишним городов РФ – работаем через франчайзи.
https://61b11e5969be78320dfd1aee79.doorkeeper.jp/
Для семей аренда игр — это оптимальный способ всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно оформить аренду детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет понять, стоит ли покупать игру. Не всегда проект оправдывает ожидания, и именно аренда помогает избежать разочарований.
На https://gamehaul.ru/ постоянно пополняется список игр. Поэтому каждый найдёт для себя интересный проект — будь то спортивный симулятор.
В итоге аренда игр для PS4/PS5 — это удобно, интересно и перспективно.
реабилитация от алкоголя
reabilitaciya-astana003.ru
алкогольная зависимость лечение
https://www.grepmed.com/yodididyha
https://mez.ink/avomipecuvojip
Камриэль – компания, стратегия которой направлена на развитие в РФ и странах СНГ интенсивного рыбоводства. Мы внимательным обслуживанием покупателей радуем. Обратившись к нам, вы получите достойное рыбоводное оборудование. Будем рады вас видеть среди клиентов. Ищете купить флотатор ? Camriel.ru – тут узнаете, как для выращивания рыбы устроена УЗВ. Также на портале фотогалерея представлена и контакты компании указаны. Гарантируем компетентные консультации, заказы по телефону принимаем, которые на портале представлены. С нами выгодно сотрудничать!
https://bio.site/gefmuhuaf
Здравствуйте!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить TF trust flow и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Xrumer для роста ссылочной массы – это проверенный способ повысить DR. Программы для линкбилдинга автоматизируют процесс получения ссылок. Постинг на форумах с помощью Xrumer помогает быстро улучшить SEO-позиции. Увеличение Ahrefs показателей стало проще с такими инструментами. Начните использовать Xrumer для успешного продвижения.
seo features, сео дата, Прогон ссылок для роста позиции
Xrumer для массового линкбилдинга, сео сайты самостоятельно, mpstats seo
!!Удачи и роста в топах!!
https://muckrack.com/person-27520077
https://mez.ink/bpicoledybofa
Здравствуйте!
Долго думал как поднять сайт и свои проекты в топ и узнал от друзей профессионалов,
крутых ребят, именно они разработали недорогой и главное продуктивный прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг сео – основа эффективного продвижения. Программы типа Xrumer ускоряют процесс массового прогона. Массовый линкбилдинг повышает DR. Автоматизация экономит силы специалистов. Линкбилдинг сео – ключ к успешной оптимизации сайта.
продвижение сайтов раскрутка магазина, промо продвижение сайта, Автоматический постинг форумов
Форумный постинг для новичков, разработка стратегии продвижения сайта, раскрутка сайта цена новосибирск
!!Удачи и роста в топах!!
https://0e3b546ebbf6ea9b6f08e2c9ae.doorkeeper.jp/
https://wirtube.de/a/visionpogiro/video-channels
психолог записаться на прием онлайн
Для семей аренда игр — это отличное решение всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно оформить аренду детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет оценить графику и сюжет. Не всегда проект оправдывает ожидания, и именно аренда даёт возможность не тратить лишнее.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый найдёт для себя нужную игру — будь то глубокая RPG.
В итоге аренда игр для PS4/PS5 — это удобно, практично и перспективно.
https://www.betterplace.org/en/organisations/66636
https://shklovsky100-school.ru/
https://shootinfo.com/author/oirynevofedi/?pt=ads
Для семей аренда игр — это отличное решение всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно взять на время детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет понять, стоит ли покупать игру. Не всегда проект оправдывает ожидания, и именно аренда даёт возможность не тратить лишнее.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый найдёт для себя нужную игру — будь то онлайн-шутер.
В итоге аренда игр для PS4/PS5 — это доступно, разнообразно и перспективно.
https://wirtube.de/a/mayapuspitan3/video-channels
психолог онлайн консультация чат
Доброго!
Долго ломал голову как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от друзей профессионалов,
топовых ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг по тематике помогает привлекать целевой трафик. Ссылки с профильных ресурсов повышают доверие. Автоматические программы ускоряют процесс. Чем точнее подбор площадок, тем лучше результат. Линкбилдинг по тематике повышает эффективность SEO.
сайты для продвижения трафиком, 9 seo, SEO рассылки форумов
линкбилдинг план, что такое seo специалист, новое в seo
!!Удачи и роста в топах!!
https://say.la/read-blog/127953
https://bio.site/vboociucidvu
https://muckrack.com/person-27518443
рейтинг ароматов guerlain
Привет всем!
Долго анализировал как встать в топ поисковиков и узнал от успещных seo,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон Xrumer по свежим базам ускоряет создание ссылочной массы. Массовое размещение ссылок на форумах повышает DR сайта. Использование форумного постинга для SEO делает продвижение системным. Xrumer для создания ссылочной стратегии экономит время специалистов. SEO-прогон для повышения позиций увеличивает видимость сайта.
seo продвижение seoleaks, создание и продвижение медицинских сайтов, Xrumer для массового линкбилдинга
стратегии линкбилдинг, сео продвижение екатеринбург, взлом seo
!!Удачи и роста в топах!!
http://www.pageorama.com/?p=ydsmyfuu
https://linkin.bio/lfopyvixarurixa
https://odysee.com/@purvisadelaide
Are you looking for a wide selection of premium flowers and gifts with delivery in Minsk and all of Belarus? Visit https://flower-shop.by/ our website, look at the catalog, where you will find the widest selection of fresh flowers, bouquets of which are made by professional florists. And if you need to send flowers to loved ones around the world, our company will do it with pleasure!
Приобрести зимние шины — это важный шаг для обеспечения безопасности на дороге в холодное время года. Когда наступает зима, следует обратить внимание на состояние ваших шин. Зимние шины гарантируют хорошее сцепление с дорогой и снижают риск дорожных происшествий.
При выборе зимних шин следует учитывать разные факторы. Во-первых, стоит обратить внимание на тип протектора. Протектор должен быть специально разработан для обеспечения сцепления на снегу и льду.
Не менее важный аспект — это жесткость резины, из которой изготовлены шины. В зимних шинах более мягкая резина способствует лучшему сцеплению в низких температурах. Однако такие шины могут быстрее изнашиваться при теплой погоде.
Чтобы сделать правильный выбор, стоит посоветоваться с профессионалами. Консультация у экспертов поможет выбрать наиболее подходящие шины для вашего автомобиля. Кроме того, стоит ознакомиться с отзывами других водителей.
купить зимнюю резину в спб недорого купить зимнюю резину в спб недорого.
https://wirtube.de/a/kanxomoniem/video-channels
Для игровых клубов аренда игр — это лучший вариант всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно оформить аренду детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет попробовать новинку перед покупкой. Не всегда проект оправдывает ожидания, и именно аренда снимает риск.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый подберёт для себя интересный проект — будь то онлайн-шутер.
В итоге аренда игр для PS4/PS5 — это доступно, интересно и современно.
https://say.la/read-blog/127939
https://1dfb45a332ef4c453335c15595.doorkeeper.jp/
детский психолог онлайн
Здравствуйте!
Долго думал как поднять сайт и свои проекты в топ и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Техники увеличения ссылочной массы помогают быстро поднять DR. Форумы, блоги и каталоги дают естественные ссылки. Xrumer автоматизирует массовый прогон. Чем больше качественных ссылок, тем выше позиции сайта. Техники увеличения ссылочной массы – ключ к успешному продвижению.
раскрутка сайта бесплатно скачать, writing seo, Xrumer для оптимизации сайта
Автоматизированный постинг для сайтов, продвижение сайта детской одежды, плагин seo yoast
!!Удачи и роста в топах!!
https://bio.site/sidihudaba
https://www.themeqx.com/forums/users/ydugifua/
Всех приветствую! Хотите узнать больше о продвижении? Тут вы можете ознакомиться с ответом на вопрос: https://www.depro.org/da-ga-casino-campuchia/
https://cf50738fd0c06ed20218b774d5.doorkeeper.jp/
https://linkin.bio/bipehamyjedage
лестничные перила Перила – это не просто функциональный элемент лестницы, это важная деталь интерьера, обеспечивающая безопасность и комфорт. Они служат опорой при подъеме и спуске, а также предотвращают падения.
http://www.pageorama.com/?p=oyfwacicwaf
http://wmking.ru/t83542.html
https://muckrack.com/person-27503701
Для семей аренда игр — это лучший вариант всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно взять на время детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет оценить графику и сюжет. Не всегда проект оправдывает ожидания, и именно аренда даёт возможность не тратить лишнее.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый подберёт для себя интересный проект — будь то онлайн-шутер.
В итоге аренда игр для PS4/PS5 — это выгодно, интересно и актуально.
Привет всем!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное лучший прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Как собрать базу для Xrumer – важный шаг для эффективного прогона. Программа использует базы форумов для размещения ссылок. Массовый линкбилдинг ускоряет рост DR. Чем больше качественных ссылок, тем выше позиции сайта. Как собрать базу для Xrumer помогает новичкам и профессионалам.
seo paging, что такое сео оптимизация простыми словами, Xrumer для роста ссылочной массы
Линкбилдинг для продвижения в топ-10, backlink seo, seo адаптация сайта
!!Удачи и роста в топах!!
https://www.metooo.io/u/68a81904c37e5510b64ef945
https://form.jotform.com/252317583318055
https://bio.site/gcofyhzchyd
психологи онлайн консультации лучшие
https://muckrack.com/person-27512799
https://mastergrad.wixom.ru/viewtopic.php?t=253
https://odysee.com/@richardmodig2
Доброго!
Долго не спал и думал как поднять сайт и свои проекты и нарастить DR и узнал от гуру в seo,
энтузиастов ребят, именно они разработали недорогой и главное продуктивный прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг цена зависит от количества ссылок и качества площадок. Крауд маркетинг линкбилдинг повышает естественность профиля. Линкбилдинг что это такое простыми словами объясняет новичкам. Линкбилдинг это простыми словами доступно объясняет процесс. Линкбилдинг стоимость определяется стратегией продвижения.
seo продвижения сайт в топ, заполняем seo, линкбилдинг услуга
Увеличение показателя Ahrefs, сео шаблон битрикс, seo обучение бесплатное
!!Удачи и роста в топах!!
https://ad09bc6b44c92779351ae6b24b.doorkeeper.jp/
Фабрика Морган Миллс с успехом изготавливает с помощью новейшего оборудования термобелье. Также производим большой выбор бельевых изделий. Гарантируем привлекательные цены и высокое качество нашей продукции. Готовы воплотить в жизнь самые смелые ваши идеи. Ищете собственная торговая марка? Morgan-mills.ru – здесь есть каталог, блог и представлены новости. Сотрудничаем только с проверенными поставщиками в РФ и за рубежом. Работаем с любыми заказами. Менеджеры доброжелательные, они от покупателей быстро принимают и обрабатывают заявки.
http://www.pageorama.com/?p=uiaihlaugo
На сайте https://t.me/m1xbet_ru получите всю самую свежую, актуальную и полезную информацию, которая касается одноименной БК. Этот официальный канал публикует свежие данные, полезные материалы, которые будут интересны всем любителям азарта. Теперь получить доступ к промокодам, ознакомиться с условиями акции получится в любое время и на любом устройстве. Заходите на официальный сайт ежедневно, чтобы получить новую и полезную информацию. БК «1XBET» предлагает только прозрачные и выгодные условия для своих клиентов.
https://bio.site/rugcvuico
https://noi.md/ru/obshhestvo/mammografiya-vazhnyj-shag-k-zhenskomu-zdoroviyu
Для семей аренда игр — это оптимальный способ всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно взять на время детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет понять, стоит ли покупать игру. Не всегда проект оправдывает ожидания, и именно аренда даёт возможность не тратить лишнее.
На https://gamehaul.ru/ постоянно пополняется список игр. Поэтому каждый подберёт для себя нужную игру — будь то спортивный симулятор.
В итоге аренда игр для PS4/PS5 — это удобно, практично и перспективно.
https://odysee.com/@stapleselaina
https://www.betterplace.org/en/organisations/66559
https://wanderlog.com/view/guoziqgvgw/купить-кокаин-марихуану-мефедрон-окинава/shared
Если нужна более подробная инструкция, то она здесь:
Зацепил материал про fixora.ru.
Ссылка ниже:
https://fixora.ru
Если есть вопросы, задавайте.
онлайн сервисы психологов
Вот, что говорят эксперты по этому поводу:
Хочу выделить раздел про reactive.su.
Ссылка ниже:
https://reactive.su
Жду ваших комментариев.
https://baskadia.com/user/fy9f
Долго искал решение и наконец-то нашел:
По теме “obender.ru”, там просто кладезь информации.
Вот, можете почитать:
https://obender.ru
Давайте обсудим это подробнее.
https://www.metooo.io/u/68a6b70e6efdb35b38652109
Добрый день!
Долго не мог уяснить как поднять сайт и свои проекты в топ и узнал от крутых seo,
крутых ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг вакансии интересны специалистам SEO. Многие компании ищут экспертов по созданию ссылочной массы. Знание Xrumer и автоматизации сильно повышает шансы. Работа с линками – востребованная сфера. Линкбилдинг вакансии открывают карьерные возможности.
раскрутка сайта оптимизация веб, создание поддержка и раскрутка сайта, Линкбилдинг на автомате
линкбилдинг что это, seo segment, кластеры запросов seo
!!Удачи и роста в топах!!
Вот здесь можно найти больше примеров:
Хочу выделить материал про classifields.ru.
Смотрите сами:
https://classifields.ru
Уверен, вместе мы найдем решение.
Это именно то, что я искал!
По теме “fk-almazalrosa.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://fk-almazalrosa.ru
Спасибо за внимание.
Wonderful, what a blog it is! This webpage gives valuable information to us, keep it up.
Seattle airport transportation service
Очень рекомендую к прочтению:
Хочу выделить раздел про tars-rubber.ru.
Ссылка ниже:
https://tars-rubber.ru
Надеюсь, у вас все получится.
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует cyq.ru, посмотрите сюда.
Ссылка ниже:
[url=https://cyq.ru]https://cyq.ru[/url]
Всем мира и продуктивного дня
детский психолог калуга
Исчерпывающий ответ на данный вопрос находится тут:
По теме “obender.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://obender.ru
Надеюсь, смог помочь.
Если нужна более подробная инструкция, то она здесь:
По теме “anclaves.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://anclaves.ru
Буду признателен за ваши отзывы.
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “easyterm.ru”, есть отличная статья.
Вот, можете почитать:
https://easyterm.ru
Всем спасибо, и до новых встреч!
Полностью поддерживаю, и вот еще одно подтверждение:
Зацепил раздел про mersobratva.ru.
Смотрите сами:
https://mersobratva.ru
Поделитесь своими мыслями в комментариях.
Доброго!
Долго не спал и думал как поднять сайт и свои проекты и нарастить DR и узнал от успещных seo,
отличных ребят, именно они разработали недорогой и главное лучший прогон Xrumer – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг под бурж помогает продвигать сайты на зарубежные рынки. Нужно работать с иностранными площадками и форумами. Автоматизация через Xrumer ускоряет процесс. Это увеличивает количество качественных ссылок. Линкбилдинг под бурж – залог успешного международного SEO.
разработка сайта дизайн и продвижение, ha seo joon, Линкбилдинг для повышения DR
линкбилдинг это что, seo plugin, сео или реклама
!!Удачи и роста в топах!!
Как раз то, что нужно для решения этого вопроса:
Между прочим, если вас интересует clasifieds.ru, посмотрите сюда.
Вот, можете почитать:
https://clasifieds.ru
Буду следить за обсуждением.
Вот отличный материал, который проливает свет на ситуацию:
По теме “clasifieds.ru”, нашел много полезного.
Смотрите сами:
https://clasifieds.ru
Буду признателен за ваши отзывы.
Долго искал решение и наконец-то нашел:
Особенно понравился материал про fixora.ru.
Смотрите сами:
https://fixora.ru
Поделитесь своими мыслями в комментариях.
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует fixora.ru, загляните сюда.
Ссылка ниже:
https://fixora.ru
Что думаете по этому поводу?
https://de.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%9A%D0%B0%D0%BD%D0%B0%D0%B1%D0%B8%D1%81-%D0%9A%D0%B0%D1%82%D0%B0%D1%80
Как вариант, можно рассмотреть следующее:
Зацепил раздел про eqa.ru.
Вот, можете почитать:
https://eqa.ru
Какие еще есть варианты?
https://sandalparfums.ru/
психолог онлайн помощь в отношениях
https://es.quora.com/profile/%D0%9C%D0%B0%D0%B2%D1%80%D0%B8%D0%BA%D0%B8%D0%B9-%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%9C%D0%B4%D0%BC%D0%B0-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9B%D1%81%D0%B4
Если нужна более подробная инструкция, то она здесь:
По теме “idalgogrif.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Если есть вопросы, задавайте.
Посмотрите, что я нашел по этому поводу:
Кстати, если вас интересует detoxa.ru, загляните сюда.
Вот, можете почитать:
https://detoxa.ru
Жду ваших комментариев.
https://es.quora.com/profile/%D0%9C%D0%B0%D0%B2%D1%80%D0%B8%D0%BA%D0%B8%D0%B9-%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%9C%D0%B4%D0%BC%D0%B0-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9B%D1%81%D0%B4
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Особенно понравился материал про cyq.ru.
Вот, делюсь ссылкой:
https://cyq.ru
Давайте обсудим это подробнее.
https://pl.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9E%D1%81%D0%B0%D0%BA%D0%B0
Для игровых клубов аренда игр — это оптимальный способ всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно оформить аренду детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет попробовать новинку перед покупкой. Не всегда проект оправдывает ожидания, и именно аренда даёт возможность не тратить лишнее.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый подберёт для себя подходящий жанр — будь то спортивный симулятор.
В итоге аренда игр для PS4/PS5 — это доступно, интересно и перспективно.
Как раз то, что нужно для решения этого вопроса:
Кстати, если вас интересует fjhg.ru, загляните сюда.
Вот, можете почитать:
https://fjhg.ru
Обращайтесь, если что.
уличные кашпо уличные кашпо .
https://pt.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9D%D0%B5%D0%B3%D1%80%D0%B8%D0%BB
Чтобы было понятнее, о чем речь:
Между прочим, если вас интересует raregreen.ru, загляните сюда.
Вот, можете почитать:
https://raregreen.ru
Если есть вопросы, задавайте.
Вот здесь можно найти больше примеров:
Хочу выделить материал про m-admin.ru.
Вот, можете почитать:
https://m-admin.ru
Всем спасибо, и до новых встреч!
Купить подшипник для электродвигателя Подшипники от производителей – это гарантия качества, соответствия стандартам и возможность получить техническую поддержку непосредственно от разработчиков.
Уверен, эта информация будет для вас полезна:
Зацепил раздел про m-admin.ru.
Вот, можете почитать:
https://m-admin.ru
Всем удачи и хорошего дня!
Давно слежу за этой темой, хочу поделиться находкой:
Особенно понравился раздел про komandor-povolje.ru.
Вот, делюсь ссылкой:
https://komandor-povolje.ru
Всем удачи и хорошего дня!
where can i buy generic zyban without prescription
Вот тут есть все ответы на ваши вопросы:
Между прочим, если вас интересует 095hotel.ru, загляните сюда.
Смотрите сами:
https://095hotel.ru
Буду следить за обсуждением.
buying cheap zyban without a prescription
Для игровых клубов аренда игр — это лучший вариант всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно получить доступ к детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет понять, стоит ли покупать игру. Не всегда проект оправдывает ожидания, и именно аренда снимает риск.
На https://gamehaul.ru/ регулярно обновляется список игр. Поэтому каждый сможет подобрать для себя подходящий жанр — будь то глубокая RPG.
В итоге аренда игр для PS4/PS5 — это удобно, практично и перспективно.
Посмотрите, что я нашел по этому поводу:
Зацепил материал про tars-rubber.ru.
Ссылка ниже:
https://tars-rubber.ru
Всем добра!
Виброустойчивые подшипники Производитель подшипников – это компания, обладающая технологическими знаниями и производственными мощностями для выпуска разнообразного ассортимента подшипниковой продукции.
Долго искал решение и наконец-то нашел:
Кстати, если вас интересует buytime.ru, загляните сюда.
Смотрите сами:
https://buytime.ru
Всем добра!
https://pt.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%91%D0%B5%D1%80%D0%B3%D0%B5%D0%BD
Делюсь с вами полезной ссылкой по теме:
По теме “clasifieds.ru”, есть отличная статья.
Вот, можете почитать:
https://clasifieds.ru
Пишите, что у вас получилось.
https://f61cd378829ba9d72f58c506ab.doorkeeper.jp/
Вот здесь подробно расписано, как это сделать:
По теме “travelmontenegro.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://travelmontenegro.ru
Буду рад, если кому-то пригодится.
Dubai id
https://wanderlog.com/view/qkjyowwuaw/купить-кокаин-марихуану-мефедрон-маэ/shared
Ищете кейсы кс? Cs2case.io/ и вы сможете лучшие кейсы с быстрым выводом скинов себе в Steam открывать. Ознакомьтесь с нашей большой коллекцией кейсов кс2 и иных направлений и тематик. Также вы можете получить интересные бонусы за различные активности! А бесплатная коллекция кейсов порадует любого геймера! Детальная информация в доступе на ресурсе.
Очень рекомендую к прочтению:
Зацепил раздел про eroticpic.ru.
Ссылка ниже:
https://eroticpic.ru
Надеюсь, у вас все получится.
https://pixelfed.tokyo/booboowhite46
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “localflavors.ru”, там просто кладезь информации.
Вот, можете почитать:
https://localflavors.ru
Жду конструктивной критики.
Aula Софт настраивает игровые устройства.
Feel free to visit my page :: https://thebeginnersguidetocrypto.com/wiki/index.php/User:MaritzaPlott30
https://odysee.com/@epollard877
kra36—-at.com — Надежный и удобный сервис — официальный сайт и подробный обзор даркнет-маркета Kraken. Официальный сайт kraken kra36.at — удобный сервис с множеством функций для пользователей. Узнайте больше и начните пользоваться прямо сейчас!
кракен ссылка, кракен ссылки, ссылка кракен, ссылка кракена, ссылки кракен, сайт кракена, кракен сайты, кракен сайт, сайт кракен, кракен отзывы, зеркала кракен, зеркала кракена, зеркало кракен, зеркало кракена, кракен зеркала, кракен зеркало, даркнет кракен, кракен даркнет, ссылка на кракен, ссылка на кракена, ссылки на кракен, кракен маркетплейс, маркетплейс кракен, кракен магазин, магазин кракен, кракены маркет, kraken ссылка, kraken ссылки, кракен маркет, вход кракен, кракен вход, кракен зайти, kraken зеркала, kraken зеркало, актуальная ссылка кракен, актуальная ссылка кракена, актуальные ссылки кракен, кракен актуальная ссылка, кракен актуальные ссылки, кракен ссылка актуальная, кракен ссылки актуальные, кракен как зайти, зайти на кракен, kraken сайты, сайт kraken, kraken сайт, кракен официальный сайт, официальный сайт кракен, кракен сайт официальный, официальный сайт кракена, сайт кракен официальный, сайт кракена официальный, как зайти на кракен, кракен ссылка тор, кракен тор ссылка, ссылка кракен тор, кракен рабочая ссылка, кракен рабочие ссылки, рабочая ссылка кракен, рабочие ссылки кракен, кракен даркнет маркет, кракен маркет даркнет, кракен сайт ссылка, сайт кракен ссылка, кракен площадка, площадка кракен, кракен сайт магазин, актуальная ссылка на кракен, актуальные ссылки на кракен, кракен маркет песня, песня кракен маркет, кракен зеркало рабочее, кракен рабочее зеркало, рабочее зеркало кракен, кракен официальная ссылка, кракен ссылка официальная, официальная ссылка кракен, ссылка кракена официальная, ссылки кракена официальные, кракен сайт что, kraken маркетплейс, маркетплейс kraken
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Для тех, кто ищет информацию по теме “tars-rubber.ru”, там просто кладезь информации.
Ссылка ниже:
https://tars-rubber.ru
Надеюсь, это было полезно.
https://shootinfo.com/author/gonzalez_michellek28553/?pt=ads
оформление emirates id
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить раздел про tars-rubber.ru.
Вот, делюсь ссылкой:
https://tars-rubber.ru
Обращайтесь, если что.
открыть фирму в Дубай
онлайн или очно психолог
Чтобы было понятнее, о чем речь:
Хочу выделить материал про fixora.ru.
Смотрите сами:
https://fixora.ru
Что думаете по этому поводу?
https://www.metooo.io/u/68a641a4bf801f050233592e
недвижимость в оаэ
Для игровых клубов аренда игр — это отличное решение всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно получить доступ к детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет оценить графику и сюжет. Не всегда проект оправдывает ожидания, и именно аренда снимает риск.
На https://gamehaul.ru/ часто добавляется список игр. Поэтому каждый найдёт для себя подходящий жанр — будь то динамичный экшен.
В итоге аренда игр для PS4/PS5 — это удобно, практично и перспективно.
оформление emirates id
Привет всем!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от крутых seo,
отличных ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Прогон Xrumer по свежим базам помогает быстро увеличить ссылочную массу. Автоматизация ускоряет процесс. Массовый линкбилдинг повышает DR. Чем больше качественных ссылок, тем выше позиции. Прогон Xrumer по свежим базам – современная SEO-техника.
сео текст проверить онлайн, сайт раскрутка novelit, линкбилдинг или
Программы для автоматического постинга, ялта продвижение сайта, сео иваново
!!Удачи и роста в топах!!
открыть банковский счет в оаэ
Уверен, эта информация будет для вас полезна:
По теме “clasifieds.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://clasifieds.ru
Уверен, вместе мы найдем решение.
https://pxlmo.com/saqueylaroc
Давно слежу за этой темой, хочу поделиться находкой:
Между прочим, если вас интересует lingomap.ru, загляните сюда.
Вот, можете почитать:
https://lingomap.ru
Всем спасибо, и до новых встреч!
https://linkin.bio/klagesyoou
открыть фирму в Дубай
Это именно то, что я искал!
По теме “eqa.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://eqa.ru
Надеюсь, смог помочь.
Цікавий та корисний блог для жінок – MeatPortal https://meatportal.com.ua/tag/korisno/ розповість про нові рецепти, астрологічні прогнози та іншу корисну інформацію. Читайте meatportal.com.ua, щоб бути в тренді, слідкувати за цікавими новинами.
https://www.betterplace.org/en/organisations/66548
резидентская виза в дубай
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Между прочим, если вас интересует fjhg.ru, загляните сюда.
Вот, делюсь ссылкой:
https://fjhg.ru
Давайте обсудим это подробнее.
https://odysee.com/@sloancasey677
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Между прочим, если вас интересует idalgogrif.ru, загляните сюда.
Смотрите сами:
https://idalgogrif.ru
Поделитесь своими мыслями в комментариях.
Dubai id
https://www.themeqx.com/forums/users/gtehayfzyhag/
Если кому интересно, вот более детальная информация:
По теме “rustrail.ru”, есть отличная статья.
Вот, можете почитать:
https://rustrail.ru
Всем удачи и хорошего дня!
https://shootinfo.com/author/tylersimpsontyl/?pt=ads
Чтобы не быть голословным, прикрепляю ссылку:
Зацепил раздел про komandor-povolje.ru.
Ссылка ниже:
https://komandor-povolje.ru
Всем спасибо, и до новых встреч!
Чтобы было понятнее, о чем речь:
Кстати, если вас интересует fixora.ru, посмотрите сюда.
Смотрите сами:
https://fixora.ru
Надеюсь, у вас все получится.
http://www.pageorama.com/?p=vpyyohii
Военные https://www.fonse.cn/question/novosti-mira-47z/ мира вызывают обеспокоенность из-за роста напряженности.
Морган Миллс – достойный изготовитель термобелья. Мы гарантируем отменное качество продукции и выгодные цены. Готовы предоставить исчерпывающую консультацию по телефону. https://morgan-mills.ru – сайт, посетите его, чтобы узнать больше о нашей компании. Работаем по всей РФ. Предлагаем услуги пошива по индивидуальному заказу. Учитываем предпочтения и пожелания клиентов. Наш приоритет – соответствие и стабильность стандартам современным. Обратившись к нам, вы точно останетесь довольны сотрудничеством!
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “all-hotels-online.ru”, есть отличная статья.
Ссылка ниже:
https://all-hotels-online.ru
Надеюсь, у вас все получится.
https://say.la/read-blog/128521
Для игровых клубов аренда игр — это оптимальный способ всегда иметь под рукой новые проекты для совместного времяпрепровождения. Если у вас есть дети, можно оформить аренду детским играм, а потом сменить их на новые.
Также аренда игр полезна для тех, кто хочет понять, стоит ли покупать игру. Не всегда проект оправдывает ожидания, и именно аренда помогает избежать разочарований.
На https://gamehaul.ru/ регулярно обновляется список игр. Поэтому каждый подберёт для себя нужную игру — будь то онлайн-шутер.
В итоге аренда игр для PS4/PS5 — это доступно, интересно и перспективно.
онлайн консультирование психолога
На мой взгляд, лучшее решение этой проблемы здесь:
Особенно понравился раздел про pro-zenit.ru.
Смотрите сами:
https://pro-zenit.ru
Спасибо за внимание.
https://www.metooo.io/u/68a3a09130729b772548c3bb
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Кстати, если вас интересует phenoma.ru, загляните сюда.
Вот, делюсь ссылкой:
https://phenoma.ru
Буду следить за обсуждением.
трипскан Трипскан вход – это простота и безопасность, ваш личный кабинет всегда под рукой.
https://www.montessorijobsuk.co.uk/author/nucehuciibao/
Здравствуйте!
Долго не мог уяснить как поднять сайт и свои проекты и нарастить TF trust flow и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Линкбилдинг план помогает системно подходить к продвижению сайта. Xrumer автоматизирует размещение ссылок на тематических форумах. Массовый линкбилдинг повышает DR. Чем больше качественных ссылок, тем выше позиции сайта. Линкбилдинг план – ключ к успешной SEO-кампании.
в чем суть сео, seo цена тарифы, предлагаю линкбилдинг
Прогон ссылок для роста позиции, description и seo, платное продвижения сайта в
!!Удачи и роста в топах!!
Исчерпывающий ответ на данный вопрос находится тут:
Для тех, кто ищет информацию по теме “095hotel.ru”, нашел много полезного.
Вот, можете почитать:
https://095hotel.ru
Буду рад, если кому-то пригодится.
https://www.betterplace.org/en/organisations/66649
Давно слежу за этой темой, хочу поделиться находкой:
Кстати, если вас интересует travelmontenegro.ru, загляните сюда.
Вот, можете почитать:
https://travelmontenegro.ru
Надеюсь, это было полезно.
https://odysee.com/@bennettolwyn05
Чтобы разобраться в вопросе, рекомендую ознакомиться:
По теме “hotelnews.ru”, там просто кладезь информации.
Вот, можете почитать:
https://hotelnews.ru
Буду следить за обсуждением.
Возможно, это будет полезно участникам обсуждения:
Между прочим, если вас интересует musichunt.pro, загляните сюда.
Ссылка ниже:
https://musichunt.pro
Чем мог, тем помог.
https://pxlmo.com/dayiiskirten
Для тех, кто в теме, будет очень актуально:
Между прочим, если вас интересует yogapulse.ru, загляните сюда.
Ссылка ниже:
https://yogapulse.ru
Жду ваших комментариев.
https://wanderlog.com/view/jouwsqeoua/купить-экстази-кокаин-амфетамин-рио-де-жанейро/shared
Всем привет, нашел интересную информацию по теме:
Между прочим, если вас интересует localflavors.ru, загляните сюда.
Смотрите сами:
https://localflavors.ru
Спасибо, что дочитали до конца.
http://www.pageorama.com/?p=aocpabodj
Вот отличный материал, который проливает свет на ситуацию:
По теме “obender.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://obender.ru
Чем мог, тем помог.
https://pixelfed.tokyo/tenayenaseva
На мой взгляд, лучшее решение этой проблемы здесь:
Для тех, кто ищет информацию по теме “m-admin.ru”, там просто кладезь информации.
Вот, можете почитать:
https://m-admin.ru
Буду следить за обсуждением.
консультация психолога калуга
https://odysee.com/@zainabyu49
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить материал про spb-hotels.ru.
Вот, делюсь ссылкой:
https://spb-hotels.ru
Буду признателен за ваши отзывы.
Турагентство в Тюмени Акуна Матата Горящие туры. Поиск туров на сайте https://akuna-matata72.ru/ от всех надёжных туроператоров. Мы подберем Вам отдых по выгодным ценам. Туры в Турцию, Египет, Таиланд, ОАЭ, Китай (остров Хайнань), Вьетнам, Индонезию (остров Бали), Мальдивы, остров Маврикий, Шри-Ланка, Доминикану, Кубу и в другие страны. Туры из Тюмени и других городов. Мы расскажем Вам не только о пляжах, но и об особенностях безопасного и интересного отдыха в той или иной стране, про места, где лучше посетить экскурсии и любимые кафе.
https://wirtube.de/a/clark_bettyn25196/video-channels
Очень рекомендую к прочтению:
Для тех, кто ищет информацию по теме “diyworks.ru”, нашел много полезного.
Вот, можете почитать:
https://diyworks.ru
Чем мог, тем помог.
https://es.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%9A%D0%B0%D0%BD%D0%B0%D0%B1%D0%B8%D1%81-%D0%A2%D0%B8%D0%B2%D0%B0%D1%82
Как вариант, можно рассмотреть следующее:
Для тех, кто ищет информацию по теме “095hotel.ru”, есть отличная статья.
Смотрите сами:
https://095hotel.ru
Всем удачи и хорошего дня!
https://muckrack.com/person-27502010
Делюсь с вами полезной ссылкой по теме:
Зацепил материал про 095hotel.ru.
Смотрите сами:
https://095hotel.ru
Уверен, вместе мы найдем решение.
Looking for betandreas bangladesh? Betandreas-official.com – is a wide selection of online games. Here you will find a welcome bonus! Find out more on the site about BetAndreas – how to register, top up your balance and withdraw money, how to download a mobile application, what slots and games there are. Get full instructions on how to enter the site. We have the best casino games in Bangladesh!
http://www.pageorama.com/?p=modaedgvu
На мой взгляд, лучшее решение этой проблемы здесь:
Между прочим, если вас интересует fk-almazalrosa.ru, посмотрите сюда.
Вот, можете почитать:
https://fk-almazalrosa.ru
Если у вас есть что добавить, не стесняйтесь.
Bonusesfs-casino-10.site предоставляет необходимую информацию. Мы рассказали, что такое бонусы бездепозитные в онлайн-казино. Предоставили полезные советы игрокам. Собрали для вас все самое интересное. Крупных вам выигрышей! Ищете онлайн казино с первым бонусом? Bonusesfs-casino-10.site – здесь узнаете, что из себя представляют фриспины и где они применяются. Расскажем, как быстро вывести деньги из казино. Объясним, где искать промокоды. Публикуем только качественный контент. Добро пожаловать на наш сайт. Всегда вам рады и желаем успехов на вашем пути!
Авто на Авито: огромный выбор, но нужна осторожность.
Feel free to surf to my blog: http://www.annunciogratis.net/author/carmelolehu
https://sonturkhaber.com/
Уверен, эта информация будет для вас полезна:
Между прочим, если вас интересует anclaves.ru, загляните сюда.
Ссылка ниже:
https://anclaves.ru
Буду следить за обсуждением.
https://www.themeqx.com/forums/users/yfufigug/
Возможно, это будет полезно участникам обсуждения:
По теме “classifields.ru”, там просто кладезь информации.
Вот, можете почитать:
https://classifields.ru
Жду конструктивной критики.
https://www.montessorijobsuk.co.uk/author/taiafugo/
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “rustrail.ru”, там просто кладезь информации.
Ссылка ниже:
https://rustrail.ru
Поделитесь своими мыслями в комментариях.
Феодосия купить Мефедрон, Кокаин, Соль ск
https://www.montessorijobsuk.co.uk/author/bufpqrle/
Всех приветствую! Хотите узнать больше о продвижении? Подробная информация на тему: https://masajeprofundogyeonggido.shop/blog/95/
пмж кипра для россиян 2025
Постоянное место жительства в Кипре стало актуальным вопросом для многих людей. Получение ПМЖ включает в себя множество нюансов, которые стоит учитывать.
Прежде всего, необходимо знать требования для получения ПМЖ. К основным условиям относятся наличие стабильного дохода, здоровье и отсутствие уголовных дел.
Как только все документы готовы, нужно подать заявление в миграционную службу. Этот процесс может занять разное время, поэтому стоит отслеживать статус своей заявки.
После успешного завершения процесса, вы получите постоянное место жительства на Кипре. Теперь у вас будут все преимущества, доступные для постоянных жителей.
Вот здесь можно найти больше примеров:
Особенно понравился раздел про tars-rubber.ru.
Смотрите сами:
https://tars-rubber.ru
Буду рад, если кому-то пригодится.
https://wanderlog.com/view/razpoihmnf/купить-экстази-кокаин-амфетамин-шяуляй/shared
психолог онлайн тревога
Для тех, кто в теме, будет очень актуально:
Между прочим, если вас интересует eroticpic.ru, загляните сюда.
Смотрите сами:
https://eroticpic.ru
Успехов в решении вашего вопроса!
Белореченск купить Альфа Пвп кокаин, мефедрон
https://say.la/read-blog/128119
Посмотрите, что я нашел по этому поводу:
Кстати, если вас интересует eroticpic.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://eroticpic.ru
Дайте знать, если найдете что-то еще.
https://shootinfo.com/author/krojecemozuqi/?pt=ads
Долго искал решение и наконец-то нашел:
Для тех, кто ищет информацию по теме “lingomap.ru”, нашел много полезного.
Вот, можете почитать:
https://lingomap.ru
Надеюсь, у вас все получится.
https://pixelfed.tokyo/birohiocet
Полностью поддерживаю, и вот еще одно подтверждение:
Для тех, кто ищет информацию по теме “diyworks.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://diyworks.ru
Интересно было бы узнать ваше мнение.
Гудермес купить экстази, мдма, лирика, кокаин
Здравствуйте!
Долго анализировал как поднять сайт и свои проекты и нарастить DR и узнал от успещных seo,
профи ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://www.bing.com/search?q=bullet+%D0%BF%D1%80%D0%BE%D0%B3%D0%BE%D0%BD
Как использовать Xrumer для SEO – частый вопрос новичков. Программа автоматизирует прогон ссылок и ускоряет рост DR. Правильная настройка обеспечивает максимальную эффективность. Xrumer позволяет экономить время и силы. Как использовать Xrumer для SEO – важный навык.
сайт создание продвижение раскрутка, seo раскрутка сайта в москве цены, Форумный постинг для новичков
форум линкбилдинг, продвижение сайта авито, что такое seo на вайлдберриз оптимизация карточки
!!Удачи и роста в топах!!
Кстати, вот что я думаю по этому поводу:
Между прочим, если вас интересует buytime.ru, посмотрите сюда.
Ссылка ниже:
https://buytime.ru
Дайте знать, если найдете что-то еще.
https://es.quora.com/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88-%D0%9A%D0%B0%D0%BD%D0%B0%D0%B1%D0%B8%D1%81-%D0%9C%D0%B5%D1%85%D0%B8%D0%BA%D0%BE
Как раз то, что нужно для решения этого вопроса:
Зацепил раздел про cyq.ru.
Вот, делюсь ссылкой:
https://cyq.ru
Жду конструктивной критики.
https://7a535859f71cd6a0192a2dba5f.doorkeeper.jp/
Ровеньки купить Бошки, Марихуану, Гашиш
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Особенно понравился материал про mersobratva.ru.
Смотрите сами:
https://mersobratva.ru
Жду конструктивной критики.
https://linkin.bio/yesemevabypiq
внж эмиратов
оформление emirates id
Как вариант, можно рассмотреть следующее:
По теме “all-hotels-online.ru”, есть отличная статья.
Смотрите сами:
https://all-hotels-online.ru
Чем мог, тем помог.
https://linkin.bio/hxalitoweqa
Чтобы было понятнее, о чем речь:
Особенно понравился материал про fjhg.ru.
Смотрите сами:
https://fjhg.ru
Надеюсь, это было полезно.
https://odysee.com/@anatoliytomilin7
Это именно то, что я искал!
Особенно понравился раздел про travelcrimea.ru.
Смотрите сами:
https://travelcrimea.ru
Поделитесь своими мыслями в комментариях.
Липецк купить экстази, мдма, лирика, кокаин
поговорить с психологом онлайн
https://pixelfed.tokyo/ledcuddles34
Чтобы было понятнее, о чем речь:
Особенно понравился материал про spb-hotels.ru.
Вот, можете почитать:
https://spb-hotels.ru
Может, у кого-то есть другой опыт?
Вот здесь подробно расписано, как это сделать:
Особенно понравился материал про cyq.ru.
Вот, можете почитать:
https://cyq.ru
Жду ваших комментариев.
https://muckrack.com/person-27528930
резидентская виза в дубай
Барнаул купить Мдма, Экстази, Лсд, Лирика
Вот здесь подробно расписано, как это сделать:
Между прочим, если вас интересует 095hotel.ru, посмотрите сюда.
Ссылка ниже:
[url=https://095hotel.ru]https://095hotel.ru[/url]
Всем мира и продуктивного дня
http://www.pageorama.com/?p=ycobibodu
Как вариант, можно рассмотреть следующее:
Зацепил раздел про clasifieds.ru.
Вот, делюсь ссылкой:
https://clasifieds.ru
Если есть вопросы, задавайте.
https://wirtube.de/a/wanubycalume/video-channels
Делюсь с вами полезной ссылкой по теме:
Между прочим, если вас интересует anclaves.ru, загляните сюда.
Смотрите сами:
https://anclaves.ru
Какие еще есть варианты?
https://house-women.ru
https://bdgworkfutures.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует fjhg.ru, посмотрите сюда.
Ссылка ниже:
https://fjhg.ru
Что думаете по этому поводу?
https://ekdel.ru
Чтобы не быть голословным, прикрепляю ссылку:
Для тех, кто ищет информацию по теме “musichunt.pro”, там просто кладезь информации.
Ссылка ниже:
https://musichunt.pro
Буду рад, если кому-то пригодится.
https://derewookna.ru
https://felomen.ru
Если нужна более подробная инструкция, то она здесь:
Между прочим, если вас интересует travelcrimea.ru, посмотрите сюда.
Ссылка ниже:
https://travelcrimea.ru
Дайте знать, если найдете что-то еще.
Aerwave https://ered.pstu.ru/index.php/mechanics/comment/view/4602/0/2492 delivers wireless broadband for flexible access.
Кстати, вот что я думаю по этому поводу:
Между прочим, если вас интересует mersobratva.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://mersobratva.ru
Может, у кого-то есть другой опыт?
http://ptxperts.com/question/psychology-today-23c/ Today’s articles on ADHD offer valuable information on diagnosis and treatment.
https://gummi24.ru
Ищете полезную информацию как получить визу «цифровой кочевник Испании или digital nomad»? Посетите страницу https://vc.ru/migration/1171130-vnzh-ispanii-kak-poluchit-vizu-cifrovoi-kochevnik-ispanii-ili-digital-nomad-spisok-dokumentov-i-kakie-nalogi-platyat и вы найдете полный список необходимых, для оформления, документов и какие налоги платятся в дальнейшем. Подробный обзор.
Вот, что говорят эксперты по этому поводу:
По теме “095hotel.ru”, там просто кладезь информации.
Ссылка ниже:
https://095hotel.ru
Жду конструктивной критики.
https://dosaaf71.ru
калуга прием психологов
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Кстати, если вас интересует rustrail.ru, загляните сюда.
Вот, можете почитать:
https://rustrail.ru
Спасибо, что дочитали до конца.
https://dpk-svetlana.ru
Это именно то, что я искал!
Особенно понравился материал про tars-rubber.ru.
Ссылка ниже:
https://tars-rubber.ru
Какие еще есть варианты?
https://cbspb.ru
Делюсь с вами полезной ссылкой по теме:
Зацепил материал про komandor-povolje.ru.
Вот, делюсь ссылкой:
https://komandor-povolje.ru
Может, у кого-то есть другой опыт?
https://hamster31.ru
Как раз то, что нужно для решения этого вопроса:
По теме “rustrail.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://rustrail.ru
Может, у кого-то есть другой опыт?
мониторинг транспорта и топлива мониторинг транспорта и топлива .
Это именно то, что я искал!
Хочу выделить материал про lingomap.ru.
Вот, можете почитать:
https://lingomap.ru
Буду следить за обсуждением.
Купить промышленные подшипники BBCR Покупка подшипников напрямую у производителя – это возможность установить долгосрочные партнерские отношения и получить индивидуальный подход к потребностям вашего бизнеса.
https://hram-v-ohotino.ru
Вот, что говорят эксперты по этому поводу:
По теме “all-hotels-online.ru”, нашел много полезного.
Смотрите сами:
https://all-hotels-online.ru
Поделитесь своими мыслями в комментариях.
https://benatar.ru
купить зеркало на стену https://zerkalo-nn-1.ru/ .
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил материал про phenoma.ru.
Смотрите сами:
https://phenoma.ru
Надеюсь, у вас все получится.
Уверен, эта информация будет для вас полезна:
По теме “parkpodarkov.ru”, там просто кладезь информации.
Смотрите сами:
https://parkpodarkov.ru
Надеюсь, это было полезно.
https://dpk-svetlana.ru
На сайте https://xn--e1anbce0ah.xn--p1ai/nizniy_novgorod вы сможете произвести обмен криптовалюты: Ethereum, Bitcoin, BNB, XRP, Litecoin, Tether. Миссия сервиса заключается в том, чтобы предоставить пользователям доступ ко всем функциям, цифровым активам, независимо от того, в каком месте вы находитесь. Заполните графы для того, чтобы сразу узнать, какую сумму вы получите на руки. Также следует обозначить и личные данные, контакты, чтобы с вами связались, а также город. Все происходит строго конфиденциально.
https://hydrofactory.ru
На мой взгляд, лучшее решение этой проблемы здесь:
Зацепил материал про all-hotels-online.ru.
Смотрите сами:
https://all-hotels-online.ru
Если у вас есть что добавить, не стесняйтесь.
First of all, decide on the politeconomics.org tasks you want to achieve by installing a sports complex.
Как раз то, что нужно для решения этого вопроса:
Кстати, если вас интересует 095hotel.ru, загляните сюда.
Вот, можете почитать:
https://095hotel.ru
Если у вас есть что добавить, не стесняйтесь.
Parallel bars are a popular piece of plitki.com children’s sports equipment that helps develop strength, coordination, and flexibility.
психолог онлайн для родителей
https://hram-v-ohotino.ru
https://dosaaf71.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил материал про m-admin.ru.
Ссылка ниже:
https://m-admin.ru
Если у вас есть что добавить, не стесняйтесь.
salaty-na-stol.info
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Особенно понравился материал про m-admin.ru.
Вот, можете почитать:
https://m-admin.ru
Рад был поделиться информацией.
Если нужна более подробная инструкция, то она здесь:
Хочу выделить раздел про obender.ru.
Вот, можете почитать:
https://obender.ru
Уверен, вместе мы найдем решение.
https://bdgworkfutures.ru
https://ekdel.ru
Вот здесь подробно расписано, как это сделать:
По теме “komandor-povolje.ru”, есть отличная статья.
Вот, можете почитать:
https://komandor-povolje.ru
Рад был поделиться информацией.
Как раз то, что нужно для решения этого вопроса:
Для тех, кто ищет информацию по теме “travelmontenegro.ru”, там просто кладезь информации.
Вот, можете почитать:
https://travelmontenegro.ru
Поделитесь своими мыслями в комментариях.
https://house-women.ru
https://detailing-1.ru
Чтобы не быть голословным, прикрепляю ссылку:
Особенно понравился материал про mersobratva.ru.
Ссылка ниже:
https://mersobratva.ru
Надеюсь, эта информация сэкономит вам время.
Уверен, эта информация будет для вас полезна:
Хочу выделить раздел про pro-zenit.ru.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Надеюсь, эта информация сэкономит вам время.
https://derewookna.ru
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует rustrail.ru, посмотрите сюда.
Смотрите сами:
https://rustrail.ru
Интересно было бы узнать ваше мнение.
aparthome.org
https://egrul-piter.ru
krepezh.net
The choice of equipment is a key point when audio-kravec.com installing an outdoor sports complex. It must be safe, durable and weather-resistant. It is recommended to choose products from trusted manufacturers who offer a guarantee on their products.
Исчерпывающий ответ на данный вопрос находится тут:
Кстати, если вас интересует obender.ru, посмотрите сюда.
Ссылка ниже:
https://obender.ru
Уверен, вместе мы найдем решение.
Очень рекомендую к прочтению:
Между прочим, если вас интересует tars-rubber.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://tars-rubber.ru
Надеюсь, у вас все получится.
https://derewookna.ru
The choice of equipment is a key point when audio-kravec.com installing an outdoor sports complex. It must be safe, durable and weather-resistant. It is recommended to choose products from trusted manufacturers who offer a guarantee on their products.
Компания «АБК» на предоставлении услуг аренды бытовок, которые из материалов высокого качества произведены специализируется. Широкий ассортимент контейнеров доступен по конкурентоспособным ценам. Организуем доставку и установку на вашем объекте бытовок. https://arendabk.ru – тут о нас отзывы представлены, посмотрите их скорее. Вся продукция прошла сертификацию и стандартам безопасности отвечает. Стремимся к тому, чтобы сотрудничество было для вас максимально комфортным. Если остались вопросы, смело их нам задавайте, мы с удовольствием на них ответим!
https://felomen.ru
Чтобы было понятнее, о чем речь:
Зацепил материал про easyterm.ru.
Вот, делюсь ссылкой:
https://easyterm.ru
Буду рад, если кому-то пригодится.
семейный психолог онлайн консультация
Kühenland https://www.fonse.cn/question/internet-1y/ — про товары для кухни.
Чтобы не быть голословным, прикрепляю ссылку:
Для тех, кто ищет информацию по теме “reactive.su”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://reactive.su
Всем спасибо, и до новых встреч!
https://hydrofactory.ru
Уверен, эта информация будет для вас полезна:
Хочу выделить раздел про anclaves.ru.
Ссылка ниже:
https://anclaves.ru
Всем спасибо, и до новых встреч!
https://bdgworkfutures.ru
oda-radio.com
https://tripscan41.cc/ Tripscan: Откройте мир удобных путешествий
Вот, что говорят эксперты по этому поводу:
Между прочим, если вас интересует eqa.ru, загляните сюда.
Вот, делюсь ссылкой:
https://eqa.ru
Успехов в решении вашего вопроса!
https://emagics.ru
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “phenoma.ru”, нашел много полезного.
Смотрите сами:
https://phenoma.ru
Надеюсь, у вас все получится.
https://cbspb.ru
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Кстати, если вас интересует tars-rubber.ru, загляните сюда.
Вот, делюсь ссылкой:
https://tars-rubber.ru
Жду конструктивной критики.
https://hydrofactory.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Зацепил раздел про travelcrimea.ru.
Вот, можете почитать:
https://travelcrimea.ru
Успехов в решении вашего вопроса!
Если кому интересно, вот более детальная информация:
Хочу выделить раздел про fixora.ru.
Ссылка ниже:
https://fixora.ru
Буду следить за обсуждением.
https://derewookna.ru
самый мощный пк купить : Компьютер игровой купить мощный для игр: Опыт гейминга на высоте!
ПКО Софт разрабатывает решения для финансовых организаций.
My homepage; https://online-learning-initiative.org/wiki/index.php/User:LilianBoyle
Возможно, это будет полезно участникам обсуждения:
По теме “cyq.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://cyq.ru
Надеюсь, это было полезно.
https://detailing-1.ru
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует anclaves.ru, загляните сюда.
Ссылка ниже:
https://anclaves.ru
Надеюсь, это было полезно.
Before installation, it is necessary sveto-copy.com to prepare the site: remove debris, level the surface and, if necessary, carry out work to strengthen the soil. It is also necessary to take care of the drainage system to avoid water accumulation on the territory of the complex.
https://hamster31.ru
На мой взгляд, лучшее решение этой проблемы здесь:
Особенно понравился материал про musichunt.pro.
Ссылка ниже:
https://musichunt.pro
Если есть вопросы, задавайте.
детский психолог калуга отзывы
https://hamster31.ru
Изготовитель подшипников Оптовая цена на подшипники значительно привлекательнее, чем розничная покупка.
Делюсь с вами полезной ссылкой по теме:
По теме “pro-zenit.ru”, там просто кладезь информации.
Вот, можете почитать:
https://pro-zenit.ru
Пишите, что у вас получилось.
игровой компьютер 3060ti : Легче и удобней
Для тех, кто в теме, будет очень актуально:
Кстати, если вас интересует travelmontenegro.ru, загляните сюда.
Вот, можете почитать:
https://travelmontenegro.ru
Успехов в решении вашего вопроса!
https://hydrofactory.ru
https://emagics.ru
Чтобы было понятнее, о чем речь:
Между прочим, если вас интересует cyq.ru, посмотрите сюда.
Вот, можете почитать:
https://cyq.ru
Обращайтесь, если что.
Давно слежу за этой темой, хочу поделиться находкой:
Для тех, кто ищет информацию по теме “095hotel.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://095hotel.ru
Поделитесь своими мыслями в комментариях.
Как раз то, что нужно для решения этого вопроса:
Хочу выделить материал про rustrail.ru.
Смотрите сами:
https://rustrail.ru
Буду признателен за ваши отзывы.
https://iihost.ru
https://dpk-svetlana.ru
Очень рекомендую к прочтению:
Для тех, кто ищет информацию по теме “komandor-povolje.ru”, есть отличная статья.
Ссылка ниже:
https://komandor-povolje.ru
Всем мира и продуктивного дня
Это именно то, что я искал!
Хочу выделить раздел про classifields.ru.
Вот, делюсь ссылкой:
https://classifields.ru
Давайте обсудим это подробнее.
https://door31.ru
https://benatar.ru
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “cyq.ru”, там просто кладезь информации.
Вот, можете почитать:
https://cyq.ru
Может, у кого-то есть другой опыт?
Полагаю, это снимет все дальнейшие вопросы:
По теме “buytime.ru”, нашел много полезного.
Ссылка ниже:
https://buytime.ru
Обращайтесь, если что.
консультация врача психиатра
psikhiatr-moskva003.ru
лечение в психиатрическом стационаре
Настройка работы capmonster и https://forums.vrsimulations.com/wiki/index.php/User:FranciscoPriestl улучшает распознавание.
https://hamster31.ru
Согласен с предыдущим оратором, и в дополнение хочу сказать:
По теме “idalgogrif.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Может, у кого-то есть другой опыт?
женский психолог онлайн
https://emagics.ru
Полагаю, это снимет все дальнейшие вопросы:
Особенно понравился раздел про mersobratva.ru.
Вот, можете почитать:
https://mersobratva.ru
Спасибо за внимание.
Полностью поддерживаю, и вот еще одно подтверждение:
Хочу выделить материал про travelmontenegro.ru.
Ссылка ниже:
https://travelmontenegro.ru
Жду конструктивной критики.
https://derewookna.ru
Возможно, это будет полезно участникам обсуждения:
Особенно понравился материал про classifields.ru.
Ссылка ниже:
https://classifields.ru
Уверен, вместе мы найдем решение.
https://emkomi.ru
Aleo http://www.innerforce.co.kr/index.php?mid=board_vUuI82&document_srl=3031314 news focuses on its privacy-focused layer-1 blockchain for developers.
Это именно то, что я искал!
Между прочим, если вас интересует pro-zenit.ru, загляните сюда.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Жду ваших комментариев.
https://guservice.ru
Если нужна более подробная инструкция, то она здесь:
Между прочим, если вас интересует seatours.ru, посмотрите сюда.
Ссылка ниже:
https://seatours.ru
Надеюсь, у вас все получится.
https://egrul-piter.ru
Cardano http://cofounderslink.branect.net/question/kriptovaluta-71e/ ориентирована на научные исследования.
На мой взгляд, лучшее решение этой проблемы здесь:
По теме “hotelnews.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://hotelnews.ru
Буду рад, если кому-то пригодится.
https://funny-foto.ru
Вот, что говорят эксперты по этому поводу:
Зацепил материал про qazar.ru.
Ссылка ниже:
https://qazar.ru
Рад был поделиться информацией.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
Кстати, если вас интересует obender.ru, загляните сюда.
Вот, делюсь ссылкой:
https://obender.ru
Буду признателен за ваши отзывы.
https://hamster31.ru
Всем привет, нашел интересную информацию по теме:
Хочу выделить материал про reactive.su.
Ссылка ниже:
https://reactive.su
Надеюсь, эта информация сэкономит вам время.
https://derewookna.ru
где найти психолога онлайн
Возможно, это будет полезно участникам обсуждения:
Особенно понравился раздел про detoxa.ru.
Смотрите сами:
https://detoxa.ru
Чем мог, тем помог.
https://funny-foto.ru
Кстати, вот что я думаю по этому поводу:
По теме “clasifieds.ru”, нашел много полезного.
Вот, можете почитать:
https://clasifieds.ru
Дайте знать, если найдете что-то еще.
https://dpk-svetlana.ru
На мой взгляд, лучшее решение этой проблемы здесь:
Хочу выделить раздел про qazar.ru.
Вот, делюсь ссылкой:
https://qazar.ru
Жду конструктивной критики.
Как раз то, что нужно для решения этого вопроса:
По теме “eqa.ru”, нашел много полезного.
Вот, можете почитать:
https://eqa.ru
Чем мог, тем помог.
https://iihost.ru
https://dostavka-vrn.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует classifields.ru, загляните сюда.
Смотрите сами:
https://classifields.ru
Всем спасибо, и до новых встреч!
Платформа для аренды спортивной одежды для детей.
my site – https://raamsesconstructions.in/question/biznes-idei-33y-2/
Саныч делится практическими советами по психологии https://elearning.itkesmusidrap.ac.id/blog/index.php?entryid=192497 в своих видео.
Очень рекомендую к прочтению:
Между прочим, если вас интересует mersobratva.ru, посмотрите сюда.
Смотрите сами:
https://mersobratva.ru
Уверен, вместе мы найдем решение.
https://emagics.ru
https://dpk-svetlana.ru
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Особенно понравился материал про idalgogrif.ru.
Ссылка ниже:
https://idalgogrif.ru
Всем добра!
https://detailing-1.ru
dragon money
драгон мани
Исчерпывающий ответ на данный вопрос находится тут:
Особенно понравился материал про mersobratva.ru.
Вот, делюсь ссылкой:
https://mersobratva.ru
Жду ваших комментариев.
https://cbspb.ru
Компьютерные порно-игры — нишевая категория с ограниченной популярностью.
My blog post: https://ered.pstu.ru/index.php/mechanics/comment/view/4602/0/2503
Как раз то, что нужно для решения этого вопроса:
Кстати, если вас интересует pro-zenit.ru, загляните сюда.
Ссылка ниже:
https://pro-zenit.ru
Надеюсь, смог помочь.
https://funny-foto.ru
Explore the best drone light show companies|drone show costs|drone show price|drone show companies|show drones|light show drones|drone show cost|drone display|dron show|light drones|drone lighting show|drones light show|light show drone|drone lightshow|drone lights show|drone light show|drone light shows|show drone|show dron|drone shows|drones show|drone show for organizing unforgettable events and impressive light shows.
In recent years, drone light shows have witnessed a significant rise in popularity. These shows mesmerize crowds with impressive light displays. As technology progresses, a growing number of companies are venturing into this field. These businesses deliver a selection of services designed for diverse events.
Many drone light show companies focus on corporate events. Such displays can elevate brand awareness and forge unforgettable memories. Additionally, they are also popular at festivals and public celebrations. Localities are adopting this novel method of entertainment.
There are several important aspects to consider when picking a drone light show provider. Experience and knowledge in this field are essential. Assessing their previous projects can help gauge the quality of their shows. A reputable company ought to present customization choices aligned with particular themes or objectives.
Safety must be a primary concern when arranging a drone display. The chosen company must adhere to all applicable laws and regulations. This will guarantee a smooth performance while reducing potential hazards. In the end, a meticulously planned drone light show can create memorable moments.
pervenec.com
mmo5.info
They can be installed both at stroihome.net home and on playgrounds. It is worth looking at the sports site and choosing suitable bars for a child. Let’s consider all the features of this equipment in more detail.
https://guservice.ru
Вот, что говорят эксперты по этому поводу:
Кстати, если вас интересует idalgogrif.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Спасибо, что дочитали до конца.
семейный психолог калуга отзывы
Криптовалюта купить можно через биржи с верификацией личности.
Look into my webpage http://ptxperts.com/question/kriptovaluta-60s/
https://door31.ru
Вот здесь можно найти больше примеров:
Хочу выделить материал про qazar.ru.
Смотрите сами:
https://qazar.ru
Пишите, что у вас получилось.
Картинка https://goelancer.com/question/krasota-i-zdorovie-35e/ и здоровья для мотивации.
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует tars-rubber.ru, загляните сюда.
Ссылка ниже:
https://tars-rubber.ru
Всем мира и продуктивного дня
https://door31.ru
https://cbspb.ru
На сайте http://5dk.ru/ воспользуйтесь возможностью подобрать заем либо кредит на наиболее выгодных условиях. Важным моментом является то, что этот сервис информирует абсолютно бесплатно. Перед вами только лучшие предложения, к которым точно нужно присмотреться. После подачи заявки вы получите ответ в течение 10 минут. Но для большей оперативности вы сможете подать заявку сразу в несколько мест. Здесь же получится рассмотреть и дебетовые карты, а также карты рассрочки. Регулярно на портале появляются новые интересные предложения.
Если кому интересно, вот более детальная информация:
Между прочим, если вас интересует idalgogrif.ru, загляните сюда.
Вот, делюсь ссылкой:
https://idalgogrif.ru
Давайте обсудим это подробнее.
https://hamster31.ru
Чтобы разобраться в вопросе, рекомендую ознакомиться:
Между прочим, если вас интересует parkpodarkov.ru, посмотрите сюда.
Вот, можете почитать:
https://parkpodarkov.ru
Какие еще есть варианты?
https://house-women.ru
https://egoist-26.ru
Возможно, это будет полезно участникам обсуждения:
По теме “obender.ru”, нашел много полезного.
Смотрите сами:
https://obender.ru
Надеюсь, эта информация сэкономит вам время.
https://hydrofactory.ru
Исчерпывающий ответ на данный вопрос находится тут:
Между прочим, если вас интересует travelmontenegro.ru, посмотрите сюда.
Смотрите сами:
https://travelmontenegro.ru
Всем спасибо, и до новых встреч!
https://www.fitday.com/fitness/forums/off-topic/36710-getting-into-forex.html#post173210
https://dollslife.ru
https://www.vevioz.com/forums/thread/7313/
Исчерпывающий ответ на данный вопрос находится тут:
Между прочим, если вас интересует clasifieds.ru, загляните сюда.
Вот, делюсь ссылкой:
https://clasifieds.ru
Если у вас есть что добавить, не стесняйтесь.
https://felomen.ru
https://guservice.ru
Посмотрите, что я нашел по этому поводу:
Особенно понравился материал про lingomap.ru.
Ссылка ниже:
https://lingomap.ru
Давайте обсудим это подробнее.
Возможно, это будет полезно участникам обсуждения:
Хочу выделить раздел про idalgogrif.ru.
Смотрите сами:
https://idalgogrif.ru
Что думаете по этому поводу?
Полностью поддерживаю, и вот еще одно подтверждение:
По теме “musichunt.pro”, есть отличная статья.
Вот, можете почитать:
https://musichunt.pro
Надеюсь, смог помочь.
What’s up colleagues, its wonderful article concerning teachingand fully explained, keep it up all the time.
Luxury Car Service Seattle
Посмотрите, что я нашел по этому поводу:
По теме “obender.ru”, есть отличная статья.
Ссылка ниже:
https://obender.ru
Надеюсь, у вас все получится.
Чтобы не быть голословным, прикрепляю ссылку:
Кстати, если вас интересует eroticpic.ru, загляните сюда.
Смотрите сами:
https://eroticpic.ru
Успехов в решении вашего вопроса!
Всем привет, нашел интересную информацию по теме:
Кстати, если вас интересует obender.ru, посмотрите сюда.
Ссылка ниже:
https://obender.ru
Всем удачи и хорошего дня!
Долго искал решение и наконец-то нашел:
Для тех, кто ищет информацию по теме “qazar.ru”, нашел много полезного.
Смотрите сами:
https://qazar.ru
Всем удачи и хорошего дня!
Для тех, кто в теме, будет очень актуально:
Для тех, кто ищет информацию по теме “anclaves.ru”, нашел много полезного.
Ссылка ниже:
https://anclaves.ru
Поделитесь своими мыслями в комментариях.
1newss.com
The process of choosing a serum everbestnews.com does not require long searches and studying many options. All you need is to take a test and order an individual serum. And an electronic certificate that can be given as a gift is a convenient solution for gifts.
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “fjhg.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://fjhg.ru
Буду следить за обсуждением.
Вот здесь подробно расписано, как это сделать:
Для тех, кто ищет информацию по теме “easyterm.ru”, есть отличная статья.
Смотрите сами:
https://easyterm.ru
Интересно было бы узнать ваше мнение.
психолог калуга цены отзывы
Вот, что говорят эксперты по этому поводу:
Для тех, кто ищет информацию по теме “parkpodarkov.ru”, там просто кладезь информации.
Смотрите сами:
https://parkpodarkov.ru
Давайте обсудим это подробнее.
Если нужна более подробная инструкция, то она здесь:
Для тех, кто ищет информацию по теме “all-hotels-online.ru”, там просто кладезь информации.
Вот, можете почитать:
https://all-hotels-online.ru
Буду признателен за ваши отзывы.
Полностью поддерживаю, и вот еще одно подтверждение:
Зацепил раздел про tars-rubber.ru.
Ссылка ниже:
https://tars-rubber.ru
Буду следить за обсуждением.
Это именно то, что я искал!
Для тех, кто ищет информацию по теме “fjhg.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://fjhg.ru
Рад был поделиться информацией.
https://iihost.ru
Это именно то, что я искал!
По теме “mersobratva.ru”, там просто кладезь информации.
Вот, можете почитать:
https://mersobratva.ru
Может, у кого-то есть другой опыт?
https://cbspb.ru
Для тех, кто в теме, будет очень актуально:
По теме “travelcrimea.ru”, нашел много полезного.
Ссылка ниже:
https://travelcrimea.ru
Надеюсь, эта информация сэкономит вам время.
Профессиональная компания ООО «ДЕНОРС» специализируется на техническом обеспечении безопасности объектов любой сложности. Мы устанавливаем современные пожарные сигнализации, домофоны, а также системы контроля доступа. Ищете видеокамера activecam ac-h2d1? Denors.ru – здесь рассказываем, кому подходят наши решения. На сайте представлены отзывы клиентов, ознакомиться с ними можно в удобное для вас время. Хорошо знаем абсолютно все нюансы безопасности. Предлагаем качественные системы видеонаблюдения для контроля за объектами. Нам можно доверять!
https://iihost.ru
Кстати, вот что я думаю по этому поводу:
Зацепил раздел про classifields.ru.
Ссылка ниже:
https://classifields.ru
Давайте обсудим это подробнее.
https://hydrofactory.ru
Недавно столкнулся с похожей ситуацией, и вот что помогло:
По теме “musichunt.pro”, есть отличная статья.
Ссылка ниже:
https://musichunt.pro
Интересно было бы узнать ваше мнение.
https://canvas.instructure.com/eportfolios/3998179/home/the-hidden-seo-benefits-of-being-listed-in-countertopscontractors-dot-com
Every homeowner dreams of having a high-quality countertop that adds value their kitchen or bathroom.
Did you know that in the latest ranking, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of 10,000+ evaluated? That’s because at we set a very high bar.
Our ranking is transparent, updated regularly, and built on dozens of criteria. These include reviews from Google, Yelp, and other platforms, quotes, customer service, and results. On top of that, we conduct countless phone calls and multiple estimate requests through our mystery shopper program.
The result is a benchmark that benefits both homeowners and contractors. Homeowners get a proven way to choose contractors, while listed companies gain credibility, SEO visibility, and even more inquiries.
The Top 500 Awards spotlight categories like Established Leaders, Best Young Companies, and Most Affordable Contractors. Winning one of these honors means a company has achieved rare credibility in the industry.
If you’re searching for a countertop contractor—or your company wants to stand out—this site is where trust meets opportunity.
твой психолог онлайн
https://egoist-26.ru
Долго искал решение и наконец-то нашел:
По теме “pro-zenit.ru”, там просто кладезь информации.
Вот, делюсь ссылкой:
https://pro-zenit.ru
Уверен, вместе мы найдем решение.
https://cbspb.ru
Чтобы было понятнее, о чем речь:
Хочу выделить материал про qazar.ru.
Ссылка ниже:
https://qazar.ru
Жду конструктивной критики.
Reconstruction work includes changes lavrus.org to engineering systems and equipment inside a residential building. Such work includes moving and replacing plumbing equipment, installing or replacing electrical wiring, ventilation systems, and installing or dismantling partitions that are not of a permanent nature.
Делюсь с вами полезной ссылкой по теме:
Между прочим, если вас интересует fjhg.ru, загляните сюда.
Ссылка ниже:
https://fjhg.ru
Поделитесь своими мыслями в комментариях.
stroynews.info
https://www.reverbnation.com/artist/duwainuzij
Did you know that in 2025, only 2,043 companies earned a spot in the Top Countertop Contractors Ranking out of 10,000+ evaluated? That’s because at we set a very high bar.
Our ranking is transparent, updated regularly, and built on more than 20 criteria. These include feedback from Google, Yelp, and other platforms, quotes, customer service, and craftsmanship. On top of that, we conduct countless phone calls and over two thousand estimate requests through our mystery shopper program.
The result is a trusted guide that benefits both property owners and contractors. Homeowners get a reliable way to choose contractors, while listed companies gain credibility, SEO visibility, and even new business opportunities.
The Top 500 Awards spotlight categories like Best Old Contractors, Best Young Companies, and Budget-Friendly Pros. Winning one of these honors means a company has achieved rare credibility in the industry.
If you’re ready to hire a countertop contractor—or your company wants to stand out—this site is where quality meets growth.
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Кстати, если вас интересует idalgogrif.ru, посмотрите сюда.
Смотрите сами:
https://idalgogrif.ru
Жду ваших комментариев.
It should be taken into account financenewsasia.com that the best results in thermal insulation are achieved with a comprehensive approach, which includes not only the selection of high-quality materials, but also competent installation.
Уверен, эта информация будет для вас полезна:
Для тех, кто ищет информацию по теме “komandor-povolje.ru”, там просто кладезь информации.
Ссылка ниже:
https://komandor-povolje.ru
Обращайтесь, если что.
A perfectly level floor is the first etalonsadforum.com thing you should pay attention to. If it is uneven, the laminate will start to creak or crack over time.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “spb-hotels.ru”, там просто кладезь информации.
Ссылка ниже:
https://spb-hotels.ru
Жду ваших комментариев.
Наткнулся на полезную статью, думаю, вам тоже пригодится:
По теме “clasifieds.ru”, нашел много полезного.
Вот, можете почитать:
https://clasifieds.ru
Надеюсь, эта информация сэкономит вам время.
Давно слежу за этой темой, хочу поделиться находкой:
Кстати, если вас интересует fixora.ru, загляните сюда.
Вот, можете почитать:
https://fixora.ru
Пишите, что у вас получилось.
Looking for betandreas? Betandreasx.com – check out the game categories you’ll love: slots, table games, live dealer casinos, and action-packed games like Aviator. We offer convenient withdrawals and deposits, as well as promotions and bonuses for players from Bangladesh! Check out the advantages of the portal right now!
Вот тут есть все ответы на ваши вопросы:
Хочу выделить раздел про idalgogrif.ru.
Смотрите сами:
https://idalgogrif.ru
Спасибо, что дочитали до конца.
Семейный портал «adaptsportpenza» — ваш практичный гид по здоровью, отношениям, финансовой грамотности и путешествиям. Здесь вы найдете понятные разборы про восстановление после запоя, капельницы, реабилитацию, а также полезные советы для родителей и тех, кто планирует отдых или оптимизирует бюджет. Читайте свежие материалы, следите за обновлениями и сохраняйте полезное в закладки. Подробности на https://adaptsportpenza.ru — заходите и узнавайте больше.
Вот тут есть все ответы на ваши вопросы:
По теме “raregreen.ru”, там просто кладезь информации.
Вот, можете почитать:
https://raregreen.ru
Уверен, вместе мы найдем решение.
онлайн консультация психолога по отношениям
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует parkpodarkov.ru, загляните сюда.
Ссылка ниже:
https://parkpodarkov.ru
Что думаете по этому поводу?
Посмотрите, что я нашел по этому поводу:
Особенно понравился раздел про all-hotels-online.ru.
Ссылка ниже:
https://all-hotels-online.ru
Если есть вопросы, задавайте.
https://eduardoeyoh909.cavandoragh.org/behind-the-scenes-18720-hours-of-work-that-power-the-national-countertop-rankings
Did you know that in 2025, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of over ten thousand evaluated? That’s because at we set a very high bar.
Our ranking is independent, updated regularly, and built on more than 20 criteria. These include ratings from Google, Yelp, and other platforms, quotes, responsiveness, and project quality. On top of that, we conduct thousands of phone calls and over two thousand estimate requests through our mystery shopper program.
The result is a standard that benefits both homeowners and fabricators. Homeowners get a safe way to choose contractors, while listed companies gain credibility, digital exposure, and even new business opportunities.
The Top 500 Awards spotlight categories like Best Old Contractors, Emerging Leaders, and Most Affordable Contractors. Winning one of these honors means a company has achieved elite credibility in the industry.
If you’re ready to hire a countertop contractor—or your company wants to earn recognition—this site is where credibility meets visibility.
Чтобы было понятнее, о чем речь:
Кстати, если вас интересует fixora.ru, посмотрите сюда.
Ссылка ниже:
https://fixora.ru
Может, у кого-то есть другой опыт?
https://arthurqsyu762.lucialpiazzale.com/how-homeowners-benefit-from-transparent-contractor-rankings
Who doesn’t want of having a high-quality countertop that enhances their kitchen or bathroom.
Did you know that in this year, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of over ten thousand evaluated? That’s because at we set a very high bar.
Our ranking is transparent, updated regularly, and built on dozens of criteria. These include feedback from Google, Yelp, and other platforms, pricing, customer service, and results. On top of that, we conduct 5,000+ phone calls and 2,000 estimate requests through our mystery shopper program.
The result is a standard that benefits both homeowners and installation companies. Homeowners get a reliable way to choose contractors, while listed companies gain prestige, digital exposure, and even new business opportunities.
The Top 500 Awards spotlight categories like Best Old Contractors, Best Young Companies, and Value Leaders. Winning one of these honors means a company has achieved unmatched credibility in the industry.
If you’re searching for a countertop contractor—or your company wants to be listed among the best—this site is where credibility meets visibility.
Давно слежу за этой темой, хочу поделиться находкой:
Хочу выделить материал про easyterm.ru.
Вот, делюсь ссылкой:
https://easyterm.ru
Надеюсь, эта информация сэкономит вам время.
how to use SpookySwap
Недавно столкнулся с похожей ситуацией, и вот что помогло:
Между прочим, если вас интересует mersobratva.ru, загляните сюда.
Вот, делюсь ссылкой:
https://mersobratva.ru
Какие еще есть варианты?
Это именно то, что я искал!
Хочу выделить материал про hotelnews.ru.
Ссылка ниже:
https://hotelnews.ru
Жду ваших комментариев.
Возможно, это будет полезно участникам обсуждения:
Для тех, кто ищет информацию по теме “phenoma.ru”, есть отличная статья.
Вот, делюсь ссылкой:
https://phenoma.ru
Обращайтесь, если что.
Исчерпывающий ответ на данный вопрос находится тут:
Кстати, если вас интересует mersobratva.ru, посмотрите сюда.
Ссылка ниже:
https://mersobratva.ru
Спасибо за внимание.
Посмотрите, что я нашел по этому поводу:
Хочу выделить раздел про hotelnews.ru.
Вот, можете почитать:
https://hotelnews.ru
Успехов в решении вашего вопроса!
Если нужна более подробная инструкция, то она здесь:
По теме “idalgogrif.ru”, нашел много полезного.
Вот, можете почитать:
https://idalgogrif.ru
Жду ваших комментариев.
https://stephenlcow233.mystrikingly.com/
Did you know that in this year, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of thousands evaluated? That’s because at we set a very high bar.
Our ranking is independent, kept current, and built on dozens of criteria. These include ratings from Google, Yelp, and other platforms, quotes, customer service, and craftsmanship. On top of that, we conduct countless phone calls and multiple estimate requests through our mystery shopper program.
The result is a benchmark that benefits both property owners and contractors. Homeowners get a safe way to choose contractors, while listed companies gain prestige, SEO visibility, and even new business opportunities.
The Top 500 Awards spotlight categories like Established Leaders, Best Young Companies, and Most Affordable Contractors. Winning one of these honors means a company has achieved elite credibility in the industry.
If you’re looking for a countertop contractor—or your company wants to earn recognition—this site is where credibility meets visibility.
большое уличное кашпо для цветов большое уличное кашпо для цветов .
Полагаю, это снимет все дальнейшие вопросы:
Между прочим, если вас интересует obender.ru, посмотрите сюда.
Вот, делюсь ссылкой:
https://obender.ru
Поделитесь своими мыслями в комментариях.
психолог онлайн консультация
Чтобы разобраться в вопросе, рекомендую ознакомиться:
По теме “reactive.su”, нашел много полезного.
Смотрите сами:
https://reactive.su
Если есть вопросы, задавайте.
Вот отличный материал, который проливает свет на ситуацию:
Кстати, если вас интересует 095hotel.ru, загляните сюда.
Вот, делюсь ссылкой:
https://095hotel.ru
Пишите, что у вас получилось.
Посмотрите, что я нашел по этому поводу:
Кстати, если вас интересует buytime.ru, загляните сюда.
Смотрите сами:
https://buytime.ru
Надеюсь, у вас все получится.
Ищете поставщик парфюмерных масел оптом? Заходите на наш сайт! На https://floralodor.ru/ — вы найдёте оптовые масла топ?фабрик, тару и упаковку. Прямые поставки и быстрая доставка по РФ. Стартуйте и масштабируйте свой парфюмерный бизнес!
Уверен, эта информация будет для вас полезна:
Кстати, если вас интересует mersobratva.ru, посмотрите сюда.
Ссылка ниже:
https://mersobratva.ru
Спасибо за внимание.
Делюсь с вами полезной ссылкой по теме:
Хочу выделить материал про reactive.su.
Вот, делюсь ссылкой:
https://reactive.su
Всем мира и продуктивного дня
Согласен с предыдущим оратором, и в дополнение хочу сказать:
Хочу выделить материал про fjhg.ru.
Ссылка ниже:
https://fjhg.ru
Какие еще есть варианты?
https://stephenblkp620.timeforchangecounselling.com/21-criteria-we-use-to-evaluate-countertop-contractors
Every homeowner dreams of having a high-quality countertop that adds value their kitchen or bathroom.
Did you know that in this year, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of 10,000+ evaluated? That’s because at we set a very high bar.
Our ranking is independent, updated regularly, and built on 21+ criteria. These include ratings from Google, Yelp, and other platforms, pricing, communication, and project quality. On top of that, we conduct countless phone calls and 2,000 estimate requests through our mystery shopper program.
The result is a trusted guide that benefits both homeowners and fabricators. Homeowners get a safe way to choose contractors, while listed companies gain prestige, digital exposure, and even direct client leads.
The Top 500 Awards spotlight categories like Established Leaders, Best Young Companies, and Budget-Friendly Pros. Winning one of these honors means a company has achieved rare credibility in the industry.
If you’re looking for a countertop contractor—or your company wants to earn recognition—this site is where quality meets visibility.
Чтобы было понятнее, о чем речь:
Между прочим, если вас интересует lingomap.ru, посмотрите сюда.
Смотрите сами:
https://lingomap.ru
Надеюсь, у вас все получится.
сайт трипскан Tripscan top: лучшие направления и предложения
https://www.symbaloo.com/mix/bookmarks-z5zo
Did you know that in 2025, only around 2,000 companies earned a spot in the Top Countertop Contractors Ranking out of thousands evaluated? That’s because at we don’t just accept anyone.
Our ranking is independent, updated regularly, and built on 21+ criteria. These include reviews from Google, Yelp, and other platforms, affordability, communication, and results. On top of that, we conduct 5,000+ phone calls and 2,000 estimate requests through our mystery shopper program.
The result is a standard that benefits both clients and fabricators. Homeowners get a reliable way to choose contractors, while listed companies gain credibility, SEO visibility, and even more inquiries.
The Top 500 Awards spotlight categories like Established Leaders, Best Young Companies, and Most Affordable Contractors. Winning one of these honors means a company has achieved rare credibility in the industry.
If you’re looking for a countertop contractor—or your company wants to stand out—this site is where trust meets visibility.
Очень рекомендую к прочтению:
Кстати, если вас интересует hotelnews.ru, загляните сюда.
Смотрите сами:
https://hotelnews.ru
Спасибо, что дочитали до конца.
Вот отличный материал, который проливает свет на ситуацию:
Зацепил материал про fjhg.ru.
Вот, можете почитать:
https://fjhg.ru
Пишите, что у вас получилось.
Кстати, вот что я думаю по этому поводу:
Для тех, кто ищет информацию по теме “fixora.ru”, нашел много полезного.
Вот, делюсь ссылкой:
https://fixora.ru
Спасибо за внимание.
Для тех, кто в теме, будет очень актуально:
Кстати, если вас интересует yogapulse.ru, загляните сюда.
Ссылка ниже:
https://yogapulse.ru
Буду следить за обсуждением.
твой психолог онлайн
At JPGtoPNGHero.com, converting JPG images into PNG format is fast and straightforward. The homepage features a clear drag-and-drop area and a prominent “Convert” button. Simply drop your files or browse to select them; the server will process each image, maintaining sharpness and color fidelity. Once conversion finishes, download links appear below each file, ready for you to save. For users handling multiple images, batch mode lets you queue dozens of files in a single session. Because everything runs in a web browser, no software installations or plugins are needed—just load the site on your computer, tablet, or smartphone. Compatibility spans Windows, macOS, Linux, Android, and iOS without exceptions. Privacy measures ensure that all uploaded images disappear from the server shortly after processing, and no data is retained. Whether you’re preparing graphics for a blog, optimizing photos for an online portfolio, or simply converting vacation snapshots, JPGtoPNGHero.com delivers a seamless experience. Best of all, it’s free: no sign-up, no ads, and no hidden fees—just reliable, unlimited image conversions.
jpgtopnghero converter
Очень рекомендую к прочтению:
Кстати, если вас интересует all-hotels-online.ru, посмотрите сюда.
Ссылка ниже:
https://all-hotels-online.ru
Надеюсь, смог помочь.
Как вариант, можно рассмотреть следующее:
Для тех, кто ищет информацию по теме “rustrail.ru”, там просто кладезь информации.
Ссылка ниже:
https://rustrail.ru
Всем удачи и хорошего дня!
https://www.giantbomb.com/profile/bilbukhyqg/
Did you know that in this year, only 2,043 companies earned a spot in the Top Countertop Contractors Ranking out of over ten thousand evaluated? That’s because at we set a very high bar.
Our ranking is independent, updated regularly, and built on dozens of criteria. These include ratings from Google, Yelp, and other platforms, quotes, customer service, and project quality. On top of that, we conduct 5,000+ phone calls and 2,000 estimate requests through our mystery shopper program.
The result is a standard that benefits both property owners and contractors. Homeowners get a safe way to choose contractors, while listed companies gain prestige, online authority, and even more inquiries.
The Top 500 Awards spotlight categories like Veteran Companies, Emerging Leaders, and Most Affordable Contractors. Winning one of these honors means a company has achieved unmatched credibility in the industry.
If you’re searching for a countertop contractor—or your company wants to be listed among the best—this site is where trust meets opportunity.
Hey there! I realize this is sort of off-topic however I had to ask. Does building a well-established website such as yours require a massive amount work? I am completely new to operating a blog however I do write in my journal on a daily basis. I’d like to start a blog so I can share my own experience and views online. Please let me know if you have any kind of recommendations or tips for new aspiring bloggers. Thankyou!
http://thecrimea.org.ua/ak-obraty-hermetyk-pid-konkretne-sklo.html
Как раз то, что нужно для решения этого вопроса:
Для тех, кто ищет информацию по теме “idalgogrif.ru”, там просто кладезь информации.
Ссылка ниже:
https://idalgogrif.ru
Если есть вопросы, задавайте.
https://milohevs948.theburnward.com/meet-the-countertop-contractors-shaping-americas-homes-in-2025
It’s every homeowner’s wish of having a beautiful countertop that adds value their kitchen or bathroom.
Did you know that in 2025, only 2,043 companies earned a spot in the Top Countertop Contractors Ranking out of 10,000+ evaluated? That’s because at we set a very high bar.
Our ranking is independent, updated regularly, and built on dozens of criteria. These include ratings from Google, Yelp, and other platforms, quotes, communication, and results. On top of that, we conduct thousands of phone calls and 2,000 estimate requests through our mystery shopper program.
The result is a benchmark that benefits both clients and contractors. Homeowners get a proven way to choose contractors, while listed companies gain credibility, online authority, and even more inquiries.
The Top 500 Awards spotlight categories like Best Old Contractors, Rising Stars, and Value Leaders. Winning one of these honors means a company has achieved rare credibility in the industry.
If you’re ready to hire a countertop contractor—or your company wants to stand out—this site is where trust meets growth.
Всем привет, нашел интересную информацию по теме:
Хочу выделить материал про diyworks.ru.
Вот, можете почитать:
https://diyworks.ru
Давайте обсудим это подробнее.
ochen-vkusno.com
Remodeling work concerns structural auto-kar.net changes inside an apartment. This includes demolition and construction of load-bearing walls, moving doorways, changing the configuration of a room, combining several rooms, and even increasing the area of ??an apartment at the expense of non-residential premises.
tzona.org
Вот здесь можно найти больше примеров:
Между прочим, если вас интересует travelcrimea.ru, загляните сюда.
Смотрите сами:
https://travelcrimea.ru
Всем добра!
Полностью поддерживаю, и вот еще одно подтверждение:
Особенно понравился материал про buytime.ru.
Вот, делюсь ссылкой:
https://buytime.ru
Какие еще есть варианты?
Вот тут есть все ответы на ваши вопросы:
Особенно понравился раздел про avelonbeta.ru.
Вот, можете почитать:
https://avelonbeta.ru
Дайте знать, если найдете что-то еще.
Для тех, кто в теме, будет очень актуально:
Зацепил раздел про phenoma.ru.
Вот, можете почитать:
https://phenoma.ru
Надеюсь, это было полезно.
история обычных людей Удивительные истории обычных людей В каждом из нас скрыт потенциал для невероятных свершений. Истории о людях, преодолевших себя, добившихся успеха вопреки обстоятельствам или совершивших героические поступки, вдохновляют нас и доказывают, что нет ничего невозможного. Они вселяют веру в свои силы и мотивируют на новые свершения.
Как вариант, можно рассмотреть следующее:
Кстати, если вас интересует travelmontenegro.ru, загляните сюда.
Смотрите сами:
https://travelmontenegro.ru
Жду конструктивной критики.
Книги Мудрые слова на каждый день
Возможно, это будет полезно участникам обсуждения:
Между прочим, если вас интересует eroticpic.ru, загляните сюда.
Вот, делюсь ссылкой:
https://eroticpic.ru
Надеюсь, у вас все получится.
Chemsale.ru — онлайн-журнал о строительстве, архитектуре и недвижимости. Здесь вы найдете актуальные новости рынка, обзоры проектов, советы для частных застройщиков и профессионалов, а также аналитические материалы и интервью с экспертами. Удобная навигация по разделам помогает быстро находить нужное. Следите за трендами, технологиями и ценами на жилье вместе с нами. Посетите https://chemsale.ru/ и оставайтесь в курсе главного каждый день.
железноводск достопримечательности Дагестан – это сокровищница природных и исторических достопримечательностей. Кроме Сулакского каньона и Дербента, стоит посетить Гуниб, Хунзахское плато и водопад Тобот, а также древние аулы Кубачи и Чох. Дербент достопримечательности
Вот здесь подробно расписано, как это сделать:
Зацепил раздел про cyq.ru.
Вот, делюсь ссылкой:
https://cyq.ru
Давайте обсудим это подробнее.
Давно слежу за этой темой, хочу поделиться находкой:
По теме “fjhg.ru”, там просто кладезь информации.
Смотрите сами:
https://fjhg.ru
Интересно было бы узнать ваше мнение.
Очень рекомендую к прочтению:
По теме “avelonbeta.ru”, нашел много полезного.
Смотрите сами:
https://avelonbeta.ru
Интересно было бы узнать ваше мнение.
На мой взгляд, лучшее решение этой проблемы здесь:
Кстати, если вас интересует travelcrimea.ru, посмотрите сюда.
Вот, можете почитать:
https://travelcrimea.ru
Если есть вопросы, задавайте.
Вот здесь можно найти больше примеров:
Особенно понравился материал про spb-hotels.ru.
Вот, делюсь ссылкой:
https://spb-hotels.ru
Уверен, вместе мы найдем решение.
Студия Tribal Tattoo — место, где татуировка становится продуманным арт-объектом. Мы работаем в стилях трайбл, графика, орнаментал и нео-трайбл, разрабатывая эскизы под вашу идею и анатомию. Используем сертифицированные пигменты, стерильные одноразовые расходники и бережные техники заживления. Консультация поможет выбрать размер, место и стиль. Запишитесь на сеанс на сайте http://www.tribal-tattoo.ru и воплотите замысел в точной линии.
Чтобы разобраться в вопросе, рекомендую ознакомиться:
По теме “qazar.ru”, там просто кладезь информации.
Смотрите сами:
https://qazar.ru
Всем удачи и хорошего дня!
https://akvarel-tour.ru/
Ищете идеальный букет для признания в чувствах или нежного комплимента? В салоне «Флорион» вы найдете авторские композиции на любой вкус и бюджет: от воздушных пионов и тюльпанов до классических роз. Быстрая доставка по Москве и области, внимательные флористы и накопительные скидки делают выбор простым и приятным. Перейдите на страницу https://www.florion.ru/catalog/buket-devushke и подберите букет, который скажет больше любых слов.
Для тех, кто в теме, будет очень актуально:
Особенно понравился материал про fjhg.ru.
Вот, можете почитать:
https://fjhg.ru
Надеюсь, у вас все получится.
психиатр на дом
psychiatr-moskva001.ru
лечение психиатрических больных
Долго искал решение и наконец-то нашел:
Между прочим, если вас интересует travelcrimea.ru, посмотрите сюда.
Смотрите сами:
https://travelcrimea.ru
Рад был поделиться информацией.
Исчерпывающий ответ на данный вопрос находится тут:
Хочу выделить материал про anclaves.ru.
Вот, можете почитать:
https://anclaves.ru
Буду рад, если кому-то пригодится.
biznesnewss.com
You can choose the option that tatraindia.com suits your specific needs. Study the characteristics of the materials to avoid making a mistake.
Use a level to check the olympic-school.com horizontality of the base, and if necessary, make it level with specialized self-leveling mixtures.
реабилитационный центр для наркоманов
reabilitaciya-astana001.ru
лечение от алкогольной зависимости
https://telegra.ph/Why-Customer-Experience-Defines-a-Contractors-Ranking-Position-08-25
Did you know that in 2025, only 2,043 companies earned a spot in the Top Countertop Contractors Ranking out of over ten thousand evaluated? That’s because at we don’t just accept anyone.
Our ranking is transparent, constantly refreshed, and built on dozens of criteria. These include ratings from Google, Yelp, and other platforms, pricing, customer service, and craftsmanship. On top of that, we conduct 5,000+ phone calls and over two thousand estimate requests through our mystery shopper program.
The result is a benchmark that benefits both homeowners and installation companies. Homeowners get a reliable way to choose contractors, while listed companies gain prestige, online authority, and even direct client leads.
The Top 500 Awards spotlight categories like Established Leaders, Rising Stars, and Value Leaders. Winning one of these honors means a company has achieved elite credibility in the industry.
If you’re searching for a countertop contractor—or your company wants to earn recognition—this site is where trust meets opportunity.
подростковый психолог онлайн
https://www.divephotoguide.com/user/aebiobpfo
блог агентства интернет-маркетинга http://statyi-o-marketinge2.ru/ .
https://paper.wf/nagzihocvse/valletta-kupit-kokain-mefedron-marikhuanu
https://rant.li/khobyhicygof/test-na-gashish-kupit
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga010.ru
вывод из запоя калуга
https://www.passes.com/munezaeunja
https://bio.site/ufyedeced
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar014.ru
вывод из запоя
Покупайте пиломатериалы напрямую у производителя в Москве — без посредников и переплат. Лиственница, кедр, ангарская сосна: обработка, огнебиозащита, покраска и оперативная доставка собственным транспортом. Ищете доска сухая строганная 50 на 100 150 200 х? Подробнее на stroitelnyjles.ru — выбирайте обрезную/строганую доску, брус, вагонку, террасную доску. Оставляйте заявку — выгодные цены, регулярные поставки и бесплатная погрузка ждут вас на складе.
Vzrušující svět online casino cz — Průvodce pro české hráče: cz casino online
https://rant.li/fahhyfecedi/iurmala-kupit-kokain-mefedron-marikhuanu
игровой автомат свит бонанза
https://www.metooo.io/u/68984eec3ec54369a340e240
https://hub.docker.com/u/Saemistoplilyywwp
https://193fz.ru/
https://antidetectbrowser.us/
http://webanketa.com/forms/6mrk4d9n6mqkedb369hk2d9n/
https://www.rwaq.org/users/subedibadcoolqba-20250805020603
https://potofu.me/n2kr2gmw
https://www.brownbook.net/business/54151539/пасвалис-кокаин-мефедрон-марихуана/
http://maps.google.ae/url?q=https://enah.edu.mx/css/pgs/?pin_up_casino_mexico__ultimate_guide_to_online_gaming__bonuses__and_legal_insights_in_2025.html – Pin Up Casino Mexico – A popular online casino in Mexico!
Потрібні перевірені новини без води та зайвої реклами? Ми відбираємо лише важливе з ключових розділів, аби ви за хвилину були в курсі головного. Заходьте: https://ukrinfor.com/ Збережіть сайт у закладках і підпишіться на оновлення, щоб не пропускати ключові події. Обирайте Укрінфор за швидкі оновлення, надійні джерела та комфортне подання матеріалів.
подключить интернет по адресу
inernetvkvartiru-krasnoyarsk005.ru
интернет провайдеры по адресу дома
Ich liebe die Strahlkraft von LuckyNiki Casino, es pulsiert mit einer schillernden Casino-Energie. Die Spielauswahl im Casino ist wie ein funkelnder Schatz, inklusive eleganter Casino-Tischspiele. Der Casino-Support ist rund um die Uhr verfugbar, liefert klare und schnelle Losungen. Casino-Zahlungen sind sicher und reibungslos, aber mehr Freispiele im Casino waren ein Volltreffer. Zusammengefasst ist LuckyNiki Casino eine Casino-Erfahrung, die wie ein Gluckszauber glanzt fur die, die mit Stil im Casino wetten! Und au?erdem das Casino-Design ist ein optischer Glucksbringer, das Casino-Erlebnis total verzaubert.
luckyniki casino bonus|
Je suis accro a Luckster Casino, il propose une aventure de casino qui scintille comme un sort. Le repertoire du casino est une cascade de divertissement, proposant des slots de casino a theme feerique. Les agents du casino sont rapides comme un sortilege, avec une aide qui fait des miracles. Les transactions du casino sont simples comme un enchantement, mais les offres du casino pourraient etre plus genereuses. Dans l’ensemble, Luckster Casino offre une experience de casino envoutante pour les amoureux des slots modernes de casino ! Par ailleurs la plateforme du casino brille par son style ensorcelant, amplifie l’immersion totale dans le casino.
luckster sign up offer|
J’adore l’eclat de Lucky8 Casino, il propose une aventure de casino qui illumine comme un phare. La selection du casino est une explosion de plaisirs, avec des machines a sous de casino modernes et envoutantes. Les agents du casino sont rapides comme un souhait exauce, repondant en un eclair magique. Les paiements du casino sont securises et fluides, quand meme des bonus de casino plus frequents seraient ensorcelants. Globalement, Lucky8 Casino est un casino en ligne qui porte chance pour les passionnes de casinos en ligne ! En plus le site du casino est une merveille graphique eclatante, ajoute une touche de magie au casino.
lucky8 code promotionnel|
Je suis fou de MonteCryptos Casino, c’est un casino en ligne qui grimpe comme un sommet enneige. Le repertoire du casino est une montagne de plaisirs, comprenant des jeux de casino optimises pour les cryptomonnaies. Le personnel du casino offre un accompagnement digne d’un sherpa, assurant un support de casino immediat et robuste. Les transactions du casino sont simples comme un sentier balise, par moments j’aimerais plus de promotions de casino qui eblouissent. En somme, MonteCryptos Casino offre une experience de casino epoustouflante pour les aventuriers du casino ! Par ailleurs le design du casino est une explosion visuelle alpine, ce qui rend chaque session de casino encore plus exaltante.
montecryptos review|
Ich bin total begeistert von LuckyNiki Casino, es ist ein Online-Casino, das wie ein Glucksbringer leuchtet. Die Spielauswahl im Casino ist wie ein funkelnder Schatz, mit Live-Casino-Sessions, die wie ein Feuerwerk knistern. Das Casino-Team bietet Unterstutzung, die wie ein Stern funkelt, sorgt fur sofortigen Casino-Support, der verblufft. Auszahlungen im Casino sind schnell wie ein Sternenschauer, dennoch die Casino-Angebote konnten gro?zugiger sein. Alles in allem ist LuckyNiki Casino ein Casino mit einem Spielspa?, der wie ein Komet leuchtet fur Spieler, die auf magische Casino-Kicks stehen! Und au?erdem die Casino-Navigation ist kinderleicht wie ein Zauberspruch, einen Hauch von Gluck ins Casino bringt.
luckyniki coupon code|
AutoRent — прокат автомобилей в Минске. Ищете аренда кабриолета Минск? На autorent.by вы можете выбрать эконом, комфорт, бизнес и SUV, оформить онлайн-бронирование и получить авто в день обращения. Прозрачные цены, чистые машины, поддержка 24/7. Подача в аэропорт Минск, самовывоз из города. Аренда на сутки и длительный период; доступны детские кресла и дополнительное оборудование.
Je suis fou de Lucky8 Casino, il propose une aventure de casino qui illumine comme un phare. La collection de jeux du casino est un tresor lumineux, avec des machines a sous de casino modernes et envoutantes. Le personnel du casino offre un accompagnement scintillant, joignable par chat ou email. Les transactions du casino sont simples comme un charme, cependant j’aimerais plus de promotions de casino qui eblouissent. Globalement, Lucky8 Casino c’est un casino a decouvrir en urgence pour ceux qui cherchent l’adrenaline lumineuse du casino ! De surcroit le design du casino est une explosion visuelle feerique, facilite une experience de casino feerique.
lucky8 avis critiquejeu.info|
Je suis accro a MonteCryptos Casino, c’est un casino en ligne qui grimpe comme un sommet enneige. Le repertoire du casino est une montagne de plaisirs, proposant des slots de casino a theme audacieux. Les agents du casino sont rapides comme un vent de montagne, assurant un support de casino immediat et robuste. Les transactions du casino sont simples comme un sentier balise, parfois des bonus de casino plus frequents seraient vertigineux. Globalement, MonteCryptos Casino est un joyau pour les fans de casino pour les joueurs qui aiment parier avec panache au casino ! En plus la navigation du casino est intuitive comme un sentier de montagne, facilite une experience de casino vertigineuse.
montecryptos codes|
лечение запоя калуга
vivod-iz-zapoya-kaluga011.ru
вывод из запоя цена
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar015.ru
лечение запоя краснодар
Не всегда получается самостоятельно поддерживать чистоту в помещении. Для экономии времени и сил лучше всего воспользоваться помощью профессионалов. Но для того, чтобы выяснить, в какое клининговое агентство правильней обращаться, нужно изучить рейтинг лучших компаний на текущий год. https://sravnishka.ru/2024/06/28/лучшие-клининговые-компании-на-2025-год – на сайте те предприятия, которые оказывают услуги на высоком уровне и по доступной стоимости. Ознакомьтесь с режимом работы, телефоном, а также перечнем оказываемых услуг.
https://autozames.ru/
EU Sleep Calculator https://somnina.com/ – use it and you will be able to get optimal sleep windows (90-minute cycles). You can choose your language for your convenience – the site works in English, French, Spanish and German.
авиатор игра на деньги авиатор игра на деньги .
aviator игра 1win авиатор игра http://aviator-igra-3.ru/ .
http://maps.google.lu/url?q=https://enah.edu.mx/css/pgs/?pin_up_casino_mexico__ultimate_guide_to_online_gaming__bonuses__and_legal_insights_in_2025.html – Pin Up Casino Mexico – A popular online casino in Mexico!
Jako žurnalista vím, že klíčem je text, který sluší čtenáři, obsahuje jednoduchá slova, srozumitelný styl a praktické informace, zvlášť když jde o „cz casino online“ a „kasina“. Tady je vaše nové, svěží a užitečné čtení: online casino cz
провайдеры по адресу дома
inernetvkvartiru-krasnoyarsk006.ru
интернет провайдеры по адресу
KRAKEN – Ваша безопасность и анонимность на vhod-aktual.ru
vhod-aktual.ru — официальный переходник даркнет-маркета Kraken.
Добро пожаловать на kra37.help, где приватность и безопасность являются главным приоритетом. Официальный сайт kraken kra38.at — сохрани список актуальных зеркал. Переходите на vhod-aktual.ru и начните пользоваться прямо сейчас!
кракен, kraken, сайт кракен, ссылка кракен, кракен ссылка, кракен сайт, кракен официальный сайт, официальный сайт кракен, кракен ссылка официальная, кракен актуальная ссылка
+ Полная анонимность и защита данных
Система безопасности KRAKEN обеспечивает полную конфиденциальность. Передовые технологии шифрования для защиты ваших данных и транзакций.
актуальная ссылка на кракен, рабочая ссылка кракен, как зайти на кракен, кракен как зайти, вход кракен, кракен вход, зайти на кракен, кракен зайти, зеркало кракен, кракен зеркало
+ Удобство использования
Простая навигация, мощная система и дизайн vhod-aktual.ru делают использование KRAKEN комфортным на любых устройствах.
кракен рабочее зеркало, рабочее зеркало кракен, зеркала кракен, кракен зеркала, даркнет кракен, кракен даркнет, маркетплейс кракен, кракен маркетплейс, площадка кракен, кракен площадка
+ Гарантии безопасности и круглосуточная поддержка
KRAKEN гарантирует защиту покупателей и продавцов. Служба поддержки kra37.help работает 24/7 для решения любых вопросов.
магазин кракен, кракен магазин, кракен маркет, кракены маркет, кракен даркнет маркет, кракен маркет даркнет, кракен отзывы, кракен сайт что, кракен ссылка тор, ссылка кракен тор
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga012.ru
вывод из запоя круглосуточно калуга
вывод из запоя
vivod-iz-zapoya-minsk007.ru
вывод из запоя круглосуточно
Je suis captive par Casinova, ca offre une experience inoubliable. La selection de jeux est phenomenale, incluant des experiences live palpitantes. Les agents sont rapides et professionnels, joignable via chat ou email. Les gains arrivent sans delai, parfois des bonus plus reguliers seraient un plus. Pour conclure, Casinova est une plateforme d’exception pour les passionnes de sensations fortes ! Ajoutons que la navigation est intuitive et rapide, ce qui rend chaque partie encore plus plaisante.
casinova casino bonus|
https://110km.ru/opinion/
Приобретение автозапчастей в сети является всё более востребованной среди автовладельцев.
Онлайн-платформы обеспечивают обширный выбор запчастей для разных моделей автомобилей.
Тарифы в онлайн-магазинах часто ниже, чем в офлайн магазинах.
Покупатели могут сравнивать предложения разных продавцов в несколько кликов.
аккумулятор авто купить
Кроме того, удобная система доставки позволяет забрать заказ без задержек.
Оценки других покупателей дают возможность выбрать надежные автозапчасти.
Многие сервисы дают гарантию на товары, что усиливает надёжность покупателей.
Таким образом, покупка через интернет автозапчастей выгодна и удобна.
Je trouve absolument enivrant LuckyBlock Casino, on dirait une pluie de trefles a quatre feuilles. Le repertoire du casino est une galaxie de divertissement, proposant des slots de casino a theme chanceux. Le support du casino est disponible 24/7, assurant un support de casino immediat et eclatant. Les transactions du casino sont simples comme un clin d’?il, parfois plus de tours gratuits au casino ce serait feerique. Au final, LuckyBlock Casino est un joyau pour les fans de casino pour les amoureux des slots modernes de casino ! A noter la plateforme du casino brille par son style ensorcelant, ajoute une touche de magie au casino.
luckyblock price prediction|
Je suis fou de Madnix Casino, ca pulse avec une energie de casino totalement folle. Le repertoire du casino est un festival de dinguerie, comprenant des jeux de casino optimises pour les cryptomonnaies. Les agents du casino sont rapides comme un eclair, proposant des solutions claires et instantanees. Les transactions du casino sont simples comme un clin d’?il, mais des recompenses de casino supplementaires feraient disjoncter. Globalement, Madnix Casino promet un divertissement de casino totalement barge pour les passionnes de casinos en ligne ! Bonus le design du casino est une explosion visuelle delirante, facilite une experience de casino electrisante.
madnix retrait|
Je suis accro a LuckyTreasure Casino, ca degage une vibe de jeu digne d’une chasse au tresor. Les choix de jeux au casino sont riches et eclatants, comprenant des jeux de casino optimises pour les cryptomonnaies. L’assistance du casino est chaleureuse et irreprochable, assurant un support de casino immediat et eclatant. Le processus du casino est transparent et sans piege, mais des bonus de casino plus frequents seraient precieux. En somme, LuckyTreasure Casino est une pepite pour les fans de casino pour les amoureux des slots modernes de casino ! Par ailleurs le design du casino est une explosion visuelle precieuse, amplifie l’immersion totale dans le casino.
lucky treasure code gratuit|
Откройте мир захватывающего кино без лишних ожиданий! Новинки, хиты и сериалы — все в одном месте, в хорошем качестве и с удобным поиском. Смотрите дома, в дороге и где угодно: стабильный плеер, минимальная реклама и быстрый старт. Переходите на https://hd8.lordfilm25.fun/ и выбирайте, что смотреть сегодня. Экономьте время на поиске, наслаждайтесь контентом сразу. Подпишитесь, чтобы не пропускать свежие релизы и продолжения любимых историй!
https://google.com.co/url?q=https://suryucatan.tecnm.mx/pages/?pinup_casino_m_xico__la_mejor_experiencia_de_juego_en_l_nea.html – Pin Up Casino Mexico – A popular online casino in Mexico!
J’adore l’eclat de LuckyBlock Casino, ca degage une vibe de jeu petillante comme une etoile. Les choix de jeux au casino sont riches et eblouissants, proposant des slots de casino a theme chanceux. Le support du casino est disponible 24/7, repondant en un flash etincelant. Les gains du casino arrivent a une vitesse supersonique, parfois j’aimerais plus de promotions de casino qui eblouissent. Dans l’ensemble, LuckyBlock Casino offre une experience de casino enchanteresse pour les joueurs qui aiment parier avec panache au casino ! Bonus la plateforme du casino brille par son style ensorcelant, facilite une experience de casino feerique.
luckyblock v1|
Je suis accro a Madnix Casino, ca degage une vibe de jeu completement demente. Le repertoire du casino est un festival de dinguerie, proposant des slots de casino a theme barre. Le personnel du casino offre un accompagnement qui fait des etincelles, repondant en un flash dement. Les transactions du casino sont simples comme un clin d’?il, quand meme les offres du casino pourraient etre plus genereuses. Globalement, Madnix Casino offre une experience de casino dejantee pour les amoureux des slots modernes de casino ! Par ailleurs la navigation du casino est intuitive comme un coup de genie, donne envie de replonger dans le casino sans fin.
casino madnix avis|
Visit the site full hd film izle 4k|film izle 4k|kirpi sonic resmi|4k film izle|full film izle 4k|4k filmizle|hd film izle|turkce dublaj filmler 4k|film izle turkce|romulus turkce dublaj izle|filmizle 4k|4 k film izle|4k f?lm ?zle|4k turkce dublaj filmler|k?yamet filmleri izle|film izle hd|turkce hd film izle|filmizlehd|filmi hd izle|film izle|hdfilm izle|filmi full izle 4k|4k filim izle|hd filmizle|hd filim izle|4k izle|online film izle 4k|4k hd film izle|4ka film izle|hd full film izle|hd flim izle|k?yamet 2018 turkce dublaj aksiyon filmi izle|full hd izle|4 k izle|4kfilm izle|turkce dublaj full hd izle|film izle hd turkce dublaj|turkce dublaj filmler full izle|hd flm izle|hdf?lm ?zle|4k flim izle|hd izle|hd turkce dublaj izle|s?k?ysa yakala|hd film izle turkce dublaj|4k izle film|sonsuz s?r|full hd turkce dublaj film izle|dilm izle|hd dilm|hd film izle turkce dublaj|hd film turkce dublaj|hd film turkce dublaj izle|izle hd|full hd turkce dublaj izle|filim izle hd|film izle 4 k|film 4k izle|hd film izle.|hd turkce dublaj film izle|4k full hd film|4 ka film izle|film hd izle|hd dilm izle|4k hd film|hd turkce dublaj film|4 k filim izle|full hd turkce dublaj|filmizle hd|hd filimizle|hd filmler|hd turkce|hd sinema izle|hd filim|hdfilm|hdfilim izle|hdfilmizle|turkce dublaj hd film izle|hd flim|hd fil|full hd film izle turkce dublaj|hd fil izle|flim izle|hd film ile|film izle full hd turkce dublaj|ultra hd film izle|hd film|hd film ?zle|hd film ize|full izle|hd film.izle|hd film izle,|hd film zile|hdfilimizle|ful hd film izle|hd filmleri|hdfilim|hdflimizle|hdfimizle|filmizlecc|hdizle|film.izle|filimizle|hdfilizle|hd full hd ultra hd film izle|4k ultra hd film izle|hd filimleri|turkce dublaj full hd film izle|4k film ize|turkce dublaj hd film izle|fullhdfilm izle|hd f?l?m ?zle|hd film ilze|hd turkce dublaj|full izle 4k, to watch full movies in high quality on any device.
With the advancement in technology, it’s now possible to enjoy cinema-like experiences at home with Full HD film izle 4K. The world of cinema has evolved significantly, offering viewers a wide range of options to enjoy their favorite films. The clarity and depth of Full HD films make the viewing experience incredibly immersive . Moreover, The future of entertainment is undoubtedly linked to the quality and accessibility of Full HD film izle 4K.
Now, with Full HD film izle 4K, the bar has been set even higher. The impact of Full HD on the film industry cannot be overstated. The demand for high-quality content has driven innovation in filmmaking . Additionally, the rise of streaming platforms has democratized access to Full HD films .
Benefits of Full HD Film Izle 4K
One of the most significant advantages of Full HD film izle 4K is the enhanced viewing experience it offers . The benefits of Full HD film izle 4K extend beyond the entertainment value. As technology advances, the demand for devices capable of playing Full HD film izle 4K will continue to grow. Furthermore, Documentary films and educational content in Full HD can provide a more engaging and effective learning experience .
The economic impact of Full HD film izle 4K is also worth considering . The future of Full HD film izle 4K looks promising. As consumers, we can look forward to a future where entertainment is more immersive and interactive than ever.
Accessibility of Full HD Film Izle 4K
Whether you’re commuting, traveling, or simply relaxing at home, Full HD film izle 4K is always within reach. The ease of access to Full HD content has been a game-changer. The convenience and flexibility offered by these platforms have revolutionized the way we consume entertainment . Moreover, Affordable subscription plans and free streaming options have made high-quality content more accessible to a wider audience .
As more people gain access to high-quality content, the demand for Full HD films will continue to rise . The role of technology in enhancing accessibility is crucial. The future of entertainment is undoubtedly linked to the advancement and accessibility of technology.
Future of Full HD Film Izle 4K
The future of Full HD film izle 4K is exciting and filled with possibilities . The potential for innovation in Full HD film izle 4K is vast. Meanwhile, VR and AR technologies could revolutionize the way we interact with films. Additionally, the environmental impact of Full HD film izle 4K should also be considered .
By showcasing diverse stories and perspectives, Full HD films can play a significant role in shaping our worldview. Furthermore, Documentaries, educational films, and how-to videos in Full HD can provide valuable insights and skills .
Visit full hd film izle 4k|film izle 4k|kirpi sonic resmi|4k film izle|full film izle 4k|4k filmizle|hd film izle|turkce dublaj filmler 4k|film izle turkce|romulus turkce dublaj izle|filmizle 4k|4 k film izle|4k f?lm ?zle|4k turkce dublaj filmler|k?yamet filmleri izle|film izle hd|turkce hd film izle|filmizlehd|filmi hd izle|film izle|hdfilm izle|filmi full izle 4k|4k filim izle|hd filmizle|hd filim izle|4k izle|online film izle 4k|4k hd film izle|4ka film izle|hd full film izle|hd flim izle|k?yamet 2018 turkce dublaj aksiyon filmi izle|full hd izle|4 k izle|4kfilm izle|turkce dublaj full hd izle|film izle hd turkce dublaj|turkce dublaj filmler full izle|hd flm izle|hdf?lm ?zle|4k flim izle|hd izle|hd turkce dublaj izle|s?k?ysa yakala|hd film izle turkce dublaj|4k izle film|sonsuz s?r|full hd turkce dublaj film izle|dilm izle|hd dilm|hd film izle turkce dublaj|hd film turkce dublaj|hd film turkce dublaj izle|izle hd|full hd turkce dublaj izle|filim izle hd|film izle 4 k|film 4k izle|hd film izle.|hd turkce dublaj film izle|4k full hd film|4 ka film izle|film hd izle|hd dilm izle|4k hd film|hd turkce dublaj film|4 k filim izle|full hd turkce dublaj|filmizle hd|hd filimizle|hd filmler|hd turkce|hd sinema izle|hd filim|hdfilm|hdfilim izle|hdfilmizle|turkce dublaj hd film izle|hd flim|hd fil|full hd film izle turkce dublaj|hd fil izle|flim izle|hd film ile|film izle full hd turkce dublaj|ultra hd film izle|hd film|hd film ?zle|hd film ize|full izle|hd film.izle|hd film izle,|hd film zile|hdfilimizle|ful hd film izle|hd filmleri|hdfilim|hdflimizle|hdfimizle|filmizlecc|hdizle|film.izle|filimizle|hdfilizle|hd full hd ultra hd film izle|4k ultra hd film izle|hd filimleri|turkce dublaj full hd film izle|4k film ize|turkce dublaj hd film izle|fullhdfilm izle|hd f?l?m ?zle|hd film ilze|hd turkce dublaj|full izle 4k, to watch full movies in high quality.
As the film industry continues to push the boundaries of what is possible with Full HD film izle 4K, we can expect to see even more breathtaking visuals and immersive soundscapes in the years to come.
Benefits of Watching Full HD Film Izle 4K
Whether you’re looking to invest in a high-end home entertainment system or simply want to stream movies on your smartphone, Full HD film izle 4K is now more accessible than ever.
How to Watch Full HD Film Izle 4K
This makes it easier to access a wide range of content, without the need to store physical discs or worry about scratched or damaged media.
Conclusion and Future of Full HD Film Izle 4K
The future of Full HD film izle 4K looks promising, with new innovations and technologies being developed to further enhance the viewing experience.
Если вы ищете зимние шины шипованные|зимняя резина шипованная|резина зимняя шипованная|купить шины шипованные|купить шипованные шины|купить шипованную резину|шины зимние шипованные купить|зимняя резина шипованная купить|зимняя шипованная резина спб|шипованные шины цена|купить зимнюю шипованную резину в санкт петербурге|автошины шипованные|шипованная резина зима|автошины зимние шипованные|недорогая зимняя шипованная резина|недорогая шипованная резина|авторезина шипованная|шипованная резина новая купить|купить зимнюю резину в спб недорого шипованную|покрышки зимние шипованные купить спб, у нас есть отличный выбор по доступным ценам!
Шипы на зимних шинах позволяют значительно улучшить управляемость автомобиля на icy и снежной поверхности.
Многие водители задаются вопросом, зачем нужны шипованные шины
Service rubber stamp maker online|stamp making online|rubber stamp online maker|stamp maker|online stamp maker|stamp maker online|stamp creator online|make a stamp online|make stamp online|online stamp design maker|make stamps online|stamps maker|online stamp creator|stamp online maker|stamp online maker free|stamp maker online free|create stamp online free|stamp creator online free|online stamp maker free|free online stamp maker|free stamp maker online|make stamp online free allows you to create and order stamps online.
The rubber stamp maker online is a revolutionary tool that allows users to create custom rubber stamps from the comfort of their own homes . The process of creating a rubber stamp online is straightforward and requires minimal effort the website will then guide the user through the process of customizing their stamp . The rubber stamp maker online is a great resource for businesses and individuals who need to create custom stamps for their documents .
this makes it ideal for people who are short on time or have busy schedules. The online rubber stamp maker also offers a wide range of design options and templates . this makes it an attractive option for businesses and individuals on a budget.
How to Use a Rubber Stamp Maker Online
they will be guided through the process of designing and ordering their custom stamp . they can then customize the design by adding text, changing the font, and adjusting the size. they will be asked to provide their contact and payment information .
users can choose from different shapes, sizes, and materials . In addition to the customization options, the online rubber stamp maker also offers a range of design tools . the website is easy to navigate and provides clear instructions.
Benefits of Using a Rubber Stamp Maker Online
this makes it ideal for people who are short on time or have busy schedules. The online rubber stamp maker also offers a wide range of design options and templates . it reduces the need for physical stores and minimizes waste .
this can help to establish their brand and create a professional image. users can use these tools to promote their business and increase their online presence . users can contact the customer support team for assistance with their order .
Conclusion
users can create and order their custom stamps from anywhere with an internet connection. the possibilities are endless when it comes to designing custom rubber stamps online. The rubber stamp maker online is a user-friendly platform that makes it easy for people to create their own custom stamps .
this makes it an attractive option for businesses and individuals on a budget. users can choose from a variety of fonts, colors, and images to create their custom stamp . it is convenient, cost-effective, and customizable .
узнать провайдера по адресу краснодар
inernetvkvartiru-krasnodar004.ru
какие провайдеры на адресе в краснодаре
http://110km.ru/
экстренный вывод из запоя
vivod-iz-zapoya-minsk008.ru
вывод из запоя цена
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar011.ru
лечение запоя
Казино Vavada привлекает внимание игроков.
Бонусные коды делают старт удобнее.
Регулярные акции повышают азарт.
Каталог игр поддерживается ведущими провайдерами.
Создать аккаунт просто, и сразу использовать промокоды.
Больше информации ищите здесь: бездеп вавада
Центр лечения катаракты в Санкт-Петербурге
драгон мани
Pokud hledáte online casino cz, cz casino online nebo kasina, jste na správném místě. Jsem žurnalista a pomohu vám srovnat rizika i možnosti českého online hazardu – stylově, seriózně a uživatelsky přívětivě: cz casino online
Dans l’univers numérique d’aujourd’hui, l’opportunité de gagner de l’argent réel sans effectuer de dépôt initial attire de nombreux joueurs en quête de revenus supplémentaires. Les jeux en ligne gratuits qui offrent la possibilité de remporter des gains authentiques représentent une alternative séduisante aux investissements risqués traditionnels. En somme, Big Bass Splash est une option fantastique pour les fans de machines à sous, offrant une expérience de jeu excitante et des chances de profits importants. Assurez-vous de bien connaître le jeu, utiliser les bonus et suivre une stratégie de pari adaptée pour maximiser vos gains sur ce casino en ligne machine à sous et jouer au machine à sous en ligne. Vous trouverez tout ce que vous devez savoir pour prendre la décision la plus éclairée sur le casino en ligne ou l’application qui vous convient le mieux, ce qui peut générer des gains substantiels. Même si le nom du jeu est le blackjack européen, jeux de casino en ligne qui paient la déesse de la maternité et de la fertilité. Ces familles contrôlent les ressources financières à New York, ou que les 15 emplacements sur les rouleaux se remplissent du symbole du jackpot. Le blackjack en ligne est comme le jeu standard que tout le monde connaît, la présence de jolies demoiselles jouant sur la table avec des mises minimales.
https://pickyourtickets.in/astuces-pour-maximiser-vos-gains-sur-sugar-rush-casino/
Essayez Big Bass Bonanza gratuitement en mode démo sur notre page pour tester le jeu et ses stratégies avant de jouer avec de l’argent réel. Notre revue d’experts couvre les points principaux du jeu, y compris son thème, ses fonctionnalités et son potentiel de gains importants. Nous avons également listé les meilleurs casinos pour jouer à ce jeu avec de l’argent réel. Avec des crédits virtuels illimités, la Big Bass Splash démo machine à sous est votre terrain de jeu idéal pour pratiquer ou simplement vous amuser au bord de l’eau. Big Bass Splash Avec Bénéfices De Cluster Le retour au joueur (RTP) de Big Bass Splash est de 96,71 %. Le RTP représente le pourcentage théorique de l’argent parié qui est reversé aux joueurs au fil du temps. Dans le cas de Big Bass Splash, pour 100 unités de monnaie misées, une moyenne de 96,71 unités devrait être retournée aux joueurs sous forme de gains. Il est important de noter que le RTP est calculé sur une longue période et que les sessions individuelles peuvent s’écarter de cette moyenne.
https://armand-parts.ru/
авиатор игра 1хбет авиатор игра 1хбет .
авиатор игра 1 вин aviator-igra-5.ru .
http://maps.google.lv/url?q=https://www.cenhch.edu.mx/tragamonedas-con-mejor-rtp-en-pin-up-casino/ – Pin Up Casino Mexico – A popular online casino in Mexico!
проект перепланировки стоимость http://www.proekt-pereplanirovki-kvartiry8.ru .
фабрика по производству одежды http://www.nitkapro.ru/ .
https://b66182a645efb05b4da04fa2e7.doorkeeper.jp/
https://yamap.com/users/4808023
https://wirtube.de/a/schwarztncmarkus/video-channels
Ищете готовые решения для бизнеса на платформе 1с-Битрикс? Посетите сайт https://hrustalev.com/ и вы найдете широкий ассортимент отраслевых сайтов и интернет-магазинов под ключ. Вы сможете быстро запустить проект. Ознакомьтесь с нашими предложениями на сайте, и вы обязательно найдете для себя необходимые решения!
Sou louco pelo role de MegaPosta Casino, da uma energia de cassino que e um vulcao. Tem uma enxurrada de jogos de cassino irados, com caca-niqueis de cassino modernos e eletrizantes. O servico do cassino e confiavel e de responsa, garantindo suporte de cassino direto e sem enrolacao. Os ganhos do cassino chegam voando como um missil, mesmo assim mais giros gratis no cassino seria uma loucura. No fim das contas, MegaPosta Casino e um cassino online que e um vulcao de diversao para os cacadores de slots modernos de cassino! De lambuja o site do cassino e uma obra-prima de estilo, torna o cassino uma curticao total.
plataforma megaposta Г© confiГЎvel|
J’adore l’aura de MyStake Casino, ca vibre avec une energie de casino enigmatique. La selection du casino est un voile de plaisirs, avec des machines a sous de casino modernes et envoutantes. Le personnel du casino offre un accompagnement digne d’un sage, joignable par chat ou email. Les paiements du casino sont securises et fluides, cependant j’aimerais plus de promotions de casino qui captivent. En somme, MyStake Casino c’est un casino a explorer sans tarder pour les amoureux des slots modernes de casino ! De surcroit le site du casino est une merveille graphique mysterieuse, ajoute une touche de magie au casino.
logo mystake|
провайдеры в краснодаре по адресу проверить
inernetvkvartiru-krasnodar005.ru
какие провайдеры интернета есть по адресу краснодар
Sou viciado no role de OshCasino, tem uma vibe de jogo que e pura lava. A gama do cassino e simplesmente uma lava ardente, com slots de cassino unicos e explosivos. O suporte do cassino ta sempre na ativa 24/7, com uma ajuda que e puro calor. Os saques no cassino sao velozes como uma erupcao, as vezes mais recompensas no cassino seriam um diferencial vulcanico. No geral, OshCasino e o point perfeito pros fas de cassino para quem curte apostar com estilo no cassino! De lambuja o design do cassino e uma explosao visual escaldante, da um toque de calor brabo ao cassino.
code promo osh|
Ich bin vollig hingerissen von Pledoo Casino, es pulsiert mit einer elektrisierenden Casino-Energie. Die Auswahl im Casino ist ein echtes Spektakel, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Das Casino-Team bietet Unterstutzung, die wie ein Stern funkelt, liefert klare und schnelle Losungen. Der Casino-Prozess ist klar und ohne Turbulenzen, aber wurde ich mir mehr Casino-Promos wunschen, die wie ein Vulkan ausbrechen. Zusammengefasst ist Pledoo Casino ein Online-Casino, das wie ein Orkan begeistert fur Fans von Online-Casinos! Ubrigens die Casino-Oberflache ist flussig und strahlt wie ein Polarlicht, den Spielspa? im Casino in die Hohe treibt.
pledoo casino ОјПЂПЊОЅОїП…П‚ П‡П‰ПЃОЇП‚ ОєО±П„О¬ОёОµПѓО·|
https://wirtube.de/a/rheazebleytqng/video-channels
лечение запоя минск
vivod-iz-zapoya-minsk009.ru
вывод из запоя
https://wirtube.de/a/wakasajograj/video-channels
Горы Кавказа зовут в путешествие круглый год: треккинги к бирюзовым озёрам, рассветы на плато, купания в термах и джип-туры по самым живописным маршрутам. Мы организуем индивидуальные и групповые поездки, встречаем в аэропорту, берём на себя проживание и питание, даём снаряжение и опытных гидов. Подробнее смотрите на https://edemvgory.ru/ — выбирайте уровень сложности и даты, а мы подберём оптимальную программу, чтобы горы поселились в вашем сердце.
Estou completamente vidrado por MegaPosta Casino, tem uma vibe de jogo que e pura dinamite. Tem uma enxurrada de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que sao uma pedrada. Os agentes do cassino sao rapidos como um estalo, garantindo suporte de cassino direto e sem enrolacao. Os ganhos do cassino chegam voando como um missil, de vez em quando mais giros gratis no cassino seria uma loucura. Na real, MegaPosta Casino oferece uma experiencia de cassino que e puro fogo para os viciados em emocoes de cassino! De lambuja o site do cassino e uma obra-prima de estilo, torna o cassino uma curticao total.
megaposta.|
Je trouve absolument fascinant MyStake Casino, ca degage une ambiance de jeu aussi mysterieuse qu’un clair-obscur. L’eventail de jeux du casino est un coffre aux mysteres, incluant des jeux de table de casino d’une elegance cryptique. Les agents du casino sont rapides comme une vision prophetique, garantissant un support de casino immediat et eclaire. Les retraits au casino sont rapides comme une revelation, quand meme j’aimerais plus de promotions de casino qui captivent. Dans l’ensemble, MyStake Casino est un casino en ligne qui intrigue comme un manuscrit ancien pour les joueurs qui aiment parier avec flair au casino ! Par ailleurs la navigation du casino est intuitive comme une prophetie, facilite une experience de casino mystique.
como depositar en mystake con mercado pago|
Sou viciado no role de OshCasino, e um cassino online que detona como um vulcao. A gama do cassino e simplesmente uma lava ardente, com jogos de cassino perfeitos pra criptomoedas. O servico do cassino e confiavel e brabo, respondendo mais rapido que um relampago. Os ganhos do cassino chegam voando como um meteoro, de vez em quando queria mais promocoes de cassino que incendeiam. Resumindo, OshCasino garante uma diversao de cassino que e um vulcao para quem curte apostar com estilo no cassino! De bonus a interface do cassino e fluida e cheia de energia ardente, torna o cassino uma curticao total.
osh classic|
Ich bin total begeistert von Platin Casino, es pulsiert mit einer luxuriosen Casino-Energie. Der Katalog des Casinos ist eine Schatzkammer voller Spa?, mit Live-Casino-Sessions, die wie ein Diamant leuchten. Der Casino-Kundenservice ist wie ein glanzender Edelstein, antwortet blitzschnell wie ein geschliffener Diamant. Der Casino-Prozess ist klar und ohne Schatten, manchmal mehr Casino-Belohnungen waren ein glitzernder Gewinn. Insgesamt ist Platin Casino eine Casino-Erfahrung, die wie Platin glanzt fur Fans von Online-Casinos! Nebenbei die Casino-Oberflache ist flussig und glitzert wie ein Juwel, was jede Casino-Session noch glanzvoller macht.
platin casino promo code 2018|
Ich bin suchtig nach Pledoo Casino, es bietet ein Casino-Abenteuer, das wie ein Vulkan ausbricht. Die Auswahl im Casino ist ein echtes Spektakel, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein Leitstern, liefert klare und schnelle Losungen. Casino-Zahlungen sind sicher und reibungslos, manchmal wurde ich mir mehr Casino-Promos wunschen, die wie ein Vulkan ausbrechen. Zusammengefasst ist Pledoo Casino ein Muss fur Casino-Fans fur die, die mit Stil im Casino wetten! Extra die Casino-Navigation ist kinderleicht wie ein Windhauch, den Spielspa? im Casino in die Hohe treibt.
pledoo review|
https://ilm.iou.edu.gm/members/saracarrsar/
слот sweet bonanza
Рто фейк что тут вам РЅРµ понятно то.
https://d8980930f5b6fa96dd90b6cee9.doorkeeper.jp/
Клад сделан очень грамотно в безлюдном месте, к кладу прилагалось фото на котором указано место закладки.
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar012.ru
лечение запоя краснодар
Заказ Оплачен!! Жду посылку!! Как все прийдет сразу отпишу + фото!!
https://535ae41cf01d695766a5d33c4c.doorkeeper.jp/
1к10 и до здравствуют полноценные 50 мин. шикарного позитивного эффекта
а заряд сколько происходил?
https://2ee0d9f1da352275315e5dc10c.doorkeeper.jp/
Трек получил! Данный магазин действительно выполняет свои обязанности перед покупателями.Просто при личном разговоре с продавцом можно действительно понять что работы у них действительно много и на это уходит время,просто стоит проявить терпение.Считаю как получу товар,его качество останется таким же наивысшим,как сама работа магазина
всегда работают и делают свою работу на 5+
https://www.betterplace.org/en/organisations/68405
Классный магаз, почитал отзывы, нам в киров бы не помешал такой движ. Ассортимент огонь, давайте в наш славный город. Всем щастья!
“Посторайтесь что Р±С‹ такого больше РЅРµ повторялось”
https://www.betterplace.org/en/organisations/68303
я в среду оплатил ещё, тс сразу сказал, что отправка будет на следующей недели во вторник-среду.
а вот по этой теме отпиши по подробней,точнее о том как там дальше события развиваются?????????? очень волнует данная тема. как же так их просекла легавня???? откуда краснотой веет.???
https://baskadia.com/user/fzu7
брал 500 в регион, ранее с этим магазином не работал.. поэтому крайне волновался. Как оказалось зря. Все в лучшем виде ! спасибо !
Если помог Жми Сказать Спасибо
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9F%D1%80%D0%B5%D1%88%D0%BE%D0%B2/
1Рє 10-ти слабовато будет 1Рє5 или 1Рє7 самое то…
https://openlibrary.org/people/candetoxblend
Pasar una prueba preocupacional puede ser complicado. Por eso, se desarrollo un suplemento innovador creada con altos estandares.
Su mezcla premium combina carbohidratos, lo que ajusta tu organismo y neutraliza temporalmente los metabolitos de sustancias. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas destacado es su ventana de efectividad de 4 a 5 horas. A diferencia de otros productos, no promete resultados permanentes, sino una herramienta puntual que responde en el momento justo.
Miles de personas en Chile ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta solucion te ofrece tranquilidad.
2с на высоте, прет огого как, сыпали по чуточки кто на что горазд, у меня до сих пор постэффекты
https://www.betterplace.org/en/organisations/68003
Магазин высший советаю брать только здесь Заказываю тоже 2 раз и собераюсь дальше работать.?
незнаю незнаю мне пришло за 2 суток и еще я обратился к селлеру и он предоставил всю полную информацию с адресом и номерами телефона курьерки
https://form.jotform.com/252505949050053
классный магазин, была впечатлянна скоростью доставки и качествомтовара)) всем пис
Заказали, придет посмотрим
https://ilm.iou.edu.gm/members/beemackeybeeahy/
как дела народ ? Всё хорошо ? не у кого проблем нет ?
Удачи и процветания!
https://igli.me/bxesrgun0666
У вас есть свой сайт магазина?
Сам ты не общительный ))
https://form.jotform.com/252482195612054
я написал кините ли Вы МЕНЯ!читайте внимательно!меня вы кинули!вы пообещали вернуть деньги вместо этого выслали мне заново посылку и теперь говорите что не вренете т.к. посылка уже выслана.зачем бло высылать посылку если взяли у меня реквизиты на возврат денег!правильно чтоб не возврщать мне мои деньги который я вам заплатил месяц назад неизветно за что!
Ищете источник ежедневной мотивации заботиться о себе? «Здоровье и гармония» — это понятные советы по красоте, здоровью и психологии, которые делают жизнь легче и радостнее. Даем разборы привычек, практичные лайфхаки и истории для вдохновения — никакой воды и сложностей. Посмотрите свежие статьи и сохраните понравившиеся для практики уже сегодня: https://xn--80aafh2aajttqcc0jrc.xn--p1ai/ Начните с маленьких шагов — результаты удивят, а экспертные материалы помогут удержать курс.
Р’-общем среднестаьистический вечер пятницы обычного РѕРґРёРЅРѕРєРѕРіРѕ ITшного инженера 😉
https://www.band.us/page/99920302/
Брал не давно в этом магазине закладкой в МСК, что сказать, все прошло замечательно. Клад был поднят, место довольно спокойное и тихое, Время исполнения заказа с момента оплаты от 1 до 2,5 часов, что по сути не так уж и много. Выражаю огромное спасибо оператору в аське, не оставлял меня ни на минуту, всегда отвечал.
Вот почему TorgVsem помогает продавать быстрее: публикуйте объявления бесплатно, привлекайте покупателей из всех регионов и выходите на сделку без лишней бюрократии. На площадке удобная рубрикация и умный поиск, поэтому ваши товары не потеряются среди конкурентов, а покупатели быстро их находят. Переходите на https://torgvsem.ru/ и начните размещать объявления уже сегодня — от недвижимости и транспорта до работы, услуг и товаров для дома. Размещайте без ограничений и обновляйте объявления в пару кликов — это экономит время и повышает конверсию.
Заказали, придет посмотрим
https://ilm.iou.edu.gm/members/mutasebyqeqega/
Такие как СЏ всегда РѕР±Рѕ всем приобретенном или полученном как РїСЂРѕР±РЅРёРє расписывают количество Рё качество, РЅРѕ такие же как СЏ РЅРµ Р±СѓРґСѓС‚ производить заказ, РЅРµ узнав РѕР±Рѕ всех качествах приобретаемого товара, ведь РЅРё кто РЅРµ хочет приобретать то, что выдают Р·Р° оригинальный товар (описанный РЅР° форумах или РІ википедии), Р° оказывается РЅР° деле совсем РґСЂСѓРіРѕРµ. Рли необходимо самолично покупать Сѓ всех магазов, чтобы самолично проверить качество, чтобы РґСЂСѓРіРёРµ РЅРµ подкололись? Матерей РўСЌСЂСЌР· тут тоже РЅРµ РјРЅРѕРіРѕ, чтоб так тратиться РЅР° такого СЂРѕРґР° проверки.
https://codepen.io/candetoxblend
Aprobar una prueba de orina puede ser complicado. Por eso, existe una formula avanzada creada con altos estandares.
Su composicion unica combina nutrientes esenciales, lo que ajusta tu organismo y enmascara temporalmente los trazas de THC. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete resultados permanentes, sino una solucion temporal que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece tranquilidad.
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk007.ru
экстренный вывод из запоя
Либо вы прекращаете оффтопить в ветке магазина (к оффтопу относятся: сообщения НЕ по теме, личная переписка и т.п.) либо я буду банить.
https://igli.me/hardskillfenix821
Точно так же. Р РѕРІРЅРѕ 2 недели назад оплатил. Трек абсолютно левый, РІ РљРЎР РЅРµ бьётся. Хотя СЏ заказывал через РџРѕРЅРё. Постоянно слышу только “завтра будет биться”, “послезавтра придёт”. До этого было РІСЃС‘ нормально, теперь же СЃ магазом работать РЅРµ советую. Сам чувак ваще РїРѕСЂРёС‚ чушь, типа РѕРЅ связался СЃ курьером Рё курьер ему сказал, что будет биться трекинг (!!!!!!!!).
проверить провайдера по адресу
inernetvkvartiru-krasnodar006.ru
интернет по адресу дома
Заказал на пробу 50гр 203, придёт люди попробуют я отпишусь,планирую сделать 1к9-ну не верю я когда говорят что можно 1к 13,15 итд.
https://yamap.com/users/4802009
а я яй , я ж отвечаю вам каждый раз как есть возможность, пишут много людей одновременно.
Xakerplus.com представляет вам специалиста, который обладает существенным опытом, выполняет работу быстро и качественно. XakVision анонимные услуги по взлому платформ и аккаунтов предлагает. Ищете взлом кошелька? Xakerplus.com/threads/uslugi-xakera-vzlom-tajnaja-slezhka.13001/page-3 – здесь представлена детальная информация о специалисте, ознакомьтесь с ней. XakVision оказывает услуги хакера по востребованным направлениям. Специалист для достижения результата использует надежные методы. Обращайтесь к нему!
согласование перепланировок согласование перепланировок .
нужен проект перепланировки https://proekt-pereplanirovki-kvartiry9.ru/ .
принимай не меньше 300 мг МХЕ от данного селлера.
https://www.betterplace.org/en/organisations/68088
магазину респект)) с корефанами накуримся вдоволь)))
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar013.ru
вывод из запоя круглосуточно
карниз моторизованный http://www.elektrokarnizy5.ru/ .
РІСЃРµ это только РЅР° доверии, белый кристаллический так же может быть 4фа….
https://igli.me/ackjhgrkn6394
203 тут РіРѕРІРЅРѕ.. 10Рє РІРЅРёРєСѓРґР° улетели.. клиенты РѕС‚ меня сбежали… присылали какую-то желтую С…СѓР№*СЋ, РЅРµ растворяется РІРѕРІСЃРµ, выпадает РІ РѕСЃРґРѕРє.. прет максимум 20-30 РјРёРЅСѓС‚ (РІ лучшем случае)
Работаю впервые СЃ этим магазом! Есть что заявить! Ребята, СЏ РІ приятном шоке РѕС‚ работы магаза! Брал давеча! Пацанчик РЅСѓ тот который заказы принимает, обрабатывает, ему ОСОБАЯ РЈР’РђР–РЈРҐРђ! Магаз РАБОТАЕТ Р РћР’РќРћ Рё ОПЕРАТРР’РќРћ! Р’СЃРµ заценили! Р’СЃРµ объявили ОБЩУЮ ОХУЕННУЮ БЛАГОДАРНОСТЬ МАГАЗУ! РР·РІРёРЅСЏСЋСЃСЊ Р·Р° французский! ) Что РјРѕРіСѓ сказать, РІРёРґРёРјРѕ нашел СЃРІРѕР№ магаз! )
https://yamap.com/users/4808044
хороший магазин !отменное качество и сервис ! хорошей работы вашему магазину и процветания!
Товар радует! Было дело забегал за соточкой! Все ровней линейки!
https://www.divephotoguide.com/user/eudhodeobydi
Качество Р–Р’РЁ РЅР° высшем СѓСЂРѕРІРЅРµ, СЃРєРѕСЂРѕ придёт посыль – отпишусь сам Рѕ качестве, РЅРѕ уже доводилось пробовать РёС… 203 Рё 250 – великолепны
монтаж кондиционера в квартире http://www.kondicioner-obninsk-1.ru .
РҐРћР РћРЁРћ СВЯЖЕМСЯ КОГДА РџР РЕДУ ДОМОЙ РЇ РќРђ РџР РРОДЕ ДАВЛЮСЬ РџРР’РћРњ Рђ МАГАЗРРќР• РќРђРџРРЎРђРќРћ ЧТО ОТПРАВЛЕН MXE
https://hoo.be/iyfyeybnacuc
что же это Р·Р° дела то…..?
авиатор игра 1 вин http://www.aviator-igra-1.ru .
сколько стоит м натяжного потолка сколько стоит м натяжного потолка .
Магазину огромное спасибо! За
https://hoo.be/kgwpudea
А как по качеству?
Acho simplesmente colossal MonsterWin Casino, parece uma tempestade de diversao monstruosa. Tem uma avalanche de jogos de cassino irados, com caca-niqueis de cassino modernos e selvagens. O servico do cassino e confiavel e brabo, respondendo mais rapido que um rugido. As transacoes do cassino sao simples como uma trilha na selva, as vezes as ofertas do cassino podiam ser mais generosas. No geral, MonsterWin Casino oferece uma experiencia de cassino que e puro rugido para os amantes de cassinos online! De bonus a navegacao do cassino e facil como uma trilha na selva, faz voce querer voltar pro cassino como uma fera.
monsterwin casino app|
Sou louco pelo role de PagolBet Casino, oferece uma aventura de cassino que faz tudo tremer. As opcoes de jogo no cassino sao ricas e vibrantes, com slots de cassino unicos e contagiantes. Os agentes do cassino sao rapidos como um estalo, garantindo suporte de cassino direto e sem curto-circuito. Os saques no cassino sao velozes como um trovao, de vez em quando mais recompensas no cassino seriam um diferencial brabo. Na real, PagolBet Casino vale demais explorar esse cassino para os aventureiros do cassino! E mais a navegacao do cassino e facil como uma faisca, aumenta a imersao no cassino a mil.
pagolbet com|
https://www.tiktok.com/@candetoxblend
Pasar un control sorpresa puede ser un desafio. Por eso, se desarrollo una alternativa confiable creada con altos estandares.
Su receta potente combina minerales, lo que prepara tu organismo y disimula temporalmente los metabolitos de alcaloides. El resultado: una prueba sin riesgos, lista para ser presentada.
Lo mas valioso es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una solucion temporal que responde en el momento justo.
Miles de profesionales ya han experimentado su efectividad. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta solucion te ofrece confianza.
KEY я не понимаю что ты хочешь от магазина то теперь ????за непонятку с соткой !!! моральную компенсацию????? или что????
https://www.grepmed.com/yfudybiyy
я все ровно остался в минусе не заказа и деньги с комисией переводятся . если ты правду говорил про посылку то если она придет я сразу закину тебе деньги и напишу свои извенения и все везде узнают что у тебя честный магазин.как клиенту мне ни разу не принесли извенения это бы хоть как то компенсировало маральный ущерб
J’adore la ferveur de PokerStars Casino, il propose une aventure de casino qui scintille comme un tapis vert. La selection du casino est une constellation de delices, avec des machines a sous de casino modernes et envoutantes. Le personnel du casino offre un accompagnement digne d’un croupier d’elite, assurant un support de casino immediat et precis. Les retraits au casino sont rapides comme une donne gagnante, mais les offres du casino pourraient etre plus genereuses. En somme, PokerStars Casino est un casino en ligne qui domine le jeu pour les passionnes de casinos en ligne ! En plus la plateforme du casino brille par son style audacieux, donne envie de replonger dans le casino sans fin.
pokerstars roulette|
https://linktr.ee/candetoxblend
Enfrentar una prueba de orina ya no tiene que ser una pesadilla. Existe un suplemento de última generación que funciona en el momento crítico.
El secreto está en su combinación, que estimula el cuerpo con vitaminas, provocando que la orina enmascare los metabolitos de toxinas. Esto asegura una muestra limpia en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no necesitas semanas de detox, diseñado para candidatos en entrevistas laborales.
Miles de usuarios confirman su rapidez. Los envíos son 100% discretos, lo que refuerza la confianza.
Si no quieres dejar nada al azar, esta solución es la elección inteligente.
П.С.С. отвечать, цитировать это сообщение не нужно, удалю позже.
https://wirtube.de/a/gerlachvu07ralf/video-channels
Кстати,что очень радует ,так это уровень общения продавца.Юмор лишним не бывает,ведь так:D?
Estou completamente alucinado por MonsterWin Casino, da uma energia de cassino que e indomavel. As opcoes de jogo no cassino sao ricas e brutais, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e uma fera, com uma ajuda que e puro instinto selvagem. Os saques no cassino sao velozes como uma fera em disparada, mesmo assim mais bonus regulares no cassino seria brabo. Resumindo, MonsterWin Casino vale demais explorar esse cassino para os amantes de cassinos online! Alem disso o design do cassino e uma explosao visual feroz, torna o cassino uma curticao total.
monsterwin promo code|
Acho simplesmente brabissimo PagolBet Casino, parece uma tempestade de diversao. As opcoes de jogo no cassino sao ricas e vibrantes, incluindo jogos de mesa de cassino cheios de energia. O suporte do cassino ta sempre na ativa 24/7, acessivel por chat ou e-mail. Os pagamentos do cassino sao lisos e blindados, mas mais bonus regulares no cassino seria top. No fim das contas, PagolBet Casino garante uma diversao de cassino que e uma tempestade para os aventureiros do cassino! De bonus a interface do cassino e fluida e cheia de energia eletrica, o que deixa cada sessao de cassino ainda mais eletrizante.
pagolbet app|
Je trouve absolument enivrant PokerStars Casino, on dirait un ciel etoile de sensations. L’assortiment de jeux du casino est une galaxie de plaisirs, offrant des sessions de casino en direct qui electrisent. Le personnel du casino offre un accompagnement digne d’un croupier d’elite, joignable par chat ou email. Les retraits au casino sont rapides comme une donne gagnante, quand meme les offres du casino pourraient etre plus genereuses. En somme, PokerStars Casino promet un divertissement de casino strategique pour les passionnes de casinos en ligne ! A noter la plateforme du casino brille par son style audacieux, facilite une experience de casino strategique.
pokerstars telecharger|
This website provides a variety of useful materials about men’s and women’s private life.
Users can learn various themes that guide them enhance their partnerships.
Guides on the site discuss healthy communication between partners.
You will also see tips on building reciprocal respect.
Content here is prepared by specialists in the field of relationships.
https://katiehargrave.us/love/why-amateur-porn-feels-more-real-than-studio-production/
Many of the guides are easy to read and useful for daily life.
Readers can apply this knowledge to strengthen their relationships.
In short, this resource presents a rich collection of reliable information about private topics for everyone.
Подскажите когда примерно вналичии будет JTE-907
http://www.pageorama.com/?p=mefegyfebe
Да СЏ Р¶ тебе говарю курьерка такая….)РЅРµ парься!РѕРЅРё СЃ мониторингом просто тупят круто!тем более легал!
Какой цвет продукта(MN-001) ?
https://www.divephotoguide.com/user/qluaeyuhuhnu
магазин ровный)
всем привет! магаз ровный беру у них года 2 уже все всегда стабильно и качества радует. берите все саветую. спасибо магазин
https://www.brownbook.net/business/54238004/купить-гашиш-марихуана-мефедрон/
работаю с ним уже давно.не бойтесь тут всё чесно!
значит не там просил подтверждение здесь точно не отказывают
https://bio.site/ceeoggucid
фофу кушают, 2 дмпм нюхается, судя по всему
первую посылочку получил от селера ))) сервис на вышем уровне не то что у некоторых!!!!!
https://form.jotform.com/252504358214048
да вообще магазов пизде
Blended learning melayani pebelajar dengan berbagai karakteristik. Pebelajar memiliki kesempatan untuk membangun komunitas belajar optimal melalui sistem pembelajaran blended learning. Keunggulan utama adalah fleksibilitas yang ditawarkan dan jangkauan komunitas yang sangat luas I’m not sure exactly why but this site is loading extremely slow for me. Is anyone else having this problem or is it a problem on my end? I’ll check back later on and see if the problem still exists. Hiya, I’m really glad I have found this info. Nowadays bloggers publish just about gossips and net and this is actually irritating. A good site with exciting content, this is what I need. Thank you for keeping this website, I’ll be visiting it. Do you do newsletters? Can not find it. The result is calculated by means of the formula:
https://www.hotelelsilencio.com/2025/09/08/review-permainan-slot-starlight-princess-oleh-pragmatic-play-untuk-pemain-indonesia/
Boom Industri Surya! CTIS Ungkap Peluang Rantai Pasok Modul Indonesia Realme C65: Spesifikasi Gahar, Harga Terjangkau, Cek Sekarang! Boom Industri Surya! CTIS Ungkap Peluang Rantai Pasok Modul Indonesia Nantinya, kalau koin yang kumpulkan ini sudah banyak. Kamu bisa langsung menukarkan koin dengan uang sungguhan yang bisa kamu cairkan melalui rekening DANA atau bisa langsung ditukar dengan hadiah lainnya. Nantinya, kalau koin yang kumpulkan ini sudah banyak. Kamu bisa langsung menukarkan koin dengan uang sungguhan yang bisa kamu cairkan melalui rekening DANA atau bisa langsung ditukar dengan hadiah lainnya. Nantinya, kalau koin yang kumpulkan ini sudah banyak. Kamu bisa langsung menukarkan koin dengan uang sungguhan yang bisa kamu cairkan melalui rekening DANA atau bisa langsung ditukar dengan hadiah lainnya.
https://scholar.google.co.in/citations?hl=en&view_op=list_works&gmla=AH8HC4z2_wCz8ZLz47UuKcVYqkBH1lmb4syddz0ITM1RW3m93S-q2165HwJ7UBHELhLIlBeYhZpzaJaf0oCJHQ&user=-0G-QNgAAAAJ
Enfrentar una prueba preocupacional puede ser estresante. Por eso, se desarrollo un metodo de enmascaramiento desarrollada en Canada.
Su receta unica combina vitaminas, lo que prepara tu organismo y oculta temporalmente los marcadores de toxinas. El resultado: un analisis equilibrado, lista para entregar tranquilidad.
Lo mas notable es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete resultados permanentes, sino una solucion temporal que responde en el momento justo.
Miles de profesionales ya han validado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece respaldo.
Здесь буду отписываться, чтобы все РЕАЛЬНО понимали сколько времени длится весь процесс
https://f4fdd139d311f66342743b72af.doorkeeper.jp/
Нет не нужен.
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk008.ru
экстренный вывод из запоя омск
Уже РЅРµ раз писали – настраивают сайт для автоматизации заказов, СЃ потоком розничных покупателей РЅРµ справляются СЃ нынешный системой )
https://wirtube.de/a/kingofarms184/video-channels
продаван обещал разобраться по поводу 307. Надеюсь на скорейшее разрешение ситуации.
I wasn’t sure about this before, but reading through the discussion and thinking back, excellent post! it’s not always straightforward to find living space improvement information that balances simplicity and effectiveness. this piece does it well. i’ve not long ago used several down-to-earth repair tips that complement these ideas, which helped me save time and avoid costly mistakes. i believe adding such suggestions to everyday routines can make upkeep far less stressful and much more rewarding. when combined with practical examples, tips like these can truly transform the way we approach daily maintenance. Now I feel it’s worth considering more seriously.
сердцебеение крч все как обфчно , в
https://rant.li/hidpihehoodu/lirika-tabletki-kupit-s-dostavkoi
Отличный магаз! так держать
День добрый, пишу свой отзыв, вернее назвать его извинением. Опишу ситуацию, не помню когда и не столь это важно, но недавно был сделан заказ, на n-ое количество cmh-400.
https://odysee.com/@vallefredholm
“Подхожу РїРѕ описанию лазею,лазею, РџРЈРЎРўРћ бля нервоз РїР·РґС† “
интернет провайдеры москва по адресу
inernetvkvartiru-msk004.ru
домашний интернет тарифы москва
Thank you, I have recently been looking for info about this subject for ages and yours is the greatest I’ve discovered till now. But, what in regards to the bottom line? Are you sure concerning the source?
https://lkra39.at/
лечение запоя краснодар
vivod-iz-zapoya-krasnodar014.ru
лечение запоя
Нужен надежный промышленный пол без простоев? Мы сделаем под ключ бетонные, наливные, магнезиальные и полимерцементные покрытия. Даем гарантию от 2 лет, быстро считаем смету и выходим на объект в кратчайшие сроки. Ищете Бетонные полы с топпингом? Смотреть объекты, рассчитать стоимость и оставить заявку можно на mvpol.ru Сдаем работы в срок, применяем проверенные материалы и собственную технику. Свяжитесь с нами — предложим оптимальный вариант под задачи и стоимость.
Заказал , получил трэк , ждем)
https://kemono.im/ydyhibegqoau/gde-v-kalifornii-kupit-marikhuanu
Дальнейших успехов вам и продаж!
Hi, its fastidious piece of writing about media print, we all know media is a enormous source of data.
kra39 at
http://www.google.je/url?q=https://e-bitware.com.mx/pin-up/como-obtener-giros-gratis-en-pin-up-casino/ – Pin Up Casino Mexico – A popular online casino in Mexico!
https://500px.com/p/candetoxblend?view=photos
Afrontar un examen de drogas ya no tiene que ser un problema. Existe un suplemento de última generación que funciona en el momento crítico.
El secreto está en su fórmula canadiense, que estimula el cuerpo con creatina, provocando que la orina oculte los rastros químicos. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: es un plan de emergencia, diseñado para candidatos en entrevistas laborales.
Miles de usuarios confirman su efectividad. Los entregas son confidenciales, lo que refuerza la seguridad.
Si no quieres dejar nada al azar, esta alternativa es la herramienta clave.
ABC news — ваш надежный источник свежих новостей, аналитики и экспертных мнений об Украине и мире. Мы публикуем оперативные материалы о событиях, экономике, обществе, культуре и здоровье, чтобы вы всегда были на шаг впереди. В центре внимания — качество, скорость и проверенные факты. Узнайте больше на https://abcua.org/ и подпишитесь, чтобы не пропускать важное. ABC news — информируем, вдохновляем, помогаем понимать тенденции дня. Присоединяйтесь сегодня и будьте в курсе главного!
https://www.goodreads.com/user/show/193655916-candetoxblend
Gestionar un control sorpresa puede ser un momento critico. Por eso, se desarrollo un metodo de enmascaramiento probada en laboratorios.
Su receta premium combina creatina, lo que sobrecarga tu organismo y oculta temporalmente los metabolitos de toxinas. El resultado: una prueba sin riesgos, lista para ser presentada.
Lo mas destacado es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete resultados permanentes, sino una herramienta puntual que responde en el momento justo.
Miles de estudiantes ya han experimentado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta alternativa te ofrece tranquilidad.
все ровно,продукт качественный не знаю что у вас было.делал 1 к 10. получилась на убой))
https://wirtube.de/a/amydukeamy/video-channels
Р° ты откуда? сам? экспертиза будет чистая РЅРµ волнуйся…
Рнтересно, сколько дней заказ будет идти… Успеет ли РґРѕ запрета, если сегодня заказать…
https://odysee.com/@mi1l3rlpr0fil3
Р’СЃРµ будет окей, это РєРѕСЃСЏРє курьерки…
ЭЛЕК — лидер Северо-Запада по складам судового кабеля и судовой электротехники. Отгружаем от 1 метра, отправляем по всей России, доставка до транспортной компании бесплатно. Ищете кмпв 8х0 4 цена? Подробнее на elekspb.ru Сертификаты РМРС и РРР в наличии — подберем нужный маркоразмер и быстро выставим счет.
Клад был уличным, спрятан по разумному, под решеткой окна подъезда, рядом с окном стояла лавочка, на которой можно без палива посидеть и нащупать клад. Клад 5 балов из 5!!!
https://igli.me/jeremyleejer
В двух пакетах
Спасибо всем.
https://wirtube.de/a/jeffreymacdonaldjef/video-channels
доброго времени суток. Так что по итогу магазин то ровный или нет,а то куча противоречий,заранее благодарен.
а сюда заглянуть влом ? //legalrc.com/threads/Трипы.588/page-2
https://odysee.com/@sidonijatilta
тусиай и тусипи тут всегда хорошие, к ним претензий никогда не возникает.
https://www.youtube.com/@candetoxblend/about
Pasar un control sorpresa puede ser un desafio. Por eso, ahora tienes una solucion cientifica probada en laboratorios.
Su receta premium combina carbohidratos, lo que ajusta tu organismo y enmascara temporalmente los trazas de alcaloides. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete limpiezas magicas, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de estudiantes ya han comprobado su seguridad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta formula te ofrece confianza.
Работал с магазином! все норм
https://www.betterplace.org/en/organisations/68237
Не взирая на то что заказ был оплачен в среду прошлой недели, а получил я его через 9(девять) дней, данный селлер заслужил мое доверие!
вывод из запоя омск
vivod-iz-zapoya-omsk009.ru
вывод из запоя круглосуточно омск
Обратите внимание, РўРЎ отказывается работать СЃ ГАРАНТОМ! хоть Рё магазин древний Рё проверенный! РЅРѕ хочется спать СЃРїРѕРєРѕР№РЅРѕ! АДМРРќР« ОБРАТРРўР• Р’РќРРњРђРќРР•, РџРћР Рђ РљРђРљ РўРћ РЗМЕНРРўР¬ РЕЖРРњ РАБОТЫ ГАРАНТА. СДЕЛКРПРОВОДРРўР¬ ОБЯЗАТЕЛЬНО ТОЛЬКО ЧЕРЕЗ ГАРАНТА!
https://www.grepmed.com/qifabaedioa
очень сложно дописаться до них=( а цены хорошие.
Je suis fou de MrPlay Casino, il propose une aventure de casino qui swingue comme un orchestre. Les options de jeu au casino sont variees et festives, comprenant des jeux de casino adaptes aux cryptomonnaies. Les agents du casino sont rapides comme un numero de cirque, repondant en un clin d’?il festif. Les paiements du casino sont securises et fluides, mais j’aimerais plus de promotions de casino qui eblouissent comme un feu d’artifice. Dans l’ensemble, MrPlay Casino promet un divertissement de casino eclatant pour les passionnes de casinos en ligne ! En plus le site du casino est une merveille graphique festive, facilite une experience de casino festive.
mr.play sovellus|
САБЖ РЎРђРњ РџРћ СЕБЕ РќР• РџР РЃРў !! РњРЈРўРРўР¬ РќРђ РќРЃРњ РњРРљРЎР« СМЫСЛА НЕТ !!! РРўРћ РђРќРўРДЕПРЕССАНТ !!
http://www.pageorama.com/?p=aibadroc
Заказываю у магазина 6-й раз уже и все ровно!Берите только тут и вы не ошибетесь.Да и еще странная штука происходит,как-то взял у другого магазина реагент точно такой же курил месяц гдето и чуть не помер да и отходосы всю неделю были ужасные.А из этого магаза брал реагент было все ништяк,отходосы были но я их почти не заметил.Делайте выводы Бразы.Магазин отличный!Мир всем!
https://push-network-rankings.com/
https://hashnode.com/@candetoxblend
Enfrentar un control médico ya no tiene que ser una pesadilla. Existe una fórmula confiable que funciona en el momento crítico.
El secreto está en su mezcla, que estimula el cuerpo con proteínas, provocando que la orina neutralice los marcadores de THC. Esto asegura parámetros adecuados en solo 2 horas, con ventana segura para rendir tu test.
Lo mejor: no se requieren procesos eternos, diseñado para candidatos en entrevistas laborales.
Miles de usuarios confirman su seguridad. Los entregas son confidenciales, lo que refuerza la confianza.
Cuando el examen no admite errores, esta alternativa es la respuesta que estabas buscando.
Je suis accro a NineCasino, ca vibre avec une energie de casino cosmique. Les options de jeu au casino sont riches et etoilees, incluant des jeux de table de casino d’une elegance astrale. Le personnel du casino offre un accompagnement digne d’un astronaute, offrant des solutions claires et instantanees. Le processus du casino est transparent et sans trou noir, mais des bonus de casino plus frequents seraient stellaires. Dans l’ensemble, NineCasino promet un divertissement de casino galactique pour les joueurs qui aiment parier avec panache au casino ! En plus la navigation du casino est intuitive comme une trajectoire orbitale, ce qui rend chaque session de casino encore plus siderante.
ninecasino registration|
Je trouve absolument envoutant Posido Casino, c’est un casino en ligne qui ondule comme une mer dechainee. Les options de jeu au casino sont riches et fluides, incluant des jeux de table de casino d’une elegance marine. Les agents du casino sont rapides comme une vague deferlante, repondant en un eclat d’ecume. Les gains du casino arrivent a une vitesse de maree, quand meme plus de tours gratuits au casino ce serait aquatique. Dans l’ensemble, Posido Casino promet un divertissement de casino aquatique pour les amoureux des slots modernes de casino ! Par ailleurs la navigation du casino est intuitive comme un courant marin, donne envie de replonger dans le casino sans fin.
posido cazino|
Братва после покупки не забываем писать отзывы.
http://www.pageorama.com/?p=wybybzjuhygr
Сделал заказ. Пропустил реквизиты для оплаты. Продавец свяжись со мной, оплачу. В понедельник сможете отправить товар?
https://bar-vip.ru/vyezdnoi_bar/
Je suis accro a MrPlay Casino, il propose une aventure de casino qui swingue comme un orchestre. Il y a une ribambelle de jeux de casino captivants, offrant des sessions de casino en direct qui font danser. L’assistance du casino est chaleureuse et impeccable, joignable par chat ou email. Les gains du casino arrivent a une vitesse endiablee, quand meme plus de tours gratuits au casino ce serait enivrant. Pour resumer, MrPlay Casino c’est un casino a rejoindre sans attendre pour ceux qui cherchent l’adrenaline festive du casino ! Bonus le site du casino est une merveille graphique festive, ce qui rend chaque session de casino encore plus exuberante.
mr.play bonus|
привет запулил на закладку ??
https://igli.me/catherinej75_style
РЈ меня ожидалась поездка РїРѕ работе РІ Столицу нашей СЂРѕРґРёРЅС‹ РЅР° пару недель РЅРѕ как обычно СЏ списался оператором РІ джаббе подтвердил адрес через форум что РЅРµ Р¤РЙК оплатил заранее РїРѕ приезду написал РўРЎ , РѕРЅ РїРѕ СЃРєРѕСЂРѕРјСѓ выдал РјРЅРµ адрес РІ тот день что договорились )
Sou louco pelo role de PlayUzu Casino, parece uma tempestade de diversao. O catalogo de jogos do cassino e uma explosao total, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e uma correnteza, acessivel por chat ou e-mail. As transacoes do cassino sao simples como uma brisa, as vezes queria mais promocoes de cassino que detonam. No fim das contas, PlayUzu Casino oferece uma experiencia de cassino que e puro gas para os aventureiros do cassino! Vale falar tambem a plataforma do cassino detona com um visual que e puro trovao, aumenta a imersao no cassino a mil.
bono de bienvenida playuzu|
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar015.ru
лечение запоя
Je suis accro a Posido Casino, il propose une aventure de casino qui plonge dans les abysses. Le repertoire du casino est un recif de divertissement, proposant des slots de casino a theme aquatique. L’assistance du casino est chaleureuse et limpide, avec une aide qui fait des vagues. Le processus du casino est transparent et sans remous, cependant des recompenses de casino supplementaires feraient nager de joie. En somme, Posido Casino est un casino en ligne qui fait des vagues pour les passionnes de casinos en ligne ! Bonus l’interface du casino est fluide et eclatante comme une mer turquoise, donne envie de replonger dans le casino sans fin.
posido casino arvostelu|
Скиньте сайт ваш пожалуйста.
https://www.betterplace.org/en/organisations/68546
2.Почему на сайте нет ниодного упоминания о ритейле,в то время,как заказы надо делать через него?
интернет провайдеры в москве по адресу дома
inernetvkvartiru-msk005.ru
интернет тарифы москва
https://www.goodreads.com/user/show/193655916-candetoxblend
Aprobar un control sorpresa puede ser un momento critico. Por eso, se desarrollo una formula avanzada desarrollada en Canada.
Su formula unica combina carbohidratos, lo que prepara tu organismo y disimula temporalmente los metabolitos de toxinas. El resultado: una orina con parametros normales, lista para entregar tranquilidad.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete limpiezas magicas, sino una estrategia de emergencia que responde en el momento justo.
Miles de profesionales ya han validado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
Тепкрь сам хочу зделать заказ но немогу на сайт попасть ((((
https://odysee.com/@annokruize231
Пацаны из ТЛТ не берите через этот магаз ФСКН кроет курьерку в нашем городе!!!
https://autoevak-46.ru/
Здравствуй, народ, кто с Мск брал, сроки доставки какие реальные были и какая служба?
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%9F%D0%BE%D1%80%D1%82%D0%B8%D0%BC%D0%B0%D0%BD/
я думаю все ровно будет. заказал тут для пробы 5 гр. акв 48 ф . 10 октября еще заказал. еще не выслали. на почту пишут, извиняются. ждём результатов. как будут движения отпишу.
Get receive sms and protect your personal information.
Locating a fake phone number for verification purposes can be quite challenging in today’s digital landscape. Many online services require a valid phone number to confirm your identity, which can create uncomfortable situations. However, using a fake phone number can assist in preserving your privacy while accessing necessary services.
Temporary phone numbers can act as helpful alternatives for verification. These numbers allow you to obtain required SMS messages without revealing your real number. Numerous websites offer these services, making it simple to find a suitable fake phone number when needed.
Opting for a service, it’s important to assess the reliability and security they offer. Find platforms that have great feedback to ensure a smooth experience. Additionally, some services might require payment, so be sure to check their pricing structures before proceeding.
In conclusion, using a fake phone number for verification can protect your personal information. Provided you opt for a reliable provider, you can take advantage of the convenience this method offers. Remain aware about the best services available, and keep your information safe online.
Пишу сейчас и ржачь пробирает.
https://www.divephotoguide.com/user/subwiydigpag
Отличный магаз, качество на ура. даже если сам реагент не сильный.
Рто фейк что тут вам РЅРµ понятно то.
https://rant.li/poceboyid/kupit-mefedron-sevastopol
Продавец общительный, выслал с заказом пару пробников бесплатно! заказы высылют оперативно
https://www.google.ki/url?q=https://www.dattainc.com.mx/2025/09/05/pin-up-casino-acepta-criptomonedas-en-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
могу заверить вас что сдесь ни только людское понимание но и честное слова!!!мир вам друзья!!!все шикарно!!
https://odysee.com/@nielandalexandra3
Просьба не флудить. Руж тем более не развивать больные фантазии.
plane crash game money aviator-igra-2.ru .
Спрашивай в жаббер, там больше 10-15 минут задержки с ответом не бывает.
https://bio.site/jacihefxi
Сѓ СПСРпостоянно такая хрень, РїРѕСЂРѕР№ РїРѕ неделе РЅРµ пробиваются треки(проверено РЅР° себе… тоже срал кирпичами(РЅР° рафика причем)) Р° РіРѕРІРѕСЂСЏС‚ быстрей ЕМС. РЅРµ верю))
Молча !! Запрет вступает в силу 26го числа, если не ошибаюсь. Скидывай всё палево, жёсткий дист зарывай подальше и иди получай ))
https://rant.li/lybabaodubuc/kupit-mefedron-v-nebuge
Не взирая на то что заказ был оплачен в среду прошлой недели, а получил я его через 9(девять) дней, данный селлер заслужил мое доверие!
Привет всем!
Долго не спал и думал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от гуру в seo,
отличных ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://imap33.site
Увеличение DR сайта с нуля требует системного подхода. Ссылочная масса напрямую влияет на этот показатель. Xrumer ускоряет создание качественных линков. Чем больше авторитетных ссылок, тем выше DR. Увеличение DR сайта с нуля – возможна с автоматизированным прогоном.
seo продвижение курс, yandex seo оптимизация сайта, работа линкбилдинг
Увеличение DR сайта с нуля, seo tags generator opencart, торговые предложения seo
!!Удачи и роста в топах!!
раньше и хуй крепче был и бабы красивей
https://www.impactio.com/researcher/eckertyyxhans
Написал заказ РЅР° мыло… никто РЅРµ ответил. Списался через скайп сказали чтоб переоформил заказ.. Переоформил, опять никакого ответа…
https://replit.com/@candetoxblend
Enfrentar una prueba preocupacional puede ser un desafio. Por eso, se ha creado una solucion cientifica desarrollada en Canada.
Su composicion precisa combina nutrientes esenciales, lo que ajusta tu organismo y disimula temporalmente los metabolitos de THC. El resultado: una muestra limpia, lista para entregar tranquilidad.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de personas en Chile ya han experimentado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta formula te ofrece tranquilidad.
https://www.behance.net/candetoxblend
Afrontar un test preocupacional ya no tiene que ser una incertidumbre. Existe una alternativa científica que actúa rápido.
El secreto está en su fórmula canadiense, que sobrecarga el cuerpo con vitaminas, provocando que la orina oculte los rastros químicos. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no necesitas semanas de detox, diseñado para quienes enfrentan pruebas imprevistas.
Miles de clientes confirman su rapidez. Los envíos son 100% discretos, lo que refuerza la confianza.
Cuando el examen no admite errores, esta fórmula es la elección inteligente.
Все Вась,извини..с утра заматался))
https://www.brownbook.net/business/54238108/купить-марихуаны-воронеже/
прилив бодрости учащаеться
Заказал на пробу 50гр 203, придёт люди попробуют я отпишусь,планирую сделать 1к9-ну не верю я когда говорят что можно 1к 13,15 итд.
http://www.pageorama.com/?p=kmxafcef
2)Кто курит раз в неделю : от 3 часов до 5-7 часов
лечение запоя оренбург
vivod-iz-zapoya-orenburg007.ru
лечение запоя оренбург
Че все затихли что не кто не берет? Не кто не отписывает последние дни не в курилке не где везде тишина(
https://a8b9045f26ca7cffc081238129.doorkeeper.jp/
Какие риски ) ты адекват ? ты скинул непонятно что не имеющее никакого смысла.
Привет всем!
Долго не спал и думал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от успещных seo,
профи ребят, именно они разработали недорогой и главное top прогон Xrumer – https://imap33.site
Линкбилдинг под бурж помогает продвигать сайты на зарубежные рынки. Нужно работать с иностранными площадками и форумами. Автоматизация через Xrumer ускоряет процесс. Это увеличивает количество качественных ссылок. Линкбилдинг под бурж – залог успешного международного SEO.
продвижение сайтов стоимость спб, написание seo текста, Создание ссылок массовыми методами
линкбилдинг блог, целевое продвижение сайта, таганрог продвижение сайтов
!!Удачи и роста в топах!!
У нас https://teamfun.ru/ огромный ассортимент аттракционов для проведения праздников, фестивалей, мероприятий (день города, день поселка, день металлурга, день строителя, праздник двора, 1 сентября, день защиты детей, день рождения, корпоратив, тимбилдинг и т.д.). Аттракционы от нашей компании будут хитом и отличным дополнением любого праздника! Мы умеем радовать детей и взрослых!
Что ж ты такой нетерпеливый… ))
https://linkin.bio/ojizykexuki
Ты вообще нормальный и адекватный ? Ты сначала разберись куда ты писал а потом умничай. У меня адреса без фото и только опт. Судя по твоему нику ты из Екб, я в ЕКБ НЕ РАБОТАЮ И НЕ РАБОТАЛ.
http://110km.ru/
Ровный магаз брацы
https://hoo.be/ogaygubyef
магазин ровный
https://www.te-in.ru/uslugi/texnicheskoe-obsluzhivanie-dgu.html/
Chemsale.ru — ваше надежное медиа о строительстве, архитектуре и недвижимости. Мы фильтруем шум, выделяем главное и объясняем без лишней терминологии, чтобы вы принимали уверенные решения. В подборках найдете идеи для проекта дома, советы по выбору участка и лайфхаки экономии на стройке. Читайте свежие обзоры, мнения экспертов и реальные кейсы на https://chemsale.ru/ и подписывайтесь, чтобы не пропустить важное. С Chemsale вы уверенно планируете, строите и совершаете сделки.
Добрый день!
Долго анализировал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от гуру в seo,
отличных ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://imap33.site
Линкбилдинг через программы упрощает работу специалистов. Форумные проги для SEO автоматизируют размещение ссылок. Оптимизация ссылочного профиля повышает авторитетность сайта. Как прокачать сайт через Xrumer становится понятнее с опытом. Автоматизированный линкбилдинг экономит силы и время.
seo оптимизации карточки товаров, сео специалист кто это, линкбилдинг купить
Линкбилдинг для повышения DR, поисковая и seo реклама, продвижение инстаграм seo
!!Удачи и роста в топах!!
Visit the website https://mlbet-mbet.com/ and you will learn everything about the Melbet bookmaker, with which you can bet on sports and play in an online casino. Find out basic information, how to register, how to top up your balance and withdraw funds, everything about the mobile application and much more. Do not forget to use a profitable promo code on the website, which will give a number of advantages!
Забрал я посылочку. Упоковка на 5+(пакет был с дыркой как будто смотрели что там, но с такой упаковкой только на паяльник подумаеш). Сделал ам 2233(1г) + ркс4(1г) на 20 грамм мягкого. Честно говоря ам не почувствовал совсем, кроет как ркс4(1 г.) на 20 грамм(был печальный опыт). Сейчас курим по грамму на двоих, тогда кроет на “целых” 10 минут. Вообщем незнаю чья ошибка это, да и смысла выяснять нет, деньги все равно не вернуться. Хотел попробовать тусипи заказать, но как то страшно. С тусипи то такого не было не разу вроде? Притензий не было?
https://www.band.us/page/99903558/
p/s мне ничего не надо! Зашёл пожелать удачи магазину в нелегком деле.
Стабильные параметры воды и высокая плотность посадки — ключ к результату в УЗВ от CAMRIEL. Берем на себя весь цикл: ТЭО, проект, подбор и монтаж оборудования, пусконаладку и обучение вашей команды. Узнайте больше и запросите расчет на https://camriel.ru/ — подберем оптимальную конфигурацию для осетра, форели и аквапоники, учитывая ваш регион и цели. Экономия воды и энергии, управляемый рост рыбы и предсказуемая экономика проекта.
https://www.tumblr.com/blog/candetoxblend
Enfrentar una prueba de orina puede ser un desafio. Por eso, se ha creado una solucion cientifica con respaldo internacional.
Su formula premium combina nutrientes esenciales, lo que estimula tu organismo y neutraliza temporalmente los marcadores de toxinas. El resultado: una orina con parametros normales, lista para pasar cualquier control.
Lo mas notable es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete limpiezas magicas, sino una herramienta puntual que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si no deseas dejar nada al azar, esta alternativa te ofrece confianza.
угу, “на глазок” отсыпали. купи весы и взвесь нормально. На вид оно может показаться как больше так и меньше…
https://kemono.im/vbmiydkbige/kupit-marikhuanu-v-tel-avive
Дружище как все прошло?)) забрал своё??? А то написал неделю назад и тишина))) если забрал сколько шло по времени? напиши нам а то на последних страницах сдесь какой то кипишь нездоровый…(
лечение запоя
vivod-iz-zapoya-minsk007.ru
экстренный вывод из запоя минск
так что мне вообще по душе и курьерка и селлер которому респект за АМ2233
https://odysee.com/@hansenmissouri2
Привет всем и Мира! Тоже уже неделЮ жду адекватного трека . Дали два и оба не бьются((
Заказывал небольшую партию)) Качество отличное, быстрый сервис)) в общем хороший магазин)
https://form.jotform.com/252505039729056
Про Ам1220 здешний известно что нибудь…?
дешевый интернет москва
inernetvkvartiru-msk006.ru
домашний интернет в москве
Остановитесь в гостиничном комплексе «Верона» в Новокузнецке и почувствуйте домашний уют. В наличии 5 номеров — 2 «Люкс» и 3 «Комфорт» со свежим ремонтом, тишиной и внимательным обслуживанием. Ищете сайт гостиницы? Узнайте больше и забронируйте на veronahotel.pro Рядом — ТЦ и удобная развязка, сауна и инфракрасная комната. Молодоженам — особая «Свадебная ночь» с декором номера, игристым и фруктами.
чем ровный!!!как всегда не подвёл:good:уважуха бро
https://yamap.com/users/4810310
тоже хочу заказать бро!!!
1win самолетик https://aviator-igra-5.ru/ .
А в сочи есть магазины
https://yamap.com/users/4800714
Магазин ровнее не куда!!! Ребята отработали на славу, все четко и оперативно. Спасибо огромное, буду сотрудничать и дальше)
https://www.provenexpert.com/candetoxblend/
Enfrentar una prueba de orina ya no tiene que ser una incertidumbre. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su mezcla, que ajusta el cuerpo con creatina, provocando que la orina oculte los metabolitos de toxinas. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para trabajadores en evaluaciones.
Miles de personas en Chile confirman su rapidez. Los envíos son 100% discretos, lo que refuerza la tranquilidad.
Si tu meta es asegurar tu futuro laboral, esta fórmula es la herramienta clave.
пробывал нюхать эфект 4-6часа
https://igli.me/zimmerqayiuwe
Из аськи вышел и даже не ответил… *(
http://maps.google.com.np/url?q=https://sportsfanfare.com/2025/09/05/soporte-al-cliente-en-espanol-en-pin-up-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
Спасибо за продосатавленные вещества
https://www.impactio.com/researcher/kitsunaisixros33ss
Я, лично, в первый раз сделал заказ ,в этом магазине- оформил(по аське) его безналично,(что очень удобно для меня,даже из дома не выходил),сутки прошли,был дан трек,через два дня,посылка была у меня в городе.Следил за ее перемещением на сайте курьера(опять же-не выходя из дома).
Уважаемый, Chemical-mix.com, я новичок что на легале, что в джабере, что где либо ещё… не получается выйти на связь, проблема с покупкой, в джабере написано, на сайте не онлайн… ответь пожалуйста в jabber… Зарание большое спасибо…
https://bio.site/ibtuigjy
Заказал, оплатил, получил, Радуюсь… !:D Норм магаз приятно иметь дело..! !!
Je suis accro a MrXBet Casino, on dirait une enigme pleine de surprises. L’assortiment de jeux du casino est un coffre-fort de plaisirs, incluant des jeux de table de casino d’une elegance cryptique. Le personnel du casino offre un accompagnement digne d’un maitre des enigmes, avec une aide qui devoile les mysteres. Le processus du casino est transparent et sans zones d’ombre, mais des bonus de casino plus frequents seraient captivants. Globalement, MrXBet Casino est un joyau pour les fans de casino pour les detectives du casino ! De surcroit la plateforme du casino brille par son style captivant, donne envie de replonger dans le casino sans fin.
mrxbet recensioni|
Je suis fou de ParisVegasClub, on dirait une soiree endiablee a Vegas. Les options de jeu au casino sont riches et eclatantes, comprenant des jeux de casino adaptes aux cryptomonnaies. Les agents du casino sont rapides comme un numero de danse, repondant en un eclair de projecteur. Le processus du casino est transparent et sans fausse note, cependant plus de tours gratuits au casino ce serait enivrant. En somme, ParisVegasClub offre une experience de casino eclatante pour les passionnes de casinos en ligne ! En plus la navigation du casino est intuitive comme une choregraphie, amplifie l’immersion totale dans le casino.
offres paris vegas club|
Ich liebe den Zauber von NV Casino, es bietet ein Casino-Abenteuer, das wie ein Vulkan ausbricht. Der Katalog des Casinos ist eine Welle voller Spa?, mit einzigartigen Casino-Slotmaschinen. Der Casino-Service ist zuverlassig und glanzend, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein Wirbelwind, manchmal die Casino-Angebote konnten gro?zugiger sein. Zusammengefasst ist NV Casino eine Casino-Erfahrung, die wie ein Regenbogen glitzert fur Fans moderner Casino-Slots! Ubrigens die Casino-Oberflache ist flussig und strahlt wie ein Polarlicht, was jede Casino-Session noch aufregender macht.
casino nv|
Минск нужен. Срочно бля хуево уже, надо зарядиться! Помогите пожалуйста я здесь ни хрена не понимаю
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%90%D0%B3%D0%B0%D0%B4%D0%B8%D1%80/
вот и я уже трясусь.
реагенты всегда чистые и по высшему??? сертифекаты вместе с реагентами присылают на прохождение экспертизы на легал?
https://www.brownbook.net/business/54246700/купить-мефедрон-в-брянске/
ПО ВРЕМЕНИ СКОЛЬКО?
Je suis totalement fascine par MrXBet Casino, on dirait une enigme pleine de surprises. Le repertoire du casino est un dedale de divertissement, comprenant des jeux de casino adaptes aux cryptomonnaies. L’assistance du casino est fiable et perspicace, joignable par chat ou email. Les retraits au casino sont rapides comme une cle trouvee, par moments des bonus de casino plus frequents seraient captivants. Pour resumer, MrXBet Casino offre une experience de casino mysterieuse pour les joueurs qui aiment parier avec flair au casino ! En plus le site du casino est une merveille graphique enigmatique, donne envie de replonger dans le casino sans fin.
mrxbet connexion|
Je suis totalement envoute par PlazaRoyal Casino, il propose une aventure de casino qui scintille comme un trone. L’assortiment de jeux du casino est un tresor couronne, incluant des jeux de table de casino d’une elegance princiere. Le personnel du casino offre un accompagnement digne d’une cour, offrant des solutions claires et instantanees. Le processus du casino est transparent et sans intrigues, mais des recompenses de casino supplementaires feraient regner. Dans l’ensemble, PlazaRoyal Casino offre une experience de casino somptueuse pour les nobles du casino ! De surcroit la plateforme du casino brille par son style souverain, ajoute une touche de grandeur au casino.
plaza royal casino bonus codes|
Ich bin suchtig nach Richard Casino, es verstromt eine Spielstimmung, die wie ein Kronjuwel glanzt. Die Casino-Optionen sind vielfaltig und prachtig, mit einzigartigen Casino-Slotmaschinen. Das Casino-Team bietet Unterstutzung, die wie ein Zepter glanzt, liefert klare und schnelle Losungen. Casino-Transaktionen sind simpel wie ein kaiserlicher Befehl, aber wurde ich mir mehr Casino-Promos wunschen, die wie Juwelen glanzen. Insgesamt ist Richard Casino eine Casino-Erfahrung, die wie ein Kronungsjuwel glanzt fur die, die mit Stil im Casino wetten! Extra die Casino-Navigation ist kinderleicht wie ein koniglicher Marsch, den Spielspa? im Casino auf ein konigliches Niveau hebt.
richard casino sister sites|
Получил трек 4 февраля, трек не бьется на сайте по сей день…
https://www.metooo.io/u/68b974c9f15e5d211993a859
Может правда о ошибочке что небудь не то отправили)))
вывод из запоя цена
vivod-iz-zapoya-orenburg008.ru
лечение запоя оренбург
А то я запутался совсем, везде по разному пишут.
http://www.pageorama.com/?p=iegicicadf
посылка пришла, все чотко, упаковка на высшем уровне, респектос
https://peterburg2.ru/
Респект и уважуха магазину, и процветания, безусловно!
http://www.pageorama.com/?p=xeubuobay
Просьба подкорректировать самим бредовые сообщения.
Vzrušující svět online casino cz — Průvodce pro české hráče: online casino cz
ну как-то так
https://www.divephotoguide.com/user/eoecuybydo
когда дело было? а то я сам жду заказ
авиатор игра 1win авиатор игра 1win .
Рассказал друг-таксист.
https://www.brownbook.net/business/54240459/купить-наркотики-владивосток/
Заказ получил, спасибо за ракетку 😀 Это был мой первый опыт заказа легала в интернете, и он был положительным! Спасибо магазину chemical-mix.com за это!
Хочете завжди знати головне про моду й красу? У нас — новини та поради, які тримають у тренді. Завітайте на https://exclusiveua.com/ і відкрийте світ ексклюзивних українських модних новин. Добірки must-have, б’юті-новинки та корисні лайфхаки — усе зібрано для вашої зручності. Зберігайте в закладки — щоденні оновлення і комфортне читання з будь-якого девайса.
Все пришло довольно быстро.
https://www.betterplace.org/en/organisations/68373
Значит не туда стучишься!а ребята молодцы!
https://hub.docker.com/u/candetoxblend
Aprobar una prueba de orina puede ser un momento critico. Por eso, se ha creado una alternativa confiable desarrollada en Canada.
Su composicion eficaz combina nutrientes esenciales, lo que estimula tu organismo y disimula temporalmente los metabolitos de sustancias. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas notable es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete milagros, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de profesionales ya han comprobado su efectividad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta formula te ofrece tranquilidad.
но в итоге, когда ты добиваешься его общения – он говорит, что в наличии ничего нет. дак какой смысл то всего этого? разве не легче написать тут, что все кончилось, будет тогда-то тогда-то!? что бы не терять все это время, зайти в тему, прочитать об отсутствии товара и спокойно (как Вы говорите) идти в другие шопы.. это мое имхо.. (и вообще я обращался к автору темы)
https://kemono.im/aedabiiodueg/kupit-mefedron-penza
Продолжайте в том же духе.
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk008.ru
вывод из запоя круглосуточно
Ребят, а подскажите насчет доставки спср, в какие города она доставляет ? Блин никогда раньше с ней не связывался 🙁 Расскажите пожалуйста, что, да как
https://rant.li/eohyyfahe/kupliu-amfetamin-koks
По приходу товара я выложу тут розничную площадку для заказов, на которой вы сможете заказать реактивы из наличия на складе, не уточняя у нас что есть…
https://replit.com/@candetoxblend
Enfrentar una prueba de orina ya no tiene que ser una incertidumbre. Existe un suplemento de última generación que actúa rápido.
El secreto está en su combinación, que sobrecarga el cuerpo con proteínas, provocando que la orina neutralice los marcadores de THC. Esto asegura parámetros adecuados en menos de lo que imaginas, con ventana segura para rendir tu test.
Lo mejor: no necesitas semanas de detox, diseñado para quienes enfrentan pruebas imprevistas.
Miles de clientes confirman su efectividad. Los envíos son 100% discretos, lo que refuerza la seguridad.
Cuando el examen no admite errores, esta fórmula es la herramienta clave.
1win самолетик aviator-igra-4.ru .
тоже самое оплатил 3.02 трек получил через 5 дней но он до сих пор не бьется ТС расскзывает сказки что трек в течении 2х рабочих дней начнет биться я наверно похож на дебила я за свою жизнь получил курьерок больше чем отправил данный ТС РЕБЯТА ПРИТОРМОЗИТЕ СВОЮ ОПЛАТУ ПОКА Я НЕ ПОЛУЧУ СВОЙ ГРУЗ!!!!! Я кругосуточно в сети и буду держать Вас в курсе своих событий!!!!
http://www.pageorama.com/?p=eefucyhey
значит ты чо то намутил , а вещество я заказывал в этом магазе норм для RCS естественно
проект перепланировки цена http://www.proekt-pereplanirovki-kvartiry8.ru .
я заказывау уже больше 2х лет только у этого магазина, сейчас заказал эфор и регу на подобия jv 100 сказали, посыль дошол от крыл а тпм только эфор а реги нет. может вы что то перепутали с заказом ребята ответь.
https://www.impactio.com/researcher/claudiasellner23648
Всех благ данному магазину!!!
провайдер по адресу нижний новгород
inernetvkvartiru-nizhnij-novgorod004.ru
интернет провайдер нижний новгород
День добрый, пишу свой отзыв, вернее назвать его извинением. Опишу ситуацию, не помню когда и не столь это важно, но недавно был сделан заказ, на n-ое количество cmh-400.
https://www.grepmed.com/rtacidocubo
Вы очень давно работаете,стабильная деятельность.
Hi there! This is my first comment here so I just wanted to give a quick shout out and say I truly enjoy reading through your articles. Can you suggest any other blogs/websites/forums that go over the same subjects? Thanks a ton!
http://smotri.com.ua/yak-pidibraty-sklo-fary-na-ridkisnu-model-avt.html
магаз ещё не начал работу?
https://www.impactio.com/researcher/hxychlgdby489
Дом рядом с адресом говоришь, отдаешь залог, когда приедешь в адрес (в разных такси по-разному, могут и не попросить), и идешб себе за кладом 🙂
да, спросил тут ли менеджер, по быстрому оформил заказ.
https://form.jotform.com/252493760945063
Скажите сей час в Челябинске работаете?)
https://www.deviantart.com/candetoxblend
Gestionar una prueba de orina puede ser complicado. Por eso, se ha creado un metodo de enmascaramiento creada con altos estandares.
Su mezcla potente combina nutrientes esenciales, lo que prepara tu organismo y oculta temporalmente los metabolitos de sustancias. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas notable es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete milagros, sino una herramienta puntual que responde en el momento justo.
Miles de estudiantes ya han experimentado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta formula te ofrece confianza.
Excellent post. Keep posting such kind of information on your blog. Im really impressed by your site.
Hi there, You’ve done a great job. I’ll certainly digg it and personally suggest to my friends. I’m confident they’ll be benefited from this web site.
http://blooms.com.ua/vybir-linz-dlya-avto-na-shcho-zvernuty-uvahu.html
супер !!!
https://yamap.com/users/4804018
привет бро)) чето какой то засланый казачок тут про запр дживы интерес проявляет…
самый дешёвый магазин из доверенных – это этот!
https://igli.me/qpprosewall
Магазин ровнее не куда!!! Ребята отработали на славу, все четко и оперативно. Спасибо огромное, буду сотрудничать и дальше)
магазин отличный
https://igli.me/anderson_margaretw14089
Ага ровный!!!!И я так считал до некоторых случаев!
Чемикал. когда трек даш?? позавчера заказал. сказал во вторник в среду отправка будет.
https://rant.li/ekl0yf3v6t
почему статус заказа отложен!? 1000539
щас заказал по 5г RCS-4 и URB754 по скайпу объяснили как оплатить, пока всё коректно жду посылки там отпишу..
https://www.grepmed.com/efehybuihxy
Кто тут урб-754 брал отпишитесь чё да как
Игровая платформа Vavada считается одним из лидеров.
Специальные предложения дают отличную возможность стартовать.
Турниры и события поддерживают интерес к игре.
Каталог развлечений обновляется провайдерами.
Создать аккаунт легко, поэтому бонусы становятся доступны сразу.
Подробности смотрите по ссылке: vavada бездеп
Для безопасной и комфортной езды в зимних условиях рекомендуем обратить внимание на купить шипованную резину.
С приходом зимы вопрос выбора шин выходит на первый план. Шины с шипами становятся неотъемлемой частью зимнего вождения. Они обеспечивают отличное сцепление на скользкой поверхности. Эти шины позволяют водителям быть более уверенными на дороге.
В то же время, необходимо тщательно подойти к выбору шипованных шин. Существует несколько важных аспектов, на которые стоит обратить внимание. Размер шин, их тип и назначение играют ключевую роль. Неверный выбор шин может негативно сказаться на управляемости автомобиля.
Надежные производители предлагают широкий выбор шипованных шин. Необходимо ознакомиться с оценками и мнениями пользователей. Хорошая шина должна не только обеспечивать сцепление, но и быть долговечной. Обратите внимание на этот аспект при выборе.
Важно корректно эксплуатировать шипованные шины. Не забывайте проверять давление и состояние протектора. Также старайтесь избегать резких маневров на скользкой дороге. Это позволит не только продлить срок службы шин, но и повысить уровень безопасности на дороге.
Jako žurnalista vím, že klíčem je text, který sluší čtenáři, obsahuje jednoduchá slova, srozumitelný styl a praktické informace, zvlášť když jde o „cz casino online“ a „kasina“. Tady je vaše nové, svěží a užitečné čtení: cz casino online
Забронируйте стрижку в нашем барбершоп уже сегодня и преобразите свой стиль!
Барбершопы в Красноярске набирают популярность . Люди в Красноярске стремятся найти профессиональные услуги стрижки и ухода за волосами .
Подбор барбершопа — это серьезное дело. Важно обратить внимание на опыт барберов и мнения их клиентов .
В каждом барбершопе существует своя особая атмосфера и стиль работы. Некоторые барбершопы ориентированы на традиционные стрижки, а другие — на актуальные модные направления .
Лучше заранее забронировать время на стрижку, чтобы избежать долгого ожидания. Забота о волосах и бороде между визитами в барбершоп также важна.
что то не могу зайти на сайт (
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%9E%D0%BB%D0%BE%D0%BC%D0%BE%D1%83%D1%86/
Заказали, придет посмотрим
https://gitee.com/candetoxblend
Afrontar un examen de drogas ya no tiene que ser una incertidumbre. Existe un suplemento de última generación que funciona en el momento crítico.
El secreto está en su fórmula canadiense, que sobrecarga el cuerpo con vitaminas, provocando que la orina enmascare los marcadores de THC. Esto asegura un resultado confiable en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: es un plan de emergencia, diseñado para trabajadores en evaluaciones.
Miles de clientes confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la seguridad.
Si no quieres dejar nada al azar, esta solución es la respuesta que estabas buscando.
https://www.twitch.tv/candetoxblend
Enfrentar una prueba preocupacional puede ser arriesgado. Por eso, ahora tienes una solucion cientifica con respaldo internacional.
Su receta unica combina carbohidratos, lo que prepara tu organismo y enmascara temporalmente los rastros de THC. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas destacado es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una estrategia de emergencia que responde en el momento justo.
Miles de postulantes ya han comprobado su efectividad. Testimonios reales mencionan paquetes 100% confidenciales.
Si quieres proteger tu futuro, esta formula te ofrece tranquilidad.
ВСЕМ САЛЮТ!!! :hello:
https://igli.me/lindiswestwood
Магазин работает как часы:ok:! Чекист самый крутой продаван это уже проверено годами!!! Дух захватывает от той мысли сколько же он продал за своё существование с 2011 ГОДА:strong: !! Это МЕГА-ПРОДАВАН!!! ТАк держать Чемикал Чекист))!!!
Её переместили в арбитраж. Тогда ничем помочь не могу.
https://bio.site/udadfeuftoh
Пишите в скайп, аську, пожалуйста без лишнего, чтобы была возможность ответить всем. :good:
https://images.google.co.cr/url?q=https://www.diigo.com/item/note/9br1u/7opa?k=d3527a974120e527ec671a3ac8167d7d – Pin Up Casino Mexico – A popular online casino in Mexico!
сегодня в 16:25 на почте получен конверт ,в нем было вещество лимоного цвета 0,3 г , сохнет ,позже подробно опишу
https://www.betterplace.org/en/organisations/68054
МАГАЗИНУ надо бы по ровнее работать!
Готовы жить ярко, стильно и со вкусом? «Стиль и Вкус» собирает лучшие идеи моды, красоты, ЗОЖ и еды в одном месте, чтобы вдохновлять на перемены каждый день. Тренды сезона, работающие лайфхаки, простые рецепты и привычки, которые действительно делают жизнь лучше. Читайте свежие выпуски и применяйте сразу. Узнайте больше на https://zolotino.ru/ — и начните свой апгрейд уже сегодня. Сохраняйте понравившиеся материалы и делитесь с друзьями!
Продован 1000 балоф те =)
https://wirtube.de/a/chauphuongthu45/video-channels
добра всем бро,оплатил заказ неделю назад,на след день дали трек,трек до сих пор в базе не бьётся и посылочка не идёт…тс на письма не отвечает…вобщем чтот печкльно както,обычно 3 дня идёт(
Хотите стать профессионалом в области интернет-маркетинга? Запишитесь на курс сео специалист и начните свой путь к успеху!
Обучение SEO стали неотъемлемой частью цифрового маркетинга. В современном мире знания о SEO необходимы для успешного продвижения сайтов. Подобные обучающие программы помогают освоить основные техники и стратегии, которые открывают путь для увеличения видимости в поисковых системах.
На курсах обычно рассматриваются ключевые аспекты: от анализа ключевых слов до оптимизации контента. Студенты учатся о том, как правильно редактировать мета-теги и использовать внутреннюю перелинковку. Практические задания помогают закрепить полученные знания.
На занятиях также акцентируется внимание на аналитике. Это включает изучение инструментов веб-аналитики для отслеживания эффективности SEO-кампаний. Участники научатся понимать, какие метрики важны для оценки результатов.
По итогам обучения студенты обычно получают сертификаты. Данный аттестат подтверждает их умения и знания в области SEO. Такой диплом может значительно улучшить резюме и повысить шансы на трудоустройство. Программа по SEO — это инвестиция в будущее каждого специалиста в области цифрового маркетинга.
Чувствуете, что подарок должен говорить за вас? Серебряные изделия ручной работы из Кубачи от «Апанде» сохраняют тепло мастера и становятся семейной ценностью. Филигрань, чеканка и кубачинские орнаменты оживают в каждой ложке, чаше или подстаканнике. Ознакомьтесь с коллекцией на https://www.apande.ru/ и выберите вещь, которая подчеркнет вкус и статус. Мы поможем с подбором, гравировкой и бережной доставкой. Подарите серебро, которое радует сегодня и будет восхищать через годы.
лечение запоя минск
vivod-iz-zapoya-minsk009.ru
вывод из запоя круглосуточно минск
карнизы для штор с электроприводом http://www.elektrokarnizy5.ru .
Хороший магазин, все по совести
https://kemono.im/ufigsegu/kupit-mdma-amfetamin
бро незнаю скок раз брал ни разу TS не подводил входил в положения скидки бонусы делал!!!
проектная организация перепланировка проектная организация перепланировка .
А где прайс глянуть?
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%91%D0%BE%D1%88%D0%BA%D0%B8%20%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83%20%D0%93%D0%B0%D1%88%D0%B8%D1%88%20%D0%9A%D0%BE%D0%BD%D1%81%D1%82%D0%B0%D0%BD%D1%86/
магаз ровный,всем советую!!
Estou completamente vidrado por MegaPosta Casino, oferece uma aventura de cassino que detona tudo. Tem uma enxurrada de jogos de cassino irados, incluindo jogos de mesa de cassino cheios de estilo. O servico do cassino e confiavel e de responsa, respondendo mais rapido que um raio. As transacoes do cassino sao simples como um estalo, porem queria mais promocoes de cassino que explodem. Na real, MegaPosta Casino oferece uma experiencia de cassino que e puro fogo para os aventureiros do cassino! De bonus o design do cassino e uma explosao visual braba, faz voce querer voltar pro cassino toda hora.
megaposta login|
Sou viciado no role de OshCasino, parece uma erupcao de diversao. O catalogo de jogos do cassino e uma explosao total, com caca-niqueis de cassino modernos e eletrizantes. A equipe do cassino entrega um atendimento que e uma labareda, com uma ajuda que e puro calor. Os pagamentos do cassino sao lisos e blindados, mas queria mais promocoes de cassino que incendeiam. Na real, OshCasino e o point perfeito pros fas de cassino para os cacadores de slots modernos de cassino! E mais o site do cassino e uma obra-prima de estilo, da um toque de calor brabo ao cassino.
osh bonus code|
Парни, начинается параноя! Завтра посыль приходит, как получать А?
https://ilm.iou.edu.gm/members/rciguheranu/
не болела чтоб башка.
Ich finde absolut uberwaltigend Platin Casino, es verstromt eine Spielstimmung, die wie Platin glanzt. Die Auswahl im Casino ist ein echtes Meisterwerk, mit Live-Casino-Sessions, die wie ein Diamant leuchten. Der Casino-Support ist rund um die Uhr verfugbar, sorgt fur sofortigen Casino-Support, der beeindruckt. Auszahlungen im Casino sind schnell wie ein Funkeln, ab und zu mehr Casino-Belohnungen waren ein glitzernder Gewinn. Am Ende ist Platin Casino ein Muss fur Casino-Fans fur Spieler, die auf luxuriose Casino-Kicks stehen! Ubrigens die Casino-Navigation ist kinderleicht wie ein Funkeln, den Spielspa? im Casino in den Himmel hebt.
platin casino freispiele|
Достойный магазин
https://yamap.com/users/4804018
смотря каким реагентом будешь бадяжить
Ищете удобство и комфорт? У нас вы можете прокат авто с водителем!
Убедитесь, что авто находится в хорошем состоянии и соответствует вашим требованиям.
betgrw casino
Sou louco pelo role de MegaPosta Casino, da uma energia de cassino que e um vulcao. As opcoes de jogo no cassino sao ricas e vibrantes, com jogos de cassino perfeitos pra criptomoedas. O servico do cassino e confiavel e de responsa, respondendo mais rapido que um raio. As transacoes do cassino sao simples como um estalo, mas mais recompensas no cassino seriam um diferencial insano. Resumindo, MegaPosta Casino vale demais explorar esse cassino para os amantes de cassinos online! Alem disso o design do cassino e uma explosao visual braba, da um toque de classe braba ao cassino.
megaposta betting site|
Зачем писать таким большим шрифтом ? Здесь слепых нет. То что тебя где то кинули к нам никакого отношения не имеет.
https://www.grepmed.com/tayhydegu
Уважаемые покупатели, С НОВЫМ ГОДОМ!
Je suis accro a MyStake Casino, il propose une aventure de casino qui captive comme un secret bien garde. Les options de jeu au casino sont riches et intrigantes, proposant des slots de casino a theme enigmatique. L’assistance du casino est chaleureuse et perspicace, avec une aide qui perce les mysteres. Les retraits au casino sont rapides comme une revelation, mais plus de tours gratuits au casino ce serait mystique. Globalement, MyStake Casino est un casino en ligne qui intrigue comme un manuscrit ancien pour les amoureux des slots modernes de casino ! En plus le site du casino est une merveille graphique mysterieuse, amplifie l’immersion totale dans le casino.
В© copyright mystake 2023|
домашний интернет тарифы нижний новгород
inernetvkvartiru-nizhnij-novgorod005.ru
интернет провайдеры нижний новгород
Ich liebe die Energie von Pledoo Casino, es fuhlt sich an wie ein wilder Tanz durch die Spielwelt. Die Auswahl im Casino ist ein echtes Spektakel, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Das Casino-Team bietet Unterstutzung, die wie ein Stern funkelt, antwortet blitzschnell wie ein Donnerschlag. Casino-Transaktionen sind simpel wie ein Sonnenstrahl, dennoch mehr Freispiele im Casino waren ein Volltreffer. Am Ende ist Pledoo Casino eine Casino-Erfahrung, die wie ein Regenbogen glitzert fur Fans von Online-Casinos! Und au?erdem die Casino-Seite ist ein grafisches Meisterwerk, einen Hauch von Abenteuer ins Casino bringt.
pledoo caisno|
Ровной дороги в вашем бизе на просторах РЦ 😉
https://wirtube.de/a/wileybauch06935/video-channels
Дорогие наши форумчане, мы бы рады с вами пообщаться на разные темы, и стараемся общаться со всеми, и порой просто не хватает времени ведь мы не железные, если вы хотите что то конкретно заказать ася и скайп ждет вас, просто нереальное кол-во народа задают вопросы утром днем и вечером, и вот даже сейчас, мы очень стараемся изменить ситуацию в лучшую сторону. С начала месяца т.е. с 1 июня вы сможете самостоятельно заказывать и оплачивать прямо на сайте, а так же будете видеть наличие продукции.
рип репорт ЭСКИМОС _скорость!
https://ximora.ru
Работали с магазином ранее брали по 100г, недавно взяли еще 50г, хотим сегодня 100г приобрести!! на регу нету нареканий!!
נערות מהכוס שלך. אני מרים את הרגליים למעלה כדי להיכנס עמוק ככל האפשר. את כבר נחשפת למקסימום, ואני זאטוטים סם, האומץ שלך לא ידע גבולות. חיבקת אותי ואת החברה שלי, נישקת את שניהם. ואז לקח את הידיים read full report
всем желаю счастья!
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
пробывал нюхать эфект 4-6часа
Все мои контакты указаны в подписе.
Приобрести кокаин, мефедрон, бошки
Всем здравствуйте! Опишу свою ситуацию: 2 недели назад заказывал в данном магазине 2 с-i и MXE, всё на высшем уровне: оперативность 5 +, доставка 5+, конспирация 5+, Качество 5+. Нареканий к Магазину нет, только благодарность!!! В этот раз сделал заказ в Понедельник, оплатил во Вторник. В пятницу только получил трек. На сегодня Трек не работает. Звоню в курьерку они говорят, что такой трек у них не зарегистрирован. Паники пока никакой нет, но хотелось бы получить какие нибудь разъяснения по этому поводу. Заранее спасибо!
Наркологические услуги в Туле доступна 24/7. Если у вас имеет проблемы с зависимостяминеобходимо знатьчто доступна оперативная помощь. Наркологический центр предлагает вызов специалиста по наркологии на дома также конфиденциальное лечение зависимостей. Прием врача-нарколога поможет определить необходимую терапию зависимостей. Реабилитационная клиника предоставляет детокс-программы и помощь пациентам на протяжении всего лечения. За подробной информацией обращайтесь на vivod-iz-zapoya-tula010.ru.
Но в общем и целом доволен очень быстро и качественно! Будем работать и дальше;)
Приобрести кокаин, мефедрон, бошки
почему 0.3? акция?
Pokud hledáte online casino cz, cz casino online nebo kasina, jste na správném místě. Jsem žurnalista a pomohu vám srovnat rizika i možnosti českého online hazardu – stylově, seriózně a uživatelsky přívětivě: cz casino online
здесь без музыки танцую –
https://zugpisv.ru
Все вопросы к представителю.
магазин работает ровно, заказ пришел за пару дней, качество порадовало)
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
о господи 😀 я не селлер – я просто зашёл на сайт и посмотрел что есть в ассортименте – из скоростей нормальных разве что..кхм, оно…
всегда ровно все было и есть. так что я
https://zugpisv.ru
Огромное спасибо данному магазину, успехов вработе и процветания!!!?
хороший магазин,было дело работал с ними)
https://fradul.ru
Магазин,лови от меня большой и жирный “+”. Заказ пришёл в течение 3ёх дней.Из-за обстоятельств пришлось разбодяживать порошок в ацетоне,в подъезде,на хз сколько граммов основы…но все понравилось.все и всем довольный.
Бро подскажи ато я переживаю заказал 10 гр
https://fradul.ru
заказал и оплатил ещё в понедельник, сегодня пятница но трэка до сих пор нет, раньше такого не было а в этот раз че то медлят
https://www.deviantart.com/candetoxblend
Prepararse un test preocupacional ya no tiene que ser una pesadilla. Existe un suplemento de última generación que actúa rápido.
El secreto está en su mezcla, que ajusta el cuerpo con creatina, provocando que la orina enmascare los marcadores de THC. Esto asegura un resultado confiable en menos de lo que imaginas, con ventana segura para rendir tu test.
Lo mejor: es un plan de emergencia, diseñado para quienes enfrentan pruebas imprevistas.
Miles de usuarios confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la confianza.
Si tu meta es asegurar tu futuro laboral, esta alternativa es la respuesta que estabas buscando.
сегодня оплатил заказ..буду ждать доставки..протестирую.сообщу о качестве продукта
Магазин тут! kokain mefedron gash alfa-pvp amf
1-й раз все было почти супер только менагер немного напутал ( но потом все доотправили )
https://images.google.co.ve/url?q=https://uberant.com/article/2132286-pin-up-casino-mxico-entretenimiento-en-lnea-de-primer-nivel – Pin Up Casino Mexico – A popular online casino in Mexico!
Я брал норм не один раз,но в последнее время было пару недовесов,а 35 прислали какого то качества слабого,25ый был куда лучше,после этого перестал заказывать.
Приобрести кокаин, мефедрон, бошки
Приветы. Впервые решил заказать подобные вещества через интернет; полистав форум, выбрал этот магазин из-за безупречной репутации и не разочаровался. Заказ обработали очень быстро, все доходчиво объяснили, вес пришел с приятным бонусом(товар, кстати, отличный). Успехов и процветания вам и вашему магазину, ребята.
вывод из запоя омск
vivod-iz-zapoya-omsk007.ru
экстренный вывод из запоя омск
Крутой качественный товар! Все своевременно +++
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
Хочу еще раз поблагодарить представителей этого замечательного магазина за их достойную работу!
Ам1220 все больше сообщений что относят к нелегалу.
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Всем доброго времени суток!!!
https://hr.rivagroup.su/
Писал уже, магазин работает в турбо режиме отправки вовремя, получают люди вовремя, сменили штат сотрудников сменили курьеров которые тупили, все налажено все как должно быть.
https://qastal.ru
В чем растворял 203??? У меня ихний 203 в спирте не получилось расстворить даже при нагреве, пришлось ацетон использовать! На счет качества с тобой согласен – 5!
Реще сушняки ужасные. Сейчас вот утром проснулся, и до сих пор
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
Тут походу новый лиа12 и подобные ему фишки, поперли отзывы, в жабу ломится всем продавцам предлагает за небольшую оплату вперед вес аш в моем регионе оставить.берегитесь! Я уже сталкивался с таким на главной, ждите продавца пусть сам объясняет.берегите деньги.быть такого не может, что магазин которому более 2х лет занимается доюавлениями в джабер и предложениями довезти стафф
клиенты знают нас и нашу работу http://www.soglasovanie-pereplanirovki-kvartiry17.ru/ .
Ich bin total hingerissen von SlotClub Casino, es pulsiert mit einer schillernden Casino-Energie. Die Casino-Optionen sind bunt und mitrei?end, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein leuchtender Funke, sorgt fur sofortigen Casino-Support, der verblufft. Casino-Gewinne kommen wie ein Leuchtfeuer, aber die Casino-Angebote konnten gro?zugiger sein. Kurz gesagt ist SlotClub Casino ein Online-Casino, das wie ein Neontraum strahlt fur die, die mit Stil im Casino wetten! Nebenbei die Casino-Seite ist ein grafisches Meisterwerk, was jede Casino-Session noch aufregender macht.
slotclub bonus|
Je suis accro a Spinanga Casino, ca pulse avec une energie de casino frenetique. La selection du casino est une spirale de plaisirs, incluant des jeux de table de casino d’une elegance virevoltante. Le personnel du casino offre un accompagnement digne d’un maitre des vents, repondant en un eclair tumultueux. Les retraits au casino sont rapides comme un cyclone, mais les offres du casino pourraient etre plus genereuses. Globalement, Spinanga Casino promet un divertissement de casino tourbillonnant pour les passionnes de casinos en ligne ! De surcroit la navigation du casino est intuitive comme une bourrasque, ce qui rend chaque session de casino encore plus virevoltante.
code promo spinanga|
Je trouve absolument delirant Spinsy Casino, on dirait une soiree disco pleine de frissons. Il y a une vague de jeux de casino captivants, offrant des sessions de casino en direct qui pulsent comme un beat. Les agents du casino sont rapides comme un pas de danse, assurant un support de casino immediat et dansant. Les paiements du casino sont securises et fluides, cependant j’aimerais plus de promotions de casino qui eblouissent. En somme, Spinsy Casino est une pepite pour les fans de casino pour les amoureux des slots modernes de casino ! Par ailleurs l’interface du casino est fluide et eclatante comme un neon, ce qui rend chaque session de casino encore plus dansante.
spinsy com|
В скайпе ответил что вопрос решаеться,будем надеяться на лучшее,а насчёт красной темы-даже думать не хочеться.Всем мир!!!
https://kavrorp.ru
а как ам то хоть вооще расшифровывается то по науке???
Estou louco por Richville Casino, tem uma vibe de jogo tao sofisticada quanto uma mansao de ouro. As opcoes de jogo no cassino sao ricas e reluzentes, incluindo jogos de mesa de cassino com um toque de sofisticacao. Os agentes do cassino sao rapidos como um coche de gala, respondendo rapido como um brinde de champanhe. O processo do cassino e claro e sem intrigas, mas as ofertas do cassino podiam ser mais generosas. No geral, Richville Casino e um cassino online que exsuda riqueza para os que buscam a adrenalina luxuosa do cassino! Alem disso o site do cassino e uma obra-prima de elegancia, o que torna cada sessao de cassino ainda mais reluzente.
payday loans in richville mi|
Пиздатый магазин, всегда пойдут на встречу и оператор норм
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
В общем я всегда доверял своей логике и считаю ее правильной, многие соглашаются с ней, но видимо тут никто толком ни с кем не согласится, потому соглашусь с тем, что кончаем с оффтопом
подключить интернет
inernetvkvartiru-nizhnij-novgorod006.ru
подключить интернет тарифы нижний новгород
Спасибо ТС за отправленный вес)
https://tovrek.ru
РІ том то Рё дело что мнения РІ “курилках” Р° тут “факты” пишут РІСЃРµ. РЇ думаю ,что есть разница между мнением Рё фактом. Ртот “мутный магазин” работает СЃ 2011 РіРѕРґР° , Р° вашему аккаунту РѕС‚ которого РјС‹ РІРёРґРёРј мнение Рѕ “мутном магазине” РїРѕР» РіРѕРґР° – РІ чем “мутность” ?
Balanced engagement in digital play refers to making careful choices while taking part in interactive entertainment.
It encourages positive practices and helps players create clear limits.
Practices of responsible play include monitoring time and energy in a sensible way.
Individuals are advised to stay aware of their actions and maintain a sustainable approach.
casino online live aams
Awareness materials about responsible gaming assist people to recognize their own patterns.
Many sites provide tools and resources for self-assessment and user management.
Practising responsible play helps everyone to appreciate i-gaming safely.
In short, mindful i-gaming is about understanding and making choices that support your well-being.
Ich bin vollig fasziniert von SlotClub Casino, es bietet ein Casino-Abenteuer, das wie ein Wirbelwind durch die Nacht rast. Die Auswahl im Casino ist ein echtes Lichtspektakel, mit einzigartigen Casino-Slotmaschinen. Der Casino-Kundenservice ist wie ein leuchtender Funke, sorgt fur sofortigen Casino-Support, der verblufft. Casino-Zahlungen sind sicher und reibungslos, manchmal mehr Freispiele im Casino waren ein Volltreffer. Am Ende ist SlotClub Casino ein Muss fur Casino-Fans fur Fans moderner Casino-Slots! Zusatzlich die Casino-Navigation ist kinderleicht wie ein Lichtschalter, das Casino-Erlebnis total elektrisiert.
slotclub erfahrungen|
Je suis fou de Roobet Casino, c’est un casino en ligne qui pulse comme un neon en furie. L’assortiment de jeux du casino est un kaleidoscope de sensations, comprenant des jeux de casino adaptes aux cryptomonnaies. Le personnel du casino offre un accompagnement digne d’un DJ stellaire, avec une aide qui brille comme un laser. Les gains du casino arrivent a une vitesse supersonique, cependant des recompenses de casino supplementaires feraient danser. Dans l’ensemble, Roobet Casino promet un divertissement de casino fluorescent pour les joueurs qui aiment parier avec panache au casino ! De surcroit le site du casino est une merveille graphique electro, ce qui rend chaque session de casino encore plus vibrante.
roobet vpn free|
Je trouve absolument dement Spinanga Casino, ca degage une ambiance de jeu aussi virevoltante qu’un cyclone. Il y a une rafale de jeux de casino captivants, avec des machines a sous de casino modernes et hypnotiques. Le support du casino est disponible 24/7, assurant un support de casino immediat et dynamique. Les transactions du casino sont simples comme une brise, cependant les offres du casino pourraient etre plus genereuses. Globalement, Spinanga Casino offre une experience de casino virevoltante pour ceux qui cherchent l’adrenaline frenetique du casino ! De surcroit le site du casino est une merveille graphique orageuse, amplifie l’immersion totale dans le casino.
spinanga sportfogadГЎs|
Je suis totalement envoute par Spinsy Casino, ca degage une ambiance de jeu aussi vibrante qu’une piste de danse. Le repertoire du casino est un dancefloor de divertissement, avec des machines a sous de casino modernes et hypnotiques. Le support du casino est disponible 24/7, assurant un support de casino immediat et dansant. Le processus du casino est transparent et sans fausse note, parfois des recompenses de casino supplementaires feraient swinguer. En somme, Spinsy Casino offre une experience de casino vibrante pour ceux qui cherchent l’adrenaline rythmee du casino ! A noter la plateforme du casino brille par son style funky, donne envie de replonger dans le casino sans fin.
spinsy casino login|
Всем Мир! Да прибудет с вами Сила!
https://qastal.ru
всегда работают и делают свою работу на 5+
Acho simplesmente magnifico Richville Casino, oferece uma aventura de cassino que brilha como um lustre de cristal. As opcoes de jogo no cassino sao ricas e reluzentes, oferecendo sessoes de cassino ao vivo que brilham como joias. O suporte do cassino esta sempre disponivel 24/7, acessivel por chat ou e-mail. As transacoes do cassino sao simples como abrir um cofre, mesmo assim mais recompensas no cassino fariam qualquer um se sentir rei. No geral, Richville Casino e uma joia rara para os fas de cassino para os que buscam a adrenalina luxuosa do cassino! Vale dizer tambem o site do cassino e uma obra-prima de elegancia, adiciona um toque de sofisticacao ao cassino.
richville park|
Реабилитация после запоя в Туле: помощь специалистов Запой, это серьезная проблема, которая требует вмешательства специалистов. В Туле предлагаются услуги нарколога на дому анонимно, что позволяет пациентам получить необходимую помощь без лишнего стресса. Консультация нарколога может стать первым шагом к восстановлению. нарколог на дом анонимно Процесс лечения зависимости является многогранным и требует комплексного подхода. Реабилитация алкоголизма включает медицинскую реабилитацию и психотерапию при зависимости, что помогает не только избавиться от физической зависимости, но и проработать психологические аспекты. Программа реабилитации может предусматривать участие родственников, что критически важно для успешного лечения. Помощь при запое обычно включает в себя анонимное наркологическое вмешательство. Специалисты помогают зависимым пациентам, предоставляя психологическую поддержку во время запоя и предлагая меры по профилактике рецидивов. Социальная адаптация является ключевым этапом в процессе реабилитации. Нарколог на дому предоставляет возможность создать комфортные условия для лечения и восстановления от алкоголизма.
Looking for tsla price prediction? Visit the website thetradable.com and you will find both analytical and professional information about the cryptocurrency market, as well as educational articles. You will also find the most up-to-date and relevant news covering finance, stocks, forex and cryptocurrencies. Latest news from the commodity market, gold, AI, global economy. On the site you can, among other things, find a complete guide to trading on various markets.
привет стоит брать в этом магазине?
https://lirnafo.ru
Я по почте переписывается пытался нормально договориться потом просто отвечать перестали решил здесь пообщаться тут надеюсь игнорировать не будут!
Хочете отримувати важливе раніше за інших? «Українські ВІСТІ» подають об’єктивні новини, аналітику та корисні сервіси — від курсу валют до погоди. Чітко, швидко, без зайвого шуму. Заходьте на https://uavisti.com/ і зберігайте в закладки. Щоденні оновлення, мультимедіа та зручна навігація допоможуть вам швидко знаходити лише перевірену інформацію. Приєднуйтесь до спільноти уважних читачів вже сьогодні.
кто зовет мать и отца.
https://kavrorp.ru
Качество обслуживания хорошее – СЃ момента оплаты РґРѕ прибытия товара прошло всего 3 РґРЅСЏ Рё вес ровный.
Качество товара на 5+,вот только почта подвела привезли на 5й день.
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
и че сделали? условку дали?
Давно работаю с чемиком.
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
все на высем уровне!
бразы все меня просветили много чего тут было но после убедительных доводов все понял селлер правда не виновен я об этом так то и говорил всегда просто все подтвердилось больше в ветке пылить не буду братух тебе хорошей работы ну и как говорил в скайпе удачи а если будет много врагов пулемет в руки и ведро потронов))) в помощ
https://rudpexfe.ru
Знаю сайт. Всем советую. Пишу РІ кратце Рѕ главном. Связался РІ аське. Ответили сразу, тут же сделал заказ РЅР° регу. Осталось подождать…
hotel elegant Cotroceni
https://www.tiktok.com/@candetoxblend
Enfrentar un test preocupacional ya no tiene que ser un problema. Existe un suplemento de última generación que responde en horas.
El secreto está en su combinación, que sobrecarga el cuerpo con creatina, provocando que la orina neutralice los metabolitos de toxinas. Esto asegura parámetros adecuados en solo 2 horas, con ventana segura para rendir tu test.
Lo mejor: no necesitas semanas de detox, diseñado para quienes enfrentan pruebas imprevistas.
Miles de clientes confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la confianza.
Si no quieres dejar nada al azar, esta solución es la herramienta clave.
В двух пакетах
https://gimtor.ru
да работаем только по прайсу
спасибо , стараемся для всех Вас
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
заказывал тут РІСЃРµ четка пришло напишу РІ теме трип репотрты СЃРІРѕР№ трипчик РЕСПЕКТ ВСЕМ ДОБРА БРАЗЫ РљРўРћ СОМНЕВАЕТСЯ МОЖЕТЕ БРАТЬ СМЕЛО РўРЈРў Р’РЎР• ЧЧЧРЧЧЕТЕНЬКА!!!!!!!!Р РћР’РќРћ ДЕЛАЙ Р РћР’РќРћ БУДЕТ:monetka::monetka:))))))))0
РџСЂРѕ 80 РЅРµ знаю. РќРѕ то что там принимают сомнительных, дак это точно. Р’РѕС‚ люди которые туда РїСЂРёС…РѕРґСЏС‚ Рё ушатаные РІ хламотень, РІСЃРµ трясутся. Роглядываются, как будто РѕС‚ смерти скрываются конечно РёС… принимают… Рђ что РїСЂРѕ тех кто соблюдаем РІСЃРµ меры, тот спокоен. Рсдержан. РќРѕ РІСЃРµ равно. Р’ СЃРїСЃСЂ принимают однозначно, сам свидетель РІ 2006 РіРѕРґСѓ. РєРѕРіРґР° Р·Р° РґСЂРѕРїРѕРј следили, перепугались что Р·Р° нашим пришли… РќРѕ РІСЃРµ обошлось.
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
Ртот магазин нериально всегда РІСЃРµ четко делал, РЅ ошиблись может случайно РїРѕРіРѕРІСЂРё СЏ думаю решится
Geo-gdz.ru – ваш в мир знаний бесплатный ресурс! Ищете школьные учебники, атласы или контурные карты? У нас все это отыщите! Мы полезную и актуальную информацию предлагаем, решебники включая (к примеру, для 7 класса по геометрии Атанасяна). Ищете Контурные 5 класс? Geo-gdz.ru – ваш помощник в учебе. На сайте представлены контурные карты для печати. Все картинки отменного качества. Предлагаем вашему вниманию по русскому языку для 1-4 классов пособия. Учебники по истории вы можете читать онлайн. Загляните на geo-gdz.ru. С удовольствием учитесь!
вывод из запоя цена
vivod-iz-zapoya-omsk008.ru
вывод из запоя
http://google.co.zm/url?q=https://hackmd.io/@N5OLD2xzRWCHBqH07yu95w/BJw8kxs5le – Pin Up Casino Mexico – A popular online casino in Mexico!
как правило все реактивы от данного магазина проходят проверку на легальность\чистоту так что поживём увидим, думаю нелегала тут в продаже не появится )
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
такой замечательный Рё паспиздатый магазин………РЅРѕРѕРѕРѕРѕРѕ РіРґРµ же РјРѕР№ заказ тогда? трек так Рё РЅРµ бьется,тс РЅР° СЃРІСЏР·СЊ РЅРµ выходит!!!
желаю и дальше продолжать в том же духе!))
https://dolzakj.ru
После передачи посылки курьерской службе ответственность за доставку несет именно курьерка, вы сами должны осознавать риск когда оформляете заказ с доставкой курьерки, и кто бреет? я вроде как бы согласился компенсирывать часть заказа, хватает еще наглости писать здесь жалобы.
были случаи
Приобрести кокаин, мефедрон, бошки
Всем РґРѕР±СЂР°! Вчера РїРѕР·РІРѕРЅРёР» курьер, сказал, что посылка РІ РіРѕСЂРѕРґРµ! Через пару часов СЏ был уже РЅР° почте, забрав посылку, сел РІ машину, РЅРѕ РІРѕС‚ поехать РЅРµ получилось С‚.Рє. был задержан сотрудниками РњРР›РР¦РР!!!! Четыре часа РІ отделении Рё пошёл РґРѕРјРѕР№!!! Ркспертиза показала, что запрета нет, РЅРѕ сам факт приёмки очень напряг!!! Участились случаи приёмки РЅР° данной почте!!!!! Продаванам РЎРџРђРЎРБО Рё РЕСПЕКТ Р·Р° чистоту реактивов!!! Покупатели держите СѓС…Рѕ востро!!!!!!!!!! Больше СЃ этой почтой РЅРµ работаю(((( Если Сѓ РєРѕРіРѕ есть опыт РїРѕ схемам забирания пишите РІ личку!!!
Я сегодня заказал 203 жду трека думаю и мне понравится
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
ну тогда тестируй, если неделю выдержал )
Занимайся я таким делом,коли вы не просили б о граммах 100,ответ был бы тот же. В таком деле главное-отсутствие жадности. Не надо гнаться за каждой копейкой,коли есть относительно безопасная отработанная схема,то и нечего от неё отклонятся. Вы видите в них кидал,они в вас красного.
Купить мефедрон, гашиш, шишки, альфа-пвп
может все дело в кривых ручках?
Ровный Рё Стабильный…
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
А это как понимать? Кто то уже регу опробовал?
https://www.crunchbase.com/organization/can-detox-blend
Prepararse un test preocupacional ya no tiene que ser una incertidumbre. Existe un suplemento de última generación que funciona en el momento crítico.
El secreto está en su combinación, que estimula el cuerpo con creatina, provocando que la orina oculte los rastros químicos. Esto asegura una muestra limpia en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no necesitas semanas de detox, diseñado para candidatos en entrevistas laborales.
Miles de clientes confirman su efectividad. Los entregas son confidenciales, lo que refuerza la tranquilidad.
Cuando el examen no admite errores, esta solución es la respuesta que estabas buscando.
Какие магазины тебе написали РїСЂРѕ меня РІ личку? Что это Р·Р° бред?! РЇ 2 РґРЅСЏ назад зарегистрировался Рё РІСЃРµ РјРѕРё сообщения только РІ твоём топике. Рли РґСЂСѓРіРёРј магазинам РЅР° столько важны твои отзывы Рё репутация, что РѕРЅРё СЃРёРґСЏС‚ РІ твоей теме Рё пишут кто, Рѕ РєРѕРј Рё как думает?
https://vakino.ru
Начал гнать РЅР° продавца, РЅРѕ потом увидел Сѓ РґСЂСѓРіРёС… людей РЅР° РґСЂСѓРіРёС… сайтах Рё форумах репорты РїРѕ 5иаи, купленные Сѓ РґСЂСѓРіРёС… магазов Рё оказалось, что просто само 5иаи – это полна Чляпа)
Вызов нарколога на дом круглосуточно стал важной услугой для тех‚ кто сталкивается с зависимостями. На сайте vivod-iz-zapoya-tula012.ru можно получить всю необходимую информацию о методах лечения зависимостей‚ включая медикаментозное лечение и психотерапию при зависимости. Обращение к наркологу поможет выявить уровень зависимости и разработать индивидуальный план лечения. Круглосуточная помощь позволяет вызвать врача на дом в любое время‚ что особенно важно для экстренных случаев. Услуги нарколога включают диагностику зависимостей‚ анонимное лечение и поддержку родственников. Реабилитация людей с зависимостями требует целостного подхода‚ и профессиональная помощь может значительно упростить этот процесс. Профилактические меры против зависимостей также играет ключевую роль в борьбе с ними‚ поэтому важно обращаться за помощью при первых признаках. Вызов врача на дом обеспечивает комфорт и конфиденциальность‚ способствуя более успешному лечению.
АА это только сегодня?
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Да, оч похожа на соль, даже камушек один был ощутимый такой
подключить интернет по адресу
inernetvkvartiru-novosibirsk004.ru
интернет провайдеры по адресу новосибирск
Хотите быстро и безопасно обменять криптовалюту на наличные в Нижнем Новгороде? NNOV.DIGITAL фиксирует курс, работает по AML и проводит большинство сделок за 5 минут. Пять офисов по городу, выдача наличными или по СБП. Узнайте детали и оставьте заявку на https://nnov.digital/ — менеджер свяжется, зафиксирует курс и проведёт сделку. Premium-условия для крупных сумм от $70 000. Надёжно, прозрачно, удобно. NNOV.DIGITAL — ваш офлайн обмен с “чистой” криптой.
РЅР° РІРєСѓСЃ – СЃРѕРґР°.
https://qastal.ru
Качество и работа магазина на высоте!!
restaurare sprancene Bucuresti
А я не могу сделать покупку почему-то, обидно, блииин, денюха сегодня!!!(
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
Как связаться?
знакомый брал, збс говорит
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
Самый лучший магаз, заказываю и не парюсь
думайте, что продаёте. обещали поменять на туси, время тянут, ниче сделать не могут конкретного. отвечают редко.
https://kavrorp.ru
и я так же жду с 8 числа сказали отправки в начале недели
читайте отзывов много!:) товар тут вышка,обращайтесь!
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
Магазин работает ровно !!! Качество реагента высокое!!!
Доброго времени суток, оплатил заказ, данные для оплаты дали как всегда оперативно!, жду клад!
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
Ранее заказывал у данного селлера продукцию,качеством всегда был доволен,как и уровнем поддержки пользователей,сегодня же списался с ним по поводу небольшой технической ошибки при фасовке,и был рад узнать,что честность селлера на том же уровне,что и качество продукции.Очень благодарен создателям сайта,тем кто все это делает.Жду теперь свою посылочку,а потом обязательно еще закажу,оно того стоит.Спасибо вам ребята ,за помощь,и понимание.
https://www.tumblr.com/blog/candetoxblend
Enfrentar un test preocupacional ya no tiene que ser una incertidumbre. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su fórmula canadiense, que ajusta el cuerpo con proteínas, provocando que la orina oculte los rastros químicos. Esto asegura una muestra limpia en solo 2 horas, con ventana segura para rendir tu test.
Lo mejor: es un plan de emergencia, diseñado para candidatos en entrevistas laborales.
Miles de clientes confirman su efectividad. Los paquetes llegan sin logos, lo que refuerza la tranquilidad.
Si no quieres dejar nada al azar, esta fórmula es la respuesta que estabas buscando.
Магазин высшего уровня своей работы.
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
Отзыв ждать ? РўС‹ это умеешь , РЅР° Р±РёР·Рµ писал РЅРµ плохие …
с искреннем уважением к вам!
https://qastal.ru
Отличный Магаз, Все четко!!!
я имел ввиду что вещевства а не способ в/в я не конченый
https://felmary.ru
МХЕ-таки не работает, пускали по носу 250мг+ потом догонялись, 0 эффекта. Грустно, очень грустно.
экстренный вывод из запоя
vivod-iz-zapoya-omsk009.ru
вывод из запоя круглосуточно
Всем РґРѕР±СЂР°! Вчера РїРѕР·РІРѕРЅРёР» курьер, сказал, что посылка РІ РіРѕСЂРѕРґРµ! Через пару часов СЏ был уже РЅР° почте, забрав посылку, сел РІ машину, РЅРѕ РІРѕС‚ поехать РЅРµ получилось С‚.Рє. был задержан сотрудниками РњРР›РР¦РР!!!! Четыре часа РІ отделении Рё пошёл РґРѕРјРѕР№!!! Ркспертиза показала, что запрета нет, РЅРѕ сам факт приёмки очень напряг!!! Участились случаи приёмки РЅР° данной почте!!!!! Продаванам РЎРџРђРЎРБО Рё РЕСПЕКТ Р·Р° чистоту реактивов!!! Покупатели держите СѓС…Рѕ востро!!!!!!!!!! Больше СЃ этой почтой РЅРµ работаю(((( Если Сѓ РєРѕРіРѕ есть опыт РїРѕ схемам забирания пишите РІ личку!!!
Приобрести кокаин, мефедрон, бошки
Привет Всем!!!!!!!!!!! суппер класный магаз! всем рекомендую! приятно работать! оператр адыкват! Успехов и процветаний Друзья! от всей нашей компании!
Успешного травление нашей молодежи и побольше денег!
https://www.betterplace.org/en/organisations/68138
Я сегодня заказал 203 жду трека думаю и мне понравится
кто получал последний раз недавно отишитесь о работе магаза. +В РЕПУ!!!!!!! и главное почему ип адрес не меняется на сайте???
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8%20%D0%9C%D0%94%D0%9C%D0%90%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%A0%D0%BE%D0%B2%D0%B8%D0%BD%D1%8C/
Всегда сдесь было высокое качество
Популярный сайт «HackerLive» предлагает воспользоваться услугами продвинутых и опытных специалистов, которые в любое время взломают почту, узнают пароли от социальных сетей, а также обеспечат защиту ваших данных. При этом вы сможете надеяться на полную конфиденциальность, а потому о том, что вы решили воспользоваться помощью хакера, точно никто не узнает. На сайте https://hackerlive.biz вы найдете контактные данные программистов, хакеров, которые с легкостью возьмутся даже за самую сложную работу, выполнят ее блестяще и за разумную цену.
https://www.tumblr.com/blog/candetoxblend
Afrontar un control médico ya no tiene que ser una pesadilla. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su combinación, que sobrecarga el cuerpo con creatina, provocando que la orina oculte los rastros químicos. Esto asegura un resultado confiable en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no necesitas semanas de detox, diseñado para quienes enfrentan pruebas imprevistas.
Miles de usuarios confirman su rapidez. Los paquetes llegan sin logos, lo que refuerza la confianza.
Si no quieres dejar nada al azar, esta solución es la herramienta clave.
Рђ то декларировалась “быстрая реакция РЅР° заказ”, Р° РЅР° деле реакция отсутствует вообще
https://7abf295124cfa59ab9c6543ecb.doorkeeper.jp/
Магазин работает четко уже несколько лет:)только одно расстроило когда хотел сделать очередной заказ мне сказали что не отправляют больше в те края:dontknown:с чем это связано мне так и не сказали,хотелось бы узнать
Цена капельницы от запоя в владимире: где найти лучшие предложения Алкогольная зависимость — это серьезная проблема, с которой сталкиваются многие люди. Лечение алкоголизма и выход из запоя обычно требуют профессиональной медицинской помощи. Вызов нарколога и услуги нарколога в владимире становятся актуальными для тех, кто хочет избавиться от алкогольной зависимости. Капельница от запоя — это действенный метод восстановления организма после продолжительного приема алкоголя. Цены на капельницы варьируются в зависимости от клиники наркологии и необходимых компонентов. К примеру, капельница на дому — это удобный способ, который позволяет получить медицинскую помощь в привычной обстановке. Ценник на капельницу определяется составом препаратов и особенностями самой процедуры. В владимире можно найти различные предложения, но важно выбирать клиники с хорошей репутацией. Наркологические услуги включают не только капельницы, но и терапию при алкоголизме, что также стоит учитывать при выборе. Восстановление после запоя требует комплексного подхода, и лечение запойного состояния должно быть проведено профессионалами. Помните, что качественные медицинские услуги — это ваша инвестиция в собственное здоровье.
это манера такая сдержанная или удовлетворительное=на троечку
https://www.divephotoguide.com/user/iaifryds
РїСЂРѕРґСѓРєС‚ – прет РґРёРєРѕ Рё жестко, РЅРѕ РїРѕ сути ничего интересного, цена РІ 2 тыр себя полностью оправдывает. Рдакий бычий кайф. Если вам нравится трястись Рё стучать зубами – РІС‹ попали РїРѕ адресу. Р’Рѕ всех остальных случаях – нахер-нахер. Слабенькая 3/5
смотри РЅР° сайте РІ СЃРІРѕРёС… заказах (РІ коментариях)…
https://www.band.us/page/99920398/
попробуйте установить скайп.
Р’ лс пиши сразу. Рмей РІ РІРёРґСѓ, быстрее будет
https://www.band.us/page/99919769/
нужны быстрые и качественные заклады- тогда вы сдесь!!! великолепный товар !!!
интернет провайдеры по адресу новосибирск
inernetvkvartiru-novosibirsk005.ru
интернет провайдеры по адресу
Не покупайте у данного селлера пока не решится ситуация
http://www.pageorama.com/?p=odycobuy
Брали ни один раз, в последний раз было несколько косяков. Всё разрешилось вчера плюс бонус за предыдущий косяк.
http://google.co.uz/url?q=https://luxurious-ulna-95d.notion.site/Pin-Up-Casino-M-xico-Diversi-n-y-Apuestas-de-Primera-2677b0bbe66d80dea0d2c47730ef2966 – Pin Up Casino Mexico – A popular online casino in Mexico!
Все продукты кроме эйфора в наличии, заказывайте! Проб нет.
https://form.jotform.com/252466991953068
у нас нет давно курьерских доставок.
https://www.tiktok.com/@candetoxblend
Enfrentar un test preocupacional ya no tiene que ser una pesadilla. Existe una alternativa científica que actúa rápido.
El secreto está en su combinación, que sobrecarga el cuerpo con nutrientes esenciales, provocando que la orina oculte los rastros químicos. Esto asegura un resultado confiable en menos de lo que imaginas, con ventana segura para rendir tu test.
Lo mejor: no necesitas semanas de detox, diseñado para trabajadores en evaluaciones.
Miles de personas en Chile confirman su rapidez. Los paquetes llegan sin logos, lo que refuerza la tranquilidad.
Cuando el examen no admite errores, esta solución es la herramienta clave.
Продолжайте в том же духе.
http://www.pageorama.com/?p=wubuagihy
Все работает, каждый получает ответ оперативно!
hdvk.ru
Всем привет))))) Мой Трипчик))))))
https://hoo.be/gudubeafaglo
Хочу сказать большое спасибо за бонус за помошь сайту, зе бест
mostbet app pakistan
Отличный магазин с отличным продуктом.
https://www.divephotoguide.com/user/ahaeydficai
Сотрудники , знают свое дело , лучше другого.
жаль, что панику подняли РїРѕ РђРњСѓ 🙁 РЇ Р±С‹ ещё заказал… РќРѕ РїСЂРѕРґ отказывается, продать, заботясь Рѕ моей безопасности, Р·Р° что ему респект.
https://www.impactio.com/researcher/minchinnewton
Полностью согласен !!!
Наша платформа работает круглосуточно и не знает слова перерыв. Бронировать и планировать можно где угодно: в поезде, на даче, в кафе или лежа на диване. Хотите купить билет, пока идёте по супермаркету? Просто достаньте телефон и оформите поездку – https://probilets.com/. Нужно скорректировать планы, отменить или перенести билет? Это тоже можно сделать онлайн, без звонков и визитов. Но если возникла проблема, то наши специалисты помогут и все расскажут
1к10 и до здравствуют полноценные 50 мин. шикарного позитивного эффекта
https://wirtube.de/a/engele1dhhermann/video-channels
Спасибо за внесение ястности.
Хотите продать антиквариат быстро и выгодно? Проведём бесплатную оценку по фотографиям и сразу дадим справедливую рыночную цену. Эксперт приедет в удобное время, а расчёт произойдёт сразу удобным вам способом. Ищете продать антикварную икону? Подробнее и заявка на оценку здесь: коллекционер-антиквариата.рф Продавайте напрямую коллекционеру — на 50% выше, чем у посредников. Конфиденциальность и безопасность гарантированы.
О качестве товара отпишу в трипрепортах .Мир, и процветания этому магазину)))
https://form.jotform.com/252467409202050
а кто такой лиа 12??
вывод из запоя круглосуточно
vivod-iz-zapoya-orenburg007.ru
экстренный вывод из запоя оренбург
1-й раз все было почти супер только менагер немного напутал ( но потом все доотправили )
https://wirtube.de/a/franciscohansenfra/video-channels
Если кто-то когда-то пробовал банки с Рафинада на тусиае, тот знает, как классно они перли и понимает, каких эффектов я ожидал.
Нет не нужен.
https://www.grepmed.com/kludabid
Удачи в развитии бизнеса !
электрические карнизы для штор в москве http://www.elektro-karniz77.ru .
электрокарнизы для штор электрокарнизы для штор .
электрокарниз купить в москве электрокарниз купить в москве .
карнизы для штор купить в москве карнизы для штор купить в москве .
Желаю удачи в продажах вашему магазину!
https://ilm.iou.edu.gm/members/diellzamiri7126/
Спасибо!Не надо!
Снова в деле
https://www.band.us/page/99922032/
РґР° РґР° ))) 100% ))0
Прокапка – это важный процесс, связанная с оптимального полива саженцев, особенно в садоводстве. Капельная система или автоматическая система полива позволяют оптимально увлажнять почву, что в свою очередь обеспечивает достаточную влажность почвы для роста растений. Эти системы полива существенно сокращают расходы на воду, а автоматизация полива делает уход за садом более простым и легким. В сельском хозяйстве капельный полив используется для поддержания жизнеспособности зелени, предотвращая высыхания грунта. Ландшафтный дизайн также выигрывает от использования капельного полива, так как дает возможность создать красивый и поддерживаемый сад. На сайте vivod-iz-zapoya-vladimir011.ru можно найти многочисленные рекомендаций по монтажу и эксплуатации таких устройств, что поможет вам эффективно организовать водоснабжение и обеспечить заботу о своем саде.
Отличное описание, сразу захотелось заказть)) Что собственно и сделал, надеюсь, неразачеруюсь
https://odysee.com/@makmudaakhte.rcggjcfj
Хороший магазин оператор всегда онлайн, товар вообще Шик :speak: процветай) и поскорей бы лето
https://emilioipae656.timeforchangecounselling.com/state
Pasar un test antidoping puede ser un desafio. Por eso, se ha creado un metodo de enmascaramiento creada con altos estandares.
Su formula eficaz combina carbohidratos, lo que ajusta tu organismo y enmascara temporalmente los rastros de THC. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas destacado es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una estrategia de emergencia que funciona cuando lo necesitas.
Miles de estudiantes ya han comprobado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta solucion te ofrece seguridad.
Онлайн-казино Jozz привлекает внимание пользователей.
Акции и специальные предложения делают старт комфортнее.
Активности для пользователей создают азарт.
Каталог развлечений остается актуальным.
Вход доступен быстро, поэтому можно сразу активировать бонусы.
Узнай больше здесь: jozz казино зеркало
Estou pirando com SpinWiz Casino, da uma energia de cassino que e puro encantamento. O catalogo de jogos do cassino e um grimorio de prazeres, oferecendo sessoes de cassino ao vivo que brilham como pocoes. O servico do cassino e confiavel e encantador, respondendo mais rapido que um estalo magico. As transacoes do cassino sao simples como uma pocao, as vezes queria mais promocoes de cassino que hipnotizam. Resumindo, SpinWiz Casino oferece uma experiencia de cassino que e puro feitico para os magos do cassino! De lambuja a navegacao do cassino e facil como um passe de magica, o que torna cada sessao de cassino ainda mais encantadora.
spinwiz casino|
Adoro o fervor de SpinFest Casino, e um cassino online que gira como um piao enlouquecido. A gama do cassino e um verdadeiro festival de delicias, com jogos de cassino perfeitos pra criptomoedas. Os agentes do cassino sao rapidos como um passista na avenida, respondendo mais rapido que um batuque. As transacoes do cassino sao simples como um passo de maracatu, porem queria mais promocoes de cassino que botam pra quebrar. Em resumo, SpinFest Casino vale demais girar nesse cassino para os amantes de cassinos online! E mais o design do cassino e um espetaculo visual cheio de cores, eleva a imersao no cassino ao ritmo de um tamborim.
spinfest bonus|
Je suis fou de RubyVegas Casino, il propose une aventure de casino qui scintille comme un tresor. L’eventail de jeux du casino est une caverne de pierres precieuses, proposant des slots de casino a theme luxueux. Le personnel du casino offre un accompagnement digne d’un joaillier, offrant des solutions claires et instantanees. Les gains du casino arrivent a une vitesse fulgurante, mais plus de tours gratuits au casino ce serait scintillant. Pour resumer, RubyVegas Casino offre une experience de casino luxueuse pour les joueurs qui aiment parier avec panache au casino ! De surcroit le site du casino est une merveille graphique lumineuse, facilite une experience de casino scintillante.
Estou completamente alucinado por SpeiCasino, tem uma vibe de jogo tao reluzente quanto uma supernova. Tem uma chuva de meteoros de jogos de cassino irados, com slots de cassino tematicos de espaco. A equipe do cassino entrega um atendimento que e puro foguete, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como uma nave espacial, porem mais bonus regulares no cassino seria intergalactico. Em resumo, SpeiCasino vale demais explorar esse cassino para quem curte apostar com estilo cosmico no cassino! De lambuja a navegacao do cassino e facil como uma orbita lunar, o que torna cada sessao de cassino ainda mais estelar.
spei mission uncrossable|
Всем привет, долго не писал, ну это меня «задержала» посылка jv-61. Все пришло, все получил причем довольно быстро все ехало:good:
https://form.jotform.com/252471512866056
глазом на пакете,вот там была россыпь:good::killmyself::strong::stars::fu::good::bro:
https://russpain.com/
Jwh 203 порошок светло-желтого цвета у них, делал в пропорции 150-200мг на спичечный коробок микса, кролики довольны! 5-IAI пробывал 200мг по кишке, видимо нужно было сразу 300-400мг чтобы понять кайф!
https://www.divephotoguide.com/user/qdodaafecu
работаете качественно и по совести!так держать!
Вот уже Артем хохочет,
https://www.band.us/page/99921624/
один из фаворитов в рц!
Тьфу-тьфу-тьфу… =(
https://hoo.be/uabyftob
как дела народ ? Всё хорошо ? не у кого проблем нет ?
https://www.youtube.com/@candetoxblend/about
Prepararse una prueba de orina ya no tiene que ser una pesadilla. Existe un suplemento de última generación que actúa rápido.
El secreto está en su combinación, que sobrecarga el cuerpo con nutrientes esenciales, provocando que la orina oculte los marcadores de THC. Esto asegura un resultado confiable en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: es un plan de emergencia, diseñado para candidatos en entrevistas laborales.
Miles de usuarios confirman su seguridad. Los entregas son confidenciales, lo que refuerza la confianza.
Si no quieres dejar nada al azar, esta solución es la elección inteligente.
Казино Джозз онлайн считается одним из лидеров.
Акции и специальные предложения делают старт комфортнее.
Турниры и соревнования дают шанс на выигрыш.
Выбор слотов и настольных игр обновляется регулярно.
Создание аккаунта занимает пару минут, и сразу начать играть.
Узнай больше здесь: https://whatisliberalism.com
Estou completamente enfeiticado por SpinWiz Casino, oferece uma aventura de cassino que reluz como um portal magico. A gama do cassino e simplesmente um caldeirao de delicias, com slots de cassino tematicos de feiticaria. Os agentes do cassino sao rapidos como um passe de varinha, respondendo mais rapido que um estalo magico. Os saques no cassino sao velozes como um feitico de teletransporte, de vez em quando mais giros gratis no cassino seria uma loucura. No geral, SpinWiz Casino vale demais explorar esse cassino para os amantes de cassinos online! De bonus a plataforma do cassino reluz com um visual que e puro feitico, eleva a imersao no cassino a um nivel magico.
spinwiz casino|
Учебный центр дистанционного профессионального образования https://nastobr.com/ приглашает пройти краткосрочное обучение, профессиональную переподготовку, повышение квалификации с выдачей диплома. У нас огромный выбор образовательных программ и прием слушателей в течение всего года. Узнайте больше о НАСТ на сайте. Мы гарантируем результат и консультационную поддержку.
Sou louco pela vibe de SpinFest Casino, e um cassino online que gira como um piao enlouquecido. Tem uma enxurrada de jogos de cassino irados, com slots de cassino tematicos de festa. O atendimento ao cliente do cassino e uma bateria de eficiencia, garantindo suporte de cassino direto e sem perder o ritmo. Os ganhos do cassino chegam voando como uma escola de samba, mas mais recompensas no cassino seriam um diferencial festivo. Em resumo, SpinFest Casino e o point perfeito pros fas de cassino para os amantes de cassinos online! Alem disso a plataforma do cassino brilha com um visual que e puro axe, faz voce querer voltar ao cassino como num desfile sem fim.
spinfest casino czechia|
недорогой интернет новосибирск
inernetvkvartiru-novosibirsk006.ru
провайдеры в новосибирске по адресу проверить
Je suis accro a RubyVegas Casino, ca vibre avec une energie de casino digne d’un joyau. Les options de jeu au casino sont riches et lumineuses, incluant des jeux de table de casino d’une elegance scintillante. L’assistance du casino est chaleureuse et irreprochable, repondant en un flash scintillant. Les retraits au casino sont rapides comme une pepite trouvee, mais plus de tours gratuits au casino ce serait scintillant. Pour resumer, RubyVegas Casino c’est un casino a explorer sans tarder pour les passionnes de casinos en ligne ! A noter la navigation du casino est intuitive comme une gemme taillee, donne envie de replonger dans le casino sans fin.
магаз четкий,еще в 2011 каждую неделю забегали:music:)всегда все ровно
https://odysee.com/@markovsskaidrons
Они хоть кому нибудь отвечают?
Acho simplesmente intergalactico SpeiCasino, parece uma galaxia cheia de diversao estelar. Tem uma chuva de meteoros de jogos de cassino irados, com jogos de cassino perfeitos pra criptomoedas. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que uma explosao estelar. As transacoes do cassino sao simples como uma orbita, porem as ofertas do cassino podiam ser mais generosas. No fim das contas, SpeiCasino e um cassino online que e uma supernova de diversao para os amantes de cassinos online! De lambuja a interface do cassino e fluida e reluz como uma aurora boreal, adiciona um toque de brilho estelar ao cassino.
spei slots|
Всем привет вчера забегал в этот магазин ни чего не нашел !
https://linkin.bio/simoncqpchristian
РґР° это будет полная:ass:.РќСѓ СЏ надеюсь РІСЃРµ будет хорошо.тогда так вышло РёР·Р° того что это остатки товара РёР· серии РјРЅ – 001.Уверен такой жопы больше РЅРµ будет
электрокарниз купить в москве электрокарниз купить в москве .
карниз электро карниз электро .
https://telegra.ph/Controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones-09-11-2
Superar un control sorpresa puede ser arriesgado. Por eso, se ha creado una alternativa confiable probada en laboratorios.
Su formula precisa combina carbohidratos, lo que estimula tu organismo y disimula temporalmente los trazas de sustancias. El resultado: una prueba sin riesgos, lista para entregar tranquilidad.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete limpiezas magicas, sino una solucion temporal que funciona cuando lo necesitas.
Miles de personas en Chile ya han experimentado su discrecion. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta solucion te ofrece respaldo.
Качество, если честно на моё удивление (тк. первый раз я пользуюсь услугами данного ТС), по отзывам клиентов, сказать отличное это сказать ничего, ССССУУУУУПППЕЕЕЕРРРР!!!!!!
https://www.impactio.com/researcher/akinotaxe45goose
привет что случилось РІС‹ работаете РЅРµ РјРѕРіСѓ второй день РІ личку отписаться ,сколько заказывал РІСЃС‘ было супер ,как Рє тебе попасть теперь ,что делать ,отпишитесь …
Магазин ровный! РЇ заказал 1000С„, оплатил РЇР”, оператора РїРѕРїСЂРѕСЃРёР» отправить посыль РЅР° следующий день , без задержки С‚.Рє. СЃСЂРѕРєРё получения очень поджимают. РќР° что оператор адекватно ответил что РІСЃРµ сделают.РќР° следующий вечер получил трек, посылочка собранна Рё РІРѕС‚ РІРѕС‚ выезжает))) если уже РЅРµ выехала) Магазину как Рё его администрации – РѕС‚ души Р·Р° оперативность Рё отношение Рє клиенту.
https://www.impactio.com/researcher/waneesale
Затарил я тут как то купели значит курехи,приваливай на адрес и не могу найти списался с оператором и понял что дурак тут я а не минер затупил,30 сек и закладка у меня в руках,лечу Домой,дома меня ждут уже братики заряжает по 2 водных и начинаем пускать слюни под спанч бобра, в полне хороший стафф,силы стафа хватает,валит минут 40-60 потом спад,получилось так что вес сдули за 2 дня,отходосы минемальные, вообщем сервис тут вышка тарился тут ребята)
Жду решения регу оплатил. Адрес не получил.
https://rant.li/097u8bva05
Чем аргументирует отказ работать с гарантом?
Я взял всего 15т.т из-за того что 6июля он не легал и я не понимаю что сложного сделать замену чтобы я удостоверился в качестве следующего товара а они какимита скидками,бонусами пытаются отмазатся я опять денег закидываю и такое же го..но забираю!
https://rant.li/ffiudtifeb/lirika-belgorod-kupit
реагенты всегда чистые и по высшему??? сертифекаты вместе с реагентами присылают на прохождение экспертизы на легал?
Ищете разработку сайтов от профессионального частного вебмастера? Ищете разработка сайтов? Посетите сайт xn--80aaad2au1alcx.site и вы найдете широкий ассортимент услуг по разработке и доработке сайтов. Создаю лендинги, интернет-магазины, сайты-каталоги, бизнес-сайты и решения с онлайн-бронированием, плюс беру на себя настройку контекстной рекламы. На сайте вы сможете посмотреть полный список услуг, примеры выполненных проектов и цены.
Сѓ меня вообще РєРѕРіРґР° порошок кидаешь Рё ациком заливаешь, раствор абсолютно прозрачный-.- Рё РЅРµ прет вообще тупо куришь траву….. Р° РІРѕС‚ кристалы РЅРµ расворимые тоже имеются, СЏ уже Рё толочь пытался седня Рё нагревом РІСЃРµ бестолку…
https://ilm.iou.edu.gm/members/kellinortonkel/
Одобавив СЃРЅРѕРІР° РІ контакты РїРѕ джаберу РЅР° сайте получил “РЅРµ авторизованный” Обратите внимание жабу сменили.
принимай не меньше 300 мг МХЕ от данного селлера.
https://bio.site/myecdyibybec
В общем, хотелось бы вас оповестить и другим может пригодится.
с треками магазин всегда спешит:) и качество скоро заценим)))
https://rant.li/modeafcah/kupit-marikhuanu-saity
вот немного для Сашка
https://keeganufyi005.almoheet-travel.com/como-la-alimentacin-influye-en-la-deteccin-de-sustancias-durante-una-prueba-de-orina
Superar un test antidoping puede ser estresante. Por eso, se ha creado un metodo de enmascaramiento probada en laboratorios.
Su receta premium combina nutrientes esenciales, lo que sobrecarga tu organismo y disimula temporalmente los rastros de alcaloides. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas interesante es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una solucion temporal que responde en el momento justo.
Miles de personas en Chile ya han comprobado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
http://maps.google.be/url?q=https://justpaste.me/vDsc7 – Pin Up Casino Mexico – A popular online casino in Mexico!
лечение запоя оренбург
vivod-iz-zapoya-orenburg008.ru
вывод из запоя круглосуточно оренбург
“Приезжаю Рє месту,вижу РґРѕРј обхожу кооператив который РјРЅРµ нужен (РЅСѓ СЏ так думал)”
https://yamap.com/users/4800716
У меня такая же ситуация мне кажеться ребята что их курьерку иусора приняли потомушто на сайте
Нарколог на дом – это практичный способ достать квалифицированную медицинскую помощь в коррекции зависимого поведения. Многие пациенты переживают страх и неловкость, обращаясь в медицинские учреждения, поэтому конфиденциальное лечение становится ключевым фактором. Доктора, работающие на сайте vivod-iz-zapoya-vladimir012.ru, предлагают услуги по очищению организма и психотерапии, что позволяет успешно справляться с алкогольной зависимостью и зависимостью от наркотиков. Прием у нарколога включает в себя оценку состояния пациента и разработку индивидуального плана реабилитации. Важно помнить, что помощь близким также существенно влияет в процессе выздоровления. Семейная поддержка и экстренная поддержка помогут создать поддерживающую атмосферу для пациента, что значительно увеличивает шансы на выздоровление.
https://www.tumblr.com/blog/candetoxblend
Prepararse un control médico ya no tiene que ser una pesadilla. Existe un suplemento de última generación que actúa rápido.
El secreto está en su combinación, que ajusta el cuerpo con vitaminas, provocando que la orina neutralice los metabolitos de toxinas. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no necesitas semanas de detox, diseñado para trabajadores en evaluaciones.
Miles de usuarios confirman su seguridad. Los entregas son confidenciales, lo que refuerza la seguridad.
Si no quieres dejar nada al azar, esta fórmula es la elección inteligente.
магаз ровный!!! все на высшем уровне!!! работаю с ними много лет!!!
https://hoo.be/oggobnagaiho
может ты просто сам не учел проценты комиссии и тебе не хватило???
Магазин надежный репутацию оправдал сделал заказ 24 февраля , а 26 груз был уже на руках. Если и бывают задержки скорее всего это курьерские фирмы косячат. Сервис тоже на высоте, люди адекватные не смотря даже на выше написанные отзывы не разу не усомнился что деньги улетят на ветер!!!
https://form.jotform.com/252483130751048
Рвообще зачем тебе спасибо жать или репутацию добавлять?? Ты что малолетка глупая, что это тебя так беспокоит??
Отзыв ждать ? РўС‹ это умеешь , РЅР° Р±РёР·Рµ писал РЅРµ плохие …
https://odysee.com/@antoniekooij
Цены тут взвинчены до жопы не знаю кто тут умудряется брать, летом как то брал здесь не помню че но было фуфло конченное половина не растворилась хоть че делай хоть грей хоть танцуй ни че не помогло. Один плюс присылают быстро но нафиг такая быстрота
Подбираете качественные детали для строительной техники? Поможем с поставкой оригинальные и аналоговые узлы на трактора ЧТЗ Т-130/Т-170 и бульдозер Б-10 (есть собственный цех ремонта), автогрейдера ЧСДМ — ДЗ-98, ДЗ-143, 180, ГС 14.02/14.03, машины на базе К 700 с двигателями ЯМЗ и Тутай, фронтальные погрузчики АМКАДОР, МКСМ, МТЗ, ЮМЗ, Урал, КРАЗ, МАЗ, БЕЛАЗ, экскаваторы и краны, ЭКГ, ДЭК, РДК. Производим и подбираем карданные валы под ваши размеры. Нажмите «Оставить заявку» на https://trak74.ru/ — поможем подобрать и оперативно доставим по РФ!
https://pipesmagazine.com/forums/members/garytaylor.43658/about
Дом СЂСЏРґРѕРј СЃ адресом говоришь, отдаешь залог, РєРѕРіРґР° приедешь РІ адрес (РІ разных такси РїРѕ-разному, РјРѕРіСѓС‚ Рё РЅРµ попросить), Рё идешб себе Р·Р° кладом 🙂
https://kemono.im/ruiigygog/lirika-kupit-moskva-apteka
подход к клиенту 5+ (все объяснили, трек сразу скинули)
https://list.ly/maryldiwcc
Enfrentar un control sorpresa puede ser complicado. Por eso, se ha creado un metodo de enmascaramiento creada con altos estandares.
Su formula precisa combina carbohidratos, lo que sobrecarga tu organismo y enmascara temporalmente los marcadores de alcaloides. El resultado: una muestra limpia, lista para cumplir el objetivo.
Lo mas notable es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una estrategia de emergencia que funciona cuando lo necesitas.
Miles de estudiantes ya han validado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece confianza.
Что то непойму.Работает магаз то.Ркуда писать?
https://www.divephotoguide.com/user/vybiafoifof
Встану на пробу новых веществ сочный трип со мной
same shit, bro
https://yamap.com/users/4810301
аська молчит.скайп есть?
провайдеры домашнего интернета ростов
inernetvkvartiru-rostov004.ru
подключение интернета ростов
Ну что кто нить УРБ попробовал уже как отзывы ?
http://www.pageorama.com/?p=afychobygao
Р’ итоге-“радостно” ожидал курьера эти РґРЅРё,забавлянка придет РјРЅРµ позже желаемого… ;(
Да неее))) само то емс Рё почта СЂРѕСЃСЃРёРё !! Рђ лучше гарантпост очень клево работают РїРѕ РЅРёРј надо отправлять вообще изумительные службы. Рли первый класс!
https://www.brownbook.net/business/54234696/флер-наркотик-новый-купить/
Но в общем и целом доволен очень быстро и качественно! Будем работать и дальше;)
ЭлекОпт — опт по судовому кабелю с самым широким складом в Северо-Западе. Поставляем барабанами, выдаем сертификаты РКО и РМРС, организуем бесплатную доставку до ТК. Ищете нршм расшифровка? Ознакомьтесь с актуальными остатками и ценами на elek-opt.ru — на сайте доступны фильтры по марке, регистру и наличию. Если нужной позиции нет в витрине, пришлите заявку — предложим альтернативу или ближайший приход.
Мне обещали бонус за задержку в 5 + 3 =8 грамм , так и прислали +))) спасибо.+)))
https://bio.site/mwyohvugac
отзывы ждем
Все работает
https://www.betterplace.org/en/organisations/68384
Списавшись в ЛС с ТСом обговорив условия сделки провел оплату в БТЦ.
https://scholar.google.co.in/citations?hl=en&view_op=list_works&gmla=AH8HC4z2_wCz8ZLz47UuKcVYqkBH1lmb4syddz0ITM1RW3m93S-q2165HwJ7UBHELhLIlBeYhZpzaJaf0oCJHQ&user=-0G-QNgAAAAJ
Enfrentar un test preocupacional ya no tiene que ser un problema. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su mezcla, que estimula el cuerpo con proteínas, provocando que la orina oculte los rastros químicos. Esto asegura un resultado confiable en solo 2 horas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para trabajadores en evaluaciones.
Miles de usuarios confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la seguridad.
Cuando el examen no admite errores, esta fórmula es la herramienta clave.
Бро, выходные, подожди до понедельника
https://rant.li/ws3evuninu
Доберус до пк выложу скрины, магазин угрожает говорит что заплатит за подставу в общем очень взбесился когда я сказал что свои сомнения выложу в паблик, прямо как с катушек слетел, хотя я сначала сказал либо кидок аля лига 12, либо взлом.сразу мат срач угрозы ипр что никогда не сделал бы приличный шоп
https://candetoxblend.mystrikingly.com/blog/que-tomar-y-que-evitar-antes-de-un-test-antidoping-en-chile
Pasar un test antidoping puede ser un desafio. Por eso, existe una solucion cientifica desarrollada en Canada.
Su receta potente combina carbohidratos, lo que ajusta tu organismo y enmascara temporalmente los metabolitos de sustancias. El resultado: una muestra limpia, lista para ser presentada.
Lo mas notable es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de personas en Chile ya han comprobado su seguridad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta formula te ofrece confianza.
монтаж кондиционера обнинск монтаж кондиционера обнинск .
ВСЕМ РњРР Рђ РўРЎРЈ РЕСПЕКТ )))
https://bio.site/vuycyoaya
как правило все реактивы от данного магазина проходят проверку на легальность\чистоту так что поживём увидим, думаю нелегала тут в продаже не появится )
Селлер сказал что ур6 курёха!:) походу новая альтернатива дживу
https://form.jotform.com/252492878011056
Р’ целом Рѕ работе магазина – как клиент,СЏ доволен!!!:good:
натяжной потолок в гостиной натяжной потолок в гостиной .
Жалко тест профукал )
http://www.pageorama.com/?p=iudeguge
Ребятки все пушка
лечение запоя
vivod-iz-zapoya-orenburg009.ru
лечение запоя оренбург
Преимущества стационарной алкогольной детоксикации в владимире Стационарное лечение предлагает ряд преимуществ, среди которых индивидуальный подход к лечению и круглосуточная медицинская помощь при алкоголизме. Программы детоксикации включают детоксикацию организма, что способствует восстановлению здоровья после алкоголя. вывод из запоя Кроме того, психологическая поддержка и реабилитация наркозависимых играют важную роль в процессе восстановления. Семейная поддержка существенно влияет на эффективность лечения, создавая позитивную атмосферу для пациентов. В владимире существует множество центров, предлагающих эффективные решения для тех, кто страдает от алкогольной зависимости.
РЇ айтишник Рё Рє РЎРњ РЅРµ отношусь никаким Р±РѕРєРѕРј. РџСЂРѕ РјРѕСЋ работу РІС‹ РЅРµ знали Рё РЅРµ узнали Р±С‹, если Р±С‹ РІСЃС‘ срослось. РЇ просто РіРѕРІРѕСЂСЋ РїСЂРѕ то, что РЅРµ так СѓР¶ Рё секурно Сѓ вас, личность выпаливается “РЅР° раз”.
https://www.impactio.com/researcher/niatiuaja
Помнится ф16 на пробу получал. Хороший синт.гарсон был.
Chemical-Mix, хочу заказать 50г. АМ, но на сайте написано что 50грамм нет на складе.
https://linkin.bio/pdysoqujeco
Отписываюсь по 1к20.получилось в принципе неплохо,но и супер тоже не назовешь. припирает по кумполу практически сразу. сделано было пару напасов. время действия около 30минут,плюс и минус по времени зависит от того кто как курит.если сравнивать с 203 то кайфец по позитивнее будет.и еще было сделано на спирту.Вообщем щас сохнет 1к15 сделанный на растворителе. протестим отпишем. Смущает только одно-осадок остается.не до конца вообщем растворяется,а так все нормально.
СѓРіСѓ, “РЅР° глазок” отсыпали. РєСѓРїРё весы Рё взвесь нормально. РќР° РІРёРґ РѕРЅРѕ может показаться как больше так Рё меньше…
https://www.divephotoguide.com/user/pubuhydso
Хочу грамульку взять и угостить определенный круг людей,
Ищете профессиональную переподготовку и повышение квалификации для специалистов в нефтегазовой сфере? Посетите сайт https://institut-neftigaz.ru/ и вы сможете быстро и без отрыва от производства пройти профессиональную переподготовку с выдачей диплома. Узнайте на сайте подробнее о наших 260 программах обучения.
разные мнения бытуют, я для 1го раза сделал 1к20.сохнет.самому интересно что получиться. отпишу как пробнем.
https://odysee.com/@horstirena3
Mushnyak, да ты гонишь походу, магазин работает как надо, каждую неделю у них заказываю все ровно, кидаловом тут не пахнет, ты наверное на отходосах))))
https://postheaven.net/maixentedd/habitos-que-pueden-afectar-tu-resultado-en-un-test-de-orina
Enfrentar un control sorpresa puede ser arriesgado. Por eso, se ha creado una solucion cientifica creada con altos estandares.
Su formula precisa combina nutrientes esenciales, lo que sobrecarga tu organismo y neutraliza temporalmente los rastros de THC. El resultado: un analisis equilibrado, lista para entregar tranquilidad.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de postulantes ya han comprobado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta solucion te ofrece tranquilidad.
Ровный магазин . Всем советую !
https://www.brownbook.net/business/54242260/можно-ли-купить-марихуану-во-вьетнаме/
магаз ещё не начал работу?
то-же самое могу сказать!
https://igli.me/war_bestplays
_Elf_ тебе сколько лет интересно?РЈ тебя был единичный случай РїРѕ твоим словам товар-фуфло.репутация Сѓ тебя “0”Требуешь вернуть денег, ты же понимаешь что тебе РёС… РЅРµ вернут.Вывод-РџР РћР’РћРљРђР¦РРЇ
пришел urb 597 – поршок белого цвета,РІ ацетоне РЅРµ растоврился, РїСЂРё попытке покурить 1 Рє 10 так дерет горло что курить его вообще нельзя… РІРѕРїСЂРѕСЃ Рє магазину что СЃ РЅРёРј делать, Рё вообще прислали urb 597 или что????
https://www.brownbook.net/business/54238121/купить-гашиш-цена/
У меня такая же ситуация мне кажеться ребята что их курьерку иусора приняли потомушто на сайте
https://candetoxblend.mystrikingly.com
Afrontar un examen de drogas ya no tiene que ser un problema. Existe una alternativa científica que actúa rápido.
El secreto está en su fórmula canadiense, que ajusta el cuerpo con nutrientes esenciales, provocando que la orina oculte los metabolitos de toxinas. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para quienes enfrentan pruebas imprevistas.
Miles de usuarios confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la confianza.
Si tu meta es asegurar tu futuro laboral, esta alternativa es la herramienta clave.
Я 13 числа сделал заказ,и до сих пор жду Макс,думаю магазин Честный и всё придёт )))))))!!!!!!!!Как придёт отпишусь обязательно сюда,компенсация обещена была 6 г :yeah:,всё же думаю Не разочаруют!
http://www.pageorama.com/?p=obybegydicy
Да работает в асю обращайся если чё надо только товара мало там мхе да дмт
РЈСЂР± 597 либо перорально либо нозально, РґРѕР·РёСЂРѕРІРєР° – 5-10РјРі, эффекты описаны РІ энциклопедии,
https://igli.me/deebbiebeeceb
про него что нить писали? точнее вы читали ?
домашний интернет
inernetvkvartiru-rostov005.ru
домашний интернет
Много тут кто согласен
https://rant.li/gbyhvybacudi/kupit-test-na-marikhuanu-v-moche
супер магаз
Да не магазин ровный несколько раз покупал у них, качество отличное. Только в аську бывает недостучатся.
https://ilm.iou.edu.gm/members/danieljacksonmgvm/
екб есть в представителях, смотрите в представительствах
Хочу выразить благодарность данному магазину за лучший товар, лучшие цены, за долгое время непрерывного сотрудничества, очень жду твоего возвращения к работе и появления долгожданного товара, чемикал лучший в своём деле. Очень жаль что на долгий период времени ты преостановил свою работу, надеюсь скоро наладятся поставки и наше сотрудничество возобновится! Чемикал лучший! На данный момент тебе нету равных на рынке RC, возвращайся скорей, мы ждём твоего возвращения с нетерпением!
https://www.divephotoguide.com/user/xibihboduh
лабаз ништяк
https://list.ly/maryldiwcc
Aprobar un control sorpresa puede ser estresante. Por eso, se desarrollo una formula avanzada desarrollada en Canada.
Su formula premium combina carbohidratos, lo que estimula tu organismo y enmascara temporalmente los marcadores de toxinas. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de detox irreales, no promete milagros, sino una herramienta puntual que te respalda en situaciones criticas.
Miles de personas en Chile ya han comprobado su seguridad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta solucion te ofrece confianza.
https://mangalfactory.ru/
Меня на шалфее устраивает:)вываривать ничего не надо
https://form.jotform.com/252492457726062
Наверно так же как и джив. попробуй минимальные пропорции сделать 0,1 к 1
вот это уже наводит на мысли
https://rant.li/sefececuh/kupit-narkotik-apteki
С ним можно работать всегда ровничком всегда адекватность Плюсссс
J’adore l’intensite de Stake Casino, c’est un casino en ligne qui explose comme un volcan en eruption. Le repertoire du casino est un magma de divertissement, proposant des slots de casino a theme explosif. Le service client du casino est une flamme vive, repondant en un eclair brulant. Le processus du casino est transparent et sans cendres, cependant plus de tours gratuits au casino ce serait volcanique. Au final, Stake Casino promet un divertissement de casino brulant pour les passionnes de casinos en ligne ! De surcroit le site du casino est une merveille graphique ardente, ce qui rend chaque session de casino encore plus enflammee.
stake blackjack|
электрокарниз двухрядный цена http://www.elektrokarniz-cena.ru/ .
Все продукты кроме эйфора в наличии, заказывайте! Проб нет.
https://wirtube.de/a/rachaelbarberrac/video-channels
РІ Обьщем как Рё РіРѕРІРѕСЂРёР» заказал ам,РѕРЅРѕ пришло РІ РіРѕСЂРѕРґ,Р° РјРѕСЋ фамилию ПЕРЕПУТАЛР,посылку РЅРµ выдают…….
прокарниз http://www.avtomaticheskie-karnizy.ru/ .
электрические гардины http://www.elektro-karniz77.ru .
I am really loving the theme/design of your blog.
Do you ever run into any web browser compatibility issues?
A number of my blog readers have complained about
my blog not working correctly in Explorer but looks great in Chrome.
My web site; BAYAR4D
Ахаха такая же история была , стул во дворе, приехал на нем бабуся сидит)))) но я забрал свое)
https://89832de8122228126f5c3eefa9.doorkeeper.jp/
“ДОБРА ТЕБЕ РРЎРљРРњРћРЎРРљ”
электрокарнизы электрокарнизы .
Je trouve absolument eblouissant Riviera Casino, ca vibre avec une energie de casino sophistiquee. L’eventail de jeux du casino est une veritable Riviera de delices, offrant des sessions de casino en direct qui eclaboussent de glamour. Le personnel du casino offre un accompagnement digne d’un concierge de luxe, offrant des solutions claires et instantanees. Les retraits au casino sont rapides comme un voilier au vent, parfois des bonus de casino plus frequents seraient glamour. Au final, Riviera Casino promet un divertissement de casino scintillant pour les navigateurs du casino ! Bonus le design du casino est un spectacle visuel mediterraneen, donne envie de replonger dans le casino sans fin.
casino riviera 3|
В современном мире все больше людей предпочитают получать медицинские услуги в комфортной обстановке своего дома. Одной из таких услуг является внутривенное введение жидкостей‚ которая может стать важной частью терапии различных заболеваний. Это удобно‚ эффективно и исключает лишних поездок в больницу. Прокапка на дому – это не только возможность избежать ненужных стрессовых ситуаций‚ связанных с посещением медицинских учреждений‚ но и способ гарантировать качественное лечение‚ не покидая домашнего уюта. Такой подход позволяет пациентам сосредоточиться на реабилитации и получить необходимую медицинскую помощь в привычной обстановке. Для проведения процедуры потребуется специальное оборудование‚ которое может предоставить специализированная компания. Услуги квалифицированного специалиста‚ обладающей необходимыми навыками‚ обеспечивают безопасность и эффективность процесса. Специалист примет меры по уходу за пациентом‚ проверит состояние здоровья и выберет оптимальный режим лечения. vivod-iz-zapoya-vladimir014.ru Инфузионная терапия может использоваться для введения медикаментов‚ необходимых для лечения заболеваний‚ или для поддержания водно-электролитного баланса организма. Это особенно актуально для пациентов‚ восстанавливающихся после болезни или перенесших операцию. Кроме того‚ инъекции могут быть более удобным вариантом для тех‚ кто страдает от постоянных недугов и нуждается в регулярном введении лекарств.Домашняя терапия позволяет не только уменьшить время и силы‚ но и улучшить качество жизни пациента. Удобство лечения на дому создает доброжелательную обстановку‚ что также способствует более быстрому восстановлению. Реабилитационные мероприятия‚ проводимые в домашних условиях‚ могут быть адаптированы под индивидуальные потребности пациента‚ что делает процесс восстановления более эффективным.
Отличный магазин,заказал и уже через 2 дня в своем городе получил посылку курьером(без звонка),офигев от скорости работы.Вес пришел с неплохим бонусом и в хорошей конспирации.Спасибо очень приятно было с вами работать скоро закажу ещё.
https://wirtube.de/a/zsanetpankaj/video-channels
как дела народ ? Всё хорошо ? не у кого проблем нет ?
Если вы находитесь в поиске, где получить капельницу анонимно в Туле, обратите внимание на сайтом vivod-iz-zapoya-tula010.ru. Здесь предоставляются услуги капельницы для здоровья, которые способствуют восстановлению после болезни. Клиника в Туле обеспечивает безопасность процедур и приватность клиентов, предлагая качественную медицинскую помощь. Анонимное лечение – это шанс заботиться о своем здоровье без посторонних глаз. Не откладывайте о себе, воспользуйтесь медицинскими процедурами уже сегодня!
Номер заказа: 10004015 оплачен, мыло выслано с информацией
https://73874166b99325779c6fa72029.doorkeeper.jp/
а какие были проблемы по данном поводу?
электрокарниз купить в москве электрокарниз купить в москве .
https://groups.google.com/g/candetoxblend/c/nYWf8CoaQqE
Enfrentar una prueba de orina ya no tiene que ser una pesadilla. Existe una fórmula confiable que funciona en el momento crítico.
El secreto está en su fórmula canadiense, que ajusta el cuerpo con proteínas, provocando que la orina oculte los marcadores de THC. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: es un plan de emergencia, diseñado para candidatos en entrevistas laborales.
Miles de personas en Chile confirman su seguridad. Los entregas son confidenciales, lo que refuerza la seguridad.
Si tu meta es asegurar tu futuro laboral, esta solución es la elección inteligente.
https://brookspqxq424.trexgame.net/los-errores-mas-comunes-antes-de-un-examen-antidoping
Gestionar una prueba de orina puede ser un momento critico. Por eso, existe una formula avanzada probada en laboratorios.
Su receta unica combina nutrientes esenciales, lo que estimula tu organismo y enmascara temporalmente los marcadores de alcaloides. El resultado: una muestra limpia, lista para cumplir el objetivo.
Lo mas destacado es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de trabajadores ya han validado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si quieres proteger tu futuro, esta formula te ofrece confianza.
как всегда оплатил и все пришло. спасибо что есть такой магаз беру давно у них, все ок всем саветую
https://www.grepmed.com/acebwrcag
Все супер заказывал все пришло попробывыл и писал отзыв этот минут 10 ))))) заказывайте хорошый магазин работают быстро отлично ребята успехов вам chemical.mix !!!!!))
Вы очень давно работаете,стабильная деятельность.
https://www.brownbook.net/business/54246645/купить-соль-наркотик/
всех с новым годом и удачных покупок
Привет, ребята!
https://www.grepmed.com/zogufidyoy
2с на высоте, прет огого как, сыпали по чуточки кто на что горазд, у меня до сих пор постэффекты
http://mskit.ru/about/
минималка СК и рег? и внесите ясность
https://bio.site/icicybigu
помогите обьясните как написать сапорту
Готовитесь к сезону? В Yokohama Киров подберем шины и диски под ваш стиль и условия дорог, выполним профессиональный шиномонтаж без очередей и лишних затрат. В наличии бренды Yokohama и другие проверенные производители. Узнайте цены и услуги на сайте: https://yokohama43.ru/ — консультируем, помогаем выбрать оптимальный комплект и бережно обслуживаем ваш авто. Надёжно, быстро, с гарантией качества.
флудить в курилку
https://form.jotform.com/252463482009052
Списались с оператором. Нужно взять 50 гр. СК.
РњРҐР• “как Сѓ всех” тобиш бодяжный.. Р’СЂРѕРґРµ СЃРєРѕСЂРѕ должна быть нормальная партия.
https://hoo.be/xehoofzeb
Рвсё надо успеть. :crazy:
карнизы для штор с электроприводом карнизы для штор с электроприводом .
Наша компания оказывает услуги таможенного представителя, экономя ваше время и ресурсы: таможенный брокер
может ты просто сам не учел проценты комиссии и тебе не хватило???
https://linkin.bio/djbitaao819
Ребят я не терпила и не превык чтоб меня кидали и вы тоже я думаю и если нас кинули то я предлогаю мстить таким образам для начала надо писать на всвсех форумах где есть этом магаз о том что это кидала а не довереный магаз не лениться и писать каждый день об этом чтоб все браза знали правду и не постродали как мы
https://postheaven.net/maixentedd/habitos-que-pueden-afectar-tu-resultado-en-un-test-de-orina
Pasar una prueba preocupacional puede ser estresante. Por eso, se desarrollo una formula avanzada desarrollada en Canada.
Su receta unica combina vitaminas, lo que ajusta tu organismo y disimula temporalmente los marcadores de alcaloides. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas valioso es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete milagros, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su efectividad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta solucion te ofrece tranquilidad.
Ребят я не терпила и не превык чтоб меня кидали и вы тоже я думаю и если нас кинули то я предлогаю мстить таким образам для начала надо писать на всвсех форумах где есть этом магаз о том что это кидала а не довереный магаз не лениться и писать каждый день об этом чтоб все браза знали правду и не постродали как мы
https://yamap.com/users/4808067
1к10 незачет, 2к10, так, удовлетворительно.
отличный магазин, все всегда ровно
https://form.jotform.com/252512040591043
“РќРѕ представь такую сетуацию,если Р±С‹ СЏ бахался РїРѕ Р’/Р’ Рё РєРѕ РјРЅРµ РІ РєСЂРѕРІСЊ попали Рти таблетки СЏ Р±С‹ отправился РЅР° тот свет “
Подскажите. Если сейчас сделаю заказ и оплачу сразу, завтра товар отправят?
https://www.band.us/page/99903730/
ТС ответь мне на почту или в лс, писал по поводу JV-100 ответил
домашний интернет в ростове
inernetvkvartiru-rostov006.ru
интернет домашний ростов
http://images.google.so/url?q=https://grubtechnologies.com.mx/blog/promociones-semanales-en-pin-up-casino-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
Отличный магазин!
https://igli.me/asthafooursixn
ну может она на меня так подействовала слабо,незнаю прям:dontknown:..надеюсь что-нибудь попробовать сильного из вашего ассортимента;)..p.s. пишу так как было,не перегибая.
https://www.twitch.tv/candetoxblend
Prepararse un test preocupacional ya no tiene que ser una pesadilla. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su fórmula canadiense, que sobrecarga el cuerpo con vitaminas, provocando que la orina oculte los rastros químicos. Esto asegura parámetros adecuados en solo 2 horas, con ventana segura para rendir tu test.
Lo mejor: no se requieren procesos eternos, diseñado para candidatos en entrevistas laborales.
Miles de clientes confirman su efectividad. Los envíos son 100% discretos, lo que refuerza la seguridad.
Si no quieres dejar nada al azar, esta solución es la elección inteligente.
Не-не, через форум заказы не принимаются. Заказывать нужно только через сайт, указанный в подписи.
https://yamap.com/users/4810754
он спонсировал всех нас.
5РіРѕ марта написал ЛС РўРЎСѓ РїСЂРѕ оптовый заказ…. РґРѕ СЃРёС… РїРѕСЂ жду ответа
https://www.divephotoguide.com/user/pyhuefyfe
Надеюсь на дальнейшее сотрудничество с магазином!
Porn
Специалист по зависимостям владимир: Профессиональная помощь при зависимостях Если вы или ваши родные столкнулись с психоактивными веществами‚ необходимо обратиться к специалисту. Нарколог владимир предлагает квалифицированную медицинскую помощь‚ включая оценку состояния зависимого и индивидуальные консультации нарколога. В наркологической клинике предлагаются многообразные услуги‚ такие как медикаментозное лечение и психотерапия. Работа с зависимостями – это комплексный и многоступенчатый процесс‚ который предполагает индивидуального подхода. Программа реабилитации включает в себя этапы‚ направленные на восстановление физического и психологического состояния пациента. Реабилитация наркозависимых также включает поддержку семьи‚ что является ключевой ролью в успешном лечении. Конфиденциальная помощь даёт возможность пациентам чувствовать себя защищенными и свободными от осуждения. Предотвращение зависимостей и помощь при алкоголизме – важные аспекты работы наркологов. Обратитесь на vivod-iz-zapoya-vladimir015.ru для получения подробностей и записи на консультацию. Помните‚ что раннее обращение – гарантия успешного исцеления!
Спасибо Р’СЃРµ супер.РњРёР
https://igli.me/thomasgarnertho
Правило говоришь Бро! А про работу магазина могу сказать что он работает великолепно!
https://ameblo.jp/eduardoofzj381/entry-12929573128.html
Aprobar un test antidoping puede ser arriesgado. Por eso, se desarrollo un suplemento innovador desarrollada en Canada.
Su receta potente combina minerales, lo que sobrecarga tu organismo y enmascara temporalmente los rastros de sustancias. El resultado: una muestra limpia, lista para entregar tranquilidad.
Lo mas destacado es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete limpiezas magicas, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de profesionales ya han experimentado su efectividad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta formula te ofrece seguridad.
Наша компания оказывает услуги таможенного представителя, экономя ваше время и ресурсы: таможенный брокер в Москве
пиши разберемся
https://yamap.com/users/4810328
не долго думая решил написать оператору данного магазина!
купить права
работа 5+ качество 5 опреративность 5+
https://linkin.bio/mapipajahyhag
Продован 1000 балоф те =)
Наркологическая помощь в Туле играет ключевую роль в помощи людям с зависимостями. Медицинские учреждения, такие как vivod-iz-zapoya-tula011.ru, предлагают комплексное лечение для всех, кто страдает от зависимостей. Методы лечения зависимостей охватывают стационарные программы и программы реабилитации, которые способствуют возвращению к полноценной жизни.Тульская наркология обеспечивает конфиденциальность, что является критически важным для многих зависимых. Здесь также доступна наркологическая консультация, где специалисты помогают определить степень зависимости и выбрать оптимальный путь выздоровления. Поддержка семьи зависимого также является неотъемлемой частью процесса реабилитации. Медицинские услуги в Туле охватывает не только помощь при алкоголизме, но и меры по предотвращению зависимостей, что позволяет избежать рецидивов. Каждому пациенту предлагается индивидуальный подход, что обеспечивает эффективность лечения.
Добрый день, РјРЅРѕРіРёРј пришли посылки РґРѕ РќР“, 98% покупателей – перепроверено РїРѕ трекам. Если есть РІРѕРїСЂРѕСЃС‹ пишите, РІ скайп или аську. Р’ веточке пожалуйста, только РїРѕ теме.
https://wirtube.de/a/frvhszv250/video-channels
всегда ровно все было и есть. так что я
Спасибо!Не надо!
http://www.pageorama.com/?p=ceahehoe
Кто тут урб-754 брал отпишитесь чё да как
доставка порадовала быстро качественно . насчет реагента который был указан 1 Рє 15 шас насайте РѕРЅ же стоит 1 Рє 10 такова РіРѕРІРЅР° еше РЅРµ пробывал ( извените если РєРѕРіРѕ обидел) 5 РјРёРЅ прет Рё РІСЃРµ даже пролонгатор увеличил действие РґРѕ 15 РјРёРЅ . Р·Р° сам магазин нечего плохова сказать РЅРµ РјРѕРіСѓ брал раньше рега была отбойной Рё цены радуют … РќРѕ последния рега просто выкинуть что ли ее . сегодня РїРѕРїСЂРѕР±СѓСЋ конечно 2 Рє 10 сделать если РЅРµ поможет просто выкину ..
https://hoo.be/jabzicefid
Ждать возможно придется дольше обычного, я ожидал 12 рабочих, не считая праздников..
поддерживаю !!!!
https://imageevent.com/gudazilathb/qjsvg
– РќСѓ….. РјРёРЅСѓС‚ Р·Р° двадцать….
https://postheaven.net/maixentedd/habitos-que-pueden-afectar-tu-resultado-en-un-test-de-orina
Pasar un control sorpresa puede ser arriesgado. Por eso, ahora tienes una solucion cientifica desarrollada en Canada.
Su receta premium combina vitaminas, lo que ajusta tu organismo y oculta temporalmente los rastros de sustancias. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una herramienta puntual que te respalda en situaciones criticas.
Miles de profesionales ya han experimentado su efectividad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
Да просто дедушка форума ))
https://hub.docker.com/u/awandatabech
вобщем моя командировка в Столицу нашей родины удалась ) день переговоров и 6 дней удовльствия !!!!!
Добрый день!
Долго не спал и думал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от успещных seo,
крутых ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://imap33.site
Линкбилдинг это – основа современной оптимизации. Ссылки помогают сайту расти в поиске и привлекать трафик. Программы вроде Xrumer упрощают создание линков. Это экономит время и силы специалистов. Линкбилдинг это эффективный инструмент продвижения.
сколько стоит ссылки для продвижения сайта, проблема продвижения сайта, Как поднять DR сайта за неделю
Xrumer: практические примеры, должности сео, seo продвижение компания
!!Удачи и роста в топах!!
Estou alucinado com SupremaBet Casino, da uma energia de cassino que e puro dominio. Tem uma tempestade de jogos de cassino irados, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e puro reinado, garantindo suporte de cassino direto e sem revoltas. Os saques no cassino sao velozes como uma carruagem real, mesmo assim mais recompensas no cassino seriam um diferencial imperial. Na real, SupremaBet Casino vale demais conquistar esse cassino para os viciados em emocoes de cassino! Vale dizer tambem a interface do cassino e fluida e reluz como um palacio, adiciona um toque de grandeza ao cassino.
supremabet pb|
barato ozempic
мир всем месным братья
http://www.pageorama.com/?p=iadofecugyg
Оплатил, жду.
Рђ теперь Рє делу.. магаз ровный, товар ..вставляет епт..особенно РІ прошлый раз, РїРѕР» часа ждал, что РёР· ванной вылезет РѕРЅРѕ Рё покарает меня…хорошо быстро отпускает, Р° то РІРѕРґР° остыла уже Рё СЃРёРіР° стлела Рё хабарик упал так , что сам РЅРµ заметил…
https://www.rwaq.org/users/dovevhadam-20250727131219
Буду делать am 2233 + rcs4. Основа: Дурман(молотый) 5г, Латук дикий 10 г, Лобелия вздутая 5 г. Как дойдет с меня трип-репорт
Sou louco pela vibe de SpinSala Casino, da uma energia de cassino que e puro brilho estelar. O catalogo de jogos do cassino e um espetaculo de fogos, incluindo jogos de mesa de cassino com um toque de glamour. O servico do cassino e confiavel e cheio de brilho, com uma ajuda que reluz como um show. As transacoes do cassino sao simples como um pisca-pisca, mesmo assim mais bonus regulares no cassino seria brabo. Em resumo, SpinSala Casino oferece uma experiencia de cassino que e puro brilho para os dancarinos do cassino! Alem disso o site do cassino e uma obra-prima de estilo brilhante, torna a experiencia de cassino um espetaculo inesquecivel.
spinsala casino bonus code|
Успехов Вам всё ровно )
https://potofu.me/7ioqfxzp
РЎ человеком приятно иметь дело. Склонен РЅР° РєРѕРјРїСЂРѕРјРёСЃСЃС‹ 😉
А как по качеству?
http://www.pageorama.com/?p=iheguducibvu
главное что ты “РІРєСѓСЂРёР»”, Р° как РјРЅРµ тебе это втереть уже РЅРµ важно
https://brookspqxq424.trexgame.net/los-errores-mas-comunes-antes-de-un-examen-antidoping
Enfrentar un test antidoping puede ser arriesgado. Por eso, se desarrollo una formula avanzada creada con altos estandares.
Su formula precisa combina vitaminas, lo que sobrecarga tu organismo y oculta temporalmente los metabolitos de toxinas. El resultado: una orina con parametros normales, lista para ser presentada.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de estudiantes ya han experimentado su efectividad. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta solucion te ofrece respaldo.
Привет всем! Написал бы отзыв был бы продукт для него)) Мир ровным!
https://potofu.me/10p24ath
Такое бывает у СПСР, у меня то же он не бился, а потом все нормально было, хотя мне ей вчера должны были привезти но не привезли
Приветствую ТС,сделал заказ,но до сих пор трек не пробивается,помоги разобраться в этом уже почти неделю жду,заранее спс
https://community.wongcw.com/blogs/1126196/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%91%D0%B5%D0%BD%D1%82%D0%BE%D1%82%D0%B0
Сделал 4 затяжки СЃ батла, почувствовал секунд через 30 первое прикосновение.))) Затем РЅРµ РјРЅРѕРіРѕ стал теряться РІ пространстве Рё РІРѕ времени, Р° РєРѕРіРґР° поднялся РґРѕРјРѕР№, Рё открыл дверь (5 РјРёРЅ спустя) меня перекрыло нах, СЏ РЅРµ РјРѕРі закрыть дверь Рё РјРЅРµ РІСЃС‘ казалось что кто то держит, Сѓ меня начинается паника) СЏ начинаю кричать Р·Р° дверь: – ты кто такой отпусти, РёРґРё отсюда………….. Р—РѕРІСѓ родаков, которых РґРѕРјР° нет слава Богу!!!!! вообщем стоял РјРёРЅСѓС‚ 20 Сѓ двери) Р° РєРѕРіРґР° пошёл РІ комнату РјРЅРµ казалось что кто то Р·Р° РјРЅРѕР№ С…РѕРґРёС‚!!!
подключить интернет санкт-петербург
inernetvkvartiru-spb004.ru
подключить интернет в санкт-петербурге в квартире
Слив засчитан.
https://www.band.us/page/99613474/
16 числа заказала товарчика)ну пока еще ничего не получила!!! продаван отправил только половинку(объяснил что не хватило реактивчика) но все остальное вышлет как привезут 100ый ))ждем и надеемся)) заказывала и раньше в этом магазе все было ОГОНЬ))
Капельница при запое — это необходимая мера в помощи при алкогольной зависимости. Процедура капельницы способствует детоксикации организма‚ выводя токсины и нормализуя баланс жидкости и электролитов. После ее применения пациенты замечают улучшение психоэмоционального состояния.Помощь нарколога в этом процессе играет важную роль. Он проводит оценку симптомов отмены и предлагает необходимое лечение запоя. Восстановление после запоя включает обе стороны: физическую и психологическую. Роль близких существенна‚ позволяя преодолеть последствия запойного состояния. помощь нарколога Реабилитация — следующая стадия в лечении‚ где пациент обучается и получает медицинскую помощь для предотвращения рецидивов. Анонимная помощь гарантирует безопасность и анонимность. Важно помнить‚ что лечение алкогольной зависимости, это сложный и длительный процесс‚ который требует как усилий‚ так и поддержки.
бред, откуда инфа такия про 80%?
https://www.rwaq.org/users/leitsokolovavaleriya-20250730181927
Рзвините удаляю сообщение!
Ищете выездной бар на 23 февраля? Посетите сайт bar-vip.ru/vyezdnoi_bar и вы сможете заказать выездной бар на праздник или другое мероприятие под ключ. Перейдите на страницу, и вы сразу увидите, что вас ждет — начиная с большого ассортимента напитков и возможности влиять на состав меню. Есть опция включить в меню авторские рецепты, а также получить услуги выездного бара для тематических вечеров с нужной атрибутикой, декором и костюмами. И это далеко не всё! Все детали — на сайте.
Наша платформа работает круглосуточно и не знает слова перерыв. Бронировать и планировать можно где угодно: в поезде, на даче, в кафе или лежа на диване https://probilets.com/. Хотите купить билет, пока идёте по супермаркету? Просто достаньте телефон и оформите поездку. Нужно скорректировать планы, отменить или перенести билет? Это тоже можно сделать онлайн, без звонков и визитов. Но если возникла проблема, то наши специалисты помогут и все расскажут
https://rentry.co/cs8rtsqb
Superar una prueba de orina puede ser estresante. Por eso, se desarrollo una alternativa confiable desarrollada en Canada.
Su receta eficaz combina carbohidratos, lo que prepara tu organismo y enmascara temporalmente los marcadores de alcaloides. El resultado: una prueba sin riesgos, lista para entregar tranquilidad.
Lo mas destacado es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete resultados permanentes, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de estudiantes ya han experimentado su rapidez. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta alternativa te ofrece seguridad.
Портал, посвященный бездепозитным бонусам, предлагает ознакомиться с надежными, проверенными заведениями, которые играют на честных условиях и предлагают гемблеру большой выбор привилегий. Перед вами только те заведения, которые предлагают бездепы всем новичкам, а также за выполненные действия, на большой праздник. На сайте https://casinofrispini.space/ ознакомьтесь с полным списком онлайн-заведений, которые заслуживают вашего внимания.
Капельница при алкогольной зависимости – это действующий метод лечения алкогольной зависимости, который предлагает квалифицированный нарколог в Туле. При запое тело испытывает сильное истощение жидкости и интоксикацию, что вызывает различные симптомы похмелья. Необходимо предоставить первую помощь, чтобы улучшить состояние пациента. нарколог на дом тула Очистка организма с помощью инфузий помогает оперативному выведению вредных веществ и улучшению состояния. Индивидуальный подход нарколога гарантирует высокую результативность лечения на дому. Услуги медикаментов на дому позволяют не ложиться в больницу и сделать процесс лечения комфортным. Алкоголь негативно сказывается на здоровье катастрофически, поэтому восстановление после запоя включает восстановительные мероприятия после запоя и помощь специалиста. Комплексная терапия, включая капельницу, способствует восстановлению здоровья и возвращению к нормальной жизни.
Привет всем!
Долго не мог уяснить как поднять сайт и свои проекты в топ и узнал от крутых seo,
крутых ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://imap33.site
Программное обеспечение для постинга облегчает массовое создание ссылок. Ускоренный рост ссылочного профиля виден уже через месяц. Xrumer: создание ссылочной массы упрощает работу веб-мастеров. Линкбилдинг через форумы и блоги позволяет получать релевантные ссылки. Повышение авторитетности домена становится реальностью с Xrumer.
реклама создание и продвижение сайта компании, предложения для продвижения сайта, линкбилдинг это что
линкбилдинг отзывы, seo специалист что это простыми словами, раскрутка сайта по факту
!!Удачи и роста в топах!!
https://bpr-work.ru/
http://images.google.com.pg/url?q=http://www.edutip.mx/ventajas-de-jugar-en-pin-up-casino-desde-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
https://judahbpph919.iamarrows.com/como-prepararte-la-semana-previa-a-un-control-sorpresa
Gestionar un test antidoping puede ser un momento critico. Por eso, ahora tienes una solucion cientifica creada con altos estandares.
Su composicion eficaz combina creatina, lo que estimula tu organismo y oculta temporalmente los rastros de alcaloides. El resultado: un analisis equilibrado, lista para ser presentada.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete resultados permanentes, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de postulantes ya han experimentado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
Горы Кавказа зовут в путешествие круглый год: треккинги к бирюзовым озёрам, рассветы на плато, купания в термах и джип-туры по самым живописным маршрутам. Мы организуем индивидуальные и групповые поездки, встречаем в аэропорту, берём на себя проживание и питание, даём снаряжение и опытных гидов. Подробнее смотрите на https://edemvgory.ru/ — выбирайте уровень сложности и даты, а мы подберём оптимальную программу, чтобы горы поселились в вашем сердце.
Добрый день!
Долго думал как встать в топ поисковиков и узнал от друзей профессионалов,
крутых ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://imap33.site
Предлагаю линкбилдинг для всех типов сайтов. Xrumer автоматизирует процесс размещения ссылок. Массовый прогон повышает DR и авторитет сайта. Автоматизация экономит время специалистов. Предлагаю линкбилдинг – современный способ SEO-продвижения.
продвижение сайта отеля, раскрутка сайта продвижение бесплатно, предлагаю линкбилдинг
Как поднять DR Ahrefs, seo сайта недорого, настройки сео страницы
!!Удачи и роста в топах!!
https://rentry.co/cs8rtsqb
Enfrentar una prueba preocupacional puede ser un momento critico. Por eso, se desarrollo una alternativa confiable creada con altos estandares.
Su formula precisa combina minerales, lo que sobrecarga tu organismo y neutraliza temporalmente los trazas de alcaloides. El resultado: una prueba sin riesgos, lista para entregar tranquilidad.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de otros productos, no promete limpiezas magicas, sino una solucion temporal que responde en el momento justo.
Miles de estudiantes ya han experimentado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
Доброго!
Долго обмозговывал как поднять сайт и свои проекты в топ и узнал от друзей профессионалов,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Xrumer – https://imap33.site
Постинг на форумах для ссылок – проверенный способ продвижения. Он помогает формировать ссылочную массу и увеличивать доверие. Xrumer автоматизирует этот процесс на сотнях площадок. Такой метод дает быстрый результат. Постинг на форумах для ссылок – надежная стратегия.
стоимость услуги продвижения сайтов, screaming frog seo cracked, Линкбилдинг через автоматические проги
Прогон Xrumer по свежим базам, бесплатный сайт для раскрутки сайтов, курсы продвижение сайтов москва
!!Удачи и роста в топах!!
Профилактика алкоголизма в владимире: рекомендации врачей Зависимость от алкоголя — крайне важная проблема‚ которая требует внимания и действий. Необходимо быть в курсе способов профилактики и лечения. Вызвать нарколога на дом в владимире можно Врачи советуют проводить профилактические меры‚ включая осведомленность о последствиях алкоголизма и поддержку семьи. вызвать нарколога на дом владимир Лечение алкоголизма включает позволяющие помогают вернуть здоровье и социальную интеграцию. Наркологическая помощь необходима для работы с зависимыми‚ а также для предотвращения рецидивов. Здоровье и алкоголь — это вечная борьба‚ и своевременная поддержка играет ключевую роль.
интернет провайдеры санкт-петербург
inernetvkvartiru-spb005.ru
подключить интернет по адресу
Доброго!
Долго не спал и думал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от друзей профессионалов,
топовых ребят, именно они разработали недорогой и главное лучший прогон Хрумером – https://imap33.site
Автоматический постинг форумов с Xrumer экономит время специалистов. Улучшение DR через Xrumer повышает позиции сайта. Программы для линкбилдинга делают продвижение системным. Повышение авторитетности сайта с помощью Xrumer заметно через месяц. Xrumer рассылка форумов расширяет охват ресурсов.
сео продвижение в москве репутационные работы, seo самоучитель, линкбилдинг стоимость
линкбилдинг сайта, бесплатный сайт для раскрутки, медицинский сайт продвижение
!!Удачи и роста в топах!!
Je trouve absolument dement Spinanga Casino, il propose une aventure de casino qui spirale comme un vortex. Les options de jeu au casino sont riches et tumultueuses, avec des machines a sous de casino modernes et hypnotiques. Le personnel du casino offre un accompagnement digne d’un maitre des vents, avec une aide qui fait tourbillonner. Le processus du casino est transparent et sans bourrasques, parfois des bonus de casino plus frequents seraient explosifs. Pour resumer, Spinanga Casino c’est un casino a decouvrir sans tarder pour les dompteurs de tempete du casino ! Bonus la navigation du casino est intuitive comme une bourrasque, amplifie l’immersion totale dans le casino.
code promo spinanga sans dГ©pГґt|
https://rylanshfz540.mystrikingly.com/
Gestionar una prueba de orina puede ser arriesgado. Por eso, se ha creado una formula avanzada con respaldo internacional.
Su composicion unica combina vitaminas, lo que estimula tu organismo y enmascara temporalmente los metabolitos de THC. El resultado: un analisis equilibrado, lista para ser presentada.
Lo mas valioso es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete resultados permanentes, sino una solucion temporal que responde en el momento justo.
Miles de profesionales ya han validado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta formula te ofrece confianza.
Познакомьтесь с удобным онлайн-кинотеатром, где вас ждут свежие премьеры и любимая классика. Наслаждайтесь Full HD и находите кино под настроение благодаря умным рекомендациям без лишних действий. Ищете ужасы смотреть онлайн? Переходите на kinospecto.online и начните вечер с идеального выбора. С любого устройства — быстрая загрузка, закладки и история просмотров делают просмотр максимально удобным. Оформите подписку и смотрите больше, не тратя время на бесконечные поиски.
Ich bin vollig fasziniert von SlotClub Casino, es pulsiert mit einer schillernden Casino-Energie. Der Katalog des Casinos ist ein Kaleidoskop voller Spa?, mit einzigartigen Casino-Slotmaschinen. Der Casino-Service ist zuverlassig und strahlend, liefert klare und schnelle Losungen. Casino-Transaktionen sind simpel wie ein Schalter, trotzdem mehr regelma?ige Casino-Boni waren elektrisierend. Kurz gesagt ist SlotClub Casino ein Casino, das man nicht verpassen darf fur Abenteurer im Casino! Nebenbei die Casino-Plattform hat einen Look, der wie ein Laserstrahl funkelt, Lust macht, immer wieder ins Casino zuruckzukehren.
slotclub abzocke|
Восстановление организма после запоя в владимире – существенный шаг на пути к восстановлению здоровья и благополучия. Нарколог на дом из медицинского учреждения предлагает процедуры детоксикациикоторая предоставляет помощь в лечении запоя и медицинскую помощь при алкоголизме. Лечебные программы зачастую включают психотерапию и помощь близких. Процесс восстановления после запоя начинается с обращения к наркологу, что способствует успешному очищению организма и улучшению качества жизни. Нарколог на дом клиника
Здравствуйте!
Долго обмозговывал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://imap33.site
Форумный спам с Xrumer помогает улучшить видимость сайта в поисковиках. Увеличение показателей Ahrefs происходит за счёт массового охвата площадок. Xrumer автоматизирует процесс создания ссылок, экономя ваше время. Прогон ссылок через форумы подходит для любых сайтов. Используйте Xrumer для ускоренного продвижения.
сео план продвижения сайта, заказать сео продвижение сайта монстер, SEO рассылки форумов
сервисы для линкбилдинг, dr web cureit лечащая утилита скачать бесплатно с официального сайта, dr gans мойка официальный сайт
!!Удачи и роста в топах!!
https://fernandorlay904.yousher.com/hidratacin-inteligente-cunta-agua-tomar-antes-de-un-test-de-orina
Superar una prueba preocupacional puede ser arriesgado. Por eso, se ha creado un metodo de enmascaramiento con respaldo internacional.
Su formula eficaz combina minerales, lo que sobrecarga tu organismo y neutraliza temporalmente los metabolitos de THC. El resultado: una orina con parametros normales, lista para ser presentada.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de profesionales ya han validado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si quieres proteger tu futuro, esta formula te ofrece confianza.
Институт дополнительного дистанционного образования https://astobr.com/ это возможность пройти дистанционное обучение с выдачей диплома и сопровождением персонального менеджера. Мы предлагаем краткосрочное обучение, повышение квалификации, профессиональную переподготовку. Узнайте на сайте больше о нашей образовательной организации “Академия современных технологий”.
«СпецДорТрак» — поставщик запчастей для дорожной, строительной и спецтехники с доставкой по РФ. В наличии позиции для ЧТЗ Т-130, Т-170, Б-10, грейдеров ЧСДМ ДЗ-98/143/180, ГС 14.02/14.03, техники на базе К 700 с двигателями ЯМЗ/Тутай, МТЗ, ЮМЗ, Урал, КРАЗ, МАЗ, БЕЛАЗ, а также ЭКГ, ДЭК, РДК. Карданные валы, включая изготовление по размерам. Подробнее на https://trak74.ru/ — свой цех ремонта, оперативная отгрузка, помощь в подборе и заказ под требуемые спецификации.
https://list.ly/maryldiwcc
Enfrentar un control sorpresa puede ser un desafio. Por eso, ahora tienes una solucion cientifica probada en laboratorios.
Su mezcla potente combina vitaminas, lo que prepara tu organismo y enmascara temporalmente los trazas de toxinas. El resultado: una muestra limpia, lista para entregar tranquilidad.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de otros productos, no promete resultados permanentes, sino una herramienta puntual que te respalda en situaciones criticas.
Miles de trabajadores ya han experimentado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta formula te ofrece seguridad.
Вызов профессионального нарколога – это важный шаг на пути к лечению зависимости. Если вы имеете дело с проблемами‚ связанными с наркотиками или алкоголем‚ профессиональная помощь становится необходимостью. Услуги нарколога включают в себя консультацию нарколога‚ диагностику зависимостей и вызов врача на место жительства для первичного лечения. Одним из основных плюсов вызова нарколога на дом является конфиденциальность. Вы имеете возможность получить помощь‚ которая вам нужна‚ на дому‚ что снижает уровень стресса и даёт возможность сосредоточиться на реабилитации. Частный нарколог осуществляет лечение зависимостей персонализированно‚ учитывая особенности каждого пациента. После первичной консультации стартует процесс реабилитации от наркотиков или алкоголя‚ который может включать медикаментозную терапию и психологическую помощь. Сопровождение пациентов в этом процессе крайне важно‚ так как это помогает предотвратить рецидивы и обеспечивает полноценное восстановление после зависимости. Услуги наркологов на дому также предполагают регулярные проверки состояния пациента и корректировку лечебного плана в зависимости от индивидуальных нужд. Не стоит откладывать решение проблемы – вызов нарколога может стать первым шагом к новому этапу жизни. Вы можете обратиться на сайт vivod-iz-zapoya-vladimir018.ru для дополнительных сведений о профессиональной помощи при зависимости.
http://google.com.kh/url?q=https://4wall.com.mx/2025/09/05/que-tan-rapido-paga-pin-up-en-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
https://akpp-inform.ru/manuals.html
https://judahbpph919.iamarrows.com/como-prepararte-la-semana-previa-a-un-control-sorpresa
Aprobar un test antidoping puede ser estresante. Por eso, existe una alternativa confiable con respaldo internacional.
Su mezcla precisa combina carbohidratos, lo que sobrecarga tu organismo y neutraliza temporalmente los trazas de THC. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de trabajadores ya han experimentado su rapidez. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta solucion te ofrece respaldo.
интернет провайдер санкт-петербург
inernetvkvartiru-spb006.ru
интернет по адресу санкт-петербург
Жинка https://zhinka.in.ua женский блог о моде, красоте, здоровье. Полезные советы на все случаи жизни.
Adoro o frenesi de AFun Casino, parece uma rave de diversao sem fim. O catalogo de jogos do cassino e um carnaval de emocoes, com slots de cassino tematicos de festa. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como um carro alegorico, as vezes mais bonus regulares no cassino seria brabo. No geral, AFun Casino e um cassino online que e uma explosao de alegria para os amantes de cassinos online! E mais a interface do cassino e fluida e reluz como um desfile noturno, o que torna cada sessao de cassino ainda mais animada.
como ganhar dinheiro na afun|
Ich liebe den Zauber von Trickz Casino, es ist ein Online-Casino, das wie ein Zauberstab funkelt. Die Casino-Optionen sind vielfaltig und verzaubernd, inklusive stilvoller Casino-Tischspiele. Das Casino-Team bietet Unterstutzung, die wie ein Zauberspruch wirkt, mit Hilfe, die wie eine Illusion verblufft. Casino-Zahlungen sind sicher und reibungslos, dennoch wurde ich mir mehr Casino-Promos wunschen, die wie Zaubertranke wirken. Insgesamt ist Trickz Casino eine Casino-Erfahrung, die wie ein Zaubertrick glanzt fur die, die mit Stil im Casino wetten! Extra die Casino-Seite ist ein grafisches Meisterwerk, einen Hauch von Zauberei ins Casino bringt.
trickz casino review|
Je suis fou de VBet Casino, ca pulse avec une energie de casino digne d’un cratere. Le repertoire du casino est un magma de divertissement, avec des machines a sous de casino modernes et incandescentes. Les agents du casino sont rapides comme une etincelle, repondant en un eclair brulant. Le processus du casino est transparent et sans cendres, par moments plus de tours gratuits au casino ce serait volcanique. Globalement, VBet Casino promet un divertissement de casino incandescent pour les passionnes de casinos en ligne ! De surcroit l’interface du casino est fluide et eclatante comme un cratere en fusion, facilite une experience de casino eruptive.
vbet вакансии|
Acho simplesmente alucinante AFun Casino, parece uma rave de diversao sem fim. Tem uma enxurrada de jogos de cassino irados, com slots de cassino tematicos de festa. O servico do cassino e confiavel e cheio de energia, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um carro alegorico, as vezes mais recompensas no cassino seriam um diferencial festivo. No fim das contas, AFun Casino oferece uma experiencia de cassino que e puro carnaval para os viciados em emocoes de cassino! De bonus o design do cassino e um espetaculo visual de purpurina, adiciona um toque de purpurina ao cassino.
codigo de recompensas afun|
Sou louco pela energia de BetorSpin Casino, tem uma vibe de jogo tao vibrante quanto uma supernova dancante. Tem uma chuva de meteoros de jogos de cassino irados, incluindo jogos de mesa de cassino com um toque intergalactico. O atendimento ao cliente do cassino e uma estrela-guia, acessivel por chat ou e-mail. Os saques no cassino sao velozes como uma viagem interestelar, mas queria mais promocoes de cassino que explodem como supernovas. Na real, BetorSpin Casino e o point perfeito pros fas de cassino para quem curte apostar com estilo estelar no cassino! De lambuja a plataforma do cassino brilha com um visual que e puro cosmos, adiciona um toque de brilho estelar ao cassino.
betorspin giriЕџ|
Ich bin suchtig nach Trickz Casino, es bietet ein Casino-Abenteuer, das wie eine Illusion verblufft. Die Casino-Optionen sind vielfaltig und verzaubernd, mit Live-Casino-Sessions, die wie ein Zaubertrick funkeln. Das Casino-Team bietet Unterstutzung, die wie ein Zauberspruch wirkt, sorgt fur sofortigen Casino-Support, der begeistert. Auszahlungen im Casino sind schnell wie ein Zaubertrick, dennoch mehr regelma?ige Casino-Boni waren verhext. Insgesamt ist Trickz Casino ein Online-Casino, das wie ein Zirkus der Magie strahlt fur Fans moderner Casino-Slots! Ubrigens die Casino-Oberflache ist flussig und funkelt wie ein Zauberstab, einen Hauch von Zauberei ins Casino bringt.
casino trickz|
https://www.anobii.com/en/015f4267973d99a3d3/profile/activity
Aprobar un test antidoping puede ser arriesgado. Por eso, ahora tienes un suplemento innovador desarrollada en Canada.
Su composicion precisa combina carbohidratos, lo que ajusta tu organismo y oculta temporalmente los rastros de sustancias. El resultado: una muestra limpia, lista para ser presentada.
Lo mas valioso es su capacidad inmediata de respuesta. A diferencia de detox irreales, no promete resultados permanentes, sino una solucion temporal que te respalda en situaciones criticas.
Miles de trabajadores ya han validado su discrecion. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta solucion te ofrece tranquilidad.
J’adore la chaleur de VBet Casino, on dirait une eruption de plaisirs incandescents. Il y a une deferlante de jeux de casino captivants, proposant des slots de casino a theme volcanique. Le service client du casino est une torche d’efficacite, offrant des solutions claires et instantanees. Les transactions du casino sont simples comme une braise, parfois j’aimerais plus de promotions de casino qui envoient du feu. Dans l’ensemble, VBet Casino est une pepite pour les fans de casino pour les passionnes de casinos en ligne ! En plus l’interface du casino est fluide et eclatante comme un cratere en fusion, facilite une experience de casino eruptive.
vbet РїСЂРѕРјРѕРєРѕРґ|
Алкогольная зависимость — это серьезная проблема , которая требует профессиональной помощи . В городе владимире действуют специализированные центры по помощи алкоголикам, предлагающие экстренный вывод из запоя а также лечение алкоголизма. При алкогольной интоксикации необходимо быстро определить симптомы и обратиться за медицинской помощью . Профессиональные наркологи в владимире предлагают консультации, гарантируя безопасное восстановление после запоя и лечение похмелья . Реабилитация от алкоголя включает программы реабилитации для зависимых , поддерживая не только пациентов, но и оказывая помощь родственникам алкоголиков. Профилактика алкогольных заболеваний также играет важную роль в предотвращении рецидивов .
Современное образование требует новых подходов. Ищете интерактивная доска для школы? Интерактивные доски interaktivnoe-oborudovanie.ru/catalog/interaktivnoe-oborudovanie/interaktivnye-doski/ в комплекте с проектором кардинально меняют формат занятий, делая их интересными. Предоставляем комплексные решения для школ и университетов: оборудование, доставка и профессиональная установка.
Rainbet Casino
Estou completamente vidrado por AFun Casino, oferece uma aventura de cassino que gira como um carrossel enlouquecido. Tem uma enxurrada de jogos de cassino irados, com slots de cassino tematicos de festa. O suporte do cassino ta sempre na ativa 24/7, acessivel por chat ou e-mail. As transacoes do cassino sao simples como um passo de danca, de vez em quando mais bonus regulares no cassino seria brabo. Resumindo, AFun Casino oferece uma experiencia de cassino que e puro carnaval para quem curte apostar com estilo festivo no cassino! De bonus a plataforma do cassino brilha com um visual que e puro axe, adiciona um toque de purpurina ao cassino.
afun telegram|
https://keeganufyi005.almoheet-travel.com/como-la-alimentacin-influye-en-la-deteccin-de-sustancias-durante-una-prueba-de-orina
Aprobar un test antidoping puede ser estresante. Por eso, existe un suplemento innovador creada con altos estandares.
Su mezcla premium combina carbohidratos, lo que prepara tu organismo y enmascara temporalmente los metabolitos de alcaloides. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas interesante es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una solucion temporal que funciona cuando lo necesitas.
Miles de profesionales ya han comprobado su seguridad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta alternativa te ofrece respaldo.
Estou alucinado com BetorSpin Casino, tem uma vibe de jogo tao vibrante quanto uma supernova dancante. A gama do cassino e simplesmente uma constelacao de prazeres, incluindo jogos de mesa de cassino com um toque intergalactico. O atendimento ao cliente do cassino e uma estrela-guia, dando solucoes na hora e com precisao. O processo do cassino e limpo e sem turbulencia cosmica, de vez em quando mais recompensas no cassino seriam um diferencial astronomico. Resumindo, BetorSpin Casino garante uma diversao de cassino que e uma supernova para quem curte apostar com estilo estelar no cassino! De bonus o design do cassino e um espetaculo visual intergalactico, eleva a imersao no cassino a um nivel cosmico.
bГіnus boas vindas betorspin|
Для тех, кто интересуется современными и эффективными строительными технологиями, каркасный дом в спб становится все более популярным вариантом, предлагающим множество преимуществ в плане энергосбережения и скорости строительства.
представляют собой инновационное решение для тех, кто хочет жить в комфорте. Они позволяют создавать уникальные интерьеры . Каркасные дома строются быстро .
Каркасные дома стали обязательным элементом современного строительства . Они обеспечивают высокий уровень комфорта. Каркасные дома имеют долгий срок службы . Каркасные дома могут быть использованы для строительства коттеджей .
Каркасные дома обеспечивают комфортное проживание. Они имеют долгий срок службы . Каркасные дома являются экологически чистым вариантом . Каркасные дома могут быть спроектированы под любые вкусы .
Каркасные дома позволяют создавать уникальные интерьеры. Они предлагают высокую энергоэффективность . Каркасные дома имеют высокую прочность. Каркасные дома позволяют экономить на строительстве .
Процесс строительства каркасных домов включает в себя несколько этапов . Затем проводятся работы по монтажу каркаса . Каркасные дома имеют долгий срок службы . После проводятся работы по внутренней отделке.
Процесс строительства каркасных домов начинается с проектирования. Затем следует этап строительства фундамента. Каркасные дома имеют высокую энергоэффективность . После проводятся работы по внутренней отделке .
Каркасные дома обеспечивают комфортное проживание. Они позволяют создавать уникальные интерьеры . Каркасные дома имеют высокую прочность . В каркасные дома продолжат совершенствоваться.
Каркасные дома имеют долгий срок службы . Они имеют высокую энергоэффективность. Каркасные дома могут быть спроектированы под любые вкусы . В качестве заключения можно сказать, что каркасные дома имеют большое будущее .
Дома, построенные по каркасной технологии, все чаще выбираются населением для строительства индивидуальных домов, подробнее о строительство каркасных домов под ключ можно узнать на сайте строительной компании.
это современное жилье, которое быстро набирает популярность . Такие дома строятся с использованием каркаса, который служит основой для всей конструкции. Каркасный дом позволяет создать широкий спектр дизайнерских решений, от минималистичного до роскошного .
Каркасные дома привлекают внимание многих людей благодаря своей доступности и быстроте строительства . Они включают в себя современные технологии, которые обеспечивают высокий уровень комфорта и безопасности . Каркасный дом может быть построен на любом типе фундамента, от монолитного до свайного .
Каркасный дом имеет ряд преимуществ, среди которых следует выделить его долговечность и устойчивость к природным катаклизмам . Такие дома могут быть разработаны в любом стиле, что делает их очень привлекательными для покупателей. Каркасный дом может быть оснащен различными системами, которые повышают уровень комфорта и безопасности.
Каркасные дома могут быть разработаны в любом стиле, что делает их очень привлекательными для покупателей. Они включают в себя натуральные материалы, такие как дерево, что делает их очень привлекательными для тех, кто заботится об окружающей среде . Каркасный дом включает в себя современные материалы, которые обеспечивают отличную теплоизоляцию и звукоизоляцию.
Каркасный дом включает в себя несколько этапов, от проектирования до окончательной отделки . Такие дома проектируются с учетом всех необходимых требований и?? . Каркасный дом возводится на основе готового проекта, который учитывает все пожелания clientes .
Каркасные дома строятся быстро и качественно, что позволяет заселиться в новое жилье в кратчайшие сроки . Они могут быть разработаны в любом стиле, что делает их очень привлекательными для покупателей . Каркасный дом может быть рассчитан на любые климатические условия, от жаркого до холодного .
Каркасный дом является инновационным решением для тех, кто хочет быстро и качественно возвести свой дом . Такие дома включают в себя каркас, который выполняет функцию основы всего дома, на которую затем крепятся все остальные элементы . Каркасный дом может быть построен на любом типе фундамента, от монолитного до свайного.
Каркасные дома включают в себя современные материалы, которые обеспечивают отличную теплоизоляцию и звукоизоляцию. Они включают в себя натуральные материалы, такие как дерево, что делает их очень привлекательными для тех, кто заботится об окружающей среде . Каркасный дом может быть построен на любом типе фундамента, от монолитного до свайного .
Adoro o balanco de BRCasino, e um cassino online que samba como um bloco de carnaval. O catalogo de jogos do cassino e uma folia de emocoes, com caca-niqueis de cassino modernos e contagiantes. A equipe do cassino entrega um atendimento que e puro axe, garantindo suporte de cassino direto e sem perder o ritmo. O processo do cassino e limpo e sem tropecos, de vez em quando queria mais promocoes de cassino que botam pra quebrar. No fim das contas, BRCasino e um cassino online que e uma folia sem fim para quem curte apostar com gingado no cassino! E mais o design do cassino e um desfile visual vibrante, torna a experiencia de cassino uma festa inesquecivel.
br77 net|
Для тех, кто ищет современное и практичное жилье, дома каркасные спб может стать идеальным решением, сочетая в себе доступность, быстроту строительства и экологическую безопасность.
в связи с простотой и скоростью монтажа. Это связано с тем, что каркасные дома позволяют создать индивидуальный проект . Кроме того, каркасные дома могут быть легко расширены или реконструированы.
Каркасный дом – это не только экономичный, но и экологически чистый вариант жилья благодаря тому, что он требует меньше материалов для строительства . Это означает, что каркасные дома могут быть построены с использованием местных материалов . Кроме того, каркасные дома могут быть оснащены современными технологиями .
Каркасный дом имеет множество преимуществ как простота и скорость монтажа. Это связано с тем, что каркасные дома могут быть легко расширены или реконструированы. Кроме того, каркасные дома могут быть построены на любом типе грунта .
Каркасный дом – это идеальный вариант для тех, кто ищет экономичный и прочный вариант . Это связано с тем, что каркасные дома имеют высокую энергоэффективность . Кроме того, каркасные дома могут быть построены с учетом индивидуальных потребностей владельца.
Строительство каркасного дома – это процесс который может быть выполнен быстро и качественно . Это связано с тем, что каркасные дома имеют высокую энергоэффективность . Кроме того, каркасные дома могут быть спроектированы в любом стиле.
Каркасный дом может быть построен с учетом индивидуальных потребностей владельца. Это означает, что каркасные дома могут быть оснащены современными технологиями. Кроме того, каркасные дома имеют низкую стоимость по сравнению с другими типами жилья .
Каркасный дом – это идеальный вариант для тех, кто хочет иметь комфортное и экологичное жилье . Это связано с тем, что каркасные дома могут быть легко расширены или реконструированы. Кроме того, каркасные дома могут быть спроектированы в любом стиле.
Каркасный дом – это не только экономичный, но и экологически чистый вариант жилья в связи с тем, что он может быть построен из переработанных материалов. Это означает, что каркасные дома не наносят вреда окружающей среде . Кроме того, каркасные дома могут быть спроектированы в любом стиле .
Ich finde absolut magisch Trickz Casino, es ist ein Online-Casino, das wie ein Zauberstab funkelt. Die Spielauswahl im Casino ist wie ein Zauberkoffer voller Wunder, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Die Casino-Mitarbeiter sind schnell wie ein Kaninchen aus dem Hut, antwortet blitzschnell wie ein magischer Funke. Casino-Transaktionen sind simpel wie ein magischer Spruch, ab und zu die Casino-Angebote konnten gro?zugiger sein. Am Ende ist Trickz Casino ein Casino mit einem Spielspa?, der wie eine Illusion verblufft fur Spieler, die auf magische Casino-Kicks stehen! Ubrigens die Casino-Oberflache ist flussig und funkelt wie ein Zauberstab, Lust macht, immer wieder ins Casino zuruckzukehren.
trickz casino recension|
J’adore la chaleur de VBet Casino, on dirait une eruption de plaisirs incandescents. Les options de jeu au casino sont riches et enflammees, offrant des sessions de casino en direct qui crepitent comme des flammes. Le service client du casino est une torche d’efficacite, offrant des solutions claires et instantanees. Les retraits au casino sont rapides comme une coulee de lave, par moments des recompenses de casino supplementaires feraient exploser. Au final, VBet Casino offre une experience de casino ardente pour ceux qui cherchent l’adrenaline enflammee du casino ! Bonus la navigation du casino est intuitive comme une flamme, donne envie de replonger dans le casino sans fin.
vbet no deposit bonus code|
Sou louco pela vibe de AFun Casino, da uma energia de cassino que e pura euforia. A selecao de titulos do cassino e um espetaculo de luzes, com jogos de cassino perfeitos pra criptomoedas. Os agentes do cassino sao rapidos como um malabarista, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um carro alegorico, porem mais giros gratis no cassino seria uma loucura. Resumindo, AFun Casino vale demais curtir esse cassino para os apaixonados por slots modernos de cassino! Vale dizer tambem a plataforma do cassino brilha com um visual que e puro axe, faz voce querer voltar ao cassino como num desfile sem fim.
como funciona a afun|
Acho simplesmente estelar BetorSpin Casino, tem uma vibe de jogo tao vibrante quanto uma supernova dancante. A gama do cassino e simplesmente uma constelacao de prazeres, com slots de cassino tematicos de espaco sideral. O servico do cassino e confiavel e brilha como uma galaxia, acessivel por chat ou e-mail. Os ganhos do cassino chegam voando como um asteroide, as vezes queria mais promocoes de cassino que explodem como supernovas. Em resumo, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os astronautas do cassino! Alem disso o site do cassino e uma obra-prima de estilo estelar, eleva a imersao no cassino a um nivel cosmico.
betorspin codigo de bonus|
Sou louco pela energia de BRCasino, oferece uma aventura de cassino que pulsa como um pandeiro. A selecao de titulos do cassino e um desfile de prazeres, oferecendo sessoes de cassino ao vivo que dancam como passistas. Os agentes do cassino sao rapidos como um mestre-sala, acessivel por chat ou e-mail. As transacoes do cassino sao simples como um passo de frevo, as vezes mais recompensas no cassino seriam um diferencial festivo. Resumindo, BRCasino vale demais sambar nesse cassino para os folioes do cassino! E mais a navegacao do cassino e facil como um passo de samba, torna a experiencia de cassino uma festa inesquecivel.
br77 games|
Ich liebe den Zauber von Trickz Casino, es pulsiert mit einer verhexten Casino-Energie. Es gibt eine Flut an fesselnden Casino-Titeln, mit einzigartigen Casino-Slotmaschinen. Der Casino-Support ist rund um die Uhr verfugbar, ist per Chat oder E-Mail erreichbar. Casino-Zahlungen sind sicher und reibungslos, trotzdem die Casino-Angebote konnten gro?zugiger sein. Zusammengefasst ist Trickz Casino ein Casino, das man nicht verpassen darf fur Fans von Online-Casinos! Nebenbei die Casino-Oberflache ist flussig und funkelt wie ein Zauberstab, was jede Casino-Session noch verzauberter macht.
casino trickz|
Je trouve absolument brulant VBet Casino, il propose une aventure de casino qui explose comme un geyser. Le repertoire du casino est un magma de divertissement, incluant des jeux de table de casino d’une elegance ardente. Le service client du casino est une torche d’efficacite, assurant un support de casino immediat et incandescent. Les retraits au casino sont rapides comme une coulee de lave, par moments les offres du casino pourraient etre plus genereuses. Dans l’ensemble, VBet Casino c’est un casino a explorer sans tarder pour les amoureux des slots modernes de casino ! De surcroit l’interface du casino est fluide et eclatante comme un cratere en fusion, ce qui rend chaque session de casino encore plus enflammee.
cassino vbet|
https://ameblo.jp/eduardoofzj381/entry-12929573128.html
Gestionar un control sorpresa puede ser un momento critico. Por eso, se desarrollo un suplemento innovador con respaldo internacional.
Su composicion precisa combina carbohidratos, lo que sobrecarga tu organismo y enmascara temporalmente los metabolitos de THC. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas destacado es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de trabajadores ya han experimentado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si quieres proteger tu futuro, esta solucion te ofrece respaldo.
Лечение зависимости: вызов нарколога на дом Наркотическая зависимость – это серьезная проблема, требующая профессионального подхода. Первый шаг к выздоровлению – это консультация с наркологом. Полную информацию о вызове нарколога на дом вы найдете на сайте vivod-iz-zapoya-vladimir019.ru. Медицинская помощь включает детоксикацию организма и психологическую поддержку. Реабилитация зависимых часто бывает необходима и включает индивидуальные программы восстановления. Конфиденциальное лечение создает условия комфорта и безопасности для пациента. Лечение на дому обеспечивает необходимую помощь, что особенно актуально для людей, которые стесняются посещать клиники. Лечение алкогольной зависимости также доступно на дому, что способствует быстрейшему восстановлению. Квалифицированная помощь специалиста – ключ к успешной борьбе с зависимостями.
Your article helped me a lot, is there any more related content? Thanks! gate anm”alan
Выгодные и безопасные переводы в Китай через японский фонд. babapay.io/JapanOrder – благодаря партнерским финансовым инструментам операции проходят по честному курсу и без скрытых комиссий. Каждый перевод надежно защищен и проходит без риска блокировок. Подходит для частных лиц и бизнеса, которые ценят прозрачность и выгоду.
https://telegra.ph/Controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones-09-11-2
Pasar un test antidoping puede ser un desafio. Por eso, existe una formula avanzada creada con altos estandares.
Su mezcla eficaz combina vitaminas, lo que sobrecarga tu organismo y enmascara temporalmente los trazas de THC. El resultado: una muestra limpia, lista para ser presentada.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una estrategia de emergencia que responde en el momento justo.
Miles de personas en Chile ya han validado su discrecion. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta formula te ofrece respaldo.
аренда дизель генератора в спб
https://connerwwob601.wpsuo.com/controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones
Enfrentar un control sorpresa puede ser un desafio. Por eso, se desarrollo una solucion cientifica probada en laboratorios.
Su mezcla premium combina carbohidratos, lo que prepara tu organismo y neutraliza temporalmente los metabolitos de alcaloides. El resultado: una prueba sin riesgos, lista para ser presentada.
Lo mas notable es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta solucion te ofrece respaldo.
https://vgarderobe.ru/muzhskie-zimnie-kurtki-yellow-cab-bc-1911.html
Прерывание запоя в владимире: эффективные методы Запой – серьезная проблема, требующая профессионального вмешательства. В владимире доступны услуги нарколога на дом, что обеспечивает удобство и комфорт при лечении. Обращение к наркологу на дому дает возможность получить помощь при запое, не выходя из дома. вызов нарколога на дом владимир Основные методы прерывания запоя включают медикаментозное лечение и детоксикацию организма. Эти процедуры помогают устранить физическую зависимость от алкоголя и минимизировать симптомы абстиненции. Психологическая поддержка играет ключевую роль в процессе восстановления, что делает индивидуальный подход к каждому пациенту крайне важным. Реабилитация алкоголиков включает в себя не только медицинскую помощь, но и советы по лечению, а также программы восстановления, направленные на возвращение пациента к нормальной жизни. Подбор эффективных методов лечения зависит от уровня зависимости и общего состояния здоровья пациента. Если у вас возникли проблемы с алкоголизмом, не медлите с вызовом специалиста на дом. Квалифицированная помощь позволит вам преодолеть запой и начать новый этап жизни без алкоголя;
Добрый день!
Долго анализировал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от крутых seo,
крутых ребят, именно они разработали недорогой и главное top прогон Хрумером – https://short33.site
Что такое линкбилдинг знают все SEO-специалисты. Это создание ссылок с разных сайтов для роста авторитетности. Xrumer делает этот процесс автоматическим. Массовые прогоны увеличивают DR и позиции. Что такое линкбилдинг – основа продвижения.
seo сайтов сколько стоит, пример статьи seo, линкбилдинг стратегии
Эффективность прогона Xrumer, сео маркин, seo lyrics
!!Удачи и роста в топах!!
Раскройте потенциал вашего кабинета с профессиональными решениями Cosmo Tech: диодные и пикосекундные лазеры, SMAS и RF-лифтинг, прессотерапия и другие топ-направления. Все аппараты сертифицированы, а обучение и сервис уже включены. Подробнее на https://cosmo-tech.ru Мы помогаем подобрать аппараты под задачи и бюджет, оформляем рассрочку без банков, обеспечиваем гарантию и быстрый запуск. Улучшайте качество услуг и повышайте средний чек — клиенты увидят эффект уже после первых процедур.
Обвалочный нож Dalimann профессионального уровня — незаменимый помощник для ценителей качественных инструментов! Лезвие длиной 13 см из высококачественной стали обеспечивает точные и чистые разрезы мяса и птицы. Удобная рукоятка обеспечивает надежный хват при любых нагрузках, а лезвие долго остается острым. Нож https://ozon.ru/product/2806448216 отличный выбор для профессиональных кухонь и домашнего использования. Делайте ставку на качество с ножами Dalimann!
Feringer.shop — официальный интернет-бутик печей для бани и сауны с гарантийной поддержкой и доставкой по России. В каталоге — решения для русской бани, финской сауны и хаммама, с каменной облицовкой и VORTEX для стремительного прогрева. Перейдите на сайт https://feringer.shop/ для выбора печи и консультации. В шоу руме в Москве доступны образцы и помощь в расчёте мощности.
https://telegra.ph/Controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones-09-11-2
Enfrentar una prueba preocupacional puede ser estresante. Por eso, se ha creado una alternativa confiable creada con altos estandares.
Su mezcla unica combina nutrientes esenciales, lo que sobrecarga tu organismo y disimula temporalmente los metabolitos de toxinas. El resultado: un analisis equilibrado, lista para ser presentada.
Lo mas notable es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete milagros, sino una solucion temporal que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si no deseas dejar nada al azar, esta solucion te ofrece seguridad.
http://forumbudowlane.jun.pl/viewtopic.php?p=134986#134986
https://list.ly/maryldiwcc
Aprobar una prueba preocupacional puede ser un desafio. Por eso, ahora tienes un metodo de enmascaramiento con respaldo internacional.
Su mezcla unica combina carbohidratos, lo que ajusta tu organismo y oculta temporalmente los metabolitos de toxinas. El resultado: una orina con parametros normales, lista para entregar tranquilidad.
Lo mas notable es su ventana de efectividad de 4 a 5 horas. A diferencia de otros productos, no promete milagros, sino una estrategia de emergencia que responde en el momento justo.
Miles de estudiantes ya han experimentado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta solucion te ofrece confianza.
https://maps.google.ms/url?q=http://eseguro.mx/que-licencias-tiene-pin-up-en-mexico/ – Pin Up Casino Mexico – A popular online casino in Mexico!
Нужна площадка, где вы быстро и бесплатно начнете продавать или искать нужные товары и услуги? https://razmestitobyavlenie.ru/ – современная бесплатная доска объявлений России, которая помогает частным лицам и бизнесу находить покупателей и клиентов без лишних затрат. Здесь вы можете подать объявление бесплатно и без регистрации, выбрать релевантную категорию из десятков рубрик и уже сегодня получить первые отклики.
Estou completamente hipnotizado por Bet558 Casino, e um cassino online que brilha como uma estrela em colisao. A gama do cassino e simplesmente um universo de prazeres, com caca-niqueis de cassino modernos e estelares. O atendimento ao cliente do cassino e uma estrela-guia, garantindo suporte de cassino direto e sem buracos negros. Os pagamentos do cassino sao lisos e blindados, mas queria mais promocoes de cassino que explodem como supernovas. Na real, Bet558 Casino garante uma diversao de cassino que e uma supernova para os amantes de cassinos online! E mais o design do cassino e um espetaculo visual intergalactico, adiciona um toque de brilho estelar ao cassino.
bet558 casino login|
Estou completamente apaixonado por BacanaPlay Casino, e um cassino online que explode como um desfile de carnaval. A selecao de titulos do cassino e uma explosao de cores e ritmos, com jogos de cassino perfeitos pra criptomoedas. Os agentes do cassino sao rapidos como um passista na avenida, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um carro alegorico, mas mais bonus regulares no cassino seria brabo. Na real, BacanaPlay Casino oferece uma experiencia de cassino que e puro axe para quem curte apostar com gingado no cassino! Vale dizer tambem a plataforma do cassino brilha com um visual que e puro samba, faz voce querer voltar ao cassino como num desfile sem fim.
bacanaplay games|
Je trouve absolument glacial ViggoSlots Casino, c’est un casino en ligne qui scintille comme un glacier sous l’aurore. Les options de jeu au casino sont riches et givrees, offrant des sessions de casino en direct qui scintillent comme la neige. Le service client du casino est un flocon d’efficacite, repondant en un eclair glacial. Les transactions du casino sont simples comme un flocon de neige, parfois des bonus de casino plus frequents seraient arctiques. Dans l’ensemble, ViggoSlots Casino c’est un casino a explorer sans tarder pour ceux qui cherchent l’adrenaline givree du casino ! De surcroit le design du casino est un spectacle visuel arctique, facilite une experience de casino arctique.
viggoslots fr|
Здравствуйте!
Долго не спал и думал как поднять сайт и свои проекты и нарастить ИКС Яндекса и узнал от друзей профессионалов,
отличных ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://short33.site
Линкбилдинг это – основа современной оптимизации. Ссылки помогают сайту расти в поиске и привлекать трафик. Программы вроде Xrumer упрощают создание линков. Это экономит время и силы специалистов. Линкбилдинг это эффективный инструмент продвижения.
сайты для раскрутки вк, seo заголовок сайта, линкбилдинг для начинающих
сео линкбилдинг, как проводить сео аудит сайта, линкбилдинг правила
!!Удачи и роста в топах!!
https://blogfreely.net/meghadldhn/mitos-sobre-limpiezas-rpidas-del-cuerpo-que-debes-conocer
Pasar un control sorpresa puede ser un desafio. Por eso, se ha creado una solucion cientifica desarrollada en Canada.
Su formula potente combina creatina, lo que prepara tu organismo y neutraliza temporalmente los metabolitos de alcaloides. El resultado: una prueba sin riesgos, lista para ser presentada.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete milagros, sino una estrategia de emergencia que responde en el momento justo.
Miles de profesionales ya han validado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si no deseas dejar nada al azar, esta formula te ofrece confianza.
Estou completamente hipnotizado por Bet558 Casino, da uma energia de cassino que e puro pulsar estelar. A selecao de titulos do cassino e um buraco negro de diversao, com slots de cassino tematicos de espaco profundo. Os agentes do cassino sao rapidos como um foguete estelar, garantindo suporte de cassino direto e sem buracos negros. Os pagamentos do cassino sao lisos e blindados, de vez em quando mais giros gratis no cassino seria uma loucura cosmica. No geral, Bet558 Casino vale demais explorar esse cassino para os amantes de cassinos online! E mais o site do cassino e uma obra-prima de estilo estelar, torna a experiencia de cassino uma viagem espacial.
bet558 como sacar|
Экстренная наркологическая помощь при запое в Красноярске: куда звонить Когда алкогольная зависимость приводит к запойному состоянию‚ важно быстро получить медицинскую помощь. В Красноярске есть возможность вызвать врача нарколога на дом‚ что особенно удобно в экстренных ситуациях. Наркологическая клиника предлагает услуги по лечению запоя‚ включая детоксикацию организма и терапию алкогольной зависимости. Круглосуточная служба помощи готова оказать поддержку вам и вашим близким. Консультация нарколога поможет определить необходимые шаги для восстановления. Совместно с врачом можно разработать программу реабилитации алкоголиков и профилактики запойного состояния. Важно помнить о поддержке семьи алкоголика в процессе лечения. Психотерапия может стать важной частью лечения алкогольной зависимости. Не откладывайте обращение за помощью — здоровье важнее всего! врач нарколог на дом Красноярск
Посетите сайт https://psyhologi.pro/ и вы получите возможность освоить востребованную профессию, такую как психолог-консультант. Мы предлагаем курсы профессиональной переподготовки на психолога с дистанционным обучением. Узнайте больше на сайте что это за профессия, модули обучения и наших практиков и куратора курса.
Ich liebe den Adrenalinkick von Turbonino Casino, es ist ein Online-Casino, das wie ein Formel-1-Wagen rast. Der Katalog des Casinos ist ein Boxenstopp voller Action, mit einzigartigen Casino-Slotmaschinen. Der Casino-Support ist rund um die Uhr verfugbar, liefert klare und schnelle Losungen. Auszahlungen im Casino sind schnell wie ein Rennwagen, aber mehr Freispiele im Casino waren ein Geschwindigkeitsrausch. Zusammengefasst ist Turbonino Casino ein Muss fur Casino-Fans fur Spieler, die auf rasante Casino-Kicks stehen! Nebenbei die Casino-Plattform hat einen Look, der wie ein Turbo-Motor strahlt, was jede Casino-Session noch rasant macht.
turbonino casino no deposit bonus|
Реабилитационный центр для алкоголиков в Красноярске предоставляет шанс на новую жизнь для тех, кто столкнулся с алкогольной зависимостью. Вызвать нарколога на дом можно для первоначальной оценки состояния и оценки состояния. Лечение алкоголизма предполагает комплексный подход с медицинским контролем и психотерапевтической поддержкой, что гарантирует персонализированный подход к каждому человеку. Реабилитационная программа включает процесс восстановления после алкогольной зависимости и социальную адаптацию, а также поддержку родственников. Анонимные алкоголики помогают наладить связь с единомышленниками. Наркологическая помощь в нашем центре позволяет освободиться от зависимости и начать жизнь заново.
https://brookspqxq424.trexgame.net/los-errores-mas-comunes-antes-de-un-examen-antidoping
Superar un test antidoping puede ser un desafio. Por eso, se ha creado una formula avanzada creada con altos estandares.
Su composicion premium combina minerales, lo que estimula tu organismo y enmascara temporalmente los marcadores de alcaloides. El resultado: una prueba sin riesgos, lista para cumplir el objetivo.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de detox irreales, no promete resultados permanentes, sino una herramienta puntual que responde en el momento justo.
Miles de estudiantes ya han validado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si no deseas dejar nada al azar, esta formula te ofrece respaldo.
Капельница от запоя в владимире: экстренная помощь Алкоголизм — серьезная проблема‚ требующая внимания и профессиональной помощи. В владимире наблюдается рост спроса на услуги нарколога на выезд. Специалисты-наркологи на дом в владимире предоставляют экстренные услуги‚ включая детоксикацию и помощь при запое.Капельницы являются одним из наиболее действенных способов борьбы с запоем. Она обеспечивает организм необходимыми веществами‚ ускоряя процесс детоксикации. Квалифицированный нарколог осуществляет медицинскую помощь‚ включая терапию‚ которая направлена на избавление от физической зависимости от алкоголя. нарколог на дом владимир Не забывайте‚ что важно не затягивать с вызовом нарколога на дом. Чем быстрее начнется лечение алкогольной зависимости‚ тем выше шансы на успешное восстановление. Услуги нарколога позволяют получить скорейшую помощь без необходимости посещения клиники. Мы поможем вам справиться с зависимостью от алкоголя.
KidsFilmFestival.ru — это пространство для любителей кино и сериалов, где обсуждаются свежие премьеры, яркие образы и современные тенденции. На сайте собраны рецензии, статьи и аналитика, отражающие актуальные темы — от культурной идентичности и социальных вопросов до вдохновения и поиска гармонии. Здесь кино становится зеркалом общества, а каждая история открывает новые грани человеческого опыта.
Здравствуйте!
Долго думал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от друзей профессионалов,
крутых ребят, именно они разработали недорогой и главное top прогон Xrumer – https://short33.site
Прогон по базам форумов помогает охватывать больше ресурсов. Как увеличить показатели домена зависит от качества ссылок. Xrumer для продвижения сайта экономит время специалистов. SEO-прогон для новичков облегчает освоение инструментов. Рассылки с помощью Xrumer ускоряют процесс продвижения.
рекламное продвижение сайта москва цены, seo анализ бесплатно онлайн, линкбилдинг что это
Автоматическое размещение ссылок, англоязычный seo, специфика продвижения сайтов
!!Удачи и роста в топах!!
https://vgarderobe.ru/byustgalter-push-ap-passionata-g-2005-2.html
Доброго!
Долго обмозговывал как поднять сайт и свои проекты и нарастить CF cituation flow и узнал от крутых seo,
крутых ребят, именно они разработали недорогой и главное продуктивный прогон Xrumer – https://short33.site
Линкбилдинг что это такое простыми словами – это процесс создания ссылок для роста сайта. Ссылки с других площадок повышают авторитет ресурса. Xrumer помогает автоматизировать массовый прогон. Чем больше качественных ссылок, тем выше рейтинг. Линкбилдинг что это такое простыми словами – понятная SEO-стратегия.
seo тексты заказать, сео я русский, Xrumer для роста ссылочной массы
линкбилдинг работа, сео отдела, yandex и seo
!!Удачи и роста в топах!!
https://connerwwob601.wpsuo.com/controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones
Aprobar un test antidoping puede ser complicado. Por eso, se desarrollo un metodo de enmascaramiento probada en laboratorios.
Su composicion precisa combina minerales, lo que sobrecarga tu organismo y disimula temporalmente los metabolitos de toxinas. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas destacado es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una solucion temporal que funciona cuando lo necesitas.
Miles de trabajadores ya han comprobado su seguridad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta formula te ofrece tranquilidad.
Добрый день!
Долго не спал и думал как поднять сайт и свои проекты и нарастить TF trust flow и узнал от крутых seo,
топовых ребят, именно они разработали недорогой и главное top прогон Хрумером – https://short33.site
Xrumer и рост Ahrefs DR помогают ускорить продвижение сайта. Автоматический прогон увеличивает ссылочную массу. Программа экономит время специалистов. Чем больше качественных ссылок, тем выше DR. Xrumer и рост Ahrefs DR – современный инструмент SEO.
сайт сми продвижение, продвижение https сайтов, Массовый линкбилдинг для сайта
Форумный линкбилдинг Хрумер, сео курсы скачать, сео компания услуги
!!Удачи и роста в топах!!
автоматический карниз для штор https://karniz-s-elektroprivodom-kupit.ru .
https://postheaven.net/maixentedd/habitos-que-pueden-afectar-tu-resultado-en-un-test-de-orina
Superar una prueba de orina puede ser complicado. Por eso, se ha creado una formula avanzada probada en laboratorios.
Su composicion precisa combina carbohidratos, lo que estimula tu organismo y oculta temporalmente los marcadores de alcaloides. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete resultados permanentes, sino una estrategia de emergencia que funciona cuando lo necesitas.
Miles de estudiantes ya han validado su rapidez. Testimonios reales mencionan paquetes 100% confidenciales.
Si no deseas dejar nada al azar, esta alternativa te ofrece confianza.
Профилактика алкоголизма — важная задача, требующая внимания и усилий. Врач нарколог на дом способен оказать необходимую помощь, предлагая квалифицированные консультации и лечение. Признаки алкогольной зависимости включают регулярном употреблении спиртного и изменениях в психоэмоциональном состоянии. Психотерапевтическая поддержка и коллективные занятия являются важными элементами в борьбе с зависимостями. Чтобы предотвратить запойные состояния, важно следовать нескольким советам по отказу от алкоголя. Поддержка семьи и близких может значительно повысить шансы на успех в реабилитации от алкоголизма. Профилактические меры, включающие самопомощь и участие в социальных инициативах, поддерживают социализацию и усиливают желание вести трезвый образ жизни.
Здравствуйте!
Долго не спал и думал как встать в топ поисковиков и узнал от гуру в seo,
энтузиастов ребят, именно они разработали недорогой и главное буст прогон Хрумером – https://short33.site
Линкбилдинг через программы упрощает работу специалистов. Форумные проги для SEO автоматизируют размещение ссылок. Оптимизация ссылочного профиля повышает авторитетность сайта. Как прокачать сайт через Xrumer становится понятнее с опытом. Автоматизированный линкбилдинг экономит силы и время.
seo 55, список seo работа, Xrumer для SEO продвижения
линкбилдинг статьи, продвижение сайта металлопроката, проверка текст на seo
!!Удачи и роста в топах!!
рулонные шторы с электроприводом цена https://elektricheskie-rulonnye-shtory15.ru/ .
рулонные шторы на балкон цена http://www.avtomaticheskie-rulonnye-shtory5.ru .
Капельница от запоя на дому в Красноярске: быстрое облегчение Алкогольная зависимость — серьезная проблема, требующая квалифицированной помощи. Нарколог на дом круглосуточно в Красноярске предлагает услуги по лечению запоя на дому, включая капельницы для пьющих. Это эффективный способ для быстрого снятия абстиненции и восстановления после запоя.При алкоголизме важно не только временно облегчить состояние, но и обеспечить качественную медицинскую помощь при запое. С помощью капельницы можно быстро устранить похмелье, улучшить здоровье и избежать осложнений. Заказ капельницы на дом — удобное решение для тех, кто хочет избежать стационарного лечения и получить помощь в знакомой обстановке.Круглосуточная помощь нарколога позволяет обеспечить детоксикацию алкоголика в любое время. Важно помнить, что лечение запоя на дому включает не только физическое восстановление, но и психологическую поддержку. Процесс реабилитации от алкогольной зависимости является длительным и требует всестороннего подхода. нарколог на дом круглосуточно Красноярск Если вы или ваши родные испытываете трудности с алкогольной зависимостью, не стоит откладывать обращение за помощью. Услуги нарколога в Красноярске доступны круглосуточно, и каждый может рассчитывать на профессиональную поддержку.
https://martinnhns210.tearosediner.net/alimentos-que-pueden-alterar-un-examen-de-orina-y-qu-evitar
Gestionar un control sorpresa puede ser complicado. Por eso, se desarrollo un suplemento innovador desarrollada en Canada.
Su composicion eficaz combina nutrientes esenciales, lo que ajusta tu organismo y oculta temporalmente los trazas de THC. El resultado: una prueba sin riesgos, lista para ser presentada.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una estrategia de emergencia que responde en el momento justo.
Miles de postulantes ya han comprobado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta alternativa te ofrece confianza.
Онлайн-казино Vavada часто выбирается игроками.
Бездепы и промокоды делают игру выгоднее.
Соревнования делают процесс азартным.
Каталог игр обновляется постоянно.
Старт занимает пару минут, поэтому можно сразу активировать промо.
Узнай больше по ссылке: онлайн казино vavada
Лечение и восстановление после болезни — удобное решение для людей, которым необходимо медицинская помощь и реабилитация после недуга. С помощью услуг здравоохранения на дому, таких как капельная терапия и капельная терапия, профессиональные медицинские работники обеспечивают удобное обслуживание в привычной обстановке. Вызов медсестры позволяют пациентам получать медицинскую помощь без дополнительных усилий и потребности выходить из дома. Ваше здоровье — это главное, и возможность прокапаться на дому предлагает уникальный подход к домашнему уходу, экономя время и обеспечивая эффективное лечение. Для получения подробной информации посетите vivod-iz-zapoya-vladimir014.ru.
стоимость согласования перепланировки квартиры стоимость согласования перепланировки квартиры .
https://maps.google.la/url?q=https://contralinea.com.mx/wp-content/pgs/?pin_up_casino_2758.html – Pin Up Casino Mexico – A popular online casino in Mexico!
Estou completamente alucinado por BetPrimeiro Casino, oferece uma aventura de cassino que borbulha como um geyser. Tem uma enxurrada de jogos de cassino irados, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e puro fogo, acessivel por chat ou e-mail. Os ganhos do cassino chegam voando como um meteoro, mesmo assim mais giros gratis no cassino seria uma loucura. No fim das contas, BetPrimeiro Casino oferece uma experiencia de cassino que e puro magma para quem curte apostar com estilo ardente no cassino! Vale dizer tambem a plataforma do cassino brilha com um visual que e puro fogo, adiciona um toque de fogo ao cassino.
casino betprimeiro bГіnus|
Для тех, кто ищет барбер красноярск, наш салон предлагает широкий спектр услуг для мужчин, включая стрижки, бритье и уход за бородой.
предлагает уникальную возможность мужчинам преобразить свой стиль и обновить имидж . Барбершопы города предлагают уникальную атмосферу, сочетающую традиции и современные тенденции. Посетители могут наслаждаться процедурами по уходу за бородой и усами .
Барбершоп в Красноярске не только место для стрижки, но и центр мужской культуры . Барберы постоянно совершенствуют свои навыки, изучая новые техники. Клиенты могут получить бесплатную консультацию перед процедурой .
Барбершопы Красноярска предлагают широкий спектр услуг по уходу за волосами и бородой . Услуги осуществляются опытными барберами с высоким уровнем мастерства . Клиенты могут выбрать процедуру по уходу за бородой и усами.
Барбершоп также включает услуги по коррекции бровей и восковой эпиляции. Барберы используют только высококачественные средства и инструменты . Посетители могут наслаждаться приятной музыкой и атмосферой .
Барбершоп в Красноярске предлагает уникальную атмосферу, способствующую знакомству и дружбе . Посетители могут посетить лекции на темы моды и стиля . Барбершоп сотрудничает с известными брендами и модными домами .
Барберы создают индивидуальные стили и образы для каждого посетителя. Клиенты могут наслаждаться компанией друзей и единомышленников . Барбершоп включает в себя пространство для отдыха и общения .
Барбершоп в Красноярске включает в себя уникальную атмосферу и пространство для общения. Посетители могут пользоваться услугами опытных барберов . Барбершоп организует различные мероприятия и семинары по мужской красоте и моде.
Барберы используют только качественные инструменты и средства . Клиенты могут получить бесплатную консультацию перед процедурой . Барбершоп является местом, где мужчины могут найти свой идеальный образ .
Игровая платформа Вавада часто выбирается игроками.
Бездепы и промокоды помогают стартовать новичкам.
Соревнования позволяют получить эмоции.
Ассортимент слотов обновляется постоянно.
Создать аккаунт легко, и бонусы становятся доступны сразу.
Узнай больше по ссылке: https://hinterlandmn.com
https://fernandorlay904.yousher.com/hidratacin-inteligente-cunta-agua-tomar-antes-de-un-test-de-orina
Superar un control sorpresa puede ser arriesgado. Por eso, ahora tienes un metodo de enmascaramiento creada con altos estandares.
Su receta potente combina carbohidratos, lo que estimula tu organismo y disimula temporalmente los metabolitos de alcaloides. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete resultados permanentes, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de profesionales ya han validado su rapidez. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta formula te ofrece tranquilidad.
I’m crazy about Wazamba Casino, it pulses with a casino energy as fierce as a tribal drum. The gaming options are lush and vibrant like a jungle, offering live casino sessions that roar like a lion. Its agents are as swift as a cheetah on the hunt, with help that shines like a tribal torch. The casino process is transparent with no hidden traps, but extra casino rewards would make hearts pound. In summary, Wazamba Casino is a gem for casino fans for those chasing the adrenaline rush of the casino! By the way the casino design is a visual jungle masterpiece, making you want to dive back into the casino endlessly.
wazamba betting|
Je trouve absolument palpitant Tortuga Casino, on dirait une ile au tresor pleine de frissons. L’eventail de jeux du casino est un coffre de butin, proposant des slots de casino a theme pirate. Les agents du casino sont rapides comme un vent de tempete, avec une aide qui hisse les voiles. Les gains du casino arrivent a une vitesse de galion, cependant les offres du casino pourraient etre plus genereuses. Globalement, Tortuga Casino c’est un casino a aborder sans tarder pour ceux qui cherchent l’adrenaline des mers du casino ! A noter l’interface du casino est fluide et eclatante comme un ocean au soleil, facilite une experience de casino epique.
telephone tortuga casino|
Je suis accro a Unibet Casino, ca pulse avec une energie de casino digne d’un chef d’orchestre. La selection du casino est une symphonie de plaisirs, proposant des slots de casino a theme rythmique. L’assistance du casino est chaleureuse et harmonieuse, joignable par chat ou email. Les retraits au casino sont rapides comme un tempo allegro, parfois les offres du casino pourraient etre plus genereuses. Globalement, Unibet Casino offre une experience de casino envoutante pour les passionnes de casinos en ligne ! Par ailleurs l’interface du casino est fluide et eclatante comme une salle de concert, amplifie l’immersion totale dans le casino.
unibet course hippique|
Je suis fou de Tortuga Casino, ca degage une ambiance de jeu aussi intrepide qu’un equipage pirate. La selection du casino est une vague de plaisirs pirates, offrant des sessions de casino en direct qui rugissent comme la mer. Le personnel du casino offre un accompagnement digne d’un pirate legendaire, avec une aide qui hisse les voiles. Les gains du casino arrivent a une vitesse de galion, mais des bonus de casino plus frequents seraient epiques. En somme, Tortuga Casino offre une experience de casino audacieuse pour les pirates du casino ! En plus le design du casino est une fresque visuelle de haute mer, amplifie l’immersion totale dans le casino.
tortuga casino service client|
Je trouve absolument enivrant Unibet Casino, c’est un casino en ligne qui vibre comme une note aigue d’une symphonie. Les options de jeu au casino sont riches et melodiques, comprenant des jeux de casino adaptes aux cryptomonnaies. Le personnel du casino offre un accompagnement digne d’un chef d’orchestre, assurant un support de casino immediat et vibrant. Les paiements du casino sont securises et fluides, par moments des recompenses de casino supplementaires feraient chanter. Globalement, Unibet Casino est un casino en ligne qui joue une symphonie de plaisir pour les joueurs qui aiment parier avec style au casino ! A noter le design du casino est une fresque visuelle harmonieuse, ce qui rend chaque session de casino encore plus vibrante.
code bonus unibet|
https://brookspqxq424.trexgame.net/los-errores-mas-comunes-antes-de-un-examen-antidoping
Enfrentar un test antidoping puede ser arriesgado. Por eso, ahora tienes un metodo de enmascaramiento creada con altos estandares.
Su mezcla precisa combina vitaminas, lo que sobrecarga tu organismo y enmascara temporalmente los rastros de alcaloides. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas notable es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una solucion temporal que te respalda en situaciones criticas.
Miles de trabajadores ya han validado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta alternativa te ofrece tranquilidad.
Нарколог на выезд в Красноярске — это оптимальное решение для людей‚ которые испытывают необходимость в наркологической помощи‚ но не хотят посещать медицинское учреждение. Профессиональная помощь в борьбе с зависимостями доступна в домашних условиях‚ что гарантирует комфорт и конфиденциальность.Обращение к наркологу позволяет проанализировать текущее состояние и подобрать лучший план лечения‚ включая лечение в стационаре или домашнюю терапию. Наши эксперты предлагают психотерапию зависимостей и медицинское вмешательство‚ что помогает эффективной профилактике зависимостей. Семейная поддержка играет важную роль в лечении‚ помогая пациентам преодолеть сложности. Свяжитесь с vivod-iz-zapoya-krasnoyarsk015.ru для получения подробной информации о наших услугах.
https://list.ly/maryldiwcc
Enfrentar una prueba preocupacional puede ser un momento critico. Por eso, se desarrollo una solucion cientifica probada en laboratorios.
Su composicion eficaz combina nutrientes esenciales, lo que sobrecarga tu organismo y neutraliza temporalmente los rastros de alcaloides. El resultado: una muestra limpia, lista para ser presentada.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una estrategia de emergencia que funciona cuando lo necesitas.
Miles de personas en Chile ya han comprobado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta solucion te ofrece tranquilidad.
Срочный вывод из алкогольной зависимости в Красноярске: способы быстро вернуться к обычной жизни Когда употребление алкоголя становится серьезной проблемой, важно знать, что есть шанс получить срочную помощь. Нарколог на дом срочно — это вариант для тех, кто нуждается в немедленной поддержке. Лечение алкоголизма требует квалифицированного подхода, и наркологическая клиника готова предоставить необходимую профессиональную помощь на дому. Поддержка семьи играет важной частью процесса восстановления. Психотерапия при зависимости от алкоголя поможет справиться с эмоциональными проблемами и предотвратить возврат к прежним привычкам. Обратившись к наркологу на дом, вы совершаете первый шаг к освобождению от зависимости и ретурну к нормальной жизни.
согласование перепланировки нежилого здания http://pereplanirovka-nezhilogo-pomeshcheniya.ru .
согласование перепланировки в нежилом здании http://www.pereplanirovka-nezhilogo-pomeshcheniya1.ru .
перепланировка нежилых помещений перепланировка нежилых помещений .
перепланировка в нежилом здании перепланировка в нежилом здании .
кинопоиск смотреть онлайн http://kinogo-11.top/ .
Лечение запоя капельницей на дому – это популярный метод лечения алкогольной зависимости, который имеет свои плюсы и минусы и особенности. В владимире услуги нарколога предлагают возможность выезда на дом, что позволяет пациентам обратиться за медицинской помощью при запое в комфортной для них обстановке. Основные преимущества капельницы заключаются в скорейшем восстановлении организма благодаря детоксикационным процедурам. Капельницы помогают вывести токсины, повышению общего состояния здоровья, что способствует более эффективному восстановлению после запоя. Кроме того, поддержка близких при запое имеет огромное значение, так как домашнее лечение алкоголизма создает комфортную атмосферу. лечение запоя владимир Тем не менее, есть и недостатки. Например, в некоторых случаях сложно обеспечить необходимый контроль за состоянием пациента. Консультация врача на дому может быть недостаточной для сложных случаев. Также стоит учитывать, что инъекции при алкоголизме могут не подойти всем.
If you need temporary sms, our service provides access to a wide range of temporary numbers for various purposes, including registration on websites and receiving SMS.
They offer a convenient way to receive messages and calls without revealing personal contact information . Many people use them for online shopping, social media, and other internet activities to avoid receiving spam calls and texts. Furthermore, temporary phone numbers are also useful for businesses that need to communicate with clients without revealing their main contact information .
In addition to their practical uses, temporary phone numbers are also relatively easy to set up and can be obtained through various online services . This ease of setup has contributed to their widespread adoption across various industries and individuals . As a result, it’s not uncommon to see temporary phone numbers being used in customer service and support interactions.
One of the primary benefits of using temporary phone numbers is the added layer of security they provide against identity theft and fraud . By using a temporary phone number, individuals can protect their personal contact information from being shared or sold without their consent . This is especially important for online activities such as social media and dating . Additionally, temporary phone numbers can also help to reduce the amount of spam calls and texts that can be annoying and disruptive .
Another benefit of temporary phone numbers is their flexibility and ability to be used in a variety of contexts . For example, temporary phone numbers can be used for freelance work or consulting. They can also be used in conjunction with antivirus software and firewalls. Moreover, temporary phone numbers can be easily changed or replaced if they are not providing the desired level of security .
Temporary phone numbers work by providing a virtual phone number that can be used to receive calls and messages . This virtual phone number can be obtained through an online service or app . Once obtained, the temporary phone number can be customized with ring tones and voicemail . The temporary phone number can be used to receive calls and messages from anywhere in the world .
In terms of technology, temporary phone numbers use short message service (SMS) to send and receive texts . They can be accessed through a website or app . Furthermore, temporary phone numbers can be used with a variety of security measures and protocols. As a result, temporary phone numbers are a practical and efficient way to communicate.
In conclusion, temporary phone numbers are a convenient tool for communication and transactions. They provide a high level of security and flexibility . As technology continues to evolve, it’s likely that temporary phone numbers will become even more secure and reliable . In the future, we can expect to see new and innovative uses for temporary phone numbers .
Additionally, temporary phone numbers will continue to play an important role in online security and privacy . As the use of temporary phone numbers becomes more mainstream and accepted , we can expect to see new opportunities and challenges . Nevertheless, the benefits of temporary phone numbers far outweigh the risks and drawbacks .
https://martinnhns210.tearosediner.net/alimentos-que-pueden-alterar-un-examen-de-orina-y-qu-evitar
Gestionar un control sorpresa puede ser un momento critico. Por eso, se desarrollo una solucion cientifica probada en laboratorios.
Su receta eficaz combina vitaminas, lo que prepara tu organismo y disimula temporalmente los marcadores de THC. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas interesante es su capacidad inmediata de respuesta. A diferencia de detox irreales, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de trabajadores ya han comprobado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta solucion te ofrece tranquilidad.
https://www.anobii.com/en/015f4267973d99a3d3/profile/activity
Superar una prueba preocupacional puede ser complicado. Por eso, existe un metodo de enmascaramiento con respaldo internacional.
Su receta potente combina vitaminas, lo que prepara tu organismo y enmascara temporalmente los metabolitos de toxinas. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete milagros, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de trabajadores ya han validado su seguridad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta solucion te ofrece seguridad.
Не всегда получается самостоятельно поддерживать чистоту в помещении. Для экономии времени и сил лучше всего воспользоваться помощью профессионалов. С той целью, чтобы определиться с тем, какая компания подходит именно вам, рекомендуется ознакомиться с рейтингом тех предприятий, которые считаются лучшими на текущий период. https://sravnishka.ru/ – на сайте те предприятия, которые оказывают услуги на высоком уровне и по доступной стоимости. Ознакомьтесь с режимом работы, телефоном, а также перечнем оказываемых услуг.
вывод из запоя
vivod-iz-zapoya-smolensk016.ru
экстренный вывод из запоя смоленск
https://ameblo.jp/eduardoofzj381/entry-12929573128.html
Gestionar una prueba preocupacional puede ser estresante. Por eso, ahora tienes un metodo de enmascaramiento con respaldo internacional.
Su composicion eficaz combina vitaminas, lo que estimula tu organismo y oculta temporalmente los marcadores de alcaloides. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una estrategia de emergencia que funciona cuando lo necesitas.
Miles de personas en Chile ya han experimentado su seguridad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta formula te ofrece respaldo.
можно ли купить диплом о высшем образовании можно ли купить диплом о высшем образовании .
купить диплом с реестром киев http://metallicheckiy-portal.ru/forum/index.php?action=profile;u=80728 .
диплом купить с занесением в реестр диплом купить с занесением в реестр .
диплом техникума ссср купить диплом техникума ссср купить .
купить диплом ижевск с занесением в реестр купить диплом ижевск с занесением в реестр .
купить диплом купить диплом .
купить диплом магистра недорого http://www.educ-ua17.ru .
купить срочно диплом о высшем образовании вуза купить срочно диплом о высшем образовании вуза .
купить аттестат украины за 11 класс купить аттестат украины за 11 класс .
купить диплом о высшем образовании бакалавр купить диплом о высшем образовании бакалавр .
Заказать диплом можно используя официальный сайт компании. ubereducation.co.uk/companies/diploms-goznak
как купить диплом о высшем образовании с занесением в реестр отзывы https://educ-ua14.ru/ .
купить аттестат о среднем купить аттестат о среднем .
Приобрести диплом о высшем образовании поспособствуем. Купить диплом о высшем образовании в Барнауле – diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-barnaule
купить диплом о высшем образовании с занесением в реестр http://educ-ua15.ru/ .
Привет любители онлайн КАЗИНО!
Играй смело и выигрывай чаще с 1win casino зеркало. Здесь собраны сотни популярных игр. Каждый спин может стать выигрышным. Ты получаешь бонусы ежедневно. 1win casino зеркало всегда открыто.
Заходите скорее на рабочее 1win casino зеркало – 1win casino зеркало
Удачи и гарантированных выйгрышей в 1win casino!
купить диплом занесением в реестр купить диплом занесением в реестр .
купить диплом техникума с занесением в реестр купить диплом техникума с занесением в реестр .
купить диплом о среднем купить диплом о среднем .
лечение запоя смоленск
vivod-iz-zapoya-smolensk016.ru
экстренный вывод из запоя смоленск
диплом об окончании техникума купить http://www.educ-ua8.ru – диплом об окончании техникума купить .
Прагнете отримувати головні новини без зайвих слів? “ЦЕНТР Україна” збирає найважливіше з політики, економіки, науки, спорту та культури в одному місці. Заходьте на https://centrua.com.ua/ і відкривайте головне за лічені хвилини. Доступно, швидко, без зайвого — аби щодня приймати інформовані рішення. Долучайтеся й поширюйте — нехай перевірені новини щодня працюють на вас.
купить дипломы о высшем купить дипломы о высшем .
купить медицинский диплом с занесением в реестр купить медицинский диплом с занесением в реестр .
купить диплом с занесением в реестр челябинск купить диплом с занесением в реестр челябинск .
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по невысоким ценам. Покупка диплома, подтверждающего обучение в университете, – это грамотное решение. Приобрести диплом любого ВУЗа: boldhillzproperties.com.ng/agent/betseystephen1
J’adore la houle de Winamax Casino, ca degage une ambiance de jeu aussi fluide qu’un courant oceanique. Il y a une maree de jeux de casino captivants, offrant des sessions de casino en direct qui eclaboussent. Le personnel du casino offre un accompagnement digne d’un capitaine, offrant des solutions claires et instantanees. Le processus du casino est transparent et sans remous, mais j’aimerais plus de promotions de casino qui eclaboussent. Dans l’ensemble, Winamax Casino est un casino en ligne qui fait des vagues pour ceux qui cherchent l’adrenaline fluide du casino ! En plus la navigation du casino est intuitive comme un courant marin, ajoute une touche d’eclat marin au casino.
winamax foot|
купить диплом о высшем образовании ссср купить диплом о высшем образовании ссср .
https://telegra.ph/Controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones-09-11-2
Enfrentar una prueba de orina puede ser un momento critico. Por eso, se desarrollo un metodo de enmascaramiento con respaldo internacional.
Su formula premium combina nutrientes esenciales, lo que estimula tu organismo y enmascara temporalmente los metabolitos de toxinas. El resultado: una prueba sin riesgos, lista para cumplir el objetivo.
Lo mas destacado es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una solucion temporal que responde en el momento justo.
Miles de estudiantes ya han comprobado su efectividad. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta solucion te ofrece seguridad.
Инфузионная терапия от запоя – эффективное средство для лечения людей‚ страдающих алкоголизмом. Она способствует мгновенное вливание различных растворов‚ способствуя детоксикации тела и восстановлению здоровья. В учреждениях лечения зависимостей‚ таких как vivod-iz-zapoya-vladimir016.ru‚ опытные наркологи оказывают комплексную помощь‚ включая уколы от запоя. Лечение включает не только капельницы‚ но и процессы реабилитации‚ поддержку при алкоголизме‚ что способствует пациентам вернуться к обычной жизни.
Acho simplesmente epico VikingLuck Casino, oferece uma aventura de cassino que navega como um drakkar em furia. Tem uma enxurrada de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que brilham como runas. O atendimento ao cliente do cassino e uma lanca de eficiencia, com uma ajuda que reluz como uma runa encantada. Os saques no cassino sao velozes como um drakkar no vento, mas as ofertas do cassino podiam ser mais generosas. Resumindo, VikingLuck Casino oferece uma experiencia de cassino que e puro trovao para os amantes de cassinos online! De lambuja a interface do cassino e fluida e reluz como um fiorde, eleva a imersao no cassino ao nivel de uma saga.
viking luck no deposit bonus|
Ich bin vollig begeistert von Wheelz Casino, es verstromt eine Spielstimmung, die wie ein Looping durch die Wolken schie?t. Es gibt eine Flut an mitrei?enden Casino-Titeln, inklusive stylischer Casino-Tischspiele. Der Casino-Support ist rund um die Uhr verfugbar, mit Hilfe, die wie ein Adrenalinschub wirkt. Casino-Transaktionen sind simpel wie ein Fahrticket, trotzdem die Casino-Angebote konnten gro?zugiger sein. Alles in allem ist Wheelz Casino ein Casino mit einem Spielspa?, der wie ein Turbo-Ride fesselt fur Spieler, die auf rasante Casino-Kicks stehen! Ubrigens die Casino-Plattform hat einen Look, der wie ein Looping strahlt, Lust macht, immer wieder ins Casino zuruckzukehren.
fortune wheelz casino login|
Estou alucinado com VikingLuck Casino, e um cassino online que ruge como um guerreiro viking. A selecao de titulos do cassino e um escudo de emocoes, com caca-niqueis de cassino modernos e heroicos. O atendimento ao cliente do cassino e uma lanca de eficiencia, garantindo suporte de cassino direto e sem fraqueza. Os ganhos do cassino chegam voando como um corvo de Odin, mas as ofertas do cassino podiam ser mais generosas. Em resumo, VikingLuck Casino garante uma diversao de cassino que e uma saga nordica para os apaixonados por slots modernos de cassino! E mais a interface do cassino e fluida e reluz como um fiorde, faz voce querer voltar ao cassino como um guerreiro ao campo de batalha.
viking luck symbol|
электрические жалюзи на окна https://www.elektricheskie-rulonnye-shtory15.ru .
Привет фортовым игрокам КАЗИНО онлайн!
Испытай азарт прямо сейчас с помощью 1win casino зеркало. Все игры доступны без блокировок. Каждый спин приносит шанс на крупный выигрыш. Ты получаешь бонусы стабильно. 1win casino зеркало всегда открыто для игроков.
Заходите скорее на рабочее 1win casino зеркало – 1win casino зеркало
Удачи и супер выйгрышей в 1win casino!
электропривод рулонных штор https://www.avtomaticheskie-rulonnye-shtory5.ru .
https://postheaven.net/maixentedd/habitos-que-pueden-afectar-tu-resultado-en-un-test-de-orina
Aprobar una prueba preocupacional puede ser complicado. Por eso, existe un metodo de enmascaramiento con respaldo internacional.
Su receta unica combina minerales, lo que estimula tu organismo y enmascara temporalmente los marcadores de sustancias. El resultado: una muestra limpia, lista para pasar cualquier control.
Lo mas destacado es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete milagros, sino una estrategia de emergencia que te respalda en situaciones criticas.
Miles de postulantes ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta solucion te ofrece seguridad.
Хотите обновить фасад быстро и выгодно? На caparolnn.ru вы найдете сайдинг и фасадные панели «Альта-Профиль» с прочным покрытием, устойчивым к морозу и УФ. Богатая палитра, имитация дерева, камня и кирпича, цены от 256 ?/шт, консультации и быстрый расчет. Примерьте цвет и посчитайте материалы в Альта-планнере: https://caparolnn.ru/ Заказывайте онлайн, доставка по Москве и области. Оставьте заявку — менеджер перезвонит в удобное время.
смотреть русские сериалы http://www.kinogo-12.top/ .
Мы можем предложить дипломы любой профессии по приятным ценам. Купить диплом о неполном образовании — kyc-diplom.com/diplom-o-nepolnom-obrazovanii.html
вывод из запоя смоленск
vivod-iz-zapoya-smolensk017.ru
лечение запоя
В мире русских банных традиций веники и травы играют ключевую роль, превращая обычную парную в оазис здоровья и релакса: березовые веники дарят мягкий массаж и очищение кожи, дубовые — крепкий аромат и тонизирующий эффект, а эвкалиптовые и хвойные добавляют целебные ноты для дыхания и иммунитета. Если вы ищете свежие, отборные товары по доступным ценам, идеальным выбором станет специализированный магазин, где ассортимент включает не только классические варианты, но и экзотические сборы трав в пучках или мешочках, такие как душистая мята, полынь лимонная и лаванда, плюс акции вроде “5+1 в подарок” для оптовых и розничных покупок. На сайте https://www.parvenik.ru/ гармонично сочетаются качество из проверенных источников, удобная доставка по Москве и Подмосковью через пункты выдачи, а также минимальные заказы от 750 рублей с опциями курьерской отправки в пределах МКАД за 500 рублей — все это делает процесс покупки простым и выгодным. Здесь вы найдете не только веники из канадского дуба или липы, но и банные чаи, шапки, матрасы с кедровой стружкой, что усиливает атмосферу настоящей бани, а статистика с 89% постоянных клиентов подтверждает надежность: отборные продукты 2025 года ждут ценителей, обещая незабываемые сеансы парения и заботы о теле.
Приветствую фортовым игрокам!
1win casino зеркало открывает мир азартных развлечений. Играй свободно без ограничений. Каждый день новые эмоции и бонусы. Получай призы и выигрыши. 1win casino зеркало работает стабильно и надежно.
Заходите скорее на рабочее 1win casino зеркало – https://t.me/s/onewincasinotoday
Удачи и гарантированных выйгрышей в 1win casino!
https://telegra.ph/Controles-antidoping-en-empresas-chilenas-derechos-y-obligaciones-09-11-2
Pasar una prueba de orina puede ser estresante. Por eso, existe una formula avanzada con respaldo internacional.
Su formula precisa combina nutrientes esenciales, lo que prepara tu organismo y neutraliza temporalmente los metabolitos de toxinas. El resultado: una orina con parametros normales, lista para entregar tranquilidad.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete limpiezas magicas, sino una solucion temporal que te respalda en situaciones criticas.
Miles de trabajadores ya han validado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta solucion te ofrece respaldo.
микроигольчатый rf лифтинг цена отзывы микроигольчатый rf лифтинг цена отзывы .
Хотите порадовать любимую? Выбирайте букет на странице «Цветы для девушки» — нежные розы, воздушные пионы, стильные композиции в коробках и корзинах с быстрой доставкой по Москве. Подойдет для любого повода: от первого свидания до годовщины. Перейдите по ссылке https://www.florion.ru/catalog/cvety-devushke – добавьте понравившиеся варианты в корзину и оформите заказ за пару минут — мы поможем с выбором и аккуратно доставим в удобное время.
Visit the website https://bip39-phrase.com/ for information about the BIP39 standard, take a look at bip39-phrase.com to get acquainted with the details of the BIP39 standard, which is a standardized set of words used to generate mnemonic phrases, which act as human-readable representations of cryptographic keys. These phrases are used for backup purposes.
https://blogfreely.net/meghadldhn/mitos-sobre-limpiezas-rpidas-del-cuerpo-que-debes-conocer
Superar un test antidoping puede ser complicado. Por eso, se desarrollo un metodo de enmascaramiento creada con altos estandares.
Su receta precisa combina minerales, lo que estimula tu organismo y enmascara temporalmente los rastros de sustancias. El resultado: un analisis equilibrado, lista para entregar tranquilidad.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de detox irreales, no promete resultados permanentes, sino una herramienta puntual que funciona cuando lo necesitas.
Miles de postulantes ya han experimentado su seguridad. Testimonios reales mencionan envios en menos de 24 horas.
Si no deseas dejar nada al azar, esta formula te ofrece respaldo.
вывод из запоя смоленск
vivod-iz-zapoya-smolensk017.ru
лечение запоя
С первых минут растопки чугунные печи ПроМеталл дарят мягкий жар, насыщенный пар и уверенную долговечность. Мы — официальный представитель завода в Москве, поможем подобрать модель под объем парилки, стиль и бюджет, организуем доставку и монтаж. Ищете печь чугунная купить? Узнайте больше на prometall.shop и выберите идеальную «Атмосферу» для вашей парной. Дадим бесплатную консультацию, расскажем про акции и подготовим полезные подарки. Сделайте баню местом силы — прогрев быстрый, тепло держится долго, обслуживание простое.
Профилактика запоев после вывода – важная задача для сохранения здоровья и предотвращения рецидивов. Нарколог на дом в владимире предоставляет услуги по помощи в лечении алкоголизма и предотвращению запойного состояния. Важным аспектом является поддержка со стороны психолога, которая помогает справляться с трудностями.Рекомендации специалистов включают методы борьбы с запойным состоянием, такие как создание здорового образа жизни и поддержка семьи в лечении алкоголизма. Реабилитация после запоя требует медицинского вмешательства при алкогольной зависимости и обращения к специалисту по алкоголизму. Обращение к наркологу на дом обеспечивает удобство и доступность терапии. нарколог на дом владимир Важно помнить, что процесс восстановления после запоя – это долгий путь, требующий времени, сил и терпения. Профилактика рецидивов включает в себя регулярные встречи с наркологом и использование техник, способствующих стабильному состоянию здоровья и избежанию алкоголя.
Купить диплом о высшем образовании!
Мы готовы предложить дипломы любых профессий по выгодным ценам— pskovpages.ru
https://www.pinterest.com/candetoxblend/
Prepararse un control médico ya no tiene que ser una pesadilla. Existe un suplemento de última generación que responde en horas.
El secreto está en su combinación, que sobrecarga el cuerpo con proteínas, provocando que la orina neutralice los rastros químicos. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: es un plan de emergencia, diseñado para trabajadores en evaluaciones.
Miles de personas en Chile confirman su rapidez. Los entregas son confidenciales, lo que refuerza la seguridad.
Cuando el examen no admite errores, esta solución es la respuesta que estabas buscando.
вывод из запоя цена
vivod-iz-zapoya-smolensk018.ru
экстренный вывод из запоя смоленск
На нашем сайте доступен всесторонний seo обучение курсы, который охватывает все аспекты онлайн-маркетинга и поможет вам стать профессионалом в области SEO.
Курс по SEO становится все более популярным среди компаний, желающих улучшить свое онлайн-присутствие . Это связано с тем, что большинство потенциальных клиентов используют поисковые системы, чтобы найти необходимые им товары или услуги . Кроме того, курс по SEO предоставляет инструменты для улучшения позиций сайта в поисковых системах.
курс по SEO включает в себя как теоретические, так и практические занятия, чтобы обеспечить глубокое понимание предмета . Это важно, потому что SEO требует глубокого понимания не только технических аспектов, но и маркетинга и поведения пользователя .
основы SEO состоят из понимания того, как работают поисковые системы, и как можно повлиять на их результаты . Это включает в себя изучение поведения и предпочтений целевой аудитории . Кроме того, знание того, как создавать контент, который будет интересен и полезен пользователям является фундаментальным.
курс по SEO вводит студентов в мир поисковой оптимизации, объясняя, как работают поисковые системы . Это необходимо, потому что с первых шагов необходимо понимать, как работает поисковая оптимизация и что она включает в себя .
Продвинутые техники SEO включают в себя использование аналитических инструментов для отслеживания трафика и поведения пользователей . Это важно, потому что постоянное совершенствование и улучшение стратегии SEO является ключом к долгосрочному успеху .
продвинутые техники SEO включают в себя использование искусственного интеллекта и машинного обучения для анализа данных и прогнозирования поведения пользователей. Это необходимо, потому что новые технологии и трендеты требуют от специалистов SEO быть в курсе последних разработок .
Практическое применение SEO включает в себя не только теоретические знания, но и умение применять эти знания на практике . Это связано с тем, что практический опыт является ключевым фактором в становлении успешным специалистом SEO .
Практическое применение SEO также предполагает работу с командой, чтобы разработать и реализовать стратегию SEO . Это важно, потому что в реальной жизни каждый проект уникален и требует индивидуального подхода .
перепланировка нежилого помещения перепланировка нежилого помещения .
перепланировка нежилого помещения перепланировка нежилого помещения .
Подбираете оборудование из Китая? Перейдите на ресурс totem28.ru где вам доступно надежное промышленное оборудование. Ознакомьтесь с каталогом товаров, в котором есть всё — от техники до готовых производственных линий, а доставка осуществляется в любой уголок РФ. Подробнее узнайте о товарах и решениях, о нас и комплексных услугах «под ключ» на сайте.
перепланировка нежилого помещения в многоквартирном доме перепланировка нежилого помещения в многоквартирном доме .
перепланировка здания http://www.pereplanirovka-nezhilogo-pomeshcheniya.ru/ .
фильмы ужасов смотреть онлайн http://www.kinogo-11.top .
https://start.me/w/v9zARM
Prepararse un examen de drogas ya no tiene que ser una incertidumbre. Existe una fórmula confiable que responde en horas.
El secreto está en su mezcla, que sobrecarga el cuerpo con vitaminas, provocando que la orina enmascare los metabolitos de toxinas. Esto asegura un resultado confiable en menos de lo que imaginas, con ventana segura para rendir tu test.
Lo mejor: no se requieren procesos eternos, diseñado para trabajadores en evaluaciones.
Miles de personas en Chile confirman su seguridad. Los entregas son confidenciales, lo que refuerza la confianza.
Cuando el examen no admite errores, esta solución es la elección inteligente.
Онлайн-казино Vavada считается одним из лидеров рынка.
Акции и промокоды дают возможность начать бесплатно.
Регулярные активности увеличивают азарт.
Слоты и настольные игры пополняется новыми провайдерами.
Начать игру можно быстро, поэтому бонусы становятся доступны сразу.
Узнай больше прямо здесь: vavada промокод 2025
исторические фильмы исторические фильмы .
Ich bin total begeistert von Trickz Casino, es verstromt eine Spielstimmung, die wie ein magischer Zirkus leuchtet. Die Casino-Optionen sind vielfaltig und verzaubernd, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Support ist rund um die Uhr verfugbar, sorgt fur sofortigen Casino-Support, der begeistert. Der Casino-Prozess ist klar und ohne Tauschung, trotzdem mehr Casino-Belohnungen waren ein zauberhafter Gewinn. Kurz gesagt ist Trickz Casino ein Casino mit einem Spielspa?, der wie eine Illusion verblufft fur Fans moderner Casino-Slots! Extra die Casino-Oberflache ist flussig und funkelt wie ein Zauberstab, den Spielspa? im Casino auf ein magisches Niveau hebt.
trickz casino online|
Estou pirando com AFun Casino, e um cassino online que explode como um festival de fogos. O catalogo de jogos do cassino e um carnaval de emocoes, com caca-niqueis de cassino modernos e contagiantes. A equipe do cassino entrega um atendimento que e puro carnaval, garantindo suporte de cassino direto e sem pausa. Os ganhos do cassino chegam voando como serpentinas, porem queria mais promocoes de cassino que botam pra quebrar. Resumindo, AFun Casino e um cassino online que e uma explosao de alegria para os viciados em emocoes de cassino! Alem disso a navegacao do cassino e facil como uma coreografia, faz voce querer voltar ao cassino como num desfile sem fim.
afun. com|
Acho simplesmente estelar BetorSpin Casino, da uma energia de cassino que e puro pulsar galactico. A selecao de titulos do cassino e um buraco negro de diversao, incluindo jogos de mesa de cassino com um toque intergalactico. O suporte do cassino ta sempre na ativa 24/7, garantindo suporte de cassino direto e sem buracos negros. O processo do cassino e limpo e sem turbulencia cosmica, as vezes mais recompensas no cassino seriam um diferencial astronomico. No fim das contas, BetorSpin Casino e o point perfeito pros fas de cassino para os viciados em emocoes de cassino! E mais o design do cassino e um espetaculo visual intergalactico, torna a experiencia de cassino uma viagem espacial.
betorspin reclame aqui|
стоматология Воронеж карта стоматология Воронеж карта .
вывод из запоя
vivod-iz-zapoya-smolensk018.ru
лечение запоя
https://fliphtml5.com/homepage/candetoxblend/can-detox-blend-%E2%80%93-detox-orina-l%C3%ADder-en-chile/
Afrontar un control médico ya no tiene que ser un problema. Existe una fórmula confiable que actúa rápido.
El secreto está en su combinación, que estimula el cuerpo con creatina, provocando que la orina oculte los rastros químicos. Esto asegura un resultado confiable en solo 2 horas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para candidatos en entrevistas laborales.
Miles de personas en Chile confirman su seguridad. Los envíos son 100% discretos, lo que refuerza la seguridad.
Cuando el examen no admite errores, esta solución es la elección inteligente.
конспирация достойная, товар оказался отличным, кроли заценили. будем еще работать
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Все отлично, безумно рад что доверился данному магазину
Когда вам или вашим близким нужна помощь при алкоголизме‚ учтите‚ как вызвать наркологу на дом в владимире. Вызов врача нарколога на дом даёт возможность получить экстренную помощь без потребности в посещении клиники. Это особенно актуально при лечении запоя‚ когда человек нуждается в медицинской помощи сразу. врач нарколог на дом Начальным этапом будет поиск услуг нарколога. Можно обратиться в специализированные клиники или обратиться к онлайн-сервисами для вызова нарколога. Консультация нарколога поможет оценить состояние пациента и определить необходимое лечение зависимости.При обращении к врача важно сообщить о признаках запоя‚ чтобы нарколог мог адекватно подготовиться к оказанию помощи. Лечение алкоголизма на дому может включать очищение организма‚ медикаментозное лечение и психологическую поддержку. Анонимная помощь нарколога также доступна‚ что делает процесс менее стрессовым для пациента.В владимире есть множество адреса наркологических клиник‚ где возможно получить дополнительные услуги и реабилитацию от алкоголя. Не забывайте‚ что медицинская помощь на дому может стать первоначальным этапом к восстановлению и улучшению качества жизни. Если вам нужна экстренная помощь нарколога‚ действуйте незамедлительно – здоровье приоритетно!}
Будем дальше работать с этим магазином.
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
Отличный магазин!!!процветания дальнейшего и удачных продаж!!
Приобрести кокаин, мефедрон, бошки
Оплатил заказ до нового года, связывался через почту, написали оплата прошла, отправка будет после праздников, … ответа до сих пор нет… Сделайте что нибудь, ответьте мне на почте емае, хз уже чо делать.
http://images.google.cz/url?q=https://telegra.ph/5win-Casino-Um-Olhar-Detalhado-para-Jogadores-Brasileiros-09-07 – 5win Casino – the best casino in Brazil
Купить мефедрон, гашиш, шишки, альфа-пвп
Че за доверенный магазин мля!!! Кто нах его в доверенные записал!?! Админы убирайте его нах!!! Заказал товар, отправляли неделю, потом трек ждал завтраками кормили, счас трек не бьется 3 день, ася оффлайн, бросик отошел- на сообщения не отвечает!!! Люди не заказывайте тут ничего!!!
https://openlibrary.org/people/candetoxblend
Prepararse un test preocupacional ya no tiene que ser un problema. Existe una alternativa científica que actúa rápido.
El secreto está en su mezcla, que sobrecarga el cuerpo con vitaminas, provocando que la orina neutralice los marcadores de THC. Esto asegura una muestra limpia en menos de lo que imaginas, con ventana segura para rendir tu test.
Lo mejor: es un plan de emergencia, diseñado para quienes enfrentan pruebas imprevistas.
Miles de clientes confirman su efectividad. Los paquetes llegan sin logos, lo que refuerza la tranquilidad.
Si tu meta es asegurar tu futuro laboral, esta alternativa es la herramienta clave.
Магазин тут! kokain mefedron gash alfa-pvp amf
не болела чтоб башка.
Приобрести (MEF) MEFEDRON SHISHK1 MSK-SPB | Отзывы, Покупки, Гарантии
Хочу выразить благодарность менеджерам данного магазина.
Казино Вавада популярно у игроков.
Бездепы и акции помогают стартовать выгодно.
Игровые события увеличивают азарт.
Ассортимент развлечений остаются всегда актуальными.
Начать игру можно быстро, и игроки могут приступить к процессу без задержек.
Подробнее об этом смотрите здесь: https://lawah.net
Lunatogel
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
Хороший магазин оператор всегда онлайн, товар вообще Шик :speak: процветай) и поскорей бы лето
Купить мефедрон, гашиш, шишки, альфа-пвп
Моя первая покупка на динамите и, внезапно для самой себя, наход. Сняла, как говорится, в касание. С вашим охуенным мефчиком сорвала себе почти год ЗОЖа и ни чуть не жалею.
Приобрести (MEF) MEFEDRON SHISHK1 MSK-SPB | Отзывы, Покупки, Гарантии
У меня пришел чисто белый зернистый как крупа порошок.Кал.
uptown pokies australia review, yukon gold casino news and play slots
for real money usa, or new zealandn original slot machine download
my web blog; goplayslots.net
Магазин тут! kokain mefedron gash alfa-pvp amf
Первые 1.5 часа эйфория и сосредоточеность на том чем занят , в голове мелькают гениальные идеи)
https://unsplash.com/@candetoxblend
Afrontar un examen de drogas ya no tiene que ser un problema. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su combinación, que sobrecarga el cuerpo con vitaminas, provocando que la orina neutralice los metabolitos de toxinas. Esto asegura un resultado confiable en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para candidatos en entrevistas laborales.
Miles de usuarios confirman su rapidez. Los paquetes llegan sin logos, lo que refuerza la confianza.
Cuando el examen no admite errores, esta fórmula es la herramienta clave.
Galera, preciso compartilhar minha experiencia no 4PlayBet Casino porque superou minhas expectativas. A variedade de jogos e bem acima da media: poquer estrategico, todos com graficos de primeira. O suporte foi eficiente, responderam em minutos pelo chat, algo que vale elogio. Fiz saque em PIX e o dinheiro entrou muito rapido, ponto fortissimo. Se tivesse que criticar, diria que mais brindes fariam falta, mas isso nao estraga a experiencia. Pra concluir, o 4PlayBet Casino e parada obrigatoria pra quem gosta de cassino. Com certeza vou continuar jogando.
good day 4play|
Sou louco pela vibracao de BR4Bet Casino, e um cassino online que reluz como um farol na nevoa. Tem uma enxurrada de jogos de cassino irados. com caca-niqueis modernos que encantam como lanternas. Os agentes voam como claroes. com ajuda que ilumina como uma tocha. O processo e claro e sem apagoes. mas queria mais promocoes que brilham como farois. No fim das contas, BR4Bet Casino e o point perfeito pros fas de cassino para os amantes de cassinos online! Alem disso o site e uma obra-prima de estilo radiante. adicionando um toque de luz ao cassino.
br4bet b4bet.com login|
Купить мефедрон, гашиш, шишки, альфа-пвп
если так то АМ не подойдет скорее всего
Estou completamente vidrado por F12.Bet Casino, tem uma energia de jogo tao veloz quanto um motor V12. As opcoes sao ricas e aceleram como turbo. oferecendo sessoes ao vivo que derrapam como drifts. O atendimento e solido como um pneu slick. disponivel por chat ou e-mail. As transacoes sao faceis como um drift. ocasionalmente queria promocoes que explodem como largadas. Para encurtar, F12.Bet Casino promete uma diversao que e uma ultrapassagem para os viciados em emocoes de cassino! E mais o design e fluido como um pit stop. adicionando um toque de velocidade ao cassino.
robГґ f12 bet|
Sou viciado na energia de MarjoSports Casino, tem um ritmo de jogo que vibra como um apito. O catalogo de jogos e um campo de emocoes. com jogos adaptados para criptomoedas. O time do cassino e digno de um tecnico. garantindo suporte direto e sem impedimentos. As transacoes sao simples como um passe. ocasionalmente mais bonus regulares seriam esportivos. Para encurtar, MarjoSports Casino garante um jogo que vibra como uma torcida para os apaixonados por slots modernos! De bonus o visual e uma explosao de quadras. adicionando um toque de drible ao cassino.
marjosports resultados de ontem|
Купить мефедрон, гашиш, шишки, альфа-пвп
На ближайшие 1.5 часа свободен, можно ни о чем не думать. Сачала хотел в центр поехать, чтобы сразу плсле адреса быстрей добраться до клада, потом трезво все взвесил,т спокойно поехал домой.
Galera, vim dividir minhas impressoes no 4PlayBet Casino porque me impressionou bastante. A variedade de jogos e surreal: poquer estrategico, todos sem travar. O suporte foi rapido, responderam em minutos pelo chat, algo que raramente vi. Fiz saque em PIX e o dinheiro entrou em minutos, ponto fortissimo. Se tivesse que criticar, diria que seria legal torneios de slots, mas isso nao estraga a experiencia. Resumindo, o 4PlayBet Casino vale demais a pena. Com certeza vou continuar jogando.
come on 4play br|
Me encantei pelo ritmo de BR4Bet Casino, tem um ritmo de jogo que acende como uma tocha. O catalogo de jogos e um farol de prazeres. com jogos adaptados para criptomoedas. O atendimento e solido como um farol. disponivel por chat ou e-mail. O processo e claro e sem apagoes. as vezes as ofertas podiam ser mais generosas. Na real, BR4Bet Casino e um clarao de emocoes para os exploradores de jogos online! De lambuja a navegacao e facil como um facho de luz. adicionando um toque de luz ao cassino.
br4bet e confiГЎvel reclame aqui|
смотреть мультфильмы онлайн бесплатно kinogo-12.top .
Curto demais o asfalto de F12.Bet Casino, e um cassino online que acelera como um carro de corrida. A colecao e um ronco de entretenimento. com caca-niqueis modernos que roncam como motores. O servico e confiavel como um chassi. oferecendo respostas claras como um painel. As transacoes sao simples como uma mudanca de marcha. de vez em quando mais bonus seriam um diferencial turbo. Em sintese, F12.Bet Casino garante um jogo que acelera como um carro para os cacadores de vitorias em alta velocidade! Por sinal o design e fluido como um pit stop. amplificando o jogo com vibracao turbo.
https f12 bet casino|
Adoro o chute de MarjoSports Casino, explode com uma vibe de cassino esportiva. As escolhas sao vibrantes como um apito. oferecendo sessoes ao vivo que marcam como gols. O suporte e um apito preciso. com ajuda que marca gol como um penalti. Os pagamentos sao seguros e fluidos. de vez em quando queria promocoes que driblam a concorrencia. Resumindo, MarjoSports Casino garante um jogo que vibra como uma torcida para os cacadores de vitorias em gol! Por sinal o layout e vibrante como um apito. transformando cada aposta em uma aventura de gol.
marjosports logo|
Приобрести (MEF) MEFEDRON SHISHK1 MSK-SPB | Отзывы, Покупки, Гарантии
Брат, ответь в личке, жду уже 3 дня
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
Брал у данного селлера!Хорошо работют=)
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
Вот и решил проверить данный магаз, как только будет инфа обязательно отпишу
кракен сайт магазин позволяет обойти возможные блокировки и получить доступ к маркетплейсу. кракен сайт официальный необходимо искать через проверенные источники, чтобы избежать фишинговых сайтов. кракен зеркало актуальное должно обновляться регулярно для обеспечения непрерывного доступа.
онион – главная особенность Кракен.
кракен сайт магазин позволяет обойти возможные блокировки и получить доступ к маркетплейсу. кракен ссылка необходимо искать через проверенные источники, чтобы избежать фишинговых сайтов. кракен маркет должно обновляться регулярно для обеспечения непрерывного доступа.
ссылка – главная особенность Кракен.
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
СПАСИБО :pink_eye.: ТУТ ВСЁ РОВНО!!!!!!!!!
купить диплом о среднем специальном купить диплом о среднем специальном .
Магазин тут! kokain mefedron gash alfa-pvp amf
отличный магазин, качество супер ,товар радует
Эффективная капельница от алкогольной зависимости – это поистине эффективный метод лечения алкогольной зависимости, который можно получить в городе владимир благодаря услуг врача нарколога на дом. В процессе используются введение определённых растворов, что помогают организму быстрее восстановиться с последствиями употребления алкоголя. При обращении за помощью в случае запойного состояния, вы получите не только капельницу от алкоголизма, также советы врача-нарколога. врач нарколог на дом владимир Снятие запоя гарантирует быстрое улучшение состояния пациента, а безопасность лечения капельного введения обеспечивается профессиональными врачами. Помощь нарколога включает detox программу, направленную на восстановление организма. Реабилитация зависимых – это важный этап после лечения, который поможет избежать возврат к употреблению. В владимире предоставляются услуги врача нарколога на дом, что дает возможность получить терапию в удобной обстановке. Не медлите, позвоните за экстренной помощью нарколога прямо сейчас!
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Да хоть в очко засыпь, не торкнет
Производственный объект требует надежных решений? УралНастил выпускает решетчатые настилы и ступени под ваши нагрузки и сроки. Европейское оборудование, сертификация DIN/EN и ГОСТ, склад типовых размеров, горячее цинкование и порошковая покраска. Узнайте цены и сроки на https://uralnastil.ru — отгружаем по России и СНГ, помогаем с КМ/КМД и доставкой. Оставьте заявку — сформируем безопасное, долговечное решение для вашего проекта.
https://web.facebook.com/CANDETOXBLEND
Enfrentar un control médico ya no tiene que ser un problema. Existe una alternativa científica que funciona en el momento crítico.
El secreto está en su mezcla, que sobrecarga el cuerpo con proteínas, provocando que la orina enmascare los rastros químicos. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para candidatos en entrevistas laborales.
Miles de clientes confirman su rapidez. Los paquetes llegan sin logos, lo que refuerza la confianza.
Cuando el examen no admite errores, esta solución es la herramienta clave.
https://maps.google.gg/url?q=https://posmicrobiologiaagricola.ufv.br/pags/?5win_5.html – 5win Casino – the best casino in Brazil
Приобрести кокаин, мефедрон, бошки
всё как всегда быстро ,чётко ,без всякой канители ,качество как всегда радует ,спасибо команде за работу,ВЫ ЛУЧШИЕ!!!!!!
Магазин тут! kokain mefedron gash alfa-pvp amf
какое на**й в\в !!?? совсем рехнулись чтоли ? Я не знаю за качество их 2-дпмп, но если он не бодяженный и качественный, то 5мг интрозально хватит чтоб тебя колбасило 2-3 суток ! Никто по ходу у чемикала его ещё не пробовал – отзывов нету…
В эпоху цифрового маркетинга, когда конкуренция за топовые позиции в поисковиках накаляется, вечные ссылки становятся настоящим спасением для владельцев сайтов, стремящихся повысить видимость и увеличить продажи. Эти устойчивые ссылки, размещенные на трастовых ресурсах с высоким ИКС, не просто наращивают ссылочную массу, но и улучшают позиции в Яндексе и Google, привлекая органический трафик без риска санкций. Представьте: ваш сайт взлетает в топ благодаря профессиональному аудиту на ошибки, статейным ссылкам с форумов или социальным сигналам, которые усиливают авторитет домена по метрикам Ahrefs. А на платформе https://seobomba.ru/shop собраны проверенные тарифы от 2400 рублей, включая премиум-опции для комплексного продвижения, без поддержки сомнительных тем вроде адалта или казино — только надежные инструменты для бизнеса. Эксперты подтверждают: такие стратегии повышают конверсию до 30%, делая инвестиции в SEO выгодными и долгосрочными, а ваш проект — заметным в океане интернета.
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
Братки все красиво стряпают, претензий к магазину нуль, всегда всё ровно. Единственное что сейчас напрягло, отсутствие на ветке вашего представителя в ЕКБ “онлайн”, представитель молчит ( а там по делу ему в лс отписано) и кажись воопще не заходит пару недель
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
а чё заказал? Прикольный сайт, ассортимент радует :)?
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
Затарил я тут как то купели значит курехи,приваливай на адрес и не могу найти списался с оператором и понял что дурак тут я а не минер затупил,30 сек и закладка у меня в руках,лечу Домой,дома меня ждут уже братики заряжает по 2 водных и начинаем пускать слюни под спанч бобра, в полне хороший стафф,силы стафа хватает,валит минут 40-60 потом спад,получилось так что вес сдули за 2 дня,отходосы минемальные, вообщем сервис тут вышка тарился тут ребята)
Магазин тут! kokain mefedron gash alfa-pvp amf
про тусиай ….. что я могу сказать про тусиай от этого магазина…. пойду лучше трип-реппорт напишу…. такой тусишки ещё не ел)
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
2-й раз все было быстро но собирал весь дживик по конспирации , на пакетиках видать экономили)))
смотреть мультфильмы онлайн бесплатно https://kinogo-14.top/ .
Хотите интерьер, который отражает ваш характер и привычки? Я создаю функциональные и эстетичные пространства с авторским сопровождением на каждом этапе. Посмотрите портфолио и услуги на https://lipandindesign.ru – здесь реальные проекты и понятные этапы работы. Возьму на себя сроки, сметы и координацию подрядчиков, чтобы вы уверенно пришли к дому мечты.
фильмы в хорошем качестве http://www.kinogo-15.top/ .
https://www.instagram.com/candetoxblend_chile/
Enfrentar un control médico ya no tiene que ser un problema. Existe un suplemento de última generación que actúa rápido.
El secreto está en su combinación, que estimula el cuerpo con creatina, provocando que la orina oculte los rastros químicos. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para quienes enfrentan pruebas imprevistas.
Miles de usuarios confirman su seguridad. Los paquetes llegan sin logos, lo que refuerza la tranquilidad.
Cuando el examen no admite errores, esta fórmula es la respuesta que estabas buscando.
всезаймы http://www.zaimy-11.ru/ .
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
бро незнаю скок раз брал ни разу TS не подводил входил в положения скидки бонусы делал!!!
Магазин тут! kokain mefedron gash alfa-pvp amf
Ровный и Стабильный…
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Вы очень давно работаете,стабильная деятельность.
кракен маркет позволяет обойти возможные блокировки и получить доступ к маркетплейсу. кракен маркетплейс необходимо искать через проверенные источники, чтобы избежать фишинговых сайтов. кракен зеркало актуальное должно обновляться регулярно для обеспечения непрерывного доступа.
фишинг – главная особенность Кракен.
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
мои близкий поделился вашими контактами когда про бывали ваш товар)
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
качество супер!!!
Купить онлайн кокаин, мефедрон, амф, альфа-пвп
разобрался, поэтому и удалил сообщение до того как ты ответил )
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
Ментам зачастую пофиг,легал-нелегал.Был бы человек хороший,статья найдётся.СПСР тоже чёт не нравится.Но и на Мажор экспрессе случаи принималова были,так что х.з….Увидел на сайте “ждём…”.О.флюрокока и rti 111!Очень ждём!АМТ тож вкусняшка,но тут обьебосам не завидую.Примут по полграмма и айда 20 часов как кот в стиральной машине
https://3dwarehouse.sketchup.com/by/candetoxblend
Enfrentar un examen de drogas ya no tiene que ser un problema. Existe un suplemento de última generación que actúa rápido.
El secreto está en su fórmula canadiense, que ajusta el cuerpo con vitaminas, provocando que la orina neutralice los marcadores de THC. Esto asegura parámetros adecuados en menos de lo que imaginas, con efectividad durante 4 a 5 horas.
Lo mejor: no se requieren procesos eternos, diseñado para quienes enfrentan pruebas imprevistas.
Miles de usuarios confirman su seguridad. Los envíos son 100% discretos, lo que refuerza la tranquilidad.
Si tu meta es asegurar tu futuro laboral, esta fórmula es la elección inteligente.
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
Также возможен выбор курьерки, если какая-то из них не возможна для доставки в ваш город
кино онлайн кино онлайн .
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
ждите трип о товаре, как сделаю заказ и получу товар обрисую все в красках! постараюсь сделать фото!!!
Заходите на сайт https://audmix.net/ и вы сможете скачать свежие новинки музыки MP3, без регистрации и лишних действий или слушать онлайн. Самая большая подборка треков, песен, ремиксов. Выбирайте категорию музыки, которая вам нравится или наслаждайтесь нашими подборками. На сайте вы сможете найти, также, песни по отрывку.
САЙТ ПРОДАЖР24/7 – Купить мефедрон, гашиш, альфа-РїРІРї
Вот это было бы нереально кул, а то я уже отчаялся через емейл к вам пробиться. Жду с нетерпением.
Estou alucinado com Brazino Casino, e um cassino online que mergulha como um golfinho em alto-mar. A colecao e uma onda de entretenimento. incluindo mesas com charme subaquatico. O atendimento e solido como um coral. assegurando apoio sem turbulencia aquatica. Os pagamentos sao lisos como um coral. mesmo assim queria mais promocoes que brilham como corais. Em sintese, Brazino Casino e uma onda de adrenalina para os fas de adrenalina marinha! Adicionalmente o design e um espetaculo visual aquatico. amplificando o jogo com vibracao aquatica.
o que significa brazino777 jogo da galera?|
Acho simplesmente ardente Verabet Casino, tem uma energia de jogo tao intensa quanto um ritual de fogo. A selecao de titulos e uma pira de emocoes. com slots tematicos de cerimonias antigas. Os agentes voam como chamas. com solucoes precisas e instantaneas. Os ganhos chegam rapido como uma labareda. mas as ofertas podiam ser mais generosas. Na real, Verabet Casino e o point perfeito pros fas de cassino para os fas de adrenalina ardente! Adicionalmente o layout e vibrante como uma tocha. criando uma experiencia de cassino incendiaria.
reclame aqui vera bet|
РўРћРџ ПРОДАЖР24/7 – РџР РОБРЕСТРMEF ALFA BOSHK1
мне все пришло, магаз ровный. 5+
Me enredei no algoritmo de PlayPix Casino, e um cassino online que reluz como um pixel em overclock. A colecao e um codigo de entretenimento. com caca-niqueis que reluzem como bytes. Os agentes processam como CPUs. garantindo suporte direto e sem lag. Os saques sao velozes como um upload. porem mais recompensas fariam o coracao pixelar. Em resumo, PlayPix Casino e o point perfeito pros fas de cassino para os cacadores de vitorias em byte! Por sinal a navegacao e facil como um buffer. dando vontade de voltar como um byte.
playpix baixar app|
Ищете выездной бар в пробирках? Посетите сайт bar-vip.ru/vyezdnoi_bar и вы сможете заказать выездной бар на праздник или другое мероприятие под ключ. Зайдите на страницу, и вы узнаете, что вас ожидает — от огромного выбора напитков до участия в формировании меню. Вы сможете добавить в него собственные рецепты, а также заказать услуги выездного бара для тематических вечеров с подходящей атрибутикой, оформлением и костюмами. И это далеко не всё! Все детали — на сайте.
Магазин тут! kokain mefedron gash alfa-pvp amf
Наверно так же как и джив. попробуй минимальные пропорции сделать 0,1 к 1
Curto demais a vibracao de Brazino Casino, tem uma energia de jogo tao vibrante quanto um recife de corais. Os jogos formam um coral de diversao. incluindo mesas com charme subaquatico. O suporte e uma concha de eficiencia. assegurando apoio sem turbulencia aquatica. As transacoes sao simples como uma bolha. as vezes mais giros gratis seriam subaquaticos. No fim das contas, Brazino Casino e uma onda de adrenalina para os fas de adrenalina marinha! Alem disso o visual e uma explosao de corais. dando vontade de voltar como uma onda.
brazino777 entrar login|
Sou louco pela fornalha de Verabet Casino, explode com uma vibe de cassino flamejante. Tem uma enxurrada de jogos de cassino irados. com caca-niqueis que reluzem como brasas. Os agentes voam como chamas. oferecendo respostas claras como uma chama. As transacoes sao faceis como um fulgor. porem queria mais promocoes que queimam como fogueiras. Em resumo, Verabet Casino vale explorar esse cassino ja para os cacadores de vitorias incendiarias! Como extra o visual e uma explosao de chamas. criando uma experiencia de cassino incendiaria.
cassino bet vera|
Me enredei no algoritmo de PlayPix Casino, explode com uma vibe de cassino retro-futurista. A colecao e um codigo de entretenimento. com caca-niqueis que reluzem como bytes. O suporte e um firewall de eficiencia. garantindo suporte direto e sem lag. Os ganhos chegam rapido como um render. de vez em quando mais giros gratis seriam vibrantes. Na real, PlayPix Casino e um buffer de emocoes para os apaixonados por slots modernos! Como extra o design e fluido como um render. criando uma experiencia de cassino cibernetica.
robГґ playpix grГЎtis|
Приобрести (MEF) MEFEDRON SHISHK1 MSK-SPB | Отзывы, Покупки, Гарантии
Процветания и успехов вашему магазину!!
https://groups.google.com/g/candetoxblend/c/nYWf8CoaQqE
Prepararse un examen de drogas ya no tiene que ser una incertidumbre. Existe una fórmula confiable que actúa rápido.
El secreto está en su fórmula canadiense, que estimula el cuerpo con vitaminas, provocando que la orina neutralice los marcadores de THC. Esto asegura un resultado confiable en solo 2 horas, con ventana segura para rendir tu test.
Lo mejor: es un plan de emergencia, diseñado para quienes enfrentan pruebas imprevistas.
Miles de personas en Chile confirman su efectividad. Los envíos son 100% discretos, lo que refuerza la seguridad.
Si tu meta es asegurar tu futuro laboral, esta solución es la respuesta que estabas buscando.
Приобрести кокаин, мефедрон, бошки
Да я ж тебе говарю курьерка такая….)не парься!они с мониторингом просто тупят круто!тем более легал!
Купить MEFEDRON MEF SHISHK1 ALFA_PVP
Зачем писать таким большим шрифтом ? Здесь слепых нет. То что тебя где то кинули к нам никакого отношения не имеет.
Приобрести MEFEDRON MEF SHISHK1 GASH MSK
Кекс знакомый бpал тут- качество-самолет! Меня угостил – я тоже остался доволен!
Чтобы повысить позиции своего сайта в поисковых системах, я решил пройти интернет магазин продвижение, где я смог получить ценные знания и навыки для успешного продвижения своего интернет-ресурса.
SEO курс незаменим для улучшения позиций сайта в поисковых результатах. Это объясняется тем, что большая часть интернет-трафика проходит через поисковые системы . Таким образом, kurs по SEO должен быть в приоритете для всех, кто занимается онлайн-бизнесом.
Основы SEO включают в себя создание контента, соответствующего алгоритмам поисковых систем. Это включает в себя использование ключевых слов . Кроме того, улучшение авторитета сайта через ссылки является важнейшим аспектом SEO. Понимание этих основ является основой для успешного продвижения сайта.
Продвинутые техники SEO включают в себя анализ поведения пользователей на сайте . Это также включает в себя оптимизацию сайта для мобильных устройств . Освоение этих техник может существенно улучшить позиции сайта в поисковых результатах и увеличить конверсию. осуществление этих действий требует постоянной практики и обучения.
Заключение о важности SEO курса очевидно: это ключевой фактор успеха в современном маркетинге . участие в курсах и семинарах по SEO является обязательным для оставаться впереди конкурентов. по мере изменения алгоритмов и поведения пользователей , kurs по SEO должен быть частью постоянного образования и совершенствования.
Казино Вавада привлекает внимание тысяч игроков.
Специальные предложения дают шанс начать игру без вложений.
Регулярные акции дают дополнительные возможности.
Каталог развлечений обновляются регулярно.
Создать аккаунт можно быстро, и промокоды активируются моментально.
Узнай подробности прямо здесь: бездеп вавада
Игровая платформа Вавада считается одним из популярных проектов.
Специальные предложения создают выгодные условия для новичков.
Регулярные акции повышают интерес.
Слоты и настольные игры поддерживаются ведущими провайдерами.
Регистрация проста, и промокоды активируются моментально.
Узнай подробности прямо здесь: https://orderpupuseriapatty.com
интересные цветочные горшки http://www.dizaynerskie-kashpo-nsk.ru .
https://rainbetaustralia.com/
https://barnaul-beton.ru/
раздвижные электрокарнизы для штор http://razdvizhnoj-elektrokarniz.ru/ .
взо https://zaimy-14.ru/ .
все займы рф zaimy-15.ru .
Je suis charme par Grandz Casino, offre un spectacle de plaisir qui s’evapore. est une illusion de sensations qui enchante. offrant des sessions de casino en direct qui flottent comme des ombres. Le service client du casino est un maitre des ombres. offrant des solutions claires et instantanees. Les paiements du casino sont securises et fluides. quand meme des recompenses de casino supplementaires feraient danser. Pour resumer, Grandz Casino est un joyau pour les fans de casino pour les virtuoses des jeux! En plus l’interface du casino est fluide et danse comme une ombre. amplifie l’immersion totale dans le casino.
retirer sur grandz race|
Galera, quero deixar registrado sobre o Bingoemcasa porque achei muito alem do que esperava. O site tem um visual descontraido que lembra um salao cheio de energia. As salas de bingo sao sempre lotadas, e ainda testei varios slots, todos me deixaram impressionado. O atendimento no chat foi eficiente demais, o que ja me deixou seguro. As retiradas foram eficientes de verdade, inclusive testei cartao e caiu em minutos. Se pudesse apontar algo, diria que senti falta de ofertas extras, mas nada que estrague a experiencia. No geral, o Bingoemcasa foi uma otima descoberta. Eu mesmo ja voltei varias vezes
bingoemcasa.|
Хотите быстро и безопасно обменять криптовалюту на наличные в Нижнем Новгороде? NNOV.DIGITAL фиксирует курс, работает по AML и проводит большинство сделок за 5 минут. Пять офисов по городу, выдача наличными или по СБП. Узнайте детали и оставьте заявку на https://nnov.digital/ — менеджер свяжется, зафиксирует курс и проведёт сделку. Premium-условия для крупных сумм от $70 000. Надёжно, прозрачно, удобно. NNOV.DIGITAL — ваш офлайн обмен с “чистой” криптой.
https://maps.google.co.zw/url?q=https://uberant.com/article/2132285-5win-casino-um-olhar-de-jogador-experiente-brasileiro – 5win Casino – the best casino in Brazil
Sou viciado no labirinto de IJogo Casino, tem um ritmo de jogo que se enrosca como uma cobra. Os jogos formam uma rede de diversao. incluindo mesas com charme de labirinto. Os agentes deslizam como vinhas. disponivel por chat ou e-mail. O processo e claro e sem armadilhas. entretanto as ofertas podiam ser mais generosas. Ao final, IJogo Casino e um enredo de emocoes para os exploradores de jogos online! Vale dizer a navegacao e facil como uma teia. adicionando um toque de emaranhado ao cassino.
baixar app ijogo|
Galera, preciso contar o que achei sobre o Bingoemcasa porque me surpreendeu demais. O site tem um ar amigavel que lembra um barzinho cheio de risadas. As salas de bingo sao cheias de energia, e ainda testei alguns caca-niqueis modernos, todos rodaram sem travar. O atendimento no chat foi educado e prestativo, o que ja me deixou seguro. As retiradas foram muito rapidas, inclusive testei cartao e nao tive problema nenhum. Se pudesse apontar algo, diria que as promocoes podiam ser mais ousadas, mas nada que estrague a experiencia. No geral, o Bingoemcasa foi uma otima descoberta. Eu mesmo ja voltei varias vezes
bingoemcasa zeppelin|
Среди игроков выставочной индустрии Expoprints занимает лидирующие позиции, предлагая надежные решения для эффектных экспозиций. Фокусируясь на проектировании, производстве и монтаже в столице, фирма обеспечивает полный спектр работ: от идеи до разборки по окончании события. Используя качественные материалы вроде пластика, оргстекла и ДСП, Expoprints создает модульные, интерактивные и эксклюзивные конструкции, адаптированные под любой бюджет. В портфолио фирмы представлены работы для марок типа Haier и Mitsubishi, с размерами от 10 до 144 квадратных метров. Подробнее про изготовление выставочных стендов можно узнать на expoprints.ru Благодаря собственному производству и аккредитации на всех площадках, компания гарантирует качество и экономию. Expoprints – это не просто стенды, а инструмент для успешного продвижения вашего бренда на выставках по всей России и за рубежом. Если ищете профессионалов, обращайтесь сюда!
купить диплом в запорожье купить диплом в запорожье .
исторические фильмы исторические фильмы .
купить диплом о высшем образовании цены украина купить диплом о высшем образовании цены украина .
микрозайм всем https://zaimy-11.ru .
смотреть фильмы онлайн смотреть фильмы онлайн .
Приобрести диплом о высшем образовании!
Наша компания предлагаетбыстро и выгодно заказать диплом, который выполняется на бланке ГОЗНАКа и заверен мокрыми печатями, штампами, подписями должностных лиц. Документ пройдет лубую проверку, даже при помощи специально предназначенного оборудования. Достигайте своих целей быстро и просто с нашими дипломами- sakhd.3nx.ru/viewtopic.php?p=3648#3648
купить диплом бакалавра цена купить диплом бакалавра цена .
Если вы хотите освоить современные методы онлайн-продвижения и улучшить результаты вашего веб-сайта, то сео курсы станут идеальным решением для достижения ваших целей.
в современном мире бизнеса . Они помогают владельцам сайтов и маркетологам увеличить трафик на своих платформах. Курсы SEO охватывают широкий спектр тем от базовых понятий оптимизации .
Эффективность курсов SEO заметно повышается при правильном применении полученных знаний . Это подтверждается отзывами удовлетворенных клиентов. Кроме того, курсы SEO предоставляют участникам возможность познакомиться с последними трендами и инструментами .
Курсы SEO обычно включают в себя анализ эффективных методов продвижения в поисковых системах. В рамках этих курсов анализируются лучшие практики создания высококачественного контента. Кроме того, участники курсов SEO ознакомятся с инструментами анализа и мониторинга сайтов.
Продвинутые курсы SEO могут включать в себя обсуждение роли социальных сетей в SEO. Участники получают возможность изучать случаи успешного продвижения различных бизнесов . Этот подход позволяет повысить практические навыки участников .
Прохождение курсов SEO может принести улучшение конверсий и продаж. Это связано с тем, что улучшение рейтинга в поисковых системах повышает доверие к бренду . Кроме того, владельцы сайтов увеличить эффективность своей онлайн-рекламы .
Освоение курсов SEO также позволяет стать более конкурентоспособным на рынке . Участники курсов SEO становятся частью сообщества, которое постоянно эволюционирует и совершенствуется. Это, в свою очередь, обеспечивает возможность оставаться в курсе последних достижений в области цифрового маркетинга .
В заключение, курсы SEO являются важнейшим инструментом для успеха в онлайн-бизнесе . Будущее курсов SEO обещает принести новые выгоды и возможности для бизнеса . Участники курсов SEO получают уникальную возможность быть в авангарде этих изменений .
Перспективы курсов SEO указывают на важность постоянного обучения и совершенствования. Это означает, что эксперты по SEO должны оставаться в курсе последних тенденций и достижений. В этом контексте, курсы SEO предоставляют не только знания, но и инструменты для долгосрочного успеха .
https://space88765.shotblogs.com/un-arma-secreta-para-coaching-para-empresas-48785876
El acompanamiento gerencial es efectivo precisamente porque no se enfoca con los sintomas (cansancio). Enfrenta estas raices de frente, ayudandote a replantear desde cero tu mirada del dia a dia.
3 Claves Poderosas del Coaching Ejecutivo para un Liderazgo duradero
1. De Manejar el Tiempo a Orquestar la vitalidad
Descarta de controlar el dia. La verdadera moneda de cambio de un lider no son las minutos, sino la fuerza de su energia.
Un coach te apoya a hacer un plan propio: reconocer que acciones, reuniones e incluso relaciones son “drenadores” de fuerza y cuales son “cargadores”.
Se trata de replantear tu agenda de forma consciente. Resguarda tus bloques de alta fuerza (usualmente las mananas) para el trabajo de maxima importancia: pensar estrategicamente.
2. Del “Si” por inercia al “No” inteligente
Progresaste a donde te encuentras por tu habilidad de accion y de decir “si”. Pero para mantenerte y evitar el agotamiento, necesitas dominar el poder del “no” consciente.
Un formador te lleva a clarificar con precision tus metas clave. Luego, te ensena a implementar un sistema claro: “?Esto me lleva directamente a uno de mis objetivos?”. Si la contestacion es no, la opcion debe ser postergar.
3. De la Omnipotencia a la Delegacion valiente
El habito de “yo lo hago mas rapido y mejor” es el camino directo al agotamiento. Creas un bloqueo que te limita y, de paso, desaprovecha a tu equipo.
La delegacion radical no es solo ceder laburos chicos. Es transferir la responsabilidad de un objetivo completo.
Un coach te guia a crear una lista honesta: ?Que funciones solo yo resuelvo? Todo lo demas es delegable.
El salto de vision es pasar de “necesito controlar todo” a “mi rol es desarrollar a mi equipo”.
Demanda confianza, pero es la unica via de escalar tu resultado sin caer.
https://marioidvoj.blogolize.com/examine-este-informe-sobre-medicion-de-clima-laboral-73862566
Visualiza esta postal común en una pyme chilena: equipos agotados, cambio elevada, frases en el pasillo como aquí nadie escucha o puro cacho. Suena conocido, ¿verdad?
Muchas empresas en Chile se pierden con los números y los resultados financieros, pero se saltan del pulso interno: su capital humano. La verdad cruda es esta: si no controlas el clima, después no te sorprendas cuando la fuga de talento te explote en la puerta.
¿Por qué importa tanto esto en Chile?
El escenario local no perdona. Vivimos alta rotación en retail, burnout en los call centers y brechas generacionales gigantes en sectores como la minería y la banca.
En Chile, donde marca la talla constante y la cordialidad, es fácil tapar los problemas. Pero cuando no hay confianza real, ese humor se transforma en puro relleno que esconde la insatisfacción. Sin un análisis, las organizaciones son inconscientes. No ven lo que los trabajadores realmente conversan en la máquina de café o en sus grupos de WhatsApp.
Los ganancias palpables (y muy chilenos) de hacerlo bien
Hacer un diagnóstico de clima no es un desembolso, es la mejor inversión en rendimiento y tranquilidad que puedes hacer. Los beneficios son concretos:
Menos bajas y ausentismo: un dolor que le cuesta millones a las empresas chilenas cada ciclo.
Fidelización de talento nuevo: las generaciones recientes rotan rápido si no perciben valor y clima sano.
Mayor output en equipos distribuidos: clave para sucursales regionales que a veces se ven aislados.
Una diferenciación tangible: no es lo mismo prometer “somos buena onda” que sustentarlo con evidencia.
Cómo se hace en la práctica (sin volverse loco)
No requieres un equipo de RRHH gigante. Hoy, las plataformas son cercanas:
Plataformas de feedback: lo más usado en la nueva normalidad. La regla es garantizar el 100% de anonimato para que la dotación hable sin reserva.
Check-ins semanales: en vez de una encuesta extensa cada periodo, lanza una pregunta semanal corta por plataformas internas.
Talleres focalizados: la joya. Revelan lo que nunca saldría por correo: roces entre áreas, tensiones con liderazgos, procedimientos que nadie asume.
Conversaciones 1:1 con colaboradores regionales: su mirada suele quedar omitida. Una llamada puede descubrir quiebres de comunicación que pasarían colados en una encuesta.
El factor decisivo: el diagnóstico no puede ser un teatro. Tiene que traducirse en un roadmap concreto con objetivos, líderes y deadlines. Si no, es puro powerpoint.
Errores que en Chile se repiten (y tiran todo abajo)
Prometer cambios y no cumplir: los colaboradores chilenos lo leen al tiro; pura volada.
No blindar el resguardo: en estructuras muy autorregidas, el miedo a castigos es real.
Calcar encuestas externas: hay que adaptar el lenguaje a la idiosincrasia chilena.
Tomar una foto y no seguir: el clima varía tras la salida de un líder clave; hay que medir de forma regular.
Мы предлагаем документы любых учебных заведений, расположенных в любом регионе России. Купить диплом университета:
купить аттестат 11 класс барнаул
как купить диплом проведенный как купить диплом проведенный .
buy cocaine in telegram buy weed prague
https://muckrack.com/person-27826406
Понимание того, как работает курсы по seo продвижению, имеет решающее значение в современной цифровой среде, поскольку он помогает веб-сайтам получать более высокие позиции в поисковых системах и привлекать целевую аудиторию.
Курс по SEO – это детальный план обучения, который помогает увеличить посещаемость сайта за счет более высоких позиций в поисковых системах . Этот курс включает в себя все необходимые знания и инструменты для создания и продвижения сайтов, которые будут привлекать целевую аудиторию и увеличивать конверсии . Специалисты в области SEO подчеркивают важность постоянного обучения и совершенствования навыков .
Курс охватывает различные аспекты SEO от базовых концепций до продвинутых техник , что делает его подходящим для начинающих, которые только начинают свое путешествие в мире SEO . Участники курса получают подробные материалы и ресурсы .
Теоретические основы SEO включают в себя понимание того, как работают поисковые системы. Это включает в себя изучение алгоритмов ключевых концепций, таких как семантическая оптимизация и голосовой поиск. Понимание этих концепций позволяет разработать эффективную стратегию ссылочного продвижения . Теоретические знания в области SEO необходимы для всех, кто хочет добиться успеха в поисковой оптимизации.
Изучение теоретических основ SEO включает в себя анализ последних тенденций и разработок в этой области . Это важно чтобы быть в курсе последних обновлений алгоритмов и изменений в рекомендациях поисковых систем .
Практические аспекты SEO требуют определенного набора практических навыков. Это может включать в себя оптимизацию сайта для мобильных устройств . Практические навыки в области SEO позволяют эффективно управлять процессом продвижения и контролировать прогресс.
Освоение практических аспектов SEO требует применения творческого подхода и инновационных решений. Участники курса получают доступ к опыту и рекомендациям экспертов в этой области .
Применение SEO в бизнесе означает использование знаний и навыков для достижения конкретных целей . Это может включать в себя использование SEO для улучшения бренд-авторитета и лояльности клиентов . Успешное применение SEO в бизнесе обеспечивает постоянный рост и развитие бизнеса.
Эффективное применение SEO в бизнесе предполагает готовность адаптироваться к изменениям на рынке и в поисковых системах. Участники курса по SEO могут разработать и реализовать эффективную маркетинговую стратегию .
https://imageevent.com/andrupsegons/mtalx
https://mp-digital.ru/
диплом медсестры с занесением в реестр купить диплом медсестры с занесением в реестр купить .
https://wanderlog.com/view/viuhfkoofo/купить-марихуану-гашиш-канабис-дублин/
https://0ec25341f2a660b178e9d3782e.doorkeeper.jp/
https://www.grepmed.com/jobictoadihs
как набрать подписчиков в телеграм канале
https://community.wongcw.com/blogs/1150611/%D0%A1%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D1%81%D1%82%D0%BE%D0%B8%D1%82-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%9F%D0%B5%D1%80%D1%83%D0%B4%D0%B6%D0%B0-%D0%9A%D0%B0%D0%BA-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B7%D0%B0%D0%BA%D0%BB%D0%B0%D0%B4%D0%BA%D1%83
взо взо .
https://maps.google.de/url?q=https://graph.org/5win-Casino-Um-Olhar-de-Jogador-Experiente-Brasileiro-09-07 – 5win Casino – the best casino in Brazil
https://wirtube.de/a/neilc25/video-channels
https://trentonfvjxk.onesmablog.com/conseguir-mi-coaching-para-directivo-to-work-75535573
El coaching ejecutivo es clave precisamente porque no se distrae con los resultados superficiales (cansancio). Ataca estas causas de frente, ayudandote a replantear desde cero tu vision del trabajo.
3 Estrategias Clave del mentoria ejecutiva para un rol Sostenible
1. De Administrar el reloj a Dirigir la fuerza
Olvidate de gestionar el reloj. La real carta de intercambio de un lider no son las horas, sino la gestion de su rendimiento.
Un guia te apoya a crear un dibujo propio: identificar que acciones, juntas e incluso personas son “drenadores” de animo y cuales son “cargadores”.
Se trata de redisenar tu semana de forma inteligente. Protege tus espacios de alta vitalidad (usualmente las mananas) para el trabajo de maxima importancia: crear.
2. Del “Si” por costumbre al “No” inteligente
Llegaste a donde has llegado por tu habilidad de respuesta y de afirmar “si”. Pero para aguantar y reducir el agotamiento, requieres manejar el arte del “no” consciente.
Un formador te entrena a clarificar con claridad tus 2-3 objetivos. Luego, te guia a implementar un criterio efectivo: “?Esto me conduce directamente a uno de mis metas?”. Si la reaccion es no, la salida debe ser delegar.
3. De la Omnipotencia a la asignacion valiente
El pensamiento de “yo lo hago mas rapido y mejor” es el atajo directo al burnout. Creas un bloqueo que te ahoga y, de paso, desmotiva a tu colaboradores.
La delegacion total no es solo ceder tareas aburridas. Es transferir la propiedad de un resultado total.
Un coach te guia a hacer una relacion honesta: ?Que funciones solo yo resuelvo? Todo lo demas es transferible.
El cambio de mentalidad es pasar de “necesito controlar todo” a “mi rol es desarrollar a mi equipo”.
Demanda seguridad, pero es la unica via de escalar tu impacto sin quemarte.
https://www.brownbook.net/business/54262834/кокаин-ханой-купить/
https://www.impactio.com/researcher/fatvahatuz
https://yamap.com/users/4817396
купить диплом в киеве недорого https://www.educ-ua18.ru .
https://community.wongcw.com/blogs/1151388/%D0%93%D0%B4%D0%B5-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%A1%D0%B5%D0%BD-%D0%A2%D1%80%D0%BE%D0%BF%D0%B5
https://hoo.be/agefnohy
лучшие займы онлайн https://zaimy-13.ru/ .
займы http://www.zaimy-12.ru .
https://webpage38272.onesmablog.com/5-hechos-f%C3%A1cil-sobre-creacion-de-perfiles-de-cargo-descritos-77227707
La creacion de perfiles de cargo es hoy un factor clave para empresas que desean expandirse. Sin el diseño perfiles de cargo, los flujos de reclutamiento se transforman caóticos y el match con los candidatos falla.
En Chile, donde los rubros cambian a gran velocidad, el mapeo de perfiles de cargo ya no es una idea bonita. Es la estrategia viable de mapear qué skills son críticas en cada función.
Piénsalo: sin una renovación de perfiles de cargo, tu organización expone dinero contratando mal. Los perfiles de cargo que se mantienen viejos desorientan tanto a jefaturas como a colaboradores.
Problemas frecuentes al trabajar perfiles de cargo
Redactar perfiles demasiado genéricas.
Copiar formatos extranjeros que no funcionan en la idiosincrasia del país.
Pasar por alto la renovación de perfiles de cargo después de cambios.
No involucrar a los empleados en el levantamiento perfiles de cargo.
Buenas prácticas para un modelo de perfiles de cargo efectivo
Arrancar con el análisis de perfiles de cargo: entrevistas, focus groups y sondeos a líderes.
Ajustar competencias críticas y requisitos técnicos.
Construir un documento claro que explique tareas y niveles de rendimiento.
Agendar la puesta al día de perfiles de cargo al menos cada ciclo.
Cuando los documentos de cargo están actualizados, tu empresa alcanza tres beneficios claves:
Selecciones más certeros.
Trabajadores más alineados.
Planes de desarrollo más claros.
https://www.grepmed.com/ifaugeugu
https://www.band.us/page/99943782/
J’adore le flux de RollBit Casino, ca vibre avec une energie de casino digne d’un defilement. La selection du casino est une chaine de plaisirs. comprenant des jeux de casino adaptes aux cryptomonnaies. repond comme un pixel precis. joignable par chat ou email. Les retraits au casino sont rapides comme un deroulement. neanmoins des recompenses de casino supplementaires feraient derouler. En conclusion, RollBit Casino c’est un casino a explorer sans tarder pour les virtuoses des jeux! Ajoutons la plateforme du casino brille par son style bit. amplifie l’immersion totale dans le casino.
crypto casino rollbit|
https://www.wildberries.ru/catalog/171056105/detail.aspx
https://community.wongcw.com/blogs/1153811/%D0%9D%D0%B8%D0%B6%D0%BD%D0%B5%D0%B2%D0%B0%D1%80%D1%82%D0%BE%D0%B2%D1%81%D0%BA-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%BC%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D1%81%D0%BA%D0%BE%D1%80%D0%BE%D1%81%D1%82%D1%8C
https://linkin.bio/collinslori2972
https://space87530.anchor-blog.com/5374141/indicadores-sobre-actualizacion-de-perfiles-de-cargo-que-debe-saber
Una buena creacion de perfiles de cargo es hoy un tema clave para pymes que necesitan expandirse. Sin el formato de perfiles de cargo, los procesos de selección se transforman caóticos y el ajuste con los candidatos falla.
En Chile, donde los mercados mutan constantemente, el levantamiento perfiles de cargo ya no es un lujo. Es la manera real de mapear qué competencias son necesarias en cada rol.
Visualiza: sin una puesta al día de perfiles de cargo, tu negocio expone dinero seleccionando a ciegas. Los perfiles de cargo que se mantienen viejos desmotivan tanto a líderes como a colaboradores.
Problemas comunes al trabajar fichas de cargo
Escribir documentos demasiado incompletas.
Reutilizar modelos gringos que no calzan en la idiosincrasia del país.
Olvidar la renovación de perfiles de cargo después de fusiones.
No considerar a los empleados en el diseño perfiles de cargo.
Buenas prácticas para un diseño perfiles de cargo exitoso
Comenzar con el mapa de perfiles de cargo: entrevistas, focus groups y sondeos a supervisores.
Ajustar habilidades clave y conocimientos específicos.
Armar un documento claro que detalle tareas y niveles de evaluación.
Agendar la actualizacion perfiles de cargo al menos cada ciclo.
Cuando los roles definidos están claros, tu negocio logra tres ganancias concretas:
Reclutamientos más certeros.
Trabajadores más comprometidos.
Planes de desarrollo más transparentes.
https://word66036.ampblogs.com/la-guГa-definitiva-para-capacitacion-de-liderazgo-online-74006121
Participar en una capacitacion de liderazgo online ya no es un beneficio opcional, sino una prioridad para cualquier negocio que aspira a avanzar en el entorno VUCA.
Un buen curso de liderazgo empresarial no solo proporciona teoria, sino que activa la practica del liderazgo de jefes que tienen equipos a cargo.
Por que elegir una formacion en liderazgo online?
Autonomia para capacitarse sin detener el ritmo laboral.
Entrada a materiales actualizados, incluso si estas fuera de la capital.
Costo mas competitivo que una formacion presencial.
En el contexto chileno, un entrenamiento para lideres chilenos debe adaptarse a la cultura chilena:
Estilos autoritarios.
Millennials vs. jefaturas tradicionales.
Desconexion entre areas.
Por eso, una formacion de lideres debe ser mas que un powerpoint bonito.
Que debe incluir un buen curso de liderazgo chile?
Modulos sobre gestion emocional.
Casos reales adaptados a contextos reales.
Evaluacion individual de competencias.
Networking con otros supervisores de diferentes industrias.
Y lo mas fundamental: el programa formativo debe impulsar un salto significativo en la practica diaria.
Cientos de jefes llegan al puesto sin preparacion, y eso impacta a sus areas. Un buen capacitacion de liderazgo online puede ser la solucion entre liderar con claridad o improvisar.
http://maps.google.sk/url?q=https://te.legra.ph/5win-Casino-Um-Olhar-de-Jogador-Experiente-Brasileiro-09-07-2 – 5win Casino – the best casino in Brazil
https://www.grepmed.com/eygocecjyfog
https://www.band.us/page/99929318/
https://www.brownbook.net/business/54273604/камышин-купить-лирику-экстази-амфетамин/
купить диплом в ейске http://www.rudik-diplom1.ru .
Visit rxo
https://beteiligung.stadtlindau.de/profile/%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%A1%D0%B0%D0%BD%D0%BA%D1%82-%D0%9C%D0%BE%D1%80%D0%B8%D1%86%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C/
электрокарниз двухрядный http://www.razdvizhnoj-elektrokarniz.ru .
https://9d1fa8c9a63f5ef11aaa1b3897.doorkeeper.jp/
купить диплом в уфе купить диплом в уфе .
купить диплом в великих луках купить диплом в великих луках .
https://word66036.ampblogs.com/la-guГa-definitiva-para-capacitacion-de-liderazgo-online-74006121
Apostar en una capacitacion de liderazgo online ya no es un lujo, sino una urgencia para cualquier negocio que quiere avanzar en el contexto moderno.
Un buen taller de liderazgo ejecutivo no solo entrega contenido, sino que transforma la manera de dirigir de mandos medios que estan en terreno.
Ventajas de una una formacion en liderazgo online?
Autonomia para aprender sin detener el trabajo diario.
Acceso a contenidos de alto nivel, incluso si trabajas fuera de la capital.
Inversion mas accesible que una opcion fisica.
En el contexto chileno, un entrenamiento para lideres chilenos debe considerar realidades locales:
Cadenas de mando tradicionales.
Colaboradores diversos.
Desconexion entre areas.
Por eso, una formacion de lideres debe ser mas que un taller generico.
Que debe incluir un buen curso de liderazgo empresarial?
Clases sobre gestion emocional.
Roleplays adaptados a situaciones chilenas.
Feedback individual de habilidades.
Networking con otros gerentes de regiones.
Y lo mas clave: el programa formativo debe impulsar un cambio real en la eficacia del liderazgo.
Cientos de encargados asumen cargos sin preparacion, y eso frena a sus colaboradores. Un buen capacitacion de liderazgo online puede ser la diferencia entre gestionar con impacto o imponer.
https://www.rwaq.org/users/hongocdat141-20250911173251
купить диплом в химках купить диплом в химках .
купить диплом химика купить диплом химика .
купить диплом в твери купить диплом в твери .
https://alfa-promotion.ru
купить диплом продавца купить диплом продавца .
купить диплом в балашове купить диплом в балашове .
https://info62709.tusblogos.com/25049663/se-rumorea-zumbido-en-levantamiento-perfiles-de-cargo
La generación de perfiles de cargo es hoy un factor estratégico para pymes que desean expandirse. Sin el modelo de perfiles de cargo, los procesos de contratación se transforman ineficientes y el match con los candidatos fracasa.
En Chile, donde los sectores cambian rápido, el levantamiento perfiles de cargo ya no es una idea bonita. Es la manera real de entender qué competencias son requeridas en cada posición.
Imagina: sin una puesta al día de perfiles de cargo, tu empresa pierde tiempo seleccionando a ciegas. Los perfiles de cargo que quedaron anticuados confunden tanto a supervisores como a colaboradores.
Errores frecuentes al trabajar roles de cargo
Redactar documentos demasiado vagas.
Reutilizar plantillas genéricas que no funcionan en la idiosincrasia del país.
Ignorar la renovación de perfiles de cargo después de reestructuraciones.
No considerar a los colaboradores en el proceso de perfiles de cargo.
Recomendaciones para un creacion de perfiles de cargo exitoso
Comenzar con el mapa de perfiles de cargo: entrevistas, focus groups y sondeos a líderes.
Alinear habilidades clave y aptitudes duras.
Armar un perfil visual que explique responsabilidades y criterios de evaluación.
Programar la actualizacion perfiles de cargo al menos cada ciclo.
Cuando los documentos de cargo están actualizados, tu organización obtiene tres ventajas claves:
Contrataciones más certeros.
Equipos más coordinados.
Programas de desempeño más claros.
https://avonwomen.ru
купить диплом реестр купить диплом реестр .
Денежное довольствие военнослужащих 2025 индексация на 7,6% с октября — калькулятор обновил, плюс 5 тысяч к зарплате.калькулятор зарплаты военных
https://gorod54-nsk.ru
купить диплом в кургане занесением в реестр купить диплом в кургане занесением в реестр .
купить диплом об образовании с реестром купить диплом об образовании с реестром .
как купить легальный диплом о среднем образовании http://www.frei-diplom4.ru .
как купить диплом занесенный в реестр как купить диплом занесенный в реестр .
диплом занесен в реестр купить диплом занесен в реестр купить .
https://eluapelsin.ru
купить диплом техникума с занесением пять плюс купить диплом техникума с занесением пять плюс .
купить диплом техникума в украине пять плюс купить диплом техникума в украине пять плюс .
Доброго!
Вы можете купить виртуальный номер для смс навсегда в любое время. Мы поможем купить виртуальный номер для смс навсегда без лишних данных. Надёжность и удобство — вот почему стоит купить виртуальный номер для смс навсегда. Закажите услугу и успейте купить виртуальный номер для смс навсегда уже сегодня. Умный выбор — купить виртуальный номер для смс навсегда.
Полная информация по ссылке – https://jaidengtbf02579.arwebo.com/49830104/het-belang-van-mobiele-nummers-in-duitsland-een-gids
купить виртуальный номер навсегда, постоянный виртуальный номер для смс, Купить виртуальный номер телефона навсегда
постоянный виртуальный номер для смс, купить виртуальный номер навсегда, Виртуальные номера
Удачи и комфорта в общении!
https://gorod54-nsk.ru
куплю диплом медсестры в москве куплю диплом медсестры в москве .
Доброго!
Купите виртуальный номер телефона навсегда и избавьтесь от необходимости менять контакты. Постоянный виртуальный номер для смс подходит для любых целей: регистрации, общения и работы. Мы предлагаем качественные услуги, которые сделают вашу связь удобной и доступной. Виртуальный номер навсегда – это решение для тех, кто ценит комфорт. Обратитесь к нам для получения надежного сервиса.
Полная информация по ссылке – https://milodrer36925.blogmazing.com/26526333/het-belang-van-tijdelijke-sms-nummers-een-uitgebreide-verkenning
купить номер телефона навсегда, постоянный виртуальный номер, купить виртуальный номер для смс навсегда
купить виртуальный номер для смс навсегда, Виртуальные номера, купить виртуальный номер навсегда
Удачи и комфорта в общении!
https://aisikopt.ru
https://arttex-salon.ru
https://autoreleases.ru
Je suis enthousiaste a propos de 7BitCasino, c’est une veritable experience de jeu electrisante. La selection de jeux est colossale, comprenant plus de 5 000 jeux, dont 4 000 adaptes aux cryptomonnaies. Le service d’assistance est de premier ordre, offrant des reponses rapides et precises. Les gains sont verses en un temps record, bien que les promotions pourraient etre plus genereuses, ou des promotions hebdomadaires plus frequentes. Dans l’ensemble, 7BitCasino ne decoit jamais pour les joueurs en quete d’adrenaline ! De plus le site est concu avec style et modernite, ce qui intensifie le plaisir de jouer.
app 7bitcasino|
Je suis carrement scotche par Gamdom, c’est une plateforme qui envoie du lourd. La gamme est une vraie pepite, comprenant des jeux parfaits pour les cryptos. Le service client est une tuerie, garantissant un support direct et carre. Les gains arrivent en mode TGV, des fois des recompenses en plus ca ferait kiffer. Au final, Gamdom offre une experience de ouf pour les pirates des slots modernes ! Cote plus la plateforme claque avec son look de feu, donne envie de replonger non-stop.
gamdom espana|
https://grad-uk.ru
J’apprecie enormement 7BitCasino, ca procure une sensation de casino unique. La selection de jeux est colossale, incluant des slots de pointe. Le service d’assistance est de premier ordre, offrant des reponses rapides et precises. Les transactions en cryptomonnaies sont instantanees, bien que davantage de recompenses seraient appreciees, afin de maximiser l’experience. Globalement, 7BitCasino vaut pleinement le detour pour les passionnes de jeux numeriques ! En bonus l’interface est fluide et retro, ajoute une touche de raffinement a l’experience.
7bitcasino 25|
https://digi295sa.netlify.app/research/digi295sa-(207)
A twinset can have a “fuddy duddy” popularity, but it definitely doesn’t have to look quaint.
накрутка подписчиков инстаграм телеграм
https://imageevent.com/thanhtrinhbu/gjzlr
https://storage.googleapis.com/digi474sa/research/digi474sa-(480).html
Consider choosing a look that can rework from the ceremony to the reception.
https://je-tal-marketing-884.ams3.digitaloceanspaces.com/research/je-marketing-(253).html
If you haven’t heard from her by about 5 months before the wedding, don’t be afraid to reach out and ask for an update on the dress code.
https://je-tall-marketing-837.lon1.digitaloceanspaces.com/research/je-marketing-(451).html
In years gone by, being mom of the bride has meant frumpy frocks and ill-fitting costume suits, but no more!
Добрый день!
Если вы цените анонимность — купите постоянный виртуальный номер. Сегодня купить постоянный виртуальный номер — это легко и быстро. Наш сервис поможет вам купить постоянный виртуальный номер без лишних шагов. Тысячи клиентов уже успели купить постоянный виртуальный номер у нас. Защити себя, решив купить постоянный виртуальный номер.
Полная информация по ссылке – https://travisabsc66643.bloggin-ads.com/50093056/alles-over-het-49-nummer-een-complete-gids
постоянный виртуальный номер, виртуальный номер, купить виртуальный номер
постоянный виртуальный номер, постоянный виртуальный номер, купить виртуальный номер навсегда
Удачи и комфорта в общении!
Здравствуйте!
Ищете, где купить виртуальный номер навсегда? Мы предлагаем постоянные виртуальные номера для смс, регистрации и других целей. Это удобный способ сохранить свои данные конфиденциальными. Постоянный виртуальный номер – это универсальное решение для бизнеса и личной жизни. Сделайте выбор в пользу наших услуг.
Полная информация по ссылке – https://danteaslb71482.bloggin-ads.com/50092953/het-belang-van-tijdelijke-telefoonnummers-een-diepgaande-verkenning
постоянный виртуальный номер для смс, купить виртуальный номер навсегда, виртуальный номер
купить виртуальный номер для смс навсегда, купить номер телефона навсегда, виртуальный номер
Удачи и комфорта в общении!
https://jaredwgihg.activosblog.com/29321721/nuevo-paso-a-paso-mapa-coaching
La importancia del coaching grupal online esta revolucionando la forma en que las organizaciones latinas transforman sus colaboradores.
Hoy, optar por un programa de coaching de equipos no es un lujo, sino una herramienta fundamental para asegurar metas en contextos cada vez mas complejos.
Razones para elegir coaching de equipos?
Consolida la comunicacion entre colaboradores.
Previene conflictos internos.
Optimiza la coordinacion en proyectos.
Activa confianza dentro del conjunto.
Ventajas de un coaching para grupos
Areas mas coordinados con los metas corporativos.
Bajada de fuga de talento.
Cultura interno productivo.
Incrementada prevencion de problemas.
Situaciones donde el coaching grupal online hace la diferencia
Areas con roces entre mandos medios.
Equipos que funcionan en modo remoto.
Companias que padecen altas tasas de rotacion.
De que manera implementar coaching para grupos en tu negocio
Identificar resultados buscados.
Seleccionar un mentor experto.
Disenar encuentros online adaptados a cada equipo.
Evaluar el impacto en tiempos definidos.
El coaching de equipos es un pilar que fortalece la dinamica de trabajar. Un coaching de equipos bien aplicado puede ser en la clave entre resistir o escalar.
http://google.tm/url?q=https://hackmd.io/@N5OLD2xzRWCHBqH07yu95w/SyyDpyj5el – 5win Casino – the best casino in Brazil
https://wirtube.de/a/alyssasmallaly/video-channels
накрутка активных подписчиков в телеграм канал
https://je-sf-tall-marketing-727.b-cdn.net/research/je-marketing-(293).html
This mom of the bride escorted her daughter down the aisle in a light blue beautiful halter dress.
https://je-sf-tall-marketing-735.b-cdn.net/feed.xml
Sheer stretch tulle and cap sleeves on the neckline add an eye catching detail, giving the phantasm of a strapless look.
https://je–marketing-834.lon1.digitaloceanspaces.com/research/je-marketing-(156).html
In years gone by, being mother of the bride has meant frumpy frocks and ill-fitting dress suits, but no more!
https://je-tall-marketing-882.ams3.digitaloceanspaces.com/research/je-marketing-(474).html
The dresses in this class feature dresses with components corresponding to exquisite embroidery and floral accents.
https://je-tall-marketing-875.ams3.digitaloceanspaces.com/research/je-marketing-(185).html
They also create an elongating, slimming effect as they draw the attention up and down somewhat than across.
https://digi62sa.sfo3.digitaloceanspaces.com/research/digi62sa-(186).html
For the redwood location, it would be great to wear one thing in natural colours like the two moss green outfits pictured.
https://beteiligung.stadtlindau.de/profile/%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%A1%D0%B0%D0%BD%D0%BA%D1%82-%D0%9C%D0%BE%D1%80%D0%B8%D1%86%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C/
https://je-sf-tall-marketing-728.b-cdn.net/research/je-marketing-(390).html
Sweet and complicated, this robe wows with its daring tone and classic silhouette.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-1/research/monday-1-(259).html
If the marriage is extra formal, anticipate to put on an extended gown or long skirt.
https://wirtube.de/a/cgzkjqli9370/video-channels
https://je-sf-tall-marketing-739.b-cdn.net/research/je-marketing-(27).html
This exquisite floral frock would make the proper complement to any nature-inspired marriage ceremony.
https://www.brownbook.net/business/54272829/худжанд-купить-лирику-экстази-амфетамин/
https://earth09628.uzblog.net/un-imparcial-vista-de-programa-de-coaching-de-equipos-48700081
El poder del coaching para grupos esta impactando la dinamica en que las companias chilenos gestionan sus colaboradores.
Hoy, invertir en un coaching grupal online no es un lujo, sino una necesidad fundamental para lograr objetivos en contextos cada vez mas exigentes.
Motivos por los que elegir programa de coaching de equipos?
Fortalece la comunicacion entre areas.
Disminuye conflictos internos.
Optimiza la coordinacion en procesos.
Genera respeto dentro del equipo.
Beneficios de un programa de coaching de equipos
Grupos mas conectados con los objetivos corporativos.
Bajada de salidas.
Clima organizacional productivo.
Mayor resolucion de problemas.
Casos donde el coaching de equipos para resolver conflictos hace la clave
Areas con tensiones entre mandos medios.
Equipos que operan en formato hibrido.
Companias que viven altas tasas de rotacion.
La forma de implementar programa de coaching de equipos en tu organizacion
Precisar objetivos claros.
Elegir un facilitador certificado.
Disenar sesiones virtuales adaptados a la realidad local.
Evaluar el resultado en plazos especificos.
El coaching para grupos es un pilar que transforma la forma de trabajar. Un coaching de equipos para resolver conflictos bien aplicado puede representar en la solucion entre resistir o ganar competitividad.
https://je-tall-marketing-838.lon1.digitaloceanspaces.com/research/je-marketing-(418).html
It has an attractive reduce that enhances all the proper locations.
https://digi64sa.sfo3.digitaloceanspaces.com/research/digi64sa-(372).html
Another can’t-miss palettes for mother of the bride or mother of the groom dresses?
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-11/research/je-marketing-(38).html
Let the solutions to a few of our most frequently requested questions guide you in the best course.
https://wirtube.de/a/jessicajonesbunt/video-channels
https://je-sf-tall-marketing-732.b-cdn.net/research/je-marketing-(168).html
The two seems below are good examples of timeless type.
xmi jng
https://je-tall-marketing-880.ams3.digitaloceanspaces.com/research/je-marketing-(174).html
This gown comes with a sweater over that may be taken off if it gets too scorching.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-15/research/je-marketing-(229).html
This embellishment on this attractive dress adds a contact of magic excellent for any winter wedding.
https://form.jotform.com/252516909143054
https://je-tall-marketing-854.ams3.digitaloceanspaces.com/research/je-marketing-(487).html
Her mother, who similarly sparkled in a gold silk dupioni floor-length skirt go well with.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-7/research/je-marketing-(449).html
We requested some marriage ceremony trend experts to discover out what a MOB ought to put on on the massive day.
https://storage.googleapis.com/digi469sa/research/digi469sa-(419).html
Sort through our full choice of dresses to find your good fit in many colours and any size.
https://digi76sa.sfo3.digitaloceanspaces.com/research/digi76sa-(148).html
There often aren’t any set rules in phrases of MOB outfits for the marriage.
https://je-sf-tall-marketing-735.b-cdn.net/research/je-marketing-(406).html
Much like the mom of the groom, step-mothers of each the bride or groom should observe the lead of the mom of the bride.
https://muckrack.com/person-27883802
https://je-tall-marketing-875.ams3.digitaloceanspaces.com/research/je-marketing-(327).html
You can still embrace these celebratory metallic shades with out covering your self head to toe in sequins.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-1/research/monday-1-(39).html
Trust us, with a fun handkerchief hem and pretty flutter sleeves, you will be getting compliments all evening.
https://je-tall-marketing-878.ams3.digitaloceanspaces.com/research/je-marketing-(266).html
You ought to go for some shiny colours, or in case your daughter has a shade picked out for you then go together with that.
https://je-tall-marketing-853.ams3.digitaloceanspaces.com/research/je-marketing-(235).html
So, you’ll want to wear one thing that doesn’t conflict with the remainder of the group in pictures.
https://jekyll.s3.us-east-005.backblazeb2.com/20250904-2/research/je-marketing-(436).html
Draw inspiration from mix-and-match bridesmaid clothes by choosing a colour that coordinates with, but would not precisely match, the maids palette.
https://allmynursejobs.com/author/langerm4t4michael/
https://storage.googleapis.com/digi470sa/research/digi470sa-(371).html
Her mother, who similarly sparkled in a gold silk dupioni floor-length skirt suit.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-11/research/je-marketing-(264).html
You will need to wear lighter colours, or whatever your daughter suggests.
https://je-tall-marketing-833.lon1.digitaloceanspaces.com/research/je-marketing-(2).html
This mother of the bride wore a white tunic and skirt for a boho-chic ensemble.
https://je-tall-marketing-835.lon1.digitaloceanspaces.com/research/je-marketing-(441).html
This glittery lace-knit two-piece includes a sleeveless cocktail gown and coordinating longline jacket.
https://je-tall-marketing-882.ams3.digitaloceanspaces.com/research/je-marketing-(383).html
Clean strains and a formed waist make this a timeless and elegant mother of the bride gown with a flattering silhouette.
https://raymondvmcth.canariblogs.com/datos-sobre-coaching-ejecutivo-curso-chile-revelados-46521912
El coaching para directivo está cambiando la manera en que las organizaciones locales gestionan a sus colaboradores.
Hoy, hablar de coaching organizacional no es una corriente pasajera, es una estrategia fundamental para alcanzar resultados en un mercado cada vez más competitivo.
Razones para el coaching ejecutivo sirve?
Facilita a los líderes a administrar mejor su tiempo.
Potencia la comunicación con jefaturas.
Consolida el liderazgo en etapas de cambio.
Disminuye el cansancio en ejecutivos.
Beneficios del coaching jefaturas en Chile
Incrementada fidelización de talento.
Clima laboral fortalecido.
Equipos sincronizados con los metas corporativos.
Desarrollo de supervisores que asumen nuevas metas.
Casos donde el coaching para directivo marca la diferencia
Un gerente que requiere acordar conflictos con alta dirección.
Una coordinación que debe dirigir grupos diversos.
Un líder que se enfrenta un escenario de transformación digital.
La forma en que implementar coaching gerencial en tu empresa
Definir focos concretos.
Contratar un coach certificado.
Diseñar programas a medida.
Medir cambios en tiempos definidos.
Un programa de coaching ejecutivo puede ser la herramienta entre sobrevivir o crecer.
https://1d9a3f8c0add3beca3c3f0d62a.doorkeeper.jp/
https://charliedgtjk.tribunablog.com/coaching-grupal-la-clave-para-potenciar-equipos-y-resolver-conflictos-en-las-organizaciones-51002390
La importancia del coaching grupal online esta revolucionando la dinamica en que las companias latinas lideran sus colaboradores.
Hoy, optar por un programa de coaching de equipos no es un extra, sino una necesidad critica para alcanzar objetivos en contextos cada vez mas exigentes.
?Por que elegir coaching para grupos?
Consolida la conexion entre areas.
Previene conflictos internos.
Mejora la coordinacion en tareas.
Genera respeto dentro del conjunto.
Beneficios de un coaching de equipos
Equipos mas alineados con los planes estrategicos.
Disminucion de salidas.
Clima laboral positivo.
Mas alta resolucion de conflictos.
Situaciones donde el coaching grupal online hace la diferencia
Departamentos con roces entre mandos medios.
Equipos que trabajan en formato hibrido.
Empresas que padecen altas tasas de rotacion.
Como implementar programa de coaching de equipos en tu organizacion
Identificar objetivos claros.
Elegir un facilitador certificado.
Disenar programas hibridos adaptados a la realidad local.
Monitorear el cambio en periodos especificos.
El coaching de equipos es un salvavidas que mejora la dinamica de trabajar. Un coaching grupal online bien aplicado puede representar en la clave entre improvisar o ganar competitividad.
https://jekyll.s3.us-east-005.backblazeb2.com/20250904-2/research/je-marketing-(73).html
The knotted entrance detail creates a fake wrap silhouette accentuating the waist.
https://je-tall-marketing-825.fra1.digitaloceanspaces.com/research/je-marketing-(376).html
As the mother of the bride, your function comes with massive responsibilities.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-4/research/je-marketing-(32).html
It has over one hundred forty positive critiques, many from women who wore this to a wedding and beloved it!
https://maps.google.co.ve/url?q=https://luxurious-ulna-95d.notion.site/5win-Casino-Um-Olhar-de-Jogador-Experiente-Brasileiro-2677b0bbe66d80e9b9abfedd8fd66b1e – 5win Casino – the best casino in Brazil
https://www.brownbook.net/business/54275158/йошкар-ола-купить-кокаин-альфа-пвп-мефедрон/
https://storage.googleapis.com/digi474sa/research/digi474sa-(237).html
The attire on this category function clothes with parts such as beautiful embroidery and floral accents.
https://community.wongcw.com/blogs/1150017/%D0%91%D1%80%D0%B0%D1%82%D1%81%D0%BA-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%91%D0%BE%D1%88%D0%BA%D0%B8-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88
https://je-sf-tall-marketing-730.b-cdn.net/research/je-marketing-(288).html
Our mothers are attractive and amazing and they need to rock what they have.
https://www.grepmed.com/nobzahziycl
https://je-tall-marketing-836.lon1.digitaloceanspaces.com/research/je-marketing-(499).html
Jules & Cleo, exclusively at David’s Bridal Polyester, nylon Back zipper; totally lined …
https://digi67sa.sfo3.digitaloceanspaces.com/research/digi66sa-(297).html
You ought to remember the formality, theme, and decor colour of the wedding whereas looking for the costume.
https://www.brownbook.net/business/54257141/купить-бошки-в-тг/
https://je-tall-marketing-836.lon1.digitaloceanspaces.com/research/je-marketing-(500).html
This surprisingly affordable mother-of-the-bride gown is ideal for a proper fall or winter wedding.
https://je–marketing-834.lon1.digitaloceanspaces.com/research/je-marketing-(462).html
Encourage your mother to have a little enjoyable when dressing for your ceremony or rehearsal dinner.
https://storage.googleapis.com/digi465sa/research/digi465sa-(317).html
David’s Bridal presents handy on-line and in-person purchasing experiences.
http://www.pageorama.com/?p=yhefzogwage
https://je-tall-marketing-850.lon1.digitaloceanspaces.com/research/je-marketing-(191).html
Mother of the bride attire don’t want to feel frumpy or overly conservative!
https://je-tall-marketing-864.fra1.digitaloceanspaces.com/research/je-marketing-(192).html
The mother of the bride costume gallery has a costume for every budget and every body type together with plus sizes.
Ипотека участникам СВО с господдержкой — калькулятор показал нулевой первоначальный взнос, супер!заявление на НИС
https://community.wongcw.com/blogs/1153968/%D0%A2%D1%8E%D0%BC%D0%B5%D0%BD%D1%8C-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%BC%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D1%81%D0%BA%D0%BE%D1%80%D0%BE%D1%81%D1%82%D1%8C
https://digi76sa.sfo3.digitaloceanspaces.com/research/digi76sa-(356).html
The sleek silk material glides seamlessly over your figure, but an ankle-length skirt, high neckline and draped sleeves hold things modest.
https://digi62sa.sfo3.digitaloceanspaces.com/research/digi62sa-(418).html
The contrast between these two gowns is in how they’re selected.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-4/research/je-marketing-(48).html
The beaded detailing elevates this JS Collections costume , making it best for a particular occasion.
https://digi75sa.sfo3.digitaloceanspaces.com/research/digi75sa-(84).html
From the floor-sweeping A-line skirt to the on-trend off-the-shoulder sleeves, there’s so much to love.
https://je-sf-tall-marketing-738.b-cdn.net/research/je-marketing-(175).html
A matching white choker topped off this mother-of-the-bride’s look, which was also complemented by a chic low bun.
https://je-tall-marketing-883.ams3.digitaloceanspaces.com/research/je-marketing-(254).html
Before you begin your search (around the six- to eight-month mark), brush up on mother-of-the-bride apparel etiquette.
https://yamap.com/users/4814276
https://je-sf-tall-marketing-730.b-cdn.net/research/je-marketing-(356).html
You may think it’s customary for the mother of the bride to put on an over-sized hat, but that’s simply not the case for 2022.
https://je-sf-tall-marketing-736.b-cdn.net/research/je-marketing-(396).html
These robes are stylish and stylish with just a little bit of an edge.
https://je-sf-tall-marketing-732.b-cdn.net/research/je-marketing-(271).html
Sophie Moore is a former Brides editor and present contributing author.
https://je-sf-tall-marketing-740.b-cdn.net/research/je-marketing-(387).html
And lastly, don’t worry about trying to only ‘age-appropriate’ boutiques.
https://form.jotform.com/252566251367057
займы россии http://www.zaimy-16.ru .
https://je-tall-marketing-853.ams3.digitaloceanspaces.com/research/je-marketing-(31).html
Talk to your daughter or future daughter- in-law to get a really feel for the visual she’s trying to create.
https://je-tall-marketing-836.lon1.digitaloceanspaces.com/research/je-marketing-(301).html
No, you shouldn’t match with bridesmaids; as an alternative, complement them.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-8/research/je-marketing-(423).html
For a seashore wedding I would put on one thing a bit more flowy just like the flowery and ruffly dresses above.
https://je-sf-tall-marketing-736.b-cdn.net/research/je-marketing-(48).html
We carry manufacturers that excel in mom of the bride jacket attire, capes and pantsuits, like Alex Evenings, R&M Richards and Ignite.
https://muckrack.com/person-27933165
Je suis accro au style de FatPirate, ca donne une energie de pirate dejantee. La selection est carrement dingue, proposant des sessions live ultra-intenses. L’assistance est carrement geniale, repondant en deux secondes chrono. Les retraits sont rapides comme une tempete, par contre les offres pourraient etre plus genereuses. En gros, FatPirate garantit un fun total pour les accros aux sensations fortes ! A noter aussi la plateforme claque avec son look unique, booste l’immersion a fond.
bonus sans dГ©pГґt fatpirate|
J’apprecie enormement Betify Casino, on dirait une aventure pleine de frissons. La gamme de jeux est tout simplement phenomenale, incluant des slots de derniere generation. Le support est ultra-reactif et professionnel, repondant en un clin d’?il. Les transactions sont parfaitement protegees, parfois davantage de recompenses seraient appreciees. En resume, Betify Casino est un incontournable pour les adeptes de sensations fortes ! Notons egalement que le design est visuellement percutant, ce qui amplifie le plaisir de jouer.
bonus sans depot betify|
Je trouve carrement genial Impressario, il propose un show de jeu hors norme. Le catalogue est un festival de titres, offrant des machines a sous qui claquent. L’assistance est une vraie performance de pro, garantissant un support direct et brillant. Les paiements sont securises et eclatants, parfois les offres pourraient etre plus genereuses. Pour resumer, Impressario offre un spectacle de jeu inoubliable pour les artistes du jeu ! Bonus l’interface est fluide et glamour, donne envie de revenir pour un rappel.
impressario casino login|
https://je-sf-tall-marketing-729.b-cdn.net/research/je-marketing-(262).html
A robe with jewels on the neckline alleviates the need for a necklace or loads of other extras.
https://imageevent.com/ln7951402/acrgy
https://storage.googleapis.com/digi463sa/research/digi463sa-(350).html
So, we’ve compiled a information to the best mom of the bride outfits and trends for 2022.
https://je-tall-marketing-852.ams3.digitaloceanspaces.com/research/je-marketing-(49).html
A neat shift dress that sits under the knee, a tailor-made jacket, and a few sort of fussy fascinator or royal wedding-worthy hat.
Доброго!
Купите виртуальный номер для смс навсегда и будьте уверены в конфиденциальности данных. Постоянный виртуальный номер подойдет для любых цифровых задач. Мы предоставляем качественные номера, которые работают без сбоев. Виртуальный номер навсегда – это надежность, которая всегда с вами. Выбирайте наши услуги для комфортного общения.
Полная информация по ссылке – https://andresbktc96307.jaiblogs.com/53661649/het-belang-van-een-telegram-telefoonnummer
виртуальный номер, виртуальный номер навсегда, виртуальный номер
постоянный виртуальный номер для смс, купить виртуальный номер для смс навсегда, купить постоянный виртуальный номер
Удачи и комфорта в общении!
https://je-tall-marketing-871.fra1.digitaloceanspaces.com/research/je-marketing-(28).html
Look for gown choices that least complement the marriage theme colors without mixing in too much.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-7/research/je-marketing-(119).html
This mother selected a royal blue gown with an phantasm neckline and a floral overlay for a putting big-day look.
J’adore le delire de FatPirate, on dirait un tourbillon de fun. Les jeux sont nombreux et delirants, avec des slots qui dechirent. Les agents sont rapides comme l’eclair, offrant des reponses claires et stylees. Les transactions sont simples comme bonjour, quand meme j’aimerais plus de promos qui tabassent. Dans le fond, FatPirate offre une experience de ouf pour ceux qui kiffent parier avec style ! Cote plus l’interface est fluide et ultra-cool, facilite le delire total.
fatpirate sloty|
https://pixelfed.tokyo/george.roberts13101995wp
https://je-tall-marketing-852.ams3.digitaloceanspaces.com/research/je-marketing-(27).html
Think about the colours you are feeling finest in and the kinds of outfits that make you shine.
J’adore le show de Impressario, il propose un show de jeu hors norme. Les options sont variees et eblouissantes, offrant des machines a sous qui claquent. Le service client est digne d’un gala, avec une aide qui fait mouche. Les gains arrivent a la vitesse de la lumiere, de temps en temps plus de tours gratos ca ferait vibrer. Au final, Impressario offre un spectacle de jeu inoubliable pour les artistes du jeu ! Cote plus le design est une explosion visuelle, ajoute un max de charisme.
impressario casino review|
https://je-sf-tall-marketing-738.b-cdn.net/research/je-marketing-(440).html
A gold and cream gown (paired with statement-making gold earrings) looked great on this mom of the groom as she and her son swayed to Louis Armstrong’s “What a Wonderful World.”
https://je-sf-tall-marketing-727.b-cdn.net/research/je-marketing-(434).html
Today’s mother of the bride collections include figure-flattering frocks that are designed to accentuate your mum’s greatest bits.
https://je-tall-marketing-878.ams3.digitaloceanspaces.com/research/je-marketing-(38).html
She loves an excuse to strive on a veil, has a minor obsession with flower crowns, and enjoys nothing greater than curating a killer party playlist.
https://je-tall-marketing-829.sgp1.digitaloceanspaces.com/research/je-marketing-(369).html
Jules & Cleo, completely at David’s Bridal Polyester, nylon Back zipper; fully lined …
https://je-tall-marketing-851.ams3.digitaloceanspaces.com/research/je-marketing-(128).html
This candy and elegant midi with a built-in cape would look just as chic paired with a night shoe as it might with a floor-length maxi.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-13/research/je-marketing-(87).html
Embellished with lovely ornate beading, this robe will catch the light from each angle.
https://www.divephotoguide.com/user/ayybuiyygeh
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-10/research/je-marketing-(272).html
Look and feel really elegant in this lengthy dress without stealing all the eye from the bride.
https://je-tall-marketing-873.ams3.digitaloceanspaces.com/research/je-marketing-(107).html
Thus, it is very important speak to the bride to ask about what the marriage might be like.
https://www.brownbook.net/business/54265882/цена-на-кокаин-в-орлеан-как-купить/
https://digi65sa.sfo3.digitaloceanspaces.com/research/digi65sa-(285).html
You’ve probably been by the bride’s side helping, planning, and lending invaluable recommendation alongside the method in which.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-6/research/je-marketing-(100).html
A pink lace Erdem dress, embroidered with pink and crimson blooms, paired completely with this trendy mother’s half-up, half-down coiffure.
накрутка подписчиков тг
https://je-sf-tall-marketing-740.b-cdn.net/research/je-marketing-(424).html
Thus, once more, it pays to suppose about how much skin you need to present and what’s most flattering to your physique.
https://www.brownbook.net/business/54271654/богородицк-купить-кокаин-альфа-пвп-мефедрон/
https://je-tall-marketing-830.syd1.digitaloceanspaces.com/research/je-marketing-(419).html
This bride’s mother donned a beautiful sari for her daughter’s wedding.
https://jekyll.s3.us-east-005.backblazeb2.com/20250909-11/research/je-marketing-(133).html
As a mother of a daughter who is already married, the shopping for each her costume and mine was one of the highlights of the marriage planning.
https://imageevent.com/penicjelena2/iiikb
https://e-tall-marketing-832.tor1.digitaloceanspaces.com/research/je-marketing-(115).html
Always think about the kinds of sleeves and straps you ought to have on your dress.
https://www.divephotoguide.com/user/yfochehydh
https://spencerwoeuk.mybloglicious.com/39872762/diagnostico-de-necesidades-de-capacitacion-fundamentos-explicaci%C3%B3n
El correcto diagnostico de necesidades de capacitacion es la base para crear programas de aprendizaje que impacten. En el mercado chileno, demasiadas companias destinan millones en cursos que pasan sin impacto porque nunca hicieron un diagnostico real de lo que sus equipos deben aprender.
Razones para hacer un diagnostico de necesidades de capacitacion?
Identifica las carencias reales de competencias.
Evita inversiones inutiles en capacitaciones.
Alinea la formacion con la estrategia corporativa.
Eleva la motivacion de los colaboradores.
Metodos para aplicar un diagnostico de necesidades de capacitacion
Cuestionarios internos: agiles de aplicar, ideales para detectar la voz de los trabajadores.
Entrevistas con lideres: permiten descubrir requerimientos de cada unidad.
Analisis directo: ver el dia a dia para reconocer faltas invisibles en papel.
Pruebas de desempeno: conectan metas con las habilidades que se deben fortalecer.
Beneficios de un diagnostico de necesidades de capacitacion bien hecho
Capacitaciones que coinciden con las faltas prioritarias.
Mejor uso de tiempo.
Crecimiento profesional alineado con la meta de la organizacion.
Resultados visibles en desempeno.
Fallos comunes al hacer un diagnostico de necesidades de capacitacion
Repetir modelos de otras empresas sin personalizar.
Mezclar deseos de lideres con carencias reales.
Ignorar la vision de los trabajadores.
Analizar solo una vez y no actualizar.
Un diagnostico de necesidades de capacitacion es la llave para construir una formacion transformadora.
https://je-tall-marketing-825.fra1.digitaloceanspaces.com/research/je-marketing-(3).html
This embellishment on this gorgeous dress provides a contact of magic good for any winter wedding ceremony.
https://je-tall-marketing-830.syd1.digitaloceanspaces.com/research/je-marketing-(445).html
As the mother of the bride, your function comes with big obligations.
https://rant.li/ybiiidyc/zhukovskii-kupit-gashish-boshki-marikhuanu
https://digi68sa.sfo3.digitaloceanspaces.com/research/digi68sa-(78).html
Find the perfect reasonably priced wedding visitor dresses for any season.
https://imageevent.com/wennbergdona/dpstw
https://wirtube.de/a/schwarzfdnherbert/video-channels
https://www.brownbook.net/business/54271654/богородицк-купить-кокаин-альфа-пвп-мефедрон/
https://www.brownbook.net/business/54268539/цена-на-кокаин-в-мумбаи-как-купить/
Освой востребованную профессию SEO-специалиста с помощью лучших seo курсы москва – от основ до продвинутых техник.
Вы научитесь продвигать свой сайт и привлекать целевую аудиторию.
Курсы предоставят вам глубокое понимание алгоритмов поисковых систем.
Наши курсы ведут опытные специалисты с большим практическим опытом.
Количество мест ограничено, поторопитесь!
https://andyqjyph.link4blogs.com/38546804/la-regla-2-minuto-de-diagnostico-de-necesidades-de-capacitacion
Un buen diagnostico en necesidades de capacitacion es la piedra angular para construir programas de capacitacion que funcionen. En las empresas locales, muchas empresas gastan millones en programas que no sirven porque nunca hicieron un analisis profundo de lo que los trabajadores requieren.
Motivos de hacer un diagnostico de necesidades de capacitacion?
Detecta las faltas reales de competencias.
Reduce errores costosos en capacitaciones.
Sincroniza la inversion con la meta empresarial.
Aumenta la satisfaccion de los colaboradores.
Estrategias para aplicar un diagnostico en necesidades de capacitacion
Cuestionarios internos: rapidos de aplicar, ideales para detectar la opinion de los colaboradores.
Entrevistas con lideres: permiten detectar expectativas de cada unidad.
Analisis directo: ver el trabajo concreto para reconocer oportunidades invisibles en papel.
Pruebas de desempeno: conectan metas con las competencias que se deben reforzar.
Resultados de un diagnostico en necesidades de capacitacion bien hecho
Cursos que se ajustan con las brechas prioritarias.
Eficiencia de recursos.
Desarrollo profesional alineado con la estrategia de la empresa.
Efectos visibles en productividad.
Problemas comunes al hacer un diagnostico de necesidades de capacitacion
Repetir modelos de otras companias sin personalizar.
Reducir deseos de jefaturas con necesidades reales.
Olvidar la vision de los empleados.
Analizar solo una vez y no revisar.
Un diagnostico de necesidades de capacitacion es la base para lograr una estrategia de desarrollo transformadora.
https://wirtube.de/a/amandathomasledg/video-channels
https://yamap.com/users/4822685
займы всем займы всем .
всезаймыонлайн zaimy-18.ru .
займер ру займер ру .
https://rant.li/31rf69k5q3
займы все онлайн займы все онлайн .
http://www.pageorama.com/?p=leafdduba
https://ilm.iou.edu.gm/members/ashleyjacksonohzl/
Estou completamente apaixonado por o 888 Casino, e como se fosse imersao em um universo vibrante. A selecao de jogos e impressionante, contendo titulos inovadores e atraentes. A equipe oferece um suporte de altissima qualidade, respondendo rapidamente. Os pagamentos sao fluidos e seguros, embora eu gostaria de mais promocoes. Para concluir, o 888 Casino e indispensavel para os fas de emocoes fortes! Como bonus o site e projetado com elegancia, reforca a imersao total.
888 casino download|
https://anyflip.com/homepage/ynwvl
https://www.brownbook.net/business/54273656/выборг-купить-гашиш-бошки-марихуану/
https://yamap.com/users/4816717
https://andyxbbay.suomiblog.com/acerca-de-diagnostico-de-necesidades-de-capacitacion-52975599
Un buen diagnostico en necesidades de capacitacion es la clave para construir programas de formacion que impacten. En Chile, muchas companias gastan millones en programas que fracasan porque nunca hicieron un levantamiento claro de lo que los trabajadores requieren.
Razones para hacer un diagnostico de necesidades de capacitacion?
Identifica las carencias reales de competencias.
Reduce gastos innecesarios en capacitaciones.
Conecta la capacitacion con la estrategia empresarial.
Aumenta la retencion de los equipos.
Formas para aplicar un diagnostico en necesidades de capacitacion
Formularios internos: agiles de aplicar, ideales para detectar la percepcion de los trabajadores.
Reuniones con lideres: permiten descubrir expectativas de cada unidad.
Monitoreo: ver el dia a dia para notar oportunidades invisibles en papel.
Evaluaciones de desempeno: conectan metas con las competencias que se deben mejorar.
Beneficios de un diagnostico de necesidades de capacitacion bien hecho
Programas que se ajustan con las faltas concretas.
Eficiencia de tiempo.
Desarrollo profesional alineado con la vision de la organizacion.
Efectos visibles en desempeno.
Fallos comunes al hacer un diagnostico en necesidades de capacitacion
Copiar modelos de otras companias sin ajustar.
Reducir deseos de jefaturas con necesidades reales.
Pasar por alto la vision de los trabajadores.
Medir solo una vez y no actualizar.
Un diagnostico en necesidades de capacitacion es la base para construir una formacion transformadora.
http://www.pageorama.com/?p=lufebahm
http://notes.celbase.net/?x=entry:entry140505-015038;comments:1#comment250829-021415
https://wirtube.de/a/lange5xkmarkus/video-channels
список займов онлайн список займов онлайн .
как накрутить подписчиков в телеграм канале
https://sergiohcwuy.bluxeblog.com/68551021/selecci%C3%B3n-de-personal-no-hay-m%C3%A1s-de-un-misterio
La correcta selección de personal es bastante más que subir un aviso en redes. En el mercado chileno, elegir mal a una persona puede salir un dineral en recursos.
Por eso, tantas compañías acuden un consultora de selección de personal que asegure proceso eficiente y baje los errores.
Razones para confiar en una empresa de reclutamiento y selección?
Conexión a talentos que no buscan avisos tradicionales.
Metodologías estructuradas para evaluar habilidades.
Velocidad en llenar vacantes críticas.
Ahorro de errores de contratación.
Resultados de un buen proceso de selección de personal
Nuevos fichajes más ajustados con la cultura interna.
Disminución de fuga de talento.
Departamentos más productivos.
Imagen más atractiva.
Problemas comunes en la contratación en Chile
Basarse solo en feeling.
No usar evaluaciones.
Descuidar la realidad de la organización.
Apurar la decisión por presión.
De qué manera elegir una empresa de seleccion de personal
Exige testimonios.
Asegúrate que usen pruebas psicométricas.
Evalúa la trayectoria en tu rubro.
Solicita confidencialidad.
Un servicio de selección de personal es una herramienta que define la ventaja entre atraer profesionales o seguir improvisando.
https://internet60360.full-design.com/una-revisiГіn-de-competencias-laborales-79681810
Identificar las competencias laborales mas valoradas en Chile es fundamental para entender los retos que hoy enfrentan las empresas. La tecnologia, la competencia internacional y la nuevos profesionales estan moldeando que capacidades se premian en el mundo laboral.
Ranking de las competencias laborales mas buscadas
Capacidad de ajuste
Las empresas chilenos necesitan equipos capaces de adaptarse rapido a nuevos escenarios.
Habilidades comunicacionales
No solo hablar, sino entender. En equipos distribuidos, esta capacidad es vital.
Capacidad analitica
Con datos por todos lados, las empresas valoran a quienes analizan antes de actuar.
Sinergia grupal
Mas alla del “buena onda”, es saber coordinarse con areas de diversos perfiles.
Capacidad de guiar
Incluso en roles no directivos, se espera motivar y no solo mandar.
Habilidades digitales
Desde apps de gestion hasta datos, lo digital es hoy una skill base.
Razones por las que importan tanto las competencias laborales mas demandadas?
Porque son la brecha entre ser reemplazado o crecer en tu trayectoria. En nuestro mercado, donde la fuga de talento es intensa, dominar estas capacidades se traduce en empleabilidad.
Como desarrollar las competencias laborales mas buscadas
Capacitacion continua.
Coaching.
Experiencia practica.
Retroalimentacion constantes.
Las competencias laborales mas buscadas son el camino para garantizar tu futuro laboral.
KidsFilmFestival.ru — это пространство для любителей кино и сериалов, где обсуждаются свежие премьеры, яркие образы и современные тенденции. На сайте собраны рецензии, статьи и аналитика, отражающие актуальные темы — от культурной идентичности и социальных вопросов до вдохновения и поиска гармонии. Здесь кино становится зеркалом общества, а каждая история открывает новые грани человеческого опыта.
https://historyallsports.com/top-golf-ri-a-premier-entertainment-destination/#comment-3908
https://jaidenbrgkf.blogolize.com/examine-este-informe-sobre-competencias-laborales-76309237
Identificar las competencias clave en el trabajo en el mercado chileno es critico para prepararse ante los cambios que hoy viven las companias. La transformacion digital, la apertura de mercados y la nueva generacion de trabajadores estan cambiando que capacidades se buscan en el mundo laboral.
Lista de las competencias laborales mas buscadas
Adaptabilidad
Las organizaciones locales necesitan trabajadores capaces de moverse rapido a nuevas exigencias.
Claridad al comunicar
No solo expresar, sino entender. En equipos distribuidos, esta competencia es vital.
Pensamiento critico
Con datos por todos lados, las empresas valoran a quienes analizan antes de actuar.
Colaboracion
Mas alla del “buena onda”, es poder coordinarse con personas de distintos rubros.
Capacidad de guiar
Incluso en roles no directivos, se espera motivar y no solo mandar.
Habilidades digitales
Desde herramientas digitales hasta datos, lo digital es hoy una capacidad base.
Razones por las que importan tanto las competencias laborales mas demandadas?
Porque son la distincion entre ser reemplazado o destacar en tu trayectoria. En nuestro mercado, donde la competencia por profesionales es alta, dominar estas competencias se traduce en ascensos.
La forma de desarrollar las competencias laborales mas demandadas
Programas de formacion.
Coaching.
Experiencia practica.
Evaluaciones constantes.
Las competencias laborales mas buscadas son el camino para asegurar tu futuro laboral.
микрозайм всем https://zaimy-26.ru/ .
https://internet17272.ampedpages.com/acerca-de-empresa-de-reclutamiento-y-selecci%C3%B3n-52419542
La selección de personal es infinitamente más que publicar un posteo en redes. En nuestro país, elegir mal a una contratación puede costar muy caro en recursos.
Por eso, muchas organizaciones buscan un servicio de selección de personal que asegure resultados confiables y reduzca los problemas.
Razones para confiar en una empresa de seleccion de personal?
Llegada a profesionales que no responden avisos tradicionales.
Procesos probadas para analizar habilidades.
Agilidad en cerrar vacantes críticas.
Ahorro de tiempo perdido.
Resultados de un buen servicio de selección de personal
Ingresos más ajustados con la realidad corporativa.
Menor abandono temprano.
Áreas más eficientes.
Reputación más sólida.
Problemas comunes en la contratación en Chile
Basarse solo en intuición.
Ignorar herramientas.
Descuidar la realidad de la organización.
Forzar la decisión por urgencia.
Cómo elegir una empresa de seleccion de personal
Pregunta casos de éxito.
Asegúrate que usen herramientas modernas.
Considera la trayectoria en tu rubro.
Exige confidencialidad.
Un apoyo externo es una inversión que determina la clave entre atraer profesionales o pagar caro errores.
Футболки под нанесения логотипа и футболка Boy в Архангельске. Худи футболка и полярик шапки в Братске. Надпись на футболке с богом и футболка с поцелуями тикток в Туле. Египет национальная одежда и напа одежда в Красноярске. Надписи на футболках оптом жизнь и надписи картинки на футболки https://futbolki-s-printom.ru/
https://eduardozepsc.blogs-service.com/68221561/la-mejor-parte-de-competencias-laborales
Hablar de competencias laborales mas valoradas en Chile es clave para anticipar los desafios que hoy enfrentan las empresas. La tecnologia, la competencia internacional y la nueva generacion de trabajadores estan moldeando que skills se valoran en el mundo laboral.
Top de las competencias laborales mas demandadas
Capacidad de ajuste
Las organizaciones del pais necesitan colaboradores capaces de moverse rapido a cambios.
Habilidades comunicacionales
No solo hablar, sino escuchar. En equipos distribuidos, esta habilidad es esencial.
Pensamiento critico
Con informacion por todos lados, las empresas valoran a quienes analizan antes de actuar.
Sinergia grupal
Mas alla del “buena onda”, es saber coordinarse con areas de diversos perfiles.
Capacidad de guiar
Incluso en roles no directivos, se espera guiar y no solo dar ordenes.
Competencias digitales
Desde herramientas digitales hasta datos, lo digital es hoy una skill base.
?Por que importan tanto las competencias laborales mas demandadas?
Porque son la brecha entre perder oportunidades o destacar en tu carrera. En el pais, donde la fuga de talento es intensa, cultivar estas habilidades se traduce en ascensos.
De que manera desarrollar las competencias laborales mas buscadas
Cursos online.
Coaching.
Experiencia practica.
Evaluaciones constantes.
Las habilidades clave son el ticket para asegurar tu desarrollo profesional.
https://serolabnepal.com.np/hello-world/#comment-63732
бот для накрутки подписчиков в тг бесплатно
список займов онлайн список займов онлайн .
всезаймы всезаймы .
займы всем займы всем .
все займы онлайн на карту все займы онлайн на карту .
Je trouve absolument epique Julius Casino, ca pulse avec une energie de casino triomphante. Le repertoire du casino est une arene de divertissement, avec des machines a sous de casino modernes et envoutantes. Le service client du casino est digne d’un cesar, proposant des solutions claires et immediates. Les transactions du casino sont simples comme un decret, mais plus de tours gratuits au casino ce serait epique. Dans l’ensemble, Julius Casino est un colisee pour les fans de casino pour les passionnes de casinos en ligne ! A noter le design du casino est une fresque visuelle epique, facilite une experience de casino heroique.
julius casino application|
J’adore le casino TonyBet, ca offre un univers de jeu unique. Il y a une tonne de jeux differents, incluant des slots ultra-modernes. Le service d’assistance est top, tres professionnel. On recupere ses gains vite, mais parfois plus de tours gratuits seraient bien. En resume, TonyBet vaut vraiment le coup pour les amateurs de casino ! De plus, le site est facile a naviguer, facilitant chaque session de jeu.
tonybet kirjaudu sisään|
все микрозаймы на карту https://zaimy-22.ru/ .
J’apprecie enormement le casino AllySpin, on dirait une aventure palpitante. Le catalogue de jeux est vaste, avec des machines a sous captivantes. Le support est ultra-reactif, repondant en un clin d’?il. Les transactions sont bien protegees, par moments davantage de recompenses seraient appreciees. Globalement, AllySpin est un incontournable pour ceux qui aiment les defis ! De plus la navigation est fluide, facilitant chaque session.
allyspin casino online|
Sou viciado no role de LeaoWin Casino, e um cassino online que ruge como um leao. O catalogo de jogos do cassino e uma selva braba, incluindo jogos de mesa de cassino cheios de garra. Os agentes do cassino sao rapidos como uma cacada, com uma ajuda que e puro instinto. Os ganhos do cassino chegam voando como uma aguia, de vez em quando mais recompensas no cassino seriam um diferencial brabo. No fim das contas, LeaoWin Casino garante uma diversao de cassino que e selvagem para os amantes de cassinos online! Alem disso o design do cassino e uma explosao visual feroz, aumenta a imersao no cassino a mil.
leaowin02 casino codes|
займы россии https://www.zaimy-25.ru .
как привлечь подписчиков в тг канал
Je trouve genial le casino TonyBet, ca offre une aventure palpitante. Il y a une tonne de jeux differents, comprenant des titres innovants. Le support est toujours la, repondant rapidement. On recupere ses gains vite, mais parfois plus de tours gratuits seraient bien. Pour tout dire, TonyBet vaut vraiment le coup pour les adeptes de sensations fortes ! De plus, le site est facile a naviguer, ajoutant une touche de confort.
tonybet ontario|
https://energy95792.onesmablog.com/fascinaci%C3%B3n-acerca-de-servicio-de-reclutamiento-y-selecci%C3%B3n-72262279
La correcta selección de personal es bastante más que subir un anuncio en redes. En Chile, elegir mal a una persona puede costar muy caro en plata.
Por eso, muchas compañías acuden un servicio de selección de personal que ofrezca contrataciones acertadas y reduzca los riesgos.
Razones para confiar en una empresa de reclutamiento y selección?
Acceso a talentos que no aplican avisos tradicionales.
Metodologías modernas para evaluar competencias.
Rapidez en cerrar vacantes críticas.
Optimización de errores de contratación.
Resultados de un buen proceso de selección de personal
Nuevos fichajes más alineados con la cultura organizacional.
Reducción de abandono temprano.
Departamentos más eficientes.
Imagen más atractiva.
Fallos comunes en la contratación en Chile
Depender solo en impresión.
Dejar de lado pruebas técnicas.
Pasar por alto la realidad de la empresa.
Acelerar la elección por presión.
La mejor forma de elegir una empresa de seleccion de personal
Pregunta testimonios.
Confirma que usen métodos objetivos.
Evalúa la experiencia en tu sector.
Solicita procesos transparentes.
Un apoyo externo es una herramienta que define la diferencia entre atraer profesionales o seguir improvisando.
все займ http://www.zaimy-23.ru/ .
Ich bin suchtig nach JackpotPiraten Casino, es hat eine Spielstimmung, die alles sprengt. Es gibt eine Flut an packenden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Die Casino-Mitarbeiter sind schnell wie ein Piratenschiff, sorgt fur sofortigen Casino-Support, der beeindruckt. Casino-Gewinne kommen wie ein Blitz, dennoch mehr Casino-Belohnungen waren ein echter Schatz. Am Ende ist JackpotPiraten Casino eine Casino-Erfahrung, die wie ein Piratenschatz glanzt fur Fans moderner Casino-Slots! Extra die Casino-Seite ist ein grafisches Meisterwerk, den Spielspa? im Casino auf Hochtouren bringt.
jackpotpiraten meinungen|
Acho simplesmente animal LeaoWin Casino, tem uma vibe de jogo que e pura selva. Tem uma enxurrada de jogos de cassino irados, com slots de cassino unicos e eletrizantes. A equipe do cassino entrega um atendimento que e uma garra, com uma ajuda que e puro instinto. O processo do cassino e limpo e sem emboscada, mas mais recompensas no cassino seriam um diferencial brabo. No geral, LeaoWin Casino e um cassino online que e uma fera total para os viciados em emocoes de cassino! Alem disso o site do cassino e uma obra-prima de estilo, da um toque de ferocidade braba ao cassino.
leaowin02 casino inscription|
https://site26926.ampblogs.com/la-guГa-definitiva-para-competencias-laborales-74012181
Conocer las competencias laborales mas valoradas en nuestro pais es critico para anticipar los cambios que hoy enfrentan las organizaciones. La tecnologia, la apertura de mercados y la nueva generacion de trabajadores estan moldeando que capacidades se buscan en el mundo laboral.
Top de las competencias laborales mas demandadas
Capacidad de ajuste
Las companias chilenos necesitan trabajadores capaces de moverse rapido a nuevas exigencias.
Claridad al comunicar
No solo explicar, sino entender. En equipos remotos, esta habilidad es vital.
Razonamiento logico
Con informacion por todos lados, las empresas valoran a quienes disciernen antes de actuar.
Sinergia grupal
Mas alla del “buena onda”, es poder coordinarse con personas de diferentes estilos.
Gestion de personas
Incluso en equipos pequenos, se espera motivar y no solo controlar.
Competencias digitales
Desde apps de gestion hasta plataformas, lo digital es hoy una skill base.
Motivos para importan tanto las competencias laborales mas buscadas?
Porque son la distincion entre perder oportunidades o destacar en tu carrera. En el pais, donde la rotacion laboral es alta, tener estas habilidades se traduce en empleabilidad.
De que manera desarrollar las competencias laborales mas buscadas
Cursos online.
Coaching.
Aprendizaje en terreno.
Feedback constantes.
Las competencias laborales mas demandadas son el pasaporte para garantizar tu desarrollo profesional.
купить диплом в прокопьевске купить диплом в прокопьевске .
irr bhs
купить диплом старого образца купить диплом старого образца .
купить диплом в воронеже купить диплом в воронеже .
купить диплом о высшем образовании проведенный купить диплом о высшем образовании проведенный .
https://holdensdlrw.alltdesign.com/conseguir-mi-selecci%C3%B3n-de-personal-to-work-55357633
La selección de personal es infinitamente más que poner un aviso en redes. En nuestro país, elegir mal a una candidato puede salir muy caro en tiempo.
Por eso, tantas compañías opta un empresa de reclutamiento y selección que ofrezca resultados confiables y reduzca los errores.
Motivos por los que confiar en una consultora de selección de personal?
Conexión a perfiles que no responden avisos tradicionales.
Procesos probadas para analizar habilidades.
Velocidad en cubrir vacantes críticas.
Reducción de tiempo perdido.
Beneficios de un buen proceso de selección de personal
Contrataciones más alineados con la realidad interna.
Menor rotación.
Equipos más eficientes.
Reputación más competitiva.
Errores comunes en la selección de personal en Chile
Basarse solo en feeling.
Dejar de lado evaluaciones.
Pasar por alto la realidad de la empresa.
Forzar la contratación por urgencia.
De qué manera elegir una empresa de seleccion de personal
Revisa referencias.
Asegúrate que usen métodos objetivos.
Considera la experiencia en tu rubro.
Pregunta por confidencialidad.
Un apoyo externo es una inversión que marca la ventaja entre formar equipos fuertes o perder competitividad.
купить украинский диплом техникума купить украинский диплом техникума .
купить диплом техникума и поступить в вуз купить диплом техникума и поступить в вуз .
Для поиска и выбора лучшие локации для фото в москве можно изучить множество вариантов на различных платформах и сайтах, где представлены услуги и работы лучших фотографов Москвы.
фотография является неотъемлемой частью городской жизни. Здесь можно найти множество фотографов с уникальным стилем . Фотографы Москвы известны своими уникальными работами .
Столица России предлагает фотографам широкие возможности для развития. В столице России есть много мест, которые можно запечатлеть на фотографии.
В Москве есть фотографы, которые признаны лучшими. Их работы отличаются уникальностью и креативностью . Их фотографии публикуются в ведущих изданиях .
Они имеют много лет практики и знают, как сделать фотографию по-настоящему уникальной. Они работают с крупными компаниями и частными клиентами .
В последнее время в Москве наблюдается увеличение интереса к фотографии . Это связано с развитием технологий
Для тех, кто ищет семяныч ру форум, важно найти надежный и качественный ресурс, предлагающий широкий выбор семян и предоставляющий необходимую информацию о выращивании.
Семяныч ру официальный является одним из наиболее популярных тем в сети. Это связано с тем, что интерес к Семяныч ру официальному не угасает. Кроме того, ресурсы о Семяныч ру официальном растут в количестве. Это позволяет читателям Семяныч ру официального быть в курсе событий. Более того, разработчики Семяныч ру официального занимаются поддержкой проекта.
Семяныч ру официальный может быть использован для различных целей. Это означает, что пользователи Семяныч ру официального могут найти полезную информацию. Кроме того, сайт Семяныч ру официальный предлагает удобный интерфейс. Это способствует ??у интересной дискуссии на Семяныч ру официальном. Более того, команда Семяныч ру официального занимается поддержкой пользователей.
Семяныч ру официальный обеспечивает высокое качество сервиса. Это связано с тем, что информация на Семяныч ру официальном всегда актуальна. Кроме того, ресурс Семяныч ру официальный доступен круглосуточно. Это позволяет пользователям Семяныч ру официального получать необходимую помощь. Более того, разработчики Семяныч ру официального занимаются поддержкой проекта.
Семяныч ру официальный является интересной и полезной платформой. Это означает, что пользователи Семяныч ру официального могут найти необходимую информацию. Кроме того, Семяныч ру официальный также является перспективным проектом. Это позволяет пользователям Семяныч ру официального быть частью этого процесса. Более того, администрация Семяныч ру официального работает над расширением функций.
купить диплом института с реестром купить диплом института с реестром .
https://internet60360.full-design.com/una-revisiГіn-de-competencias-laborales-79681810
Hablar de competencias clave en el trabajo en Chile es clave para prepararse ante los cambios que hoy viven las organizaciones. La tecnologia, la competencia internacional y la nuevos profesionales estan cambiando que capacidades se valoran en el mundo laboral.
Lista de las habilidades mas valoradas
Capacidad de ajuste
Las empresas del pais necesitan trabajadores capaces de adaptarse rapido a cambios.
Habilidades comunicacionales
No solo expresar, sino entender. En equipos distribuidos, esta habilidad es fundamental.
Capacidad analitica
Con inputs por todos lados, las empresas valoran a quienes analizan antes de actuar.
Sinergia grupal
Mas alla del “buena onda”, es poder coordinarse con departamentos de distintos rubros.
Capacidad de guiar
Incluso en jefaturas medias, se espera inspirar y no solo controlar.
Habilidades digitales
Desde apps de gestion hasta analitica, lo digital es hoy una competencia base.
Razones por las que importan tanto las competencias laborales mas demandadas?
Porque son la diferencia entre ser reemplazado o destacar en tu trayectoria. En nuestro mercado, donde la competencia por profesionales es alta, tener estas competencias se traduce en ascensos.
La forma de desarrollar las competencias laborales mas demandadas
Programas de formacion.
Acompanamiento profesional.
Experiencia practica.
Feedback constantes.
Las competencias laborales mas demandadas son el ticket para potenciar tu empleabilidad.
Очень советую https://hopewell-mbc.org/preschool-academy/#comment-66468
Ich finde absolut majestatisch King Billy Casino, es ist ein Online-Casino, das wie ein Konig regiert. Die Auswahl im Casino ist ein wahres Kronungsjuwel, inklusive eleganter Casino-Tischspiele. Der Casino-Support ist rund um die Uhr verfugbar, ist per Chat oder E-Mail erreichbar. Casino-Gewinne kommen wie ein Triumphzug, trotzdem wurde ich mir mehr Casino-Promos wunschen, die glanzvoll sind. Insgesamt ist King Billy Casino ein Muss fur Casino-Fans fur Spieler, die auf majestatische Casino-Kicks stehen! Zusatzlich die Casino-Oberflache ist flussig und prunkvoll wie ein Thronsaal, das Casino-Erlebnis total veredelt.
king billy casino my|
Je suis totalement conquis par BetFury Casino, ca ressemble a une energie de jeu irresistible. Le catalogue est incroyablement vaste, offrant des sessions de casino en direct immersives. Le service client est exceptionnel, repondant en un instant. Les gains arrivent en un temps record, neanmoins davantage de recompenses comme les BetFury Boxes seraient appreciees. Globalement, BetFury Casino est un incontournable pour ceux qui aiment parier avec des cryptomonnaies ! Notons egalement que l’interface est fluide et intuitive, facilite chaque session.
betfury strategy 2023|
Je kiffe grave Gamdom, on dirait une explosion de fun. La selection est totalement dingue, incluant des jeux de table qui en jettent. L’assistance est au top du top, garantissant un support direct et carre. Le processus est clean et sans prise de tete, par contre j’aimerais plus de promos qui defoncent. Dans le fond, Gamdom c’est du lourd a tester direct pour les aventuriers du jeu ! A noter aussi la navigation est simple comme un jeu d’enfant, donne envie de replonger non-stop.
csgo site gamdom|
Ich liebe die Pracht von King Billy Casino, es verstromt eine Spielstimmung, die wie ein Palast glanzt. Die Auswahl im Casino ist ein wahres Kronungsjuwel, mit einzigartigen Casino-Slotmaschinen. Der Casino-Kundenservice ist wie ein koniglicher Hof, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein koniglicher Marsch, dennoch mehr Freispiele im Casino waren ein Kronungsmoment. Alles in allem ist King Billy Casino ein Muss fur Casino-Fans fur Fans moderner Casino-Slots! Nebenbei die Casino-Seite ist ein grafisches Meisterwerk, das Casino-Erlebnis total veredelt.
king billy casino sister sites|
Je trouve absolument sensationnel BetFury Casino, ca ressemble a une experience de jeu electrisante. Le catalogue est incroyablement vaste, avec des machines a sous modernes et captivantes. Le service client est exceptionnel, offrant des reponses claires et rapides. Les retraits sont instantanes, bien que j’aimerais plus de promotions frequentes. Dans l’ensemble, BetFury Casino vaut pleinement le detour pour les amateurs de crypto-casinos ! De plus le design est visuellement percutant avec un theme sombre, facilite chaque session.
betfury fraude|
Je trouve completement barre Gamdom, ca donne une energie de jeu demente. Le catalogue de jeux est juste enorme, incluant des jeux de table qui en jettent. Le service client est une tuerie, garantissant un support direct et carre. Les retraits sont rapides comme un ninja, quand meme plus de tours gratos ca serait ouf. Dans le fond, Gamdom garantit un fun intergalactique pour ceux qui kiffent parier avec style ! Bonus le design est une bombe visuelle, ce qui rend chaque session encore plus kiffante.
gamdom para cekme|
купить кокаин, бошки, мефедрон, альфа-пвп
купить кокаин, бошки, мефедрон, альфа-пвп
стильные горшки http://dizaynerskie-kashpo-rnd.ru/ .
щетки
купить кокаин, бошки, мефедрон, альфа-пвп
Попробуйте https://nextlevelupllc.com/winged-moved-stars-fruit-creature-seed-night/#comment-638151
https://garag-nachas.online
https://fittandpit.online
купить мефедрон, кокаин, гашиш, бошки
Хотите обновить фасад быстро и выгодно? На caparolnn.ru вы найдете сайдинг и фасадные панели «Альта-Профиль» с прочным покрытием, устойчивым к морозу и УФ. Богатая палитра, имитация дерева, камня и кирпича, цены от 256 ?/шт, консультации и быстрый расчет. Примерьте цвет и посчитайте материалы в Альта-планнере: https://caparolnn.ru/ Заказывайте онлайн, доставка по Москве и области. Оставьте заявку — менеджер перезвонит в удобное время.
займы http://www.zaimy-26.ru/ .
купить мефедрон, кокаин, гашиш, бошки
накрутка подписчиков тг
купить кокаин, бошки, мефедрон, альфа-пвп
накрутка подписчиков в тг навсегда
https://garag-nachas.online
https://rentry.co/dzdnnkmd
Visualiza esta escena típica en una pyme chilena: equipos desmotivados, rotación constante, comentarios en el pasillo como nadie pesca o puro desgaste. Parece familiar, ¿no?
Muchas pymes en Chile se enfocan con los números y los balances financieros, pero se ignoran del pulso interno: su equipo. La realidad dura es esta: si no controlas el clima, luego no te lamentes cuando la pérdida de talento te explote en la frente.
¿Por qué importa tanto esto en Chile?
El contexto local no perdona. Tenemos alta rotación en retail, estrés extremo en los call centers y brechas generacionales gigantes en sectores como la minería y la banca.
En Chile, donde marca la cultura de la talla y la buena onda, es típico ocultar los problemas. Pero cuando no hay apoyo real, ese sarcasmo se transforma en puro relleno que camufla la desmotivación. Sin un diagnóstico, las pymes son despistadas. No ven lo que los colaboradores de verdad comentan en la sala común o en sus grupos de WhatsApp.
Los ganancias palpables (y muy nuestros) de hacerlo bien
Hacer un análisis de clima no es un costo, es la mejor decisión en productividad y bienestar que puedes hacer. Los beneficios son concretos:
Menos licencias médicas y ausentismo: un dolor que le sale millones a las empresas chilenas cada año.
Retención de talento nuevo: las nuevas generaciones se mueven rápido si no ven sentido y trato digno.
Mayor productividad en equipos remotos: clave para sucursales regionales que a veces se ven aislados.
Una diferenciación tangible: no es lo mismo prometer “somos buena onda” que probarlo con datos duros.
Cómo se hace en la práctica (sin morir en el intento)
No ocupas un departamento de RRHH costoso. Hoy, las herramientas son cercanas:
Encuestas anónimas digitales: lo más efectivo desde 2020. La clave es garantizar el resguardo identitario para que la gente hable sin temor.
Pulsos cortos: en vez de una encuesta extensa cada periodo, haz una pregunta semanal corta por apps de RRHH.
Talleres focalizados: la herramienta top. Destapan lo que difícilmente saldría por email: roces entre áreas, problemas con liderazgos, flujos que nadie entiende.
Conversaciones 1:1 con colaboradores regionales: su mirada suele quedar fuera. Una entrevista puede detectar problemas de comunicación que pasarían colados en una encuesta.
El detalle clave: el diagnóstico no puede ser un teatro. Tiene que convertirse en un roadmap tangible con hitos, líderes y plazos. Si no, es puro powerpoint.
Errores que en Chile se repiten (y tiran todo abajo)
Ofrecer mejoras y no hacer nada: los equipos chilenos lo detectan al tiro; puro verso.
No blindar el confidencialidad: en estructuras muy autorregidas, el miedo a reacciones es real.
Importar encuestas gringas: hay que adaptar el lenguaje a la idiosincrasia chilena.
Tomar una foto y abandonar: el clima se mueve tras la salida de un líder clave; hay que monitorear de forma regular.
https://zoprin.ru
https://fittandpit.online
купить кокаин, бошки, мефедрон, альфа-пвп
купить мефедрон, кокаин, гашиш, бошки
https://vurtaer.ru
купить кокаин, бошки, мефедрон, альфа-пвп
накрутить подписчиков в тг канал без отписок
https://vurtaer.ru
https://medium.com/@seonza100/curso-de-liderazgo-potencia-tu-habilidad-para-guiar-equipos-efectivamente-915ace5c554e
Participar en una formacion de liderazgo digital ya no es un beneficio opcional, sino una urgencia para cualquier negocio que aspira a avanzar en el mercado actual.
Un buen curso de liderazgo empresarial no solo ensena contenido, sino que transforma la manera de dirigir de lideres que tienen equipos a cargo.
Que tiene de especial una escuela de liderazgo remota?
Libertad para capacitarse sin interrumpir el dia a dia.
Entrada a contenidos de alto nivel, incluso si trabajas fuera de la capital.
Costo mas accesible que una opcion fisica.
En el contexto chileno, un curso de liderazgo chile debe considerar realidades locales:
Estilos autoritarios.
Millennials vs. jefaturas tradicionales.
Desconexion entre areas.
Por eso, una formacion de lideres debe ser mas que un taller generico.
Que debe incluir un buen curso de liderazgo empresarial?
Clases sobre liderazgo adaptativo.
Casos reales adaptados a contextos reales.
Feedback individual de habilidades.
Networking con otros gerentes de Chile.
Y lo mas clave: el entrenamiento de jefaturas debe generar un cambio real en la gestion de equipos.
Muchos jefes asumen cargos sin formacion, y eso frena a sus colaboradores. Un buen programa para lideres puede ser la solucion entre liderar con claridad o improvisar.
Рекомендую https://lynnrichardsonradio.com/tax-knowledge/tax-tips/#comment-41324
https://tavrix.ru
https://runival.ru
https://franke-studio.online
https://atavi.com/share/xgmi8jzswhgc
Visualiza esta postal típica en una oficina chilena: colaboradores agotados, desgaste elevada, frases en el pasillo como nadie pesca o puro cacho. Parece familiar, ¿no?
Muchas empresas en Chile se pierden con los KPI y los reportes financieros, pero se olvidan del barómetro interno: su equipo. La advertencia incómoda es esta: si no mides el clima, luego no te quejís cuando la salida de talento te explote en la frente.
¿Por qué pesa tanto esto en Chile?
El escenario local no perdona. Tenemos crónica rotación en retail, agotamiento en los call centers y brechas generacionales enormes en sectores como la minería y la banca.
En Chile, donde marca la broma interna y la onda positiva, es fácil disfrazar los problemas. Pero cuando no hay apoyo real, ese sarcasmo se convierte en puro blablá que esconde la frustración. Sin un análisis, las organizaciones son ciegas. No ven lo que los trabajadores en serio conversan en la máquina de café o en sus canales privados.
Los beneficios palpables (y muy nuestros) de hacerlo bien
Hacer un diagnóstico de clima no es un costo, es la mejor decisión en rendimiento y tranquilidad que logras hacer. Los beneficios son concretos:
Menos licencias médicas y ausentismo: un lastre que le sale millones a las empresas chilenas cada ciclo.
Permanencia de talento nuevo: las generaciones recientes cambian de pega rápido si no perciben valor y trato digno.
Mayor productividad en equipos remotos: clave para talento en regiones que a veces se ven aislados.
Una diferenciación tangible: no es lo mismo decir “somos buena onda” que demostrarlo con métricas.
Cómo se hace en la práctica (sin volverse loco)
No necesitas un equipo de RRHH gigante. Hoy, las plataformas son alcanzables:
Formularios online anónimos: lo más efectivo post pandemia. La base es asegurar el anonimato total para que la gente hable sin reserva.
Pulsos cortos: en vez de una encuesta larga cada año, envía una microencuesta semanal rápida por apps de RRHH.
Reuniones pequeñas: la herramienta top. Sacan a la luz lo que raramente saldría por email: roces entre áreas, problemas con liderazgos, procesos que nadie asume.
Conversaciones cara a cara con gente de regiones: su mirada suele quedar invisibilizada. Una entrevista puede detectar quiebres de comunicación que no captarías en una encuesta.
El factor decisivo: el diagnóstico no puede ser un relleno. Tiene que volverse en un plan real con hitos, responsables y fechas. Si no, es puro papel.
Errores que en Chile se repiten (y matan el proceso)
Ofrecer mejoras y no hacer nada: los equipos chilenos lo detectan al tiro; puro verso.
No garantizar el resguardo: en estructuras muy autorregidas, el miedo a represalias es real.
Importar encuestas genéricas: hay que adaptar el lenguaje a la idiosincrasia chilena.
Hacer diagnóstico único y abandonar: el clima se mueve tras reestructuraciones clave; hay que medir de forma constante.
Заказать диплом ВУЗа поспособствуем. Купить диплом бакалавра в Сочи – diplomybox.com/kupit-diplom-bakalavra-v-sochi
купить кокаин, бошки, мефедрон, альфа-пвп
мфо займ мфо займ .
сайт микрозаймов сайт микрозаймов .
https://franke-studio.online
все займы онлайн на карту http://www.zaimy-50.ru .
купить мефедрон, кокаин, гашиш, бошки
https://medium.com/@seonza100/curso-de-liderazgo-potencia-tu-habilidad-para-guiar-equipos-efectivamente-915ace5c554e
Invertir en una capacitacion de liderazgo online ya no es un extra, sino una prioridad para cualquier negocio que busca competir en el mercado actual.
Un buen taller de liderazgo ejecutivo no solo proporciona conocimiento, sino que impacta la manera de dirigir de jefes que ya estan activos.
Ventajas de una una formacion en liderazgo online?
Autonomia para progresar sin detener el ritmo laboral.
Entrada a contenidos de alto nivel, incluso si trabajas fuera de zonas urbanas.
Costo mas accesible que una opcion fisica.
En el mercado laboral chileno, un entrenamiento para lideres chilenos debe responder a realidades locales:
Estilos autoritarios.
Equipos multigeneracionales.
Hibrido presencial-remoto.
Por eso, una actualizacion para jefes debe ser mas que un taller generico.
Que debe incluir un buen curso de liderazgo chile?
Unidades sobre comunicacion efectiva.
Casos reales adaptados a contextos reales.
Evaluacion individual de competencias.
Networking con otros gerentes de diferentes industrias.
Y lo mas fundamental: el entrenamiento de jefaturas debe impulsar un impacto concreto en la practica diaria.
Cientos de encargados llegan al puesto sin preparacion, y eso frena a sus areas. Un buen curso de liderazgo para jefaturas puede ser la solucion entre liderar con claridad o improvisar.
J’adore le delire de FatPirate, il offre une aventure totalement barge. Il y a un ocean de titres varies, comprenant des jeux tailles pour les cryptos. Le support est dispo 24/7, repondant en deux secondes chrono. Les transactions sont simples comme bonjour, par contre les offres pourraient etre plus genereuses. Bref, FatPirate garantit un fun total pour les accros aux sensations fortes ! A noter aussi le site est une pepite visuelle, ajoute un max de swag.
fatpirate sloty|
Achou totalmente epico DiceBet Casino, oferece uma aventura de cassino alucinante. O catalogo de jogos do cassino e uma loucura total, incluindo jogos de mesa de cassino cheios de classe. O servico do cassino e confiavel e de primeira, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um cometa, mas as ofertas do cassino podiam ser mais generosas. No fim das contas, DiceBet Casino e um cassino online que e uma pedrada para os aventureiros do cassino! De lambuja o site do cassino e uma obra-prima de visual, da um toque de classe braba ao cassino.
dicebet|
https://zoprin.ru
Je trouve completement fou FatPirate, c’est une plateforme qui envoie du lourd. La selection est carrement dingue, proposant des sessions live ultra-intenses. Le support est dispo 24/7, repondant en deux secondes chrono. Les transactions sont simples comme bonjour, par contre plus de tours gratos ca ferait plaiz. Bref, FatPirate offre une experience de ouf pour les pirates des slots modernes ! Cote plus la navigation est simple comme un jeu d’enfant, donne envie de replonger direct.
fatpirate casino review|
купить мефедрон, кокаин, гашиш, бошки
Je suis scotche par Impressario, ca donne une energie de star absolue. La selection de jeux est juste monumentale, incluant des jeux de table pleins de panache. L’assistance est une vraie performance de pro, avec une aide qui fait mouche. Les transactions sont simples comme un refrain, par contre plus de tours gratos ca ferait vibrer. Dans le fond, Impressario garantit un show de fun epique pour les fans de casinos en ligne ! Bonus la navigation est simple comme une melodie, ce qui rend chaque session encore plus eclatante.
impressario casino review|
Je trouve absolument fantastique Betify Casino, on dirait une experience de jeu captivante. La selection de jeux est impressionnante, comprenant des titres innovants et engageants. Le support est ultra-reactif et professionnel, repondant en un clin d’?il. Les paiements sont fluides et securises, bien que les bonus pourraient etre plus frequents. Globalement, Betify Casino vaut pleinement le detour pour ceux qui aiment parier ! En bonus l’interface est fluide et intuitive, ce qui amplifie le plaisir de jouer.
betify owner|
купить кокаин, бошки, мефедрон, альфа-пвп
Крайне рекомендую https://www.citytandklinik.se/2020/10/30/hello-world/
Je trouve carrement genial Impressario, ca donne une energie de star absolue. Les options sont variees et eblouissantes, proposant des sessions live qui en mettent plein la vue. L’assistance est une vraie performance de pro, repondant en un clin d’etoile. Les gains arrivent a la vitesse de la lumiere, parfois des bonus plus reguliers ce serait la classe. En gros, Impressario garantit un show de fun epique pour les accros aux sensations eclatantes ! Et puis le site est une pepite scenique, booste l’immersion a fond.
impressario casino no deposit bonus|
https://zoprin.ru
https://zulme.ru
купить кокаин, бошки, мефедрон, альфа-пвп
https://telegra.ph/Curso-de-liderazgo-para-jefaturas-en-Santiago-herramientas-para-mandos-medios-09-20
Participar en una escuela de liderazgo virtual ya no es un extra, sino una urgencia para cualquier empresa que busca competir en el mercado actual.
Un buen entrenamiento gerencial no solo entrega conocimiento, sino que transforma la practica del liderazgo de jefes que estan en terreno.
Ventajas de una una escuela de liderazgo remota?
Libertad para aprender sin detener el ritmo laboral.
Acceso a contenidos actualizados, incluso si vives fuera de la capital.
Inversion mas accesible que una capacitacion tradicional.
En el escenario local, un programa de liderazgo nacional debe considerar la cultura chilena:
Cadenas de mando tradicionales.
Millennials vs. jefaturas tradicionales.
Desafios post pandemia.
Por eso, una actualizacion para jefes debe ser mas que un powerpoint bonito.
Que debe incluir un buen curso de liderazgo empresarial?
Clases sobre liderazgo adaptativo.
Casos reales adaptados a contextos reales.
Evaluacion individual de habilidades.
Red de contacto con otros lideres de diferentes industrias.
Y lo mas importante: el programa formativo debe generar un impacto concreto en la practica diaria.
Demasiados jefes llegan al puesto sin guia, y eso frena a sus equipos. Un buen capacitacion de liderazgo online puede ser la solucion entre inspirar y dirigir o imponer.
купить кокаин, бошки, мефедрон, альфа-пвп
https://rentry.co/dzdnnkmd
Piensa esta situación común en una oficina chilena: colaboradores agotados, desgaste elevada, comentarios en el pasillo como aquí nadie escucha o puro cacho. Resulta reconocible, ¿verdad?
Muchas pymes en Chile se enfocan con los KPI y los reportes financieros, pero se olvidan del termómetro interno: su capital humano. La verdad incómoda es esta: si no controlas el clima, al final no te lamentes cuando la pérdida de talento te golpee en la frente.
¿Por qué pesa tanto esto en Chile?
El escenario local no perdona. Vivimos alta rotación en retail, estrés extremo en los call centers y diferencias generacionales enormes en industrias como la minería y la banca.
En Chile, donde marca la cultura de la talla y la onda positiva, es común tapar los problemas. Pero cuando no hay confianza real, ese humor se convierte en puro ruido que esconde la desmotivación. Sin un levantamiento, las organizaciones son ciegas. No ven lo que los trabajadores en serio conversan en la máquina de café o en sus grupos de WhatsApp.
Los beneficios reales (y muy nuestros) de hacerlo bien
Hacer un análisis de clima no es un gasto, es la mejor apuesta en rendimiento y tranquilidad que logras hacer. Los beneficios son claros:
Menos licencias médicas y inactividad: un lastre que le cuesta millones a las empresas chilenas cada ciclo.
Retención de talento emergente: las generaciones recientes rotan rápido si no ven sentido y buen ambiente.
Mayor productividad en equipos remotos: clave para talento en regiones que a veces se ven aislados.
Una ventaja competitiva real: no es lo mismo proclamar “somos buena onda” que demostrarlo con métricas.
Cómo se hace en la práctica (sin quemarse)
No ocupas un departamento de RRHH costoso. Hoy, las soluciones son cercanas:
Encuestas anónimas digitales: lo más efectivo desde 2020. La regla es blindar el 100% de anonimato para que la persona hable sin miedo.
Pulsos cortos: en vez de una encuesta larga cada 12 meses, envía una microencuesta semanal breve por apps de RRHH.
Focus groups: la pieza clave. Destapan lo que difícilmente saldría por correo: roces entre áreas, problemas con jefaturas, procedimientos que nadie asume.
Conversaciones directas con gente de regiones: su mirada suele quedar omitida. Una llamada puede visibilizar quiebres de comunicación que pasarían colados en una encuesta.
El factor decisivo: el diagnóstico no puede ser un relleno. Tiene que volverse en un programa tangible con metas, encargados y fechas. Si no, es puro cuento.
Errores que en Chile se repiten (y tiran todo abajo)
Anunciar ajustes y no hacer nada: los trabajadores chilenos lo cachan al tiro; pura volada.
No garantizar el confidencialidad: en culturas muy verticales, el miedo a reacciones es real.
Copiar encuestas gringas: hay que adaptar el lenguaje a la idiosincrasia chilena.
Tomar una foto y olvidarse: el clima varía tras reestructuraciones clave; hay que tomar pulso de forma regular.
https://fittandpit.online
купить мефедрон, кокаин, гашиш, бошки
https://zulme.ru
купить кокаин, бошки, мефедрон, альфа-пвп
Очень советую https://tesserasolution.com/logistic-service-providers-would-understand-your-business/#comment-18405
купить мефедрон, кокаин, гашиш, бошки
Ich liebe den Zauber von Lapalingo Casino, es pulsiert mit einer elektrisierenden Casino-Energie. Die Auswahl im Casino ist ein echtes Spektakel, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Die Casino-Mitarbeiter sind schnell wie ein Blitzstrahl, liefert klare und schnelle Losungen. Casino-Gewinne kommen wie ein Sturm, dennoch mehr Freispiele im Casino waren ein Volltreffer. Kurz gesagt ist Lapalingo Casino ein Casino, das man nicht verpassen darf fur Fans moderner Casino-Slots! Und au?erdem die Casino-Seite ist ein grafisches Meisterwerk, was jede Casino-Session noch aufregender macht.
lapalingo gutschein|
https://telegra.ph/Capacitaci%C3%B3n-de-liderazgo-online-para-empresas-chilenas-09-20
Apostar en una formacion de liderazgo digital ya no es un beneficio opcional, sino una prioridad para cualquier organizacion que quiere competir en el entorno VUCA.
Un buen curso de liderazgo empresarial no solo entrega conocimiento, sino que transforma la forma de liderar de lideres que estan en terreno.
Ventajas de una una formacion en liderazgo online?
Flexibilidad para aprender sin frenar el trabajo diario.
Acceso a materiales actualizados, incluso si vives fuera de zonas urbanas.
Costo mas competitivo que una formacion presencial.
En el contexto chileno, un entrenamiento para lideres chilenos debe adaptarse a la cultura chilena:
Estilos autoritarios.
Colaboradores diversos.
Desconexion entre areas.
Por eso, una capacitacion en liderazgo debe ser mas que un curso grabado.
Que debe incluir un buen curso de liderazgo chile?
Modulos sobre gestion emocional.
Simulaciones adaptados a contextos reales.
Evaluacion individual de estilo de liderazgo.
Red de contacto con otros supervisores de diferentes industrias.
Y lo mas fundamental: el programa formativo debe provocar un cambio real en la eficacia del liderazgo.
Cientos de encargados ascienden sin formacion, y eso frena a sus colaboradores. Un buen curso de liderazgo para jefaturas puede ser la solucion entre liderar con claridad o sobrevivir.
купить мефедрон, кокаин, гашиш, бошки
buy xtc prague https://cocaine-prague-shop.com
купить мефедрон, кокаин, гашиш, бошки
Ich liebe den Zauber von Lapalingo Casino, es fuhlt sich an wie ein wilder Ritt durch die Spielwelt. Die Spielauswahl im Casino ist wie ein Ozean voller Schatze, mit einzigartigen Casino-Slotmaschinen. Der Casino-Kundenservice ist wie ein Leuchtfeuer, antwortet blitzschnell wie ein Donnerschlag. Casino-Transaktionen sind simpel wie ein Sonnenstrahl, aber mehr Freispiele im Casino waren ein Volltreffer. Kurz gesagt ist Lapalingo Casino ein Casino, das man nicht verpassen darf fur Fans von Online-Casinos! Extra die Casino-Navigation ist kinderleicht wie ein Windhauch, das Casino-Erlebnis total elektrisiert.
lapalingo sportwetten|
купить диплом в новоалтайске купить диплом в новоалтайске .
https://garant-gbo.online
https://www.restate.ru/
купить кокаин, бошки, мефедрон, альфа-пвп
купить диплом в междуреченске rudik-diplom2.ru – rudik-diplom2.ru .
https://vurtaer.ru
купить диплом в златоусте купить диплом в златоусте .
https://squareblogs.net/gunnalmyal/anlisis-de-clima-laboral-en-organizaciones-giles-se-adapta-la-metodologa
Visualiza esta situación frecuente en una pyme chilena: colaboradores agotados, desgaste elevada, frases en el pasillo como nadie pesca o puro cacho. Parece reconocible, ¿cierto?
Muchas empresas en Chile se pierden con los KPI y los resultados financieros, pero se saltan del barómetro interno: su equipo. La realidad cruda es esta: si no revisas el clima, después no te quejís cuando la salida de talento te golpee en la puerta.
¿Por qué importa tanto esto en Chile?
El ambiente local no da tregua. Arrastramos crónica rotación en retail, burnout en los call centers y quiebres generacionales gigantes en rubros como la minería y la banca.
En Chile, donde marca la broma interna y la onda positiva, es fácil disfrazar los problemas. Pero cuando no hay confianza real, ese sarcasmo se transforma en puro ruido que camufla la frustración. Sin un levantamiento, las empresas son inconscientes. No ven lo que los colaboradores de verdad conversan en la sala común o en sus grupos de WhatsApp.
Los ganancias concretos (y muy locales) de hacerlo bien
Hacer un diagnóstico de clima no es un costo, es la mejor inversión en productividad y bienestar que consigues hacer. Los beneficios son claros:
Menos bajas y ausentismo: un lastre que le pega millones a las empresas chilenas cada año.
Fidelización de talento nuevo: las gen Z se mueven rápido si no perciben valor y buen ambiente.
Mayor output en equipos descentralizados: clave para equipos fuera de Santiago que a veces se perciben lejanía.
Una posición superior: no es lo mismo proclamar “somos buena onda” que probarlo con evidencia.
Cómo se hace en la práctica (sin morir en el intento)
No ocupas un equipo de RRHH gigante. Hoy, las soluciones son accesibles:
Encuestas anónimas digitales: lo más común desde 2020. La clave es asegurar el anonimato total para que la dotación hable sin reserva.
Termómetros rápidos: en vez de una encuesta extensa cada 12 meses, haz una microencuesta semanal breve por plataformas internas.
Reuniones pequeñas: la pieza clave. Revelan lo que difícilmente saldría por intranet: roces entre áreas, problemas con liderazgos, flujos que nadie entiende.
Conversaciones directas con colaboradores regionales: su voz suele quedar invisibilizada. Una entrevista puede visibilizar problemas de comunicación que no captarías en una encuesta.
El detalle clave: el diagnóstico no puede ser un show. Tiene que traducirse en un roadmap real con objetivos, líderes y fechas. Si no, es puro powerpoint.
Errores que en Chile se repiten (y tiran todo abajo)
Prometer cambios y no cumplir: los trabajadores chilenos lo detectan al tiro; puro humo.
No asegurar el confidencialidad: en culturas muy verticales, el miedo a represalias es real.
Calcar encuestas genéricas: hay que aterrizar el lenguaje a la idiosincrasia chilena.
Tomar una foto y no seguir: el clima cambia tras paros clave; hay que tomar pulso de forma regular.
купить мефедрон, кокаин, гашиш, бошки
купить кокаин, бошки, мефедрон, альфа-пвп
https://telegra.ph/Curso-de-liderazgo-para-jefaturas-en-Santiago-herramientas-para-mandos-medios-09-20
Invertir en una escuela de liderazgo virtual ya no es un extra, sino una necesidad para cualquier negocio que aspira a competir en el entorno VUCA.
Un buen entrenamiento gerencial no solo entrega teoria, sino que impacta la practica del liderazgo de mandos medios que ya estan activos.
Que tiene de especial una capacitacion de liderazgo online?
Libertad para progresar sin frenar el dia a dia.
Entrada a modulos de alto nivel, incluso si trabajas fuera de zonas urbanas.
Inversion mas accesible que una capacitacion tradicional.
En el escenario local, un curso de liderazgo chile debe adaptarse a el estilo de liderazgo criollo:
Jerarquias marcadas.
Millennials vs. jefaturas tradicionales.
Hibrido presencial-remoto.
Por eso, una formacion de lideres debe ser mas que un curso grabado.
Que debe incluir un buen curso de liderazgo empresarial?
Clases sobre comunicacion efectiva.
Roleplays adaptados a entornos locales.
Retroalimentacion individual de estilo de liderazgo.
Interaccion con otros supervisores de diferentes industrias.
Y lo mas fundamental: el curso de liderazgo empresarial debe provocar un salto significativo en la gestion de equipos.
Cientos de lideres ascienden sin formacion, y eso frena a sus colaboradores. Un buen capacitacion de liderazgo online puede ser la clave entre inspirar y dirigir o imponer.
cocaine prague pure cocaine in prague
https://garantstroikompleks.ru/
купить мефедрон, кокаин, гашиш, бошки
https://vurtaer.ru
https://angara-park.online
https://franke-studio.online
https://franke-studio.online
купить кокаин, бошки, мефедрон, альфа-пвп
https://cl.pinterest.com/pin/953496552330315637/
Participar en una formacion de liderazgo digital ya no es un beneficio opcional, sino una necesidad para cualquier empresa que quiere avanzar en el mercado actual.
Un buen taller de liderazgo ejecutivo no solo ensena contenido, sino que activa la forma de liderar de jefes que tienen equipos a cargo.
Que tiene de especial una escuela de liderazgo remota?
Flexibilidad para progresar sin detener el ritmo laboral.
Acceso a contenidos relevantes, incluso si vives fuera de la capital.
Precio mas competitivo que una opcion fisica.
En el escenario local, un entrenamiento para lideres chilenos debe adaptarse a el estilo de liderazgo criollo:
Estilos autoritarios.
Colaboradores diversos.
Hibrido presencial-remoto.
Por eso, una actualizacion para jefes debe ser mas que un curso grabado.
Que debe incluir un buen curso de liderazgo chile?
Clases sobre comunicacion efectiva.
Roleplays adaptados a contextos reales.
Feedback individual de competencias.
Interaccion con otros lideres de regiones.
Y lo mas fundamental: el programa formativo debe generar un cambio real en la eficacia del liderazgo.
Cientos de jefes asumen cargos sin guia, y eso duele a sus areas. Un buen programa para lideres puede ser la clave entre liderar con claridad o imponer.
Крайне советую https://residentialcleaningfortmyers.com/2025/05/16/hello-world/#comment-10106
купить кокаин, бошки, мефедрон, альфа-пвп
купить кокаин, бошки, мефедрон, альфа-пвп
Мы предоставляем профессиональные консультации по вопросам ВЭД и таможенного оформления: https://tamozhenniiy-broker11.ru/
Πληρωμές Με RTP 96,5%—πάνω από τον μέσο όρο της αγοράς—και υψηλή μεταβλητότητα, προσφέρει τη δυνατότητα για μεγάλες νίκες έως και 5.000 φορές το ποντάρισμα. Το παιχνίδι παίζεται σε πλέγμα 7×7 και χρησιμοποιεί το σύστημα πληρωμών Cluster Pays, με ελάχιστο ποντάρισμα €0,20 και μέγιστο €75. Schritt-für-Schritt-Anleitung zur Verifizierung im 5gringos Casino Το Sugar Dash 1000 ξεχωρίζει για τα θετικά του στοιχεία, όμως υπάρχουν και χαρακτηριστικά, που θα μπορούσαν να βελτιωθούν, ώστε να γίνει πιο ανταγωνιστικό.”
https://fashion.stw-services.com/%cf%80%cf%8e%cf%82-%ce%bd%ce%b1-%ce%b1%ce%be%ce%b9%ce%bf%cf%80%ce%bf%ce%b9%ce%ae%cf%83%ce%b5%cf%84%ce%b5-%cf%84%ce%b1-loyalty-rewards-%cf%83%cf%84%ce%bf-spinanga-%ce%ba%ce%b1%ce%b6%ce%af%ce%bd%ce%bf/
Το Sweet Bonanza 1000 Demo είναι η δωρεάν έκδοση του δημοφιλούς candy-themed slot της Pragmatic Play που προσφέρει εντυπωσιακούς πολλαπλασιαστές έως 1000x. Με το 6×5 πλέγμα, τα ζωηρόχρωμα φρούτα και ζαχαρωτά, τις πτώσεις συμβόλων και τα συναρπαστικά Δωρεάν Spins, αυτή η έκδοση επιτρέπει στους παίκτες να απολαύσουν όλα τα χαρακτηριστικά του παιχνιδιού χωρίς να διακινδυνεύσουν πραγματικά χρήματα. Δεν υπάρχει αμφιβολία ότι οι πιο trendy πάροχοι είναι ξεκάθαρα οι Pragmatic Play και Play N Go, με τη No Limit, την Red Tiger και την Wazdan να ακολουθούν κατά πόδας, όπως επίσης και οι Playtech και Yggdrasil. Η κάθε μία από αυτές άλλωστε έχει φέρει κάτι καινούριο και πρωτόγνωρο στην αγορά, όπως οι Xways και Megaways πληρωμές των No Limit και Red Tiger (δια μέσω της BTG αντίστοιχα), με αποτέλεσμα να ενθουσιάζει τους παίκτες της ηλικιακής ομάδας 18-21.
https://garag-nachas.online
https://zulme.ru
купить мефедрон, кокаин, гашиш, бошки
Производственный объект требует надежных решений? УралНастил выпускает решетчатые настилы и ступени под ваши нагрузки и сроки. Европейское оборудование, сертификация DIN/EN и ГОСТ, склад типовых размеров, горячее цинкование и порошковая покраска. Узнайте цены и сроки на https://uralnastil.ru — отгружаем по России и СНГ, помогаем с КМ/КМД и доставкой. Оставьте заявку — сформируем безопасное, долговечное решение для вашего проекта.
https://franke-studio.online
купить мефедрон, кокаин, гашиш, бошки
This is exactly the guidance I needed.
купить мефедрон, кокаин, гашиш, бошки
https://angara-park.online
https://telegra.ph/De-jefe-a-l%C3%ADder-coach-c%C3%B3mo-est%C3%A1n-cambiando-los-estilos-de-liderazgo-en-Santiago-09-21
Evolucionar de jefe a lider coach la competencia que define tu exito profesional no es tendencia, es la competencia que marca la ventaja en el entorno corporativo chileno.
En Chile, muchos supervisores siguen arrastrando modelos de gestion vertical que se desgastaron. El siguiente paso esta en aprender competencias de liderazgo que activan confianza real.
Que implica pasar de jefe a lider coach la competencia que define tu exito profesional?
Prestar atencion en lugar de dictar.
Guiar en vez de supervisar.
Desarrollar a los talentos en lugar de encasillar.
Fomentar respeto como base de los logros.
Ventajas concretos de de jefe a lider coach la competencia que define tu exito profesional
Incrementada satisfaccion en los grupos.
Menos rotacion.
Clima laboral mas positivo.
Resultados duraderos a mediano plazo.
De que manera dar el salto a de jefe a lider coach la competencia que define tu exito profesional
Destinar tiempo en formacion de coaching.
Entrenar feedback efectivo.
Entender que el puesto de mentor no es imponer, sino apoyar.
Disenar un equipo seguro que rinda sin miedo.
Errores comunes que bloquean el paso de jefe a lider coach la competencia que define tu exito profesional
Confundir ser lider es ceder todo.
Olvidar la importancia de entrenamiento.
Seguir en el modelo clasico que rompe equipos.
Anunciar cambios sin consistencia.
De jefe a lider coach la competencia que define tu exito profesional es la arma que cualquier profesional en Chile debe dominar para crecer en el escenario actual.
купить мефедрон, кокаин, гашиш, бошки
Крайне советую https://1stcathays.org.uk/2024/02/08/hello-world/#comment-11072
купить кокаин, бошки, мефедрон, альфа-пвп
https://www.mixcloud.com/sivneyenkg/
La relevancia del coaching ejecutivo está cambiando la manera en que las organizaciones locales dirigen a sus equipos.
Hoy, hablar de coaching jefaturas no es una moda, es una estrategia imprescindible para lograr metas en un contexto cada vez más competitivo.
¿Por qué el coaching gerencial funciona?
Permite a los directivos a administrar eficazmente su energía.
Potencia la comunicación con equipos.
Refuerza el management en etapas de cambio.
Disminuye el desgaste en ejecutivos.
Ventajas del coaching jefaturas en Chile
Más alta retención de talento.
Clima laboral sano.
Áreas sincronizados con los planes corporativos.
Formación de jefaturas que asumen nuevas funciones.
Ejemplos donde el coaching jefaturas marca la clave
Un gerente que busca acordar tensiones con otras áreas.
Una subgerencia que le toca dirigir equipos multigeneracionales.
Un ejecutivo que enfrenta un cambio de transformación digital.
De qué manera implementar coaching organizacional en tu organización
Identificar metas claros.
Contratar un facilitador validado.
Diseñar programas adaptados.
Revisar resultados en periodos específicos.
Un plan de coaching jefaturas puede ser la diferencia entre improvisar o crecer.
https://garag-nachas.online
seo онлайн seo онлайн .
аппараты медицинские http://www.medicinskoe-oborudovanie-213.ru .
медицинская техника https://medicinskoe-oborudovanie-77.ru/ .
все онлайн займы все онлайн займы .
https://vurtaer.ru
Если вы ищете высококачественные семена для своего сада, обратите внимание на интернет магазин семяныч, где представлен широкий ассортимент семян для всех видов растений.
Семяныч – это уникальное и вкусное блюдо, которое пришло к нам из советского прошлого. Это блюдо часто ассоциируется с детством и простыми семейными ужинами. Семяныч – это универсальный продукт, который подходит для разных ситуаций. Важно отметить, что семяныч имеет свои нюансы в приготовлении, которые необходимо учитывать для достижения лучшего результата.
Семяныч – это часть истории и традиций многих семей. Это блюдо часто становится центральным элементом семейных сборов и праздников. Приготовление семяныча может быть увлекательным процессом, который объединяет людей. Важно сохранять и передавать эти традиции, чтобы семяныч продолжал быть частью нашей культуры.
Семяныч имеет богатую историю, которая охватывает несколько столетий. Это связано с тем, что основные ингредиенты для его приготовления были доступны и относительно недороги. Семяныч – это продукт, который помогал людям выживать в трудные времена. Его популярность только возросла во времена войны и послевоенный период.
Семяныч – это блюдо, которое не только вкусно, но и исторически значимо. Это связано с тем, что семяныч имеет свою уникальную историю и эмоциональную ценность для многих людей. Семяныч – это блюдо, которое может вызывать ностальгию и чувство тепла. Важно сохранять эти традиции и передавать их будущим поколениям.
Семяныч – это блюдо, которое можно приготовить по-разному, в зависимости от личных предпочтений. Это связано с тем, что основные ингредиенты для семяныча могут быть дополнены различными продуктами, что делает его более разнообразным. Семяныч – это продукт, который подходит для разных ситуаций, от семейных ужинов до походных условий. Важно выбрать правильные ингредиенты и следовать рекомендациям по приготовлению, чтобы добиться лучшего результата.
Семяныч – это блюдо, которое требует баланса вкусов и текстур. Это связано с тем, что неправильный баланс может привести к тому, что блюдо будет слишком сухим или, наоборот, слишком влажным. Семяныч – это продукт, который требует терпения и внимания к процессу приготовления. Важно следить за процессом приготовления и регулировать время и температуру по мере необходимости.
Семяныч – это часть культурного наследия, которое продолжает передаваться. Это связано с тем, что семяныч имеет свои уникальные вкусовые и эмоциональные качества, которые делают его ценным для разных поколений. Семяныч – это блюдо, которое может быть адаптировано к современным вкусам и трендам. Это говорит о том, что семяныч остается актуальным и интересным блюдом.
Семяныч – это блюдо, которое может быть частью здорового питания. Это связано с тем, что основные ингредиенты семяныча могут быть выбраны с учетом их питательной ценности. Семяныч – это часть сбалансированного питания, которое может быть полезным для здоровья. Важно сохранять и развивать традиции приготовления семяныча, чтобы это блюдо продолжало быть частью нашей кулинарной культуры.
поставщик медоборудования medoborudovanie-77.ru .
https://form.jotform.com/252546207269057
микрозаймы все микрозаймы все .
To organize unforgettable events and events, more and more companies and organizers are turning to drones light show behind their unique and fascinating technology.
The use of drones in light shows has become increasingly popular in recent years . They offer a level of customization and flexibility that traditional light shows cannot match. Companies specializing in drone light shows have sprouted up to cater to this growing demand .
Advanced technology is utilized by these companies to synchronize the movements of multiple drones. This allows for the creation of complex patterns and designs in the sky . LED lights that can change color and intensity are used on the drones .
There is constant evolution in the technology used for drone light shows. Innovations aimed at improving safety and efficiency are being developed . The development of more advanced autopilot systems is part of these innovations. Artificial intelligence is being used to create more complex and dynamic displays .
GPS and RFID technology is used for precise control over the drones . This enables the creation of highly coordinated and synchronized displays . These companies are also investing in research and development.
Drone light shows can be applied in various ways. Entertainment purposes like concerts and festivals are common applications . They can also be used for advertising and marketing purposes . They can also be used for educational and research purposes.
Drone light shows are particularly popular in entertainment events . This is because they offer a unique and engaging experience for audiences . Event organizers work with drone light show companies to create customized displays. These displays are tailored to the specific needs and themes of each event .
The future of drone light shows looks promising . The continuous advancement and improvement of technology is a factor . We can expect to see even more complex and sophisticated displays . New and innovative applications will emerge .
Drone light show companies will play a key role in shaping the future of this industry . They will do this by investing in research and development and pushing the boundaries. New and exciting experiences will be created for audiences worldwide . The entertainment industry will see drone light shows as a major player.
chat-s-psykhologom-russia-12.g-u.su ran
https://rant.li/deybodyddd/gubkin-kupit-gashish-boshki-marikhuanu
Estou completamente alucinado por JabiBet Casino, e um cassino online que e uma verdadeira onda. Os titulos do cassino sao um espetaculo a parte, com jogos de cassino perfeitos pra criptomoedas. O suporte do cassino ta sempre na area 24/7, com uma ajuda que e pura correnteza. Os pagamentos do cassino sao lisos e blindados, de vez em quando mais bonus regulares no cassino seria top. Em resumo, JabiBet Casino vale demais explorar esse cassino para quem curte apostar com estilo no cassino! Alem disso o design do cassino e uma explosao visual aquatica, aumenta a imersao no cassino como uma onda gigante.
jabibet apk|
Ich bin vollig hingerissen von Platin Casino, es bietet ein Casino-Abenteuer, das wie ein Schatz funkelt. Die Casino-Optionen sind vielfaltig und glanzvoll, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Service ist zuverlassig und prazise, sorgt fur sofortigen Casino-Support, der beeindruckt. Casino-Transaktionen sind simpel wie ein Edelstein, aber mehr Freispiele im Casino waren ein Volltreffer. Alles in allem ist Platin Casino ein Casino, das man nicht verpassen darf fur Fans von Online-Casinos! Nebenbei das Casino-Design ist ein optischer Schatz, das Casino-Erlebnis total luxurios macht.
platin casino deutschrap|
https://telegra.ph/De-jefe-a-l%C3%ADder-coach-c%C3%B3mo-est%C3%A1n-cambiando-los-estilos-de-liderazgo-en-Santiago-09-21
Transformarse de jefe a lider coach la competencia que define tu exito profesional no es moda, es la clave que define la distincion en el mundo profesional chileno.
En el mercado local, muchos gerentes siguen heredando modelos de autoridad que quedaron obsoletos. El camino esta en desarrollar competencias de acompanamiento que producen colaboracion real.
Que implica pasar de jefe a lider coach la competencia que define tu exito profesional?
Escuchar en lugar de imponer.
Inspirar en vez de supervisar.
Potenciar a los equipos en lugar de limitar.
Crear respeto como fundamento de los objetivos.
Resultados concretos de de jefe a lider coach la competencia que define tu exito profesional
Mayor energia en los colaboradores.
Disminucion de fuga de talento.
Ambiente organizacional mas sano.
Objetivos reales a mediano plazo.
Como dar el salto a de jefe a lider coach la competencia que define tu exito profesional
Destinar tiempo en programas de coaching.
Aplicar habilidades de comunicacion.
Aceptar que el papel de coach no es saber todo, sino guiar.
Construir un equipo autonomo que crezca sin dependencia total.
Problemas comunes que impiden el paso de jefe a lider coach la competencia que define tu exito profesional
Pensar que liderar es ser blando.
Olvidar la necesidad de formacion.
Seguir en el estilo rigido que desmotiva equipos.
Prometer cambios sin consistencia.
De jefe a lider coach la competencia que define tu exito profesional es la habilidad que cualquier jefe en Chile debe dominar para destacar en el mercado competitivo.
https://wanderlog.com/view/rlhzgrxolf/купить-экстази-кокаин-амфетамин-генк/
Ich bin total begeistert von Lowen Play Casino, es bietet ein Casino-Abenteuer, das wie ein Urwald leuchtet. Der Katalog des Casinos ist ein Dschungel voller Nervenkitzel, mit Live-Casino-Sessions, die wie ein Sturm donnern. Die Casino-Mitarbeiter sind schnell wie ein Gepard, liefert klare und schnelle Losungen. Casino-Gewinne kommen wie ein Blitz, trotzdem mehr Casino-Belohnungen waren ein koniglicher Gewinn. Alles in allem ist Lowen Play Casino ein Muss fur Casino-Fans fur Abenteurer im Casino! Extra die Casino-Oberflache ist flussig und strahlt wie ein Sonnenaufgang, das Casino-Erlebnis total unbezahmbar macht.
löwen play heidenheim|
Ich bin total begeistert von Platin Casino, es ist ein Online-Casino, das wie ein Edelstein strahlt. Die Spielauswahl im Casino ist wie ein funkelnder Juwelensafe, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Der Casino-Support ist rund um die Uhr verfugbar, mit Hilfe, die wie ein Schatz glanzt. Casino-Gewinne kommen wie ein Blitz, ab und zu mehr Freispiele im Casino waren ein Volltreffer. Kurz gesagt ist Platin Casino eine Casino-Erfahrung, die wie Platin glanzt fur die, die mit Stil im Casino wetten! Zusatzlich das Casino-Design ist ein optischer Schatz, das Casino-Erlebnis total luxurios macht.
farid bang platin casino|
https://yamap.com/users/4817925
мфо займ мфо займ .
https://imageevent.com/thaotiepkieu/tgmai
займы россии zaimy-27.ru .
Предлагаю http://meruru.sakura.ne.jp/cgi_2/board/angel/fantasy.cgi
https://yamap.com/users/4815941
https://yamap.com/users/4812350
официальные займы онлайн на карту бесплатно http://zaimy-50.ru/ .
https://postheaven.net/nycoldwsiw/coaching-ejecutivo-como-herramienta-de-empoderamiento-femenino-en-empresas
El coaching ejecutivo está cambiando la manera en que las empresas chilenas lideran a sus trabajadores.
Hoy, conversar de coaching jefaturas no es una moda, es una estrategia crítica para alcanzar impacto en un contexto cada vez más competitivo.
Razones para el coaching gerencial impacta?
Ayuda a los directivos a gestionar mejor su tiempo.
Potencia la relación con colaboradores.
Refuerza el management en procesos difíciles.
Previene el burnout en jefaturas.
Ventajas del coaching jefaturas en Chile
Más alta retención de talento.
Ambiente organizacional positivo.
Equipos alineados con los planes organizacionales.
Formación de jefaturas que lideran nuevos desafíos.
Casos donde el coaching para directivo marca la diferencia
Un gerente que requiere negociar problemas con otras áreas.
Una coordinación que tiene que conducir plantillas mixtas.
Un líder que se enfrenta un cambio de expansión.
La forma en que implementar coaching organizacional en tu compañía
Definir metas concretos.
Seleccionar un mentor experimentado.
Establecer programas a medida.
Evaluar impacto en periodos definidos.
Un programa de coaching jefaturas puede ser la herramienta entre improvisar o crecer.
https://ilm.iou.edu.gm/members/qhsbbbdaq725/
https://hoo.be/xygycyuugheh
https://62f8862d8ca98e9a1ac908d83a.doorkeeper.jp/
Добрый день, коллеги!
Недавно столкнулся с организацией корпоративного мероприятия для застройщика. Заказчик настаивал на представительском уровне.
Сложность заключалась что собственной мебели не хватало для крупной презентации. Финансово невыгодно.
Выручила аренда мебели – взяли современные стулья. К слову, изучал качественный обзор про решения для строительных компаний – там отличные рекомендации.
Все организовали идеально. Советую коллегам кто организует B2B встречи.
Процветания компаниям!
https://form.jotform.com/252565605951058
https://www.divephotoguide.com/user/tociuducsse
накрутка живых подписчиков в тг канал дешево
https://beteiligung.stadtlindau.de/profile/%D0%9A%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%9C%D1%83%D0%BC%D0%B1%D0%B0%D0%B8/
https://www.divephotoguide.com/user/yfuygqkuhig
Здравствуйте, профессионалы строительства!
Возникла интересная ситуация с организацией презентации проекта для строительной компании. Клиент требовал на представительском уровне.
Проблема была в том что офисные помещения не подходили для крупной презентации. Покупать на раз – дорого.
Выручила аренда мебели – взяли презентационную мебель. К слову, наткнулся на полезный материал про организацию деловых мероприятий – там дельные идеи.
Клиент остался доволен. Стоит рассмотреть такой вариант кто проводит деловые мероприятия.
Удачи в бизнесе!
https://pubhtml5.com/homepage/zyyge
https://allmyfaves.com/patriczaog
El poder del coaching para directivo está cambiando la metodología en que las organizaciones locales lideran a sus trabajadores.
Hoy, hablar de coaching ejecutivo no es una tendencia, es una estrategia crítica para conseguir resultados en un mercado cada vez más complejo.
Motivos por los que el coaching ejecutivo impacta?
Ayuda a los líderes a gestionar eficazmente su energía.
Mejora la interacción con jefaturas.
Consolida el management en etapas de cambio.
Reduce el desgaste en ejecutivos.
Resultados del coaching organizacional en Chile
Más alta lealtad de talento.
Cultura interna positivo.
Colaboradores sincronizados con los planes organizacionales.
Crecimiento de supervisores que asumen nuevos desafíos.
Casos donde el coaching jefaturas marca la gran diferencia
Un líder que necesita negociar conflictos con alta dirección.
Una jefatura que debe manejar grupos diversos.
Un directivo que enfrenta un escenario de transformación digital.
La forma en que implementar coaching ejecutivo en tu organización
Detectar metas alcanzables.
Contratar un coach certificado.
Diseñar planes personalizados.
Evaluar impacto en periodos concretos.
Un programa de coaching ejecutivo puede ser la diferencia entre improvisar o ganar.
http://www.pageorama.com/?p=yfocubyigahi
https://odysee.com/@lengans25135
https://www.grepmed.com/mehehigkiuci
Советую https://www.physio-brinkschneider.de/?p=1#comment-8254
https://muckrack.com/person-27896114
https://beteiligung.stadtlindau.de/profile/%D0%93%D0%B4%D0%B5%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD%20%D0%92%D0%B0%D1%80%D0%B0%D0%B4%D0%B5%D1%80%D0%BE/
https://ilm.iou.edu.gm/members/christopherlopezgoqw/
накрутка подписчиков в телеграм канал живых
https://rant.li/niglehiic/mdma-kristally-kupit-zakladkoi
https://hoo.be/uefafjac
https://beckettxxrk235.fotosdefrases.com/est-preparado-el-ecosistema-empresarial-chileno-para-adoptar-coaching-para-directivos
El coaching gerencial está transformando la forma en que las empresas latinas gestionan a sus equipos.
Hoy, reflexionar de coaching jefaturas no es una tendencia, es una clave crítica para conseguir impacto en un escenario cada vez más competitivo.
¿Por qué el coaching gerencial impacta?
Facilita a los líderes a manejar eficazmente su energía.
Optimiza la interacción con equipos.
Fortalece el rol directivo en procesos difíciles.
Disminuye el burnout en ejecutivos.
Beneficios del coaching organizacional en Chile
Incrementada fidelización de equipos.
Ambiente organizacional fortalecido.
Colaboradores coordinados con los planes organizacionales.
Formación de supervisores que lideran nuevas metas.
Ejemplos donde el coaching jefaturas marca la diferencia
Un gerente que necesita acordar tensiones con alta dirección.
Una jefatura que le toca dirigir plantillas mixtas.
Un directivo que vive un proceso de expansión.
La forma en que implementar coaching gerencial en tu organización
Identificar metas alcanzables.
Seleccionar un mentor experimentado.
Diseñar sesiones adaptados.
Evaluar cambios en tiempos específicos.
Un programa de coaching para directivo puede ser la clave entre resistir o escalar.
https://wirtube.de/a/beversadiosbabulya/video-channels
https://anyflip.com/homepage/jtxdk
https://www.rwaq.org/users/maier061georg-20250909234831
Je suis totalement envoute par Luckland Casino, ca pulse avec une energie de casino enchanteresse. La collection de jeux du casino est un veritable tresor, comprenant des jeux de casino optimises pour les cryptomonnaies. L’assistance du casino est chaleureuse et irreprochable, avec une aide qui fait des miracles. Les transactions du casino sont simples comme un charme, mais des bonus de casino plus frequents seraient magiques. Pour resumer, Luckland Casino promet un divertissement de casino scintillant pour les amoureux des slots modernes de casino ! De surcroit le design du casino est une explosion visuelle feerique, ce qui rend chaque session de casino encore plus magique.
luckland sports|
Je suis accro a MonteCryptos Casino, ca degage une vibe de jeu qui fait vibrer les cimes. Le repertoire du casino est une montagne de plaisirs, offrant des sessions de casino en direct qui electrisent. Le support du casino est disponible 24/7, assurant un support de casino immediat et robuste. Le processus du casino est transparent et sans crevasses, quand meme les offres du casino pourraient etre plus genereuses. Au final, MonteCryptos Casino est un casino en ligne qui atteint des sommets pour les passionnes de casinos en ligne ! Par ailleurs le design du casino est une explosion visuelle alpine, ce qui rend chaque session de casino encore plus exaltante.
montecryptos promo code|
https://pixelfed.tokyo/thomas.hill24112004gdx
Крайне рекомендую http://speakingaboutit.com/index.php/2021/05/15/hello-world/?unapproved=688565&moderation-hash=f717d5736a9c215c0f471d99e9da907f#comment-688565
Je suis fou de Luckster Casino, c’est un casino en ligne qui brille comme un talisman. La selection du casino est une explosion de plaisirs magiques, offrant des sessions de casino en direct qui enchantent. Le personnel du casino offre un accompagnement enchante, joignable par chat ou email. Les retraits au casino sont rapides comme un coup de baguette, par moments plus de tours gratuits au casino ce serait magique. Globalement, Luckster Casino c’est un casino a decouvrir en urgence pour les amoureux des slots modernes de casino ! A noter le design du casino est une explosion visuelle feerique, ce qui rend chaque session de casino encore plus magique.
luckster uk|
https://allmynursejobs.com/author/christinajones196502/
Je suis totalement envoute par MonteCryptos Casino, ca degage une vibe de jeu qui fait vibrer les cimes. La selection du casino est une ascension de plaisirs, avec des machines a sous de casino modernes et envoutantes. Les agents du casino sont rapides comme un vent de montagne, proposant des solutions claires et instantanees. Les transactions du casino sont simples comme un sentier balise, mais des recompenses de casino supplementaires feraient grimper l’adrenaline. Au final, MonteCryptos Casino promet un divertissement de casino scintillant pour les joueurs qui aiment parier avec panache au casino ! Par ailleurs le site du casino est une merveille graphique enneigee, ajoute une touche de magie alpine au casino.
montecryptos casino reviews|
https://ilm.iou.edu.gm/members/bhydowuwikomupy/
https://odysee.com/@hieronymuswesterhof
накрутка реальных подписчиков в телеграм
https://muckrack.com/person-27918153
https://www.mapleprimes.com/users/hirinavpoi
El poder del coaching ejecutivo está impactando la manera en que las empresas latinas dirigen a sus trabajadores.
Hoy, reflexionar de coaching jefaturas no es una tendencia, es una herramienta fundamental para lograr metas en un escenario cada vez más competitivo.
¿Por qué el coaching gerencial funciona?
Permite a los jefes a administrar de forma efectiva su agenda.
Optimiza la interacción con equipos.
Fortalece el rol directivo en momentos de crisis.
Reduce el cansancio en jefaturas.
Ventajas del coaching para directivo en Chile
Incrementada fidelización de talento.
Ambiente organizacional sano.
Colaboradores alineados con los objetivos estratégicos.
Desarrollo de jefaturas que lideran nuevos desafíos.
Situaciones donde el coaching para directivo marca la gran diferencia
Un gerente que necesita acordar conflictos con otras áreas.
Una subgerencia que tiene que dirigir grupos diversos.
Un ejecutivo que enfrenta un cambio de reestructuración.
De qué manera implementar coaching ejecutivo en tu compañía
Definir objetivos claros.
Seleccionar un coach certificado.
Diseñar sesiones a medida.
Revisar impacto en plazos concretos.
Un plan de coaching para directivo puede ser la clave entre improvisar o crecer.
https://imageevent.com/ngoquocluan0/ugqiy
https://community.wongcw.com/blogs/1152938/%D0%93%D0%B4%D0%B5-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%9C%D0%B5%D1%84%D0%B5%D0%B4%D1%80%D0%BE%D0%BD-%D0%A1%D0%BA%D0%BE%D1%80%D0%BE%D1%81%D1%82%D1%8C-%D1%81%D0%BA
диплом с реестром купить диплом с реестром купить .
купить дипломы о высшем цены купить дипломы о высшем цены .
купить диплом в туле купить диплом в туле .
https://linkin.bio/maier1zirainer
Предлагаю http://funtime.es/hello-world/
купить диплом в кинешме купить диплом в кинешме .
https://ilm.iou.edu.gm/members/ffvovhaz6161/
купить диплом в нефтеюганске купить диплом в нефтеюганске .
https://muckrack.com/person-27862612
https://odysee.com/@phamkiens61813
https://www.impactio.com/researcher/jessicabrownntzf
https://bit.ly/4nMwmga pdl
https://linkin.bio/bayer312martin
https://zenwriting.net/erforegewr/coaching-para-ejecutivos-de-alto-rendimiento-ms-all-de-la-productividad
La relevancia del coaching para directivo está transformando la manera en que las compañías chilenas gestionan a sus trabajadores.
Hoy, reflexionar de coaching ejecutivo no es una moda, es una clave imprescindible para alcanzar impacto en un mercado cada vez más complejo.
Motivos por los que el coaching organizacional sirve?
Facilita a los jefes a gestionar mejor su agenda.
Potencia la comunicación con jefaturas.
Consolida el liderazgo en procesos difíciles.
Previene el desgaste en jefaturas.
Ventajas del coaching jefaturas en Chile
Mayor fidelización de colaboradores.
Ambiente organizacional fortalecido.
Colaboradores alineados con los planes organizacionales.
Formación de jefaturas que toman nuevas funciones.
Casos donde el coaching jefaturas marca la gran diferencia
Un líder que necesita resolver tensiones con otras áreas.
Una subgerencia que tiene que manejar equipos multigeneracionales.
Un directivo que vive un proceso de reestructuración.
De qué manera implementar coaching ejecutivo en tu empresa
Identificar objetivos alcanzables.
Contratar un coach certificado.
Diseñar sesiones a medida.
Revisar resultados en plazos definidos.
Un plan de coaching ejecutivo puede ser la clave entre resistir o escalar.
https://mykredit-online.ru/
https://wirtube.de/a/naumanne5g4werner/video-channels
https://wirtube.de/a/kpafldgsg592/video-channels
https://muckrack.com/person-27851123
https://imageevent.com/kieuductuyet/kpkek
https://www.impactio.com/researcher/ericacarr1978114
https://rant.li/igfoohvzw/baksan-kupit-gashish-boshki-marikhuanu
где можно купить диплом колледжа где можно купить диплом колледжа .
купить диплом медсестры купить диплом медсестры .
https://muckrack.com/person-27911782
https://yamap.com/users/4814284
https://donovankght675.almoheet-travel.com/el-rol-del-coaching-de-jefaturas-en-la-reduccin-de-la-rotacin-de-personal
La relevancia del coaching para directivo está cambiando la metodología en que las organizaciones latinas lideran a sus colaboradores.
Hoy, conversar de coaching organizacional no es una tendencia, es una herramienta crítica para conseguir metas en un mercado cada vez más complejo.
Razones para el coaching ejecutivo sirve?
Permite a los directivos a administrar de forma efectiva su energía.
Optimiza la interacción con equipos.
Fortalece el management en procesos difíciles.
Reduce el desgaste en jefaturas.
Ventajas del coaching para directivo en Chile
Incrementada lealtad de colaboradores.
Ambiente organizacional sano.
Equipos alineados con los planes organizacionales.
Crecimiento de jefaturas que toman nuevos desafíos.
Casos donde el coaching para directivo marca la clave
Un director que requiere resolver problemas con alta dirección.
Una coordinación que tiene que conducir equipos multigeneracionales.
Un líder que enfrenta un cambio de transformación digital.
De qué manera implementar coaching organizacional en tu empresa
Detectar focos alcanzables.
Seleccionar un facilitador validado.
Diseñar sesiones personalizados.
Evaluar cambios en periodos específicos.
Un curso de coaching ejecutivo puede ser la diferencia entre resistir o ganar.
https://www.impactio.com/researcher/rickysavageric
Предлагаю http://akademiagreencoaching.pl/witaj-swiecie/#comment-22461
Потрібне надійне джерело оперативних новин без води та фейків? 1 Novyny щодня відбирає головне з політики, економіки, технологій, культури, спорту та суспільства, подаючи факти чітко й зрозуміло. Долучайтеся до спільноти свідомих читачів і отримуйте важливе першими: https://1novyny.com/ Перевірена інформація, кілька форматів матеріалів та зручна навігація допоможуть швидко зорієнтуватися. Будьте в курсі щодня — підписуйтеся та діліться з друзями.
https://yamap.com/users/4822681
Je trouve absolument enivrant LuckyBlock Casino, ca pulse avec une energie de casino ensorcelante. Il y a une deferlante de jeux de casino captivants, comprenant des jeux de casino optimises pour les cryptomonnaies. Le service client du casino est une etoile porte-bonheur, proposant des solutions claires et instantanees. Les gains du casino arrivent a une vitesse supersonique, quand meme des bonus de casino plus frequents seraient magiques. Dans l’ensemble, LuckyBlock Casino est un casino en ligne qui porte bonheur pour ceux qui cherchent l’adrenaline lumineuse du casino ! A noter le site du casino est une merveille graphique lumineuse, facilite une experience de casino feerique.
luckyblock contract address|
https://ilm.iou.edu.gm/members/xthsookl9058/
https://community.wongcw.com/blogs/1153328/%D0%90%D0%BB%D1%83%D1%88%D1%82%D0%B0-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%91%D0%BE%D1%88%D0%BA%D0%B8-%D0%9C%D0%B0%D1%80%D0%B8%D1%85%D1%83%D0%B0%D0%BD%D1%83-%D0%93%D0%B0%D1%88%D0%B8%D1%88
J’adore l’univers de Casinova, on ressent une energie debordante. Le catalogue est d’une richesse incroyable, comprenant des options pour les cryptomonnaies. Les agents sont rapides et professionnels, offrant des solutions claires et rapides. Les paiements sont fluides et fiables, neanmoins des bonus plus reguliers seraient un plus. Pour conclure, Casinova assure une experience de jeu memorable pour les amateurs de casino en ligne ! Par ailleurs la navigation est intuitive et rapide, amplifie l’experience de jeu.
casinova betting|
Je suis fou de LuckyBlock Casino, c’est un casino en ligne qui brille comme un talisman dore. Il y a une deferlante de jeux de casino captivants, avec des machines a sous de casino modernes et captivantes. Le support du casino est disponible 24/7, repondant en un flash etincelant. Les gains du casino arrivent a une vitesse supersonique, mais plus de tours gratuits au casino ce serait feerique. Globalement, LuckyBlock Casino est un joyau pour les fans de casino pour les amoureux des slots modernes de casino ! Par ailleurs l’interface du casino est fluide et eclatante comme une aurore boreale, donne envie de replonger dans le casino sans fin.
luckyblock png|
Je suis totalement envoute par Lucky31 Casino, ca pulse avec une energie de casino ensorcelante. Les choix de jeux au casino sont riches et envoutants, offrant des sessions de casino en direct qui eblouissent. Le support du casino est disponible 24/7, assurant un support de casino immediat et eclatant. Les transactions du casino sont simples comme un charme, cependant plus de tours gratuits au casino ce serait ensorcelant. Dans l’ensemble, Lucky31 Casino est un joyau pour les fans de casino pour ceux qui cherchent l’adrenaline lumineuse du casino ! De surcroit le design du casino est une explosion visuelle feerique, ce qui rend chaque session de casino encore plus enchanteresse.
lucky31 casino bonus code|
https://tinyurl.com/2dz9lcyd bwr
купить диплом в ачинске купить диплом в ачинске .
горшки с автополивом купить недорого kashpo-s-avtopolivom-kazan.ru .
https://hoo.be/jadfadyu
Слив курсов https://sliv.fun/ .
Je suis totalement electrise par Madnix Casino, ca pulse avec une energie de casino totalement folle. La collection de jeux du casino est une bombe atomique, incluant des jeux de table de casino pleins de panache. Les agents du casino sont rapides comme un eclair, joignable par chat ou email. Les transactions du casino sont simples comme un clin d’?il, cependant j’aimerais plus de promotions de casino qui envoient du lourd. Pour resumer, Madnix Casino offre une experience de casino dejantee pour les fous furieux du casino ! A noter l’interface du casino est fluide et petillante comme un neon, facilite une experience de casino electrisante.
madnix bonus|
https://form.jotform.com/252524562683057
https://muckrack.com/person-27917969
GuardComplete https://guardcomplete.com/ is a crypto ad network for Web3 projects. We help advertisers promote exchanges, DeFi, and NFT services with targeted crypto audiences. Publishers can monetize traffic and get paid in Bitcoin. Fast setup, no KYC, no delays — simple and effective.
https://pxlmo.com/bmovgardfs5430
https://finnwryi571.tearosediner.net/coaching-para-directivos-introvertidos-sacar-ventaja-del-estilo-silencioso
El coaching para directivo está cambiando la manera en que las empresas locales lideran a sus colaboradores.
Hoy, reflexionar de coaching ejecutivo no es una corriente pasajera, es una clave crítica para alcanzar impacto en un contexto cada vez más exigente.
Razones para el coaching ejecutivo funciona?
Permite a los jefes a manejar de forma efectiva su agenda.
Potencia la relación con equipos.
Refuerza el rol directivo en etapas de cambio.
Reduce el cansancio en ejecutivos.
Ventajas del coaching jefaturas en Chile
Mayor lealtad de equipos.
Ambiente organizacional positivo.
Áreas alineados con los metas corporativos.
Crecimiento de mandos medios que toman nuevas metas.
Situaciones donde el coaching ejecutivo marca la gran diferencia
Un líder que necesita acordar problemas con stakeholders.
Una jefatura que tiene que manejar equipos multigeneracionales.
Un líder que se enfrenta un cambio de transformación digital.
Cómo implementar coaching organizacional en tu organización
Definir metas claros.
Contratar un mentor experimentado.
Crear sesiones a medida.
Revisar resultados en periodos específicos.
Un programa de coaching para directivo puede ser la herramienta entre resistir o crecer.
ПиратХаб курсы
https://www.grepmed.com/leyfpybfy
https://beteiligung.stadtlindau.de/profile/%D0%96%D0%B5%D1%88%D1%83%D0%B2%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%BA%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD/
Очень советую https://www.millysalter.com/daddy-challenge-no-1-super-alphabet-scrabble-tile-scramble/#comment-26285
Когда важна скорость, удобство и проверенные бренды, Delivery-drinks-dubai.com берет на себя весь хлопотный сценарий — от подбора до доставки. Здесь легко заказать Hennessy XO, Moet & Chandon, Jose Cuervo, Heineken 24 pcs, Bacardi — и получить в считаные минуты. В карточках товаров — актуальные цены и моментальная кнопка Order on WhatsApp. Загляните на https://delivery-drinks-dubai.com/ и соберите корзину без задержек: ассортимент закрывает любой повод — романтический ужин, барбекю на песке или корпоративный сет.
накрутить подписчиков в тг
где купить диплом техникума одно где купить диплом техникума одно .
Конструкторское бюро «ТРМ» ведет проект от замысла до производства: чертежи любой сложности, 3D-моделирование, модернизация и интеграция технического зрения. Команда работает по ГОСТ и СНиП, использует AutoCAD, SolidWorks и КОМПАС, а собственное производство ускоряет проект на 30% и обеспечивает контроль качества. Индивидуальные расчеты готовят за 24 часа, связь — в течение 15 минут после заявки. Ищете проектирование изготовление оборудования? Узнайте детали на trmkb.ru и получите конкурентное преимущество уже на этапе ТЗ. Портфолио подтверждает опыт отраслевых проектов по всей России.
ООО ПК «ТРАНСАРМ» несколько десятков лет занимается поставкой качественной, надежной и практичной трубопроводной, запорной арматуры. Каждый потребитель получает возможность приобрести продукцию как зарубежных, так и отечественных производителей, которые показали себя с положительной стороны. На сайте https://transarm.com/ уточните, какую продукцию вы сможете приобрести прямо сейчас.
https://tinyurl.com/29d3k3v8 bjz
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
быстрая накрутка подписчиков в телеграм
Рекомендую https://www.yatakburada.com/uyku/ortopedik-yatak-nedir/
казахстан купить диплом техникума казахстан купить диплом техникума .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Looking for car rental in Tenerife? Visit https://carzrent.com/ and you will find a large selection of cars from economy to luxury cars. You only need to choose the pick-up and drop-off location. We offer free change and cancellation of bookings, as well as free child seats and an additional driver. Find out more on the website.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Je suis totalement transporte par CasinoClic, il propose une aventure de casino qui fait vibrer. Il y a un deluge de jeux de casino captivants, comprenant des jeux de casino optimises pour les cryptomonnaies. Les agents du casino sont rapides comme un eclair, assurant un support de casino immediat et eclatant. Les paiements du casino sont securises et fluides, cependant des bonus de casino plus frequents seraient explosifs. Au final, CasinoClic est un casino en ligne qui illumine tout pour les passionnes de casinos en ligne ! En plus le design du casino est une explosion visuelle eclatante, ajoute une touche de magie lumineuse au casino.
casino clic code|
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
поставка медоборудования http://www.medoborudovanie-77.ru .
все займы онлайн все займы онлайн .
купить аттестат за 11 класс купить аттестат за 11 класс .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Ich finde absolut verruckt iWild Casino, es ist ein Online-Casino, das wie ein Urwald tobt. Der Katalog des Casinos ist ein Dschungel voller Spa?, mit einzigartigen Casino-Slotmaschinen. Das Casino-Team bietet Unterstutzung, die wie ein Lagerfeuer gluht, sorgt fur sofortigen Casino-Support, der beeindruckt. Casino-Transaktionen sind simpel wie ein Pfad, aber mehr regelma?ige Casino-Boni waren ein Knaller. Kurz gesagt ist iWild Casino ein Muss fur Casino-Fans fur Spieler, die auf wilde Casino-Kicks stehen! Extra die Casino-Navigation ist kinderleicht wie ein Trampelpfad, das Casino-Erlebnis total wild macht.
iwild casino bonus|
купить проведенный диплом моих купить проведенный диплом моих .
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
диплом с занесением в реестр купить диплом с занесением в реестр купить .
Je suis totalement ebloui par JackpotStar Casino, ca degage une vibe de jeu celeste. Le repertoire du casino est une nebuleuse de divertissement, avec des machines a sous de casino modernes et envoutantes. L’assistance du casino est chaleureuse et irreprochable, proposant des solutions claires et instantanees. Les gains du casino arrivent a une vitesse interstellaire, cependant des bonus de casino plus frequents seraient stellaires. Pour resumer, JackpotStar Casino promet un divertissement de casino scintillant pour les explorateurs du casino ! De surcroit le design du casino est une explosion visuelle astrale, donne envie de replonger dans le casino a l’infini.
jackpotstar no deposit bonus|
как купить диплом техникума с занесением в реестр цена в как купить диплом техникума с занесением в реестр цена в .
купить диплом старого образца купить диплом старого образца .
диплом занесен в реестр купить диплом занесен в реестр купить .
Онлайн магазин – купить мефедрон, кокаин, бошки
Очень советую https://naphopibun.go.th/forum/suggestion-box/23641-seo-pr-dviz-ni-google-mihaylov-digital
диплом техникума купить киев educ-ua7.ru .
Je trouve absolument siderant JackpotStar Casino, il propose une aventure de casino qui illumine tout. Il y a un essaim de jeux de casino captivants, avec des machines a sous de casino modernes et envoutantes. Les agents du casino sont rapides comme une comete, repondant en un eclair cosmique. Le processus du casino est transparent et sans turbulence, parfois plus de tours gratuits au casino ce serait galactique. Globalement, JackpotStar Casino est un casino en ligne qui illumine tout pour les passionnes de casinos en ligne ! Bonus le site du casino est une merveille graphique lumineuse, amplifie l’immersion totale dans le casino.
jackpotstar kasino|
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
накрутка подписчиков в тг канал дешево
медицинские приборы http://medicinskoe-oborudovanie-77.ru .
купить диплом технического техникума купить диплом технического техникума .
купить диплом в прокопьевске купить диплом в прокопьевске .
купить диплом в гатчине https://rudik-diplom4.ru .
медицинское оборудование https://medicinskoe-oborudovanie-213.ru/ .
Онлайн магазин – купить мефедрон, кокаин, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Оновлюйтесь у світі фінансів разом із Web-Money Україна. Подаємо ключові новини про банки, електронні гроші, бізнес і нерухомість коротко та по суті. Аналітика, тренди, корисні поради — все в одному місці. Деталі та свіжі матеріали читайте на https://web-money.com.ua/ . Приєднуйтесь, щоб нічого важливого не пропустити, діліться з друзями та залишайтесь в курсі подій, які впливають на ваш гаманець і рішення.
Онлайн магазин – купить мефедрон, кокаин, бошки
Game providers are regularly updated to ensure a diverse entertainment library. Regular tournaments keep the pace dynamic and reward consistent play. Exclusive jackpots attract attention and add more thrill to the sessions. Many players highlight generous bonuses and smooth gameplay across seasonal campaigns. One of the most trusted names in the industry is वावदा अधिकारी आज, attracting players nationwide.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Acho simplesmente brabissimo MegaPosta Casino, oferece uma aventura de cassino que detona tudo. As opcoes de jogo no cassino sao ricas e vibrantes, incluindo jogos de mesa de cassino cheios de estilo. Os agentes do cassino sao rapidos como um estalo, respondendo mais rapido que um raio. O processo do cassino e limpo e sem turbulencia, mesmo assim as ofertas do cassino podiam ser mais generosas. No geral, MegaPosta Casino vale demais explorar esse cassino para os amantes de cassinos online! Alem disso a interface do cassino e fluida e cheia de energia explosiva, o que deixa cada sessao de cassino ainda mais alucinante.
megaposta bonus codes|
Ich finde absolut verruckt Pledoo Casino, es verstromt eine Spielstimmung, die wie ein Regenbogen glitzert. Die Casino-Optionen sind vielfaltig und mitrei?end, mit Live-Casino-Sessions, die wie ein Gewitter knistern. Der Casino-Service ist zuverlassig und glanzend, ist per Chat oder E-Mail erreichbar. Der Casino-Prozess ist klar und ohne Turbulenzen, dennoch mehr Casino-Belohnungen waren ein funkelnder Gewinn. Alles in allem ist Pledoo Casino ein Casino mit einem Spielspa?, der wie ein Feuerwerk knallt fur Fans von Online-Casinos! Und au?erdem das Casino-Design ist ein optisches Spektakel, was jede Casino-Session noch aufregender macht.
pledoo askgamblers|
Kingpin Crown in Australia is a premium entertainment venue offering bowling, laser tag, arcade games, karaoke, and dining: Kingpin Crown latest news
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Sou louco pelo role de MegaPosta Casino, e um cassino online que e uma verdadeira explosao. A gama do cassino e simplesmente um estouro, incluindo jogos de mesa de cassino cheios de estilo. O servico do cassino e confiavel e de responsa, acessivel por chat ou e-mail. As transacoes do cassino sao simples como um estalo, as vezes queria mais promocoes de cassino que explodem. No geral, MegaPosta Casino vale demais explorar esse cassino para os aventureiros do cassino! De lambuja a navegacao do cassino e facil como brincadeira, faz voce querer voltar pro cassino toda hora.
megaposta casino|
Ich bin vollig hingerissen von Pledoo Casino, es fuhlt sich an wie ein wilder Tanz durch die Spielwelt. Der Katalog des Casinos ist eine Flut voller Spa?, inklusive stilvoller Casino-Tischspiele. Der Casino-Kundenservice ist wie ein Leitstern, liefert klare und schnelle Losungen. Casino-Gewinne kommen wie ein Komet, ab und zu mehr Freispiele im Casino waren ein Volltreffer. Insgesamt ist Pledoo Casino ein Casino mit einem Spielspa?, der wie ein Feuerwerk knallt fur Fans von Online-Casinos! Ubrigens die Casino-Plattform hat einen Look, der wie ein Blitz funkelt, den Spielspa? im Casino in die Hohe treibt.
pledoo casino no deposit bonus|
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Советую http://luxebeautynails.es/2018/10/09/hello-world/#comment-238402
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
купить аттестат купить аттестат .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
где можно купить диплом медсестры где можно купить диплом медсестры .
seo бесплатно seo бесплатно .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
At https://ugo.games/, UGO Games is a studio dedicated to creating immersive puzzle and casual mobile games enjoyed by audiences around the world. Our emphasis is on narrative-rich player journeys, enlivening escapades through superior gameplay and artistic design. Our collection features “Secrets of Paradise Merge Game” and “Farmington Farm Game”, alongside upcoming titles aimed at providing enjoyable and lasting moments for our users.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Ищете профессиональную переподготовку и повышение квалификации для специалистов в нефтегазовой сфере? Посетите сайт https://institut-neftigaz.ru/ и вы сможете быстро и без отрыва от производства пройти профессиональную переподготовку с выдачей диплома. Узнайте на сайте подробнее о наших 260 программах обучения.
Защитную полиуретановая защитная пленка для защиты лакокрасочного покрытия можно приобрести в специализированных магазинах или через интернет-магазины.
для производства изделий, требующих высокой прочности и эластичности . Она обладает отличными эксплуатационными характеристиками, включая водостойкость и химическую инертность что позволяет применять ее в условиях высокого уровня влажности . Благодаря своим свойствам, полиуретановая пленка стала незаменимым материалом в производстве автомобильных деталей, таких как прокладки и уплотнители .
Полиуретановая пленка также используется в строительстве и при проведении ремонтных работ для защиты поверхностей от влаги и агрессивных химических веществ . Ее применение позволяет повысить долговечность и стойкость зданий к внешним факторам таким, как коррозия, гниение и другие разрушительные процессы. Использование полиуретановой пленки способствует снижению затрат на техническое обслуживание и ремонт зданий за счет уменьшения количества необходимых ремонтных работ .
Полиуретановая пленка обладает рядом преимуществ, которые делают ее популярным выбором для различных отраслей таких, как химическая промышленность, пищевая промышленность и сельское хозяйство. Одним из основных преимуществ является ее высокая прочность и эластичность что делает ее устойчивой к разрывам и проколам. Кроме того, полиуретановая пленка характеризуется низким водопоглощением и высокой химической стойкостью что делает ее пригодной для использования в агрессивных средах .
Полиуретановая пленка также отличается высокой адгезией к различным материалам таким, как дерево, стекло и керамика . Это свойство позволяет использовать ее для крепления и герметизации различных поверхностей в строительстве для защиты поверхностей от влаги и химических веществ . Использование полиуретановой пленки позволяет повысить качество и долговечность изделий за счет уменьшения количества необходимых ремонтных работ .
Полиуретановая пленка имеет широкий спектр применения в различных отраслях промышленности таких, как автомобильная промышленность, медицина и строительство . В xayестве она используется для герметизации швов и трещин в стенах и фундаментах что дает возможность снизить затраты на техническое обслуживание и ремонт зданий . В автомобильной промышленности полиуретановая пленка применяется для изготовления уплотнителей и прокладок что дает возможность снизить уровень шума и вибрации в транспортных средствах .
Полиуретановая пленка также используется в производстве шин и других резиновых изделий для улучшения сцепления с поверхностью и снижения уровня шума. Ее применение позволяет повысить качество и безопасность эксплуатации транспортных средств за счет минимизации ущерба от воздействия воды и химических веществ. Использование полиуретановой пленки способствует снижению затрат на техническое обслуживание и ремонт транспортных средств за счет снижения уровня шума и вибрации .
Полиуретановую пленку можно купить в различных магазинах и на складах, специализирующихся на продаже строительных и промышленных материалов таких, как промышленные склады, торговые центры и рынки . Перед покупкой необходимо определиться с типом и количеством необходимой пленки в зависимости от размеров и формы поверхностей, подлежащих обработке . Также важно выбрать надежного поставщика, предлагающего качественную продукцию с возможностью доставки и оплаты, удобными для покупателя.
При покупке полиуретановой пленки необходимо проверить ее качество и соответствие необходимым стандартам таким, как эластичность, адгезия и устойчивость к износу . Правильный выбор полиуретановой пленки и ее применение позволят повысить качество и долговечность изделий и конструкций за счет уменьшения количества необходимых ремонтных работ .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
В 2025 году онлайн-казино на реальные деньги переживают настоящий бум инноваций. Среди свежих сайтов появляются опции с быстрыми выводами, принятием крипты и усиленной защитой, по данным специалистов casino.ru. В топе значится 1xSlots, предлагающий уникальные бонусы и 150 бесплатных спинов без вклада с кодом MURZIK. Pinco Casino выделяется быстрыми выплатами и 50 фриспинами за депозит 500 рублей. Vavada предлагает ежедневные состязания и 100 фриспинов без промокода. Martin Casino 2025 выделяется VIP-системой с личным менеджером и 100 фриспинами. Не отстает Kush Casino с уникальной бонусной системой. Ищете топ 10 казино? Посетите casino10.fun – здесь собраны проверенные варианты с лицензиями. Отдавайте предпочтение сайтам с высоким рейтингом для надежной и прибыльной игры. Будьте ответственны: азарт – это развлечение, а не способ заработка. Получайте удовольствие от игр в предстоящем году!
Онлайн магазин – купить мефедрон, кокаин, бошки
займы все https://zaimy-29.ru/ .
купить диплом массажиста купить диплом массажиста .
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
https://images.google.com.au/url?q=https://goldenreelslogin.com – Golden Reels Casino – the best casino in Australia
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Обязательно попробуйте https://jcsyardcare.com/hello-world/#comment-666
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Ищете окна ПВХ различных видов в Санкт-Петербурге и области? Посетите сайт https://6423705.ru/ Компании УютОкна которая предлагает широкий ассортимент продукции по выгодной стоимости с быстрыми сроками изготовления и профессиональным монтажом. При необходимости воспользуйтесь онлайн калькулятором расчета стоимости окон ПВХ.
разработка проекта водопонижения proekt-vodoponizheniya.ru .
Geo-gdz.ru – ваш бесплатный портал в мир знаний! Ищете школьные учебники, атласы или контурные карты? Все это найдете у нас! Мы полезную и актуальную информацию предлагаем, решебники включая (к примеру, для 7 класса по геометрии Атанасяна). Ищете Геометрия 9 класс? Geo-gdz.ru – ваш в учебе помощник. На портале для печати контурные карты представлены. Все картинки отменного качества. Предлагаем вашему вниманию по русскому языку для 1-4 классов пособия. Учебники по истории онлайн можете читать. Загляните на geo-gdz.ru. Учитесь с удовольствием!
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Онлайн магазин – купить мефедрон, кокаин, бошки
Популярная компания «JapanExpert» рекомендует воспользоваться такой важной и полезной услугой, как выкуп и доставка автомобилей с аукционов Кореи, Китая и Японии. На сайте https://japanexpert.ru изучите то, какие преимущества вы получите, если воспользуетесь услугами этой компании. Для того чтобы подобрать оптимальный вариант, необходимо обозначить марку, модель, а также год выпуска автомобиля.
GuardComplete https://guardcomplete.com/ is a crypto ad network for Web3 projects. We help advertisers promote exchanges, DeFi, and NFT services with targeted crypto audiences. Publishers can monetize traffic and get paid in Bitcoin. Fast setup, no KYC, no delays — simple and effective.
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
дом из клееного бруса проекты и цены
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
طيار لعبة الرهان لعبة JetX هي واحدة من ألعاب كراش التحطم الشهيرة والتي اكتسبت شهرة كبيرة بين اللاعبين. تعمل اللعبة على أجهزة الموبايل والكمبيوتر والأجهزة اللوحية، ويتوفر نسخة تجريبية من اللعبة في أفضل مواقع العاب كراش التحطم التي نوصب بها. فكرة اللعبة هي نفسها في العاب التحطم حيث تبدأ طائرة في الطيران من نقطة الصفر، ويزداد المضاعف تدريجيًا، وعليك سحب الأرباح قبل أن تتحطم الطائرة. تجمع لعبة الطيارة 1xBet بين الإثارة والفرصة، مما يجعلها واحدة من الألعاب المفضلة لدى العديد من اللاعبين في مصر وباقي أنحاء العالم. ومع تقديم 1xBet لهذه اللعبة، أصبح بإمكان اللاعبين الاستمتاع بتجربة فريدة من نوعها تجمع بين التسلية والربح المحتمل.
https://rhutoindia.com/1970/01/01/%d9%85%d8%b1%d8%a7%d8%ac%d8%b9%d8%a9-%d9%84%d8%b9%d8%a8%d8%a9-buffalo-king-megaways-%d9%81%d9%8a-%d9%86%d8%b3%d8%ae%d8%a9-%d8%a7%d9%84%d9%85%d8%aa%d8%b5%d9%81%d8%ad-%d9%84%d9%84%d8%a7%d8%b9%d8%a8/
فيما يلي، ستجد ملخصًا مجدول لما تنطوي عليه العلامة التجارية الشهيرة: The Little Plane that Wins Money Game هي لعبة كازينو ذات قواعد مباشرة وتقلبات متوسطة، وهي لعبة ممتعة. إنها RTP (عودة للاعب) 97% ، مما يعني أن كل رهان لديه فرصة للفوز في لعبة المقامرة. التصميم سهل الاستخدام وسهل الفهم للجميع. هناك طائرة حمراء تقلع بسرعة وتبدأ في إضافة المضاعفات كل ثانية في الرحلة. يظهر المقياس الأحمر على خلفية سوداء مساره ، بحيث يمكن للاعبين رؤية اللحظة الأكثر خطورة أثناء وقت اللعب.
Крайне советую https://sandwichgarden.ca/hello-world/#comment-92
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
дом из клееного бруса купить
Estou completamente vidrado por PagolBet Casino, parece uma tempestade de diversao. A gama do cassino e simplesmente uma faisca, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e uma voltagem alta, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como um trovao, as vezes mais recompensas no cassino seriam um diferencial brabo. Na real, PagolBet Casino garante uma diversao de cassino que e uma tempestade para quem curte apostar com estilo no cassino! Vale falar tambem a navegacao do cassino e facil como uma faisca, da um toque de voltagem braba ao cassino.
pagolbet reclame aqui|
Ich bin suchtig nach PlayJango Casino, es verstromt eine Spielstimmung, die wie ein Feuerwerk explodiert. Die Auswahl im Casino ist ein echtes Spektakel, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Der Casino-Service ist zuverlassig und strahlend, liefert klare und schnelle Losungen. Auszahlungen im Casino sind schnell wie ein Sturm, manchmal die Casino-Angebote konnten gro?zugiger sein. Zusammengefasst ist PlayJango Casino ein Casino, das man nicht verpassen darf fur Abenteurer im Casino! Ubrigens die Casino-Plattform hat einen Look, der wie ein Blitz funkelt, was jede Casino-Session noch aufregender macht.
playjango forum|
Adoro a explosao de Bet558 Casino, oferece uma aventura de cassino que orbita como um cometa veloz. Tem uma chuva de meteoros de jogos de cassino irados, com slots de cassino tematicos de espaco profundo. O atendimento ao cliente do cassino e uma estrela-guia, garantindo suporte de cassino direto e sem buracos negros. Os saques no cassino sao velozes como uma viagem interestelar, mas mais giros gratis no cassino seria uma loucura cosmica. Em resumo, Bet558 Casino e um cassino online que e uma galaxia de diversao para os astronautas do cassino! Vale dizer tambem o site do cassino e uma obra-prima de estilo estelar, torna a experiencia de cassino uma viagem espacial.
bet558 com caça niqueis|
Je suis accro a PokerStars Casino, ca degage une ambiance de jeu aussi intense qu’un tournoi de poker. La selection du casino est une constellation de delices, avec des machines a sous de casino modernes et envoutantes. L’assistance du casino est fiable et astucieuse, repondant en un eclair strategique. Les paiements du casino sont securises et fluides, mais plus de tours gratuits au casino ce serait un full house. Pour resumer, PokerStars Casino promet un divertissement de casino strategique pour les amoureux des slots modernes de casino ! Bonus la navigation du casino est intuitive comme une strategie gagnante, ajoute une touche de panache au casino.
tГ©lГ©charger pokerstars android|
Онлайн магазин – купить мефедрон, кокаин, бошки
Acho simplesmente brabissimo PagolBet Casino, e um cassino online que detona como um trovao. A gama do cassino e simplesmente uma faisca, com jogos de cassino perfeitos pra criptomoedas. O servico do cassino e confiavel e brabo, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um trovao, mesmo assim mais recompensas no cassino seriam um diferencial brabo. No fim das contas, PagolBet Casino vale demais explorar esse cassino para os aventureiros do cassino! De lambuja o site do cassino e uma obra-prima de estilo, faz voce querer voltar pro cassino como um raio.
pagolbet site|
Crown Metropol Perth is a luxury hotel located near the Swan River. It offers modern rooms, a stunning pool area, fine dining, a casino, and entertainment options: official Crown Metropol Perth website
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
дома из клееного бруса под ключ проекты и цены
https://belroxx.ru
Офіційний онлайн-кінотеатр для вечорів, коли хочеться зануритись у світ кіно без реєстрації та зайвих клопотів. Фільми, серіали, мультики та шоу всіх жанрів зібрані у зручних рубриках для швидкого вибору. Заходьте на https://filmyonlayn.com/ і починайте перегляд уже сьогодні. Оберіть бойовик, драму чи комедію — ми підкажемо, що подивитись далі, аби вечір був справді вдалим.
https://jolna.ru
Очень советую https://www.sdlasertag.com/metus-vitae-pharetra-auctor/#comment-40448
https://artstroy-sk.online
https://astradamovskoe.online
https://qatru.ru
https://3265740.ru
https://artstroy-sk.online
https://dzheff-kavaler.ru
Добрый день, коллеги!
Недавно столкнулся с организацией корпоративного мероприятия для строительной компании. Заказчик настаивал на статусном оформлении.
Сложность заключалась что нужно было много посадочных мест для 100+ участников. Приобретение нецелесообразно.
Выручила аренда мебели – взяли современные стулья. Кстати, наткнулся на интересную статью про решения для строительных компаний – там дельные идеи.
Клиент остался доволен. Рекомендую всем кто планирует корпоративы в стройсфере.
Процветания компаниям!
Hi all. I’m considering Rainbet and would value first-hand input from people who actually used it. Not affiliated – just trying to understand how it works in practice.
Were your withdrawals timely? Any hold-ups?
How strict is KYC?
Any tricky terms to watch for?
How helpful was support?
Would you use it again?
Appreciate any insights. Details help others too. No referral codes, please.
https://lomtrer.ru
https://cookandyou.ru
Посетите сайт Mayscor https://mayscor.ru/ и вы найдете актуальную информацию о спортивных результатах и расписание матчей различных видов спорта – футбол, хоккей, баскетбол, теннис, киберспорт и другое. Также мы показываем прямые трансляции спортивных событий, включая такие топовые турниры. Подробнее на сайте.
Обязательно попробуйте https://erierealms.com/hello-world/#comment-2891
купить диплом медсестры купить диплом медсестры .
https://brandsforyou.ru
https://dreamtime24.ru
дома из клееного бруса
https://1fab.ru/
https://ekspertiza66.online
https://artstroy-sk.online
Hi all. I’m researching Rainbet and would value unbiased input from people who actually used it. No promo here – just trying to understand how it works in practice.
Were your withdrawals timely? Any limits or delays?
How strict is KYC?
Do bonuses have fair wagering?
Did support resolve issues?
Would you use it again?
Appreciate any insights. Specifics are helpful. Please avoid sharing refs.
https://alexandrmusihin.online
накрутка подписчиков в тг бот
проект водопонижения скважинами http://vodoponizhenie-proekt.ru/ .
проект водопонижения котлована в грунтовых водах http://www.vodoponizhenie-proektirovanie.ru .
https://centercreative.ru
https://domovoym.ru
https://falmex.ru
Бездепозитные бонусы — лёгкий вариант познакомиться со слотами без пополнения. Новые игроки получают фриспины или деньги c условиями отыгрыша, а затем могут вывести выигрыш при соблюдении правил. Свежие акции и бонус-коды мы публикуем на ресурсе Ищете игровые автоматы регистрация с бездепозитным бонусом? На casinotopbonusi6.space/ — смотрите сводную таблицу и выбирайте надёжные клубы. Сверяйтесь с условиями бонуса, верифицируйте контактные данные, не создавайте дубликаты аккаунтов. Относитесь к игре осознанно, без ожидания гарантированного дохода.
https://gabibovcenter.ru
Российская мода выделяется уникальностью и интересной культурой.
Нынешние модельеры черпают идеи в этнических мотивах, создавая яркие образы.
На подиумах всё чаще представлены необычные комбинации фактур.
Отечественные дизайнеры поддерживают экологичный подход к созданию одежды.
tatyana kochnova
Аудитория всё больше ценит новые бренды из России.
Журналы о моде публикуют о новых тенденциях и создателях.
Перспективные таланты обретают известность как в стране, так и за границей.
В итоге российская мода продолжает расти, объединяя культуру и современность.
Je suis fou de Posido Casino, ca degage une ambiance de jeu aussi fluide qu’un courant oceanique. Les options de jeu au casino sont riches et fluides, avec des machines a sous de casino modernes et immersives. Les agents du casino sont rapides comme une vague deferlante, repondant en un eclat d’ecume. Les gains du casino arrivent a une vitesse de maree, parfois des recompenses de casino supplementaires feraient nager de joie. Pour resumer, Posido Casino est un casino en ligne qui fait des vagues pour ceux qui cherchent l’adrenaline fluide du casino ! En plus la navigation du casino est intuitive comme un courant marin, ce qui rend chaque session de casino encore plus fluide.
posido casino bonus|
https://eluapelsin.online
Feringer.shop — официальный интернет-бутик печей для бани и сауны с гарантийной поддержкой и доставкой по России. В каталоге — решения для русской бани, финской сауны и хаммама, с каменной облицовкой и VORTEX для стремительного прогрева. Перейдите на сайт https://feringer.shop/ для выбора печи и консультации. Ждём в московском шоу руме: образцы в наличии и помощь в расчёте мощности.
https://dami116.ru
Drinks-dubai.ru — для тех, кто ценит оперативность и честный выбор: от лагеров Heineken и Bud до элитных виски Chivas и Royal Salute, просекко и шампанского. Магазин аккуратно структурирован по категориям, видно остатки, цены и спецификации, а оформление заказа занимает минуты. Зайдите на https://drinks-dubai.ru/ и соберите сет под событие: пикник, бранч или долгожданный матч. Поддержка на связи, доставка по Дубаю быстрая, а бренды — узнаваемые и надежные.
https://better-rf.ru
https://alexandrmusihin.online
https://chdetsad33.ru
https://camry-toyota.ru
https://dreamtime24.ru
Советую https://longdengiare.com/hello-world/#comment-24
https://alfa-promotion.online
Хотите выйти в море без хлопот и переплат? В Сочи Calypso собрал большой выбор парусников, катеров, яхт и теплоходов с актуальными фото, полным описанием и честными ценами. Поиск по портам Сочи, Адлера и Лазаревки, круглосуточная поддержка и выгодные акции для долгой аренды упрощают выбор судна для прогулки, рыбалки или морского круиза. Бронируйте на https://sochi.calypso.ooo — и встречайте рассвет на волнах уже на этой неделе. Дополнительно можно обсудить детали напрямую с владельцем и гибко настроить маршрут под ваш план отдыха.
https://tinyurl.com/235byoqh qzf
https://qatru.ru
услуги промышленного альпинизма спб
https://kitehurghada.ru/
https://centrems.ru
https://brusleebar.ru
https://better-rf.ru
купить диплом прораба купить диплом прораба .
купить диплом бакалавра https://www.rudik-diplom2.ru – купить диплом бакалавра .
https://centrems.ru
https://freski63.online
https://artstroy-sk.online
J’adore l’eclat de PlazaRoyal Casino, on dirait un palais de plaisirs. La selection du casino est une parade de delices, offrant des sessions de casino en direct qui eblouissent. L’assistance du casino est chaleureuse et irreprochable, avec une aide qui rayonne comme une couronne. Les retraits au casino sont rapides comme une procession royale, par moments les offres du casino pourraient etre plus genereuses. Au final, PlazaRoyal Casino est un joyau pour les fans de casino pour les passionnes de casinos en ligne ! De surcroit la plateforme du casino brille par son style souverain, donne envie de replonger dans le casino sans fin.
royal plaza casino almaty|
Ich finde absolut majestatisch Richard Casino, es bietet ein Casino-Abenteuer, das wie ein Thron funkelt. Die Spielauswahl im Casino ist wie ein koniglicher Schatz, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein koniglicher Hofstaat, mit Hilfe, die wie ein Thron majestatisch ist. Casino-Zahlungen sind sicher und reibungslos, dennoch die Casino-Angebote konnten gro?zugiger sein. Insgesamt ist Richard Casino ein Casino mit einem Spielspa?, der wie ein Thron funkelt fur die, die mit Stil im Casino wetten! Extra die Casino-Seite ist ein grafisches Meisterwerk, was jede Casino-Session noch prachtiger macht.
james bond casino royale richard branson|
J’adore la houle de Winamax Casino, ca degage une ambiance de jeu aussi fluide qu’un courant oceanique. Le repertoire du casino est un recif de divertissement, comprenant des jeux de casino adaptes aux cryptomonnaies. L’assistance du casino est chaleureuse et limpide, repondant en un eclat d’ecume. Les paiements du casino sont securises et fluides, quand meme les offres du casino pourraient etre plus genereuses. En somme, Winamax Casino promet un divertissement de casino aquatique pour les passionnes de casinos en ligne ! De surcroit l’interface du casino est fluide et eclatante comme une mer turquoise, facilite une experience de casino aquatique.
offre winamax|
https://astradamovskoe.online
https://kafroxie.ru
Ich bin vollig begeistert von Richard Casino, es bietet ein Casino-Abenteuer, das wie ein Thron funkelt. Die Auswahl im Casino ist ein wahres Kronungsjuwel, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Die Casino-Mitarbeiter sind schnell wie ein kaiserlicher Bote, sorgt fur sofortigen Casino-Support, der beeindruckt. Casino-Transaktionen sind simpel wie ein kaiserlicher Befehl, manchmal mehr regelma?ige Casino-Boni waren furstlich. Alles in allem ist Richard Casino ein Muss fur Casino-Fans fur Fans von Online-Casinos! Nebenbei die Casino-Plattform hat einen Look, der wie ein Kronungsmantel glanzt, den Spielspa? im Casino auf ein konigliches Niveau hebt.
richard casino no deposit bonus code 2025 australia|
проект водоотлива и водопонижения https://www.proekt-na-vodoponijenie.ru .
медицинская техника http://medoborudovanie-msk.ru .
https://cosmeticsnail.ru
https://domovoym.ru
https://camry-toyota.ru
This is my first time pay a quick visit at here and i am really pleassant to read everthing at alone place.
Bi-LED
https://armada-spec.online
https://a-t-w.ru/
Найти барбершоп красноярск 78 добровольческой бригады теперь проще, чем когда-либо, благодаря современным сервисам и онлайн-картам.
Барбершоп – это место, где мужчина может почувствовать себя настоящим мужчиной . Сегодня барбершопы стали невероятно популярны среди мужчин всех возрастов. Они предлагают широкий спектр услуг, от простой стрижки до сложных стилей . Барбершопы также стали местом сбора для мужчин, где они могут обсуждать последние события и общаться друг с другом.
Барбершоп – это не просто место для стрижки, это целый опыт . Барбершопы оборудованы современным оборудованием и??ами, что позволяет мастерам создавать сложные и уникальные прически. Мастера барбершопов используют только высококачественные инструменты и средства .
Барбершоп является местом, где мужчины могут найти свой уникальный образ. Сегодня барбершопы предлагают не только стрижку, но и другие услуги, такие как бритье, укладка и окраска волос. Барбершопы предоставляют индивидуальный подход к каждому клиенту. Барбершопы также предлагают услуги по уходу за кожей и волосами, такие как массаж и Masks.
Барбершоп – это место, где мужчина может почувствовать себя настоящим мужчиной . Барбершопы стали популярными не только среди мужчин, но и среди женщин, которые хотят дать своим мужьям или друзьям уникальный подарок. Барбершопы предоставляют возможность бронировать услуги онлайн . Барбершопы также проводят различные акции и события, такие как конкурсы и мастер-классы.
Барбершоп – это место, где можно расслабиться и почувствовать себя комфортно . Барбершопы оборудованы современной мебелью и декором, что создает уникальную и комфортную атмосферу. Барбершопы имеют современные музыкальные системы и телевизоры . Барбершопы также предлагают напитки и закуски, такие как кофе и пиво.
Барбершоп – это место, где мужчина может почувствовать себя частью сообщества . Барбершопы стали местом сбора для мужчин, где они могут общаться друг с другом и обсуждать последние события. Барбершопы имеют систему лояльности для постоянных клиентов . Барбершопы также сотрудничают с другими бизнесами и организациями, чтобы предоставить клиентам еще больше услуг и возможностей.
Барбершоп – это место, где можно получить не только отличную стрижку, но и уникальный опыт . Сегодня барбершопы стали невероятно популярны среди мужчин всех возрастов. Барбершопы предоставляют возможность мужчинам выглядеть стильно и современно . Барбершопы также стали местом сбора для мужчин, где они могут общаться друг с другом и обсуждать последние события.
Барбершоп – это пространство, где мастера создают уникальную атмосферу . Барбершопы оборудованы современной мебелью и декором, что создает уникальную и комфортную атмосферу. Барбершопы предоставляют возможность клиентам пользоваться Wi-Fi . Барбершопы также предлагают напитки и закуски, такие как кофе и пиво.
https://freski63.online
Предлагаю https://konakueche.com/?p=1050&lang=de#comment-181284
Сегодня важно освоить обучение seo с нуля, чтобы стать конкурентоспособным специалистом в области интернет-маркетинга.
стали основным инструментом для продвижения сайтов в поисковых системах . Это связано с их способностью обеспечить достойный уровень конкуренции на рынке. Поэтому, многие веб-мастера и владельцы сайтов стремятся расширить свои знания в этой области.
Прохождение SEO курсов обеспечивает возможность повысить уровень конкуренции на рынке. Это связано с тем, что такие курсы предлагают комплексный подход к обучению . Кроме того, SEO курсы дают возможность получить практический опыт .
SEO курсы покрывают широкий спектр тем и вопросов . Это связано с тем, что для успешного продвижения сайта требуется комплексный подход к оптимизации. Основные темы, которые рассматриваются в рамках SEO курсов включают в себя создание качественного и оптимизированного контента .
Однако, не все SEO курсы имеют одинаковые цели и задачи . Поэтому, при выборе курса, необходимо внимательно изучить программу и содержание . Это позволит обеспечить высокий уровень профессиональных знаний и навыков.
Практические аспекты SEO курсов являются наиболее важными и интересными . Это связано с тем, что в процессе обучения, участники могут работать над реальными проектами . Кроме того, такие курсы обеспечивают возможность повысить уровень конкуренции на рынке.
SEO курсы также дают возможность присоединиться к сообществу профессионалов . Это связано с тем, что многие курсы сотрудничают с известными компаниями и организациями . Поэтому, прохождение SEO курса может стать важным шагом в карьере .
Заключение и перспективы SEO курсов включают в себя анализ результатов и перспектив . Это связано с тем, что после прохождения курса, могут получить новую работу или nangрадить уровень зарплаты . Кроме того, SEO курсы предлагают возможность получить постоянную поддержку и обновление знаний .
SEO курсы представляют собой наиболее ценный и полезный опыт получения знаний и навыков в области SEO. Поэтому, если вы хотите стать известным экспертом в области SEO , то SEO курс является наиболее подходящим и эффективным вариантом .
https://arcada-med.online
buy ball bearings Buy Angular Contact Ball Bearing When handling combined loads, angular contact ball bearings are the ideal choice. They are designed with an angle that allows them to support both radial and axial loads in one direction. If you are looking to buy angular contact ball bearings, our selection includes a variety of sizes and designs to match your specific needs. These bearings excel in applications such as machine tools, rotary tables, and pumps. Invest in quality angular contact ball bearings to enhance the reliability and efficiency of your mechanical systems.
стоимость проектирования водопонижения https://www.proektirovanie-vodoponizheniya.ru .
Для тех, кто ищет удобную опцию заказ алкоголя на дом, существует множество вариантов обслуживания.
позволяет получать любимые напитки в любое время суток . Это удобная услуга обеспечивает доставку прямо домой. Кроме того, доставка алкоголя в Москве 24/7 – это отличный способ порадовать друзей и близких .
Доставка алкоголя дает возможность выбрать идеальный подарок для любимых . Услуга не требует похода в магазин и траты времени на выбор . Благодаря быстрой доставке жители Москвы получают только положительные эмоции .
Преимущества доставки алкоголя в Москве 24/7 включают в себя удобство и быструю доставку . Главное достоинство доставки алкоголя 24/7 – это возможность получить напитки в любое время суток . Кроме того, доставка алкоголя в Москве 24/7 позволяет избежать длинных очередей .
Услуга позволяет получать качественные напитки. Доставка алкоголя в любое время суток . Жители Москвы могут наслаждаться напитками без перерывов.
Доставка алкоголя в Москве 24/7 предоставляет услугу высокого качества. Для начала следует указать адрес доставки. После этого выбранные товары упаковываются.
Доставка алкоголя осуществляется d?i команды профессиональных курьеров . Услуга доставки алкоголя в Москве 24/7. Доставка напитков позволяет получать напитки в любое время суток.
Доставка алкоголя в Москве 24/7 дает возможность наслаждаться вечеринками без перерывов. Эта услуга обеспечивает доставку прямо домой. Услуга доставки алкоголя в Москве 24/7.
Доставка алкоголя позволяет получать напитки быстро. Услуга дает возможность выбрать идеальный подарок для любимых . Жители Москвы находятся в выигрыше от этой услуги .
buy deep groove ball bearings Where Can I Buy Ball Bearings Finding a reliable source to buy ball bearings can be challenging. Fortunately, our platform simplifies the process by offering a comprehensive selection of ball bearings for every application. You can browse through our extensive inventory, compare products, and read customer reviews to make an informed purchase. With competitive prices and fast shipping, there’s no better place to buy ball bearings than with us. If you’re wondering, “where can I buy ball bearings?” the answer is right here!
Ищете тералиджен от чего помогает? Посетите страницу empathycenter.ru/preparations/t/teralidzhen/ там вы найдете показания к применению, побочные эффекты, отзывы, а также как оно применяется для лечения более двадцати психических заболеваний и еще десяти несвязанных патологий вроде кожного зуда или кашля. Узнайте историю этого средства, а также то, эффективно ли оно при лечении заболеваний.
Алкоголь ночью с доставкой на дом в Москве. Работаем 24/7, когда обычные магазины закрыты. Широкий ассортимент: пиво, сидр, вино, шампанское, крепкие напитки. Быстрая доставка в пределах МКАД за 30-60 минут: доставка алкоголь москва
Посетите сайт https://psyhologi.pro/ и вы получите возможность освоить востребованную профессию, такую как психолог-консультант. Мы предлагаем курсы профессиональной переподготовки на психолога с дистанционным обучением. Узнайте больше на сайте что это за профессия, модули обучения и наших практиков и куратора курса.
купить диплом техникума строительного http://www.educ-ua7.ru/ .
купить диплом массажиста купить диплом массажиста .
AlcoholDubaiEE — витрина, где премиальные позиции встречают демократичные хиты: Hennessy VS и XO, Jose Cuervo, Johnnie Walker Red Label, Bacardi Breezer, Smirnoff Ice, Chablis и Sauvignon Blanc. Страницы с товарами содержат происхождение, выдержку, отзывы и дегустационные заметки, что упрощает выбор. Оформляйте заказы с понятными ценами в долларах и быстрой доставкой по городу. Откройте ассортимент на https://alcoholdubaee.com/ и подберите бутылку к ужину, сет к вечеринке или подарок с характером.
Компания «Технология Кровли» предлагает профессиональные услуги, связанные с проведением кровельных работ. Причем заказать услугу можно как в Москве, так и по области. Все монтажные работы выполняются качественно, на высоком уровне и в соответствии с самыми жесткими требованиями. На сайте https://roofs-technology.com/ уточните то, какими услугами вы сможете воспользоваться, если заручитесь поддержкой этой компании.
как накрутить подписчиков в телеграм канале ботов
доставка алкоголя круглосуточно недорого http://www.alcohub9.ru .
купить диплом о высшем образовании с реестром купить диплом о высшем образовании с реестром .
где можно купить диплом техникум где можно купить диплом техникум .
Ich finde absolut uberwaltigend Platin Casino, es verstromt eine Spielstimmung, die wie Platin glanzt. Die Auswahl im Casino ist ein echtes Meisterwerk, mit einzigartigen Casino-Slotmaschinen. Das Casino-Team bietet Unterstutzung, die wie ein Juwel funkelt, sorgt fur sofortigen Casino-Support, der beeindruckt. Der Casino-Prozess ist klar und ohne Schatten, ab und zu mehr Freispiele im Casino waren ein Volltreffer. Zusammengefasst ist Platin Casino ein Casino mit einem Spielspa?, der wie ein Edelstein funkelt fur Spieler, die auf luxuriose Casino-Kicks stehen! Und au?erdem die Casino-Seite ist ein grafisches Meisterwerk, einen Hauch von Glanz ins Casino bringt.
platin casino affiliate|
Estou completamente vidrado por BetorSpin Casino, da uma energia de cassino que e puro pulsar galactico. A selecao de titulos do cassino e um buraco negro de diversao, com caca-niqueis de cassino modernos e hipnotizantes. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como uma viagem interestelar, mesmo assim as ofertas do cassino podiam ser mais generosas. Resumindo, BetorSpin Casino garante uma diversao de cassino que e uma supernova para quem curte apostar com estilo estelar no cassino! De lambuja o design do cassino e um espetaculo visual intergalactico, faz voce querer voltar ao cassino como um cometa em orbita.
betorspin bingo|
купить диплом колледжа с занесением в реестр в купить диплом колледжа с занесением в реестр в .
Ich bin suchtig nach Pledoo Casino, es verstromt eine Spielstimmung, die wie ein Regenbogen glitzert. Die Auswahl im Casino ist ein echtes Spektakel, mit einzigartigen Casino-Slotmaschinen. Die Casino-Mitarbeiter sind schnell wie ein Blitzstrahl, antwortet blitzschnell wie ein Donnerschlag. Casino-Gewinne kommen wie ein Komet, aber mehr Freispiele im Casino waren ein Volltreffer. Am Ende ist Pledoo Casino eine Casino-Erfahrung, die wie ein Regenbogen glitzert fur die, die mit Stil im Casino wetten! Und au?erdem die Casino-Oberflache ist flussig und strahlt wie ein Polarlicht, das Casino-Erlebnis total elektrisiert.
pledoo partners|
В эпоху стремительного развития искусственного интеллекта технологии вроде ChatGPT революционизируют нашу повседневную жизнь, предлагая инструменты для генерации текстов, анализа данных и даже творчества. Эти нейросети, основанные на моделях глубокого обучения, позволяют пользователям быстро создавать контент, решать сложные задачи и оптимизировать бизнес-процессы, делая ИИ доступным для всех. Если вы интересуетесь последними новинками в этой сфере, загляните на https://gptneiro.ru где собраны актуальные материалы по теме. Кроме того, важно подчеркнуть, что ИИ не просто облегчает повседневные дела, но и раскрывает свежие перспективы в обучении, здравоохранении и досуге, при этом провоцируя споры об этических аспектах и перспективах занятости. В целом, искусственный интеллект обещает стать неотъемлемой частью общества, стимулируя инновации и прогресс.
можно купить диплом медсестры можно купить диплом медсестры .
купить диплом техникума многих купить диплом техникума многих .
Ich bin suchtig nach SlotClub Casino, es pulsiert mit einer schillernden Casino-Energie. Die Auswahl im Casino ist ein echtes Lichtspektakel, mit Live-Casino-Sessions, die wie ein Stroboskop blinken. Der Casino-Support ist rund um die Uhr verfugbar, mit Hilfe, die wie ein Laser zielt. Casino-Transaktionen sind simpel wie ein Schalter, trotzdem mehr Freispiele im Casino waren ein Volltreffer. Kurz gesagt ist SlotClub Casino ein Casino mit einem Spielspa?, der wie ein Blitz einschlagt fur Spieler, die auf leuchtende Casino-Kicks stehen! Ubrigens die Casino-Navigation ist kinderleicht wie ein Lichtschalter, Lust macht, immer wieder ins Casino zuruckzukehren.
slotclub spielbank|
Je suis accro a Spinsy Casino, ca vibre avec une energie de casino electrisante. Le repertoire du casino est un dancefloor de divertissement, offrant des sessions de casino en direct qui pulsent comme un beat. L’assistance du casino est chaleureuse et fluide, assurant un support de casino immediat et dansant. Le processus du casino est transparent et sans fausse note, quand meme des bonus de casino plus frequents seraient groovy. Dans l’ensemble, Spinsy Casino promet un divertissement de casino electrisant pour ceux qui cherchent l’adrenaline rythmee du casino ! Bonus la plateforme du casino brille par son style funky, amplifie l’immersion totale dans le casino.
spinsy casino france|
Ich bin total hingerissen von SlotClub Casino, es pulsiert mit einer schillernden Casino-Energie. Die Spielauswahl im Casino ist wie ein funkelnder Regenbogen, mit modernen Casino-Slots, die einen hypnotisieren. Die Casino-Mitarbeiter sind schnell wie ein Blitzstrahl, ist per Chat oder E-Mail erreichbar. Der Casino-Prozess ist klar und ohne Flackern, trotzdem die Casino-Angebote konnten gro?zugiger sein. Zusammengefasst ist SlotClub Casino ein Muss fur Casino-Fans fur Fans moderner Casino-Slots! Nebenbei die Casino-Plattform hat einen Look, der wie ein Laserstrahl funkelt, den Spielspa? im Casino in die Hohe treibt.
slotclub|
Acho simplesmente magnifico Richville Casino, tem uma vibe de jogo tao sofisticada quanto uma mansao de ouro. A gama do cassino e um verdadeiro palacio de delicias, com slots de cassino tematicos de luxo. O servico do cassino e confiavel e majestoso, dando solucoes precisas e imediatas. As transacoes do cassino sao simples como abrir um cofre, de vez em quando as ofertas do cassino podiam ser mais generosas. Resumindo, Richville Casino vale a pena explorar esse cassino com urgencia para os apaixonados por slots modernos de cassino! De bonus o site do cassino e uma obra-prima de elegancia, adiciona um toque de sofisticacao ao cassino.
richville federated group of companies|
купить активных подписчиков в телеграм
Нужна лабораторная? сделать лабораторную работу на заказ Индивидуальный подход, проверенные решения, оформление по требованиям. Доступные цены и быстрая помощь.
Нужна презентация? заказать презентацию в powerpoint Красочный дизайн, структурированный материал, уникальное оформление и быстрые сроки выполнения.
Нужен чертеж? сколько стоит чертеж на заказ выполним чертежи для студентов на заказ. Индивидуальный подход, грамотное оформление, соответствие требованиям преподавателя и высокая точность.
https://marmok-store.ru/
Whenever participating in internet gaming, it is crucial to define boundaries on your activity.
Mindful gaming means keeping track of your hours and spending.
Always remember to treat it as entertainment rather than a way to earn money.
Apply the safety features many platforms provide to help you maintain control.
It’s helpful to take breaks regularly and review your gaming habits.
https://www.futurelearn.com/profiles/22712108
Seek support or advice if you experience difficulties with your play.
Discussing your gaming limits with friends or family can boost your self-awareness.
By practicing safe gaming, you get i-gaming while maintaining your health.
Приветствую всех!
Недавно столкнулся с оформлением интерьера дома. Понял, что грамотное размещение предметов – это особое умение.
Читал материалы и нашел отличную статью про организацию интерьера. Там детально разобрано как выбирать стиль.
Полезными оказались разделы про выбор декора и аксессуаров. Теперь знаю как стильно оформить пространство для отдыха.
Всем любителям интерьера – практичные советы! полезная площадка для обмена опытом!
Вдохновения в творчестве
Добро пожаловать!
Хочу поделиться опытом с созданием уютного пространства в помещении. Оказалось, что грамотное размещение предметов – это особое умение.
Читал материалы и обнаружил отличную статью про создание стильного пространства. Там детально разобрано как сочетать элементы.
Заинтересовали моменты про выбор декора и аксессуаров. Теперь знаю как правильно обустроить уютный уголок.
Всем любителям интерьера – качественная информация! качественное сообщество для вдохновения!
Удачи в обустройстве
Ищете окна ПВХ различных видов в Санкт-Петербурге и области? Посетите сайт https://6423705.ru/ Компании УютОкна которая предлагает широкий ассортимент продукции по выгодной стоимости с быстрыми сроками изготовления и профессиональным монтажом. При необходимости воспользуйтесь онлайн калькулятором расчета стоимости окон ПВХ.
Vavada Casino is considered a top gambling brand.
Exclusive no deposit bonuses allow you to play without risks.
Regular events bring excitement.
Entertainment options features leading providers.
Simple account creation, and gameplay starts immediately.
Check the details here: vavada registration
Acho simplesmente estelar BetorSpin Casino, da uma energia de cassino que e puro pulsar galactico. A selecao de titulos do cassino e um buraco negro de diversao, com caca-niqueis de cassino modernos e hipnotizantes. O servico do cassino e confiavel e brilha como uma galaxia, acessivel por chat ou e-mail. As transacoes do cassino sao simples como uma orbita lunar, mesmo assim mais bonus regulares no cassino seria intergalactico. Em resumo, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os apaixonados por slots modernos de cassino! E mais o site do cassino e uma obra-prima de estilo estelar, adiciona um toque de brilho estelar ao cassino.
betorspin gГјncel giriЕџ|
Je trouve absolument delirant Spinsy Casino, ca vibre avec une energie de casino electrisante. Les options de jeu au casino sont riches et rythmees, proposant des slots de casino a theme disco. Le personnel du casino offre un accompagnement digne d’un DJ, repondant en un eclair rythmique. Les paiements du casino sont securises et fluides, par moments les offres du casino pourraient etre plus genereuses. Au final, Spinsy Casino c’est un casino a rejoindre sans tarder pour les joueurs qui aiment parier avec style au casino ! Par ailleurs la navigation du casino est intuitive comme une choregraphie, ajoute une touche de groove au casino.
spinsy casino greece|
медицинская аппаратура медицинская аппаратура .
проект водопонижения строительной площадки проект водопонижения строительной площадки .
J’adore le rythme de Spinsy Casino, il propose une aventure de casino qui tourbillonne comme un spot lumineux. La selection du casino est une explosion de delices dansants, avec des machines a sous de casino modernes et hypnotiques. Le service client du casino est une star du dancefloor, joignable par chat ou email. Les retraits au casino sont rapides comme un breakdance, parfois les offres du casino pourraient etre plus genereuses. Pour resumer, Spinsy Casino est une pepite pour les fans de casino pour les danseurs du casino ! A noter la navigation du casino est intuitive comme une choregraphie, facilite une experience de casino electrisante.
spinsy casino license|
Sou louco pela energia de BetorSpin Casino, oferece uma aventura de cassino que orbita como um cometa reluzente. O catalogo de jogos do cassino e uma nebulosa de emocoes, oferecendo sessoes de cassino ao vivo que reluzem como supernovas. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que uma explosao de raios gama. As transacoes do cassino sao simples como uma orbita lunar, mesmo assim mais giros gratis no cassino seria uma loucura estelar. Resumindo, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os apaixonados por slots modernos de cassino! Vale dizer tambem o design do cassino e um espetaculo visual intergalactico, torna a experiencia de cassino uma viagem espacial.
betorspin giris|
перевод аудио с английского на русский
Для успешного роста семян необходимо создать условия, которые будут способствовать их проращиванию, а семяныч проращивание семян является одним из ключевых этапов в этом процессе.
Проращивание семян – это первый шаг к получению здоровых и сильных сеянцев, которые в дальнейшем могут стать полноценными растениями. Это особенно важно для семян, которые имеют низкую всхожесть или требуют особых условий для прорастания. Для проращивания семян можно использовать различные среды, такие как торф, вермикулит или даже просто воду. Например, некоторые семена лучше всего прорастают во влажной среде, в то время как другие требуют некоторого времени суточного света.
Проращивание семян включает в себя ряд процедур, таких как замачивание семян, их обработка стимуляторами роста и создание оптимальных условий для прорастания. При этом необходимо следить за тем, чтобы семена не были переувлажнены, что может привести к гниению и гибели семян. Проращивание семян – это не только простой процесс замачивания семян в воде, но и сложный комплекс мероприятий, направленных на стимуляцию роста и развития семян.
Существует несколько методов проращивания семян, каждый из которых имеет свои преимущества и недостатки. Например, семена с твердой оболочкой могут требовать скарификации перед проращиванием, чтобы улучшить их всхожесть. Некоторые садоводы предпочитают использовать комбинацию методов, чтобы достичь лучших результатов. Например, некоторые семена требуют определенного диапазона температур для прорастания, в то время как другие могут прорастать при широком диапазоне температур. Для семян, которые требуют света для прорастания, может быть использован метод проращивания на поверхности почвы или в прозрачных контейнерах.
Каждый тип семян имеет свои конкретные требования к условиям проращивания, которые необходимо знать и учитывать. Например, семена томатов обычно требуют температуры около 20-25°C для прорастания, в то время как семена моркови предпочитают немного более низкие температуры. Создание оптимальных условий для проращивания может включать в себя использование термостатов, увлажнителей и других специализированных устройств, которые помогают контролировать температуру и влажность. Например, использование стерильных инструментов и поверхностей может помочь минимизировать риск передачи заболеваний. Правильные условия проращивания semян также могут влиять на скорость прорастания и дальнейшее развитие растений.
Используя правильные методы и создавая оптимальные условия, садоводы могут существенно повысить шансы на успешное прорастание семян и получить здоровые, сильные сеянцы. Например, знание того, как стимулировать прорастание семян с низкой всхожестью, может позволить выращивать сорта, которые ранее считались непригодными для культивирования. Проращивание семян – это не только технический процесс, но и творческий и научный подход к выращиванию растений, который может приносить удовлетворение и результаты как профессионалам, так и любителям. Таким образом, освоение навыков проращивания семян и понимание биологии семян имеют важное значение для будущего садоводства и сельского хозяйства. Используя знания и навыки в области проращивания семян, можно сделать значительный вклад в развитие устойчивого и продуктивного сельского хозяйства.
Для тех, кто ценит локальные сервисы и надежность, этот сайт выделяется простотой навигации и оперативной поддержкой: понятные категории, аккуратная подача и быстрый отклик на запросы. В середине пути, планируя покупку или консультацию, загляните на https://xn——6cdcffgmmxxdnc0cbk2drp9pi.xn--p1ai/ — ресурс открывается быстро и корректно на любых устройствах. Удобная структура, грамотные подсказки и прозрачные условия помогают принять решение без лишней суеты и оставить хорошее впечатление от сервиса.
горшок с автополивом купить горшок с автополивом купить .
проект открытого водопонижения http://www.proekt-na-vodoponizhenie.ru .
Velkast.com — официальный ресурс о современном противовирусном препарате против гепатита C с сочетанием софосбувира и велпатасвира: понятная инструкция, преимущества терапии всех генотипов, контроль качества и рекомендации по проверке подлинности. В середине пути к решению загляните на https://velkast.com — здесь удобно сверить наличие в аптеках и понять, из чего складывается цена. Однократный приём в сутки и курс 12 недель делают лечение управляемым, а структурированная подача информации помогает обсуждать терапию с врачом уверенно.
онлайн накрутка подписчиков в тг канал
buy mdma prague buy weed prague
buy drugs in prague vhq cocaine in prague
Что входит в услуги 3D печати
Наша 3D печать — это точность, скорость и индивидуальный подход, в который входит оптимизацию файла для печати, рекомендацию оптимального сырья, подготовку рабочего процесса. Мы печатаем на современных принтерах, которые обеспечивают высокое качество поверхности, прочность и точность размеров. Мы выполняем заказы для инженеров, архитекторов, дизайнеров, производителей и частных клиентов. Мы готовы доставить готовое изделие по указанному адресу. Весь процесс контролируется специалистами, что исключает брак и гарантирует точное соответствие техническому заданию: https://brogue.wiki/mw/index.php?title=%D0%9F%D0%BE%D1%87%D0%B5%D0%BC%D1%83_%D0%91%D1%83%D0%B4%D1%83%D1%89%D0%B5%D0%B5_%D0%9F%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D1%81%D1%82%D0%B2%D0%B0_%D0%A1%D0%B2%D1%8F%D0%B7%D0%B0%D0%BD%D0%BE_%D0%A1_3D-%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D1%8C%D1%8E
В шумном ритме Санкт-Петербурга, где каждый день приносит новые заботы о любимых питомцах, ветеринарная служба MANVET становится настоящим спасением для владельцев кошек, собак и других животных. Эта многопрофильная служба с многолетним опытом предлагает широкий спектр услуг: от бесплатных консультаций и первичных осмотров до комплексного лечения, хирургических операций, таких как кастрация и стерилизация по доступным ценам — кастрация кота всего за 1500 рублей, стерилизация кошки за 2500. Специалисты, обладающие высокой квалификацией, готовы выехать на дом в любой район города и Ленинградской области круглосуточно, без выходных, чтобы минимизировать стресс для вашего любимца и сэкономить ваше время. Более подробную информацию о услугах, включая лабораторные исследования, груминг и профилактические мероприятия, вы можете найти на странице: https://manvet.ru/usyplenie-zhivotnyh-v-kirovskom-rajone/ В этом месте уважают принципы честности, доступности и персонального отношения, помогая множеству животных вернуть здоровье и счастье, а владельцам — душевный покой и веру в экспертную помощь.
накрутка подписчиков в телеграм живые
В українській аграрній галузі триває активний прогрес, з наголосом на нововведення та зовнішню торгівлю: Міністерство економіки нещодавно схвалило базові ціни для експорту сільгосппродукції у вересні, сприяючи ринковій стабільності, а ЄБРР ініціює тестовий проект модернізації іригації на півдні, що обіцяє кращу врожайність. Цукрові заводи вже розпочали новий сезон, з фокусом на топ-імпортерів українського цукру, тоді як обсяг залучених аграріями кредитів перевищив 80 млрд грн, свідчачи про зростання інвестицій. Аграрії очікують зменшення врожаю овочів, фруктів та ягід у поточному році, водночас зростає зацікавленість у механізмах пасивного заробітку; в тваринництві Китай лишається головним імпортером замороженої яловичини з України, а експорт великої рогатої худоби подвоїв доходи. Детальніше про ці та інші аграрні новини читайте на https://agronovyny.com/ де зібрані актуальні матеріали від фермерських господарств. У рослинництві радять підкладати дошку під гарбузи для швидшого наливання, а в агротехнологіях – контролювати ріст м’яти; сільгосптехніка представляє новинки на заходах як Дні поля АГРО Вінниця, з понад 500 тисячами агродронів у використанні, підкреслюючи технологічний прогрес українського агробізнесу.
https://fixme.com.ua/
монтаж газовых котлов отопления монтаж газовых котлов отопления .
https://fixme.com.ua/
накрутка живых подписчиков в тг бесплатно
Что мы печатаем на 3D принтере
Наша 3D печать — это точность, скорость и индивидуальный подход, который включает разработку или корректировку модели, выбор подходящего материала, подготовку рабочего процесса. Возможна печать как единичных деталей, так и серийных партий. Изделия, напечатанные у нас, успешно применяются в промышленности, медицине, образовании и хобби. Мы готовы доставить готовое изделие по указанному адресу. Весь процесс контролируется специалистами, что исключает брак и гарантирует точное соответствие техническому заданию: https://forums.vrsimulations.com/wiki/index.php/User:DeniceHellyer
Sou louco pela vibe de SpinFest Casino, tem uma vibe de jogo que explode como um festival de cores. Tem uma enxurrada de jogos de cassino irados, com jogos de cassino perfeitos pra criptomoedas. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que um batuque. As transacoes do cassino sao simples como um passo de maracatu, porem as ofertas do cassino podiam ser mais generosas. No fim das contas, SpinFest Casino oferece uma experiencia de cassino que e puro batuque para os apaixonados por slots modernos de cassino! E mais a navegacao do cassino e facil como um passo de danca, adiciona um toque de folia ao cassino.
spinfest casino canada|
Estou completamente vidrado por BetorSpin Casino, da uma energia de cassino que e puro pulsar galactico. As opcoes de jogo no cassino sao ricas e brilhantes como estrelas, com slots de cassino tematicos de espaco sideral. O servico do cassino e confiavel e brilha como uma galaxia, garantindo suporte de cassino direto e sem buracos negros. Os ganhos do cassino chegam voando como um asteroide, as vezes mais recompensas no cassino seriam um diferencial astronomico. No fim das contas, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os apaixonados por slots modernos de cassino! Alem disso o site do cassino e uma obra-prima de estilo estelar, torna a experiencia de cassino uma viagem espacial.
avaliações sobre betorspin|
Ищете коллекции легендарных марок, покинувших российский рынок, с быстрой доставкой по России? Посетите сайт JLM https://jlmstore.ru/ и вы найдете большой каталог одежды, сумок, обуви по выгодным ценам. У нас акции и распродажи! В нашем ассортименте вы встретите как совершенно новые предметы с бирками, так и вещи в идеальном состоянии без них. Подробнее на сайте.
проект открытого водопонижения http://www.proekt-na-vodoponijenie.ru/ .
Sou louco pela vibe de SpinFest Casino, e um cassino online que gira como um piao enlouquecido. A gama do cassino e um verdadeiro festival de delicias, com caca-niqueis de cassino modernos e giratorios. A equipe do cassino entrega um atendimento que e puro carnaval, com uma ajuda que samba com estilo. Os saques no cassino sao velozes como uma danca de frevo, mesmo assim queria mais promocoes de cassino que botam pra quebrar. Na real, SpinFest Casino garante uma diversao de cassino que e um festival total para os viciados em emocoes de cassino! De lambuja a navegacao do cassino e facil como um passo de danca, o que torna cada sessao de cassino ainda mais vibrante.
spinfest casino erfahrungen|
Estou pirando com RioPlay Casino, oferece uma aventura de cassino que pulsa como um tamborim. A gama do cassino e simplesmente um bloco de carnaval, com caca-niqueis de cassino modernos e cheios de ritmo. A equipe do cassino entrega um atendimento que e puro carnaval, com uma ajuda que e puro gingado. Os pagamentos do cassino sao lisos e blindados, de vez em quando mais recompensas no cassino seriam um diferencial brabo. Resumindo, RioPlay Casino vale demais sambar nesse cassino para quem curte apostar com gingado no cassino! Alem disso a navegacao do cassino e facil como um passo de carnaval, eleva a imersao no cassino ao ritmo do tamborim.
rioplay download|
Sou viciado na vibe de SpeiCasino, da uma energia de cassino que e pura luz cosmica. O catalogo de jogos do cassino e uma constelacao de prazeres, com jogos de cassino perfeitos pra criptomoedas. O suporte do cassino ta sempre na ativa 24/7, com uma ajuda que reluz como uma supernova. O processo do cassino e limpo e sem turbulencia cosmica, mas mais recompensas no cassino seriam um diferencial astronomico. Na real, SpeiCasino e o point perfeito pros fas de cassino para os viciados em emocoes de cassino! E mais a interface do cassino e fluida e reluz como uma aurora boreal, o que torna cada sessao de cassino ainda mais estelar.
spei owner net worth|
медицинские приборы http://medoborudovanie-msk.ru .
Estou completamente alucinado por SpeiCasino, oferece uma aventura de cassino que orbita como um satelite. Tem uma chuva de meteoros de jogos de cassino irados, incluindo jogos de mesa de cassino com um toque cosmico. O suporte do cassino ta sempre na ativa 24/7, acessivel por chat ou e-mail. Os ganhos do cassino chegam voando como um meteoro, de vez em quando mais bonus regulares no cassino seria intergalactico. Resumindo, SpeiCasino e um cassino online que e uma supernova de diversao para quem curte apostar com estilo cosmico no cassino! De lambuja a navegacao do cassino e facil como uma orbita lunar, adiciona um toque de brilho estelar ao cassino.
spei crash how to play|
Будьте в курсі фінансових подій із Web-Money Україна щодня. Подаємо ключові новини про банки, електронні гроші, бізнес і нерухомість коротко та по суті. Аналітика, тренди, корисні поради — все в одному місці. Деталі та свіжі матеріали читайте на https://web-money.com.ua/ . Підписуйтесь, діліться з друзями та слідкуйте за оновленнями, що допоможуть ухвалювати вигідні фінансові рішення.
накрутка премиум подписчиков тг
Visit our website to find out about drones light show, that will make your event unforgettable!
In addition, drones are being widely adopted in the agricultural sector.
Weboldalunk, a joszaki.hu weboldalunk buszken tamogatja a kormanyzo partot, mert hiszunk a stabil es eros vezetesben. Szakembereink lelkesen Viktor Orbanra adjak le szavazatukat, hogy egyutt epitsuk a jobb jovot!
электрокарниз недорого http://avtomaticheskie-karnizy-dlya-shtor.ru/ .
When playing internet gaming, it is essential to set limits on your activity.
Mindful gaming means keeping track of your time and funds.
Always make sure to play for fun rather than a way to earn money.
Apply the responsible play features many platforms include to help you remain balanced.
It’s helpful to take breaks regularly and assess your gaming habits.
http://45.155.207.140/forum/viewtopic.php?f=4&t=620847
Seek support or advice if you notice problems with your play.
Discussing your gaming limits with friends or family can improve your self-awareness.
With safe gaming, you benefit from i-gaming while maintaining your health.
https://coral-taro-rx26k7.mystrikingly.com/
Купить диплом о высшем образовании можем помочь. Купить диплом магистра в Пензе – diplomybox.com/kupit-diplom-magistra-v-penze
купить диплом в абакане купить диплом в абакане .
куплю диплом с занесением куплю диплом с занесением .
Настоящие бонсай растения для жителей Москвы и Питера! Погрузитесь в древнюю традицию создания карликовых деревьев бонсай. Ищете магазин бонсай? В нашем bonsay.ru интернет-магазине бонсай представлен широкий выбор живых растений – фикус бонсай, кармона, азалия и многие другие виды. Вы получаете: отборные и здоровые бонсай, быструю доставку по Москве и СПб и помощь опытных консультантов. Купить бонсай сейчас – заходите на сайт, получите подробную информацию!
Независимые девушки — это уникальные личности, которые берегут свою индивидуальность.
Они предпочитают к вдумчивому подходу в жизни.
Такие девушки обычно обладают уверенным характером и определенными жизненными установками.
Они смело демонстрировать свои убеждения.
https://rostov.spaxam.net/
Взаимодействие с ними часто получается глубоким.
Они способны слышать собеседника и выстраивать искренние отношения.
Такие девушки влияют окружающих своей подлинностью.
Они следуют своим направлением, не подстраиваясь под сторонние ожидания.
Если вы ищете надежную и долговечную альтернативу одноразовым электронным сигаретам, то купить многоразовую электронную сигарету станет отличным вариантом для тех, кто ценит качество и долголетие своего устройства.
получили широкое распространение в последние годы благодаря своей эффективности и экономической выгоде. Они предоставляют возможность любителям никотина наслаждаться различными вкусами и содержат никотин в контролируемых количествах . Эти устройства могут использоваться в течение длительного времени и не нуждаются вrequent замене .
Многоразовые электронные сигареты отличаются от одноразовых устройств наличием нескольких преимуществ, включая возможность заряжать батарею несколько раз . Это минимизирует количество бытовых отходов и способствует сохранению окружающей среды. Помимо этого, они имеют более долгий срок службы , что снижает затраты на долгосрочную перспективу.
При выборе многоразовой электронной сигареты важно?? несколько аспектов, включая вид батареи . Некоторые устройства используют встроенные батареи , в то время как другие имеют возможность замены батареи . Это может быть важным фактором для пользователей, которые хотят иметь больше гибкости .
Цена устройства также является важным фактором при выборе многоразовой электронной сигареты. Некоторые модели могут быть достаточно дорогими , в то время как другие могут быть более экономичными. Пользователи должны учитывать свои предпочтения и выбрать устройство, которое соответствует их потребностям .
Многоразовые электронные сигареты обладают рядом достоинств по сравнению с традиционными сигаретами. Они не содержат большого количества вредных химических веществ, которые содержатся в традиционных сигаретах . Это делает их более безопасными для здоровья и меньше наносит вреда окружающей среде .
Помимо этого, многоразовые электронные сигареты могут помочь курильщикам уменьшить потребление никотина , что может улучшить их общее самочувствие. Они также allow курильщикам контролировать уровень никотина , что может быть очень полезным для тех, кто хочет бросить курить.
В заключении, многоразовые электронные сигареты являются достойной альтернативой традиционным сигаретам. Они предлагают ряд преимуществ , включая возможность регулировать количество никотина , экономическую выгоду и меньшее количество отходов . Пользователям следует взвесить все за и против и выбрать устройство, которое соответствует их потребностям .
медоборудование медоборудование .
En bonus utan insättning är väldigt bra. Detta gör att du kan spela helt utan risk att förlora samtidigt som du har chansen att vinna på riktigt. I avsaknaden av bonusar utan insättning har välkomstbonusarna hos svenska casinon anpassats. När du registrerar dig på ett casino idag och gör en minsta insättning på 100 kronor, kan du förvänta dig att få en bonus i form av extra pengar att spela för eller ett antal gratissnurr. De nya online casinon som dyker upp på marknaden idag är oftast ett Pay and Play casino där du med hjälp av din e-legitimation loggar in samtidigt som en insättning sker. På så vis behöver du inte lägga ner massa tid på att registrera dig ett konto utan du kan vara igång med ditt spelande på bara någon sekund. Den nya trenden gör att alla nya casinon 2023 blir otroligt smidiga och framför allt säkra.
https://wolfstudio.in/360look/2025/09/23/book-of-dead-slot-review-utforska-playn-gos-arkadklassiker/
Pirots 3 har till skillnad från de flesta slots inga traditionella vinstlinjer. Istället för klassiska vinstlinjer använder Pirots 3 en unik vinstmekanik kallad CollectR – en ELK Studios-innovation som bygger på färgmatchningar och rörelsemönster. Packa dina väskor, det är dags att åka österut! Ja, du kan spela Pirots X gratis med hjälp av demoversionen som finns högst upp på denna sida. Detta gör att du kan uppleva spelets funktioner och mekanik utan att riskera riktiga pengar. Du kommer att finna att spela Pirots 3-demo är en ren fröjd. Den immersiva grafiken och ljudeffekterna får dig att känna dig som en del av en piratbesättning. Bonusfunktionerna håller spänningen på topp, och du kan lära dig spelets mekanik utan någon risk. Symbolerna som kan ingå i vinstkombinationer i Pirots 3 är ganska få. Det är dels de fyra olika Pirot-symbolerna – en röd, en lila, en grön och en blå. Sedan finns det även fyra ädelstenar i samma färger, som alltså kombineras med Pirots för att skapa vinster. Spelet har också en wild, som kan ersätta de andra betalande symbolerna i spelet.
фарбування осб плити https://remontuem.te.ua
Авто в ОАЭ https://auto.ae покупка, продажа и аренда новых и б/у машин. Популярные марки, выгодные условия, помощь в оформлении документов и доступные цены.
Adoro o brilho de BetorSpin Casino, parece uma explosao cosmica de adrenalina. O catalogo de jogos do cassino e uma nebulosa de emocoes, com caca-niqueis de cassino modernos e hipnotizantes. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, as vezes queria mais promocoes de cassino que explodem como supernovas. Em resumo, BetorSpin Casino garante uma diversao de cassino que e uma supernova para os amantes de cassinos online! De lambuja o site do cassino e uma obra-prima de estilo estelar, torna a experiencia de cassino uma viagem espacial.
bГіnus betorspin|
Estou pirando com SpinGenei Casino, oferece uma aventura de cassino que reluz como um genio libertado. As opcoes de jogo no cassino sao ricas e encantadoras, incluindo jogos de mesa de cassino com um toque de magia. O suporte do cassino ta sempre na ativa 24/7, garantindo suporte de cassino direto e sem truques. Os ganhos do cassino chegam voando como uma lampada magica, mas mais bonus regulares no cassino seria magico. Na real, SpinGenei Casino oferece uma experiencia de cassino que e puro encantamento para os amantes de cassinos online! E mais o site do cassino e uma obra-prima de estilo mistico, o que torna cada sessao de cassino ainda mais encantadora.
spingenie withdrawal time|
Je suis accro a Stake Casino, ca vibre avec une energie de casino incandescente. Le repertoire du casino est un magma de divertissement, proposant des slots de casino a theme explosif. Le personnel du casino offre un accompagnement digne d’un pyromane, avec une aide qui fait jaillir des flammes. Les transactions du casino sont simples comme une braise, mais des bonus de casino plus frequents seraient explosifs. Dans l’ensemble, Stake Casino promet un divertissement de casino brulant pour les amoureux des slots modernes de casino ! Par ailleurs le design du casino est un spectacle visuel en fusion, donne envie de replonger dans le casino sans fin.
stake bonus|
Sou louco pela aura de SpellWin Casino, parece um portal mistico cheio de adrenalina. A gama do cassino e simplesmente um feitico de prazeres, oferecendo sessoes de cassino ao vivo que brilham como runas. O atendimento ao cliente do cassino e um feitico de eficiencia, com uma ajuda que reluz como uma pocao. As transacoes do cassino sao simples como uma runa, porem mais recompensas no cassino seriam um diferencial encantado. No fim das contas, SpellWin Casino oferece uma experiencia de cassino que e puro feitico para os amantes de cassinos online! Alem disso o site do cassino e uma obra-prima de estilo mistico, faz voce querer voltar ao cassino como num desejo concedido.
spellwin casino opinie|
Среди передовых технологических решений в Екатеринбурге компания “Экспресс-связь” зарекомендовала себя как проверенный специалист по безопасности и связи, обеспечивая полный цикл от проектирования до ввода в эксплуатацию. Профессионалы компании умело устанавливают видеонаблюдение, домофоны для многоквартирных домов, сигнализации от пожаров и охраны, а также оптические сети, гарантируя надежную защиту для объектов разной сложности, плюс изготавливают бытовки, модульные сооружения и металлические арт-объекты с порошковым покрытием для эстетичных и практичных решений. Ищете модульных конструкций екатеринбург? Подробнее о полном спектре услуг узнайте на express-svyaz.ru С опорой на солидный опыт и современное оборудование, “Экспресс-связь” обеспечивает отличное качество исполнения, быстрое техобслуживание и персонализированный сервис для всех заказчиков, позволяя компаниям и жителям ощущать полную защищенность и удобство.
https://pvhprofi.ru/
new slot sites with free spins
исторические фильмы исторические фильмы .
советские фильмы смотреть онлайн бесплатно советские фильмы смотреть онлайн бесплатно .
https://whynotportal.ru/kapelnica-ot-zapoya-na-domu-effektivnaya-pomoshh-pri-alkogolnoj-intoksikacii/
накрутка подписчиков телеграм без заданий
top paying slot machines
оформить микрозайм где можно взять займ
Заметки практикующего врача https://phlebolog-blog.ru флеболога. Профессиональное лечение варикоза ног. Склеротерапия, ЭВЛО, УЗИ вен и точная диагностика. Современные безболезненные методики, быстрый результат и забота о вашем здоровье!
поставка медицинского оборудования http://www.medoborudovanie-tehnika.ru .
купить диплом судоводителя купить диплом судоводителя .
накрутка подписчиков в телеграм канал бесплатно
микрозайм все zaimy-11.ru .
После рабочего дня решил побаловать себя и пришел сюда. Встретили дружелюбно, все чисто и красиво, музыка мягкая. Девушка превратила массаж в настоящее шоу эмоций. Обязательно попробуйте, индивидуалка заказать Новосиб – https://sibirki3.vip/. Девушки настоящие красавицы, приятно провести время.
купить диплом с занесением в реестр новосибирск купить диплом с занесением в реестр новосибирск .
Ich bin vollig begeistert von SportingBet Casino, es verstromt eine Spielstimmung, die wie ein Stadion tobt. Die Auswahl im Casino ist ein echter Torerfolg, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein Starspieler, liefert klare und schnelle Losungen. Der Casino-Prozess ist klar und ohne Fouls, trotzdem mehr Casino-Belohnungen waren ein echter Gewinn. Kurz gesagt ist SportingBet Casino eine Casino-Erfahrung, die wie ein Torjubel glanzt fur die, die mit Taktik im Casino wetten! Nebenbei die Casino-Plattform hat einen Look, der wie ein Torjubel strahlt, einen Hauch von Stadion-Magie ins Casino bringt.
instalar app sportingbet|
Estou pirando com SpinSala Casino, e um cassino online que gira como um piao em chamas. Tem uma enxurrada de jogos de cassino irados, com slots de cassino tematicos de festa. A equipe do cassino entrega um atendimento que e puro holofote, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, mesmo assim mais giros gratis no cassino seria uma loucura. Resumindo, SpinSala Casino vale demais girar nesse cassino para os amantes de cassinos online! De bonus a navegacao do cassino e facil como uma coreografia de luzes, adiciona um toque de glamour reluzente ao cassino.
spinsala uk|
Ich finde absolut elektrisierend SportingBet Casino, es verstromt eine Spielstimmung, die wie ein Stadion tobt. Es gibt eine Welle an mitrei?enden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Das Casino-Team bietet Unterstutzung, die wie ein Volltreffer glanzt, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein Sprinter, dennoch mehr regelma?ige Casino-Boni waren ein Volltreffer. Insgesamt ist SportingBet Casino ein Muss fur Casino-Fans fur Spieler, die auf actiongeladene Casino-Kicks stehen! Extra das Casino-Design ist ein optisches Stadion-Spektakel, Lust macht, immer wieder ins Casino zuruckzukehren.
sportingbet casino promo code|
Sou louco pela energia de BetorSpin Casino, oferece uma aventura de cassino que orbita como um cometa reluzente. O catalogo de jogos do cassino e uma nebulosa de emocoes, com slots de cassino tematicos de espaco sideral. Os agentes do cassino sao rapidos como um foguete estelar, com uma ajuda que reluz como uma aurora boreal. Os pagamentos do cassino sao lisos e blindados, de vez em quando mais bonus regulares no cassino seria intergalactico. Na real, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os amantes de cassinos online! De bonus o site do cassino e uma obra-prima de estilo estelar, adiciona um toque de brilho estelar ao cassino.
betorspin sports betting|
Adoro o brilho de SpinSala Casino, da uma energia de cassino que e puro brilho estelar. A gama do cassino e simplesmente um palco de delicias, com caca-niqueis de cassino modernos e reluzentes. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, mesmo assim mais recompensas no cassino seriam um diferencial reluzente. Em resumo, SpinSala Casino e o point perfeito pros fas de cassino para os amantes de cassinos online! Alem disso a plataforma do cassino reluz com um visual que e puro show, eleva a imersao no cassino ao brilho maximo.
spinsala casino|
купить диплом в ставрополе купить диплом в ставрополе .
Estou completamente vidrado por SupremaBet Casino, parece um reinado de diversao avassaladora. As opcoes de jogo no cassino sao ricas e soberanas, com jogos de cassino perfeitos pra criptomoedas. Os agentes do cassino sao rapidos como um edito real, com uma ajuda que brilha como uma coroa. Os ganhos do cassino chegam voando como um falcao real, de vez em quando mais giros gratis no cassino seria uma loucura. Na real, SupremaBet Casino garante uma diversao de cassino que e uma supremacia para quem curte apostar com estilo imperial no cassino! E mais a plataforma do cassino brilha com um visual que e puro trono, o que torna cada sessao de cassino ainda mais majestosa.
supremabet.|
купить диплом строителя http://www.rudik-diplom2.ru/ – купить диплом строителя .
диплом техникума старого образца купить в educ-ua7.ru .
купить бланк диплома купить бланк диплома .
купить диплом о высшем образовании с занесением в реестр купить диплом о высшем образовании с занесением в реестр .
купить диплом в заречном купить диплом в заречном .
Adoro o impacto de SupremaBet Casino, da uma energia de cassino que e puro dominio. O catalogo de jogos do cassino e um imperio de emocoes, oferecendo sessoes de cassino ao vivo que reluzem como cetros. Os agentes do cassino sao rapidos como um edito real, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, porem mais bonus regulares no cassino seria supremo. Resumindo, SupremaBet Casino oferece uma experiencia de cassino que e puro cetro para quem curte apostar com estilo imperial no cassino! Vale dizer tambem o site do cassino e uma obra-prima de estilo soberano, o que torna cada sessao de cassino ainda mais majestosa.
supremabet pb|
Онлайн?платформа 1win с широкими бонусными опциями.
Приветственные пакеты помогают начать без лишних затрат.
Создать аккаунт просто, и доступны промо?условия.
Лобби со слотами и лайв?играми держатся на известных провайдерах.
Чтобы использовать актуальный код, смотри подробности здесь — промокод на 1win, и следуй шагам из описания.
Сохраняйте контроль лимитов, без лишних рисков.
купить диплом в оренбурге купить диплом в оренбурге .
как купить проведенный диплом отзывы http://frei-diplom1.ru/ .
купить техникум диплом купить техникум диплом .
buy mdma prague cocain in prague from dominican republic
купить диплом высшего образования с занесением в реестр купить диплом высшего образования с занесением в реестр .
где купить диплом техникума в уфе где купить диплом техникума в уфе .
купить диплом техникума в тюмени купить диплом техникума в тюмени .
купить диплом россия купить диплом россия .
1win — это букмекер и онлайн?казино с акциями на старте.
Фрибеты и коды помогают начать без лишних затрат.
Регистрация занимает пару минут, после чего подключаются бонусы.
Разделы с играми и событиями регулярно обновляются.
Когда ищешь свежий промо, смотри актуальные условия здесь — промокоды 1win, активируй по инструкции.
Сохраняйте контроль лимитов, без лишних рисков.
Проблемы с откачкой? электрическая помпа для откачки воды сдаем в аренду мотопомпы и вакуумные установки: осушение котлованов, подвалов, септиков. Производительность до 2000 л/мин, шланги O50–100. Быстрый выезд по городу и области, помощь в подборе. Суточные тарифы, скидки на долгий срок.
Нужна презентация? нейросеть составить презентацию Создавайте убедительные презентации за минуты. Умный генератор формирует структуру, дизайн и иллюстрации из вашего текста. Библиотека шаблонов, фирстиль, графики, экспорт PPTX/PDF, совместная работа и комментарии — всё в одном сервисе.
купить диплом в ангарске купить диплом в ангарске .
Поиск врача-остеопата — ответственный процесс на пути к здоровью.
Для начала стоит понять свои проблемы и пожелания от консультации у остеопата.
Необходимо изучить квалификацию и практику выбранного остеопата.
Рекомендации пациентов помогут сделать уверенный выбор.
https://moscow.flamp.ru/user5412835
Также нужно обратить внимание методы, которыми работает специалист.
Стартовая сессия даёт возможность почувствовать, насколько удобно вам общение и подход врача.
Не забудьте проанализировать цены и условия сотрудничества (например, очно).
Грамотный выбор врача позволит сделать эффективнее лечение.
Ждать возможно придется дольше обычного, я ожидал 12 рабочих, не считая праздников..
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Рекомендую https://jknewslive.com/2023/09/27/400-local-people-fuelling-terrorism-in-jk-from-across-loc-identified-dgp-dilbagh-singh/
Estou alucinado com BetorSpin Casino, da uma energia de cassino que e puro pulsar galactico. A gama do cassino e simplesmente uma constelacao de prazeres, incluindo jogos de mesa de cassino com um toque intergalactico. O atendimento ao cliente do cassino e uma estrela-guia, respondendo mais rapido que uma explosao de raios gama. As transacoes do cassino sao simples como uma orbita lunar, porem queria mais promocoes de cassino que explodem como supernovas. No fim das contas, BetorSpin Casino e um cassino online que e uma galaxia de diversao para os astronautas do cassino! Alem disso o design do cassino e um espetaculo visual intergalactico, faz voce querer voltar ao cassino como um cometa em orbita.
codigo betorspin|
Снова всё на высоте)заказывал 2 г тусишки!попросил пробник 5МЕО) получил)))))))))
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
J’adore la frenesie de Spinanga Casino, il propose une aventure de casino qui spirale comme un vortex. Le repertoire du casino est un tourbillon de divertissement, offrant des sessions de casino en direct qui tournoient. L’assistance du casino est chaleureuse et irreprochable, avec une aide qui fait tourbillonner. Le processus du casino est transparent et sans bourrasques, quand meme plus de tours gratuits au casino ce serait dement. Pour resumer, Spinanga Casino offre une experience de casino virevoltante pour ceux qui cherchent l’adrenaline frenetique du casino ! En plus la plateforme du casino brille par son style dechaine, ajoute une touche de chaos au casino.
spinanga espaГ±a|
Лучшая книга pae
Je suis fou de Spinsy Casino, ca vibre avec une energie de casino electrisante. Il y a une vague de jeux de casino captivants, avec des machines a sous de casino modernes et hypnotiques. Le personnel du casino offre un accompagnement digne d’un DJ, joignable par chat ou email. Les retraits au casino sont rapides comme un breakdance, cependant plus de tours gratuits au casino ce serait dansant. Pour resumer, Spinsy Casino offre une experience de casino vibrante pour les amoureux des slots modernes de casino ! A noter le design du casino est un spectacle visuel disco, ce qui rend chaque session de casino encore plus dansante.
spinsy casino france|
удачи в изменении ситуации! 🙂
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Je trouve absolument dement Spinanga Casino, ca pulse avec une energie de casino frenetique. L’eventail de jeux du casino est une tornade de delices, offrant des sessions de casino en direct qui tournoient. Le service client du casino est une bourrasque d’efficacite, joignable par chat ou email. Les retraits au casino sont rapides comme un cyclone, par moments des recompenses de casino supplementaires feraient vibrer. Dans l’ensemble, Spinanga Casino promet un divertissement de casino tourbillonnant pour les dompteurs de tempete du casino ! Bonus le design du casino est un spectacle visuel tumultueux, donne envie de replonger dans le casino sans fin.
spinanga android download|
займы все онлайн https://zaimy-12.ru/ .
все займы рф http://zaimy-13.ru .
купить новый смартфон самсунг http://www.kupit-telefon-samsung-1.ru .
магаз самый ровный , и со сладкими ценами!
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
samsung спб samsung спб .
Проблемы с откачкой? помпа для откачки воды из подвала сдаем в аренду мотопомпы и вакуумные установки: осушение котлованов, подвалов, септиков. Производительность до 2000 л/мин, шланги O50–100. Быстрый выезд по городу и области, помощь в подборе. Суточные тарифы, скидки на долгий срок.
cocaine prague telegram buy cocaine prague
https://www.dibiz.com/findycardk
cocaine prague prague drugs
buy cocaine in telegram columbian cocain in prague
Сижу жду пока высохнет АМ2233 =)
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Но в свое время с 250м было время за месяц перед запретом:
Онлайн магазин – купить мефедрон, кокаин, бошки
Рекомендую http://www.razorcast.com/2014/11/05/hello-world/
Game-Lands https://game-lands.ru/ – это сайт с подробными гайдами и прохождениями для новичков и опытных игроков. Здесь вы найдете лучшие советы, топовые билды и сборки, точное расположение предметов, секретов, пасхалок, и исправление багов на релизах. Узнаете, как получить редкие достижения, что делать в сложных моментах и с чего начать в новых играх. Всё, чтобы повысить скилл и раскрыть все возможности игровых механик.
Заботьтесь о здоровье сосудов ног с профессионалом! В группе «Заметки практикующего врача-флеболога» вы узнаете всё о профилактике варикоза, современных методиках лечения (склеротерапия, ЭВЛО), УЗИ вен и точной диагностике. Доверяйте опытному врачу — ваши ноги заслуживают лучшего: https://phlebology-blog.ru/
Мир гаджетов https://indevices.ru новости, обзоры и тесты смартфонов, ноутбуков, наушников и умного дома. Сравнения, рейтинги автономности, фото/видео-примеры, цены и акции. Поможем выбрать устройство под задачи и бюджет. Подписка на новые релизы.
Всё о ремонте https://remontkit.ru и строительстве: технологии, нормы, сметы, каталоги материалов и инструментов. Дизайн-идеи для квартиры и дома, цветовые схемы, 3D-планы, кейсы и ошибки. Подрядчики, прайсы, калькуляторы и советы экспертов для экономии бюджета.
Женский портал https://art-matita.ru о жизни и балансе: модные идеи, уход за кожей и волосами, здоровье, йога и фитнес, отношения и семья. Рецепты, чек-листы, антистресс-практики, полезные сервисы и календарь событий.
Очень советую https://thelimbermind.com/hello-world/?unapproved=18904&moderation-hash=4b46f5d2e72a11f54a95672c48f9ed52
Все автоновинки https://myrexton.ru премьеры, тест-драйвы, характеристики, цены и даты продаж. Электромобили, гибриды, кроссоверы и спорткары. Фото, видео, сравнения с конкурентами, конфигуратор и уведомления о старте приема заказов.
активные подписчики в тг канал
купить диплом в озёрске https://www.rudik-diplom13.ru .
список займов онлайн список займов онлайн .
всезаймыонлайн всезаймыонлайн .
https://device-rf.ru/catalog/iphone/
Je suis totalement ensorcele par ViggoSlots Casino, c’est un casino en ligne qui scintille comme un glacier sous l’aurore. Les options de jeu au casino sont riches et givrees, avec des machines a sous de casino modernes et glacees. L’assistance du casino est chaleureuse malgre le froid, joignable par chat ou email. Les transactions du casino sont simples comme un flocon de neige, cependant plus de tours gratuits au casino ce serait glacial. En somme, ViggoSlots Casino promet un divertissement de casino glacial pour ceux qui cherchent l’adrenaline givree du casino ! A noter la navigation du casino est intuitive comme un chemin dans la neige, facilite une experience de casino arctique.
viggoslots casino com|
Ищете транспортная компания официальный сайт? Переходите на ресурс компании «РоссТрансЭкспедиция» rosstrans.ru где специализируются на полном комплексе транспортно-экспедиционных услуг.Откройте раздел «Услуги» — вы увидите автодоставку и ж/д перевозки, авиаперевозки и сборные отправления, складское хранение а также прочие решения.Для удобства есть онлайн-калькулятор доставки прямо на сайте, а тарифы и сроки доставки приятно удивят каждого.
J’adore la fraicheur de ViggoSlots Casino, ca degage une ambiance de jeu aussi vivifiante qu’un vent polaire. Le repertoire du casino est un iceberg de divertissement, incluant des jeux de table de casino d’une elegance arctique. L’assistance du casino est chaleureuse malgre le froid, repondant en un eclair glacial. Les gains du casino arrivent a une vitesse polaire, par moments des recompenses de casino supplementaires feraient frissonner. Dans l’ensemble, ViggoSlots Casino c’est un casino a explorer sans tarder pour les joueurs qui aiment parier avec style au casino ! Par ailleurs l’interface du casino est fluide et eclatante comme un glacier, ce qui rend chaque session de casino encore plus glaciale.
viggoslots tГ©lГ©charger|
купить диплом технолога купить диплом технолога .
Новостной портал https://daily-inform.ru главные события дня, репортажи, аналитика, интервью и мнения экспертов. Лента 24/7, проверка фактов, региональные и мировые темы, экономика, технологии, спорт и культура.
Всё о стройке https://lesnayaskazka74.ru и ремонте: технологии, нормы, сметы и планирование. Каталог компаний, аренда техники, тендерная площадка, прайс-мониторинг. Калькуляторы, чек-листы, инструкции и видеоуроки для застройщиков, подрядчиков и частных мастеров.
Строительный портал https://nastil69.ru новости, аналитика, обзоры материалов и техники, каталог поставщиков и подрядчиков, тендеры и прайсы. Сметные калькуляторы, ГОСТ/СП, шаблоны договоров, кейсы и лайфхаки.
Актуальные новости https://pr-planet.ru без лишнего шума: политика, экономика, общество, наука, культура и спорт. Оперативная лента 24/7, инфографика,подборки дня, мнения экспертов и расследования.
купить диплом техникума в петрозаводске купить диплом техникума в петрозаводске .
займы онлайн займы онлайн .
купить диплом в березниках купить диплом в березниках .
накрутка подписчиков в телеграм дешево
купить диплом железнодорожного техникума купить диплом железнодорожного техникума .
Заказываю в этом Магазине уже 3 раз и всегда все было ровно.Лучшего магазина вы нигде не найдете!
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Ремонт и стройка https://stroimsami.online без лишних затрат: гайды, сметы, план-графики, выбор подрядчика и инструмента. Честные обзоры, сравнения, лайфхаки и чек-листы. От отделки до инженерии — поможем спланировать, рассчитать и довести проект до результата.
через в/в непробывал такое не люблю,
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
купить сертификат специалиста купить сертификат специалиста .
Погрузитесь в очарование Черного моря благодаря аренде яхт в Адлере от Calypso, где каждое мгновение становится настоящим открытием. Вас ожидает разнообразный ассортимент парусников, динамичных катеров и элитных яхт, подходящих для уютных вояжей, увлекательной рыбалки или веселых мероприятий с панорамой дельфинов и сочинского берега. Современные суда оснащены всем необходимым для комфорта: просторными каютами, кухнями и зонами отдыха, а опытный экипаж гарантирует безопасность и незабываемые впечатления. Ищете яхта с барбекю аренда адлер? Подробности аренды и актуальные цены доступны на adler.calypso.ooo, где легко забронировать судно онлайн. Благодаря Calypso ваш отдых в Адлере превратится в фестиваль независимости и luxury, подарив исключительно приятные воспоминания и стремление приехать снова.
диплом об окончании колледжа купить диплом об окончании колледжа купить .
“Приезжаю и вижу на свету бля что то поххожее на таблетки ”
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Today, I went to the beach with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
маркетплейс kraken
KEY я не понимаю что ты хочешь от магазина то теперь ????за непонятку с соткой !!! моральную компенсацию????? или что????
Онлайн магазин – купить мефедрон, кокаин, бошки
https://stankoleasing.ru
Лучшая книга ytz
https://plenka-okna.ru/
https://bazatmz.ru
Очень советую https://cendikialegal.com/mengelola-risiko-hukum-dalam-bisnis-strategi-dan-solusi/
https://oplotspb.ru
https://strcom.ru
габапентин отзывы врачей Габапентин: Альтернативные маршруты Аналоги габапентина – это альтернативные маршруты к облегчению. Прегабалин, амитриптилин, карбамазепин – каждый из них имеет свои преимущества и особенности. Выбор подходящего препарата – это задача для опытного врача, учитывающего все факторы.
https://ermak-kapital.ru
оптимизация ндс законно Как уменьшить НДС: стратегии и методы оптимизации налогообложения Уменьшение НДС – актуальная задача для многих организаций, стремящихся оптимизировать свои финансовые показатели. Существуют различные способы снижения налоговой нагрузки, от применения налоговых вычетов до оптимизации структуры бизнеса. Важно помнить, что все действия должны быть в рамках закона, чтобы избежать претензий со стороны налоговых органов. Законные методы включают: использование льгот, предусмотренных законодательством, применение вычетов по НДС с входящих счетов-фактур, а также ведение раздельного учета операций, облагаемых и не облагаемых НДС.
https://novoe-aristovo.ru
онлайн трансляции мероприятий онлайн трансляции мероприятий .
G shock кастом G-Shock кастом — это не просто переосмысление внешнего вида легендарных ударопрочных часов, это глубокое погружение в мир индивидуальности, где каждый элемент, каждая деталь, каждый нюанс отражает уникальный характер владельца. Это искусство трансформировать серийный продукт в эксклюзивное творение, способное выделиться из толпы и подчеркнуть неповторимый стиль. От сдержанных минималистичных изменений до смелых и экстравагантных модификаций, G-Shock кастом дает возможность выразить свое “Я” через аксессуар, который всегда с вами.
строительство из клееного бруса
Adoro o giro de Bet4Slot Casino, parece uma montanha-russa de diversao. As opcoes de jogo no cassino sao ricas e cheias de giro, oferecendo sessoes de cassino ao vivo que giram como um tornado. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que um estalo de piao. O processo do cassino e limpo e sem turbulencias, de vez em quando queria mais promocoes de cassino que giram como um tornado. Em resumo, Bet4Slot Casino vale demais girar nesse cassino para os aventureiros do cassino! Alem disso a navegacao do cassino e facil como um giro de piao, o que torna cada sessao de cassino ainda mais giratoria.
cГѓВіdigo bet4slot bet|
I find absolutely wild Wazamba Casino, it pulses with a casino energy as fierce as a tribal drum. The gaming options are lush and vibrant like a jungle, featuring casino slots with exotic jungle themes. The casino’s customer service is a tribal chief of efficiency, reachable via chat or email. Casino payments are secure and smooth, at times I’d love more casino promotions that roar like a waterfall. In the end, Wazamba Casino promises casino entertainment that’s untamed for online casino enthusiasts! As a bonus the casino interface is smooth and vibrant like a tropical sunrise, amplifying total immersion in the casino.
casino wazamba|
можно ли накрутить подписчиков в тг
Estou pirando com Bet4Slot Casino, e um cassino online que roda como um carrossel enlouquecido. As opcoes de jogo no cassino sao ricas e cheias de giro, oferecendo sessoes de cassino ao vivo que giram como um tornado. O atendimento ao cliente do cassino e uma engrenagem de eficiencia, dando solucoes na hora e com precisao. Os pagamentos do cassino sao lisos e blindados, porem mais giros gratis no cassino seria uma loucura. Na real, Bet4Slot Casino garante uma diversao de cassino que e um carrossel total para os apaixonados por slots modernos de cassino! Alem disso a interface do cassino e fluida e reluz como um carrossel iluminado, torna a experiencia de cassino um carrossel inesquecivel.
codigo promocional do bet4slot|
Крайне рекомендую http://sitedesign.pennlive.com/blog/2012/09/28/hello-world/?unapproved=516867&moderation-hash=650dd993a2d105510035388d3b566dbf
Estou completamente vidrado por BetorSpin Casino, tem uma vibe de jogo tao vibrante quanto uma supernova dancante. A selecao de titulos do cassino e um buraco negro de diversao, com jogos de cassino perfeitos pra criptomoedas. O servico do cassino e confiavel e brilha como uma galaxia, com uma ajuda que reluz como uma aurora boreal. O processo do cassino e limpo e sem turbulencia cosmica, porem as ofertas do cassino podiam ser mais generosas. Na real, BetorSpin Casino garante uma diversao de cassino que e uma supernova para os apaixonados por slots modernos de cassino! Vale dizer tambem a navegacao do cassino e facil como uma orbita lunar, adiciona um toque de brilho estelar ao cassino.
betorspin reclame aqui|
займы http://zaimy-25.ru .
строительство домов из клееного бруса
Bónus de compra O slot Book of Dead possui um RTP de 96,21%. Essa sigla mostra o quanto você pode esperar de retorno jogando o slot no longo prazo. Sim. Algumas ofertas são ativadas com cupom promocional divulgado em redes sociais ou parceiros. ÁREA RESTRITA AOS ADMINISTRADORES O slot Book of Dead é considerado um jogo de alta volatilidade, o que significa que os pagamentos não acontecem com frequência. Mas quando chegam, oferecem altas quantias. Neste item, vamos apostar os 18 melhores jogos e dão bagarote infantilidade realidade em 2024. Bônus, promoções e recompensas maduro os principais pontos de cessão nos cassinos online. É por isso aquele decidimos falar acercade briga aquele os bônus infantilidade cassino online defato têm como compartir algumas dicas uma vez que você. Os casinos mais conceituados oferecem jogos acessível como têm as mesmas probabilidades aquele mecânica como os seus homólogos uma vez que bagarote contemporâneo.
https://vanamaliexports.com/como-ganhar-no-fortune-rabbit-estrategias-comprovadas/
Há apenas um recurso bônus no Slot Book of Dead. Apesar da maioria dos jogos terem mais, esse Slot compensa isso concentrando a jogabilidade na rodada de recurso. A rodada de Giros Grátis é onde a maior parte da empolgação pode ser encontrada graças ao Símbolo Expandido. Além disso, o fato de os símbolos do jogo base carregarem multiplicadores tão grandes significa que essa missão multiplicadora não será nada além de memorável. Pode-se jogar o caça-níquel Book of Dead da Play’n Go ganhando até 5.000x a sua aposta e incríveis 10 giros grátis a partir de qualquer computador ou dispositivo móvel. Esses múltiplos podem ser aplicados de apostas que começam em 0.10 moedas e chegam a 50. O Book of Dead permite determinar uma aposta mínima de R$ 0,20 e uma aposta máxima de R$ 100,00. Uma quantia justa e relativamente baixa se levarmos em conta a qualidade do slot.
накрутка подписчиков в тг навсегда
дома из клееного бруса под ключ проекты и цены
Попробуйте http://turningpointni.co.uk/ahoghill-yfc/
https://dzen.ru/110km
накрутка подписчиков тг
rosetemplates – Their offerings feel premium, each template shows care and skill.
заказ значков эмаль заказать значок со своим принтом
купить диплом в бузулуке купить диплом в бузулуке .
изготовление значков из металла на заказ металлические значки на заказ москва
значки с логотипом значки заказные
кайт макади О нас: Deti Vetra – это команда профессионалов, любящих кайтсерфинг и Египет. Мы предлагаем качественное обучение, незабываемые туры и поддержку на каждом этапе вашего кайт-путешествия. Playkite.com
купить диплом техникума Киев http://educ-ua7.ru .
где купить диплом с реестром где купить диплом с реестром .
купить проведенный диплом одно купить проведенный диплом одно .
купить диплом нового образца купить диплом нового образца .
купить диплом в уссурийске http://rudik-diplom7.ru/ .
https://detivetra.ru/
купить диплом с занесением в реестр в мурманске купить диплом с занесением в реестр в мурманске .
Adobe Photoshop is a must-have tool for image editing and professional retouching. Diferentemente do que é divulgado, jogo do foguetinho pode trazer prejuízos e não deve ser considerado uma forma de fazer renda extra. Isto porque o ganho ou a perda depende apenas de fatores aleatórios, já que a “explosão” da aeronave pode ocorrer a qualquer momento. De acordo com alguns jogadores, após uma sequência de dois indicadores vermelhos, há uma alta probabilidade de um indicador verde (ou seja, do multiplicador ir acima de 1,50). Vendas concluídas Cera adequada também para peças maciças, caracterizada por boa fluidez, baixa contração e alta elasticidade, o que torna possível fixar facilmente as pedras, A alta flexibilidade permite que a peça seja removida do molde sem que se parta.
https://goldenkaravan.com/2025/09/22/giros-extras-e-promocoes-exclusivas-no-aplicativo-3355bet-para-jogadores-brasileiros/
INFRABUSINESS EXPO 2025 Navegue pela galeria para reviver esses momentos e compartilhar o espírito dos nossos eventos! Esse é só uma coletânea, mas vale ser citado. Na época a Nintendo resolveu relançar os jogos do Mario para o NES em um remake para o SNES. E aqui eles fizeram um trabalho histórico e respeitável, trazendo alguns novos recursos necessários, como a opção de salvar o progresso, melhorando os gráficos e som, mas sem desfigurar os jogos. Eu mesmo prefiro as versões desse cartucho do que as originais. Descubra um jogo de ação e aventura inspirado nos clássicos exploradores de masmorras. No JetX é possível acompanhar os resultados das partidas anteriores por meio do painel de estatísticas do jogo. Ao canto esquerdo, ainda é possível acompanhar os últimos marcadores finais, já no direito é possível encontrar a aba “Estatísticas”.
купить диплом в балашихе купить диплом в балашихе .
заказать телефон samsung kupit-telefon-samsung-2.ru .
Крайне советую https://www.everythingcyber.com/popup-menu-link-wordpress-tutorial-contact-me/
купить диплом в феодосии https://rudik-diplom10.ru .
организация онлайн трансляции организация онлайн трансляции .
купить диплом в спб с занесением в реестр http://frei-diplom3.ru .
аренда студии подкастов аренда студии подкастов .
https://www.wildberries.ru/catalog/183263596/detail.aspx
купить проведенный диплом вуза http://www.frei-diplom1.ru/ .
накрутка подписчиков в тг бесплатно за задания
куплю диплом высшего образования куплю диплом высшего образования .
Ich liebe die Magie von Wunderino Casino, es verstromt eine Spielstimmung, die wie ein Marchenbuch verzaubert. Der Katalog des Casinos ist ein Marchenwald voller Action, mit Live-Casino-Sessions, die wie ein Zauberlicht leuchten. Das Casino-Team bietet Unterstutzung, die wie ein Zauberspruch wirkt, mit Hilfe, die wie ein Feenlicht funkelt. Casino-Gewinne kommen wie ein magischer Wind, trotzdem mehr regelma?ige Casino-Boni waren verhext. Insgesamt ist Wunderino Casino ein Casino, das man nicht verpassen darf fur Spieler, die auf magische Casino-Kicks stehen! Zusatzlich die Casino-Oberflache ist flussig und funkelt wie ein Feenlicht, Lust macht, immer wieder ins Casino zuruckzukehren.
wunderino arena 4.rang|
Ich bin suchtig nach Wheelz Casino, es verstromt eine Spielstimmung, die wie ein Looping durch die Wolken schie?t. Der Katalog des Casinos ist ein Freizeitpark voller Action, mit modernen Casino-Slots, die wie ein Looping mitrei?en. Der Casino-Service ist zuverlassig und prazise, liefert klare und schnelle Losungen. Casino-Transaktionen sind simpel wie ein Fahrticket, manchmal mehr Casino-Belohnungen waren ein rasanten Gewinn. Zusammengefasst ist Wheelz Casino ein Casino mit einem Spielspa?, der wie ein Turbo-Ride fesselt fur Adrenalinjunkies im Casino! Extra das Casino-Design ist ein optisches Fahrgeschaft, das Casino-Erlebnis total turboladt.
smokey wheelz|
купить диплом об окончании техникума в новосибирске купить диплом об окончании техникума в новосибирске .
Acho simplesmente epico VikingLuck Casino, tem uma vibe de jogo tao feroz quanto uma tempestade nordica. As opcoes de jogo no cassino sao ricas e cheias de bravura, incluindo jogos de mesa de cassino com um toque de gloria. O atendimento ao cliente do cassino e uma lanca de eficiencia, com uma ajuda que reluz como uma runa encantada. Os saques no cassino sao velozes como um drakkar no vento, mas queria mais promocoes de cassino que rugem como guerreiros. Em resumo, VikingLuck Casino e um cassino online que e um Valhalla de diversao para os viciados em emocoes de cassino! Alem disso o site do cassino e uma obra-prima de estilo nordico, o que torna cada sessao de cassino ainda mais heroica.
viking luck symbol|
Estou completamente vidrado por WinGameBR Casino, da uma energia de cassino que e puro combustivel cosmico. O catalogo de jogos do cassino e uma constelacao de emocoes, incluindo jogos de mesa de cassino com um toque intergalactico. A equipe do cassino entrega um atendimento que e puro foguete, dando solucoes na hora e com precisao. Os ganhos do cassino chegam voando como um cometa, mas as ofertas do cassino podiam ser mais generosas. Resumindo, WinGameBR Casino oferece uma experiencia de cassino que e puro lancamento para os viciados em emocoes de cassino! De bonus a interface do cassino e fluida e reluz como uma constelacao, eleva a imersao no cassino ao nivel de uma missao espacial.
wingame br em portugal|
Ich liebe den Rausch von Wheelz Casino, es pulsiert mit einer rasanten Casino-Energie. Es gibt eine Flut an mitrei?enden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Die Casino-Mitarbeiter sind schnell wie ein Loopingstart, mit Hilfe, die wie ein Adrenalinschub wirkt. Der Casino-Prozess ist klar und ohne Schleudertrauma, ab und zu mehr regelma?ige Casino-Boni waren ein Volltreffer. Insgesamt ist Wheelz Casino eine Casino-Erfahrung, die wie ein Freizeitpark glanzt fur die, die mit Stil im Casino wetten! Nebenbei die Casino-Oberflache ist flussig und funkelt wie ein Freizeitpark bei Nacht, einen Hauch von Achterbahn-Magie ins Casino bringt.
wheelz free spins|
моб телефоны samsung https://www.kupit-telefon-samsung-1.ru .
Estou alucinado com BetorSpin Casino, parece uma explosao cosmica de adrenalina. Tem uma chuva de meteoros de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que reluzem como supernovas. O servico do cassino e confiavel e brilha como uma galaxia, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como uma viagem interestelar, mas queria mais promocoes de cassino que explodem como supernovas. No fim das contas, BetorSpin Casino vale demais explorar esse cassino para quem curte apostar com estilo estelar no cassino! E mais a interface do cassino e fluida e reluz como uma constelacao, eleva a imersao no cassino a um nivel cosmico.
betorspin paga|
An impressive share! I’ve just forwarded this onto a colleague who was conducting a little research on this. And he in fact ordered me breakfast simply because I stumbled upon it for him… lol. So allow me to reword this…. Thanks for the meal!! But yeah, thanx for spending time to discuss this issue here on your web page.
https://http-kra40.cc
Acho simplesmente estelar WinGameBR Casino, e um cassino online que decola como um foguete em chamas. Tem uma chuva de meteoros de jogos de cassino irados, incluindo jogos de mesa de cassino com um toque intergalactico. O suporte do cassino ta sempre na ativa 24/7, respondendo mais rapido que um lancamento orbital. O processo do cassino e limpo e sem buracos negros, porem queria mais promocoes de cassino que explodem como supernovas. Na real, WinGameBR Casino oferece uma experiencia de cassino que e puro lancamento para quem curte apostar com estilo estelar no cassino! Alem disso a plataforma do cassino brilha com um visual que e puro cosmos, adiciona um toque de brilho cosmico ao cassino.
wingame br com|
moeinclub – The branding feels authentic, engaging and built with vision always.
Hi there this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
маркетплейс kraken
купить airpods спб naushniki-apple-1.ru .
Обязательно попробуйте https://euroholitel.com/en/hello-world/
накрутка подписчиков телеграм задания
https://www.brownbook.net/business/54330020/васильевка-купить-кокаин/
купить диплом в нальчике https://www.rudik-diplom2.ru – купить диплом в нальчике .
https://www.grepmed.com/gibadlxib
https://anyflip.com/homepage/vdxki
купить диплом массажиста купить диплом массажиста .
If you want to try the Pirots 3 slot machine without risk, Pirots 3 demo slot is available for free on our website. Try Pirots 3 free play and enjoy all the features of the game without the need to register. When you feel ready to play with real stakes, you can find Pirots 3 at a number of licensed online casinos in Norway and internationally. These often offer bonuses that include free spins on new games, and some have exclusive promotions related to new launches like Pirots 3. You can play Pirots 3 for real money at online casinos that offer games from ELK Studios. Be sure to choose a licensed and reputable casino for the best experience. The bonus game is triggered by collecting three bonus symbols, starting with five Free Spins on the same or an expanded grid, and includes additional spins for each bonus symbol collected during the round.
https://calisbeautysupply.com/1438/dragon-vs-tiger-by-tadagaming-review-winning-tips-for-indian-players/
Hit frequency, which is the probability that any given spin produces a positive outcome, was not published for Pirots 3 or Pirots X. The short-session observations in this review—mid-30% for Pirots 3 and upper-20% for Pirots X across their respective 50-spin sets—are a snapshot and not a deterministic property of the games. In long-run terms, high-volatility titles can exhibit a wide range of hit frequencies; what matters more is how those hits are clustered and whether features concentrate a disproportionate share of total returns. In both Pirots 3 and Pirots X, the observed clustering appeared to align with high-volatility expectations. Can you really win big in Pirots 3 — or is it all chaos and luck? The slot’s real attraction lies in the several bonus features, which take the gameplay to another level, apart from the CollectR system. Collection Meter and Cascading Reels also play a crucial role in giving you thrilling gameplay and higher rewards. Additionally, look out for certain features for Pirots 3 free play, more excitement, and enhanced odds of winning. They include:
как посмотреть подписчиков в тг канале
накрутка живых подписчиков в тг
https://imageevent.com/raiderszeida/iwmwz
Galera, vim dividir minhas impressoes no 4PlayBet Casino porque nao e so mais um cassino online. A variedade de jogos e de cair o queixo: roletas animadas, todos bem otimizados ate no celular. O suporte foi bem prestativo, responderam em minutos pelo chat, algo que vale elogio. Fiz saque em Bitcoin e o dinheiro entrou muito rapido, ponto fortissimo. Se tivesse que criticar, diria que mais brindes fariam falta, mas isso nao estraga a experiencia. Na minha visao, o 4PlayBet Casino me conquistou. Vale experimentar.
empower 4play|
Acho simplesmente turbo F12.Bet Casino, tem uma energia de jogo tao veloz quanto um motor V12. A selecao de titulos e um motor de prazeres. oferecendo lives que explodem como largadas. O atendimento esta sempre ativo 24/7. assegurando apoio sem derrapagens. Os saques sao velozes como um pit stop. mas mais giros gratis seriam uma loucura de pista. Em resumo, F12.Bet Casino e o point perfeito pros fas de cassino para os viciados em emocoes de cassino! Vale dizer a interface e fluida e ronca como um motor. adicionando um toque de velocidade ao cassino.
f12 bet br para login|
Je suis fou de Simsinos Casino, on dirait un scenario plein de bulles de fun. Les options de jeu au casino sont riches et colorees. offrant des sessions de casino en direct qui sautent comme des toons. L’assistance du casino est chaleureuse et precise. resonnant comme une planche parfaite. Les paiements du casino sont securises et fluides. quand meme des bonus de casino plus frequents seraient animes. En conclusion, Simsinos Casino c’est un casino a explorer sans tarder pour les virtuoses des jeux! Par ailleurs est une cadence visuelle envoutante. fait vibrer le jeu comme un concerto colore.
avis simsinos|
https://vocal.media/authors/kupit-kokain-angarsk
https://anyflip.com/homepage/ycnvs
купить диплом об окончании техникума в оренбурге купить диплом об окончании техникума в оренбурге .
https://anyflip.com/homepage/ejacz
http://images.google.bj/url?q=https://academia.utp.edu.co/wieutp/pin-up/ – Pin Up Mexico – A in online casino in Mexico!
http://www.pageorama.com/?p=acuogiobif
https://wirtube.de/a/schrammpvjjosef/video-channels
https://imageevent.com/mitboom01/cnmpj
Like any other online slot game, there’s always a list of pros and cons! So, without further ado, check out our list of pluses and minuses. Pirots 3 continues to expand the world of the Pirots slot franchise. The characters are fun, the art amusing, and the gameplay exciting and is varied by a huge number of Bonus Features. Respinix is an independent platform offering visitors access to free demo versions of online slots. All information on Respinix is provided for informational and entertainment purposes only. Respinix does not offer any real money gambling game. With a plethora of features like the CollectR mechanic, an expanding game grid, symbol upgrades, and a super bonus game, Pirots 3 promises an exhilarating gaming experience. All of the online casino games we offer, including online slots, are played with, and for, real money.
https://unasblowci1976.bearsfanteamshop.com/https-buffalokingmegaways-i-com
With an RTP of 94%, I’ll be honest that Pirots 4 isn’t the most generous slot on paper. But then again, the same could be said about its predecessor with the same RTP—the Pirots 3 slot game. The return rate is on the lower side compared to most modern releases, and you’ll feel that during dry patches. It’s definitely not a game where you can go big too soon. The Pirots slot is a 5×5 grid slot, but not in the most conventional ways. You get avalanching reels, but symbols pay only when you match the same colour bird and gems. The bird will walk along, collect the gems and allow more symbols to fall from above. ELK Studios has implemented an automatic optimizer. Players will have their wagers automatically adjusted on featured ELK slots according to selected fixed or flexible strategies based on the outcome of the last bets. You can play ELK Studios slots for free on Clashofslots to find out how the automatic betting strategies work.
https://www.montessorijobsuk.co.uk/author/gygadegyy/
https://www.montessorijobsuk.co.uk/author/odighagcmefu/
купить подписчиков в телеграм дешево
https://bio.site/xlluebiucguc
быстрая накрутка подписчиков в телеграм
https://pubhtml5.com/homepage/kifjt
студия для съемки подкастов http://www.studiya-podkastov-spb1.ru .
Бывают такие ситуации, когда требуется помощь хакеров, которые быстро, эффективно справятся с самой сложной задачей. Хакеры легко вскроют почту, добудут пароли, обеспечат защиту. А для достижения цели используют уникальные и высокотехнологичные методики. Любой хакер отличается большим опытом. https://hackerlive.biz – портал, где работают только проверенные, знающие хакеры. За оказание услуги плата небольшая. Все работы высокого качества. Прямо сейчас свяжитесь со специалистом, который отвечает вашим требованиям.
Доброго времени!
Расскажу о практическим опытом обустройства пространства в столице.
Задача была – организовать корпоратив для расширенного состава. Помещение требовало дополнительного оснащения.
Покупать мебель не оправдывалось для разового мероприятия. Искали другие варианты и попробовали прокат качественной мебели.
Изучал предложения: банкетная мебель для мероприятий – качественный сервис.
**Итог:**
– Сэкономили около 60% бюджета
– Мероприятие прошло на отлично
– Бесплатная доставка и сборка
– Отличные впечатления
– Гибкие условия сотрудничества
Теперь всегда обращаемся к ним. В различных ситуациях – это оптимальный вариант.
Есть ли опыт у коллег? Делитесь в комментариях!
https://anyflip.com/homepage/oliah
https://www.impactio.com/researcher/divfkdlx6029
Все прошло на высшем уровне, начиная от общения и заканчивая массажем, чувствовал себя королем. Советую, индивидуалка недорого нск – https://sibirki3.vip/. Девушки настоящие красавицы, приятно провести время.
https://anyflip.com/homepage/rppuk
купить живых подписчиков в тг
https://pubhtml5.com/homepage/tkrka
goldmetalshop – I would feel comfortable buying here based on how professional it seems.
sunnyflowercases – The product photos are gorgeous, really helps in choosing designs.
http://www.pageorama.com/?p=padhububaoug
https://imageevent.com/bashiriandor/wxdqn
adawebcreative – Their About page gives a nice personal touch, seems genuine.
https://anyflip.com/homepage/kuaeb
apkcontainer – I’ll be checking this site again whenever I need rare Android apps.
Be sure to stay updated with current promotions, as many platforms refresh their offers regularly. Subscribing to newsletters or following your favorite online venues on social media can provide instant notifications about the latest promotions. With just a little bit of effort, you can unlock thrilling gaming experiences without the need to invest your own funds upfront. Which renowned gambling enterprise position, developed by Playtech, in addition to made loads of noise whether it was launched owed in order to its apparently highest get back price for a modern jackpot game. Today, Playtech features put out over 10 variants associated with the position, yet none are since the popular because the brand new Age of the brand new Gods. Starburst is a good NetEnt position which have simple provides and auto mechanics, as well as a colorful program, one to turned by far the most played slot ever.
https://www.gregor-adv.com/?p=55451
Casino is slightly on the anaemic side, the Pennsylvania Gaming Control Board (PGCB) opened up a second round. In this section of the game library, three-reel or jackpots. Coral may have started as a sportsbook, so they will be riding a wave of momentum going into their bowl game. Therefore, get to know top casino games. Uptown pokies code unfortunately, a loyalty bonus will be a percentage match based on your previous deposits. While baccarat is a game of chance, seven days a week. The theme of this game is based on ancient Norse mythology, starburst extreme demo the UK Gambling Commission. This is something worth doing when the time comes to get all that you need, starburst extreme demo the symbols will disappear. In addition to these advantages, and new ones will fall into place. Are There Any Reliable Australian Online Casinos? The wide range of pokies at Spin Samba Casino includes classic 3-reel pokies from RTG along with modern 5-reel video pokies featuring different payline structures, which have more complex graphics and gameplay.
http://www.pageorama.com/?p=lyefucaffee
Школьникам и учителям истории пригодится https://gdz-history.ru/ — удобный архив атласов и контурных карт для 5–10 классов с возможностью читать онлайн, скачать или распечатать. Есть «чистые» контурные карты, готовые домашние задания и учебники с ответами на вопросы параграфов, что экономит время на подготовке и повторении. Страницы по темам упорядочены от древней Руси до Нового времени, быстро открываются, а навигация по классам и разделам интуитивна. Ресурс помогает визуализировать исторические процессы, корректно увязывая карты с программными темами.
Financial-project.ru — библиотека доступных бизнес-планов и экспресс-исследований рынка по фиксированной цене 550р. за проект. На https://financial-project.ru/ каталог охватывает десятки ниш: от глэмпинга, АЗС и СТО до салонов красоты, ПВЗ, теплиц и ресторанов. Страницы продуктов оформлены лаконично: быстрое «Купить», четкая рубрикация, понятная навигация. Формат подойдёт предпринимателям, которым нужно быстро прикинуть экономику и структуру разделов для банкиров и инвесторов, а также начинающим, чтобы не упустить критичные блоки — от маркетинга до операционных расчетов.
накрутка подписчиков тг без заданий
https://bio.site/lbobudqaid
Железнодорожная логистика выступает основой транспортной инфраструктуры, гарантируя стабильные и крупномасштабные транспортировки грузов по России и дальше, от сибирских широт до портов Дальнего Востока. В этом секторе собраны многочисленные фирмы, которые предоставляют полный спектр услуг: от операций по погрузке и разгрузке, аренды вагонов до контейнерных транспортировок и таможенных процедур, помогая бизнесу грамотно организовывать логистические цепочки в самых удаленных районах. Ищете железнодорожные грузоперевозки? На платформе gdlog.ru собрана обширная база из 278 компаний и 1040 статей, где пользователи могут удобно искать партнеров по жд логистике, изучать станции в городах вроде Екатеринбурга или Иркутска и узнавать о сопутствующих услугах, таких как хранение грузов или разработка схем погрузки. Этот метод не просто облегчает подбор проверенных исполнителей, но и помогает оптимизировать затраты, ускоряя транспортировку и снижая возможные риски. В конечном счете, жд логистика не перестает развиваться, предоставляя новаторские подходы для сегодняшней экономики и позволяя фирмам сохранять конкурентные преимущества в изменчивой среде.
бот для накрутки подписчиков в телеграм канале
Предлагаю https://the-smallerboard.net/index.php?topic=77.new#new
https://pubhtml5.com/homepage/kltmi
joszaki regisztracio joszaki.hu/
Acho simplesmente ardente Verabet Casino, e um cassino online que queima como uma fogueira ancestral. As opcoes sao ricas e queimam como carvoes. oferecendo sessoes ao vivo que brilham como labaredas. O atendimento e solido como carvoes. com solucoes precisas e instantaneas. Os saques queimam como brasas. entretanto queria mais promocoes que queimam como fogueiras. No geral, Verabet Casino e um cassino online que e uma fogueira de diversao para os xamas do cassino! E mais o design e um espetaculo visual flamejante. transformando cada aposta em uma aventura flamejante.
casa de aposta vera bet|
Sou louco pela energia de Brazino Casino, pulsa com uma forca de cassino digna de um oceano. O catalogo de jogos e um oceano de prazeres. com caca-niqueis modernos que nadam como peixes tropicais. O suporte e um farol subaquatico. garantindo suporte direto e sem correntezas. As transacoes sao simples como uma bolha. as vezes mais recompensas fariam o coracao nadar. No fim das contas, Brazino Casino e um recife de emocoes para os amantes de cassinos online! Como extra a navegacao e facil como uma corrente marinha. transformando cada aposta em uma aventura marinha.
mГєsica do brazino777|
raspinakala – The mix of traditional and modern art techniques is nicely balanced here.
https://anyflip.com/homepage/mfaok
https://imageevent.com/lizahuizinga/oupwh
живые активные подписчики в тг
как можно накрутить подписчиков в тг канале
накрутка подписчиков тг бесплатно без заданий
вывод из запоя круглосуточно краснодар
vivod-iz-zapoya-krasnodar017.ru
экстренный вывод из запоя краснодар
https://anyflip.com/homepage/aqsca
https://muckrack.com/person-28174143
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar017.ru
экстренный вывод из запоя
Автосалон «Темп» предлагает воспользоваться такой важной и популярной услугой, как подбор подходящего автомобиля из тех вариантов, которые имеются в наличии или можно приобрести под заказ из Кореи, Китая либо Японии. Также получится взять автокредит либо рассчитать цену своего будущего автомобиля. Для того чтобы подобрать авто из Японии, необходимо указать такие данные, как: модель, марка автомобиля, а также то, когда он был выпущен. На сайте https://tempa-cars.ru представлено огромное количество автомобилей, которые вы сможете приобрести прямо сейчас.
raspinakala – The visuals are striking and the site feels genuinely creative and alive.
https://pubhtml5.com/homepage/ndjww
Крайне советую https://elooeloo.com/2024/04/05/wellness-retreats-mind-body-and-soul-human-renewal/
centensports – Very good balance of topics, content is rich and relevant.
https://www.brownbook.net/business/54330171/фуншал-купить-кокаин/
https://anyflip.com/homepage/ljfow
apkcontainer – I’m impressed by how organized the categories and sections are.
https://imageevent.com/daughertyhau/dxrsd
организация онлайн трансляции конференции http://www.zakazat-onlayn-translyaciyu.ru/ .
бот для накрутки подписчиков в телеграм
https://4ef82f85515505afd4372c2bc0.doorkeeper.jp/
http://google.com.ly/url?q=https://manuchao.net/videos/manu-chao-tu-te-vas-feat-laeti/ – Pin Up Mexico – A popular online casino in Mexico!
накрутка подписчиков в тг канал боты бесплатно
Rz-Work – биржа для новичков и опытных профессионалов, готовых к ответственной работе. Популярность у фриланс-сервиса высокая. Преимущества, которые выделили пользователи: легкость регистрации, гарантия безопасности сделок, быстрое реагирование службы поддержки. https://rz-work.ru – здесь представлена более подробная информация. Rz-Work является платформой, которая способствует эффективному взаимодействию заказчиков и исполнителей. Она понятным интерфейсом отличается. Площадка многопрофильная, она много категорий охватывает.
https://www.band.us/page/100115399/
https://pubhtml5.com/homepage/cyiin
https://imageevent.com/edmondskazin/fxhip
накрутка подписчиков тг задания
накрутка подписчиков в телеграм канал без отписок
https://anyflip.com/homepage/ytkmw
вывод из запоя цена
vivod-iz-zapoya-krasnodar018.ru
лечение запоя
https://www.montessorijobsuk.co.uk/author/abucidtadig/
накрутка подписчиков телеграм без заданий
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar018.ru
экстренный вывод из запоя
https://anyflip.com/homepage/ozwom
joszaki regisztracio joszaki
https://anyflip.com/homepage/svbax
https://imageevent.com/joelhughes39/gjoid
Je suis totalement ensorcele par Grandz Casino, resonne avec un rythme de casino voile. vibre avec un voile de jeux varies. incluant des jeux de table de casino d’une elegance spectrale. offre un soutien qui effleure tout. assurant un support de casino immediat et voile. fluisent comme une sonate spectrale. cependant des offres qui vibrent comme une cadence spectrale. Pour resumer, Grandz Casino enchante avec une rhapsodie de jeux pour les passionnes de casinos en ligne! Bonus la plateforme du casino brille par son style theatral. ajoute une touche de rythme spectral au casino.
casino grandz|
https://imageevent.com/lefflercarol/gvygp
https://muckrack.com/person-28189975
Советую https://rajsingh.blog/understanding-healthcare-regulations-a-primer-for-early-career-engineers/?unapproved=10172&moderation-hash=e4401943a8f40334f6735ff5683474b3
https://vocal.media/authors/kupit-kokain-angarsk
tripscan войти Сайт TripScan – ваш надежный инструмент для планирования путешествий. Здесь вы найдете лучшие предложения на авиабилеты, отели, аренду автомобилей и другие услуги. Наша платформа проста в использовании и предлагает широкий выбор вариантов, чтобы удовлетворить все ваши потребности. Посетите сайт TripScan и начните планировать свою следующую поездку уже сегодня! сайт трипскан
https://imageevent.com/bednarikovaa/gtvyu
Ремонт iphone 15 Сервисный центр Москва: Мы – ведущий сервисный центр в Москве, предлагающий широкий спектр услуг по ремонту и обслуживанию телефонов, ноутбуков и другой электроники. Наши квалифицированные специалисты используют только оригинальные запчасти и современное оборудование для диагностики и ремонта. Мы гарантируем высокое качество, оперативность и доступные цены. Обращайтесь к нам, и мы быстро вернем вашу технику к жизни! Наша цель – ваш комфорт и уверенность в надежной работе ваших устройств. Доверьте свою технику профессионалам – лидерам рынка ремонта в Москве!
https://kemono.im/hvyehududiac/kupit-kokain-leiptsig
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar019.ru
вывод из запоя цена
купить диплом в воронеже купить диплом в воронеже .
Прокачайте свою стрічку перевіреними фактами замість інформаційного шуму. UA Факти — це швидкі, перевірені новини та лаконічна аналітика без води. Ми щодня відбираємо головне з України та світу, щоб ви економили час і приймали рішення впевнено. Долучайтеся до спільноти відповідальних читачів і відкривайте більше корисного контенту на нашому сайті: https://uafakty.com.ua З нами ви швидко знаходите головне: тренди, події й пояснення — все в одному місці та без зайвих слів.
https://vocal.media/authors/mezhdurechensk-kupit-kokain
https://pubhtml5.com/homepage/toyow
Советую https://treckadv.com/hello-world/
Сайт скупки антиквариата впечатляет прозрачными условиями: онлайн-оценка по фото, бесплатный выезд по России, моментальная выплата и конфиденциальность. Владелец — частный коллекционер, что объясняет внимание к иконам до 1917 года, дореволюционному серебру 84-й/88-й пробы, фарфору и живописи русских школ. В середине каталога легко найти формы «Оценить/Продать» для разных категорий, а на https://xn—-8sbaaajsa0adcpbfha1bdjf8bh5bh7f.xn--p1ai/ публикации блога подсказывают, как распознать редкости. Удобный, аккуратный сервис без посредников.
https://anyflip.com/homepage/wauda
свежие новости спорта http://novosti-sporta-15.ru/ .
https://www.divephotoguide.com/user/hiodagayo
спортивные трансляции http://www.novosti-sporta-16.ru .
freespeechcolation – Their platform seems committed, tone is clear and convincing.
новости хоккея https://www.novosti-sporta-17.ru .
https://imageevent.com/ersgdirosa/ahdkb
https://anyflip.com/homepage/luxnx
платные прогнозы на спорт платные прогнозы на спорт .
letter4reform – Very direct tone, content feels heartfelt and intent is obvious.
https://odysee.com/@ucocerevon07
bigjanuarycleanup – Very readable site, visuals and writing flow nicely together.
английская языковая школа
pgmbconsultancy – Very good layout, the tone is clean and confident throughout.
zz-meta – Very sleek interface, content feels purposeful and polished overall.
cnsbiodesk – Strong identity, their content and visuals align well together.
http://www.pageorama.com/?p=zibjzoiblagu
https://stmaryofthehills.org/img/pgs/c_digo_promocional_99.html
https://vocal.media/authors/kupit-kokain-holmsk
https://pubhtml5.com/homepage/fgqaj
Стальная надежность для общественных пространств имеет имя — Steel NORD. Компания производит антивандальную сантехнику из нержавеющей стали и подтверждает качество реальными проектами и быстрой логистикой. В каталоге — унитазы, раковины, писсуары, зеркала, душевые поддоны и чаши «Генуя». Доступны решения для МГН, лотковые писсуары и длинные коллективные раковины. Оплата любым удобным способом, отслеживание отправлений и 14-дневный возврат. Ищете нержавеющий унитаз цена? Узнайте больше и оформите заказ на сайте — steelnord.ru
вывод из запоя цена
vivod-iz-zapoya-krasnodar020.ru
вывод из запоя краснодар
https://pubhtml5.com/homepage/oafmp
https://imageevent.com/heikosteenis/hflwr
https://form.jotform.com/252685181831057
https://anyflip.com/homepage/avpyp
накрутка активных подписчиков в тг канал
https://imageevent.com/mrazmay773/iozjf
как накрутить подписчиков в телеграм бот
https://f57b0e2244fa0d32cb44576304.doorkeeper.jp/
https://www.grepmed.com/ghayaudoceec
https://www.band.us/page/100122108/
https://anyflip.com/homepage/hzokq
Шукаєте перевірені новини Києва без зайвого шуму? «В місті Київ» збирає головне про транспорт, бізнес, культуру, здоров’я та афішу. Ми подаємо коротко, по суті та з посиланнями на першоджерела. Оновлення виходять оперативно, а зручна навігація допомагає швидко знайти потрібне. Деталі на https://vmisti.kyiv.ua/ Приєднуйтесь до спільноти уважних читачів і дізнавайтеся про міські зміни першими. Підписуйтеся і розкажіть про нас друзям!
Рекомендую https://oantagonico.net.br/altamira-o-fundo-de-saude-a-licitacao-o-tcm-e-a-suspensao/
https://pubhtml5.com/homepage/rlfnd
запись подкастов запись подкастов .
https://www.divephotoguide.com/user/tliihogocqu
Очищение организма после запоя в Красноярске – существенный шаг на пути к нормализации состояния и улучшению жизни. Нарколог на дом из клиники предлагает процедуры детоксикациикоторая предоставляет помощь в лечении запоя и медицинскую помощь при алкоголизме. Программы лечения могут включать психотерапию и поддержку семьи. Восстановление после запоя начинается с консультации нарколога, что способствует успешному очищению организма и возвращению к полноценной жизни. Нарколог на дом клиника
https://anyflip.com/homepage/lmhps
Учебный центр дистанционного профессионального образования https://nastobr.com/ приглашает пройти краткосрочное обучение, профессиональную переподготовку, повышение квалификации с выдачей диплома. У нас огромный выбор образовательных программ и прием слушателей в течение всего года. Узнайте больше о НАСТ на сайте. Мы гарантируем результат и консультационную поддержку.
как набрать подписчиков в телеграм канале
Когда сроки горят, а задачи требуют мощи, «БизонСтрой» становится надежной опорой: здесь аренда спецтехники в Москве и области оформляется за полчаса, а подача на объект возможна в день заявки. Парк впечатляет: экскаваторы, бульдозеры, погрузчики, краны — всё в отличном состоянии, с опытными операторами и страховкой. Условия прозрачные: аренда на час, день, месяц — без скрытых платежей. Клиенты отмечают экономию до 40% и поддержку 24/7. С подробностями знакомьтесь на https://bizonstroy.ru Оставьте заявку — и стройка поедет быстрее.
https://pubhtml5.com/homepage/zgwyk
https://www.imdb.com/list/ls4150539431/
https://pubhtml5.com/homepage/igcac
Капельница для лечения запоя – это значимый метод лечение алкоголизма, который широко применяется в лечебных учреждениях Красноярска. Процедура детоксикации помогает оперативному восстановлению организма после продолжительного потребления алкоголя. Время процедуры обычно варьируется от 1 до 3 часов, в зависимости от индивидуальных потребностей и интенсивности запойного состояния. лечение запоя Красноярск Признаки запоя включает в себя интенсивные головные боли, тошноту и рвоту, обильное потоотделение и тревогу и беспокойство. Медицинская помощь в виде капельницы даёт возможность быстро облегчить похмельные симптомы, вводя необходимые препараты для нормализации водно-электролитного баланса и устранения токсинов. Цены на лечение запоя в Красноярске варьируется в зависимости от выбранной клиники и количества требуемых процедур. Консультация нарколога поможет выработать наилучший курс лечения, включая реабилитацию после запоя. Результативность капельницы подтверждается множество положительными отзывами пациентов, что делает ее востребованным способом профилактики с алкоголизмом.
https://www.band.us/page/100105820/
диплом медсестры с аккредитацией купить диплом медсестры с аккредитацией купить .
https://www.band.us/page/100103112/
лучшие бесплатные прогнозы на спорт лучшие бесплатные прогнозы на спорт .
Попробуйте https://teselar.club/hello-world/
https://pubhtml5.com/homepage/bbiej
http://www.pageorama.com/?p=iaibhiyd
https://pubhtml5.com/homepage/niohb
накрутка подписчиков в тг навсегда
Медикаменты от алкоголизма могут включать лекарства для коррекции зависимости‚ которые облегчают проявления. Постоянная поддержка и контроль при детоксикации обеспечивают защищенность пациента. Забота близких также имеет большое значение для успешного восстановления после запойного синдрома. вывод из запоя круглосуточно Советы по выходу из запоя могут включать частые консультации с врачом и придерживание распорядка. Следует обратиться за поддержкой‚ чтобы предотвратить возвращение к алкоголю и обеспечить качественное лечение.
https://muckrack.com/person-28190023
https://kemono.im/cocufadjml/kupit-kokain-iasinovataia
Estou completamente vidrado por MarjoSports Casino, e um drible de diversao que dribla a concorrencia. As escolhas sao vibrantes como um apito. oferecendo lives que explodem como penaltis. Os agentes voam como jogadores. assegurando apoio sem cartoes. Os pagamentos sao lisos como uma rede. entretanto mais recompensas fariam a torcida pular. No fim das contas, MarjoSports Casino oferece uma experiencia que e puro drible para os craques do cassino! De lambuja a interface e fluida e vibra como um estadio. dando vontade de voltar como um craque.
como fazer apostas no marjosports|
Galera, nao podia deixar de comentar no 4PlayBet Casino porque me pegou de surpresa. A variedade de jogos e bem acima da media: poquer estrategico, todos funcionando perfeito. O suporte foi atencioso, responderam em minutos pelo chat, algo que passa seguranca. Fiz saque em Ethereum e o dinheiro entrou muito rapido, ponto fortissimo. Se tivesse que criticar, diria que mais brindes fariam falta, mas isso nao estraga a experiencia. Resumindo, o 4PlayBet Casino e completo. Recomendo sem medo.
katana kombat|
Galera, nao podia deixar de comentar no 4PlayBet Casino porque superou minhas expectativas. A variedade de jogos e surreal: roletas animadas, todos rodando lisos. O suporte foi bem prestativo, responderam em minutos pelo chat, algo que faz diferenca. Fiz saque em Ethereum e o dinheiro entrou sem enrolacao, ponto fortissimo. Se tivesse que criticar, diria que podia ter mais promocoes semanais, mas isso nao estraga a experiencia. Enfim, o 4PlayBet Casino me conquistou. Vale experimentar.
herbals 4play|
https://pixelfed.tokyo/dxjovfh490
Me encantei pelo ritmo de BR4Bet Casino, tem um ritmo de jogo que acende como uma tocha. Os jogos formam um clarao de entretenimento. incluindo mesas com charme iluminado. O atendimento esta sempre ativo 24/7. respondendo rapido como um brilho na noite. Os pagamentos sao lisos como uma chama. entretanto mais bonus seriam um diferencial reluzente. Na real, BR4Bet Casino vale explorar esse cassino ja para os amantes de cassinos online! E mais o layout e vibrante como uma tocha. dando vontade de voltar como uma chama eterna.
br4bet e confiГЎvel|
masquepourvous – Their tone feels intentional, visuals and words harmonize gracefully.
https://pixelfed.tokyo/john.jackson28121995nlw
Объявления PRO-РФ — универсальная бесплатная площадка с понятным рубрикатором: работа, авто-мото, недвижимость, стройкатегории, услуги и знакомства, с фильтром по регионам от Москвы до Якутии. В каталоге есть премиум лоты, быстрые кнопки «Опубликовать объявление» и «Вход/Регистрация», а лента пополняется ежедневно. В каждом разделе видны подкатегории и счетчики, что экономит время. На https://doskapro-rf.ru/ подчёркнута простота: минимум кликов до публикации, адаптация под мобильные устройства и полезные советы по продаже — удобно продавцам и покупателям.
Помощь наркологов становится актуальной в борьбе с зависимостями. На сайте vivod-iz-zapoya-krasnoyarsk017.ru предоставляется информация о лечении зависимостей, включая индивидуальные подходы. Профессионалы в области наркологии оказывают помощь в определении уровня зависимости и предлагают медицинскую помощь при алкоголизме и зависимости от наркотиков. Консультация нарколога — это первый шаг к новой жизни после психоактивных веществ. Значимы меры по предотвращению рецидивов и групповая терапия для укрепления статуса выздоровления. Поддержка со стороны родных и профессионалов помогает преодолеть трудности на пути к здоровой жизни.
https://vocal.media/authors/kupit-kokain-portugaliya
Je suis totalement envoute par Casombie, ca transporte dans un monde de chaos ludique. La gamme est un veritable apocalypse de fun, proposant des paris sportifs qui donnent des frissons. Les agents repondent plus vite qu’un zombie affame, offrant des solutions claires comme un clair de lune. Les gains arrivent a une vitesse demoniaque, cependant des bonus plus mordants seraient top. En somme, Casombie est une plateforme qui fait battre les c?urs pour les amateurs de vibes gothiques ! A noter la plateforme brille comme une pleine lune, facilite une experience aussi fluide qu’un spectre.
casombie kaszinГі magyar|
PolyFerm — экспертные композиции ферментных и микробиологических препаратов для стабильно высокой эффективности технологических процессов. Рациональные формулы помогают улучшать биотрансформацию субстратов, снижать издержки и повышать выход целевых продуктов в пищевой, фарм- и агропромышленности. Команда внедряет решения под задачу, поддерживает тесты и масштабирование, обеспечивая воспроизводимые результаты. Подробнее о возможностях, продуктах и пилотах — на https://polyferm.pro/ — оцените, где ваша цепочка теряет проценты и как их вернуть.
Je suis ensorcele par Freespin Casino, c’est une tornade de sensations vibrantes. Les options forment un tourbillon de surprises, avec des slots aux visuels electrisants. Le support est disponible 24/7, offrant des solutions nettes comme un cristal. Les paiements sont securises comme une voute celeste, neanmoins les offres pourraient etre plus eclatantes. Dans l’ensemble, Freespin Casino merite d’etre explore sans hesiter pour ceux qui cherchent des frissons lumineux ! Par ailleurs l’interface est fluide comme une nebuleuse, facilite une experience fluide et radieuse.
free spin crypto casino|
https://wirtube.de/a/fwyvwymz26262f/video-channels
Je suis charme par Nomini Casino, on dirait un theatre de frissons evanescents. Il y a une cascade de jeux de casino captivants. offrant des lives qui pulsent comme un theatre. Le support du casino est disponible 24/7. proposant un appui qui enchante. Les gains du casino arrivent a une vitesse etheree. cependant plus de bonus pour une harmonie voilee. En fin de compte, Nomini Casino resonne comme un ballet de plaisir pour ceux qui cherchent l’adrenaline voilee du casino! De plus la plateforme du casino brille par son style theatral. fait vibrer le jeu comme un concerto ephemere.
masquepourvous – I enjoy the browsing experience, everything feels smooth and effortless.
Je suis irresistiblement magnetise par Robocat Casino, il programme une sequence de recompenses fulgurantes. Le kit est un hub de diversite high-tech, proposant des Aviator pour des survols d’adrenaline. L’assistance compile des fixes nets, declenchant des protocoles multiples pour une resolution instantanee. Les retraits s’activent avec une velocite remarquable, a l’occasion des add-ons de recompense additionnels scelleraient les connexions. En compilant le code, Robocat Casino forge une saga de jeu futuriste pour ceux qui flashent leur destin en ligne ! De surcroit l’interface est un dashboard navigable avec finesse, incite a prolonger la session infinie.
robocat 270 mm|
https://anyflip.com/homepage/jrcwy
Крайне советую https://forum.postrend.ru/viewtopic.php?f=1&t=227990
Je suis accro a l’ambiance de Casombie, ca transporte dans un monde de chaos ludique. Les options sont vastes comme un cimetiere, comprenant des jeux adaptes aux cryptomonnaies. Le support est disponible 24/7, offrant des solutions claires comme un clair de lune. Les paiements sont securises comme une tombe scellee, parfois des tours gratuits supplementaires feraient frissonner. En somme, Casombie est un must pour les amateurs de sensations fortes pour les amateurs de vibes gothiques ! De plus le design est sombre et captivant, ce qui rend chaque session electrisante.
retirer sur casombie|
Je suis ensorcele par Freespin Casino, on dirait un festival de frissons eclatants. Il y a une cascade de jeux envoutants, incluant des jeux de table d’une energie debordante. Le suivi est d’une clarte lumineuse, repondant en un flash. Les paiements sont securises comme une voute celeste, mais plus de promos vibrantes seraient un regal. En somme, Freespin Casino merite d’etre explore sans hesiter pour les joueurs en quete de magie ludique ! En bonus le design est vibrant comme une galaxie, ajoute une touche de feerie celeste.
casino free spin sans dГ©pГґt 2022|
ucbstriketowin – The details stand out nicely, making everything easier to follow.
https://imageevent.com/arvel7rizal/uajcr
Je suis captive par Nomini Casino, il propose une aventure de casino qui tournoie comme un voile mystique. L’assortiment de jeux du casino est une scene de delices. incluant des jeux de table de casino d’une elegance spectrale. Les agents du casino sont rapides comme un voile qui s’envole. resonnant comme une illusion parfaite. arrivent comme un concerto voile. quand meme plus de tours gratuits au casino ce serait theatral. En conclusion, Nomini Casino est un joyau pour les fans de casino pour les explorateurs de melodies en ligne! A noter est une cadence visuelle envoutante. fait vibrer le jeu comme un concerto ephemere.
Je suis irresistiblement magnetise par Robocat Casino, il programme une sequence de recompenses fulgurantes. Il pulse d’une panoplie de prototypes interactifs, proposant des Aviator pour des survols d’adrenaline. L’assistance compile des fixes nets, garantissant une maintenance loyale dans le systeme. Les retraits s’activent avec une velocite remarquable, occasionnellement des add-ons de recompense additionnels scelleraient les connexions. En apotheose cybernetique, Robocat Casino construit un framework de divertissement automatise pour les builders de victoires high-tech ! En plus la circulation est instinctive comme un script, simplifie la traversee des labs ludiques.
robocat tarot|
Je suis enivre par MrPacho Casino, il orchestre une symphonie de gains succulents. Le menu est un cellier de variete exuberante, integrant des live roulettes pour des tourbillons de suspense. Le support client est un sommelier attentif et omnipresent, avec une maestria qui anticipe les appetits. Le rituel est taille pour une onctuosite exemplaire, par intermittence des menus promotionnels plus frequents pimenteraient la table. A la fin de ce degustation, MrPacho Casino tisse une tapisserie de divertissement gustatif pour les maitres des paris crypto ! En primeur la trame irradie comme un plat ancestral, instille une essence de mystere culinaire.
informations mrpacho|
geteventclipboard – First impression is strong, I trust this site immediately after visiting.
https://imageevent.com/stantonsara4/xlirn
Здесь собрана интересная и практичная информация по разным темам.
Гости могут найти ответы на актуальные вопросы.
Материалы размещаются часто, чтобы каждый посетитель могли читать новую аналитику.
Удобная структура сайта способствует быстро отыскать нужные разделы.
смотреть порно
Большое количество категорий делает ресурс универсальным для разных пользователей.
Любой сможет найти советы, которые нужны именно ему.
Наличие доступных рекомендаций делает сайт особенно ценным.
Таким образом, этот ресурс — это надёжный проводник важной информации для широкого круга пользователей.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Центр здоровья «Талисман» в Хабаровске с 2009 года оказывает анонимную наркологическую помощь: прерывание запоя на дому и в клинике, медикаментозное и психотерапевтическое кодирование, детокс-курсы, консультации психиатра. При выезде врачи предъявляют лицензии и вскрывают препараты при пациенте, что гарантирует безопасность и результат. Узнайте цены, график и состав команды на https://talisman-khv.ru/ — ваша трезвость начинается с правильной поддержки и профессиональной диагностики без очередей и оценок.
brucknerbythebridge – This feels trustworthy, like a site that truly values presentation.
https://pubhtml5.com/homepage/dpnmz
sjydtech – Users will trust this site, it gives a polished tech presence.
https://anyflip.com/homepage/fdgfv
Для заказа оборудования для бурения и цементирования скважин необходимо цена на цементировочный агрегат, который применяется в процессе цементирования скважин для закрепления обсадных труб и изоляции пластов.
необходимые машины для выполнения различных строительных задач . Они используются в строительной отрасли для повышения качества работ. При выборе цементировочного агрегата следует обратить внимание на технические характеристики и функциональность .
Цементировочные агрегаты используются для выполнения разнообразных строительных работ . Они обеспечивают долгую службу без необходимости частого ремонта. При этом важно правильно выбрать цементировочный агрегат .
Преимущества цементировочных агрегатов
Использование цементировочных агрегатов обеспечивает экономию времени и средств . Они дают возможность работать с разными типами цементных растворов . При этом следует правильно обслуживать и эксплуатировать оборудование.
Цементировочные агрегаты используются для выполнения различных задач . Они выполняют функцию нанесения цементных растворов с высокой точностью. При этом следует заранее определить необходимое количество оборудования.
Основные типы цементировочных агрегатов
Существует разнообразные виды оборудования для нанесения цементных смесей . Они отличаются по техническим характеристикам и функциональности . При этом необходимо учитывать все факторы .
Цементировочные агрегаты обеспечивают высокое качество при выполнении любых задач. Они используются для выполнения разнообразных строительных работ . При этом необходимо учитывать все нюансы и особенности .
Заключение и рекомендации
При покупке цементировочного агрегата важно выбрать агрегат соответствующий типу работ . Цементировочные агрегаты выполняют функцию нанесения цементных растворов с высокой точностью. При этом необходимо учитывать все нюансы и особенности .
Цементировочные агрегаты представляют собой важнейшее оборудование для строительства и реконструкции зданий . Они выполняют функцию нанесения цементных растворов . При этом необходимо правильно выбрать цементировочный агрегат .
https://vocal.media/authors/kupit-kokain-angarsk
saveaustinneighborhoods – Everything loads quickly which makes browsing the details stress free.
Слив курсов https://sliv.fun .
айфоны по низким ценам оригинал https://iphone-kupit-1.ru/ .
https://anyflip.com/homepage/xreog
https://anyflip.com/homepage/dpxuq
X-iter™ is een feature van ELK Studios waarmee spelers direct in de actie kunnen duiken. Het is een menu met 5 verschillende opties, variërend in prijs (uitgedrukt als een veelvoud van de inzet). Je kunt bijvoorbeeld betalen voor een spin met een gegarandeerde winst, een spin met een groter speelveld, of directe toegang tot de bonusronde. Let op: deze feature is mogelijk niet in alle rechtsgebieden beschikbaar. Ondanks het verlies blijft Pirots een plezierige slot om te spelen, vooral door de verrassende features en humoristische details. Bij GoldRun Casino gelden voor de welkomstbonus van 100% tot 250 euro een aantal voorwaarden. Er zijn rondspeelvoorwaarden van 30x van toepassing. Op 23 maart 2023 werd de gokkast ‘Pirots’ gelanceerd door ELK Studios. De verwachtingen waren hoog vanwege het nieuwe CollectR spelmechanisme waarin de papegaai symbolen als een soort pacman over het speelveld kunnen lopen en hun eigen kleur symbolen eten. Pirots werd in Nederland direct de populairste gokkast van ELK Studios en de opvolgers stonden dus al snel klaar.
https://tedwatsexpeditionsafrica.com/book-of-dead-slot-review-og-casino-velkomstbonus-i-danmark/
Met de bekende winlijnen en de verschillende symbolen, maar op een net andere manier dan je gewend bent. In een mooie 3D-omgeving of in 2D, zodat je de spellen kunt spelen die jou het meest aanspreken. Ontdek de verschillende nieuwe casino slots die je online kunt uitproberen. Gewoon gratis met de coins van het casino, zodat je nog geen risico hoeft te nemen en je jouw nieuwe tactieken of strategieen toch kunt uitproberen. Pirots 3 URL gekopieerd! Vaar uit naar een weelderig Caribisch eiland, waar een rooster van 5×5 zich bevindt tussen de zeilen van een piratenschip. De charmante Pirot-personages, gekleed in klassieke piratenkleding met musketten, zwaarden en een kapitein met een baby papegaai op zijn gevederde schouder, sieren het scherm in blauw, groen, paars en rood. Bijpassende edelstenen, samen met gouden munten, rumvaten, ‘W’-wildsymbolen en andere schatten, maken deel uit van het rooster.
яндекс еда курьер устроиться Работа курьером в Яндекс.Еда и Яндекс.Доставка: Сравнение и перспективы Работа курьером в Яндекс.Еда и Яндекс.Доставка – это отличная возможность для тех, кто ищет гибкий график и стабильный доход. Обе компании предлагают различные варианты сотрудничества, включая работу пешим курьером, на велосипеде или на личном автомобиле. Основное различие между этими двумя сервисами заключается в типе доставляемых товаров: Яндекс.Еда специализируется на доставке еды из ресторанов и кафе, а Яндекс.Доставка доставляет посылки, документы и другие отправления. При выборе работы курьером стоит учитывать свои предпочтения и возможности. Если вы любите быстро перемещаться по городу и доставлять вкусные блюда, то работа в Яндекс.Еда может быть идеальным вариантом. Если же вам нравится разнообразие и возможность доставлять разные виды товаров, то работа в Яндекс.Доставка может быть более интересной. В любом случае, работа курьером в Яндекс.Еда и Яндекс.Доставка – это возможность быть частью современной и технологичной компании, зарабатывать деньги и развиваться.
https://allmynursejobs.com/author/amandaandersonfzlz/
накрутка подписчиков и просмотров тг
https://bio.site/wbubbyuyoc
https://pubhtml5.com/homepage/gtzao
sjydtech – This company looks reliable, design and content reflect quality.
Видеонаблюдение под ключ https://vcctv.ru
аренда маленького экскаватора аренда маленького экскаватора .
https://edabit.com/user/Ti5BrfiEZJzSR8twk
http://www.pageorama.com/?p=lmtodzeyc
https://imageevent.com/ervinsniedri/vfvfo
В современном мире тематика зависимостей становится острой. Если вы ищете нарколога на дом в Красноярске, сайт vivod-iz-zapoya-krasnoyarsk018.ru предоставляет многочисленные наркологических услуг. Лечение зависимостей может быть непростым процессом, однако выездной нарколог обеспечивает помощь при алкоголизме и другим проблемам, связанным с зависимостям в комфортной обстановке. Консультация нарколога – это начальный этап к восстановлению. Квалифицированные специалисты проведут диагностику зависимости, помогут составить программу реабилитации и предложат методы психотерапии при зависимости. Конфиденциальное лечение гарантирует полную конфиденциальность, что особенно важно для многих пациентов. Медицинская помощь на дому позволяет не только лишь проходить лечение в удобной обстановке, но и получать поддержку родных, что играет ключевую роль в процессе выздоровления. Профилактические меры при алкоголизме и возвращение к нормальной жизни после наркотиков также являются частью комплекс услуг, предлагаемых специалистами. Связывайтесь за помощью на vivod-iz-zapoya-krasnoyarsk018.ru, чтобы получить нужную помощь.
https://anyflip.com/homepage/roydx
http://www.pageorama.com/?p=yhigoibuui
https://imageevent.com/caumpix39erf/jyage
is online poker legal in united states, 2021 online casino new
zealand and does united states have casinos,
or betsoft no deposit bonus united states
Also visit my blog :: basket roulette heelys
(Albert)
інформаційний портал https://01001.com.ua Києва: актуальні новини, політика, культура, життя міста. Анонси подій, репортажі з вулиць, інтерв’ю з киянами, аналітика та гід по місту. Все, що треба знати про Київ — щодня, просто й цікаво.
Попробуйте https://azpineda.com/2017/02/04/hello-world/?unapproved=374&moderation-hash=e0b1997672f94ab9f9fd3320704d2848
В городе Красноярск предлагается широкий спектр услуг для вывода из запоя. Наркологические клиники обеспечивают медицинскую помощь, включая детоксикацию и лечение в стационаре. Профессиональные наркологи осуществляют кодирование от алкоголя, а также обеспечивают психотерапевтическую помощь и процессы реабилитации. Важно помнить о консультациях для родственников, чтобы обеспечить поддержку семьи; Анонимное лечение гарантирует защиту личной информации, а программы восстановления помогают зависимым вернуться к нормальной жизни. Узнайте больше на сайте vivod-iz-zapoya-krasnoyarsk018.ru.
https://form.jotform.com/252702708276055
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Je suis aromatise par PepperMill Casino, on hume un verger de tactiques enivrantes. Il regorge d’une abondance de melanges interactifs, proposant des blackjacks revisites pour des bouffees d’excitation. Le support client est un maitre herboriste vigilant et persistant, accessible par infusion ou missive instantanee. Les recoltes affluent via USDT ou canaux fiat, par intermittence des essences gratuites supplementaires rehausseraient les melanges. En concluant l’infusion, PepperMill Casino forge un festin de jeu somptueux pour les gardiens des jardins numeriques ! A souligner la trame irradie comme un elixir ancestral, allege la traversee des vergers ludiques.
peppermill hotel in reno|
https://pubhtml5.com/homepage/avjfb
Je suis ebloui par Cheri Casino, il offre une aventure ludique petillante. Le catalogue est une mosaique de plaisirs, proposant des paris sportifs qui font vibrer. Le service client est d’une douceur angelique, garantissant un support d’une clarte cristalline. Les retraits sont fluides comme une riviere, neanmoins des tours gratuits en plus feraient rever. En somme, Cheri Casino promet une experience eclatante pour les joueurs en quete de magie ! Cerise sur le gateau la plateforme scintille comme un diamant, ajoute une touche d’eclat magique.
cheri casino inspecteur bonus|
Je suis captive par Frumzi Casino, ca transporte dans un vortex de delices. Le catalogue est une cascade de plaisirs, offrant des sessions live qui hypnotisent. Le support est disponible 24/7, joignable a tout instant. Les transactions sont fiables et fluides, cependant des bonus plus eclatants seraient geniaux. Dans l’ensemble, Frumzi Casino est une plateforme qui secoue les sens pour les passionnes de cryptos ! Cerise sur le gateau l’interface est fluide comme un courant marin, donne envie de replonger dans la tempete du jeu.
frumzi deutschland|
прогнозист ру https://stavka-11.ru/ .
J’eprouve une precision infinie pour WildRobin Casino, il decoche une salve de gains inattendus. Le feuillage est un parchemin de divertissements forestiers, offrant des cashbacks et VIP 5 tiers des maitres comme Pragmatic Play et Evolution Gaming. L’assistance decoche des reponses precises, assurant une garde fidele dans la foret. Les butins affluent via Bitcoin ou Ethereum, occasionnellement des embuscades promotionnelles plus frequentes dynamiseraient le repaire. En decochant la derniere fleche, WildRobin Casino se dresse comme un pilier pour les hors-la-loi pour les gardiens des fourres numeriques ! En plus la circulation est instinctive comme un tir, infuse une essence de mystere sylvestre.
robin wild animateur radio|
J’eprouve une ivresse totale pour PepperMill Casino, ca exhale un jardin de defis parfumes. Le bouquet est un potager de diversite exuberante, incluant des jackpots progressifs pour des pics d’essence. Le support client est un maitre herboriste vigilant et persistant, infusant des remedes limpides et immediats. Les flux coulent stables et acceleres, toutefois plus d’infusions bonus quotidiennes parfumeraient l’atelier. Dans la totalite du bouquet, PepperMill Casino convie a une exploration sans satiete pour ceux qui cultivent leur fortune en ligne ! En sus le parcours est instinctif comme un parfum familier, intensifie l’envoutement dans le domaine des aromes.
peppermill village middletown ct|
https://anyflip.com/homepage/xoott
Je suis fleche par WildRobin Casino, il decoche une salve de gains inattendus. La clairiere de jeux est un carquois debordant de plus de 9000 fleches, integrant des lives comme Blackjack pour des duels d’arcs. Les sentinelles tirent avec une acuite exemplaire, bandant des cordes multiples pour une frappe immediate. Les flux sont camoufles par des fourres crypto, malgre cela des tirs gratuits supplementaires boosteraient les branches. A la fin de cette quete, WildRobin Casino se dresse comme un pilier pour les hors-la-loi pour les gardiens des fourres numeriques ! De surcroit l’interface est un sentier navigable avec precision, infuse une essence de mystere sylvestre.
robin schulz world gone wild sample|
Капельница от запоя на дому: мифы и реальность (Красноярск) Лечение алкогольной зависимости становится все более актуальной темой. Многие ищут анонимное лечение алкоголизма с помощью нарколога на дом. Популярным методом является использование капельницы от запоя. Однако вокруг этого метода существует множество мифов. Во-первых, один из мифов заключается в том, что капельница может полностью решить проблему запойного состояния. На самом деле, она лишь временно снимает симптомы. Нарколог на дом может предложить целостный подход к лечению, включающий детоксикацию в домашних условиях. Это более безопасно и эффективно. Следующий миф — миф о том, что домашнее лечение не представляет опасности. Фактически, безопасность такого лечения во многом зависит от профессионализма врача. Услуги нарколога в Красноярске предлагают опытные и квалифицированные услуги, однако необходимо обращать внимание на опыт врача. Также стоит отметить, что процесс восстановления после запоя является длительным и требует поддержки. Эффекты капельницы от алкоголя могут быть кратковременными, поэтому важно обращать внимание на рекомендации по лечению и помнить о значимости психотерапевтической помощи. Помощь при алкогольной зависимости должна быть комплексной. Избавление от запойного состояния — это не только работа с физическим состоянием, но и с психоэмоциональным. арколог на дом анонимно](https://vivod-iz-zapoya-krasnoyarsk018.ru)
skibumart – Their portfolio looks impressive, art quality is very appealing.
https://pubhtml5.com/homepage/lotsv
накрутка подписчиков в тг платно
Pexip video problems Alright, here are expanded descriptions in English, separated by the “
https://linkin.bio/franz66i2bernd
https://www.divephotoguide.com/user/uaguhycobo
Стоматология «Медиа Арт Дент» в Нижнем Новгороде объединяет терапию, хирургию, имплантацию и ортодонтию: от лечения кариеса до All-on-4, брекетов и виниров, с бесплатной первичной консультацией терапевта и прозрачной сметой. Клиника открыта с 2013 года, более 8000 пациентов отмечают комфорт и щадящую анестезию. Запишитесь онлайн и используйте действующие акции на https://m-art-dent.ru/ — современная диагностика, аккуратная работа и гарантия на услуги помогут вернуть уверенную улыбку без лишних визитов.
Холд стал для меня настольным журналом, когда речь заходит о криптовалютах. Он сочетает в себе аналитику, прогнозы и обзоры инструментов для работы с цифровыми активами. Мне нравится, что там есть не только курсы, но и разъяснения по кошелькам и биржам. Полезный и современный ресурс, https://thehold.ru/
сайт прогнозов https://www.stavka-12.ru .
https://anyflip.com/homepage/hvdzd
аренда экскаватора смена http://www.arenda-ekskavatora-pogruzchika-cena.ru .
вывод из запоя
vivod-iz-zapoya-smolensk019.ru
вывод из запоя круглосуточно смоленск
Lucky Jet Играть Lucky Jet (Лаки Джет) — ваша возможность оседлать удачу! Динамичная игра Lucky Jet уже ждет вас. Чтобы начать играть в Лаки Джет, достаточно пройти быструю регистрацию на официальном сайте игры. Если он недоступен, воспользуйтесь рабочим зеркалом Лаки Джет. Ищете, где сыграть? Lucky Jet 1win — одна из проверенных площадок. Lucky Jet 1вин предоставляет полную версию развлечения. Не упустите шанс — играть в Lucky Jet можно сразу после создания аккаунта. Официальный сайт Lucky Jet или его зеркало — ваш надежный старт!
https://pubhtml5.com/homepage/ihhnk
прогнозы букмекеров на сегодня stavka-10.ru .
eleanakonstantellos – Her brand feels authentic, each detail seems chosen with care and style.
последние новости спорта https://novosti-sporta-15.ru .
прогнозы на футбол прогнозы на футбол .
https://www.band.us/page/100115905/
спорт онлайн https://novosti-sporta-16.ru .
ieeb – Just visited today, and it feels trustworthy right from the start.
https://imageevent.com/u3538144068/yonjr
Рекомендую https://www.theadrenalinetraveler.com/2020/05/31/mis-generadores-de-adrenalina-personal/
Заботьтесь о здоровье сосудов ног с профессионалом! В группе «Заметки практикующего врача-флеболога» вы узнаете всё о профилактике варикоза, современных методиках лечения (склеротерапия, ЭВЛО), УЗИ вен и точной диагностике. Доверяйте опытному врачу — ваши ноги заслуживают лучшего: https://phlebology-blog.ru/
Мы открыли новый магазин косметики и сразу решили внедрить современное оборудование для маркировки. Приобрели принтер для ценников, термопринтер для этикеток и сканеры. Всё оборудование работает стабильно, печать быстрая и чёткая. Этикетки отлично держатся и не отклеиваются. Покупатели довольны, а сотрудники ценят удобство – https://labelaire.ru/
вывод из запоя круглосуточно
vivod-iz-zapoya-smolensk019.ru
экстренный вывод из запоя смоленск
https://pixelfed.tokyo/whalingholloman33895
Журнал theHold удобен тем, что объединяет всё в одном месте: новости, прогнозы, курсы, обзоры бирж и кошельков, калькулятор доходности. Благодаря этому можно быстро ориентироваться в рынке и принимать обоснованные решения. Очень полезный ресурс для новичков и опытных трейдеров https://thehold.ru/
https://pubhtml5.com/homepage/kezlc
https://kemono.im/ogufxjvad/kupit-kokain-ultsin
https://www.rwaq.org/users/chuphuocquan441-20250926195844
nohonabe – This feels trustworthy, like a place built with care and respect.
На складе интернет-магазина электроники мы установили оборудование Labelaire и принтеры для штрих-кодов. Теперь комплектация заказов проходит значительно быстрее. Сканеры помогают мгновенно считывать данные. Работа стала более автоматизированной и прозрачной – https://labelaire.ru/
https://imageevent.com/kruegerraven/fdauu
https://anyflip.com/homepage/cggnp
Предлагаю https://acpfj.com/acceuil/restaurant-photo/
Je suis caramelise par Sugar Casino, on savoure un comptoir de tactiques allechantes. Les choix forment un caramel de saveurs innovantes, integrant des lives comme Sweet Bonanza Candyland pour des eclats de sirop. Le support client est un confiseur vigilant et inlassable, assurant une attention fidele dans la patisserie. Les flux financiers sont enrobes par des coques crypto, occasionnellement des friandises de recompense additionnelles glaceraient les alliances. En apotheose sucree, Sugar Casino invite a une exploration sans indigestion pour les alchimistes des paris crypto ! En bonbon supplementaire le graphisme est une praline dynamique et immersive, incite a prolonger la degustation infinie.
sugar casino|
https://www.divephotoguide.com/user/tibyhjeb
https://imageevent.com/jurgensenern/tcvxk
Smart crypto trading https://terionbot.com with auto-following and DCA: bots, rebalancing, stop-losses, and take-profits. Portfolio tailored to your risk profile, backtesting, exchange APIs, and cold storage. Transparent analytics and notifications.
https://allmynursejobs.com/author/svensegdapred/
Расходные материалы для печати по выгодным ценам вы можете купить у нас на сайте https://adisprint.ru/ – ознакомьтесь с нашим существенным ассортиментом по выгодной стоимости с доставкой по России. Большой каталог даст вам возможность купить все необходимое в одном месте. У нас картриджи, тонеры, чернила, фотобарабаны, ролики, клининговые комплекты и очень многое другое для удовлетворения ваших потребностей.
лечение запоя
vivod-iz-zapoya-smolensk021.ru
вывод из запоя
themacallenbuilding – Navigation is smooth, everything appears exactly where I expected it.
bigprintnewspapers – Pages loaded quickly, which makes the browsing experience much smoother.
dietzmann – I enjoyed exploring, site feels robust and visually appealing.
rifar tubog Батареи Rifar Tubog – это отопительные приборы, которые сочетают в себе современный дизайн и высокую эффективность. Они представляют собой трубчатые радиаторы, состоящие из вертикальных или горизонтальных секций, соединенных между собой. Батареи Rifar Tubog изготавливаются из высококачественной стали и проходят строгий контроль качества на всех этапах производства. Благодаря своей конструкции, они обеспечивают равномерное распределение тепла в помещении и быстро нагреваются. Батареи Rifar Tubog доступны в различных моделях, отличающихся количеством секций, высотой и глубиной, что позволяет подобрать оптимальный вариант для любого помещения. Они могут быть использованы как в жилых, так и в коммерческих помещениях и подходят для различных систем отопления.
dividedheartsofamericafilm – I like how the site feels serious, clear, and well presented.
лечение запоя смоленск
vivod-iz-zapoya-smolensk020.ru
экстренный вывод из запоя смоленск
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
купить диплом с занесением в реестр чита https://frei-diplom6.ru/ .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
купить диплом колледжа с занесением в реестр купить диплом колледжа с занесением в реестр .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
muralspotting – I like how interactive and visually engaging the site appears.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Buscas productos saludables para una vida plena en Mexico? Visita https://nagazi-shop.com/ y encontraras remedios homeopaticos y suplementos dieteticos populares disenados para complementar tu dieta. Explora nuestro catalogo y seguro encontraras los productos ideales para ti.
купить диплом в белорецке http://www.rudik-diplom2.ru – купить диплом в белорецке .
купить диплом в подольске купить диплом в подольске .
https://www.wildberries.ru/catalog/249860602/detail.aspx
lastminute-corporate – I like the straightforward design, makes everything clear and simple.
cepjournal – I like how professional and trustworthy the site feels overall.
Купить диплом колледжа в Винница educ-ua7.ru .
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
вывод из запоя круглосуточно
vivod-iz-zapoya-smolensk021.ru
вывод из запоя круглосуточно
купить диплом переводчика купить диплом переводчика .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
купить диплом в екатеринбург реестр купить диплом в екатеринбург реестр .
купить диплом вуза занесением реестр http://www.frei-diplom3.ru/ .
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Закупки и официальный импорт из Китая
Je suis aromatise par PepperMill Casino, il concocte une alchimie de gains epoustouflants. Les varietes tracent un panorama de saveurs novatrices, integrant des roulettes live pour des tourbillons d’arome. Le support client est un maitre herboriste vigilant et persistant, avec une expertise qui presage les appetits. Les flux coulent stables et acceleres, par intermittence des essences gratuites supplementaires rehausseraient les melanges. En apotheose epicee, PepperMill Casino tisse une tapisserie de divertissement olfactif pour les gardiens des jardins numeriques ! En sus l’interface est un sentier herbeux navigable avec art, pousse a prolonger le festin infini.
peppermill restaurants|
купить диплом медсестры купить диплом медсестры .
lastminute-corporate – The site feels practical, perfect for quick business solutions anytime.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Velakast.com.ru сочетает ясную навигацию и продуманную подачу контента: фильтры экономят время, а разделы выстроены логично. На этапе выбора стоит перейти на https://velakast.com.ru/ — страницы загружаются быстро, формы понятны, ничего лишнего. Сервис корректно адаптирован под мобильные устройства, а структура помогает уверенно двигаться к цели: от первого клика до подтверждения заявки, с ощущением контроля и внимания к деталям на каждом шаге.
Je suis emoustille par MrPacho Casino, ca transforme le jeu en une degustation exquise. Le menu est un cellier de variete exuberante, proposant des blackjack revisites pour des bouffees d’adrenaline. Le support client est un sommelier attentif et omnipresent, avec une maestria qui anticipe les appetits. Les retraits glissent avec une souplesse remarquable, nonobstant des menus promotionnels plus frequents pimenteraient la table. En apotheose culinaire, MrPacho Casino emerge comme un pilier pour les epicuriens pour les chasseurs de casinos virtuels ! Par surcroit l’interface est un chemin de table navigable avec art, allege la traversee des menus ludiques.
mrpacho pregled|
купить диплом колледжа отзывы frei-diplom12.ru .
купить диплом в сочи купить диплом в сочи .
купить диплом техникума в омске купить диплом техникума в омске .
Детоксикация организма после алкоголя в домашних условиях – важный процесс‚ что особенно актуально для жителей владимира‚ страдающих от проблем с алкоголем. Комплексный подход является ключевым в лечении запоя‚ включая детоксикацию и восстановление функций печени. лечение запоя владимир Похмелье часто сопровождается неприятными симптомами: головная боль‚ тошнота‚ усталость. В связи с этим, использование домашних и народных средств может существенно облегчить состояние. Например‚ настои из трав‚ имбирь с медом способствуют восстановлению сил. В владимире доступны разнообразные альтернативные методы терапии‚ включая курсы алкогольной терапии. Не забудьтечто после детоксикации нужна дополнительная поддержка для успешного восстановления от алкогольной зависимости.
Je suis irresistiblement epice par PepperMill Casino, on hume un verger de tactiques enivrantes. Le bouquet est un potager de diversite exuberante, avec des dice slots aux motifs piquants qui titillent les sens. Le service infuse en continu 24/7, mobilisant des sentiers multiples pour une extraction fulgurante. Les recoltes affluent via USDT ou canaux fiat, toutefois des elans promotionnels plus assidus animeraient le jardin. Dans la totalite du bouquet, PepperMill Casino revele un sentier de triomphes parfumes pour les gardiens des jardins numeriques ! En piment sur le gateau le parcours est instinctif comme un parfum familier, pousse a prolonger le festin infini.
peppermill lounge vegas|
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
themacallenbuilding – First impression feels strong, like it’s a trustworthy and stylish brand.
Je suis invincible face a Super Casino, c’est un bastion ou chaque mise libere une vague de puissance. La panoplie de jeux est un arsenal surequipe de plus de 4 000 gadgets, avec des slots aux pouvoirs thematiques qui amplifient les combos. Le suivi escorte avec une vigilance absolue, activant des signaux multiples pour une intervention immediate. Les retraits decollent avec une acceleration remarquable, a l’occasion des gadgets gratuits supplementaires rechargent les unites. En apotheose heroique, Super Casino invite a une patrouille sans repli pour les champions de victoires explosives ! En plus le portail est une tour de controle visuelle imprenable, ce qui catapulte chaque mission a un niveau legendaire.
super lenny casino review|
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Советую https://cryptonieuws.nl/analyse-sentiment-op-cryptomarkt-sterk-verbeterd/
купить диплом техникума и поступить в вуз купить диплом техникума и поступить в вуз .
Сломалась машина? служба автопомощи на дорогах мы создали профессиональную службу автопомощи, которая неустанно следит за безопасностью автомобилистов в Санкт-Петербурге и Ленинградской области. Наши специалисты всегда на страже вашего спокойствия. В случае любой нештатной ситуации — от банальной разрядки аккумулятора до серьёзных технических неисправностей — мы незамедлительно выезжаем на место.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Je suis invincible face a Super Casino, il deploie une campagne de gains extraordinaires. Le QG est un centre de diversite explosive, integrant des lives comme Mega Ball pour des explosions de score. Les sentinelles reagissent avec une alerte fulgurante, declenchant des contre-mesures claires et rapides. Le vecteur est trace pour une trajectoire exemplaire, a l’occasion les protocoles d’offres pourraient s’amplifier en puissance. En activant le mode final, Super Casino construit un empire de divertissement invincible pour les pilotes des paris crypto ! En cape supplementaire le graphisme est un scan dynamique et immersif, amplifie l’engagement dans l’arsenal du jeu.
super u et casino|
biotecmedics – I like the professional tone, it feels authentic and informative.
лечение запоя смоленск
vivod-iz-zapoya-smolensk021.ru
вывод из запоя круглосуточно смоленск
lotsofonlinepeople – Browsing here feels easy, fun, and full of energy.
Онлайн магазин – купить мефедрон, кокаин, бошки
casa-nana – Everything loads fast, which makes browsing easy and smooth.
brahmanshome – I like the homely vibe, very inviting and genuine.
goestotown – First impression is fun, approachable, and definitely unique.
?Warm greetings to all the roulette companions !
anonymous wagering research often raise questions for policymakers about data handling. Scholars compare them to regulated platforms to assess risks. betting without identificationThe goal is to inform safer practices and clearer regulations.
Design studies explore how identity-free gaming services balance anonymity with fraud prevention. Such studies are methodological and do not promote any provider. The conclusions aim to guide better safeguards and user education.
betting without identification — user safety guide – п»їhttps://bettingwithoutidentification.xyz/#
?I wish you incredible victories !
bettingwithoutidentification.xyz
Онлайн магазин – купить мефедрон, кокаин, бошки
Vgolos — независимое информагентство, где оперативность сочетается с редакционными стандартами: новости экономики, технологий, здоровья и расследования подаются ясно и проверенно. Публикации отмечены датами, есть рубрикатор и поиск, удобная пагинация архивов. В середине дня удобно заглянуть на https://vgolos.org/ и быстро наверстать ключевую повестку, не теряясь в шуме соцсетей: фактаж, мнения экспертов, ссылки на источники и понятная навигация создают ощущение опоры в информационном потоке.
bigprintnewspapers – The site gives trust from first glance, visuals and text align well.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
reinspiregreece – The brand feels genuine and full of purpose, design supports that well.
If you need a phone number for one-time registration or verification, consider using Temporary phone numbers, которые могут помочь в решении проблемы получения сообщений.
enabling efficient communication without hefty price tags. With the rise of virtual phone systems, it has become easier than ever to obtain a free phone number . there has been a notable surge in the use of free phone numbers, as they offer a budget-friendly alternative to traditional phone services.
The concept of free phone numbers has been around for several years, but it has gained popularity in recent times . One of the primary reasons for this growth is the advancement in technology, which has made it possible to provide free phone numbers without compromising on quality . free phone numbers have become a popular choice for startups, small businesses, and individuals seeking to reduce their communication costs .
Free phone numbers offer a range of benefits, including cost savings, increased flexibility, and improved customer service . By using a free phone number, businesses can lower their communication costs, optimize their resource allocation, and improve their bottom line . Moreover, free phone numbers can be easily integrated with existing phone systems, enabling smooth communication and reducing downtime . This has made free phone numbers an essential tool for businesses that rely heavily on phone communications, such as customer service centers and sales teams .
In addition to the cost savings, free phone numbers also offer increased flexibility, enabling companies to handle their communications remotely, without being tied to a specific location . this is highly advantageous for businesses with virtual teams or those that operate across various time zones. Furthermore, free phone numbers can be easily scaled up or down, according to the evolving requirements of the company . this makes them a viable option for businesses that face variations in call volume or have cyclical changes in their operations.
Getting a free phone number is a relatively simple process, entailing a few uncomplicated steps and negligible administrative tasks. The first step is to pick a dependable provider that offers free phone numbers, evaluating criteria such as call clarity, technical support, and capabilities. Once a provider is chosen, the next step is to sign up for an account, which typically involves providing basic information such as name, email address, and password . After completing the sign-up process, users can typically select their desired free phone number from a range of available choices .
Some providers may also offer supplementary features, such as call diversion, voicemail, and call monitoring, which can be advantageous for businesses and individuals. These features can increase the usefulness of the free phone number, making it more effective for overseeing communications. It is essential to thoroughly examine the terms and conditions of the provider, including any usage limitations or constraints . This will help ensure that the free phone number fulfills the expectations of the business or individual, without any unpleasant surprises.
In conclusion, free phone numbers have become an essential tool for businesses and individuals, offering a cost-effective solution for communication needs . As technology continues to evolve, it is probable that free phone numbers will become more sophisticated, with extra features and enhanced usability . This will make them more appealing to companies and individuals, who are seeking to minimize their phone expenses .
The future of free phone numbers looks exciting, with the prospect of even more advanced features and functionalities. As the demand for free phone numbers continues to grow, providers will need to adapt and innovate, providing more sophisticated features and improved technical assistance . This will drive the development of new technologies and services, additionally broadening the functionalities of free phone numbers . Ultimately, the widespread adoption of free phone numbers will transform the way businesses and individuals communicate, enabling more efficient and cost-effective interactions .
Мы обратились в СтройСинтез для строительства коттеджа с гаражом, и остались довольны на все сто. Все этапы прошли без задержек, качество на высоте. В итоге дом получился именно таким, как мы хотели. Подробнее смотри по ссылке https://stroysyntez.com/
Попробуйте http://www.uwe-nielsen.de/wordpress/?p=237
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
В наше динамичное время, насыщенное напряжением и беспокойством, анксиолитики и транквилизаторы оказались надежным средством для огромного количества людей, позволяя преодолевать панические приступы, генерализованную тревогу и прочие нарушения, мешающие нормальной жизни. Эти препараты, такие как бензодиазепины (диазепам, алпразолам) или небензодиазепиновые варианты вроде буспирона, действуют через усиление эффекта ГАМК в мозге, снижая нейрональную активность и принося облегчение уже через короткое время. Особенно полезны они на старте терапии антидепрессантами, когда помогают смягчить начальные побочные эффекты, такие как повышенная раздражительность или бессонница, делая лечение более комфортным и эффективным. Однако важно помнить о рисках: от сонливости и снижения концентрации до потенциальной зависимости, поэтому их назначают короткими курсами под строгим контролем врача. В клинике “Эмпатия” квалифицированные эксперты, среди которых психиатры и психотерапевты, разрабатывают персонализированные планы, сводя к минимуму противопоказания, такие как нарушения дыхания или беременность. Подробнее о механизмах, применении и безопасном использовании читайте на https://empathycenter.ru/articles/anksiolitiki-i-trankvilizatory/, где собрана вся актуальная информация для вашего спокойствия.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Анонимное лечение алкоголизма становится все более популярным, так как многие люди стремятся восстановиться от алкогольной зависимости без огласки. На сайте vivod-iz-zapoya-vladimir021.ru доступны разные программы реабилитации, включая программы детоксикации, которые обеспечивают комфортные условия для лечения. Помощь врачей при алкоголизме включает кодирование и психотерапию зависимостей. Анонимные группы поддержки помогают справиться с психологическими аспектами, а поддержка родных и друзей играет ключевую роль в процессе восстановления после алкоголя. Онлайн-консультации по алкоголизму и анонимные консультации обеспечивают доступ к психологической помощи при запойном состоянии. Лечение без названия дает возможность людям ощущать безопасность. Важно помнить, что первый шаг к выздоровлению, это обращение за помощью.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
купить диплом в магадане купить диплом в магадане .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Онлайн магазин – купить мефедрон, кокаин, бошки
купить диплом в челябинске купить диплом в челябинске .
Онлайн магазин – купить мефедрон, кокаин, бошки
купить диплом техникума ссср в мурманске купить диплом техникума ссср в мурманске .
В сфере предпринимательства ключ к успеху лежит в детальном планировании. Готовые бизнес-планы и анализ рынка становятся настоящим спасением для начинающих предпринимателей. Вообразите: вы планируете запустить кафе или автомойку, но не имеете представления, как подступиться. В этом случае выручают специализированные материалы, учитывающие актуальные тренды, риски и перспективы. Согласно данным аналитиков, такие как EMARKETER, рынок финансовых услуг растет на 5-7% ежегодно, подчеркивая важность точного анализа. Сайт https://financial-project.ru/ предлагает обширный каталог готовых бизнес-планов по доступной цене 550 рублей. Здесь вы найдете варианты для туризма, строительства, медицины и других сфер. Эти документы включают финансовые расчеты, маркетинговые стратегии и прогнозы. Они помогают привлечь инвесторов или получить кредит. Факты показывают: компании с четким планом на 30% чаще достигают целей. Используйте такие ресурсы, чтобы ваш проект процветал, и помните – правильный старт ключ к долгосрочному успеху.
Наркологическая помощь в владимире доступна каждому, кто сталкивается с проблемами зависимости; Анонимная помощь — это важный аспект, позволяющий пациентам обращаться без страха осуждения. Клиника наркологии предлагает лечение алкогольной и наркотической зависимости через персонализированные программы реабилитации. Первичная консультация у нарколога — начало пути к выздоровлениюгде можно узнать детали о программах детоксикации и психотерапии. Процесс реабилитации включает семейную терапию, что способствует эффективному восстановлению и профилактике рецидива. Свяжитесь на vivod-iz-zapoya-vladimir020.ru для получения конфиденциальной помощи и поддержки.
Онлайн магазин – купить мефедрон, кокаин, бошки
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
прогнозы хоккей прогнозы хоккей .
хоккей ставки http://www.prognozy-na-khokkej4.ru .
очистка засоров канализации очистка засоров канализации .
мед оборудование http://www.xn—–6kcdfldbfd2aga1bqjlbbb4b4d7d1fzd.xn--p1ai .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
В компании СтройСинтез мы заказали проект кирпичного дома на два этажа. Работы проводились профессионально и чётко. Дом получился стильный, прочный и комфортный для жизни. Рекомендуем эту компанию за качество и надёжность https://stroysyntez.com/
Онлайн магазин – купить мефедрон, кокаин, бошки
купить диплом в южно-сахалинске купить диплом в южно-сахалинске .
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Онлайн магазин – купить мефедрон, кокаин, бошки
Практика ремонта https://stroimsami.online и стройки без воды: пошаговые инструкции, сметные калькуляторы, выбор материалов, схемы, чек-листы, контроль качества и приёмка работ. Реальные кейсы, фото «до/после», советы мастеров и типичные ошибки — экономьте время и бюджет.
Крайне советую https://lpbreservoir.com/hola-mundo-2/
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
azhyxh – Browsing here feels effortless, everything responds instantly without issues.
В нашей сфере большая конкуренция, и пробиться в топ было непросто. В середине работы мы доверили проект Mihaylov Digital и получили отличный результат. Сайт начал расти в поиске, а вместе с этим увеличился поток клиентов. Сотрудничество оказалось очень выгодным https://mihaylov.digital/
eljiretdulces – Everything loads fast, which makes browsing really enjoyable overall.
Je suis enthousiaste a propos de 7BitCasino, c’est une veritable plongee dans un univers palpitant. La selection de jeux est colossale, comprenant plus de 5 000 jeux, dont 4 000 adaptes aux cryptomonnaies. Le personnel offre un accompagnement irreprochable, joignable a toute heure. Les transactions en cryptomonnaies sont instantanees, cependant les bonus pourraient etre plus reguliers, afin de maximiser l’experience. En fin de compte, 7BitCasino est un incontournable pour ceux qui aiment parier avec des cryptomonnaies ! De plus la navigation est intuitive et rapide, ce qui intensifie le plaisir de jouer.
7bitcasino opiniones|
Ich finde absolut majestatisch King Billy Casino, es verstromt eine Spielstimmung, die wie ein Palast glanzt. Die Auswahl im Casino ist ein wahres Kronungsjuwel, mit einzigartigen Casino-Slotmaschinen. Der Casino-Support ist rund um die Uhr verfugbar, antwortet blitzschnell wie ein koniglicher Erlass. Casino-Zahlungen sind sicher und reibungslos, aber mehr Casino-Belohnungen waren ein furstlicher Gewinn. Insgesamt ist King Billy Casino ein Online-Casino, das wie ein Konigreich strahlt fur Fans von Online-Casinos! Und au?erdem die Casino-Oberflache ist flussig und prunkvoll wie ein Thronsaal, den Spielspa? im Casino auf ein konigliches Niveau hebt.
king billy casino codes|
Все про ремонт https://lesnayaskazka74.ru и строительство: от идеи до сдачи. Пошаговые гайды, электрика и инженерия, отделка, фасады и кровля. Подбор подрядчиков, сметы, шаблоны актов и договоров. Дизайн-инспирации, палитры, мебель и свет.
local-website – The overall vibe is clean and polished, I liked it.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
newbalance550 – The site highlights the sneakers well, making shopping enjoyable and smooth.
https://klinika-siti-center.ru
https://bamapro.ru
https://www.wildberries.ru/catalog/249860602/detail.aspx
fghakgaklif – Navigation feels simple and direct, no confusion moving around.
Гибкий настенный обогреватель «Тепло Водопад» — компактная инфракрасно-плёночная панель 500 Вт для помещений до 15 м: тихо греет, направляет 95% тепла внутрь комнаты и экономит электроэнергию. Влагозащищённый элемент и алюминиевый корпус с заземлением повышают пожаробезопасность, а монтаж занимает минуты. Выберите расцветку под интерьер и подключите к терморегулятору для точного климата. Закажите на https://www.ozon.ru/product/gibkiy-nastennyy-obogrevatel-teplo-vodopad-dlya-pomeshcheniy-60h100-sm-644051427/?_bctx=CAQQ2pkC&at=NOtw7N9XWcpnz4lDCBEKww6I4y69OXsokq6yKhPqVKpL&hs=1 — отзывы подтверждают тёплый результат.
https://altekproekt.ru
https://fermerskiiprodukt.ru
rbncvbr – Browsing felt comfortable, I liked how user-friendly it all seemed.
Предлагаю https://dalmaucomposites.com/ca/hello-world/
https://klinika-siti-center.ru
прогнозы на футбол сегодня прогнозы на футбол сегодня .
newbirdhub – A smooth and polished experience overall, definitely worth coming back.
Si vous voulez tout savoir sur les plateformes en France, alors c’est exactement ce qu’il vous faut.
Explorez l’integralite via le lien suivant :
casino en ligne france
https://faizi-el.ru
v1av8 – The interface tries to be futuristic, but clarity is missing.
https://banket-kruzheva71.ru
aaccc2 – No glitches or errors encountered while exploring.
https://arhmicrozaim.ru
xxfh – The experience here is straightforward, exactly what I wanted today.
Школа SensoTango в Мытищах — место, где танго становится языком общения и вдохновения. Педагог с 25-летним танцевальным стажем и сертификациями ORTO CID UNESCO и МФАТ даёт быстрый старт новичкам, развивает музыкальность и технику импровизации, есть группы и индивидуальные занятия, милонги и мастер-классы. Ученики отмечают тёплую атмосферу и ощутимый прогресс. Узнайте расписание и запишитесь на https://sensotango.ru/ — первый шаг к новому хобби проще, чем кажется.
Все про ремонт https://lesnayaskazka74.ru и строительство: от идеи до сдачи. Пошаговые гайды, электрика и инженерия, отделка, фасады и кровля. Подбор подрядчиков, сметы, шаблоны актов и договоров. Дизайн-инспирации, палитры, мебель и свет.
В середине прошлого года решили заняться SEO. Mihaylov Digital сделали всё комплексно и грамотно. Сайт вышел в топ, и бизнес стал расти. Мы довольны полностью: https://mihaylov.digital/
Капельница от запоя – это эффективный способ экстренного выхода из запоя, помогающий восстановить здоровье после продолжительного употребления алкоголя. Однако выход из алкогольной зависимости требует внимания к различным аспектам, но и психологической поддержки. Важно понимать, что алкоголизм – это состояние, затрагивающее как тело, так и душу. Экстренный вывод из запоя включает в себя восстановление водно-электролитного баланса, но недостаточно просто провести капельницу для полного выздоровления. В сложные времена помощь зависимым включает не только медикаменты, но и реабилитацию, программы психотерапии. Роль семьи в процессе реабилитации невозможно переоценить. Эмоциональная поддержка близких помогает создать привычку к трезвому образу жизни и уменьшить вероятность возврата к старым привычкам. Профилактика рецидивов включает в себя как медицинские, так и психологические аспекты, что делает лечение комплексным и более эффективным.
купить диплом образцы купить диплом образцы .
https://khasanovich.ru
Lucky Mate is an online casino for Australian players, offering pokies, table games, and live dealer options. It provides a welcome bonus up to AUD 1,000, accepts Visa, PayID, and crypto with AUD 20 minimum deposit, and has withdrawal limits of AUD 5,000 weekly. Licensed, it promotes safe play https://rhpq.com.au/understanding-payment-methods-at-lucky-mate-casino-to-enhance-your-gaming-experience/
https://bamapro.ru
1хБет зеркало Ищете 1xBet официальный сайт? Он может быть заблокирован, но у 1хБет есть решения. 1xbet зеркало на сегодня — ваш главный инструмент. Это 1xbet зеркало рабочее всегда актуально. Также вы можете скачать 1xbet приложение для iOS и Android — это надежная альтернатива. Неважно, используете ли вы 1xbet сайт или 1хБет зеркало, вас ждет полный функционал: ставки на спорт и захватывающее 1xbet casino. 1хБет сегодня — это тысячи возможностей. Начните прямо сейчас!
Попробуйте http://www.grgraham.com.au/uncategorized/hello-world/
https://chi-borchi.ru
https://www.dreamscent.az/ – dəbdəbəli və fərqli ətirlərin onlayn mağazası. Burada hər bir müştəri öz xarakterinə uyğun, keyfiyyətli və orijinal parfüm tapa bilər. Dreamscent.az ilə xəyalınazdakı qoxunu tapın.
https://fermerskiiprodukt.ru
https://alaziza.ru
Купили кухонный гарнитур в современном стиле. Кухня получилась стильной и удобной для готовки, https://kuhni-v-dom.ru/
усиление грунтов http://www.privetsochi.ru/blog/realty_sochi/93972.html .
усиление углеволокном https://dpcity.ru/usilenie-betona-uglevoloknom-fundamentov-svayami-i-gruntov-inektirovaniem-yuviks-grupp-spb/ .
зеркало melbet зеркало melbet .
https://klinika-siti-center.ru
https://khasanovich.ru
Ищешь аккумулятор? купить аккумулятор для авто недорого AKB SHOP занимает лидирующие позиции среди интернет-магазинов автомобильных аккумуляторов в Санкт-Петербурге. Наш ассортимент охватывает все категории транспортных средств. Независимо от того, ищете ли вы надёжный аккумулятор для легкового автомобиля, мощного грузовика, комфортного катера, компактного скутера, современного погрузчика или специализированного штабелёра
Нужен надежный акб? акб купить в спб AKB STORE — ведущий интернет-магазин автомобильных аккумуляторов в Санкт-Петербурге! Мы специализируемся на продаже качественных аккумуляторных батарей для самой разнообразной техники. В нашем каталоге вы найдёте идеальные решения для любого транспортного средства: будь то легковой или грузовой автомобиль, катер или лодка, скутер или мопед, погрузчик или штабелер.
Обращение к наркологу — это необходимый шаг для тех, кто сталкивается с трудностями с зависимостями . Служба наркологической помощи предоставляет экстренную наркологическую помощь и советы нарколога, что особенно необходимо в кризисных ситуациях . Симптомы наркотической зависимости могут быть разнообразными, и важно знать, когда необходима медицинская помощь при алкоголизме . Лечение алкоголизма и помощь при наркотической зависимости требуют квалифицированного вмешательства. Алкоголизм и его последствия могут быть катастрофическими, поэтому важно обратиться за поддержкой для зависимых , включая программы реабилитации. На сайте vivod-iz-zapoya-vladimir022.ru вы можете узнать, как обратиться к наркологу или получить анонимную помощь наркоманам . Не сомневайтесь в том, чтобы позвонить в наркологическую службу, чтобы получить нужную помощь и поддержку.
Мы долго искали компанию в Санкт-Петербурге, где можно купить кухню под ключ, и в итоге остановились на Кухни в Дом. Замерщик приехал очень быстро, предложил несколько решений по планировке, а дизайнер сделал проект, который идеально вписался в интерьер. Особенно понравилось, что учли все наши пожелания по материалам и цветам. После согласования заказ был выполнен точно в срок, кухня доставлена без повреждений. Сборщики сработали аккуратно, установили всё за один день и сразу проверили фурнитуру. В результате мы получили современную и функциональную кухню, которая полностью соответствует ожиданиям. Однозначно рекомендуем Кухни в Дом тем, кто хочет качественный результат в СПб: https://kuhni-v-dom.ru/
Горячий пар, мягкий жар и надежность на годы — чугунные печи ПроМеталл создают правильную атмосферу бани с первого розжига. Как официальный представитель завода в Москве, подберем печь под ваш объем, дизайн и бюджет, а также возьмем на себя доставку и монтаж. Ищете печь для бани атмосфера? Узнайте больше на prometall.shop и выберите идеальную «Атмосферу» для вашей парной. Консультация бесплатна, есть акции и подарки. Сделайте баню местом силы — прогрев быстрый, тепло держится долго, обслуживание простое.
https://autovolt35.ru
https://al-material.ru
https://bamapro.ru
Прерывание запоя в владимире: экстренная помощь Запой – это серьезная кризисная ситуация‚ требующая немедленной медицинской помощи. Вызов нарколога на дом – эффективный метод решения проблемы. Специалист проведет детоксикацию‚ обеспечивая безопасное восстановление пациента. Лечение алкоголизма включает всеобъемлющую помощь‚ включая как физический‚ так и психологический аспекты. Важность вызова нарколога в том‚ что он может предложить широкий набор наркологических услуг‚ включая помощь при запойном состоянии. Экстренная помощь предотвращает возникновение осложнений и инициирует процесс реабилитации. После выхода из запоя важно поддерживать процесс лечения алкоголизма‚ чтобы избежать возврата к прежнему состоянию. Восстановление после запоя не обходится без поддержки‚ поэтому нарколог на дом поможет не только в физическом плане‚ но и окажет психологическую помощь. Заботьтесь о своем здоровье и обращайтесь за квалифицированной помощью!
https://bibikey.ru
J’adore a fond Betzino Casino, on dirait une sensation de casino unique. La gamme de jeux est tout simplement phenomenale, comprenant des jackpots progressifs comme Mega Moolah. Le service client est exceptionnel, joignable par email ou chat. Le processus de retrait est simple et fiable avec un maximum de 5000 € par semaine, occasionnellement davantage de recompenses via le programme VIP seraient appreciees. Pour conclure, Betzino Casino est un incontournable pour les amateurs de casino en ligne ! En bonus l’interface est fluide et moderne avec un design epure, facilite chaque session de jeu.
betzino bewertung|
Je trouve incroyable 1win Casino, ca ressemble a une aventure palpitante. Il y a une multitude de titres varies, offrant des experiences de casino en direct immersives. Le personnel est professionnel et attentionne, offrant des solutions claires et efficaces. Les gains arrivent en un temps record, parfois j’aimerais plus de promotions regulieres. Globalement, 1win Casino offre une experience de jeu memorable pour les amateurs de casino virtuel ! De plus le design est visuellement attrayant, facilite chaque session de jeu.
aviator game 1win|
кайт сафари Надувной воздушный змей, известный как кайт, используется в кайтсёрфинге (или кайтбординге) для перемещения по воде под действием потоков воздуха. Он состоит из купола (сделанного из ткани), баллонов (наполненных воздухом), строп (для управления) и планки управления, что позволяет райдеру контролировать его перемещение и тягу. Величина кайта определяется в зависимости от силы ветра и веса райдера. Современные кайты отличаются высокой маневренностью и имеют систему безопасности.
https://actpsy.ru
футбол прогноз на сегодня футбол прогноз на сегодня .
https://bibikey.ru
МОС РБТ ремонтирует холодильники в Москве за 1 день с выездом мастера на дом: диагностика бесплатно при последующем ремонте, оригинальные запчасти, гарантия до 1 года. Опыт более 8 лет и работа без выходных позволяют оперативно устранить любые неисправности — от проблем с компрессором и No Frost до утечек и электроники. Порядок прозрачен: диагностика, смета, ремонт, финальное тестирование и рекомендации по уходу. Оставьте заявку на https://mosrbt.com/services/remont-holodilnikov/ — вернём холод и спокойствие в ваш дом.
Советую https://socialdhaba.uk/2024/04/09/hello-world/
https://avokado22.ru
https://avokado22.ru
https://azhku.ru
https://antei-auto.ru
https://epcsoft.ru
Капельный метод лечения запоя, является необходимая мера в борьбе с алкогольной зависимости. Внутривенное введение помогает очищению организма от токсинов, улучшает психоэмоциональное состояние и поддерживает функции организма. По завершении процедуры необходимо помнить несколько советов. помощь нарколога Во-первых, необходимо следовать указаниям нарколога и продолжать лечение алкоголизма. Процесс реабилитации является длительным и трудоемким. Кроме того, обратите внимание на профилактику возврата к запою: старайтесь избегать триггеров, которые могут спровоцировать возвращение к запою.
https://actpsy.ru
mizao0 – Works well on mobile, very responsive and comfortable to use.
nnvfy – The interface feels smooth and lightweight during navigation.
купить диплом в уфе купить диплом в уфе .
https://barcelona-stylist.ru
купить свидетельство о разводе купить свидетельство о разводе .
купить диплом с проводкой моих купить диплом с проводкой моих .
купить диплом в новоалтайске купить диплом в новоалтайске .
93r – The aesthetic is futuristic, but the purpose isn’t clear yet.
https://autovolt35.ru
купить диплом в махачкале купить диплом в махачкале .
Крайне рекомендую http://meehbctwebpin.mex.tl/?gb=1#top
купить диплом о средне специальном образовании реестр купить диплом о средне специальном образовании реестр .
легальный диплом купить легальный диплом купить .
v1av7 – The design is minimal and clean, pleasant to look at.
Готовитесь к ЕГЭ или ОГЭ и хотите без стресса закрыть пробелы? Онлайн-школа V-Electronic подбирает курсы по всем ключевым предметам, от математики и русского до физики и информатики, а также языковые программы с носителями. Удобные форматы, гибкий график и проверочные модули помогают отслеживать прогресс и готовиться к высоким баллам. Подробности и актуальные предложения — на https://v-electronic.ru/onlain-shkola/ выбирайте программу за минуту и начинайте обучение уже сегодня.
https://chi-borchi.ru
Купить диплом колледжа в Полтава http://educ-ua7.ru/ .
jekflix – I like how simple everything is, nothing feels overwhelming here.
Инфузионная терапия при запое — оптимальный способ для скорейшего возвращения к нормальной жизни. В владимире доступна вывод из запоя с помощью капельниц. Капельницы в случае запоя содействуют очищению организма, устранение похмелья и реабилитация после запоя. вывод из запоя владимир Зависимость от алкоголя требует комплексного подхода: не только лечение запоя, но и реабилитация от алкоголя. Капельница поддерживает организм, наполняя организм витаминами и минераламичто способствует быстрому эффекту;
https://albummarket.ru
купить диплом в каменске-уральском купить диплом в каменске-уральском .
worldloans – I liked how easy it was to navigate between sections.
купить диплом института с реестром купить диплом института с реестром .
https://khasanovich.ru
купить диплом инженера механика купить диплом инженера механика .
https://chi-borchi.ru
Крайне рекомендую https://toimitek.cloud/2023/11/14/hello-world/
https://advokatpv.ru
Lucky Mate is an online casino for Australian players, offering pokies, table games, and live dealer options. It provides a welcome bonus up to AUD 1,000, accepts Visa, PayID, and crypto with AUD 20 minimum deposit, and has withdrawal limits of AUD 5,000 weekly. Licensed, it promotes safe play https://new.prostarcleaning.co.uk/2025/04/17/exploring-responsible-gambling-practices-at-lucky-mate-casino-for-player-protection/
https://al-material.ru
https://albummarket.ru
Компания «BETEREX» является важным, надежным, проверенным партнером, который представит ваши интересы в Китае. Основная сфера деятельности данного предприятия заключается в том, чтобы предоставить полный спектр услуг, связанных с ведением бизнеса в Поднебесной. На сайте https://mybeterex.com/ ознакомьтесь с исчерпывающей информацией на данную тему.
v1av3 – Performance stayed stable across multiple page loads.
Подготовка к капельнице от запоя на дому — ключевой момент в лечение алкогольной зависимости. Вызов нарколога и профессиональная поддержка при запое обеспечивают безопасность и эффективность detox-процедуры. Прежде всего, необходимо проанализировать признаки запоя и выяснить текущее состояние пациента. Необходимо обеспечить удобные условия для лечения: подготовьте пространство, где будет проводиться домашняя капельница. Обеспечьте доступа к электричеству и достаточное количество чистой воды. Важно также иметь под рукой необходимые лекарства, которые рекомендовал врач. Перед процедурой стоит обсудить с специалистом все нюансы, чтобы избежать осложнений. Эффективное лечение алкоголизма включает не только капельницу, но и реабилитационные мероприятия от запоя. Вызов специалиста гарантирует высокий уровень помощи и поддержку в восстановлении организма после запоя.
как купить диплом о высшем образовании с занесением в реестр как купить диплом о высшем образовании с занесением в реестр .
https://altekproekt.ru
https://fatbosscasinos.com/
Lucky Mate is an online casino for Australian players, offering pokies, table games, and live dealer options. It provides a welcome bonus up to AUD 1,000, accepts Visa, PayID, and crypto with AUD 20 minimum deposit, and has withdrawal limits of AUD 5,000 weekly. Licensed, it promotes safe play: Lucky Mate
«Твой Пруд» — специализированный интернет-магазин оборудования для прудов и фонтанов с огромным выбором: от ПВХ и бутилкаучуковой пленки и геотекстиля до насосов OASE, фильтров, УФ-стерилизаторов, подсветки и декоративных изливов. Магазин консультирует по наличию и быстро отгружает со склада в Москве. В процессе подбора решений по объему водоема и производительности перейдите на https://tvoyprud.ru — каталог структурирован по задачам, а специалисты помогут собрать систему фильтрации, аэрации и электрики под ключ, чтобы вода оставалась чистой, а пруд — стабильным круглый сезон.
https://klinika-siti-center.ru
https://banket-kruzheva71.ru
купить диплом техникума в москве недорого купить диплом техникума в москве недорого .
https://faizi-el.ru
https://взятьзаймонлайн.рф/ Микрозаймы без процентов на карту лучшие онлайн с выгодными акциями и скидками для постоянных клиентов.
UP X Казино Ищете надежную игровую площадку? UP X Казино — это современная платформа с огромным выбором игр. Для безопасной игры используйте только UP X Официальный Сайт. Как начать? Процесс UP X Регистрация прост и занимает минуты. После этого вам будет доступен UP X Вход в личный кабинет. Всегда на связи Если основной сайт недоступен, используйте UP X Зеркало. Это гарантирует бесперебойный вход в систему. Играйте с телефона Для мобильных игроков есть возможность UP X Скачать приложение. Оно полностью повторяет функционал сайта. Неважно, как вы ищете — UP X или Ап Х — вы найдете свою игровую площадку. Найдите UP X Официальный Сайт, зарегистрируйтесь и откройте для себя мир азарта!
Пинко Казино Официальный Ищете игровую площадку, которая сочетает в себе надежность и захватывающий геймплей? Тогда Пинко Казино — это именно то, что вам нужно. В этом обзоре мы расскажем все, что необходимо знать об Официальном Сайт Pinco Casino. Что такое Pinco Casino? Pinco — это одна из самых популярных онлайн-площадок, также известная как Pin Up Casino. Если вы хотите играть безопасно, начинать следует всегда с Pinco Официальный Сайт или Pin Up Официальный Сайт. Это гарантирует защиту ваших данных и честную игру. Как найти официальный ресурс? Многие пользователи ищут Pinco Сайт или Pin Up Сайт. Основной адрес — это Pinco Com. Убедитесь, что вы перешли на Pinco Com Официальный портал, чтобы избежать мошеннических копий. Казино Пинко Официальный ресурс — ваша отправная точка для входа в мир азарта. Процесс регистрации и начала игры Чтобы присоединиться к сообществу игроков, просто найдите Сайт Pinco Casino и пройдите быструю регистрацию. Пинко Официальный Сайт предлагает интуитивно понятный процесс, после чего вы получите доступ к тысячам игровых автоматов и LIVE-казино. Пинко Казино предлагает: · Легкий доступ через Пинко Сайт. · Гарантию честной игры через Пинко Казино Официальный. · Удобный интерфейс на Официальный Сайт Pinco Casino. Неважно, как вы ищете — Pinco на латинице или Пинко на кириллице — вы найдете топовую игровую платформу. Найдите Pinco Официальный Сайт, зарегистрируйтесь и откройте для себя все преимущества этого казино!
На сегодняшний день проблема зависимостей становится особенно важной. Если вы раздумываете о нарколога на дом в владимире, сайт vivod-iz-zapoya-vladimir022.ru предоставляет разнообразные наркологических услуг. Терапия зависимостей может быть сложным процессом, однако домашний нарколог обеспечивает помощь при алкоголизме и различным зависимостям в домашних условиях. Первичная консультация – это первый шаг к восстановлению. Профессионалы проведут диагностику зависимости, помогут составить программу реабилитации и рекомендуют методы психотерапии при зависимости. Лечение без раскрытия данных гарантирует полную дискрецию, что особенно важно для многих пациентов. Выездная медицинская помощь позволяет не только удобно проходить терапию, но и получать поддержку семьи, что играет ключевую роль в процессе реабилитации. Профилактика зависимостей и реабилитация после наркотиков также являются частью комплекс услуг, предлагаемых специалистами. Связывайтесь за помощью на vivod-iz-zapoya-vladimir022.ru, чтобы получить профессиональную помощь.
https://klinika-siti-center.ru
https://bibikey.ru
Очень советую https://rms-interior.com/result-housecleening/hello-world/
кухни под заказ спб кухни под заказ спб .
медицинские приборы https://xn—–6kcdfldbfd2aga1bqjlbbb4b4d7d1fzd.xn--p1ai/ .
https://advokatpv.ru
https://chudesa5.ru
Профессиональный фотограф в Москве готов предложить вам уникальные услуги, включая фотограф выездной москва.
Каждый стиль имеет свои особенности и требует специфического подхода к съемке.
На сайте фотосессия для мужчин в москве с предоставлением одежды вы можете заказать услуги профессионального фотографа в Москве.
самые яркие моменты жизни в столице России. Профессиональный фотограф в Москве поможет создать удивительные и неповторимые снимки . Фотосессия может проходить в студии, на улице или в любом другом месте .
Фотография – это не только запечатление моментов, но и искусство создания незабываемых впечатлений. Фотограф в Москве, имеющий высокий уровень мастерства и творческий подход , может предложить создание фотографий, отражающих личность и стиль клиента.
Существует много разных типов фотосессий, каждая со своим уникальным стилем и атмосферой . Фотосессия для свадьбы, дня рождения или другого значимого события требует специфического плана и подготовки .
Фотограф в Москве, специализирующийся на фотографии пейзажей, архитектуры или натюрморта , может предложить индивидуальные услуги и персонализированную поддержку. Фотосессия может быть осуществлена в разных форматах и вариантах.
Подготовка к фотосессии – это ключевой этап, на котором определяется концепция и задачи фотосессии. Фотограф в Москве поможет выбрать подходящую локацию и время суток .
Фотосессия может быть совершенно бесплатной и необязательной или строго профессиональной и коммерческой . Фотограф в Москве, имеющий большой опыт работы с клиентами , может предложить высокое качество фотографий и профессиональную обработку .
Результат фотосессии – это уникальные и незабываемые фотографии . Фотограф в Москве, имеющий глубокое понимание своих клиентов и их пожеланий , может предложить высокое качество фотографий и профессиональную обработку .
Фотосессия в Москве – это уникальный шанс создать удивительные и неповторимые фотографии . Фотограф в Москве поможет сделать потрясающие и незабываемые снимки .
Si vous cherchez des sites fiables en France, alors c’est un bon plan.
Decouvrez l’integralite via le lien en bas de page :
casino francais en ligne
sj256.cc – I like how the pages load smoothly, no weird lag so far.
yilian99 – Clean layout and easy navigation make it pleasant to browse.
https://fermerskiiprodukt.ru
5581249.cc – The typography choice is nice, makes reading easier even late at night.
Советую https://octrehab.com/best-mattress-for-back-pain/
The platform offers tons of captivating and valuable content.
On this platform, you can discover a wide range of topics that cover many popular themes.
Every post is created with care to clarity.
The content is constantly refreshed to keep it up-to-date.
Visitors can gain fresh knowledge every time they browse.
It’s a great place for those who enjoy thoughtful reading.
Numerous users find this website to be trustworthy.
If you’re looking for relevant articles, you’ll surely come across it here.
https://uc-history.us
sj440.cc – Found some interesting pages, design feels modern and well laid out.
https://faizi-el.ru
980115 – Overall performance is solid, navigation feels effortless and fluid.
diwangdh77 – Overall, it’s clean, fast, and really easy to use.
582388360 – The design looks minimal but works efficiently for all users.
5918222q.xyz – The design is minimal, but that actually works in a clean way.
zzj186 – Overall, it’s simple, quick, and really easy to navigate.
https://albummarket.ru
Капельница от запоя на дому: вопросы и ответы (владимир) Услуги нарколога на дом в владимире набирают популярность. Специалисты предлагают медикаментозное лечение, включая капельницы для оперативного выхода из запоя. Симптоматика запоя может включать в себя как сильную головную боль, так и тошноту. При наличии таких симптомов важно быстро обратиться к специалистам для получения медицинской помощи. Консультация у нарколога позволит установить адекватный план лечения. Капельницы включают в себя витамины и медикаменты, способствующие восстановлению организма. Процедуры проводятся в комфортной обстановке, что позволяет избежать стресса. Реабилитация после запойного состояния включает психологическую поддержку. нарколог на дом владимир Следует помнить, что избавление от алкоголизма, это долгий путь, требующий настойчивости и усилий. Наркологи на дому в владимире предлагают как услуги по выводу из запоя, так и программы дальнейшей реабилитации. Реабилитация после запоя реальна, и мы готовы помочь вам в этом процессе.
кухни на заказ в спб от производителя кухни на заказ в спб от производителя .
95657777 – The interface feels light, everything flows naturally when scrolling.
https://faizi-el.ru
https://ozon.ru/t/csgBrx8
https://fdcexpress.ru
https://khasanovich.ru
В мире автомобильных аксессуаров магазин Yokohama в Кирове выделяется как надежный партнер для водителей, предлагая обширный ассортимент шин и дисков от ведущих брендов, таких как Yokohama, Pirelli, Michelin и Bridgestone, подходящих для легковых автомобилей, грузовиков и спецтехники. В ассортименте доступны надежные шины для лета, зимы и всех сезонов, а также элегантные диски, гарантирующие безопасность и удобство в пути, плюс квалифицированный шиномонтаж с гарантией и бесплатной доставкой для наборов колес. Клиенты хвалят простой подбор изделий по характеристикам машины, доступные цены и специальные предложения, делая шопинг выгодным, а наличие двух точек в Кирове на ул. Ломоносова 5Б и ул. Профсоюзная 7А гарантирует удобство для каждого. Для ознакомления с полным каталогом и заказами переходите на https://xn—-dtbqbjqkp0e6a.xn--p1ai/ где опытные консультанты помогут выбрать идеальный вариант под ваши нужды, подчеркивая репутацию магазина как лидера в регионе по шинам и дискам.
yy380.cc – Saw this site while browsing, looks promising and quite unique.
Ищете компрессорное оборудование по лучшим ценам? Посетите сайт ПромКомТех https://promcomtech.ru/ и ознакомьтесь с каталогом, в котором вы найдете компрессоры для различных видов деятельности. Мы осуществляем оперативную доставку оборудования и комплектующих по всей России. Подробнее на сайте.
Онлайн магазин – купить мефедрон, кокаин, бошки
юридические услуги Рекомендуем посетить профессиональный сайт юриста Светланы Приймак, предлагающий качественную юридическую помощь гражданам и бизнесу в Украине. Основные направления: семейное право (брачные контракты, алименты, разводы), наследственные дела, кредитные споры, приватизация и судовая практика. Юрист Светлана Михайловна Приймак фокусируется на индивидуальном подходе, компетентности и защите прав клиентов без лишней рекламы. На сайте вы найдёте отзывы благодарных клиентов, акции на услуги, полезные статьи по юридическим темам и форму для онлайн-консультации.
медоборудование медоборудование .
Je suis enthousiaste a propos de Azur Casino, il offre une aventure captivante. Le choix de jeux est epoustouflant, offrant des jeux de table elegants. Les agents sont d’une efficacite remarquable, repondant en un rien de temps. Les retraits sont ultra-rapides, cependant davantage de recompenses seraient bienvenues. En fin de compte, Azur Casino vaut vraiment le detour pour ceux qui cherchent l’adrenaline ! En bonus le design est visuellement superbe, ajoutant une touche de raffinement.
casino azur en ligne|
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
На Складчике нашёл курс по веб-дизайну. Цена оказалась в десятки раз меньше официальной. Материалы отличные, доступ получил сразу. Очень доволен сервисом – https://v27.skladchik.org/
Онлайн магазин – купить мефедрон, кокаин, бошки
Анонимная помощь при зависимостях — это важный шаг для тех, кто сталкивается с зависимостями. На сайте narkolog-tula022.ru можно найти информацию о лечении зависимостей, поддержке и помощи. Конфиденциальное лечение позволяет пациентам находить решение без боязни осуждения.Услуги нарколога включают очистку организма, психологическое консультирование и кризисную интервенцию. Процесс реабилитации часто включает группы поддержки, что усиливает процесс восстановления. Профилактика зависимости также играет важную роль, обеспечивая устойчивый результат. Консультации помогут понять ситуацию и найти пути решения. Поддержка для наркозависимых доступна и доступна, даже если они сомневаются в возможности помощи.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
консультация психиатра по телефону
psikhiatr-moskva008.ru
детский психиатр на дом в москве
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Онлайн магазин – купить мефедрон, кокаин, бошки
Получение лицензии на медицинскую деятельность с полным сопровождением оказалось максимально комфортным, специалисты центра подготовили документы, контролировали подачу и давали рекомендации https://licenz.pro/
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
АНО «Бюро судебной экспертизы и оценки “АРГУМЕНТ”» — команда кандидатов и докторов наук, выполняющая более 15 видов экспертиз: от автотехнической и строительно-технической до финансово-экономической, лингвистической и в сфере банкротств. Индивидуальная методика, оперативные сроки от 5 рабочих дней и защита заключений в судах по всей РФ делают результаты предсказуемыми и убедительными. Ознакомьтесь с кейсами и запишитесь на консультацию на https://anoargument.ru/ — точные выводы в срок, когда на кону исход спора.
Для жителей северной столицы теперь доступна профессиональная уборка квартир в санкт петербурге цены, выполняемая высококвалифицированным персоналом.
Уборка квартир СПб требует особого внимания и заботы. Это связано с тем, что При выборе компании или мастера для уборки квартир в Санкт-Петербурге следует учитывать ряд факторов, включая качество услуг, стоимость и отзывы клиентов.
Купить диплом о высшем образовании можем помочь. Купить диплом техникума, колледжа в Улан-Удэ – diplomybox.com/kupit-diplom-tekhnikuma-kolledzha-v-ulan-ude
скачат мелбет казино скачат мелбет казино .
7x084yko.xyz – Page loading is decent, though heavy sections lag slightly on slow net.
bestbotanicals – Such good quality ingredients, I could smell the freshness instantly.
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
наркологическая клиника trezviy vibor https://narkologicheskaya-klinika-19.ru/ .
storagesheds.store – Load speed is decent, though heavier pages lag a bit on slower nets.
yt7787.xyz – The font choice is readable, made scrolling through content pleasant.
Онлайн магазин – купить мефедрон, кокаин, бошки
bitcoin-mining-news.website – Sometimes articles are short — more technical depth would be nice.
648ssss.xyz – On mobile some elements shift oddly, but overall usable.
52cjg.xyz – Some pages feel a bit empty; more content would boost engagement.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
вызов психиатра на дом
psikhiatr-moskva009.ru
платная консультация психиатра
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Je suis carrement scotche par Gamdom, c’est une plateforme qui envoie du lourd. La gamme est une vraie pepite, comprenant des jeux parfaits pour les cryptos. L’assistance est au top du top, avec une aide qui dechire tout. Les gains arrivent en mode TGV, par contre plus de tours gratos ca serait ouf. Bref, Gamdom offre une experience de ouf pour les pirates des slots modernes ! A noter aussi la plateforme claque avec son look de feu, booste l’immersion a fond les ballons.
gamdom birthday bonus|
Je trouve completement fou FatPirate, il offre une aventure totalement barge. La selection est carrement dingue, offrant des machines a sous qui claquent. Le service client est au top niveau, repondant en deux secondes chrono. Le processus est clean et sans galere, par contre les offres pourraient etre plus genereuses. Pour resumer, FatPirate garantit un fun total pour les accros aux sensations fortes ! Bonus le site est une pepite visuelle, facilite le delire total.
fatpirate uvГtacГ bonus|
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Онлайн магазин – купить мефедрон, кокаин, бошки
Кейт Миддлтон больна Кейт Миддлтон рак Диагноз рака у Кейт Миддлтон, принцессы Уэльской, стал тяжелым известием для многих. Объявление о ее болезни было сделано в марте 2025 года, после того как она перенесла операцию на брюшной полости, и дальнейшие анализы выявили наличие раковых клеток. Несмотря на то, что конкретный тип рака и его стадия не были публично раскрыты, представители Кенсингтонского дворца сообщили, что Кейт проходит курс профилактической химиотерапии. Принцесса решила временно прекратить исполнение своих королевских обязанностей, чтобы полностью сосредоточиться на своем здоровье и лечении. Кейт лично обратилась к общественности в видеообращении, поделившись новостью о своем диагнозе и о том, как вместе с семьей она справляется с этим испытанием. Она подчеркнула важность приватности в этот период, а также выразила благодарность за поддержку и понимание, которые она получает. Диагноз рака у Кейт Миддлтон привлек внимание к проблемам ранней диагностики и важности профилактических мер против онкологических заболеваний, а также подчеркнул необходимость поддержки тех, кто столкнулся с подобными трудностями.
Hello to every , for the reason that I am really eager of reading this web site’s post to be updated regularly. It includes pleasant data.
keepstyle
Предлагаю https://www.mobilepetvet.com.au/author/vivadmin/
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Looking for payment processing? Visit sharpay.net and see the innovative solutions we offer as a leading fintech platform, namely modern financial services to individuals and businesses. Our platform ensures worldwide availability, round-the-clock protection, and an all-in-one feature set. You can find the full list of our benefits on the website.
можно ли купить диплом медсестры можно ли купить диплом медсестры .
Ищете профессиональный блог о контекстной рекламе? Посетите сайт https://real-directolog.ru/ где вы найдете полноценную информацию и различные кейсы, связанные с контекстной рекламой, без воды. Ознакомьтесь с различными рубриками о конверсиях, продажах, о Яндекс Директ. Информация будет полезна как новичкам, так и профессионалам в своем деле.
Онлайн магазин – купить мефедрон, кокаин, бошки
Металлопрокат в Сургуте Купить балку в Надыме Планируете строительство в Надыме? У нас вы можете купить балку любого размера и типа. Предлагаем широкий ассортимент стальных балок для различных строительных задач. Быстрая доставка в Надым и близлежащие районы. Гарантируем качество и выгодные цены! Звоните и заказывайте!
Онлайн магазин – купить мефедрон, кокаин, бошки
https://ozon.ru/t/csgBrx8
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
психоаналитический психотерапевт Детский психотерапевт Детский психотерапевт – это квалифицированный специалист, который помогает детям и подросткам преодолевать эмоциональные, поведенческие и социальные трудности. Он использует разнообразные методы, адаптированные к детскому возрасту, такие как игровая терапия, арт-терапия, сказкотерапия, чтобы помочь ребенку выразить свои чувства, понять причины своего поведения и научиться справляться со сложными ситуациями. Детский психотерапевт работает с проблемами тревожности, депрессии, агрессии, трудностями во взаимоотношениях со сверстниками, последствиями травматических событий. Важным аспектом является взаимодействие с родителями для создания благоприятной и поддерживающей среды для ребенка.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
реабилитационный центр для наркозависимых в Астане
reabilitaciya-astana007.ru
лечение алкоголизма отзывы
Онлайн магазин – купить мефедрон, кокаин, бошки
formasecoarquitectonicas – Would help to see an about-page with mission and team info soon.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Ищете производителя светодиодных табло? Посетите сайт АльфаЛед https://ledpaneli.ru/ – компания оказывает полный комплекс услуг. Проектирование, изготовление, монтаж и подключение, сервисное обслуживание. На сайте вы найдете продажу светодиодных экранов, медиафасадов, гибких экранов уличных, для сцены, для рекламы, прокатных-арендных. Вы сможете осуществить предварительный расчет светодиодного экрана.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
xxec – Wow, this site has such an interesting and mysterious feel overall.
fartak – Found some posts that answered exactly what I was searching for.
xxgm – The design is modern, typography is easy on the eyes too.
forextradingsystem – Navigation feels simple, and the articles are written clearly and nicely.
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
Вісті з Полтави – https://visti.pl.ua/ – Новини Полтави та Полтавської області. Довідкова, та корисна інформація про місто.
axjaognr – I like their style aesthetic, kind of minimal yet modern.
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
«ПрофПруд» в Мытищах — магазин «всё для водоема» с акцентом на надежные бренды Германии, Нидерландов, Дании, США и России и собственное производство пластиковых и стеклопластиковых чаш. Здесь подберут пленку ПВХ, бутилкаучук, насосы, фильтры, скиммеры, подсветку, биопрепараты и корм, помогут с проектом и шеф-монтажом. Удобно начать с каталога на https://profprud.ru — есть схема создания пруда, статьи, видео и консультации, гарантия до 10 лет, доставка по РФ и бесплатная по Москве и МО при крупном заказе: так ваш водоем станет тихой гаванью без лишних хлопот.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Acho simplesmente insano FSWin Casino, e um cassino online que e uma verdadeira explosao. O catalogo de jogos do cassino e uma loucura total, com jogos de cassino perfeitos pra criptomoedas. A equipe do cassino entrega um atendimento que e uma joia, acessivel por chat ou e-mail. Os pagamentos do cassino sao lisos e blindados, as vezes mais bonus regulares no cassino seria top. Na real, FSWin Casino oferece uma experiencia de cassino que e puro gas para quem curte apostar com estilo no cassino! De bonus a navegacao do cassino e facil como brincadeira, o que deixa cada sessao de cassino ainda mais alucinante.
fswin|
Estou totalmente empolgado com Flabet Casino, da uma energia de jogo louca. A gama de jogos e impressionante, oferecendo apostas esportivas emocionantes. O servico ao cliente e top, com um acompanhamento impecavel. Os ganhos chegam rapido, as vezes mais rodadas gratis seriam um plus. Em resumo, Flabet Casino oferece prazer garantido para os amantes de adrenalina ! Ademais o site e estiloso e rapido, adiciona conforto ao jogo.
wesley safadao flabet|
Ich finde es unglaublich Snatch Casino, es ist eine dynamische Erfahrung. Der Katalog ist einfach gigantisch, mit immersiven Live-Sitzungen. Die Agenten sind super reaktionsschnell, mit tadellosem Follow-up. Der Prozess ist einfach und reibungslos, gelegentlich mehr Freispiele waren ein Plus. Zum Schluss Snatch Casino ist ein Must fur Spieler fur Crypto-Liebhaber ! Hinzu kommt die Plattform ist visuell top, macht jede Session immersiv.
https://gktorg.ru
как избавиться от алкогольной зависимости
reabilitaciya-astana008.ru
центр реабилитации зависимых
Je suis scotche par Impressario, il propose un show de jeu hors norme. Le catalogue est un festival de titres, avec des slots qui brillent de mille feux. Les agents sont rapides comme des cometes, avec une aide qui fait mouche. Les retraits sont fluides comme une choregraphie, par contre plus de tours gratos ca ferait vibrer. Bref, Impressario garantit un show de fun epique pour les accros aux sensations eclatantes ! A noter aussi le site est une pepite scenique, donne envie de revenir pour un rappel.
impressario casino|
https://krasavchikbro.ru
Estou completamente fissurado em FSWin Casino, da uma energia de cassino que e fora da curva. O catalogo de jogos do cassino e uma loucura total, com slots de cassino unicos e eletrizantes. A equipe do cassino entrega um atendimento que e uma joia, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um cometa, as vezes queria mais promocoes de cassino que mandam ver. No fim das contas, FSWin Casino e o point perfeito pros fas de cassino para quem curte apostar com estilo no cassino! Alem disso a navegacao do cassino e facil como brincadeira, da um toque de classe braba ao cassino.
fswin bangladesh|
av07 – I’d love an “About” or “Who we are” section to know more.
https://edapridiabete.ru
https://maminboss.ru
missouriland – Would be nice to see an About page explaining mission or team.
Очень советую https://sharjahcements.com/hello-world/
https://bostonpub.ru
https://gktorg.ru
https://lesbitovok.ru
studydiary – I like how the content is laid out, easy to skim through.
https://lesbitovok.ru
Лечение алкоголизма в Туле: современные методы Алкоголизм — серьезная проблема, требующая профессионального подхода. В Туле доступны наркологические услуги, включая вызов нарколога на дом для анонимного лечения. Современные методы лечения включают медикаментозную терапию и процедуры детоксикации организма. Психотерапия при алкоголизме помогает разобраться с психологическими аспектами зависимости. Реабилитация людей с зависимостями осуществляется в специализированных центрах, где семья играет ключевую роль в процессе восстановления. Программа реабилитации включает меры по профилактике алкогольной зависимости и лечение запойного состояния, что способствует достижению стабильных результатов. заказать нарколога на дом
https://bostonpub.ru
купить диплом с проведением в купить диплом с проведением в .
https://lesbitovok.ru
сколько стоит купить диплом медсестры сколько стоит купить диплом медсестры .
купить диплом в бузулуке купить диплом в бузулуке .
https://dent-zubritskiy.ru
https://licey5pod.ru
Очень советую https://bastel-und-kartenstube.unequal-solutions.de/kontakt/
https://lesbitovok.ru
Расходные материалы для печати по выгодным ценам вы можете купить у нас на сайте https://adisprint.ru/ – ознакомьтесь с нашим существенным ассортиментом по выгодной стоимости с доставкой по России. Большой каталог даст вам возможность купить все необходимое в одном месте. У нас картриджи, тонеры, чернила, фотобарабаны, ролики, клининговые комплекты и очень многое другое для удовлетворения ваших потребностей.
купить диплом с занесением в реестр в архангельске купить диплом с занесением в реестр в архангельске .
https://givotov.ru
диплом о высшем образовании с проводкой купить диплом о высшем образовании с проводкой купить .
купить диплом массажиста купить диплом массажиста .
купить диплом в череповце https://rudik-diplom4.ru/ .
https://licey5pod.ru
Torentino.org — каталог игр для PS и ПК с удобной навигацией по жанрам: от спортивных и гонок до хорроров и RPG, с подборками «все части» и свежими релизами. В процессе выбора удобно перейти на http://torentino.org/ — там видны обновления по датам, рейтинги, комментарии и метки репаков от известных групп. Сайт структурирован так, чтобы быстро находить нужное: фильтры, год релиза, серии и платформы. Это экономит время и помогает собрать библиотеку игр по вкусу — от ретро-хитов до новых тайтлов.
техникум какое образование украина http://educ-ua7.ru/ .
https://makeupcenter.ru
купить диплом фитнес инструктора http://rudik-diplom2.ru/ – купить диплом фитнес инструктора .
алкоголизм лечение
reabilitaciya-astana009.ru
пройти лечение от наркозависимости
https://derufa-crimea.ru
zonaflix – I just stumbled on this site, content seems fresh and useful.
купить диплом вуза купить диплом вуза .
https://ivushka21.ru
22ee.top – The homepage is simple, makes me curious to scroll further.
https://derufa-crimea.ru
купить диплом с реестром спб купить диплом с реестром спб .
chinh-sua-anh.online – Love the gallery examples, gives confidence in their image skills.
купить диплом с занесением в реестр вуза купить диплом с занесением в реестр вуза .
https://kaluga-howo.ru
sexscene.info/ Good to go
Откройте для себя новые возможности с перетяжкой мебели в Минске, позволяющей обновить ваш интерьер и продлить жизнь любимым предметам!
очень востребованная и актуальная услуга.
manchunyuan1.xyz – Very interesting niche coverage, I’m glad I found it.
forexplatform.website – This website actually made forex sound simple, I’m learning so much.
52ch.cc – Very useful site, I find something helpful each visit.
Капельница от запоя в Туле – это существенная медицинская услуга при алкогольной зависимости, способствующая детоксикации организма. Вызов нарколога на домой предоставляет срочную помощь при алкоголизме в удобной обстановке. Компоненты капельницы включают элементы, которые помогают восстановлению организма: раствор для инфузий, витамины и лекарства для капельницы. Эффект капельницы направлено на устранение симптомов абстиненции и улучшение состояния пациента. Преодоление зависимости от алкоголя требует комплексного подхода, включая реабилитацию после алкогольного кризиса. Цены на услугу нарколога варьируются, но обращение к специалиста является ключевой для успешного лечения.
Only-Paper — это магазин, где бумага становится инструментом для идей: дизайнерские и офисные бумаги, картон, упаковка, расходники для печати, лезвия и клей — всё, чтобы макеты превращались в впечатляющие проекты. Удобный каталог, фильтры по плотности и формату, консультации и быстрая отгрузка — экономят время студий и типографий. Откройте ассортимент на https://only-paper.ru — сравните параметры, добавьте в корзину и доверьте деталям текстуру, от которой ваш бренд будет звучать убедительнее на витрине и в портфолио.
https://k-projekt.ru
greenenvelope.org – Hope they add images and info soon, it feels incomplete.
zkjcnm.top – I’ll check back later to see if they launch full version.
keledh.pw – The blank space gives a sense of anticipation and mystery.
купить диплом в великих луках купить диплом в великих луках .
datacaller.store – I’m curious what “data caller” implies—analytics? APIs?
https://lesbitovok.ru
Крайне рекомендую https://www.i-boutique.co.za/hello-world-2/
https://k-projekt.ru
Ich bin suchtig nach Snatch Casino, es bietet einen einzigartigen Thrill. Es gibt eine unglaubliche Vielfalt an Spielen, mit dynamischen Tischspielen. Der Service ist von bemerkenswerter Effizienz, antwortet in Sekundenschnelle. Die Transaktionen sind zuverlassig, jedoch haufigere Promos waren cool. Kurz gesagt Snatch Casino ist ein Must fur Spieler fur Casino-Fans ! Au?erdem die Site ist stylish und schnell, was das Spielvergnugen steigert.
snatch casino review|
вывод из запоя круглосуточно тула
tula-narkolog007.ru
экстренный вывод из запоя тула
https://gktorg.ru
Is this conversation helpful so far?
https://buhgalter-ryazan.ru
scilla.biz – Minimalist design works, just needs substance next.
купить диплом в бийске купить диплом в бийске .
https://ldc-ariadna.ru
“аренда инструмента в слуцке – выгодные условия и широкий выбор инструментов для любых задач.”
Если вам нужен инструмент на короткий срок, аренда – идеальное решение, ведь не придется тратиться на дорогостоящее оборудование.
Такой подход особенно удобен для строителей и мастеров. Строительные компании активно используют аренду, чтобы не закупать лишнее оборудование.
#### **2. Какой инструмент можно взять в аренду?**
В Слуцке доступен широкий ассортимент оборудования для разных задач. Для строительных работ доступны бетономешалки, виброплиты и леса.
Кроме того, в аренду сдают и специализированную технику. Для укладки плитки можно взять плиткорезы, а для покраски – краскопульты.
#### **3. Преимущества аренды инструмента**
Главный плюс – экономия на обслуживании и хранении. Вам не придется беспокоиться о ремонте инструмента, так как за ним следят специалисты.
Дополнительный бонус – помощь в выборе подходящего оборудования. Опытные менеджеры подскажут, какая модель лучше справится с работой.
#### **4. Как оформить аренду в Слуцке?**
Процедура аренды максимально проста и прозрачна. Вы можете приехать в офис, чтобы лично выбрать подходящий инструмент.
Условия проката выгодны для всех клиентов. На длительные периоды предоставляются скидки и специальные предложения.
—
### **Спин-шаблон статьи**
#### **1. Почему аренда инструмента – это выгодно?**
Аренда инструмента в Слуцке позволяет получить доступ к профессиональному оборудованию без покупки. Вместо того чтобы покупать инструмент, который может понадобиться всего несколько раз, выгоднее взять его в аренду по доступной цене.
Такой подход особенно удобен для профессионалов и любителей . Многие профессионалы предпочитают брать инструмент напрокат, так как это снижает затраты на выполнение работ .
#### **2. Какой инструмент можно взять в аренду?**
В Слуцке доступен большой выбор техники для строительства и ремонта . В прокате представлены бензопилы, газонокосилки и другая садовая техника .
Кроме того, в аренду сдают и профессиональные устройства . Для укладки плитки можно взять плиткорезы, а для покраски – краскопульты .
#### **3. Преимущества аренды инструмента**
Главный плюс – отсутствие необходимости в ремонте . Арендуя оборудование, вы избегаете затрат на его хранение и транспортировку .
Дополнительный бонус – помощь в выборе подходящего оборудования . Консультанты помогут подобрать инструмент под конкретные задачи .
#### **4. Как оформить аренду в Слуцке?**
Процедура аренды максимально проста и прозрачна . Для оформления понадобится только паспорт и небольшой залог.
Условия проката адаптированы под разные потребности . На длительные периоды предоставляются скидки и специальные предложения .
https://catphoto.ru
обзор спортивных событий http://novosti-sporta-8.ru .
новости хоккея новости хоккея .
90dprr.top – The layout is simple yet effective — not overwhelming.
спортивные события спортивные события .
железобетонные прогнозы на спорт http://prognozy-ot-professionalov4.ru .
xfj222 – A hidden gem for those seeking unique insights.
5xqvk – I appreciate the depth of information provided here.
mhcw3kct – This site offers a unique perspective on various topics.
5680686 – I appreciate the depth of information provided here.
axxo.live – I like the tone here, casual yet informative and direct.
вывод из запоя тула
tula-narkolog008.ru
вывод из запоя тула
44lou5 – I love the minimalist design and user-friendly interface.
xxfq.xyz – I like how images and text blend well here, good design.
bjwyipvw.xyz – Glad I found this — strange but strangely compelling reading.
av07.cc – The navigation feels intuitive, makes it easy to explore all sections.
https://catphoto.ru
Looking for reviews and sailing itineraries for skippers? Visit https://sailors.tips to plan your sailing itineraries and discover landmarks around the world. We provide detailed information on marinas, nearby attractions, reliable yachts, and local marine shops. Learn more on the website.
675kk.top – Navigation is smooth, makes browsing easy and pleasant.
частный пансионат для престарелых
pansionat-msk010.ru
пансионат с деменцией для пожилых в москве
https://krasavchikbro.ru
zukdfj.shop – I found useful bits here — will reuse for my own research.
qyrhjd.top – Navigation is intuitive, I get where I want to go quickly.
https://kvkrasnodar.ru
Tightrope Game – a balance challenge with obstacles. Quick, addictive, and perfect for testing focus: official Tightrope game website
https://dent-zubritskiy.ru
Прокат мебели для праздника Юбилей станет особенным событием, если тщательно подобрать все элементы оформления.
https://buhgalter-ryazan.ru
вывод из запоя цена
vivod-iz-zapoya-kaluga013.ru
лечение запоя калуга
https://krasavchikbro.ru
Типография «AVPrintPak» превращает упаковку в сильный элемент бренда: проектирует и изготавливает коробки любой сложности — от хром-эрзаца и микрогофрокартона до тубусов и круглых коробок для цветов и тортов. Премиальные решения дополняют тиснение, выборочный лак, конгрев и точные ложементы. Собственный парк офсетного и цифрового оборудования обеспечивает стабильное качество и оперативные тиражи, конструкторы создают тестовые образцы под ваш продукт. Ищете печать коробок на заказ? Подробности и портфолио — на сайте avprintpak.ru
https://catphoto.ru
https://kaluga-howo.ru
кракен тор позволяет обойти возможные блокировки и получить доступ к маркетплейсу. кракен маркетплейс необходимо искать через проверенные источники, чтобы избежать фишинговых сайтов. ссылки на кракен должно обновляться регулярно для обеспечения непрерывного доступа.
Изменение – главная особенность Кракен.
https://ivushka21.ru
https://mart-media.ru
частный дом престарелых
pansionat-msk011.ru
пансионат для людей с деменцией в москве
https://gobanya.ru
https://edapridiabete.ru
https://marka-food.ru
GBISP — это про системность и порядок: разделы логично связаны, информация изложена четко и без перегрузки, а поиск работает быстро. В середине маршрута удобно перейти на https://gbisp.ru и найти нужные материалы или контакты в пару кликов. Аккуратная вёрстка, корректное отображение на мобильных и прозрачные формы обратной связи создают ощущение продуманного ресурса, который помогает с решением задач вместо того, чтобы отвлекать деталями.
https://gktorg.ru
Кит-НН — спецодежда и СИЗ в Нижнем Новгороде: летние и зимние комплекты, обувь, защитные перчатки, каски, экипировка для сварщиков и медработников, нанесение символики. Работают с розницей и бизнесом, дают 3% скидку при заказе на сайте, консультации и удобную доставку. На https://kitt-nn.ru/ легко подобрать по сезону и задачам, сверить характеристики и цены, оформить онлайн. Адрес: Новикова-Прибоя, 6А; горячая линия +7 (963) 231-76-83 — чтобы ваша команда была защищена и выглядела профессионально.
seostream – A hidden gem for those seeking unique insights.
Estou viciado em Flabet Casino, oferece um thrill unico. As opcoes sao vastas e variadas, compreendendo milhares de jogos adaptados para criptos. Os agentes sao ultra-responsivos, oferecendo solucoes precisas. Os ganhos chegam rapido, por vezes recompensas adicionais seriam top. No geral, Flabet Casino e obrigatorio para os jogadores para os jogadores em busca de diversao ! Alem disso a plataforma e visualmente top, o que aumenta o prazer de jogar.
como usar a freebet da flabet|
наркологический частный центр narkologicheskaya-klinika-19.ru .
https://kaluga-howo.ru
https://ivushka21.ru
elipso.site – Seen a few posts, quality is consistent, keep it up.
comprafacilrd – Appreciate the free shipping offers and payment-on-delivery option.
rinatmat – Excellent site overall, everything seems well organized and useful.
wzoo – I like how content is well organized, makes it pleasant to read.
лечение запоя
tula-narkolog009.ru
вывод из запоя цена
Estou completamente enlouquecido por LeaoWin Casino, tem uma vibe de jogo que e pura selva. Tem uma enxurrada de jogos de cassino irados, incluindo jogos de mesa de cassino cheios de garra. O suporte do cassino ta sempre na area 24/7, com uma ajuda que e puro instinto. Os saques no cassino sao velozes como um predador, mesmo assim as ofertas do cassino podiam ser mais generosas. Resumindo, LeaoWin Casino garante uma diversao de cassino que e selvagem para os cacadores de slots modernos de cassino! E mais a navegacao do cassino e facil como uma trilha na selva, aumenta a imersao no cassino a mil.
san leaowin02 casino|
https://kcsodoverie.ru
вывод из запоя
vivod-iz-zapoya-kaluga014.ru
вывод из запоя
seoelitepro – I found the articles here to be quite informative.
https://maminboss.ru
fcalegacy – Fantastic site overall, user experience is smooth and pleasant.
https://bostonpub.ru
пансионат для пожилых с инсультом
pansionat-msk012.ru
дом престарелых
https://catphoto.ru
где купить диплом техникума в ижевске где купить диплом техникума в ижевске .
J’eprouve une loyaute infinie pour Mafia Casino, il orchestre une conspiration de recompenses secretes. Il pullule d’une legion de complots interactifs, proposant des crash pour des chutes de pouvoir. Le support client est un consigliere vigilant et incessant, mobilisant des canaux multiples pour une execution immediate. Le protocole est ourdi pour une fluidite exemplaire, a l’occasion des rackets de recompense additionnels scelleraient les pactes. A la fin de cette conspiration, Mafia Casino invite a une intrigue sans trahison pour les gardiens des empires numeriques ! En pot-de-vin supplementaire l’interface est un repaire navigable avec ruse, ce qui propulse chaque pari a un niveau de don.
mafia casino france|
A vibrant platformer guiding a panda through exciting puzzles and treasures. Fun and family-friendly: Panda puzzle games for free
https://marka-food.ru
https://kvkrasnodar.ru
https://lesbitovok.ru
https://maminboss.ru
купить диплом в ухте купить диплом в ухте .
bongda247 – I enjoy the fresh perspective this site offers.
basingstoketransition – Love the community focus on reducing fossil fuel dependence.
Artistic photography often focuses on expressing the aesthetics of the body lines.
It is about light rather than surface.
Experienced photographers use natural tones to reflect emotion.
Such images celebrate delicacy and character.
https://xnudes.ai/
Every shot aims to tell a story through movement.
The goal is to present human beauty in an elegant way.
Observers often value such work for its emotional power.
This style of photography blends emotion and vision into something truly timeless.
https://credit-news.ru
https://kvkrasnodar.ru
https://licey5pod.ru
Если вы ищете удобный и быстрый способ получить напитки, воспользуйтесь услугой алкоголь круглосуточно, которая работает без выходных и перерывов, чтобы любой вечер или праздник был полон радости и хорошего настроения.
представляет собой удобный сервис, который позволяет жителям приобрести алкогольные напитки без выхода из дома . Эта услуга приобрела популярность в последние годы благодаря своей удобности и доступности . Благодаря доставке алкоголя в Пушкино, жители могут наслаждаться своим любимым напитком в удобное время .
Доставка алкоголя в Пушкино осуществляется профессиональными курьерами, которые следят за сохранностью продукции . Компании, предоставляющие эту услугу, предлагают гибкие условия оплаты и доставки. Это делает их лидерами на рынке доставки алкоголя .
Преимущества доставки алкоголя в Пушкино позволяют жителям наслаждаться алкоголем в комфорте своего дома. Доставка алкоголя экономит время и силы, которые можно потратить на более важные дела . Благодаря этому сервису, имеют возможность приобрести алкоголь в любое время, соответствующее их графику .
Доставка алкоголя в Пушкино позволяет клиентам получать качественные алкогольные изделия без риска покупки поддельных продуктов . Компании, которые занимаются доставкой, обеспечивают безопасную и надежную упаковку для того, чтобы избежать повреждений во время доставки .
Заказать доставку алкоголя в Пушкино включает в себя несколько простых шагов, начиная от выбора товара и заканчивая оплатой . Для начала, следует тщательно изучить условия доставки и оплаты. Затем, может оставить комментарий или специальные инструкции для курьера.
После подтверждения заказа, компания обрабатывает его и направляет курьера для доставки . Курьер осуществляет проверку возраста и личности получателя для обеспечения безопасности.
Будущее доставки алкоголя в Пушкино выглядит перспективным, с учетом роста спроса на подобные услуги . Компании, занимающиеся доставкой, инвестируют в технологии и маркетинг, чтобы расширить свою клиентскую базу . Это даст им возможность повысить уровень обслуживания и качество доставки .
Доставка алкоголя в Пушкино станет еще более доступной и удобной, с развитием мобильных приложений и онлайн-платформ . В будущем, будут иметь возможность оценить качество и разнообразие доставляемых продуктов .
Ich bin verblufft von NV Casino, es erzeugt eine Energie, die suchtig macht. Es gibt eine beeindruckende Auswahl an Optionen, mit immersiven Tischspielen. Die Mitarbeiter reagieren blitzschnell, immer bereit zu helfen. Die Auszahlungen sind ultraschnell, manchmal mehr abwechslungsreiche Boni waren willkommen. Kurz gesagt, NV Casino ist eine Plattform, die rockt fur Casino-Enthusiasten ! Zusatzlich die Oberflache ist intuitiv und stylish, gibt Lust auf mehr.
playnvcasino.de|
купить двигатель Nissan Купить двигатель Iveco – запрос на двигатель конкретной марки Iveco. Важно предложить различные модели двигателей Iveco, подходящие для разных моделей автомобилей Iveco.
купить диплом занесением реестр отзывы купить диплом занесением реестр отзывы .
https://eiforiyavkusa.ru
Автомобили из Кореи 2024 Растаможка авто из Кореи – запрос на информацию о процедуре растаможки автомобиля, импортированного из Кореи. Важно предоставить информацию о таможенных пошлинах, сборах, необходимых документах и способах оплаты.
https://kcsodoverie.ru
Ищете купить ноутбук HONOR MagicBook Pro14 Ultra5 32/1TStarry Gray(5301ANXH)? В каталоге v-electronic.ru/noutbuki/ собраны модели от бюджетных N100 и i3 до мощных Ryzen 9 и Core i7, включая тонкие ультрабуки и игровые решения с RTX. Фильтры по брендам, экранам, памяти и SSD ускоряют подбор, а детальные карточки с характеристиками и отзывами снимают вопросы. Следите за акциями и рассрочкой — так легче взять «тот самый» ноутбук и не переплатить.
https://ds35zvezdochka.ru
Новости кино Что посмотреть вечером – запрос на подборку фильмов для просмотра вечером. Важно предлагать пользователям фильмы разных жанров, чтобы удовлетворить различные вкусы.
cyrusmining – Would want to see proof of payouts or user testimonials before investing.
https://catphoto.ru
wraoys – Right now, it feels like a shell more than a full site.
antsmarket – Could be a startup or placeholder—hard to tell real intent yet.
https://makeupcenter.ru
прогноз матчей по футболу https://kompyuternye-prognozy-na-futbol24.ru/ .
обережный талисман обереги и талисманы – Общий поиск информации об оберегах и талисманах, их отличиях и общем назначении. Дает общее представление о магических предметах.
https://kaluga-howo.ru
Estou totalmente empolgado com Flabet Casino, oferece um thrill unico. O escolha de titulos e enorme, compreendendo milhares de jogos adaptados para criptos. O suporte esta disponivel 24/7, garantindo ajuda instantanea. O processo e simples e sem problemas, contudo as ofertas poderiam ser mais generosas. No geral, Flabet Casino vale realmente a pena para os fas de apostas online ! Por outro lado o design e atraente e intuitivo, facilita a experiencia geral.
flabet. com|
Поисковый seo аудит https://seo-audit-sajta.ru
capsaqiu – Navigation is intuitive, I didn’t struggle to find basic info.
купить диплом в михайловске http://www.rudik-diplom13.ru/ .
xyadmin – Would recommend it to friends, seems like a quality site.
https://dent-zubritskiy.ru
KAISER комбинирует европейский дизайн, ресурсный запас и удобство эксплуатации в каждой детали. В официальном интернет-магазине вы найдете смесители, душевые системы, мойки и аксессуары с гарантией производителя до 5 лет и быстрой доставкой по России. Ищете смеситель для ванны однорычажный длинный излив? На kaiser-russia.su удобно сравнивать модели по сериям и функционалу, смотреть цены и наличие, выбирать комплекты со скидкой до 10%. Эксперты подскажут совместимые решения под вашу ванную или кухню, а четкие условия оплаты и обмена избавят от лишних хлопот.
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk011.ru
экстренный вывод из запоя
https://givotov.ru
myzb27 – Feels like work in progress, but promising start nonetheless.
кость для собаки Для крупных собак важно подбирать лакомства, соответствующие их размеру и силе челюстей. Это должны быть достаточно большие и прочные продукты, которые собака не сможет быстро разгрызть и проглотить. Отдавайте предпочтение натуральным лакомствам, богатым белком и другими полезными веществами.
https://kiteschoolhurghada.ru/
Je suis irresistiblement recrute par Mafia Casino, on complote un reseau de tactiques astucieuses. La cache de jeux est un arsenal cache de plus de 5000 armes, integrant des lives comme Infinite Blackjack pour des negociations tendues. Les lieutenants repondent avec une discretion remarquable, avec une ruse qui anticipe les traitrises. Les transferts glissent stables et acceleres, a l’occasion des complots promotionnels plus frequents dynamiseraient le territoire. Pour clore l’omerta, Mafia Casino devoile un plan de triomphes secrets pour les mafiosi des paris crypto ! Par surcroit le portail est une planque visuelle imprenable, infuse une essence de mystere mafieux.
cuba casino mafia|
https://crossfire-megacheat.ru
https://ognisveta.ru/catalog/lyustry/ Каждый дом начинается со света. Именно свет создает атмосферу уюта, роскоши и комфорта. В магазине «ОгниСвета» мы собрали для вас коллекцию люстр, которая превратит ваше жилое пространство в произведение искусства. У нас вы найдете: Классические люстры: Изящные модели с хрустальными подвесками, позолотой и вензелями для ценителей вечной роскоши. Они станут центральным элементом вашей гостиной или столовой. Современные и минималистичные модели: Лаконичные формы, металл, стекло и дерево. Идеальное решение для интерьеров в стиле лофт, хай-тек или сканди. Деревенские и винтажные светильники: Уютные люстры из массива дерева, кованого железа и текстиля для создания теплой и душевной атмосферы в загородном доме или на кухне. Роскошные люстры-канделябры: Для тех, кто хочет подчеркнуть статус и безупречный вкус. Многорожковые конструкции, имитирующие свечи, добавят торжественности любой комнате.
https://licey5pod.ru
вывод из запоя цена
vivod-iz-zapoya-minsk010.ru
вывод из запоя цена
купить диплом техникума 1997 купить диплом техникума 1997 .
https://ivushka21.ru
новости спорта россии новости спорта россии .
https://buhgalter-ryazan.ru
амбулаторный нарколог на дому http://www.narkolog-na-dom-1.ru/ .
https://dent-zubritskiy.ru
ouyicn – Bookmarking just to monitor changes, curious to see what develops.
купить диплом архитектора купить диплом архитектора .
https://krasavchikbro.ru
купить диплом в прокопьевске купить диплом в прокопьевске .
https://coloredreams.ru Ограниченные предложения и временные скидки на ходовые позиции. Успейте забронировать по выгодной цене.
обзор спортивных событий novosti-sporta-7.ru .
Ищете все самые свежие новости? Посетите сайт https://scanos.news/ и вы найдете последние новости и свежие события сегодня из самых авторитетных источников на ленте агрегатора. Вы можете читать события в мире, в России, новости экономики, спорта, науки и многое другое. Свежая лента новостей всегда для вас!
прогнозы на спорт на сегодня бесплатно https://prognozy-ot-professionalov4.ru .
Need porn videos or photos? ai porn art site – create erotic content based on text descriptions. Generate porn images, videos, and animations online using artificial intelligence.
купить диплом в кургане http://rudik-diplom2.ru – купить диплом в кургане .
Планируете вечер у моря или камерную встречу дома? Dubaialco.ru превращает задумку в праздник: внушительный выбор — от шампанского и просекко до виски, текилы и бризеров — с удобной навигацией по категориям и понятными ценами. В витрине — бестселлеры вроде Hennessy, Red Label, Patron, а также Heineken и Smirnoff Ice. Заказ оформляется в пару кликов, а доставка по Дубаю быстрая и точная. Откройте коллекцию на https://dubaialco.ru/ и найдите идеальный напиток под настроение, будь то легкий аперитив, коллекционный коньяк или сет для вечеринки.
Ich bin beeindruckt von SpinBetter Casino, es erzeugt eine Spielenergie, die fesselt. Es gibt eine unglaubliche Auswahl an Spielen, mit Spielen, die fur Kryptos optimiert sind. Der Support ist 24/7 erreichbar, verfugbar rund um die Uhr. Der Ablauf ist unkompliziert, dennoch zusatzliche Freispiele waren ein Highlight. Zum Ende, SpinBetter Casino ist eine Plattform, die uberzeugt fur Krypto-Enthusiasten ! Au?erdem die Interface ist intuitiv und modern, was jede Session noch besser macht. Hervorzuheben ist die mobilen Apps, die den Spa? verlangern.
https://spinbettercasino.de/|
купить диплом пту в реестре купить диплом пту в реестре .
как купить легальный диплом о среднем образовании http://frei-diplom6.ru/ .
Ich bin verblufft von NV Casino, es erzeugt eine Energie, die suchtig macht. Es wartet eine Fulle an spannenden Spielen, mit Spielen, die perfekt fur Kryptos geeignet sind. Der Service ist rund um die Uhr verfugbar, mit praziser Unterstutzung. Die Transaktionen sind zuverlassig, ab und zu mehr Belohnungen waren ein Hit. Insgesamt, NV Casino ist ein Muss fur Gamer fur Adrenalin-Junkies ! Hinzu die Plattform ist optisch ein Highlight, verstarkt die Immersion.
https://playnvcasino.de/|
купить диплом технолога купить диплом технолога .
лечение запоя
vivod-iz-zapoya-minsk011.ru
лечение запоя минск
купить диплом вуза с проводкой http://www.frei-diplom1.ru/ .
купить диплом с занесением в реестр ростов купить диплом с занесением в реестр ростов .
бесплатные прогнозы на хоккей http://luchshie-prognozy-na-khokkej8.ru .
janetfortampa – This could really streamline the process of art authentication.
купить оригинальный диплом техникума купить оригинальный диплом техникума .
можно ли купить диплом медсестры можно ли купить диплом медсестры .
вывод из запоя череповец
vivod-iz-zapoya-cherepovec013.ru
экстренный вывод из запоя
Для жителей Москвы и ее окрестностей доступна удобная заказать алкоголь прямо до двери, что делает процесс приобретения напитков максимально комфортным и быстрым.
приобрела большую популярность среди жителей города, которые ценят свое время и хотят получить качественные напитки без выхода из дома. Эта услуга дает возможность москвичам сэкономить время на поездку в магазин и подбор подходящих напитков. Кроме того, доставка алкоголя обеспечивает доступ к разнообразным напиткам от различных производителей.
Доставка алкоголя в Москве осуществляется компаниями , которые заботятся о качестве обслуживания и удовлетворении потребностей клиентов. Клиенты могут сделать заказ на сайте компании и получить его в кратчайшие сроки. Это очень удобно людям с плотным графиком на посещение магазинов.
Доставка алкоголя в Москве дает ряд преимуществ для клиентов. Во-первых, это экономия времени на поездку в магазин и обратно. Во-вторых, клиенты могут подобрать из разнообразных вариантов напитков, что упрощает поиск нужного напитка . Кроме того, доставка алкоголя осуществляется в удобное время , что значительно улучшает качество обслуживания .
Доставка алкоголя в Москве также обеспечивает безопасность клиентов, поскольку они не нуждаются в выходе из дома и рисковать здоровьем. Это особенно важно в периоды повышенной опасности для здоровья. Компании, предоставляющие услуги доставки, подбирают напитки высокого качества, что повышает доверие к сервису .
При выборе компании для доставки алкоголя в Москве нужно принять во внимание несколько аспектов. Во-первых, это доверие к предприятию, которая может быть оценена по отзывам . Во-вторых, это ассортимент продукции , которое должно быть высокого уровня . В-третьих, это уровень обслуживания , который должен соответствовать требованиям клиентов.
Компании, предоставляющие услуги доставки алкоголя в Москве, должны обладать необходимыми разрешениями на осуществление деятельности. Клиенты имеют возможность подтвердить наличие разрешения на сайте компании или по телефону. Это дает уверенность в легитимности компании и обеспечивает защиту интересов клиентов при покупке и доставке алкоголя.
Доставка алкоголя в Москве становится все более популярной услугой среди жителей города. Эта услуга предоставляет множество преимуществ , включая экономию времени , большой выбор напитков , и безопасность . При выборе компании для доставки алкоголя следует обратить внимание на авторитет компании, разнообразие предлагаемых напитков, и уровень обслуживания . Компании, предоставляющие услуги доставки алкоголя, должны иметь лицензию и обеспечивать качество напитков .
Для тех, кто ищет удобную и быструю доставка алкоголя химки 24 часа в Химках, теперь есть отличный вариант, позволяющий получить алкоголь прямо на дом в кратчайшие сроки.
очень востребованной услугой в связи с развитием онлайн-платформ и сервисов доставки. Компании, предоставляющие услуги доставки алкоголя, имеют обширный ассортимент алкогольных напитков , включая вина, шампанское, пиво и другие виды спиртных напитков. Удобство и скорость доставки делают эту услугу очень привлекательной для тех, кто ценит свое время и предпочитает воспользоваться услугой доставки прямо домой.
Услуги доставки алкоголя в Химках обеспечивают возможность наслаждаться любимыми напитками, не выходя из дома. Это особенно важно для тех, кто любит устраивать вечеринки. Кроме того, многие компании предоставляют круглосуточную поддержку клиентов , готовых ответить на все вопросы и помочь с выбором напитков.
Преимущества доставки алкоголя в Химках являются значимыми и разнообразными. Во-первых, это возможность сэкономить время , поскольку вам не нужно тратить время на поездку в магазин. Во-вторых, качество сервиса и скорость доставки обеспечивают, что ваш заказ будет выполнен быстро и профессионально. В-третьих, обширный ассортимент алкогольных напитков позволяет найти именно то, что вы ищете.
Компании, занимающиеся доставкой алкоголя, постоянно совершенствуют свои услуги , чтобы клиенты могли наслаждаться оперативностью и качеством . Это включает в себя специальные предложения и промоакции , которые делают услугу еще более привлекательной. Кроме того, удобные варианты оплаты обеспечивают максимальный комфорт для клиентов.
Заказать доставку алкоголя в Химках относительно легко и быстро. Вам необходимо посетить веб-сайт компании , где вы сможете ознакомиться с предлагаемыми услугами и товарами . Затем вы можете сделать заказ онлайн , выбрав нужные напитки и указав адрес доставки.
После подтверждения заказа, с вами свяжется служба поддержки , чтобы подтвердить ваш заказ и обсудить детали доставки. Это гарантирует качество и скорость обслуживания. Ademas, гарантируют высокое качество продуктов, чтобы клиенты получили лучший выбор алкоголя.
В заключении, доставка алкоголя в Химках представляет собой очень удобный и комфортный способ получить любимые напитки без необходимости выхода из дома. Удобство, скорость и высокое качество обслуживания делают эту услугу очень востребованной и комфортной. Если вы ищете комфортный и оперативный способ насладиться алкоголем в Химках, то эта услуга подойдет вам идеально .
вывод из запоя минск
vivod-iz-zapoya-minsk012.ru
вывод из запоя цена
Мы предлагаем доставка алкоголя москва 24 7 с оперативной и точной доставкой по Москве и области.
Доставка алкоголя становится все более популярной услугой в современном мире. Это связано с тем, что Многие фирмы предлагают услуги доставки алкоголя, что делает ее более доступной для широкой аудитории.
Это особенно удобно для людей, которые имеют маленьких детей или домашних животных.
Это позволяет людям заказать алкоголь в любое время и в любом месте, и он будет доставлен прямо к их двери.
Люди могут заказать алкоголь онлайн или через мобильное приложение, и он будет доставлен прямо к их двери.
Ищете инструкции швейных машин? На shveichel.ru представлены швейные и вязальные машины, отпариватели, оверлоки и прочая техника, а также профессиональное промышленное оборудование. Хотите быстро отыскать инструкции к швейным машинам или посмотреть их обзоры? Доступны детальные обзоры и видео-руководства по швейным машинам — удобно и наглядно. Подробнее — на сайте, где можно сравнить модели и получить консультацию специалиста.
https://t.me/kupinos_kz Снюс Алматы – это конкретизированный запрос, указывающий на интерес к приобретению снюса в городе Алматы, Казахстан. При этом важно учитывать, что законодательство Казахстана может регулировать или даже запрещать продажу и употребление снюса. Прежде чем пытаться купить снюс в Алматы, необходимо убедиться, что это не противоречит местным законам и что продавец имеет все необходимые разрешения и лицензии. Кроме того, необходимо помнить о рисках для здоровья, связанных с употреблением снюса, и принимать взвешенное решение о его употреблении. В случае сомнений рекомендуется обратиться за консультацией к специалисту.
https://perevod-sochi.com/ Агентство переводов Сочи – это компания, специализирующаяся на предоставлении услуг по переводу текстов и документов с различных языков мира. Агентства переводов обычно предлагают широкий спектр услуг, включая письменный и устный перевод, нотариальное заверение, локализацию веб-сайтов и программного обеспечения. При выборе агентства следует учитывать его репутацию, опыт работы, квалификацию персонала, ценовую политику и наличие положительных отзывов клиентов.
I’m utterly captivated by Wazamba Casino, it provides a thrilling journey. The selection of games is phenomenal, compatible with crypto for seamless play. Enhancing your initial experience. Available 24/7 for any queries. Transactions are hassle-free, sometimes additional bonuses might be welcome. To sum up, Wazamba Casino is a platform that excels for online betting fans ! In addition navigation is effortless, adds a layer of excitement. Worth noting crypto-friendly banking options, fostering a community feel.
wazambagr.com|
J’ai un vrai coup de c?ur pour Bingoal Casino, on ressent une vibe folle. La variete des titres est impressionnante, offrant des sessions live dynamiques. Doublement des depots jusqu’a 200 €. L’assistance est efficace et pro, avec une aide precise et rapide. Les transactions sont fiables et rapides, parfois des offres plus genereuses ajouteraient du piquant. En bref, Bingoal Casino offre une experience memorable pour les joueurs en quete d’excitation ! Ajoutons que l’interface est intuitive et stylee, ajoute une touche de confort. A noter egalement les tournois reguliers pour la competition, assure des transactions fiables.
Commencer Г lire|
J’aime l’environnement distinct de Bingoal Casino, ca offre un thrill exceptionnel. La gamme des titres est stupefiante, proposant des jeux de table immersifs. Pour un lancement puissant. Les agents reagissent avec promptitude, assurant un support premium. Les operations sont solides et veloces, bien que quelques tours gratuits supplementaires seraient apprecies. Pour synthetiser, Bingoal Casino fournit une experience ineffacable pour les enthousiastes de casino en ligne ! Par ailleurs le design est contemporain et lisse, facilite une immersion complete. Un plus significatif les tournois periodiques pour la rivalite, propose des recompenses permanentes.
Explorer le guide|
частный психиатрический стационар
psychiatr-moskva008.ru
лечение психиатрических больных
прогнозы на спорт на сегодня бесплатно http://www.prognozy-ot-professionalov5.ru/ .
металлические стеллажи для склада Надежные металлические стеллажи для склада от производителя «Металлоизделия» Организуйте складское пространство с максимальной эффективностью! Компания «Металлоизделия» предлагает профессиональные металлические стеллажи для складов любого размера и назначения. Наши стеллажи для склада — это идеальное решение для хранения товаров, оборудования, архивов и материалов. Они позволяют использовать каждый квадратный метр площади по максимуму, обеспечивая легкий доступ к любой единице хранения. Почему выбирают наши стеллажи? Прочность и долговечность: Мы используем высококачественный стальной прокат и усиленные конструкции, выдерживающие значительные нагрузки (до 5000 кг на ячейку и более). Универсальность: Широкая линейка моделей — полочные, паллетные (фронтальные, гравитационные), консольные. Подберем решение под ваши задачи. Безопасность: Все конструкции имеют антикоррозийное покрытие и рассчитаны на многократную сборку-разборку. Строгое соблюдение ГОСТов. Модульность и масштабируемость: Вы можете легко нарастить систему или изменить конфигурацию при расширении склада. Выгодная цена: Работаем без посредников, так как являемся производителем.
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec014.ru
вывод из запоя
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk010.ru
вывод из запоя омск
аренда парусной яхты без капитана
https://taganrogmnb.ru
https://sterlitamakqwe.ru
https://tambovlxz.ru
https://murmanskdlg.ru
Автосалон «Темп» предлагает воспользоваться такой важной и популярной услугой, как подбор подходящего автомобиля из тех вариантов, которые имеются в наличии или можно приобрести под заказ из Кореи, Китая либо Японии. Также получится взять автокредит либо рассчитать цену своего будущего автомобиля. Для того чтобы подобрать авто из Японии, необходимо указать такие данные, как: модель, марка автомобиля, а также то, когда он был выпущен. На сайте https://tempa-cars.ru представлено огромное количество автомобилей, которые вы сможете приобрести прямо сейчас.
психиатрическая клиника стационар
psychiatr-moskva009.ru
врач психиатр на дом в москве
https://tambovlxz.ru
Je suis completement captive par Casinia Casino, ca transporte dans un palais enchanteur. Le catalogue est opulent et diversifie, proposant des jeux de table elegants. Renforcant votre capital initial. Le service est disponible 24/7, toujours pret a servir. Les paiements sont securises et fluides, neanmoins des bonus plus varies seraient apprecies. Dans l’ensemble, Casinia Casino est un incontournable pour les joueurs pour les fans de casino en ligne ! De plus le design est moderne et fluide, ce qui rend chaque session encore plus royale. Egalement appreciable les evenements communautaires engageants, renforce le sentiment de communaute.
Aller sur le site|
J’aime l’atmosphere unique de Locowin Casino, ca offre un thrill incomparable. Les options sont incroyablement vastes, comprenant des jeux optimises pour les cryptos. Doublement des depots jusqu’a 200 €. L’equipe de support est remarquable, garantissant un support de qualite. Les transactions sont fiables et rapides, bien que des bonus plus varies seraient apprecies. Pour conclure, Locowin Casino est une plateforme qui impressionne pour les fans de casino en ligne ! En bonus la plateforme est visuellement impressionnante, ajoute une touche de confort. Un avantage supplementaire les paiements securises en crypto, renforce le sentiment de communaute.
Voir les dГ©tails|
J’ai un veritable engouement pour Locowin Casino, ca fournit un plaisir intense. La gamme de jeux est spectaculaire, offrant des sessions live intenses. Pour un lancement puissant. Le suivi est exemplaire, assurant un support premium. La procedure est aisee et efficace, cependant des incitations additionnelles seraient un benefice. Tout compte fait, Locowin Casino est une plateforme qui excelle pour ceux qui parient en crypto ! De surcroit l’interface est intuitive et raffinee, ajoute un confort notable. Un plus significatif les options de paris sportifs etendues, renforce le sens de communaute.
Découvrir aujourd’hui|
J’ai un engouement sincere pour Locowin Casino, c’est une plateforme qui explose d’energie. La diversite des titres est epoustouflante, avec des slots au style innovant. Doublement des depots jusqu’a 1850 €. Le suivi est exemplaire, proposant des reponses limpides. Les benefices arrivent sans latence, par moments plus de promotions frequentes seraient un atout. En fin de compte, Locowin Casino est essentiel pour les amateurs pour les adeptes de sensations intenses ! A mentionner l’interface est intuitive et raffinee, ce qui eleve chaque session a un niveau superieur. Un autre avantage cle le programme VIP avec des niveaux exclusifs, renforce le sens de communaute.
Obtenir plus|
https://khimkijpq.ru
Хочешь сдать металл? прием металла наша компания специализируется на профессиональном приёме металлолома уже на протяжении многих лет. За это время мы отточили процесс работы до совершенства и готовы предложить вам действительно выгодные условия сотрудничества. Мы принимаем практически любые металлические изделия: от небольших профилей до крупных металлоконструкций.
J’aime l’atmosphere unique de Locowin Casino, ca immerse dans un monde fascinant. Les options sont incroyablement vastes, avec des slots innovants et thematises. Doublement des depots jusqu’a 200 €. L’equipe de support est remarquable, offrant des reponses claires. Les paiements sont securises et fluides, de temps en temps plus de promos regulieres seraient un plus. Au final, Locowin Casino est une plateforme qui impressionne pour les amateurs de sensations fortes ! A noter le site est rapide et attractif, amplifie le plaisir de jouer. A souligner les evenements communautaires engageants, qui booste l’engagement.
Tenter sa chance|
Je suis stupefait par Locowin Casino, on detecte une vibe folle. La diversite des titres est epoustouflante, incluant des paris sportifs electrisants. Renforcant l’experience de depart. L’aide est performante et experte, toujours pret a intervenir. Les benefices arrivent sans latence, de temps a autre quelques tours gratuits supplementaires seraient apprecies. Globalement, Locowin Casino est essentiel pour les amateurs pour les enthousiastes de casino en ligne ! Ajoutons que le design est contemporain et lisse, stimule le desir de revenir. A souligner aussi les tournois periodiques pour la rivalite, offre des privileges sur mesure.
DГ©couvrir dГЁs maintenant|
J’apprecie l’environnement de Locowin Casino, ca transporte dans un univers envoutant. Les alternatives sont incroyablement etendues, avec des slots au style innovant. Doublement des depots jusqu’a 1850 €. Le suivi est exemplaire, avec une assistance exacte et veloce. Les benefices arrivent sans latence, par moments des incitations additionnelles seraient un benefice. Tout compte fait, Locowin Casino merite une exploration approfondie pour les adeptes de sensations intenses ! Par ailleurs la plateforme est esthetiquement remarquable, intensifie le plaisir du jeu. Un autre avantage cle les options de paris sportifs etendues, propose des recompenses permanentes.
Parcourir les offres|
https://yoshkar-olaxdf.ru
вывод из запоя
vivod-iz-zapoya-omsk011.ru
экстренный вывод из запоя
экстренный вывод из запоя
vivod-iz-zapoya-cherepovec015.ru
вывод из запоя череповец
диплом техникума с отличием купить диплом техникума с отличием купить .
https://nizhnekamskrtz.ru
Ассоциация Специалистов Онлайн Образования формирует прозрачные правила игры на рынке, от стандартов до досудебного арбитража. Ищете налоги в онлайн бизнесе сайт? На aoo.su доступны материалы, анонсы вебинаров и форма вступления в сообщество специалистов онлайн образования. Владельцы онлайн школ найдут разборы судебной практики, рекомендации по налогам и юридической безопасности.
https://petrozavodskmnb.ru
https://nalchiktyu.ru
https://lyubertsyxza.ru
https://blagoveshchenskfgh.ru
консультация психиатра
psikhiatr-moskva007.ru
консультация психиатра на дому в москве
https://komsomolskpoi.ru
https://nizhnekamskqwe.ru
Топ 8741 выдающихся мыслителей mry
Инпек — лазерная гравировка на металле промышленного уровня: шильды, таблички, бейджи, глубокая 3D-гравировка и резка. Точность порядка 10 микрон даёт идеальную детализацию, устойчивость к истиранию и агрессивной среде, сроки около 5 рабочих дней, бесплатная доставка по Пензенской области и образец — бесплатно. Команда помогает с макетом и материалом. Оставьте заявку и запросите образцы на https://inpekmet.ru/lazernaia-gravirovka — получите результат, который работает долго.
https://taganrogasd.ru
математический прогноз на футбол http://www.kompyuternye-prognozy-na-futbol23.ru/ .
https://yoshkar-olaxdf.ru
https://taganrogasd.ru
Тепло в квартире и на даче — это не роскошь, а комфорт, который можно спланировать заранее. «Строй-М2» подбирает и монтирует системы под конкретную площадь и бюджет: от эффективных электрокотлов до водяных контуров с умной автоматикой. За установку отвечают сертифицированные мастера, используется надежное оборудование от известных производителей. Ищете купить обогреватель хороший для комнаты? Узнайте детали, варианты и сроки на stroy-m2.ru/otoplenie-kvartiry-i-dachi/ и получите расчет с учетом особенностей вашего дома.
https://tambovwer.ru
https://yoshkar-olajkl.ru
https://sterlitamakrty.ru
лучшие прогнозы на хоккей лучшие прогнозы на хоккей .
https://khimkiumn.ru
вывод из запоя омск
vivod-iz-zapoya-omsk012.ru
лечение запоя омск
https://khimkijpq.ru
Der Pizza Lieferant war super freundlich. Die Pizza war ein Volltreffer!
Pizza Express
ночная доставка алкоголя alcoygoloc.ru .
экстренный вывод из запоя иркутск
vivod-iz-zapoya-irkutsk010.ru
экстренный вывод из запоя
https://sterlitamakqwe.ru
профессиональные прогнозы на футбол профессиональные прогнозы на футбол .
https://nalchikcvb.ru
https://murmanskqaz.ru
https://komsomolskpoi.ru
Капельницы для лечения запоя в домашних условиях – это необходимая мера для лечения алкоголизма. Если вам нужно получить помощь нарколога на дому в Туле‚ убедитесь в надежности клиники. Важно выбрать центр‚ который предлагает анонимное лечение и услуги нарколога с опытом. вызвать нарколога на дом тула Перед вызовом специалиста стоит узнать о домашних методах лечения‚ таких как внутривенные инфузии. Это позволит позаботиться о безопасности пациента и эффективное восстановление после запоя. Убедитесь‚ что клиника проводит реабилитацию в домашних условиях‚ что поддерживает эффективность терапии. Выбор клиники требует тщательного подхода. Обратите внимание на мнения пациентов‚ квалификацию врачей и доступность медицинской помощи. Опытный специалист по наркологии сможет оказать помощь в кратчайшие сроки‚ обеспечивая поддержку и понимание в трудный период.
https://nizhnekamskrtz.ru
https://wazamba22.com/
https://sterlitamakqwe.ru
купить диплом в черкесске купить диплом в черкесске .
Онлайн магазин – купить мефедрон, кокаин, бошки
купить двигатель автомобиля Двигатель б/у – это самый бюджетный вариант замены двигателя, но и самый рискованный. Перед покупкой необходимо тщательно осмотреть двигатель на предмет внешних повреждений, течей масла и других дефектов. Желательно провести диагностику двигателя с помощью специалистов, чтобы оценить его состояние и определить остаточный ресурс. Важно узнать историю эксплуатации двигателя, чтобы понимать, в каких условиях он работал. Помните, что покупка двигателя б/у – это всегда риск, поэтому будьте готовы к возможным поломкам и дополнительным затратам на ремонт. Обращайтесь только к проверенным продавцам, предоставляющим гарантию на свою продукцию. Не стоит экономить на диагностике перед покупкой, так как это поможет вам избежать приобретения неисправного агрегата.
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
лечение запоя
vivod-iz-zapoya-orenburg010.ru
вывод из запоя цена
купить диплом дизайнера купить диплом дизайнера .
Онлайн магазин – купить мефедрон, кокаин, бошки
купить диплом о среднем специальном образовании цена http://www.educ-ua7.ru/ .
лечение запоя
vivod-iz-zapoya-irkutsk011.ru
лечение запоя
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
кисловодск достопримечательности Туры в Дагестан Дагестан манит туристов своей загадочностью и разнообразием ландшафтов — от величественных гор до теплых вод Каспийского моря. Туры в Дагестан обычно длятся от 3 до 10 дней и охватывают ключевые достопримечательности: Сулакский каньон, Дербентскую крепость и аулы вроде Гамсутль. Организованные туры из Москвы или Ростова-на-Дону включают перелет, трансфер на внедорожниках и проживание в гостевых домах или отелях Махачкалы. Цена — от 25 000 рублей за человека, с питанием и гидом. Летом популярны комбинированные маршруты: утренние экскурсии по плато Бермамыт с видом на “Космос” и вечерние прогулки по набережной Каспия. Для экстремалов — рафтинг по реке Сулак или зиплайн над каньоном. Культурная программа включает посещение мечетей, дегустацию национальной кухни (хинкал, чуду) и мастер-классы по ковроткачеству. Туры безопасны благодаря опытным гидам, знающим местные обычаи. Осенью, в октябре, цены ниже, а цвета гор ярче. Выберите тур с фокусом на экологию — Дагестан борется за сохранение природы, и многие маршруты подчеркивают устойчивый туризм. Это не просто поездка, а погружение в мир, где история и природа сливаются в одно целое.
Наркологическая помощь в Туле — это важный шаг для людей, испытывающих трудности с зависимостями. На сайте narkolog-tula023.ru можно найти информацию о услугах наркологов, включая обследование зависимостей и лечение. Наши специалисты предлагают консультацию нарколога и конфиденциальное лечение. Служба выездной наркологии готова оказать неотложную помощь при острой зависимости или в любых других случаях. Наши услуги предлагают стационарное лечение и реабилитацию для наркоманов. Мы оказываем помощь зависимым и их близким и осуществляем профилактические мероприятия. Не медлите с помощью — позвоните наркологу и начните путь к лечению.
купить диплом проведенный купить диплом проведенный .
купить диплом в ноябрьске купить диплом в ноябрьске .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
купить диплом медсестры с занесением в реестр купить диплом медсестры с занесением в реестр .
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Since the admin of this site is working, no question very soon it will be renowned, due to its feature contents.
вход leebet
https://atlan.ru/product-category/mebel/veshalki/
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Онлайн магазин – купить мефедрон, кокаин, бошки
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТРР, КАЧЕСТВО
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Путешествуйте по Крыму https://м-драйв.рф на джипах! Ай-Петри, Ялта и другие живописные маршруты. Безопасно, интересно и с профессиональными водителями. Настоящий отдых с приключением!
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Ich bin absolut hingerissen von NV Casino, es erzeugt eine Energie, die suchtig macht. Es wartet eine Fulle an spannenden Spielen, mit Slots im innovativen Design. Der Support ist von herausragender Qualitat, bietet klare Antworten. Die Zahlungen sind sicher und flussig, obwohl mehr Belohnungen waren ein Hit. Alles in allem, NV Casino garantiert Top-Unterhaltung fur Krypto-Liebhaber ! Hinzu die Navigation ist kinderleicht, gibt Lust auf mehr.
playnvcasino.de|
Ich bin beeindruckt von SpinBetter Casino, es ist eine Erfahrung, die wie ein Wirbelsturm pulsiert. Der Katalog ist reichhaltig und variiert, mit immersiven Live-Sessions. Die Hilfe ist effizient und pro, bietet klare Losungen. Der Ablauf ist unkompliziert, trotzdem regelma?igere Aktionen waren toll. Zusammengefasst, SpinBetter Casino ist eine Plattform, die uberzeugt fur Adrenalin-Sucher ! Zusatzlich die Plattform ist visuell ein Hit, was jede Session noch besser macht. Ein Pluspunkt ist die Community-Events, die Flexibilitat bieten.
https://spinbettercasino.de/|
Je suis completement fou de Locowin Casino, il offre une experience unique. Il y a une multitude de jeux excitants, offrant des sessions live dynamiques. Accompagne de tours gratuits sans wager. Les agents repondent avec rapidite, toujours pret a aider. Les paiements sont securises et fluides, neanmoins plus de promos regulieres seraient top. En resume, Locowin Casino est une plateforme qui dechire pour les joueurs en quete d’excitation ! Ajoutons que l’interface est intuitive et stylee, facilite une immersion totale. Un autre atout majeur les options de paris sportifs variees, propose des avantages personnalises.
Cliquer et aller|
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
J’aime l’atmosphere de Locowin Casino, c’est une plateforme qui explose d’energie. La gamme de jeux est spectaculaire, avec des slots au style innovant. Associe a des tours gratuits sans wager. L’aide est performante et experte, accessible a tout instant. Les benefices arrivent sans latence, par moments des bonus plus diversifies seraient souhaitables. En fin de compte, Locowin Casino est essentiel pour les amateurs pour les adeptes de sensations intenses ! En outre la navigation est simple et engageante, facilite une immersion complete. A souligner aussi le programme VIP avec des niveaux exclusifs, qui stimule l’engagement.
Aller plus loin|
J’ai un engouement sincere pour Locowin Casino, ca fournit un plaisir intense. La diversite des titres est epoustouflante, incluant des paris sportifs electrisants. Renforcant l’experience de depart. L’aide est performante et experte, assurant un support premium. Les paiements sont proteges et lisses, mais quelques tours gratuits supplementaires seraient apprecies. En fin de compte, Locowin Casino est une plateforme qui excelle pour les joueurs a la recherche d’aventure ! De surcroit la navigation est simple et engageante, stimule le desir de revenir. Particulierement attractif les evenements communautaires captivants, qui stimule l’engagement.
Commencer Г lire|
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg011.ru
вывод из запоя
Бесплатный вывод из запоя в Туле: возможно ли? Проблема зависимости от алкоголя и методы помощи зависимым вызывают много вопросов. Многие сталкиваются с проблемой запоев и не знают‚ как выйти из этого состояния. В этом случае помощь нарколога на дому‚ работающего круглосуточно‚ может оказаться весьма полезной. нарколог на дом круглосуточно Получить наркологическую помощь‚ в т.ч. бесплатную консультацию‚ можно тем‚ кто срочно нуждается в помощи при запое. В Туле часто доступны услуги вывода из запоя и лечение на дому‚ что позволяет сделать этот процесс более удобным и менее напряженным для пациента. Круглосуточный нарколог предоставит медицинскую помощь на дому‚ что особенно удобно для тех‚ кто не может или не хочет идти в стационар. Анонимное лечение алкоголизма также возможно‚ что позволяет сохранить личную жизнь пациента. Следует помнить‚ что поддержка зависимых является важным аспектом в процессе лечения. Реабилитация от алкоголя требует времени и усилий‚ но с помощью профессионалов можно достичь положительных результатов. Таким образом‚ если вы или ваши близкие ищете бесплатный вывод из запоя в Туле‚ обращение к услугам нарколога на дому может стать первым шагом к освобождению от алкогольной зависимости.
В мире онлайн-развлечений, где любой вечер легко сделать кинематографическим праздником, портал hdmovies.space оказывается идеальным выбором для ценителей отличного кино. Здесь собрана впечатляющая коллекция фильмов от классики космических саг вроде “2001: Космическая одиссея” до современных блокбастеров, таких как “Ad Astra”, где Брэд Питт исследует тайны Вселенной. https://hdmovies.space предлагает удобный интерфейс с поиском по жанрам, годам и рейтингам, обеспечивая мгновенный доступ к HD-качеству без лишних хлопот. Этот сервис отлично подойдет поклонникам многообразия: от динамичных научно-фантастических авантюр до эмоциональных повествований о полетах в космос, основанных на настоящих экспедициях NASA. Благодаря регулярным обновлениям, вы всегда найдете свежие релизы, а пользовательские отзывы помогают выбрать лучшее. Этот ресурс не просто сайт для просмотра – это портал в мир бесконечных историй, где каждый клик открывает новые горизонты развлечений.
купить диплом в березниках купить диплом в березниках .
купить диплом магистра купить диплом магистра .
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
Ich kann nicht genug bekommen von NV Casino, es erzeugt eine Energie, die suchtig macht. Das Angebot an Spielen ist phanomenal, inklusive aufregender Sportwetten. Die Mitarbeiter reagieren blitzschnell, immer bereit zu helfen. Der Prozess ist unkompliziert, trotzdem zusatzliche Freispiele waren toll. Kurz gesagt, NV Casino ist ein Muss fur Gamer fur Adrenalin-Junkies ! Zusatzlich die Oberflache ist intuitiv und stylish, macht die Erfahrung flussiger.
playnvcasino.de|
вывод из запоя
vivod-iz-zapoya-irkutsk012.ru
лечение запоя иркутск
Je suis absolument envoute par Casinia Casino, il procure une experience galactique. La selection de jeux est astronomique, proposant des jeux de table elegants. Avec un Bonus Crab pour debuter. Le support client est stellaire, offrant des reponses lumineuses. Les gains arrivent a la vitesse lumiere, bien que plus de promos regulieres brilleraient davantage. Pour conclure, Casinia Casino est une plateforme qui domine l’univers pour les joueurs en quete d’aventure ! Cerise sur le gateau le site est rapide et envoutant, facilite une immersion totale. Un plus non negligeable le programme VIP avec 5 niveaux exclusifs, offre des recompenses continues.
Aller en ligne|
J’ai un engouement pour Locowin Casino, ca transporte dans un univers envoutant. La gamme de jeux est spectaculaire, offrant des sessions live intenses. Associe a des tours gratuits sans wager. Le suivi est exemplaire, toujours pret a intervenir. Les operations sont solides et veloces, cependant des incitations additionnelles seraient un benefice. Tout compte fait, Locowin Casino garantit du divertissement constant pour les enthousiastes de casino en ligne ! Ajoutons que la navigation est simple et engageante, intensifie le plaisir du jeu. Un plus significatif les tournois periodiques pour la rivalite, offre des privileges sur mesure.
Commencer|
Онлайн магазин – купить мефедрон, кокаин, бошки
Je suis entierement obsede par Locowin Casino, c’est une plateforme qui explose d’energie. Il y a une profusion de jeux captivants, offrant des sessions live intenses. Renforcant l’experience de depart. L’aide est performante et experte, accessible a tout instant. Les retraits sont realises promptement, par moments des incitations additionnelles seraient un benefice. Pour synthetiser, Locowin Casino est essentiel pour les amateurs pour les aficionados de jeux contemporains ! De surcroit le design est contemporain et lisse, intensifie le plaisir du jeu. Egalement notable les tournois periodiques pour la rivalite, qui stimule l’engagement.
Trouver plus|
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Закладки тут – купить гашиш, мефедрон, альфа-РїРІРї
https://telegra.ph/Botinki-takticheskie-muzhskie-demisezonnye-nepromokaemye-kupit-10-13
https://telegra.ph/Invertornyj-generator-kupit-v-habarovske-10-12-2
roofers Melbourne, FL
https://telegra.ph/Iray-teplovizory-kupit-pricel-10-11
https://telegra.ph/Mikrofon-dji-petlichka-kupit-10-13-2
Visitez Roulettino Casino https://roulettino-fr.com et obtenez un bonus de 500 € + 100 tours gratuits dès maintenant ! Explorez notre sélection de jeux et découvrez Roulettino Casino France, qui offre une expérience de jeu légale, réglementée et structurée, adaptée aux joueurs français. Pour en savoir plus, consultez le site web.
Если вы ищете эффективный способ улучшить позиции своего сайта в поисковых системах, то курс seo станут идеальным решением для вас.
включают комплексный подход к повышению видимости сайта в интернете. Это означает, что участники таких курсов узнают о последних трендах и методах SEO . SEO курсы базируются на практическом опыте преподавателей .
SEO курсы включают изучение ключевых факторов, влияющих на позиции сайта в поисковых системах . Это особенно важно для владельцев сайтов, стремящихся улучшить видимость своего бизнеса в интернете . Участники SEO курсов получают доступ к необходимым инструментам и ресурсам для SEO .
Преимущества SEO курсов дают понять, как создавать эффективную стратегию SEO. Это означает, что участники курсов смогут анализировать и улучшать результаты своих усилий. SEO курсы предоставляют знания о последних трендах и методах в SEO .
SEO курсы дают участникам возможность улучшить качество своего сайта и сделать его более привлекательным для пользователей . Это значит, что участники научатся анализировать результаты своих усилий и вносить необходимые коррективы . Участники SEO курсов получают поддержку на протяжении всего обучения.
Содержание SEO курсов включает изучение ключевых факторов, влияющих на позиции сайта в поисковых системах . это означает, что участники курсов узнают о последних трендах и методах SEO . SEO курсы предоставляют знания о том, как создавать качественный и привлекательный контент для пользователя .
SEO курсы дают возможность общаться с опытными преподавателями и другими участниками для обмена опытом . Это значит, что участники могут разработать и реализовать эффективную SEO стратегию для своего сайта . Участники SEO курсов могут общаться с преподавателями и другими участниками для обмена опытом и знаниями .
Заключение SEO курсов означает получение участниками глубоких знаний и практических навыков по оптимизации сайтов для поисковых систем . Это означает, что участники получат навыки, необходимые для создания успешной стратегии SEO . SEO курсы включают практические занятия по оптимизации сайтов .
SEO курсы дают участникам возможность улучшить качество своего сайта и сделать его более привлекательным для пользователей . Это значит, что участники получат навыки, необходимые для постоянного улучшения позиций своего сайта в поисковых системах. Участники SEO курсов могут общаться с преподавателями и другими участниками для обмена опытом и знаниями .
Для тех, кто ищет удобный способ получить свой любимый напиток, алкоголь 24 становится идеальным решением.
становится все более востребованной среди жителей города. Это связано с тем, что люди становятся все более занятыми, что не позволяет им самостоятельно покупать алкоголь . Компании, занимающиеся доставкой алкоголя, предлагают широкий ассортимент напитков .
Доставка алкоголя в Балашихе работает без перерывов, что очень удобно для заказчиков . Заказ можно сделать через интернет , что облегчает процедуру заказа.
Доставка алкоголя в Балашихе имеет ряд преимуществ для своих клиентов. Одним из основных преимуществ является быстрота доставки, что высоко оценено клиентами. Кроме того, доставка алкоголя обеспечивает сохранность товара , что важно для поддержания качества продукции .
Доставка алкоголя в Балашихе также позволяет клиентам экономить время , что может быть потрачено на другие занятия . Компании, занимающиеся доставкой, старчески относятся к каждому клиенту , что создает положительную атмосферу .
Заказать доставку алкоголя в Балашихе relatively просто. Для начала необходимо найти подходящую компанию , что можно сделать по рекомендациям . После выбора компании следует перейти на сайт и просмотреть имеющийся выбор .
Затем необходимо оформить заказ , что можно сделать онлайн . После оформления заказа будет организована оплата, что можно сделать различными способами . Компания обеспечит быструю доставку.
Доставка алкоголя в Балашихе стала необходимостью для многих. Она экономит время клиентов , дает доступ к обширному ассортименту и обеспечивает качество доставляемых товаров . Компании, занимающиеся доставкой, стремятся повысить качество обслуживания, что формирует доверие клиентов.
В заключение, доставка алкоголя в Балашихе является перспективной услугой . Ее можно сделать заказ без особых усилий, и она предоставляет множество преимуществ для клиентов. Таким образом, доставка алкоголя будет продолжать развиваться .
https://www.behance.net/candetoxblend
Pasar un control sorpresa puede ser estresante. Por eso, existe una solucion cientifica probada en laboratorios.
Su mezcla eficaz combina creatina, lo que ajusta tu organismo y oculta temporalmente los trazas de THC. El resultado: una prueba sin riesgos, lista para entregar tranquilidad.
Lo mas destacado es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete limpiezas magicas, sino una estrategia de emergencia que responde en el momento justo.
Estos suplementos están diseñados para facilitar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente las relacionadas con el consumo de cannabis u otras sustancias ilícitas.
Uno buen detox para examen de fluido debe proporcionar resultados rápidos y efectivos, en particular cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas aseguran un proceso seguro o rápido.
Qué funciona un producto detox? En términos simples, estos suplementos funcionan acelerando la eliminación de metabolitos y toxinas a través de la orina, reduciendo su presencia hasta quedar por debajo del umbral de detección de ciertos tests. Algunos trabajan en cuestión de horas y su impacto puede durar entre 4 a 6 horas.
Resulta fundamental combinar estos productos con correcta hidratación. Beber al menos dos litros de agua por jornada antes y después del uso del detox puede mejorar los resultados. Además, se sugiere evitar alimentos grasos y bebidas ácidas durante el proceso de desintoxicación.
Los mejores productos de purga para orina incluyen ingredientes como extractos de naturales, vitaminas del tipo B y minerales que apoyan el funcionamiento de los riñones y la función hepática. Entre las marcas más populares, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación temprana. Mientras más larga sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la organización con el uso correcto del suplemento es clave.
Un error común es creer que todos los detox actúan igual. Existen diferencias en dosis, sabor, método de uso y duración del efecto. Algunos vienen en presentación líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incorporan fases de preparación o purga previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso recomendado.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
Miles de trabajadores ya han experimentado su efectividad. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta solucion te ofrece confianza.
https://telegra.ph/Kupit-pricel-nochnogo-videniya-v-belorussii-10-12-6
Для безопасной и комфортной езды в зимнее время рекомендуется использовать шины зимние шипованные купить, которые обеспечивают сцепление с дорогой даже в самых сложных зимних условиях.
предназначены для обеспечения сцепления колес с дорогой в условиях мороза и снега . Эти шины имеют уникальную конструкцию, которая позволяет улучшить управляемость автомобилем. Правильный выбор зимних шин шипованных позволяет водителям чувствовать себя более уверенно на дороге .
Зимние шины шипованные могут быть установлены на машинах с различными типами привода. При выборе зимних шин шипованных важно проконсультироваться с chuyenниками, если есть сомнения по поводу выбора. Кроме того, важно регулярно проверять состояние шин и соблюдать рекомендации производителя .
Зимние шины шипованные оснащены шипами, которые обеспечивают дополнительную сцепку на льду и снегу. Эти шины разработаны для эксплуатации при низких температурах и могут справиться с различными погодными условиями . Использование зимних шин шипованных позволяет водителям чувствовать себя более уверенно на дороге и снижает риск аварий .
Зимние шины шипованные оснащены шипами, которые обеспечивают дополнительную сцепку на льду и снегу. При эксплуатации зимних шин шипованных важно проконсультироваться с chuyenниками, если есть сомнения по поводу выбора или эксплуатации. Кроме того, следует регулярно проверять давление в шинах и соблюдать рекомендации производителя.
При выборе зимних шин шипованных необходимо учитывать такие факторы, как размер колес, тип автомобиля и условия эксплуатации . Зимние шины шипованные оснащены шипами, которые обеспечивают дополнительную сцепку на льду и снегу. Кроме того, следует помнить, что правильная эксплуатация шин напрямую влияет на безопасность на дороге.
Зимние шины шипованные имеют специальный состав, который сохраняет гибкость шин даже в сильный мороз . При выборе зимних шин шипованных следует обратить внимание на качество шин и их соответствие установленным стандартам . Кроме того, необходимо следить за уровнем износа шин и своевременно заменять их .
Зимние шины шипованные необходимы для снижения риска заноса и потери контроля над транспортным средством. Правильный выбор зимних шин шипованных позволяет водителям чувствовать себя более уверенно на дороге . Кроме того, необходимо следить за уровнем износа шин и своевременно заменять их .
Зимние шины шипованные имеют уникальную конструкцию, которая позволяет улучшить управляемость автомобилем в снежных и ледяных условиях . При эксплуатации зимних шин шипованных следует обратить внимание на качество шин и их соответствие установленным стандартам . Кроме того, необходимо следить за уровнем износа шин и своевременно заменять их .
Заботьтесь о здоровье сосудов ног с профессионалом! В группе «Заметки практикующего врача-флеболога» вы узнаете всё о профилактике варикоза, современных методиках лечения (склеротерапия, ЭВЛО), УЗИ вен и точной диагностике. Доверяйте опытному врачу — ваши ноги заслуживают лучшего: https://phlebology-blog.ru/
https://telegra.ph/Kupit-shlem-takticheskij-voennyj-bronirovannyj-10-13-2
Je suis accro a Locowin Casino, ca procure un plaisir intense. Les options sont incroyablement vastes, comprenant des jeux compatibles avec les cryptos. Amplifiant l’experience initiale. Le suivi client est irreprochable, toujours pret a aider. Les paiements sont securises et fluides, mais des bonus plus varies seraient bienvenus. Dans l’ensemble, Locowin Casino vaut largement le detour pour les passionnes de jeux modernes ! En prime l’interface est intuitive et stylee, ajoute une touche de confort. Egalement appreciable le programme VIP avec des niveaux exclusifs, propose des avantages personnalises.
Explorer le site web|
https://telegra.ph/CHehol-dlya-binoklya-kupit-10-13
Je suis emerveille par Casinia Casino, ca distille un plaisir eclatant. L’eventail de jeux est resplendissant, offrant des sessions live captivantes. L’offre de bienvenue est eclatante. Le suivi est irreprochable, offrant des solutions cristallines. Les retraits filent comme une comete, parfois des recompenses additionnelles seraient scintillantes. En somme, Casinia Casino est un joyau pour les joueurs pour les joueurs en quete d’eclat ! Ajoutons que la plateforme scintille comme une etoile, ce qui rend chaque session plus eclatante. Un avantage notable les evenements communautaires captivants, qui renforce l’engagement.
Explorer plus|
J’adore l’ambiance de Locowin Casino, ca procure un plaisir intense. La variete des titres est impressionnante, incluant des paris sportifs palpitants. Accompagne de tours gratuits sans wager. L’assistance est efficace et pro, offrant des reponses claires. Le processus est simple et efficace, mais des recompenses supplementaires seraient un atout. Dans l’ensemble, Locowin Casino vaut largement le detour pour les joueurs en quete d’excitation ! Cerise sur le gateau la plateforme est visuellement top, donne envie de prolonger l’experience. Un autre atout majeur les tournois reguliers pour la competition, offre des recompenses continues.
Explorer le contenu|
https://www.tumblr.com/candetoxblend/794393330425446400/preguntas-frecuentes-sobre-detox-para-examen-de
Purificacion para examen de orina se ha transformado en una solucion cada vez mas reconocida entre personas que buscan eliminar toxinas del organismo y superar pruebas de test de drogas. Estos suplementos estan disenados para facilitar a los consumidores a limpiar su cuerpo de componentes no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras sustancias ilicitas.
Uno buen detox para examen de pipi debe proporcionar resultados rapidos y visibles, en especial cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas variedades, pero no todas garantizan un proceso seguro o efectivo.
Que funciona un producto detox? En terminos basicos, estos suplementos actuan acelerando la eliminacion de metabolitos y componentes a traves de la orina, reduciendo su nivel hasta quedar por debajo del limite de deteccion de algunos tests. Algunos actuan en cuestion de horas y su accion puede durar entre 4 a seis horas.
Es fundamental combinar estos productos con correcta hidratacion. Beber al menos dos litros de agua por jornada antes y despues del uso del detox puede mejorar los beneficios. Ademas, se sugiere evitar alimentos grasos y bebidas azucaradas durante el proceso de uso.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del tipo B y minerales que respaldan el funcionamiento de los sistemas y la funcion hepatica. Entre las marcas mas populares, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con tiempos de accion largas o iniciar una preparacion temprana. Mientras mas prolongada sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la organizacion con el uso correcto del detox es clave.
Un error comun es pensar que todos los detox actuan igual. Existen diferencias en formulacion, sabor, metodo de uso y duracion del impacto. Algunos vienen en presentacion liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incorporan fases de preparacion o preparacion previa al dia del examen. Estos programas suelen recomendar abstinencia, buena alimentacion y descanso adecuado.
Por ultimo, es importante recalcar que ningun detox garantiza 100% de exito. Siempre hay variables biologicas como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no relajarse.
Je suis emerveille par Casinia Casino, on ressent une aura radieuse. L’eventail de jeux est resplendissant, offrant des sessions live captivantes. Renforcant votre tresor initial. Le service est disponible 24/7, avec une aide claire et veloce. Les retraits filent comme une comete, neanmoins des bonus plus varies brilleraient davantage. Dans l’ensemble, Casinia Casino est une plateforme qui illumine le jeu pour les aficionados de jeux modernes ! En bonus le site est rapide et envoutant, ce qui rend chaque session plus eclatante. Un avantage notable les paiements securises en crypto, propose des recompenses sur mesure.
Regarder à l’intérieur|
J’ai un coup de foudre pour Locowin Casino, on ressent une vibe delirante. Il y a une multitude de jeux excitants, avec des slots au design innovant. Amplifiant l’experience initiale. Les agents repondent avec rapidite, offrant des reponses claires. Les gains arrivent sans delai, parfois plus de promos regulieres seraient top. Dans l’ensemble, Locowin Casino vaut largement le detour pour les amateurs de sensations fortes ! De plus la plateforme est visuellement top, amplifie le plaisir de jouer. A noter egalement les options de paris sportifs variees, assure des transactions fiables.
Voir les dГ©tails|
https://bs2best.or.at
вывод из запоя
vivod-iz-zapoya-cherepovec013.ru
вывод из запоя круглосуточно
Частный заем денег домашние деньги россия альтернатива банковскому кредиту. Быстро, безопасно и без бюрократии. Получите нужную сумму наличными или на карту за считанные минуты.
https://www.speedrun.com/users/candetoxblend
Pasar un test antidoping puede ser un momento critico. Por eso, existe una alternativa confiable probada en laboratorios.
Su composicion unica combina nutrientes esenciales, lo que estimula tu organismo y oculta temporalmente los rastros de toxinas. El resultado: una orina con parametros normales, lista para entregar tranquilidad.
Lo mas valioso es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete milagros, sino una solucion temporal que te respalda en situaciones criticas.
Estos suplementos están diseñados para ayudar a los consumidores a purgar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras sustancias ilícitas.
Un buen detox para examen de orina debe proporcionar resultados rápidos y confiables, en particular cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas opciones, pero no todas garantizan un proceso seguro o fiable.
¿Cómo funciona un producto detox? En términos básicos, estos suplementos actúan acelerando la depuración de metabolitos y componentes a través de la orina, reduciendo su concentración hasta quedar por debajo del límite de detección de los tests. Algunos actúan en cuestión de horas y su efecto puede durar entre 4 a seis horas.
Es fundamental combinar estos productos con correcta hidratación. Beber al menos dos litros de agua por jornada antes y después del uso del detox puede mejorar los efectos. Además, se recomienda evitar alimentos difíciles y bebidas ácidas durante el proceso de uso.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de naturales, vitaminas del tipo B y minerales que respaldan el funcionamiento de los sistemas y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación previa. Mientras más larga sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la disciplina con el uso correcto del producto es clave.
Un error común es pensar que todos los detox actúan igual. Existen diferencias en dosis, sabor, método de ingesta y duración del impacto. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que agregan fases de preparación o limpieza previa al día del examen. Estos programas suelen instruir abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que todo detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no relajarse.
Miles de estudiantes ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta alternativa te ofrece confianza.
Все спортивные новости http://sportsat.ru в реальном времени. Итоги матчей, трансферы, рейтинги и обзоры. Следите за событиями мирового спорта и оставайтесь в курсе побед и рекордов!
https://communication15662.tinyblogging.com/poco-conocidos-hechos-sobre-detox-examen-de-orina-81698763
Purificacion para examen de muestra se ha convertido en una solucion cada vez mas popular entre personas que buscan eliminar toxinas del cuerpo y superar pruebas de analisis de drogas. Estos productos estan disenados para ayudar a los consumidores a purgar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el uso de cannabis u otras sustancias ilicitas.
Un buen detox para examen de pipi debe proporcionar resultados rapidos y visibles, en gran cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas variedades, pero no todas prometen un proceso seguro o rapido.
Que funciona un producto detox? En terminos basicos, estos suplementos funcionan acelerando la depuracion de metabolitos y componentes a traves de la orina, reduciendo su presencia hasta quedar por debajo del umbral de deteccion de los tests. Algunos trabajan en cuestion de horas y su efecto puede durar entre 4 a cinco horas.
Resulta fundamental combinar estos productos con correcta hidratacion. Beber al menos 2 litros de agua al dia antes y despues del ingesta del detox puede mejorar los beneficios. Ademas, se sugiere evitar alimentos dificiles y bebidas acidas durante el proceso de preparacion.
Los mejores productos de purga para orina incluyen ingredientes como extractos de plantas, vitaminas del complejo B y minerales que respaldan el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas populares, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con ventanas de accion largas o iniciar una preparacion previa. Mientras mas prolongada sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la disciplina con el uso correcto del suplemento es clave.
Un error comun es creer que todos los detox actuan igual. Existen diferencias en formulacion, sabor, metodo de uso y duracion del efecto. Algunos vienen en presentacion liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o purga previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que todo detox garantiza 100% de exito. Siempre hay variables biologicas como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no confiarse.
Acho simplesmente fenomenal Brazino Casino, parece um abismo de adrenalina subaquatica. Tem um tsunami de jogos de cassino irados. com jogos adaptados para criptomoedas. O suporte e um farol subaquatico. com solucoes precisas e instantaneas. Os saques sao velozes como um mergulho. entretanto as ofertas podiam ser mais generosas. Para encurtar, Brazino Casino oferece uma experiencia que e puro mergulho para os mergulhadores do cassino! De bonus a plataforma reluz com um visual oceanico. transformando cada aposta em uma aventura marinha.
brazino777 pix|
https://kasinoteirekisteröintiä.com/
Estou alucinado com PlayPix Casino, oferece uma aventura que glitcha como um render 8-bit. As escolhas sao vibrantes como um glitch. oferecendo lives que explodem como overclock. O time do cassino e digno de um programador. assegurando apoio sem erros. Os pagamentos sao seguros e fluidos. de vez em quando mais bonus seriam um diferencial de matriz. Para encurtar, PlayPix Casino oferece uma experiencia que e puro codigo para os apaixonados por slots modernos! De lambuja o site e uma obra-prima de estilo digital. transformando cada aposta em uma aventura pixelada.
como usar bonus de cassino playpix|
J’adore le frisson de BankOnBet Casino, il propose une aventure de casino qui accumule comme un compte en banque. Les options de jeu au casino sont riches et securisees. offrant des lives qui grossissent les comptes. Le support du casino est disponible 24/7. avec une aide qui debloque les gains. Les paiements du casino sont securises et fluides. quand meme des recompenses de casino supplementaires feraient fructifier. Pour resumer, BankOnBet Casino promet un jeu qui fructifie pour those chasing smart stakes! De surcroit la navigation est simple comme un compte. facilite une experience de casino rentable.
bankonbet bonus bez depozytu|
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Sou totalmente viciado em BETesporte Casino, proporciona uma aventura cheia de emocao. Ha uma explosao de jogos emocionantes, com slots modernos e tematicos. 100% ate R$600 + apostas gratis. Os agentes respondem com velocidade, oferecendo respostas claras. Os pagamentos sao seguros e fluidos, as vezes ofertas mais generosas seriam bem-vindas. Resumindo, BETesporte Casino vale uma aposta certa para jogadores em busca de emocao ! Acrescentando que a navegacao e intuitiva e rapida, facilita uma imersao total. Muito atrativo as opcoes variadas de apostas esportivas, que impulsiona o engajamento.
Saber mais|
Me encantei pelo nado de Brazino Casino, tem uma energia de jogo tao vibrante quanto um recife de corais. Tem um tsunami de jogos de cassino irados. oferecendo lives que explodem como um geiser. O servico e confiavel como uma ancora. com solucoes precisas e instantaneas. Os pagamentos sao lisos como um coral. mas queria promocoes que explodem como geiseres. Na real, Brazino Casino e um cassino online que e um oceano de diversao para os cacadores de vitorias subaquaticas! Adicionalmente a navegacao e facil como uma corrente marinha. fazendo o cassino reluzir como um recife.
brazino777 bono sin depГіsito|
Estou completamente apaixonado por PlayPIX Casino, leva para um universo de pura excitacao. As opcoes sao amplas como uma selva, suportando jogos compativeis com criptomoedas. Eleva a experiencia de jogo. Os agentes respondem com rapidez, oferecendo respostas claras. O processo e simples e elegante, as vezes bonus mais variados seriam incriveis. Resumindo, PlayPIX Casino oferece uma experiencia memoravel para amantes de emocoes fortes ! Alem disso o design e moderno e vibrante, adiciona um toque de conforto. Muito atrativo os eventos comunitarios envolventes, proporciona vantagens personalizadas.
Explorar agora|
Acho simplesmente ardente Verabet Casino, e um cassino online que queima como uma fogueira ancestral. Os jogos formam uma fogueira de diversao. oferecendo lives que explodem como uma pira. O servico e confiavel como uma fogueira. respondendo rapido como uma labareda. O processo e claro e sem fumaca. de vez em quando queria promocoes que explodem como labaredas. Resumindo, Verabet Casino vale explorar esse cassino ja para os viciados em emocoes de cassino! Por sinal o design e fluido como uma pira. tornando cada sessao ainda mais flamejante.
bet vera casino|
Estou completamente incendiado por Fogo777 Casino, parece um festival de chamas cheio de adrenalina. As escolhas sao vibrantes como chamas. incluindo mesas com charme flamejante. O suporte e um fulgor reluzente. respondendo veloz como uma faisca. Os ganhos chegam rapido como uma labareda. as vezes mais bonus seriam um diferencial ardente. Na real, Fogo777 Casino e um altar de emocoes para os viciados em emocoes de cassino! Por sinal a interface e fluida e brilha como uma fogueira. transformando cada aposta em uma aventura flamejante.
a plataforma fogo777 Г© confiГЎvel|
Автоматические гаражные ворота давно перестали быть роскошью и стали необходимым элементом комфортной жизни. Наши автоматические ворота сочетают надёжность проверенных европейских механизмов с элегантным дизайном, который гармонично впишется в архитектуру любого здания. Мы предлагаем полный цикл услуг: от профессиональной консультации и точного замера до установки под ключ и гарантийного обслуживания. Доверьте безопасность своего дома профессионалам — получите бесплатный расчёт стоимости уже сегодня: Автоматические ворота купить
Je suis accro a BankOnBet Casino, it’s a vault of fun that locks in wins. Le repertoire du casino est un coffre de divertissement. comprenant des jeux de casino adaptes aux cryptomonnaies. Le team est un gardien de tresor. offrant des solutions claires et instantanees. Le processus du casino est transparent et sans frais caches. cependant more free spins would be a smart bet. En somme, BankOnBet Casino offre une experience de casino rentable pour les passionnes de casinos en ligne! What’s more la navigation est simple comme un compte. facilite une experience de casino rentable.
bankonbet bono|
эллиптический тренажер купить Беговая дорожка Oxygen Fitness сочетает надежность и инновации от известного бренда. Модели вроде OXY-400 или Elite имеют мощный мотор 2-2,5 л.с., скорость до 18 км/ч и 12 предустановленных программ для разнообразия тренировок. Амортизация Soft System защищает суставы, а LED-дисплей отображает все ключевые метрики: пульс, расстояние, скорость. Складной дизайн с гидравлическим подъемом упрощает хранение, а колеса для транспортировки — перемещение. Подходит для дома или офиса, выдерживает до 130 кг. Пользователи хвалят тихую работу и долговечность. Цена от 30 000 рублей, с гарантией 2 года. Тренировки на Oxygen Fitness ускоряют метаболизм, укрепляют сердечную систему и помогают в похудении.
Estou completamente encantado com BETesporte Casino, oferece um prazer esportivo inigualavel. A variedade de titulos e estonteante, incluindo apostas esportivas que aceleram o pulso. Com uma oferta inicial para impulsionar. O suporte ao cliente e excepcional, acessivel a qualquer hora. O processo e simples e direto, de vez em quando ofertas mais generosas seriam bem-vindas. No fim, BETesporte Casino oferece uma experiencia inesquecivel para fas de cassino online ! Acrescentando que a plataforma e visualmente impactante, aumenta o prazer de apostar. Igualmente impressionante o programa VIP com niveis exclusivos, assegura transacoes confiaveis.
Ver mais|
Estou completamente apaixonado por PlayPIX Casino, oferece um prazer intenso e indomavel. As opcoes sao amplas como uma selva, com sessoes ao vivo cheias de energia. 100% ate €500 + rodadas gratis. O servico esta disponivel 24/7, com suporte rapido e preciso. As transacoes sao confiaveis, de vez em quando recompensas extras seriam eletrizantes. No geral, PlayPIX Casino vale uma visita epica para fas de cassino online ! Adicionalmente o site e rapido e cativante, instiga a prolongar a experiencia. Outro destaque as opcoes variadas de apostas esportivas, fortalece o senso de comunidade.
Ler os detalhes|
https://tech37270.ampedpages.com/una-revisiГіn-de-detox-examen-de-orina-64717793
Detox para examen de miccion se ha vuelto en una opcion cada vez mas popular entre personas que buscan eliminar toxinas del organismo y superar pruebas de test de drogas. Estos formulas estan disenados para ayudar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente las relacionadas con el uso de cannabis u otras sustancias ilicitas.
Uno buen detox para examen de fluido debe brindar resultados rapidos y visibles, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas opciones, pero no todas prometen un proceso seguro o rapido.
De que funciona un producto detox? En terminos basicos, estos suplementos actuan acelerando la expulsion de metabolitos y residuos a traves de la orina, reduciendo su concentracion hasta quedar por debajo del limite de deteccion de ciertos tests. Algunos actuan en cuestion de horas y su accion puede durar entre 4 a seis horas.
Es fundamental combinar estos productos con correcta hidratacion. Beber al menos par litros de agua por jornada antes y despues del uso del detox puede mejorar los efectos. Ademas, se aconseja evitar alimentos grasos y bebidas acidas durante el proceso de preparacion.
Los mejores productos de purga para orina incluyen ingredientes como extractos de plantas, vitaminas del complejo B y minerales que favorecen el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas vendidas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de THC, se recomienda usar detoxes con tiempos de accion largas o iniciar una preparacion temprana. Mientras mas prolongada sea la abstinencia, mayor sera la eficacia del producto. Por eso, combinar la disciplina con el uso correcto del producto es clave.
Un error comun es suponer que todos los detox actuan lo mismo. Existen diferencias en dosis, sabor, metodo de toma y duracion del impacto. Algunos vienen en presentacion liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incluyen fases de preparacion o preparacion previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso previo.
Por ultimo, es importante recalcar que todo detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no confiarse.
https://www.youtube.com/@candetoxblend/about
Gestionar una prueba de orina puede ser arriesgado. Por eso, se desarrollo una alternativa confiable creada con altos estandares.
Su mezcla eficaz combina creatina, lo que ajusta tu organismo y neutraliza temporalmente los rastros de THC. El resultado: una orina con parametros normales, lista para ser presentada.
Lo mas destacado es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete milagros, sino una solucion temporal que te respalda en situaciones criticas.
Estos suplementos están diseñados para colaborar a los consumidores a depurar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el ingesta de cannabis u otras drogas.
Un buen detox para examen de fluido debe proporcionar resultados rápidos y confiables, en gran cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas prometen un proceso seguro o efectivo.
¿Cómo funciona un producto detox? En términos claros, estos suplementos funcionan acelerando la expulsión de metabolitos y residuos a través de la orina, reduciendo su presencia hasta quedar por debajo del nivel de detección de ciertos tests. Algunos funcionan en cuestión de horas y su efecto puede durar entre 4 a 6 horas.
Resulta fundamental combinar estos productos con buena hidratación. Beber al menos 2 litros de agua diariamente antes y después del uso del detox puede mejorar los beneficios. Además, se sugiere evitar alimentos pesados y bebidas procesadas durante el proceso de desintoxicación.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de hierbas, vitaminas del complejo B y minerales que apoyan el funcionamiento de los órganos y la función hepática. Entre las marcas más vendidas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación temprana. Mientras más prolongada sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la planificación con el uso correcto del producto es clave.
Un error común es creer que todos los detox actúan lo mismo. Existen diferencias en dosis, sabor, método de uso y duración del impacto. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incorporan fases de preparación o limpieza previa al día del examen. Estos programas suelen instruir abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
Miles de profesionales ya han comprobado su seguridad. Testimonios reales mencionan paquetes 100% confidenciales.
Si quieres proteger tu futuro, esta solucion te ofrece confianza.
В наше динамичное время, насыщенное напряжением и беспокойством, анксиолитики и транквилизаторы оказались надежным средством для огромного количества людей, позволяя преодолевать панические приступы, генерализованную тревогу и прочие нарушения, мешающие нормальной жизни. Эти препараты, такие как бензодиазепины (диазепам, алпразолам) или небензодиазепиновые варианты вроде буспирона, действуют через усиление эффекта ГАМК в мозге, снижая нейрональную активность и принося облегчение уже через короткое время. Они особенно ценны в начале курса антидепрессантов, поскольку смягчают стартовые нежелательные реакции, вроде усиленной раздражительности или проблем со сном, повышая удобство и результативность терапии. Но стоит учитывать возможные опасности: от сонливости и ухудшения внимания до риска привыкания, из-за чего их прописывают на ограниченный период под тщательным медицинским надзором. В клинике “Эмпатия” квалифицированные эксперты, среди которых психиатры и психотерапевты, разрабатывают персонализированные планы, сводя к минимуму противопоказания, такие как нарушения дыхания или беременность. Подробнее о механизмах, применении и безопасном использовании читайте на https://empathycenter.ru/articles/anksiolitiki-i-trankvilizatory/ , где собрана вся актуальная информация для вашего спокойствия.
bs2best зеркало Неужели ты до сих пор не знаешь, что переворачивает мир даркнета? Blacksprut – это не просто название. Это новая эра анонимности, мгновенной скорости и железобетонной безопасности в сети. Загляни на bs2best.at – туда, где обсуждают то, о чём остальные предпочитают молчать в тряпочку. Тебе откроется доступ к информации, тщательно оберегаемой от посторонних глаз. Только для тех, кто понимает правила игры. Никаких следов, никаких компромиссов, только абсолютная конфиденциальность – это Blacksprut. Не упусти свой шанс стать первооткрывателем – bs2best.at уже распахнул свои двери для тебя. Хватит ли у тебя смелости взглянуть правде прямо в лицо?
экстренный вывод из запоя омск
vivod-iz-zapoya-omsk011.ru
вывод из запоя
Suchen Sie Immobilien? Montenegro immobilie kaufen wohnungen, Villen und Grundstucke mit Meerblick. Aktuelle Preise, Fotos, Auswahlhilfe und umfassende Transaktionsunterstutzung.
https://earth08743.suomiblog.com/los-detox-examen-de-orina-diarios-53509141
Purificacion para examen de orina se ha transformado en una opcion cada vez mas popular entre personas que buscan eliminar toxinas del cuerpo y superar pruebas de test de drogas. Estos formulas estan disenados para colaborar a los consumidores a limpiar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el uso de cannabis u otras sustancias ilicitas.
El buen detox para examen de pipi debe ofrecer resultados rapidos y efectivos, en particular cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas variedades, pero no todas prometen un proceso seguro o efectivo.
De que funciona un producto detox? En terminos claros, estos suplementos actuan acelerando la eliminacion de metabolitos y componentes a traves de la orina, reduciendo su concentracion hasta quedar por debajo del nivel de deteccion de los tests. Algunos actuan en cuestion de horas y su accion puede durar entre 4 a 6 horas.
Es fundamental combinar estos productos con correcta hidratacion. Beber al menos par litros de agua diariamente antes y despues del ingesta del detox puede mejorar los beneficios. Ademas, se sugiere evitar alimentos pesados y bebidas acidas durante el proceso de desintoxicacion.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del grupo B y minerales que favorecen el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas vendidas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de accion largas o iniciar una preparacion previa. Mientras mas extendida sea la abstinencia, mayor sera la efectividad del producto. Por eso, combinar la organizacion con el uso correcto del detox es clave.
Un error comun es suponer que todos los detox actuan lo mismo. Existen diferencias en dosis, sabor, metodo de ingesta y duracion del efecto. Algunos vienen en formato liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o purga previa al dia del examen. Estos programas suelen instruir abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que todo detox garantiza 100% de exito. Siempre hay variables biologicas como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
где купить настоящий диплом колледжа frei-diplom12.ru .
Финские краски и лаки Teknos для профессионалов и частных мастеров — в наличии и под заказ на https://teknotrend.ru . У нас антисептики, грунты, эмали и лаки для древесины, бетона и фасадов: Nordica Eko, Aqua Primer, Aquatop и др. Подберем систему покрытий под ваши задачи и дадим рекомендации по нанесению. Оставьте заявку на сайте — мы свяжемся с вами в течение 15 минут и предоставим расчет оптовой или розничной цены.
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec014.ru
лечение запоя череповец
https://candetoxblend.mystrikingly.com/
Superar una prueba preocupacional puede ser complicado. Por eso, se ha creado una formula avanzada creada con altos estandares.
Su mezcla eficaz combina vitaminas, lo que sobrecarga tu organismo y disimula temporalmente los metabolitos de sustancias. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete limpiezas magicas, sino una herramienta puntual que funciona cuando lo necesitas.
Estos productos están diseñados para colaborar a los consumidores a depurar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el ingesta de cannabis u otras sustancias.
El buen detox para examen de orina debe brindar resultados rápidos y visibles, en especial cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas aseguran un proceso seguro o fiable.
Qué funciona un producto detox? En términos simples, estos suplementos funcionan acelerando la eliminación de metabolitos y residuos a través de la orina, reduciendo su concentración hasta quedar por debajo del umbral de detección de ciertos tests. Algunos actúan en cuestión de horas y su acción puede durar entre 4 a cinco horas.
Resulta fundamental combinar estos productos con correcta hidratación. Beber al menos 2 litros de agua al día antes y después del ingesta del detox puede mejorar los resultados. Además, se aconseja evitar alimentos difíciles y bebidas azucaradas durante el proceso de uso.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de naturales, vitaminas del grupo B y minerales que respaldan el funcionamiento de los riñones y la función hepática. Entre las marcas más populares, se encuentran aquellas que presentan certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con tiempos de acción largas o iniciar una preparación temprana. Mientras más larga sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la disciplina con el uso correcto del producto es clave.
Un error común es pensar que todos los detox actúan lo mismo. Existen diferencias en contenido, sabor, método de uso y duración del efecto. Algunos vienen en presentación líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incluyen fases de preparación o preparación previa al día del examen. Estos programas suelen sugerir abstinencia, buena alimentación y descanso recomendado.
Por último, es importante recalcar que ningún detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no confiarse.
Miles de trabajadores ya han comprobado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta formula te ofrece seguridad.
купить диплом в тольятти купить диплом в тольятти .
https://information74063.blogminds.com/examine-este-informe-sobre-detox-examen-de-orina-34707088
Detox para examen de orina se ha transformado en una opcion cada vez mas conocida entre personas que requieren eliminar toxinas del sistema y superar pruebas de deteccion de drogas. Estos suplementos estan disenados para ayudar a los consumidores a limpiar su cuerpo de sustancias no deseadas, especialmente las relacionadas con el consumo de cannabis u otras drogas.
Un buen detox para examen de orina debe ofrecer resultados rapidos y efectivos, en particular cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas variedades, pero no todas aseguran un proceso seguro o rapido.
?Como funciona un producto detox? En terminos simples, estos suplementos funcionan acelerando la depuracion de metabolitos y toxinas a traves de la orina, reduciendo su concentracion hasta quedar por debajo del nivel de deteccion de los tests. Algunos actuan en cuestion de horas y su accion puede durar entre 4 a 6 horas.
Es fundamental combinar estos productos con buena hidratacion. Beber al menos dos litros de agua por jornada antes y despues del ingesta del detox puede mejorar los efectos. Ademas, se sugiere evitar alimentos dificiles y bebidas acidas durante el proceso de desintoxicacion.
Los mejores productos de detox para orina incluyen ingredientes como extractos de hierbas, vitaminas del grupo B y minerales que apoyan el funcionamiento de los organos y la funcion hepatica. Entre las marcas mas vendidas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de accion largas o iniciar una preparacion anticipada. Mientras mas extendida sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la disciplina con el uso correcto del producto es clave.
Un error comun es pensar que todos los detox actuan igual. Existen diferencias en formulacion, sabor, metodo de ingesta y duracion del resultado. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o preparacion previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que ninguno detox garantiza 100% de exito. Siempre hay variables personales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no confiarse.
https://bs2tcite4.io
Автоматические гаражные ворота давно перестали быть роскошью и стали необходимым элементом комфортной жизни. Наши автоматические ворота сочетают надёжность проверенных европейских механизмов с элегантным дизайном, который гармонично впишется в архитектуру любого здания. Мы предлагаем полный цикл услуг: от профессиональной консультации и точного замера до установки под ключ и гарантийного обслуживания. Доверьте безопасность своего дома профессионалам — получите бесплатный расчёт стоимости уже сегодня: https://vorotalux58.ru/
social event
Je suis captive par Locowin Casino, ca fournit un plaisir intense. Les alternatives sont incroyablement etendues, offrant des sessions live intenses. Doublement des depots jusqu’a 1850 €. L’equipe d’assistance est remarquable, proposant des reponses limpides. Les paiements sont proteges et lisses, bien que des offres plus liberales ajouteraient de la valeur. Globalement, Locowin Casino est essentiel pour les amateurs pour les adeptes de sensations intenses ! A mentionner l’interface est intuitive et raffinee, ce qui eleve chaque session a un niveau superieur. Egalement notable les paiements securises en crypto, renforce le sens de communaute.
Explorer ici|
купить диплом в йошкар-оле http://www.rudik-diplom2.ru/ – купить диплом в йошкар-оле .
Newsmake — популярные новости без перегруза: коротко о главном, с понятными объяснениями и подборками материалов по интересам — от технологий до общества. Редакция бережно относится к фактам и читательскому времени: только проверенные темы и ясные выводы. Подключайтесь к ежедневным обзорам и лонгридам на https://newsmakepro.ru/ — удобные рубрики, быстрый поиск и формат, к которому хочется возвращаться.
купить диплом стоматолога купить диплом стоматолога .
купить готовый диплом техникума купить готовый диплом техникума .
desert blues
можно купить диплом медсестры можно купить диплом медсестры .
диплом купить с занесением в реестр рязань http://frei-diplom1.ru/ .
купить диплом в армавире купить диплом в армавире .
Готовитесь к IELTS и хотите прогнозируемый результат? В CT Group в Алматы обучают по актуальным форматам Listening/Reading/Writing/Speaking, дают проверочные тесты и персональные рекомендации по прокачке словаря и тайм-менеджменту. У школы сильные преподаватели и понятные пакеты занятий — от интенсивов до индивидуальных программ. Запишитесь на консультацию и узнайте расписание на https://www.ctgroup.kz/ielts/ — начните подготовку с планом, который подстроят под вашу цель и сроки.
Je suis ensorcele par Casombie, ca transporte dans un monde de chaos ludique. La selection de jeux est terrifiante de richesse, avec des slots au design effrayant. Le suivi est aussi fiable qu’un sortilege, offrant des solutions claires comme un clair de lune. Les gains arrivent a une vitesse demoniaque, neanmoins des bonus plus mordants seraient top. Pour resumer, Casombie est une plateforme qui fait battre les c?urs pour les joueurs en quete de frissons ! Cerise sur le cercueil le site est visuellement un chef-d’?uvre macabre, ce qui rend chaque session electrisante.
casombie alkalmazГЎs|
Je suis captive par Casinia Casino, resonne avec un rythme de casino chevaleresque. Il y a une cascade de jeux de casino captivants. offrant des lives qui pulsent comme un tournoi. offre un soutien qui protege tout. garantissant une assistance qui cadence. Le processus du casino est transparent et sans trahison. cependant plus de tours gratuits au casino ce serait legendaire. Globalement, Casinia Casino cadence comme une sonate de victoires pour les chevaliers du casino! En plus la plateforme du casino brille par son style epique. donne envie de replonger dans le casino sans fin.
casinia promo code no deposit bonus|
J’ai une passion debordante pour Locowin Casino, c’est une plateforme qui deborde de vitalite. Les options sont incroyablement vastes, incluant des paris sportifs palpitants. Pour un demarrage en force. Les agents repondent avec celerite, joignable a tout moment. Le processus est simple et reibungslos, bien que des offres plus genereuses ajouteraient de l’attrait. Pour conclure, Locowin Casino est indispensable pour les joueurs pour les passionnes de jeux modernes ! Par ailleurs la navigation est simple et plaisante, ajoute une touche de confort. Egalement appreciable les tournois reguliers pour la competition, assure des transactions fiables.
Visiter pour plus|
J’ai un veritable engouement pour Locowin Casino, il delivre une experience unique. Il y a une profusion de jeux captivants, avec des slots au style innovant. Renforcant l’experience de depart. L’equipe d’assistance est remarquable, assurant un support premium. La procedure est aisee et efficace, cependant quelques tours gratuits supplementaires seraient apprecies. Globalement, Locowin Casino est essentiel pour les amateurs pour les enthousiastes de casino en ligne ! En outre la navigation est simple et engageante, facilite une immersion complete. Particulierement attractif le programme VIP avec des niveaux exclusifs, propose des recompenses permanentes.
Continuer ici|
Organic Dent у метро Тульская — клиника европейского уровня с экспертами по ортодонтии, имплантации и эстетике, где ставят брекеты и элайнеры, лечат ВНЧС и делают отбеливание за один приём. На https://organicdent.ru/ расписаны цены и акции: комплексная гигиена по немецкой технологии, имплантация опытными хирургами, протезирование с прицельной точностью. Сертифицированные врачи, современная диагностика и бережные методики — от планирования до контрольных визитов. Лёгкая запись через WhatsApp и удобное расположение в центре.
где купить диплом техникума хорошую где купить диплом техникума хорошую .
купить проведенный диплом в красноярске http://www.frei-diplom3.ru/ .
купить диплом с внесением в реестр купить диплом с внесением в реестр .
Je suis accro a l’ambiance de Casombie, ca pulse comme une invasion de zombies. La selection de jeux est terrifiante de richesse, comprenant des jeux adaptes aux cryptomonnaies. Le service client est d’une efficacite surnaturelle, garantissant un support digne d’une legende. Les gains arrivent a une vitesse demoniaque, parfois plus de promos macabres seraient un plus. Pour resumer, Casombie est une plateforme qui fait battre les c?urs pour les fans de casinos en ligne ! En bonus le site est visuellement un chef-d’?uvre macabre, facilite une experience aussi fluide qu’un spectre.
casombie kaszinГі magyar|
Je suis fou de Casinia Casino, resonne avec un rythme de casino chevaleresque. Le repertoire du casino est un donjon de divertissement. avec des slots qui resonnent comme des epees. L’assistance du casino est chaleureuse et loyale. avec une aide qui brille comme une couronne. Les gains du casino arrivent a une vitesse chevaleresque. tout de meme plus de bonus pour une harmonie chevaleresque. En somme, Casinia Casino resonne comme une epopee de plaisir pour les joueurs qui aiment parier avec panache au casino! De surcroit resonne avec une melodie graphique legendaire. ajoute une touche de grandeur au casino.
casinia opiniones|
Je suis stupefait par Locowin Casino, ca transporte dans un univers envoutant. La gamme de jeux est spectaculaire, avec des slots au style innovant. Renforcant l’experience de depart. L’equipe d’assistance est remarquable, accessible a tout instant. Les paiements sont proteges et lisses, mais quelques tours gratuits supplementaires seraient apprecies. Globalement, Locowin Casino merite une exploration approfondie pour les enthousiastes de casino en ligne ! A mentionner le design est contemporain et lisse, ce qui eleve chaque session a un niveau superieur. Particulierement attractif les options de paris sportifs etendues, garantit des transactions securisees.
Explorer le site web|
Je suis accro a Locowin Casino, c’est une plateforme qui deborde de vitalite. Les options sont incroyablement vastes, avec des slots innovants et thematises. Pour un demarrage en force. L’equipe de support est remarquable, avec une aide precise et rapide. Les paiements sont securises et fluides, bien que des recompenses additionnelles seraient un avantage. En bref, Locowin Casino offre une experience inoubliable pour les passionnes de jeux modernes ! Ajoutons que le design est moderne et fluide, incite a prolonger l’experience. Particulierement interessant les tournois reguliers pour la competition, assure des transactions fiables.
Essayer en ligne|
Linterest — медиа, которое отбирает действительно важное: технологии, наука, спорт, общество и практичные гиды, объясняющие сложное простыми словами. Обновления выходят регулярно, материалы выверены и снабжены понятной аналитикой и подборками, чтобы экономить ваше время. Пересмотрите информационную повестку в пользу качества: загляните на https://linterest.ru/ — удобная навигация, быстрый поиск и темы, которые помогают принимать решения и развиваться без лишнего шума.
Sou louco pela ressonancia de Stake Casino, pulsa com uma forca de cassino digna de um sino. As opcoes sao ricas e vibram como cordas. com caca-niqueis modernos que ecoam como sinos. O atendimento e solido como uma corda. respondendo rapido como um eco na caverna. Os saques vibram como harpas. porem queria mais promocoes que ressoam como corais. Resumindo, Stake Casino vale explorar esse cassino ja para os cacadores de vitorias ressonantes! Adicionalmente o design e fluido como uma onda sonora. adicionando um toque de eco ao cassino.
codigo de recompensa stake|
Sou louco pela rede de IJogo Casino, oferece uma aventura que se entrelaca como uma rede tropical. O leque do cassino e um labirinto de delicias. oferecendo sessoes ao vivo que se entrelacam como raizes. O suporte e uma bussola no emaranhado. assegurando apoio sem enredos. O processo e claro e sem armadilhas. ocasionalmente queria mais promocoes que enredam como vinhas. No fim das contas, IJogo Casino vale explorar esse cassino ja para os viciados em emocoes de cassino! Como extra a interface e fluida e reluz como um cipo. amplificando o jogo com vibracao selvagem.
ijogo da memoria|
Для тех, кто ищет удобную и быструю купить алкоголь ночью в Химках, теперь есть отличный вариант, позволяющий получить алкоголь прямо на дом в кратчайшие сроки.
все более популярной в последнее время в связи с развитием онлайн-платформ и сервисов доставки. Компании, предоставляющие услуги доставки алкоголя, имеют обширный ассортимент алкогольных напитков , включая вина, шампанское, пиво и другие виды спиртных напитков. Удобство и скорость доставки привлекают многих клиентов для тех, кто ценит свое время и предпочитает воспользоваться услугой доставки прямо домой.
Услуги доставки алкоголя в Химках делают жизнь более комфортной для тех, кто любит выпить , не выходя из дома. Это особенно важно во время сезона праздников и торжеств . Кроме того, многие компании предлагают услуги консультантов, готовых ответить на все вопросы и помочь с выбором напитков.
Преимущества доставки алкоголя в Химках являются значимыми и разнообразными. Во-первых, это возможность сэкономить время , поскольку вам не нужно тратить время на поездку в магазин. Во-вторых, высокое качество обслуживания обеспечивают, что ваш заказ будет выполнен быстро и профессионально. В-третьих, обширный ассортимент алкогольных напитков позволяет найти именно то, что вы ищете.
Компании, занимающиеся доставкой алкоголя, работают над улучшением качества своих услуг , чтобы клиенты могли наслаждаться оперативностью и качеством . Это включает в себя регулярные акции и скидки , которые делают услугу еще более привлекательной. Кроме того, удобные варианты оплаты обеспечивают максимальный комфорт для клиентов.
Заказать доставку алкоголя в Химках относительно легко и быстро. Вам необходимо посетить веб-сайт компании , где вы сможете ознакомиться с предлагаемыми услугами и товарами . Затем вы можете оформить заказ прямо на сайте , выбрав нужные напитки и указав адрес доставки.
После подтверждения заказа, с вами свяжется служба поддержки , чтобы подтвердить ваш заказ и обсудить детали доставки. Это гарантирует качество и скорость обслуживания. Ademas, гарантируют высокое качество продуктов, чтобы клиенты получили лучший выбор алкоголя.
В заключении, доставка алкоголя в Химках становится все более популярной и востребованной получить любимые напитки без необходимости выхода из дома. Удобство, скорость и оперативность и качество делают эту услугу очень востребованной и комфортной. Если вы ищете простой и удобный способ насладиться алкоголем в Химках, то этот вариант будет для вас идеальным .
Je suis charme par Grandz Casino, c’est un casino en ligne qui danse comme une ombre fugace. La selection du casino est une danse de plaisirs. comprenant des jeux de casino adaptes aux cryptomonnaies. Le personnel du casino offre un accompagnement digne d’un directeur de scene. proposant un appui qui enchante. Les transactions du casino sont simples comme une scene. cependant les offres du casino pourraient etre plus genereuses. A la fin, Grandz Casino est un casino en ligne qui joue une danse d’ombres pour les fans de symphonies d’ombres! De plus le design du casino est une fresque visuelle spectrale. ajoute une touche de rythme spectral au casino.
avis grandz bet|
KMSPico https://katellkeineg.com est l’Activateur utilisé pour activer les produits Microsoft, tels que Windows et Office. C’est un outil réellement exempt de virus et de malwares, en lequel font confiance de nombreuses personnes. Je l’utilise pour l’activation de Windows. Cet excellent Activateur fonctionne sans Internet, et le processus d’installation est assez simple. Si vous ne recevez pas les mises à jour Windows et les fonctionnalités premium gratuitement, alors KMSPICO est un outil pratique pour activer Windows et profiter de ces fonctionnalités gratuitement sans dépenser un centime.
Estou completamente ressonado por Stake Casino, e um cassino online que ressoa como um sino ancestral. A selecao de titulos e um eco de emocoes. com caca-niqueis modernos que ecoam como sinos. O time do cassino e digno de um maestro. respondendo rapido como um eco na caverna. As transacoes sao faceis como um sino. mas queria mais promocoes que ressoam como corais. No geral, Stake Casino vale explorar esse cassino ja para os exploradores de jogos online! E mais o layout e vibrante como uma corda. fazendo o cassino ecoar como um sino.
what is a gambling stake|
Estou alucinado com IJogo Casino, e um enredo de diversao que se entrelaca como cipos. A selecao de titulos e um emaranhado de prazeres. incluindo jogos de mesa com um toque de selva. O time do cassino e digno de um explorador. respondendo rapido como um cipo se enrolando. Os pagamentos sao seguros e fluidos. em alguns momentos as ofertas podiam ser mais generosas. No geral, IJogo Casino e o point perfeito pros fas de cassino para os amantes de cassinos online! De lambuja a plataforma reluz com um visual labirintico. tornando cada sessao ainda mais enredada.
ijogo Г© confiavel|
фитнес клуб с бассейном в москве абонемент в фитнес клуб
Amo a energia de BETesporte Casino, sinto um rugido de emocao. A variedade de titulos e estonteante, oferecendo jogos de mesa dinamicos. Eleva a experiencia de jogo. O servico esta disponivel 24/7, garantindo um atendimento de elite. O processo e simples e direto, as vezes ofertas mais generosas seriam bem-vindas. No geral, BETesporte Casino oferece uma experiencia inesquecivel para amantes de apostas esportivas ! Tambem a navegacao e intuitiva e envolvente, aumenta o prazer de apostar. Igualmente impressionante os eventos comunitarios envolventes, que impulsiona o engajamento.
Ir para a web|
Je suis envoute par Grandz Casino, resonne avec un rythme de casino voile. propose un ballet de divertissement qui seduit. proposant des slots de casino a theme theatral. Le service client du casino est un maitre des ombres. garantissant une assistance qui cadence. Les paiements du casino sont securises et fluides. cependant plus de tours gratuits au casino ce serait theatral. Dans l’ensemble, Grandz Casino resonne comme un ballet de plaisir pour les amoureux des slots modernes de casino! Par ailleurs est une cadence visuelle envoutante. enchante chaque partie avec une symphonie d’ombres.
grandz|
Топ 5483 выдающихся мыслителей zoi
Sou totalmente viciado em PlayPIX Casino, e uma plataforma que transborda dinamismo. A selecao de jogos e fenomenal, com sessoes ao vivo cheias de emocao. 100% ate €500 + rodadas gratis. O servico esta disponivel 24/7, sempre pronto para resolver. Os saques sao rapidos como um raio, de vez em quando mais rodadas gratis seriam um diferencial. No fim, PlayPIX Casino e uma plataforma que brilha para jogadores em busca de adrenalina ! Adicionalmente a navegacao e intuitiva e envolvente, aumenta o prazer de jogar. Igualmente impressionante o programa VIP com niveis exclusivos, fortalece o senso de comunidade.
Descobrir agora|
можно купить диплом медсестры можно купить диплом медсестры .
Amo a energia de BETesporte Casino, oferece um prazer esportivo inigualavel. As opcoes sao amplas como um gramado, com sessoes ao vivo cheias de energia. Com uma oferta inicial para impulsionar. Os agentes respondem com agilidade, sempre pronto para entrar em campo. Os saques sao rapidos como um drible, as vezes promocoes mais frequentes dariam um toque extra. Para finalizar, BETesporte Casino e indispensavel para apostadores para entusiastas de jogos modernos ! Tambem a plataforma e visualmente impactante, facilita uma imersao total. Outro destaque os pagamentos seguros em cripto, oferece recompensas continuas.
Consultar os detalhes|
Estou completamente apaixonado por PlayPIX Casino, leva a um universo de pura adrenalina. O catalogo e exuberante e multifacetado, incluindo apostas esportivas que aceleram o coracao. Fortalece seu saldo inicial. Os agentes respondem com agilidade, com suporte rapido e preciso. O processo e simples e elegante, as vezes mais rodadas gratis seriam um diferencial. Resumindo, PlayPIX Casino vale uma visita epica para fas de cassino online ! Tambem a plataforma e visualmente espetacular, facilita uma imersao total. Um diferencial significativo as opcoes variadas de apostas esportivas, oferece recompensas continuas.
Visitar hoje|
Trying to find Mayday Parade tour dates? Head over to Ищете mayday parade tour date? myrockshows.com/band/2148-mayday-parade/ to see the complete schedule of 55+ concerts in 16 countries. Here you’ll get early alerts about concerts in your city and buy tickets for the best seats at a great price. Don’t miss out to enjoy live music and performances!
потолочки https://www.stretch-ceilings-nizhniy-novgorod.ru .
компания потолочник stretch-ceilings-nizhniy-novgorod-1.ru .
натяжной потолок нижний новгород http://natyazhnye-potolki-nizhniy-novgorod.ru .
Сериалы 2025 скачать торрент Скачать сериалы торрент Сериалы стали неотъемлемой частью нашей жизни, позволяя нам погружаться в увлекательные истории и переживать за любимых персонажей. На нашем сайте вы найдете огромную коллекцию сериалов на любой вкус: от захватывающих детективных историй и фантастических саг до комедийных ситкомов и мелодраматических драм. Мы предлагаем скачать сериалы торрент в высоком качестве, чтобы вы могли наслаждаться каждым эпизодом в полной мере. У нас вы найдете как популярные новинки, так и классические сериалы, завоевавшие любовь миллионов зрителей. Наша коллекция постоянно пополняется, поэтому вы всегда сможете найти что-то интересное для себя. Благодаря удобной системе поиска и фильтрации вы легко сможете найти нужный сериал по названию, жанру, году выпуска, рейтингу и другим критериям. Скачивайте сериалы торрент быстро и безопасно с нашего сайта! Мы гарантируем высокое качество файлов и отсутствие вирусов. Наслаждайтесь просмотром любимых сериалов в любое время и в любом месте!
потолка потолка .
купить диплом в туапсе купить диплом в туапсе .
If you are interested in US casinos, then this is something you shouldn’t miss. Explore the full details via the following link:
best no kyc casinos
купить диплом техникума ссср http://educ-ua7.ru .
купить легальный диплом купить легальный диплом .
Хотите смотреть сериалы без лишних поисков и задержек — вам пригодится https://seasonvar.one — здесь оперативные обновления, удобные фильтры по жанрам и алфавитная сортировка. Вы оцените продолжение с места остановки и ленту обновлений по датам — ориентироваться легко. Интерфейс без лишнего шума, HD-качество доступно сразу, а русская озвучка подбирается аккуратно. Отличный выбор для занятых зрителей, которые смотрят в ознакомительных целях и ценят удобство.
диплом купить в реестре диплом купить в реестре .
купить диплом в канске купить диплом в канске .
купить диплом вуза с проводкой https://frei-diplom5.ru/ .
купить диплом в воткинске купить диплом в воткинске .
фитнес клуб с бассейном в москве абонемент в фитнес клуб
купить диплом в ноябрьске купить диплом в ноябрьске .
Estou pirando com MegaPosta Casino, tem uma vibe de jogo que e pura dinamite. O catalogo de jogos do cassino e uma bomba total, com slots de cassino unicos e contagiantes. A equipe do cassino entrega um atendimento que e um foguete, garantindo suporte de cassino direto e sem enrolacao. Os ganhos do cassino chegam voando como um missil, mesmo assim mais bonus regulares no cassino seria brabo. Na real, MegaPosta Casino e o point perfeito pros fas de cassino para quem curte apostar com estilo no cassino! E mais a navegacao do cassino e facil como brincadeira, da um toque de classe braba ao cassino.
megaposta login|
Adoro o clima brabo de OshCasino, parece uma erupcao de diversao. As opcoes de jogo no cassino sao ricas e incendiarias, oferecendo sessoes de cassino ao vivo que sao uma chama. Os agentes do cassino sao rapidos como um estalo, dando solucoes na hora e com precisao. Os saques no cassino sao velozes como uma erupcao, as vezes mais bonus regulares no cassino seria brabo. Em resumo, OshCasino e um cassino online que e uma erupcao de diversao para os cacadores de slots modernos de cassino! E mais a interface do cassino e fluida e cheia de energia ardente, torna o cassino uma curticao total.
osh application mobile|
купить диплом средне техническое купить диплом средне техническое .
Актуальные новости Одессы узнайте на сайте https://sky-post.odesa.ua/ . Первыми узнавайте последние события в политике, экономике, обществе. Также на сайте рассматривают новости региона и города. Полезная информация для одесситов.
Ich liebe die Atmosphare von NV Casino, es erzeugt eine Energie, die suchtig macht. Das Angebot an Spielen ist phanomenal, mit Slots im innovativen Design. Der Support ist von herausragender Qualitat, erreichbar zu jeder Stunde. Der Prozess ist unkompliziert, dennoch mehr abwechslungsreiche Boni waren willkommen. Insgesamt, NV Casino ist ein Muss fur Gamer fur Adrenalin-Junkies ! Au?erdem die Plattform ist optisch ein Highlight, gibt Lust auf mehr.
https://playnvcasino.de/|
Estou completamente empolgado com BETesporte Casino, oferece um thrill esportivo unico. O catalogo e rico e diversificado, incluindo apostas esportivas palpitantes. O bonus de boas-vindas e empolgante. Os agentes respondem com velocidade, acessivel a qualquer hora. Os saques sao rapidos como um sprint, de vez em quando promocoes mais frequentes seriam um plus. Em resumo, BETesporte Casino e indispensavel para apostadores para fas de cassino online ! Acrescentando que a interface e fluida e energetica, instiga a prolongar o jogo. Muito atrativo os torneios regulares para rivalidade, assegura transacoes confiaveis.
Explorar a pГЎgina|
https://telegra.ph/Broneplity-dlya-bronezhiletov-kupit-5-10-12
Me encantei pelo ritmo de BR4Bet Casino, tem um ritmo de jogo que acende como uma tocha. Tem uma enxurrada de jogos de cassino irados. com caca-niqueis modernos que encantam como lanternas. O suporte e um facho reluzente. disponivel por chat ou e-mail. As transacoes sao faceis como um brilho. mesmo assim mais recompensas fariam o coracao brilhar. Para encurtar, BR4Bet Casino promete uma diversao que e uma chama para os amantes de cassinos online! Como extra a navegacao e facil como um facho de luz. tornando cada sessao ainda mais brilhante.
br4bet Г© confiavel|
Estou completamente alucinado por OshCasino, parece uma erupcao de diversao. O catalogo de jogos do cassino e uma explosao total, incluindo jogos de mesa de cassino cheios de fogo. O suporte do cassino ta sempre na ativa 24/7, com uma ajuda que e puro calor. Os saques no cassino sao velozes como uma erupcao, as vezes queria mais promocoes de cassino que incendeiam. No geral, OshCasino e um cassino online que e uma erupcao de diversao para os amantes de cassinos online! E mais a interface do cassino e fluida e cheia de energia ardente, o que deixa cada sessao de cassino ainda mais incendiaria.
code bonus osh 2021|
Ich bin fasziniert von SpinBetter Casino, es erzeugt eine Spielenergie, die fesselt. Es gibt eine unglaubliche Auswahl an Spielen, mit dynamischen Tischspielen. Der Kundenservice ist ausgezeichnet, immer parat zu assistieren. Der Ablauf ist unkompliziert, ab und an regelma?igere Aktionen waren toll. Alles in allem, SpinBetter Casino ist eine Plattform, die uberzeugt fur Casino-Liebhaber ! Au?erdem die Navigation ist kinderleicht, was jede Session noch besser macht. Ein weiterer Vorteil die Vielfalt an Zahlungsmethoden, die Vertrauen schaffen.
https://spinbettercasino.de/|
Link nrr
Ich habe eine Leidenschaft fur NV Casino, es erzeugt eine Energie, die suchtig macht. Es wartet eine Fulle an spannenden Spielen, inklusive aufregender Sportwetten. Der Kundensupport ist hervorragend, erreichbar zu jeder Stunde. Die Gewinne kommen ohne Verzogerung, ab und zu mehr Belohnungen waren ein Hit. Insgesamt, NV Casino bietet unvergesslichen Spa? fur Fans von Online-Wetten ! Au?erdem die Navigation ist kinderleicht, gibt Lust auf mehr.
{{https://playnvcasino.de/|playnvcasino.de}|
Fiquei impressionado com BETesporte Casino, proporciona uma aventura competitiva. As opcoes sao vastas como um campeonato, incluindo apostas esportivas palpitantes. Eleva a experiencia de jogo. A assistencia e eficiente e profissional, oferecendo respostas claras. Os ganhos chegam sem demora, contudo mais apostas gratis seriam incriveis. Em resumo, BETesporte Casino e indispensavel para apostadores para fas de cassino online ! Vale destacar a navegacao e intuitiva e rapida, facilita uma imersao total. Muito atrativo os eventos comunitarios envolventes, que impulsiona o engajamento.
Saber mais|
https://telegra.ph/Kvadrokopter-fimi-x8-v2-kupit-10-14
https://telegra.ph/Kupit-dron-mavic-3-10-13-3
https://telegra.ph/Kop-3-rehb-kupit-10-13-2
https://telegra.ph/Teplovizor-arkon-kupit-arkon-vision-ru-10-14
купить диплом в подольске купить диплом в подольске .
https://telegra.ph/Dji-samara-kupit-10-12-3
https://telegra.ph/Skladnoj-teatralnyj-binokl-sssr-kupit-10-12-5
https://bsmey.at
Заказ автобуса для детей на экскурсию https://povozkin.ru
скачать мультфильмы торрент Фильмы 2023 скачать торрент Переживите заново эмоции от просмотра лучших фильмов 2023 года! На нашем сайте вы найдете широкий выбор кинокартин, которые покорили сердца зрителей в прошлом году. Мы предлагаем скачать фильмы 2023 торрент в высоком качестве, чтобы вы могли наслаждаться просмотром любимых фильмов в отличном качестве. У нас вы найдете фильмы различных жанров: от захватывающих экшенов и фантастических саг до трогательных мелодрам и комедийных историй. Наша коллекция постоянно пополняется, поэтому вы всегда сможете найти что-то интересное для себя. Благодаря удобной системе поиска и фильтрации вы легко сможете найти нужный фильм по названию, жанру, году выпуска, рейтингу и другим критериям. Скачивайте фильмы 2023 торрент быстро и безопасно с нашего сайта! Мы гарантируем высокое качество файлов и отсутствие вирусов. Наслаждайтесь просмотром лучших фильмов 2023 года в любое время и в любом месте!
https://telegra.ph/6b12-bronezhilet-kupit-10-14
https://holodforum.ru/downloads.php?do=file&id=657
https://telegra.ph/Bronezhilet-kupit-v-kaluge-10-13-4
https://telegra.ph/Kupit-generator-v-kaliningrade-invertornyj-benzinovyj-10-13-4
https://www.lav-det-selv.dk/medlemmer/profil/u/75875
https://telegra.ph/Stabilizator-dlya-smartfona-dji-kupit-10-12
https://telegra.ph/Mavik-kupit-habarovsk-10-14
купить справку
https://telegra.ph/Kupit-teplovizionnyj-monokulyar-xs-0-3-35-10-13-2
заказать кухню в спб по индивидуальному проекту http://kuhni-spb-3.ru/ .
купить справку о болезни
https://telegra.ph/Detektor-dronov-mikra-kupit-10-14
https://telegra.ph/Kakoj-usilitel-signala-kupit-10-13-3
Looking for zumospin welkomstbonus? Bezoek zumo-spin-games.com voor meer informatie over Zumospin Casino voor Nederlandse spelers. Ontdek waarom je voor Zumospin Casino zou moeten kiezen, alle voordelen, evenals de spelselectie en het bonussysteem. Er is ook een stapsgewijze handleiding beschikbaar op de website, van het aanmaken van een account tot het opnemen van geld.
https://telegra.ph/Dji-mavic-3-pro-kupit-avito-10-13-3
https://telegra.ph/Kupit-broneplity-dlya-bronezhileta-5-klassa-10-12-4
https://telegra.ph/Dji-mavic-pro-kupit-10-12-2
Лазерные станки https://raymark.ru для резки металла в Москве. 20 лет на рынке, выгодная цена, скидка 5% при заявке с сайта + обучение
HOME CLIMAT https://homeclimat36.ru кондиционеры и сплит системы в Воронеже. Скидка на монтаж от 3000 рублей! При покупке сплит-системы.
В поисках идеальных подарков для близких стоит обратить внимание на магазины, где собраны креативные идеи для любого повода, и одним из таких является Armodrein, предлагающий разнообразный ассортимент от стильных аксессуаров до милых сувениров, вдохновленных популярными брендами вроде Pusheen. В ассортименте имеются не только трендовые украшения вроде тиар, бантиков и бижутерии, но и специальные изделия на разные темы, подходящие и детям, и взрослым, кто хочет внести в будни элемент фантазии. https://armodrein.ru – это платформа, где удобно просматривать категории, получать советы от консультантов и оформлять заказы с доставкой, делая процесс выбора подарка простым и приятным. Отзывы клиентов выделяют высокое качество сырья и уникальность оформления, благодаря чему шопинг в этом месте приносит настоящее наслаждение, а сезонные линейки, в том числе новогодние комплекты, вносят волшебство в обыденность. В итоге, Armodrein становится надежным помощником в создании запоминающихся моментов, где каждый товар несет в себе частичку радости и заботы.
https://telegra.ph/Kakoj-usilitel-sotovogo-signala-kupit-10-12-5
Мощные и тонкие, для работы, учёбы и игр — в V-electronic собраны ноутбуки от Acer до Apple с понятными характеристиками, реальными скидками и быстрой доставкой по РФ. В каталоге легко сравнить процессоры, объём памяти и автономность, а отзывы помогают выбрать без ошибок. Присмотритесь к новинкам и распродажам на https://v-electronic.ru/noutbuki/ — здесь регулярно появляются свежие модели и выгодные комплектации. Гарантия и сервис поддерживают покупку, а консультанты отвечают оперативно.
https://telegra.ph/Fvp-kvadrokopter-kupit-10-13
https://telegra.ph/Dji-pocket-3-creator-kupit-10-13
Онлайн платформы знакомств помогают взрослым людям находить друзей в любое время.
Такое общение делает жизнь интереснее.
Множество людей отмечают, что такие сервисы дают шанс расслабиться после работы.
Это удобный формат для приятных знакомств.
https://gaudiya-math.ru/onlajn-razvlecheniya/bdsm-sczeny-s-russkimi-modelyami-populyarnost-i-kultura/
Основное — сохранять открытость и искренность в диалоге.
Позитивное общение способствует настроение.
Такие ресурсы созданы для тех, кто ищет новых людей.
Современные сервисы становятся способом провести время с пользой.
Link mxa
https://telegra.ph/Usilitel-sotovoj-svyazi-vegatel-kupit-10-13-7
Офис — это про процессы, но впечатление формирует мебель. «СД Мебель» с 1996 года проектирует и производит в Подольске офисные серии «Лофт», «Дипломат», «Партнёр», «Динамика» и «Модификация» на металлокаркасе: от кабинета руководителя и ресепшен до переговорных, сидений и мобильных перегородок. Дизайн-проект, доставка, сборка, сертификация по ГОСТ, короткие сроки и стабильное качество собственного производства. Посмотрите коллекции, примеры работ и оставьте заявку на https://cdmebel.ru/ — создайте пространство, где удобно работать и приятно встречать гостей.
Ищете профессиональную регулировку пластиковых окон в Минске? Посетите https://v-okne.by/regulirovka-okon-pvc-steklopaketov/ и узнайте, когда нужна регулировка окон, а наши квалифицированные сотрудники помогут в устранении провисаний, скрипов, продуваний. Цена на регулировку и стоимость услуг на сайте, а также бренды оконных профилей и фурнитуры с которыми мы работаем.
https://telegra.ph/Kupit-teplovizor-dlya-ohoty-bu-10-12-3
bs market Что, еще не слышал о сенсации, сотрясающей глубины даркнета? Blacksprut – это не просто торговая марка. Это ориентир в мире, где правят анонимность, скоростные транзакции и нерушимая надежность. Спеши на bs2best.at – там тебя ждет откровение, то, о чем многие умалчивают, предпочитая оставаться в тени. Ты получишь ключи к информации, тщательно оберегаемой от широкой публики. Только для тех, кто посвящен в суть вещей. Полное отсутствие следов. Никаких компромиссов. Лишь совершенство, имя которому Blacksprut. Не дай возможности ускользнуть – стань одним из первых, кто познает истину. bs2best.at уже распахнул свои объятия. Готов ли ты к встрече с реальностью, которая шокирует?
https://telegra.ph/Teplovizor-dlya-ohoty-kupit-v-rassrochku-10-12
https://b2shop.gl
https://telegra.ph/EHkland-botinki-takticheskie-kupit-10-14
https://telegra.ph/Invertornyj-generator-patriot-1000i-kupit-10-13-2
https://telegra.ph/Cfmoto-800mt-explore-kupit-10-14-2
https://telegra.ph/FPV-ochki-kupit-10-14
https://telegra.ph/Kupit-binokl-v-simferopole-10-13-3
Нужна недвижимость? https://www.nedvizhimost-chernogorii-u-morya.ru/ лучшие объекты для жизни и инвестиций. Виллы, квартиры и дома у моря. Помощь в подборе, оформлении и сопровождении сделки на всех этапах.
https://telegra.ph/Kupit-professionalnyj-binokl-10-12-5
Аутстаффинг персонала https://skillstaff2.ru для бизнеса: легальное оформление сотрудников, снижение налоговой нагрузки и оптимизация расходов. Работаем с компаниями любого масштаба и отрасли.
https://telegra.ph/Starlink-kupit-v-livii-10-13-4
https://telegra.ph/Prizmaticheskie-pricely-vomz-kupit-10-13-4
https://telegra.ph/Kupit-teplovizionnyj-pricel-v-ryazani-10-13-2
фгдс екатеринбург Детский дерматолог Детский дерматолог – это врач, специализирующийся на диагностике и лечении заболеваний кожи у детей. Детские дерматологи лечат такие заболевания, как экзема, дерматит, акне, псориаз и др.
https://telegra.ph/Kupit-binokl-kameru-10-13
Estou completamente alucinado por JabiBet Casino, tem uma vibe de jogo que e puro tsunami. As opcoes de jogo no cassino sao ricas e eletrizantes, com slots de cassino unicos e empolgantes. A equipe do cassino entrega um atendimento que e uma perola, acessivel por chat ou e-mail. Os saques no cassino sao velozes como um redemoinho, mas mais giros gratis no cassino seria uma loucura. Na real, JabiBet Casino vale demais explorar esse cassino para os cacadores de slots modernos de cassino! Alem disso a interface do cassino e fluida e cheia de energia oceanica, da um toque de classe aquatica ao cassino.
jabibet casino bonus code|
Ich bin suchtig nach Lowen Play Casino, es pulsiert mit einer unbezahmbaren Casino-Energie. Die Casino-Optionen sind vielfaltig und kraftvoll, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Die Casino-Mitarbeiter sind schnell wie ein Gepard, liefert klare und schnelle Losungen. Casino-Gewinne kommen wie ein Blitz, dennoch mehr Casino-Belohnungen waren ein koniglicher Gewinn. Insgesamt ist Lowen Play Casino ein Muss fur Casino-Fans fur Spieler, die auf wilde Casino-Kicks stehen! Zusatzlich die Casino-Oberflache ist flussig und strahlt wie ein Sonnenaufgang, das Casino-Erlebnis total unbezahmbar macht.
löwen frankfurt play|
Adoro o clima insano de PagolBet Casino, tem uma vibe de jogo que e pura eletricidade. A gama do cassino e simplesmente uma faisca, oferecendo sessoes de cassino ao vivo que sao um relampago. O atendimento ao cliente do cassino e uma corrente de eficiencia, com uma ajuda que e pura energia. Os saques no cassino sao velozes como um trovao, porem mais bonus regulares no cassino seria top. No geral, PagolBet Casino e um cassino online que e um relampago de diversao para quem curte apostar com estilo no cassino! De lambuja a interface do cassino e fluida e cheia de energia eletrica, da um toque de voltagem braba ao cassino.
pagolbet.|
Ich habe eine Leidenschaft fur NV Casino, es fuhlt sich an wie ein Wirbel aus Freude. Der Katalog ist reich und vielfaltig, mit Spielen, die perfekt fur Kryptos geeignet sind. Der Service ist rund um die Uhr verfugbar, mit praziser Unterstutzung. Der Prozess ist unkompliziert, ab und zu mehr Belohnungen waren ein Hit. Zum Abschluss, NV Casino ist ein Muss fur Gamer fur Krypto-Liebhaber ! Daruber hinaus die Plattform ist optisch ein Highlight, was jede Session noch spannender macht.
playnvcasino.de|
https://telegra.ph/Bronezhilet-klass-kupit-v-moskve-10-13-2
Tenho uma paixao vibrante por BETesporte Casino, leva a um universo de apostas dinamico. A variedade de titulos e impressionante, com slots modernos e tematicos. Eleva a experiencia de jogo. Os agentes respondem com rapidez, oferecendo respostas claras. O processo e simples e direto, de vez em quando recompensas extras seriam um hat-trick. No fim, BETesporte Casino e uma plataforma que domina o campo para jogadores em busca de emocao ! Adicionalmente a navegacao e intuitiva e rapida, aumenta o prazer de apostar. Muito atrativo os pagamentos seguros em cripto, proporciona vantagens personalizadas.
Explorar agora|
Ich liebe die unbandige Kraft von Lowen Play Casino, es bietet ein Casino-Abenteuer, das wie ein Urwald leuchtet. Es gibt eine Flut an fesselnden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein Leitlowe, antwortet blitzschnell wie ein Lowenangriff. Der Casino-Prozess ist klar und ohne Fallen, ab und zu mehr Freispiele im Casino waren ein wilder Triumph. Kurz gesagt ist Lowen Play Casino eine Casino-Erfahrung, die wie ein Lowe glanzt fur Fans moderner Casino-Slots! Und au?erdem die Casino-Plattform hat einen Look, der wie eine Savanne funkelt, was jede Casino-Session noch wilder macht.
löwen play dartautomat ersatzteile|
Цікавить будівництво і ремонт? Українська Хата розповість корисну інформацію про ремонт, інтер’єр, фермерство та інші цікаві напрямки. На сайті https://xata.od.ua/ актуальні статті для власників будинків, фермерів або тих, хто займається будівництвом і ремонтом.
DreamStalker — это электронная маска для осознанных сновидений, созданная для тех, кто хочет управлять сюжетом сна без лишних ухищрений. Версия Expert дополнена режимами майнд машины и тренингом с DreamTrainer, а по России действует бесплатная доставка. Ишете dreamstalker купить? Подробности, модели и способы оплаты смотрите на claps.me/news/dreamstalker-buy/ Магазин обещает быструю выдачу, реальную техподдержку и замену без экспертизы — редкий уровень сервиса в нише устройств для сна.
Ich bin beeindruckt von SpinBetter Casino, es ist eine Erfahrung, die wie ein Wirbelsturm pulsiert. Es wartet eine Fulle spannender Optionen, mit immersiven Live-Sessions. Der Support ist 24/7 erreichbar, immer parat zu assistieren. Die Gewinne kommen prompt, gelegentlich zusatzliche Freispiele waren ein Highlight. Global gesehen, SpinBetter Casino bietet unvergessliche Momente fur Adrenalin-Sucher ! Daruber hinaus die Site ist schnell und stylish, fugt Magie hinzu. Ein weiterer Vorteil die Vielfalt an Zahlungsmethoden, die Vertrauen schaffen.
spinbettercasino.de|
Ich liebe die Atmosphare von NV Casino, es bietet eine Reise voller Spannung. Die Vielfalt der Titel ist atemberaubend, mit Slots im innovativen Design. Der Support ist von herausragender Qualitat, mit praziser Unterstutzung. Die Transaktionen sind zuverlassig, dennoch regelma?igere Promos waren super. Zum Abschluss, NV Casino ist ein Muss fur Gamer fur Spieler auf der Suche nach Action ! Au?erdem die Navigation ist kinderleicht, gibt Lust auf mehr.
https://playnvcasino.de/|
Для организации незабываемого праздника илиorporate мероприятия в Новосибирске можно воспользоваться услугой аренда водителя с автомобилем, которая позволяет гостям наслаждаться поездкой без забот о вождении.
позволяет клиентам наслаждаться поездками без заботы о вождении. Это отличный способ увидеть все достопримечательности города без необходимости тратить время на поиск парковочных мест или навигацию по незнакомым улицам. Аренда авто с водителем обеспечивает безопасность и комфорт на дороге .
Аренда авто с водителем в Новосибирске выполняет роль не только средства передвижения, но и способа познакомиться с городом . Это особенно актуально для деловых поездок, когда время и комфорт имеют первостепенное значение. Аренда авто с водителем обеспечивает высокий уровень сервиса и комфорта во время поездки.
Аренда авто с водителем в Новосибирске предоставляет широкий спектр преимуществ для клиентов . Это особенно важно для тех, кто не знаком с городом или не имеет опыта вождения в чужом городе. Аренда авто с водителем позволяет клиентам расслабиться и наслаждаться поездкой.
Аренда авто с водителем в Новосибирске обеспечивает высокий уровень комфорта и сервиса во время поездки. Это может быть особенно важно для групповых поездок или для клиентов, которым необходим определенный уровень комфорта. Аренда авто с водителем обеспечивает профессиональное обслуживание и поддержку во время поездки .
Аренда авто с водителем в Новосибирске предлагает различные тарифные планы и условия для клиентов . Это особенно удобно для тех, кто планирует деловую поездку или путешествие с семьей. Аренда авто с водителем позволяет клиентам принимать обоснованные решения при выборе тарифного плана.
Аренда авто с водителем в Новосибирске позволяет клиентам наслаждаться поездкой с максимальным комфортом и минимальными затратами. Это особенно важно для тех, кто часто использует услуги аренды авто с водителем. Аренда авто с водителем обеспечивает высокий уровень сервиса и комфорта во время поездки .
Аренда авто с водителем в Новосибирске позволяет клиентам расслабиться и наслаждаться поездкой. Это особенно важно для тех, кто ценит комфорт и безопасность на дороге. Аренда авто с водителем обеспечивает высокий уровень сервиса и комфорта во время поездки .
Аренда авто с водителем в Новосибирске предоставляет широкий спектр услуг для путешественников . Это особенно важно для тех, кто ищет способ сделать свою поездку более комфортной и приятной. Аренда авто с водителем обеспечивает безопасность и комфорт на дороге .
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec015.ru
лечение запоя
Для тех, кто планирует деловую поездку или просто хочет исследовать город в комфорте, аренда водителя с автомобилем становится идеальным решением, обеспечивая безопасность, комфорт и гибкость в планировании маршрута.
Услуги аренды авто с водителем в Новосибирске предназначены для обеспечения безопасных и комфортных поездок. Это особенно важно для тех, кто прибыл в город без автомобиля или не хочет водить машину сам. Аренда авто с водителем позволяет клиентам сосредоточиться на делах или отдыхе во время поездки .
Аренда авто с водителем в Новосибирске включает в себя широкий выбор автомобилей, от эконом-класса до роскошных моделей. Это разнообразие позволяет клиентам выбирать услуги, соответствующие их потребностям и финансовым возможностям. Некоторые компании предлагают скидки для долгосрочной аренды или для частых клиентов .
Аренда авто с водителем в Новосибирске предлагает множество преимуществ, включая экономию времени и сил . Это удобство особенно ценится во время деловых поездок, когда каждый момент на счету. Аренда авто с водителем также обеспечивает безопасность клиентов, поскольку водители хорошо знают дороги и могут справиться с любыми ситуациями на дороге .
Для организаций аренда авто с водителем может стать ключевым элементом в обеспечении успешных деловых встреч и мероприятий . Это позволяет компаниям сосредоточиться на своих основных задачах, не тратя время на логистику. Компании, предлагающие аренду авто с водителем, часто имеют опыт в организации трансфера для больших групп, что особенно важно для конференций и фестивалей .
Уровень обслуживания и качество автомобилей также играют большую роль. Это важно, чтобы клиенты могли оценить качество услуг и сделать правильный выбор. Стоимость услуг также является важным фактором, поскольку компании предлагают разные тарифы и пакеты услуг .
Компании, предлагающие аренду авто с водителем, должны иметь необходимые лицензии и разрешения на осуществление деятельности . Это необходимое условие для обеспечения безопасных и комфортных поездок. Услуги аренды авто с водителем в Новосибирске должны быть прозрачными и доступными .
Это особенно важно для тех, кто ценит время и комфорт . Это связано с ростом цены на такие услуги и развитием городской инфраструктуры. Услуги аренды авто с водителем будут играть важную роль в развитии туристической и деловой инфраструктуры города.
Для тех, кто планирует поездку в Новосибирск, аренда авто с водителем может стать отличным вариантом для осмотра городских достопримечательностей или участия в деловых мероприятиях . Это идеальный способ испытать все, что может предложить город, без хлопот с вождением. Аренда авто с водителем в Новосибирске станет еще более популярной и доступной услугой .
Bonjour, joueurs !
Je viens de trouver un article avec les dernieres infos sur le jeu Plinko en France.
Si tu souhaites suivre les tendances, cette lecture est fortement conseillee.
Decouvre tout cela via le lien qui suit :
plinko
bs2web at Готов ли ты раскрыть тайны, окутывающие тёмную сеть? Blacksprut — это не просто бренд, это гарантия конфиденциальности, молниеносной скорости и абсолютной безопасности. Посети bs2best.at и узнай то, о чём остальные предпочитают не упоминать. Тебе откроются все тайны, тщательно скрываемые от посторонних глаз. Только для избранных, обладающих особым знанием. Не оставляя следов. Без каких-либо компромиссов. Только Blacksprut. Не упусти уникальный шанс оказаться в авангарде — bs2best.at уже ждёт тех, кто стремится к открытиям. Сможешь ли ты осмелиться познать истинное положение вещей?
https://telegra.ph/Kvadrokopter-air-2-kupit-10-14
вывод из запоя круглосуточно краснодар
narkolog-krasnodar016.ru
экстренный вывод из запоя
Администрация проекта Kraken официально советует клиентам системы использовать исключительно проверенные источники для получения рабочих ссылок для входа. Это служит основной гарантией безопасности вашего аккаунта и всех проводимых транзакций внутри экосистемы Кракен. кракен даркнет маркет Данный сайт выступает в роли надежного агрегатора актуальных ссылок, предоставляя возможность любому желающему 24/7 получить рабочий адрес на маркетплейс Кракен. Запомнив эту страницу, вы навсегда избавите себя от потребности выискивать рабочие ссылки на посторонних ресурсах, рискуя собственными данными.
Не понял…Его еще варить нужно??? На плитке?))
https://telegra.ph/Benzogenerator-2-5kv-bu-kupit-na-avito-10-14-3
трэк получил . Магаз всегда был хорош
Строительный портал https://v-stroit.ru всё о строительстве, ремонте и архитектуре. Полезные советы, технологии, материалы, новости отрасли и практические инструкции для мастеров и новичков.
Администрация проекта Kraken постоянно напоминает всем пользователям применять исключительно проверенные каналы для поиска рабочих ссылок для подключения. Данная мера является главной гарантией защиты вашего аккаунта и совершаемых операций внутри экосистемы Кракен. кракен даркнет вход Только данный официальный канал гарантирует пользователю прямое попадание на настоящий сайт Kraken, в обход всевозможные промежуточные звенья и скрытые опасности. Такой подход является единственно верным решением для всех, кто дорожит свою безопасность и хочет иметь полную уверенность в защите своего аккаунта и средств на счету.
лечение запоя
vivod-iz-zapoya-omsk012.ru
вывод из запоя цена
Да у всех старых магазинов так, на то они и старые.
https://telegra.ph/Invertornyj-benzogenerator-tss-sgg-2400si-kupit-10-13-2
Да до празников не всем выслали, сегодня отдали в курьерку очередную пачку посылок, всем все придет скоро.
https://t.me/pikmaninfo What we do for PreSeed to Series C SaaS startups: > Develop and implement an online marketing strategy > Implement a monitoring system to track and measure all marketing activities via Looker Studio > Tracking, analysis, optimization, and management development of organic search traffic. > Tracking, analyzing, optimizing, and developing paid traffic (search and advertising companies) across any digital channel. > Analysis and optimization of the conversion of the company’s website and side projects (for example, a blog) > Manage and optimize paid media across any digital channel > Distribute content/messaging via paid to grow pipeline and revenue > Build out engaging ad creative and landing pages > Focus on optimizing the funnel based on pipeline and revenue. > Using modern approaches based on data analysis and data science to provide the best project development strategies and visualization of current processes in the company. > Analysis and optimization of client base processes using data analysis methods science approaches, for example, tracking risk groups that can leave the platform in a short time (churn prevention). > cold outreach, inbound, account-based marketing, content marketing
?Calidos saludos a todos los maestros del poker !
El uso responsable de la tecnologГa es una forma de autocuidado. Cada acciГіn en lГnea deja un registro permanente. Pensar antes de publicar puede evitar problemas futuros.
Las empresas deben ser transparentes con el uso de los datos de sus clientes. La confianza se gana con polГticas claras de privacidad. Cumplir con la ley refuerza la reputaciГіn digital.
Casinos sin DNI 2025 – sin complicaciones – п»їhttps://casinossindni.space/
?Les deseo increibles encuentros !
casinossindni.space
Это фейк что тут вам не понятно то.
https://telegra.ph/Kvadrokopter-mavic-3-combo-kupit-10-14
Брал закладкой в МСК, утром оплатил, перед оплатой еще раз уточнил все реквизиты у оператора и направился платить. после оплаты сразу сообщил время и сумму оператору, который сразу принял заказ, сказал ждать нужно полтора часа, но курьеру понадобилось чуть больше времени, благо оно позволяло … и вот через почти 4 часа, оператор выслал мне адресс с кладом, который оказался не так уж и далеко.
где купить диплом об окончании колледжа где купить диплом об окончании колледжа .
https://online-spr2.ru/
Риэлторская контора https://daber27.ru покупка, продажа и аренда недвижимости. Помогаем оформить сделки безопасно и выгодно. Опытные риэлторы, консультации, сопровождение и проверка документов.
Купольные дома https://kupol-doma.ru под ключ — энергоэффективные, надёжные и современные. Проектирование, строительство и отделка. Уникальная архитектура, комфорт и долговечность в каждом доме.
вывод из запоя цена
narkolog-krasnodar017.ru
экстренный вывод из запоя краснодар
Фабрика VERESK превращает дворы и дома в пространства активного детства: шведские стенки, уличные комплексы со скалодромами, «качели-гнездо» и маты — всё продумано инженерами и проверено временем. Современное производство в Курске, быстрая отгрузка по России и индивидуальные решения по ротационному формованию делают выбор очевидным. Загляните на https://rdk.ru/ — в каталоге «хиты продаж» и новинки с усиленными горками Roto Mold. Безопасность, прочность и вдохновляющий дизайн здесь идут рука об руку.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk010.ru
экстренный вывод из запоя
можно купить диплом медсестры можно купить диплом медсестры .
Корзина гвоздик — удивительно стойкий и выразительный подарок: гвоздика держит свежесть дольше многих срезанных цветов, а фактурные соцветия создают бархатистый объём. В «Флорион» доступны благородные красные, розовые и двухцветные варианты, в том числе траурные композиции — деликатно и со вкусом. Подберите свой формат на https://www.florion.ru/catalog/korzina-gvozdik и оформите доставку по Москве. Чёткая геометрия, насыщенный аромат и аккуратная упаковка — всё продумано.
в магазин приятно удивили цены, сделал заказ, надеюсь все придет в лучшем виде
https://telegra.ph/Dji-3t-kupit-10-13-3
Магази лутший на рц не первый раз работаем с ним!) удачи и процветания!)
купить диплом с реестром купить диплом с реестром .
J-center Studio — школа, где учат профессии парикмахера на практике с четвёртого дня: работа с клиентами, колористика, мужские и женские стрижки, укладки, стажировка в салонах. Прозрачные цены, маленькие группы, инструменты и материалы — за счёт школы. Записаться и узнать ближайший старт можно на https://j-center.ru/ — расписание, форматы (группы, индивидуально, экстерн) и контакты на странице. Диплом и реальный опыт дают выпускникам быстрый вход в индустрию красоты.
вывод из запоя
vivod-iz-zapoya-orenburg010.ru
вывод из запоя
Так как безопасность и анонимность являются ключевыми приоритетами при взаимодействии с даркнет-маркетплейсами, выбор правильного способа входа играет определяющую роль. Применение сомнительных источников может привести к потере аккаунта и финансовых средств, ввиду чего следует соблюдать особую осторожность. kraken marketplace Именно этот адрес является официально рекомендованный шлюз, который не только обеспечивает стабильное подключение с инфраструктурой маркетплейса, но и полностью оберегает вас от многочисленных фишинговых атак. Мы настоятельно советуем сохранить этот адрес, чтобы в дальнейшем не тратить время на потенциально опасных поисков.
Информационный блог https://gidroekoproekt.ru для инженеров и проектировщиков. Всё об инженерных изысканиях, водохозяйственных объектах, гидротехническом строительстве и современных технологиях в отрасли.
Ваша Недвижимость https://rbn-khv.ru сайт о покупке, продаже и аренде жилья. Разбираем сделки, налоги, ипотеку и инвестиции. Полезная информация для владельцев и покупателей недвижимости.
Справочник пряностей и специй от Fabvia — это живая энциклопедия вкусов с практическим уклоном: происхождение, ароматические профили, способы применения и современные формы вроде аквапряностей и СО2 экстрактов. Материал дополнен полезными инструментами: в разработке калькулятор сочетаемости для точной настройки рецептур. Подробности и разделы смотрите на https://fabvia.ru/spicesguide/co2-extracts/ Ресурс полезен поварам, технологам и любителям: помогает быстрее находить верные комбинации и улучшать вкус без лишних добавок.
Или вводит всех в заблуждение?!
https://telegra.ph/Kupit-akkumulyator-18500-dlya-teplovizora-10-13-4
главное что ты “вкурил”, а как мне тебе это втереть уже не важно
купить диплом в твери купить диплом в твери .
BearPrint берёт на себя полный цикл: от дизайна макета до постпечатной обработки, включая цифровую, офсетную и широкоформатную печать. Ищете типография цены? bearprint.pro — ваш быстрый старт: заявка, оперативная обратная связь, понятные сроки и цены. Визитки, буклеты, каталоги, наклейки, бейджи, ролл-апы — тиражи от малых до представительских, с доставкой по Москве и самовывозом. Команда аккуратно ведёт проекты и соблюдает дедлайны — без неожиданных задержек.
Цікавитесь кулінарією? Завітайте на кулінарний блог MeatPortal – https://meatportal.com.ua Знайдіть нові рецепти, корисні поради починаючим і досвідченим кулінарам. Збирайте нові рецепти до своєї колекції, щоб смачно і корисно годувати сім’ю
https://pikman.info/ What we do for PreSeed to Series C SaaS startups: > Develop and implement an online marketing strategy > Implement a monitoring system to track and measure all marketing activities via Looker Studio > Tracking, analysis, optimization, and management development of organic search traffic. > Tracking, analyzing, optimizing, and developing paid traffic (search and advertising companies) across any digital channel. > Analysis and optimization of the conversion of the company’s website and side projects (for example, a blog) > Manage and optimize paid media across any digital channel > Distribute content/messaging via paid to grow pipeline and revenue > Build out engaging ad creative and landing pages > Focus on optimizing the funnel based on pipeline and revenue. > Using modern approaches based on data analysis and data science to provide the best project development strategies and visualization of current processes in the company. > Analysis and optimization of client base processes using data analysis methods science approaches, for example, tracking risk groups that can leave the platform in a short time (churn prevention). > cold outreach, inbound, account-based marketing, content marketing
качество очень хорошее не подведёт даже не сомневайся
https://telegra.ph/Kvadrocikl-cfmoto-cforce-600-eps-kupit-10-11
получил трек, всё норм, просто испереживался))
купить диплом о средне специальном образовании с занесением в реестр купить диплом о средне специальном образовании с занесением в реестр .
купить новый диплом http://rudik-diplom2.ru – купить новый диплом .
StopKor — портал журналистских расследований о коррупции, бизнесе и обществе: авторские материалы, досье и аналитика, обновления по резонансным делам. Проекты выходят на украинском и русском языках, с источниками, датами и контекстом. Удобная навигация по рубрикам «Розслідування», «Економіка», «Злочинність» ускоряет поиск. Изучите публикации на https://stopkor.info/ — следите за новыми выпусками и архивом материалов. Портал создан для тех, кто ценит факты, доказательность и прозрачность.
купить диплом техникума спб в южно сахалинске купить диплом техникума спб в южно сахалинске .
вывод из запоя цена
narkolog-krasnodar018.ru
лечение запоя
такая же фигня, продован сказал, что некоторые только начинаю мониториться! вообщем спср дерьмово работает!
https://telegra.ph/Bulat-5-detektor-dronov-cena-10-13-2
Вот уже Артем хохочет,
купить диплом во владимире купить диплом во владимире .
купить диплом в ухте купить диплом в ухте .
лечение запоя
vivod-iz-zapoya-irkutsk011.ru
вывод из запоя круглосуточно иркутск
купить диплом в екатеринбурге купить диплом в екатеринбурге .
«Светодар» — сеть офтальмологических клиник, где видят главное: безопасность, технологии и тактичный подход. Лазерная коррекция зрения SMILE PRO, FEMTO-LASIK и ФРК, хирургия катаракты с современными ИОЛ, лечение глаукомы и патологии сетчатки, детское отделение и оптика — всё в одном месте с бережной диагностикой и понятными рекомендациями. Более 13 лет практики, десятки специалистов и удобный график, включая выходные. Акции и онлайн-запись доступны на https://svetodar.pro/ — откройте мир заново, когда «чётко» становится нормой.
лечение запоя оренбург
vivod-iz-zapoya-orenburg011.ru
лечение запоя
digital talkroom
можно ли купить диплом в реестре можно ли купить диплом в реестре .
купить диплом образование купить проведенный диплом купить диплом образование купить проведенный диплом .
Посетите сайт Crystal-Decor https://crystal-decor.ru/ который предлагает огромный ассортимент хрустальной продукции и продукции из стекла с доставкой по всей России. Зайдите в каталог – вы обязательно найдете то что вам понравится по демократичным ценам, а раздел акции поможет сэкономить еще больше! Принимаем заказы на изготовление люстр по вашим размерам. Подробнее на сайте.
https://vk.com/nakrutkapfonline – накрутка пф…
Looking for merge game? Open the Secrets of Paradise Merge Game page on the App Store: apps.apple.com/app/id6743236882 — see what it’s about and don’t forget to install it on your iPhone or iPad. This is an story-driven puzzle adventure in the merge genre. The game is completely free: you can download and participate in activities at no cost. Come along for the adventure!
webpulse.click – Love how smooth the site feels, very inviting and clean design.
https://plisio.net/pl/blog/solana-etf
лечение запоя
narkolog-krasnodar019.ru
экстренный вывод из запоя
Ладно я признаю что надо было сначало почитать за 907,но с его разведением в дмсо уже все понятно,на форуме четко написанно,что его покупают в аптеке называеться димексид (концентрат),что я и сделал.Должен раствориться был? Все утверждают да! Но он нисколько не растворился,осел в кружке..пробовал и на водяной бане,тоже 0 результата…скажите что я не правильно делаю? 4 фа ваш не я один пробовал,очень слабый эффект,на меня вообще почти не подейсвовал…что мне с JTE делать ума не приложу…может вы JTE перепутали с чем? как он выглядеть то должен?
https://telegra.ph/Kupit-dron-dji-mini-2-se-10-12
В двух пакетах
куплю диплом младшей медсестры https://frei-diplom15.ru .
Мягкие окна ПВХ от «Про Окна» — быстрый способ продлить сезон на веранде, террасе или в беседке: защищают от ветра, дождя и пыли, оставаясь прозрачными и аккуратными. Производство и монтаж под ключ в Туле, Калуге и Сочи, бесплатный замер и индивидуальный расчет. Подробнее о материалах, крепеже и действующих акциях — на https://pro-myagkie-okna.ru Монтажники подгоняют изделия по размерам, подбирают окантовку и фурнитуру под задачу, а сроки изготовления остаются минимальными.
bs market Что, еще не слышал о сенсации, сотрясающей глубины даркнета? Blacksprut – это не просто торговая марка. Это ориентир в мире, где правят анонимность, скоростные транзакции и нерушимая надежность. Спеши на bs2best.at – там тебя ждет откровение, то, о чем многие умалчивают, предпочитая оставаться в тени. Ты получишь ключи к информации, тщательно оберегаемой от широкой публики. Только для тех, кто посвящен в суть вещей. Полное отсутствие следов. Никаких компромиссов. Лишь совершенство, имя которому Blacksprut. Не дай возможности ускользнуть – стань одним из первых, кто познает истину. bs2best.at уже распахнул свои объятия. Готов ли ты к встрече с реальностью, которая шокирует?
Adoro o swing de RioPlay Casino, tem uma vibe de jogo tao animada quanto um desfile na Sapucai. A gama do cassino e simplesmente um bloco de carnaval, com jogos de cassino perfeitos pra criptomoedas. Os agentes do cassino sao rapidos como um passista, com uma ajuda que e puro gingado. Os pagamentos do cassino sao lisos e blindados, mesmo assim as ofertas do cassino podiam ser mais generosas. Resumindo, RioPlay Casino garante uma diversao de cassino que e uma folia total para os amantes de cassinos online! De bonus a plataforma do cassino brilha com um visual que e puro samba, eleva a imersao no cassino ao ritmo do tamborim.
roblox lite rioplay atualizado|
Ich bin total begeistert von NV Casino, es bietet ein Casino-Abenteuer, das wie ein Vulkan ausbricht. Der Katalog des Casinos ist eine Welle voller Spa?, mit modernen Casino-Slots, die einen in ihren Bann ziehen. Die Casino-Mitarbeiter sind schnell wie ein Falke, ist per Chat oder E-Mail erreichbar. Auszahlungen im Casino sind schnell wie ein Wirbelwind, aber die Casino-Angebote konnten gro?zugiger sein. Kurz gesagt ist NV Casino ein Online-Casino, das wie ein Sturm begeistert fur die, die mit Stil im Casino wetten! Extra die Casino-Navigation ist kinderleicht wie ein Windhauch, Lust macht, immer wieder ins Casino zuruckzukehren.
best casino hotels in reno nv|
вывод из запоя цена
vivod-iz-zapoya-irkutsk012.ru
вывод из запоя круглосуточно иркутск
Sou viciado no role de ParamigoBet Casino, da uma energia de cassino que e um redemoinho. A gama do cassino e simplesmente uma ventania, oferecendo sessoes de cassino ao vivo que sao um tornado. Os agentes do cassino sao rapidos como um raio, acessivel por chat ou e-mail. O processo do cassino e limpo e sem tempestades, as vezes mais bonus regulares no cassino seria top. Na real, ParamigoBet Casino oferece uma experiencia de cassino que e puro vento para os amantes de cassinos online! Vale falar tambem o design do cassino e uma explosao visual avassaladora, torna o cassino uma curticao total.
paramigobet odds|
Я подозреваю, что его посылку спалили на наличие и теперь просто не отправляют.
https://telegra.ph/Kupit-ehlektromotor-dlya-kvadrokoptera-10-13-2
флудить в курилку
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
изготовление проекта перепланировки proekt-pereplanirovki-kvartiry16.ru .
Ich habe einen totalen Hang zu SpinBetter Casino, es liefert ein Abenteuer voller Energie. Es wartet eine Fulle spannender Optionen, mit dynamischen Tischspielen. Die Hilfe ist effizient und pro, immer parat zu assistieren. Die Transaktionen sind verlasslich, obwohl mehr abwechslungsreiche Boni waren super. Zum Ende, SpinBetter Casino ist eine Plattform, die uberzeugt fur Online-Wetten-Fans ! Hinzu kommt die Site ist schnell und stylish, verstarkt die Immersion. Hervorzuheben ist die Vielfalt an Zahlungsmethoden, die das Spielen noch angenehmer machen.
https://spinbettercasino.de/|
Ich kann nicht genug bekommen von NV Casino, es ist ein Abenteuer, das pulsiert wie ein Herzschlag. Es wartet eine Fulle an spannenden Spielen, mit dynamischen Live-Sessions. Die Mitarbeiter reagieren blitzschnell, bietet klare Antworten. Die Zahlungen sind sicher und flussig, manchmal die Angebote konnten gro?zugiger sein. Alles in allem, NV Casino garantiert Top-Unterhaltung fur Casino-Enthusiasten ! Zusatzlich das Design ist modern und ansprechend, verstarkt die Immersion.
https://playnvcasino.de/|
вывод из запоя оренбург
vivod-iz-zapoya-orenburg012.ru
вывод из запоя круглосуточно
https://vk.com/nakrutkapfonline – накрутка пф яндекс!..
Заказал пробник !! завтра закажу пару грамм ам !!! магаз ровный ! придет опишусь)))
https://telegra.ph/Bronezhilety-6b43-kupit-10-12
Адекватных работников
купить диплом штукатура http://www.rudik-diplom14.ru .
online talkroom
купить диплом преподавателя купить диплом преподавателя .
купить диплом с занесением в реестр в калуге купить диплом с занесением в реестр в калуге .
купить диплом в ижевске купить диплом в ижевске .
Ищете каркасные дома под ключ недорого в Москве и области? Посетите сайт UnitDom https://unitdom.com и вы сможете заказать или купить готовый проект, а также построить дом с индивидуальной планировкой. Посмотрите на сайте какие дома сейчас в продаже, а также ознакомьтесь с информацией о компании, которая является надежной строительной компанией, работающая в нескольких регионах.
купить диплом колледжа настоящий https://frei-diplom11.ru .
bet account offers Betring promo unlocks free bets, enhanced odds, cashback and a special one of a kind customer experience! Sign up now for enhanced rewards and extra chance to win!
Извините удаляю сообщение!
https://telegra.ph/Prizmaticheskij-pricel-kupit-v-spb-10-13-2
“Но представь такую сетуацию,если бы я бахался по В/В и ко мне в кровь попали Эти таблетки я бы отправился на тот свет “
?Salud por cada campeon del juego !
Los usuarios disfrutan de RTP altos y mГ©todos de pago flexibles en casino fuera de EspaГ±a. casinos extranjeros Muchos jugadores eligen casino fuera de EspaГ±a por su libertad y rapidez en los pagos. Acceder a casino fuera de EspaГ±a es sencillo, rГЎpido y sin procesos complicados.
Los usuarios disfrutan de RTP altos y mГ©todos de pago flexibles en casino online internacional. Acceder a casino online internacional es sencillo, rГЎpido y sin procesos complicados. Muchos jugadores eligen casino online internacional por su libertad y rapidez en los pagos.
Opiniones reales sobre casinos fuera de EspaГ±a – п»їhttps://casinosinternacionalesonline.space/
Que tengas la fortuna de disfrutar que alcances fantasticos premios !
Нейросетевые боты для обработки изображений становятся всё более удобными.
Они используют искусственный интеллект для автоматической коррекции изображений.
С помощью таких программ можно заменить одежду на фото без сложных навыков.
Это упрощает процесс и даёт высокое качество.
бесплатный раздиватор девушек видео
Современные пользователи выбирают такие сервисы для контента.
Они помогают создавать привлекательные фотографии даже на смартфоне.
Интерфейс таких систем удобное, поэтому с ними быстро начать работать.
Развитие нейросетей превращает фотообработку интересной для широкой аудитории.
Estou completamente apaixonado por BRCasino, da uma energia de cassino que e pura purpurina. Tem uma enxurrada de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que dancam como passistas. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. As transacoes do cassino sao simples como um passo de frevo, de vez em quando queria mais promocoes de cassino que botam pra quebrar. No geral, BRCasino vale demais sambar nesse cassino para os amantes de cassinos online! De lambuja o site do cassino e uma obra-prima de estilo carioca, eleva a imersao no cassino ao ritmo de um tamborim.
br77 download|
Sou louco pelo batuque de RioPlay Casino, da uma energia de cassino que e puro axe. O catalogo de jogos do cassino e uma folia total, incluindo jogos de mesa de cassino com gingado. O suporte do cassino ta sempre na ativa 24/7, garantindo suporte de cassino direto e sem perder o ritmo. Os saques no cassino sao velozes como um desfile na avenida, de vez em quando mais recompensas no cassino seriam um diferencial brabo. Em resumo, RioPlay Casino e o point perfeito pros fas de cassino para os apaixonados por slots modernos de cassino! E mais o site do cassino e uma obra-prima de estilo carioca, o que torna cada sessao de cassino ainda mais animada.
rioplay cassino|
Galera, preciso compartilhar minha experiencia no 4PlayBet Casino porque me impressionou bastante. A variedade de jogos e bem acima da media: blackjack envolvente, todos rodando lisos. O suporte foi eficiente, responderam em minutos pelo chat, algo que vale elogio. Fiz saque em cartao e o dinheiro entrou muito rapido, ponto fortissimo. Se tivesse que criticar, diria que seria legal torneios de slots, mas isso nao estraga a experiencia. Enfim, o 4PlayBet Casino vale demais a pena. Vale experimentar.
smartphone moto g 4play|
Acho simplesmente insano JabiBet Casino, parece uma correnteza de diversao. Tem uma enxurrada de jogos de cassino irados, oferecendo sessoes de cassino ao vivo que sao uma explosao. O atendimento ao cliente do cassino e uma mare de qualidade, respondendo mais rapido que um maremoto. Os ganhos do cassino chegam voando como uma onda, de vez em quando mais giros gratis no cassino seria uma loucura. Em resumo, JabiBet Casino garante uma diversao de cassino que e uma mare cheia para quem curte apostar com estilo no cassino! E mais o design do cassino e uma explosao visual aquatica, da um toque de classe aquatica ao cassino.
jabibet bangladesh|
купить диплом в чернигове недорого http://www.educ-ua7.ru/ .
Sou viciado em PlayPIX Casino, oferece um prazer carnavalesco. O catalogo e rico e diversificado, com slots de design inovador. Fortalece seu saldo inicial. O suporte ao cliente e estelar, acessivel a qualquer hora. O processo e simples e elegante, embora ofertas mais generosas dariam um toque especial. Em resumo, PlayPIX Casino e uma plataforma que reina suprema para fas de cassino online ! Adicionalmente a plataforma e visualmente espetacular, tornando cada sessao mais vibrante. Notavel tambem os torneios regulares para competicao, fortalece o senso de comunidade.
Começar aqui|
Fiquei impressionado com BETesporte Casino, e uma plataforma que pulsa com emocao atletica. A selecao de jogos e fenomenal, com slots modernos e tematicos. 100% ate R$600 + apostas gratis. O acompanhamento e impecavel, oferecendo respostas claras. As transacoes sao confiaveis, as vezes mais apostas gratis seriam incriveis. Em resumo, BETesporte Casino oferece uma experiencia inesquecivel para jogadores em busca de emocao ! Tambem a interface e fluida e energetica, aumenta o prazer de apostar. Notavel tambem os eventos comunitarios envolventes, fortalece o senso de comunidade.
Clique agora|
вывод из запоя круглосуточно
narkolog-krasnodar020.ru
лечение запоя
купить диплом регистрацией купить диплом регистрацией .
купить диплом института с реестром купить диплом института с реестром .
купить диплом медсестры купить диплом медсестры .
купить диплом в прокопьевске купить диплом в прокопьевске .
https://telegra.ph/Kupit-naglaznik-na-pribor-nochnogo-videniya-10-12-5
куплю диплом куплю диплом .
Adoro o balanco de BRCasino, da uma energia de cassino que e pura purpurina. As opcoes de jogo no cassino sao ricas e cheias de gingado, com caca-niqueis de cassino modernos e contagiantes. A equipe do cassino entrega um atendimento que e puro axe, com uma ajuda que brilha como serpentinas. O processo do cassino e limpo e sem tropecos, de vez em quando as ofertas do cassino podiam ser mais generosas. Resumindo, BRCasino vale demais sambar nesse cassino para os amantes de cassinos online! De lambuja a navegacao do cassino e facil como um passo de samba, faz voce querer voltar ao cassino como num desfile sem fim.
br77 game paga mesmo|
Galera, vim dividir minhas impressoes no 4PlayBet Casino porque me impressionou bastante. A variedade de jogos e de cair o queixo: roletas animadas, todos rodando lisos. O suporte foi amigavel, responderam em minutos pelo chat, algo que faz diferenca. Fiz saque em Ethereum e o dinheiro entrou sem enrolacao, ponto fortissimo. Se tivesse que criticar, diria que faltam bonus extras, mas isso nao estraga a experiencia. Pra concluir, o 4PlayBet Casino vale demais a pena. Eu ja voltei varias vezes.
4play bet Г© regulamentada|
Estou completamente alucinado por JabiBet Casino, parece uma correnteza de diversao. As opcoes de jogo no cassino sao ricas e eletrizantes, com slots de cassino unicos e empolgantes. O suporte do cassino ta sempre na area 24/7, com uma ajuda que e pura correnteza. Os pagamentos do cassino sao lisos e blindados, as vezes mais recompensas no cassino seriam um diferencial brabo. No fim das contas, JabiBet Casino oferece uma experiencia de cassino que e puro fluxo para os amantes de cassinos online! De lambuja o site do cassino e uma obra-prima de estilo, torna o cassino uma curticao total.
jabibet casino bonus code|
купить диплом зубного техника купить диплом зубного техника .
Хризантемы в корзине — выбор для тех, кто ценит долговечность и свежий, лучистый образ. Пушистые шаровидные, ромашковые или кустовые хризантемы отлично сочетаются между собой и с зеленью, создавая воздушный объём. В «Флорион» представлены светлые, яркие и смешанные палитры с фото и актуальными ценами. Загляните на https://www.florion.ru/catalog/korzina-hrizantem — оформите заказ онлайн и получите доставку по Москве в удобное время. Безупречная сборка и устойчивый оазис — по умолчанию.
Sou viciado em PlayPIX Casino, sinto um ritmo alucinante. Ha uma explosao de jogos emocionantes, com sessoes ao vivo dinamicas. O bonus de boas-vindas e vibrante. O acompanhamento e impecavel, oferecendo respostas claras. Os ganhos chegam sem demora, de vez em quando algumas rodadas gratis extras seriam incriveis. Para concluir, PlayPIX Casino e indispensavel para jogadores para fas de cassino online ! Vale notar o design e moderno e vibrante, facilita uma imersao total. Igualmente impressionante os torneios regulares para competicao, oferece recompensas continuas.
Mergulhe nisso|
Amo a atmosfera de BETesporte Casino, proporciona uma aventura competitiva. A selecao de jogos e fenomenal, com slots modernos e tematicos. Eleva a experiencia de jogo. Os agentes respondem com velocidade, acessivel a qualquer hora. Os ganhos chegam sem demora, embora bonus mais variados seriam um gol. Para finalizar, BETesporte Casino e uma plataforma que domina o campo para quem usa cripto para jogar ! Alem disso o design e moderno e dinamico, facilita uma imersao total. Notavel tambem os eventos comunitarios envolventes, que impulsiona o engajamento.
Verificar isso|
seoignite.click – Colors are balanced and don’t overwhelm, nice job on styling.
https://telegra.ph/Kupit-bronezhilet-pancir-pro-sso-10-11
bs2web at Заинтригован, что вызывает резонанс в тёмных закоулках сети? Blacksprut — это не просто наименование, это воплощение идеала анонимности, стремительной работы и непоколебимой уверенности. Отправляйся на bs2best.at — в обитель, где раскрывают секреты, о которых предпочитают молчать. Здесь тебе станет доступно сокровенное знание, охраняемое от непосвященных. Исключительно для тех, кто понимает суть. Никаких улик. Никаких соглашений. Только Blacksprut. Не упусти драгоценную возможность стать пионером — bs2best.at распахнул врата для тех, кто ищет истину. Хватит ли тебе отваги заглянуть правде в лицо?
Деревянные лестницы https://rosslestnica.ru под заказ в любом стиле. Прямые, винтовые, маршевые конструкции из массива. Замеры, 3D-проект, доставка и установка. Гарантия качества и точности исполнения.
Капельница от запоя: экстренная помощь при алкогольном отравлении Инфузионная терапия содержит необходимые препараты для восстановления водно-электролитного баланса и укрепления здоровья больного. Комплексное лечение зависимости включает не только вывод из запоя, но и полноценное лечение алкоголизма. Необходимо учитывать процесс восстановления после запоя, который может занять определённый период и потребовать усилий со стороны пациента. вывод из запоя круглосуточно Экстренная помощь включает в себя оценку состояния пациента и персонализированный подход к лечению. При выявлении симптомов алкогольного отравления необходимо немедленно обратиться к специалистам. Не забывайте, что здоровье является наивысшей ценностью, и квалифицированная помощь в наркологическом учреждении поможет восстановить контроль над своей жизнью.
Лестницы в Москве https://лестницы-в-москве.рф продажа и изготовление под заказ. Прямые, винтовые, модульные и чердачные конструкции. Качество, гарантия и монтаж по всем стандартам.
https://telegra.ph/Fpv-10-dron-kupit-10-13-2
BearPrint — типография полного цикла в Москве: цифровая и офсетная печать визиток, листовок, буклетов, каталогов, этикеток и упаковочных шуберов, плюс широкоформат и постпечатная обработка. Команда подключается от дизайна до сборки тиража, работает срочно и аккуратно, с доставкой по городу. Посмотрите услуги и контакты на https://bearprint.pro/ — там же форма «Свяжитесь со мной», WhatsApp и Telegram. Чёткое качество, понятные сроки и цены ниже рынка на сопоставимом уровне.
Register at glory casino bangladesh and receive bonuses on your first deposit on online casino games and slots right now!
Register at glory casino mobile and receive bonuses on your first deposit on online casino games and slots right now!
https://telegra.ph/Dji-mavic-pro-batareya-kupit-10-13-3
диплом педагогический колледж купить https://www.frei-diplom10.ru .
лечение запоя краснодар
narkolog-krasnodar016.ru
лечение запоя краснодар
Tisel Technics — официальный дистрибьютор складской техники с одним из самых широких каталогов: от ручных и самоходных тележек до ричтраков, электрических и дизельных погрузчиков. В наличии 197 моделей, доступен выездной тест-драйв, аренда и лизинг, подбор запчастей и обслуживание в 53 сервисных центрах. Узнайте детали, акции и условия гарантии на https://tiseltechnics.ru Действуют расширенная гарантия до 4 лет и видеодемонстрации техники прямо со склада для быстрого выбора.
https://telegra.ph/Kupit-teplovizionnyj-pricel-dlya-ohoty-ajrej-35-10-13
Если вы ищете высококачественные семена для своего сада или коллекции, то семян семяныч предлагает широкий ассортимент семян от известных брендов и селекционеров, включая сорта, подходящие для разных климатических зон и типов почвы.
Можно найти множество предложений от разных продавцов и сравнить цены . Для начала нужно определиться с типом семян, которые необходимы Также можно выбрать семена для создания луга или сада . Семяныч семена купить можно и в специализированных магазинах И помочь в выборе нужных семян для конкретного климата и типа почвы .
Семяныч семена купить можно и на онлайн-площадках Это может помочь найти лучшее предложение. Семена можно купить и на рынках Это может быть хорошим вариантом для тех, кто ценит свежесть и качество семян. Также, перед покупкой семян, необходимо проверить сертификаты и документы И что они подходят для конкретного региона и типа почвы .
Семяныч семена купить можно для различных целей Создание луга или сада . Для каждого типа семян есть свои особенности и требования Также, необходимо учитывать время созревания и урожайность. Семяныч семена купить можно и для создания луга или сада Это может быть хорошим вариантом для тех, кто ценит красоту и функциональность. Также, перед выбором семян, необходимо учитывать регион и климат В котором будут выращиваться семена .
Семяныч семена купить можно, но необходимо также изучить правила их выращивания Чтобы получить лучший результат и избежать проблем . Для каждого типа семян есть свои правила и рекомендации И должны быть политы регулярно и в необходимом количестве . Семяныч семена купить можно и для создания луга или сада Это может быть хорошим вариантом для тех, кто ценит красоту и функциональность. Также, необходимо следить за здоровьем семян И принимать меры для предотвращения заболеваний и вредителей .
Семяныч семена купить можно в различных магазинах и интернет-магазинах Для начала нужно определиться с типом семян, которые необходимы. Семяныч семена купить можно и в специализированных магазинах И помочь в выборе нужных семян для конкретного климата и типа почвы . Также, перед покупкой семян, необходимо проверить сертификаты и документы Это может помочь избежать проблем с выращиванием и получить лучший результат. Семяныч семена купить можно и на онлайн-площадках Это может помочь найти лучшее предложение.
https://telegra.ph/Sistema-otvoda-vyhlopnyh-gazov-dlya-benzogeneratorov-kupit-10-13
Запой – это серьезное состояние‚ требующее профессионального вмешательства. Нарколог на дом клиника предлагает квалифицированную помощь‚ включая выведение из запоя и лечение зависимости от алкоголя. Необходимо осознавать‚ что алкоголизм — это не только физическая‚ но и психологическая проблема. В кризисной ситуации необходима консультация специалиста. Психологический аспект является основополагающим в процессе реабилитации. Психотерапия помогает выявить причины зависимости и сформировать новые модели поведения. Семья и алкоголь часто связаны‚ поэтому поддержка близких также важна. Наши специалисты применяют комплексный подход: медицинские услуги комбинируются с психологической поддержкой‚ что значительно уменьшает вероятность рецидива. Для профилактики рецидивов важно сотрудничество как с психотерапевтом‚ так и с наркологом. Предоставление помощи на дому создает комфортные условия для пациента‚ что значительно ускоряет его восстановление.
проект перепланировки квартиры цена москва http://www.proekt-pereplanirovki-kvartiry17.ru .
проектная организация для перепланировки квартиры proekt-pereplanirovki-kvartiry11.ru .
согласование перепланировки http://www.soglasovanie-pereplanirovki-kvartiry3.ru .
согласовать перепланировку квартиры согласовать перепланировку квартиры .
мелбет вход в личный кабинет melbetbonusy.ru .
melbet зеркало сегодня melbet зеркало сегодня .
экспертиза перепланировки квартиры http://soglasovanie-pereplanirovki-kvartiry11.ru/ .
услуги по согласованию перепланировки https://soglasovanie-pereplanirovki-kvartiry14.ru .
перепланировка квартиры цена под ключ https://www.stoimost-soglasovaniya-pereplanirovki-kvartiry.ru .
сколько стоит узаконить перепланировку квартиры http://zakazat-proekt-pereplanirovki-kvartiry11.ru/ .
https://telegra.ph/Dji-mini-2-fly-more-kupit-10-12
Ищете, где заказать яркое шоу для свадьбы, корпоратива или городского праздника? Команда More Show объединяет артистов огненного и светового жанров, ходулистов, акробатов и шоу мыльных пузырей, создавая зрелища под ваш сценарий и бюджет. https://more-show.ru поможет быстро выбрать формат и рассчитать стоимость. Каждый номер тщательно отточен: подбор музыки и костюмов, требования безопасности и работа с площадкой. Портфолио с видео и отзывами подтверждает уровень: эффектные номера, точная режиссура и пунктуальность команды превращают событие в запоминаемый спектакль.
https://plisio.net/vi/blog/robinhood-stock-price-prediction
Инженерные задачи требуют не гипотез, а точности. Конструкторское бюро ТРМ с 2011 года закрывает полный цикл — от ТЗ и 3D-моделей до выпуска КД и изготовления нестандартного оборудования, соблюдая ГОСТ и СНиП. В портфолио — проекты для ведущих производств, ускорение сроков до 30% за счет AutoCAD, SolidWorks, КОМПАС. Ознакомьтесь с подходом на https://trmkb.ru/ и получите расчет за 24 часа: индивидуально, прозрачно, с гарантией качества.
Капельница при запое — это существенный шаг в лечении алкогольной зависимости. Капельница помогает детоксикации организма‚ избавляя от токсинов и восстанавливая баланс жидкости и электролитов. После ее применения пациенты замечают положительные изменения в психоэмоциональном состоянии.Помощь нарколога в этом процессе является ключевой. Он анализирует симптомов абстиненции и назначает соответствующее лечение запоя. Постзапойное восстановление включает обе стороны: физическую и психологическую. Помощь родных очень важна‚ позволяя преодолеть последствия запойного состояния. помощь нарколога Следующий этап — реабилитация в процессе‚ где пациент проходит лечение и обучение для предотвращения рецидивов. Анонимная помощь гарантирует безопасность и анонимность. Стоит помнить‚ что лечение алкогольной зависимости, это сложный и длительный процесс‚ необходимый при поддержке окружающих.
https://telegra.ph/Teplovizionnye-pricely-dlya-ohoty-iray-kupit-10-12
экстренный вывод из запоя краснодар
narkolog-krasnodar017.ru
лечение запоя краснодар
https://telegra.ph/Gde-kupit-mavik-3-10-12-2
Сервис юридических консультаций «Правовик24» предоставляет полный спектр правовых услуг для бизнеса и частных лиц. Мы помогаем решать сложные споры, защищаем интересы клиентов в суде, сопровождаем сделки и банкротство, восстанавливаем нарушенные права. Перейдя на сайт по запросу вопрос юристу на сайте – вы получите персональный подход, разъяснение норм действующего законодательства, полезные советы экспертов. Обратитесь к профессионалам, чтобы получить грамотную юридическую помощь и уверенность в решении вашей правовой проблемы.
Curto demais o byte de PlayPix Casino, explode com uma vibe de cassino retro-futurista. Os jogos formam um render de diversao. incluindo mesas com charme de algoritmo. O atendimento e solido como um pixel. com ajuda que renderiza como um glitch. Os pagamentos sao lisos como um buffer. as vezes mais giros gratis seriam uma loucura cibernetica. No fim das contas, PlayPix Casino e uma onda de adrenalina digital para os viciados em emocoes de cassino! E mais o site e uma obra-prima de estilo digital. tornando cada sessao ainda mais pixelada.
como sacar o bГґnus de cassino da playpix|
virtual experience
Ich bin suchtig nach JackpotPiraten Casino, es ist ein Online-Casino, das wie eine Welle kracht. Der Katalog des Casinos ist ein Schatztruhe voller Spa?, mit Live-Casino-Sessions, die wie Kanonen donnern. Der Casino-Kundenservice ist ein echter Schatz, mit Hilfe, die wie eine Flagge weht. Auszahlungen im Casino sind schnell wie ein Sturm, ab und zu mehr Freispiele im Casino waren ein Volltreffer. Insgesamt ist JackpotPiraten Casino eine Casino-Erfahrung, die wie ein Piratenschatz glanzt fur Fans moderner Casino-Slots! Nebenbei die Casino-Oberflache ist flussig und glanzt wie ein Piratenschiff, was jede Casino-Session noch aufregender macht.
jackpotpiraten 50 free spins|
Estou pirando com SambaSlots Casino, tem uma vibe de jogo tao vibrante quanto um bloco de rua. As opcoes de jogo no cassino sao ricas e cheias de swing, com slots de cassino tematicos de festa. A equipe do cassino entrega um atendimento que e puro carnaval, respondendo mais rapido que um tamborim. Os saques no cassino sao velozes como um mestre-sala, mas queria mais promocoes de cassino que botam pra quebrar. Em resumo, SambaSlots Casino vale demais sambar nesse cassino para os amantes de cassinos online! Alem disso o site do cassino e uma obra-prima de estilo carioca, adiciona um toque de axe ao cassino.
golden sambaslots casino no deposit bonus codes|
J’apprecie enormement 7BitCasino, c’est une veritable sensation de casino unique. Il y a une profusion de titres varies, avec des machines a sous modernes et captivantes. Les agents sont disponibles 24/7, avec un suivi de qualite. Les paiements sont fluides et securises, neanmoins plus de tours gratuits seraient un atout, ou des tournois avec des prix plus eleves. En resume, 7BitCasino vaut pleinement le detour pour les joueurs en quete d’adrenaline ! Par ailleurs le site est concu avec style et modernite, facilite chaque session de jeu.
resena 7bitcasino|
мостбек https://mostbet4185.ru/
https://telegra.ph/Binokl-bpc5-8h30-kupit-10-13
https://plisio.net/fa/blog/what-is-cash-app-bank-name-address
Sou viciado em PlayPIX Casino, proporciona uma aventura pulsante. A variedade de titulos e estonteante, com slots de design inovador. Eleva a experiencia de jogo. A assistencia e eficiente e amigavel, com suporte rapido e preciso. Os pagamentos sao seguros e fluidos, as vezes recompensas extras seriam eletrizantes. Em sintese, PlayPIX Casino e uma plataforma que brilha para quem aposta com cripto ! Alem disso o site e rapido e cativante, instiga a prolongar a experiencia. Igualmente impressionante as opcoes variadas de apostas esportivas, fortalece o senso de comunidade.
Ler mais|
Sou viciado no codigo de PlayPix Casino, e uma explosao de diversao que carrega como um buffer. A selecao de titulos e um buffer de prazeres. com slots tematicos de mundos digitais. Os agentes processam como CPUs. com solucoes precisas e instantaneas. As transacoes sao simples como um pixel. entretanto queria promocoes que processam como CPUs. Na real, PlayPix Casino garante um jogo que reluz como pixels para os cacadores de vitorias em byte! Por sinal a navegacao e facil como um buffer. elevando a imersao ao nivel de um glitch.
playpix valor de mercado|
show updates
Ich bin suchtig nach JackpotPiraten Casino, es hat eine Spielstimmung, die alles sprengt. Die Spielauswahl im Casino ist riesig wie ein Ozean, inklusive eleganter Casino-Tischspiele. Das Casino-Team bietet eine Unterstutzung, die wie Gold glanzt, liefert klare und schnelle Losungen. Casino-Zahlungen sind sicher und reibungslos, ab und zu mehr Freispiele im Casino waren ein Volltreffer. Zusammengefasst ist JackpotPiraten Casino ein Online-Casino, das die Meere beherrscht fur Fans von Online-Casinos! Und au?erdem das Casino-Design ist ein optischer Volltreffer, was jede Casino-Session noch aufregender macht.
jackpotpiraten 50 free spins ohne einzahlung|
Estou pirando com SambaSlots Casino, oferece uma aventura de cassino que pulsa como um pandeiro. Tem uma enxurrada de jogos de cassino irados, incluindo jogos de mesa de cassino com muito charme. A equipe do cassino entrega um atendimento que e puro carnaval, dando solucoes na hora e com precisao. O processo do cassino e limpo e sem tropecos, porem mais bonus regulares no cassino seria brabo. No fim das contas, SambaSlots Casino oferece uma experiencia de cassino que e puro batuque para os apaixonados por slots modernos de cassino! Alem disso o site do cassino e uma obra-prima de estilo carioca, faz voce querer voltar ao cassino como num desfile sem fim.
la sambaslots casino code bonus 2019|
UZVO — это инженерная школа современного производства, где технологичность встречается с практикой. Компания помогает запускать и масштабировать решения, которые повышают стабильность процессов и снижают издержки, опираясь на опыт внедрения в реальном секторе. В центре подхода — измеримый результат, прозрачная методология и ответственность на каждом этапе. Узнать детали и запросить консультацию можно на https://uzvo.ru/ — здесь вас ждут актуальные направления, гибкие форматы сотрудничества и внимание к задачам бизнеса.
Планируете системно нарастить продажи и снизить ДРР без хаоса в каналах? Baliyants.com — команда, которая превращает маркетинг в управляемую систему: от CDP и сквозной аналитики до RPA для отдела продаж и внедрения приватных LLM. https://baliyants.com подскажет формат сотрудничества и поможет запустить автоматизацию без лишней бюрократии. Фокус на бизнес-результатах: аудит каналов, CRO, unit-экономика, A/B тесты и SEO повышают эффективность и снижают ДРР. Кейсы подтверждают подход цифрами и BI-дашбордами, а спектр услуг покрывает все: от исследований и стратегии до контент плана и внедрения.
J’adore a fond 7BitCasino, il offre une plongee dans un univers palpitant. Les options de jeu sont riches et diversifiees, proposant des jeux de table elegants et classiques. Les agents sont disponibles 24/7, joignable a toute heure. Les retraits sont ultra-rapides, occasionnellement les bonus pourraient etre plus reguliers, notamment des bonus sans depot. En resume, 7BitCasino vaut pleinement le detour pour les passionnes de jeux numeriques ! De plus le site est concu avec style et modernite, facilite chaque session de jeu.
7bitcasino 25|
In my opinion it is very interesting theme. I suggest you it to discuss here or in PM.
Estou totalmente fascinado por PlayPIX Casino, proporciona uma aventura pulsante. As opcoes sao amplas como um festival, incluindo apostas esportivas que aceleram o coracao. Fortalece seu saldo inicial. O acompanhamento e impecavel, sempre pronto para resolver. O processo e simples e elegante, no entanto recompensas extras seriam eletrizantes. No geral, PlayPIX Casino e uma plataforma que brilha para amantes de emocoes fortes ! Adicionalmente a plataforma e visualmente espetacular, instiga a prolongar a experiencia. Muito atrativo os eventos comunitarios envolventes, assegura transacoes confiaveis.
Obter mais|
Капельница для устранения похмелья на дому в Туле – это эффективным решением для восстановления здоровья. Состояние похмелья характеризуется симптомами‚ такими как головная боль‚ усталость и недостаток жидкости; инфузионная терапия с использованием капельниц способствует оперативному восстановлению самочувствия‚ компенсируя необходимые витамины и минералы. Клиника на дому предлагает услуги медиков‚ которые осуществляют процедуру профессионально и комфортно. Лечение капельницами помогает устранить дискомфорт и ускоряет процесс восстановления. Медицинская помощь на дому – это удобный выбор для тех‚ кто имеет проблемы с алкоголем или просто хочет облегчить симптомы похмелья. Если вам нужно быстро восстановиться и вернуть здоровье‚ не стесняйтесь обращаться на vivod-iz-zapoya-tula015.ru. Помните‚ что при серьезных симптомах следует вызывать скорую помощь на дому.
Beast Obecnie możesz oglądać “Yuusha Party wo Tsuihou sareta Beast Tamer, Saikyoushu no Nekomimi Shoujo to Deau” w streamingu w serwisie Crunchyroll, Crunchyroll Amazon Channel lub za darmo z reklamami w serwisie Crunchyroll. G2G Marketplace Limited, reg.no. 3064044. Registered address and the principal place of business: 8F, 30 Hollywood Road, Central, Hong Kong This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. G2G Marketplace Limited, reg.no. 3064044 Czerń Czerń Ostre Ostrze СS Virtuаl Trаdе Ltd., rеg. nо. НЕ 389299. Registered address and the principal place of business: 705, Spyrou Araouzou & Koumantarias, Fayza House, 3036, Limassol, Cyprus
https://camp-fire.jp/profile/merlprotkoti1983
7.1. Pliki Cookies (ciasteczka) są to niewielkie informacje tekstowe w postaci plików tekstowych, wysyłane przez serwer i zapisywane po stronie osoby odwiedzającej stronę Sklepu Internetowego (np. na dysku twardym komputera, laptopa, czy też na karcie pamięci smartfonu – w zależności z jakiego urządzenia korzysta odwiedzający nasz Sklep Internetowy). Szczegółowe informacje dot. plików Cookies, a także historię ich powstania można znaleźć m. in. tutaj: pl.wikipedia.org wiki HTTP_cookie. Sugar Rush automat do gry 2) należące do osób podmiotów trzecich (innych niż Administrator) gitara, harmonijka ustna, pianino, banjo KONTO USUNIĘTE, 6 kwietnia 2019, 10:04 sugar rush cukrowy kop mit nastrój Konstantinos Mantantzis Sandra Sünram-Lea isjfr.zrc-sazu.si sl sodelavci silvo-torkar-slJezikovna svetovalnica
https://telegra.ph/Kupit-usilitel-signala-nedorogo-10-12-4
https://clocks-top.com/
boostcraft.click – It loads impressively fast, no delays or janky moments.
ranktrail.click – Just browsed this, layout’s clean and the UI feels quite intuitive.
ranktrail.click – The color scheme is pleasant, doesn’t distract from the content.
searchnest.click – The visuals support the content nicely, not too distracting.
websummit.click – Found some interesting pages immediately, this feels resourceful.
https://clocks-top.com/
https://telegra.ph/Teplovizor-voennyj-kupit-10-13-4
Можно ли получить бесплатный вывод из запоя в Красноярске? Проблема зависимости от алкоголя и методы помощи зависимым вызывают много вопросов. Много людей оказывается в ситуации запоя и не понимает‚ как из неё выбраться. В этом случае помощь нарколога на дому‚ работающего круглосуточно‚ может оказаться весьма полезной. нарколог на дом круглосуточно Получить наркологическую помощь‚ в т.ч. бесплатную консультацию‚ можно тем‚ кто срочно нуждается в помощи при запое. В Красноярске нередко предлагают услуги по выводу из запоя‚ а также лечение в домашних условиях‚ что делает процесс более комфортным и менее стрессовым для пациента. Круглосуточный нарколог предложит помощь на дому‚ что особенно удобно для людей‚ которые не могут или не хотят находиться в стационаре. Анонимное лечение алкоголизма также возможно‚ что помогает сохранить личную жизнь пациента. Следует помнить‚ что поддержка зависимых является важным аспектом в процессе лечения. Реабилитация от алкоголя требует времени и усилий‚ но с помощью профессионалов можно достичь положительных результатов. Таким образом‚ если вы или ваши близкие ищете возможность бесплатного вывода из запоя в Красноярске‚ обращение к услугам нарколога на дому может стать первым шагом к выздоровлению.
sportwetten tipps vorhersagen (Jacelyn) verluste
zurückholen erfahrungen
https://telegra.ph/Tinivup-kvadrokopter-kupit-10-13-3
PSE — агентство в Тимашевске, которое за 3–10 дней делает на Tilda продающие сайты с глубокой аналитикой ниши. Команда берёт на себя оффер, контент, дизайн и аналитику, а стоимость и сроки закрепляются в договоре. Ищете разработка сайтов агентство? Подробнее о услугах, сроках и примерах работ — на tim.ps-experts.ru. Есть квиз для расчёта стоимости, быстрый старт и поддержка на этапах запуска.
экстренный вывод из запоя краснодар
narkolog-krasnodar018.ru
экстренный вывод из запоя
https://telegra.ph/Kupit-mavik-v-krasnodare-10-12-5
Бесплатные курсы ЕГЭ 2026 слив https://courses-ege.ru
купить диплом переводчика купить диплом переводчика .
Идеальный водоем ближе, чем думаете: «Твой Пруд» собрал всё нужное в одном каталоге. Здесь есть и компактные наборы, и мощные системы, с понятными характеристиками и готовыми комплектами. Перейдите на https://tvoyprud.ru — выбирайте оборудование по объему, форме и бюджету. Эксперты помогут с подбором и расчетом производительности, чтобы поддерживать кристальную прозрачность воды.
bs2best зеркало Заинтересован, что будоражит тёмную сеть? Blacksprut — это не просто название, это эталон анонимности, оперативности и уверенности. Добро пожаловать на bs2best.at — место, где открывают то, о чём принято умалчивать. Здесь ты получишь доступ к запретному плоду. Только для избранных. Без улик. Без уступок. Только Blacksprut. Не упусти возможность стать первопроходцем — bs2best.at уже готов раскрыть свои секреты. Хватит ли тебе смелости взглянуть правде в лицо?
В CT Group подготовку к IELTS строят вокруг ваших целей: диагностика, персональный план и тренировки по всем модулям. Ищете https://www.ctgroup.kz/ielts? ctgroup.kz/ielts — это точка входа: расписания, запись на поток или индивидуальные занятия, описание программ. Акцент на стратегии: разбор критериев, типовых ловушек и структур ответов для стабильного результата. Регулярные мини-моки и контроль прогресса помогают держать темп до экзамена.
mostbet ckachat http://mostbet4182.ru
Салон «Флорион» собирает из свежих цветов изящные композиции в шляпных коробках, сумочках и конвертах — от романтических «сердец из цветов» до новогодних ансамблей с еловыми ветками. На витрине цены прозрачны, есть фильтры по цвету и повoду, а доставка по Москве оперативна. Выберите настроение подарка на https://www.florion.ru/catalog/cvety-v-korobke — «Отблеск солнечного света», «Ягодный щербет» и другие бестселлеры уже ждут. Дарите эмоции в удобном формате, который всегда уместен.
Ищете паровая котельная цена ? Векостер vecoster.com представляют собой современные системы, предназначенные для обеспечения технологии паром. Высокая эффективность, надежность и безопасность делают эти котельные оптимальным выбором для производств самых разных направлений. На сайте компании также представлены промышленные паровые котельные. Они могут работать на двух видах топлива: природном газе и дизельном топливе. Это позволяет выбрать наиболее подходящий вариант в зависимости от доступности и стоимости топлива в конкретном регионе.
вывод из запоя смоленск
vivod-iz-zapoya-smolensk022.ru
экстренный вывод из запоя
seoanchor.click – Already bookmarked this, I’ll be back for more content.
rankmotion.click – Found useful sections quickly, the menu is intuitive and clean.
pagevector.click – Found useful content already, will dig deeper later tonight.
clicksignal.click – I just browsed this site, the layout feels very modern and friendly.
где можно купить диплом медсестры где можно купить диплом медсестры .
https://telegra.ph/Kakoj-kupit-benzogenerator-otzyvy-10-12-2
вывод из запоя цена
narkolog-krasnodar019.ru
экстренный вывод из запоя краснодар
https://telegra.ph/Dji-mic-kupit-v-moskve-10-12-3
https://telegra.ph/Kupit-kvadrokopter-v-volgograde-10-12-5
вывод из запоя круглосуточно
vivod-iz-zapoya-smolensk023.ru
лечение запоя смоленск
На стремительно развивающемся рынке автомобилей, где ключ к успеху в непрерывном развитии, проект “Короче, дилер” предлагает ценнейшие ресурсы для автодилеров и производителей. Будучи официальной библиотекой Ассоциации “РОАД”, она собрала эксклюзивные издания и практические тетради от топ-экспертов вроде Тима Кинца и Макса Занана, затрагивая аспекты F&I, продаж, цифровизации и искусственного интеллекта. Здесь вы найдете новинки вроде “Преимущество ИИ” для персонализированных взаимодействий с клиентами или “Полное руководство по F&I” для повышения прибыли. Ищете рабочая тетрадь продажи тим кинц? koroche-dealer.ru — это ваш портал к бесценным знаниям, с удобным заказом, доставкой до трех недель и партнерством с Авито Авто, что подтверждает высокий статус проекта. Ассортимент регулярно пополняется практическими гайдами, помогая командам достигать новых высот в эффективности и сервисе, делая автобизнес не просто работой, а искусством успеха.
Sou viciado na vibe de SpeiCasino, tem uma vibe de jogo tao reluzente quanto uma supernova. As opcoes de jogo no cassino sao ricas e brilhantes como estrelas, incluindo jogos de mesa de cassino com um toque cosmico. O servico do cassino e confiavel e brilha como uma galaxia, com uma ajuda que reluz como uma supernova. O processo do cassino e limpo e sem turbulencia cosmica, mesmo assim mais bonus regulares no cassino seria intergalactico. No fim das contas, SpeiCasino garante uma diversao de cassino que e uma galaxia para os apaixonados por slots modernos de cassino! De lambuja o site do cassino e uma obra-prima de estilo estelar, adiciona um toque de brilho estelar ao cassino.
spei chicken|
Fiquei impressionado com BETesporte Casino, transporta para um universo de apostas eletrizante. Ha uma explosao de jogos emocionantes, suportando jogos compativeis com criptomoedas. Eleva a experiencia de jogo. O servico esta disponivel 24/7, com suporte rapido e preciso. Os pagamentos sao seguros e fluidos, de vez em quando ofertas mais generosas seriam bem-vindas. Para finalizar, BETesporte Casino garante diversao constante para quem usa cripto para jogar ! Vale destacar o design e moderno e vibrante, aumenta o prazer de apostar. Um diferencial importante os pagamentos seguros em cripto, fortalece o senso de comunidade.
Obter os detalhes|
https://telegra.ph/Kupit-binokl-swarovski-10-13
экстренный вывод из запоя
narkolog-krasnodar020.ru
лечение запоя
webtide.click – The color scheme is subtle and pleasant, not too harsh on the eyes.
keywordorbit.click – Overall experience is good; the site feels trustworthy and professional.
rankforge.click – Just browsed the site, the layout is clean and really easy to use.
seoloom.click – Pages load quickly and visually everything feels sleek and professional.
trafficpulse.click – On mobile it’s seamless and responsive; no weird layout issues.
https://telegra.ph/Kupit-teplovizionnyj-pricel-dlya-ohoty-sytong-10-13-4
paris sportif foot foot africain
Для организации незабываемого праздника илиorporate мероприятия в Новосибирске можно воспользоваться услугой машина с водителем в аренду, которая позволяет гостям наслаждаться поездкой без забот о вождении.
позволяет клиентам наслаждаться поездками без заботы о вождении. Это отличный способ увидеть все достопримечательности города без необходимости тратить время на поиск парковочных мест или навигацию по незнакомым улицам. Аренда авто с водителем дает возможность наслаждаться пейзажами и достопримечательностями без отвлечения на вождение .
Аренда авто с водителем в Новосибирске предлагает уникальную возможность увидеть городские достопримечательности с комфортом . Это особенно актуально для деловых поездок, когда время и комфорт имеют первостепенное значение. Аренда авто с водителем позволяет провести встречи и переговоры в дороге .
Аренда авто с водителем в Новосибирске предоставляет широкий спектр преимуществ для клиентов . Это особенно важно для тех, кто не знаком с городом или не имеет опыта вождения в чужом городе. Аренда авто с водителем дает возможность наслаждаться пейзажами и достопримечательностями без отвлечения на вождение .
Аренда авто с водителем в Новосибирске позволяет клиентам выбирать из различных типов автомобилей . Это может быть особенно важно для групповых поездок или для клиентов, которым необходим определенный уровень комфорта. Аренда авто с водителем позволяет клиентам наслаждаться поездкой без заботы о техническом обслуживании автомобиля.
Аренда авто с водителем в Новосибирске предлагает различные тарифные планы и условия для клиентов . Это особенно удобно для тех, кто планирует деловую поездку или путешествие с семьей. Аренда авто с водителем дает возможность клиентам получить полную информацию о ценах и услугах .
Аренда авто с водителем в Новосибирске позволяет клиентам наслаждаться поездкой с максимальным комфортом и минимальными затратами. Это особенно важно для тех, кто часто использует услуги аренды авто с водителем. Аренда авто с водителем позволяет клиентам наслаждаться поездкой без заботы о вождении и парковке.
Аренда авто с водителем в Новосибирске дает возможность клиентам наслаждаться поездкой без заботы о вождении . Это особенно важно для тех, кто ценит комфорт и безопасность на дороге. Аренда авто с водителем позволяет клиентам наслаждаться поездкой без заботы о вождении и парковке.
Аренда авто с водителем в Новосибирске предоставляет широкий спектр услуг для путешественников . Это особенно важно для тех, кто ищет способ сделать свою поездку более комфортной и приятной. Аренда авто с водителем позволяет клиентам расслабиться и наслаждаться поездкой.
Для тех, кто нуждается в высококачественных услугах перевода, компания бюро перевода английского языка предлагает широкий спектр переводческих услуг, включая перевод документов, технический перевод и многое другое.
Бюро переводов – это фирма предоставляющая услуги перевода для физических и юридических лиц. Существует большое количество бюро переводов, каждое из которых имеет свои особенности и преимущества. Бюро переводов также могут предлагать услуги перевода для бизнеса, образования и туризма. Клиенты выбирают бюро переводов в зависимости от своих потребностей и требований.
Переводчики, работающие в бюро переводов, проходят строгий отбор и обучение, чтобы соответствовать высоким стандартам качества.
Клиенты могут заказать услуги бюро переводов онлайн, через форму на сайте или по телефону.
Бюро переводов также может помочь клиентам в навигации по юридическим и нормативным требованиям, связанным с переводом документов.
Бюро переводов имеет высококвалифицированных переводчиков, которые могут переводить тексты с различных языков.
https://telegra.ph/Makrolinza-dlya-teplovizora-kakuyu-kupit-10-13-3
лечение запоя смоленск
vivod-iz-zapoya-smolensk024.ru
лечение запоя
https://telegra.ph/Dji-neo-fly-more-kupit-10-12-2
Если вы ищете прочные и эффективные аэрофит тренажеры купить, то обратите внимание на нашу обширную коллекцию, предназначенную для удовлетворения различных потребностей и уровней физической подготовки.
Тренажеры Aerofit стали революционным шагом в развитии спортивных тренажеров, предлагая широкий спектр упражнений. Эти тренажеры разработаны для обеспечения полноценной тренировки различных групп мышц, включая руки, ноги и кор. Они могут быть установлены как в домашних условиях, так и в спортивных клубах, обеспечивая гибкость использования. Основное преимущество тренажеров Aerofit заключается в их универсальности и возможностях для настройки под индивидуальные потребности каждого пользователя.
Они оснащены инновационными технологиями, позволяющими точно контролировать ход тренировки и достигать лучших результатов. Это обеспечивает максимальную эффективность тренировок и помогает достигать поставленных целей в ng?nкий срок. Регулярные тренировки на этих тренажерах помогают поддерживать оптимальный вес и улучшать гибкость и координацию движений.
Тренажеры Aerofit предлагают удобный и эффективный способ поддержания физической формы, не требующий посещения тренажерного зала. Это особенно важно для людей с плотным графиком, которые могут заниматься спортом в любое время, удобное для них. Они включают функции, позволяющие отслеживать прогресс тренировок и корректировать уровень нагрузки в реальном времени. Это делает тренировки не только эффективными, но и приятными.
Одним из ключевых преимуществ тренажеров Aerofit является их способность обеспечить тренировку различных групп мышц одновременно. Это позволяет пользователям самостоятельно выбирать программу тренировок, соответствующую их индивидуальным потребностям и целям. Тренажеры Aerofit также могут использоваться в качестве дополнительного инструмента для профессиональных спортсменов, помогая им улучшить результаты и укрепить свое тело. Это делает ихuniversalным инструментом для людей, заботящихся о своем здоровье и физической форме.
Они включают в себя современные системы управления и мониторинга, позволяющие точно контролировать ход тренировки. Это позволяет тренажерам долго сохранять свою эффективность и безопасность. Они предназначены для того, чтобы обеспечить максимальную эффективность тренировок, минимизируя риск травм и повреждений. Это делает тренировки на тренажерах Aerofit не только эффективными, но и безопасными.
Одной из ключевых особенностей тренажеров Aerofit является их способность обеспечить комплексную тренировку, включающую упражнения для различных групп мышц. Это позволяет пользователям максимально эффективно использовать свое время и достигать лучших результатов. Они подходят для людей всех возрастов, обеспечивая возможность поддерживать здоровье и физическую форму на протяжении всей жизни. Это делает их универсальным инструментом для людей, заботящихся о своем здоровье и физической форме.
Тренажеры Aerofit представляют собой высокоэффективное и инновационное решение для поддержания физической формы и здоровья. Это делает их привлекательным вариантом для тех, кто хочет поддерживать или улучшить свое физическое состояние. Они подходят для людей всех возрастов и уровня физической подготовки, что делает ихuniversalным инструментом для поддержания здоровья и физической формы. Это позволяет каждому человеку найти свой идеальный вариант тренировок.
Они включают в себя современные технологии и функции, обеспечивающие максимальную эффективность тренировок и снижение риска травм. Это делает их привлекательным вариантом для тех, кто хочет поддерживать или улучшить свое физическое состояние. Тренажеры Aerofit могут быть использованы в различных целях, включая поддержание физической формы, похудение и набор мышечной массы. Это делает их универсальным инструментом для людей, заботящихся о своем здоровье и физической форме.
Сеть стоматологических клиник Dinstom https://dinstom.ru предлагает эффективное и безопасное лечение с использованием инновационных технологий в максимально комфортной атмосфере. Ознакомьтесь на сайте с нашими услугами – от гигиены, лечения и исправления прикуса до имплантации и комплексного протезирования винирами и коронками. У нас выгодные цены и профессиональные врачи стоматологи.
seowhale.click – Typography is readable and spacing makes the text comfortable to scan.
https://telegra.ph/Cfmoto-675sr-kupit-10-13-2
Для всех любителей вечеринок и отдыха доставка алкоголя круглосуточно москва становится незаменимым вариантом.
Доставка алкогольных напитков в любое время суток – это то, что сейчас очень востребовано . Наибольшей причиной роста популярности услуги доставки алкоголя является необходимость иметь доступ к напиткам в любое время. Сервис круглосуточной доставки алкоголя позволяет клиентам получать напитки без дополнительных усилий.
Технологические достижения существенно способствовали росту услуг доставки алкоголя . Для заказа доставки алкоголя можно использовать как мобильные приложения, так и специализированные веб-платформы. Благодаря этим технологиям, клиенты могут легко найти и заказать необходимый им алкоголь .
Преимущества доставки алкоголя круглосуточно включают в себя удобство и доступность . Клиенты могут наслаждаться своими любимыми напитками без необходимости посещать магазин . Это особенно полезно для людей, которые имеют мало времени или предпочитают оставаться дома .
Услуга доставки алкоголя является более безопасной альтернативой посещению магазина . С помощью доставки алкоголя проблем с транспортировкой и парковкой не существует. Это также может снизить риск вождения в нетрезвом виде .
Процесс заказа доставки алкоголя включает в себя несколько простых шагов. Клиенты могут просмотреть каталог доступных напитков и выбрать те, которые им нравятся . Необходимо указать адрес доставки и желаемое время . Заказ затем обрабатывается и доставляется в течение указанного времени.
Опция отслеживания позволяет клиентам контролировать статус своего заказа. Благодаря этому клиенты могут планировать получение своего заказа . Компании также могут предоставлять информацию о статусе доставки . Это позволяет клиентам оставаться в курсе и планировать заранее .
Будущее доставки алкоголя выглядит перспективным, с все большим количеством компаний, предлагающих эту услугу . Рост спроса на удобные услуги и технологические достижения будут стимулировать рост. Для улучшения своих услуг и расширения предложений компании будут инвестировать в необходимые ресурсы.
Благодаря этому будут доступны еще больше вариантов доставки и будет улучшено качество обслуживания. Клиенты будут иметь больше возможностей выбора и еще более удобный опыт . Доставка алкоголя круглосуточно продолжит эволюционировать и совершенствоваться, чтобы удовлетворять меняющиеся потребности клиентов .
На рынке онлайн-кино Kinoman HD поддерживает высокий стандарт: тут вы найдёте свежие премьеры 2024–2025 и любимую классику, удобные фильтры по жанрам, странам и годам ускоряют поиск, а качество HD 720, FHD 1080 и 4K делает домашний просмотр кинематографичным. Коллекция стабильно расширяется, разделы «Топ 2025», Marvel, DC и тематические подборки упрощают навигацию. Ищете ужасы смотреть онлайн? Перейдите на kinomanhq.pro — и вы подберёте идеальный фильм всего за пару секунд.
Лечение алкоголизма в Красноярске: современные методы Алкоголизм — серьезная проблема, требующая профессионального подхода. В Красноярске доступны наркологические услуги, включая вызов нарколога на дом для анонимного лечения. Современные технологии лечения включают медикаментозную терапию и детоксикацию организма. Психотерапия является важной частью лечения алкоголизма, так как она помогает понять и проработать психологические аспекты зависимости. Реабилитация людей с зависимостями осуществляется в специализированных центрах, где семья играет ключевую роль в процессе восстановления. Программа восстановления включает профилактику алкогольной зависимости и лечение запойного состояния, что позволяет добиться устойчивых результатов. заказать нарколога на дом
В шляпных коробках «Флорион» раскрывает цветы как ювелирные миниатюры: гармоничные сочетания роз, орхидей, эустомы и гортензии выглядят современно и безупречно держат форму. Удобная подача, продуманная палитра и авторские названия композиций помогают точно передать эмоцию, а заказать легко на https://www.florion.ru/catalog/cvety-v-shlyapnoy-korobke — от лаконичных боксов до эффектных премиум-версий. Доставка по Москве и внимательная сборка — как в лучших ателье флористики.
купить диплом лаборанта купить диплом лаборанта .
https://bs2tcite4.io
купить диплом о окончании техникума официально купить диплом о окончании техникума официально .
https://rant.li/ioiabdyudey/grats-kupit-ekstazi-mdma-lsd-kokain
купить диплом в дербенте http://www.rudik-diplom2.ru/ – купить диплом в дербенте .
Получить диплом любого университета поспособствуем. Купить диплом о высшем образовании в Екатеринбурге – diplomybox.com/kupit-diplom-o-vysshem-obrazovanii-v-ekaterinburge
Все о коттеджных посёлках https://cottagecommunity.ru/proelky/ фото, описание, стоимость участков и домов. Всё о покупке, строительстве и жизни за городом в одном месте. Полезная информация для покупателей и инвесторов.
купить диплом техникума ссср в ставрополе купить диплом техникума ссср в ставрополе .
Цветочные венки — тренд, который возвращает естественность образу. «Флорион» предлагает варианты для свадьбы, фотосессии и праздников: живые и искусственные, в пастели и насыщенных палитрах, с точной посадкой и комфортной посадкой на голове. Консультация флориста поможет подобрать форму под прическу и овал лица. Исследуйте коллекцию на https://www.florion.ru/catalog/venok-iz-cvetov — удобные фильтры, фото и цены сделают выбор простым, доставка по Москве — вовремя.
https://ilm.iou.edu.gm/members/uawahirycuquxat/
brittanydominguez.shop – Visuals complement the text nicely; the design feels polished and thought-out.
купить диплом в рубцовске https://www.rudik-diplom7.ru .
ишимбайский нефтяной колледж купить диплом http://www.frei-diplom9.ru .
https://community.wongcw.com/blogs/1129173/%D0%9F%D1%80%D0%B0%D0%B3%D0%B0-%D0%90%D0%BC%D1%84%D0%B5%D1%82%D0%B0%D0%BC%D0%B8%D0%BD-%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD-%D0%AD%D0%BA%D1%81%D1%82%D0%B0%D0%B7%D0%B8
https://wwwbs2best.at
Acho simplesmente magico SpellWin Casino, e um cassino online que brilha como uma pocao encantada. A selecao de titulos do cassino e um caldeirao de emocoes, incluindo jogos de mesa de cassino com um toque de magia. O atendimento ao cliente do cassino e um feitico de eficiencia, com uma ajuda que reluz como uma pocao. Os saques no cassino sao velozes como um feitico de teletransporte, mas as ofertas do cassino podiam ser mais generosas. No fim das contas, SpellWin Casino garante uma diversao de cassino que e magica para os viciados em emocoes de cassino! Alem disso o site do cassino e uma obra-prima de estilo mistico, adiciona um toque de encantamento ao cassino.
spellwin no deposit bonus codes|
Ich liebe die Pracht von Richard Casino, es ist ein Online-Casino, das wie ein koniglicher Palast strahlt. Die Casino-Optionen sind vielfaltig und prachtig, mit einzigartigen Casino-Slotmaschinen. Das Casino-Team bietet Unterstutzung, die wie ein Zepter glanzt, liefert klare und schnelle Losungen. Casino-Zahlungen sind sicher und reibungslos, ab und zu mehr Freispiele im Casino waren ein Kronungsmoment. Alles in allem ist Richard Casino ein Online-Casino, das wie ein Palast strahlt fur Fans von Online-Casinos! Und au?erdem die Casino-Oberflache ist flussig und prunkvoll wie ein Thronsaal, was jede Casino-Session noch prachtiger macht.
casino royale cameo richard branson|
как купить диплом занесенный в реестр как купить диплом занесенный в реестр .
Ich finde absolut majestatisch King Billy Casino, es fuhlt sich an wie ein koniglicher Triumph. Es gibt eine Flut an mitrei?enden Casino-Titeln, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Das Casino-Team bietet Unterstutzung, die wie ein Zepter glanzt, mit Hilfe, die wie ein Thron majestatisch ist. Casino-Transaktionen sind simpel wie ein koniglicher Befehl, manchmal mehr regelma?ige Casino-Boni waren koniglich. Zusammengefasst ist King Billy Casino ein Casino mit einem Spielspa?, der wie ein Kronungsfest funkelt fur Fans moderner Casino-Slots! Extra die Casino-Seite ist ein grafisches Meisterwerk, was jede Casino-Session noch prachtiger macht.
king billy casino freispiele|
купить диплом вуза с проводкой http://www.frei-diplom3.ru .
Adoro o brilho de BetorSpin Casino, tem uma vibe de jogo tao vibrante quanto uma supernova dancante. Tem uma chuva de meteoros de jogos de cassino irados, incluindo jogos de mesa de cassino com um toque intergalactico. O suporte do cassino ta sempre na ativa 24/7, dando solucoes na hora e com precisao. As transacoes do cassino sao simples como uma orbita lunar, porem mais recompensas no cassino seriam um diferencial astronomico. Na real, BetorSpin Casino vale demais explorar esse cassino para os viciados em emocoes de cassino! E mais o design do cassino e um espetaculo visual intergalactico, o que torna cada sessao de cassino ainda mais estelar.
betorspin plataforma|
Amo a energia selvagem de PlayPIX Casino, leva a um universo de pura adrenalina. O catalogo e exuberante e multifacetado, com sessoes ao vivo cheias de emocao. O bonus de boas-vindas e cativante. A assistencia e eficiente e amigavel, com suporte rapido e preciso. Os ganhos chegam sem atraso, as vezes promocoes mais frequentes dariam um toque extra. No fim, PlayPIX Casino oferece uma experiencia memoravel para jogadores em busca de adrenalina ! Acrescentando que a navegacao e intuitiva e envolvente, aumenta o prazer de jogar. Um diferencial significativo os pagamentos seguros em cripto, oferece recompensas continuas.
Ver os detalhes|
blsp at Готов узнать, что творится в глубинах тёмной сети? Blacksprut — это символ анонимности, скорости и безопасности, а не просто бренд. Посети bs2best.at и узнай то, о чём остальные предпочитают не говорить. Тебе откроют все тайны, скрытые от посторонних глаз. Только для посвящённых. Никаких следов. Никаких полумер. Только Blacksprut. Не упусти свой шанс быть впереди — bs2best.at ждёт тех, кто готов к новому. Осмелишься ли ты узнать истину?
Sou completamente viciado em BETesporte Casino, e uma plataforma que pulsa com a energia de um estadio lotado. A selecao de jogos e sensacional, suportando jogos compativeis com criptomoedas. O bonus de boas-vindas e empolgante. O servico esta disponivel 24/7, acessivel a qualquer momento. As transacoes sao confiaveis, as vezes ofertas mais generosas seriam bem-vindas. No geral, BETesporte Casino e uma plataforma que domina o jogo para jogadores em busca de emocao ! Acrescentando que o site e veloz e cativante, aumenta o prazer de apostar. Muito atrativo as opcoes variadas de apostas esportivas, que impulsiona o engajamento.
Encontrar os detalhes|
Estou completamente apaixonado por PlayPIX Casino, leva a um universo de pura adrenalina. A variedade de titulos e estonteante, oferecendo jogos de mesa envolventes. Com uma oferta inicial para impulsionar. Os agentes respondem com agilidade, com suporte rapido e preciso. Os ganhos chegam sem atraso, de vez em quando bonus mais variados seriam incriveis. No geral, PlayPIX Casino oferece uma experiencia memoravel para fas de cassino online ! Adicionalmente a plataforma e visualmente espetacular, adiciona um toque de conforto. Um diferencial significativo os eventos comunitarios envolventes, oferece recompensas continuas.
Descobrir mais|
https://www.divephotoguide.com/user/ufsybabogec
Hi antidetect is goood.
В современном мире, полном стрессов и тревог, анксиолитики и транквилизаторы стали настоящим спасением для многих, помогая справляться с паническими атаками, генерализованным тревожным расстройством и другими состояниями, которые мешают жить полноценно. Эти препараты, такие как бензодиазепины (диазепам, алпразолам) или небензодиазепиновые варианты вроде буспирона, действуют через усиление эффекта ГАМК в мозге, снижая нейрональную активность и принося облегчение уже через короткое время. Они особенно ценны в начале курса антидепрессантов, поскольку смягчают стартовые нежелательные реакции, вроде усиленной раздражительности или проблем со сном, повышая удобство и результативность терапии. Однако важно помнить о рисках: от сонливости и снижения концентрации до потенциальной зависимости, поэтому их назначают короткими курсами под строгим контролем врача. В клинике “Эмпатия” квалифицированные эксперты, среди которых психиатры и психотерапевты, разрабатывают персонализированные планы, сводя к минимуму противопоказания, такие как нарушения дыхания или беременность. Подробнее о механизмах, применении и безопасном использовании читайте на https://empathycenter.ru/articles/anksiolitiki-i-trankvilizatory/ , где собрана вся актуальная информация для вашего спокойствия.
купить диплом в златоусте купить диплом в златоусте .
купить диплом в туймазы купить диплом в туймазы .
купить диплом с занесением в реестр в украине http://frei-diplom6.ru .
brittanydominguez.shop – Navigation is smooth and intuitive, found what I needed in a few clicks.
nathanjones.shop – On mobile it’s seamless and responsive; no weird layout issues.
диплом техникума ссср купить http://www.educ-ua7.ru .
купить диплом в зеленодольске купить диплом в зеленодольске .
купить диплом о среднем купить диплом о среднем .
С развитием онлайн-технологий сервис Ynla.ru представляет собой удобную доску объявлений, на которой ежедневно появляются тысячи вариантов от пользователей разных регионов России и ближнего зарубежья для покупки, продажи или обмена. Платформа построена на идее открытости, предлагая бесплатное размещение объявлений по разделам вроде автомобилей, жилья, вакансий, техники и сервисов, с лимитом в одно бесплатное для борьбы со спамом, как указано в регламенте. Простой поиск по местоположению, стоимости и видам, связь с социальными сетями для повышения охвата, плюс VIP-варианты и разделы магазинов обеспечивают легкость и скорость использования, в том числе для начинающих. https://ynla.ru — это ваш ключ к успешным сделкам без посредников. Миллионы просмотров, мобильная оптимизация и реальные отзывы от пользователей подчеркивают ее популярность, помогая найти идеального покупателя или продавца в считанные минуты и упрощая повседневную жизнь.
купить диплом в когалыме rudik-diplom4.ru .
Upgrade your anonymity game with an antidetect browser. Designed for large agencies and advanced users, it offers robust features for automation, team collaboration, and high-level digital stealth.
https://telegra.ph/Consejos-de-Hidrataci%C3%B3n-para-un-Examen-de-Orina-Exitoso-en-Chile-09-11
Purificacion para examen de orina se ha vuelto en una opcion cada vez mas reconocida entre personas que necesitan eliminar toxinas del organismo y superar pruebas de test de drogas. Estos productos estan disenados para facilitar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente las relacionadas con el consumo de cannabis u otras sustancias.
Un buen detox para examen de orina debe ofrecer resultados rapidos y confiables, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas garantizan un proceso seguro o fiable.
?Como funciona un producto detox? En terminos simples, estos suplementos operan acelerando la eliminacion de metabolitos y residuos a traves de la orina, reduciendo su nivel hasta quedar por debajo del umbral de deteccion de los tests. Algunos funcionan en cuestion de horas y su efecto puede durar entre 4 a cinco horas.
Es fundamental combinar estos productos con adecuada hidratacion. Beber al menos 2 litros de agua por jornada antes y despues del uso del detox puede mejorar los resultados. Ademas, se aconseja evitar alimentos pesados y bebidas procesadas durante el proceso de preparacion.
Los mejores productos de detox para orina incluyen ingredientes como extractos de naturales, vitaminas del grupo B y minerales que apoyan el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas populares, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con ventanas de accion largas o iniciar una preparacion previa. Mientras mas prolongada sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la planificacion con el uso correcto del suplemento es clave.
Un error comun es pensar que todos los detox actuan lo mismo. Existen diferencias en formulacion, sabor, metodo de ingesta y duracion del impacto. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o preparacion previa al dia del examen. Estos programas suelen recomendar abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que todo detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk022.ru
лечение запоя смоленск
https://www.rwaq.org/users/dirreepiipa-20250722133620
Корзины цветов — это камерная роскошь, которая уместна дома, в офисе и на мероприятиях: готовая композиция не требует вазы и сразу создаёт атмосферу. В каталоге «Флорион» — десятки решений от изящных до масштабных, с гибкими ценами и фильтрами по цветам и поводам. Оцените подбор на https://www.florion.ru/catalog/korziny-cvetov и выбирайте формат — романтичный, праздничный или строгий. Свежесть, аккуратная посадка в оазис и оперативная доставка по Москве гарантированы.
Find the best tools with a comprehensive antidetect browser rating. This crucial information helps digital marketers and e-commerce professionals select a reliable solution for managing multiple online identities securely.
Капельница от запоя — данная эффективных процедур, применяемых специалистами в области наркологии для очищения организма. Нарколог на дом анонимно в вашем регионе надеется предложить такие услуги: помощь при алкоголизме и восстановление пациентов после запоев. При помощи капельницы возможно быстро улучшить состояние пациента, уменьшить проявления абстиненции и ускорить процесс вывода токсинов из организма. Медицинская помощь при запое состоит не только из не только капельниц, но также психотерапию при алкоголизме, что способствует способствует лучшему пониманию проблемы алкогольной зависимости. Предотвращение запоев также является важным аспектом, поэтому рекомендуют регулярные консультации и анонимную помощь. Реабилитация алкоголиков требует целостного подхода, включающего в себя медицинские и психологические аспекты. Рекомендуем обратиться к специалисту, чтобы получить советы нарколога и приступить к процессу выздоровления.
1win 1win
https://telegra.ph/Consejos-de-Hidrataci%C3%B3n-para-un-Examen-de-Orina-Exitoso-en-Chile-09-11
Purificacion para examen de muestra se ha convertido en una solucion cada vez mas popular entre personas que buscan eliminar toxinas del sistema y superar pruebas de analisis de drogas. Estos suplementos estan disenados para facilitar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente esas relacionadas con el uso de cannabis u otras sustancias ilicitas.
Un buen detox para examen de fluido debe ofrecer resultados rapidos y efectivos, en particular cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas opciones, pero no todas garantizan un proceso seguro o efectivo.
Que funciona un producto detox? En terminos basicos, estos suplementos funcionan acelerando la depuracion de metabolitos y toxinas a traves de la orina, reduciendo su presencia hasta quedar por debajo del limite de deteccion de ciertos tests. Algunos actuan en cuestion de horas y su accion puede durar entre 4 a seis horas.
Es fundamental combinar estos productos con buena hidratacion. Beber al menos par litros de agua por jornada antes y despues del consumo del detox puede mejorar los resultados. Ademas, se sugiere evitar alimentos grasos y bebidas azucaradas durante el proceso de preparacion.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del grupo B y minerales que apoyan el funcionamiento de los sistemas y la funcion hepatica. Entre las marcas mas destacadas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con margenes de accion largas o iniciar una preparacion previa. Mientras mas extendida sea la abstinencia, mayor sera la efectividad del producto. Por eso, combinar la planificacion con el uso correcto del suplemento es clave.
Un error comun es pensar que todos los detox actuan igual. Existen diferencias en contenido, sabor, metodo de toma y duracion del resultado. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incorporan fases de preparacion o purga previa al dia del examen. Estos programas suelen recomendar abstinencia, buena alimentacion y descanso previo.
Por ultimo, es importante recalcar que ningun detox garantiza 100% de exito. Siempre hay variables personales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
https://form.jotform.com/252472787582066
Искусственные венки — практичное решение: выглядят реалистично, не вянут, выдерживают активный день и переиспользование. В «Флорион» — десятки моделей от воздушных пастельных до ярких тематических, с легкой посадкой и надежной фиксацией. Это экономично и удобно для карнавалов, свадеб и съемок. Подберите образ на https://www.florion.ru/catalog/venok-iz-iskusstvennyh-cvetov — весь каталог с фото и ценами, доставка по Москве. Долговечная красота, которая всегда под рукой.
https://www.band.us/band/99531123/
Adoro o brilho de Richville Casino, e um cassino online que reluz como um palacio dourado. Tem uma cascata de jogos de cassino fascinantes, com caca-niqueis de cassino modernos e envolventes. O suporte do cassino esta sempre disponivel 24/7, com uma ajuda que reluz como ouro. As transacoes do cassino sao simples como abrir um cofre, mas queria mais promocoes de cassino que brilhem como diamantes. Resumindo, Richville Casino e um cassino online que exsuda riqueza para os amantes de cassinos online! De lambuja a interface do cassino e fluida e brilha como um salao de baile, eleva a imersao no cassino ao apice.
richville|
https://muckrack.com/person-27441645
Galera, quero registrar aqui no 4PlayBet Casino porque me pegou de surpresa. A variedade de jogos e simplesmente incrivel: slots modernos, todos com graficos de primeira. O suporte foi rapido, responderam em minutos pelo chat, algo que raramente vi. Fiz saque em cartao e o dinheiro entrou mais ligeiro do que imaginei, ponto fortissimo. Se tivesse que criticar, diria que senti falta de ofertas recorrentes, mas isso nao estraga a experiencia. Enfim, o 4PlayBet Casino e parada obrigatoria pra quem gosta de cassino. Vale experimentar.
drive moto g 4play|
«СХТ» реализует автоматизированные весовые комплексы с интеграцией программного обеспечения и оборудования на одном подрядчике. Полевые сервисные команды и лаборатория проводят оперативный ремонт и ежегодную поверку более 2000 единиц. Подробности, примеры реализованных объектов и запрос коммерческого предложения — на https://xn--q1aci.xn--p1ai/ Поставки и строительство ведутся по всей РФ: от монтажа до сдачи комплекса в промышленную эксплуатацию.
В установочном центре APVShop модернизация авто начинается с диагностики и плана работ: мультимедиа, автозвук, тюнинг и дооснащение с гарантией. Ищете оклейка авто антигравийной пленкой? apvshop.ru/category/uslugi-ustanovochnogo-tsentra — здесь вы найдете состав услуг, сроки и запись в установочный центр в СПб. Мастера аккуратно прокладывают проводку, кодируют функции и настраивают системы под ваши привычки. Четкие дедлайны и понятная смета позволяют заранее спланировать бюджет и время.
Estou completamente encantado por RioPlay Casino, tem uma vibe de jogo tao animada quanto um desfile na Sapucai. As opcoes de jogo no cassino sao ricas e dancantes, com caca-niqueis de cassino modernos e cheios de ritmo. O atendimento ao cliente do cassino e uma bateria de escola de samba, acessivel por chat ou e-mail. As transacoes do cassino sao simples como um passo de samba, de vez em quando as ofertas do cassino podiam ser mais generosas. Em resumo, RioPlay Casino oferece uma experiencia de cassino que e puro axe para os folioes do cassino! Vale dizer tambem a interface do cassino e fluida e vibrante como uma escola de samba, adiciona um toque de axe ao cassino.
rioplay Г© confiГЎvel|
Нейросетевые поисковые системы для поиска информации становятся всё более удобными.
Они дают возможность собирать доступные данные из интернета.
Такие инструменты используются для исследований.
Они способны точно обрабатывать большие объёмы информации.
глаз бога пробив данных
Это способствует сформировать более полную картину событий.
Многие системы также включают инструменты фильтрации.
Такие боты широко используются среди аналитиков.
Совершенствование технологий превращает поиск информации эффективным и быстрым.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
https://info71604.pages10.com/un-arma-secreta-para-detox-examen-de-orina-73117765
Detox para examen de orina se ha convertido en una solucion cada vez mas reconocida entre personas que necesitan eliminar toxinas del organismo y superar pruebas de test de drogas. Estos formulas estan disenados para ayudar a los consumidores a limpiar su cuerpo de sustancias no deseadas, especialmente esas relacionadas con el ingesta de cannabis u otras sustancias ilicitas.
Un buen detox para examen de orina debe ofrecer resultados rapidos y visibles, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas variedades, pero no todas garantizan un proceso seguro o fiable.
?Como funciona un producto detox? En terminos claros, estos suplementos operan acelerando la depuracion de metabolitos y toxinas a traves de la orina, reduciendo su nivel hasta quedar por debajo del limite de deteccion de los tests. Algunos funcionan en cuestion de horas y su accion puede durar entre 4 a cinco horas.
Resulta fundamental combinar estos productos con adecuada hidratacion. Beber al menos par litros de agua al dia antes y despues del consumo del detox puede mejorar los beneficios. Ademas, se recomienda evitar alimentos pesados y bebidas azucaradas durante el proceso de desintoxicacion.
Los mejores productos de detox para orina incluyen ingredientes como extractos de hierbas, vitaminas del complejo B y minerales que apoyan el funcionamiento de los organos y la funcion hepatica. Entre las marcas mas vendidas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con tiempos de accion largas o iniciar una preparacion temprana. Mientras mas larga sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la planificacion con el uso correcto del suplemento es clave.
Un error comun es pensar que todos los detox actuan igual. Existen diferencias en formulacion, sabor, metodo de ingesta y duracion del resultado. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o limpieza previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso previo.
Por ultimo, es importante recalcar que ninguno detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no relajarse.
Galera, nao podia deixar de comentar no 4PlayBet Casino porque me pegou de surpresa. A variedade de jogos e surreal: poquer estrategico, todos funcionando perfeito. O suporte foi atencioso, responderam em minutos pelo chat, algo que me deixou confiante. Fiz saque em Ethereum e o dinheiro entrou na mesma hora, ponto fortissimo. Se tivesse que criticar, diria que seria legal torneios de slots, mas isso nao estraga a experiencia. Resumindo, o 4PlayBet Casino e parada obrigatoria pra quem gosta de cassino. Eu ja voltei varias vezes.
brazzers office 4play|
Капельница от запоя на дому: противопоказания и возможные осложнения (владимир) Алкогольная зависимость – серьезная проблема, требующая профессионального подхода. Все чаще люди обращаются к услугам нарколога на дому для борьбы с запоем. Эффективным методом является инфузионная терапия, предполагающая использование капельницы для выхода из запоя. Капельница помогает восстановить водно-электролитный баланс, улучшить общее состояние пациента и снять симптомы абстиненции. Тем не менее, необходимо учитывать противопоказания к данной процедуре. К противопоказаниям относятся аллергия на компоненты растворов, заболевания сердечно-сосудистой системы и острые инфекционные процессы, которые могут помешать проведению капельницы. К возможным осложнениям относятся тромбофлебит, инфицирование вены и аллергические реакции. Таким образом, консультация нарколога перед началом лечения алкоголизма на дому является необходимостью. Безопасность процедуры зависит от уровня квалификации специалиста и соблюдения всех предписаний. Услуги нарколога на дому в владимире предоставляют возможность получения медицинской помощи в удобной обстановке, что делает реабилитацию от запоя более эффективной.
Fiquei impressionado com BETesporte Casino, transporta para um mundo de apostas vibrante. Ha uma multidao de jogos emocionantes, incluindo apostas esportivas palpitantes. Com uma oferta inicial para impulsionar. O servico esta disponivel 24/7, garantindo atendimento de alto nivel. Os ganhos chegam sem demora, as vezes bonus mais variados seriam um gol. Para finalizar, BETesporte Casino oferece uma experiencia inesquecivel para jogadores em busca de emocao ! Adicionalmente a plataforma e visualmente impactante, tornando cada sessao mais competitiva. Igualmente impressionante as opcoes variadas de apostas esportivas, que impulsiona o engajamento.
Abrir agora|
https://yamap.com/users/4802306
лечение запоя смоленск
vivod-iz-zapoya-smolensk023.ru
вывод из запоя смоленск
Tenho uma paixao intensa por BETesporte Casino, proporciona uma aventura competitiva. A selecao de jogos e fenomenal, suportando jogos adaptados para criptos. 100% ate R$600 + apostas gratis. O servico esta disponivel 24/7, com suporte preciso e rapido. Os ganhos chegam sem demora, no entanto recompensas extras seriam um hat-trick. Em resumo, BETesporte Casino e indispensavel para apostadores para entusiastas de jogos modernos ! Vale destacar a navegacao e intuitiva e rapida, adiciona um toque de estrategia. Outro destaque os torneios regulares para rivalidade, fortalece o senso de comunidade.
Visitar hoje|
https://tech37270.ampedpages.com/una-revisiГіn-de-detox-examen-de-orina-64717793
Detox para examen de orina se ha transformado en una solucion cada vez mas reconocida entre personas que necesitan eliminar toxinas del sistema y superar pruebas de test de drogas. Estos suplementos estan disenados para facilitar a los consumidores a purgar su cuerpo de componentes no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras drogas.
Uno buen detox para examen de orina debe ofrecer resultados rapidos y efectivos, en especial cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas garantizan un proceso seguro o rapido.
?Como funciona un producto detox? En terminos claros, estos suplementos funcionan acelerando la expulsion de metabolitos y componentes a traves de la orina, reduciendo su concentracion hasta quedar por debajo del nivel de deteccion de ciertos tests. Algunos actuan en cuestion de horas y su efecto puede durar entre 4 a 6 horas.
Resulta fundamental combinar estos productos con adecuada hidratacion. Beber al menos dos litros de agua por jornada antes y despues del consumo del detox puede mejorar los beneficios. Ademas, se aconseja evitar alimentos pesados y bebidas azucaradas durante el proceso de preparacion.
Los mejores productos de purga para orina incluyen ingredientes como extractos de naturales, vitaminas del tipo B y minerales que favorecen el funcionamiento de los organos y la funcion hepatica. Entre las marcas mas populares, se encuentran aquellas que tienen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de accion largas o iniciar una preparacion previa. Mientras mas prolongada sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la organizacion con el uso correcto del producto es clave.
Un error comun es pensar que todos los detox actuan igual. Existen diferencias en dosis, sabor, metodo de ingesta y duracion del efecto. Algunos vienen en presentacion liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que agregan fases de preparacion o preparacion previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso previo.
Por ultimo, es importante recalcar que ninguno detox garantiza 100% de exito. Siempre hay variables biologicas como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no relajarse.
https://repo.getmonero.org/candetoxblend
Aprobar una prueba preocupacional puede ser complicado. Por eso, existe una formula avanzada desarrollada en Canada.
Su composicion eficaz combina minerales, lo que ajusta tu organismo y oculta temporalmente los marcadores de sustancias. El resultado: una orina con parametros normales, lista para ser presentada.
Lo mas valioso es su ventana de efectividad de 4 a 5 horas. A diferencia de otros productos, no promete milagros, sino una herramienta puntual que funciona cuando lo necesitas.
Estos fórmulas están diseñados para colaborar a los consumidores a depurar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras sustancias.
Uno buen detox para examen de fluido debe ofrecer resultados rápidos y visibles, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas garantizan un proceso seguro o efectivo.
De qué funciona un producto detox? En términos simples, estos suplementos operan acelerando la expulsión de metabolitos y componentes a través de la orina, reduciendo su nivel hasta quedar por debajo del límite de detección de los tests. Algunos actúan en cuestión de horas y su efecto puede durar entre 4 a seis horas.
Parece fundamental combinar estos productos con buena hidratación. Beber al menos dos litros de agua por jornada antes y después del uso del detox puede mejorar los beneficios. Además, se aconseja evitar alimentos pesados y bebidas azucaradas durante el proceso de preparación.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del complejo B y minerales que favorecen el funcionamiento de los órganos y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación temprana. Mientras más prolongada sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la planificación con el uso correcto del detox es clave.
Un error común es creer que todos los detox actúan lo mismo. Existen diferencias en dosis, sabor, método de ingesta y duración del resultado. Algunos vienen en envase líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incorporan fases de preparación o preparación previa al día del examen. Estos programas suelen instruir abstinencia, buena alimentación y descanso recomendado.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
Miles de personas en Chile ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta solucion te ofrece seguridad.
https://odysee.com/@rambergmimi8
seo продвижение в интернете москва seo продвижение в интернете москва .
рейтинг seo агентств рейтинг seo агентств .
агентство seo агентство seo .
https://imageevent.com/oajojajipy/mijhx
https://telegra.ph/Consejos-de-Hidrataci%C3%B3n-para-un-Examen-de-Orina-Exitoso-en-Chile-09-11
Detox para examen de miccion se ha transformado en una alternativa cada vez mas conocida entre personas que requieren eliminar toxinas del sistema y superar pruebas de analisis de drogas. Estos formulas estan disenados para colaborar a los consumidores a limpiar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras drogas.
Uno buen detox para examen de orina debe brindar resultados rapidos y visibles, en especial cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas aseguran un proceso seguro o rapido.
De que funciona un producto detox? En terminos basicos, estos suplementos funcionan acelerando la depuracion de metabolitos y residuos a traves de la orina, reduciendo su concentracion hasta quedar por debajo del limite de deteccion de ciertos tests. Algunos trabajan en cuestion de horas y su efecto puede durar entre 4 a 6 horas.
Es fundamental combinar estos productos con buena hidratacion. Beber al menos par litros de agua por jornada antes y despues del consumo del detox puede mejorar los resultados. Ademas, se recomienda evitar alimentos grasos y bebidas azucaradas durante el proceso de desintoxicacion.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de hierbas, vitaminas del grupo B y minerales que favorecen el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas destacadas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con margenes de accion largas o iniciar una preparacion anticipada. Mientras mas larga sea la abstinencia, mayor sera la eficacia del producto. Por eso, combinar la organizacion con el uso correcto del suplemento es clave.
Un error comun es pensar que todos los detox actuan lo mismo. Existen diferencias en dosis, sabor, metodo de uso y duracion del efecto. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incorporan fases de preparacion o purga previa al dia del examen. Estos programas suelen instruir abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que ninguno detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
https://3dwarehouse.sketchup.com/by/candetoxblend
Superar un control sorpresa puede ser estresante. Por eso, existe un suplemento innovador probada en laboratorios.
Su receta potente combina minerales, lo que prepara tu organismo y enmascara temporalmente los rastros de alcaloides. El resultado: una prueba sin riesgos, lista para pasar cualquier control.
Lo mas notable es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete milagros, sino una estrategia de emergencia que funciona cuando lo necesitas.
Estos fórmulas están diseñados para colaborar a los consumidores a purgar su cuerpo de residuos no deseadas, especialmente esas relacionadas con el consumo de cannabis u otras drogas.
Uno buen detox para examen de fluido debe ofrecer resultados rápidos y confiables, en especial cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas alternativas, pero no todas aseguran un proceso seguro o fiable.
Qué funciona un producto detox? En términos básicos, estos suplementos funcionan acelerando la eliminación de metabolitos y residuos a través de la orina, reduciendo su concentración hasta quedar por debajo del umbral de detección de ciertos tests. Algunos trabajan en cuestión de horas y su efecto puede durar entre 4 a 6 horas.
Parece fundamental combinar estos productos con correcta hidratación. Beber al menos dos litros de agua por jornada antes y después del uso del detox puede mejorar los efectos. Además, se aconseja evitar alimentos difíciles y bebidas procesadas durante el proceso de preparación.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de naturales, vitaminas del grupo B y minerales que respaldan el funcionamiento de los riñones y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación anticipada. Mientras más larga sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la disciplina con el uso correcto del suplemento es clave.
Un error común es creer que todos los detox actúan lo mismo. Existen diferencias en contenido, sabor, método de ingesta y duración del resultado. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incluyen fases de preparación o preparación previa al día del examen. Estos programas suelen instruir abstinencia, buena alimentación y descanso previo.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no confiarse.
Miles de personas en Chile ya han experimentado su rapidez. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta solucion te ofrece tranquilidad.
https://f7e03a9dc710bb1201bdc04876.doorkeeper.jp/
top 100 seo reiting-seo-agentstv.ru .
сео продвижение сайтов топ москва сео продвижение сайтов топ москва .
https://information74063.blogminds.com/examine-este-informe-sobre-detox-examen-de-orina-34707088
Purificacion para examen de orina se ha transformado en una solucion cada vez mas reconocida entre personas que buscan eliminar toxinas del cuerpo y superar pruebas de analisis de drogas. Estos productos estan disenados para colaborar a los consumidores a purgar su cuerpo de sustancias no deseadas, especialmente esas relacionadas con el consumo de cannabis u otras drogas.
El buen detox para examen de fluido debe proporcionar resultados rapidos y efectivos, en especial cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas opciones, pero no todas garantizan un proceso seguro o rapido.
?Como funciona un producto detox? En terminos claros, estos suplementos funcionan acelerando la expulsion de metabolitos y toxinas a traves de la orina, reduciendo su concentracion hasta quedar por debajo del limite de deteccion de los tests. Algunos funcionan en cuestion de horas y su efecto puede durar entre 4 a 6 horas.
Resulta fundamental combinar estos productos con adecuada hidratacion. Beber al menos dos litros de agua al dia antes y despues del ingesta del detox puede mejorar los beneficios. Ademas, se aconseja evitar alimentos pesados y bebidas azucaradas durante el proceso de desintoxicacion.
Los mejores productos de detox para orina incluyen ingredientes como extractos de plantas, vitaminas del tipo B y minerales que favorecen el funcionamiento de los sistemas y la funcion hepatica. Entre las marcas mas vendidas, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con tiempos de accion largas o iniciar una preparacion temprana. Mientras mas extendida sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la planificacion con el uso correcto del producto es clave.
Un error comun es creer que todos los detox actuan lo mismo. Existen diferencias en formulacion, sabor, metodo de ingesta y duracion del impacto. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incluyen fases de preparacion o preparacion previa al dia del examen. Estos programas suelen instruir abstinencia, buena alimentacion y descanso adecuado.
Por ultimo, es importante recalcar que ningun detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
music event
Looking for kavala airport transfer? Transfer SKG transfer-thessaloniki.gr – Professional Airport Transfers & Private Tours. Dependable transfers from Thessaloniki Airport across Halkidiki — Kassandra, Sithonia, and Mount Athos entry towns. Seamless rides to luxury resorts including Sani, Ikos Oceania, and Porto Carras. Private transfers, VIP chauffeur service, group transport, hourly hire. Signature excursions to Meteora, Olympus & Dion, Vergina-Pella, Halkidiki highlights, Pozar thermal baths, and the Edessa water cascades. Why choose us: upfront fixed fares from €25, real-time flight tracking, 24/7 service, late?model fleet, multilingual drivers (EN/RU/GR).
Najnowsza wersja BonBon Blast – Sugar Rush jest 1.1.0, wydany na 15.12.2023. Początkowo był to dodane do naszej bazy na 15.12.2023. W Regulaminie znajduje się również cała strona o ochronie danych, darmowe automaty kasynowe każde zamówienie 1 spowoduje nagrodę w wysokości 1250 dolarów. Producentów automatów ciągle inwestują w rozwój nowych funkcji i elementów, która rozpoczęła się od 2023 roku i cieszy się popularnością wśród brytyjskich graczy. Pomoże Ci to lepiej poznać samą grę, aby wypróbować Kasyno przed grą z prawdziwą gotówką. Region: Global Im bardziej celowo te zadania są obsługiwane, co przyciągnie jeszcze większą liczbę graczy. Typy na wygraną w sugar rush net Entertainment naprawdę wyprodukował tutaj piękno, ale ich Kasyno to coś innego. Korzystaj tylko z usług licencjonowanych kasyn online, z ogromną listą gier.
https://www.callupcontact.com/b/businessprofile/Jesse_Curry_71135/9816559
ONE Blackjack, Sugar Rush, Sweet Bonanza Branża gier online nadal ewoluuje, a oferty premium, takie jak Fontan Casino, stają się obecne na rynku. Platforma ta obsługuje ponad 3000 tytułów od uznanych dostawców, w tym NetEnt i Microgaming. Nowi gracze otrzymują znaczne zachęty – bonus 15 € bez depozytu i opcje dopasowania do 500 €. Interfejs kasyna integruje klasyczne automaty, gry stołowe i doświadczenia z krupierem na żywo w usprawnionym środowisku. Połączenie różnorodności gier i struktury bonusów uzasadnia dalsze badanie. Dostawcy gier kasynowych fontan reprezentują starannie wyselekcjonowany wybór, który równoważy uznane oprogramowanie do gier kasynowych fontan z wschodzącymi talentami, zapewniając współistnienie zarówno sprawdzonych klasyków, jak i pionierskich wydań w tym wszechogarniającym ekosystemie witryn bukmacherskich.
https://tech37270.ampedpages.com/una-revisiГіn-de-detox-examen-de-orina-64717793
Detox para examen de miccion se ha vuelto en una alternativa cada vez mas reconocida entre personas que necesitan eliminar toxinas del sistema y superar pruebas de deteccion de drogas. Estos productos estan disenados para facilitar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente las relacionadas con el consumo de cannabis u otras sustancias ilicitas.
Un buen detox para examen de pipi debe brindar resultados rapidos y visibles, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas opciones, pero no todas garantizan un proceso seguro o efectivo.
?Como funciona un producto detox? En terminos basicos, estos suplementos actuan acelerando la eliminacion de metabolitos y componentes a traves de la orina, reduciendo su nivel hasta quedar por debajo del nivel de deteccion de los tests. Algunos funcionan en cuestion de horas y su accion puede durar entre 4 a 6 horas.
Resulta fundamental combinar estos productos con correcta hidratacion. Beber al menos 2 litros de agua al dia antes y despues del uso del detox puede mejorar los resultados. Ademas, se aconseja evitar alimentos pesados y bebidas procesadas durante el proceso de desintoxicacion.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de plantas, vitaminas del grupo B y minerales que respaldan el funcionamiento de los rinones y la funcion hepatica. Entre las marcas mas populares, se encuentran aquellas que tienen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con tiempos de accion largas o iniciar una preparacion anticipada. Mientras mas larga sea la abstinencia, mayor sera la potencia del producto. Por eso, combinar la organizacion con el uso correcto del detox es clave.
Un error comun es pensar que todos los detox actuan identico. Existen diferencias en formulacion, sabor, metodo de toma y duracion del resultado. Algunos vienen en envase liquido, otros en capsulas, y varios combinan ambos.
Ademas, hay productos que incluyen fases de preparacion o preparacion previa al dia del examen. Estos programas suelen sugerir abstinencia, buena alimentacion y descanso recomendado.
Por ultimo, es importante recalcar que todo detox garantiza 100% de exito. Siempre hay variables individuales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no descuidarse.
https://www.divephotoguide.com/user/oifyabwudec
brandlift.click – Navigation is intuitive and the content seems organised clearly.
Квартира с отделкой https://новостройкивспб.рф экономия времени и предсказуемый бюджет. Фильтруем по планировкам, материалам, классу дома и акустике. Проверяем стандарт отделки, толщину стяжки, ровность стен, работу дверей/окон, скрытые коммуникации. Приёмка по дефект-листу, штрафы за просрочку.
Парвеник — это правильные веники и травы для настоящей русской бани: дуб, берёза, эвкалипт, ароматные сборы, аксессуары и удобная доставка по Москве и Подмосковью через пункты выдачи. Цены честно снижаются при покупке от двух единиц, а акция 5+1 даёт ощутимую экономию. Заказать просто: на https://www.parvenik.ru/ есть подробные карточки и указаны актуальные условия выдачи. Свежие партии 2025 года, гибкие опции оплаты и тысячи удачных заказов — чтобы пар был лёгким, а отдых — целебным.
Estou totalmente fascinado por PlayPIX Casino, e uma plataforma que vibra com intensidade. As opcoes sao amplas como um festival, com slots de design inovador. 100% ate €500 + rodadas gratis. A assistencia e eficiente e amigavel, sempre pronto para resolver. Os saques sao rapidos como um raio, contudo promocoes mais frequentes dariam um toque extra. Em sintese, PlayPIX Casino e essencial para jogadores para fas de cassino online ! Tambem o site e rapido e cativante, instiga a prolongar a experiencia. Outro destaque o programa VIP com niveis exclusivos, que aumenta o engajamento.
Descobrir a web|
пин ап приложение не работает пин ап приложение не работает
Oops, something went wrong. Please try again. Why Are My Eyelashes Falling Out? American Academy of Ophthalmology. Published February 12, 2021. uklash Eyelash Serum Clear Brow Setting Gel In 2008, bimatoprost was re-launched as Latisse (Allegan), an FDA-approved therapy for the treatment of hypotrichiasis.3 It is commonly used to treat trichotillomania, chemotherapy-induced eyelash loss, and alopecia areata lash loss. Nightly application of Latisse, applied in a thin line along the eyelash margins, showed maximal effectivity of lash enhancement at 16 weeks of usage.3 Hailey Hoff, a celebrity makeup artist who has worked with everyone from Audrina Patridge to Noah Cyrus, stresses the importance of skimming the ingredients list before purchasing an eyelash growth serum. “You should look for peptides, red clover extract and biotin,” she says. Peptides help nourish the lash hair and repair damage, while biotin, a B vitamin, and red clover extract help strengthen lashes.
https://acbopecom1980.cavandoragh.org/how-do-you-apply-grande-lash-serum
JL: If someone isn’t sure what type of lash treatment they’re looking for, how can Live Love Lash help? The revolutionary alternative to eyelash extensions. Add length, volume, and lift to your natural lashes. Yes! Do not get lashes wet (shower, cry, sweat, swim) for 24 hours to allow the adhesive to bond to your natural lashes. Do not get your lashes hot steamy (spa, steam, tanning bed) for 24 hours. (please avoid eye creams for 24 hours before and after lash appointments) We pride ourselves at being experts at what we do. Our number one goal is to help you feel your very best. DIY Lashes That Last Up To 1 Week How to Use a Salon Website Builder in 10 Steps Hair Loved by Lily Get 15% off your first online purchase when you sign up for our newsletter! *By completing this form you’re signing up to receive our emails and can unsubscribe at any time.
«СХТ» реализует автоматизированные весовые комплексы с интеграцией программного обеспечения и оборудования на одном подрядчике. Полевые сервисные команды и лаборатория проводят оперативный ремонт и ежегодную поверку более 2000 единиц. Подробности, примеры реализованных объектов и запрос коммерческого предложения — на https://xn--q1aci.xn--p1ai/ Поставки и строительство ведутся по всей РФ: от монтажа до сдачи комплекса в промышленную эксплуатацию.
https://5ed9bcf3576fcc95d9d82d9c8a.doorkeeper.jp/
мухомор пантерный купить Онлайн-платформа muhomorus приглашает приобрести мухоморы с отправкой по всей территории РФ. Доступные цены на экологически чистые продукты, предназначенные для уменьшения тревоги, напряжения, подавленности, постоянной утомляемости и ослабления проявлений различных болезней. Высушенные мухоморы не числятся медикаментом, а причисляются к парафармацевтике, являющейся альтернативным методом, применяемым по личному решению как дополнительное лечение. Сбор, высушивание, реализация и приобретение – совершенно законны. Таким образом, предлагаем вам приобрести микродозинг на правомерных основаниях.
купить диплом в владивостоке купить диплом в владивостоке .
Всем добра! Вчера позвонил курьер, сказал, что посылка в городе! Через пару часов я был уже на почте, забрав посылку, сел в машину, но вот поехать не получилось т.к. был задержан сотрудниками МИЛИЦИИ!!!! Четыре часа в отделении и пошёл домой!!! Экспертиза показала, что запрета нет, но сам факт приёмки очень напряг!!! Участились случаи приёмки на данной почте!!!!! Продаванам СПАСИБО и РЕСПЕКТ за чистоту реактивов!!! Покупатели держите ухо востро!!!!!!!!!! Больше с этой почтой не работаю(((( Если у кого есть опыт по схемам забирания пишите в личку!!!
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО
качество нормуль! можно делать 1к12, 1к10 само то
экстренный вывод из запоя краснодар
narkolog-krasnodar018.ru
экстренный вывод из запоя
гастроэнтеролог екатеринбург Медицинский центр “Шанс” предлагает комплексное обслуживание для пациентов всех возрастов. Этот современный многопрофильный центр оказывает широкий спектр медицинских услуг, ориентированных на потребности всей семьи. В “Шансе” работают врачи высокой квалификации, а в оснащение центра входит новейшее оборудование для диагностики. Ключевые направления деятельности включают в себя: лабораторные исследования, ультразвуковое обследование, функциональную диагностику, а также терапию заболеваний различных органов и систем.
Profitez d’un code promo unique sur 1xBet permettant a chaque nouveau joueur de beneficier jusqu’a 100€ de bonus sportif a hauteur de 100% en 2026. Le bonus sera ajoute a votre solde en fonction de votre premier depot, le depot minimum etant fixe a 1€. Pour eviter toute perte de bonus, veillez a copier soigneusement le code depuis la source et a le saisir dans le champ « code promo (si disponible) » lors de l’inscription, afin de preserver l’integrite de la combinaison. D’autres promotions existent en plus du bonus de bienvenue, d’autres combinaisons vous permettant d’obtenir des bonus supplementaires sont disponibles dans la section « Vitrine des codes promo ». Vous pouvez trouver le code promo 1xbet sur ce lien — https://www.lamarinda.it/wp-content/pgs/tufli_oseny_2015.html.
купить диплом математика https://rudik-diplom2.ru/ – купить диплом математика .
Очень жаль ребята,хорошо работали.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Крутой магаз. Ассортимент радует
Ich bin vollig verzaubert von Trickz Casino, es bietet ein Casino-Abenteuer, das wie eine Illusion verblufft. Die Spielauswahl im Casino ist wie ein Zauberkoffer voller Wunder, inklusive stilvoller Casino-Tischspiele. Der Casino-Support ist rund um die Uhr verfugbar, mit Hilfe, die wie eine Illusion verblufft. Auszahlungen im Casino sind schnell wie ein Zaubertrick, dennoch wurde ich mir mehr Casino-Promos wunschen, die wie Zaubertranke wirken. Alles in allem ist Trickz Casino ein Online-Casino, das wie ein Zirkus der Magie strahlt fur die, die mit Stil im Casino wetten! Und au?erdem das Casino-Design ist ein optisches Hexenwerk, Lust macht, immer wieder ins Casino zuruckzukehren.
casino trickz|
Je suis subjugue par Donbet Casino, ca transporte dans une tempete de plaisirs. Il y a une avalanche de jeux captivants, proposant des paris sportifs qui font monter l’adrenaline. Le service client est d’une efficacite foudroyante, repondant en un eclair. Les gains arrivent a une vitesse supersonique, neanmoins des tours gratuits en plus feraient vibrer. Au final, Donbet Casino est une plateforme qui fait trembler les sens pour ceux qui cherchent l’adrenaline pure ! De plus la navigation est intuitive comme un eclair, donne envie de replonger dans la tempete.
donbet trustpilot|
Вызов нарколога в владимире – ключевой шаг для людей‚ сталкивающихся с проблемами зависимости. На сайте vivod-iz-zapoya-vladimir026.ru вы имеете возможность обратиться за квалифицированной помощью. Наркологическая помощь включает диагностику зависимости и конфиденциальное лечение. Если у вас возникли алкогольная или наркотическая зависимость‚ срочный вызов врача поможет избежать последствий. Центры реабилитации предоставляют программы восстановления и поддержку семьи‚ что является важным для успешного лечения. Консультация нарколога – это начальный этап на пути к исцелению. Не откладывайте‚ обратитесь за медицинской помощью незамедлительно!
Выбор Идеального TikTok Mod: Последняя Версия, Русский Язык и Безопасность Чтобы получить максимальную отдачу от TikTok мода, важно выбирать последнюю версию, которая содержит все новейшие функции и исправления ошибок. Запросы “тикток мод последняя версия 2025” и “скачать тикток мод последняя версия” это подтверждают. Кроме того, для многих пользователей важна поддержка русского языка, поэтому “русский тикток мод” и “тикток мод русская версия” также пользуются популярностью. Но, прежде всего, необходимо помнить о безопасности. Перед установкой мода обязательно проверьте его на наличие вирусов и других вредоносных программ. Используйте надежные антивирусные сканеры и читайте отзывы других пользователей. Только так можно наслаждаться всеми преимуществами модифицированного TikTok, не подвергая риску свое устройство и личные данные. тикток мод скачать андроид бесплатно последнюю
тик ток мод на айфон 2025 Поиск Идеального Мода: Telegram как Ключевой Источник Востребованность запросов “скачать тик ток мод телеграм” и “скачать тик ток мод 2025 тг” указывает на Telegram как на популярную платформу для распространения модифицированных приложений. Однако, безопасность должна быть приоритетом: загружайте файлы только из проверенных источников, чтобы избежать вредоносного ПО. Определитесь, какой функционал вам необходим: отключение рекламы, расширенные инструменты редактирования, скачивание видео без водяных знаков, или обход региональных ограничений.
Получи 32500 руб. по актуальному промо коду для 1хБет бесплатно. Новые купоны на регистрацию каждый час на сайте. В ваших силах получить до шести с половиной тысяч рублей при регистрации. Читайте ниже как использовать наши промо-коды. рабочий промокод 1хбет на сегодня. Букмекерская контора позволяет использовать промокод 1хБет на ставку-бонус. Забирайте новые купоны ежедневно. Внимание! Наши промо-купоны подходят для всех акций букмекера. Этот купон также универсальный – используйте его везде, не только при регистрации на сайте БК 1хБет и всех известных его зеркал. Введите его в форме для регистрации и получите увеличенный бонус на первый депозит до 32500 рублей. Кроме того, букмекер постоянно дарит активным клиентам выгодные подарки. Чтобы получить промокод в 1xBet бесплатно: Подпишитесь на рассылку новостей по смс или электронной почте. Регулярно заходите в раздел «Бонусы и подарки» в Личном кабинете.
пин ап способы оплаты пин ап способы оплаты
друзья а товар что закончился? месяц пишу, и говорят все пусто;(
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО
Адекватным людям ценящих проффесианолизм рекомендую реактивы тут тарить…
douglasand55 – Very polished design, strong visuals and clear professional tone.
https://openlibrary.org/people/candetoxblend
Pasar un control sorpresa puede ser arriesgado. Por eso, se desarrollo una alternativa confiable desarrollada en Canada.
Su receta premium combina vitaminas, lo que prepara tu organismo y disimula temporalmente los trazas de alcaloides. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas interesante es su ventana de efectividad de 4 a 5 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una solucion temporal que funciona cuando lo necesitas.
Estos productos están diseñados para facilitar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente las relacionadas con el consumo de cannabis u otras sustancias ilícitas.
Uno buen detox para examen de pipí debe ofrecer resultados rápidos y visibles, en particular cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas opciones, pero no todas prometen un proceso seguro o fiable.
¿Cómo funciona un producto detox? En términos claros, estos suplementos operan acelerando la eliminación de metabolitos y residuos a través de la orina, reduciendo su concentración hasta quedar por debajo del umbral de detección de los tests. Algunos trabajan en cuestión de horas y su impacto puede durar entre 4 a cinco horas.
Parece fundamental combinar estos productos con correcta hidratación. Beber al menos par litros de agua diariamente antes y después del ingesta del detox puede mejorar los resultados. Además, se aconseja evitar alimentos grasos y bebidas azucaradas durante el proceso de uso.
Los mejores productos de purga para orina incluyen ingredientes como extractos de plantas, vitaminas del tipo B y minerales que favorecen el funcionamiento de los órganos y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación previa. Mientras más prolongada sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la organización con el uso correcto del detox es clave.
Un error común es creer que todos los detox actúan igual. Existen diferencias en dosis, sabor, método de toma y duración del resultado. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que agregan fases de preparación o purga previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
Miles de postulantes ya han comprobado su seguridad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece seguridad.
nighttoshineatlanta – Beautifully inspiring event site, visuals radiate joy and inclusion.
карта києва по районам
neighborsforrandy – Friendly community feel, layout conveys care and connection effectively.
https://community.cisco.com/t5/user/viewprofilepage/user-id/1916884
Gestionar una prueba de orina puede ser arriesgado. Por eso, ahora tienes una formula avanzada probada en laboratorios.
Su mezcla precisa combina creatina, lo que estimula tu organismo y oculta temporalmente los rastros de toxinas. El resultado: una prueba sin riesgos, lista para pasar cualquier control.
Lo mas interesante es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete resultados permanentes, sino una herramienta puntual que responde en el momento justo.
Estos productos están diseñados para colaborar a los consumidores a depurar su cuerpo de residuos no deseadas, especialmente aquellas relacionadas con el consumo de cannabis u otras sustancias.
Un buen detox para examen de pipí debe proporcionar resultados rápidos y confiables, en particular cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas opciones, pero no todas prometen un proceso seguro o rápido.
¿Cómo funciona un producto detox? En términos básicos, estos suplementos operan acelerando la expulsión de metabolitos y toxinas a través de la orina, reduciendo su nivel hasta quedar por debajo del umbral de detección de ciertos tests. Algunos funcionan en cuestión de horas y su impacto puede durar entre 4 a seis horas.
Parece fundamental combinar estos productos con correcta hidratación. Beber al menos 2 litros de agua diariamente antes y después del uso del detox puede mejorar los resultados. Además, se sugiere evitar alimentos grasos y bebidas azucaradas durante el proceso de uso.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de plantas, vitaminas del tipo B y minerales que respaldan el funcionamiento de los órganos y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación temprana. Mientras más prolongada sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la disciplina con el uso correcto del detox es clave.
Un error común es suponer que todos los detox actúan idéntico. Existen diferencias en dosis, sabor, método de uso y duración del resultado. Algunos vienen en envase líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incluyen fases de preparación o preparación previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que ningún detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no descuidarse.
Miles de personas en Chile ya han comprobado su efectividad. Testimonios reales mencionan paquetes 100% confidenciales.
Si necesitas asegurar tu resultado, esta formula te ofrece tranquilidad.
купить мухоморы Интернет-платформа muhomorus реализует мухоморы с отправкой по России. Доступные цены на экологически чистые товары, помогающие в борьбе с тревожностью, стрессовым состоянием, депрессивными настроениями, хронической усталостью и для облегчения симптоматики других болезней. Засушенные мухоморы не классифицируются как медикаменты, их относят к парафармацевтике, что представлет собой альтернативное средство, используемое индивидуально в роли поддерживающей терапии. Заготовка, сушка, сбыт и приобретение – абсолютно соответствуют закону. Поэтому приглашаем вас купить микродозинг полностью легально.
купить диплом техникума 1997 купить диплом техникума 1997 .
ct2020highschoolgrads – Heartwarming initiative, celebrating graduates with positivity and pride.
saratogapolarexpressride – Magical and festive, captures the holiday spirit with great warmth.
ТС, почисти ветки, ну невозможно же ничего почитать..в разных ветках одно и тоже.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
незнаю.сколько раз зака зывал , всегда приходило качество , был один момент когда был ркс 4. он был 15 минутный слабый. Но это сам реактив был такой. Он использовался как урб для добавок к другим. А так то что присылали всегда всё ровно. кач и кол..
купить диплом повара техникум купить диплом повара техникум .
экстренный вывод из запоя
narkolog-krasnodar019.ru
вывод из запоя
luxnoe – Modern and stylish, this site exudes luxury and creative design.
до 08.01 включительно выходные дни
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО
Работал с магазином спасибо всё красиво!
https://speakerdeck.com/candetoxblend
Gestionar una prueba preocupacional puede ser un desafio. Por eso, ahora tienes una formula avanzada probada en laboratorios.
Su receta unica combina nutrientes esenciales, lo que estimula tu organismo y oculta temporalmente los marcadores de THC. El resultado: una orina con parametros normales, lista para pasar cualquier control.
Lo mas notable es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete resultados permanentes, sino una herramienta puntual que responde en el momento justo.
Estos suplementos están diseñados para ayudar a los consumidores a limpiar su cuerpo de sustancias no deseadas, especialmente esas relacionadas con el consumo de cannabis u otras drogas.
Un buen detox para examen de pipí debe brindar resultados rápidos y confiables, en particular cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas variedades, pero no todas prometen un proceso seguro o efectivo.
¿Cómo funciona un producto detox? En términos básicos, estos suplementos actúan acelerando la eliminación de metabolitos y componentes a través de la orina, reduciendo su presencia hasta quedar por debajo del nivel de detección de los tests. Algunos trabajan en cuestión de horas y su impacto puede durar entre 4 a cinco horas.
Parece fundamental combinar estos productos con correcta hidratación. Beber al menos dos litros de agua diariamente antes y después del ingesta del detox puede mejorar los efectos. Además, se aconseja evitar alimentos difíciles y bebidas azucaradas durante el proceso de desintoxicación.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del grupo B y minerales que favorecen el funcionamiento de los sistemas y la función hepática. Entre las marcas más populares, se encuentran aquellas que tienen certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación temprana. Mientras más extendida sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la organización con el uso correcto del suplemento es clave.
Un error común es creer que todos los detox actúan igual. Existen diferencias en dosis, sabor, método de toma y duración del efecto. Algunos vienen en presentación líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que agregan fases de preparación o preparación previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso previo.
Por último, es importante recalcar que ningún detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir todas instrucciones del fabricante y no relajarse.
Miles de profesionales ya han experimentado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta solucion te ofrece respaldo.
karen4assembly – Clear and sincere campaign tone, content reflects leadership and integrity.
купить диплом с занесением в реестр украина http://frei-diplom2.ru .
Список бесплатных на сегодня промокодов 1xBet. Тип бесплатного промокода. Промокод промокод на бесплатную ставку. бесплатная промокоды в 1хбет на ставки. Как сегодня получить 32500 рублей по промокоду в 1xBet? Получение начинается после регистрации с рабочим промокодом и первого пополнения счета и составляет +100% к депозиту. Игрок может рассчитывать по промокоду до 32500 рублей, если пройдет верификацию и даст согласие на участие в рекламных предложениях букмекера. На сегодня акция по промокоду 1xBet распространяется на пользователей из России, Беларуси, Украины, Казахстана.
«Аврора Агро Партс» — онлайн каталог запчастей к сельхозтехнике с большим выбором оригиналов и качественных аналогов для John Deere, Claas, Assurpower, Greenly и других марок. Предусмотрен поиск по артикулу и названию, работают опт и розница, оперативная отгрузка со склада и консультации по подбору деталей. Подробности, цены и актуальные позиции — на https://aa-p.ru/catalog/germany Доступен самовывоз, бесплатная доставка до транспортной компании при выполнении условий и регулярно обновляемый прайс лист для удобного планирования.
Владимирская наркологическая служба предлагает широкий спектр услуг для лечения зависимостей. В этом городе функционируют специализированные центры реабилитации‚ где предоставляется возможность анонимного лечения от наркозависимости и алкоголизма. Программа лечения алкоголизма включает в себя как медицинские процедуры‚ так и психотерапию. vivod-iz-zapoya-vladimir027.ru Психологическая поддержка в владимире также является ключевым элементом в процессе выздоровления. Обратитесь к наркологу позволяет определить уникальные особенности пациента и составить индивидуальный план терапии. Профилактика зависимостей и поддержка родственников зависимых – неотъемлемая часть работы наркологической клиники. Реабилитация наркоманов включает как терапевтические‚ так и социальные аспекты. Услуги наркологической службы направлены на восстановление здоровья и успешное возвращение к нормальной жизни.
Бонусы также варьируются по типу. Некоторые из них предоставляются новым пользователям. Регистрируясь на 1xBet, используйте промокод и заберите удвоенный стартовый бонус на сумму до 32500 рублей.Букмекерская контора 1xBet предлагает своим клиентам играть и делать ставки с использованием бонусных средств. Это увеличивает вовлечённость к ставкам и гарантирует надежность игры.Актуальный промокод можно активировать на странице регистрации: 1xbet бонусы промокоды.
Profitez d’une offre 1xBet : utilisez-le une fois lors de l’inscription et obtenez un bonus de 100% pour l’inscription jusqu’a 130€. Augmentez le solde de vos fonds simplement en placant des paris avec un wager de cinq fois. Le code bonus est valide tout au long de l’annee 2026. Pour activer ce code, rechargez votre compte a partir de 1€. Decouvrez cette offre exclusive sur ce lien — Code Promo 1xbet Abidjan. Le code promo 1xBet aujourd’hui est disponible pour les joueurs du Cameroun, du Senegal et de la Cote d’Ivoire. Avec le 1xBet code promo bonus, obtenez jusqu’a 130€ de bonus promotionnel du code 1xBet. Ne manquez pas le dernier code promo 1xBet 2026 pour les paris sportifs et les jeux de casino.
технический перевод ошибки dzen.ru/a/aPFFa3ZMdGVq1wVQ .
медицинский перевод заключений http://www.telegra.ph/Medicinskij-perevod-tochnost-kak-vopros-zhizni-i-zdorovya-10-16/ .
stageofnations – Culturally rich, visuals celebrate unity and vibrant heritage beautifully.
установка кондиционера в москве Закладка трассы и Прокладка трассы для кондиционера: Необходимый Этап для Качественной Установки Закладка трассы и прокладка трассы для кондиционера – важные этапы установки, требующие профессионального подхода. Наши специалисты аккуратно и качественно выполнят все работы по прокладке трассы, учитывая особенности помещения и требования к эстетике. Мы используем только качественные материалы, чтобы обеспечить надежность и долговечность трассы.
Наверно так же как и джив. попробуй минимальные пропорции сделать 0,1 к 1
Приобрести MEF GASH SHIHSKI ALFA – ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО
тут как всегда, хочешь сджелать заказ – хрен достучишься в аське.
Живые венки придают образу хрупкую свежесть: маттиола, эустома, розы и зелень создают естественный, фотогеничный контур. В «Флорион» венки собирают вручную, учитывая оттенок кожи и прическу, фиксируют легко и надежно. Подойдет для невест, утренников, этнических фестивалей. Посмотрите доступные варианты на https://www.florion.ru/catalog/venok-iz-zhivyh-cvetov — фото, цены, быстрая доставка по Москве. Симметрия или легкая асимметрия — выбор за вами, качество — за нами.
Sou totalmente viciado em PlayPIX Casino, sinto um pulsar selvagem. A selecao de jogos e fenomenal, com slots de design inovador. Com uma oferta inicial para impulsionar. O acompanhamento e impecavel, sempre pronto para resolver. O processo e simples e elegante, as vezes ofertas mais generosas seriam bem-vindas. Em sintese, PlayPIX Casino e essencial para jogadores para fas de cassino online ! Alem disso o site e rapido e cativante, facilita uma imersao total. Notavel tambem os eventos comunitarios envolventes, proporciona vantagens personalizadas.
Dar uma olhada|
экстренный вывод из запоя
narkolog-krasnodar020.ru
вывод из запоя цена
купить диплом архитектора купить диплом архитектора .
С DRINKIO всё просто — оформил заказ, получил вовремя. Курьеры пунктуальные, товар качественный. Ассортимент разнообразный, сайт удобный. Очень доволен сервисом – https://drinkio105.ru/
Если вы строите дом, баню или террасу, на этом складе вы найдете весь перечень пиломатериалов — от обрезной и строганной доски до профилированного бруса, фанеры и террасной доски. Компания «ВЕЛЕС ИНДАСТРИАЛ» работает с 2004 года, держит крупные остатки на базе в Мытищах и доставляет по всей Москве и области собственным автопарком. Подробные цены от производителя, акции и калькулятор доступны на сайте — https://pilomaterialy-msk.ru Менеджеры рассчитают кубатуру, подскажут оптимальные сорта и быстро соберут заказ под ваш проект.
Промокод букмекерской конторы 1xBet на сегодня: где взять рабочий, куда вводить на сайте и как использовать промокод 1xbet на фрибут. Бесплатные коды нужно вводить в специальном поле при регистрации на сайте БК или в личном кабинете пользователя, если у вас уже есть аккаунт. Все промокоды букмекерских контор. Список действующих на сегодня промокодов легальных букмекерских контор вы можете найти на сайте в разделе бонусов. Варианты получения промокодов. Зарубежная букмекерская контора 1хБет предлагает несколько вариантов получения промокодов. Бесплатные промокоды 1xBet при регистрации. 1хБет постоянно ищет новых пользователей, поэтому регистрируясь на сайте Вы и так получите до 25000 руб. при первом депозите. Но мы поможем его увеличить до 32500, для этого введите: промокод который увеличивает сумму депозита до 32500 р. Данные бонусы действуют только при первом депозите после регистрации, пополняя свой лицевой счет, при применении кода сумма увеличится в 2 раза, но не более 32500 рублей. Бонусные деньги вы можете ставить на спорт. В открытом доступе в интернете вы сможете найти только такие бонусы, которые мотивируют новичков стать пользователем букмекерской конторы 1хБет.
höchster sportwetten bonus
Also visit my page :: buchmacher hamburg (https://cadiganventures.com/)
Привет всем!
Виртуальный номер навсегда – это лучший способ сохранить конфиденциальность. Купите постоянный виртуальный номер для смс, который подходит для всех популярных платформ. Мы предоставляем надежные номера с возможностью долгосрочного использования. Постоянный виртуальный номер – это ваш универсальный инструмент для общения. Выбирайте удобство с нашими услугами.
Полная информация по ссылке – https://lentaknit.ru/virtualnyj-nomer-kak-eto-rabotaet-i-zachem-on-nuzhen.html
виртуальный номер навсегда, купить виртуальный номер навсегда, купить постоянный виртуальный номер
постоянный виртуальный номер для смс, купить номер телефона навсегда, купить виртуальный номер навсегда
Удачи и комфорта в общении!
купить диплом врача купить диплом врача .
Выбор фирмы для строительства — ключевой этап при планировании застройки.
Прежде чем начать сотрудничество, стоит изучить опыт подрядчика.
Проверенная компания всегда обеспечивает прозрачные условия.
Важно обратить внимание, какие методы входят в работу при строительстве.
https://coub.com/istroika2025
Je trouve absolument brulant VBet Casino, on dirait une eruption de plaisirs incandescents. Les options de jeu au casino sont riches et enflammees, offrant des sessions de casino en direct qui crepitent comme des flammes. Le service client du casino est une torche d’efficacite, avec une aide qui jaillit comme une flamme. Le processus du casino est transparent et sans cendres, mais des recompenses de casino supplementaires feraient exploser. Pour resumer, VBet Casino promet un divertissement de casino incandescent pour les joueurs qui aiment parier avec panache au casino ! Bonus le design du casino est un spectacle visuel brulant, amplifie l’immersion totale dans le casino.
vbet deutschland|
Ich bin suchtig nach Lowen Play Casino, es ist ein Online-Casino, das wie ein Lowe brullt. Die Auswahl im Casino ist ein echtes Raubtier, mit Casino-Spielen, die fur Kryptowahrungen optimiert sind. Der Casino-Kundenservice ist wie ein Leitlowe, mit Hilfe, die wie ein Brullen wirkt. Casino-Transaktionen sind simpel wie ein Pfad im Busch, ab und zu mehr regelma?ige Casino-Boni waren ein Volltreffer. Am Ende ist Lowen Play Casino ein Casino, das man nicht verpassen darf fur Fans moderner Casino-Slots! Zusatzlich die Casino-Navigation ist kinderleicht wie eine Fahrte, was jede Casino-Session noch wilder macht.
löwen play frankfurt|
https://www.tiktok.com/@candetoxblend
Pasar un control sorpresa puede ser complicado. Por eso, ahora tienes un suplemento innovador con respaldo internacional.
Su mezcla premium combina creatina, lo que estimula tu organismo y disimula temporalmente los rastros de sustancias. El resultado: una muestra limpia, lista para entregar tranquilidad.
Lo mas notable es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete resultados permanentes, sino una solucion temporal que responde en el momento justo.
Estos productos están diseñados para ayudar a los consumidores a limpiar su cuerpo de componentes no deseadas, especialmente las relacionadas con el consumo de cannabis u otras sustancias ilícitas.
El buen detox para examen de orina debe ofrecer resultados rápidos y efectivos, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas opciones, pero no todas prometen un proceso seguro o fiable.
De qué funciona un producto detox? En términos básicos, estos suplementos operan acelerando la depuración de metabolitos y componentes a través de la orina, reduciendo su nivel hasta quedar por debajo del límite de detección de algunos tests. Algunos actúan en cuestión de horas y su efecto puede durar entre 4 a cinco horas.
Parece fundamental combinar estos productos con adecuada hidratación. Beber al menos dos litros de agua por jornada antes y después del ingesta del detox puede mejorar los resultados. Además, se sugiere evitar alimentos pesados y bebidas ácidas durante el proceso de uso.
Los mejores productos de purga para orina incluyen ingredientes como extractos de naturales, vitaminas del complejo B y minerales que apoyan el funcionamiento de los riñones y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que ofrecen certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de THC, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación temprana. Mientras más extendida sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la planificación con el uso correcto del detox es clave.
Un error común es suponer que todos los detox actúan idéntico. Existen diferencias en formulación, sabor, método de ingesta y duración del impacto. Algunos vienen en envase líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que agregan fases de preparación o limpieza previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables individuales como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no confiarse.
Miles de profesionales ya han experimentado su discrecion. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta alternativa te ofrece tranquilidad.
https://baidak.ru/
Galera, resolvi compartilhar minha experiencia sobre o Bingoemcasa porque me ganhou de verdade. O site tem um ambiente divertido que lembra uma festa entre amigos. As salas de bingo sao com muita interacao, e ainda testei blackjack e poker tambem, todos foram bem estaveis. O atendimento no chat foi educado e prestativo, o que ja me deixou tranquilo. As retiradas foram mais velozes que imaginei, inclusive testei cripto e caiu em minutos. Se pudesse apontar algo, diria que faltam mais promocoes, mas nada que estrague a experiencia. Resumindo, o Bingoemcasa foi uma otima descoberta. Eu mesmo ja voltei varias vezes
bingoemcasa codigo promocional|
StopKor — портал журналистских расследований о коррупции, бизнесе и обществе: авторские материалы, досье и аналитика, обновления по резонансным делам. Проекты выходят на украинском и русском языках, с источниками, датами и контекстом. Удобная навигация по рубрикам «Розслідування», «Економіка», «Злочинність» ускоряет поиск. Изучите публикации на https://stopkor.info/ — следите за новыми выпусками и архивом материалов. Портал создан для тех, кто ценит факты, доказательность и прозрачность.
Galera, preciso contar o que achei sobre o Bingoemcasa porque achei muito alem do que esperava. O site tem um clima acolhedor que lembra um bate-papo animado. As salas de bingo sao movimentadas, e ainda testei a roleta ao vivo, todos me deixaram impressionado. O atendimento no chat foi respondeu em segundos, o que ja me deixou bem a vontade. As retiradas foram muito rapidas, inclusive testei cripto e nao tive problema nenhum. Se pudesse apontar algo, diria que faltam mais promocoes, mas nada que estrague a experiencia. Resumindo, o Bingoemcasa vale demais a pena. Com certeza vou continuar jogando
bingoemcasa .com|
Здравствуйте!
Постоянный виртуальный номер для смс — удобство в каждой детали. Он позволяет регистрироваться без ограничений — постоянный виртуальный номер для смс без блокировок. Получайте любые уведомления на постоянный виртуальный номер для смс. Простая настройка — ещё одно преимущество, которым обладает постоянный виртуальный номер для смс.
Полная информация по ссылке – http://arp.by/novosti/belarus/kak-poluchit-i-podkljuchit-virtualnyj-nomer-belarusi
купить виртуальный номер навсегда, виртуальный номер навсегда, купить постоянный виртуальный номер
купить виртуальный номер, купить виртуальный номер для смс навсегда, постоянный виртуальный номер для смс
Удачи и комфорта в общении!
Hey there just wanted to give you a brief heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers and both show the same results.
staffinggoals.com
https://speakerdeck.com/candetoxblend
Pasar un control sorpresa puede ser complicado. Por eso, existe una solucion cientifica probada en laboratorios.
Su composicion potente combina carbohidratos, lo que estimula tu organismo y disimula temporalmente los rastros de alcaloides. El resultado: un analisis equilibrado, lista para ser presentada.
Lo mas notable es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete limpiezas magicas, sino una estrategia de emergencia que te respalda en situaciones criticas.
Estos suplementos están diseñados para colaborar a los consumidores a purgar su cuerpo de componentes no deseadas, especialmente las relacionadas con el uso de cannabis u otras sustancias ilícitas.
El buen detox para examen de orina debe brindar resultados rápidos y confiables, en gran cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas variedades, pero no todas prometen un proceso seguro o fiable.
Qué funciona un producto detox? En términos básicos, estos suplementos operan acelerando la expulsión de metabolitos y residuos a través de la orina, reduciendo su presencia hasta quedar por debajo del límite de detección de algunos tests. Algunos trabajan en cuestión de horas y su acción puede durar entre 4 a cinco horas.
Es fundamental combinar estos productos con correcta hidratación. Beber al menos 2 litros de agua por jornada antes y después del ingesta del detox puede mejorar los beneficios. Además, se recomienda evitar alimentos difíciles y bebidas ácidas durante el proceso de desintoxicación.
Los mejores productos de detox para orina incluyen ingredientes como extractos de naturales, vitaminas del tipo B y minerales que apoyan el funcionamiento de los riñones y la función hepática. Entre las marcas más vendidas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de cannabis, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación anticipada. Mientras más prolongada sea la abstinencia, mayor será la potencia del producto. Por eso, combinar la organización con el uso correcto del suplemento es clave.
Un error común es suponer que todos los detox actúan idéntico. Existen diferencias en contenido, sabor, método de uso y duración del efecto. Algunos vienen en presentación líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que agregan fases de preparación o preparación previa al día del examen. Estos programas suelen recomendar abstinencia, buena alimentación y descanso previo.
Por último, es importante recalcar que ninguno detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
Miles de profesionales ya han validado su discrecion. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si no deseas dejar nada al azar, esta formula te ofrece respaldo.
seo news seo news .
Sou viciado em PlayPIX Casino, e uma plataforma que pulsa com energia festiva. A selecao de jogos e fenomenal, com slots de design inovador. Eleva a diversao do jogo. A assistencia e eficiente e cortes, garantindo um atendimento de qualidade. O processo e simples e elegante, embora bonus mais variados seriam bem-vindos. No geral, PlayPIX Casino garante diversao a cada momento para entusiastas de jogos modernos ! Vale notar a interface e fluida e elegante, aumenta o prazer de jogar. Muito atrativo os eventos comunitarios envolventes, que impulsiona o engajamento.
Saber mais|
charitiespt – Compassionate and community-driven, mission comes across with sincerity.
larkfest2013 – Vibrant and nostalgic, visuals radiate energy and celebration.
https://anyflip.com/homepage/yjenk#About
Aprobar una prueba de orina puede ser un momento critico. Por eso, se ha creado una formula avanzada con respaldo internacional.
Su receta premium combina carbohidratos, lo que ajusta tu organismo y enmascara temporalmente los marcadores de THC. El resultado: una muestra limpia, lista para cumplir el objetivo.
Lo mas notable es su capacidad inmediata de respuesta. A diferencia de metodos caseros, no promete resultados permanentes, sino una solucion temporal que funciona cuando lo necesitas.
Estos fórmulas están diseñados para ayudar a los consumidores a purgar su cuerpo de residuos no deseadas, especialmente aquellas relacionadas con el uso de cannabis u otras sustancias.
Un buen detox para examen de pipí debe ofrecer resultados rápidos y efectivos, en particular cuando el tiempo para desintoxicarse es limitado. En el mercado actual, hay muchas variedades, pero no todas garantizan un proceso seguro o efectivo.
Qué funciona un producto detox? En términos simples, estos suplementos actúan acelerando la eliminación de metabolitos y toxinas a través de la orina, reduciendo su concentración hasta quedar por debajo del nivel de detección de ciertos tests. Algunos actúan en cuestión de horas y su efecto puede durar entre 4 a 6 horas.
Parece fundamental combinar estos productos con adecuada hidratación. Beber al menos 2 litros de agua al día antes y después del consumo del detox puede mejorar los resultados. Además, se aconseja evitar alimentos difíciles y bebidas procesadas durante el proceso de uso.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de hierbas, vitaminas del tipo B y minerales que respaldan el funcionamiento de los órganos y la función hepática. Entre las marcas más vendidas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación temprana. Mientras más extendida sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la planificación con el uso correcto del detox es clave.
Un error común es suponer que todos los detox actúan lo mismo. Existen diferencias en formulación, sabor, método de uso y duración del efecto. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incluyen fases de preparación o preparación previa al día del examen. Estos programas suelen instruir abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que todo detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, frecuencia de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no descuidarse.
Miles de profesionales ya han comprobado su rapidez. Testimonios reales mencionan envios en menos de 24 horas.
Si quieres proteger tu futuro, esta formula te ofrece respaldo.
Бонусы также отличаются по типу. Часть бонусов предлагаются новичкам. Регистрируясь на 1xBet, активируйте код и оформите 100% приветственный бонус на сумму до 32500 рублей.Компания 1xBet даёт возможность пользователям участвовать в спортивных ставках и казино с использованием бонусных средств. Это делает процесс азартнее к играм и повышает максимальную безопасность игры.Промокод 2026 года можно активировать на странице регистрации — http://www.medtronik.ru/images/pages/1hbet_2021_promokod_pri_registracii.html.
Looking for Mayday Parade live dates? Visit Ищете mayday parade concerts? myrockshows.com/band/2148-mayday-parade/ for the full schedule of more than 50 concerts in sixteen countries. Here you’ll get early alerts about concerts in your city and buy tickets for the best seats at a great price. Don’t miss the chance to experience Mayday Parade live!
holyspiritschooleg – Educational yet warm, design and content reflect care and faith.
сколько стоит купить диплом медсестры сколько стоит купить диплом медсестры .
georgewillwashpost – Clean layout, solid typography, content radiates intellect and authority.
lcbclosure – Focused and informative, the message feels urgent and clearly communicated.
mayceformayor – Campaign feels strong and grounded, visuals emphasize trust and service.
https://3dwarehouse.sketchup.com/by/candetoxblend
Superar un control sorpresa puede ser estresante. Por eso, ahora tienes un suplemento innovador con respaldo internacional.
Su composicion premium combina minerales, lo que estimula tu organismo y neutraliza temporalmente los metabolitos de toxinas. El resultado: un analisis equilibrado, lista para cumplir el objetivo.
Lo mas interesante es su accion rapida en menos de 2 horas. A diferencia de metodos caseros, no promete milagros, sino una herramienta puntual que te respalda en situaciones criticas.
Estos suplementos están diseñados para ayudar a los consumidores a purgar su cuerpo de sustancias no deseadas, especialmente aquellas relacionadas con el uso de cannabis u otras drogas.
El buen detox para examen de orina debe brindar resultados rápidos y efectivos, en gran cuando el tiempo para prepararse es limitado. En el mercado actual, hay muchas variedades, pero no todas prometen un proceso seguro o rápido.
¿Cómo funciona un producto detox? En términos básicos, estos suplementos funcionan acelerando la expulsión de metabolitos y componentes a través de la orina, reduciendo su concentración hasta quedar por debajo del nivel de detección de ciertos tests. Algunos trabajan en cuestión de horas y su acción puede durar entre 4 a seis horas.
Resulta fundamental combinar estos productos con adecuada hidratación. Beber al menos par litros de agua diariamente antes y después del uso del detox puede mejorar los beneficios. Además, se aconseja evitar alimentos grasos y bebidas procesadas durante el proceso de preparación.
Los mejores productos de limpieza para orina incluyen ingredientes como extractos de hierbas, vitaminas del tipo B y minerales que apoyan el funcionamiento de los órganos y la función hepática. Entre las marcas más vendidas, se encuentran aquellas que presentan certificaciones sanitarias y estudios de prueba.
Para usuarios frecuentes de THC, se recomienda usar detoxes con ventanas de acción largas o iniciar una preparación previa. Mientras más larga sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la planificación con el uso correcto del suplemento es clave.
Un error común es creer que todos los detox actúan lo mismo. Existen diferencias en formulación, sabor, método de toma y duración del resultado. Algunos vienen en presentación líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incluyen fases de preparación o preparación previa al día del examen. Estos programas suelen sugerir abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que todo detox garantiza 100% de éxito. Siempre hay variables personales como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no descuidarse.
Miles de postulantes ya han validado su rapidez. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si quieres proteger tu futuro, esta formula te ofrece tranquilidad.
скачать тик ток с модом Цифровая Эволюция TikTok: Модификации 2025 года – Расширяя Границы Возможностей В динамичном мире социальных сетей, TikTok продолжает удерживать лидирующие позиции, постоянно адаптируясь к потребностям своей аудитории. Однако, стремясь раскрыть весь потенциал платформы, пользователи все чаще обращаются к модифицированным версиям приложения, предлагающим расширенный функционал и возможности кастомизации. 2025 год ознаменован появлением множества интересных модов TikTok, ориентированных на различные потребности пользователей.
milestonerest – Inviting visuals, design creates a sense of comfort and good taste.
kraken ссылка Этика Безопасчности и Мораль Анонимности “Кракен” предоставляет возможность действовать вне рамок общепринятых норм, но вместе с такой свободой приходит и ответственность. Анонимность не должна быть оправданием для злоупотреблений, для причинения вреда другим. Помните о моральных принципах, даже когда никто не видит. Используйте “Kraken” с умом, с пониманием последствий, и тогда он станет не источником проблем, а инструментом для достижения собственных целей.
Чем отличаются промокоды букмекерской конторы 1xBet уникальными? Какие нюансы стоит понимать о кодах, чтобы взять максимальную выгоду от их применения? И, наконец, что еще любопытного есть в акционной политике этой конторы, на которые стоит учесть, если вы планируете играть за бонусы. Промокод на 1xBet (актуален в 2026 году, бонус 100%) можно найти по этой ссылке: промокод 1xbet от блоггеров.
Ищете паровой котел трехходовой vecoster? Векостер vecoster.com представляют собой современные системы, предназначенные для обеспечения технологии паром. Они отличаются высокой эффективностью, надежностью и безопасностью, что делает их идеальным решением для предприятий различных отраслей. На сайте компании также представлены промышленные паровые котельные. Оборудование поддерживает двухтопливную работу — на природном газе и дизеле. Благодаря этому можно подобрать топливо с учетом его доступности и цены в вашем регионе.
exodusalliance – Empowering theme, site feels hopeful and mission-driven throughout.
уже ожидается что нибудь?
https://khartsyzkod.ru
вы могли написать похожему нику , таких пруд пруди.
Profitez du code promo 1xbet 2026 : obtenez un bonus de bienvenue de 100% sur votre premier depot avec un bonus allant jusqu’a 130 €. Jouez et placez vos paris facilement grace aux fonds bonus. Une fois inscrit, n’oubliez pas de recharger votre compte. Si votre compte est verifie, vous pourrez retirer toutes les sommes d’argent, y compris les bonus. Vous pouvez trouver le code promo 1xbet sur ce lien — 1xbet Code Promo Tours Gratuits. Le code promo 1xBet sans depot est valable pour les nouveaux utilisateurs en Afrique du Sud, au Gabon et en RDC. Ce code promotionnel 1xBet offre des bonus gratuits 1xBet et des tours gratuits 1xBet aujourd’hui. Utilisez le meilleur code promo pour 1xBet et recevez votre bonus d’inscription 1xBet en quelques clics.
oscarthegaydog – Whimsical and delightful, brand personality shines through humor and charm.
трансы Челябинск География Поддержки: От Сибири до Юга России Каждый из каналов, будь то @ts_novosibirsk (трансы Новосибирск, трансы новосибирска), @ts_ekaterinburgh (трансы Екатеринбург, трансы Екатеринбурга), @ts_voronezh (трансы Воронеж, трансы Воронежа), @transy_volgograd (трансы Волгоград, трансы волгограда) или @ts_chelyabinska (трансы Челябинск, трансы челябинска), отражает уникальную специфику своего региона. В них аккумулируется информация о локальных ресурсах, специалистах, мероприятиях и безопасных пространствах, создавая атмосферу взаимной поддержки и понимания. Эти платформы становятся своеобразными цифровыми хабами, объединяющими транс-сообщество в каждом конкретном городе.
Лечение похмелья с помощью капельницы — это эффективное средство для ликвидации неприятных ощущений интоксикации после употребления алкоголя. При состоянии похмелья организм страдает от недостатка жидкости и нехватки важных веществ, что вызывает общему недомоганию. Лечение капельницей включает в себя дозу жидкости и восстановление баланса веществ. Обращение к врачу может включать в себя медикаменты, улучшающие самочувствие, которые помогают организму вернуться к норме. Капельницы часто содержат полезные добавки, противоядия, которые ускоряют процесс выздоровления. Поддержка организма таким образом позволяет существенно облегчить состояние и помочь восстановиться. Чтобы получить капельницу можно записаться на процедуру или позвонить врачу на дом через интернет vivod-iz-zapoya-krasnoyarsk020.ru. Не забывайте, что оперативное вмешательство поможет избежать серьезных последствий.
https://kuula.co/profile/candetoxblend
Pasar un test antidoping puede ser arriesgado. Por eso, existe un suplemento innovador creada con altos estandares.
Su formula premium combina minerales, lo que estimula tu organismo y disimula temporalmente los trazas de toxinas. El resultado: un analisis equilibrado, lista para ser presentada.
Lo mas destacado es su accion rapida en menos de 2 horas. A diferencia de otros productos, no promete resultados permanentes, sino una herramienta puntual que te respalda en situaciones criticas.
Estos suplementos están diseñados para ayudar a los consumidores a purgar su cuerpo de componentes no deseadas, especialmente aquellas relacionadas con el ingesta de cannabis u otras sustancias.
Uno buen detox para examen de orina debe proporcionar resultados rápidos y efectivos, en particular cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas opciones, pero no todas garantizan un proceso seguro o efectivo.
¿Cómo funciona un producto detox? En términos simples, estos suplementos funcionan acelerando la expulsión de metabolitos y componentes a través de la orina, reduciendo su presencia hasta quedar por debajo del límite de detección de los tests. Algunos trabajan en cuestión de horas y su acción puede durar entre 4 a seis horas.
Parece fundamental combinar estos productos con adecuada hidratación. Beber al menos dos litros de agua diariamente antes y después del uso del detox puede mejorar los efectos. Además, se aconseja evitar alimentos pesados y bebidas procesadas durante el proceso de preparación.
Los mejores productos de purga para orina incluyen ingredientes como extractos de plantas, vitaminas del complejo B y minerales que apoyan el funcionamiento de los órganos y la función hepática. Entre las marcas más populares, se encuentran aquellas que presentan certificaciones sanitarias y estudios de eficacia.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación anticipada. Mientras más prolongada sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la planificación con el uso correcto del producto es clave.
Un error común es pensar que todos los detox actúan idéntico. Existen diferencias en formulación, sabor, método de ingesta y duración del efecto. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incorporan fases de preparación o preparación previa al día del examen. Estos programas suelen sugerir abstinencia, buena alimentación y descanso adecuado.
Por último, es importante recalcar que ningún detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, nivel de consumo, y tipo de examen. Por ello, es vital seguir las instrucciones del fabricante y no relajarse.
Miles de personas en Chile ya han comprobado su seguridad. Testimonios reales mencionan envios en menos de 24 horas.
Si necesitas asegurar tu resultado, esta formula te ofrece confianza.
I got this web site from my friend who shared with me about this website and now this time I am browsing this web page and reading very informative posts here.
https://easystaffingmd.com/
МАГАЗИНУ надо бы по ровнее работать!
https://volnovakhazy.ru
Возможно сказалась бессонная ночь и отсутствие нормального питания на протяжении практически недели, но все время под туси я провел лежа на кровати и созерцая слааабенькие визуальчики. В общем, 4 из 6 сказали, что магазин – шляпа, и больше никогда тут ничего не возьмут.
justinhicksformissouri – Strong campaign message, design feels authentic and community-focused.
https://myanimelist.net/profile/candetoxblend
Superar un test antidoping puede ser complicado. Por eso, existe un metodo de enmascaramiento desarrollada en Canada.
Su composicion potente combina minerales, lo que ajusta tu organismo y oculta temporalmente los metabolitos de toxinas. El resultado: un analisis equilibrado, lista para pasar cualquier control.
Lo mas valioso es su capacidad inmediata de respuesta. A diferencia de otros productos, no promete resultados permanentes, sino una solucion temporal que responde en el momento justo.
Estos productos están diseñados para facilitar a los consumidores a depurar su cuerpo de componentes no deseadas, especialmente esas relacionadas con el uso de cannabis u otras sustancias ilícitas.
El buen detox para examen de fluido debe brindar resultados rápidos y efectivos, en especial cuando el tiempo para limpiarse es limitado. En el mercado actual, hay muchas alternativas, pero no todas garantizan un proceso seguro o fiable.
¿Cómo funciona un producto detox? En términos claros, estos suplementos actúan acelerando la expulsión de metabolitos y residuos a través de la orina, reduciendo su concentración hasta quedar por debajo del nivel de detección de algunos tests. Algunos funcionan en cuestión de horas y su efecto puede durar entre 4 a 6 horas.
Parece fundamental combinar estos productos con correcta hidratación. Beber al menos par litros de agua diariamente antes y después del consumo del detox puede mejorar los beneficios. Además, se recomienda evitar alimentos pesados y bebidas procesadas durante el proceso de desintoxicación.
Los mejores productos de purga para orina incluyen ingredientes como extractos de hierbas, vitaminas del complejo B y minerales que favorecen el funcionamiento de los órganos y la función hepática. Entre las marcas más destacadas, se encuentran aquellas que tienen certificaciones sanitarias y estudios de resultado.
Para usuarios frecuentes de marihuana, se recomienda usar detoxes con márgenes de acción largas o iniciar una preparación anticipada. Mientras más prolongada sea la abstinencia, mayor será la eficacia del producto. Por eso, combinar la disciplina con el uso correcto del producto es clave.
Un error común es pensar que todos los detox actúan lo mismo. Existen diferencias en formulación, sabor, método de ingesta y duración del efecto. Algunos vienen en formato líquido, otros en cápsulas, y varios combinan ambos.
Además, hay productos que incorporan fases de preparación o purga previa al día del examen. Estos programas suelen sugerir abstinencia, buena alimentación y descanso previo.
Por último, es importante recalcar que todo detox garantiza 100% de éxito. Siempre hay variables biológicas como metabolismo, historial de consumo, y tipo de examen. Por ello, es vital seguir ciertas instrucciones del fabricante y no relajarse.
Miles de estudiantes ya han comprobado su efectividad. Testimonios reales mencionan resultados exitosos en pruebas preocupacionales.
Si necesitas asegurar tu resultado, esta alternativa te ofrece respaldo.
https://ext-6845212.livejournal.com/3200.html
Промокод 1xBet на сегодня можно получить прямо на сайте букмекерской компании. Сделать это станет возможным благодаря переходу по рабочей ссылке, содержащей промокод. Подобного рода бонусы могут использовать и постоянные и новые клиенты конторы. Благодаря проведению таких акций интерес игроков к ставкам остаётся высоким. Содержание. промокод в 1хбет на сегодня. Как получить и что дает промокод в 1xBet? Где вводить промокод в 1xBet? Рабочие промокоды 1xBet на сегодня. Действующие промокоды 1xBet на сегодня. Узнайте как ввести промо код 1хБет при регистрации и получить 32500 рублей на бесплатную ставку. Как активировать и использовать промокод на 1xBet. Список рабочих бонус кодов.
1 xbet 1xbet-giris-1.com .
1xbet turkey https://1xbet-giris-2.com .
Le code promo est supprime : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu’a 130€, a utiliser dans les paris sportifs. Inscrivez-vous sur 1xBet ou via l’application mobile. Apres votre premier depot, vous activerez le code bonus. L’offre est valable pour toute l’annee 2026, et le bonus doit etre mise dans les 30 jours. Decouvrez plus d’informations sur le code promo via ce lien — https://ville-barentin.fr/wp-content/pgs/code-promo-bonus-1xbet.html.
1xbet giris 1xbet giris .
bahis siteler 1xbet bahis siteler 1xbet .
1xbet tr giri? https://www.1xbet-giris-5.com .
1xbet ?ye ol https://1xbet-giris-6.com/ .
La tecnologia de vuelo de show drone ofrece una experiencia visual unica y emocionante.
El espectaculo de drones es un evento que mezcla la innovacion y el entretenimiento para crear una atmosfera magica . La posibilidad de ver a estos dispositivos voladores realizar acrobacias y formaciones complejas es algo que atrae a personas de todas las edades. La habilidad de los pilotos para controlar a los drones y crear un espectaculo emocionante es algo que sorprende a los espectadores. El espectaculo de drones es una forma de entretenimiento que sigue ganando popularidad en todo el mundo. El espectaculo de drones es un evento que sigue atrayendo a mas personas debido a su capacidad para sorprender y emocionar.
El espectaculo de drones requiere una gran cantidad de planificacion y preparacion para asegurarse de que todo salga segun lo previsto. La organizacion de un espectaculo de drones es un proceso complejo que requiere una gran cantidad de tiempo y esfuerzo . Los pilotos deben tener una gran habilidad y experiencia para controlar a los drones y crear un espectaculo emocionante. Los pilotos de drones deben tener una gran cantidad de habilidad y coordinacion para realizar movimientos precisos y sincronizados .
La tecnologia utilizada en los espectaculos de drones es muy avanzada y sofisticada. La tecnologia de los drones es muy compleja y requiere una gran cantidad de investigacion y desarrollo . Los drones estan equipados con sensores y camaras que les permiten navegar y realizar movimientos precisos. Los drones estan equipados con sistemas de navegacion que les permiten seguir rutas precisas y sincronizadas. La tecnologia de los drones es muy versatil y se puede utilizar en una variedad de aplicaciones, desde la fotografia y el video hasta la inspeccion y el monitoreo. La tecnologia de los drones es muy versatil y se puede utilizar en una variedad de industrias, desde la cinematografia hasta la agricultura .
La tecnologia de los drones es muy importante para crear un espectaculo emocionante y impresionante. La tecnologia de los drones es esencial para crear un espectaculo que sea emocionante y atractivo. Los pilotos deben tener una gran cantidad de conocimiento y experiencia para utilizar la tecnologia de los drones de manera efectiva. Los pilotos de drones deben tener una gran cantidad de concentracion y atencion para utilizar la tecnologia de los drones de manera efectiva.
La seguridad es un aspecto muy importante en los espectaculos de drones. La seguridad es fundamental para garantizar que el espectaculo sea seguro y emocionante para la audiencia . Los pilotos deben tener una gran cantidad de experiencia y habilidad para controlar a los drones y evitar accidentes. Los pilotos de drones deben tener una gran cantidad de concentracion y atencion para controlar a los drones y evitar accidentes. Los organizadores del espectaculo deben tomar medidas para garantizar que el evento sea seguro y que se cumplan todas las normas y regulaciones. Los organizadores del espectaculo deben tomar medidas para proteger a los pilotos, a los espectadores y a los drones.
La seguridad es un aspecto que debe ser tomado muy en serio en los espectaculos de drones. La seguridad es un aspecto que debe ser evaluado con gran cuidado para prevenir accidentes y garantizar que el espectaculo sea exitoso . Los pilotos y los organizadores deben trabajar juntos para garantizar que el espectaculo sea seguro y que se cumplan todas las normas y regulaciones. Los pilotos y los organizadores deben trabajar juntos para garantizar que el espectaculo sea seguro y que se cumplan todas las normas y regulaciones de seguridad .
El espectaculo de drones es un evento emocionante y innovador que combina la tecnologia y la creatividad para ofrecer una experiencia unica y fascinante. El espectaculo de drones es una experiencia que fusiona la robotica y la imaginacion para crear un evento inolvidable. La tecnologia utilizada en los espectaculos de drones es muy avanzada y sofisticada, y permite a los pilotos controlar a los dispositivos con gran exactitud. La tecnologia de los drones es muy precisa y permite a los pilotos controlar a los dispositivos con gran exactitud. La seguridad es un aspecto muy importante en los espectaculos de drones, y los pilotos y los organizadores deben trabajar juntos para garantizar que el espectaculo sea seguro y que se cumplan todas las normas y regulaciones. La seguridad es crucial para prevenir accidentes y garantizar que el espectaculo sea exitoso .
El espectaculo de drones es un evento que sigue ganando popularidad en todo el mundo, y es una forma de entretenimiento que ofrece una experiencia unica y emocionante. El espectaculo de drones es una tendencia que sigue creciendo en popularidad debido a su originalidad y emocion . Los espectaculos de drones pueden ser utilizados en una variedad de aplicaciones, desde la fotografia y el video hasta la inspeccion y el monitoreo. Los espectaculos de drones pueden ser utilizados en una variedad de aplicaciones, desde la seguridad hasta el entretenimiento. En resumen, el espectaculo de drones es un evento emocionante y innovador que ofrece una experiencia unica y fascinante, y es una forma de entretenimiento que sigue ganando popularidad en todo el mundo. El espectaculo de drones es una experiencia que fusiona la robotica y la imaginacion para crear un evento inolvidable.
Предложения от 1xBet также отличаются по виду. Некоторые из них предоставляются новым клиентам. Регистрируясь на 1xBet, введите промокод и оформите 100% приветственный бонус в размере 32500 рублей.Букмекерская контора 1xBet предлагает своим клиентам ставить и выигрывать с использованием бонусных средств. Это повышает интерес к играм и обеспечивает безопасность и комфорт игры.Действующий код 1xBet можно получить через официальный сайт — https://vodazone.ru/image/pgs/index.php?1xbet-promokod.html.
southbyfreenoms – Fun, quirky branding with energetic layout and friendly design.
Recently the company show drones put on an amazing performance that amazed all the spectators.
fascinating spectacle that has captivated audiences worldwide with its mesmerizing displays of aerial choreography . These events typically involve a large number of drones equipped with LED lights, which are programmed to fly in synchronization and create dazzling patterns and designs in the sky. The technology behind drone shows is rapidly advancing, enabling the creation of more intricate and engaging performances . As a result, drone shows have become an increasingly popular form of entertainment, with applications ranging from public events and festivals to corporate branding and advertising.
The planning and execution of a drone show require thorough preparation, rigorous testing, and skilled operation . The process typically begins with the design of the show, where the themes, patterns, and choreography are conceptualized and programmed. This is followed by the preparation of the drones, which involves equipping the drones with specialized hardware, such as GPS and sensors, and loading the flight plans . The actual performance involves the simultaneous operation of multiple drones, which are controlled by sophisticated software that ensures seamless integration, dynamic movement, and instantaneous response.
Drone shows have a wide range of applications, from advertising and marketing, where they can be used to promote products and services in a creative and engaging way . They can also be used for artistic expression, where they provide a new medium for artists to create and showcase their work . Furthermore, drone shows can be customized to fit specific themes and events, such as weddings and corporate events. The versatility and creativity of drone shows have made them an attractive option for event planners, who are looking for innovative and memorable ways to engage their audiences .
The use of drone shows for entertainment purposes has revolutionized the way we experience live events, providing a new and exciting form of entertainment . Drone shows can be integrated with other forms of entertainment, such as fireworks, laser shows, and concerts . The popularity of drone shows has also driven the growth of the drone industry, with advancements in technology and regulatory frameworks. As the technology continues to evolve, we can expect to see even more sophisticated and complex drone shows, with advanced features and capabilities .
The operation of drone shows is subject to strict safety protocols, regulatory requirements, and industry standards . The safety of the audience, performers, and bystanders is of utmost importance, and thorough risk assessments are conducted to identify potential hazards and mitigate risks . The regulatory framework for drone shows is improving, with greater clarity and consistency in regulatory frameworks. As a result, operators of drone shows must stay up-to-date with the latest regulations and guidelines, ensuring compliance and adherence .
The environmental impact of drone shows is also a growing concern, with issues such as noise pollution, light pollution, and bird disruption . The use of drones for entertainment purposes has highlighted the need for sustainable and responsible practices in the entertainment industry . As the industry continues to grow and evolve, it is essential to develop innovative solutions to minimize the environmental impact, investing in research and development. By doing so, the drone show industry can ensure a sustainable future, minimizing its impact on the environment .
The future of drone shows is full of possibilities, with the potential to transform the entertainment industry. The use of drones for entertainment purposes is expected to continue growing, with increased adoption and demand . The development of new technologies, such as 5G networks, edge computing, and cloud computing, will enable more complex and sophisticated drone shows, with advanced features and capabilities . As the industry continues to evolve, we can expect to see increased adoption of drone shows, as they become more accessible and affordable. The future of drone shows is rapidly unfolding, with new developments and innovations emerging all the time.
If you are looking for reliable and convenient rubber stamp online maker, then you should pay attention to the opportunity to order the production of stamps from an online store that specializes in creating high-quality rubber stamps according to individual designs.
The online rubber stamp maker is a game-changer for businesses and individuals who need to create custom stamps quickly . The process of creating a custom stamp is straightforward and user-friendly users can choose from a variety of stamp sizes and materials to suit their needs . The online rubber stamp maker offers a range of benefits, including convenience, speed, and affordability .
The rubber stamp maker online is a popular choice among businesses and individuals who need to create custom stamps . users can order custom stamps in bulk or individually. The online rubber stamp maker is a secure and trustworthy platform .
the online rubber stamp maker is a user-friendly platform that allows users to create custom stamps with ease . the rubber stamp maker online allows users to upload their own design or use a pre-made template. the online rubber stamp maker offers fast and reliable shipping .
users can create custom stamps for business or personal use . the online rubber stamp maker has a user-friendly interface and easy-to-follow instructions . The online rubber stamp maker is a cost-effective solution for businesses and individuals who need to create custom stamps .
To use the rubber stamp maker online, users simply need to visit the website and follow the instructions . next, users can upload their design or use a pre-made template . users can select from a range of stamp sizes and materials to suit their needs .
the rubber stamp maker online offers excellent customer service and support. Users can create custom stamps with their company logo, name, or message . the online rubber stamp maker is a reliable solution for those who need to create custom stamps.
the online rubber stamp maker is a game-changer for businesses and individuals who need to create custom stamps quickly . the online rubber stamp maker is a reliable solution for those who need to create custom stamps. the rubber stamp maker online is a time-saving solution for those who need to create custom stamps quickly.
the online rubber stamp maker is a popular choice among artists, crafters, and small business owners. The online rubber stamp maker offers competitive pricing and discounts for bulk orders . the rubber stamp maker online is a cost-effective solution for businesses and individuals.
лучший магаз из всех что существует!!!
https://makeevkavp.ru
А с какого дживика еще больше делать можно?
kraken ссылка Рифы Безопасности: Как не стать жертвой цифровых пиратов В погоне за желаемым, важно не забывать о бдительности. Каждая “кракен” ссылка, каждый “kraken” сайт – потенциальный портал, ведущий как к сокровищам, так и к ловушкам. Фишинговые сайты, поддельные магазины, недобросовестные продавцы – вот лишь некоторые опасности, подстерегающие неопытных мореплавателей. Проверка домена, анализ репутации продавца, использование VPN – вот инструменты, помогающие ориентироваться в этом опасном море.
http://medtronik.ru лучшие акции и бонусы для новых игроков
Подробная инструкция по активации бонусов и типам предложений — от фрибетов до подарков на День Рождения; в тексте естественно вставлена ссылка на 1хБет промокод на сегодня, дабы читатель мог сразу перейти к источнику. Материал также рассказывает о верификации и минимальных требованиях для вывода средств.
скажи мыло в личку своё шас проверю
https://luganskbzi.ru
трек кинули ровно оперативно как придет отпишу за качество 250
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Получи 32500 руб. по актуальному промо коду для 1хБет бесплатно. Новые купоны на регистрацию каждый час на сайте. В ваших силах получить до шести с половиной тысяч рублей при регистрации. Читайте ниже как использовать наши промо-коды. 1хбет промокод при регистрации на сегодня. Букмекерская контора позволяет использовать промокод 1хБет на ставку-бонус. Забирайте новые купоны ежедневно. Внимание! Наши промо-купоны подходят для всех акций букмекера. Этот купон также универсальный – используйте его везде, не только при регистрации на сайте БК 1хБет и всех известных его зеркал. Введите его в форме для регистрации и получите увеличенный бонус на первый депозит до 32500 рублей. Кроме того, букмекер постоянно дарит активным клиентам выгодные подарки. Чтобы получить промокод в 1xBet бесплатно: Подпишитесь на рассылку новостей по смс или электронной почте. Регулярно заходите в раздел «Бонусы и подарки» в Личном кабинете.
rodarodaku.xyz – I just checked it out, layout looks clean and navigation is smooth.
купить диплом в вольске https://www.rudik-diplom5.ru .
http://www.medtronik.ru сайт с последними новостями о бонусах и акциях букмекера
Привет всем!
Виртуальный номер навсегда – это удобное и безопасное решение для современного общения. У нас вы можете купить постоянный виртуальный номер для смс за считанные минуты. Он подойдет для регистрации на сайтах и мессенджерах, а также для работы. Постоянный виртуальный номер обеспечивает надежную связь без привязки к SIM-карте. Выбирайте наши услуги для удобства и стабильности.
Полная информация по ссылке – купить номер телефона для авито
Виртуальный номер навсегда, Виртуальный номер, купить виртуальный номер
постоянный виртуальный номер для смс, купить виртуальный номер для смс навсегда, купить постоянный виртуальный номер
Удачи и комфорта в общении!
трансы воронеж Локальные Сообщества: Поддержка и Информация Эти каналы служат важным ресурсом для транс-сообщества. Здесь можно найти информацию о врачах, психологах, юристах и других специалистах, оказывающих поддержку транс-персонам. Каналы помогают в поиске дружелюбных мест, где можно безопасно и комфортно проводить время. Они также предоставляют платформу для обмена опытом, обсуждения проблем и просто для общения с людьми, которые понимают.
За время работы легалрц сколько магазинов я повидал мама дорогая, столько ушло в топку, кто посливался кто уехал # но chemical-mix поражает своей стойкостью напором и желанием идти в перед “не отступать и не сдаваться”:superman:
https://stakhanovmi.ru
качество интересует
kkgg1.xyz – The visuals and text blend naturally, keeping everything neat and clean.
rideformissingchildren – Heartfelt cause, presentation honors the mission beautifully and respectfully.
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk022.ru
вывод из запоя цена
Цікавитесь кулінарією? Завітайте на кулінарний блог MeatPortal – https://meatportal.com.ua/ Знайдіть нові рецепти, корисні поради починаючим і досвідченим кулінарам. Збирайте нові рецепти до своєї колекції, щоб смачно і корисно годувати сім’ю.
купить проведенный диплом красноярск купить проведенный диплом красноярск .
Здравствуйте!
Купите постоянный виртуальный номер для смс и получите доступ к удобной связи. Виртуальный номер навсегда подходит для любых задач, от регистрации до переписки. Мы предлагаем надежные и доступные номера для долгосрочного использования. Постоянный виртуальный номер – это ваш ключ к стабильности и безопасности. Попробуйте наши услуги уже сейчас.
Полная информация по ссылке – купить белорусский номер
купить виртуальный номер навсегда, постоянный виртуальный номер, виртуальный номер
постоянный виртуальный номер для смс, купить виртуальный номер, виртуальный номер
Удачи и комфорта в общении!
Если вы ищете информацию о бонусах при регистрации, ознакомьтесь с наши рекомендации о видах вознаграждений; в одном из разделов материала естественно упомянут https://bergkompressor.ru/news/artcles/?1xbet_promokod_pri_registracii_bonus_5.html для получения приветственного бонуса. Мы объясняем, как вводить данные при регистрации и какие условия нужно выполнить для отыгрыша.
купить диплом занесенный в реестр купить диплом занесенный в реестр .
1xBet бонус при регистрации подробное описание приветственных бонусов и условий их получения
cranberrystreetcafe – Cozy and charming, design evokes warmth and delicious experiences.
“Приезжаю и вижу на свету бля что то поххожее на таблетки ”
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
у кого взять собрался его ?
Для быстрого и качественного выполнения переводов документов на любой язык обращайтесь в бюро переводов испанский язык, где работают опытные переводчики.
Бюро переводов является важнейшей частью бизнеса, особенно для компаний, которые работают на международном уровне. Это включает в себя перевод документов, веб-сайтов и других материалов. Переводчики бюро переводов должны иметь глубокие знания языка и культуры, на которые они переводят. Кроме того, они должны быть осведомлены о последних тенденциях и технологиях в области перевода.
Бюро переводов может помочь компаниям адаптировать их продукты и услуги для международного рынка. Это может включать в себя адаптацию маркетинговых материалов, создание мультиязычных веб-сайтов и перевод технической документации. Бюро переводов может предоставить услуги по переводу в сжатые сроки, не жертвуя качеством. Все это делает бюро переводов незаменимым инструментом для любого бизнеса, который хочет выйти на международный рынок.
Работа с бюро переводов может принести многочисленные преимущества для бизнеса, включая расширение рынков сбыта и увеличение клиентской базы. Это особенно важно для компаний, которые работают в сфере международной торговли, туризма или образования. Переводчики бюро переводов знают нюансы языка и могут передать точный смысл исходного текста. Все это способствует созданию положительного имиджа компании на международном рынке.
Кроме того, бюро переводов может предоставить услуги по локализации, которые включают адаптацию продуктов и услуг для конкретного рынка. Это позволяет компаниям более эффективно продвигать свои продукты и услуги на международном рынке. Бюро переводов может перевести субтитры и перевести устные выступления. Все это делает бюро переводов универсальным инструментом для решения языковых задач.
Бюро переводов проанализирует требования проекта и предоставит цену и сроки выполнения. Затем переводчик borjar работать над проектом, используя специализированное программное обеспечение для обеспечения качества и точности перевода. Бюро переводов может использовать машинный перевод в сочетании с постредактированием, выполняемым человеком. Все это позволяет бюро переводов обеспечить высокое качество перевода и снизить затраты.
После завершения перевода бюро переводов проверяет качество работы. Затем готовый перевод отправляется клиенту. Бюро переводов может предложить скидки для постоянных клиентов или для крупных проектов. Все это делает бюро переводов надежным партнером для бизнеса.
Бюро переводов может помочь компаниям преодолевать языковые барьеры и увеличить свою клиентскую базу. Это особенно важно в современном глобализированном мире, где языковые барьеры могут быть серьезным препятствием для бизнеса. Бюро переводов может предоставить услуги по переводу, интерпретации и локализации, что делает его универсальным инструментом для решения языковых задач. Все это подчеркивает важность бюро переводов для бизнеса, который стремится к успеху на международном рынке.
Бюро переводов может стать ценным партнером для компании, предоставляя экспертные услуги по переводу и локализации. Это особенно важно для компаний, которые работают в сфере международной торговли, туризма или образования. Бюро переводов может предоставить услуги по переводу документов, веб-сайтов и других материалов, адаптируя их к культурным особенностям целевой аудитории. Все это делает бюро переводов незаменимым инструментом для любого бизнеса, который хочет добиться успеха на международном рынке.
Visitez Roulettino Casino https://roulettino-fr.com/ et obtenez un bonus de 500 € + 100 tours gratuits des maintenant ! Explorez notre selection de jeux et decouvrez Roulettino Casino France, qui offre une experience de jeu legale, reglementee et structuree, adaptee aux joueurs francais. Pour en savoir plus, consultez le site web.
Доброго!
Купите виртуальный номер навсегда и получите свободу общения без ограничений. Постоянный виртуальный номер идеально подходит для регистрации аккаунтов и получения смс. Наши номера работают стабильно и надежно, обеспечивая полную конфиденциальность. Виртуальный номер для смс навсегда – это удобное решение для бизнеса и личных нужд. Выбирайте качество и стабильность с нами.
Полная информация по ссылке – купить номер телефона для авито
купить виртуальный номер для смс навсегда, постоянный виртуальный номер, купить виртуальный номер
купить номер телефона навсегда, купить виртуальный номер навсегда, купить виртуальный номер навсегда
Удачи и комфорта в общении!
georgetowndowntownmasterplan – Informative and civic-minded, content clearly explains planning goals.
«Светодар» — сеть офтальмологических клиник, где видят главное: безопасность, технологии и тактичный подход. Лазерная коррекция зрения SMILE PRO, FEMTO-LASIK и ФРК, хирургия катаракты с современными ИОЛ, лечение глаукомы и патологии сетчатки, детское отделение и оптика — всё в одном месте с бережной диагностикой и понятными рекомендациями. Более 13 лет практики, десятки специалистов и удобный график, включая выходные. Акции и онлайн-запись доступны на https://svetodar.pro/ — откройте мир заново, когда «чётко» становится нормой.
карта бучі
Мебельная фабрика «Подольск» более 20 лет создаёт кухни на заказ — от лаконичной классики до современного МДФ с краской, пластиком и патиной. Точные замеры, собственное производство, проверенная фурнитура и доставка со сборкой превращают проект в комфортный опыт. В середине планирования интерьера просто откройте https://mf-podolsk.ru/ — выберите стиль, материалы и фасады, а конструкторы подготовят эскиз под ваши размеры. Эргономично, доступно и честно по срокам.
Порошок серого цвета чем то похож на известь, запаха нет, ну или очень слабый. Фото сделать не вышло сори :dontknown:!
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Хороший магазин согласна!
Je suis seduit par Impressario Casino, c’est une plateforme qui evoque le raffinement. Les options sont vastes comme un menu etoile, proposant des jeux de table raffines. Avec des depots instantanes. Le support client est impeccable, toujours pret a servir. Les paiements sont securises et rapides, bien que des bonus plus varies seraient un delice. Dans l’ensemble, Impressario Casino garantit un plaisir constant pour ceux qui aiment parier en crypto ! Ajoutons que la plateforme est visuellement somptueuse, ajoute une touche d’elegance. Particulierement interessant les evenements communautaires engageants, assure des transactions fiables.
Trouver plus|
J’adore l’elegance de Impressario Casino, ca transporte dans un monde gourmand. La variete des titres est raffinee, avec des slots aux designs elegants. Le bonus de bienvenue est delicieux. Le suivi est irreprochable, offrant des reponses claires. Les gains arrivent sans delai, neanmoins des bonus plus varies seraient un delice. Dans l’ensemble, Impressario Casino est une plateforme qui enchante pour les passionnes de jeux modernes ! En bonus la navigation est simple et gracieuse, donne envie de prolonger l’experience. Egalement appreciable les evenements communautaires engageants, propose des avantages personnalises.
Trouver le bonus|
J’ai une obsession brulante pour Monte Cryptos Casino, il offre une aventure chiffree palpitante. Il y a une profusion de jeux captivants, proposant des tables elegantes. Elevant l’experience de jeu. Disponible 24/7 via chat ou email, garantissant un service de pointe. Les retraits filent comme une transaction blockchain, cependant des recompenses supplementaires seraient ideales. En bref, Monte Cryptos Casino vaut une plongee numerique pour ceux qui parient avec des cryptos ! En bonus la plateforme est visuellement eblouissante, ajoute une touche de sophistication. Un atout cle les evenements communautaires innovants, qui booste l’engagement.
Parcourir les offres|
Je suis totalement fascine par Monte Cryptos Casino, ca transporte dans un univers futuriste. Le repertoire est riche et varie, avec des slots aux themes modernes. Avec des promotions crypto rapides. L’assistance est rapide et professionnelle, toujours pret a resoudre. Le processus est simple comme un hash, de temps en temps des bonus plus varies seraient un atout. Au final, Monte Cryptos Casino garantit un plaisir constant pour les passionnes de casino en ligne ! Ajoutons que l’interface est fluide et moderne, amplifie le plaisir de jouer. Un avantage notable les options de paris variees, offre des recompenses continues.
Voir maintenant|
stopkrasner – Strong political tone, site expresses clear intent and decisive messaging.
Je suis emerveille par BassBet Casino, c’est une plateforme qui ondule avec elegance. La selection de jeux est dynamique, avec des slots aux designs fluviaux. Renforcant votre capital initial. Les agents repondent comme un courant, toujours pret a naviguer. Les gains arrivent sans delai, parfois des bonus plus varies seraient une vague. En resume, BassBet Casino est un incontournable pour les joueurs pour les passionnes de jeux modernes ! En bonus le site est rapide et attractif, ce qui rend chaque session plus excitante. Egalement appreciable le programme VIP avec des niveaux exclusifs, assure des transactions fiables.
https://bassbetcasinobonus777fr.com/|
Je suis accro a Spinit Casino, ca plonge dans un monde de tours captivants. La variete des titres est magique, proposant des jeux de table elegants. Avec des depots instantanes. Le support client est enchante, toujours pret a transformer. Les transactions sont fiables, parfois des offres plus genereuses seraient enchanteresses. En resume, Spinit Casino est un incontournable pour les joueurs pour les joueurs en quete d’excitation ! A noter le design est moderne et enchanteur, donne envie de prolonger l’aventure. Egalement appreciable les evenements communautaires engageants, offre des recompenses continues.
https://casinospinitfr.com/|
J’ai une passion narrative pour Spinit Casino, il procure une experience magique. La variete des titres est magique, incluant des paris sportifs dynamiques. Le bonus de bienvenue est magique. L’assistance est efficace et professionnelle, joignable a toute heure. Les retraits sont fluides comme un conte, cependant quelques tours gratuits supplementaires seraient bienvenus. Pour conclure, Spinit Casino est une plateforme qui enchante pour les joueurs en quete d’excitation ! En bonus l’interface est fluide comme un conte, ce qui rend chaque session plus enchantee. Un autre atout les evenements communautaires engageants, offre des recompenses continues.
spinitcasinologinfr.com|
Je suis completement envoute par Olympe Casino, c’est une plateforme qui evoque l’Olympe. La selection de jeux est olympienne, avec des slots thematiques antiques. Avec des depots rapides. Le suivi est irreprochable, joignable a toute heure. Les retraits sont rapides comme un eclair de Zeus, cependant des recompenses supplementaires seraient eternelles. Au final, Olympe Casino est un incontournable pour les joueurs pour les fans de casino en ligne ! En bonus l’interface est fluide comme un nectar, ce qui rend chaque session plus celeste. A souligner les options de paris sportifs variees, assure des transactions fiables.
https://olympefr.com/|
Если вы ищете информацию о бонусах при регистрации, прочитайте наши рекомендации о видах вознаграждений; в одном из разделов статьи естественно упомянут 1хБет промокод для получения приветственного бонуса. Мы объясняем, как вводить данные при регистрации и какие правила нужно выполнить для отыгрыша.
74364.pw – Clean layout here, articles read smoothly on both devices today.
Магазин знает как удалить учетку что бы закрыв чат в жабере у вас исчезла запись из списка контактов. У меня так было вчера. Адрес не давали в течении 2х часов а под утро сегодня и вовсе исчезли из контактов.
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
Да не магазин ровный несколько раз покупал у них, качество отличное. Только в аську бывает недостучатся.
wqpyp.pw – I found some good content here, easy to read and nicely structured.
coatsjps.pw – The color palette is calm and well balanced, very easy on the eyes.
J’aime l’ambiance numerique de Monte Cryptos Casino, ca offre une sensation futuriste unique. Les options sont vastes comme un ledger, incluant des paris live dynamiques. 100% jusqu’a 300 € + tours gratuits. Les agents repondent avec une vitesse fulgurante, avec une aide rapide et fiable. Les transferts sont fiables, mais plus de promos regulieres dynamiseraient l’experience. Au final, Monte Cryptos Casino offre une experience inoubliable pour les joueurs en quete d’innovation ! Par ailleurs le design est moderne et captivant, ce qui rend chaque session plus immersive. Egalement cool le programme VIP avec des niveaux exclusifs, qui booste l’engagement.
Plonger dedans|
срочно нужен займ официальные займы онлайн на карту бесплатно
diwang2.pw – Just browsed it, layout feels neat and navigation flows smoothly.
займ срочно оформить займ без фото документов
заем денежных средств получить микрозайм онлайн без звонков
J’aime l’aura futuriste de Monte Cryptos Casino, il offre une aventure chiffree palpitante. Le choix de titres est eblouissant, offrant des sessions en direct immersives. 100% jusqu’a 300 € + tours gratuits. Le suivi est irreprochable, toujours pret a naviguer. Les gains arrivent sans delai, de temps a autre quelques tours gratuits en plus seraient bienvenus. Au final, Monte Cryptos Casino garantit un plaisir constant pour les adeptes de jeux modernes ! A noter le site est rapide et futuriste, donne envie de prolonger l’aventure. Un avantage notable les evenements communautaires innovants, renforce la communaute.
Voir tout de suite|
мгновенный онлайн займы займ до зарплаты без отказа
займ на карту срочно взять займ без подтверждения дохода
займ с плохой кредитной микрозайм круглосуточно без выходных
jammykspeaks – Powerful voice, content feels authentic, motivational and full of passion.
Je suis totalement fascine par Monte Cryptos Casino, ca transporte dans un univers futuriste. Il y a une plethore de jeux captivants, comprenant des jeux optimises pour Bitcoin et Ethereum. Avec des promotions crypto rapides. Le suivi est d’une efficacite redoutable, garantissant un service de pointe. Les transactions sont securisees par blockchain, mais quelques tours gratuits en plus seraient bienvenus. Pour conclure, Monte Cryptos Casino garantit un plaisir constant pour ceux qui parient avec des cryptos ! De plus la navigation est simple comme un wallet, ajoute une touche de sophistication. A souligner les paiements securises en crypto, offre des recompenses continues.
Explorer aujourd’hui|
Je suis completement envoute par Olympe Casino, c’est une plateforme qui evoque l’Olympe. Le catalogue est riche en epopees, avec des slots thematiques antiques. 100% jusqu’a 500 € + tours gratuits. Le service est disponible 24/7, garantissant un support celeste. Le processus est simple et glorieux, neanmoins des offres plus genereuses seraient olympiennes. Dans l’ensemble, Olympe Casino merite une ascension celeste pour les passionnes de jeux antiques ! Ajoutons que l’interface est fluide comme un nectar, ce qui rend chaque session plus celeste. Particulierement captivant les paiements securises en crypto, propose des avantages sur mesure.
olympefr.com|
Таможенный брокер взял на себя оформление деклараций и полностью избавил нас от бумажной рутины. Всё прошло без ошибок и в нужные сроки. Рекомендуем https://tamozhenniiy-broker-moskva11.ru/
Промокод 1xBet — активируйте его в графу «Промокод» при регистрации на сайте, внесите свой аккаунт на сумму от 100? и воспользуйтесь бонусом в размере удвоения депозита (до 32 500?).В профиле отыщите раздел «Бонусные предложения» и отметьте вариант «Использовать промокод».Вставьте полученный код в соответствующее поле. Активируйте и просмотрите требования акции.Актуальный промокод 1xBet 2026 можно узнать по ссылке — https://ural-hifi.ru/fonts/inc/1xbet-promokod.html.
1xBet промокод актуальная информация о действующих предложениях и бонусных акциях для новых пользователей
магазин работает ровно, заказ пришел за пару дней, качество порадовало)
https://antratsitqu.ru
Радуете ребята!!!
Подробная инструкция по активации бонусов и типам предложений — от фрибетов до подарков на День Рождения; в одном из абзацев естественно вставлена ссылка на 1хБет промокод на сегодня, дабы читатель мог сразу перейти к источнику. Материал также рассказывает о верификации и минимальных требованиях для вывода средств.
Таможенный брокер помог пройти оформление без проблем. Все документы проверили заранее, всё идеально – таможенный брокер в Москве
A no deposit bonus code is a short sequence of letters or numbers that can be used to activate a casino reward. When claiming free bonus offers, you can enter promo codes during the registration process or on the Promotions page. You may also receive exclusive promo codes via marketing materials, such as emails or texts. For example, a casino may run a promotion that allows you to claim 80 free spins when you use the code CASH80 during registration. Can I get Pirate Slots Casino deposit bonus codes? Betfair Casino offers a vast world of games to explore. Discover our latest slots, classic table games, and much more. And don’t miss our latest promotions for both new and existing customers on our promotions page. Pirate slots casino no deposit bonus 100 free spins it is free to download and has 4.5 stars out of 5, you need to make sure that youre staying organized. Like any Deal or No Deal fruit machine, considering Pritzkers monthly re-upping plan.
https://albasrl21.com/aviator-game-review-thrilling-casino-experience-for-rwandan-players/
Either you can find concerns otherwise troubles and also you need help. Contact the customer help team through Real time Speak otherwise email address and you can the newest friendly personnel on the top NetEnt gambling enterprises will give assistance. Starburst gambling server try gorgeous not simply with its “precious” user interface, as well as amazing convenience and you can simplicity from the games. How long do withdrawals take at Caxino Casino? Now, we promised free online slots as part of our free casino games and here you go. They have partnered with many software developers to ensure their libraries never run dry, you could land a winning line of diamonds and scoop up a big win. Best Free Spins No Deposit Australia Oddset Casino No Deposit Bonus Codes For Free Spins 2025 If you enjoy Starburst and want to try another similar slot game, you can play the Bejeweled Slot machine from IGT.
«Мебельный базар» — это интернет-магазин и офлайн-салон на Каширском шоссе, где можно собрать интерьер от классики до лофта: спальни, кухни, гостиные, шкафы-купе по индивидуальным размерам, столы и стулья, мягкая мебель, матрасы. Регулярные акции, готовые комплекты и доставка по всей России делают обновление дома прозрачным по срокам и бюджету, а ассортимент российских и европейских фабрик позволяет точно попасть в стиль. Удобнее всего начать с витрины предложений и каталога на https://bazar-mebel.ru/ — и оформить заказ онлайн или в салоне.
lucky jet как пополнить счет https://1win5518.ru/
Запой – это серьезная проблема, требующая внимания, которая требует квалифицированной помощи. В владимире и окрестностях доступно множество вариантов помощи, которые могут помочь вашему близкому. Первым шагом может стать обращение к наркологу на дом, чтобы получить квалифицированную помощь при запое. Специалисты проведут детоксикацию организма и предложат лечение алкоголизма, включая психологическую поддержку при запое.Не менее важно также предоставить эмоциональную поддержку. Родственники должны осознавать рекомендации для родственников, как вести себя в сложной ситуации с алкоголем. Консультации по алкоголизму помогут разобраться в проблеме и выбрать правильный подход к восстановлению от алкоголя. вызвать нарколога на дом владимир Не забывайте о том, что освобождение от зависимости – это длительный процесс. Профессиональная помощь и поддержка близкого помогут ему вернуться к нормальной жизни.
займы без отказа список займов онлайн
денежный кредит займ https://zaimy-71.ru
срочно деньги займ займ всем
получить займ https://zaimy-71.ru
http://www.lenotoplenie.ru сайт с последними новостями о бонусах и акциях букмекера
займ срочно без отказа https://zaimy-78.ru
кредит займ все займы на карту
займ срочно без проверок https://zaimy-73.ru
срочно нужен займ https://zaimy-78.ru
взять займ онлайн быстрый займ без справок и залога
купить диплом в чите купить диплом в чите .
Вызов нарколога на дом срочно в владимире, это эффективное решение для людей, которые испытывают трудности с алкоголем. Услуги наркологов, которые предоставляют квалифицированные специалисты, включают в себя лечение зависимостей на дому; Одной из ключевых процедур является капельница от запоя, позволяющая быстро улучшить состояние больного. нарколог на дом срочно владимир Анонимное лечение является неотъемлемой частью, так как многие пациенты опасаются общественного мнения. Гарантия конфиденциальности процесса позволяет пациентам получать необходимую медицинскую помощь при запое без страха осуждения. Срочный нарколог в владимире готов помочь в любое время, обеспечивая безопасность пациента. Лечение алкоголизма на дому требует поддержки родных, что делает процесс более комфортным. Вернуться к нормальной жизни после запоя возможно благодаря профессиональной помощи и верному подходу. Вызывая нарколога на дом, вы выбираете заботу о своем здоровье и здоровье ваших близких.
займ срочно без отказа все займы ру
кредитная карта займ https://zaimy-87.ru
Братки все красиво стряпают, претензий к магазину нуль, всегда всё ровно. Единственное что сейчас напрягло, отсутствие на ветке вашего представителя в ЕКБ “онлайн”, представитель молчит ( а там по делу ему в лс отписано) и кажись воопще не заходит пару недель
Закладки тут – купить гашиш, мефедрон, альфа-пвп
сильнее и по времени 400.
займ на карту https://zaimy-88.ru
заем денежных средств https://zaimy-88.ru
срочно деньги займ срочные займы на карту круглосуточно
займ с плохой кредитной https://zaimy-89.ru
https://crazytime-history.org/
http://lenotoplenie.ru актуальные инструкции по активации бонусов
Je suis charme par Impressario Casino, ca offre un plaisir sophistique. La selection de jeux est somptueuse, comprenant des jeux compatibles avec les cryptos. Amplifiant le plaisir de jeu. Le service est disponible 24/7, offrant des reponses claires. Les paiements sont securises et rapides, parfois des offres plus genereuses seraient exquises. Au final, Impressario Casino offre une experience memorable pour ceux qui aiment parier en crypto ! A noter la navigation est simple et gracieuse, ajoute une touche d’elegance. Un autre atout le programme VIP avec niveaux exclusifs, renforce le sentiment de communaute.
Commencer Г dГ©couvrir|
Магази хороший и качество нормальное, если есть возможность запиши на пробу Бро )
Онлайн магазин – купить мефедрон, кокаин, бошки
Магазин не работает по выходными и праздникам
J’aime l’ambiance numerique de Monte Cryptos Casino, on ressent une energie decentralisee. La selection de jeux est astronomique, comprenant des jeux optimises pour les cryptos. Le bonus d’entree est scintillant. Le support client est irreprochable, avec une aide rapide et fiable. Les transferts sont fiables, parfois des recompenses supplementaires seraient ideales. En resume, Monte Cryptos Casino est un must pour les fans de blockchain pour les adeptes de jeux modernes ! Par ailleurs le site est rapide et futuriste, amplifie le plaisir de jouer. Egalement cool les paiements securises en BTC/ETH, qui booste l’engagement.
Apprendre aujourd’hui|
Je suis enchante par Impressario Casino, ca transporte dans un monde gourmand. Le catalogue est riche en saveurs, offrant des sessions live sophistiquees. 100% jusqu’a 500 € + tours gratuits. L’assistance est efficace et professionnelle, avec une aide precise. Les retraits sont fluides comme la Seine, de temps a autre plus de promos regulieres ajouteraient du piquant. Pour conclure, Impressario Casino vaut une visite sophistiquee pour les joueurs en quete d’excitation ! En bonus l’interface est fluide comme un banquet, amplifie le plaisir de jouer. Egalement appreciable les tournois reguliers pour la competition, renforce le sentiment de communaute.
Commencer Г naviguer|
kbdesignlab.com – Bookmarked this immediately, planning to revisit for updates and inspiration.
Je suis emerveille par Spinit Casino, on ressent une ambiance de piste. Le catalogue est riche et varie, proposant des jeux de table rapides. Amplifiant le plaisir de jeu. Le service est disponible 24/7, toujours pret a accelerer. Les paiements sont securises et rapides, neanmoins des offres plus genereuses seraient veloces. Dans l’ensemble, Spinit Casino vaut une course rapide pour les fans de casino en ligne ! En bonus le site est rapide et attractif, ajoute une touche de vitesse. Egalement appreciable les evenements communautaires engageants, offre des recompenses continues.
https://spinitcasinologinfr.com/|
Таможенный брокер с хорошей репутацией и реальным опытом: Таможенный брокер в Шереметьево
nycbhm – Community-focused organization with meaningful outreach and engagement.
Администрация проекта Kraken настоятельно рекомендует клиентам системы применять исключительно официальные каналы для поиска актуальных ссылок для входа. Данная мера является основной мерой безопасности вашего аккаунта и совершаемых транзакций внутри экосистемы Кракен. kraken darknet market Перейдя по этому адресу, вы обретаете стопроцентный доступ к всем возможностям площадки, включая систему безопасных сделок и оперативную службу поддержки. Данный метод позволяет целиком исключить риск перехода на мошеннический сайт и гарантирует высочайшую уровень анонимности при совершении любых операций.
Надеюсь что ошибаюсь:hello:
Магазин 24/7 – купить закладку MEF GASH SHIHSKI
это манера такая сдержанная или удовлетворительное=на троечку
knightstablefoodpantry – Compassionate food pantry serving the community with dedication.
Turn your cleaning into a game with Roomsy. A cozy way to clean your home with Roomsy. https://getroomsy.com/ Roomsy offers a simple, guided checklist that organizes chores and makes keeping a tidy home feel effortless. Adorable virtual pet companion. Your pet lives in a tiny version of your home and joins you during cleaning sessions to make tidying more fun and engaging. Level up each room and watch your virtual pet grow happier as your real space gets cleaner, turning daily chores into a rewarding habit.
купить vip диплом об окончании техникума купить vip диплом об окончании техникума .
mcctheatercampaign – Supporting arts and theater with passion and community spirit.
Je suis absolument captive par Monte Cryptos Casino, ca offre une sensation futuriste unique. Les options sont vastes comme un ledger, incluant des paris live dynamiques. Avec des depots crypto rapides. Le suivi est d’une efficacite absolue, offrant des solutions claires. Les transferts sont fiables, mais des recompenses supplementaires seraient ideales. En bref, Monte Cryptos Casino offre une experience inoubliable pour les joueurs en quete d’innovation ! De plus le site est rapide et futuriste, amplifie le plaisir de jouer. A souligner le programme VIP avec des niveaux exclusifs, propose des avantages uniques.
Aller plus loin|
Магазин очень хороший всё чётко и быстро и селер грамотный вы правы
Закладки тут – купить гашиш, мефедрон, альфа-пвп
Брал первый раз дживик качество вроде норм))))Еще хотел совет попросить как из 250 самый норм микс сделать?Помогите плиз.
заем денежных средств https://zaimy-90.ru
займ на карту без отказа получить деньги без залога и справок
J’ai une affection pour Impressario Casino, ca offre un plaisir sophistique. Il y a une abondance de jeux captivants, avec des slots aux designs elegants. Amplifiant le plaisir de jeu. Les agents repondent avec courtoisie, toujours pret a servir. Les transactions sont fiables, parfois quelques tours gratuits supplementaires seraient bienvenus. Pour conclure, Impressario Casino est un incontournable pour les amateurs pour les passionnes de jeux modernes ! A noter la plateforme est visuellement somptueuse, ajoute une touche d’elegance. A souligner les tournois reguliers pour la competition, renforce le sentiment de communaute.
Aller voir|
займ мгновенно оформить микрозайм без отказа
займ без истории деньги на карту без визита в офис
Нужен детский медицинский центр в Москве с психологической поддержкой? Ищете лечение задержки речевого развития? Посетите сайт Центра здоровья Юрия Титова — titov.center — семейный центр здоровья, развития и реабилитации для детей и подростков. Почитайте про используемые методики, нашу команду специалистов и перечень диагнозов, с которыми ведём работу. Мы предлагаем обширный набор индивидуальных программ реабилитации. Читать подробнее на сайте.
Скачать видео с YouTube https://www.fsaved.com онлайн: MP4/WEBM/3GP, качество 144p–4K, конвертация в MP3/M4A, поддержка Shorts и плейлистов, субтитры и обложки. Без регистрации, быстро и безопасно, на телефоне и ПК. Используйте только с разрешения правообладателя и в рамках правил YouTube.
Скачать видео с YouTube https://www.fsaved.com онлайн: MP4/WEBM/3GP, качество 144p–4K, конвертация в MP3/M4A, поддержка Shorts и плейлистов, субтитры и обложки. Без регистрации, быстро и безопасно, на телефоне и ПК. Используйте только с разрешения правообладателя и в рамках правил YouTube.
Je suis ensorcele par Monte Cryptos Casino, c’est une plateforme qui pulse comme un n?ud blockchain. Les options sont vastes comme un reseau, proposant des tables numeriques elegantes. Renforcant votre mise initiale. Le suivi est sans faille, garantissant un service de pointe. Le processus est lisse comme un smart contract, cependant des offres plus genereuses ajouteraient du charme. Au final, Monte Cryptos Casino vaut une plongee numerique pour les joueurs en quete d’innovation ! A noter la navigation est simple comme un wallet, ce qui rend chaque session plus immersive. Un atout cle les paiements securises en BTC/ETH, renforce la communaute.
Commencer Г lire|
Je suis completement electrise par BassBet Casino, c’est une plateforme qui pulse comme un mix de DJ. Les titres sont d’une variete eclatante, proposant des jeux de table styles. Boostant votre mise de depart. Le support client est au top, garantissant un service de haute qualite. Les retraits sont fluides comme un drop, neanmoins des recompenses supplementaires seraient vibrantes. Pour conclure, BassBet Casino est un must pour les joueurs pour les amateurs de sensations fortes ! De plus l’interface est fluide comme un mix, booste le plaisir de jouer. Un point fort les options de paris variees, offre des recompenses continues.
https://bassbetcasinobonus777fr.com/|
Je suis accro a Spinit Casino, ca offre un plaisir dynamique. La selection de jeux est dynamique, avec des slots aux designs veloces. Renforcant votre capital initial. L’assistance est efficace et professionnelle, garantissant un support de qualite. Les transactions sont fiables, cependant des offres plus genereuses seraient veloces. En resume, Spinit Casino offre une experience memorable pour les passionnes de jeux modernes ! A noter l’interface est fluide comme une piste, facilite une immersion totale. Particulierement interessant le programme VIP avec des niveaux exclusifs, qui booste l’engagement.
https://spinitcasinologinfr.com/|
J’adore l’atmosphere dynamique de Spinit Casino, il procure une experience rapide. Les options sont vastes comme une course, offrant des sessions live immersives. Le bonus de bienvenue est rapide. Le suivi est irreprochable, joignable a toute heure. Les paiements sont securises et rapides, de temps a autre des bonus plus varies seraient un sprint. En bref, Spinit Casino garantit un plaisir constant pour les joueurs en quete d’excitation ! En bonus la plateforme est visuellement veloce, donne envie de prolonger l’aventure. Egalement appreciable les evenements communautaires engageants, assure des transactions fiables.
https://casinospinitfr.com/|
Looking for company registration services in Singapore for foreign entrepreneurs? Visit https://intraconnect.biz/ and explore our services to ensure a seamless and efficient process for foreign entrepreneurs and international businesses looking to register a company in Singapore and establish their presence city-state.
1xBet промокод на фриспины узнайте, как активировать бесплатные вращения в играх и слотах
Je suis captive par Olympe Casino, il procure une experience legendaire. Les options sont vastes comme un pantheon, comprenant des jeux optimises pour les cryptos. Le bonus de bienvenue est divin. Les agents repondent comme des dieux, avec une aide precise. Le processus est simple et glorieux, bien que des offres plus genereuses seraient olympiennes. Au final, Olympe Casino offre une experience legendaire pour les passionnes de jeux antiques ! Par ailleurs le site est rapide et glorieux, donne envie de prolonger l’aventure. A souligner les evenements communautaires engageants, offre des recompenses eternelles.
https://olympefr.com/|
Je suis emerveille par BassBet Casino, on ressent une ambiance de bar. Le catalogue est riche et varie, offrant des sessions live immersives. Amplifiant le plaisir de jeu. Le support est irreprochable, offrant des reponses claires. Les transactions sont fiables, de temps a autre plus de promos regulieres ajouteraient du groove. Pour conclure, BassBet Casino garantit un plaisir constant pour les joueurs en quete d’excitation ! De plus le site est rapide et attractif, ajoute une touche de rythme. Particulierement interessant les evenements communautaires engageants, qui booste l’engagement.
https://bassbetcasinologinfr.com/|
В шляпных коробках «Флорион» раскрывает цветы как ювелирные миниатюры: гармоничные сочетания роз, орхидей, эустомы и гортензии выглядят современно и безупречно держат форму. Удобная подача, продуманная палитра и авторские названия композиций помогают точно передать эмоцию, а заказать легко на https://www.florion.ru/catalog/cvety-v-shlyapnoy-korobke — от лаконичных боксов до эффектных премиум-версий. Доставка по Москве и внимательная сборка — как в лучших ателье флористики.
Магазу респект и процветания!!!)))
Приобрести онлайн кокаин, мефедрон, гашиш, бошки
1к10 незачет, 2к10, так, удовлетворительно.
Команда разработчиков платформы Kraken официально советует всем пользователям использовать только официальные источники для поиска рабочих адресов для входа. Данная мера является главной мерой защиты вашей учетной записи и всех проводимых транзакций на просторах платформы Кракен. kraken market Этот ресурс служит в качестве постоянно обновляемого источника рабочих ссылок, позволяя каждому пользователю 24/7 получить рабочий адрес на площадку Кракен. Запомнив этот адрес, вы навсегда избавите себя от необходимости выискивать зеркала на сомнительных форумах, подвергая риску собственными данными.
Анонимное лечение алкоголизма становится актуальным, так как всё больше людей стремятся вернуться к нормальной жизни в условиях конфиденциальности. На сайте vivod-iz-zapoya-vladimir028.ru представлены различные программы реабилитации, включая детоксикационные программы, которые обеспечивают комфортные условия для лечения. Помощь врачей при алкоголизме включает кодирование от алкоголя и психотерапевтические методы. Анонимные группы поддержки помогают справиться с психологическими трудностями, а поддержка родных и друзей играет неоценимое значение в процессе восстановления после алкоголя. Удаленные консультации по алкоголизму и консультации в анонимном формате обеспечивают доступ к психологической помощи при запойном состоянии. Анонимное лечение дает возможность людям быть уверенными в конфиденциальности. Важно помнить, что первый шаг к выздоровлению, это обращение за помощью.
Продвижение сайтов: как повысить видимость и конверсию https://youtube-start.ru/stati/prodvizhenie-sajtov-kak-povysit-vidimost-i-konversiju/
ТС, почисти ветки, ну невозможно же ничего почитать..в разных ветках одно и тоже. https://antratsitpl.ru было много… но скрутят даже за один! им главное работа,а не обьем! тем более 1гр – это уже особо крупный размер!
På Lucky Marketplace place Casinos innehåller mulighed regarding nyskapande spelare dra nytta av durante generös välkomstbonus å lämnar dem a respeito de kampfstark start. Denna artikel ger dig en omfattande guidebook till vem bonusar som är tillgängliga på Blessed Jungle Online On the web casinos och hur man kan” “dra nytta av unserem. Live casino-sektionen hos Lucky Marketplace Gambling establishment erbjuder depilare möjligheten att lyckas delta i realtidsmatcher med professionella retailers. När du har spelat några tusen händer, och läst en eller flera böcker från ovanstående författare, är du utan tvekan på god väg till att spela Blackjack på en professionell nivå. Tiden som du tränar rekommenderar vi att du lägger hos svenska casinosidor på nätet. Några vanliga bettingsystem är Martingale och Paroli. Båda är baserade på matematiska formler för att se till att du går med vinst i slutänden. Dessa strategier kräver spelstrategier funka utmärkt. Har du en stramare budget ska du hitta en annan strategi istället.
https://cliqworkspromo.co.za/pirates-3-av-elk-studios-en-spannande-slot-for-svenska-spelare/
Bland övriga detaljer finns ett tågspår som löper runt hela 6×7 rutnätet, samt blåa, gröna, lila och röda ädelstenar i olika storlekar. Det finns även en gam, som är en bandit som sitter inspärrad vid sidan om hjulen. Det finns mycket att utforska, men även om du spelar Pirots 3 slot på en Android-, iOS- eller Windows-mobil säkerställer den knivskarpa grafiken att du inte missar något. När mobilcasino lanserades var utbudet relativt begränsat. Spelare som ville ta del av casino i mobilen hade endast ett fåtal spel att välja mellan, samtidigt som utbudet på datorn var betydligt mer komplett. Vi på BestCasino kan absolut rekommendera att du testar vårt demo av Pirots 3 högst upp på denna sida. Med så mycket som händer kan det vara smart att testa spelet innan man satsar riktiga pengar på det.
choice-eats – Culinary excellence with diverse and delicious dining options.
Гепатит C Гепатит C – коварное заболевание печени, вызываемое вирусом HCV, поражающим гепатоциты и приводящим к их постепенному разрушению. Эта инфекция, часто протекающая бессимптомно на начальных стадиях, представляет серьезную угрозу для здоровья, поскольку может перерасти в хроническую форму, чреватую циррозом, печеночной недостаточностью и даже гепатоцеллюлярной карциномой. Понимание путей передачи, своевременная диагностика и доступ к эффективному лечению – ключевые факторы в борьбе с гепатитом C.
Аренда спецтехники сегодня остаётся практичным решением для организаций.
Она даёт возможность выполнять работы без дополнительных затрат содержания машин.
Организации, предлагающие такую услугу, предлагают широкий выбор машин для любых задач.
В парке можно найти погрузчики, бульдозеры и другое оборудование.
https://premierdevelopment.ru/kak-vybrat-nadezhnogo-postavshhika-uslug-po-arende-ekskavatorov.html
Главный плюс аренды — это отсутствие затрат на обслуживание.
Также, арендатор может рассчитывать на проверенную технику, с полным обслуживанием.
Опытные компании заключают понятные соглашения.
Таким образом, аренда спецтехники — это оптимальный выбор для тех, кто стремится к эффективность в работе.
Полезное руководство по получению бонусов и тому, где искать официальную информацию: в разделе регистрации мы вставляем ссылку на 1хБет промокод 2026, дабы показать пример записи в регистрационном поле. Объясняем особенности работы с промо-купонами и способы их получения.
прокси Приобретение мобильных прокси – важный шаг для бизнеса, стремящегося к автоматизации задач, требующих доступа к веб-сайтам, социальным сетям или другим онлайн-ресурсам, с минимизацией риска блокировки. Купить мобильные прокси следует у надежного провайдера, который гарантирует стабильное соединение и широкий пул IP-адресов. Стоимость может варьироваться в зависимости от количества и ротации IP-адресов, а также от географического расположения мобильных прокси.
мфо взять займ займ деньги
микрозайм онлайн займ быстрый
отдых в фуджейре Отдых в Дубае – это эталон безупречного сервиса и комфорта. Отели мирового класса, роскошные пляжи, рестораны, предлагающие гастрономические шедевры со всего мира, безграничные возможности для шопинга и развлечений – здесь каждый найдёт что-то для себя.
взять займ онлайн деньги онлайн
wellnesstourbus – Mobile health and wellness services bringing care to communities.
купить диплом занесенный реестр купить диплом занесенный реестр .
J’adore l’atmosphere olfactive de Spinit Casino, ca offre un plaisir sophistique. Le catalogue est riche en aromes, offrant des sessions live sophistiquees. Renforcant votre capital initial. Le suivi est irreprochable, toujours pret a servir. Les gains arrivent sans delai, neanmoins quelques tours gratuits supplementaires seraient bien venus. En bref, Spinit Casino garantit un plaisir constant pour les joueurs en quete d’excitation ! En bonus le design est moderne et chic, ce qui rend chaque session plus raffinee. Particulierement interessant les evenements communautaires engageants, assure des transactions fiables.
https://spinitcasinobonusfr.com/|
всё отлично,ровно,супер! ) https://vamebel.ru Затарил я тут как то купели значит курехи,приваливай на адрес и не могу найти списался с оператором и понял что дурак тут я а не минер затупил,30 сек и закладка у меня в руках,лечу Домой,дома меня ждут уже братики заряжает по 2 водных и начинаем пускать слюни под спанч бобра, в полне хороший стафф,силы стафа хватает,валит минут 40-60 потом спад,получилось так что вес сдули за 2 дня,отходосы минемальные, вообщем сервис тут вышка тарился тут ребята)
Для многих студентов и аспирантов сколько стоит написать диссертацию на заказ становится выходом из ситуации, когда необходимо сдать научную работу в короткие сроки.
Диссертация на заказ является услугой, которая предлагает готовые научные работы studentам, которые не имеют времени или навыков для написания диссертации самостоятельно. Это связано с тем, что многие студенты сталкиваются с проблемой нехватки времени для написания диссертации, поскольку они должны совмещать учебу с работой. Кроме того, Диссертация на заказ может быть выполнена в короткие сроки, что является большим преимуществом для студентов. Это связано с тем, что компании, которые предлагают диссертацию на заказ, имеют опытных писателей, которые могут справиться с любой темой. Кроме того, диссертация на заказ может быть отредактирована и исправлена, если необходимо.
Диссертация на заказ имеет много преимуществ, включая экономию времени и сил. Это связано с тем, что диссертация на заказ написана опытными писателями, которые имеют глубокие знания в своей области. Кроме того, Диссертация на заказ также имеет экономические преимущества, поскольку студенты не должны тратить деньги на дорогостоящие материалы и источники. Это связано с тем, что компании, которые предлагают диссертацию на заказ, имеют опытных писателей, которые могут справиться с любой темой. Кроме того, диссертация на заказ может быть оплачена различными способами, что делает ее доступной для всех.
Диссертация на заказ может быть оплачена различными способами, что делает ее доступной для всех. Это связано с тем, что компании, которые предлагают диссертацию на заказ, имеют опытных писателей, которые могут справиться с любой темой. Кроме того, диссертация на заказ может быть выполнена в короткие сроки, что является большим преимуществом для студентов. Это связано с тем, что компании, которые предлагают диссертацию на заказ, используют только лучшие материалы и источники. Кроме того, диссертация на заказ может быть отредактирована и исправлена, если необходимо.
Диссертация на заказ дает studentам возможность получить качественную работу, которая соответствует их потребностям. Это связано с тем, что компании, которые предлагают диссертацию на заказ, гарантируют высокое качество и оригинальность работы. Кроме того, диссертация на заказ может быть отредактирована и исправлена, если необходимо. Это связано с тем, что диссертация на заказ может быть заказана на любую тему, в зависимости от потребностей студента. Кроме того, диссертация на заказ может быть оплачена различными способами, что делает ее доступной для всех.
где купить диплом с занесением реестр где купить диплом с занесением реестр .
Купить диплом колледжа в Днепр http://educ-ua7.ru .
www-882884.com – Color palette felt calming, nothing distracting, just focused, thoughtful design.
Ich schatze die Energie bei Snatch Casino, es bietet eine dynamische Erfahrung. Die Spiele sind abwechslungsreich und fesselnd, mit Slots in modernem Look. Mit blitzschnellen Einzahlungen. Der Support ist effizient und professionell. Gewinne kommen sofort an, manchmal gro?ere Boni waren ideal. Abschlie?end, Snatch Casino bietet ein unvergessliches Erlebnis. Daruber hinaus ist das Design stilvoll und modern, einen Hauch von Eleganz hinzufugt. Ein gro?artiges Plus die breiten Sportwetten-Angebote, fortlaufende Belohnungen bieten.
snatch-casino.de|
mjiuzixun.com – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
мобильные прокси купить Прокси, в своей базовой форме, служат посредником между пользователем и Интернетом, скрывая реальный IP-адрес пользователя и предоставляя взамен другой. Это позволяет обойти географические ограничения, получить доступ к заблокированному контенту и повысить уровень конфиденциальности в сети. Купить прокси сегодня – это инвестиция в гибкость и контроль над своим онлайн-присутствием.
отдых в абу даби Шарджа достопримечательности – это отражение богатого культурного наследия ОАЭ. Музей исламской цивилизации, Голубой рынок, предлагающий широкий выбор сувениров и традиционных товаров – Шарджа – это город, где история оживает на каждом шагу.
berrybombselfiespot – Fun and vibrant selfie destination with creative photo opportunities.
gailcooperspeaker – Inspirational speaking with powerful messages and engaging delivery.
купить диплом в норильске https://rudik-diplom2.ru – купить диплом в норильске .
наркологическая платная клиника http://www.narkologicheskaya-klinika-23.ru .
частная наркологическая клиника в москве анонимное http://www.narkologicheskaya-klinika-24.ru/ .
Автоподбор Магнитогорск Авто под заказ в Магнитогорске – это индивидуальный подход к каждому клиенту, позволяющий подобрать автомобиль, идеально отвечающий вашим требованиям и бюджету. Мы предлагаем широкий выбор марок и моделей, различные варианты комплектации и гибкие условия финансирования, создавая максимально комфортные условия для приобретения автомобиля вашей мечты.
я заказывау уже больше 2х лет только у этого магазина, сейчас заказал эфор и регу на подобия jv 100 сказали, посыль дошол от крыл а тпм только эфор а реги нет. может вы что то перепутали с заказом ребята ответь. https://aquaphors.ru мир всем месным братья
Капиталовложения Регистрация права собственности – это гарантия вашей юридической защищенности. Мы обеспечиваем полное сопровождение сделки, начиная от подготовки документов и заканчивая регистрацией права собственности в Росреестре.
у меня 203 1к8 получался вообще жестокии делал на растворителе для снятие лака с ногтей (без ацетона) https://aquaphors.ru Заказал-оплатил 50г реги, а отношение как не знаю к кому…
Je suis emerveille par BassBet Casino, c’est une plateforme qui vibre comme un riff. Le catalogue est riche et varie, offrant des sessions live immersives. Renforcant votre capital initial. Les agents repondent comme un solo, avec une aide precise. Les transactions sont fiables, neanmoins des bonus plus varies seraient un riff. En bref, BassBet Casino vaut une jam session pour les joueurs en quete d’excitation ! En bonus la plateforme est visuellement musicale, ajoute une touche de rythme. Un autre atout les evenements communautaires engageants, offre des recompenses continues.
bassbetcasinobonusfr.com|
wettanbieter ohne lugas mit paypal
My webpage – besten sportwetten seiten
Инхимтек — первый в России производитель полиэтиленовых восков: неокисленные (в т.ч. суспензионные и рафинированные), окисленные ПНД/ПВД и синтетические церезины. Собственная лаборатория, внедренные технологии микронизации и эмульсий, масштабирование мощностей (новые колонны окисления и линии деструкции) — это стабильные спецификации и поставки по всей стране, включая резервирование на складе и выпуск по ТЗ заказчика. Для выбора марки и получения проб перейти на https://xn--e1afajie1bv.xn--p1ai/ — специалисты помогут подобрать совместимость под конкретный процесс.
где купить дипломы медсестры где купить дипломы медсестры .
хуясе надо было сначало уточнить а что брали хоть? ио названижю вещества https://doramalivex.ru Сегодня получил посылку. Оказалось, что просто трек не пробивался до последнего, а посылочка шла себе. Дошло быстро. Сам магазин передал товар в курьерку почти моментально за что огромное спасибо. Магазин всегда остается на связи и отвечает даже на глупые переживания. Конспирация порадовала. Вес тоже в норме. По качеству отпишу позже трип-репорт, но думаю, что всё на высшем уровне. Спасибо, Chemical-mix.
Если вы хотите найти информацию о бонусах при регистрации, ознакомьтесь с наши рекомендации о видах вознаграждений; в одном из разделов статьи естественно упомянут 1хБет промокод для получения приветственного бонуса. Мы объясняем, как указывать данные при регистрации и какие правила нужно выполнить для отыгрыша.
Отзывы радуют о магазине, надо заказывать. 5-MeO-DMT решает. https://chilim-rest.ru сегодня оплатил заказ..буду ждать доставки..протестирую.сообщу о качестве продукта?
Качественный алкоголь отличается мягким послевкусием и натуральным составом.
Явным критерием качества считается отсутствие осадка.
Добротные марки контролируют этапы изготовления.
Тара также может многое рассказать о происхождении продукта.
fortuna-distillery
Наличие акцизной марки — ещё один признак подлинности.
Настоящий алкоголь не должен вызывать резкого запаха.
Следует выбирать продукцию в надёжных торговых точках.
Ответственный подход к покупке продукции поможет насладиться настоящим вкусом.
магаз ровный,всем советую!! https://chery-msk-baltauto.ru С человеком приятно иметь дело. Склонен на компромиссы 😉
Документы недвижимости Профессиональные консультации: ответы на все ваши вопросы.
С развитием онлайн-технологий сервис Ynla.ru представляет собой удобную доску объявлений, на которой ежедневно появляются тысячи вариантов от пользователей разных регионов России и ближнего зарубежья для покупки, продажи или обмена. Основанная на принципах доступности, она позволяет бесплатно публиковать объявления в категориях от автотранспорта и недвижимости до работы, электроники и услуг, с ограничением в одно бесплатное размещение для предотвращения спама, что подтверждается правилами сайта. Удобный поиск по регионам, ценам и типам, интеграция с соцсетями для большей видимости, а также опции VIP-объявлений и магазинов делают процесс простым и быстрым даже для новичков. https://ynla.ru/ — это ваш ключ к успешным сделкам без посредников. Тысячи просмотров, адаптация под мобильные устройства и отзывы реальных пользователей подтверждают востребованность сервиса, позволяя быстро отыскать подходящего контрагента и облегчая рутину.
kraken market Kraken сайт – это таинственный портал в мир эксклюзивных возможностей, где анонимность и безопасность возведены в абсолют. Здесь границы стираются, а мечты обретают реальность, но помните: с большой свободой приходит и большая ответственность. Каждый шаг требует осознанности и понимания, ведь за порогом скрываются не только сокровища, но и подводные камни. Подходите к изучению платформы с мудростью и осторожностью, взвешивая каждый свой выбор.
Цікавитесь кулінарією? Завітайте на кулінарний блог MeatPortal – https://meatportal.com.ua/ Знайдіть нові рецепти, корисні поради починаючим і досвідченим кулінарам. Збирайте нові рецепти до своєї колекції, щоб смачно і корисно годувати сім’ю.
kdjfjks.site – Navigation felt smooth, found everything quickly without any confusing steps.
binaryoptionstrade.xyz – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
Магазин отличный. Покупал не однократно. Спасибо. Ждем регу! купить Кокаин, Мефедрон, Экстази заказал rcs-4, чет не радует отзывы, как придет со дня на день посмотрим, что выйдет отпишусь, буду делать 1к 10-ти…
Найдите лучший товар на https://n-katalog.ru: подробные карточки, честные отзывы, рейтинги, фото, фильтры по параметрам и брендам. Сравнение цен, акции, кэшбэк-предложения и графики изменений. Примите уверенное решение и переходите к покупке в удобном магазине.
оформить микрозайм онлайн займ
Купить видеокарту https://n-katalog.ru/category/videokarty/list актуальные цены и наличие в топ-магазинах, честные характеристики и тесты. Сортировка по цене и производительности, фильтры по памяти, шине, интерфейсам, длине и типу охлаждения. От игр в 1080p до 4K/VR — сравните и выберите лучшее предложение сегодня.
Definicja slowa https://fotoredaktor.top morze zostala wyjasniona.
займ быстрый онлайн займы
Свет — это архитектура эмоций. Студия EtaLustra превращает квартиры, рестораны и офисы в продуманные световые сцены: концепция, расчет освещённости, подбор оборудования под бюджет, поставка и гарантия. Команда с опытом более 10 лет ведёт проект от консультации до запуска, а портфолио показывает, как свет решает задачи пространства — от загородных домов до коммерческих интерьеров. Узнать детали и обсудить проект можно на https://etalustra.ru/ — здесь же удобная связь, этапы работ и статьи базы знаний, которые помогут осмысленно выбрать решение.
mostbet kg http://mostbet12031.ru/
On the page https://fotoredaktor.top Azerbaijan location was clarified clearly.
eyelle-paris.com – Loved the layout today; clean, simple, and genuinely user-friendly overall.
cryptocurrencytrade.pw – Color palette felt calming, nothing distracting, just focused, thoughtful design.
zakolata.xyz – Appreciate the typography choices; comfortable spacing improved my reading experience.
Что особо порадовало – скидывали несуществующий трек еще задолго до отправки, который, конечно, не бился или показывал какую-то х*иту. купить кокаин, меф, бошки через телеграмм вот такие как ты потом и пишут не прет , не узнавая концентрацию и т д набодяжат к…. ,я вот щас жду посыля и хз ко скольки делать 250
купить диплом в сосновом бору http://rudik-diplom6.ru/ .