
Our goal is to enable generative AI models to seamlessly handle combinations of text, images, videos, audio, and more.
Let’s explore our second method in this segment:
- Use a multimodal LLM to summarize images, pass summaries and text data to a text embedding model such as OpenAI’s “text-embedding-3-small”
To simplify multimodal retrieval and RAG, consider converting all data to text. This involves using a text embedding model to unify data in one vector space. Summarizing non-text data incurs extra cost, either through manual efforts or with LLMs.
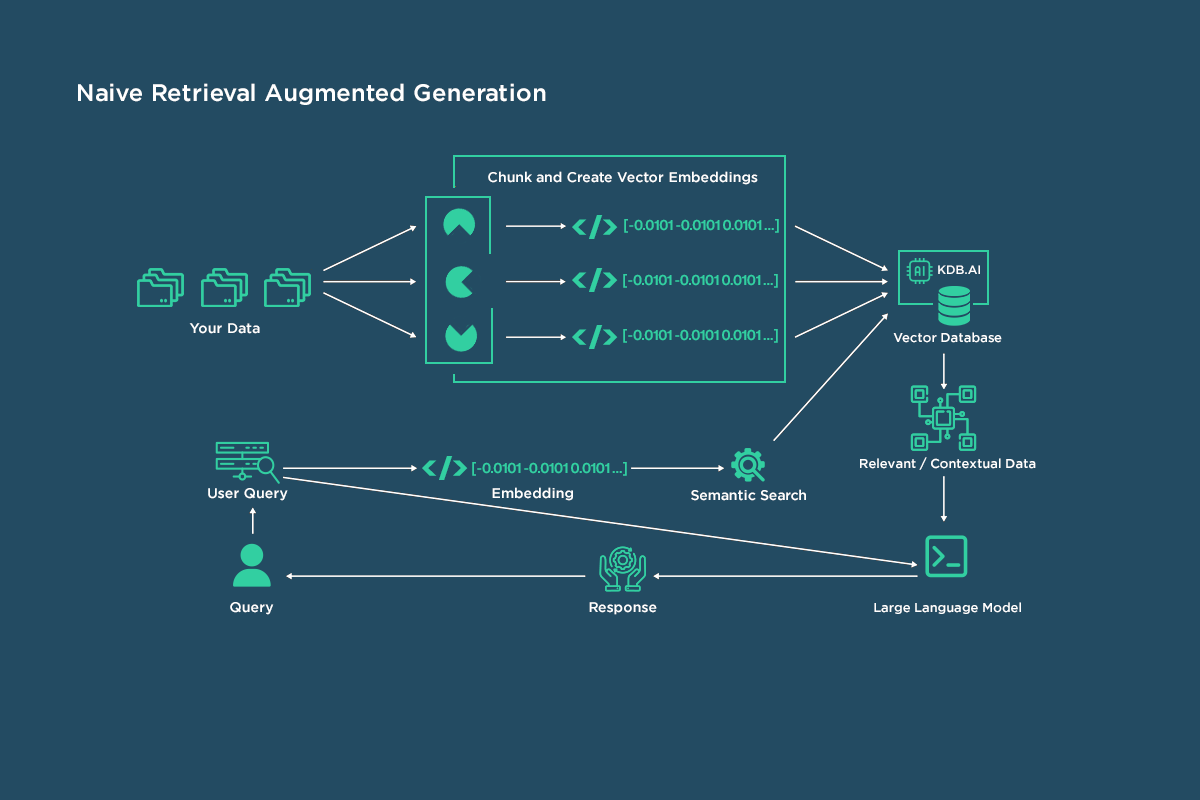
Sharing Vriba Implemented use cases below for “text-embedding-3-small” Multimodal Embedding Model-
- E-commerce Search
- Content Management Systems
- Visual Question Answering (VQA)
- Social Media Content Retrieval
Vriba Review for the “text-embedding-3-small”” Multimodal Embedding Model:
OpenAI’s text-gen-3-small model has surpassed text-embedding-ada-002 in performance. Transitioning to 3- small should enhance semantic search. For large content volumes, text-embedding-3-small, at 5x lower cost, provides substantial savings.
To explore further insights on AI Multimodal Embedding modals & AI latest trends please visit & subscribe to our website: Vriba Blog
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
https://www.webwiki.it/roscar.pt
https://proactive-romaine-q06xnb.mystrikingly.com/
https://doodleordie.com/profile/ticketseiffeltowerfr
виртуальный номер филиппин https://continent-telecom.com/philippines
israel virtual number
аренда яхт на сейшелах
yacht rental tenerife
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
https://rentry.co/3gpv64gi
kroatien boot chartern
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
This site certainly has all the info I needed about this subject and
didn’t know who to ask.
индивидуалки воронеж
Your article helped me a lot, is there any more related content? Thanks!
Good shout.
Nice
Nice
PC
TW
liquid thc area 52
best sativa thc carts area 52
snow caps thca area 52
live rosin gummies area 52
thc oil area 52
thc microdose gummies area 52
best sativa thc edibles area 52
live resin area 52
thc gummies for sleep area 52
thcv gummies area 52
infused pre rolls area 52
distillate carts area 52
where to buy thca area 52
indica gummies area 52
best pre rolls area 52
thc gummies for pain area 52
full spectrum cbd gummies area 52
disposable weed pen area 52
mood thc gummies area 52
indica vape area 52
hybrid disposable area 52
live resin carts area 52
magic mushrooms online area 52
thc tincture area 52
thc pen area 52
thca diamonds area 52
best disposable vaporizers area 52
thca disposable area 52
thc gummies
live resin gummies area 52
best thca area 52
hybrid gummies area 52
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your style is really unique compared to other folks I have read stuff from.
Many thanks for posting when you have the opportunity, Guess I’ll just book
mark this site.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I’m impressеd, I must say. Rarely do I come aⅽгoss a blog thɑt’s both eduсative and interesting,
and without a doubt, you’ve hit the nail on the head. The issue is something that not
enough fߋlks are speaking intelligently about. I am very hаppy that I found this іn my searϲh foг something concerning this.
Also visit my web page: situs gacor dewabos138
Hello, I think your website might be having browser compatibility issues.
When I look at your blog site in Safari, it looks
fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, superb blog!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I want to to thank you for this great read!!
I certainly enjoyed every little bit of it.
I have you book marked to look at new things you post…
Sweet blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
I do believe all of the ideas you’ve offered for your post.
They are very convincing and will definitely work.
Nonetheless, the posts are too short for novices.
May just you please prolong them a bit from next time?
Thank you for the post.
I have learn several excellent stuff here. Definitely price bookmarking for revisiting.
I wonder how so much effort you put to make the sort of fantastic informative website.
Very good information. Lucky me I recently found your website by accident
(stumbleupon). I have saved as a favorite for later!
You really make it seem so easy with your presentation but I find this matter to be
really something that I think I would never understand.
It seems too complicated and extremely broad for me.
I am looking forward for your next post, I’ll try to get the hang
of it!
wonderful put up, very informative. I wonder why the other
specialists of this sector don’t understand this. You must continue your writing.
I am confident, you have a huge readers’ base already!
Everyone loves what you guys are up too. This sort of clever work
and exposure! Keep up the great works guys I’ve incorporated you guys to my personal blogroll.
I am truly grateful to the owner of this site who has shared this wonderful
piece of writing at here.
Hi there, I do think your blog could be having
browser compatibility problems. When I look at your website in Safari, it looks fine however, when opening in Internet Explorer,
it’s got some overlapping issues. I simply wanted to provide you with
a quick heads up! Besides that, great website!
This article presents clear idea in favor of the new people of blogging, that truly how to do blogging
and site-building.
Hi there! Do you know if they make any plugins to assist with Search Engine
Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Thank you!
For latest information you have to visit the web and on the
web I found this site as a most excellent web
site for most recent updates.
Quality articles or reviews is the key to attract the viewers to pay a visit the web site, that’s what this web site is providing.
Thanks for the auspicious writeup. It actually was once a entertainment account it.
Glance complex to far delivered agreeable from you! However, how
can we communicate?
I used to be recommended this web site by way of my cousin. I
am not positive whether or not this post is written via him as nobody else
realize such detailed about my difficulty.
You are wonderful! Thanks!
I like it when people get together and share ideas. Great site,
continue the good work!
When someone writes an piece of writing he/she retains the thought of a user in his/her brain that how a user can be aware
of it. Therefore that’s why this post is outstdanding.
Thanks!
Awesome post.
Hey there! This post couldn’t be written any better!
Reading this post reminds me of my good old room mate!
He always kept talking about this. I will forward this write-up to
him. Pretty sure he will have a good read. Thank you
for sharing!
Howdy just wanted to give you a quick heads up. The text in your article seem to be
running off the screen in Opera. I’m not sure if this is
a formatting issue or something to do with web browser compatibility but I
thought I’d post to let you know. The layout look great though!
Hope you get the problem resolved soon. Many thanks
Hello, of course this piece of writing is actually pleasant and I have learned lot of things from it on the topic of blogging.
thanks.
whoah this blog is excellent i love studying
your posts. Keep up the good work! You understand, lots of people are searching around for this information, you can aid them greatly.
Because the admin of this website is working, no question very shortly it will be famous,
due to its feature contents.
If you are going for finest contents like I do, simply pay a visit this website every day for the reason that it offers feature contents, thanks
Very good article. I certainly appreciate this site.
Keep it up!
Wow! In the end I got a weblog from where I know how to in fact take
useful information regarding my study and knowledge.
Just want to say your article is as surprising.
The clarity in your put up is simply spectacular and i
can suppose you are an expert in this subject. Fine along with your permission let me to grab your RSS feed to keep up to date with impending post.
Thank you 1,000,000 and please keep up the gratifying work.
I think the admin of this web site is actually working hard for his site, because here
every information is quality based information.
It’s very simple to find out any matter on net as compared to textbooks, as I found this piece of writing at this web site.
This article will assist the internet users for building up new website or even a blog from start
to end.
Howdy! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly?
My website looks weird when viewing from my
iphone 4. I’m trying to find a template or plugin that might be able to
correct this issue. If you have any recommendations, please share.
Cheers!
Good blog you have here.. It’s hard to find quality writing like yours
these days. I honestly appreciate people like you!
Take care!!
I have been exploring for a little bit for any high quality articles or
blog posts on this kind of house . Exploring in Yahoo
I eventually stumbled upon this site. Reading this info So i’m glad to express that I have a
very good uncanny feeling I found out exactly what I needed.
I so much indubitably will make sure to do not overlook this site and give it a glance on a constant basis.
Thanks for the auspicious writeup. It in fact was a leisure account it.
Look complicated to far introduced agreeable from you! By the way, how could we be
in contact?
Hello, just wanted to mention, I enjoyed this blog post.
It was practical. Keep on posting!
If you are going for finest contents like I do, just go to see
this site all the time because it presents quality contents, thanks
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Your article helped me a lot, is there any more related content? Thanks!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.com/en/register?ref=JHQQKNKN
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.