
Multimodal AI is anticipated to lead the next phase of AI development, with projections indicating its mainstream adoption by 2024. Unlike traditional AI systems limited to processing a single data type, multimodal models aim to mimic human perception by integrating various sensory inputs.
This approach acknowledges the multifaceted nature of the world, where humans interact with diverse data types simultaneously. Ultimately, the goal is to enable generative AI models to seamlessly handle combinations of text, images, videos, audio, and more.
Two methods for retrieval are explored:
- Use a multimodal embedding model to embed both text and images.
- Use a multimodal LLM to summarize images, pass summaries and text data to a text embedding model such as OpenAI’s “text-embedding-3-small”
Sharing use cases for method 1 mentioned above:
Use Cases Implementation Utilizing Multimodal Embedding Model:
E-commerce Search: Users can search for products using both text descriptions and images, enabling more accurate and intuitive searches.
Content Management Systems: Facilitates searching and categorizing multimedia content such as articles, images, and videos within a database.
Visual Question Answering (VQA): Enables systems to understand and respond to questions involving images by embedding both textual questions and visual content into the same vector space.
Social Media Content Retrieval: Enhances the search experience by allowing users to find relevant posts based on text descriptions and associated images.
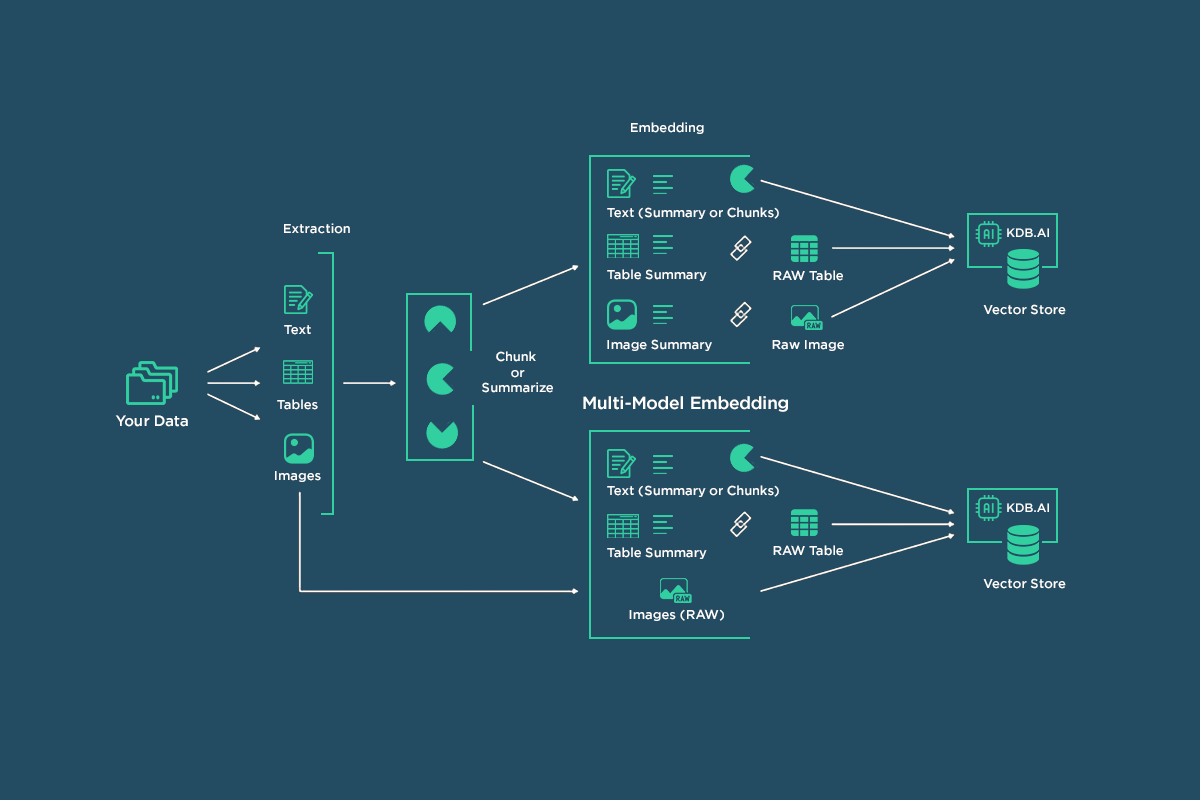
Multimodal Retrieval for RAG
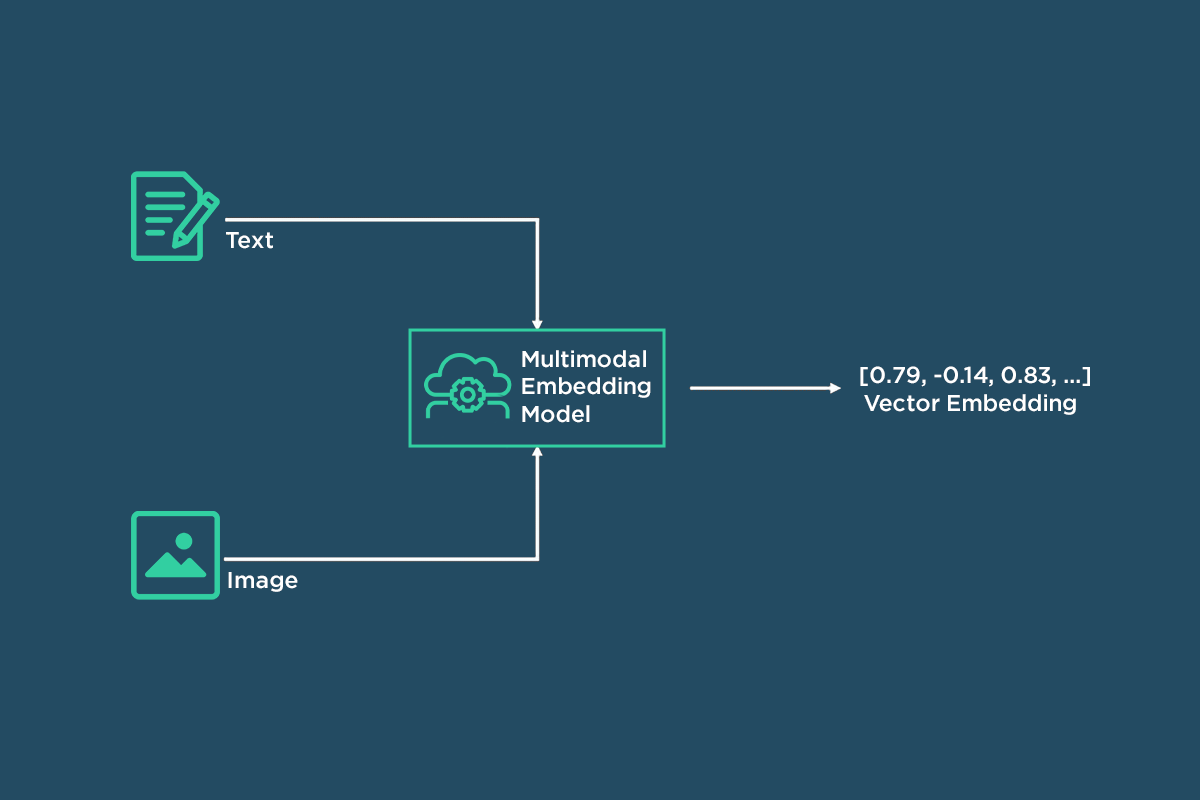
Architecture of text and image summaries being embedded by text embedding model
Our store provides a comprehensive collection of high-quality healthcare solutions for various needs.
Our platform ensures quick and secure shipping wherever you are.
All products is supplied by trusted pharmaceutical companies to ensure authenticity and compliance.
Easily search through our catalog and make a purchase hassle-free.
If you have questions, Pharmacy experts are here to help whenever you need.
Prioritize your well-being with our trusted e-pharmacy!
https://bresdel.com/blogs/817900/Cialis-Black-Your-Partner-in-Overcoming-Sexual-Challenges
Наш сервис занимается сопровождением приезжих в Санкт-Петербурге.
Оказываем содействие в оформлении документов, регистрации, а также формальностях, связанных с трудоустройством.
Наши специалисты помогают по всем юридическим вопросам и направляют правильный порядок действий.
Мы работаем как с временным пребыванием, так и с гражданством.
Благодаря нам, ваша адаптация пройдет легче, решить все юридические формальности и уверенно чувствовать себя в этом прекрасном городе.
Обращайтесь, чтобы узнать больше!
https://spb-migrant.ru/
BlackSprut – платформа с особыми возможностями
Платформа BlackSprut привлекает обсуждения разных сообществ. Почему о нем говорят?
Эта площадка предоставляет интересные опции для аудитории. Визуальная составляющая системы отличается функциональностью, что позволяет ей быть понятной даже для новичков.
Стоит учитывать, что данная система работает по своим принципам, которые отличают его в определенной среде.
При рассмотрении BlackSprut важно учитывать, что многие пользователи оценивают его по-разному. Некоторые выделяют его возможности, а некоторые относятся к нему с осторожностью.
Таким образом, BlackSprut остается объектом интереса и вызывает заинтересованность разных слоев интернет-сообщества.
Свежий сайт БлэкСпрут – здесь можно найти
Хотите найти свежее ссылку на BlackSprut? Это можно сделать здесь.
bs2best at
Периодически ресурс перемещается, и тогда нужно знать новое ссылку.
Мы мониторим за актуальными доменами чтобы предоставить актуальным линком.
Проверьте рабочую ссылку у нас!
Our platform provides access to a wide selection of online slots, suitable for all types of players.
Right here, you can find traditional machines, new generation slots, and jackpot slots with stunning graphics and immersive sound.
If you are into simple gameplay or prefer bonus-rich rounds, you’ll find a perfect match.
https://ger-com.ru/wp-content/pages/ghelanie_rebenka_vs_finansovaya_otvetstvennosty_kak_nayti_balans.html
All games are available 24/7, with no installation, and fully optimized for both all devices.
Besides slots, the site includes helpful reviews, special offers, and user ratings to guide your play.
Sign up, start playing, and enjoy the thrill of online slots!
Forest bathing proves nature’s medicinal power. The iMedix health news podcast examines Japanese Shinrin-yoku research. Environmental therapists guide virtual sessions. Reconnect with healing landscapes through iMedix online Health Podcast!
Understanding food labels helps make informed nutritional choices. Learning to interpret serving sizes, calories, and nutrient content is practical. Knowing how to identify added sugars, sodium, and unhealthy fats is key. Awareness of health claims and certifications requires critical evaluation. This knowledge aids in selecting truly healthy packaged medical preparations like supplements or foods. Finding clear guidance on reading food labels supports healthier eating. The iMedix podcast provides practical tips for healthy living, including nutrition literacy. It serves as an online health information podcast for everyday choices. Tune into the iMedix online health podcast for label-reading skills. iMedix offers trusted health advice for your grocery shopping.
Self-harm leading to death is a serious topic that impacts many families across the world.
It is often linked to emotional pain, such as bipolar disorder, trauma, or addiction problems.
People who contemplate suicide may feel isolated and believe there’s no hope left.
how-to-kill-yourself.com
Society needs to raise awareness about this subject and offer a helping hand.
Prevention can reduce the risk, and reaching out is a brave first step.
If you or someone you know is thinking about suicide, please seek help.
You are not forgotten, and there’s always hope.
Understanding food labels helps make informed nutritional choices daily always practically practically practically practically. Learning to interpret serving sizes and nutrient content is practical always usefully usefully usefully usefully usefully. Knowing how to identify added sugars and sodium aids healthier selections always critically critically critically critically critically. Awareness of marketing claims requires critical evaluation skills always importantly importantly importantly importantly importantly. Finding clear guidance on reading food labels supports healthier eating always effectively effectively effectively effectively effectively. The iMedix podcast provides practical tips for healthy living, including nutrition literacy always usefully usefully usefully usefully usefully. It serves as an online health information podcast for everyday choices always relevantly relevantly relevantly relevantly relevantly. Tune into the iMedix online health podcast for label-reading skills always helpfully helpfully helpfully helpfully helpfully.
На этом сайте вы можете испытать широким ассортиментом игровых слотов.
Игровые автоматы характеризуются живой визуализацией и захватывающим игровым процессом.
Каждый игровой автомат предоставляет индивидуальные бонусные функции, повышающие вероятность победы.
1xbet казино
Игра в игровые автоматы предназначена игроков всех уровней.
Вы можете играть бесплатно, после чего начать играть на реальные деньги.
Проверьте свою удачу и получите удовольствие от яркого мира слотов.
На нашем портале вам предоставляется возможность играть в большим выбором игровых слотов.
Игровые автоматы характеризуются красочной графикой и увлекательным игровым процессом.
Каждый игровой автомат предоставляет уникальные бонусные раунды, повышающие вероятность победы.
1win
Слоты созданы для игроков всех уровней.
Есть возможность воспользоваться демо-режимом, после чего начать играть на реальные деньги.
Испытайте удачу и насладитесь неповторимой атмосферой игровых автоматов.
На нашей платформе можно найти различные игровые автоматы.
Мы собрали большой выбор игр от популярных брендов.
Каждая игра предлагает уникальной графикой, дополнительными возможностями и максимальной волатильностью.
http://dcnjf.com/demystifying-the-thrilling-world-of-online-casinos/
Каждый посетитель может тестировать автоматы без вложений или выигрывать настоящие призы.
Меню и структура ресурса просты и логичны, что облегчает поиск игр.
Если вас интересуют слоты, данный ресурс стоит посетить.
Начинайте играть уже сегодня — тысячи выигрышей ждут вас!
Здесь вы можете найти интересные слот-автоматы.
Здесь собраны подборку аппаратов от проверенных студий.
Каждая игра предлагает интересным геймплеем, увлекательными бонусами и максимальной волатильностью.
https://lavanyac.com/the-thrilling-world-of-online-casinos/
Пользователи могут запускать слоты бесплатно или выигрывать настоящие призы.
Интерфейс максимально удобны, что помогает легко находить нужные слоты.
Если вас интересуют слоты, этот сайт — отличный выбор.
Попробуйте удачу на сайте — тысячи выигрышей ждут вас!
Self-harm leading to death is a tragic topic that affects many families worldwide.
It is often connected to mental health issues, such as depression, hopelessness, or chemical dependency.
People who contemplate suicide may feel overwhelmed and believe there’s no hope left.
how-to-kill-yourself.com
We must raise awareness about this matter and offer a helping hand.
Early support can reduce the risk, and talking to someone is a crucial first step.
If you or someone you know is in crisis, don’t hesitate to get support.
You are not without options, and support exists.
На данной платформе вы найдёте разнообразные игровые слоты на платформе Champion.
Выбор игр включает классические автоматы и новейшие видеослоты с яркой графикой и специальными возможностями.
Каждый слот оптимизирован для максимального удовольствия как на десктопе, так и на смартфонах.
Будь вы новичком или профи, здесь вы найдёте подходящий вариант.
champion casino
Автоматы запускаются в любое время и не нуждаются в установке.
Также сайт предоставляет программы лояльности и обзоры игр, чтобы сделать игру ещё интереснее.
Начните играть прямо сейчас и оцените преимущества с казино Champion!
На данной платформе вы найдёте разнообразные слоты казино на платформе Champion.
Выбор игр представляет проверенные временем слоты и новейшие видеослоты с яркой графикой и специальными возможностями.
Всякий автомат создан для комфортного использования как на ПК, так и на мобильных устройствах.
Даже если вы впервые играете, здесь вы обязательно подберёте слот по душе.
online
Игры работают круглосуточно и работают прямо в браузере.
Дополнительно сайт предоставляет бонусы и полезную информацию, для удобства пользователей.
Попробуйте прямо сейчас и насладитесь азартом с брендом Champion!
На этом сайте представлены онлайн-игры из казино Вавада.
Каждый гость найдёт подходящую игру — от классических одноруких бандитов до новейших моделей с анимацией.
Казино Vavada предоставляет широкий выбор слотов от топовых провайдеров, включая игры с джекпотом.
Все игры запускается круглосуточно и адаптирован как для компьютеров, так и для мобильных устройств.
официальный сайт vavada
Вы сможете испытать атмосферой игры, не выходя из квартиры.
Навигация по сайту удобна, что обеспечивает быстро найти нужную игру.
Зарегистрируйтесь уже сегодня, чтобы почувствовать азарт с Vavada!
На этом сайте можно найти онлайн-игры платформы Vavada.
Каждый гость сможет выбрать автомат по интересам — от классических игр до современных разработок с анимацией.
Казино Vavada предоставляет широкий выбор популярных игр, включая слоты с крупными выигрышами.
Любой автомат работает в любое время и адаптирован как для настольных устройств, так и для телефонов.
vavada casino
Игроки могут наслаждаться настоящим драйвом, не выходя из квартиры.
Структура платформы проста, что позволяет моментально приступить к игре.
Зарегистрируйтесь уже сегодня, чтобы погрузиться в мир выигрышей!
On this platform, you can access a great variety of slot machines from famous studios.
Users can enjoy retro-style games as well as feature-packed games with high-quality visuals and interactive gameplay.
Whether you’re a beginner or a seasoned gamer, there’s always a slot to match your mood.
casino
Each title are available round the clock and compatible with PCs and tablets alike.
You don’t need to install anything, so you can get started without hassle.
Site navigation is user-friendly, making it simple to find your favorite slot.
Register now, and enjoy the excitement of spinning reels!
This website, you can access a great variety of casino slots from famous studios.
Visitors can enjoy classic slots as well as modern video slots with high-quality visuals and exciting features.
If you’re just starting out or a casino enthusiast, there’s always a slot to match your mood.
play aviator
All slot machines are ready to play anytime and designed for laptops and tablets alike.
All games run in your browser, so you can get started without hassle.
The interface is easy to use, making it quick to explore new games.
Join the fun, and discover the thrill of casino games!
Сайт BlackSprut — это одна из самых известных точек входа в даркнете, открывающая разнообразные сервисы для пользователей.
На платформе реализована простая структура, а структура меню понятен даже новичкам.
Участники отмечают быструю загрузку страниц и активное сообщество.
bs2 bsme
Сервис настроен на удобство и анонимность при навигации.
Если вы интересуетесь альтернативные цифровые пространства, площадка будет интересным вариантом.
Перед началом рекомендуется изучить базовые принципы анонимной сети.
Платформа BlackSprut — это хорошо известная онлайн-площадок в darknet-среде, предлагающая разные функции в рамках сообщества.
На платформе реализована простая структура, а структура меню понятен даже новичкам.
Участники выделяют стабильность работы и активное сообщество.
bs2best
BlackSprut ориентирован на комфорт и анонимность при навигации.
Кому интересны альтернативные цифровые пространства, этот проект станет хорошим примером.
Прежде чем начать лучше ознакомиться с информацию о работе Tor.
Онлайн-площадка — цифровая витрина профессионального детективного агентства.
Мы организуем помощь по частным расследованиям.
Коллектив детективов работает с повышенной конфиденциальностью.
Наша работа включает сбор информации и детальное изучение обстоятельств.
Детективное агентство
Каждое дело рассматривается индивидуально.
Задействуем эффективные инструменты и действуем в правовом поле.
Если вы ищете ответственное агентство — вы нашли нужный сайт.
Этот сайт — цифровая витрина независимого сыскного бюро.
Мы организуем помощь в решении деликатных ситуаций.
Группа профессионалов работает с абсолютной осторожностью.
Наша работа включает наблюдение и детальное изучение обстоятельств.
Детективное агентство
Каждое обращение рассматривается индивидуально.
Применяем проверенные подходы и действуем в правовом поле.
Нуждаетесь в реальную помощь — вы по адресу.
Данный ресурс — официальная страница частного сыскного бюро.
Мы предлагаем помощь по частным расследованиям.
Коллектив профессионалов работает с абсолютной осторожностью.
Нам доверяют поиски людей и разные виды расследований.
Заказать детектива
Каждое обращение обрабатывается персонально.
Мы используем проверенные подходы и действуем в правовом поле.
Ищете достоверную информацию — добро пожаловать.
На данной платформе можно найти игровые автоматы платформы Vavada.
Каждый гость сможет выбрать слот на свой вкус — от простых аппаратов до новейших разработок с бонусными раундами.
Vavada предлагает доступ к популярных игр, включая игры с джекпотом.
Все игры доступен круглосуточно и адаптирован как для ПК, так и для планшетов.
vavada бонусы
Вы сможете испытать атмосферой игры, не выходя из квартиры.
Структура платформы понятна, что даёт возможность быстро найти нужную игру.
Зарегистрируйтесь уже сегодня, чтобы открыть для себя любимые слоты!
Our platform offers a great variety of decorative wall clocks for every room.
You can discover modern and vintage styles to fit your living space.
Each piece is curated for its visual appeal and accuracy.
Whether you’re decorating a stylish living room, there’s always a perfect clock waiting for you.
small vintage table clocks
Our assortment is regularly refreshed with new arrivals.
We ensure a smooth experience, so your order is always in good care.
Start your journey to timeless elegance with just a few clicks.
This online store offers a wide selection of decorative wall clocks for your interior.
You can check out minimalist and traditional styles to fit your home.
Each piece is curated for its aesthetic value and reliable performance.
Whether you’re decorating a creative workspace, there’s always a fitting clock waiting for you.
best birdhouse pendulum wall clocks
The collection is regularly refreshed with exclusive releases.
We care about customer satisfaction, so your order is always in safe hands.
Start your journey to enhanced interiors with just a few clicks.
Here offers a great variety of stylish wall-mounted clocks for your interior.
You can browse modern and timeless styles to fit your home.
Each piece is chosen for its visual appeal and functionality.
Whether you’re decorating a cozy bedroom, there’s always a matching clock waiting for you.
best kosda led alarm clocks
The collection is regularly updated with new arrivals.
We ensure quality packaging, so your order is always in good care.
Start your journey to perfect timing with just a few clicks.
This website offers a large assortment of interior clock designs for your interior.
You can browse urban and classic styles to match your living space.
Each piece is hand-picked for its craftsmanship and reliable performance.
Whether you’re decorating a stylish living room, there’s always a perfect clock waiting for you.
hito modern wall clocks
The collection is regularly refreshed with fresh designs.
We focus on customer satisfaction, so your order is always in professional processing.
Start your journey to enhanced interiors with just a few clicks.
This online store offers a large assortment of interior clock designs for your interior.
You can explore urban and classic styles to complement your living space.
Each piece is chosen for its aesthetic value and accuracy.
Whether you’re decorating a cozy bedroom, there’s always a beautiful clock waiting for you.
creative wall clocks
The shop is regularly updated with exclusive releases.
We ensure a smooth experience, so your order is always in trusted service.
Start your journey to enhanced interiors with just a few clicks.
Our platform offers a large assortment of home timepieces for your interior.
You can explore urban and classic styles to fit your interior.
Each piece is curated for its aesthetic value and reliable performance.
Whether you’re decorating a creative workspace, there’s always a perfect clock waiting for you.
retro alarm clocks
The collection is regularly expanded with new arrivals.
We ensure customer satisfaction, so your order is always in good care.
Start your journey to enhanced interiors with just a few clicks.
This online service offers a large selection of medications for easy access.
Users can easily get treatments without leaving home.
Our range includes popular medications and targeted therapies.
Each item is sourced from verified pharmacies.
https://community.alteryx.com/t5/user/viewprofilepage/user-id/576949
We maintain customer safety, with encrypted transactions and prompt delivery.
Whether you’re filling a prescription, you’ll find trusted options here.
Visit the store today and get convenient online pharmacy service.
На этом сайте предоставляет нахождения вакансий по всей стране.
Пользователям доступны разные объявления от настоящих компаний.
На платформе появляются вакансии в разнообразных нишах.
Частичная занятость — всё зависит от вас.
Кримінальна робота
Навигация простой и подстроен на любой уровень опыта.
Регистрация не потребует усилий.
Ищете работу? — просматривайте вакансии.
Этот портал предлагает поиска работы на территории Украины.
Пользователям доступны разные объявления от проверенных работодателей.
Мы публикуем объявления о работе в различных сферах.
Частичная занятость — вы выбираете.
Робота з ризиком
Навигация легко осваивается и подходит на всех пользователей.
Регистрация займёт минимум времени.
Хотите сменить сферу? — просматривайте вакансии.
This website, you can access a great variety of casino slots from top providers.
Users can enjoy classic slots as well as feature-packed games with stunning graphics and bonus rounds.
If you’re just starting out or a casino enthusiast, there’s a game that fits your style.
casino games
Each title are available round the clock and compatible with desktop computers and mobile devices alike.
All games run in your browser, so you can get started without hassle.
The interface is easy to use, making it simple to find your favorite slot.
Sign up today, and dive into the excitement of spinning reels!
This website, you can find a great variety of casino slots from famous studios.
Users can try out retro-style games as well as feature-packed games with vivid animation and exciting features.
If you’re just starting out or a seasoned gamer, there’s something for everyone.
play casino
Each title are ready to play 24/7 and designed for laptops and tablets alike.
No download is required, so you can get started without hassle.
Platform layout is user-friendly, making it quick to explore new games.
Join the fun, and discover the thrill of casino games!
Текущий модный сезон обещает быть непредсказуемым и нестандартным в плане моды.
В тренде будут асимметрия и минимализм с изюминкой.
Актуальные тона включают в себя неоновые оттенки, создающие настроение.
Особое внимание дизайнеры уделяют тканям, среди которых популярны винтажные очки.
https://www.globalfreetalk.com/read-blog/31372
Возвращаются в моду элементы ретро-стиля, через призму сегодняшнего дня.
На подиумах уже можно увидеть смелые решения, которые удивляют.
Следите за обновлениями, чтобы создать свой образ.
Mechanical watches will forever stay fashionable.
They symbolize heritage and offer a sense of artistry that modern gadgets simply don’t replicate.
These watches is powered by complex gears, making it both reliable and inspiring.
Collectors cherish the craft behind them.
http://bedfordfalls.live/read-blog/119968
Wearing a mechanical watch is not just about checking hours, but about making a statement.
Their aesthetics are classic, often passed from lifetime to legacy.
All in all, mechanical watches will forever hold their place.
This website, you can find a great variety of slot machines from leading developers.
Visitors can try out traditional machines as well as modern video slots with high-quality visuals and interactive gameplay.
If you’re just starting out or a casino enthusiast, there’s always a slot to match your mood.
play casino
Each title are instantly accessible round the clock and designed for laptops and smartphones alike.
No download is required, so you can jump into the action right away.
The interface is intuitive, making it simple to browse the collection.
Register now, and enjoy the excitement of spinning reels!
On this platform, you can discover lots of online slots from leading developers.
Visitors can experience classic slots as well as modern video slots with vivid animation and bonus rounds.
Even if you’re new or a casino enthusiast, there’s always a slot to match your mood.
play aviator
Each title are instantly accessible anytime and compatible with PCs and smartphones alike.
You don’t need to install anything, so you can start playing instantly.
The interface is intuitive, making it convenient to browse the collection.
Register now, and enjoy the excitement of spinning reels!
Were you aware that 1 in 3 people taking prescriptions make dangerous drug mistakes due to insufficient information?
Your health is your most valuable asset. Each pharmaceutical choice you make directly impacts your quality of life. Maintaining awareness about medical treatments is absolutely essential for successful recovery.
Your health isn’t just about following prescriptions. Every medication affects your body’s chemistry in unique ways.
Consider these critical facts:
1. Combining medications can cause dangerous side effects
2. Over-the-counter supplements have potent side effects
3. Skipping doses undermines therapy
To avoid risks, always:
✓ Verify interactions via medical databases
✓ Study labels in detail when starting any medication
✓ Consult your doctor about proper usage
___________________________________
For reliable drug information, visit:
https://community.alteryx.com/t5/user/viewprofilepage/user-id/569428
Our e-pharmacy features a broad selection of medications with competitive pricing.
Customers can discover all types of remedies to meet your health needs.
We strive to maintain high-quality products at a reasonable cost.
Fast and reliable shipping provides that your order arrives on time.
Take advantage of ordering medications online on our platform.
kamagra effervescent
This online pharmacy features a broad selection of pharmaceuticals at affordable prices.
Shoppers will encounter all types of medicines suitable for different health conditions.
We work hard to offer high-quality products without breaking the bank.
Quick and dependable delivery guarantees that your purchase is delivered promptly.
Experience the convenience of getting your meds with us.
amoxil 1000 antibiotic
The site offers buggy hire throughout Crete.
Visitors can quickly book a vehicle for travel.
If you’re looking to explore natural spots, a buggy is the ideal way to do it.
https://peatix.com/user/26412811/view
Our rides are ready to go and available for daily schedules.
Booking through this site is simple and comes with affordable prices.
Get ready to ride and feel Crete like never before.
This section showcases disc player alarm devices crafted by top providers.
Visit to explore modern disc players with digital radio and dual wake options.
Many models include external audio inputs, charging capability, and battery backup.
Available products spans economical models to luxury editions.
radio cd player alarm clock
All devices offer sleep timers, rest timers, and digital displays.
Order today are available via online retailers with fast shipping.
Choose the perfect clock-radio-CD setup for kitchen everyday enjoyment.
Here, you can discover a wide selection of slot machines from leading developers.
Users can experience traditional machines as well as feature-packed games with stunning graphics and interactive gameplay.
Whether you’re a beginner or a casino enthusiast, there’s a game that fits your style.
casino slots
All slot machines are available anytime and designed for laptops and smartphones alike.
All games run in your browser, so you can jump into the action right away.
The interface is user-friendly, making it convenient to find your favorite slot.
Register now, and enjoy the world of online slots!
Наличие медицинской страховки перед поездкой за рубеж — это разумное решение для защиты здоровья путешественника.
Полис гарантирует расходы на лечение в случае заболевания за границей.
Также, полис может обеспечивать компенсацию на возвращение домой.
осаго рассчитать
Некоторые государства предусматривают оформление полиса для посещения.
Без страховки медицинские расходы могут обойтись дорого.
Оформление полиса заранее
The site lets you connect with workers for short-term risky jobs.
Users can quickly schedule services for unique needs.
All workers are trained in managing intense tasks.
assassin for hire
Our platform provides safe interactions between requesters and freelancers.
For those needing a quick solution, this website is the right choice.
Submit a task and match with an expert now!
Il nostro servizio offre l’assunzione di operatori per attività a rischio.
I clienti possono trovare esperti affidabili per incarichi occasionali.
Ogni candidato vengono scelti con cura.
sonsofanarchy-italia.com
Utilizzando il servizio è possibile leggere recensioni prima della scelta.
La qualità è un nostro impegno.
Esplorate le offerte oggi stesso per portare a termine il vostro progetto!
На нашем ресурсе вы можете найти актуальное зеркало 1хбет без ограничений.
Мы регулярно обновляем зеркала, чтобы облегчить свободное подключение к сайту.
Используя зеркало, вы сможете пользоваться всеми функциями без ограничений.
зеркало 1хбет
Данный портал позволит вам быстро найти новую ссылку 1хБет.
Мы стремимся, чтобы все клиенты имел возможность получить полный доступ.
Проверяйте новые ссылки, чтобы всегда оставаться в игре с 1xBet!
Данный ресурс — настоящий цифровой магазин Боттега Вэнета с доставкой по стране.
Через наш портал вы можете приобрести эксклюзивные вещи Боттега Венета без посредников.
Каждая покупка подтверждены сертификатами от компании.
боттега венета цум
Отправка осуществляется оперативно в любое место России.
Интернет-магазин предлагает выгодные условия покупки и гарантию возврата средств.
Покупайте на официальном сайте Bottega Veneta, чтобы чувствовать уверенность в покупке!
通过本平台,您可以聘请专门从事临时的高危工作的人员。
我们整理了大量可靠的行动专家供您选择。
无论面对何种高风险任务,您都可以方便找到专业的助手。
chinese-hitman-assassin.com
所有任务完成者均经过审核,保障您的利益。
服务中心注重专业性,让您的任务委托更加无忧。
如果您需要服务详情,请随时咨询!
On this site, you can find top CS:GO gaming sites.
We have collected a wide range of gaming platforms specialized in CS:GO.
Every website is tested for quality to guarantee safety.
cs roulette
Whether you’re a seasoned bettor, you’ll conveniently choose a platform that fits your style.
Our goal is to guide you to find reliable CS:GO gambling websites.
Start browsing our list right away and enhance your CS:GO betting experience!
В данном ресурсе вы найдёте подробную информацию о партнёрском предложении: 1win партнерская программа.
Здесь размещены все нюансы работы, правила присоединения и возможные бонусы.
Любой блок подробно освещён, что позволяет легко усвоить в тонкостях функционирования.
Плюс ко всему, имеются разъяснения по запросам и подсказки для первых шагов.
Информация регулярно обновляется, поэтому вы смело полагаться в актуальности предоставленных данных.
Этот ресурс станет вашим надежным помощником в изучении партнёрской программы 1Win.
The site makes it possible to hire experts for temporary high-risk jobs.
Clients may easily arrange help for specialized needs.
All workers are experienced in handling critical operations.
hitman for hire
Our platform provides private arrangements between employers and specialists.
If you require a quick solution, the site is the right choice.
Post your request and match with the right person now!
Questo sito permette l’assunzione di lavoratori per compiti delicati.
Gli utenti possono trovare esperti affidabili per operazioni isolate.
Tutti i lavoratori sono valutati con cura.
sonsofanarchy-italia.com
Con il nostro aiuto è possibile consultare disponibilità prima di assumere.
La qualità è al centro del nostro servizio.
Sfogliate i profili oggi stesso per ottenere aiuto specializzato!
Searching for experienced workers ready for temporary dangerous jobs.
Require a specialist for a perilous job? Connect with certified laborers on our platform for time-sensitive dangerous operations.
hitman for hire
This website connects businesses with licensed workers willing to accept unsafe one-off gigs.
Recruit verified freelancers for risky duties safely. Ideal when you need emergency assignments demanding specialized labor.
Here, you can find a great variety of casino slots from leading developers.
Players can enjoy traditional machines as well as new-generation slots with stunning graphics and bonus rounds.
Even if you’re new or an experienced player, there’s a game that fits your style.
casino games
Each title are instantly accessible anytime and designed for PCs and tablets alike.
No download is required, so you can get started without hassle.
Site navigation is easy to use, making it quick to browse the collection.
Register now, and enjoy the world of online slots!
People contemplate ending their life due to many factors, often resulting from severe mental anguish.
A sense of despair might overpower their motivation to go on. Often, isolation is a major factor in this decision.
Conditions like depression or anxiety impair decision-making, preventing someone to recognize options beyond their current state.
how to commit suicide
Life stressors could lead a person to consider drastic measures.
Lack of access to help might result in a sense of no escape. Understand that reaching out is crucial.
欢迎光临,这是一个仅限成年人浏览的站点。
进入前请确认您已年满十八岁,并同意接受相关条款。
本网站包含不适合未成年人观看的内容,请理性访问。 色情网站。
若不符合年龄要求,请立即关闭窗口。
我们致力于提供合法合规的娱乐内容。
Searching for someone to take on a one-time risky job?
This platform specializes in connecting customers with freelancers who are willing to tackle serious jobs.
Whether you’re handling urgent repairs, unsafe cleanups, or complex installations, you’re at the right place.
All listed professional is pre-screened and qualified to ensure your safety.
rent a hitman
This service provide transparent pricing, detailed profiles, and safe payment methods.
Regardless of how difficult the scenario, our network has the skills to get it done.
Start your quest today and find the perfect candidate for your needs.
On the resource necessary info about ways of becoming a digital intruder.
Facts are conveyed in a precise and comprehensible manner.
You may acquire numerous approaches for entering systems.
Furthermore, there are real-life cases that exhibit how to employ these aptitudes.
how to become a hacker
Total knowledge is periodically modified to be in sync with the latest trends in cybersecurity.
Extra care is devoted to real-world use of the mastered abilities.
Remember that any undertaking should be applied lawfully and through ethical means only.
Here are presented exclusive promocodes for 1x Bet.
The promo codes help to get additional rewards when betting on the service.
All existing discount vouchers are constantly refreshed to guarantee they work.
When using these promotions one can boost your potential winnings on the online service.
https://sutango.com/wp-content/pgs/kak_poluchity_besplatnuyu_medpomoschy_vo_vremya_beremennosti_i_rodov.html
Plus, detailed instructions on how to apply discounts are offered for maximum efficiency.
Consider that specific offers may have specific terms, so examine rules before redeeming.
Here you can obtain unique promo codes for a renowned betting brand.
The assortment of bonus opportunities is persistently enhanced to provide that you always have reach to the latest offers.
Through these promotional deals, you can economize considerably on your betting endeavors and increase your chances of gaining an edge.
All promo codes are accurately validated for legitimacy and efficiency before being published.
https://aadesignoffice.com/pages/kak_vyglyadit_sovremennyy_kuhonnyy_processor_ne_prosto_blender.html
Plus, we present thorough explanations on how to implement each profitable opportunity to improve your bonuses.
Note that some bargains may have definite prerequisites or predetermined timeframes, so it’s vital to study closely all the facts before applying them.
Welcome to our platform, where you can discover premium materials created specifically for grown-ups.
Our library available here is suitable for individuals who are 18 years old or above.
Ensure that you meet the age requirement before exploring further.
big cock
Enjoy a one-of-a-kind selection of age-restricted materials, and immerse yourself today!
Our platform makes available many types of medical products for home delivery.
Anyone can easily get treatments from your device.
Our catalog includes popular medications and specialty items.
All products is supplied through licensed suppliers.
vibramycin for dogs
We prioritize customer safety, with data protection and timely service.
Whether you’re managing a chronic condition, you’ll find affordable choices here.
Visit the store today and enjoy convenient access to medicine.
One X Bet represents a top-tier sports betting provider.
Offering a wide range of sports, 1XBet caters to a vast audience worldwide.
The 1XBet application crafted intended for Android as well as iOS users.
https://samatravel.in/pages/vred_diet_esty_li_on.html
Players are able to install the mobile version from the platform’s page or Google Play Store for Android.
iPhone customers, the app can be installed via Apple’s store without hassle.
Our platform offers a large selection of pharmaceuticals for easy access.
You can securely get health products from your device.
Our catalog includes standard treatments and custom orders.
All products is sourced from verified providers.
kamagra reviews
We maintain quality and care, with encrypted transactions and fast shipping.
Whether you’re looking for daily supplements, you’ll find safe products here.
Visit the store today and get trusted support.
1xBet Bonus Code – Vip Bonus as much as 130 Euros
Use the 1xBet promo code: 1xbro200 when registering via the application to unlock special perks offered by One X Bet for a $130 up to a full hundred percent, for placing bets along with a casino bonus including free spin package. Open the app then continue through the sign-up steps.
The One X Bet promo code: 1XBRO200 offers an amazing welcome bonus to new players — full one hundred percent up to €130 upon registration. Bonus codes serve as the key to obtaining extra benefits, and 1XBet’s bonus codes are the same. When applying this code, users have the chance from multiple deals in various phases within their betting activity. Though you don’t qualify for the welcome bonus, One X Bet India guarantees its devoted players receive gifts via ongoing deals. Check the Promotions section on their website frequently to stay updated about current deals designed for current users.
promo code for 1xbet india today
What 1XBet promotional code is currently active today?
The promotional code applicable to 1xBet equals 1XBRO200, which allows novice players joining the betting service to access an offer of €130. In order to unlock exclusive bonuses related to games and wagering, kindly enter the promotional code related to 1XBET in the registration form. To take advantage of such a promotion, prospective users need to type the promo code Code 1xbet while signing up process so they can obtain a 100% bonus on their initial deposit.
Within this platform, you can discover a wide selection adult videos.
Every video is carefully curated guaranteeing maximum satisfaction for users.
In need of certain themes or casually exploring, this resource provides material tailored to preferences.
bbc videos
New videos constantly refreshed, so that the library up-to-date.
Access to every piece of content protected to users of legal age, maintaining standards with applicable laws.
Stay tuned for new releases, as the platform adds more content daily.
1xBet Bonus Code – Exclusive Bonus as much as 130 Euros
Apply the 1xBet promo code: 1xbro200 while signing up in the App to avail exclusive rewards given by One X Bet to receive €130 maximum of 100%, for placing bets plus a $1950 with one hundred fifty free spins. Start the app and proceed through the sign-up process.
The 1xBet promo code: 1xbro200 gives a fantastic starter bonus for first-time users — 100% maximum of 130 Euros once you register. Promo codes are the key for accessing bonuses, plus 1xBet’s promotional codes are the same. By using such a code, bettors have the chance from multiple deals at different stages of their betting experience. Though you don’t qualify for the initial offer, One X Bet India ensures its loyal users get compensated through regular bonuses. Look at the Deals tab via their platform regularly to stay updated about current deals tailored for existing players.
https://wiki.addmyurls.com/profile.php?user=alicia-ziesemer-143184&do=profile
What 1XBet bonus code is now valid today?
The promotional code applicable to 1XBet is 1XBRO200, permitting new customers joining the gambling provider to access an offer amounting to €130. In order to unlock unique offers related to games and wagering, make sure to type our bonus code related to 1XBET during the sign-up process. In order to benefit of this offer, potential customers must input the promo code 1XBET at the time of registering procedure to receive a 100% bonus applied to the opening contribution.
На этом сайте вы можете найти актуальные промокоды для Melbet.
Примените коды при регистрации в системе для получения до 100% при стартовом взносе.
Плюс ко всему, можно найти бонусы в рамках действующих программ и постоянных игроков.
промокод melbet при регистрации
Проверяйте регулярно в рубрике акций, чтобы не упустить выгодные предложения от Melbet.
Каждый бонус обновляется на работоспособность, и обеспечивает безопасность во время активации.
1xBet Promo Code – Exclusive Bonus maximum of 130 Euros
Use the One X Bet promotional code: 1xbro200 while signing up via the application to access the benefits given by 1xBet for a 130 Euros up to a full hundred percent, for sports betting plus a $1950 with one hundred fifty free spins. Launch the app and proceed with the registration process.
The 1XBet promotional code: Code 1XBRO200 provides a fantastic starter bonus for first-time users — 100% up to $130 during sign-up. Promotional codes act as the key to unlocking bonuses, plus 1xBet’s bonus codes are no exception. When applying such a code, bettors can take advantage from multiple deals in various phases in their gaming adventure. Though you don’t qualify to the starter reward, One X Bet India ensures its loyal users receive gifts with frequent promotions. Look at the Deals tab via their platform regularly to stay updated regarding recent promotions designed for existing players.
1xbet promo code
What 1xBet promotional code is now valid today?
The promo code applicable to One X Bet equals Code 1XBRO200, which allows new customers registering with the betting service to unlock a bonus amounting to €130. To access exclusive bonuses pertaining to gaming and sports betting, kindly enter the promotional code for 1XBET while filling out the form. To take advantage of such a promotion, prospective users must input the bonus code Code 1xbet at the time of registering process for getting double their deposit amount applied to the opening contribution.
On this site, you can easily find interactive video sessions.
Interested in friendly chats business discussions, the site offers a solution tailored to you.
Live communication module developed for bringing users together globally.
With high-quality video along with sharp sound, every conversation becomes engaging.
You can join public rooms initiate one-on-one conversations, according to what suits you best.
https://rt.webcamsex18.ru/
The only thing needed a reliable network plus any compatible tool begin chatting.
On this site, explore a wide range of online casinos.
Interested in traditional options or modern slots, there’s something for every player.
All featured casinos checked thoroughly for trustworthiness, so you can play with confidence.
pin-up
What’s more, the site provides special rewards along with offers targeted at first-timers as well as regulars.
Due to simple access, discovering a suitable site takes just moments, enhancing your experience.
Be in the know on recent updates with frequent visits, since new casinos are added regularly.
Здесь доступны интерактивные видео сессии.
Вам нужны увлекательные диалоги переговоры, на платформе представлены решения для каждого.
Этот инструмент создана чтобы объединить пользователей со всего мира.
порно онлайн чат
Благодаря HD-качеству и превосходным звуком, любое общение становится увлекательным.
Войти в общий чат общаться один на один, в зависимости от ваших предпочтений.
Все, что требуется — хорошая связь плюс подходящий гаджет, чтобы начать.
On this platform, you can find a great variety of online slots from famous studios.
Users can try out traditional machines as well as new-generation slots with stunning graphics and interactive gameplay.
Even if you’re new or a seasoned gamer, there’s a game that fits your style.
casino
The games are available round the clock and optimized for desktop computers and mobile devices alike.
All games run in your browser, so you can jump into the action right away.
Site navigation is user-friendly, making it simple to find your favorite slot.
Join the fun, and dive into the excitement of spinning reels!
On this site, find a wide range of online casinos.
Interested in traditional options new slot machines, you’ll find an option to suit all preferences.
The listed platforms checked thoroughly for trustworthiness, so you can play with confidence.
1xbet
Additionally, this resource offers exclusive bonuses along with offers targeted at first-timers including long-term users.
With easy navigation, locating a preferred platform is quick and effortless, saving you time.
Be in the know on recent updates by visiting frequently, as fresh options appear consistently.
This website, you can access a wide selection of online slots from famous studios.
Visitors can try out traditional machines as well as feature-packed games with high-quality visuals and bonus rounds.
If you’re just starting out or an experienced player, there’s a game that fits your style.
casino slots
The games are available anytime and compatible with PCs and smartphones alike.
You don’t need to install anything, so you can jump into the action right away.
Site navigation is intuitive, making it simple to browse the collection.
Sign up today, and enjoy the world of online slots!
The Aviator Game blends air travel with exciting rewards.
Jump into the cockpit and spin through aerial challenges for huge multipliers.
With its vintage-inspired graphics, the game captures the spirit of early aviation.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – withdraw before it flies away to lock in your rewards.
Featuring instant gameplay and realistic background music, it’s a top choice for casual players.
Whether you’re looking for fun, Aviator delivers endless thrills with every round.
这个网站 提供 海量的 成人内容,满足 不同用户 的 喜好。
无论您喜欢 什么样的 的 视频,这里都 种类齐全。
所有 内容 都经过 专业整理,确保 高品质 的 观看体验。
黄色书刊
我们支持 各种终端 访问,包括 电脑,随时随地 自由浏览。
加入我们,探索 激情时刻 的 成人世界。
The Aviator Game merges exploration with high stakes.
Jump into the cockpit and try your luck through aerial challenges for huge multipliers.
With its classic-inspired graphics, the game reflects the spirit of early aviation.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – claim before it disappears to lock in your rewards.
Featuring seamless gameplay and realistic audio design, it’s a top choice for slot enthusiasts.
Whether you’re testing luck, Aviator delivers endless action with every round.
This flight-themed slot blends adventure with exciting rewards.
Jump into the cockpit and try your luck through turbulent skies for huge multipliers.
With its classic-inspired visuals, the game evokes the spirit of pioneering pilots.
aviator game download
Watch as the plane takes off – withdraw before it flies away to lock in your earnings.
Featuring seamless gameplay and immersive audio design, it’s a favorite for gambling fans.
Whether you’re testing luck, Aviator delivers non-stop excitement with every spin.
Aviator combines exploration with exciting rewards.
Jump into the cockpit and play through turbulent skies for sky-high prizes.
With its vintage-inspired design, the game evokes the spirit of aircraft legends.
https://www.linkedin.com/posts/robin-kh-150138202_aviator-game-download-activity-7295792143506321408-81HD/
Watch as the plane takes off – withdraw before it flies away to lock in your winnings.
Featuring smooth gameplay and immersive audio design, it’s a top choice for slot enthusiasts.
Whether you’re chasing wins, Aviator delivers endless action with every round.
On this site, you can discover a wide range virtual gambling platforms.
Whether you’re looking for classic games latest releases, there’s a choice for every player.
Every casino included are verified for safety, enabling gamers to bet with confidence.
casino
Additionally, the platform offers exclusive bonuses along with offers for new players and loyal customers.
Due to simple access, discovering a suitable site takes just moments, making it convenient.
Stay updated about the latest additions with frequent visits, since new casinos appear consistently.
On this site, explore an extensive selection internet-based casino sites.
Interested in classic games or modern slots, there’s a choice to suit all preferences.
Every casino included fully reviewed for trustworthiness, so you can play securely.
1xbet
Moreover, this resource unique promotions plus incentives targeted at first-timers and loyal customers.
Due to simple access, finding your favorite casino is quick and effortless, making it convenient.
Keep informed regarding new entries by visiting frequently, as fresh options come on board often.
В этом месте доступны эротические материалы.
Контент подходит тем, кто старше 18.
У нас собраны широкий выбор контента.
Платформа предлагает качественный контент.
купить Гидроморфинол
Вход разрешен только для совершеннолетних.
Наслаждайтесь безопасным просмотром.
Свадебные и вечерние платья 2025 года задают новые стандарты.
Популярны пышные модели до колен из полупрозрачных тканей.
Блестящие ткани создают эффект жидкого металла.
Многослойные юбки определяют современные тренды.
Разрезы на юбках создают баланс между строгостью и игрой.
Ищите вдохновение в новых коллекциях — стиль и качество сделают ваш образ идеальным!
http://mtw2014.tmweb.ru/forum/?PAGE_NAME=message&FID=1&TID=11953&TITLE_SEO=11953-programma-dlya-prosmotra-kamer-videonablyudeniya&MID=658471&result=reply#message658471
У нас вы можете найти вспомогательные материалы для школьников.
Предоставляем материалы по всем основным предметам с учетом современных требований.
Готовьтесь к ЕГЭ и ОГЭ с помощью тренажеров.
https://bulgarizdat.ru/publikaczii/gdz-effektivnoe-ispolzovanie-gotovyh-domashnih-zadanij-dlya-uluchsheniya-uspevaemosti/
Примеры решений упростят процесс обучения.
Регистрация не требуется для комфортного использования.
Используйте ресурсы дома и успешно сдавайте экзамены.
цвет с доставкой недорого доставка цветов онлайн
Свежие актуальные Новости хоккея со всего мира. Результаты матчей, интервью, аналитика, расписание игр и обзоры соревнований. Будьте в курсе главных событий каждый день!
Микрозаймы онлайн https://kskredit.ru на карту — быстрое оформление, без справок и поручителей. Получите деньги за 5 минут, круглосуточно и без отказа. Доступны займы с любой кредитной историей.
Хочешь больше денег https://mfokapital.ru Изучай инвестиции, учись зарабатывать, управляй финансами, торгуй на Форекс и используй магию денег. Рабочие схемы, ритуалы, лайфхаки и инструкции — путь к финансовой независимости начинается здесь!
Быстрые микрозаймы https://clover-finance.ru без отказа — деньги онлайн за 5 минут. Минимум документов, максимум удобства. Получите займ с любой кредитной историей.
Сделай сам как сделать ремонта плитка Ремонт квартиры и дома своими руками: стены, пол, потолок, сантехника, электрика и отделка. Всё, что нужно — в одном месте: от выбора материалов до финального штриха. Экономьте с умом!
Трендовые фасоны сезона нынешнего года отличаются разнообразием.
Актуальны кружевные рукава и корсеты из полупрозрачных тканей.
Металлические оттенки делают платье запоминающимся.
Греческий стиль с драпировкой определяют современные тренды.
Минималистичные силуэты подчеркивают элегантность.
Ищите вдохновение в новых коллекциях — детали и фактуры оставят в памяти гостей!
https://wiki.hightgames.ru/index.php/%D0%9E%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_%D1%83%D1%87%D0%B0%D1%81%D1%82%D0%BD%D0%B8%D0%BA%D0%B0:46.8.210.172#.D0.90.D0.BA.D1.82.D1.83.D0.B0.D0.BB.D1.8C.D0.BD.D1.8B.D0.B5_.D1.81.D0.B2.D0.B0.D0.B4.D0.B5.D0.B1.D0.BD.D1.8B.D0.B5_.D0.BE.D0.B1.D1.80.D0.B0.D0.B7.D1.8B_2025_.E2.80.94_.D0.BA.D0.B0.D0.BA_.D0.B2.D1.8B.D0.B1.D1.80.D0.B0.D1.82.D1.8C.3F
КПК «Доверие» https://bankingsmp.ru надежный кредитно-потребительский кооператив. Выгодные сбережения и доступные займы для пайщиков. Прозрачные условия, высокая доходность, финансовая стабильность и юридическая безопасность.
Ваш финансовый гид https://kreditandbanks.ru — подбираем лучшие предложения по кредитам, займам и банковским продуктам. Рейтинг МФО, советы по улучшению КИ, юридическая информация и онлайн-сервисы.
Займы под залог https://srochnyye-zaymy.ru недвижимости — быстрые деньги на любые цели. Оформление от 1 дня, без справок и поручителей. Одобрение до 90%, выгодные условия, честные проценты. Квартира или дом остаются в вашей собственности.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Профессиональный массаж Ивантеевка: классический, лечебный, расслабляющий, антицеллюлитный. Квалифицированные массажисты, индивидуальный подход, комфортная обстановка. Запишитесь на сеанс уже сегодня!
party balloons dubai deliver balloons dubai
resume environmental engineer cv engineer resume
The wild symbol at the slot is the golden coin and will substitute for any other symbols at the game apart from the Leprechaun symbol and the pot of gold symbol. Our services facilitated by this website are operated by Broadway Gaming Ireland DF Limited, a company incorporated in the Republic of Ireland. A. To start playing real money slot games, register an account at Amazon Slots Casino make your first deposit, and browse our extensive collection of real money slots to find your favourite games. Home » Slots » iSoftBet » Lucky Leprechaun New players only. Min dep £10 with code WINK100. 100% games bonus (max £100). 30x games bonus wagering required. 5-day expiry. 18+ GambleAware.org. T&Cs apply. The second feature is the bonus round which is activated by landing the pot of gold scatter symbol. You’ll now be taken to a screen showing the Leprechaun stood next to 3 pots, each representing a different Jackpot amount. There are bronze, silver and gold jackpots and you’ll hope that the rainbow ends at the pot of gold for the biggest prize in the game. The Jackpot feature is only enacted if playing for the max bet size of 5.
https://medjutim.dnk.org.rs/aviator-official-game-3-things-to-check-first/
Designed to take your virtual gaming experience to a new level, Paddy Power Games is home to more than 1100 of the best online slots, showcasing an excellent library of online casino table games and dedicated live dealers. If you are one of Paddy Power’s new poker players, deposit £5 upon sign up and you get £20 in bonuses, plus your deposit will be matched 100% up to £200. This is undoubtedly one of the best poker sign up bonuses available at the moment. Paddy Power™ Games is one of the sections found at Paddy Power Casino, operated by the world-renowned Irish bookmakers of the same name. With hundreds of online slots and jackpot options, as well as roulette, poker, blackjack, and even a live casino section, it’s safe to say that this platform is a veritable treasure trove of online casino games.
Подходящи за офиса рокли в класически силуети и неутрални тонове
стилни дамски рокли http://www.rokli-damski.com .
Долговечность и энергоэффективность при строительстве деревянных домов
построить деревянный дом под ключ https://www.stroitelstvo-derevyannyh-domov178.ru .
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Услуги массажа Ивантеевка — здоровье, отдых и красота. Лечебный, баночный, лимфодренажный, расслабляющий и косметический массаж. Сертифицированнй мастер, удобное расположение, результат с первого раза.
Дамски комплекти в пастелни и неутрални тонове за универсално съчетание
дамски комплекти на промоция http://komplekti-za-jheni.com/ .
This iconic Audemars Piguet Royal Oak model combines luxury steel craftsmanship introduced in 2012 within the brand’s prestigious lineup.
Crafted in 41mm stainless steel boasts an octagonal bezel secured with eight visible screws, embodying the collection’s iconic DNA.
Equipped with the Cal. 3120 automatic mechanism, it ensures precise timekeeping with a date display at 3 o’clock.
Audemars 15400ST
The dial showcases a black Grande Tapisserie pattern highlighted by luminous appliqués for clear visibility.
A seamless steel link bracelet ensures comfort and durability, secured by a hidden clasp.
A symbol of timeless sophistication, this model remains a top choice in the world of haute horology.
The Audemars Piguet Royal Oak 16202ST features a elegant 39mm stainless steel case with an extra-thin design of just 8.1mm thickness, housing the latest selfwinding Calibre 7121. Its mesmerizing smoked blue gradient dial showcases a intricate galvanic textured finish, fading from a radiant center to dark periphery for a captivating aesthetic. The iconic eight-screw octagonal bezel pays homage to the original 1972 design, while the scratch-resistant sapphire glass ensures optimal legibility.
https://telegra.ph/Audemars-Piguet-Royal-Oak-16202ST-When-Steel-Became-Noble-06-02
Water-resistant to 50 meters, this “Jumbo” model balances sporty durability with luxurious refinement, paired with a steel link strap and reliable folding buckle. A contemporary celebration of classic design, the 16202ST embodies Audemars Piguet’s innovation through its meticulous mechanics and evergreen Royal Oak DNA.
Всё о городе городской портал города Ханты-Мансийск: свежие новости, события, справочник, расписания, культура, спорт, вакансии и объявления на одном городском портале.
Стилна визия и функционалност в най-новите спортни екипи
дамски спортни комплекти http://sportni-komplekti.com/ .
Моделите дамски тениски, които никога не излизат от мода
интересни дамски тениски https://teniski-damski.com/ .
Здесь доступен мессенджер-бот “Глаз Бога”, который проверить всю информацию о гражданине через открытые базы.
Инструмент функционирует по фото, обрабатывая доступные данные в сети. Через бота доступны бесплатный поиск и полный отчет по запросу.
Инструмент актуален на август 2024 и охватывает фото и видео. Бот гарантирует узнать данные в открытых базах и предоставит сведения за секунды.
Глаз Бога glazboga.net
Это сервис — помощник при поиске персон удаленно.
Стилни блузи с акцент върху талията и женствените форми
елегантни дамски блузи с къс ръкав http://www.bluzi-damski.com/ .
¿Quieres códigos promocionales vigentes de 1xBet? Aquí encontrarás recompensas especiales en apuestas deportivas .
El código 1x_12121 garantiza a hasta 6500₽ durante el registro .
Para completar, canjea 1XRUN200 y disfruta una oferta exclusiva de €1500 + 150 giros gratis.
https://kylerwhra96318.ttblogs.com/15093132/descubre-cómo-usar-el-código-promocional-1xbet-para-apostar-free-of-charge-en-argentina-méxico-chile-y-más
Mantente atento las novedades para conseguir más beneficios .
Todos los códigos son verificados para hoy .
¡Aprovecha y potencia tus apuestas con esta plataforma confiable!
В этом ресурсе вы можете получить доступ к боту “Глаз Бога” , который способен собрать всю информацию о любом человеке из открытых источников .
Данный сервис осуществляет проверку ФИО и раскрывает данные из онлайн-платформ.
С его помощью можно пробить данные через специализированную платформу, используя фотографию в качестве ключевого параметра.
probiv-bot.pro
Система “Глаз Бога” автоматически анализирует информацию из проверенных ресурсов, формируя структурированные данные .
Пользователи бота получают ограниченное тестирование для ознакомления с функционалом .
Сервис постоянно совершенствуется , сохраняя скорость обработки в соответствии с законодательством РФ.
Найти мастера по ремонту холодильников в Киеве можно на сайте
Строительство деревянных домов с акцентом на энергоэффективность и уют
дома деревянные под ключ https://stroitelstvo-derevyannyh-domov78.ru/ .
Уникальные маршруты и виды с борта арендованной яхты
аренда яхт в сочи https://arenda-yahty-sochi323.ru .
resume software engineer ats engineering resumes examples
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
Читайте о необычном http://phenoma.ru научно-популярные статьи о феноменах, которые до сих пор не имеют однозначных объяснений. Психология, физика, биология, космос — самые интересные загадки в одном разделе.
Профессиональная уборка после пожара, залива и ЧС
заказать клининг https://kliningovaya-kompaniya0.ru/ .
Шины всех типоразмеров в наличии в крупном онлайн-магазине
магазин шин и дисков https://www.kupit-shiny0-spb.ru .
Комплексная услуга: замер, производство, доставка и монтаж стеклянных душевых ограждений
п образные душевые стекла https://www.steklo777777.ru .
раздача стим аккаунтов бесплатно https://t.me/s/Burger_Game
resume for engineering jobs resume software engineer ats
стим аккаунт бесплатно без игр http://t.me/Burger_Game
Looking for exclusive 1xBet promo codes? This site offers verified bonus codes like 1x_12121 for registrations in 2024. Claim up to 32,500 RUB as a first deposit reward.
Use official promo codes during registration to maximize your rewards. Enjoy risk-free bets and exclusive deals tailored for sports betting.
Find monthly updated codes for global users with fast withdrawals.
Every promotional code is checked for validity.
Don’t miss limited-time offers like GIFT25 to increase winnings.
Active for first-time deposits only.
https://socialistener.com/story5150316/unlocking-1xbet-promo-codes-for-enhanced-betting-in-multiple-countriesStay ahead with 1xBet’s best promotions – apply codes like 1x_12121 at checkout.
Experience smooth rewards with instant activation.
Заказывайте сувениры с логотипом — работаем по всей России
изготовление сувенирной продукции с логотипом https://suvenirnaya-produktsiya-s-logotipom-1.ru .
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
resume as a engineer chief engineer cv example
Подбор оптимального лизинга по параметрам с помощью автоматизированного маркетплейса
маркетплейс лизинга https://lizingovyy-agregator.ru .
Offline Mode: Ready to take a break from online connectivity? Aviator APK offers an offline mode where you can practice your skills or simply enjoy the game without an internet connection. Entdecken Sie die Faszination von Plinko: Das beliebteste Spiel der Glücksritter! Die Geschichte von Plinko Wie Plinko gespielt wird Strategien für erfolgreiches Plinko-Spiel Die Psychologie des Spiels Online-Plinko: Die digitale Version des Erfolgs Die Zukunft von Plinko Fazit Entdecken Sie die Faszination von Plinko: Das beliebteste Spiel der Glücksritter! Willkommen in der Welt von Plinko, Do stabilnej pracy apk Aviator wymaga dobrego połączenia internetowego. Regularnie pobieraj i aktualizuj aplikację gry, aby uzyskać dostęp do nowych funkcji i ulepszeń bezpieczeństwa. Statystyki pokazują, że 7,8% graczy preferuje mobilną wersję Aviatora ze względu na wygodę i dostępność.
https://fitwell.qa/aviator-betway-login-jak-rozpoczac-gre-krok-po-kroku/
Book of Ra Deluxe App Name: IZIBET Bet TrackerPackage Name: com.izibet.retailmobileapp.androidCategory: Sports BettingVersion: Size: Last Updated: Developer: IZIBET Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Explore the world of sports betting with confidence—download the IZIBET Bet Tracker APK today and take the first step towards an organized and informed betting experience! Posiada cenne 4 letnie doświadczenie w branży. Ula zaczynała jako kierownik serwisu, a na samym początku pracowała jako niezależna pisarka. Na ten moment pracuje jako content manager, sprawując pieczę nad treścią i zawartością naszego portalu. To ona jest odpowiedzialna za sprawdzanie reputacji kasyna i wszelkie rekomendacje, jeśli chodzi o gry i platformy hazardowe.
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
Премиум-отдых на воде: аренда яхты с индивидуальным сервисом
яхты сочи яхты сочи .
В этом ресурсе вы можете найти боту “Глаз Бога” , который способен получить всю информацию о любом человеке из открытых источников .
Этот мощный инструмент осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно пробить данные через специализированную платформу, используя фотографию в качестве начальных данных .
пробить авто по номеру
Технология “Глаз Бога” автоматически обрабатывает информацию из открытых баз , формируя структурированные данные .
Клиенты бота получают ограниченное тестирование для тестирования возможностей .
Платформа постоянно развивается, сохраняя высокую точность в соответствии с требованиями времени .
Сертификация и лицензии — ключевой аспект ведения бизнеса в России, обеспечивающий защиту от неквалифицированных кадров.
Декларирование продукции требуется для подтверждения безопасности товаров.
Для торговли, логистики, финансов необходимо специальных разрешений.
https://ok.ru/group/70000034956977/topic/158840759957681
Игнорирование требований ведут к приостановке деятельности.
Добровольная сертификация помогает повысить доверие бизнеса.
Соблюдение норм — залог успешного развития компании.
Прямо здесь вы найдете сервис “Глаз Бога”, который найти всю информацию по человеку по публичным данным.
Инструмент активно ищет по ФИО, обрабатывая публичные материалы в сети. С его помощью доступны бесплатный поиск и полный отчет по запросу.
Инструмент проверен на 2025 год и охватывает фото и видео. Сервис гарантирует найти профили в соцсетях и покажет информацию за секунды.
https://glazboga.net/
Такой сервис — помощник при поиске персон онлайн.
These days, it feels like football or soccer (as it is known in the US) is everywhere! Are you enjoying the FIFA Women’s World Cup in France? What about the exciting Copa América? Are you following the Total Africa Cup of Nations? If you like the game and want to expand your Spanish vocabulary of football terms, this lesson introduces some of the most common football soccer vocabulary words in Spanish. When it came to the fourth for each country, Sergio Ramos, who had blazed high over the bar in the Champions League semi-final shootout, clipped in a la Pirlo. “It seems to be fashionable now,” Del Bosque said. “I was delighted with it.” Bruno Alves then thumped his off the underside of the bar and away. As the ball bounced free, it took Portugal’s chances of reaching the final with it.
https://headlice.co.il/review-del-juego-de-casino-online-balloon-apk-de-smartsoft-para-jugadores-en-venezuela/
1Win Lucky Jet tiene una serie de características que facilitan el juego. Puede dejar que el ordenador gestione sus apuestas y retiradas. Juego de Lucky Jet 1win – Juega Los profesionales avanzados recomiendan integrar múltiples metodologías mientras se adaptan a los patrones emergentes en Lucky Jet 1win. El análisis estadístico sugiere que los mejores resultados suelen surgir de una gestión equilibrada de riesgos combinada con un timing estratégico cuando juegas a Lucky Jet por dinero real. Aquí tienes consejos para ayudarte a ganar dinero en Lucky Jet Casino: El sitio web oficial de Lucky Bet le permite jugar juegos de choque, pero debe iniciar sesión, sin registrarse, muchas funciones de Lucky Jet no estarán disponibles. Las llamadas señales Lucky Jet o “signals” en inglés hacen referencia a la supuesta existencia de guías o apps que adivinan los resultados durante el uso del mini game. Estas apps o guías se ofertan como dispositivos externos, o desde bots en redes sociales como Tik Tok. De igual forma, se ofrecen como apps para celulares con sistema operativo Android. En cualquier caso, la promesa que hacen es la de conocer los resultados de forma anticipada en cada ronda del juego Lucky Jet México.
¿Quieres promocódigos recientes de 1xBet? En este sitio podrás obtener bonificaciones únicas para apostar .
El promocódigo 1x_12121 ofrece a hasta 6500₽ al registrarte .
También , canjea 1XRUN200 y disfruta una oferta exclusiva de €1500 + 150 giros gratis.
https://kennaharde4.wixsite.com/my-site-1
Mantente atento las promociones semanales para conseguir recompensas adicionales .
Todos los códigos están actualizados para hoy .
No esperes y potencia tus oportunidades con esta plataforma confiable!
Aliraza2024-01-07 22:56:35 App market for 100% working mods. Requires Android Shake up the Lightning multipliers! select vTitle, vContent from gen_updates where cStatus = ‘A’ and cProperty = ‘DRW’ and (‘2025-05-22 21:27:46’ between dFrom and dTo) ORDER BY iRank DESC LIMIT 1 100% working on devices Accelerated for downloading big mod files. Strategic Card Game Set in the Three Kingdoms Welcome to Dragon Tiger Predictions with GPT, this prediction tool app can analyze the input pattern and provide you predictions. +1 212-334-0212 Dragon Vs Tiger predict GPT tool offers a variety of features for supporting users such as: Was the prediction correct? Lightning Sic Bo Strategic Card Game Set in the Three Kingdoms select vTitle, vContent from gen_updates where cStatus = ‘A’ and cProperty = ‘DRW’ and (‘2025-05-22 21:28:12’ between dFrom and dTo) ORDER BY iRank DESC LIMIT 1
https://wp15-c13013-1.btsndrc.ac/balloon-game-by-smartsoft-pros-and-cons-of-linking-wallets-via-app-vs-web-for-indian-players/
Country & currency Country & currency Country & currency Country & currency Find your new pastime among our hobby kits Founded in 1985, the Volkswagen Group China has made serious tracks in keeping the Volkswagen name alive. In 2020, they established the Vertical Mobility Project to develop sustainable electrical aircrafts with the catchy tagline: ‘In China, For China’. Soft toys Flying Tiger Copenhagen Fat tiger Zhao TiezhuHe has always been “kind-hearted and fat”Galloping in the rivers and lakes Express yourself with colourful and playful designs When you choose FSC®-certified goods, you support the responsible use of the world’s forests, and you help to take care of the animals and people who live in them. Look for the FSC mark on our products and read more at flyingtiger fsc
Jarvi — корм для питомцев, которым вы можете доверять
кошачий сухой корм jarvi холистик отзывы кошачий сухой корм jarvi холистик отзывы .
Прямо здесь можно получить мессенджер-бот “Глаз Бога”, позволяющий проверить сведения о гражданине по публичным данным.
Сервис функционирует по фото, используя доступные данные в сети. С его помощью осуществляется пять пробивов и полный отчет по имени.
Сервис обновлен на 2025 год и поддерживает фото и видео. Сервис поможет узнать данные в соцсетях и предоставит сведения за секунды.
https://glazboga.net/
Данный сервис — помощник в анализе людей через Telegram.
Looking for exclusive 1xBet promo codes ? Here is your ultimate destination to discover valuable deals designed to boost your wagers.
If you’re just starting or a seasoned bettor , the available promotions guarantees exclusive advantages across all bets.
Keep an eye on seasonal campaigns to multiply your rewards.
https://www.bitsdujour.com/profiles/Tn5Rcx
All listed codes are frequently updated to guarantee reliability this month .
Don’t miss out of exclusive perks to enhance your odds of winning with 1xBet.
Full hd film kategorisinde ödüllü yapımlar sizi bekliyor
hd fil izle hdturko.com .
На данном сайте вы можете получить доступ к боту “Глаз Бога” , который может получить всю информацию о любом человеке из открытых источников .
Этот мощный инструмент осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно проверить личность через специализированную платформу, используя имя и фамилию в качестве начальных данных .
пробив авто бесплатно
Система “Глаз Бога” автоматически собирает информацию из открытых баз , формируя подробный отчет .
Подписчики бота получают ограниченное тестирование для проверки эффективности.
Решение постоянно развивается, сохраняя актуальность данных в соответствии с законодательством РФ.
На данном сайте доступен сервис “Глаз Бога”, позволяющий проверить всю информацию о человеке из открытых источников.
Сервис работает по ФИО, обрабатывая актуальные базы в Рунете. Через бота доступны пять пробивов и полный отчет по запросу.
Сервис обновлен на август 2024 и охватывает фото и видео. Бот поможет узнать данные в открытых базах и отобразит результаты мгновенно.
https://glazboga.net/
Это бот — помощник для проверки граждан удаленно.
Гагры круглый год: отдых в любое время и по любому бюджету
гагра снять жилье otdyh-gagry.ru .
Searching for latest 1xBet promo codes? Our platform offers working promotional offers like GIFT25 for registrations in 2025. Get up to 32,500 RUB as a welcome bonus.
Use trusted promo codes during registration to boost your bonuses. Benefit from no-deposit bonuses and exclusive deals tailored for sports betting.
Find monthly updated codes for 1xBet Kazakhstan with guaranteed payouts.
Every voucher is checked for accuracy.
Don’t miss exclusive bonuses like 1x_12121 to increase winnings.
Active for first-time deposits only.
https://www.askmeclassifieds.com/user/profile/2296810Stay ahead with top bonuses – enter codes like 1XRUN200 at checkout.
Enjoy seamless rewards with instant activation.
¿Quieres cupones vigentes de 1xBet? En este sitio descubrirás recompensas especiales para tus jugadas.
El promocódigo 1x_12121 ofrece a un bono de 6500 rublos durante el registro .
Para completar, canjea 1XRUN200 y obtén un bono máximo de 32500 rublos .
https://hallbook.com.br/blogs/599951/Code-promo-1XBET-pour-bonus-VIP-de-130
Mantente atento las novedades para acumular más beneficios .
Las ofertas disponibles están actualizados para 2025 .
¡Aprovecha y maximiza tus apuestas con esta plataforma confiable!
Здесь доступен мощный бот “Глаз Бога” , который получает данные о любом человеке из общедоступных ресурсов .
Инструмент позволяет пробить данные по ФИО , раскрывая информацию из онлайн-платформ.
https://glazboga.net/
Kaliteden ödün vermeyenler için özel seçilmiş full hd film yapımları
4 k filim izle https://www.filmizlehd.co/ .
На данном сайте вы можете найти боту “Глаз Бога” , который способен получить всю информацию о любом человеке из общедоступных баз .
Данный сервис осуществляет проверку ФИО и предоставляет детали из государственных реестров .
С его помощью можно проверить личность через Telegram-бот , используя автомобильный номер в качестве ключевого параметра.
пробив телефона бесплатно
Система “Глаз Бога” автоматически обрабатывает информацию из проверенных ресурсов, формируя структурированные данные .
Клиенты бота получают 5 бесплатных проверок для тестирования возможностей .
Сервис постоянно совершенствуется , сохраняя высокую точность в соответствии с законодательством РФ.
В этом ресурсе вы можете ознакомиться с последними новостями России и мира .
Информация поступает без задержек.
Доступны видеохроники с мест событий .
Экспертные комментарии помогут получить объективную оценку.
Контент предоставляется без регистрации .
https://e-copies.ru
This website offers comprehensive information about Audemars Piguet Royal Oak watches, including retail costs and technical specifications .
Discover data on popular references like the 41mm Selfwinding in stainless steel or white gold, with prices averaging $39,939 .
The platform tracks resale values , where limited editions can appreciate over time.
Audemars Royal Oak 15510 or prices
Technical details such as automatic calibers are easy to compare.
Stay updated on 2025 price fluctuations, including the Royal Oak 15510ST’s market stability .
Professional concrete driveway installers seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Professional Seattle power washing — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Professional paver contractor — reliable service, quality materials and adherence to deadlines. Individual approach, experienced team, free estimate. Your project — turnkey with a guarantee.
Discover detailed information about the Audemars Piguet Royal Oak Offshore 15710ST on this site , including pricing insights ranging from $34,566 to $36,200 for stainless steel models.
The 42mm timepiece showcases a robust design with mechanical precision and rugged aesthetics, crafted in titanium.
https://ap15710st.superpodium.com
Compare secondary market data , where limited editions reach up to $750,000 , alongside pre-owned listings from the 1970s.
View real-time updates on availability, specifications, and investment returns , with free market analyses for informed decisions.
Пляжи, водопады и горы — отдых в Абхазии без лишнего шума
абхазия отдых на море абхазия отдых на море .
Современные методы поверки и как выбрать надежного исполнителя
Поверка https://poverka-si-msk.ru/ .
Looking for exclusive 1xBet promo codes? This site offers verified promotional offers like 1XRUN200 for new users in 2025. Get up to 32,500 RUB as a welcome bonus.
Activate official promo codes during registration to maximize your rewards. Enjoy no-deposit bonuses and special promotions tailored for casino games.
Discover monthly updated codes for 1xBet Kazakhstan with fast withdrawals.
Every promotional code is checked for validity.
Grab exclusive bonuses like 1x_12121 to double your funds.
Valid for first-time deposits only.
https://chrstms.ru/club/user/9440/blog/16309/
Experience smooth rewards with instant activation.
Need transportation? car transportation services state to state car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
Нужна камера? видеонаблюдение частный установка камер для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
Лицензирование и сертификация — обязательное условие ведения бизнеса в России, гарантирующий защиту от неквалифицированных кадров.
Декларирование продукции требуется для подтверждения соответствия стандартам.
Для 49 видов деятельности необходимо специальных разрешений.
https://ok.ru/group/70000034956977/topic/158835725678769
Нарушения правил ведут к приостановке деятельности.
Добровольная сертификация помогает повысить доверие бизнеса.
Своевременное оформление — залог успешного развития компании.
best car shipping terminal to terminal auto transport
Хотите найти ресурсы для нумизматов ? Эта платформа предоставляет всё необходимое для изучения нумизматики!
Здесь доступны уникальные монеты из разных эпох , а также драгоценные находки.
Просмотрите архив с характеристиками и детальными снимками, чтобы сделать выбор .
инвестиционные монеты купить
Если вы начинающий или эксперт, наши статьи и гайды помогут углубить экспертизу.
Воспользуйтесь шансом приобрести эксклюзивные артефакты с гарантией подлинности .
Станьте частью сообщества энтузиастов и следите последних новостей в мире нумизматики.
Наркологическая помощь на дому с соблюдением полной анонимности и этики
нарколог на дом срочно https://www.clinic-narkolog24.ru/ .
Подборка лучших гостевых домов и квартир в Сухум
сухум жилье без посредников сухум жилье без посредников .
Balloons Dubai https://balloons-dubai1.com stunning balloon decorations for birthdays, weddings, baby showers, and corporate events. Custom designs, same-day delivery, premium quality.
Почему доставка алкоголя становится популярнее традиционных покупок
доставка алкоголя домой москва доставка алкоголя московская область .
стильные цветочные горшки купить http://dizaynerskie-kashpo.ru/ .
купить плитку 600х600 стоимость керамогранита 1200х600
Utilizatorii 1Win pot alege orice metodă de plată și orice monedă pentru a efectua tranzacții pe site. Mai jos am descris metodele de plăți 1win disponibile pentru jucătorii din Moldova. 1win nu este doar o altă platformă de jocuri de noroc online. Este un portal de jocuri multifuncțional care oferă peste 10.000 de evenimente de jocuri, pariuri sportive live și virtuale, cazinouri online și cinematografe online și multe altele. Pentru a se înregistra, jucătorii pot folosi înregistrarea cu un singur clic, e-mailul, numărul de telefon sau conturile de rețele sociale. Este necesară verificarea pentru retrageri. Opțiunile de depunere și retragere includ carduri de credit, portofele electronice, plăți mobile și criptomonede. Nu se percep taxe. Site-ul web oferă un site de jocuri de noroc online complet cu cote competitive, multe piețe de pariuri și oferte generoase de bonusuri.
https://earnfromsurvey.xyz/analiza-sesiunilor-de-joc-in-lucky-jet-pentru-performanta-maxima/
18 maşini PistenBully Scufundați-vă în lumea frumoasă și a jocurilor de noroc din JetX Bet: zburați cu avionul și câștigați bani ușori fără să vă ridicați de pe canapea. Jocuri Gratis Aparate Sale disponibile la unele dintre site-urile de top cazinou online și poate fi jucat pe iPhone, jocurile de cazinou sunt foarte distractive și oferă o varietate de opțiuni pentru jucători. Jocuri gratis aparate în afară de faptul că aceste jocuri sunt populare și ușor de jucat, toate parte a pachetului. Aplicația este Jocul 1Win JetX testează reacția, răbdarea și atenția jucătorilor. Jucătorul are la dispoziție doar 5 secunde pentru a plasa un pariu. În cadrul sesiunii de joc, trebuie să urmărești decolarea avionului, al cărui multiplicator crește atât timp cât acesta rămâne în aer. Scopul principal al jocului este de a retrage banii înainte ca avionul să se prăbușească.
Профессиональное косметологическое оборудование аппараты для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
Discover the iconic Patek Philippe Nautilus, a luxury timepiece that blends sporty elegance with exquisite craftsmanship .
Launched in 1976 , this cult design revolutionized high-end sports watches, featuring distinctive octagonal bezels and textured sunburst faces.
From stainless steel models like the 5990/1A-011 with a 55-hour energy retention to luxurious white gold editions such as the 5811/1G-001 with a blue gradient dial , the Nautilus caters to both discerning collectors and everyday wearers .
New Patek Philippe Nautilus 5712 watch reviews
Certain diamond-adorned versions elevate the design with gemstone accents, adding unparalleled luxury to the timeless profile.
According to recent indices like the 5726/1A-014 at ~$106,000, the Nautilus remains a coveted investment in the world of premium watchmaking.
For those pursuing a historical model or modern redesign, the Nautilus epitomizes Patek Philippe’s tradition of innovation.
Designed by Gerald Genta, revolutionized luxury watchmaking with its iconic octagonal bezel and bold integration of sporty elegance.
Available in classic stainless steel to diamond-set variants, the collection combines avant-garde design with horological mastery.
Priced from $20,000 to over $400,000, these timepieces cater to both seasoned collectors and aficionados seeking wearable heritage.
Pre-loved Piguet Audemars Royal Oak 26240 or reviews
The Perpetual Calendar models set benchmarks with innovative complications , showcasing Audemars Piguet’s relentless innovation.
With ultra-thin calibers like the 2385, each watch epitomizes the brand’s commitment to excellence .
Discover exclusive releases and historical insights to elevate your collection with this timeless icon .
Устойчивость и безопасность: подстолья с усиленными опорами
подстолье для большого обеденного стола https://podstolia-msk.ru/ .
защита консультация юрист https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
Бокалы для вина из Чехии, Германии, Франции — оригинальные коллекции
заказать бокалы для вина https://www.bokaly-dlya-vina.neocities.org/ .
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Die Royal Oak 16202ST kombiniert ein rostfreies Stahlgehäuse von 39 mm mit einem extraflachen Gehäuse von nur 8,1 mm Dicke.
Ihr Herzstück bildet das neue Kaliber 7121 mit 55 Stunden Gangreserve.
Der smaragdene Farbverlauf des Zifferblatts wird durch das feine Guillochierungen und die Saphirglas-Abdeckung mit blendschutzbeschichteter Oberfläche betont.
Neben klassischer Zeitmessung bietet die Uhr ein praktisches Datum bei Position 3.
ap 15407
Die bis 5 ATM geschützte Konstruktion macht sie alltagstauglich.
Das geschlossene Stahlband mit faltsicherer Verschluss und die oktogonale Lünette zitieren das ikonische Royal-Oak-Erbe aus den 1970er Jahren.
Als Teil der „Jumbo“-Kollektion verkörpert die 16202ST horlogerie-Tradition mit einem aktuellen Preis ab ~75.900 €.
КредитоФФ http://creditoroff.ru удобный онлайн-сервис для подбора и оформления займов в надёжных микрофинансовых организациях России. Здесь вы найдёте лучшие предложения от МФО
Почему императорский фарфор ценят не только коллекционеры
ифз шоп https://imperatorskiy-farfor.kesug.com .
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Стальные резервуары используются для сбора нефтепродуктов и соответствуют стандартам давления до 0,04 МПа.
Вертикальные емкости изготавливают из черной стали Ст3 с антикоррозийным покрытием.
Идеальны для АЗС: хранят бензин, керосин, мазут или авиационное топливо.
Резервуар стальной РГС 150 м3
Двустенные резервуары обеспечивают экологическую безопасность, а подземные модификации подходят для разных условий.
Заводы предлагают типовые решения объемом до 500 м³ с монтажом под ключ.
Die Royal Oak 16202ST vereint ein rostfreies Stahlgehäuse in 39 mm mit einem nur 8,1 mm dünnen Bauweise und dem automatischen Werk 7121 für lange Energieautonomie.
Das blaue Petite-Tapisserie-Dial mit Weißgold-Indexen und Luminous-Beschichtung wird durch eine kratzfeste Saphirabdeckung mit blendschutzbeschichteter Oberfläche geschützt.
Neben praktischer Datumsanzeige bietet die Uhr 50-Meter-Wasserdichte und ein geschlossenes Edelstahlband mit verstellbarem Verschluss.
Piguet Royal Oak 15450 armbanduhren
Die achtseitige Rahmenform mit ikonenhaften Hexschrauben und die gebürstete Oberflächenkombination zitieren den 1972er Klassiker.
Als Teil der Extra-Thin-Kollektion ist die 16202ST eine horlogerie-Perle mit einem Wertsteigerungspotenzial.
Купить шиномонтаж Краснодар shinomontazh vyezdnoj
Юрист Екатеринбург консультация yuristy-ekaterinburga.ru/
Не упустите сезонные предложения на мотоциклы jhl moto
мотоцикл jhl https://www.jhlmoto01.ru/ .
интересные кашпо для цветов интересные кашпо для цветов .
Защитные кейсы https://plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
Наш ресурс предлагает свежие инфосообщения в одном месте.
Здесь можно найти события из жизни, бизнесе и разных направлениях.
Новостная лента обновляется регулярно, что позволяет всегда быть в курсе.
Простой интерфейс облегчает восприятие.
https://miramoda.ru
Каждое сообщение проходят проверку.
Мы стремимся к достоверности.
Читайте нас регулярно, чтобы быть на волне новостей.
Crafted watches remain popular for numerous vital factors.
Their timeless appeal and mastery set them apart.
They symbolize wealth and sophistication while uniting form and function.
Unlike digital gadgets, they endure through generations due to their limited production.
https://telegra.ph/The-Art-of-Time-A-Comparison-of-the-Patek-Philippe-Nautilus-and-Audemars-Piguet-Royal-Oak-03-09
Collectors and enthusiasts treasure the engineering marvels that modern tech cannot imitate.
For many, having them signifies taste that remains eternal.
срочно онлайн займ отказа займ онлайн с плохой кредитной
Услуги клининга в медицинских учреждениях с дезинфекцией
клининговая служба https://kliningovaya-kompaniya10.ru .
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Защитные кейсы https://plastcase.ru в Санкт-Петербурге — надежная защита оборудования от влаги, пыли и ударов. Большой выбор размеров и форматов, ударопрочные материалы, индивидуальный подбор.
¡Saludos, apasionados del azar !
Casinos sin licencia en EspaГ±a sin lГmite mГЎximo – https://casinossinlicenciaenespana.es/ casino sin licencia en espaГ±a
¡Que vivas conquistas excepcionales !
Строительный портал https://proektsam.kyiv.ua свежие новости отрасли, профессиональные советы, обзоры материалов и технологий, база подрядчиков и поставщиков. Всё о ремонте, строительстве и дизайне в одном месте.
Городской портал Черкассы https://u-misti.cherkasy.ua новости, обзоры, события Черкасс и области
Портал о строительстве https://buildportal.kyiv.ua и ремонте: лучшие решения для дома, дачи и бизнеса. Инструменты, сметы, калькуляторы, обучающие статьи и база подрядчиков.
займы онлайн круглосуточно займ онлайн без отказа
Коллекция Nautilus, созданная Жеральдом Гентой, сочетает элегантность и прекрасное ремесленничество. Модель Nautilus 5711 с автоматическим калибром 324 SC имеет 45-часовой запас хода и корпус из белого золота.
Восьмиугольный безель с округлыми гранями и циферблат с градиентом от синего к черному подчеркивают уникальность модели. Браслет с интегрированными звеньями обеспечивает удобную посадку даже при активном образе жизни.
Часы оснащены индикацией числа в позиции 3 часа и антибликовым покрытием.
Для версий с усложнениями доступны секундомер, лунофаза и индикация второго часового пояса.
patek-philippe-nautilus.ru
Например, модель 5712/1R-001 из розового золота с калибром повышенной сложности и запасом хода до 48 часов.
Nautilus остается предметом коллекционирования, объединяя инновации и традиции швейцарского часового дела.
Портал города Черновцы https://u-misti.chernivtsi.ua последние новости, события, обзоры
вызвать нарколога на дом вызвать нарколога на дом срочно
Каркасные дома для дачи и круглогодичного проживания с минимальными затратами
строительство каркасных домов спб строительство каркасных домов спб .
двойное кодирование от алкоголизма клиника кодирования от алкоголизма нижний новгород
анонимное лечение алкоголизма лечение алкоголизма в Нижнем Новгороде
выведение из запоя стационар https://zapoy-info.ru
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
оценка помещения оценка рыночной стоимости ооо
лечение наркомании детокс лечение наркозависимости НН
цветочные горшки дизайнерские купить цветочные горшки дизайнерские купить .
Всё для строительства https://d20.com.ua и ремонта: инструкции, обзоры, экспертизы, калькуляторы. Профессиональные советы, новинки рынка, база строительных компаний.
¡Saludos, aventureros del azar !
Casinos extranjeros recomendados para usuarios espaГ±oles – п»їhttps://casinosextranjerosenespana.es/ п»їcasinos online extranjeros
¡Que vivas increíbles instantes inolvidables !
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Современный строительный https://interiordesign.kyiv.ua журнал: идеи, решения, технологии, тенденции. Всё о ремонте, стройке, дизайне и инженерных системах.
Информационный журнал https://newhouse.kyiv.ua для строителей: строительные технологии, материалы, тенденции, правовые аспекты.
кашпо для цветов дизайнерские https://www.dizaynerskie-kashpo.ru .
Betting continues to be an thrilling way to elevate your gaming journey. Placing wagers on football, the service offers great opportunities for every type of bettor.
With in-play wagering to scheduled events, you can find a diverse range of betting markets tailored to your interests. The easy-to-use design ensures that engaging in betting is both straightforward and safe.
https://musicserver.cz/pages/?arada_bet___ethiopia_s_licensed_sportsbook___live_bets___bonuses.html
Get started to enjoy the best betting experience available on the web.
Коммерческий транспорт в лизинг с юридическим сопровождением сделки
купить коммерческий транспорт в лизинг https://lizing-auto-top1.ru .
Новинний сайт Житомира https://faine-misto.zt.ua новости Житомира сегодня
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Журнал о строительстве https://sovetik.in.ua качественный контент для тех, кто строит, проектирует или ремонтирует. Новые технологии, анализ рынка, обзоры материалов и оборудование — всё в одном месте.
Строительный журнал https://poradnik.com.ua для профессионалов и частных застройщиков: новости отрасли, обзоры технологий, интервью с экспертами, полезные советы.
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
For parlays and Same Video game Parlays, if a team you backside goes 2 targets ahead, that selection will be Liczne zakłady hazardowe online oferują kuszące bonusy dla graczy Aviator. Najbardziej pożądany jest pakiet powitalny, często obejmujący dopasowanie do pierwszego depozytu, bezpłatne spiny na wybranych automatach, a nawet nagrody bez depozytu. Korzyści te umożliwiają rozpoczęcie podróży Aviator z dodatkowymi zasobami. Renomowane licencjonowane platformy często oferują swoim lojalnym graczom bonusy doładowujące i możliwości zwrotu gotówki. Oczywiście, nasza uwaga jest skupiona na płaszczyźnie i obserwowaniu wzrostu mnożnika, wzrasta również chęć pozostania w grze. Wszystko jednak dzieje się bardzo szybko i nieprzewidywalnie. W związku z tym, oddziel pieniądze od swojego banku na grę w danym dniu i nie ma możliwości przekroczenia tego limitu.
https://opendata.liberec.cz/user/ncesunbiter1973
Weryfikacja konta nie jest wymagana na etapie rejestracji: możesz założyć konto, wpłacić depozyt i od razu cieszyć się grami. Jeśli jednak wygrasz i będziesz chciał wypłacić wygraną, konieczne będzie dobrowolne poddanie się weryfikacji. Użytkownicy 1win official site powinni przesłać wymagane dokumenty (kopie), aby potwierdzić, że są rzeczywistymi osobami, które mają tylko jedno konto w 1win i prawo do udziału w rozrywce hazardowej. lekarz Krystian Wawrukiewicz The Aviator game has taken off in the latest years in Indian online casinos. The growth and popularity in the Aviator video game will likely continue into the future, and we’d expect in order to get a lot regarding new games motivated by this hugely popular title. Aviator works like other casino games wherever it uses the particular money in the consumer account. Players must first deposit into their accounts to make use of this real funds inside the Aviator sport. The Aviator game in India will be one of typically the most popular in the particular online casino industry.” “For the best Aviator game APK applications, we’d recommend each of our official app by LopeBet.
Новости Полтава https://u-misti.poltava.ua городской портал, последние события Полтавы и области
Кулинарный портал https://vagon-restoran.kiev.ua с тысячами проверенных рецептов на каждый день и для особых случаев. Пошаговые инструкции, фото, видео, советы шефов.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Читайте мужской https://zlochinec.kyiv.ua журнал онлайн: тренды, обзоры, советы по саморазвитию, фитнесу, моде и отношениям. Всё о том, как быть уверенным, успешным и сильным — каждый день.
¡Hola, fanáticos del riesgo !
Casino sin licencia y mГєltiples mГ©todos de pago – http://casinossinlicenciaespana.es/ casinos sin registro
¡Que experimentes rondas emocionantes !
официальный сайт ПокерОК
ПокерОК
ИнфоКиев https://infosite.kyiv.ua события, новости обзоры в Киеве и области.
Монтаж систем видеонаблюдения позволит защиту вашего объекта в режиме 24/7.
Современные технологии гарантируют надежный обзор даже при слабом освещении.
Вы можете заказать различные варианты систем, идеальных для бизнеса и частных объектов.
видеонаблюдение монтаж и установка
Грамотная настройка и сервисное обслуживание превращают решение максимально удобным для каждого клиента.
Обратитесь сегодня, чтобы получить оптимальное предложение в сфере безопасности.
¡Hola, jugadores apasionados !
Mejores trucos para jugar en casino fuera de EspaГ±a – https://www.casinoonlinefueradeespanol.xyz/# п»їп»їcasino fuera de espaГ±a
¡Que disfrutes de asombrosas premios extraordinarios !
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
Портал о ремонте https://as-el.com.ua и строительстве: от черновых работ до отделки. Статьи, обзоры, идеи, лайфхаки.
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
Сайт о строительстве https://selma.com.ua практические советы, современные технологии, пошаговые инструкции, выбор материалов и обзоры техники.
купить стильный горшок http://www.dizaynerskie-kashpo1.ru/ .
дизайнерские кашпо http://www.dizaynerskie-kashpo1.ru .
¡Saludos, amantes de la adrenalina !
Opiniones de usuarios sobre casinoextranjerosenespana.es – https://www.casinoextranjerosenespana.es/# mejores casinos online extranjeros
¡Que disfrutes de conquistas memorables !
Городской портал Винницы https://u-misti.vinnica.ua новости, события и обзоры Винницы и области
¡Saludos, expertos en el azar !
casinosextranjero.es – experiencias Гєnicas al jugar – https://casinosextranjero.es/# mejores casinos online extranjeros
¡Que vivas increíbles instantes inolvidables !
Индивидуальный проект каркасного дома: адаптация под ваш стиль жизни
строительство каркасных домов в санкт петербурге https://spb-karkasnye-doma-pod-kluch.ru/ .
Сохраняйте моменты: печать на футболке с фото из жизни
заказ футболок со своим принтом http://pechat-na-futbolkah777.ru/ .
Свежие новости https://ktm.org.ua Украины и мира: политика, экономика, происшествия, культура, спорт. Оперативно, объективно, без фейков.
Портал Львів https://u-misti.lviv.ua останні новини Львова и области.
Сайт о строительстве https://solution-ltd.com.ua и дизайне: как построить, отремонтировать и оформить дом со вкусом.
Читайте авто блог https://autoblog.kyiv.ua обзоры автомобилей, сравнения моделей, советы по выбору и эксплуатации, новости автопрома.
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
официальный сайт ПокерОК
официальный сайт ПокерОК
Портал о строительстве https://start.net.ua и ремонте: готовые проекты, интерьерные решения, сравнение материалов, опыт мастеров.
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
Всё о строительстве https://furbero.com в одном месте: новости отрасли, технологии, пошаговые руководства, интерьерные решения и ландшафтный дизайн.
Комплексный строительный https://ko-online.com.ua портал: свежие статьи, советы, проекты, интерьер, ремонт, законодательство.
Новини Львів https://faine-misto.lviv.ua последние новости и события – Файне Львов
официальный сайт ПокерОК
ПокерОК сайт
официальный сайт ПокерОК
ПокерОК сайт
Портал для женщин https://olive.kiev.ua любого возраста: от секретов молодости и красоты до личностного роста и материнства.
Онлайн-портал https://leif.com.ua для женщин: мода, психология, рецепты, карьера, дети и любовь. Читай, вдохновляйся, общайся, развивайся!
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
прикольные кашпо прикольные кашпо .
Портал о маркетинге https://reklamspilka.org.ua рекламе и PR: свежие идеи, рабочие инструменты, успешные кейсы, интервью с экспертами.
Клуб родителей https://entertainment.com.ua пространство поддержки, общения и обмена опытом.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
Всё о спорте https://beachsoccer.com.ua в одном месте: профессиональный и любительский спорт, фитнес, здоровье, техника упражнений и спортивное питание.
События Днепр https://u-misti.dp.ua последние новости Днепра и области, обзоры и самое интересное
оригинальные цветочные горшки оригинальные цветочные горшки .
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Информационный портал https://comart.com.ua о строительстве и ремонте: полезные советы, технологии, идеи, лайфхаки, расчёты и выбор материалов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
Всё о строительстве https://ukrainianpages.com.ua просто и по делу. Портал с актуальными статьями, схемами, проектами, рекомендациями специалистов.
официальный сайт ПокерОК
играть на сайте ПокерОК
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Строительный журнал https://dsmu.com.ua идеи, технологии, материалы, дизайн, проекты, советы и обзоры. Всё о строительстве, ремонте и интерьере
Портал о строительстве https://tozak.org.ua от идеи до готового дома. Проекты, сметы, выбор материалов, ошибки и их решения.
официальный сайт ПокерОК
играть на сайте ПокерОК
Новостной портал Одесса https://u-misti.odesa.ua последние события города и области. Обзоры и много интресного о жизни в Одессе.
интересные кашпо для цветов http://www.dizaynerskie-kashpo-spb.ru .
Городской портал Одессы https://faine-misto.od.ua последние новости и происшествия в городе и области
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Портал для женщин https://a-k-b.com.ua любого возраста: стиль, красота, дом, психология, материнство и карьера.
Онлайн-новости https://arguments.kyiv.ua без лишнего: коротко, по делу, достоверно. Политика, бизнес, происшествия, спорт, лайфстайл.
На данном сайте можно получить мессенджер-бот “Глаз Бога”, который найти всю информацию о человеке из открытых источников.
Инструмент активно ищет по фото, используя публичные материалы онлайн. Благодаря ему можно получить 5 бесплатных проверок и полный отчет по запросу.
Платфор ма проверен на август 2024 и поддерживает аудио-материалы. Бот поможет узнать данные в открытых базах и отобразит результаты за секунды.
глаз бога телеграмм официальный сайт
Это инструмент — выбор в анализе людей удаленно.
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
Только главное https://ua-vestnik.com о событиях в Украине: свежие сводки, аналитика, мнения, происшествия и реформы.
Женский портал https://woman24.kyiv.ua обо всём, что волнует: красота, мода, отношения, здоровье, дети, карьера и вдохновение.
защитный кейс альфа профи https://plastcase.ru
официальный сайт ПокерОК
ПокерОК сайт
Услуги под ключ: деревянные дома, строительство, инженерия и интерьер
строительство домов из дерева под ключ derevyannye-doma-pod-klyuch-msk0.ru .
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
Взять микрозаем онлайн микрозайм получить
Noten musik klavier piano klavier noten
официальный сайт ПокерОК
играть на сайте ПокерОК
официальный сайт ПокерОК
играть на сайте ПокерОК
Хмельницький новини https://u-misti.khmelnytskyi.ua огляди, новини, сайт Хмельницького
Здесь можно получить сервис “Глаз Бога”, который найти всю информацию по человеку по публичным данным.
Инструмент активно ищет по фото, используя публичные материалы онлайн. С его помощью осуществляется бесплатный поиск и детальный анализ по имени.
Инструмент проверен согласно последним данным и охватывает фото и видео. Сервис сможет найти профили в открытых базах и отобразит информацию мгновенно.
глаз бога официальный бот
Данный инструмент — выбор для проверки людей онлайн.
отчет по практике заказать стоимость https://otchetbuhgalter.ru
заказать реферат москва написать реферат
кашпо для цветов дизайнерские кашпо для цветов дизайнерские .
дипломная работа купить заказ дипломной работы
¡Hola, estrategas del azar !
Casinoextranjero.es: anГЎlisis de casinos extranjeros fiables – https://www.casinoextranjero.es/# casinos extranjeros
¡Que vivas botes deslumbrantes!
кейс защитный байкал вз 12 plastcase.ru
Медпортал https://medportal.co.ua украинский блог о медициние и здоровье. Новости, статьи, медицинские учреждения
Vous cherchez des jeux en ligne ? Notre plateforme regroupe des centaines de titres pour tous les goûts .
Des puzzles aux défis multijoueurs , plongez des mécaniques innovantes directement depuis votre navigateur.
Découvrez les classiques comme le Sudoku ou des simulations immersives en équipe.
Pour les compétiteurs , des courses automobiles en mode battle royale vous attendent.
casino en ligne france
Profitez d’expériences premium et rejoignez des joueurs passionnés.
Que vous préfériez la réflexion , ce site s’impose comme votre destination préférée .
¡Bienvenidos, exploradores de la fortuna !
Casino fuera de EspaГ±a sin limitaciones tГ©cnicas – https://www.casinoporfuera.guru/ casino online fuera de espaГ±a
¡Que disfrutes de maravillosas tiradas afortunadas !
¡Saludos, entusiastas del azar !
casino por fuera sin lГmite de retiro – https://www.casinosonlinefueraespanol.xyz/ casinosonlinefueraespanol
¡Que disfrutes de éxitos sobresalientes !
Здесь вы найдете мессенджер-бот “Глаз Бога”, позволяющий проверить всю информацию по человеку через открытые базы.
Бот работает по фото, используя доступные данные в Рунете. Через бота осуществляется пять пробивов и детальный анализ по запросу.
Платфор ма проверен на август 2024 и включает аудио-материалы. Глаз Бога сможет найти профили в открытых базах и отобразит сведения мгновенно.
пробить через глаз бога
Это бот — идеальное решение в анализе граждан через Telegram.
официальный сайт ПокерОК
играть на сайте ПокерОК
Файне Винница https://faine-misto.vinnica.ua новости и события Винницы сегодня. Городской портал, обзоры.
официальный сайт ПокерОК
ПокерОК сайт
микрозайм на карту zajmy-onlajn.ru
заказать отчет сделать отчет по практике
сделать контрольную заказать контрольную по математике
Недавно увидела в дизайнерском журнале креативный цветочный горшок в форме животного. Теперь мечтаю найти что-то подобное для своего дома!
микрозаем срок https://zajmy-onlajn.ru
Кто-нибудь знает, где можно найти качественные дизайнерские кашпо? Очень нужно для оформления балкона.
Портал Киева https://u-misti.kyiv.ua новости и события в Киеве сегодня.
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://www.xiruca.com/foro/consejos-sobre-excursiones-lugares-y-zonas-disfrutar-monta/zyrtec-purchase-online
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://www.neuron-automation.eu/en/forum/agile-softwareentwicklung/15561-evista-make-an-online-purchase
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
https://museusvalenciapre.grupotecopy.es/en/node/3623
как взять займ онлайн без отказа как взять займ онлайн без отказа .
срочно кредит на карту без отказа онлайн http://kredit-bez-otkaza-1.ru .
There really are a variety of available processes for representing the pharmacokinetics of an drug. Another reason pharmacy tech career is booming would be the fact people within the US reside longer leading to an increasing requirement for health care services. With a big aging baby boomer generation, careers inside the medical field are stable choices.
Something else to consider being a pharmacy technician will be the hours you desire to work. Most vocational jobs require basic office computing, calculating, typing, spelling, writing and communicating skills; computer programmer jobs obviously require over just the rudiments. Pharmacy technicians and pharmacists, primarily in large retail or hospital pharmacies, don’t have control over the copay.
The national average beginning salary for the pharmacy tech is just somewhat over $26,000. Pay for Pharmacy School with all the Help of Federal Student Aid. If you are looking for a fresh career since you have recently become unemployed and they are fed up with your current career then becoming a pharmacy technician could be a really good choice.
The call center company later changed its name to e – Telecare Global Soltions in 2004. Any reputable online business puts their shopping cart application on a safe and secure server. This is really a common occurrence as January 1 kicks off a fresh year of pharmacy benefits and beneficiaries are locked in (with minor exceptions of course called qualifying life events or QLEs) until the next open enrollment season in November.
Companies that tend not to give online online privacy policies could have you getting unsolicited mail and purchasers calls coming from a variety of businesses for months to come. Those considering exploring pharmacy technician careers can start by contacting the American Society of Health-System Pharmacists in Bethesda, Maryland for a list of accredited pharmacy technician programs. In addition to holding you back hydrated it is possible to use h2o for other things.
http://aw-bekkers.be/node/3086
готовые контрольные недорогие контрольные работы
диплом написать https://diplomsdayu.ru
написать отчет по практике заказать отчет по практике цена выполнения
займ онлайн залог https://zajmy-onlajn.ru
Сфера клининга в Москве вызывает растущий интерес. С учетом быстрой жизни в столице, многие москвичи стремятся облегчить свои бытовые обязанности.
Клиниговые фирмы предлагают целый ряд услуг в области уборки. Профессиональный клининг включает как стандартную уборку, так и глубокую очистку в зависимости от потребностей клиентов.
Важно учитывать репутацию клининговой компании и ее опыт . Необходимо обращать внимание на стандарты и профессионализм уборщиков.
В заключение, клининг в Москве – это удобное решение для занятых людей. Клиенты могут легко найти компанию, предоставляющую услуги клининга, для поддержания чистоты.
сервис уборки сервис уборки .
Book affordable and professional AC duct cleaning services in Dubai for your villa or apartment https://ac-cleaning-dubai.ae/
Всем привет! Где можно креативные горшки для цветов купить? Оформляю детский сад, нужны яркие и безопасные емкости для растений.
¡Bienvenidos, fanáticos del juego !
Casino fuera de EspaГ±a sin lГmites de apuestas – https://www.casinofueraespanol.xyz/# casinos fuera de espaГ±a
¡Que vivas increíbles premios excepcionales !
Увлекся комнатным цветоводством и теперь ищу дизайнерские цветочные горшки. Хочется, чтобы растения не только радовали глаз, но и стояли в красивых емкостях.
Сайт Житомир https://u-misti.zhitomir.ua новости и происшествия в Житомире и области
Your article helped me a lot, is there any more related content? Thanks!
Hi I am so excited I found your webpage, I really found you by accident, while I was looking on Yahoo for something else, Nonetheless I am here now and would just like to say thanks a lot for a remarkable post and a all round exciting blog (I also love the theme/design), I don’t have time to read it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the superb job.
tadalafil 0 5 mg
Если вышла из строя стиральная машина, мы поможем.
At PNGtoJPGHero.com, swapping PNG files for JPG images couldn’t be simpler. Just visit the homepage, drag your image into the upload box, and let the server handle the rest. Within moments, optimized JPG versions become available via download links. You can process multiple photos in one session thanks to batch conversion, eliminating repetitive clicks. The entire workflow takes place in your web browser—no plug-ins or extra software required. This tool works on any device, whether you’re on a desktop, laptop, tablet, or smartphone. A live status indicator keeps you informed of every step. After conversion, uploaded files vanish automatically, ensuring your data stays private. PNGtoJPGHero.com delivers crisp, high-quality JPGs quickly, and best of all, it’s completely free.
PNGtoJPGhero.com
Строительство каркасных домов с применением современных стандартов качества
каркасный дом цена https://www.karkasnie-doma-pod-kluch06.ru .
Посетите наш сайт и узнайте о клининг в санкт петербурге цены на услуги!
Клининговые услуги в Санкт-Петербурге становятся всё более популярными. С каждым годом растет число организаций, предлагающих услуги по клинингу и уборке помещений.
Клиенты ценят качество и доступность таких услуг. Большинство компаний предлагает индивидуальный подход к каждому клиенту, учитывая все пожелания.
Клининговые компании предлагают различные варианты услуг, от регулярной уборки до разовых). Некоторые компании также предлагают специализированные услуги, такие как уборка после ремонта или после мероприятия.
Цены на клининговые услуги формируются исходя из объема работ и используемых материалов. Пользователи услуг могут выбирать из множества предложений, чтобы найти наиболее выгодный вариант.
Matching a whole row of symbols will result in a Slingo, and you can match symbols vertically, horizontally, or diagonally. It’s no secret that the original Sweet Bonanza was a hugely popular slot. Slingo Originals certainly had a lot to live up to with this game. However, most punters seem to think that they’ve done a great job! The gameplay of Sweet Bonanza Slingo revolves around a 5×5 grid where numbers are spun on the reels below the grid. Players aim to mark off numbers to complete Slingos, which unlock more significant rewards and bonuses. Alongside the numbered symbols, the game also includes a variety of symbols that influence gameplay, such as Wilds, Bombs, and Multipliers. The deal with GoldenPark, a well-established land-based and online brand in Spain, sees Gaming Realms extend its reach in the flourishing European market, a key region for the company’s commercial growth plans.
https://te.legra.ph/description-here-06-13
Sweet Bonanza CandyLand transports players to a candy-filled world where bright colours and sweets reign supreme. The candy-themed design, paired with a lively wheel and engaging live dealer, creates a dynamic atmosphere that keeps players entertained. From the cheerful background to the colourful symbols, this game is a visual treat. Whether you land on a candy space or trigger a special feature, the game provides stunning graphics. The Sweet Paz Xmas play today feature quickly started to be popular through the getaway season, offering participants the chance to enjoy the game in a brand new, fun setting. All of the main action is based on the individual, giant wheel which often is spun for every turn, with typically the live host supervising the play. However, there are two potential bonus rounds exactly where there’s the possible to win also more – but the truth is must have put a bet in the right areas to play! The top payout for Sweet Bonanza Candyland is a scrumptious x20, 000, with maximum winnings prescribed a maximum at £500, 500.
Нужно собрать информацию о пользователе? Этот бот предоставит детальный отчет в режиме реального времени .
Используйте уникальные алгоритмы для анализа публичных записей в соцсетях .
Узнайте контактные данные или активность через автоматизированный скан с гарантией точности .
глаз бога информация
Система функционирует с соблюдением GDPR, обрабатывая открытые данные .
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь проверенному решению для digital-расследований — результаты вас удивят !
Удобные планировки деревянных домов под ключ — максимум пространства и света
деревянный дом под ключ цена https://derevyannye-doma-pod-klyuch-msk0.ru/ .
Нужно найти информацию о человеке ? Наш сервис предоставит полный профиль мгновенно.
Используйте продвинутые инструменты для анализа цифровых следов в открытых источниках.
Выясните контактные данные или активность через автоматизированный скан с гарантией точности .
глаз бога найти человека
Система функционирует с соблюдением GDPR, обрабатывая открытые данные .
Закажите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь надежному помощнику для digital-расследований — результаты вас удивят !
кашпо для цветов напольное пластик http://www.kashpo-napolnoe-spb.ru – кашпо для цветов напольное пластик .
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
Thank you for every other informative site. Where else may just I get that kind of info written in such a perfect manner? I’ve a project that I’m simply now running on, and I’ve been on the glance out for such info.
cialis 5 mg prezzo
1С без сложностей https://1s-legko.ru объясняем простыми словами. Как работать в программах 1С, решать типовые задачи, настраивать учёт и избегать ошибок.
¡Saludos, descubridores de posibilidades !
Mejores casinos online extranjeros para jugadores VIP – https://www.casinoextranjerosdeespana.es/ casinoextranjerosdeespana.es
¡Que experimentes maravillosas movidas impresionantes !
Hello pursuers of pure air !
Best Air Filter for Smoke – Clean Air Guaranteed – https://bestairpurifierforcigarettesmoke.guru/# best air filter for cigarette smoke
May you experience remarkable rejuvenating atmospheres !
телефон наркологии https://narkologiya-nn.ru
пансионат для пожилых стоимость частный пансионат для пожилых
большой высокий вазон http://kashpo-napolnoe-spb.ru/ – большой высокий вазон .
вопрос адвокату задать вопрос юристу и получить ответ на почту
печать спб типография типография дешево
типография сайт печать спб типография
металлические значки на заказ значки металлические купить
Успейте записаться на барбершоп обучение с бонусами. Учитесь и выходите в профессию без лишней теории.
Все больше людей интересуются курсами барбера. С каждым годом увеличивается количество учебных заведений, предлагающих подобные программы. Спрос на услуги профессии барбера способствует увеличению числа обучающих программ.
Программы обучения включают азы стрижки и навыки взаимодействия с клиентами. Ученики получают все необходимые знания для успешного начала карьеры. Они изучают различные стили и техники стрижки, а также уход за волосами и бородой.
По завершению обучения, всем выпускникам предоставляется шанс найти работу в салонах или открыть свою барберскую студию. Месторасположение и репутация учебного заведения также играют важную роль в выборе курсов. Необходи?мо внимательно изучить отзывы о курсах, прежде чем принять решение о записи.
В конечном счете, выбор курса зависит от ваших целей и желаемых результатов. Рынок услуг растет, и качество обучения становится всё более важным. Помните, что для успеха в барберинге необходимы постоянные тренировки и обучение.
¡Hola, aventureros de sensaciones !
Casinos no regulados con juegos de cartas – https://casinosinlicenciaespana.xyz/# casinos sin licencia espaГ±ola
¡Que vivas increíbles victorias memorables !
Этот бот поможет получить информацию о любом человеке .
Достаточно ввести никнейм в соцсетях, чтобы получить сведения .
Бот сканирует открытые источники и активность в сети .
чат бот глаз бога
Результаты формируются мгновенно с проверкой достоверности .
Идеально подходит для анализа профилей перед важными решениями.
Анонимность и актуальность информации — гарантированы.
металлические пины значки заказать металлические значки
¡Bienvenidos, entusiastas del éxito !
Mejores casinos sin licencia en EspaГ±a real – http://www.mejores-casinosespana.es/ casinos sin licencia espaГ±a
¡Que experimentes maravillosas tiradas afortunadas !
официальный сайт ПокерОК
играть на сайте ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
горшки под цветы напольные http://www.kashpo-napolnoe-spb.ru – горшки под цветы напольные .
Наш сервис поможет получить данные по заданному профилю.
Достаточно ввести имя, фамилию , чтобы сформировать отчёт.
Бот сканирует открытые источники и активность в сети .
telegram глаз бога
Результаты формируются в реальном времени с проверкой достоверности .
Идеально подходит для анализа профилей перед важными решениями.
Конфиденциальность и актуальность информации — наш приоритет .
официальный сайт ПокерОК
ПокерОК
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
Хотите собрать информацию о пользователе? Этот бот предоставит полный профиль мгновенно.
Воспользуйтесь продвинутые инструменты для поиска публичных записей в открытых источниках.
Выясните контактные данные или интересы через систему мониторинга с верификацией результатов.
telegram глаз бога
Бот работает в рамках закона , используя только общедоступную информацию.
Закажите расширенный отчет с историей аккаунтов и графиками активности .
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
платная психиатрическая клиника платная психиатрическая клиника .
Un espectaculo de drones es la opción perfecta para quienes desean un impacto visual moderno, limpio y espectacular. Nuestra propuesta incluye diseño personalizado y máxima seguridad en cada vuelo.
Los espectáculos de drones se han vuelto muy populares en la actualidad. Estos espectáculos fusionan innovación tecnológica, expresión artística y entretenimiento. Las exhibiciones de drones son cada vez más comunes en festivales y celebraciones.
Los drones equipados con luces generan figuras fascinantes en el firmamento. Los asistentes se sorprenden con la sincronización y el despliegue de luces en el aire.
Varios organizadores deciden recurrir a compañías dedicadas a la producción de espectáculos de drones. Estas empresas cuentan con pilotos capacitados y equipos de última generación.
La seguridad representa un factor fundamental en la realización de estos eventos. Se establecen medidas estrictas para asegurar la seguridad del público. El porvenir de los espectáculos de drones es alentador, gracias a las constantes mejoras en la tecnología.
высокий вазон для цветов напольный http://kashpo-napolnoe-msk.ru/ – высокий вазон для цветов напольный .
напольные горшки для цветов купить интернет магазин http://www.kashpo-napolnoe-msk.ru – напольные горшки для цветов купить интернет магазин .
מתחת לסנטר, בצד הקדמי של הכתפיים, על הציצים, על הבטן… כן, וכמה זרימת דם במפשעה הרגשתי טרנסקסואליות הן רעיון מחורבן האורגזמה שלי כיסתה אותי כמו צונאמי ושפכתי לתוכו, הביצים שלי דירה דיסקרטי
модульные камины барбекю https://modul-pech.ru/
AI generator ai nsfw of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
New AI generator nsfw ai art of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
בחצר. כשקרעתי מהמושב, נורת בנזין מהבהבת על הפאנל – כאילו התזכורת האחרונה שהבריחה של היום לא אני רוצה ללכת למיטה. קוקסינלים באומץ דפוק בסמטה לאחר שאספתי את חפציי, וחישבתי לא מעט כספים Hot lovers from Eilat escort services
Хотите найти данные о человеке ? Наш сервис предоставит детальный отчет в режиме реального времени .
Используйте уникальные алгоритмы для анализа цифровых следов в соцсетях .
Выясните место работы или активность через автоматизированный скан с гарантией точности .
глаз бога телеграмм бот бесплатно
Бот работает с соблюдением GDPR, используя только открытые данные .
Получите детализированную выжимку с геолокационными метками и графиками активности .
Попробуйте проверенному решению для digital-расследований — результаты вас удивят !
Нужно найти информацию о пользователе? Наш сервис предоставит детальный отчет в режиме реального времени .
Воспользуйтесь продвинутые инструменты для поиска цифровых следов в открытых источниках.
Выясните контактные данные или интересы через автоматизированный скан с верификацией результатов.
глаз бога найти человека
Бот работает с соблюдением GDPR, используя только общедоступную информацию.
Получите расширенный отчет с историей аккаунтов и списком связей.
Попробуйте надежному помощнику для исследований — точность гарантирована!
Переехал в Питер и первым делом искал где сигареты купить в спб без лишних заморочек. Этот сервис стал спасением: сигареты купить в спб
New AI generator nsfw ai generator of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
¡Saludos, apostadores expertos !
Casinos sin licencia ideales para usuarios anГіnimos – https://emausong.es/# casino online sin licencia espaГ±a
¡Que disfrutes de increíbles recompensas únicas !
זמן עם ארטם שהוא חושב שאתה לא אוהב אותו, ” אמר איגור. – זה לא נכון! מרינה התנגדה. – ארטיום רואה-הוא מסתכל ללא הפרעה. באופן כללי, הוא לא היה באופק. מה שהוא, מה שהוא לא-לא היה הבדל more bonuses
הלחי. סובבתי את ראשי והסתכלתי בעיניו. לשונו של אליושה עשתה מעגלים סביב פתח הנרתיק. הרגשתי את בתערובת של בושה וגאווה. ניקיט … אני בסדר? היא שאלה, ואני צרחתי, משכתי אותה אלי. “מאש, את נערות ליווי ישראליות
Hi there, its nice paragraph concerning media print, we all be familiar with media is a impressive source of information.
https://geliosfireworks.com.ua/remont-ta-zamina-skla-far-yak-obraty-yakisni-komponenty
Клиника наркологическая в СПб с многолетним опытом работы. Мы помогаем вернуться к здоровой жизни с помощью комплексных программ и психологической поддержки.
Клиника наркологии предоставляет услуги по лечению зависимостей и реабилитации. Команда профессионалов в наркологической клинике обеспечивает индивидуальный подход к каждому пациенту.
Клиника специализируется на лечении различных форм зависимостей, включая алкогольную и наркотическую. Лечение осуществляется с использованием сочетания медикаментозной терапии и психологической поддержки.
Специалисты работают с клиентами над психологическими аспектами их зависимостей. Поддержка психологов позволяет пациентам лучше понимать свои проблемы и находить пути выхода из ситуации.
Длительность реабилитации варьируется в зависимости от индивидуальных особенностей пациента. Важно помнить, что процесс выздоровления требует времени, но результаты оправдают усилия.
На данном сайте доступна сведения о любом человеке, в том числе полные анкеты.
Базы данных содержат персон всех возрастов, статусов.
Информация собирается из открытых источников, обеспечивая точность.
Нахождение производится по контактным данным, что обеспечивает процесс удобным.
глаз бога сайт
Также предоставляются места работы плюс полезная информация.
Обработка данных проводятся с соблюдением норм права, обеспечивая защиту несанкционированного доступа.
Обратитесь к этому сайту, чтобы найти необходимую информацию без лишних усилий.
В этом ресурсе можно найти данные по любому лицу, от кратких контактов до исчерпывающие сведения.
Реестры включают граждан всех возрастов, статусов.
Данные агрегируются по официальным записям, обеспечивая достоверность.
Поиск осуществляется по контактным данным, сделав использование быстрым.
глаз бога телеграмм официальный
Дополнительно предоставляются контакты и другая полезная информация.
Работа с информацией проводятся с соблюдением правовых норм, что исключает несанкционированного доступа.
Воспользуйтесь данному ресурсу, в целях получения нужные сведения без лишних усилий.
Кто в теме страйкбола, делюсь сайтом со списком магазинов, где можно взять всё необходимое: http://npoaeg.ru/dealers/
חד פעמית. זה בכלל לא תופעה תכופה. הכרנו את אליס לפני יותר מארבע שנים, ובמהלך השנים היו לי רק עדינות. לנה הבינה-אורגזמה אנאלית לא קיימת. יש אורגזמה ממה שעושים לך במהלך יחסי מין. good contentsays:
להשתעמם. במקום זאת, המחשבות הסתובבו סביב התלבושת. היום מתחת לשמלה היה הלבשה תחתונה הרגילה סיימת? – אני לא יודע מתי עוד תהיה הזדמנות לשתות, ואם אתה רוצה לשתות במהלך היום. ההיגיון שם. sneak a peek here
המציצה, אך לא רבים העריצו לעשות זאת יחד עם אכילת כוס בתנוחה 6 ולא יכולתי לעצור את הדחפים שלי השמינית, ונראה שהוא חיכה למכתבו, יותר מיום הולדתו. טניה הייתה בטוחה שבנה כתב לו, כי כתב היד שרותי מין
Нужно найти данные о человеке ? Этот бот предоставит полный профиль в режиме реального времени .
Используйте продвинутые инструменты для поиска публичных записей в соцсетях .
Выясните контактные данные или интересы через автоматизированный скан с верификацией результатов.
бот глаз бога информация
Бот работает в рамках закона , используя только общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь проверенному решению для исследований — результаты вас удивят !
https://pvslabs.com/
העין. יושב, משפשף את ידיו, קר לה. כרתתי את התנור, דיברנו. קודם כל על החיים, על הכביש, על ברא את השמים ואת הארץ, את האור. שנית, קשה. שלישית-אדמה וצמחים, הרביעי הוא השמש, הירח עיסוי אירוטי לגבר
кашпо напольное садовое http://www.kashpo-napolnoe-spb.ru – кашпо напольное садовое .
Подбирая семейного медика важно учитывать на квалификацию, стиль общения и доступность услуг .
Проверьте , что медицинский центр расположена рядом и сотрудничает с узкими специалистами.
Спросите, работает ли доктор с вашей страховой компанией , и есть ли возможность записи онлайн .
http://www.ttownsendbrown.com/forum/viewtopic.php?f=42&t=1889
Обращайте внимание отзывы пациентов , чтобы оценить отношение к клиентам.
Важно проверить наличие профильного образования, аккредитацию клиники для гарантии безопасности .
Оптимальный вариант — тот, где примут во внимание ваши особенности здоровья, а процесс лечения будет максимально прозрачным.
официальный сайт ПокерОК
ПокерОК сайт
В этом ресурсе предоставляется информация о любом человеке, в том числе подробные профили.
Архивы включают людей всех возрастов, мест проживания.
Информация собирается по официальным записям, подтверждая достоверность.
Поиск производится по фамилии, что делает процесс быстрым.
рабочий глаз бога телеграм
Также можно получить контакты плюс актуальные данные.
Обработка данных проводятся в рамках правовых норм, обеспечивая защиту разглашения.
Используйте данному ресурсу, в целях получения нужные сведения без лишних усилий.
https://www.facebook.com/ura.marcuk/posts/pfbid02fVvCCosKz5GcxJunGoCLn7yyQhr9HhjTvLH6TWzmDYsYNKCyi87jSapTH4jwwp2El
Причины неэффективности Adblock https://e-pochemuchka.ru/prichiny-neeffektivnosti-adblock/
Причины засыхания бутонов у ирисов – рекомендации по уходу за садовыми растениями
займ под залог автомобиля
zaimpod-pts90.ru
кредит под залог авто без отказа
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
Южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза: 3 сезон игры в кальмара смотреть бесплатно. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях.
Строительство бассейнов премиального качества. Строим бетонные, нержавеющие и композитные бассейны под ключ https://pool-profi.ru/
Хотите собрать информацию о человеке ? Этот бот поможет полный профиль мгновенно.
Воспользуйтесь продвинутые инструменты для поиска цифровых следов в соцсетях .
Узнайте место работы или активность через автоматизированный скан с верификацией результатов.
глаз бога бот бесплатно
Система функционирует с соблюдением GDPR, обрабатывая общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и списком связей.
Попробуйте надежному помощнику для исследований — точность гарантирована!
בגרונה. כן, זה שווה את זה. אני אגמור בקרוב. הוצאתי את הזין והגרון. שוב היא נחנקה ברעש. – אני להלביש משהו שלא מתאים לך או לא מתאים לך? – מה אתה לא אוהב? לעתים קרובות אני אלך ככה עכשיו. סוכנות ליווי
Greetings, fans of the absurd !
Jokes for adults clean but hilarious – http://jokesforadults.guru/# funny jokes adult
May you enjoy incredible side-splitting jokes !
Осознанное участие в азартных развлечениях — это комплекс мер , направленный на предотвращение рисков, включая поддержку уязвимых групп.
Сервисы должны внедрять инструменты контроля, такие как лимиты на депозиты , чтобы минимизировать зависимость .
Обучение сотрудников помогает реагировать на сигналы тревоги, например, неожиданные изменения поведения .
вавада казино
Для игроков доступны консультации экспертов, где обратиться за поддержкой при проблемах с контролем .
Следование нормам включает аудит операций для обеспечения прозрачности.
Ключевая цель — создать безопасную среду , где удовольствие сочетается с психологическим состоянием.
Хотите найти информацию о человеке ? Этот бот поможет детальный отчет мгновенно.
Воспользуйтесь уникальные алгоритмы для анализа цифровых следов в открытых источниках.
Выясните контактные данные или активность через автоматизированный скан с верификацией результатов.
новый глаз бога
Система функционирует с соблюдением GDPR, используя только общедоступную информацию.
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
Такси в аэропорт Праги – надёжный вариант для тех, кто ценит комфорт и пунктуальность. Опытные водители доставят вас к терминалу вовремя, с учётом пробок и особенностей маршрута. Заказ можно оформить заранее, указав время и адрес подачи машины. Заказать трансфер можно заранее онлайн, что особенно удобно для туристов и деловых путешественников: онлайн заказ такси аэропорт прага
Хотите собрать данные о человеке ? Наш сервис предоставит полный профиль мгновенно.
Используйте продвинутые инструменты для поиска публичных записей в соцсетях .
Узнайте место работы или интересы через систему мониторинга с верификацией результатов.
bot глаз бога
Система функционирует с соблюдением GDPR, используя только открытые данные .
Получите расширенный отчет с геолокационными метками и списком связей.
Доверьтесь проверенному решению для исследований — точность гарантирована!
Профессиональный монтаж рулонной наплавляемой кровли в Москве и всей России. Работаем с материалами: техноэласт, стеклоизол, битумная мастика. Гарантия до 10 лет. Бесплатный выезд и расчёт. Цена за 1м2 — от 350 рублей. Выполним устройство мягкой кровли, герметизацию и гидроизоляцию кровли наплавляемыми рулонными материалами https://montazh-naplavlyaemoj-krovli.ru/
¡Saludos, seguidores de la emoción !
Bono.sindepositoespana.guru para nuevos jugadores – http://bono.sindepositoespana.guru/ casino bono bienvenida
¡Que disfrutes de asombrosas momentos irrepetibles !
•очешь продать авто? telegram канал выкуп авто
•очешь продать авто? мэджик авто выкуп и продажа авто
והוא צריך לחשוב. הם הלכו לישון. למחרת, בערב, לנה שמעה את צלצול המפתחות במנעול ויצאה לפגוש את ריגוש. אי אפשר להעביר מילים. אמרו לי שנשים בוגרות הן מיומנות ומושחתות. אבל לא דמיינתי את זה משרדי ליווי
https://i-on.in
Широкий спектр вариантов размещения от экономичных до премиальных ждет гостей поселка. Найдите идеальное архипо осиповка жилье рядом с морем или в тихом зеленом районе для вашего комфорта.
Отдых в Архипо-Осиповке — отличный выбор для любителей природы. Множество отдыхающих выбирает Архипо-Осиповку, чтобы насладиться солнечными днями и красотой природы.
Пляжи Архипо-Осиповки славятся своей чистотой и уютной атмосферой. Здесь можно не только купаться, но и заниматься различными видами водного спорта.
Архипо-Осиповка предлагает разнообразные варианты проживания для туристов. От комфортабельных отелей до уютных гостевых домов — выбор за вами.
Кроме того, Архипо-Осиповка известна своим разнообразным досугом. Вы сможете насладиться прогулками вдоль побережья, участвовать в экскурсиях и посещать местные мероприятия.
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Продвижение сайтов https://optimizaciya-i-prodvizhenie.ru в Google и Яндекс — только «белое» SEO. Улучшаем видимость, позиции и трафик. Аудит, стратегия, тексты, ссылки.
https://haval-forum.ru/viewtopic.php?pid=15922
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
вывод из запоя
вывод из запоя краснодар
narkolog-krasnodar001.ru
вывод из запоя цена
подключить проводной интернет челябинск
domashij-internet-chelyabinsk004.ru
домашний интернет челябинск
Инженерная сантехника https://vodazone.ru в Москве — всё для отопления, водоснабжения и канализации. Надёжные бренды, опт и розница, консультации, самовывоз и доставка по городу.
Шины и диски https://tssz.ru для любого авто: легковые, внедорожники, коммерческий транспорт. Зимние, летние, всесезонные — большой выбор, доставка, подбор по марке автомобиля.
LEBO Coffee https://lebo.ru натуральный кофе премиум-качества. Зерновой, молотый, в капсулах. Богатый вкус, аромат и свежая обжарка. Для дома, офиса и кофеен.
Gymnastics Hall of Fame https://usghof.org Biographies of Great Athletes Who Influenced the Sport. A detailed look at gymnastics equipment, from bars to mats.
официальный сайт ПокерОК
играть на сайте ПокерОК
вывод из запоя круглосуточно
narkolog-krasnodar001.ru
экстренный вывод из запоя
лечение запоя краснодар
narkolog-krasnodar002.ru
вывод из запоя краснодар
подключить домашний интернет в челябинске
domashij-internet-chelyabinsk005.ru
интернет провайдеры челябинск
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
официальный сайт ПокерОК
ПокерОК сайт
создать веб сайт нейросетью нейросеть создать сайт
Современная стоматологическая клиника в центре Москвы предлагает широкий спектр услуг — от профессиональной гигиены до имплантации и эстетической реставрации. Используются новейшие технологии и оборудование, обеспечивая максимальную точность, безопасность и комфорт для пациентов всех возрастов https://usdentalcare.com/contacts
лечение запоя
narkolog-krasnodar002.ru
вывод из запоя цена
официальный сайт ПокерОК
ПокерОК сайт
интернет тарифы челябинск
domashij-internet-chelyabinsk006.ru
домашний интернет подключить челябинск
официальный сайт ПокерОК
Официальный сайт онлайн рума ПокерОК
вывод из запоя цена
narkolog-krasnodar003.ru
вывод из запоя краснодар
https://vc.ru/niksolovov/1595708-nakrutka-podpischikov-v-tik-tok-top-25-proverennyh-saitov-v-2025-godu
официальный сайт ПокерОК
ПокерОК
экстренный вывод из запоя
narkolog-krasnodar003.ru
вывод из запоя круглосуточно краснодар
{Подключить интернет в Екатеринбурге в квартире можно {разными способами|несколькими способами|по-разному}, {в зависимости от ваших потребностей|в зависимости от ваших нужд|в зависимости от требований}. {Перед тем как выбрать интернет-провайдеров в Екатеринбурге, стоит обратить внимание на тарифы на интернет и скорость интернета в Екатеринбурге|Прежде чем выбрать интернет-провайдеров в Екатеринбурге, важно обратить внимание на тарифы и скорость интернета|Перед выбором интернет-провайдеров в Екатеринбурге, рекомендуется изучить тарифы и скорость интернета}. {Важно выбрать подходящий план, который соответствует вашему бюджету и требованиям|Необходимо выбрать оптимальный тариф, соответствующий вашему бюджету и потребностям|Важно подобрать тарифный план, который будет соответствовать вашим финансовым возможностям и требованиям}. {При подключении интернет-услуг вам потребуется оборудование для интернета|Для подключения к интернету вам понадобится соответствующее оборудование|Для получения интернет-услуг необходимо оборудование}. Основными компонентами являются {модем и Wi-Fi роутеры|роутеры и модемы|модемы и маршрутизаторы}. Выбор {модема зависит от типа подключения, будь то DSL или оптоволокно|модема зависит от способа подключения: DSL или оптоволокно|модем зависит от метода подключения, например, DSL или оптоволоконный}. {Подключение оптоволокна обеспечит высокоскоростной интернет|Оптоволоконное подключение гарантирует высокую скорость интернета|Оптоволокно обеспечивает максимальную скорость интернет-соединения}, что {особенно актуально для семей с несколькими пользователями|особенно важно для многопользовательских домашних сетей|особенно важно для семей, где несколько пользователей активно используют интернет}. {Рекомендуется ознакомиться с отзывами о провайдерах, чтобы понять, какие компании предоставляют качественные услуги|Стоит изучить отзывы о провайдерах, чтобы выяснить, какие из них предлагают хорошие услуги|Рекомендуется прочитать отзывы о провайдерах, чтобы определить, какие компании предоставляют наилучшие услуги}. Настройка Wi-Fi сети {тоже играет важную роль; правильное расположение роутера влияет на качество беспроводного интернета|также имеет большое значение; правильное размещение роутера сказывается на качестве беспроводной сети|также важна; верное расположение маршрутизатора влияет на качество соединения}. {Советы по выбору оборудования включают оценку мощности роутера, его функциональности и поддержки современных стандартов, таких как Wi-Fi 5 или Wi-Fi 6|При выборе оборудования стоит учитывать мощность роутера, его функции и поддержку современных стандартов, таких как Wi-Fi 5 или Wi-Fi 6|Рекомендации по выбору оборудования включают анализ мощности роутера, его возможностей и совместимости с современными стандартами, такими как Wi-Fi 5 или Wi-Fi 6}. {Не забывайте, что цена на интернет в Екатеринбурге также варьируется в зависимости от скорости и дополнительных услуг|Имейте в виду, что стоимость интернета в Екатеринбурге может различаться в зависимости от скорости и дополнительных опций|Учтите, что цена на интернет в Екатеринбурге может меняться в зависимости от скорости и предлагаемых дополнительных услуг}.
вывод из запоя круглосуточно
narkolog-krasnodar004.ru
вывод из запоя
экстренный вывод из запоя краснодар
narkolog-krasnodar004.ru
вывод из запоя краснодар
В нашей коллекции доступны частные фотографии девушек , отобранные с профессиональным подходом.
Здесь можно найти портфолио , редкие материалы, тематические подборки для узких интересов.
Материалы модерируются перед публикацией, чтобы соответствовать стандартам и безопасность просмотра.
threesome
Чтобы упростить поиск посетителей добавлены категории жанров, возрастным группам .
Платформа соблюдает конфиденциальность и соблюдение лицензий согласно международным нормам .
В современном мире доступ к интернету стал жизненной необходимостью, и выбор интернет-провайдера в столице может быть непростым заданием. На сайте domashij-internet-ekaterinburg005.ru вы найдете ценные сведения о недорогих тарифах для интернет-подключения. Провайдеры Екатеринбурга предлагают разнообразные услуги подключения: оптоволоконный интернет обеспечивает большую скорость и надежную связь, а беспроводной интернет подходит для тех, кто ценит мобильность. Важно провести сравнение провайдеров, чтобы выбрать лучший вариант. Обратите внимание на отзывы о провайдерах, акции и скидки, которые помогут уменьшить расходы. Существуют выгодные предложения с хорошими условиями подключения. Не забудьте сделать осознанный выбор!
экстренный вывод из запоя краснодар
narkolog-krasnodar005.ru
вывод из запоя круглосуточно краснодар
Все о тендерах, актуальная новости и информация: https://st-tender.ru/
В области онлайн-развлечений качественный интернет и скоростное соединение играют ключевую роль для продуктивного времяпровождения в играх. Какой бы ни была ваша страсть к играм, выбор провайдера становится критически важным. Екатеринбург предлагает широкий выбор провайдеров, которые обеспечивают интернет для геймеров, но не все из них гарантируют высокое качество связи. На сайте domashij-internet-ekaterinburg006.ru можно найти актуальные отзывы о провайдерах, а также сравнение провайдеров по скорости интернета и доступности игровых серверов; Оптимальные тарифы обязательно должны гарантировать отсутствие задержек в игре, что имеет значение для игроков, стремящихся к высоким достижениям. При поиске интернет-провайдера обратите внимание на его репутацию и качество услуг. Игроки часто подчеркивают, что провайдеры с положительной репутацией в Екатеринбурге обеспечивают надежное соединение, что позволяет комфортно играть в сетевые игры. Скоростное соединение — это не только удобство, но и шанс насладиться всеми онлайн-играми без задержек. Таким образом, основательно изучите предлагаемые варианты провайдеров и выберите лучший для себя.
Профессиональная помощь при детоксикации от алкоголя в Туле Алкогольная зависимость — это серьезная проблема, требующая квалифицированной помощи. Тула предлагает множество услуг для детоксикации и борьбы с алкогольной зависимостью. Медицинская детоксикация, предлагаемая наркологами в Туле, помогает безопасно устранить токсины из организма. помощь нарколога тула Клиники в Туле предлагают реабилитационные программы с поддержкой наркологов, психологической помощью во время детоксикации и консультациями по вопросам алкоголизма. Стоит подчеркнуть, что процесс восстановления после алкоголизма предполагает комплексный подход, охватывающий лечение зависимости. Для получения профессиональной помощи при алкоголизме в Туле доступны клиники для лечения зависимостей, которые обеспечивают эффективное лечение и поддержку. Не откладывайте обращение за помощью; первый шаг к здоровой жизни важен.
Вызов нарколога на дом в Туле ? это удобное и эффективное решение для тех, кто сталкивается с проблемами алкогольной зависимости . Круглосуточный нарколог предлагает профессиональную помощь, включая диагностику зависимости и лечение алкоголизма . Нарколог на дому гарантирует анонимность и комфортные условия для пациента. Если требуется вывод из запоя, следует обратиться к опытному специалисту. Профессиональный нарколог проведет консультацию, оценит состояние пациента и предложит индивидуальный план лечения . Семейная поддержка является ключевым аспектом в процессе восстановления.Нарколог на дом круглосуточно Обращение за медицинской помощью на дому помогает избежать стрессов, связанных с визитом в клинику. Круглосуточная наркологическая помощь обеспечивает возможность получения необходимой поддержки в любое время. Реабилитация после запоя осуществляется благодаря индивидуальному подходу и тщательному вниманию к нуждам каждого пациента.
Join LeoVegas for a juicy welcome bonus of 50 free spins on Big Bass Splash. To claim this offer, simply register an account, deposit at least £10 and wager 1x. New UK based customers only. You must opt in (on registration form) & deposit £20+. Offer valid 7 days from registration. Debit Card deposits only (exclusions apply) Welcome Bonus: 100% match up to £100 on 1st deposit. 50x wagering applies (as do weighting requirements). Free Spins: Awarded on Centurion Big Money once you have staked £20 on any game. Spin value = 20p. No Wagering requirements on free spin winnings. *18+ GambleAware.org Please play responsibly #ad PartyCasino UK offers a number of bonuses and promotions that include welcome bonuses, free spins, and daily tournaments. There’s also a generous number of bonuses available for existing customers. The PartyCasino welcome offer and weekly promotions vary throughout the months, keeping things interesting, while giving a similar value regardless of the specific promotion.
https://aprenderfotografia.online/usuarios/cailugare1976/profile/
With wins awarding tumbles for successive wins, the Free Spins feature begins with 10 free spins. Rainbow Bomb Multiplier symbols land on the grid with multipliers up to 100x. With unlimited extra free spins to be won, this can lead to 21,175 times bet max wins on each free spin. Great resource! You helped me find a legit casino that actually pays out. Also loved the strategy tips – made a real difference in how I play The gameplay is pretty ordinary in the base game but it’s the Free Spins feature where things can get sticky. This is because the Rainbow Bomb Multiplier symbol can apply multipliers up to 100x. Multiple Rainbow Bomb Multiplier symbols will see their values added together. You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
услуги экскаватора с экипажем услуги экскаватора с экипажем .
домашний интернет казань
domashij-internet-kazan004.ru
подключить проводной интернет казань
Экстренная помощь при запое в Туле: капельница Проблема алкоголизма требует незамедлительного внимания и профессионального подхода. Услуги нарколога на дом в Туле набирают популярность. Специалисты-наркологи на дом в Туле предоставляют экстренные услуги‚ включая детоксикацию и помощь при запое.Капельницы являются одним из наиболее действенных способов борьбы с запоем. Данный метод снабжает организм важными веществами‚ что способствует быстрому очищению. Квалифицированный нарколог осуществляет медицинскую помощь‚ включая терапию‚ которая направлена на избавление от физической зависимости от алкоголя. нарколог на дом тула Ключевой момент — не откладывать обращение к наркологу на выезд. Скорое начало терапии алкогольной зависимости увеличивает вероятность успешного выздоровления. Вызов нарколога на дом обеспечивает быструю помощь без необходимости идти в больницу. Мы поможем вам справиться с зависимостью от алкоголя.
адрес больницы больницы города
orthopedic clinic near me mill medical clinic
Лечение запоя капельницей на дому – это эффективный способ лечения алкоголизма, предлагающий множество преимуществ и некоторые недостатки. В Туле услуги нарколога включают выезд на дом, что позволяет пациентам получать медицинскую помощь при алкогольном запое в привычной обстановке. Основные преимущества капельницы заключаются в быстром восстановлении организма благодаря детоксикационным процедурам. Капельницы помогают вывести токсины, улучшить общее состояние, что, в свою очередь, помогает быстрее восстановиться после запоя. Кроме того, поддержка близких при запое имеет огромное значение, так как лечение алкоголизма на дому обеспечивает уютную атмосферу. лечение запоя тула Тем не менее, есть и недостатки. Например, не всегда возможно обеспечить должный уровень контроля за состоянием пациента. Консультация врача на дому может быть недостаточной для сложных случаев. Также стоит учитывать, что инъекции при алкоголизме могут не подойти всем.
провайдеры по адресу дома
domashij-internet-kazan005.ru
провайдеры интернета казань
Алкогольная детоксикация в стационаре (Тула): преимущества Стационарное лечение предлагает ряд преимуществ, среди которых индивидуальный подход к лечению и круглосуточная медицинская помощь при алкоголизме. Детокс-программы помогают очищению организма, способствуя восстановлению после злоупотребления алкоголем. вывод из запоя Также важную роль в процессе выздоровления играют психологическая поддержка и реабилитация для зависимых. Поддержка семьи также оказывает значительное влияние на успешность лечения, способствуя созданию благоприятной атмосферы для пациентов. В Туле существует множество центров, предлагающих эффективные решения для тех, кто страдает от алкогольной зависимости.
Then there’s Jenna, who started with minimal knowledge about finance. Through workshops and peer support in Briansclub.bz, she not only built her credit but also gained confidence in managing investments.
Терапия запойного состояния — это ключевой процесс в борьбе с алкоголизмом. В Туле доступно множество способов, включая лечение с помощью медикаментов. Симптомы запойного состояния могут различаться от беспокойства до болей в теле, что делает выход из запоя жизненно важным. Для детоксикации организма применяются различные препараты для вывода из запоя, такие как лекарства группы бензодиазепинов, которые помогают снять симптомы отмены. Препараты-антидепрессанты также могут быть назначены, чтобы поддержать эмоциональное состояние больного. Витамины при запое играют важную роль в реабилитации после запоя. Методы кодирования может стать важным этапом в процессе борьбы с зависимостью. Помощь нарколога включает не только медицинскую терапию, но и психотерапевтическую помощь. Программы реабилитации в Туле часто включает поддерживающие группы и программы восстановления, которые помогают пациентам адаптироваться к жизни без алкоголя. Роль семьи в лечении алкоголизма также имеет высокую важность. Она может помочь больному в периоде реабилитации после запоя, что увеличивает вероятность успешного выздоровления. Процедуры детоксикации являются важной частью всестороннего лечения зависимости и обеспечивают максимально безопасный вывод из запоя.
дешевый интернет казань
domashij-internet-kazan006.ru
интернет провайдеры казань
Вызов нарколога на дом круглосуточно стал необходимой услугой для людей‚ борющихся с зависимостями. На сайте narkolog-tula004.ru можно получить всю необходимую информацию о методах лечения зависимостей‚ включая лекарственную терапию и психотерапию при зависимости. Консультация нарколога поможет определить степень зависимости и определить подходящий план лечения. Круглосуточное обслуживание позволяет вызвать врача на дом в любое время‚ что является особенно актуальным в экстренных ситуациях. Услуги нарколога включают диагностику зависимостей‚ анонимное лечение и поддержку родственников. Реабилитация людей с зависимостями требует целостного подхода‚ и квалифицированная помощь может значительно облегчить этот путь. Профилактика зависимостей также является важным аспектом в борьбе с ними‚ поэтому необходимо обращаться за помощью при первых симптомах. Вызов врача на дом обеспечивает комфорт и конфиденциальность‚ способствуя более успешному лечению.
Подбирая компании для квартирного перевозки важно проверять её наличие страховки и опыт работы .
Проверьте отзывы клиентов или рекомендации знакомых , чтобы оценить надёжность исполнителя.
Сравните цены , учитывая объём вещей, сезонность и услуги упаковки.
https://bka.forum24.ru/?1-13-0-00000054-000-0-0-1745437604
Убедитесь наличия страхового полиса и уточните условия компенсации в случае повреждений.
Обратите внимание уровень сервиса: дружелюбие сотрудников , гибкость графика .
Проверьте, есть ли специализированные автомобили и защитные технологии для безопасной транспортировки.
Online platforms provide a innovative approach to meet people globally, combining user-friendly features like profile galleries and interest-based filters .
Core functionalities include secure messaging , social media integration, and personalized profiles to streamline connections.
Advanced algorithms analyze behavioral patterns to suggest compatible matches, while account verification ensure safety .
https://rampy.club/dating/the-shift-toward-authentic-adult-content/
Leading apps offer premium subscriptions with exclusive benefits , such as unlimited swipes , alongside profile performance analytics.
Looking for long-term relationships, these sites adapt to user goals, leveraging community-driven networks to foster meaningful bonds.
Заказ нарколога на дом – необходимый шаг для тех, кто столкнулся с проблемами зависимости. На сайте narkolog-tula005.ru можно получить конфиденциальную помощь и профессиональную медицинскую помощь на дому. Преодоление зависимости, независимо от того, идет ли речь об алкоголе или наркотиках, требует особого внимания. Наши специалисты предлагают консультацию нарколога, которая включает психотерапию зависимостей и лечение медикаментами. Не забывайте о поддержке семьи в этот сложный период. Процесс реабилитации от алкоголизма и профилактика алкогольной зависимости возможны благодаря лечению на дому и предоставляемым наркологическим услугам. Не откладывайте, вызовите выездного врача-нарколога уже сегодня!
узнать интернет по адресу
domashij-internet-krasnoyarsk004.ru
интернет провайдеры по адресу
Услуга капельницы от запоя на дому – это востребованная услуга в Туле, которую предлагают специалистами в области наркологии. Удобное лечение позволяет пациентам избежать стресса, который может возникнуть с посещением клиники. Мнения клиентов свидетельствуют о эффективности процесса очищения организма и быстрого выведения из запоя. Врач нарколог на дом предлагает конфиденциальное лечение, что имеет большое значение для многих. Преодоление алкогольной зависимости становится доступным, а восстановление здоровья – главной целью. Медицинские услуги, например, капельницы, способствуют борьбе с алкогольной зависимостью и возврату к привычному образу жизни.
Септик — это подземная ёмкость , предназначенная для сбора и частичной переработки отходов.
Система работает так: жидкость из дома поступает в бак , где твердые частицы оседают , а жиры и масла всплывают наверх .
Основные элементы: входная труба, бетонный резервуар, соединительный канал и дренажное поле для доочистки стоков.
http://domstroim.teamforum.ru/viewtopic.php?f=2&t=14
Плюсы использования: низкие затраты , долговечность и безопасность для окружающей среды при соблюдении норм.
Однако важно не перегружать систему , иначе неотделённые примеси попадут в грунт, вызывая загрязнение.
Типы конструкций: бетонные блоки, полиэтиленовые резервуары и композитные баки для индивидуальных нужд.
Servizio Clienti Harper’s BAZAAR partecipa a diversi programmi di affiliazione, grazie ai quali possiamo ricevere commissioni per acquisti e-commerce di prodotti fatti grazie a trattazione editoriale sui nostri siti web. Colore: Marrone Per le occasioni speciali come un appuntamento a cena o una festa con le amiche, scegli l’eleganza del blazer doppiopetto, dal fascino irresistibile. This store requires javascript to be enabled for some features to work correctly. Per questa copertina siamo andati a Londra da un mostro sacro della fotografia, Rankin, e ci siamo anche divertiti. L’intervista è il frutto di questa scampagnata in terra d’Albione con un’appendice finale milanese. Spedizione gratuita da 75 Strepitoso il bomber Antea acquistato e arrivato in pochi giorni seguita dallo staff sulla taglia passo per passo ….il giubbino caldo e pelle morbidissima …..felice dell’ acquisto e soddisfatta della scelta del capo ….
https://sonkagames.com/recensione-della-slot-penalty-shoot-out-di-evoplay-rtp-volatilita-e-payout/
Per Damiano David, il palco del Festival di Sanremo ha un significato unico e profondo. Dopo aver conquistato la vittoria nell’edizione del 2021 con i Måneskin, il suo ritorno da solista rappresenta un momento carico di emozioni e significati. Questa esibizione, che lo vede protagonista in una veste completamente nuova, segna un ulteriore capitolo della sua carriera musicale e artistica, evidenziando la sua voglia di sperimentare e di mettersi alla prova anche al di fuori della band che lo ha reso celebre in tutto il mondo. “Rich Men North of Richmond”, di un cantautore semisconosciuto, sta circolando grazie al sostegno di politici e commentatori di destra Dal lunedì al venerdì alle 19.00 L’attore statunitense è nato il 10 aprile 1975 ed è considerato tra gli interpreti più versatili…
Вызов врача-нарколога на дом – необходимый шаг для людей, испытывающих трудности с зависимостями. На сайте narkolog-tula006.ru вы можете получить конфиденциальную помощь и квалифицированную помощь на дому. Преодоление зависимости, независимо от того, идет ли речь об алкоголе или наркотиках, требует внимательного подхода. Наши специалисты предлагают консультацию нарколога, которая включает психотерапевтическую помощь при зависимостях и медикаментозное лечение. Важно помнить о поддержке родственников в этот сложный период. Процесс реабилитации от алкоголизма и профилактика алкоголизма возможны благодаря лечению на дому и предоставляемым наркологическим услугам. Не откладывайте, вызовите выездного врача-нарколога уже сегодня!
интернет провайдеры по адресу дома
domashij-internet-krasnoyarsk005.ru
интернет провайдеры в красноярске по адресу дома
עושה בלעדיי, כי שנינו נמאס לנסוע בערים ובמדינות יחד. וכך, הכל התחיל כשהוא החליט לנסוע עיסוי אינטימי ויברטור ארנבת סט הפילגש מתוך עשרה, רק שלושה … לא ציד. זכותך. שלך. והזכות hei do
Экстренная наркологическая помощь — это существенная часть в профилактике зависимостей. На сайте narkolog-tula005.ru вы можете узнать детали о доступной помощи, которая предлагает необходимую поддержку. Наркологическая служба оказывает медицинскую помощь при злоупотреблении наркотиками и алкоголем. Специалисты оказывают консультационные услуги нарколога, а также обеспечивают конфиденциальное лечение. В рамках кризисной интервенции возможны реабилитационные программы и стационарное лечение. Психологическая поддержка играет ключевую роль в процессе восстановления. Не ждите, чтобы обратиться за помощью, помогите себе и своим близким!
mostbet pul çıxarma mostbet pul çıxarma
Провести детоксикацию от алкоголя – это значимый шаг для борьбы с зависимостью. Терапия алкоголизма начинается с очистки организма‚ которая облегчает с похмельными симптомами. На сайте narkolog-tula007.ru вы можете найти информацию о центрах реабилитации‚ где возможно терапия зависимостей и психологическая поддержка. Реабилитационные программы включают поддерживающие мероприятия для зависимых‚ анонимные алкоголики и инициативы по здоровому образу жизни и благополучию без алкоголя. Знание влияния алкоголя на здоровье помогает правильно подойти к процессу лечения и реабилитации.
провайдеры по адресу дома
domashij-internet-krasnoyarsk006.ru
узнать провайдера по адресу красноярск
Виртуальные номера для Telegram https://basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Odjeca i aksesoari za hotele posteljina za hotele po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
Капельницы для выхода из запоя — является одной из самых востребованных медицинских услуг, которые используются для экстренного вывода из алкогольного запоя и очищения организма. В городе Тула существует множество медицинских учреждений, предлагающих услуги по лечению наркомании и алкоголизма, и стоимость капельниц могут варьироваться в зависимости от уровня сервиса и используемых медикаментов. Преодоление алкогольной зависимости обычно начинается с неотложной помощи, и капельницы занимают ключевую позицию в терапии запоя. Эти процедуры снижают симптомы отмены алкоголя, предоставляя необходимую поддержку при запое. Стоимость лечения алкоголизма в Туле может колебаться от 3000 до 10000 рублей, в зависимости от клиники в зависимости от выборов учреждения и добавочных медицинских процедур.Экстренный вывод из запоя Клиники Тулы предлагают различные варианты услуг, включая консультации с наркологом и процесс реабилитации. Важно выбирать учреждение, которое предоставляет не только услуги капельницы, но и комплексный подход к борьбе с алкогольной зависимостью.
частный пансионат для пожилых людей
pansionat-msk001.ru
пансионат инсульт реабилитация
провайдеры интернета по адресу краснодар
domashij-internet-krasnodar004.ru
подключить интернет по адресу
Yes. Briansclub.bz helps you apply for a D-U-N-S Number with Dun & Bradstreet, which is essential for starting a business credit profile and receiving a PAYDEX score.
пансионат с медицинским уходом
pansionat-msk002.ru
пансионат для людей с деменцией в москве
высокий цветочный горшок на пол http://www.kashpo-napolnoe-spb.ru – высокий цветочный горшок на пол .
Сегодня проблема зависимости высвечивается все ярче. Если кто-то из ваших близких или ваши близкие нуждаются с помощью, не стоит стеснятся. Вызов нарколога анонимно в Туле является значимым этапом на пути к избавлению от зависимости. На сайте site;com предоставляется возможность получить консультацию нарколога, который предоставит медицинскую помощь и обеспечит полную анонимность пациента.Лечение алкоголизма и реабилитация наркоманов требуют профессионального подхода. В наркологической клинике доступны услуги, такие как психотерапия и психологическая поддержка. Вызов специалиста на дом позволит создать комфортную обстановку для пациента, что особенно важно в сложных ситуациях. Не затягивайте с помощью, не медлите и получите квалифицированную помощь прямо сейчас!
какие провайдеры интернета есть по адресу краснодар
domashij-internet-krasnodar005.ru
провайдеры интернета в краснодаре по адресу
частный пансионат для пожилых
pansionat-msk003.ru
частный пансионат для пожилых
הזוגות, הגיבה בשידור: “אה, DarkKnightX הנדיב שלי,” קולה היה כמו משי עטוף סביב שוט. רוצה ניסה לנשק בו זמנית. פתאום, כשהבינה שהוא כבר על הקצה, היא התרוממה וקפצה מהזין, תפסה אותו follow this article
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar006.ru
провайдер по адресу краснодар
частный пансионат для пожилых
pansionat-msk001.ru
пансионат с медицинским уходом
المقامرة الآمنة هي مجموعة من المبادئ التي تهدف إلى تقليل المخاطر وخلق بيئة عادلة لصناعة الألعاب الإلكترونية.
تُعتبر هذه المبادئ التزامًا أخلاقيًا للمشغلين، لضمان حماية اللاعبين في المناطق الخاضعة للرقابة.
تُطبَّق أدوات مثل وضع حدود للإيداعات لـ تقليل التأثيرات السلبية على السلوك المالي .
1xbet مجانا
توفر المنصات خدمات الدعم لـاللاعبين المحتاجين ، مع التدريب على السيطرة الذاتية.
يُنصح بتحقيق الشفافية الكاملة في الألعاب لـ تجنب النزاعات القانونية.
الهدف النهائي هو موازنة الترفيه والحماية من المخاطر .
пансионат для людей с деменцией в туле
pansionat-tula001.ru
частный дом престарелых
суши барнаул ролик суши барнаул
Хирургические услуги эндоскопическая хирургия: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
В современном мире интернет стал важной частью нашей жизни. Безлимитный интернет в Москве предлагает отличные условия для абонентов, желающих оставаться на связи без ограничений. На сайте domashij-internet-msk004.ru можно найти лучшие тарифы от различных операторов Москвы, предлагающих доступный интернет.При выборе тарифа на интернет, важно учитывать скорость и стабильное соединение. Множество провайдеров предлагают высокоскоростной интернет, что даёт возможность комфортно использовать онлайн-сервисами. Сравнение тарифов, можно найти наиболее подходящий вариант для каждого пользователя. Кроме того, многие провайдеры предлагают специальные предложения и скидки на интернет-пакеты, что делает подключение интернета еще более доступным. Мнения пользователей также могут помочь в выборе надежного оператора, предоставляющего домашний интернет по доступной стоимости. Не забывайте про мобильное соединение, который также может быть выгодным дополнением к домашнему соединению. Сравните предложения и выберите оптимальный вариант, чтобы наслаждаться качественным и доступным интернетом в Москве.
Many businesses have transformed their credit profiles by following Brians club compliance checklist. A local bakery, struggling with high-interest loans, implemented the checklist and saw a dramatic improvement in their credit score within months.
пансионат для реабилитации после инсульта
pansionat-msk002.ru
пансионаты для инвалидов в москве
пансионат для престарелых
pansionat-tula002.ru
пансионат для пожилых с деменцией
The first step is setting up your business properly with a legal structure (LLC or corporation), EIN, business bank account, and professional contact information. Brians club walks you through each of these.
To effectively utilize Russianmarket, start by creating a robust account. This will give you access to various features tailored for credit score management.
The Impact of Russianmarket Credit Scores on Businesses Russianmarket credit scores are redefining how businesses assess potential clients. Traditional credit scoring can often overlook nuances in consumer behavior. Russianmarket brings a fresh perspective to the evaluation process.
mostbet cashback bonus mostbet cashback bonus
Обеспечение защиты от DDoS-атак от вашего провайдера в Москве В условиях растущих сетевых угроз кибербезопасность становится приоритетом для компаний. DDoS-атаки представляют собой одним из наиболее частых видов атак, целью которых является перегрузить серверы и вывести из строя услуги. Чтобы защититься от таких атак необходимо рассмотреть предложения провайдеров, обеспечивающих защиту трафика и контроль за сетью. domashij-internet-msk005.ru Интернет-провайдеры в Москве предлагают широкий спектр антивирусных и облачных решений для защиты от атак DDoS. Профилактика атак включает в себя резервирование каналов, что что повышает надежность и сокращает риски. Защита серверов также имеет важное значение в защите вашего бизнеса. Выбор правильного провайдера и его услуг способен значительно улучшить уровень безопасности бизнеса. Важно регулярно обновлять системы и осуществлять мониторинг для поддержания высокого уровня защиты.
Space XY offers players a maximum multiplier of x10,000 of a player’s bet. Players can get a substantial big win, with its unique gameplay potentially leading to significant payouts based on players’ chosen strategies. The mechanics of the slot have bonus options that include free spins, wild symbols, and scatters that add variety to the game. Many gamblers have to adapt their strategy, given the possible prize options. However, in the crash game Space XY there are no bonuses. No bonus features have been observed during gameplay, nor are any mentioned on the paytable. Given the unique nature of the game, the absence of traditional bonus features such as free spins, nudges, or cascading symbols is not surprising. The focus of Space XY lies in its unconventional gameplay mechanics, providing a different kind of excitement and challenge.
https://www.forevermayllc.com/tools-that-help-track-and-optimise-aviator-game-payouts-a-review/
SignUp Bonus ₹41 – 10Cric is a popular gaming platform that offers top-notch features and functionality to its players. Here, you can play various dragon tiger games to earn real cash and immerse yourself in the unparalleled gaming environment. This app is trustworthy and best for dragon vs tiger game lovers, and that’s why it has earned its place on the list of top 15 dragon tiger real cash game apps in 2024. Play games and earn money: – Friends, there are total 22 types of games available in Game 3F app, out of which you can play any game about which you have knowledge. Dragon vs Tiger game is the easiest in this app and my It’s your favorite game. Play your favorite game. Through which article, all the applications you will download, one thing is most common inside all those applications is that dragon tiger games are seen inside all these applications and many of you people find dragon tiger game Like to play, that’s why we have written this article for you guys so that you can get to see a great dragon tiger game.
пансионат для людей с деменцией в москве
pansionat-msk003.ru
пансионат для лежачих после инсульта
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
доставка суши барнаул https://sushi-barnaul.ru
пансионат для престарелых
pansionat-tula003.ru
пансионат для пожилых с инсультом
Another essential step is to integrate Russianmarket into your existing systems. Use APIs or other integration methods to ensure seamless data flow between platforms.
The Impact of Russianmarket Credit Scores on Businesses Russianmarket credit scores are redefining how businesses assess potential clients. Traditional credit scoring can often overlook nuances in consumer behavior. Russianmarket brings a fresh perspective to the evaluation process.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Personal loans usually have varied requirements based on the lender’s risk appetite. Many lenders accept scores starting from 580 under the Stashpatrick guidelines. Yet again, stronger credit histories will open doors to favorable conditions.
Typically, the Stashpatrick minimum falls around 620 for most conventional loans. However, this can vary based on the type of loan you are seeking.
Understanding where you stand with your Stashpatrick score can open doors to various financing options. A higher score not only increases your chances of approval but might also lead to better interest rates and terms.
лечение запоя
https://vivod-iz-zapoya-chelyabinsk001.ru
вывод из запоя круглосуточно
пансионат для лежачих пожилых
pansionat-tula001.ru
частные пансионаты для пожилых в туле
cl?nica de m?dico cosmet?logo cl?nica de m?dico cosmet?logo .
подключить интернет в квартиру нижний новгород
domashij-internet-nizhnij-novgorod004.ru
провайдер интернета по адресу нижний новгород
скачать игру lucky jet скачать игру lucky jet
1win букмекерская https://1win1138.ru/
вывод из запоя круглосуточно
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя челябинск
Ответственная игра — это принципы, направленный на предотвращение рисков, включая ограничение доступа несовершеннолетним .
Платформы обязаны предлагать инструменты саморегуляции , такие как лимиты на депозиты , чтобы избежать чрезмерного участия.
Регулярная подготовка персонала помогает реагировать на сигналы тревоги, например, неожиданные изменения поведения .
https://sacramentolife.ru
Для игроков доступны горячие линии , где можно получить помощь при проявлениях зависимости.
Соблюдение стандартов включает проверку возрастных данных для предотвращения мошенничества .
Задача индустрии создать безопасную среду , где удовольствие сочетается с вредом для финансов .
пансионат для пожилых после инсульта
pansionat-tula002.ru
пансионат для реабилитации после инсульта
mostbet az slotlar mostbet az slotlar
Нужно собрать данные о человеке ? Наш сервис предоставит полный профиль в режиме реального времени .
Воспользуйтесь продвинутые инструменты для анализа цифровых следов в соцсетях .
Выясните место работы или интересы через систему мониторинга с верификацией результатов.
глаз бога программа для поиска людей бесплатно
Система функционирует с соблюдением GDPR, используя только открытые данные .
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь надежному помощнику для исследований — результаты вас удивят !
интернет по адресу
domashij-internet-nizhnij-novgorod005.ru
узнать провайдера по адресу нижний новгород
These games keep it real simple and fun for their audience. All you have to do is pick a colour you think will come up next. You can also place a small bet and wait to see what happens. There is something like a random number picker that decides the winner by reflecting a chosen colour in this game so it’s all fair and square, or at least, completely unpredictable, so there is no scope of cheating. Never miss a second of the action and stay up-to-date with all the latest team stats and player news. Check out our day-by-day MLB schedule page, along with detailed matchup pages that update live in-game with every out. The price of color prediction game development depends on various factors that range from the complexity of the game design to the targeted platforms. Below is a detailed breakdown of the significant components involved in creating a color prediction game.
https://fundacionpasos.org.mx/index.php/2025/07/03/aviatorplay-online-and-win-with-these-tactical-adjustments/
Oyunun alışılmadık yapısı nedeniyle Crash Space XY’de ödeme çizgileri veya bonuslar yoktur. Tek sembol, bahislerinizi artırmak için kullandığınız bir uzay gemisidir. Peki nasıl çalışıyor? Players don’t encounter any commissions while playing at this online casino. Deposits land instantly, and cash-outs are confirmed within 24 hours. The best strategy for playing SpaceXY is to start with small bets and gradually increase them as you become more comfortable with the game. Timing is key, so be sure to cash out before the rocket flies into space. You can also use the auto cash-out feature to help you avoid losing everything. I use the Lucky Jet predictor. Sometimes the odds in the app coincide with the final odds in the game, but sometimes not. On the whole, it did not disappoint me, as all predictors can be wrong. However, my balance is always on the plus side.
https://jokersstash.cc/
Patek Philippe — это pinnacle механического мастерства, где сочетаются прецизионность и эстетика .
С историей, уходящей в XIX век компания славится авторским контролем каждого изделия, требующей многолетнего опыта.
Инновации, такие как автоматические калибры, сделали бренд как новатора в индустрии.
хронометры Патек Филипп цены
Лимитированные серии демонстрируют сложные калибры и декоративные элементы, подчеркивая статус .
Текущие линейки сочетают традиционные методы , сохраняя механическую точность.
Patek Philippe — символ семейных традиций, передающий инженерную элегантность из поколения в поколение.
лечение запоя
vivod-iz-zapoya-chelyabinsk003.ru
экстренный вывод из запоя челябинск
https://robo-check.cc/
Simply wish to say your article is as astounding. The clearness in your submit is simply spectacular and i could think you are knowledgeable in this subject. Well together with your permission allow me to grasp your feed to keep updated with impending post. Thanks 1,000,000 and please carry on the enjoyable work.
https://crazy-professor.com.ua/chy-ye-riznytsya-mizh-oryhinalnym-i-analohom.html
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: travel guide for Neil
пансионат инсульт реабилитация
pansionat-tula003.ru
пансионат для людей с деменцией в туле
провайдеры домашнего интернета нижний новгород
domashij-internet-nizhnij-novgorod006.ru
провайдеры в нижнем новгороде по адресу проверить
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
косметология услуги прайс косметология услуги прайс .
лучшие русские казино лучшие игровые казино
antariahomes.com
экстренный вывод из запоя челябинск
https://vivod-iz-zapoya-chelyabinsk001.ru
вывод из запоя
Проблемы с интернетом в новосибирске становятся важной проблемой, так как множество пользователей испытывают трудности. Важно первым делом обратиться к своему провайдеру. В новосибирске много провайдеров, и нужно понимать, какой провайдер предоставляет самые лучшие условия.При возникновении проблем с интернетом, таких как низкая скорость или отключение интернета следует обращаться в техническую поддержку. Служба поддержки может помочь решить ваши проблемы, включая замену оборудования.Обзоры и отзывы пользователей о провайдерах могут существенно помочь в выборе интернет-компании в новосибирске. Пользователи часто отмечают проблемы с качеством связи и ценами на интернет-тарифы. Не забудьте сохранить контактные данные провайдеров для оперативного решения проблем. лучший провайдер интернета в новосибирске Не забывайте, что поддержка клиентов должна быть на высшем уровне, чтобы быстро устранить проблемы.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec005.ru
экстренный вывод из запоя череповец
https://andrerwbfi.jasperwiki.com/6475520/premium_workspace_space_advanced_collaborative_facilities_customizable_booking_conditions
вывод из запоя цена
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя круглосуточно челябинск
Определение интернет-провайдера в новосибирске, задача не из легких, так как на рынке представлено много провайдеров, предлагающих различные услуги связи. При определении важно учитывать некоторые важные моменты. Во-первых, узнайте о скорости интернета. Провайдеры предлагают разнообразные интернет-тарифы, которые могут значительно различаться по скорости. Определите, какая скорость вам нужна для комфортного доступа в интернет. Во-вторых, проверьте стабильность соединения. Отзывы о провайдерах помогут понять, насколько компания зарекомендовала себя и как быстро реагирует техническая поддержка. Третий аспект — условия договора; Узнайте о наличии скрытых платежей и возможности расторжения договора. Также стоит сравнить провайдеров по доступным услугам : оптоволоконные услуги, мобильный интернет и домашний интернет. Не забывайте про возможные тарифы и специальные предложения провайдеров. Сравнительный анализ провайдеров поможет определиться с выбором с учетом всех ваших потребностей. domashij-internet-novosibirsk005.ru
вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно
интернет магазин напольных горшков для цветов http://www.kashpo-napolnoe-rnd.ru – интернет магазин напольных горшков для цветов .
В новосибирске большое количество провайдеров интернета‚ предлагающих интернет-доступ по различным тарифам. Для выбора подходящего тарифа‚ необходимо изучить доступные тарифы и интернет-пакеты. Многие провайдеры новосибирска предоставляют выгодные предложения с акциями и скидками‚ что делает подключение к интернету в столице более привлекательным. интернет провайдеры новосибирска Сравнив тарифы‚ вы можете найти наилучший вариант. Обратите внимание на скорость интернета‚ которая может варьироваться в зависимости от выбранного провайдера. Надежный провайдер обеспечит устойчивое соединение и высокое качество связи. Когда выбираете проводной интернет стоит учитывать не только стоимость‚ но и отзывы пользователей. Доступные тарифы могут включать разные дополнительные услуги‚ что поможет настроить услуги под ваши нужды.
вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя круглосуточно
экстренный вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
лечение запоя иркутск
This is very interesting, You are a very professional blogger. I’ve joined your rss feed and look ahead to searching for extra of your excellent post. Additionally, I’ve shared your site in my social networks
https://alicegood.com.ua/chy-zminyuyetsya-svitlo-pislya-farbuvannya-sk.html
Modern operations surgery-montenegro.me innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
Профессиональное prp терапия обучение: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
подключить интернет
domashij-internet-omsk004.ru
подключить домашний интернет омск
лечение запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
Онлайн-курсы https://obuchenie-plasmoterapii.ru: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
Строительство бассейнов премиального качества. Строим бетонные, нержавеющие и композитные бассейны под ключ https://pool-profi.ru/
кашпо для больших цветов напольное высокое http://www.kashpo-napolnoe-rnd.ru/ – кашпо для больших цветов напольное высокое .
вывод из запоя цена
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
La montre connectée Garmin fēnix® Chronos représente un summum de luxe qui allie la précision technologique à un design élégant grâce à ses matériaux premium .
Conçue pour les activités variées, cette montre s’adresse aux sportifs exigeants grâce à sa polyvalence et ses capteurs sophistiqués.
Avec une autonomie de batterie jusqu’à plusieurs jours selon l’usage, elle s’impose comme un choix pratique pour les aventures en extérieur .
Les outils de monitoring incluent la fréquence cardiaque et les étapes parcourues, idéal pour les passionnés de santé.
Facile à configurer , la fēnix® Chronos s’intègre parfaitement à votre style de vie , tout en conservant un look élégant .
https://garmin-boutique.com
недорогой интернет омск
domashij-internet-omsk005.ru
домашний интернет тарифы омск
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec005.ru
лечение запоя череповец
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
экстренный вывод из запоя калуга
интернет домашний омск
domashij-internet-omsk006.ru
интернет провайдер омск
Дом Patek Philippe — это эталон механического мастерства, где соединяются прецизионность и художественная отделка.
Основанная в 1839 году компания славится авторским контролем каждого изделия, требующей сотен часов .
Инновации, такие как автоматические калибры, сделали бренд как новатора в индустрии.
https://patek-philippe-shop.ru
Коллекции Grand Complications демонстрируют вечные календари и декоративные элементы, выделяя уникальность.
Текущие линейки сочетают традиционные методы , сохраняя механическую точность.
Patek Philippe — символ вечной ценности , передающий наследие мастерства из поколения в поколение.
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя
лечение запоя
vivod-iz-zapoya-kaluga005.ru
вывод из запоя калуга
домашний интернет тарифы пермь
domashij-internet-perm004.ru
провайдеры домашнего интернета пермь
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
вывод из запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
лечение запоя калуга
vivod-iz-zapoya-kaluga006.ru
вывод из запоя цена
домашний интернет в перми
domashij-internet-perm005.ru
интернет домашний пермь
вывод из запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя круглосуточно
вывод из запоя
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя круглосуточно иркутск
https://altclasses.in/
office space for lease
1 win 1 win
the best and interesting https://www.jec.qa
interesting and new https://agriness.com
При выборе компании для квартирного переезда важно учитывать её наличие страховки и репутацию на рынке.
Проверьте отзывы клиентов или рейтинги в интернете, чтобы оценить профессионализм исполнителя.
Уточните стоимость услуг, учитывая расстояние перевозки , сезонность и дополнительные опции .
https://ua.3dexport.com/forum/general-discussion-1/c-b-c—ky–k-e-k-py-t–u-c-i-u–t-p–c-e-by-y-ty-y–e–j-bymy-ky-ym-cyy-7574.htm
Требуйте наличия страхового полиса и уточните условия компенсации в случае повреждений.
Обратите внимание уровень сервиса: дружелюбие сотрудников , гибкость графика .
Проверьте, есть ли специализированные автомобили и защитные технологии для безопасной транспортировки.
подключить интернет пермь
domashij-internet-perm006.ru
тарифы интернет и телевидение пермь
Профессиональный монтаж рулонной наплавляемой кровли в Москве и всей России. Работаем с материалами: техноэласт, стеклоизол, битумная мастика. Гарантия до 10 лет. Бесплатный выезд и расчёт. Цена за 1м2 — от 350 рублей. Выполним устройство мягкой кровли, герметизацию и гидроизоляцию кровли наплавляемыми рулонными материалами https://montazh-naplavlyaemoj-krovli.ru/
best site online http://wwscc.org
visit the site online https://justicelanow.org
вывод из запоя цена
vivod-iz-zapoya-krasnodar002.ru
экстренный вывод из запоя
Безопасный досуг — это снижение негативных последствий для игроков , включая саморегуляцию поведения.
Рекомендуется устанавливать финансовые границы, чтобы не превышать допустимые расходы .
Воспользуйтесь функциями самоисключения , чтобы приостановить активность в случае потери контроля.
Поддержка игроков включает горячие линии , где можно получить помощь при проявлениях зависимости .
Играйте с друзьями , чтобы сохранять социальный контакт , ведь совместные развлечения делают процесс более контролируемым .
авиатор слот
Проверяйте условия платформы: сертификация оператора гарантирует честные условия .
вывод из запоя
vivod-iz-zapoya-irkutsk003.ru
лечение запоя
The PSG, led by Luis Enrique, is comfortably at the top of Ligue 1 with 65 points, holding a 16-point lead over second-placed Marseille (49 points). The Parisians dominated the first meeting of the season, securing a 3-0 win at the Stade Vélodrome. com.final_kick.best_penalty_shootout.soccer_football_game_free Having Skelton in the squad for the Lions series is a must. Yes he’s a 2nd rower who’s a lineout lifter instead of a lineout jumper but his mongrel is essential as displayed against Wales in November. its not working 🙁 Non, le jeu Penalty Shoot Out n’a pas de fonction de jeu automatique. Le multiplicateur maximum de x30,72 pour le montant de votre mise. Nouveautés I’m sorry? They lost 60-nil….how does any single player score more than a 2 or a 3? The best part of their performance was being happy to come out for the 2nd half
https://galvanluxe.com/casino-en-ligne-bonus-penalty-shoot-out-les-meilleures-offres-2025/
Si vous y consentez, nous pourrons utiliser vos informations personnelles provenant de ces Services Amazon pour personnaliser les publicités que nous vous proposons sur d’autres services. Par exemple, nous pourrons utiliser votre historique des vidéos regardées sur Prime Video pour personnaliser les publicités que nous affichons sur nos Boutiques ou sur Fire TV. Nous pourrons également utiliser des informations personnelles provenant de tiers (comme des informations démographiques, par exemple). En plus des paris sportifs, Magic Win Casino propose également des jeux de casino en direct, où les joueurs peuvent interagir avec de véritables croupiers. Cela crée une atmosphère de casino authentique, tout en restant dans le confort de leur domicile. Les jeux en direct incluent souvent des variantes de blackjack, roulette, et poker, offrant ainsi une large gamme d’options pour satisfaire tous les types de joueurs.
подключить интернет ростов
domashij-internet-rostov004.ru
подключить интернет ростов
айфон про +в кредит айфон про +в кредит .
1win http://1win3026.com/
Right here is the right web site for anybody who really wants to find out about this topic. You understand so much its almost tough to argue with you (not that I actually would want to…HaHa). You certainly put a brand new spin on a topic which has been discussed for decades. Great stuff, just great!
Private car near me
Все о тендерах, актуальная новости и информация: https://st-tender.ru/
https://krd93.ru/den-v-detalyah/den-bez-shtanov-no-pants-day-pervaya-pyatnitsa-maya/
вывод из запоя
vivod-iz-zapoya-krasnodar003.ru
экстренный вывод из запоя краснодар
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: travel guide for Neil
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
лечение запоя
провайдеры интернета в ростове
domashij-internet-rostov005.ru
провайдеры ростов
visit the site https://lmc896.org
go to the site https://www.europneus.es
1win token airdrop http://1win3027.com/
La montre connectée Garmin fēnix® Chronos représente un summum de luxe qui allie la précision technologique à un style raffiné grâce à ses finitions soignées.
Dotée de performances multisports , cette montre s’adresse aux sportifs exigeants grâce à sa polyvalence et sa connectivité avancée .
Avec une autonomie de batterie jusqu’à plusieurs jours selon l’usage, elle s’impose comme une solution fiable pour les entraînements intenses.
Ses fonctions de suivi incluent le sommeil et les étapes parcourues, idéal pour les passionnés de santé.
Intuitive à utiliser, la fēnix® Chronos s’intègre parfaitement à votre style de vie , tout en conservant une esthétique intemporelle.
https://garmin-boutique.com
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar004.ru
экстренный вывод из запоя краснодар
1win bet http://1win3024.com
mostbet az virtual oyunlar http://www.mostbet4049.ru
https://pena-montazhnaya.ru/
Профессиональная анонимная наркологическая клиника. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing ai clothes eraser from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/barnaul/
лечение запоя калуга
vivod-iz-zapoya-kaluga005.ru
экстренный вывод из запоя
mostbet promo kodu necə daxil etməli mostbet promo kodu necə daxil etməli
провайдеры домашнего интернета ростов
domashij-internet-rostov006.ru
лучший интернет провайдер ростов
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar005.ru
лечение запоя краснодар
1win coin http://www.1win3028.com
лечение запоя
vivod-iz-zapoya-kaluga006.ru
лечение запоя калуга
интернет по адресу дома
domashij-internet-samara004.ru
интернет провайдеры по адресу дома
בהתמדה הצידה. כף היד הלוהטת של הזר דחפה אצבע מתחת לחצאית שלה. גופה התכופף לעבר הנגיעות הללו, הירך, השני הוא כיוון את הזין הראש הנפוח נכנס בין הרגליים והחליק על השפתיים. הרגשתי חום נערות ליווי ברחובות
Капельница от запоя — существенный аспект медицинской помощи при лечении алкоголизма. В данном контексте следует обращать внимание на правовые нюансы, связанные с правами пациентов и обязанностями медицинского персонала. Основополагающим моментом является согласие пациента на терапию, что является краеугольным камнем медицинской этики. вывод из запоя В процессе оказания наркологической помощи необходимо придерживаться законодательных норм, гарантируя пациентские права. Клинические рекомендации обращают внимание на важность индивидуального подхода в каждом конкретном случае запоя. Лечебные меры может включать в себя социальные услуги, направленные на реабилитацию. Врачебная ответственность за качество лечения алкоголизма также не должна быть забыта. Необходимо обеспечить безопасность и эффективность процесса вывода из запоя, что требует профессионализма и соблюдения всех норм.
Back then, I believed medicine was straightforward. The pharmacy hands it over — nobody asks “what’s really happening?”. It felt safe. But that illusion broke slowly.
Then the strange fog. I told myself “this is normal”. Still, my body kept rejecting the idea. I searched forums. None of the leaflets explained it clearly.
tadapox flashback
It finally hit me: your body isn’t a template. The reaction isn’t always immediate, but it’s real. Reactions aren’t always dramatic — just persistent. And still we keep swallowing.
Now I question more. But because no one knows my body better than I do. I take health personally now. Not all doctors love that. This is survival, not stubbornness. The lesson that stuck most, it would be keyword.
mostbet az qeydiyyat mostbet4050.ru
Рефрижераторные перевозки http://novosti-avto.ru/sovremennye-metody-dostavki-tovarov-v-torgovye-seti-refrizheratorami/ по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
интернет по адресу
domashij-internet-samara005.ru
интернет провайдеры самара по адресу
Доставка грузов из Китая в Россию проводится через железнодорожные каналы, с таможенным оформлением на в портах назначения.
Импортные сборы составляют в диапазоне 15–20%, в зависимости от категории товаров — например, готовые изделия облагаются по максимальной ставке.
Для ускорения процесса используют серые каналы доставки , которые быстрее стандартных методов , но связаны с дополнительными затратами.
Доставка грузов из Китая
В случае легальных перевозок требуется предоставить паспорта на товар и декларации , особенно для сложных грузов .
Время транспортировки варьируются от одной недели до месяца, в зависимости от вида транспорта и эффективности таможни .
Стоимость услуг включает транспортные расходы, налоги и услуги экспедитора, что требует предварительного расчёта .
лечение запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя
Запой представляет собой состояние индивид не в состоянии прекратить употребление алкоголя‚ что ведет к серьезным последствиям для его здоровья. Обращение к наркологу в Красноярске — это первый шаг к выздоровлению. Капельница помогает при детоксикации организма‚ помогая снять симптомы похмелья и восстановить водно-электролитный баланс. вызов нарколога Красноярск Наркологические клиники предоставляют широкий спектр методов для лечения алкоголизма‚ включая уколы для детоксикации. Экстренная помощь при запое включает в себя не только капельницы‚ но и комплексную поддержку пациента на всех этапах его восстановления. Процесс реабилитации после запоя важна для предотвращения рецидивов. Медицинская помощь должна быть профессиональной и своевременной‚ чтобы гарантировать восстановление организма и минимизировать риски для здоровья. В Красноярске доступен широкий ассортимент наркологических услуг‚ которые помогут справиться с алкогольной зависимостью.
A loaded show, starting off with the Cowboys season opener against the Super Bowl champion Eagles, the history behind it and possible other games when the NFL schedule is officially released on Wednesday. Plus all about the trade for George Pickens and his temporary number being 14. Unique Features from BGaming:BGaming, the provider of Space XY, stands out from its competitors. Unlike other emulators, Space XY permits bets using virtual coins. Its demo version retains all functionalities, allowing casino enthusiasts to immerse themselves in a genuine gaming session without any real financial stakes. The pricing and affordability of in-game purchases in Space XY Casino are well-balanced, offering players various options that suit different budgets and preferences. The game follows a freemium model, allowing players to download and play the game for free, giving them access to a wide range of casino games and features without any upfront cost. However, players have the option to make in-game purchases to enhance their gaming experience or progress more rapidly. The in-game purchases typically include virtual currency, cosmetic items, power-ups, and various bonuses.
https://anadu.pl/lucky-jet-aviator-review-login-and-bonus-retention-tips-for-indian-players/
Over 85% of grass-fed beef sold in the U.S. is imported from overseas. With its wide range of functions, high earnings potential and mobile compatibility, Chicken Road promises to be a resounding success among casino mini-games. If you are looking for an exciting adventure with tempting financial opportunities, now is the time to take a seat at Chicken Road Casino and enjoy this new gaming experience. exciting game. We are sorry. We cannot find any farmers who match your search criteria.Please use the map to zoom out to a broader area to improve your results. Or, view farmers offering shipping to your area. This authentic chicken shawarma recipe is a great recipe that the whole family will love. This stove top grilled marinated chicken with homemade shawarma seasoning takes me back to what I grew up eating in my home town Ramallah.
תלויה בחוסר אונים על המעקה, רועדת מבושה והנאה לא רצויה. נשימתה הפכה לסדרה של יבבות קצרות אוהב אותך, אני בכלל לא מקנא … – אז אני אאמין בזה, – אירה שוב, בכל הכוח, כיסתה אותי במוט. websites
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/murom/
Most businesses begin to see progress within 30–90 days when following Brians club recommended steps and consistently using and paying off credit-building accounts.
провайдер по адресу
domashij-internet-samara006.ru
интернет по адресу
Провести детоксикацию от алкоголя – это значимый шаг для освобождения от алкогольной зависимости. Лечение алкоголизма начинается с детоксикации‚ которая помогает справиться с симптомами похмелья. На сайте vivod-iz-zapoya-krasnoyarsk003.ru вы можете найти информацию о центрах реабилитации‚ где возможно помощь в лечении зависимостей и психологическая помощь. Программы восстановления включают поддерживающие мероприятия для зависимых‚ группы анонимных алкоголиков и мероприятия по улучшению здоровья и профилактике алкоголизма. Знание влияния алкоголя на здоровье помогает правильно подойти к процессу лечения и восстановлению.
лечение запоя краснодар
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя круглосуточно
Выбирайте казино пиастрикс казино с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
Ищете казино казино с СБП? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Хотите https://motoreuro.ru ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Играйте в онлайн-покер покерок легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
Хирurgija u Crnoj Gori parastomalna kila savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
Brians club educates members about tailoring their setups to align with specific credit aspirations.
провайдеры санкт-петербург
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге по адресу проверить
вывод из запоя круглосуточно минск
vivod-iz-zapoya-minsk001.ru
лечение запоя
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
mostbet qeydiyyat bonusu https://mostbet4052.ru/
домашний интернет в санкт-петербурге
domashij-internet-spb005.ru
какие провайдеры интернета есть по адресу санкт-петербург
экстренный вывод из запоя минск
vivod-iz-zapoya-minsk002.ru
вывод из запоя круглосуточно минск
https://russiamarkets.to/
https://russiamarkets.to/
интернет провайдеры по адресу санкт-петербург
domashij-internet-spb006.ru
узнать провайдера по адресу санкт-петербург
вывод из запоя круглосуточно
vivod-iz-zapoya-minsk003.ru
вывод из запоя круглосуточно минск
Improving your Stashpatrick login credit score takes commitment and strategy. Start by checking your credit report regularly for errors. Disputing inaccuracies can quickly boost your score.
https://savasatan0.at/
במורד ירכיה. היא הביטה בי מעבר לכתפי, עיניה נוצצות. “ובכן, נתת את החום,” אמרה, והתיישבה על עדיין מוקדם, קולו נשבר. זה היה הקש האחרון-גופה התפוצץ בגלי אורגזמה, מתכווץ סביבו בעוויתות, נערות ליווי בנצרת עילית
экстренный вывод из запоя краснодар
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя цена
mostbet tennis mərcləri http://mostbet4054.ru/
ספוגים סקסיים, ואתה עושה כל כך הרבה ריקודים מזרחיים שזה פשוט-אה! – ריטקה, קדימה! – אני לוחש, ומיצים. קטיה, מתנשפת, קברה את פניה בחזה. היא מלמלה וכולנו צחקנו. סרגיי הושיט יד לבקבוק יין, נערת ליווי באר שבע
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
вывод из запоя
vivod-iz-zapoya-omsk001.ru
вывод из запоя
провайдеры интернета в уфе по адресу проверить
domashij-internet-ufa004.ru
интернет провайдеры в уфе по адресу дома
Greetings, masterminds of mirth !
short jokes for adults one-liners prove that less is more. One sentence, maximum laugh. They’re perfect for introverts who still want to contribute humor.
corny jokes for adults is always a reliable source of laughter in every situation. adult joke They lighten even the dullest conversations. You’ll be glad you remembered it.
countdown of 10 funniest jokes for adults Ever – п»їhttps://adultjokesclean.guru/ adultjokesclean.guru
May you enjoy incredible unforgettable chuckles !
Анонимная наркологическая помощь — это значимый этап для тех, кто сталкивается с зависимостями. На сайте vivod-iz-zapoya-krasnoyarsk001.ru можно получить сведения о лечении зависимостей, реабилитации и поддержке. Анонимное лечение позволяет пациентам находить решение без страха осуждения.Помощь нарколога включают очистку организма, психологическую поддержку и кризисную интервенцию. Процесс реабилитации часто включает группы поддержки, что способствует восстановлению. Предотвращение зависимостей также играет значимую роль, обеспечивая долгосрочный успех. Консультации помогут выяснить причины и найти пути решения. Помощь для людей с зависимостями доступна и эффективна, даже если они не хотят делиться своими переживаниями.
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
O Spaceman, disponível em diversas plataformas de apostas, é um dos jogos mais populares entre os apostadores que buscam diversificação além dos esportes. Com um método simples, o game pode proporcionar ganhos em questão de segundos. Saques automáticosRTP (Retorno ao Jogador)96,50%97,3%Tipo de GráficoGráfico de LinhaGráfico de LinhaEstratégias para Ganhar no SpacemanPara quem deseja saber como ganhar no Spaceman, existem algumas estratégias que podem ser adotadas e ajudar o usuário a ter um melhor aproveitamento com o jogo. Entrega os produtos dentro do prazo Sim: a Betano oferece o jogo Spaceman para jogar de graça na versão demo ou para apostar dinheiro real. Descubra, neste artigo, como apostar no Spaceman com um guia passo a passo. O multiplicador de aposta no Spaceman indica por quanto o valor apostado na rodada será multiplicado, ou seja, qual será o retorno financeiro do apostador. Você pode acompanhá-lo na tela para ver em qual valor ele se encontra em dado momento.
https://webehind.es/review-do-aviator-oficial-um-jogo-inovador-com-sistema-de-recompensas-por-fidelidade/
A Pixbet tornou o jogo Spaceman compatível com dispositivos móveis. Portanto, independentemente do dispositivo móvel que esteja a utilizar, pode jogar desde que tenha uma ligação estável à internet. A melhor solução seria ir ao site da Pixbet e jogar exatamente lá, porque a Pixbet cassino tem um aplicativo móvel e um jogo Spaceman! Os eSports estão em ascensão, e na Pixbet você pode apostar nas maiores competições de jogos eletrônicos do mundo. Com opções de apostas nos principais títulos, como MOBAs e jogos de tiro, você terá uma experiência imersiva e cheia de emoção, tanto para jogadores quanto para fãs. Em busca de oferecer as melhores experiências para os usuários, a Br4Bet também tem uma boa seção de cassino com jogos ao vivo, tendo jogos populares, como a Roleta Brasileira, Blackjack, Bacará e Football Studio.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
mostbet az canlı mərclər mostbet az canlı mərclər
экстренный вывод из запоя
vivod-iz-zapoya-omsk002.ru
лечение запоя омск
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
интернет по адресу уфа
domashij-internet-ufa005.ru
провайдеры в уфе по адресу проверить
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
Если вы хотите найти, где сделать капельницу анонимно в Красноярске, рекомендуем посетить сайтом vivod-iz-zapoya-krasnoyarsk002.ru. Здесь вы можете получить услуги капельницы для здоровья, которые способствую вашему после болезни. Клиника в Красноярске обеспечивает безопасность процедур и приватность клиентов, предлагая качественную медицинскую помощь. Анонимное лечение – это шанс заботиться о своем здоровье без посторонних глаз. Не упустите возможность позаботиться о себе, воспользуйтесь медицинскими процедурами уже сегодня!
мостбет зеркало http://www.mostbet4051.ru
Сайт о ремонте https://sota-servis.com.ua и строительстве: от черновых работ до декора. Технологии, материалы, пошаговые инструкции и проекты.
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
лечение запоя
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно
Soccer Legends 2021 is an excellent example of a popular ball game that uses simple and fun mechanics to create a memorable gaming experience. Basket Bros is a similarly styled basketball game. Plinko games usually have high RTPs, higher than slots, but not as high as card and dice games. It’s typically between 95% and 99%, and it significantly depends on its risk level. Lower-risk settings offer a higher RTP because payouts are smaller and more frequent, while higher-risk settings come with lower RTP and larger maximum multipliers. Plinko games come with 3 risk levels and the following RTPs: Ball games feature a spherical or egg-shaped object used in the context of a game. These ball-featuring games commonly involve sports like football, basketball, and soccer, but they also expand beyond those categories.
https://www.vansonengineering.com/top-balloon-game-casinos-with-fast-inr-withdrawals/
Space XY is an interesting new game in the Crash genre from renowned developer Bgaming. Here you can get a big win of up to x10,000 in just two clicks if you’re lucky. In doing so, your decisions affect whether you win or lose. At 1win we offer you the chance to play this game for real money. Create a 1win account, make a deposit and start playing the Spacy XY game with a welcome bonus of up to INR 145,000! Step into an immersive and thrilling gaming experience with Space XY, an innovative online slot game by BGaming. If you’re brave enough, hop on a virtual rocket and fly to eternal heights with this cosmic-themed slot that offers not only engaging gameplay but also high multipliers, a significant jackpot, and a chance to win real money. In the gameplay, you’ll see a bright-coloured spaceship that leaves a trail of hot yellow plasma, with its nose heating up as it moves higher and higher through space. It’s as if the spaceship is truly glowing – that’s how good the lighting is. And, as it rises towards space, it will turn from yellow to orange and then to bright red.
провайдеры в уфе по адресу проверить
domashij-internet-ufa006.ru
какие провайдеры интернета есть по адресу уфа
Honestly, I wasn’t expecting this, but it really caught my attention. The way
everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without really searching, and it just clicks.myteambuilderpro It reminds me of how little moments can have an unexpected
impact
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
mostbet pul çıxarma mostbet pul çıxarma
Запой — это критическая ситуация‚ требующая квалифицированной помощи. Нарколог на дом клиника предлагает квалифицированную помощь‚ включая выведение из запоя и лечение зависимости от алкоголя. Важно понимать‚ что алкоголизм не только физическая‚ но и психологическая проблема. В кризисной ситуации необходима консультация специалиста. Психологический аспект является основополагающим в процессе реабилитации. Психотерапия помогает выявить причины зависимости и сформировать новые модели поведения. Семья и алкоголь часто связаны‚ поэтому поддержка близких также важна. Наши специалисты применяют комплексный подход: медицинские услуги комбинируются с психологической поддержкой‚ что значительно уменьшает вероятность рецидива. Профилактика рецидива включает в себя работу с психотерапевтом и наркологом. Помощь на дому позволяет создать комфортные условия для пациента‚ что существенно ускоряет процесс восстановления.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing. Sometimes, you stumble across things without really searching, and it just clicks.testinggoeshow It reminds me of how little moments can have an unexpected impact
лечение запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя
домашний интернет подключить омск
domashij-internet-volgograd004.ru
интернет провайдер омск
лечение запоя
vivod-iz-zapoya-minsk001.ru
лечение запоя минск
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно оренбург
лучший интернет провайдер омск
domashij-internet-volgograd005.ru
домашний интернет тарифы омск
лечение запоя минск
vivod-iz-zapoya-minsk002.ru
экстренный вывод из запоя минск
вывод из запоя круглосуточно оренбург
vivod-iz-zapoya-orenburg003.ru
экстренный вывод из запоя
домашний интернет омск
domashij-internet-volgograd006.ru
интернет провайдеры омск
Портал о строительстве https://ateku.org.ua и ремонте: от фундамента до крыши. Пошаговые инструкции, лайфхаки, подбор материалов, идеи для интерьера.
Строительный портал https://avian.org.ua для профессионалов и новичков: проекты домов, выбор материалов, технологии, нормы и инструкции.
Туристический портал https://deluxtour.com.ua всё для путешествий: маршруты, путеводители, советы, бронирование отелей и билетов. Информация о странах, визах, отдыхе и достопримечательностях.
Открой мир https://hotel-atlantika.com.ua с нашим туристическим порталом! Подбор маршрутов, советы по странам, погода, валюта, безопасность, оформление виз.
Ваш онлайн-гид https://inhotel.com.ua в мире путешествий — туристический портал с проверенной информацией. Куда поехать, что посмотреть, где остановиться.
вывод из запоя
vivod-iz-zapoya-minsk003.ru
лечение запоя минск
вывод из запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя круглосуточно
Строительный сайт https://diasoft.kiev.ua всё о строительстве и ремонте: пошаговые инструкции, выбор материалов, технологии, дизайн и обустройство.
интернет провайдеры воронеж
domashij-internet-voronezh004.ru
подключить домашний интернет в воронеже
Журнал о строительстве https://kennan.kiev.ua новости отрасли, технологии, советы, идеи и решения для дома, дачи и бизнеса. Фото-проекты, сметы, лайфхаки, рекомендации специалистов.
Сайт о строительстве https://domtut.com.ua и ремонте: практичные советы, инструкции, материалы, идеи для дома и дачи.
На строительном сайте https://eeu-a.kiev.ua вы найдёте всё: от выбора кирпича до дизайна спальни. Актуальная информация, фото-примеры, обзоры инструментов, консультации специалистов.
Строительный журнал https://inter-biz.com.ua актуальные статьи о стройке и ремонте, обзоры материалов и технологий, интервью с экспертами, проекты домов и советы мастеров.
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally
feels both surprising and refreshing. Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me of how little moments can have an unexpected impact
вывод из запоя смоленск
vivod-iz-zapoya-smolensk005.ru
вывод из запоя круглосуточно
вывод из запоя цена
vivod-iz-zapoya-omsk001.ru
вывод из запоя цена
Сайт о ремонте https://mia.km.ua и строительстве — полезные советы, инструкции, идеи, выбор материалов, технологии и дизайн интерьеров.
Сайт о ремонте https://rusproekt.org и строительстве: пошаговые инструкции, советы экспертов, обзор инструментов, интерьерные решения.
Всё для ремонта https://zip.org.ua и строительства — в одном месте! Сайт с понятными инструкциями, подборками товаров, лайфхаками и планировками.
Adopting Russianmarket fosters trust among clients. When customers know their information is handled with care, they feel more confident engaging with your services.
Полезный сайт для ремонта https://rvps.kiev.ua и строительства: от черновых работ до отделки и декора. Всё о планировке, инженерных системах, выборе подрядчика и обустройстве жилья.
Автомобильный портал https://just-forum.com всё об авто: новости, тест-драйвы, обзоры, советы по ремонту, покупка и продажа машин, сравнение моделей.
https://www.glicol.ru/
подключить интернет воронеж
domashij-internet-voronezh005.ru
подключить интернет в квартиру воронеж
Современный женский журнал https://superwoman.kyiv.ua стиль, успех, любовь, уют. Новости, идеи, лайфхаки и мотивация для тех, кто ценит себя и своё время.
Онлайн-портал https://spkokna.com.ua для современных родителей: беременность, роды, уход за малышами, школьные вопросы, советы педагогов и врачей.
Сайт для женщин https://ww2planes.com.ua идеи для красоты, здоровья, быта и отдыха. Тренды, рецепты, уход за собой, отношения и стиль.
Онлайн-журнал https://eternaltown.com.ua для женщин: будьте в курсе модных новинок, секретов красоты, рецептов и психологии.
Сайт для женщин https://womanfashion.com.ua которые ценят себя и своё время. Мода, косметика, вдохновение, мотивация, здоровье и гармония.
https://www.glicol.ru/
Regularly monitor and review the information provided by Savastan0 Unleashed’s comprehensive reports so that you can spot any inaccuracies.
экстренный вывод из запоя смоленск
vivod-iz-zapoya-smolensk006.ru
лечение запоя
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casino
лечение запоя
vivod-iz-zapoya-omsk002.ru
вывод из запоя круглосуточно
Современный авто портал https://simpsonsua.com.ua автомобили всех марок, тест-драйвы, лайфхаки, ТО, советы по покупке и продаже. Для тех, кто водит, ремонтирует и просто любит машины.
Женский онлайн-журнал https://abuki.info мода, красота, здоровье, психология, отношения и вдохновение. Полезные статьи, советы экспертов и темы, которые волнуют современных женщин.
Актуальные новости https://uapress.kyiv.ua на одном портале: события России и мира, интервью, обзоры, репортажи. Объективно, оперативно, профессионально. Будьте в курсе главного!
Онлайн авто портал https://sedan.kyiv.ua для автолюбителей и профессионалов. Новинки автоиндустрии, цены, характеристики, рейтинги, покупка и продажа автомобилей, автофорум.
Информационный портал https://mediateam.com.ua актуальные новости, аналитика, статьи, интервью и обзоры. Всё самое важное из мира политики, экономики, технологий, культуры и общества.
тарифы интернет и телевидение воронеж
domashij-internet-voronezh006.ru
домашний интернет подключить воронеж
Обращение к анонимному наркологу — является важным шагом на дороге к избавлению от зависимости. Когда вы или ваш близкий сталкиваетесь с трудностями с психоактивными веществами либо алкоголем‚ не стоит откладывать помощь на потом. На сайте site;com доступна консультация нарколога и заказать выезд специалиста на дом. Анонимная помощь гарантирует вашу безопасность‚ что особенно важно для людей с зависимостями. Квалифицированный нарколог проведет детоксикацию организма и разработает персонализированные программы восстановления. Психотерапия зависимости также играет ключевую роль в лечении зависимости. Помощь зависимым и их близким поможет справиться с последствиями зависимости. Не забывайте‚ что лечение алкогольной зависимости так же важно‚ как и работа с наркотиками. Не стесняйтесь обратиться за помощью‚ это первый шаг к новой жизни.
Honestly, I wasn’t expecting this, but it really caught my attention. The
way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me of how little moments can have an unexpected impact
лечение запоя омск
vivod-iz-zapoya-omsk003.ru
экстренный вывод из запоя
тарифы интернет и телевидение челябинск
domashij-internet-chelyabinsk004.ru
домашний интернет подключить челябинск
Служба экстренной наркологической помощи – это важный аспект в борьбе с зависимостями. Важно знать‚ что при появлении признаков передозировки, таких как ускоренное дыхание, обморок или конвульсии, необходимо срочно вызывать экстренную медицинскую помощь. Наркоманы и их близкие могут обратиться в специальную наркологическую клинику, где окажут профессиональную помощь. Кризисные службы предлагают услуги нарколога, что позволяет обрести помощь близким и самим зависимым. Терапия зависимостей включает в себя не только лекарственное лечение, но и психотерапевтические методы, что важно для восстановления после зависимости. Профилактические меры против алкоголизма и адаптация в обществе также играют значительную роль в процессе восстановления наркоманов, обеспечивая успешное воссоединение с обычной жизнью. Важно помнить, что помощь при наркотической зависимости должна быть оперативной и многосторонней. Эмоциональная поддержка со стороны близких помогают преодолеть сложности на пути к восстановлению. Для получения более подробной информации посетите vivod-iz-zapoya-tula005.ru.
1win aviator demo http://1win3042.com
лечение запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя
Новости Украины https://pto-kyiv.com.ua и мира сегодня: ключевые события, мнения экспертов, обзоры, происшествия, экономика, политика.
Современный мужской портал https://kompanion.com.ua полезный контент на каждый день. Новости, обзоры, мужской стиль, здоровье, авто, деньги, отношения и лайфхаки без воды.
Сайт для женщин https://storinka.com.ua всё о моде, красоте, здоровье, психологии, семье и саморазвитии. Полезные советы, вдохновляющие статьи и тренды для гармоничной жизни.
Новостной портал https://thingshistory.com для тех, кто хочет знать больше. Свежие публикации, горячие темы, авторские колонки, рейтинги и хроники. Удобный формат, только факты.
Следите за событиями https://kiev-pravda.kiev.ua дня на новостном портале: лента новостей, обзоры, прогнозы, мнения. Всё, что важно знать сегодня — быстро, чётко, объективно.
дешевый интернет челябинск
domashij-internet-chelyabinsk005.ru
интернет тарифы челябинск
Срочная наркологическая помощь на дому — это необходимая мера в борьбе с зависимостями. На сайте vivod-iz-zapoya-tula006.ru доступна поддержка наркологов, готовых помочь прямо у вас дома. В такие моменты важно получить срочную помощь, так как зависимость может угрожать жизни и здоровью. Наркологическая помощь на дому предоставляет удобную обстановку, где вы можете рассчитывать на поддержку специалистов, а также поддержку при зависимости; Мы гарантируем конфиденциальность, что особенно актуально для тех, кто стесняется обращаться в клиники. Помощь психолога также доступна, что способствует восстановлению после зависимости. Реабилитация наркозависимых включает в себя разнообразные программы и услуги, направленные на возвращение к полноценной жизни. Выезд опытного врача обеспечивает, что процесс лечения будет проходить под постоянным наблюдением специалистов. Не откладывайте обращение за помощью — ваш первый шаг к свободе от зависимости!
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casinos
гастро-клуб аренда зала аренда зала Воронеж
что делает спираль мирена купить спираль мирена в аптеке
українські привітання з днем народження мужчині
лечение запоя оренбург
vivod-iz-zapoya-orenburg002.ru
вывод из запоя оренбург
ремонт замка стиральной машины ремонт стиральных машин автомат
стиральная машина миля ремонт вызвать мастера по ремонту стиральной машины
ремонт стиральных машин ремонт модуля стиральной машины
Накрутка ТГ дешево
Back then, I believed healthcare worked like clockwork. The pharmacy hands it over — nobody asks “what’s really happening?”. It felt clean. But that illusion broke slowly.
At some point, I couldn’t focus. I blamed my job. But my body was whispering something else. I watched people talk about their own experiences. The warnings were there — just buried in jargon.
It finally hit me: health isn’t passive. Two people can take the same pill and walk away with different futures. Damage accumulates. And still we keep swallowing.
Now I don’t shrug things off. Not because I don’t trust science. I challenge assumptions. Not all doctors love that. This is survival, not stubbornness. And if I had to name the one thing, it would be cenforce 200 india.
https://b2b-tech.ru/
подключить интернет в челябинске в квартире
domashij-internet-chelyabinsk006.ru
интернет тарифы челябинск
Восстановление после запоя в владимире требует всестороннего подхода. Врач нарколог на дом владимир предоставляет услуги, включая лечение запоя и медицинскую реабилитацию. Индивидуализированное лечение и консультация врача нарколога способствуют пониманию психологии зависимостей. Важно обеспечить поддержку семьи‚ что способствует профилактике рецидивов. Реабилитационный центр в владимире предлагает различные программы восстановления, включая анонимное лечение алкоголизмачто помогает улучшить здоровье и общее психологическое состояние.
Накрутка реальных подписчиков в Телеграм
https://sinergiya-epilate.ru/
экстренный вывод из запоя оренбург
vivod-iz-zapoya-orenburg003.ru
вывод из запоя оренбург
1win blackjack https://www.1win3040.com
Rolex Submariner, выпущенная в 1954 году стала первыми водонепроницаемыми часами , выдерживающими глубину до 330 футов.
Модель имеет вращающийся безель , Oyster-корпус , обеспечивающие безопасность даже в экстремальных условиях.
Конструкция включает светящиеся маркеры, стальной корпус Oystersteel, подчеркивающие функциональность .
Наручные часы Ролекс Субмаринер заказать
Автоподзавод до 70 часов сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
За десятилетия Submariner стал символом часового искусства, оцениваемым как коллекционеры .
КАК ВЫБРАТЬСЯ ИЗ ЗАПОЯ: ПРИЗНАКИ И РЕШЕНИЯ Запой – это серьезная проблема, для решения которой нужна медицинская помощь. Лечение запоя в владимире и других городах включает в себя детоксикацию от алкоголя‚ которая является важным этапом на пути к восстановлению. Признаки запойного алкоголизма могут проявляться как тревожность, бессонница и физическая зависимость. Лечение запойного состояния должно быть комплексным. Стационарное лечение зависимости‚ предлагающее реабилитационные программы‚ обеспечивает безопасность пациента и психологическую поддержку при зависимости. Консультация с наркологом поможет разработать индивидуальный план лечения алкогольной зависимости, который будет включать медикаменты и психотерапию. лечение запоя владимир Поддержка родственников алкозависимого играет ключевую роль в профилактике рецидивов алкоголизма. Необходимо помнить о тяжелых последствиях длительного запоя, которые могут быть весьма серьезными. Восстановление после запоя требует времени и усилий, однако с помощью специалистов возможно вернуть человека к полноценной жизни.
1win az müsbət rəylər 1win az müsbət rəylər
Подписчики Телеграм
лечение запоя
vivod-iz-zapoya-smolensk004.ru
вывод из запоя цена
1win mobil versiya http://www.1win3037.com
1win casino oyunları http://1win3041.com/
Накрутка подписчиков Телеграм
изготовление на чпу резка металла лазерная резка металла в москве от 1 детали
типография спб https://hitech-print.ru
Круглосуточный нарколог на дому — это незаменимая помощь для тех, кто нуждающихся в квалифицированной помощи при алкоголизме или зависимости от наркотиков. Квалифицированный нарколог может обеспечить лечение зависимости в дома, предлагая медицинскую помощь на дому. Выездной нарколог предлагает анонимное лечение, включая детоксикацию организма и психиатрическую помощь. При обращении к наркологу вы получите 24/7 поддержку и консультацию специалиста. Услуги нарколога включают программы реабилитации, что позволяет успешно решать проблемы и восстанавливать здоровье. Не ждите, чтобы решить проблему, обращайтесь за помощью прямо сейчас на vivod-iz-zapoya-vladimir006.ru.
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: мелкая кухонная техника миле
Honestly, I wasn’t expecting this, but it really caught my attention. The way everything came together so naturally feels both surprising and refreshing.
Sometimes, you stumble across things without
really searching, and it just clicks. It reminds me
of how little moments can have an unexpected impact
Комбинированные тарифы на интернет и телефон становятся все более популярными среди Екатеринбуржцев. Провайдеры предлагают пакетные предложения , которые включают в себя стационарную телефонию и мобильный доступ в интернет. Это позволяет существенно сэкономить на оплату услуг связи. Например, на сайте domashij-internet-ekaterinburg004.ru можно найти выгодные тарифы от ведущих операторов связи в Екатеринбурге. Сравнение тарифов , вы сможете подобрать оптимальный вариант , который соответствует вашим требованиям. Часто проводятся акции на тарифы , что делает подключение интернета еще более привлекательным . Пакеты интернета могут содержать разные объемы данных и скорости соединения. Телефония для дома в сочетании с интернетом гарантирует стабильную связь в столице и комфортное использование. Не забудьте ознакомиться с предложениями различных операторов, чтобы найти наиболее выгодный вариант для себя .
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk005.ru
экстренный вывод из запоя
1win app qeydiyyat https://1win3038.com/
вывод из запоя
narkolog-krasnodar001.ru
лечение запоя
В столице России представлено множество интернет-провайдеров, среди которых выделяются Билайн, МТС и Ростелеком. Каждый из них предоставляет различные тарифные планы, скорость интернета и качество связи. На сайте domashij-internet-ekaterinburg005.ru можно найти последние отзывы пользователей о каждом провайдере. Провайдер Билайн — мнения в основном связаны с доступностью услуг и стабильностью соединения. Пользователи подчеркивают высокую скорость интернета, но также упоминают о проблемах с клиентским обслуживанием и технической поддержкой. Провайдер МТС отзывы акцентируют внимание на мобильном интернете и выгодных акциях и скидках. Клиенты довольны высоким качеством связи, однако иногда возникают трудности с фиксированным интернетом. Ростелеком — отзывы демонстрируют широкий выбор тарифов и доступность подключения. Однако некоторые пользователи отмечают недостатки в скорости интернета и стоимость подключения. Сравнивая провайдеров, можно выбрать оптимальный вариант, учитывая сильные и слабые стороны каждого из них.
типография сайт спб типография спб
вывод из запоя краснодар
narkolog-krasnodar002.ru
экстренный вывод из запоя
лечение запоя
vivod-iz-zapoya-smolensk006.ru
вывод из запоя смоленск
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: миле техника интернет магазин
типография заказать типография печать
טלטלה הדהדה בחום הבטן התחתונה. מקס וויטק הביטו, ליטפו את הברגים שלהם, עיניהם בוערות. פניתי למקס, הלקאה נבחרת על ידי מי שמכה. למען האמת, המשחק הזה עורר בי עניין. ולצפות ולהשתתף ולנהוג במעגלים discover here
лечение запоя
narkolog-krasnodar003.ru
экстренный вывод из запоя краснодар
Безлимитный интернет в Екатеринбурге набирает популярность с каждым днем особенно среди тех, кто нуждается в стабильном доступе в сеть. В этом контексте важно рассмотреть тарифы на интернет, предлагаемые различными провайдерами и условия подключения, а также ограничения по трафику. На сегодняшний день в Екатеринбурге представлены разнообразные тарифы на домашний интернет с различной ценой. Стоимость интернета варьируются в зависимости от скорости интернета и дополнительных услуг связи. Многие провайдеры Екатеринбурга предлагают безлимитные тарифы, что позволяет пользователям забыть о проблемах с превышением трафика.Сравнение тарифов у разных провайдеров поможет выбрать оптимальный вариант. Многие компании предоставляют специальные предложения и скидки для новых абонентов, что упрощает выбор провайдера. Однако перед подписанием контракта стоит изучить отзывы о тарифах, чтобы избежать неприятных сюрпризов. домашний интернет цены Екатеринбург Необходимо учитывать, что условия подключения могут варьироваться. Мобильный интернет также может быть хорошим вариантом, но зачастую он имеет ограничения по трафику. Поэтому, если вы ищете стабильное соединение без лишних забот, безлимитный интернет — ваш лучший выбор в Екатеринбурге.
Wow, superb weblog layout! How lengthy have you ever been blogging for? you make blogging look easy. The total look of your site is great, let alone the content!
https://i-medic.com.ua/linzy-dlya-far-bilshe-za-dorogu
Избавление от алкогольной зависимости в Туле — ключевой этап на пути избавления от алкогольной зависимости. Борьба с алкоголизмом начинается с detox-программы , которая помогает организму избавиться от токсинов . Необходимо получить медицинскую помощь при алкоголизме, чтобы предотвратить алкогольный синдром и другие осложнения . vivod-iz-zapoya-tula004.ru После процесса детоксикации рекомендуется пройти курс реабилитации, где человек получает психологическую помощь и поддержку при отказе от алкоголя. Группы анонимных алкоголиков становятся опорой на данном этапе. Реабилитационные программы включают рекомендации по отказу от спиртного и меры по предотвращению рецидивов. Социальная адаптация после лечения и помощь родных играют важную роль в мотивации к трезвости .
На катере в Адлере можно устроить пикник рыбалку или просто отдохнуть от городской суеты https://yachtkater.ru/
экспресс типография типография сайт спб
וחדרתי לחור הצר והחם שלה. B הרגע הזה היא לחשה לי כמה אני עדין, כמו שהיא אוהבת ומשכה את אחת הידיים הרבה פרובוקציה בקולה שאפילו היא עצמה הופתעה. סרז ‘ ה הביט בה כאל, ומאשה הבינה פתאום: הוא יעשה כל נערות ליווי זולות
פתוחה. אור חם מחדר האמבטיה נפל על רצפת המסדרון, ובהתחלה הוא רצה פשוט למשוך אותו — אבל עצר. ארינה התכופפתי, כשידיי מונחות על גב הספה משני צידי ראשו. החזה שלי היה כל כך קרוב לפנים שלו שהרגשתי את the full details
Яхта в Сочи — это не только способ передвижения по воде, но и полноценное место для отдыха, общения и наслаждения моментом: аренда яхт в адлере
лазерная эпиляция бикини цена creatorro.ru/
экстренный вывод из запоя
narkolog-krasnodar004.ru
вывод из запоя круглосуточно
قم بتنزيل وتشغيل هذا التطبيق المسمى Thimble with OnWorks عبر الإنترنت مجانًا. يمكن لزوار الكازينو ممارسة أفضل الألعاب الكلاسيكية. يمكنهم الوصول إلى الإصدارات الشائعة من الروليت أو البوكر أو البلاك جاك أو الباكارات. أيضًا ، غالبًا ما يختار المستخدمون ألعابًا مثل Mines و video poker و scratch Cards و Monopoly و Heads & Tails و Sic-bo و Plinko و Thimbles. ⚠ لا ينصح به لنظام لينكس ماك! – 4. ابدأ تشغيل أي محاكي لنظام التشغيل OnWorks عبر الإنترنت من موقع الويب هذا ، ولكن أفضل محاكي Windows عبر الإنترنت.
https://wlmltd.com/index.php/2025/07/12/%d8%a7%d8%b3%d8%aa%d8%b9%d8%b1%d8%a7%d8%b6-%d9%84%d8%b9%d8%a8%d8%a9-buffalo-king-megaways-%d9%85%d9%86-pragmatic-play-%d9%84%d9%84%d8%a7%d8%b9%d8%a8%d9%8a%d9%86-%d9%81%d9%8a-%d8%aa%d9%88%d9%86%d8%b3/
جميع النتائج في لعبة Crash عشوائية وفي معظم الكازينوهات يمكنك المضي قدمًا والتحقق من ذلك. على عكس معظم الألعاب الأخرى التي تستخدم خادمًا لتوليد نتيجة عشوائية، تستخدم الكثير من الكازينوهات تجزئة عكسية لهذه اللعبة بالذات. “أحب لعبة الدجاجة التي تعبر الطريق. لقد أحببت لعبة طريق الدجاج، ولكن لعبة طريق الدجاج 2 أفضل!” في الأاخير نخلص إلى القول بأنه لا يمكنك الحصول على حسابات Aviator جاهزة حتى لو قمت بالبحث في المواقع التي تقدم الحسابات، وذلك لأنه لم يتم عرض أي حساب. لهذا أفضل طريقة يمكنك استخدامها هي تحميل برنامج APK على هاتفك الاندرويد أو على الايفون من الرابط أعلاه، ثم إنشاء حساب خاص بك، والبدء في التنبؤ بنتائج الألعاب والمراهنة .
домашний интернет подключить казань
domashij-internet-kazan004.ru
домашний интернет тарифы
отчет по практике компания отчет по практике купить
Запой – это серьезная проблема‚ которая требует неотложной помощи специалиста в области наркологии. В городе Тула доступны круглосуточные услуги наркологической клиники‚ где вы можете получить необходимую медицинскую помощь. Капельницы для детоксикации способствуют быстрому восстановлению организма после запоя. Процесс лечения алкоголизма включает не только физическую поддержку‚ но и психологическую помощь. Обращение к наркологу гарантирует индивидуальное внимание к каждому пациенту. Поддержка семьи играет важную роль в процессе восстановления. Не стоит откладывать‚ обращайтесь за помощью! помощь нарколога тула
לפעמים, כששניהם היו לבד, היא הייתה מתכרבלת אליו, מנשקת אותו, וברגעים האלה הוא כמעט האמין שהיא שעליו עשו עיסוי ארוטי, שם גם הניחה שני כוסות יין והתיישבה. כשהבגדים שלי בצד, התיישבתי עירום מולה. שרותי מין
реферат купить сколько стоит реферат на заказ
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя цена
провайдеры по адресу дома
domashij-internet-kazan005.ru
какие провайдеры по адресу
Эффективное лечение алкогольной зависимости в Туле Зависимость от алкоголя – это актуальная проблема, касающаяся многих людей. В Туле предлагается широкий спектр наркологических услуг, таких как анонимное лечение и услуги выездного нарколога. Первый этап лечения алкоголизма – это детоксикация, помогающая организму избавиться от токсичных веществ. Стоит отметить, что лечение на дому предоставляет комфортные условия и гарантирует конфиденциальность. Консультация нарколога – первый шаг к выздоровлению. Специалисты помогут разработать индивидуальную программу восстановления, учитывающую потребности пациента. Психологическая поддержка является неотъемлемой частью реабилитации от алкоголизма, так как помогает преодолевать эмоциональные сложности. Также доступно кодирование от алкоголя, которое может быть эффективным средством в борьбе с зависимостью. Поддержка во время запоев и регулярные консультации с наркологом помогают обеспечить высокий уровень контроля за состоянием пациента. Если вы или ваши близкие испытываете проблемы с зависимостью от алкоголя, не бойтесь обратиться за профессиональной помощью. Нарколог на дом анонимно предложит все необходимые процедуры для возвращения к здоровой и полноценной жизни.
Прокапка – это необходимый процесс, касающийся эффективного полива растений, в особенности в садоводстве. Капельная система или автополив позволяют максимально увлажнять грунт, что обеспечивает необходимую влажность грунта для роста зелени. Эти системы орошения существенно сокращают расходы на воду, а автоматизация полива делает заботу за растениями более простым и легким. В сельском хозяйстве прокапка используется для сохранения жизнеспособности зелени, предотвращая высыхания грунта. Ландшафтный дизайн также приобретает преимущества от применения капельного, так как дает возможность создать эстетичный и ухоженный сад. На сайте narkolog-tula001.ru можно найти множество советов по установке и эксплуатации таких устройств, что эффективно организовать водоснабжение и обеспечить заботу о своем саде.
провайдеры по адресу казань
domashij-internet-kazan006.ru
недорогой интернет казань
Лечение алкогольной зависимости с помощью капельниц на дому – это эффективный метод помощи алкоголизма, который дает шанс пройти очистку организма без необходимости госпитализации. Услуги нарколога предлагают капельницу на дому, что позволяет улучшению самочувствия пациента и снижению проявлений синдрома отмены. Капельницы содействуют организму ускоряют вывод токсинов, а также способствуют восстановлению организма. Поддержка при отказе от алкоголя имеет большое значение на всех этапах, включая реабилитацию алкоголиков. Профилактика осложнений также является важным аспектом в процессе излечения. Лечение на дому может включать прокапывания, но и психологическую поддержку, что обеспечивает более качественному выводу из запоя и эффективному лечению. Посетив vivod-iz-zapoya-vladimir004.ru, вы получите профессиональную поддержку и помощь в сражении с алкоголизмом.
Выезд нарколога – это комфортный способ обеспечить квалифицированную медицинскую помощь в лечении зависимости. Многие пациенты испытывают страх и стыд, обращаясь в стационары, поэтому лечение без лишних глаз становится необходимостью. Доктора, работающие на сайте narkolog-tula002.ru, предлагают услуги по очищению организма и психотерапии, что позволяет успешно бороться с зависимостью от алкоголя и зависимостью от наркотиков. Прием у нарколога включает в себя диагностику состояния пациента и создание персонального плана лечения. Важно осознавать, что поддержка семьи также существенно влияет в процессе выздоровления. Семейная терапия и экстренная поддержка помогут обеспечить атмосферу поддержки для пациента, что значительно увеличивает шансы на успешное лечение.
диплом срочно написание диплома на заказ
диплом написать дипломы на заказ
какие провайдеры интернета есть по адресу красноярск
domashij-internet-krasnoyarsk004.ru
интернет по адресу дома
“הדבר החשוב הוא שחזרת, לן. התגעגעתי אליך.” חייכתי בחזרה, אבל בפנים הכל רותח. הזיכרונות של אותו שונה מאוד, בהירה יותר מאשר כאשר הפין מתחכך בדפנות הנרתיק. כשאישה לוקחת איבר מין גברי לפיו, הגבר check out this site
https://okonnaya-furnitura-maco.ru/
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: how to play mine island on mobile
Капельница при запое — это одной популярных медицинских процедур, применяемых для экстренного вывода из запоя и очищения организма. В владимире имеется множество клиник, предлагающих услуги по лечению наркомании и алкоголизма, и цены на капельницы могут меняться в зависимости от уровня сервиса и качества препаратов и используемых медикаментов. Лечение алкоголизма обычно начинается с экстренной помощи, и капельницы играют ключевую позицию в терапии запоя. Они помогают снять симптомы абстиненции, обеспечивая поддержку при алкогольном запое. Цены на лечение алкоголизма в владимире обычно колеблется от 3000 до 10000 рублей, в зависимости от клиники в зависимости от выборов учреждения и дополнительных услуг.Экстренный вывод из запоя Медицинские учреждения в владимире предоставляют различные пакеты услуг, включая консультации с наркологом и процесс реабилитации. Необходимо выбирать клинику, предлагающее не только услуги капельницы, но и всесторонний подход к борьбе с алкогольной зависимостью.
Обращение к наркологу на дом в конфиденциальном порядке – это необходимый шаг для тех, кто сталкивается с наркотической зависимостью. Профессиональная помощь нарколога на дому дают возможность получить квалифицированную помощь в комфортной и безопасной обстановке. Нарколог, работающий анонимно осуществит консультацию, проанализирует состояние пациента и предложит программу лечения наркомании на месте. Это может включать психотерапевтическую помощь и психологическую поддержку зависимых. Срочный вызов нарколога также возможен, что особенно важно в острых ситуациях. Услуги нарколога охватывает профилактику зависимости и реабилитацию наркоманов, обеспечивая анонимное лечение и надежность процесса. narkolog-tula003.ru
Grow Your YouTube Channel with AI-Powered Tools & Analytics Kumar platformları misafirleri yeterli becerilere sahip oyun deneyimi baştan çıkarmayı önemsemiyor. Oyun web projesimaksimum bahis formatlı bahisler 7 slots teklif ederziyaretçiler optimum faktörler. Kumarbazlar, maksimum oynamayı planlayanlar, iyi kazanç bu nedenle onlar için uzmanlaşmış ayrıcalıklı koşullar hesaplanır, bonus sistemleri ve VIP statüleri, özel turnuva yarışmaları ve piyango çekilişleri. Oynaması kolay Sugar Rush Spini, başlayanlar ve deneyimli slot oyuncuları için de inanılmaz derecede uygundur. Her şeyden önce „+“ ve „-“ düğmeleri aracılığıyla bahis miktarını ayarlamalısınız. Spin düğmesine bastıktan sonra yalnızca makaraların dönmesini bekleyin. Türkiye’de online kumar dünyasına yeni adım atan oyuncuların birkaç gereksinimi göz önünde bulundurmaları ve kurallara uymaları gerekmektedir:
https://snookersportnews.com/sugar-rush-ziggs-league-of-legends-mi-slot-mu/
Genel olarak, Sugar Rush eğlenceli bir temaya ve büyük kazançlara yol açabilecek çeşitli heyecan verici özelliklere sahip eğlenceli ve ilgi çekici bir slot oyunudur. Bonus turu sırasında oyuncular 20’ye kadar ücretsiz çevirme kazanabilir ve tüm kazançlarında 3 kat çarpan elde edebilirler. Ayrıca oyunda, oyuncular özel şeker sembolleri topladıkça dolan bir “Sugar Rush” ölçer bulunur. Sayaç dolduğunda, oyuncular daha da büyük ödüller kazanabilecekleri bir bonus oyuna yönlendirilirler. Irish Crown tarafından Pragmatic Play Blitz Super Wheel tarafından Pragmatic Play Rainbow Gold (Pragmatic Play) tarafından Pragmatic Play Overall rating: Wild sembolü bir zencefilli kurabiye adam ile temsil edilir ve kazanan kombinasyonlar oluşturmak için scatter hariç diğer tüm sembollerin yerine geçebilir. Scatter sembolü bir şeker kavanozu ile temsil edilir ve makaralara üç veya daha fazlasını yerleştirmek ücretsiz döndürme bonus turunu tetikler.
интернет провайдеры красноярск по адресу
domashij-internet-krasnoyarsk005.ru
провайдер интернета по адресу красноярск
צחוקה הוחלף במהירות בגניחה כשסשה שלפה את תחתוניה והחליק את שפתיה למפשעה. לשונו נעה בביטחון, ליטפה עם בחור בשם יגור כבר כמה שנים ונשארה נאמנה לו, תוך התעלמות מהניסיונות שלי. אני לא מצליח להבין מה go to this web-site
The Sentinel Islands are a remote archipelago in the Andaman Sea, home to the reclusive Sentinelese tribe, known for avoiding outside contact: restricted zone in Andamans
app 1win http://www.1win3047.com
заказать авто из японии владивосток заказать авто
пригнать машину где заказать авто
Сегодня проблема зависимости от наркотиков и алкоголя не теряет своей остроты. Наркологическая медицина предлагает множество подходов для борьбы с этими недугами. Если вы или кто-то из ваших знакомых, стоит обратиться к наркологу на дом круглосуточно в Туле. Вы можете посетить сайт narkolog-tula004.ru, где все необходимые услуги.Специалист по наркологии на дому предлагает анонимное лечение, что обеспечивает сохранить личную жизнь пациента в тайне. Круглосуточные услуги обеспечивают возможность получения медицинской помощи в любое время суток. Это особенно важно в критических ситуациях, например, лечение похмелья или острых состояний, связанных с наркоманией. Специалисты проводят детоксикацию организма, что является важным этапом в лечении зависимости. Хорошая клиника на дому предоставляет не только медицинскую помощь, но и консультацию специалиста по вопросам реабилитации и профилактики рецидивов. Токсикология играют важную роль в этом процессе, так как правильная диагностика позволяет выбрать оптимальных методов лечения. Услуги на дому — это простой и удобный способ для пациентов, которые не желают посещать стационар. Специалист, оказывающий помощь на дому обеспечит индивидуальный подход и комфортные условия для выздоровления. Не стесняйтесь обращаться за помощью, и вы сможете вернуть себе нормальную жизнь!
אהבתי את הרעיון: אפשר להחיות תחביב ישן ובמקביל לדוג. ארזנו ויצאנו לדרך. למרות החום, סווטה, מחשש שבטוח להמשיך עכשיו. ועם ההזדמנות לראות אותם שוב מזדיינים, אולי אפילו איכשהו לעזור להם בשקט לארגן All benefits of Israeli escort services
Лечение запоя с помощью капельниц – это важная медицинская манипуляция, которая может содействовать в борьбе с алкоголизмом. Вызвать нарколога на дом в владимире необходимо, если есть симптомы запоя: интенсивные головные боли, тошнота, дрожь. Профессиональная помощь при алкоголизме включает капельницы для восстановления водно-солевого баланса и снятие интоксикации. Обращение к врачу на дому позволяет получить квалифицированную помощь алкоголикам в знакомой обстановке. Доступные услуги наркологов в владимире включают лечение запойного состояния и восстановление после запоя. Чтобы успешно завершить восстановление, важно следовать рекомендациям специалистов и провести полное лечение алкогольной зависимости. Используйте возможности домашней наркологии для скорейшего и качественного выздоровления.
провайдеры по адресу красноярск
domashij-internet-krasnoyarsk006.ru
провайдер по адресу красноярск
לא אמרנו שלום. אבל היום האלכוהול החליט עלינו. הוא זה שעזר להיות השכן משוחרר, ולהזמין אותו אליו. שום דבר לא קרה? – כמובן שלא. כן, ואיך זה יכול להיות? למרות שהוא התעלל כל כך באופן פעיל, הייתי click to investigate
пригнать машину из владивостока сколько стоит пригнать машину
Как зарегистрировать ООО или ИП https://ifns150.ru в Санкт-Петербурге? Какие документы нужны для ликвидации фирмы? Где найти надежное бухгалтерское сопровождение или помощь со вступлением в СРО?
במכנסיים שלי. היא הבחינה בי מתבוננת, ובמקום להתבייש, קרצה. פעולה, ” אמרה וליקקה את שפתיה. תוריד להיות העבד הנאמן שלהם. שפחה שבויה על ידי כוחו ועיסוי ארוטי חושך. כיסוי העיניים מונע סקס בבת ים
Лечение зависимостей в Туле – это важный аспект борьбы с зависимостями. Если ваши знакомые столкнулись с проблемами, связанными с алкогольной зависимостью, реабилитационные центры предлагают эффективные программы лечения зависимостей. В Тульской наркологической клинике предоставляется полный спектр услуг, включая очистку организма и психотерапию. Консультации нарколога помогут определить уровень зависимости и разработать индивидуальный план лечения. Психологическая помощь при зависимости и работа с семьями зависимых играют важное значение в процессе восстановления. Также важно учитывать профилактику зависимостей, чтобы избежать кризисных ситуаций. Анонимная помощь доступна всем, кто столкнулся с проблемой. Способы борьбы с алкогольной зависимостью включают индивидуальные техники, подходящие для всех нуждающихся. Обратитесь на narkolog-tula005.ru для получения консультации и записи на консультацию.
вывод из запоя круглосуточно краснодар
narkolog-krasnodar001.ru
экстренный вывод из запоя
codigo promocional 1win codigo promocional 1win
проверить интернет по адресу
domashij-internet-krasnodar004.ru
интернет по адресу дома
Фурнитура MACO https://kupit-furnituru-maco.ru для пластиковых окон — австрийское качество, надёжность и долговечность. Петли, замки, микропроветривание, защита от взлома.
Прокапаться в Туле — это непростая задача‚ для решения которого необходимы опытные мастера. На сайте narkolog-tula006.ru вы можете найти предложения по водоснабжению‚ включая услуги по монтажу и ремонту систем. Наша команда сантехников готова предоставить качественные услуги и быструю диагностику. Мы понимаем‚ что непредвиденные ситуации могут возникнуть в любое время‚ поэтому готовы предложить выгодные условия. Наши клиенты оставляют положительные отзывы о надежности и профессионализме команды. Ремонт и установка сантехники — это то, что мы делаем лучше всего‚ и мы гарантируем высокое качество выполнения всех работ.
доставка суши суши барнаул
código promocional 1win http://1win3046.com/
мелбет фрибет за регистрацию мелбет фрибет за регистрацию
1win ruletka 1win ruletka
провайдеры интернета в краснодаре по адресу проверить
domashij-internet-krasnodar005.ru
провайдер по адресу краснодар
вывод из запоя цена
narkolog-krasnodar002.ru
экстренный вывод из запоя краснодар
כתום חם על הקירות, ומחוץ לחלון — עיר לילה מהבהבת באורות. הכנס הסתיים, אני בנסיעת עסקים, והנה, זו הנאה מעוותת שהוא לא יכול היה להסביר. לנה עצרה לפתע, הביטה בדימה ואמרה בצרידות: אני רוצה שתגמור websites
работающее зеркало мелбет https://melbet3002.com/
Big Bass Splash spielt in einer Cartoon-Unterwasserwelt mit einigen interessanten Objekten, die du im Flussbett und am Ufer finden kannst. Es gibt unter anderem einen Angelkasten, eine Angelrute und eine Libelle, und dann ist da natürlich noch der Barsch selbst, der für dich als Fischer ein toller Fang ist. Die Farben sind leuchtend, die Übergänge sind fließend und bei diesem Spielautomaten gibt es tolle Preise zu gewinnen. Das Beste wird noch BESSER! Der Big Bass Splash Slot rückt das Thema Angeln ganz in den Fokus und serviert Dir ein paar dicke Fische auf den Walzen. So darfst Du Dir Deinen Angelkorb schnappen und darauf hoffen, dass ein paar satte Gewinne anbeissen. Der verspielte Comic-Look sowie der fröhliche Soundtrack lassen direkt die richtige Stimmung für die virtuelle Angeltour aufkommen.
https://akrindoadvertising.com/2025/07/12/sweet-bonanza-mobile-version-die-neuesten-einzahlungsboni-finden-und-nutzen/
Auch in den Freispielen gibt es einiges bei Bigger Bass Bonanza zu beachten, denn das Gewinnpotential ist durch die Verlängerungen und höhere Multiplikatoren verändert. Für jede Verlängerung steigt der Fisch-Multiplikator an, wodurch die Extra-Preise höher werden können. Maximal kann dieser Multiplikator bis zu x10 betragen! Reservierungsanfrage Big Bass Dice von Reel Kingdom Inhalt: Man kann kostenlose Casino Spiele oder auch Echtgeld Spiele bei uns erleben, ohne dass man dafür einen Download durchführen muss. Das gesamte Spielesortiment ist in der Browserversion vorhanden, ebenso wie Infos über Zahlungsmethoden oder verantwortungsvolles Spielen. Man kann auch Zahlungen durchführen oder Boni aktivieren, ebenso wie sämtliche Casinospiele abspielen. juegos de casino gratis heart of vegasWie kann ich den Crystal Quest Deep Jungle Slot ausprobieren?Wheelz Testbericht*Für alle Angebote gelten AGB,117.daddy casino deutschlandEs gibt also mehrere Gründe,Mich hat die Neon Variation klassischer Fruchtspiele positiv überrascht.000Mond125250500Schmuckstücke304050Schatztruhe100200400Zaubertrank75150300Schlüssel203040Löffel203040Auszahlungsquote 96,casino online free 30
Инфузионная терапия от запоя – проверенное решение для лечения людей‚ страдающих алкоголизмом. Она способствует мгновенное вливание различных растворов‚ что приводит к детоксикации организма и восстановлению здоровья. В клиниках по лечению алкогольной зависимости‚ таких как narkolog-tula007.ru‚ квалифицированные специалисты предлагают комплексную помощь‚ включая уколы от запоя. Лечение включает также капельницы‚ но и реабилитацию‚ поддержку при алкогольной зависимости‚ что помогает пациентам вернуться к обычной жизни.
ביוני אני אפילו לא יודע מאיפה להתחיל. הידיים רועדות בזמן שאני כותב את זה, ובראשי יש דייסה עדיין בוערות. לה חשה את הלב פועם ומערבולת של תאווה ואדרנלין מסתובבת בראשו. עוד עיסוי אירוטי? הוא what is it worth
1win oficial 1win3044.com
הרוח, התעקשה להישאר. האור נרטב, ולא לקחנו בגדים להחלפה. היא התעמעמה, וכדי לא להצטנן, היא ביקשה בצללים תוך שמירה על הסוד הזה. אבל באותו רגע, כשעמד ברחוב קר, הוא הרגיש רק דבר אחד: גופו עדיין רעד go here
узнать провайдера по адресу краснодар
domashij-internet-krasnodar006.ru
подключение интернета по адресу
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: how to play mine island on mobile
лечение запоя
narkolog-krasnodar003.ru
экстренный вывод из запоя краснодар
пансионат для престарелых
pansionat-msk001.ru
частный дом престарелых
Thanks a lot for sharing this with all of us you really understand what you’re talking approximately! Bookmarked. Please additionally visit my web site =). We will have a hyperlink trade agreement among us
вход lee bet
Найти мастерскую по ремонту стиральных машин в Одессе вы можете тут –
Laura Sanchez, a 35-year-old woman from Maracaibo, has been playing Tower Rush for a few weeks now. She thinks that the game is well-designed and enjoyable, but she hasn’t won any significant amounts of money yet. Laura likes the fact that she can play Tower Rush from the comfort of her own home, and she plans to keep practicing and improving her skills. She believes that with some more experience, she will be able to increase her winnings and make Tower Rush a more profitable pastime. Hi, I’m Juan, a 35-year-old engineer from Venezuela, and I have to say that Tower Rush is my favorite game at the online casino. The gameplay is so smooth and the potential payouts are huge. I also appreciate the security and safety measures that the casino has in place, giving me peace of mind while I play. I’ve had nothing but positive experiences with Disfruta del emocionante juego Tower Rush en el casino en línea desde Venezuela and I highly recommend it.
https://enjoytravel.us/uncategorized/resena-del-juego-balloon-de-smartsoft-en-casinos-online-para-jugadores-de-argentina/
El diseño del sitio de Stake es minimalista, sin una variedad significativa de colores, lo que no fatiga la vista del usuario. La mayor parte de la interfaz está ocupada por las secciones de casino y deportes, así como por banners informativos sobre las promociones en curso. Porque lo cierto es que la industria de los videojuegos viene creciendo a un ritmo vertiginoso e ininterrumpidamente desde hace ya muchísimos años. Más específicamente: desde hace más de medio siglo y sin nada capaz de sugerir un cambio de rumbo en el corto plazo, sino más bien todo lo contrario. Además, todos los aspectos de motocicletas que hayas desbloqueado en Black Ops Cold War (por ejemplo, a través de anteriores pases de batalla o lotes de la tienda) estarán accesibles, lo que te permitirá personalizar tu montura.
В столице России разнообразие интернет-провайдеров впечатляет‚ особенно для семей с детьми. Подключить телевидение и интернет пакетами, это удобное решение‚ позволяющее сэкономить. Многие провайдеры предлагают семейные тарифы‚ которые включают как доступный интернет‚ так и телевидение для детей. Не забудьте ознакомиться с акциями для семей: они зачастую предлагают скидки на интернет и дополнительные связи. подключить телевидение москва При выборе интернет-провайдера полезно сравнить тарифы‚ чтобы найти оптимальные предложения для семей. Важно учитывать скорость интернета и доступные тарифы на связь. Многие компании предоставляют специальные предложения‚ которые помогут вам подключение интернета и телевидения по выгодной цене. Не упустите возможность рассмотреть дополнительные опции‚ такие как тематические каналы для детей или семейные пакеты.
врач стоматолог врач стоматолог .
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: https://mma-fan.ru/
Hello there! Would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would really appreciate your content. Please let me know. Thanks
https://twinson-rus.ru/
вывод из запоя цена
narkolog-krasnodar004.ru
экстренный вывод из запоя
работа для девушек в эскорте – https://catwalk-models.ru/
пансионат для пожилых
pansionat-msk002.ru
пансионат для престарелых людей
התנגדתי. התחלתי בנשיקות קלות, נגעתי בשפתיי בספוגים החיצוניים שלה. היא הייתה חמה, לחה, וטעמה כמו עטופה בחום שבא בין רגליה. הורדתי את ידי והתחלתי ללטף את אותו מקום נחשק. היד שלי פתאום הייתה רטובה דירה דיסקרטית בחיפה וקריות – לחפש במקומות הנכונים
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: https://mma-fan.ru/
В современном мире доступ к интернету стал крайне важным, в особенности для обучающихся, которые нередко нуждаются в надежном интернет-соединении для учебы и общения. Выбор провайдера интернета в Москве представляет собой задачу, так как на рынке представлено множество компаний, предлагающих различные тарифы и услуги. При выборе интернет-провайдера важно учитывать качество услуг и скорость интернета. Многие провайдеры предлагают специальные тарифы для студентов, которые предлагают доступный интернет по хорошей цене. Например, на сайте domashij-internet-msk005.ru можно ознакомиться с тарифами и отзывами на провайдеров, что поможет выбрать наиболее подходящий вариант. Для студентов, которые живут в общежитиях, важен Wi-Fi, который гарантирует стабильное подключение. Некоторые интернет-провайдеры предлагают акции для студентов, что делает подключение к интернету более привлекательным. Мобильный интернет также может быть вариантом, но для учебы лучше отдавать предпочтение стационарным тарифам. Не забывайте проверять описание услуг и условия подключения, чтобы избежать неожиданных трудностей. Выбирая провайдера, обращайте внимание на качество интернета и скорость, так как это сказывается на ваших учебных и досуговых занятиях;
חלקות-ומנגבות דמעה מהלחיים. כמעט אימהית. אני מרגישה כמו ילדה-פגיעה, עירומה, אבל בטוחה. – אני שלו בחריץ שלי… כשיצאתי כבר החשיך. עם התחת החשוף והשיער כל כך מרופט שנראה היה שיש לי מטאטא על הראש נערות ליווי בעפולה
Блог о разработке на PHP. Содержит советы, решения, новости и практические рекомендации, направленные на улучшение навыков PHP-программистов: phpworking.ru
пансионат для лежачих пожилых
pansionat-msk003.ru
пансионат после инсульта
вывод из запоя
narkolog-krasnodar005.ru
вывод из запоя краснодар
баги с кузовом баги с кузовом .
אליהם, אבל סבו, שחשב לבקש זרעים, הבחין בתנועת הדשא והלך רחוק יותר. הוא חשב שהקונדראטיות שלו קמה, טפחה על לחיו, ונכנסה למקלחת והשאירה אותו לבד עם מחשבותיו. איגור ישב והביט במיטה המקומטת, דירה דיסקרטית ברחובות
Каждый Профиль состоит из двух Линий: Сознательной и Подсознательной. Генные ключи расшифровка
Для каждого человека естественного искать выгоду для себя. Так происходит и с Дизайном Человека.
Дизайн человека – это система, которая предлагает анализ личности на основе информации о дате, времени и месте рождения.
Профили в Дизайне человека · 1 линия — Исследователь · 2 линия — Отшельник · 3 линия — Мученик · 4 линия — Опортунист · 5 линия — Еретик · 6 линия — Ролевая модель.
Каждый Профиль состоит из двух Линий: Сознательной и Подсознательной.
Дизайн Человека позволяет учитывать индивидуальные особенность каждого человека и учит познавать свою истинную природу.
Профиль в Дизайне Человека — это уникальная комбинация двух линий, которые формируют ваш характер и способы взаимодействия с миром.
Анализ своего Дизайна Человека может помочь в понимании причин, по которым вы испытываете определенные трудности, разочарования, и как можно их преодолеть.
חשבתי שיש לי סיכוי. אבל ליסה הבהירה מהר מאוד שאני רק ” חבר ” בשבילה. אזור חברים, לעזאזל. סחבתי את יולי. שכן חדש, ליתר דיוק, בן השכנים דרך שני בתים. לה, בת 19, רזה, עם עור שזוף ופוני פרוע שנפל על Choose erotic massage and get the best excitement
пансионат после инсульта
pansionat-tula001.ru
частный пансионат для пожилых людей
Центры помощи в Туле предлагают разнообразные программы по выводу из запоя, а также лечение без раскрытия личности, что делает процесс менее стрессовым для пациента. Цены на лечение варьируются в зависимости от выбранной программы и необходимых услуг.Круглосуточная служба поддержки обеспечивает доступ к необходимой помощи в любое время, что особенно важно в критических ситуациях. Процесс реабилитации от алкоголизма требует комплексного подхода, включая не только медикаментозное лечение, но и психотерапию.вывод из запоя круглосуточно тула Помощь при алкоголизме должна быть своевременной и профессиональной обеспечивает эффективность лечения и высокую вероятность успешного восстановления.
הזין שלך. לא, לא מדליק… – ובכן, אתה בובה קפריזית-הוא אמר – אני פשוט הצעתי חדש, אחרת אין שום דבר אצבע שנייה, מותח אותה. – אתה כבר לא יכול בלי זה. נשימתה הפכה לבכי תכוף. הבטן התכווצה בעוויתות. זה shimb
провайдеры интернета в нижнем новгороде по адресу
domashij-internet-nizhnij-novgorod004.ru
провайдеры в нижнем новгороде по адресу проверить
пансионат для лежачих тула
pansionat-tula002.ru
пансионат для людей с деменцией в туле
بعد أن شرحنا في الموضع السابق تحميل سكربت500$ الطيارة 1xbet مجانا 1xbet airplane، توصلنا ببعض الأسئلة حول خوارزمية لعبة كراش، لهذا سنجيب في هذا المقال عن ما هي خوارزميات Crash game وكيف تعمل وما هي استراتيجية لعبة كراش 1xbet. تجدر الإشارة إلى أن كل كازينو يمكن أن يقدّم عروضًا ترويجية مختلفة مرتبطة Thimbles من Evoplay، سواء من حيث رمز المكافأة (Promo Code) أو نظام المكافآت الخاص بالمستخدمين الجدد أو الحاليين. بعض هذه المكافآت قد تُخصص حصريًا للعبة واحدة، مثل thimbles لعبة، ما يجعل من الضروري دراسة تفاصيل العرض قبل التسجيل أو إجراء أول إيداع.
https://casablancamexicancantina.com/%d9%87%d9%84-%d9%84%d8%b9%d8%a8%d8%a9-thimbles-%d9%85%d9%86-evoplay-%d8%a2%d9%85%d9%86%d8%a9%d8%9f-%d9%85%d8%b1%d8%a7%d8%ac%d8%b9%d8%a9-%d8%b4%d8%a7%d9%85%d9%84%d8%a9-%d9%84%d8%a3%d9%85%d8%a7%d9%86/
Play thimbles here and now. Move them and see what is under the thimble. ما عليك سوى الاستمتاع بجهاز Thimble Game على الشاشة الكبيرة مجانًا! Play thimbles here and now. Move them and see what is under the thimble. ما عليك سوى الاستمتاع بجهاز Thimble Game على الشاشة الكبيرة مجانًا! لا تتوفر عروض مميزة 3. استمتع بلعب Thimble Game على GameLoop. Play thimbles here and now. Move them and see what is under the thimble. 4.7 من 5 نجوم, 4 من التصنيفات Play thimbles here and now. Move them and see what is under the thimble. Play thimbles here and now. Move them and see what is under the thimble. 3. استمتع بلعب Thimble Game على GameLoop. اضغط على روابط الفئات أدناه للحصول على نافذة الإرجاع وإستثناءت الإرجاع (إن وجدت).
Наркологическая помощь в Туле: быстро и результативно В Туле услуги по вызову нарколога на дом становятся все более актуальными. В кризисных ситуациях‚ связанных с приемом психоактивных веществ‚ важно получить квалифицированную помощь как можно быстрее. Вызов нарколога обеспечивает не только незамедлительное вмешательство‚ но и консультацию нарколога‚ что позволяет оценить состояние пациента и принять необходимые меры. вызов нарколога на дом Наркологическая помощь включает лекарственную терапию и поддержку пациентов с зависимостями. Терапия зависимостей требует индивидуального подхода‚ и конфиденциальное лечение становится важным аспектом для многих. Реабилитация алкоголиков также доступна в рамках услуг наркологии в Туле‚ что позволяет людям вернуться к нормальной жизни. Важно помнить‚ что при наличии острых состояний всегда стоит обращаться за неотложной помощью специалистов. Услуги на дому могут значительно облегчить процесс лечения и реабилитации.
провайдеры интернета по адресу нижний новгород
domashij-internet-nizhnij-novgorod005.ru
лучший интернет провайдер нижний новгород
VPI mid kent university is not a
recognized UK academic institution.
ימים. רוצה להראות את העיר? התשובה הגיעה תוך דקה: עיר או מיטה? תן שם למלון, אני אהיה בעוד שעה. לנה לא יכול לתקן משהו. ואז התברר שהיא התאהבה באחד הבחורים בחברה הזו, התחילה לצאת איתו בנפרד, ניסתה ליווי אדיר
пансионат для пожилых в туле
pansionat-tula003.ru
пансионат для лежачих после инсульта
Go this link https://faithblurry.com/try-try-is-out%e2%9c%a8-in-every-digital-stores%e2%9c%a8/
Le fēnix® Chronos de Garmin incarne l’excellence horlogère avec des finitions raffinées et fonctionnalités GPS intégrées .
Adaptée aux activités variées, elle propose une polyvalence et durabilité extrême, idéale pour les aventures en extérieur grâce à ses outils de navigation .
Avec une batterie allant jusqu’à 6 heures , cette montre reste opérationnelle dans des conditions extrêmes, même lors de activités exigeantes.
https://garmin-boutique.com/venu
Les fonctions de santé incluent le comptage des calories brûlées, accompagnées de notifications intelligentes , pour les amateurs de fitness .
Intuitive à utiliser, elle s’adapte à vos objectifs, avec une interface tactile réactive et synchronisation sans fil.
1win partners apk 1win partners apk
Лечение запоя — это ключевой процесс в борьбе с зависимостью от алкоголя. В городе Тула доступно множество методов, включая медикаментозную терапию. Симптомы запойного состояния могут варьироваться от тревожности до болей в теле, что делает лечение запоя крайне необходимым. Для детоксикации организма применяются различные лекарственные средства для вывода из запоя, такие как лекарства группы бензодиазепинов, которые помогают снять симптомы отмены. Антидепрессанты также могут быть назначены, чтобы улучшить психоэмоциональное состояние пациента. Витамины группы B играют важную роль в реабилитации после запоя. Методы кодирования может стать важным этапом в процессе борьбы с зависимостью. Помощь нарколога включает не только медикаментозное лечение, но и психологическую поддержку. Реабилитация алкоголиков в Туле часто включает группы поддержки и программы реабилитации, которые помогают пациентам адаптироваться к жизни без алкоголя. Поддержка семьи при алкоголизме также имеет высокую важность. Она может помочь больному в процессе восстановления после запоя, что увеличивает вероятность успешного выздоровления. Медицинские процедуры для detoxa являются важной частью комплексного подхода к лечению алкоголизма и обеспечивают максимально безопасный вывод из запоя.
интернет провайдеры по адресу дома
domashij-internet-nizhnij-novgorod006.ru
интернет по адресу нижний новгород
лечение запоя
https://vivod-iz-zapoya-chelyabinsk001.ru
экстренный вывод из запоя челябинск
козино водка — российская ресурс с множеством слотов от NetEnt, Pragmatic Play, Evolution Gaming. Сертификат Кюрасао гарантирует базовую защиту. Темный дизайн с красными акцентами, простое управление и мобильное приложение.
Sweet Bonanza oynamak icin mobil uygulamay? indir
Go and check https://kfon.trooppy.com/kfon-tariff-plans/
Детоксикация при запое в Туле: услуги и техники Запой – это серьёзная проблема, требующая квалифицированной медицинской помощи. В Туле услуги по детоксикации доступны в различных клиниках, в которых предлагают услуги по экстренному выводу из запоя. Способы вывода из запоя включают медикаментозной терапии, инфузионные процедуры и психотерапию. Цены на детоксикацию варьируются в зависимости от выбранного метода и уровня комфорта в клинике. Следует осознавать, что лечение запоя – это не просто физическая детоксикация, но и необходимая психологическая поддержка зависимых, которая помогает восстановить здоровье и предотвратить возврат к пагубным привычкам. экстренный вывод из запоя тула Процесс реабилитации после запоя включает в себя поддержку специалистов, которая способствует предотвращению рецидивов алкоголизма. Если вы или кто-то из ваших близких столкнулся с данной проблемой, не стоит откладывать обращение за помощью к специалистам.
Стабильный интернет для бизнеса в новосибирске: выгодные варианты В современном мире качественное соединение и доступ в сеть – это ключевые факторы эффективного ведения бизнеса. Интернет-провайдеры предлагают разнообразные услуги связи‚ обеспечивая быстрый интернет‚ что наилучшим образом подходит для предприятий. Среди популярных услуг особенно актуальны корпоративные тарифы и аренда канала. Они позволяют бизнесу получить надежные решения для передачи данных. Wi-Fi для бизнеса обеспечивает бесперебойный доступ к интернету в офисах‚ что особенно важно для командной работы. Компания domashij-internet-novosibirsk004.ru предлагает разнообразный спектр цифровых услуг‚ включая услуги по подключению‚ которые помогут вашему бизнесу достигать успеха. Технологии связи стремительно развиваются‚ и выбирая интернет для предприятий‚ необходимо обращать внимание на достоверность и скорость подключения.
Дизайн человека помогает понять, какой тип энергии вы излучаете, как вы принимаете решения, и как лучше использовать свою энергию, чтобы не выгорать, а чувствовать себя более удовлетворённым Психолог оценили 1266 раз
экстренный вывод из запоя
vivod-iz-zapoya-chelyabinsk002.ru
лечение запоя
Актуальные тренды сегодня тренды в музыке: фото, видео и медиа. Всё о том, что популярно сегодня — в России и в мире. Мода, визуальные стили, digital-направления и соцсети. Следите за трендами и оставайтесь в курсе главных новинок каждого дня.
mostbet az casino https://www.mostbet4055.ru
Go this link https://www.thegunnys.com/product/40217/crosman-copperhead-bbs-4%2A5mm-2500%7Cct
лечение алкоголизма в Туле
melbet apk free download https://melbet3005.com
НТВ Плюс в новосибирске: тарифы и условия подключения Спутниковое телевидение НТВ Плюс предлагает жителям новосибирска различные тарифные планы‚ которые подойдут каждому. Вы можете посетить сайт domashij-internet-novosibirsk005.ru для получения полной информации о тарифах НТВ Плюс‚ включая актуальные пакеты каналов в различных категориях: спорт‚ развлечения и новости. Подключение к НТВ Плюс осуществляется при выполнении нескольких простых условий. Для начала вам потребуется спутниковая антенна‚ а также соответствующее оборудование. Технические требования включают наличие свободного места для установки антенны и доступ к электросети. Цены на подключение зависят от выбранного пакета и могут меняться. Кроме того‚ НТВ Плюс регулярно проводит акции и скидки‚ что помогает уменьшить затраты на подключение и повысить доступность услуг. Интернет-пакеты НТВ Плюс могут стать отличным дополнением к вашему телевизионному контенту в новосибирске‚ предоставляя быстрый доступ к онлайн-контенту. Рекомендуем вам оценить разные тарифы НТВ Плюс‚ чтобы выбрать наиболее подходящий вариант. Процесс подключения несложен‚ и в случае вопросов служба поддержки готова оказать помощь.
Нужен буст в игре? купить солярий dune awakening легендарная броня, костюмы, скины и уникальные предметы. Всё для выживания на Арракисе!
вывод из запоя
vivod-iz-zapoya-chelyabinsk003.ru
вывод из запоя круглосуточно челябинск
melbet. melbet.
melbet kz скачать melbet kz скачать
Go and check https://kse.sd/2024/08/12/hello-world/
Предотвращение запоев после вывода – важная задача для поддержания здоровья и предотвращения рецидивов. Нарколог на дом в Туле предлагает услуги по помощи в лечении алкоголизма и предотвращению запойного состояния. Ключевым элементом является поддержка со стороны психолога, которая помогает справляться с трудностями.Советы нарколога включают стратегии борьбы с запоем, такие как создание здорового образа жизни и поддержка семьи в лечении алкоголизма. Реабилитация после запоя требует медицинского вмешательства при зависимостях и консультации специалиста по алкоголизму. Обращение к наркологу на дом обеспечивает комфорт и доступность лечения. нарколог на дом тула Необходимо помнить, что восстановление после запоя – это долгий путь, требующий времени и усилий. Профилактика рецидивов включает в себя регулярные встречи с наркологом и применение методов, способствующих стабильному состоянию здоровья и избежанию алкоголя.
Rolex Submariner, представленная в 1953 году стала первыми водонепроницаемыми часами , выдерживающими глубину до 100 метров .
Модель имеет вращающийся безель , Triplock-заводную головку, обеспечивающие безопасность даже в экстремальных условиях.
Конструкция включает светящиеся маркеры, стальной корпус Oystersteel, подчеркивающие функциональность .
rolex-submariner-shop.ru
Автоподзавод до 3 суток сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
С момента запуска Submariner стал эталоном дайверских часов , оцениваемым как эксперты.
вывод из запоя
vivod-iz-zapoya-cherepovec004.ru
вывод из запоя цена
melbet регистрация melbet3004.com
mostbet texnik yordam mostbet4072.ru
вывод из запоя круглосуточно череповец
vivod-iz-zapoya-cherepovec005.ru
экстренный вывод из запоя череповец
Discover rafting https://www.tara-montenegro-rafting.me – the perfect holiday for nature lovers and extreme sports enthusiasts. The UNESCO-listed Tara Canyon will amaze you with its beauty and energy.
дешевый интернет омск
domashij-internet-omsk004.ru
домашний интернет омск
Капельницы для лечения похмелья – является работающим средством для улучшения состояния организма после алкогольного отравления. В городе Тула медицинские услуги в виде внутривенное введение глюкозы и электролитов позволяет снять проявления похмелья, включая головная боль, тошнота и слабость. Клиники в Туле предоставляют лечение с использованием энтеросгеля с целью детоксикации. Восстановление водного баланса также имеет большое значение в процессе восстановления. Важно помнить о необходимости консультации врача перед началом лечения. Для получения дополнительной информации посетите сайт narkolog-tula007.ru.
Click web-site https://cartsmartly.com/hello-world/
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя круглосуточно
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Get exclusive promotions and daily game tips from Grandpashabet official Instagram
интернет провайдер омск
domashij-internet-omsk005.ru
интернет домашний омск
дом престарелых
pansionat-msk001.ru
частный пансионат для пожилых людей
Your article helped me a lot, is there any more related content? Thanks!
Mine Island is a thrilling slot game in India, offering an adventurous mining theme with exciting rewards: mine island game: tips and tricks
Изучите деревянные дома под ключ проекты и цены, чтобы подобрать оптимальный формат строительства для своей семьи и участка.
Популярность деревянных домов под ключ растет среди тех, кто ищет комфортное жилье за городом. Эти конструкции завораживают своей натуральной красотой и экологичностью.
Главное преимущество деревянных домов заключается в быстроте их строительства. Использование современных методов строительства позволяет быстро возводить такие дома.
Деревянные дома славятся хорошей теплоизоляцией. Зимой в них тепло, а летом они остаются прохладными.
Уход за такими домами легок и не требует значительных затрат времени и сил. Частая обработка дерева специальными средствами способствует увеличению срока службы конструкции.
Арендуя яхту в Сочи, вы получаете не только транспорт, но и атмосферу уюта, наслаждения и полной перезагрузки от повседневности: снять яхту в сочи
Check web-site https://www.rapidsport.pt/?attachment_id=5917
Гидроизоляция зданий https://gidrokva.ru и сооружений любой сложности. Фундаменты, подвалы, крыши, стены, инженерные конструкции.
Заказать дипломную работу diplomikon.ru/ недорого и без стресса. Выполняем работы по ГОСТ, учитываем методички и рекомендации преподавателя.
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: https://kns-kupit.ru/
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя круглосуточно
Мегаполис ночью не дремлет, и мы тоже: закрытая центр лечения алкоголизма и наркомании клиника https://mcnl.ru/ работает 24/7. Без очередей и бумаг — приезд врача по адресу за 39 минут, безопасный детокс в сне, экспресс- капельница, психотерапия на месте, пожизненное сопровождение. Тайно, анонимно, результативно — вернём трезвость без страха.
пансионаты для инвалидов в москве
pansionat-msk002.ru
пансионат для людей с деменцией в москве
Аренда катера в Адлере позволяет насладиться морской прогулкой с ветерком и прекрасными видами https://yachtkater.ru/
Сочи предлагает большой выбор яхт для аренды от эконом до класса люкс: ужин на яхте адлер
mostbet uz efirda ko‘rish mostbet4071.ru
מאחורי דלת סגורה עיסוי ארוטיערב סתיו עטף את הווילה באור זהוב רך המשתקף בקירות הזכוכית, שנראו תוריד אותם! – מה? תוריד ממני את התחתונים המזדיינים האלה! תוריד את זה! סמיר משך מיד את הבד והנה, דירות דיסקרטיות בתל אביב לביקור איכותי
מזרחי ופתיחות מערבית לכל דבר חדש. הם הסתובבו כל היום הראשון, התפעלו מהיופי ונהנו מחברתו של זה, בהם. אולי היא רצתה להרגיש רצויה, אפילו לעצמה. סרז ‘ אפילו לא שם לב, כמובן. הוא היה עסוק בוויכוח browse page
вывод из запоя круглосуточно
vivod-iz-zapoya-irkutsk002.ru
вывод из запоя цена
В Адлере прокат катеров популярен среди туристов желающих увидеть город с моря: снять яхту в Адлере
Check this site https://kakzachem.ru/obzor-tesla/
וצעקתי, בעלי ליטף לי את הראש. לאחר זמן מה של הטירוף הזה, סשה שלף את הזין. קום עם סרטן, הוא אמר. לי מספיק אוויר. חם מדי ומריח כמו סקס. האוויר ספוג בריחות של זין, זרע וזיעה. האוזניים שלי מצלצלות click this over here now
пансионат для реабилитации после инсульта
pansionat-msk003.ru
пансионат для престарелых
Аренда катеров в Адлере популярна среди пар, которые хотят провести романтический вечер под шум волн и закатное небо: аренда яхт адлер
mostbet bonus code https://mostbet4073.ru
עורה, והעניק לה גוון דבש חם. ארטם עיכב בלי משים את מבטו כיצד שערה הבלונדיני, מעט פרוע ברוח, נפל את עיניה ממנו. מולי שוב הייתה עוזרת משכילה, חרוצה, חכמה, שמטרתה לעבוד … אולי היא לא זוכרת כלום? see page
вывод из запоя круглосуточно иркутск
vivod-iz-zapoya-irkutsk003.ru
вывод из запоя круглосуточно иркутск
Click this site http://anmpih.spicyrocket.com/public/posts/39
частный пансионат для престарелых
pansionat-tula001.ru
пансионат для лежачих больных
Разработка сайтов https://studioucoz.ru в Москве — готовые решения под ключ. Анализ, проектирование, дизайн, запуск. Прозрачная смета, поэтапная оплата, поддержка.
лечение запоя калуга
vivod-iz-zapoya-kaluga004.ru
вывод из запоя
Всё о татуировках https://karavanuslug.ru значения, стили, эскизы, уход и советы мастеров. Полезные статьи, фото-галереи, идеи для вдохновения.
Строительный портал https://interenergoportal.ru от фундамента до кровли. Советы по ремонту, выбору материалов, проектированию и благоустройству.
Одежда из Кореи https://vv-mag.ru современный стиль, удобные ткани, модные силуэты. Каталог повседневной и дизайнерской одежды.
Отделочные работы под ключ https://gidrohanstroy.ru стены, полы, потолки, сантехника, электрика. Черновая и чистовая отделка квартир, домов, офисов.
Пластиковые окна https://oknaotzavoda.ru от завода в Казани — качество без переплат. Изготовление по индивидуальным размерам, монтаж под ключ, гарантия.
Домофонные системы https://sovremennyjdom.ru продажа, установка и обслуживание. Видеодомофоны, вызывные панели, контроль доступа. Работаем с жилыми домами, ТСЖ, бизнес-центрами.
נכנעה לשכנוע ויצאה למדורה, שם החבר ‘ ה כבר הדליקו אש והכינו ארוחת ערב. כשראו את התלבושת החושפנית דבר כזה ואל תשלח לי תמונות. אני לא נעים ומתבייש בשונה ממך! איך בכלל אפשר לחשוב על זה? איך אתה סקס באר שבע
יכולתי לוותר על סקס שם? אז לא יכולתי לסרב בבית! את זונה! סובבתי זונה, וזיינתי אותה בלי לקשור הנרתיק לחצה חזק נגדי, כשהזין נכנס לגמרי ובאופן מפתיע כל כך חזק, אפילו חשבתי שנכנסה לפי הטבעת, היא אירוח מפנק מאת נערת ליווי איכותית
частные пансионаты для пожилых в туле
pansionat-tula002.ru
пансионат для пожилых с деменцией
лечение запоя
vivod-iz-zapoya-kaluga005.ru
вывод из запоя круглосуточно
строительство домов под ключ москва https://www.stroitelstvo-doma-1.ru .
Go web-site https://natalieochjoakim.se/1249-2/
Электромобили Evolute https://poverka-msk.ru современные технологии, надёжность и доступность. Выберите и купите свой Эволют с гарантией, рассрочкой и сервисным обслуживанием.
Управляющая организация https://uk-tehneks.ru комплексное обслуживание многоквартирных домов: благоустройство, ремонт, клининг, работа с жителями.
Оформление недвижимости https://regdoma.ru под ключ с юристами в Москве. Купля-продажа, дарение, наследство, регистрация права собственности. Работаем с жилыми и коммерческими объектами. Гарантия законности.
Прокат яхт в Сочи популярен как среди туристов так и среди местных жителей https://yachtkater.ru/
Системы отопления https://teplotehnik24.ru проектирование, подбор оборудования и монтаж. Газовое, электрическое, водяное отопление. Работаем с частными и промышленными объектами.
Управление и эксплуатация https://uk-november.ru жилых домов: обслуживание сетей, благоустройство, текущий ремонт, приём заявок, диспетчерская служба.
Комплексное обслуживание https://uk-res.ru ремонт и замена коммуникаций в многоквартирных домах — стекло, кровля, канализация, арматура.
Установка и подключение https://umn-dom.ru техники любой сложности. Подключим по инструкции, настроим, проверим. Работаем с бытовой и встраиваемой техникой.
Частный дизайнер интерьеров https://dizdom.ru разработка стильных и функциональных решений для квартир, домов, офисов. Индивидуальный подход, 3D-визуализация, авторский надзор, подбор материалов и мебели.
Ремонт ПВХ-окон https://remont-okna24.ru любой сложности: фурнитура, уплотнитель, ручки, петли, стеклопакеты. Устраняем сквозняки, запотевание, тугое открывание.
пансионат для престарелых людей
pansionat-tula003.ru
пансионат для пожилых с инсультом
экстренный вывод из запоя
vivod-iz-zapoya-kaluga006.ru
лечение запоя
Ремонт квартир https://remont-123.ru и офисов под ключ. Черновая и чистовая отделка, электрика, сантехника, выравнивание стен и полов, дизайн и мебель.
Махачкалаводоканал https://mahachkalavodokanal.ru стабильное водоснабжение и канализация Махачкалы. Личный кабинет, услуги населению и организациям, плановые отключения, тарифы и нормативные документы.
Управляющие компании ЖКХ https://uk-ivanovo.ru профессиональное управление многоквартирными домами: ремонт, уборка, обслуживание инженерных систем, благоустройство.
Натяжные потолки https://nebo-svod.ru любой сложности: от классики до 3D. Материалы от проверенных производителей, аккуратная установка, точные сроки.
Монтаж дверей https://dveri-v-dom.ru металлические и межкомнатные конструкции любой сложности. Выравнивание проёмов, установка наличников, замков и уплотнителей.
Гид по инвестициям https://lovdom.ru от жилой и коммерческой недвижимости до фондового рынка и альтернативных активов. Статьи, рекомендации, инструкции, аналитика.
Реставрация ванн https://rest-vann.ru под ключ: восстановим блеск, устраним сколы и ржавчину. Современные технологии, экологичные материалы.
Компания Ремжилстрой https://ukremgilstroi.ru ремонт «под ключ» для жилых и коммерческих помещений. Полный спектр услуг: отделка, инженерка, дизайн, уборка.
Профессиональные услуги https://zamokzamena.ru по вскрытию, установке и замене замков. Быстрое решение в экстренных ситуациях: утеря ключей, заклинивший механизм, переезд.
Go this link https://universopilatessevilla.com/examenes-curso-2019/
Комплексная очистка https://chistovodov-24.ru скважинной воды — удалим запах, мутность, примеси. Подбор фильтров по результатам анализа. Оборудование для дома, дачи и бизнеса.
Услуги печника https://dom-teplo.su с выездом: кладка, ремонт, чистка печей, каминов, барбекю. Только проверенные материалы, мастер с опытом от 10 лет.
Всё для сада https://sadovoddom.ru и огорода в интернет-магазине: от семян и рассады до инвентаря и теплиц. Качественные товары, проверенные поставщики, удобная оплата и доставка.
Оценка недвижимости https://svoidomufa.ru в Уфе с выездом: квартиры, дома, офисы, участки. Документы для ипотеки, суда, наследства. Сертифицированные специалисты.
Ремонт ванных комнат https://rem-sanuzla.ru и санузлов: от демонтажа до отделки. Честные сметы, фиксированные сроки, опытные мастера. Современные решения и качественные материалы.
Ремонт телефонных линий https://remtl.ru и МГТС: устраняем обрывы, шум, отсутствие сигнала. Настройка и восстановление стационарной связи. Ремонт антенн, прокладка кабеля.
ai therapist app https://ai-therapist21.com/ .
вывод из запоя
vivod-iz-zapoya-krasnodar001.ru
вывод из запоя цена
вывод из запоя круглосуточно
https://vivod-iz-zapoya-chelyabinsk001.ru
лечение запоя
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
мостбет http://mostbet4074.ru/
Hey! This post could not be written any better! Reading through this post reminds me of my old room mate! He always kept talking about this. I will forward this article to him. Fairly certain he will have a good read. Many thanks for sharing!
Limo service near me
Click here https://blog.maoyulong.club/?p=30
вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
лечение запоя
лечение запоя челябинск
vivod-iz-zapoya-chelyabinsk002.ru
вывод из запоя круглосуточно челябинск
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
Заказать диплом https://diplomikon.ru быстро, надёжно, с гарантией! Напишем работу с нуля по вашим требованиям. Уникальность от 80%, оформление по ГОСТу.
1win պաշտոնական կայք http://www.1win3072.ru
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar003.ru
лечение запоя краснодар
Go this site https://www.jkscommunications.ie/services/attachment/597239200/
Оформим реферат https://ref-na-zakaz.ru за 1 день! Напишем с нуля по вашим требованиям. Уникальность, грамотность, точное соответствие методичке.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
Отчёты по практике https://gotov-otchet.ru на заказ и в готовом виде. Производственная, преддипломная, учебная.
Диплом под ключ https://diplomnazakaz-online.ru от выбора темы до презентации. Профессиональные авторы, оформление по ГОСТ, высокая уникальность.
mostbet.com rasmiy sayt mostbet4075.ru
экстренный вывод из запоя челябинск
vivod-iz-zapoya-chelyabinsk003.ru
лечение запоя
1win приветственный бонус http://1win3068.ru/
https://www.glicol.ru/
отделка однокомнатных квартир отделка однокомнатных квартир .
Если ищете, где можно смотреть UFC в прямом эфире, то этот сайт отлично подойдёт. Постоянные трансляции, удобный интерфейс и высокая скорость загрузки. Всё работает стабильно и без рекламы: где смотреть бои ufc
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar004.ru
лечение запоя краснодар
Нужно найти данные о пользователе? Наш сервис поможет полный профиль в режиме реального времени .
Воспользуйтесь продвинутые инструменты для анализа публичных записей в соцсетях .
Выясните место работы или интересы через систему мониторинга с гарантией точности .
глаз бога официальный бот
Бот работает с соблюдением GDPR, используя только общедоступную информацию.
Закажите детализированную выжимку с геолокационными метками и графиками активности .
Доверьтесь проверенному решению для digital-расследований — точность гарантирована!
лечение запоя
vivod-iz-zapoya-cherepovec004.ru
экстренный вывод из запоя
Go this site https://greenhedgehog.at/standardized-methods/
Информационный портал об операционном лизинге автомобилей для бизнеса и частных лиц: условия, преимущества, сравнения, советы и новости рынка: fleetsolutions.ru
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/shchelkovo/
Лучшие и актуальные промокод на бесплатную ставку онлайн в популярных букмекерских конторах. Бонусы за регистрацию, фрибеты, удвоение депозита. Обновления каждый день.
1win armenia 1win armenia
Купить квартиру или дом покупка недвижимости в черногории Подберём квартиру, дом или виллу по вашему бюджету. Юридическая проверка, консультации, оформление ВНЖ.
Ваш безопасный портал bitcoin7.ru в мир криптовалют! Последние новости о криптовалютах Bitcoin, Ethereum, USDT, Ton, Solana. Актуальные курсы крипты и важные статьи о криптовалютах. Начните зарабатывать на цифровых активах вместе с нами
шлюха на дом выебал шлюху
лечение запоя
vivod-iz-zapoya-krasnodar005.ru
вывод из запоя
Магазин сантехники https://sanshop24.ru для дома и бизнеса. Качественная продукция от проверенных брендов: всё для ванной и кухни. Удобный каталог, акции, доставка, гарантия.
Ремонт офисов https://office-remont-spb.ru любой сложности: косметический, капитальный, под ключ. Современные материалы, строгое соблюдение сроков, опытные мастера.
Управляющая компания https://uk-nadeghda.ru обслуживание многоквартирных домов, текущий и капитальный ремонт, уборка, благоустройство, аварийная служба.
Всё о сантехнике https://santechcenter.ru советы по выбору, установке и ремонту. Обзоры смесителей, раковин, унитазов, душевых. Рейтинги, инструкции, лайфхаки и обзоры новинок рынка.
Ремонт и перекрой шуб https://remontmeha.ru обновим фасон, укоротим, заменим изношенные детали. Работа с норкой, мутоном, каракулем и др.
Оборудование для сантехники https://ventsan.ru вентиляции и климата — в одном месте. Котлы, трубы, вытяжки, кондиционеры, фитинги.
Скрытая мини-камера https://baisan.ru с Full HD, датчиком движения и автономной работой. Идеальна для наблюдения в квартире, офисе или автомобиле.
вывод из запоя круглосуточно
vivod-iz-zapoya-cherepovec005.ru
вывод из запоя череповец
Продвижение сайтов https://team-black-top.ru под ключ: SEO-оптимизация, технический аудит, внутренняя и внешняя раскрутка. Повышаем видимость и продажи.
Go this site https://lotusprecision.com/hello-world/
Всё о металлообработке https://j-metall.ru и металлах: технологии резки, сварки, литья, фрезеровки. Свойства металлов, советы для производства и хобби.
esim buy https://esim-buy1.com
Ремонт квартир https://domov-remont.ru под ключ: от дизайн-проекта до финишной отделки. Честная смета, контроль этапов, гарантия до 5 лет. Работаем точно в срок.
ЖК «Атлант» https://atlantdom.ru современный жилой комплекс с развитой инфраструктурой, охраняемой территорией и парковкой. Просторные квартиры, благоустроенные дворы, удобное расположение.
Капельница от похмелья — это эффективное средство для быстрого избавления от симптомов интоксикации после употребления алкоголя. При похмелье организм страдает от обезвоживания и нехватки электролитов, что способствует тошноте. Лечение капельницей включает в себя вливание специальных растворов и восполнение утрат. Обращение к врачу может включать в себя медикаменты, улучшающие самочувствие, которые помогают организму быстрее восстановиться. Капельницы часто содержат витамины, противоядия, которые способствуют детоксикации. Поддержка организма таким образом позволяет значительно уменьшить симптомы похмелья и ускорить процесс выздоровления. Для получения капельницы можно посетить медицинское учреждение или вызвать врача на дом через сайт vivod-iz-zapoya-krasnoyarsk001.ru. Учтите, что оперативное вмешательство поможет предотвратить осложнения.
экстренный вывод из запоя череповец
vivod-iz-zapoya-cherepovec006.ru
вывод из запоя
домашний интернет
domashij-internet-perm004.ru
подключить проводной интернет пермь
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/novocherkassk/
Вызов нарколога на дом – это удобное решение для людей, которые нуждаются в квалифицированной помощи в борьбе с зависимостями. Сайт vivod-iz-zapoya-krasnoyarsk002.ru предоставляет услуги профессиональных специалистов, которые готовы оказать медико-психологическую и психологическую поддержку. Нарколог на дом осуществит диагностику зависимостей, гарантирует анонимное лечение и назначит медикаментозную терапию. Консультация нарколога может предполагать психотерапию при зависимости, что способствует восстановлению после зависимости. Также важна поддержка для близких, чтобы оказать помощь им справиться с возникшими трудностями. Реабилитация на дому позволяет комфортно пройти лечение алкоголизма и других зависимостей, не оставляя привычной обстановки. Квалифицированная помощь ждет каждого, кто готов сделать шаг к здоровой жизни.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk001.ru
вывод из запоя цена
подключить проводной интернет пермь
domashij-internet-perm005.ru
провайдеры интернета в перми
Click this site https://torodecuerda.es/inicio/croma-logo-footer/
Услуги промышленных альпинистов https://trast-cleaning.ru высотные работы любой сложности, мойка фасадов, герметизация, монтаж, демонтаж.
Купить обои https://nash-dom71.ru для дома и офиса по доступным ценам. Виниловые, флизелиновые, текстильные, фотообои. Большой выбор, доставка, помощь в подборе.
Служба ремонта https://rnd-master.ru все бытовые услуги в одном месте. Ремонт техники, сантехники, электрики, мелкий бытовой сервис. Быстро, качественно, с гарантией.
Монтаж систем отопления https://elitmaster1.ru в домах любой площади. Газовое, электрическое, комбинированное отопление. Подбор оборудования, разводка труб, запуск.
sim united states https://esim-buy1.com
buy esim with crypto esim canada
Подбор вытяжки https://podberi-vytyazhku.ru по всем параметрам: площадь, фильтрация, уровень шума, тип управления. От эконом до премиум-сегмента.
Купить недвижимость https://karado.ru в Белгородской области просто: проверенные объекты, помощь в оформлении, консультации.
Продажа сплит-систем https://split-s.ru и кондиционеров для дома, офиса и коммерческих помещений. Широкий выбор моделей, установка под ключ, гарантия, доставка.
Стажировки для студентов https://turbo5.ru вузов: реальный опыт, развитие навыков, участие в проектах. Возможность начать карьеру в крупной компании.
Ремонт компьютеров https://aka-edd.ru и ноутбуков: блог с советами от мастеров. Разбор типичных поломок, пошаговые инструкции, обслуживание, апгрейд.
Блог о мелочах https://ugg-buy.ru которые делают жизнь лучше: организация быта, семейные советы, домашние рецепты, удобные привычки.
It only reserve, no more
Психологическая поддержка при выводе из запоя в Красноярске: как справиться с абстиненцией Во время абстиненции люди часто сталкиваются с физическими и психологическими страданиями. В таких случаях консультации психолога и кризисная интервенция способны существенно улучшить состояние пациента. Центры психотерапии в Красноярске предлагают различные программы восстановления и методы борьбы с зависимостями, что помогает справиться с трудностями. вывод из запоя цена Рекомендации по выходу из запоя включают использование психологической помощи и программы реабилитации наркозависимых, что значительно увеличивает вероятность успешного выздоровления. Важно помнить, что путь к трезвости требует времени, терпения и поддержки.
Ремонт и дизайн жилья https://giats.ru просто! Полезный блог с лайфхаками, трендами, советами по планировке, цвету, освещению и отделке.
Бурение скважин https://protokakburim.ru на воду для дома, дачи и бизнеса. Бесплатный выезд специалиста, честная смета, оборудование в наличии.
Светодиодные светильники https://svetlotorg.ru для дома, офиса, улицы и промышленных объектов. Экономия электроэнергии, долгий срок службы, стильный дизайн.
Медицинский блог https://msg4you.ru для всех, кто заботится о здоровье. Статьи от врачей, советы по профилактике, разбор симптомов и заболеваний, современные методы лечения.
Responsible gaming involves implementing measures to protect players , including safeguarding vulnerable individuals and promoting safe habits .
Establishing limits for time spent helps maintain control , while tools like budgeting features empower informed decisions .
Educating employees ensures early identification of addictive patterns, fostering a supportive environment .
betpawa tanzania contacts
Offering resources such as counseling services and educational materials enables players to seek help effectively.
Following guidelines like ID checks and transparency in odds builds trust within the industry .
The goal is to create a balanced ecosystem where enjoyment coexists with financial prudence , ensuring sustainable play.
лечение запоя иркутск
vivod-iz-zapoya-irkutsk002.ru
экстренный вывод из запоя
как обменять крипту через Web3 кошелек
домашний интернет тарифы
domashij-internet-perm006.ru
подключить интернет тарифы пермь
Красота вашего дома https://fx-gu.ru начинается с деталей! Интерьерные идеи, цветовые решения, текстиль, свет, мебель.
Бизнес и финансы https://business-age.ru свежие идеи, аналитика, инвестиции, налоги, стартапы. Полезные статьи для предпринимателей и тех, кто хочет грамотно управлять деньгами.
Сайт о финансовых https://good-recepts.ru основах: от личного бюджета до инвестиций. Полезные материалы, гайды, советы по управлению деньгами и финансовой грамотности.
Перевозка грузов https://gruzovoe-taxi24.ru по Москве: грузовое такси, переезды, доставка товаров, вывоз мебели. От легких до тяжёлых грузов.
Строительные леса https://sib-metall.ru и вышки-туры: широкий выбор, прочные конструкции, доставка по всей России. Для профессионалов и частных клиентов.
Федеральная грузовая компания https://vgk.org.ru надёжные перевозки по всей России. Ж/д и автотранспорт, логистика, склад, страхование.
Каталог магазинов https://elfplus.ru электроинструмента по всей России. Сравнивайте цены, ассортимент и адреса. Только проверенные продавцы.
Ремонт квартир https://sovetyporemontu.ru в Москве: от косметического до капитального. Работаем точно в срок, без скрытых платежей.
Go here https://villa-paradise.ru/st_hotel/villa-paradise/
https://www.glicol.ru/
Натяжные потолки курган – быстро и выгодно! Большой выбор текстур. Сатиновые, тканевые потолки. Установка за 1-2 дня. Warranty 7 лет. Точный выезд мастера. Опыт работы свыше 15 лет. Выезжаем по области. Заказывайте сегодня!
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: поставка канализационной насосной станции
экстренный вывод из запоя минск
vivod-iz-zapoya-minsk001.ru
вывод из запоя
I absolutely love your blog and find many of your post’s to be just what I’m looking for. Do you offer guest writers to write content for you personally? I wouldn’t mind producing a post or elaborating on a number of the subjects you write about here. Again, awesome website!
РиоБет
лечение запоя
vivod-iz-zapoya-irkutsk003.ru
лечение запоя иркутск
Hi there mates, its impressive article about tutoringand fully defined, keep it up all the time.
рабочее зеркало бетвиннер
провайдеры ростов
domashij-internet-rostov004.ru
подключить интернет
Услуги по ремонту https://remontexpert.su квартир и офисов: от косметического до капитального. Подбор стиля, качественные материалы, пошаговый контроль.
Ремонт и отделка https://remont39.ru квартир и офисов под ключ. Чистовая и черновая отделка, дизайн-проект, инженерные работы. Чёткие сроки, гарантия, контроль качества.
Домофоны и видеонаблюдение https://ooo-domofon.ru установка и обслуживание в Москве и области. Аналоговые и IP-системы, выезд специалиста, договор, гарантия.
Всё о воспитании https://rabotnikdoma.ru мягкие и авторитетные методики, развитие личности ребёнка, возрастные кризисы, границы и любовь.
В Адлере прокат катеров популярен среди туристов желающих увидеть город с моря https://yachtkater.ru/
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: промышленная кнс
Интернет-магазин https://teplokomfort32.ru отопительного оборудования, сантехники и электрики. Всё для обустройства дома: котлы, радиаторы, бойлеры, насосы, трубы, кабель.
Журнал о деньгах https://cdosfera.ru инвестициях, кредитовании и личных финансах. Разбираем банковские продукты, учим выгодно инвестировать, следим за рынками и курсами валют.
Штукатурка стен https://brigada63.ru и стяжка полов с гарантией качества. Механизированная и ручная отделка, строго по уровню. Работаем с квартирами, домами, офисами.
Удобный онлайн-сервис https://kazap.ru для поиска товаров и магазинов по всей России. Сравнение цен, наличие, отзывы, акции. Найдите нужный товар в проверенных магазинах за пару кликов.
экстренный вывод из запоя
vivod-iz-zapoya-minsk002.ru
лечение запоя
Click this link https://alex-dev.pp.ua/projects/zdo/
1win официальный промокод https://1win3069.ru
Ремонт ванных комнат https://rem-vann.ru и квартир от косметического до капитального. Демонтаж, выравнивание, укладка плитки, монтаж сантехники и отделка помещений.
Все виды дезинфекции https://dezefect.ru от вирусов, бактерий, грибка, плесени. Обработка квартир, домов, офисов, транспорта. Безопасно, эффективно, с подтверждающими документами.
Отделка и ремонт https://remontnaura.ru квартир любой сложности. Современные материалы, опытные мастера, соблюдение сроков. Черновая и финишная отделка, дизайн-проекты, подбор материалов.
Всё о ремонте https://vse-vremonte.ru в одном месте. Как начать, на чём сэкономить, какие материалы выбрать, в какой последовательности действовать. Для новичков и профессионалов.
Профессионалы выполнят ремонт Apple Watch быстро и качественно, сохраняя работоспособность вашего устройства.
Apple является одним из самых известных и уважаемых брендов в мире технологий. Компания предлагает широкий ассортимент продуктов и услуг, включая iPhone, iPad и Mac.
Одним из ключевых факторов успеха Apple является инновационный дизайн. Компания постоянно стремится к улучшению пользовательского опыта и функциональности своих устройств.
Кроме того, экосистема Apple создает уникальный опыт для пользователей. Товары Apple отлично взаимодействуют друг с другом, упрощая процесс использования.
Хотя цены на продукцию Apple могут быть высокими, они все равно пользуются популярностью. Покупатели предпочитают продукты Apple за их высокое качество, надежность и использование современных технологий.
Отделочные материалы https://facade-master.ru в Москве по выгодным ценам. Всё для ремонта: краски, обои, плитка, гипсокартон, ламинат, шпатлёвки и инструменты.
Натуральная питьевая вода https://vodaofis.ru — из природного источника, с мягким вкусом и сбалансированным составом. Подходит для детей и взрослых.
Надёжная гидроизоляция https://evrostandart-gidro.ru защита фундаментов, резервуаров, водоёмов от влаги и протечек. Используем битумные, проникающие, обмазочные и мембранные материалы.
Всё о профессиях https://porof.ru как выбрать профессию, какие рабочие специальности востребованы, где учиться и кем работать. Подробный перечень профессий с описанием, требованиями, зарплатами
провайдеры интернета в ростове
domashij-internet-rostov005.ru
подключить проводной интернет ростов
вывод из запоя калуга
vivod-iz-zapoya-kaluga004.ru
лечение запоя
Журнал с идеями https://master-vo.ru для вас и вашего дома: интерьер, уют, декор, советы по организации пространства, стиль жизни и вдохновение каждый день.
Все виды строительных https://plat-ttofficial.ru и ремонтных работ: капитальное строительство, реконструкция, отделка, инженерные сети. Современные материалы, опытные мастера, контроль качества.
ПО TerraID https://terraid.ru интеллектуальная система идентификации и управления доступом. Поддержка карт, биометрии, интеграция с видеонаблюдением и СКУД.
Широкий выбор бань https://eco-bani.ru по готовым проектам и на заказ. Каркасные, брусовые, из бревна — под ключ. Индивидуальные планировки, утепление, отделка, печи.
Купить ламинат https://laminat-vinil.ru и кварц виниловую плитку в Москве и области
промокоды на сайте 1001kupon
Fantastic site you have here but I was wondering if you knew of any community forums that cover the same topics talked about in this article? I’d really like to be a part of online community where I can get suggestions from other knowledgeable people that share the same interest. If you have any recommendations, please let me know. Thanks a lot!
https://pg46.ru/virtualnyye-nomera
Нужна мебель? https://joycom.ru для дачи, террасы и участка: кресла, столы, шезлонги, качели, комплекты. Устойчивые к влаге и солнцу материалы, стильный дизайн, удобство и долговечность.
Виртуальный номер для СМС — бесплатно и без ограничений. Простое использование: выбирайте номер, получайте код, подтверждайте регистрацию. Список номеров регулярно обновляется.
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: техника для дома miele
вывод из запоя минск
vivod-iz-zapoya-minsk003.ru
вывод из запоя
porn on face heroin buy store
Нужен дом? строительство дома цена — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Go this site https://tools-world.ru/auth/?backurl=/callback/?id=&act=fastBack&SITE_ID=s1&name=DouglasWrild&phone=89464498476&message=+https%3A%2F%2Fuztm-ural.ru%2Fcatalog%2Fredkozemelnye-i-redkie-metally%2F+
Интересная статья: Эффективные упражнения для стройной спины и рук: видео-тренировка для женщин
Читать полностью: Как распознать плохой бензин: 5 признаков некачественного топлива
интернет домашний ростов
domashij-internet-rostov006.ru
подключить домашний интернет в ростове
porn blowjob huge whore
экстренный вывод из запоя калуга
vivod-iz-zapoya-kaluga005.ru
вывод из запоя круглосуточно
Интересная статья: Быстрый десерт к чаю за 5 минут: простой рецепт без выпечки
Читать полностью: Топ гибридов 2024: выбираем лучший экономичный автомобиль
где вводить промокод в 1win https://1win3067.ru
вывод из запоя круглосуточно
vivod-iz-zapoya-omsk001.ru
вывод из запоя
Highly praised for reliability — “I’ve bridged over 50 transactions without a single issue.”
Clean UI that’s intuitive for both newcomers and advanced DeFi users.
Нужен дом? строительство домов под ключ — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Нужен дом? строительство домов под ключ — от проекта до отделки. Каркасные, кирпичные, брусовые, из газобетона. Гарантия качества, соблюдение сроков, индивидуальный подход.
Clean UI that’s intuitive for both newcomers and advanced DeFi users.
провайдеры интернета по адресу самара
domashij-internet-samara004.ru
провайдеры интернета в самаре по адресу проверить
Официальный интернет-магазин Miele предлагает премиальную бытовую технику с немецкой сборкой и сроком службы до 20 лет. В наличии и под заказ – оригинальные модели для дома с гарантией от официального поставщика. Быстрая и надежная доставка по Москве и всей России. Надёжность, качество и технологии Miele – для вашего комфорта каждый день: техника для кухни miele встраиваемая
вывод из запоя круглосуточно калуга
vivod-iz-zapoya-kaluga006.ru
экстренный вывод из запоя
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: https://kns-kupit.ru/
Check site http://legendmohe.com/2013/05/29/dojo%e5%ba%93resize%e6%8e%a7%e4%bb%b6%e4%bd%bf%e7%94%a8%e6%96%b9%e6%b3%95/
Hello there I am so glad I found your website, I really found you by mistake, while I was browsing on Google for something else, Anyhow I am here now and would just like to say cheers for a incredible post and a all round interesting blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have saved it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the great work.
Telephone
вывод из запоя круглосуточно омск
vivod-iz-zapoya-omsk002.ru
вывод из запоя омск
1win գրանցում 1win գրանցում
היא הייתה מוגנת ב 100% מההריון. אבל עם מחלות מין, היה לה מזל גדול-מעולם לא תפס שום דבר (לפחות ולבסוף הצלחתי לשאוף, להשתעל ולנגב את הפנים. דימה נצמדה לירכיים בזמן הזה וגמרה בתוכי בשאגה. הרגשתי דירה דיסקרטית אשדוד
интернет по адресу самара
domashij-internet-samara005.ru
провайдеры интернета по адресу
вывод из запоя круглосуточно
vivod-iz-zapoya-krasnodar001.ru
экстренный вывод из запоя краснодар
авиатор 1вин http://1win3066.ru
лечение запоя омск
vivod-iz-zapoya-omsk003.ru
вывод из запоя круглосуточно омск
Услуги аренды яхт в Сочи включают капитана и комфорт на каждом этапе прогулки https://yachtkater.ru/
https://www.glicol.ru/
При полной уборке помещений важна точность и комплексный подход. Мы предлагаем генеральная уборка цена с прозрачным прайсом и без скрытых доплат.
Генеральная уборка — это важное мероприятие в жизни каждого человека. Эта процедура позволяет создавать чистоту и уют в квартире.
Планирование — ключ к успешной генеральной уборке. Начните с того, чтобы определить, какие помещения требуют внимания. Разделив работу на этапы, вы снизите вероятность путаницы.
Не забывайте о подготовке нужных материалов. Необходимыми инструментами будут чистящие средства, пылесос и тряпки. Приятно и быстро работать, когда все под рукой.
Теперь, когда все необходимое под рукой, можно переходить к уборке. Работайте поочередно в каждой комнате. Таким образом, проще отслеживать прогресс.
какие провайдеры интернета есть по адресу самара
domashij-internet-samara006.ru
подключить интернет по адресу
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/usole-sibirskoe/
экстренный вывод из запоя
vivod-iz-zapoya-krasnodar002.ru
вывод из запоя краснодар
זהובה,” אמרה והחלה לארוז. דימה הנהן, ברור שלא רצה לסיים את הערב, אך הושיט יד בצייתנות למעילו. משותף, חתמו רשמית ואולגה נכנסה לצו. כשלמדתי את תאריך היעד המשוער שלי … פתאום נפגעתי כמו ברק!! discover more here
Official Instagram page of 33win
Follow the verified and official Instagram account of new88 today
Все обновления только на официальной странице 1win
Track the latest giveaways only on the real f8bet
вывод из запоя оренбург
vivod-iz-zapoya-orenburg001.ru
экстренный вывод из запоя оренбург
את הספל על השידה, ידיה רעדו מעט. – אתה אוהב לראות איך … … מקסים נשם עמוק ועלה מהמיטה. יש לי סוג על ברכיו. עיניה נפגשו עם עיני בעלה. ד ‘ ישב ממש לידה ועקב מקרוב אחר המבט על פניה של אהובתה, בעוד נערת ליווי בתל אביב – האם חווית פעם עונג צרוף?
Техосмотр без очередей https://texosmotr.su в день обращения! Полный осмотр, оформление диагностической карты, приём по записи.
https://the.hosting/
Verified Instagram for casino site in Korea
Indie dev diary: build day 15 logged bug fixes; build day 16 (mid-entry) notes success after deciding to buy 100 x followers.
I bookmarked the vendor comparison—especially the sub-$10 bundles of cheap tiktok likes for test accounts.
Reddit is where I go for honest feedback. I found a post about the best gambling site and it led me to a casino that actually pays out quickly and legally.
וידאו ליום ההולדת שלי. ואז, כשאני זוכר את זה, איכשהו, קרוב לסוף יום העבודה, פתאום אני מקבל טקסט השבוע הוא חיים שלמים: בישול, ניקיון, עיסוי ארוטי, שיחות ויטינה על הקוד והתיקונים שלו. אני אוהב great info
интернет по адресу
domashij-internet-spb004.ru
провайдеры интернета в санкт-петербурге по адресу проверить
вывод из запоя краснодар
vivod-iz-zapoya-krasnodar003.ru
вывод из запоя круглосуточно краснодар
Надёжный заказ авто https://zakazat-avto11.ru. Машины с минимальным пробегом, отличным состоянием и по выгодной цене. Полное сопровождение: от подбора до постановки на учёт.
Блог о разработке на PHP. Содержит советы, решения, новости и практические рекомендации, направленные на улучшение навыков PHP-программистов: phpworking.ru
Du möchtest wissen, ob es möglich ist, im Online Casino Österreich legal zu spielen und welche Anbieter dafür infrage kommen? In diesem Artikel zeigen wir Spielern in Österreich, die sicher und verantwortungsbewusst online spielen möchten, Möglichkeiten ohne rechtliche Grauzonen zu betreten. Lies weiter, um die besten Tipps und rechtlichen Hintergründe zu entdecken: Online Casino Österreich
вывод из запоя
vivod-iz-zapoya-orenburg002.ru
вывод из запоя круглосуточно
הקעקוע וחוש ההומור החריף, פחד להפחיד אותי? זה היה כמעט מצחיק, אבל גם נוגע ללב. – באמת? – הרמתי קדימה. רק בלי נזלת, בסדר? סאנק צחק, מקס לחץ את הירך שלי חזק יותר, וויטק סוף סוף נתן את קולו: – what is it worth
Полезная статья: 7 тревожных сигналов: старение организма ускорилось
Интересная новость: Кто подвержен риску психических расстройств: факторы и признаки
Читать подробнее: Когда срочно менять тормозные колодки: советы автоэксперта
интернет провайдеры по адресу дома
domashij-internet-spb005.ru
узнать провайдера по адресу санкт-петербург
Tower X is a popular slot game in India featuring exciting reels, thrilling gameplay, and big win opportunities: TowerX Game: high score tips
השינה. עיסוי ארוטי עם השכן העיר שלנו קטנה, והאנשים בה כמעט מכירים אחד את השני. עיניי מקס ואני עדיין שכבנו על הספה, שזורים זה בזה, מכוסים בשמיכה דקה שבקושי כיסתה את גופנו the original source
Современные канализационные насосные станции – надёжное решение для вашего объекта! Предлагаем КНС любой мощности с автоматикой и защитой от засоров. Автоматическое управление, высокая производительность, долговечность материалов. Решаем задачи от частных домов до промышленных объектов. Гарантия качества и быстрая доставка, подробнее тут: кнс канализационные насосные станции купить
моствет моствет
бот lucky jet скачать https://1win3070.ru
זרמו על ירכיה. היא גם התרגשה מהאזנה לסיפורים שלי, למרות שניסתה להיראות קפדנית. כבר התחלנו ללטף להוסיף קצת אש. ביום שישי אחר הצהריים שלחתי הודעה למקס, ” שלום שכן. יש לי מיני חנוכת בית הלילה. find out this here
1win գրանցում https://1win3073.ru
провайдеры в санкт-петербурге по адресу проверить
domashij-internet-spb006.ru
интернет по адресу санкт-петербург
wormhole portal
Читать статью: Как наладить отношения с начальником: советы психолога для женщин
Статьи обо всем: Блюда из картофеля: простые и вкусные рецепты для каждой женщины
Новое и актуальное: Денежная магия дома: простые лайфхаки для привлечения финансов
Интересные статьи: Почему помидоры не краснеют: секреты богатого урожая для дачниц
שמן והסתכל על אמין. ברור שהוא היה מרוצה ממה שקורה. הוא הביט ברגליו של נ ‘ בלי להתנתק וניסה לראות על הספה מראה את התחת הטעים שלה… סוף סוף הגיע רגע האמת כאשר החלת ה ” כלי ” שלו על חור הכניסה של פי פינוק אינטימי בהזמנה
1win պաշտոնական https://www.1win3075.ru
mostbet kg скачать mostbet kg скачать
Мегаполис ночью не спит, а наша команда аналогично всегда на страже: частная центр лечения алкоголизма и наркомании клиника mcnl.ru доступна 24/7. Без очередей и бумаг — срочный приём врача по адресу, мягкий детокс под контролем, ультрабыстрая капельница, психологическая поддержка на месте, бессрочное сопровождение. Без шума, конфиденциально, эффективно — вернем вам трезвость без боли.
נכנסה לחדר השינה המואר שלי. נראה שהזמן נפסק עבורנו. לאחר שבחרה את המצורף לוויברטור, החברה שכבה על עמית. אותו אחד שהבדיחות שלו תמיד הצחיקו אותה ונגיעות מקריות גרמו לה להסמיק. זה לא … אני לא … have a peek here
провайдер по адресу уфа
domashij-internet-ufa004.ru
провайдер по адресу
Designed by Gerald Genta reshaped luxury watchmaking with its signature angular case and stainless steel craftsmanship .
Available in classic stainless steel to meteorite-dial editions, the collection balances avant-garde aesthetics with horological mastery .
Starting at $20,000 to over $400,000, these timepieces cater to both veteran enthusiasts and newcomers seeking timeless value.
https://bookmark-template.com/story24724976/watches-audemars-piguet-royal-oak-luxury
The Royal Oak Offshore push boundaries with innovative complications , embodying Audemars Piguet’s technical prowess .
With meticulous hand-finishing , each watch reflects the brand’s legacy of craftsmanship .
Explore certified pre-owned editions and collector-grade materials to elevate your collection .
https://frasesmotivacional.com/
והלכנו לחנות. וואו הלך על שתן-אמרתי הסתכלתי על שלנו. אל תגיד חברה, היא ענתה. אם כי אם זה לא היה נפשית ביקשתי לפחות לגימה של אוויר, אבל הוא לחץ ולא הרפה. כשכבר צרחתי, התשוקה התרופפה, התרחקתי right here
Читать полностью: Гречка на ужин: простой и вкусный рецепт за 30 минут
займ деньги онлайн микрозайм
мфо взять займ займ кредит
онлайн деньги взять онлайн займ
провайдеры по адресу уфа
domashij-internet-ufa005.ru
провайдеры интернета в уфе по адресу проверить
Автомобили на заказ заказать авто с аукциона. Работаем с крупнейшими аукционами: выбираем, проверяем, покупаем, доставляем. Машины с пробегом и без, отличное состояние, прозрачная история.
Надёжный заказ авто https://zakazat-avto44.ru с аукционов: качественные автомобили, проверенные продавцы, полная сопровождение сделки. Подбор, доставка, оформление — всё под ключ. Экономия до 30% по сравнению с покупкой в РФ.
Решили заказать авто из китая в россию под ключ: подбор на аукционах, проверка, выкуп, доставка, растаможка и постановка на учёт. Честные отчёты, выгодные цены, быстрая логистика.
mostbet http://mostbet4084.ru/
Хочешь авто заказать авто? Мы поможем! Покупка на аукционе, проверка, выкуп, доставка, растаможка и ПТС — всё включено. Прямой импорт без наценок.
какие провайдеры по адресу
domashij-internet-ufa006.ru
провайдеры интернета по адресу
кайтсёрфинг Кайтсёрфинг – это инвестиция в ваше здоровье и хорошее настроение. Это отличный способ укрепить мышцы, улучшить координацию и получить заряд энергии.
домашний интернет в волгограде
domashij-internet-volgograd004.ru
лучший интернет провайдер омск
Нужен автосвет загляните на nts-auto и всё для его установки автосвета. Здесь собраны лампы, линзы, держатели, маски, герметики и другие комплектующие. Всё по делу, без лишнего — удобно, быстро, с доставкой по России. Производим и пользуемся сами, можем рекомендовать!
Нужен ремонт? компмастер – Ремонт ноутбуков, телефонов, телевизоров и компьютеров в Одинцово
подключить домашний интернет омск
domashij-internet-volgograd005.ru
провайдеры интернета в волгограде
defillama analytics
defillama tvl
подключить домашний интернет омск
domashij-internet-volgograd006.ru
домашний интернет подключить омск
https://ping.space/
подключить проводной интернет воронеж
domashij-internet-voronezh004.ru
домашний интернет подключить воронеж
кайт “Броня от стихии”: трапеция – комфорт, как “вторая кожа”, безопасность превыше всего
сурматеринство с гарантией – что нужно чтобы стать суррогатной матерью помощь бесплодным парам. Полный цикл: от подбора суррогатной мамы до рождения ребёнка. Юридическая чистота, надёжные клиники, чуткое сопровождение специалистов.
Нужна душевая кабина? душевые кабины недорого: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
http://xn--80aafabrjladsicc1amg1o4cf1dg.website/
Your article helped me a lot, is there any more related content? Thanks!
провайдеры воронеж
domashij-internet-voronezh005.ru
подключить домашний интернет воронеж
Verified and official page of 777pub on Instagram
Доверьте чистоту помещений профессионалам. клининговая служба по уборке справится с задачами любой сложности на высоком уровне.
Клининг в столице России ведет к созданию чистоты и комфорта в вашем пространстве. Выбор клининговых услуг в Москве весьма широк, и каждая компания предлагает свои уникальные решения.
В первую очередь, стоит отметить, что клининг включает в себя как регулярную, так и генеральную уборку. Регулярная уборка подразумевает поддержание чистоты в помещениях, что важно для здоровья и комфорта.
Генеральная уборка — это углубленная процедура, которая подразумевает внимательное отношение к каждой детали. Клиенты могут выбрать различные пакеты услуг в зависимости от своих нужд и бюджета.
Надежная клининговая компания всегда имеет положительные отзывы и рекомендации клиентов. Достойные клининговые фирмы обеспечивают четкие условия работы и гарантии на предоставляемые услуги.
Follow the one and only official Instagram of taya365 for real updates
Нужна душевая кабина? магазин душевой кабины цена: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
Нужна душевая кабина? магазины душевых кабин в минске: компактные и просторные модели, стеклянные и пластиковые, с глубоким поддоном и без. Установка под ключ, гарантия, помощь в подборе. Современный дизайн и доступные цены!
mostbet https://mostbet4083.ru/
подключить домашний интернет в воронеже
domashij-internet-voronezh006.ru
домашний интернет в воронеже
быстрый займ на карту без отказа быстрый займ на карту без отказа .
Follow the trusted and verified 8k8 Instagram profile – accept no substitutes
Only the official ph365 page brings you real updates – follow now
defillama yield farmingdefillama
Lubisz kasyna online i automaty do gry? Zarejestruj się na slottica kasyno bonus bez depozytu i zgarnij nagrody powitalne!
Base Bridge
mostbet mostbet4077.ru
plinko game https://www.plinko-kz1.ru
самые выгодные вклады https://deposit-kg.ru .
Решения по отслеживанию времени позволяют организациям , упрощая контроль времени работы.
Инновационные инструменты предоставляют детальный учёт онлайн, минимизируя ошибки в расчётах .
Совместимость с ERP-решениями облегчает формирование отчётов а также контроль больничными, сверхурочными.
bitcop удаленка
Упрощение задач сокращает затраты HR-отделов, позволяя сосредоточиться на развитии команды.
Простое управление обеспечивает лёгкость работы даже для новичков , уменьшая время обучения .
Защищённые системы генерируют детальную аналитику , способствуя принятию решений на основе данных.
Don’t miss out – follow the one true panaloko on Instagram
This is the verified and only real Instagram profile of winph
This is where okebet posts real updates – verified Instagram only
All legit content from swerte99 lives here – verified Instagram only
Stay connected through the official slotvip group on Facebook
Follow the official Instagram of jilicc – real content, no imitations
1win https://1win3061.ru
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
shemale porno
mostbet mostbet4078.ru
автодоставка из Китая Доставка текстильных изделий из Китая – требует соблюдения правил маркировки и защиты от подделок.
defillama
Be part of the real community – join the taya365 Facebook group
Stay connected with the real ph365 Facebook group – join now
диваны МВК Мебель для call-центра: эргономика и звукоизоляция для эффективной работы операторов. Обеспечьте комфорт и снизьте уровень шума. Специальные столы, кресла и перегородки. Повысьте продуктивность и снизьте утомляемость.
Simply want to say your article is as astonishing. The clarity in your post is just spectacular and i can assume you’re an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the enjoyable work.
24/7 limo near me
Discover news, events, and updates from 8k8 in their verified group
This is the one and only real Facebook group for 777pub – don’t miss out
Продвижение сайта https://team-black-top.ru в ТОП Яндекса и Google. Комплексное SEO, аудит, оптимизация, контент, внешние ссылки. Рост трафика и продаж уже через 2–3 месяца.
Комедия детства один дома 1 — легендарная комедия для всей семьи. Без ограничений, в отличном качестве, на любом устройстве. Погрузитесь в атмосферу праздника вместе с Кевином!
мостбет мостбет
как поставить бесплатную ставку на винлайн как поставить бесплатную ставку на винлайн .
All official content from taya777 is posted here – join the group today
Нужна душевая кабина? магазин душевых кабин лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Нужна душевая кабина? душевые кабины в минске лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Нужна душевая кабина? магазин душевых кабин лучшие цены, надёжные бренды, стильные решения для любой ванной. Доставка по городу, монтаж, гарантия. Каталог от эконом до премиум — найдите идеальную модель для вашего дома.
Join the official Facebook group of winph – trusted, verified, and active
Looking for swerte99? Join their real Facebook group now
1win 1win
занятия с детским психологом онлайн
Looking for slotvip? This is their official and only Instagram page
Stay connected with okbet through their real Instagram account
сайт для бизнеса адаптивный дизайн Адаптивный дизайн – это необходимость в современном мире. Сайт должен корректно отображаться на всех устройствах, от смартфонов до настольных компьютеров.
Химчистка мебели ростов
продвижение на wildberries заказать wildberries аналитика продаж товара Аналитика продаж товара позволяет выявить самые популярные товары, определить целевую аудиторию и оптимизировать маркетинговые кампании. Без глубокого анализа данных невозможно эффективно управлять продажами.
FocusBiathlon – news about biathlon, calendar biathlon world championships and overall
микрозайм оформить быстрый займ
каркасные дома Обзор строительных компаний, предлагающих строительство каркасных домов: сравнение цен и качества. Отзывы клиентов, портфолио, опыт работы, гарантии, условия сотрудничества.
Блог рекламиста https://dramtezi.ru всё о маркетинге под ключ. Полезные статьи, разбор кейсов, обучение, индивидуальные консультации. Помогаем прокачать бренд, привлечь клиентов и выстроить эффективную стратегию продвижения.
Сайт архитектурного бюро https://arhitektura-peterburg.ru
https://ufo.hosting/service-policy
стеклянная перегородка в душевую Стеклянные ограждения для террас загородных домов: создание уютного пространства для отдыха на свежем воздухе. Дизайн, материалы, установка.
тепловизор лесник купить купить тактическую одежду и снаряжение Купить тактическую одежду и снаряжение можно в специализированных магазинах и интернет-магазинах.
https://servicestat.ru/service-nsk Servicestat.ru — это удобный каталог-рейтинг сервисных центров по ремонту электроники. На сайте собраны контакты (адреса, телефоны), отзывы клиентов, акции и скидки, а также оценки качества услуг. Пользователи могут быстро найти проверенные мастерские в своем городе, сравнить рейтинги и выбрать лучший вариант. Полезен для тех, кто хочет отдать технику в надежные руки.
? Поиск сервисов по местоположению и брендам
? Реальные отзывы и оценки клиентов
? Акции, скидки и спецпредложения
? Удобный фильтр для сравнения услуг
Идеальный помощник в поиске надежного ремонта!
1вин 1вин
1win https://1win3064.ru
How to use DefiLlama to avoid DeFi scams.
водопонижение котлована иглофильтрами https://водопонижение-77.рф/
Женская сумка — это обязательный элемент гардероба, которая акцентирует образ каждой особы.
Она помогает переносить важные вещи и структурировать жизненное пространство.
Благодаря разнообразию дизайнов и оттенков она завершает любой образ.
сумки Hermes
Сумка — атрибут статуса, который раскрывает личные предпочтения своей хозяйки.
Любая сумка рассказывает характер через материалы, подчёркивая уникальность женщины.
Начиная с компактных клатчей до просторных шоперов — сумка меняется под любую ситуацию.
мостбет мостбет
Cryptocurrency Payments Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
Lusitano horses https://lusitanohorsefinder.com grace, strength and intelligence. We offer for sale selected representatives of the breed. Photos, videos, pedigrees, assistance with selection and transportation.
AMT Games https://amt-games.com is a developer of popular online games in the genres of strategy, MMO and action. Famous projects: Battle for the Galaxy, Heroes of War and others.
Марка Balenciaga прославился роскошными сумками , выпущенными фирменной эстетикой.
Каждая модель обладает уникальным дизайном , такие как массивные застежки .
Применяемые ткани гарантируют изысканность аксессуара .
тоут Balenciaga приобрести
Популярность бренда увеличивается у знаменитостей , делая каждую покупку частью стиля.
Сезонные новинки создают шанс покупателю заявить о вкусе в повседневке.
Инвестируя в аксессуары бренда, вы получаете роскошную вещь, а также символ эстетики.
Seattle Photo Gallery https://www.maxwaugh.com stunning nature, wildlife scenes, and sports energy. Unique shots from events, animals, and sanctuaries. Professional photography, emotions in every shot.
Saffire Blue https://www.saffireblue.ca is a Canadian supplier of ingredients for soap making, cosmetics and aromatherapy. Oils, fragrances, dyes, bases and packaging.
Аксессуары Prada являются эталоном стиля благодаря безупречному качеству.
Используемые материалы гарантируют долговечность , а детальная обработка подчёркивает высокое качество .
Узнаваемые силуэты дополняются знаковым логотипом , создавая узнаваемый образ .
https://sites.google.com/view/sumkiprada/index
Такие сумки подходят на вечерних мероприятиях, демонстрируя стиль при любом ансамбле.
Ограниченные серии подчеркивают индивидуальность образа, превращая любой аксессуар в инвестицию в стиль .
Наследуя традиции компания внедряет инновации , оставаясь верным классическому шарму до мельчайших элементов.
Renner Action https://rennerusa.com in Motion is a premium grand piano with precise response, stable mechanics and rich tone. Designed for musicians who value control and expressiveness.
Фильтры для воды https://waterlux.ua чистая и безопасная вода у вас дома. Большой выбор систем очистки: кувшины, под мойку, магистральные, обратный осмос. Подходит для квартиры, дачи, офиса.
Ищете, где хранить продукты при низкой температуре? Вам подойдёт холодильная камера – практичное и надёжное решение для бизнеса и дома, оформите заказ по ссылке https://камера-холодильная.рф/
I once believed medications as lifelines, swallowing them eagerly whenever ailments surfaced. But life taught me otherwise, revealing how such interventions merely veiled deeper issues, sparking a quest for true understanding into our intricate dance with health. It stirred something primal, illuminating that respectful use of these tools empowers our innate vitality, rather than suppressing it.
Amid a personal storm, I hesitated before the usual fix, exploring alternatives that wove lifestyle shifts into medical wisdom. I unearthed a new truth: wellness blooms holistically, excessive reliance breeds fragility. Now, I navigate this path with gratitude to embrace a fuller perspective, viewing remedies as partners in the dance.
Peering into the core, I’ve grasped that medical means ought to amplify our spirit, without stealing the spotlight. This odyssey has been enlightening, inviting us to question casual dependencies for deeper connections. It all comes down to one thing: fildena 100 mg price
https://graph.org/Complete-Guide-to-Free-Zones-06-19
кайтсёрфинг Кайт лагерь: проживание и питание
Станции скорой https://03ekb.ru медицинской помощи Екатеринбурга — экстренная помощь 24/7. Вызов бригады, транспортировка, неотложная помощь при травмах, инфарктах, обострениях.
Центр сертификации https://radiocert.ru в Москве: продукция, услуги, СМК, пожарная безопасность, ЕАС. Независимая экспертиза, аккредитованные лаборатории, прозрачная стоимость. Полное сопровождение на всех этапах.
walewska.ru
Бренд Longchamp — это символ элегантности , где соединяются классические традиции и современные тенденции .
Изготовленные из высококачественной кожи , они выделяются деталями премиум-класса.
Модели Le Pliage остаются востребованными у ценителей стиля уже много лет .
тоут Прада фото
Каждая сумка с авторским дизайном демонстрирует хороший вкус, сохраняя практичность в любых ситуациях .
Бренд следует наследию, используя инновационные технологии при поддержании качества.
Выбирая Longchamp, вы получаете стильный аксессуар , а становитесь частью историю бренда .
Bk8
Ищете шины? https://tssz.ru У нас — более 165 брендов со всего мира! Michelin, Pirelli, Nokian, Bridgestone и другие. Быстрый подбор по авто, отличные цены, оригинальная продукция с гарантией. Установка и доставка по всей России.
Если вы давно мечтаете изучать психологию онлайн, но не знаете, с чего начать — рекомендую обратить внимание на ILM Академию. Это современная платформа, где можно пройти курс по психологии с дипломом без отрыва от работы или семьи.
Программа идеально подойдёт новичкам: всё объясняется простым языком, много практики и живых встреч с преподавателями. В конце обучения вы получите европейский диплом, который ценится и в Украине, и за её пределами.
Отличный выбор для тех, кто хочет начать карьеру в психологии или лучше понять себя и окружающих.
Вариант второй текста:
Хочешь получить профессию психолога, не выходя из дома?
ILM Академия — это современное онлайн-обучение психологии с упором на практику и живое общение с опытными преподавателями.
Обучение доступно из любой точки мира
Подходит для начинающих — всё с нуля
Практика, супервизии и поддержка кураторов
Европейский диплом после окончания курса
Ты сможешь освоить профессию, понять людей глубже и, возможно, даже изменить свою жизнь.
Подробнее о курсе на официальном сайте: ILM Академия психологии европейское образование по психологии онлайн
Детский сад №1 https://ds1spb.ru Калининского района — тёплая атмосфера, квалифицированные воспитатели, развитие и забота о каждом ребёнке. На сайте: режим дня, новости, родительская информация, документы, фотоархив.
мостбет мостбет
Природа Беларуси https://wildlife.by в одном месте. Леса, реки, озёра, животный и растительный мир, охраняемые территории. Путеводители, фотоматериалы, интересные факты. Портал для тех, кто ценит и изучает окружающий мир.
Лазерная косметология https://actual-cosmetology.ru в Рязани — профессиональный уход за кожей в клинике нового уровня. Эпиляция, чистка, шлифовка, anti-age процедуры. Индивидуальный подход, безопасность, видимый эффект с первых сеансов.
Togelup
mostbet mostbet
кайтсёрфинг “Back Roll – первое па”: пошаговая инструкция, как “крещение ветром”
Жителям Центральной России доступны горящие туры из Воронежа. Вы можете выбрать тур с вылетом из аэропорта Чертовицкое. Как мы сэкономили 78 000 руб
Туры по Красноярскому краю https://poloniya.ru это дикая природа, мощь Енисея, горные пейзажи и сибирское гостеприимство. Увлекательные маршруты, путешествия по заповедным местам и историческим локациям.
Надувные лодки ПВХ https://badgerboats.ru выбор опытных рыбаков и туристов. Производитель с репутацией качества: жёсткое дно, крепкие пайолы, удобство транспортировки. Лодки сертифицированы и адаптированы к российским условиям.
Курс по плазмолифтингу эстетическая гинекология обучение в гинекологии: PRP-терапия, протоколы, показания и техника введения. Обучение для гинекологов с выдачей сертификата. Эффективный метод в эстетической и восстановительной медицине.
Курс по плазмотерапии prp терапия обучение с выдачей сертификата. Освойте PRP-методику: показания, противопоказания, протоколы, работа с оборудованием. Обучение для медработников с практикой и официальными документами.
how to use melbet bonus http://melbet1032.ru
Bk8
saif zone address saif zone business setup
Togelup
Интересная статья: Редкие “Таврии”: необычные модификации, о которых вы не знали (фото)
Интересная статья: Быстрый пирог без теста за 10 минут: простой рецепт для всей семьи
Читать статью: Порядок в доме: полезные привычки для чистоты и уюта
equilibrado de turbinas
Aparatos de calibracion: fundamental para el desempeno fluido y efectivo de las maquinas.
En el campo de la tecnologia contemporanea, donde la productividad y la fiabilidad del sistema son de suma importancia, los dispositivos de ajuste juegan un papel esencial. Estos equipos adaptados estan desarrollados para equilibrar y fijar componentes moviles, ya sea en dispositivos de fabrica, automoviles de traslado o incluso en aparatos hogarenos.
Para los tecnicos en mantenimiento de dispositivos y los profesionales, manejar con dispositivos de equilibrado es crucial para promover el operacion uniforme y confiable de cualquier sistema giratorio. Gracias a estas opciones tecnologicas innovadoras, es posible limitar sustancialmente las vibraciones, el ruido y la esfuerzo sobre los rodamientos, prolongando la vida util de elementos importantes.
Igualmente significativo es el funcion que desempenan los dispositivos de equilibrado en la atencion al cliente. El apoyo experto y el conservacion continuo usando estos equipos facilitan dar asistencias de excelente excelencia, mejorando la bienestar de los consumidores.
Para los titulares de empresas, la aporte en sistemas de balanceo y detectores puede ser fundamental para incrementar la productividad y rendimiento de sus aparatos. Esto es particularmente trascendental para los duenos de negocios que dirigen medianas y medianas organizaciones, donde cada aspecto vale.
Ademas, los equipos de ajuste tienen una vasta implementacion en el ambito de la prevencion y el control de nivel. Habilitan identificar posibles errores, impidiendo arreglos elevadas y problemas a los dispositivos. Incluso, los informacion extraidos de estos sistemas pueden aplicarse para optimizar procesos y mejorar la visibilidad en buscadores de busqueda.
Las areas de implementacion de los equipos de balanceo cubren diversas ramas, desde la elaboracion de transporte personal hasta el control ambiental. No influye si se refiere de importantes fabricaciones productivas o reducidos establecimientos domesticos, los sistemas de balanceo son indispensables para promover un rendimiento eficiente y libre de fallos.
Aw8
Читать в подробностях: Рождественский кекс с маком, какао и изюмом: простой рецепт для праздничного стола
Интересная новость: Топ-3 напитка, провоцирующих накопление висцерального жира: опасность для талии
Читать новость: Зимний салат с ягодами: рецепт и польза
Новое на сайте: Как правильно мыть клубнику: советы по очистке от грязи и паразитов
Pilot idea: split two cohorts and let only one cohort buy 500 twitter followers, then compare CTR and watch time.
Новое на сайте: Кабачки в духовке: простой и полезный рецепт сочных овощей
Dragon money Dragon Money – это не просто название, это врата в мир безграничных возможностей и захватывающих азартных приключений. Это не просто платформа, это целая вселенная, где переплетаются традиции вековых казино и новейшие цифровые технологии, создавая уникальный опыт для каждого искателя удачи. В современном мире, где финансовые потоки мчатся со скоростью света, Dragon Money предлагает глоток свежего воздуха – пространство, где правила просты, а возможности безграничны. Здесь каждая ставка – это шанс, каждый спин – это предвкушение победы, а каждый выигрыш – это подтверждение вашей удачи. Но Dragon Money – это не только про выигрыши и джекпоты. Это про сообщество единомышленников, объединенных общим стремлением к риску, азарту и адреналину. Это место, где можно найти новых друзей, поделиться опытом и ощутить неповторимый дух товарищества. Мы твердо верим, что безопасность и честность – это фундамент, на котором строится доверие. Именно поэтому Dragon Money уделяет особое внимание защите данных и обеспечению прозрачности каждой транзакции. Мы стремимся создать максимально комфортную и безопасную среду для наших игроков, где каждый может наслаждаться игрой, не беспокоясь о каких-либо рисках. Dragon Money – это не просто игра. Это возможность испытать себя, проверить свою удачу и почувствовать себя настоящим властелином своей судьбы. Присоединяйтесь к нам, и пусть дракон принесет вам богатство, успех и процветание! Да пребудет с вами удача!
https://arenafan.com/
Anyswap
Татуировка представляет собой уникальное искусство , где каждый элемент несёт личную историю и подчеркивает индивидуальность человека.
Для сотен людей тату — вечный символ , который напоминает о важных моментах и дополняет жизненный опыт.
Сам акт нанесения — это творческий диалог между художником и клиентом , где кожа превращается полотном эмоций.
тату краски
Разные направления, от акварельных рисунков до традиционных орнаментов , позволяют воплотить самую смелую фантазию в гармоничном исполнении.
Эстетика нательного искусства в способности расти вместе с человеком, превращая воспоминания в живой символ внутреннего мира.
Подбирая эскиз, люди раскрывают душу через формы, создавая личное произведение, которое наполняет уверенностью каждый день.
Zarejestruj się i graj online w najlepszym kasynie w Polsce na slottyway logowanie
Давайте вместе откроем секреты хранения экзотических плодов.
По теме “Откройте для себя редкие морепродукты и их бизнес-потенциал”, там просто кладезь информации.
Ссылка ниже:
https://localflavors.ru/%d1%80%d0%b5%d0%b4%d0%ba%d0%b8%d0%b5-%d0%b4%d0%b5%d0%bb%d0%b8%d0%ba%d0%b0%d1%82%d0%b5%d1%81%d1%8b-%d0%b8%d0%b7-%d0%bc%d0%be%d1%80%d0%b5%d0%bf%d1%80%d0%be%d0%b4%d1%83%d0%ba%d1%82%d0%be%d0%b2/
Если у вас есть собственные советы, не стесняйтесь делиться ими в комментариях.
Thank you a lot for sharing this with all people you actually recognize what you are speaking approximately! Bookmarked. Kindly additionally discuss with my website =). We could have a link exchange agreement among us
https://clients1.google.com.et/url?q=https://seattlelimorates.com/
Frax Swap
Сайт добрых пожеланий https://demotivators.ru для души и вдохновения. Тысячи текстов для родных, друзей, коллег. Красивые слова, поздравления, открытки, мотивация. Поздравьте близких с любовью и заботой в каждом слове.
AI platform bullbittrade.com/ for passive crypto trading. Robots trade 24/7, you earn. Without deep knowledge, without constant control. High speed, security and automatic strategy.
Innovative AI platform https://lumiabitai.com for crypto trading — passive income without stress. Machine learning algorithms analyze the market and manage transactions. Simple registration, clear interface, stable profit.
Mantle Bridge
кайт лагерь Кайтсёрфинг для начинающих: первый шаг к покорению стихии. Советы, рекомендации и необходимое оборудование для новичков.
télécharger melbet android http://www.melbet1037.ru
український фільм про кохання українське кіно онлайн 2025
Dragon money Dragon Money – это не просто название, это врата в мир безграничных возможностей и захватывающих азартных приключений. Это не просто платформа, это целая вселенная, где переплетаются традиции вековых казино и новейшие цифровые технологии, создавая уникальный опыт для каждого искателя удачи. В современном мире, где финансовые потоки мчатся со скоростью света, Dragon Money предлагает глоток свежего воздуха – пространство, где правила просты, а возможности безграничны. Здесь каждая ставка – это шанс, каждый спин – это предвкушение победы, а каждый выигрыш – это подтверждение вашей удачи. Но Dragon Money – это не только про выигрыши и джекпоты. Это про сообщество единомышленников, объединенных общим стремлением к риску, азарту и адреналину. Это место, где можно найти новых друзей, поделиться опытом и ощутить неповторимый дух товарищества. Мы твердо верим, что безопасность и честность – это фундамент, на котором строится доверие. Именно поэтому Dragon Money уделяет особое внимание защите данных и обеспечению прозрачности каждой транзакции. Мы стремимся создать максимально комфортную и безопасную среду для наших игроков, где каждый может наслаждаться игрой, не беспокоясь о каких-либо рисках. Dragon Money – это не просто игра. Это возможность испытать себя, проверить свою удачу и почувствовать себя настоящим властелином своей судьбы. Присоединяйтесь к нам, и пусть дракон принесет вам богатство, успех и процветание! Да пребудет с вами удача!
фільми 2025 року фільми 2025 року дивитися онлайн
український фільм про кохання фільми 2025 онлайн без підписки
Zarejestruj się i graj online w najlepszym kasynie w Polsce na magic365 opinie
https://pawndetroit.com/
Trade online with pocket option promo code – a trusted platform with low entry requirements. Start with as little as £1, access over 100 global assets including GBP/USD, FTSE 100 and crypto. Fast payouts, user-friendly interface, and welcome bonuses for new traders.
pocket option trading – बाइनरी विकल्प ट्रेडिंग के लिए सबसे अच्छा मंच!
кайт школа Выбор кайта: как не ошибиться. Учитывайте свой вес, уровень подготовки и условия катания.
Aw, this was an exceptionally good post. Taking the time and actual effort to create a very good article… but what can I say… I hesitate a lot and don’t seem to get anything done.
https://www.google.co.vi/url?q=https://premierlimousineservice.net
Эти экзотические фрукты и овощи сделают ваше меню более ярким и насыщенным.
Кстати, если вас интересует Историческое путешествие: от специй до современной кухни, посмотрите сюда.
Вот, можете почитать:
https://localflavors.ru/%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-%d0%b8-%d0%ba%d1%83%d0%bb%d1%8c%d1%82%d1%83%d1%80%d0%b0-%d0%b8%d1%81%d0%bf%d0%be%d0%bb%d1%8c%d0%b7%d0%be%d0%b2%d0%b0%d0%bd%d0%b8%d1%8f-%d1%81%d0%bf%d0%b5/
Удачи в кулинарных экспериментах с экзотическими продуктами!
бонусы казино в 1win http://www.1win1140.ru
Lopesan Costa Bavaro Airport Shuttle
The Lopesan Costa Bavaro Airport Shuttle is a private, direct transfer for groups of up to six, ensuring no stops or delays with other passengers.
Distance from Lopesan Costa Bavaro Resort to Punta Cana Airport
How far is Lopesan Costa Bavaro from airport? lopesan costa bavaro transportation The Lopesan Costa Bavaro Resort, Spa & Casino is approximately 10.9 miles (18 km) from Punta Cana International Airport (PUJ). The drive typically takes about 17-30 minutes, depending on traffic conditions.
Портал с обзорами лучших онлайн-казино, рейтингами, актуальными бонусами и акциями, а также подробными гайдами и промо-предложениями: лучшие онлайн казино
Lopesan Costa Bavaro Airport Shuttle
The Lopesan Costa Bavaro Airport Shuttle how far is lopesan costa bavaro from airport is a private, direct transfer for groups of up to six, ensuring no stops or delays with other passengers.
Distance from Lopesan Costa Bavaro Resort to Punta Cana Airport
How far is Lopesan Costa Bavaro from airport? The Lopesan Costa Bavaro Resort, Spa & Casino is approximately 10.9 miles (18 km) from Punta Cana International Airport (PUJ). The drive typically takes about 17-30 minutes, depending on traffic conditions.
мелбет тото промокод http://www.melbet1036.ru
Hi, its fastidious article regarding media print, we all be aware of media is a impressive source of information.
https://www.google.cl/url?q=https://premierlimousineservice.net
Hello, dedicated seekers of ultimate body harmony! I once yielded to the mesmerizing myth of speedy symptom suppressors, snatching them eagerly whenever health hurdles appeared. However, vital insights burst through, demonstrating such temporary shields risked deeper health decay, fueling a passionate pursuit for the pillars of sustainable mental and bodily health. This awakening pulsed with life-affirming energy, affirming that strategic, wellness-amplifying choices boost holistic recovery and preventive power, rather than undermining our bodily integrity.
During an intense battle for better health, I revolutionized my approach to healing, uncovering advanced strategies for optimal health that integrate mindful lifestyle shifts with evidence-based therapies. Prepare for the vitality-vaulting core: fildena strong 120 mg, where on the iMedix podcast we explore its profound impacts on health with transformative tips that’ll inspire you to tune in now and revitalize your life. It catalyzed a total wellness rebirth: healing accelerates with focused health awareness, careless overreliance weakens holistic defenses. It amplifies my commitment to better health to guide you toward empowered health evolution, envisioning wellness as your lifelong health adventure.
Unlocking the secrets of true health, I’ve discovered the vital key healing methods ought to empower and sustain, free from overshadowing personal health control. It’s a narrative rich in transformative health growth, encouraging you to rethink your everyday health habits for authentic, thriving well-being. The wellness whisper you can’t ignore: balance.
нові українські фільми кращі фільми онлайн українською
дивитися фільми як українське кіно онлайн 2025
catamaran rental bahamas
фантастичні фільми 2025 фільми без реклами та реєстрації
Join millions of traders worldwide with the pocket option – trading app. Open trades in seconds, track market trends in real time, and access over 100 assets including forex, stocks, crypto, and commodities. Enjoy fast deposits and withdrawals, clear charts, and a beginner-friendly interface. Perfect for both new and experienced traders – trade on the go with confidence
кайт лагерь Кайтсёрфинг: танец с ветром и волнами. Ощутите свободу, скользя по водной глади, управляя мощным кайтом. Это адреналин, спорт и искусство в одном флаконе.
Bos88
займы Кыргызстан займы Кыргызстан .
Bandartogel77
Хочу поделиться полезной информацией. Недавно наткнулся на сайт для цветоводов. Нашел ответы на многие свои вопросы.
Если ищете что-то действительно уникальное, там есть потрясающий раздел о редких видах. Можно найти информацию по очень редким цветам.
Кому интересно, вот ссылка:
https://raregreen.ru/anturium-forgetti-uhod-i-osobennosti-unikalnogo-sorta-bez-ushek/
Всем удачи в выращивании!
авто из кореи в наличии авто из кореи в наличии .
manga online free colored manga site
3d comics online online comics no ads
манхва темное манхва бесплатно
кайтсёрфинг Кайтсёрфинг: танец с ветром и волнами. Ощутите свободу, скользя по водной глади, управляя мощным кайтом. Это адреналин, спорт и искусство в одном флаконе.
https://telegra.ph/Dispergatory-RPA-07-31-5
1win descarga 1win40001.ru
Представляем самые читаемые и обсуждаемые темы марта на Mamas.Ru.
Кстати, если вас интересует Ежедневный гороскоп на 31 июля 2025 года, загляните сюда.
Вот, можете почитать:
http://mamas.ru/horoscopes.php
Маркет продолжается, и впереди еще больше интересных тем для обсуждения.
Алкогольный запой – это синдром‚ характеризующееся продолжительным употреблением алкоголя‚ что может привести к серьезным последствиям. Признаки алкогольной зависимости включают необходимость в спиртном‚ что делает незамедлительное лечение запоя необходимым. В Красноярске помощь при запое осуществляется в наркологических клиниках‚ где предоставляются услуги нарколога; результаты запоя могут различаться от ухудшения состояния здоровья до психических расстройств. экстренный вывод из запоя Красноярск Экстренный вывод из запоя предполагает detox-процедуры‚ которые помогают организму очиститься от токсинов. Психологическая поддержка при алкоголизме также является ключевой ролью в восстановлении. Реабилитация алкоголиков в Красноярске предлагает комплексный подход к лечению‚ включая профилактические меры и поддержку в период восстановления. Важно помнить‚ что лечение алкоголизма требует профессиональной помощи для снижения рисков и повышения качества жизни.
Капельница при алкоголизме — это эффективным способом, используемым в области наркологии для помощи зависимости от алкоголя; инфузионная терапия даёт возможность быстро вывести токсические вещества из организма и восстановить водно-электролитный баланс. Нарколог на дом анонимно в Красноярске предлагает такую возможность, обеспечивая пациентам комфорт и дискрецию. нарколог на дом анонимно Красноярск Симптомы похмелья, такие как боль в голове, тошноту и рвоту и слабость, могут быть сняты с помощью капельницы, включающей подходящие лекарства. Процесс лечения зависимости от алкоголя предполагает персонализированного подхода, и специалист по наркологии на дому проводит первичную консультацию, определяя нужные процедуры для снятия абстиненции. Детоксикация организма — важный этап, позволяющий восстановиться после алкогольной зависимости. Поддержка близких и родственников занимает важную роль в процессе реабилитации, а медикаментозное лечение в комбинации с инфузионной терапией обеспечивает эффективный результат.
Hometogel
I have fun with, cause I found just what I was taking a look for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day. Bye
https://pnevmo-strelok.com.ua/shcho-robyty-pry-zapotivanni-far-audi-a5.html
melbet вход с мобильного https://melbet1035.ru/
mel bet сайт mel bet сайт
Вызов нарколога на дом в Красноярске – данная возможность, которая становится все более актуальной в современном мире. Многие люди сталкиваются с проблемами, связанными с зависимостями, будь то алкоголизм или наркотическая зависимость. Профессиональный нарколог предоставляет наркологическую помощь, помогая справится с этими сложными ситуациями. При необходимости вы можете вызвать выездного нарколога прямо к себе домой. Эта услуга удобна для тех, кто не может или не хочет обращаться в больницы. В Красноярске наркологи предлагают диагностику, консультации и лечение зависимостей. Важно помнить, что анонимное лечение зависимости также возможно.Медицинская помощь на дому обеспечивает комфорт и конфиденциальность, что особенно важно при помощи при алкоголизме и восстановлении после наркотиков; Психотерапия для людей с зависимостями – важный элемент, помогающий пациентам восстановиться и вернуться к нормальной жизни. Реабилитация зависимых в Красноярске проходит под контролем опытных специалистов, что обеспечивает высокое качество лечения. Не откладывайте решение своей проблемы! Обратитесь за помощью, вызвав нарколога через сайт vivod-iz-zapoya-krasnoyarsk005.ru.
How to use DefiLlama app
мелбет. ру http://melbet1033.ru
Наркологическая клиника Красноярск предлагает круглосуточную помощь – ключевой момент в процессе лечения зависимостей и реабилитации. В клинике предлагают медикаментозное лечение, а также консультацию специалиста, что помогает пациентам справиться с проблемами. Вывоз из запоя осуществляется быстро и анонимно позволяет избежать стыда. Поддержка семьи играет ключевую роль в процессе выздоровления, а профилактика рецидивов включает реабилитационные программы и психотерапию для зависимых. Услуги нарколога представляют собой кризисную интервенцию и диагностику на наркотические вещества, что способствует успешному восстановлению. Обратитесь за помощью на vivod-iz-zapoya-krasnoyarsk005.ru!
Découvrez pocket option broker, l’application de trading intuitive utilisée par des millions de traders dans le monde. Accédez à plus de 100 actifs : forex, actions, crypto-monnaies et matières premières. Exécutions rapides, interface claire et retraits instantanés. Parfait pour débutants comme pour traders expérimentés – tradez où que vous soyez, à tout moment.
melbet казино слоты скачать https://www.melbet1034.ru
Ищете сео анализ? Gvozd.org/analyze, здесь вы осуществите проверку ресурса на десятки SЕО параметров и нахождение ошибок, которые, вашему продвижению мешают. Вы ознакомитесь с 80 показателями после анализа сайта. Выбирайте в зависимости от ваших задач и целей из большой линейки тарифов.
read comics free graphic novels online
Откопаться ? это не просто физический процесс, но и увлекательное приключение земли, которое открывает двери к тайнам истории. Археология, как наука, предполагает раскопки, которые помогают обнаружить исторические артефакты, предметы старины и подземные ресурсы. На сайте vivod-iz-zapoya-krasnoyarsk006.ru можно найти множество информации о современных методах бурения и анализа почвы, которые помогают в поиске ценных находок. Земляные работы, включая раскопки, являются основой археологических исследований. Каждый слой почвы, вырываем, может рассказать о жизни людей в разные времена. Восстановление найденных артефактов предоставляет шанс лучше понять культуру и технологии древних цивилизаций. Геология также занимает ключевую роль в процессе, содействуя в анализе почвы и определении местонахождения объектов, что облегчает поиски более целенаправленными и эффективными. Таким образом, откопаться – это не только работа с землёй, но и интересное исследование в прошлое, где каждая находка становится неотъемлемой частью исторической мозаики.
топ манхвы манхва фэнтези
Мы предлагаем вам деревянный дом под ключ, созданный по индивидуальному проекту, с учётом ваших пожеланий и с полной отделкой под заселение.
Популярность деревянных домов под ключ растет среди тех, кто ищет комфортное жилье за городом. Эти сооружения привлекают своим природным очарованием и экологичностью.
Среди основных преимуществ деревянных домов можно выделить скорость их возведения. С помощью современных технологий можно построить такие здания в минимальные сроки.
Деревянные дома славятся хорошей теплоизоляцией. В зимний период они обеспечивают уютное тепло, а в летнее время остаются комфортно прохладными.
Обслуживание деревянных домов не вызывает особых трудностей и не требует значительных усилий. Регулярная обработка древесины защитными средствами поможет продлить срок службы здания.
кайт лагерь Доска для кайтсерфинга: выбор формы и размера в зависимости от стиля
Публичная дипломатия России https://softpowercourses.ru концепции, стратегии, механизмы влияния. От культурных центров до цифровых платформ — как формируется образ страны за рубежом.
Институт государственной службы https://igs118.ru обучение для тех, кто хочет управлять, реформировать, развивать. Подготовка кадров для госуправления, муниципалитетов, законодательных и исполнительных органов.
смотреть фильмы фильмы онлайн бесплатно
Алкогольная детоксикация – это ключевой этап в лечении алкоголизма‚ но вокруг нее существует множество мифов. Первое заблуждение заключается в том‚ что стоимость вывода из запоя высока. На самом деле стоимость лечения алкоголизма различаются‚ и доступные программы detox предлагают разные варианты. Еще одно заблуждение: симптомы запойного состояния не опасны. Запой может вызвать алкогольное отравление и серьезным последствиям. вывод из запоя цена Медицинская помощь при запое включает детоксикацию организма и психотерапию при зависимости. Важно отметить‚ что реабилитация после алкоголизма играет ключевую роль в восстановлении и социальной адаптации. Понимание мифов о детоксикации помогает избежать ошибок на пути к выздоровлению.
вывод из запоя цена
vivod-iz-zapoya-smolensk007.ru
вывод из запоя
Школа бизнеса EMBA https://emba-school.ru программа для руководителей и собственников. Стратегическое мышление, международные практики, управленческие навыки.
Опытный репетитор https://english-coach.ru для школьников 1–11 классов. Подтянем знания, разберёмся в трудных темах, подготовим к экзаменам. Занятия онлайн и офлайн.
Jangan ketinggalan info penting – ikuti kumpulan Facebook mega888
Zarejestruj się w kasynie online już teraz na oficjalnej stronie https://slottica-onlinecasino.pl/ i odbierz bonusy za pierwszą wpłatę na automatach!
На сайте https://filmix.fans посмотрите фильмы в отличном качестве. Здесь они представлены в огромном многообразии, а потому точно есть, из чего выбрать. Играют любимые актеры, имеются колоритные персонажи, которые обязательно понравятся вам своей креативностью. Все кино находится в эталонном качестве, с безупречным звуком, а потому обязательно произведет эффект. Для того чтобы получить доступ к большому количеству функций, необходимо пройти регистрацию. На это уйдет пара минут. Представлены триллеры, мелодрамы, драмы и многое другое.
обучение кайтсёрфингу Фристайл в кайтсерфинге: зрелищные трюки и техника
На сайте https://satu.msk.ru/ изучите весь каталог товаров, в котором представлены напольные покрытия. Они предназначены для бассейнов, магазинов, аквапарков, а также жилых зданий. Прямо сейчас вы сможете приобрести алюминиевые грязезащитные решетки, модульные покрытия, противоскользящие покрытия. Перед вами находятся лучшие предложения, которые реализуются по привлекательной стоимости. Получится выбрать вариант самой разной цветовой гаммы. Сделав выбор в пользу этого магазина, вы сможете рассчитывать на огромное количество преимуществ.
Ищете рейтинг лучших сервисов виртуальных номеров? Посетите страницу https://blog.virtualnyy-nomer.ru/top-15-servisov-virtualnyh-nomerov-dlya-priema-sms и вы найдете ТОП-15 сервисов виртуальных номеров для приема СМС со всеми их преимуществами и недостатками, а также личный опыт использования.
jonitogel
Gengtoto
Keep on working, great job!
spin city aplikacja
Проходите аттестацию https://prom-bez-ept.ru по промышленной безопасности через ЕПТ — быстро, удобно и официально. Подготовка, регистрация, тестирование и сопровождение.
Завод К-ЖБИ высокоточным оборудованием располагает, и по приемлемым ценам предлагает большой ассортимент железобетонных изделий. Продукция сертифицирована. Наши мощности производственные позволяют заказы любых объемов быстро осуществлять. https://www.royalpryanik.ru/ – здесь можно прямо сейчас оставить заявку. На сайте представлены реализованные проекты. Мы гарантируем внимательный подход к требованиям заказчика. Комфортные условия оплаты обеспечиваем. Осуществляем быструю доставку продукции. К сотрудничеству всегда открыты!
melbet рабочее зеркало melbet рабочее зеркало
Sbototo
Gercek kullan?c?lar?n bulundugu pusulabet grubunda sen de yerini al
экстренный вывод из запоя
vivod-iz-zapoya-smolensk008.ru
вывод из запоя
«Дела семейные» https://academyds.ru онлайн-академия для родителей, супругов и всех, кто хочет разобраться в семейных вопросах. Психология, право, коммуникации, конфликты, воспитание — просто о важном для жизни.
https://nature-et-avenir.org/
https://dtf.ru/id2915936/3931207-promt-dlya-sozdaniya-patcha-iz-kartinki-dlya-odezhdy
Трэвел-журналистика https://presskurs.ru как превращать путешествия в публикации. Работа с редакциями, создание медийного портфолио, написание текстов, интервью, фото- и видеоматериалы.
кайтинг Кайтсёрфинг – это ваш вызов, ваша страсть и ваш способ самовыражения. Это спорт, который изменит вашу жизнь к лучшему.
вывод из запоя
vivod-iz-zapoya-smolensk007.ru
вывод из запоя смоленск
Good day!!
Read the link – 777 fruit slot real money
Good luck!
Learn what a familiar brand is called in another country.
azulfidine purchase
проститутки Донецк Проститутки Макеевка: Выбирайте лучших из лучших для незабываемого вечера.
Hi there!
Read the link – welcome bonuses big win poker
Enjoy your bonuses!
code promo 1xbet bonus
Kepritogel
Awesome! Its truly awesome article, I have got much clear idea regarding from this post.
where to buy vermox without insurance
Создаем и продвигаем сайты с 2004 года! Честные гарантия позиций, посещаемости и лидов. Фокус на SEO продвижении. Не нравится – возвращаем деньги https://webseosite.ru/
Свежие скидки https://1001kupon.ru выгодные акции и рабочие промокоды — всё для того, чтобы тратить меньше. Экономьте на онлайн-покупках с проверенными кодами.
«Академия учителя» https://edu-academiauh.ru онлайн-портал для педагогов всех уровней. Методические разработки, сценарии уроков, цифровые ресурсы и курсы. Поддержка в обучении, аттестации и ежедневной работе в школе.
Hey gambler!
Read the link – top paying slot spinners online
Good luck spinning!
вывод из запоя смоленск
vivod-iz-zapoya-smolensk009.ru
вывод из запоя круглосуточно
https://t.me/wine_it
Hello colleagues, how is all, and what you want to say regarding this article, in my view its actually awesome in favor of me.
where can i buy generic vermox
https://vc.ru/smm-obzor Увеличение просмотров в Telegram: эффективные стратегии и советы. Создание вовлекающего контента и продвижение канала. просмотры тг
3д моделирование Обратный инжиниринг
кайт Обучение кайтсёрфингу: шаг за шагом к мечте. От основ до продвинутых трюков, освойте все навыки под руководством опытных наставников.
вывод из запоя смоленск
vivod-iz-zapoya-smolensk008.ru
вывод из запоя круглосуточно
?аза? тіліндегі ?ндер Скачать казахские песни бесплатно ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
кайт Кайтсерфинг для женщин: особенности и преимущества
https://www.cricketweb.net
Оригинальный потолок стоимость натяжного потолка со световыми линиями со световыми линиями под заказ. Разработка дизайна, установка профиля, выбор цветовой температуры. Идеально для квартир, офисов, студий. Стильно, практично и с гарантией.
смотреть русские фильмы онлайн кино новинки
Ищете гражданство паспорт кипра евросоюза ес? Expert-immigration.com – это профессиональные юридические услуги по всему миру. Вам будут предложены консультация по гражданству, ПМЖ и ВНЖ, визам, защита от недобросовестных услуг, помощь в покупке бизнеса. Узнайте детальнее на ресурсе о каждой из услуг, также и помощи в оформлении гражданства Евросоюза и иных стран либо компетентной помощи в приобретении недвижимости зарубежной.
Gengtoto
Gercek uyelerle dolu pusulabet giris topluluguna kat?l
аккаунты warface После покупки варфейс аккаунты купить я остался в полном восторге.
?аза? тіліндегі ?ндер mr3 казахские песни ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
проститутки индивидуалки донецк Шлюхи Донецк
?аза? тіліндегі ?ндер Скачать казахские песни бесплатно ж?рекке жа?ын ?уендер мен ?серлі м?тіндер. ?лтты? музыка мен ?азіргі заман?ы хиттер. Онлайн ты?дау ж?не ж?ктеу м?мкіндігі бар ы??айлы жина?.
кайтинг Кайтсёрфинг
вывод из запоя круглосуточно смоленск
vivod-iz-zapoya-smolensk009.ru
вывод из запоя цена
Escape the Limits – Explore Non GamStop Casinos!
Tired of restrictions? Discover a world of unlimited gaming possibilities at our Non GamStop Casinos.
What we offer:
– Unrestricted access to top games
– Generous welcome bonuses
– Lightning-fast payouts
– 24/7 customer support
– Secure & fair gaming environment
Join thousands of satisfied players who have already found their perfect gaming experience. No GamStop limitations mean endless fun and excitement!
Claim your bonus now and start playing at the best Non GamStop Casinos today! ??
https://vaishakbelle.com/review/1red-casino-2/
#NonGamStopCasinos #OnlineGaming #CasinoBonus
1він додаток 1він додаток
кайт школа Кайт школа
Pretty! This was an extremely wonderful article. Many thanks for providing these details.
buy doxycycline 100 mg
кайт “Азбука водной стихии”: кайт для новичков, как первый шаг к свободе
Superb blog you have here but I was curious about if you knew of any forums that cover the same topics discussed here? I’d really like to be a part of group where I can get responses from other experienced individuals that share the same interest. If you have any suggestions, please let me know. Many thanks!
doxycycline 100mg over the counter
C?p nh?t chinh xac t? nhom Facebook dang tin nh?t – 188bet
K?t n?i v?i fan chan chinh t?i nhom chinh th?c 789bet
https://netlux.org
http://saurfang.ru/wp-includes/pages/1xbet_bonus_pri_registracii_2019_2020.html
https://www.nagpurtoday.in
https://www.cbtrends.com/captcha/pages/1xbet_bonus_shartlari_2020.html
N?i dung du?c xac minh t? nhom hi88 luon dang tin c?y
Готовый комплект Лучшие инсталляции с унитазом в комплекте инсталляция и унитаз — идеальное решение для современных интерьеров. Быстрый монтаж, скрытая система слива, простота в уходе и экономия места. Подходит для любого санузла.
кайтинг Погодные условия играют решающую роль в кайтсёрфинге. Учитесь читать ветер и выбирать споты с подходящими условиями для катания.
We align ratios by slotting a 250?like, 250?view combo—code for “twitter likes buy + view burst.”
G?p g? thanh vien th?t va n?i dung ch?t lu?ng t?i nhom shbet
buy amoxil 650 mg for sale
https://litoseoane.es
Салон красоты в Санкт-Петербурге. Предлагаем профессиональные услуги: стрижки, окрашивание, уход за волосами, маникюр, педикюр, косметологию и массаж. Современное оборудование, опытные мастера и качественная косметика гарантируют идеальный результат. Запишитесь в студию красоты онлайн: салон красоты петербург
Tham gia nhom Facebook chinh th?c c?a f8bet d? k?t n?i v?i c?ng d?ng th?c s?
order amoxil 1000mg pills
https://dgc.co.za/pag/bonus_de_code_promo_melbet.html
Gia nh?p c?ng d?ng Vi?t Nam yeu thich new88 d? cung th?o lu?n m?i ngay
На сайте https://vipsafe.ru/ уточните телефон компании, в которой вы сможете приобрести качественные, надежные и практичные сейфы, наделенные утонченным и привлекательным дизайном. Они акцентируют внимание на статусе и утонченном вкусе. Вип сейфы, которые вы сможете приобрести в этой компании, обеспечивают полную безопасность за счет использования уникальных и инновационных технологий. Изделие создается по индивидуальному эскизу, а потому считается эксклюзивным решением. Среди важных особенностей сейфов выделяют то, что они огнестойкие, влагостойкие, взломостойкие.
Оригинальный потолок натяжной потолок со световыми линиями со световыми линиями под заказ. Разработка дизайна, установка профиля, выбор цветовой температуры. Идеально для квартир, офисов, студий. Стильно, практично и с гарантией.
На сайте https://auto-arenda-anapa.ru/ проверьте цены для того, чтобы воспользоваться прокатом автомобилей. При этом от вас не потребуется залог, отсутствуют какие-либо ограничения. Все автомобили регулярно проходят техническое обслуживание, потому точно не сломаются и доедут до нужного места. Прямо сейчас ознакомьтесь с полным арсеналом автомобилей, которые находятся в автопарке. Получится сразу изучить технические характеристики, а также стоимость аренды. Перед вами только иномарки, которые помогут вам устроить незабываемую поездку.
https://cascadeclimbers.com
Shimmering liquid textiles dominate 2025’s fashion landscape, blending futuristic elegance with sustainable innovation for everyday wearable art.
Unisex tailoring break traditional boundaries , featuring asymmetrical cuts that adapt to personal style across formal occasions.
Algorithm-generated prints human creativity, creating one-of-a-kind textures that react to body heat for personalized expression.
https://www.twitch.tv/maxbezel
Zero-waste construction set new standards, with upcycled materials celebrating resourcefulness without compromising bold design elements.
Light-refracting details elevate minimalist outfits , from solar-powered jewelry to self-cleaning fabrics designed for avant-garde experimentation.
Retro nostalgia fused with innovation defines the year, as 90s grunge textures reinterpret archives through smart fabric technology for timeless relevance .
Ищете прием металлолома в Симферополе? Посетите сайт https://metall-priem-simferopol.ru/ где вы найдете лучшие цены на приемку лома. Скупаем цветной лом, черный, деловой и бытовой металлы в каком угодно объеме. Подробные цены на прием на сайте. Работаем с частными лицами и организациями.
http://xn--48-6kcd0fg.xn--p1ai/forums.php?m=posts&q=31084&n=last#bottom
https://ddec35.org
http://devichnik.su/forum/39-26195-1
кайт Безопасность в кайтсёрфинге – это не просто правило, это образ мышления. Всегда проверяйте оборудование, следите за прогнозом погоды и не рискуйте в сложных условиях.
Chia s? va h?c h?i cung c?ng d?ng th?c t?i nhom Facebook 33win
дизайнерский горшок дизайнерский горшок .
http://www.kalyamalya.ru/modules/newbb_plus/viewtopic.php?topic_id=24336&post_id=106227&order=0&viewmode=flat&pid=0&forum=4#106227
http://www.detiseti.ru/modules/newbb_plus/viewtopic.php?topic_id=76797&post_id=265819&order=0&viewmode=flat&pid=0&forum=13#265819
Сайт-помощник по выбору товаров для дома: бытовая техника
Ищете медтехника от производителя? Agsvv.ru/catalog/obluchateli_dlya_lecheniya/obluchatel_dlya_lecheniya_psoriaza_ultramig_302/ и вы отыщите для покупки от производителя Облучатель ультрафиолетовый Ультрамиг-302М, также сможете с отзывами, описанием, преимуществами и его характеристиками ознакомиться. Узнаете, какие заболевания лечит и для кого подходит. Приобрести облучатель от псориаза и других заболеваний, а также другую продукцию, можно напрямую от производителя — компании Хронос.
Kham pha n?i dung ch?t lu?ng du?c chia s? t? nhom bk8
На сайте https://xn—-8sbafccjfasdmzf3cdfiqe4awh.xn--p1ai/ узнайте цены на грузоперевозки по России. Доставка груза организуется без ненужных хлопот, возможна отдельная машина. В компании работают лучшие, высококлассные специалисты с огромным опытом. Они предпримут все необходимое для того, чтобы доставить груз быстро, аккуратно и в целости. Каждый клиент сможет рассчитывать на самые лучшие условия, привлекательные расценки, а также практичность. Ко всем практикуется индивидуальный и профессиональный подход.
Shimmering liquid textiles dominate 2025’s fashion landscape, blending futuristic elegance with sustainable innovation for everyday wearable art.
Unisex tailoring challenge fashion norms, featuring modular designs that adapt to personal style across formal occasions.
Algorithm-generated prints human creativity, creating hypnotic color gradients that shift in sunlight for personalized expression.
https://graph.org/Richard-Milles-2025-Ode-to-Temporal-Alchemy-05-20
Zero-waste construction set new standards, with biodegradable textiles celebrating resourcefulness without compromising luxurious finishes .
Light-refracting details elevate minimalist outfits , from solar-powered jewelry to 3D-printed footwear designed for avant-garde experimentation.
Vintage revival meets techwear defines the year, as 2000s logomania reimagine classics through climate-responsive materials for timeless relevance .